
Abstract
Second language (L2) learners often face a number of obstacles in acquiring target-like speech production patterns. This study examines L1 Japanese speakers’ production of L2 English /l/ to investigate how they implement position-dependent allophonic variation while overcoming mismatches between Japanese (L1) and English (L2) in (1) the number of liquid phonemes, (2) their allophonic distributions, and (3) syllable structure. Acoustic and articulatory (ultrasound) analyses of word-initial and word-final English /l/ produced by thirteen L1 Japanese-L2 English speakers and nine L1 English speakers show that L1 Japanese-L2 English speakers produce target-like lateral allophony acoustically, although their lateral production is overall clearer (i.e., less velarised) than that of L1 English speakers. By contrast, L1 Japanese-L2 English speakers’ articulation is non-target-like, characterised by different tongue shape dimensions and the absence of coronal-dorsal timing patterns found in L1 English speakers’ production. Overall, the results highlight the complex nature of L2 speech production, in which L2 speakers utilise a wider range of phonetic cues to overcome learning challenges than is commonly assumed.
Keywords
1 Introduction
This study investigates how second-language (L2) learners produce the phonetic systems in their L2 speech production. It is widely known that L2 learners must overcome various structural differences between their first language (L1) and their L2 to produce target-like pronunciation. One of the most obvious challenges lies in differences in phonological systems, which require L2 learners to establish meaningful phonemic contrasts in the L2. In addition to this phonological difference, L2 learners need to learn how to phonetically implement the phonemes in their L2; the phonetic realisations of a phoneme, for instance, can be conditioned by differences in syllabic positions, including onset vs. coda. In acquiring target-like L2 segments, therefore, learners face a multitude of challenges: they must adjust phonetic cues not only to establish meaningful phonological contrasts but also to match phonemes with appropriate phonetic realisations under specific prosodic conditions. The importance of these phonetic details is highlighted in theoretical frameworks of L2 speech learning. The Speech Learning Model (SLM) explicitly hypothesises that mapping between L1 and L2 segmental categories occurs at the level of positionally conditioned allophones (Flege & Bohn, 2021). Previous empirical work also demonstrates that the allophonic variation in the learner’s L1 could both hinder or facilitate L2 speech perception and production (Colantoni et al., 2023; Olsen, 2012; Solon, 2017). Investigating L2 learners’ implementation of within-category allophonic variation in their L2 speech production helps us better understand how the phonetic systems interact between their L1 and L2.
This study considers allophonic variation of English lateral /l/ produced by L1 Japanese-L2 English speakers. This case provides a unique and interesting contribution to the existing body of L2 speech learning research. English laterals provide a good testing ground for looking into the within-category allophonic variation, given the well-known positional allophony (Recasens, 2012; Sproat & Fujimura, 1993; Turton, 2017). L2 acquisition of lateral allophony, however, has been mainly investigated with L1-L2 pairings where both languages (1) have a common phoneme /l/ while differing in allophonic variation and (2) have similar syllable structure. The case of L1 Japanese speakers’ production of L2 English liquid allophony differs from previous research in that (1) Japanese has only one liquid phoneme, /r/, which is phonetically distinct from English /l/, and that (2) Japanese allows the liquid consonant to appear only syllable-initially, as opposed to English allowing it in both syllable-initial and -final positions. This means that L1 Japanese speakers must adjust their acoustic and articulatory strategies not only to produce the novel lateral consonant /l/, but also to associate its phonetic realisations with syllabic positions appropriately. Combining acoustic and articulatory evidence, this study aims to gain insights into how L2 speakers overcome a multitude of difficulties to acquire the phonetic systems in their L2.
The data and codes used in the analysis are publicly available in the OSF repository at https://osf.io/5sx7t/.
1.1 Acquisition of phonetic systems in the target language
When learning a second language (L2), L2 learners are faced with many structural differences between the two languages that they need to process. One factor includes segmental targets, in which L2 learners need to acquire the necessary acoustic and articulatory cues to make a phonemic contrast in the target language (Chang, 2019). Depending on the L1-L2 pairings, certain phonemic contrasts are harder for L2 learners to learn, including a tense-lax vowel contrast in English for L1 Spanish speakers (e.g., Escudero, 2001) and a contrast between liquids /l/ and /ɹ/ in L2 English for L1 Japanese speakers (e.g., Aoyama et al., 2004). Theoretical frameworks agree that L2 speech learning occurs based on the learner’s L1. In some cases, they could simply reuse the phonemic categories that exist in their L1, which would bear little difficulty in acquiring the L2 phonemic contrast. In other cases, however, they need to adjust the existing phonemic boundaries in their L1 to accommodate the phonemic contrast in L2, which could involve some degree of difficulty (Best & Tyler, 2007; Escudero, 2005).
Even though languages may have the same phoneme in their phonological inventories, each language differs in the way the phoneme is realised phonetically. In English, for example, voiceless stop consonants get aspirated when they occur at the onset of a stressed syllable (e.g., as in
Acquisition of positional allophonic variation has been posited as a core mechanism in the theoretical frameworks of L2 speech learning. The Speech Learning Model (SLM) and its revised version (SLM-r) specifically posit that L2 speech learning occurs at the level of positional allophones (Flege & Bohn, 2021). Under their view, L2 speech production accuracy depends on how L2 sounds are classified in relation to the closest L1 sound through the equivalence classification mechanism. They hypothesise that representations of both L1 and L2 sound categories co-exist in the common phonetic space. A new L2 category is likely to be formed, for instance, when the L2 learner perceives the nonnative sound to be sufficiently auditorily distinct from the closest L1 counterpart, which provides a necessary condition for accurate production of the L2 sound (Nagle & Baese-Berk, 2022). In contrast, L2 categories are merged when L2 sounds are perceived to be similar to the closest L1 category, resulting in both L1 and L2 sounds being perceptually linked and becoming ‘diaphones’ (Chang, 2019). In this case, production of L1 and L2 sounds is approximated with each other, resulting in ‘accented’ L2 production (Chang, 2019; Nagle & Baese-Berk, 2022).
The claim that phonetic category formation occurs at the level of positional allophones is corroborated by previous findings that L2 learners’ perceptual gains in one position do not necessarily generalise to other positions (Iverson et al., 2005) and that L2 learners do not necessarily acquire all the acoustic cues at the same time to produce allophonic variation of a given L2 phoneme (Colantoni & Steele, 2008). This assumption differs from other models of L2 speech learning, such as the Perceptual Assimilation Model for L2 speech learning (PAM-L2; Best & Tyler, 2007) in which their primary focus is on perception of phonological contrasts.
1.2 Allophonic variation of English laterals
English laterals /l/ exhibit relatively clear positionally conditioned allophonic variation, making them a suitable testing ground for examining the acquisition of allophonic variation in L2 speech production. English /l/ is an alveolar lateral approximant involving occlusions made in the alveolar or dental region and the airflow mechanism around one or both sides of the tongue (Narayanan et al., 1997). Syllable-initial laterals tend to yield a ‘clearer’ percept, whereas syllable-final laterals tend to be ‘darker’. The clear-dark contrast correlates acoustically with the second formant (F2) frequencies, with the clear /l/s produced with a higher F2 than the dark counterparts (Narayanan et al., 1997; Sproat & Fujimura, 1993). Extending this, the distance between F2 and F1 is also a good index of the lateral darkness, which may correlate with the degree of tongue dorsum retraction (Kirkham et al., 2020; Sproat & Fujimura, 1993).
In the articulatory domain, the clear-dark variation of English laterals is commonly examined in terms of differences in midsagittal tongue shape and spatiotemporal coordination between tongue tip (coronal) and tongue body (dorsal) gestures. Syllable-final, ‘dark’ /l/s exhibit a larger magnitude of dorsal gesture, and it reaches its maximum retraction prior to the tongue tip reaching the maximum displacement (Sproat & Fujimura, 1993). In contrast, the syllable-initial, ‘clearer’ /l/s often involves either a synchronous timing of the two gestures or the coronal gesture preceding the dorsal gesture (Proctor et al., 2019; Sproat & Fujimura, 1993). The coordination pattern between the coronal and dorsal gesture could signal the degree of syllable affinity of the consonant, given that such a gestural coordination pattern of syllable-initial and syllable-final consonants can also be observed for laterals across languages (Gick et al., 2006) as well as the other class of sonorants such as nasals (Krakow, 1999) and glides (Gick, 2004).
While such a categorical nature of onset-coda lateral allophony has been well-documented, recent quantitative studies argue that the degree of lateral darkness may vary across dialects of English. Some dialects of British English have overall ‘dark’ realisations of laterals, including Leeds and Manchester, as opposed to overall ‘clear’ realisations in Newcastle (Carter & Local, 2007; Turton, 2017). Laterals in American English are also shown to be overall dark, although the initial laterals are still clearer than the coda counterparts (Recasens, 2012). Given this variability in the realisation of lateral allophonic variation, both categoricity and gradience may need to coincide with the phonetic systems of laterals in English (Sproat & Fujimura, 1993; Turton, 2017). The clear-dark positional contrast could result from both a general principle regarding the implementation of syllable-initial and -final consonants (‘intrinsic allophones’) and the presence of distinct articulatory targets for initial and final allophones (‘extrinsic allophones’), the latter of which includes British English (RP), Newcastle and American English (Recasens, 2012). Nevertheless, there is an overall trend across languages/dialects that syllable-initial /l/s are clearer than the final /l/s (Gick et al., 2006; Kirkham et al., 2020; Recasens, 2012).
1.3 L2 acquisition of English lateral allophony by L1 Japanese speakers
This study investigates the acoustics and articulation of English lateral allophony produced by first-language (L1) Japanese speakers who learn English as their foreign language (L1 Japanese-L2 English speakers henceforth). L1 Japanese-L2 English speakers are well-known for their substantial difficulty in making a clear distinction between English liquid consonants /l/ and /ɹ/ in both perception and production (e.g., Aoyama et al., 2019; Bradlow et al., 1997; Iverson et al., 2005), and such findings constitute important pieces of evidence in L2 speech learning theories (Best & Tyler, 2007; Escudero, 2005; Flege & Bohn, 2021). However, previous research has commonly focused on their perception and production of the phonemic contrast between English /l/ and /ɹ/ and little research has addressed their L2 production of allophonic variation within each liquid category. Their production of L2 English allophony, therefore, would provide an important theoretical background in better understanding the phonetic nature of L2 speech learning.
L2 acquisition of English lateral allophony in general is well-researched in L2 speech learning research. Cases that are usually considered in the previous literature include the L1-L2 pairings in which both languages share /l/ as a phoneme but differ in the allophonic distribution and in the phonetic implementation. It has been shown that L2 learners can make a contrast between onset and coda /l/s in a similar pattern found in their target language, but the specific phonetic implementations seem to be influenced by the lateral quality in their L1, including an overall clearer realisation across the syllabic positions in the production of L2 English laterals by Spanish-English bilinguals (Barlow et al., 2013; Colantoni et al., 2023), Korean-English bilinguals (Chung & Kim, 2021; Hwang et al., 2019), Sylheti-English bilinguals (Kirkham & McCarthy, 2021) and Gaelic-English bilinguals (Nance & Kirkham, 2023). The opposite is also true, where L1 American English-speaking learners of Spanish produced Spanish /l/ with an overall darker realisation than L1 Spanish speakers (Solon, 2017). However, the English-like positional effect was only observed for learners who were less proficient in L2 Spanish, suggesting that it is possible to inhibit the L1-like positional allophony to realise more Spanish-like (lack of) positional allophony (Solon, 2017). These studies suggest that, while bilingual and L2 speakers classify the L2 English laterals as similar sounds to the lateral categories in their L1, they could still establish two distinct categories between the onset and coda laterals, supporting the SLM’s prediction that L2 category formation occurs at the phonetic level (Barlow et al., 2013; Hwang et al., 2019).
The case of L1 Japanese-L2 English speakers’ production of English lateral allophony adds an interesting perspective in understanding the L1-L2 interaction of phonetic systems due to the following two reasons. First, unlike previous cases, the learners’ L1 (Japanese) and L2 (English) do not share the same phoneme in the liquid systems. Japanese has one liquid phoneme, usually considered as a rhotic /r/, whereas English has two: a lateral /l/ and a rhotic /ɹ/. Japanese /r/ is canonically realised as an alveolar tap or flap [ɾ], as opposed to approximant realisations in English (Vance, 2008). L1 Japanese-L2 English speakers classify English /l/ as a poor instance of Japanese /r/ (Aoyama et al., 2004). According to SLM/SLM-r, this is considered as a ‘similar’ scenario in which L1 and L2 phonetic categories are merged, likely resulting in an accented production of the L2 sounds (Flege & Bohn, 2021). Furthermore, the lateral and rhotic approximants [l] and [ɹ] are considered to be free allophones arising from stylistic and idiosyncratic variation (Arai, 2013). All these structural differences in liquid systems would mean that a more substantial difficulty is involved for L1 Japanese-L2 English speakers in acquiring L2 English liquid systems, compared to the other cases that have been considered previously; they have to acquire necessary acoustic and articulatory cues not only to implement language-specific phonetic allophonic rules but also to realise differences in equivalent phonemic categories between L1 and L2.
One key difference between the realisation of L1 Japanese /r/ and L2 English /l/ may lie in how coronal and dorsal gestures are controlled. Given that the L2 English lateral category would be merged with the L1 category for Japanese /r/, it could be hypothesised that they may reuse the articulation for [ɾ] when producing L2 English laterals. While both segments involve tongue tip movement, they may differ in the presence of dorsal target and, as a consequence, vocalic coarticulation. It is suggested in previous articulatory studies that the tongue body movement for alveolar taps/flaps is not under the speaker’s active articulatory control and that the tongue body shape might therefore be determined largely by the neighbouring vowels (Maekawa, 2023; Recasens, 1991). The lateral approximant /l/, on the other hand, can be generally characterised with distinct coronal and dorsal targets, making it resistant to vocalic coarticulation, especially for dark /l/s (Recasens & Rodríguez, 2016). Indeed, a previous acoustic study demonstrates a variable shape of F2-F1 formant trajectories for word-initial /l/ and /ɹ/ across vowel contexts for L1 Japanese-L2 English speakers, as opposed to a consistent shape pattern found for L1 English speakers (Nagamine, 2024a). Similarly, an ultrasound study highlights a smaller degree of tongue retraction for L1 Japanese-L2 English speakers producing word-medial /l/ than for L1 English speakers (Nagamine, 2023). A lack of a dorsal target for alveolar taps/flaps could mean that L1 Japanese-L2 English speakers may not differentiate coronal and dorsal gestures as clearly as L1 English speakers, a similar view as in the motor differentiation model for complex segments (Gick et al., 2007). Overall, these findings broadly support the possibility that L1 Japanese-L2 English speakers may have less control over tongue dorsum movement when producing L2 English /l/.
In addition, differences in L1 phonotactic knowledge and syllable structures could influence how articulatory gestures are organised within a syllable. English allows a wide range of syllable structures, with a possibility of complex consonant clusters in both onset and coda positions. Japanese, on the other hand, has a relatively restricted set of syllable structure possibilities. The majority of Japanese syllables are CV structures and the coda consonant is only reserved for a nasal /N/, a mora obstruent /Q/ (i.e., constituting a geminate obstruent) and a lengthening phoneme /H/ (i.e., turning a short vowel into a long vowel) (Vance, 2008). Also, Japanese is considered as a mora-timing language, in which a mora is a phonological unit distinguishing the syllable weight between e.g., CV (one mora) and CVC (two morae) structures (Otake, 2015). This could result in re-syllabification of the word-final consonants; for instance, vowel epenthesis after the word-final consonant is commonly attested in loanword adaptation from English into Japanese in L2 English production (Kubozono, 2015; Li & Juffs, 2014).
Previous research demonstrates that the influence of L1 phonotactic knowledge on the production of nonnative consonants can be manifested in articulatory (mis)timing; L1 American English speakers, for example, showed a trace of ‘transitional schwa’ in the word-initial /zC-/ sequence that is not permitted in American English (Davidson, 2006). More broadly, as mentioned earlier, the coordination of coronal and dorsal gestures in English laterals may follow a principle of gestural affinity, in which a tighter constriction is attracted to the syllable margin, whereas a wider constriction to the syllable nuclei (Krakow, 1999; Sproat & Fujimura, 1993). A lack of syllable-final liquids in Japanese could, therefore, influence the articulation that L1 Japanese-L2 English speakers employ in signalling the onset-coda English lateral allophony; a lack of syllable-final liquids in L1 Japanese would mean that L1 Japanese speakers may resort to a similar articulatory strategy for the positional contrast in the L2 English lateral allophony.
Despite much general attention to the L1 Japanese-L2 English speakers’ acquisition of L2 English liquids in the previous literature, there is little articulatory evidence in their production of L2 English liquids, resulting in a poor understanding of the articulatory mechanisms underlying their non-target-like production of English /l/. A few existing studies, nevertheless, provide insights as to how they might possibly signal the L2 lateral allophony. Using electropalatography (EPG), for instance, Kochetov (2022) demonstrates that L1 Japanese-L2 English speakers produce syllable-initial laterals with an overall greater degree of anterior linguopalatal contact compared to the syllable-final laterals, which could suggest that they could at least signal onset-coda English lateral allophony in the anterior part of the tongue. However, Nagamine (2022) did not find much tongue shape difference for the onset-coda allophony in the midsagittal ultrasound data, even for the speakers who make a clear initial-final contrast in acoustics (F2-F1), although it remained unclear how ‘target-like’ their production was, given the lack of L1 English speakers’ data. It is also possible that L2 articulation of English lateral allophony involves a substantial degree of individual variation, as shown in Kochetov (2022), especially for the syllable-final laterals. Moore et al. (2018) argue that the degree of articulatory variability may depend on the learners’ L2 proficiency, in which more advanced L2 learners may show a consistent tongue shape pattern compared to those who are less proficient, although the positional variation of L2 English allophony was not explored systematically. Overall, although L1 Japanese-L2 English speakers might show some articulatory difference between onset and coda English laterals, even a covert difference that does not reveal itself in the acoustic signal, its exact nature remains inconclusive, calling for more systematic, quantitative studies.
1.4 The current study
The overall objective of the current study is to provide a systematic and quantitative investigation of L2 lateral allophony produced by L1 Japanese-L2 English speakers through combining acoustic and articulatory (ultrasound) analyses. Extending the previous acoustic/articulatory studies (e.g., Nagamine, 2022, 2023, 2024a), the current study aims to directly assess how L1 Japanese-L2 English speakers produce L2 English lateral allophony by comparing syllable-initial and -final /l/s.
The acoustic analysis explores how they signal the positional allophones of L2 English laterals and how they compare to the production by L1 English speakers along the F2-F1 dimension. The articulatory analysis concerns tongue shape differences between the two allophones and the intergestural timing between coronal and dorsal gestures. The tongue shape analysis is motivated by previous research looking into the lateral allophony within L1 English showing that laterals exhibit a lower and more retracted tongue shape in the final position compared to the initial position. In addition, the current study includes intergestural timing analysis capturing the kinematic coordination patterns between coronal and dorsal gestures, which could offer insights into how L1 Japanese-L2 English learners may overcome L1-L2 differences in segmental realisation and syllable structure.
The analysis is guided by the following two research questions:
2 Methods
2.1 Participants
The dataset analysed in this study comprises simultaneous acoustic and high-speed ultrasound recordings from 22 speakers. This includes nine L1 English speakers (seven female, two male) aged 22–39 years (M = 28.56, SD = 4.88) and 13 L1 Japanese-L2 English speakers (six female, seven male) aged 18–21 years (M = 19.69, SD = 0.95) at the time of recording. This is a subset of a larger data collection, in which originally 55 speakers (41 L1 Japanese-L2 English speakers and 14 L1 English speakers) were recorded. Speakers included in this study were selected on the basis of overall ultrasound image clarity and confidence in tongue spline estimation; only speakers whose ultrasound data show the whole midsagittal tongue shape absolutely clearly from the tongue tip to the tongue root have been chosen. Although the tongue spline estimation programme, the DeepLabCut (DLC) plug-in in Articulate Assistant Advanced (AAA), is capable of estimating tongue tip location even when obscured by mandibular shadow, the intergestural timing analysis conducted here requires the tongue tip to be imaged very clearly.
In the participant population included in the current study, L1 English speakers were born and raised at least until 13 years old either in the United States (n = 5) or in Canada (n = 4) and resided in the United Kingdom for their study or work when recording took place. They all identified themselves as fluent L1 English speakers and rated their fluency as seven (1 = I do not speak English at all, 7 = No problem in using English in daily life). L1 Japanese-L2 English speakers were all undergraduate students enrolled at a university in central and western Japan. They were born and raised in Japan using Japanese, and they studied English mostly through the school curriculum, with a mean overseas experience being approximately 3 weeks (0.71 months,
2.2 Materials
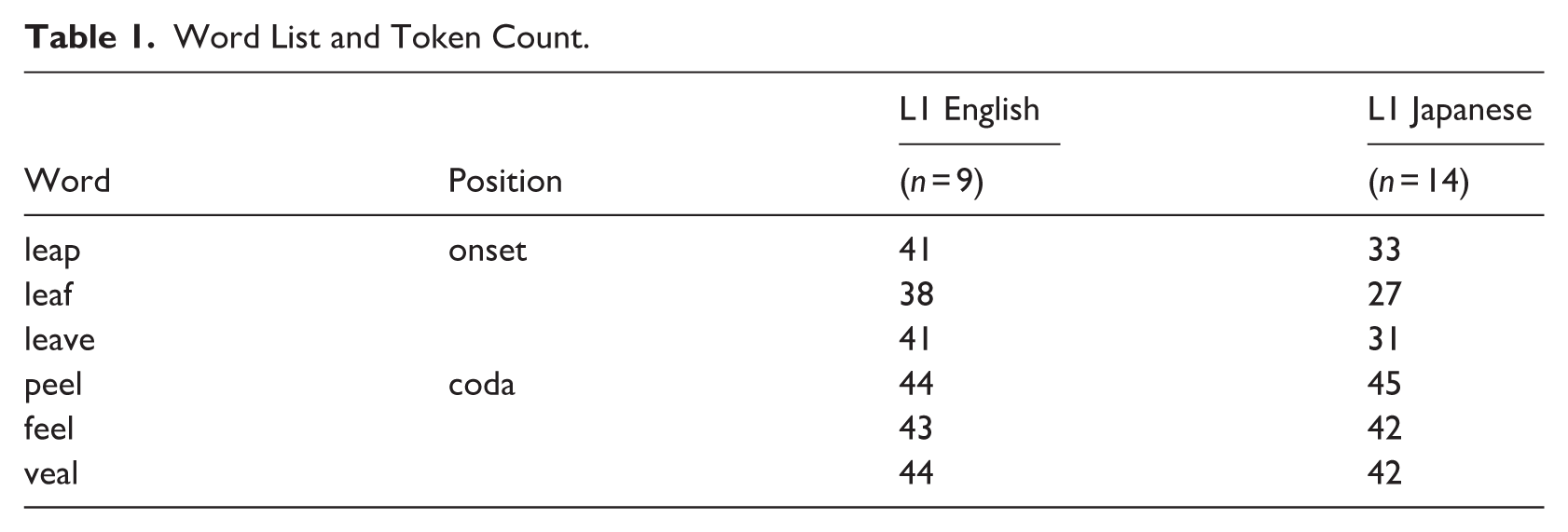
The materials in this study consist of six monosyllabic CVC words beginning or ending with English /l/: peel, leap, feel, leaf, veal, and leave. The vowel environment is kept consistent as /i/ to keep vowel quality maximally similar between Japanese and English, even in the case of L1 substitution for L1 Japanese-L2 English speakers. The target words are such that onset and coda words are mirror images of each other, sharing the same sets of phonemes and differing only in their sequences (cf. Gick et al., 2006). The other consonant is always a labial or a labiodental consonant (i.e., /f/, /p/, /v/) to minimise lingual coarticulation while facilitating acoustic segmentation. This results in six words with onset-coda lateral contrast. The word list is shown in Table 1 alongside the token counts.
Word List and Token Count.
2.3 Data collection procedure
Data collection was conducted between October and December 2022, in a quiet room at universities in Japan for L1 Japanese speakers and in soundproof recording booths at universities in the United Kingdom for L1 English speakers. At the time of recording L1 Japanese speakers, COVID-19 measures were still in place, mandating air ventilation at all times, so there was minor fan noise in the audio recording for some of the L1 Japanese speakers’ data.
Midsagittal ultrasound tongue imaging data were collected using a Telemed MicrUS system with a 64-element probe of 20 mm radius. The prompt presentation and recording were made on the Articulate Assistant Advanced (AAA) software version 220.5.1 (Articulate Instruments, 2022). Participants wore an UltraFit probe stabilisation headset to stabilise the probe relative to head movement (Spreafico et al., 2018). Recording parameters for ultrasound tongue imaging were optimised per speaker at the start of the recording, with the field of view ranging between 80% and 100% (91.6°–101.2° FOV), the depth between 80 mm and 100 mm, and the probe frequency between 2 MHz and 4 MHz. This resulted in a frame rate of approximately 80 frames per second. The audio recording, also recorded on the AAA software, was made using an Opus 55 MK ii condenser microphone attached to the UltraFit headset, pre-amplified and digitised at 44.1 kHz with 16-bit quantisation using a Sound Device USB Pre-2 audio interface.
In the recording venue, participants sat in front of a laptop computer displaying the prompt on the AAA software. After participants were informed about the experiment and signed on the consent form, the UltraFit headset was fitted and an optimal recording setting was explored for each participant. Once the hardware fitting completed, each participant’s bite plane was recorded by having them bite a thin plastic plate, which was used to standardise the coordinate system across participants in the analysis stage (Scobbie et al., 2011). After this, their palate shape was recorded by having them swallow a glass of water. This preparatory phase took approximately 20 minutes, although it took longer for some participants due to difficulties in headset fitting and identifying recording parameters for clear tongue images. The participant’s side-profile lip video was also recorded using a small camera mounted on the UltraFit headset extension, but the lip data will not be analysed or presented in this article.
During the word-list recording, participants read the individual target words one by one. The order of the target words was randomised but kept consistent across participants. The prompt display was delayed by 1,000 ms after the onset of ultrasound recording to prevent participants from taking a preparatory tongue posture for the initial consonant. The instructions associated with recording were given entirely in English for both L1 English and L1 Japanese-L2 English speakers by the first author (an L1 Japanese speaker) in consideration of the participant’s language mode (Grosjean, 2008). Participants produced each token between two and five times. The number of repetitions varied due primarily to a strict turnaround time restriction on the recording venues and software processing time. As a consequence, some speakers only managed to produce a small number of tokens. Although this would inevitably increase inter-speaker variability, alongside the between-group difference in the number of participants, an attempt is taken to account for this through the random effect structures in the statistical modelling.
2.4 Data analysis
This study combines acoustic and articulatory analyses to assess English lateral onset-coda allophony holistically. First, acoustic analysis is based on the F2-F1 measure taken at the lateral midpoint, which has been used as a proxy for the degree of tongue dorsum retraction and thus an index of the overall lateral quality (Kirkham et al., 2020; Nance & Kirkham, 2023; Sproat & Fujimura, 1993). Second, articulatory analysis aims to investigate differences between onset and coda laterals in midsagittal tongue shape and in intergestural timing. While time-varying characteristics have been argued to be important in studies of laterals elsewhere (e.g., Nagamine, 2024a), this study utilises a static, midpoint measurement of F2-F1 and tongue shape to facilitate meaningful comparisons for position and speaker groups; the timing difference between the two groups of speakers would be complemented by the intergestural analysis. The data and codes used in the analysis are publicly available in the OSF repository at https://osf.io/5sx7t/.
A parallel acoustic-articulatory corpus of 471 tokens is developed to maximise the compatibility between analyses, following the procedures described below. The corpus includes 120 tokens of onset /l/ and 131 tokens of coda /l/ for L1 English speakers, and 91 onset tokens and 129 coda tokens for L1 Japanese speakers.
2.4.1 Acoustic analysis
Prior to the analysis, the acoustic signals were downsampled to 22,050 Hz and high-pass filtered with a cut-off frequency of 70 Hz. Automatic phone-level segmentation was then performed using Montreal Forced Aligner (MFA) version 2.0.6 (McAuliffe et al., 2017). The segmented boundaries were then visually inspected and adjusted wherever necessary using Praat (Boersma & Weenink, 2022).
In acoustic segmentation, lateral intervals are defined as a steady-state or an approximately steady-state of F2, guided by an abrupt change in amplitude (Lawson et al., 2011). While this is inevitably only an approximation of lateral production that involves various stages, including the transition into and out of the neighbouring vowels (Carter & Local, 2007; Nance & Kirkham, 2023), this is a common measure that has been used to characterise the onset-coda allophony and thus facilitates comparison of the results from this study with that of previous research (e.g., (Aoyama et al., 2019; Flege et al., 1995). The transition into and out of the vowel is included in the vowel interval. It was, however, extremely difficult to identify such an F2 steady state for some lateral tokens produced by L1 Japanese-L2 English speakers, presumably due to possible L1 substitution with alveolar taps/flaps [ɾ]. In addition, audio quality of some tokens only allowed for the identification of the lateral onset due to poorer recording quality. In these cases, although segmentation was still possible, the lateral-vowel boundary was complemented by the author’s auditory judgement.
Formant frequencies were extracted using Fast Track, a Praat plug-in for automatic formant estimation (Barreda, 2021). Fast Track performs up to 24 formant estimation rounds per token, with varying ceiling frequencies, and autoselects the best-fit settings based on a regression analysis. In this study, Fast Track returned estimations of three formants (F1, F2 and F3) that are binned into 11 equi-distant time points during the lateral interval (point 1 = onset, point 6 = midpoint, point 11 = offset), with the range of upper formant frequencies being between 5,000 and 7,000 Hz for female speakers and between 4,500 and 6,500 Hz for male speakers, as per the Fast Track recommendation. Inaccuracies in formant estimation were corrected either through visual inspection and selection of a better analysis or by removing the token from the dataset. Formants were not estimated for 62 tokens that were shorter than 30 ms as they were automatically removed from Fast Track.
Among the 11 time points, this analysis focuses on the formant frequencies aggregated into the temporal midpoint (i.e., point 6). While spectral analysis at articulatorily-defined event (e.g., maximal dorsal displacement) would provide a more accurate picture given a correspondence with the F2-F1 measure, the midpoint F2-F1 measurement is the only consistent data point across the tokens because the articulatory data processing suggested that L1 Japanese speakers do not necessarily show the maximal dorsal displacement during the acoustic lateral interval.
2.4.2 Tongue shape analysis
The first analysis of articulatory data is a comparison of midsagittal tongue shape. Tongue splines were estimated using the DeepLabCut (DLC) plug-in on the AAA software for the whole duration of each recording for each word (Mathis et al., 2018; Wrench & Balch-Tomes, 2022). DLC estimates the tongue surface by tracking 11 key points (“knots”) along the tongue based on the pre-trained neural network model, and the x/y coordinates of the key points were then exported in millimetres. When exporting the data, the x/y coordinates were standardised and rotated relative to each speaker’s bite plane measured prior to the word list recording (Scobbie et al., 2011).
The precision of tongue spline estimation was visually checked by the author, and only the speakers whose images clearly captured the large area of the tongue surface from the tongue tip to the tongue root were chosen, constituting the participant population in this study. In addition, once the speakers had been selected, nine further tokens were excluded due to audio-ultrasound synchronisation issues and inaccurate tongue estimation.
To capture the tongue shape differences quantitatively, Principal Component Analysis (PCA) was performed on the midsagittal ultrasound tongue images extracted at the lateral midpoint (Johnson, 2008). PCA is a common approach in recent quantitative articulatory research using ultrasound (e.g., Nance & Kirkham, 2023). It identifies the main modes of variation for each of the 11 DLC knots and decomposes them into (1) overall mean, (2) principal components (PCs) expressing the direction of each variation, and (3) PC scores expressing the degree of variation along each eigenvector. The advantage of PCA, as has been demonstrated in a number of previous studies, is that it allows us to (1) reconstruct the tongue shape variation back on the original midsagittal plane, facilitating the interpretation of each PC, and (2) quantify the major modes of variation in tongue shape, which could then be used as input for statistical modelling. The current study employs Multivariate Functional Principal Component Analysis (MFPCA) to better account for the spatial dependencies between the neighbouring DLC knots (Coretta & Sakr, n.d.; Gubian et al., 2015).
2.4.3 Intergestural timing analysis
The second articulatory analysis concerns the intergestural timing between coronal and dorsal gestures. The intergestural timing analysis here considers the tongue movement over lateral-vowel sequences for the initial lateral tokens (i.e.,
The core analysis here is to identify the ultrasound frames corresponding to the maximal displacement of coronal and dorsal gestures. To identify the functional and meaningful tongue regions representing the coronal and dorsal gestures, correlation coefficients for the 11 DLC knots were calculated based on the hierarchical correlational clustering using the cor function and the corrplot package (Wei & Simko, 2024).
The correlation analysis considered horizontal (x) and vertical (y) coordinate values across the 11 DLC knots throughout the analysis window (see Figure 1 for knot labels). Prior to analysis, position trajectories for all knots were smoothed using a fifth-order Butterworth filter with a cut-off frequency of 10 Hz, applied via the filtfilt function in the signal package (Ligges et al., 2023), which performs smoothing without phase distortion (cf. Ying et al., 2021). Hierarchical correlational clustering suggested strong correlations among knots 9–11 and among knots 3–6, with correlation coefficients approaching r = 1.00 and reaching statistical significance (p < .05). These knot groupings were therefore taken to index coronal (knots 9–11) and dorsal (knots 3–6) gestures, respectively. (Please see Appendix A for the details of the correlation analysis.) For each gestural region, the multidimensional knot trajectories were further reduced to a one-dimensional signal using Principal Component Analysis (PCA). In both cases, the first principal component (PC1) captured coordinated tongue movement along the anteroposterior and superoinferior dimensions, accounting for 74.50% of the variance in the dorsal region and 69.46% in the coronal region. PC1 was thus taken to provide an adequate summary of overall coronal and dorsal gestural movement in two-dimensional space.
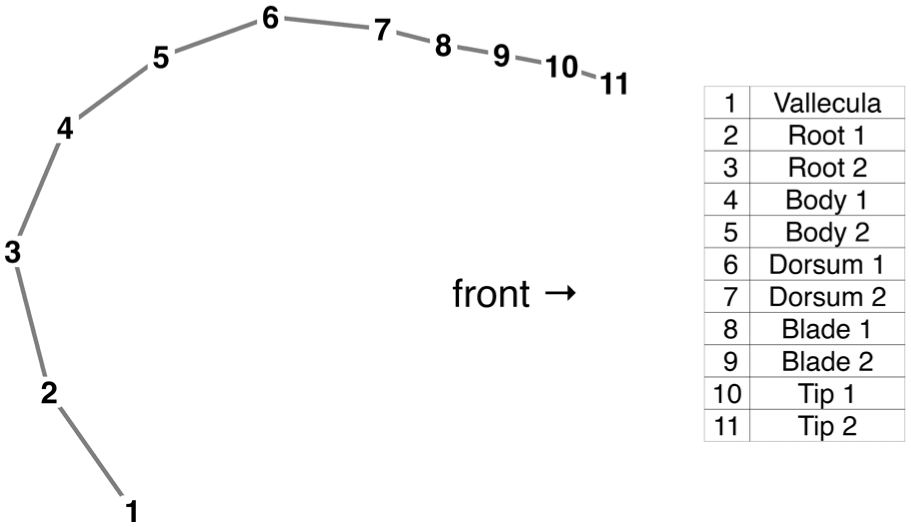
Illustration of the 11 DLC key points along the midsagittal tongue shape, adapted from Wrench and Balch-Tomes (2022, p. 7).
The coronal and dorsal gestural targets were identified based on their position and velocity profiles, in which the position signal corresponds to the within-speaker z-normalised PC1 scores summarising the DLC knots for coronal and dorsal regions. The velocity signal was derived as the absolute value of the first derivative of the PC1 trajectories, calculated via the central_difference function in the tadaR package (Kirkham, 2024).
An example of the position and velocity trajectories is shown in Figure 2. Articulation of English /l/ involves tongue tip raising and tongue dorsum retraction, which should correspond to a local maximum in the coronal position trajectory and a local minimum in the dorsal position trajectory. When the tongue reaches the articulatory target, it typically undergoes a brief reduction in movement, resulting in a local minimum in velocity. This velocity minimum provides a consistent cue for identifying both coronal and dorsal gestures and is therefore used to define the coronal and dorsal gestural peaks in the present study.
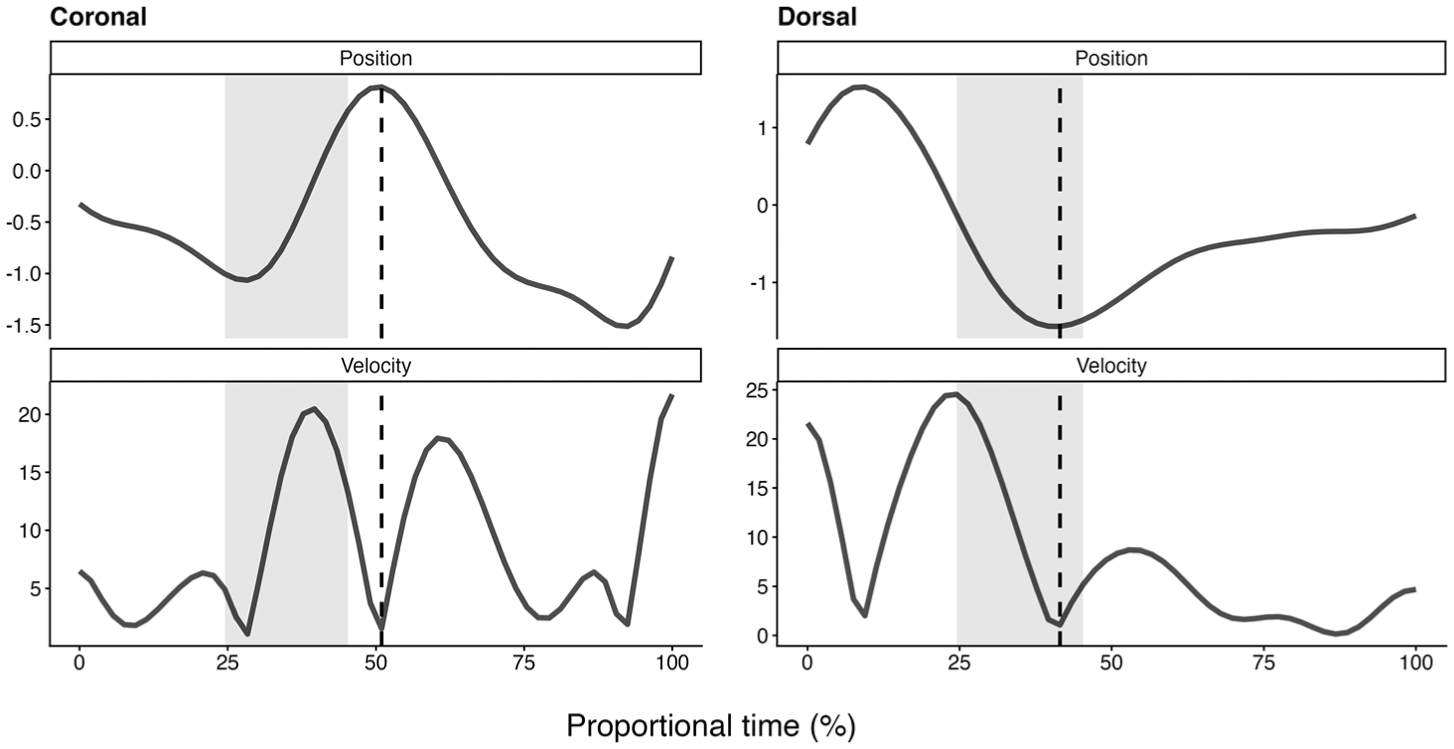
Example of the position and velocity trajectories for an L1 English female speaker (h5s4x3) producing feel.
This study uses the Tip Delay measure as an index of the timing relations between coronal and dorsal gestures, calculated by the following formula:

The measure has been commonly used to characterise the degree of lateral darkness (Sproat & Fujimura, 1993; Ying et al., 2021). A negative lag indicates that coronal gesture is achieved before dorsal gesture, whereas a positive lag means that dorsal gesture precedes coronal gesture. The Tip Delay of zero indicates that two gestures are achieved synchronously.
2.4.4 Statistical analysis
Bayesian linear mixed-effects models were fitted using the brms package (Bürkner, 2017), to (1) directly quantify the degree of uncertainty in the parameter estimation due to a relatively small number of data points, and (2) allow for a greater flexibility in the random effect structure specifications to accurately account for a substantial inter-speaker variability given the imbalanced number of participants between groups and the different number of production tokens per speaker (Kruschke, 2015; Roettger et al., 2019).
Across all analyses, the fixed-effects structure was held constant, including L1 (two levels: English vs. Japanese), position (two levels: initial vs. final), and their interaction. Gender (two levels: female vs. male) was also included as a fixed effect, as it has been shown to influence related acoustic and articulatory measures in previous work using a comparable dataset (Nagamine, 2024a). L2 proficiency was not included as a fixed effect because the available proficiency measures did not provide sufficiently fine-grained or independent information to support its inclusion. Specifically, proficiency assessment varied across L1 Japanese-L2 English participants, self-rated proficiency was confounded with L1 status, and the L1 Japanese-L2 English group was relatively homogeneous with respect to proficiency (Nagamine, 2024a).
The outcome variable for the acoustic analysis is raw F2-F1 in Hertz, considering that it achieves some degree of between-speaker vocal tract normalisation (Kirkham et al., 2020; Syrdal & Gopal, 1986) and that it allows us to incorporate the findings of previous research in the prior distribution specifications in a relatively straightforward manner (e.g., Aoyama et al., 2019; Kirkham et al., 2020; Sproat & Fujimura, 1993). Separate models are constructed for each PC dimension for the tongue shape analysis identified via MFPCA, predicting the PC scores (within-speaker z-normalised) as a function of L1, position, gender, and L1-position interaction. Finally, the statistical model for the intergestural timing includes the Tip Delay measure in milliseconds, following the previous research (Sproat & Fujimura, 1993; Ying et al., 2021).
All statistical models were run with four sampling chains with 2,000 iterations with the warm-up period of 1,000 iterations, resulting in a total of 4,000 posterior draws (i.e., samples used to calculate the posterior distributions). Models assumed a Gaussian distribution for the outcome variables and the fixed effect variables are treatment coded, in which the baseline level is the initial /l/ produced by L1 English female speakers. All models included random intercepts for speaker and word, with a by-speaker random slope for position and a by-word random slope for L1. The models employ the weakly informative priors, whose parameter specifications are determined based on the values reported in the previous literature and are adjusted based on the prior sensitivity check wherever necessary, following the procedure described in the learnB4SS tutorial (Coretta et al., 2023). All the models successfully converge, with the Rhat
In the results section below, regression coefficients
3 Results
3.1 Acoustic analysis
The first analysis concerns acoustic differences between onset and coda tokens of English /l/. As an index of lateral darkness, F2-F1 values were extracted at the liquid midpoint, which are visualised in Figure 3. Overall, both L1 English and L1 Japanese-L2 English speakers seem to make a distinction between the onset and coda laterals, in which initial tokens show higher F2-F1 values (L1 English speakers: M = 828.56 Hz, SD = 278.21; L1 Japanese-L2 English speakers: M = 1,079.30 Hz, SD = 309.19) than final tokens (L1 English speakers: M = 550.37 Hz, SD = 127.59; L1 Japanese speakers: M = 942.92 Hz, SD = 399.46). Overall, these results suggest that both L1 English and L1 Japanese-L2 English speakers make a contrast between onset and coda laterals, but that L1 Japanese-L2 English speakers’ acoustic realisations of laterals are overall clearer, characterised by higher F2-F1 values than those of L1 English speakers.
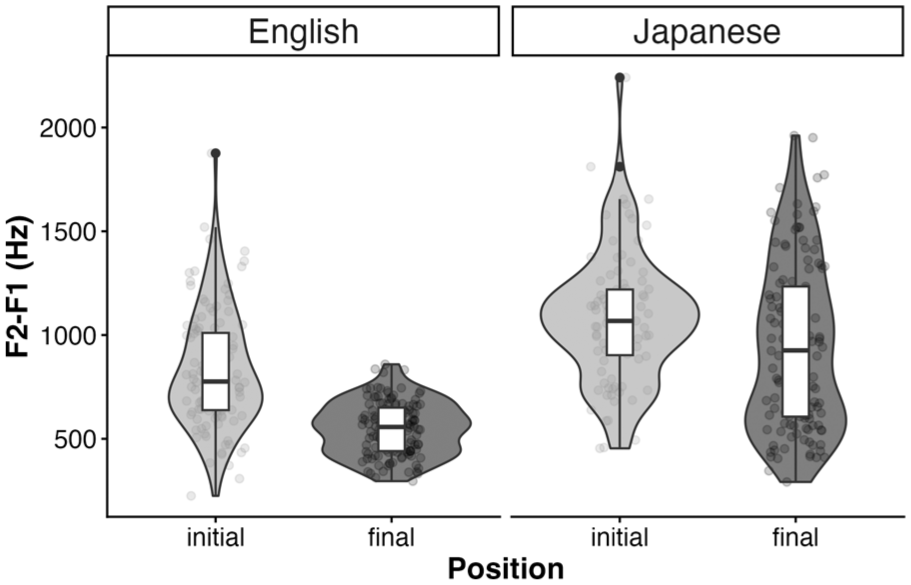
F2-F1 (Hz) at the lateral midpoint for L1 English (left) and L1 Japanese-L2 English speakers (right).
Figure 4 shows the posterior distributions for regression coefficients from the F2-F1 statistical model. It demonstrates credible effects of L1
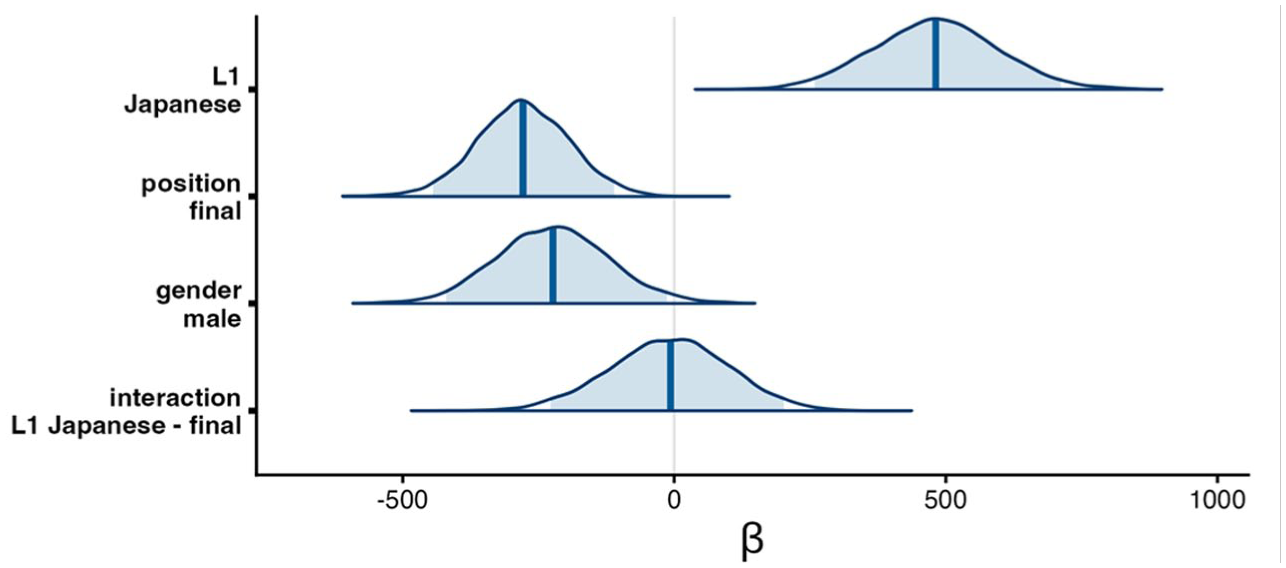
Posterior distributions of regression coefficients from the midpoint F2F1 analysis.
To summarise, the acoustic analysis here demonstrates credible effects of L1 and position but not the interaction between them. This means that both L1 Japanese-L2 English and L1 English speakers make a contrast between onset and coda laterals, whereas F2-F1 is overall higher for L1 Japanese-L2 English speakers than for L1 English speakers.
3.2 Midsagittal tongue shape
We now turn to the articulatory data involving midsagittal tongue shape collected using ultrasound tongue imaging. To draw an overall picture, the raw tongue shape extracted at the lateral midpoint is visualised in Figure 5.
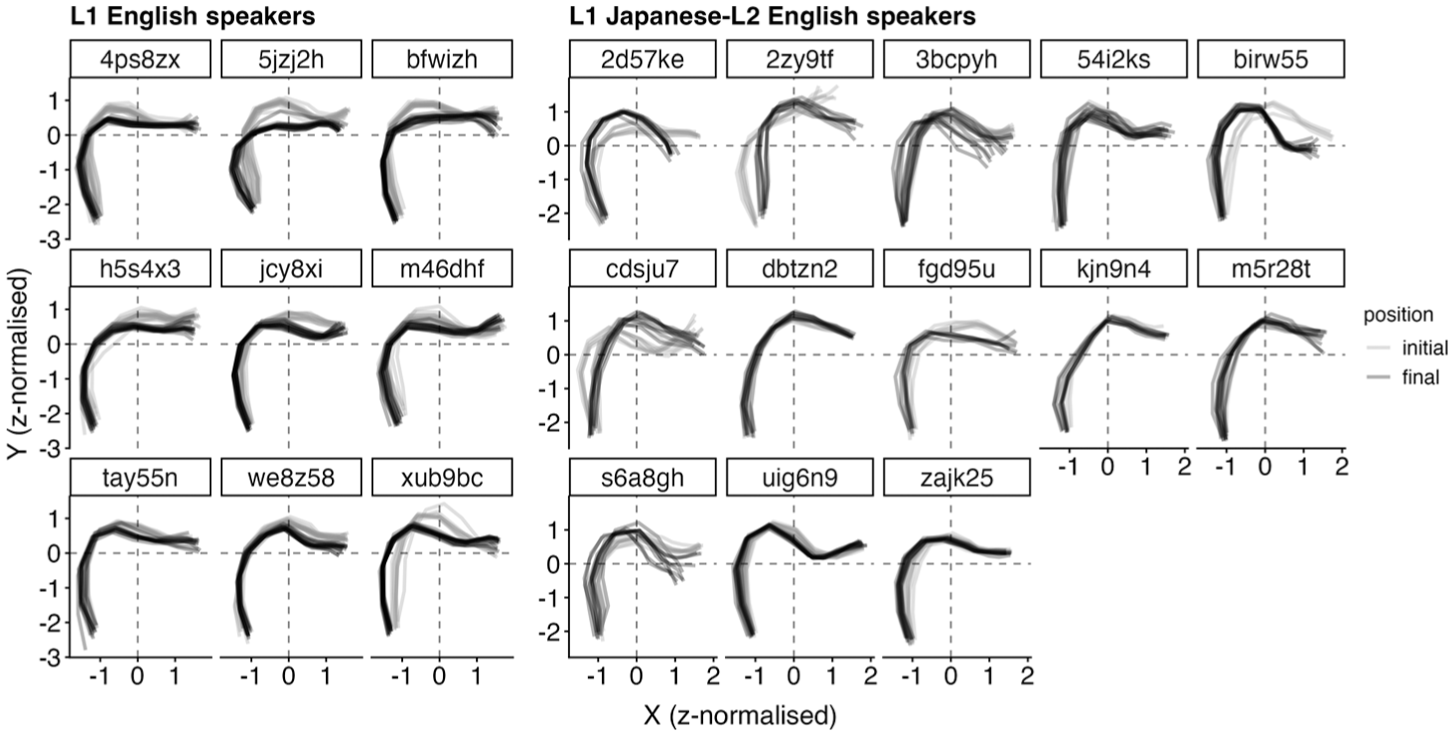
Midsagittal tongue shape extracted at the midpoint of the acoustically-defined liquid interval for English /l/.
L1 English speakers make a relatively clear onset-coda contrast for English /l/, in which their overall tongue shape is consistently lower for final tokens (darker grey) than for initial tokens (lighter grey). The difference is particularly pronounced around the tongue blade. The degree of tongue retraction varies across speakers, with five speakers (4ps8zx, 5jzj2h, bfwizh, jcy8xi, and xub9bc) showing a greater degree of tongue body retraction in the final position than in the initial position. Although the rest of the speakers show a smaller difference between the onset and coda laterals, the tendency is similar to that of the first five speakers, in that the tongue blade is lowered for final laterals compared to initial laterals.
L1 Japanese-L2 English speakers, on the other hand, exhibit a somewhat more complex pattern and the magnitude of the onset-coda difference is relatively small. Speakers birw55 and fdg95u exhibit a target-like pattern, in which the tongue blade region is lower for the final tokens than for the initial tokens. Speaker 3bcpyh shows a slight tongue body retraction for some of the final tokens. Two further speakers, 2zy9tf and cdsju7, show a reversed pattern such that their tongue is lower and more retracted for the initial tokens than for the final tokens. Finally, the rest of the speakers employ almost identical tongue shape for both onset and coda /l/s.
The MFPCA analysis decomposes the tongue shape variation into nine principal components. This study focuses on the first two PCs that account for 38.48% (PC1) and 26.73% (PC2). A common analytic approach is to retain PCs that explain more than 5% of variance in the data, which would include PC3 (15.13%) and PC4 (10.47%) (Baayen, 2008; Turton, 2015). In this study, however, the first two PCs are deemed to be sufficient to highlight between-group differences, given that the interpretation of higher PCs tends to involve higher-order differences and thus is less straightforward. Also, the first two PCs already capture between-group differences in tongue shape variation, meaning that these PCs capture the key variations relevant to understanding L1-specific tongue shape differences. Further details about PCs 3 and 4, including the tongue shape reconstruction, are included in the online supplementary materials.
The left panel in Figure 6 shows the reconstructed tongue shape based on PCs 1 and 2, respectively, illustrating the variation captured in each PC dimension. PC1 captures the overall high-low and front-back dimension, in which higher PC scores correspond to a higher and fronter tongue, shown in lighter grey. The lower the PC scores, on the other hand, the lower and more retracted the tongue overall. PC2 primarily captures tongue shape variability that seems to correlate with the tongue tip movement, in which higher PC scores would mean a lower tongue tip and a higher tongue body. Smaller PC scores, on the other hand, correspond to a higher tongue tip with a generally lower tongue body.
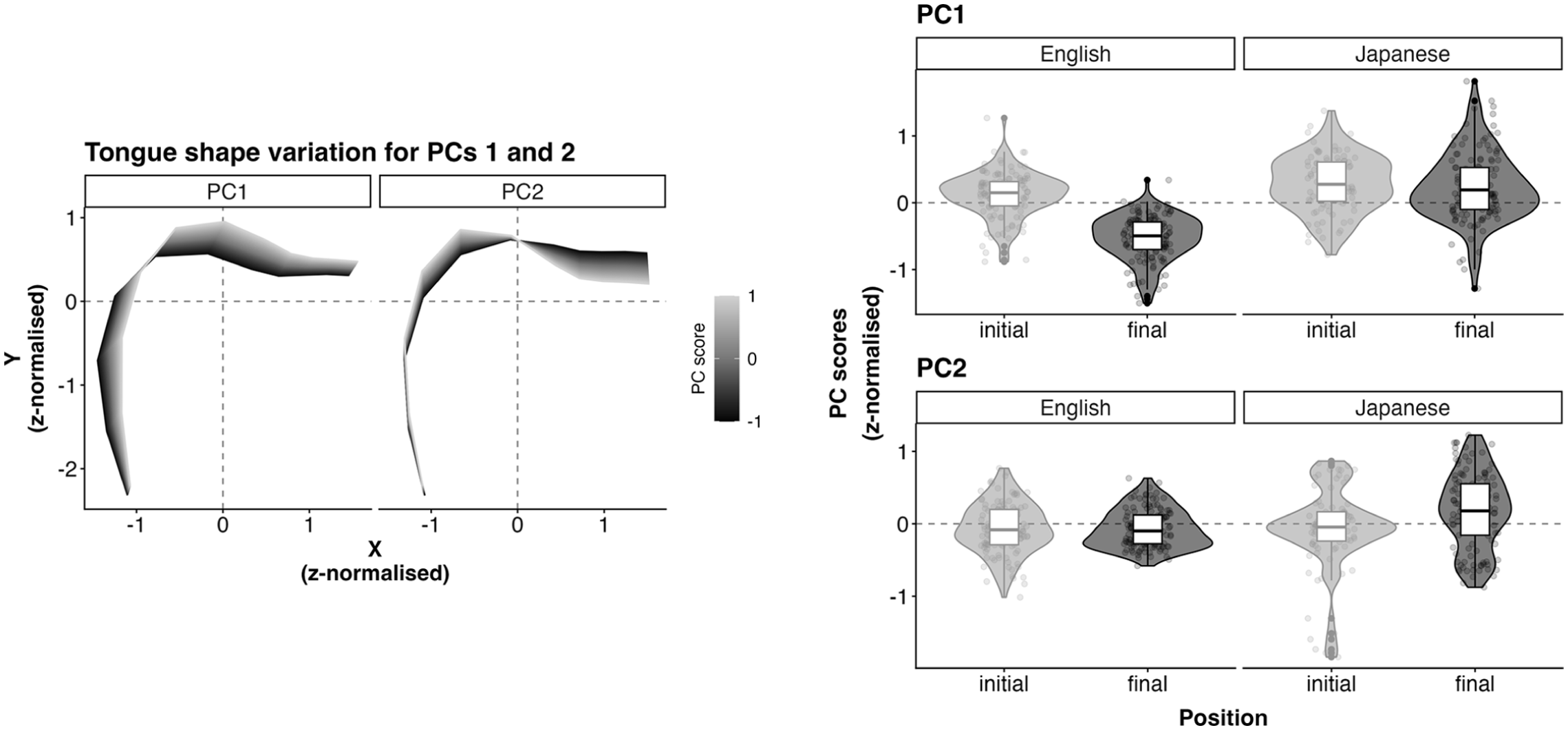
Tongue shape variation captured by PC1 and PC2 (left) and PC score distributions for PC1 (top right) and PC2 (bottom right).
The PC scores are statistically modelled in separate models for PCs 1 and 2. The PC score distributions are visualised in the right panel in Figure 6 and the regression coefficients are shown in Figure 7. The full details of the model output are included in Tables B2 and B3 in Appendix B.
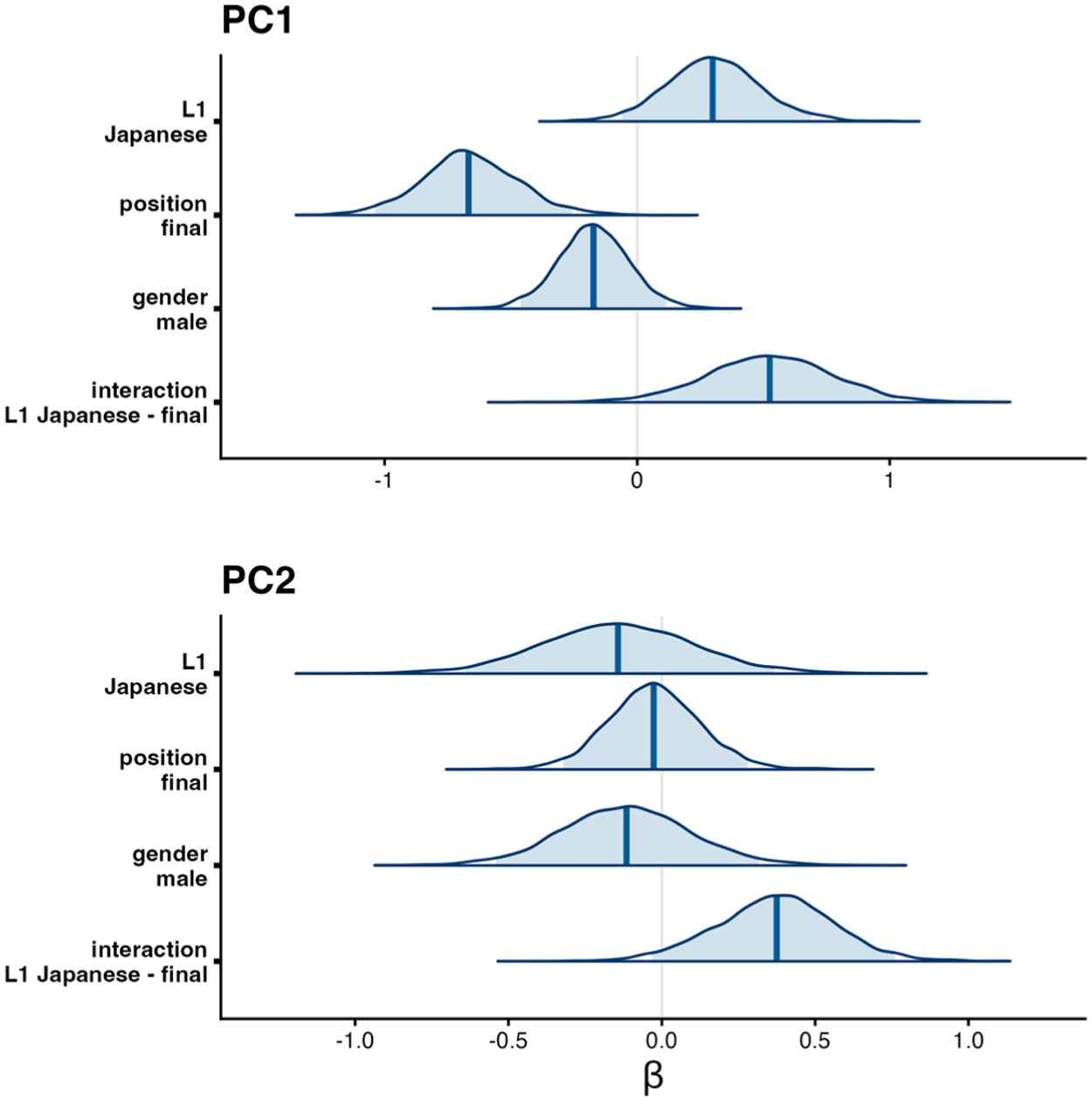
Posterior distributions of regression coefficients for PC1 (top) and PC2 (bottom) from the tongue shape analysis.
The statistical model for PC1 suggests a clear onset-coda contrast for L1 English speakers, whereas it is less clear for L1 Japanese-L2 English speakers. As illustrated in Figure 7, the PC1 model suggests credible effects of position
The PC2 scores in Figure 6 suggest that the onset-coda contrast may be greater for L1 Japanese-L2 English speakers than for L1 English speakers along this dimension. Overall, the PC2 model showed little evidence for credible effects of position
Overall, the analysis here demonstrates some L1-specific patterns in tongue shape variation between onset and coda laterals. L1 English speakers show a relatively consistent tongue shape pattern, in which their tongue is higher for onset laterals than for coda laterals. L1 Japanese-L2 English speakers, on the other hand, show a greater tongue shape variability, with some of them showing little contrast between onset and coda laterals. The MFPCA analysis further provides the nature of L1-specific variability: L1 English speakers differentiate the onset-coda lateral tongue shape along the overall high-low and front-back movement, captured by PC1. L1 Japanese speakers, on the other hand, showed consistently high PC1 scores across positions and thus little tongue shape contrast along PC1. The PC2 dimension captures the tongue shape variability associated with the tongue tip, along which L1 Japanese speakers seem to differentiate onset-coda laterals. L1 English speakers, on the other hand, showed little onset-coda contrast along this dimension.
3.3 Intergestural timing
Finally, the Tip Delay (i.e., the time lag between the coronal and dorsal gestures) is visualised in Figure 8. Negative Tip Delay values indicate that the coronal gesture precedes the dorsal gesture, whereas positive values indicate the reverse. A Tip Delay of zero indicates that the two gestures are achieved simultaneously.
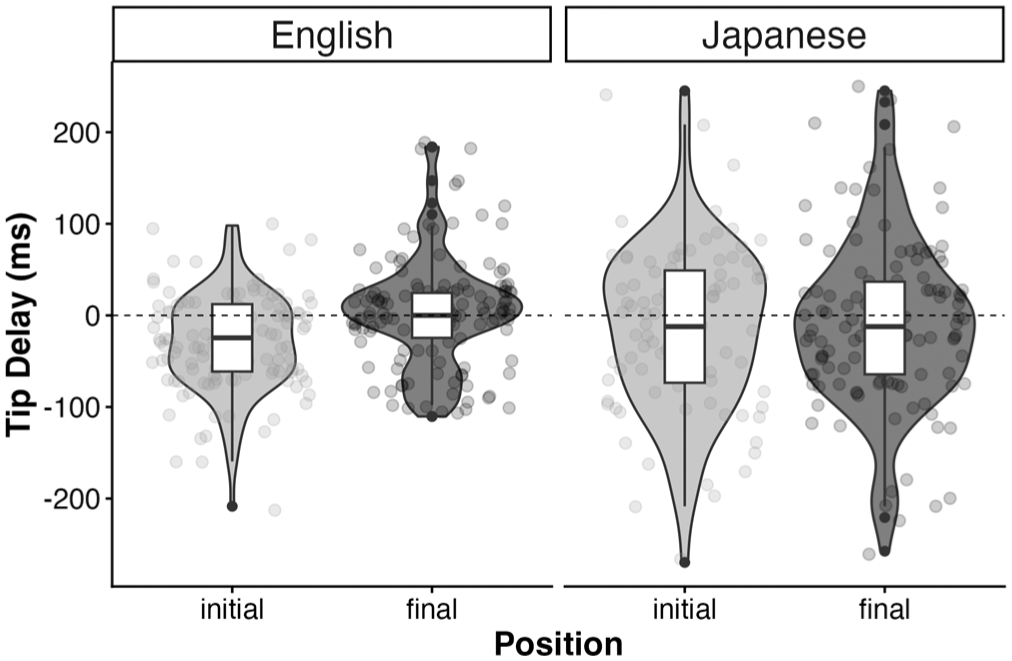
Time lag between coronal and dorsal gestures for initial and final laterals, produced by L1 English (left column) and L1 Japanese speakers (right column).
Although the magnitude of Tip Delay is overall small, L1 English speakers show a relatively clear onset-coda distinction in the timing pattern, in which the coronal gesture leads the dorsal gesture in the initial position (M = -30.04 ms, SD = 52.48), whereas the opposite pattern is marginally observed in the final position (M = 4.59 ms, SD = 60.13). The timing lag for L1 Japanese-L2 English speakers, on the other hand, is even smaller in magnitude. For both initial and final positions, the Tip Delay is negative (initial: M = -14.55 ms, SD = 88.86, final: M = -8.89 ms, SD = 92.31), suggesting that the coronal gesture tends to precede the dorsal gesture in both positions.
Tip Delay is modelled as a function of L1, position, gender, and the interaction between L1 and position in a Bayesian linear mixed-effect model. The regression coefficients are visualised in Figure 9 and further details can be found in Table B4 in Appendix B. The model is overall uncertain on the credibility of these effects, given that the 95% credible intervals for all fixed effects and the interaction encompass zero (L1:
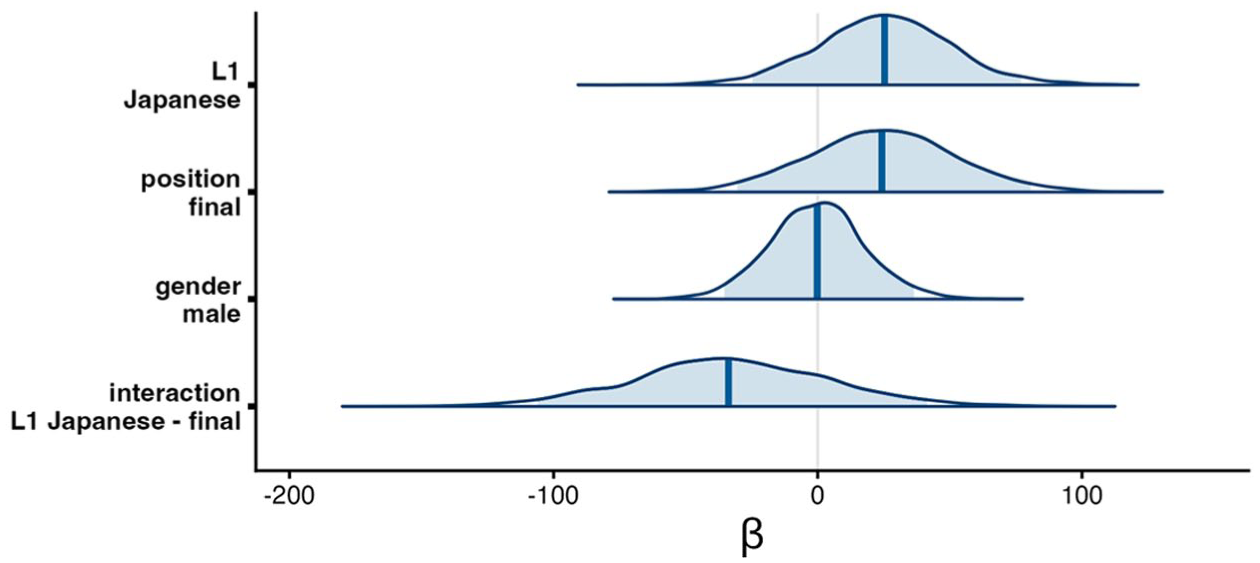
Posterior distributions of regression coefficients for Tip Delay (ms). Blue shading indicates 95% credible intervals; vertical blue lines indicate the median.
The uncertainty in effect estimation is also reflected in the post hoc pairwise comparisons, in which neither L1 English nor L1 Japanese-L2 English speakers show a fully decisive timing contrast between onset and coda laterals (L1 English speakers:
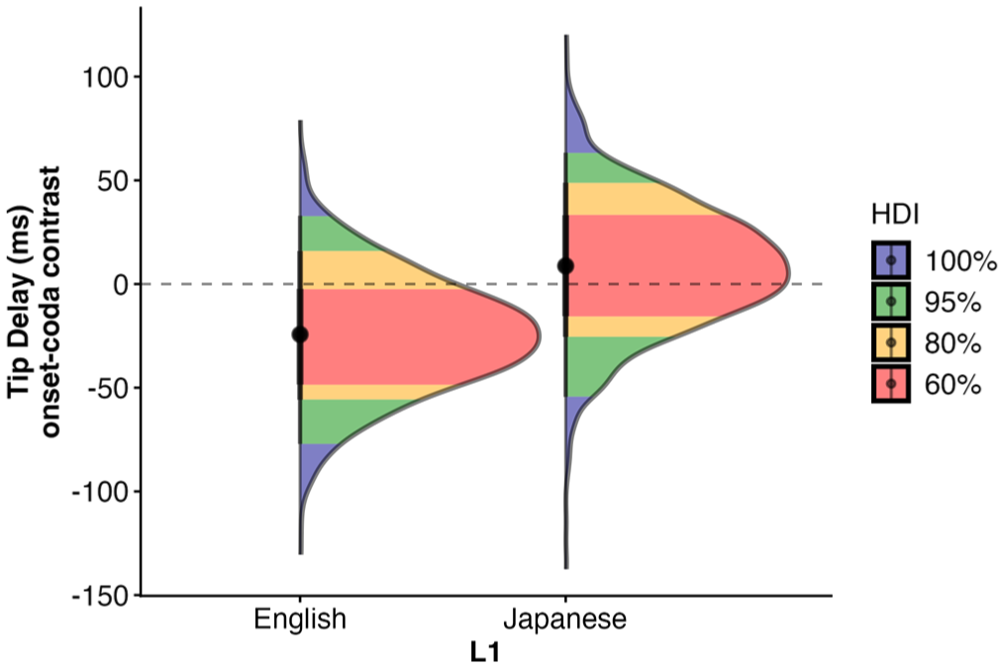
Posterior distributions for the onset-coda contrast in intergestural timing (ms).
To summarise, the intergestural timing results remain inconclusive due to substantial uncertainty, as reflected in wide posterior distributions and large standard deviations; for all fixed effects and interaction terms, the 95% credible intervals include zero as a plausible value. A closer examination of the post hoc pairwise comparisons, however, provides a more graded picture of this uncertainty: the onset-coda contrast appears more probable for L1 English speakers than for L1 Japanese-L2 English speakers.
4 Discussion
This study investigates the acoustic and articulatory characteristics of English lateral allophony produced by L1 English and L1 Japanese-L2 English speakers. The analysis is guided by two research questions, asking whether L1 Japanese-L2 English speakers make an onset-coda contrast in producing L2 English laterals, and if so, how they signal such allophonic variation.
The first research question is partially supported by the acoustic and tongue shape analyses. L1 Japanese-L2 English speakers make a clear contrast along the F2-F1 dimension in acoustics, a similar pattern to that of L1 English speakers. Both groups of speakers commonly show lower F2-F1 values for the coda laterals (i.e., darker) than for the onset laterals; however, the F2-F1 values for L1 Japanese-L2 English speakers are generally higher than those of L1 English speakers. The tongue shape analysis also finds that L1 Japanese-L2 English speakers differentiate tongue shape between onset and coda laterals primarily along the PC2 dimension, which captures the tongue tip height and associated variation along the tongue posterior. The intergestural timing analysis, however, does not provide clear evidence of the onset-coda distinction in the L1 Japanese-L2 English speakers’ production.
The nature of their production, addressed in the second research question, offers a somewhat complex picture. Despite a clear onset-coda contrast in acoustics, L1 Japanese-L2 English speakers’ production is found to be overall clearer across the two positions than that of L1 English speakers. In the tongue shape analysis, the two speaker groups differ in which dimension they signal the onset-coda lateral contrast: i.e., PC1 (overall height/frontness dimension) for L1 English speakers and PC2 (tongue tip height) for L1 Japanese-L2 English speakers. Finally, there is a tendency for the coronal gesture to lead the dorsal gesture in L1 English speakers’ production of initial laterals compared to their coda lateral production, whereas such timing contrast is not found for L1 Japanese-L2 English speakers.
Overall, these findings illustrate complex acoustic-articulatory relationships in L2 speech production, in which target-like acoustics do not always entail target-like articulation. It could be suggested that L2 speakers employ non-target articulation to achieve the target-like acoustic characteristics when producing L2 segments. This study also demonstrates that articulatory data are particularly useful in highlighting the mechanical source of difficulty in L2 speech production, offering deeper insights into the nature of L1 L2 interaction. Below, I discuss the findings in the light of: (1) L1 and L2 production of English lateral allophony, and (2) broader theoretical implications to L2 speech production.
4.1 Acoustic and articulatory characteristics of L2 English lateral allophony
L1 Japanese-L2 English speakers show a clear contrast between onset and coda laterals along the F2-F1 dimension in acoustics, agreeing with the previous research (Nagamine, 2022). A new insight here, however, is their overall clearer realisation of laterals, characterised by higher F2-F1 values, than that of L1 English speakers. This could be contextualised in the previous research in which L2 learners tend to ‘inherit’ the lateral quality from their L1 to their production of L2 English laterals while maintaining the onset-coda contrast (e.g., Barlow et al., 2013; Chung & Kim, 2021; Colantoni et al., 2023; Hwang et al., 2019; Kirkham & McCarthy, 2021; Solon, 2017). The underlying mechanism of the ‘/l/-lightening’ suggested in this study, however, may be different from the mechanisms discussed in the previous research, because the learners’ L1 (Japanese) does not have /l/ in its phonemic inventory. Acoustic data alone, therefore, do not seem to explain why L1 Japanese-L2 English speakers’ production is overall lighter than that of L1 English speakers.
The articulatory data helps us further explain the production of L2 English lateral allophony by L1 Japanese-L2 English speakers. Important considerations here include (1) the interactions between L1 and L2 phonetic categories, as claimed in SLM/SLM-r, and (2) the difference in articulatory properties between them. Previous L2 speech learning research has commonly argued that L1 Japanese-L2 English speakers assimilate English /l/ as a poor instance of Japanese /r/ (Aoyama et al., 2004). Given that the organisation of phonetic categories constitutes a basis for L2 speech production, as hypothesised by SLM/SLM-r, a plausible possibility is that L1 Japanese-L2 English speakers carry over the articulatory strategy for Japanese /r/ (i.e., alveolar taps/flaps [ɾ]) when producing L2 English /l/. Although this possibility has been put forward in the previous acoustic studies for L2 English /ɹ/, it has not been supported by articulatory data, leaving the claim inconclusive (Saito & van Poeteren, 2018). The articulatory data for this L1-L2 interaction could, therefore, help us explain non-target-like articulation for L1 Japanese-L2 English speakers, which may involve a less active dorsal gesture (Proctor et al., 2019; Recasens, 1991; Recasens & Rodríguez, 2016).
The tongue shape comparison demonstrates that L1 Japanese-L2 English speakers show onset-coda contrast along the PC2 dimension, as opposed to L1 English speakers along PC1. PC1 captures the overall adjustment of the tongue along the high-low and front-back dimension, which would require the global control of the whole tongue. PC2, on the other hand, seems to primarily capture the variation around the tongue tip and the associated movement of the tongue posterior. It could be argued that L1 Japanese-L2 English speakers differentiate tongue shapes by raising and lowering the anterior tongue, as opposed to L1 English speakers using the full extent of the midsagittal tongue. The active tongue tip movement and a less prominent tongue body movement appears to be a reasonable account in light of the articulation of alveolar taps and flaps [ɾ], in which the tongue dorsum needs to be somewhat stabilised to allow for a ballistic tongue tip movement (Recasens, 1991). The articulatory movements captured by PCs 1 and 2 would still result in a greater degree of tongue tip raising for the onset laterals than for the coda laterals, which could explain a comparable degree of anterior linguopalatal contact between L1 English and L1 Japanese-L2 English speakers’ production of onset /l/ in a previous EPG study (Kochetov, 2022).
Another possible explanation involves differences in the degree of tongue lateralisation, as suggested by an anonymous reviewer. L1 English speakers’ holistic midsagittal tongue shape manoeuvre, as evidenced by the PC1 results, may facilitate tongue narrowing on the coronal plane, resulting in the formation of lateral airflow channels. Although the current results do not offer direct insights into the active nature of tongue lateralisation discussed in previous research (Browman & Goldstein, 1995; Sproat & Fujimura, 1993; Strycharczuk et al., 2020; Ying et al., 2021), it is not entirely implausible that the observed midsagittal differences relate to lateral tongue posture. Indeed, previous impressionistic descriptions of articulatory settings suggest that the lateral margins of the tongue are anchored to the palate in English but to the floor of the mouth in Japanese (Honikman, 1964; Someda, 1966). Furthermore, recent experimental studies demonstrate that lateral bracing enables effective articulation of most English sounds (Gick et al., 2017) and that L1 Japanese speakers with low L2 English proficiency exhibit tongue lateral positions that differ from those of L1 English speakers even during pre-speech pauses (Wilson & Kanada, 2014). Overall, while somewhat speculative, the current midsagittal results may point towards between-group differences in coronal tongue shape and lateralisation, although more empirical studies are needed to fully investigate this possibility.
The between-group difference could further be supported by the intergestural timing analysis. On the one hand, we have observed an expected tendency for L1 English speakers, in which coronal gesture precedes dorsal gesture in the onset position, whereas this difference in timing is smaller in the coda position. Although it is still somewhat unexpected to find an almost synchronous timing for the coda position, this is not totally surprising given a small magnitude of gestural timing lag reported in the previous research, in some of which no statistically significant effects were found: e.g., an overall average of 22 ms for Australian English (Ying et al., 2021) and 28 ms for American English (Sproat & Fujimura, 1993), and an approximate range between −57.6 and 18.2 ms for Western Canadian English (Gick et al., 2006). Some of the previous research also argue that dorsal gesture may be correlated more with the degree of tongue mid lowering than tongue dorsum retraction itself, which could account for a smaller magnitude of the intergestural timing lag in this study (Sproat & Fujimura, 1993; Ying et al., 2021). Indeed, tongue mid lowering is indicated in the tongue shape analysis in this study (cf. Figure 5), which could have provided a more reliable correlate for the dorsal gesture. Nevertheless, the findings in the present study are broadly in the same direction as in the previous research, with the degree of uncertainty encoded in the posterior distributions in the Bayesian linear mixed-effect modelling employed in this study.
L1 Japanese-L2 English speakers, on the other hand, show almost synchronous coronal-dorsal timing across both syllabic positions, demonstrated by even a greater degree of uncertainty in the onset-coda timing contrast than for L1 English speakers (cf. Figure 10). This suggests that L1 Japanese-L2 English speakers’ English lateral allophony might involve different gestural organisations from that of L1 English speakers. Two possibilities can be proposed to account for the lack of onset-coda timing contrast. First, as has been discussed already in the tongue shape analysis, L1 Japanese-L2 English speakers may redeploy less active dorsal gesture from Japanese /r/ as a result of L1-L2 interaction of phonetic categories. Previous research shows that alveolar taps and flaps do not involve active dorsal gesture and are thus susceptible to vocalic dorsal coarticulation (Maekawa, 2023; Recasens, 1991). Carrying over this articulatory behaviour for their L1 Japanese [ɾ], they might not be able to exert an independent control over dorsal gesture when producing L2 English laterals, resulting in a lack of clear onset-coda timing contrast.
Another possible account is the difference in syllable structure between Japanese and English. The prevalence of CV syllable structures and the mora-timing in L1 Japanese often leads to vowel epenthesis that can be attested in loanword adaptation from English to Japanese, and in L1 Japanese speakers’ production of L2 English (Kubozono, 2015; Li & Juffs, 2014). L1-specific phonotactic knowledge has been shown to influence the perception of coda laterals by L1 Mandarin-L2 English speakers, in which they perceive the vocalic component in coda laterals as a separate vowel (e.g., /u/) (Wang et al., 2023). It is possible that L1 Japanese speakers’ production may be influenced by their existing phonotactic and orthographic knowledge, in which they might regard coda laterals as a sequence of a tap and a back vowel, similarly to the findings of Wang et al. (2023). This is a feasible possibility in light of the orthographic convention of the loanwords from English to Japanese, in which word-final liquids are usually notated with a Japanese mora symbol ‘る’ /ru/. Previous perceptual research shows that L1 Japanese speakers hear a /w/- or /u/-like percept when hearing English liquids in perception (Best & Strange, 1992; Guion et al., 2000). In production, L1 Japanese speakers tend to resort to vowel epenthesis as opposed to other modification strategies (e.g., deletion) (Li & Juffs, 2014). They also struggle to differentiate word-initial lateral from the following vowel in the /u/ environment in production (Nagamine, 2024a). The possibility that L1 Japanese-L2 English speakers may anticipate an ‘illusionary’ /u/ after the coda lateral, suggested by an anonymous reviewer, is also suggested in an ultrasound biofeedback training study (Yamane et al., 2025).
Overall, the key findings from this study are that L1 Japanese-L2 English speakers use non-target-like articulation to achieve target-like acoustics in differentiating the word-initial and -final L2 English laterals. The current study demonstrates that L2 speech production may involve a more complex picture than has been understood in the previous research in which the majority of conclusions have been drawn from acoustic data.
4.2 Beyond acoustics: articulatory complexity in L2 speech production
The current study demonstrates major articulatory differences between L1 English and L1 Japanese-L2 English speakers in producing English lateral positional allophony despite similar acoustic patterns. The acoustic results could suggest that the L1 Japanese-L2 English speakers in this study develop two separate phonetic categories for onset and coda laterals. The case of L1 Japanese-L2 English speakers’ production of L2 English liquids constitutes an important basis for our understanding of L2 speech learning given the extremely substantial difficulty involved. Few studies, however, have addressed how the two positional allophonic variations of L2 English laterals might be merged into L1 Japanese /r/ category, because the majority of previous empirical research focuses on how the phonemic contrast of English /l/ and /ɹ/ could be assimilated into the L1 Japanese /r/ category. Whereas a more elaborate study design than a simple speech production study is required to formally assess the nature of phonetic category formation (e.g., Hattori & Iverson, 2009), the current study adds supporting evidence to the key assumption of SLM/SLM-r that phonetic categories are formulated at the level of positional allophony as far as acoustics is concerned.
The articulatory results could also support the SLM/SLM-r’s postulation of allophone-level phonetic category formation, although these possibilities remain speculative due to a general lack of articulatory grounding in L2 speech research. While the tongue shape results could still suggest separate categories for onset and coda laterals, a lack of intergestural timing seems to suggest that L1 Japanese-L2 English speakers do not clearly differentiate the positional allophony of laterals. One way to account for the lack of a timing difference is that the phonetic category formation is position-dependent, such that L1 Japanese-L2 English speakers might assimilate both onset and coda laterals into the syllable-initial Japanese /r/ category, given a consistent slight precedence of coronal gesture across both syllable positions. This account seems feasible given the syllable structure difference between Japanese and English, in which Japanese /r/ only occurs at the syllable-initial position. Previous studies also report a position-dependent nature of perceptual accuracy of English /l/ and /ɹ/, which constitutes the empirical basis of the SLM/SLM-r’s postulation (Bradlow et al., 1997; Iverson et al., 2005).
At the same time, there is also a possibility that onset and coda laterals are assimilated into different categories. This possibility is better explained with Perceptual Assimilation Model for L2 speech learning (PAM-L2), which hypothesises that L2 learners assimilate L2 phonemic contrast into their L1 phonology based on direct perception of articulatory gestures (Best & Tyler, 2007). According to PAM-L2, L2 learners identify L1 and L2 sounds as functionally equivalent when involving the same set of articulatory gestures, and we may be potentially able to study how they are organised through the production data (Best & Tyler, 2007; Nagle & Baese-Berk, 2022).
Previous articulatory works demonstrate a position-dependent nature of gestural organisation for segments that involve multiple articulatory gestures. A general consensus here is that a gesture involving a wider vocal tract constriction is attracted to the syllable nucleus than the ‘narrower’ gesture, which explains that dorsal gesture would precede coronal gesture at the syllable-final position. (Krakow, 1999; Proctor et al., 2019; Sproat & Fujimura, 1993). Whereas the dorsal gesture needs to be actively coordinated to realise the position-dependent gestural organisation, the possible lack of dorsal gesture in Japanese and the syllable structure difference between Japanese and English, as discussed above, might influence the way L1 Japanese-L2 English speakers organise articulatory gestures for L2 English laterals. The tongue shape analysis, on one hand, seems to suggest that they make the onset-coda contrast primarily with the coronal gesture, which could be seen as equivalent to the tongue tip movement for Japanese /r/ (Gick, 2004; Sproat & Fujimura, 1993). On the other hand, there is a possibility that coda /l/s are assimilated into another phonological category, such as a sequence of alveolar tap and a back vowel /ɾu/, given a greater prominence of dorsal (i.e., vocalic) gesture (Krakow, 1999; Sproat & Fujimura, 1993). In short, this leads us to a possibility that, for instance, upon producing a word pair leap and peal, L1 Japanese-L2 English speakers might organise the articulatory gestures fundamentally as gestural sequences such a [
To summarise, the current study demonstrates that articulatory data helps us better understand the nature of the interaction between the L2 speakers’ L1 and L2 in L2 speech production. Whereas articulatory mechanisms are usually inferred from the acoustic measurements, the acoustic and articulatory findings in this study suggest that they do not always show an expected (i.e., target-like) relationship. Although the preliminary and thus speculative nature of the discussion needs to be highlighted, further articulatory studies are needed in order for us to understand how L2 speech production is shaped.
4.3 Methodological contributions, limitations and future directions
The articulatory component of this study joins a growing number of studies aiming to provide articulatory insights into L2 speech production (e.g., Colantoni et al., 2023). Notably, it demonstrates the usefulness of ultrasound tongue imaging in assessing the holistic picture of midsagittal tongue shape and the more localised kinematic patterns for different parts of the tongue. Ultrasound has a clear advantage in its capability of imaging the posterior part of the tongue, which has been inaccessible by other methods such as electromagnetic articulography (EMA) or electropalatography (EPG). Furthermore, recent improvements in frame rates and tongue spline estimation techniques make ultrasound a potent candidate for kinematic analysis (Kirkham & Strycharczuk, 2025). The L1 Japanese-L2 English speakers’ data included in this study were recorded outside the laboratory (i.e., the university classrooms in Japan), thanks to ultrasound’s increased portability, particularly suitable for fieldwork. With an increased ease in articulatory data collection using ultrasound, future studies could look not only at the acoustic properties but also at the articulatory aspects of L2 speech production to capture the nature of L2 speech production that acoustics alone may not fully characterise.
At the same time, as suggested by the tongue shape results, lateral tongue kinematics is a crucial aspect for better understanding the nature and acquisition of lateral consonants. Although ultrasound can also be used to study tongue shape on the coronal plane (e.g., Wilson et al., 2025), a growing number of EMA-ultrasound co-registration studies integrate the advantages of both techniques, enabling the investigation of holistic midsagittal tongue shape alongside three-dimensional flesh-point tracking with high spatiotemporal resolution (e.g., Strycharczuk et al., 2020). Tongue lateralisation remains an active area of inquiry in research on lateral consonants (e.g., Ying et al., 2021); recent advancements in articulatory techniques will facilitate a deeper understanding of the relationships between midsagittal and coronal gestures involved in the production of lateral consonants.
The data set analysed in this study is relatively small in size, consisting of a total of 471 tokens, which could be considered underpowered in the frequentist framework of statistical analysis. Bayesian linear mixed-effects modelling was adapted in this study to mitigate the chance of false positives while expressing the degree of uncertainty in parameter estimation in the width of the posterior distributions. The issue of running a frequentist regression model on a very small data set is summarised in Sóskuthy et al. (2023). In addition, the Bayesian framework offers a gradient interpretation about the probability of the estimated parameters, which helps us fully explore the modelling outcomes beyond just accepting or rejecting the null hypothesis, as demonstrated in the post hoc pairwise comparison for the intergestural timing analysis (cf. Figure 10). Overall, the current study contributes to the existing body of research by showcasing an alternative statistical tool that allows for a reliable, quantitative assessment of the acoustics and articulatory data even for a smaller sample size.
It has become apparent that, despite the rich amount of previous research, articulatory data are relatively scarce in the topic of L1 Japanese-L2 English speakers’ production of L2 English liquids. The gestural account of L1-L2 interaction in the previous section had to be speculative, largely due to an immediate gap of literature addressing the articulatory/gestural nature of Japanese /r/. Although previous studies demonstrate a less active nature of dorsal gesture of alveolar taps and flaps for Catalan (Recasens, 1991), an alternative proposal has been put forward that all liquid consonants can be characterised by the presence of coronal and dorsal gestures (Proctor, 2011; Proctor et al., 2019). Whether a dorsal gesture is active or not is crucial in advancing the topic, especially in light of the gestural framework posited in PAM-L2 (Best & Tyler, 2007). The role of the tongue dorsum for Japanese /r/ remains unclear; whereas an EMA study demonstrates that Japanese /r/ might be characterised with a somewhat retracted tongue dorsum, which could suggest a gestural specification for tongue dorsum, an ultrasound study claims that dorsal gesture is not specified for Japanese /r/ (Morimoto, 2020; Yamane et al., 2015). The insights into the dorsal involvement for Japanese /r/ could be obtained by studying its regional variation; although there is little research addressing this issue, one previous study reported a longer vowel duration for /d/ and /r/ in speech produced by a Kansai Japanese (western Japanese) speaker, compared to a Tokyo Japanese speaker (Sugito, 1985). Given that both articulatory insights are obtained by studying regional variations of laterals in English (e.g., Carter & Local, 2007; Kirkham et al., 2020; Turton, 2017), a similar approach could also be taken in Japanese, which could lead to a much better understanding of the typology of the liquid consonants in the world’s languages.
5 Conclusion
This study investigates the production of English lateral positional allophony by L1 English and L1 Japanese-L2 English speakers. It combines acoustic (F2-F1) and articulatory analyses (tongue shape and intergestural timing) to obtain a holistic picture of the nature of L2 speech production. L1 Japanese-L2 English speakers make an onset-coda lateral contrast along the F2-F1 dimension, but their lateral realisation is overall clearer than that of L1 English speakers. Two speaker groups differ in the way they differentiate tongue shapes, in which L1 English speakers exhibit a global height/frontness difference, whereas L1 Japanese-L2 English speakers signal the onset-coda contrast primarily around the tongue tip. Finally, although neither group shows a clear onset-coda contrast in coronal-dorsal gestural timing, L1 English speakers show an expected tendency in which coronal gesture precedes dorsal gesture for the onset /l/. L1 Japanese-L2 English speakers, on the other hand, show little timing contrast between onset and coda laterals.
The findings overall suggest a complex interaction between the learner’s L1 and L2 when the two languages do not have the same phoneme. In such a case, this study highlights that the acoustic findings may underestimate the variability that could be seen in the articulatory domain. In particular, the results are discussed in light of the two theoretical frameworks of L2 speech learning, demonstrating that articulatory evidence is crucial in advancing our understanding of the underlying mechanism of L2 speech production resulting from a complex L1-L2 interaction. Despite an apparent lack of articulatory data in the field, it has been demonstrated that future articulatory research will further advance our understanding of the mechanical source of foreign accents in L2 speech production.
Footnotes
Appendix A Correlation between DLC knots
Appendix B Statistical results
Acknowledgements
This is part of the author’s PhD research at Lancaster University in the United Kingdom. I thank the following individuals for their support and encouragement in enabling the research project: Claire Nance, Sam Kirkham, Bronwen Evans, Noriko Nakanishi, and Yuri Nishio. Thank you, Alan Wrench, for all your technical support in ultrasound and for your dedication to making ultrasound accessible.
Ethical considerations
This research is approved by ethics committees at Lancaster University, Kobe Gakuin University, and Meijo University.
Consent to participate
Informed consent was obtained from all participants.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is financially supported by the Graduate Scholarship for Degree-Seeking Students by the Japan Student Services Organization (JASSO) [ID: 20SD10500601] and the 2022 Research Grant by the Murata Science Foundation [grant number: M22助人027] awarded to the author. Codes and data supporting the findings in this article are publicly available at ![]() .
.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.