
Abstract
In speech perception, listeners tend to hear real words rather than non-words on a physically balanced real word—non-word continuum (lexical bias effect). Bourguignon et al. found a similar effect in speech production: With spectral auditory feedback perturbations, they altered vowels toward other vowels thereby causing a shift in lexical status (from word to non-word or vice versa) or not. This study tests whether the lexical bias effect can be extended to the temporal domain in speech production. We perturbed the German vowels /a/ and /a:/ in real words toward the respective other phoneme using a real-time temporal auditory feedback adaptation paradigm. This manipulation pushed the percepts either toward another real word (lexical condition) or not (non-lexical condition). In both perturbation setups (stretching short /a/, or compressing long /a:/), speakers counteracted the perturbation with productions opposing the direction of perturbation. However, response magnitude was similar across conditions, that is, independent of a shift in lexical status. The results indicate that, in the temporal domain, speakers do not heavily rely on higher-level linguistic information, but rather are principally oriented toward maintaining phonemic identification. These findings further imply that temporal and spectral parameters in speech production and perception are governed by different processing strategies.
1 Introduction
Humans perform innumerable motor tasks every day. Speaking is one of the most complex uniquely-human motor tasks carried out on a daily basis. In speech, a large set of muscles of the speech apparatus is coordinated to form language-specific acoustic outcomes such as syllables or words. This coordination requires the precise interplay of neurological and motor systems to ensure precision in timing and sequencing, as well as in the spectral shape of the intended speech segments. In so doing, the system incorporates information from the auditory and tactile senses. In speech acquisition, mental representations of speech segments are built using information about how a speech segment should sound (auditory feedback) and feel (somatosensory feedback). Learned speech segments can then be read-out in a feedforward manner by solely relying on mentally stored articulatory motor patterns (Guenther, 2016, pp. 193–194). For speech as a rapid high-precision motor skill, building this feedforward representation is crucial, since sensory information can only be perceived with a delay, that is, after the production has already been initiated. After initiation, the feedback channels provide guidance for evaluating and controlling the ongoing speech production process. If the feedback does not match the predictions, corrective movements can be initiated, constituting a feedback-feedforward loop (Perkell, 2012). Over the last decades, exploring the establishment and representation of speech segments has been of vital interest in speech research. An effective method for examining the role of auditory feedback in speech production and the representation of speech segments is through auditory feedback perturbations.
In auditory feedback perturbations, a parameter in the speech signal, such as a formant frequency of a vowel, is altered in real-time and sent back to the speaker via headphones, thus masking their naturally produced feedback. In response, speakers typically alter their ongoing productions with adjustments in the opposite direction to the applied shift—they compensate for the auditory error. For example, the seminal studies of Houde and Jordan (1998, 2002) inter alia shifted vowel formants of /ε/ so that the vowel sounded more like /ɪ/. Subsequently, the speaker compensated in the opposite direction of the formant shift, producing a vowel that sounded more like /æ/. Compensatory adjustments to an ongoing feedback shift can occur in the ongoing speech production process with a latency of 120 to 200 ms (online compensation, Purcell and Munhall, 2006b; Tourville et al., 2008); adjustments can, however, even persist into a phase where normal, masked, or no feedback is provided. The latter indicates an update and retuning of the underlying representation, usually referred to as adaptation (see Caudrelier & Rochet-Capellan, 2019 for an overview).
In determining the guiding forces behind such responses, several studies have indicated that speakers’ responses are sensitive to the linguistic and/or phonological system of their native language(s) and do not linearly mirror any frequency shift independent of phonological surroundings. Niziolek and Guenther (2013), for example, introduced formant shifts that fell either comfortably within the speaker’s vowel category (e.g., shifting /ε/ in /bεd/ toward another phonetic realization of /ε/), and perturbations that fell near/across a phonemic boundary (e.g., shifting /ε/ in /bεd/ toward a version that sounded more like /bæd/). They found that the amount of compensation was three times larger when the shift fell near a phonemic boundary, indicating that the feedback-feedforward integration is sensitive to linguistic categories, with speakers aiming to maintain the intended category in production. Another study, by Mitsuya et al. (2011), examined the effect of phoneme boundaries in two different native speaker groups to test for the influence of the speakers’ native phonological systems. They examined responses to first formant (F1) shifts in English speakers producing the English /ε/, native Japanese speakers producing the Japanese /e/, and native Japanese learners of English producing the English /ε/. All vowels were embedded in mono-syllabic real words in the respective languages. While all three speaker groups showed similar response patterns to a decrease of F1 in the auditory feedback (i.e., when the resulting percept approached /ɪ/ in English or /i/ in Japanese), in the other condition, both Japanese groups compensated less than the native English group to the increase of F1 in /e/ and /ε/, when the percept was shifted toward /æ/. Mitsuya et al. (2011) concluded that the reduced compensation in the Japanese groups could be an effect of the auditory feedback shift failing to approach another vowel category in their native language: While in English both shifting directions lead to a percept that is close to another vowel in their system (/ɪ/ and /æ/, respectively), in Japanese, only the decrease of F1 might have resulted in another phoneme (/i/). The perturbed vowel percept of an increased F1 did not fall into the region of another existing vowel in Japanese and could hence more easily be accepted as a production of the intended vowel category (/e/). These results have been taken to suggest that the phonological system of a language modulates the impact of auditory feedback during speech production, visible in larger compensatory responses when the feedback shift approaches another phonemic category in the speakers’ native language. While discussing this latter study it is of particular relevance for our present investigation to note that the shift to another phonemic category was closely tied to a shift in lexical identity: For the perturbed mono-syllabic real words in both languages, the upward perturbation shifted the vowels not only toward other phonemes but also toward other lexical items in both languages.
A review of the literature on adaptation to spectrally shifted auditory feedback leads to the conclusion that the majority of studies perturbed vowels in words toward other existing (and therefore phonotactically legal) words, with the vowel of interest being the distinctive element in the minimal pair (see, for example, MacDonald et al., 2010; Nault & Munhall, 2020; Purcell & Munhall, 2006a). However, phoneme boundaries do exist dissociated from lexical boundaries (i.e., it is possible to recognize vowels in isolation or in non-word contexts) and with most of the mentioned studies the contribution of phonemic and lexical identity remains blurred. To examine the connection between lexical and phonemic identification, Bourguignon et al. (2014) investigated the role of lexical status (e.g., shifting from a real word to a non-word) dissociated from phoneme boundaries. Their motivation rose from the bias of the speech production system (as revealed in slips of the tongue) to rather confound phonemes in words when the permutation results in another real word (Baars et al., 1975). This phenomenon resembles the lexical bias effect that has previously been observed in speech perception: When speakers were exposed to stimuli on a continuum between a word (dash) and a non-word (tash), their responses were biased toward word-perception over non-word perception (Ganong, 1980). While this lexical bias effect robustly shows in speech perception, it is not yet well established to what extent lexical biases affect self-perception. The study by Bourguignon et al. (2014) used feedback manipulations of vowels that either maintained the lexical status, for example, from a real word to another real word or shifted the lexical status, for example, from a real word to a pseudo-word. Specifically, in that study, the F1 in the vowel /ε/ was shifted in all target words downward toward /ɪ/. Thus, the shift always crossed a phonemic boundary, but with a special interest in higher-order linguistic processing. The design consisted of four conditions, of which two caused a change in lexical status from real word to pseudo-word (e.g., less–liss) and vice versa (e.g., kess–kiss), and two conditions that did not change the lexical status (from real word to real word, e.g., mess–miss; and pseudo-word to a pseudo-word, e.g., ness-niss). In that study, responses to the F1 shift were more pronounced in perturbations that changed a pseudo-word to a real word than a real word to a pseudo-word; and a real word to another real word compared with when a real word was changed to a pseudo-word. In contrast, no difference was found between the two conditions in which the perturbation caused no change in lexical status (pseudo-word to pseudo-word and real word to real word). In sum, the study by Bourguignon et al. (2014) indicated that the lexical bias effect can indeed be observed in speech production, whereby a spectral auditory shift toward a(nother) real word is more saliently perceived as an error and counteracted for to a higher extent than a shift of similar size that does not result in a(nother) real word.
Similar to the study by Bourguignon et al. (2014), the dissertation by Frank (2011) investigated the effect of lexical biases on speech production in self-produced speech with auditory feedback perturbations. Frank (2011) used formant shifts of F1 to alter a real word (e.g., “bed” toward “bid”) with a special interest in whether the heard feedback is another real word (heard competitor) and whether the expected opposing response (here: “bad”) would also be a real word (spoken competitor) or not. With different experimental paradigms that either had a heard competitor, a spoken competitor, both or neither, this study found weaker adaptive responses for words with a spoken competitor and stronger adaptive responses for perturbed words with a heard competitor.
Intriguingly, the majority of auditory feedback perturbation studies have focused on spectral properties of speech. Yet, the lexical bias effect also works with temporal properties of speech. Notably, the first study by Ganong (1980) assessed a phoneme contrast that is cued by duration (voice onset time [VOT]: dash—tash). More recently, a few studies have started to delve into the malleability of temporal parameters in speech by stretching or compressing parts of the speech signal in real time and observing speakers’ reactions. These studies provided evidence that not only spectral but also temporal information in speech production is guided via auditory feedback and possesses representations that, in some cases, can be updated (or adapted, Floegel et al., 2020; Karlin et al., 2021; Karlin & Parrell, 2022; Mitsuya et al., 2014; Oschkinat & Hoole, 2020, 2022). In response to these temporal manipulations, speakers adjusted segment durations in the opposite direction of the shift by shortening segments that were stretched in manipulation, and lengthened segments that were compressed (and delayed by the amount of previous stretching) in the auditory feedback. In some cases, these adjustments remained after perturbation was removed (adaptation). Technically, in temporal manipulations, opposing responses of perturbed segments can only be adaptive (on a trial-to-trial basis) and not online compensatory, even if the adjusted production patterns do not persist for long after perturbation is removed. This is due to the nature of temporal perturbations: because a segment must be perceived in its entirety before the duration can be determined, corrective responses can only be initiated for the next production attempt, hence with an updated motor command. In addition to adaptation, in temporal perturbations, lengthening responses or a slowing down of the segments following stretched segment(s) was to be observed (reactive feedback control). This reactive feedback control response emerges within the ongoing production process and is thus an online response, presumably evoked by the delay caused by the stretching perturbation, and the different relative durations of segments within a word. That is, if the onset of a word is stretched, the following vowel will start with a delay (delayed by the amount of onset stretching). The reactive response might be a slowing down due to the delayed auditory feedback (DAF), and additionally due to distorted durations within the syllable: Since the onset is stretched, speakers may want to lengthen following segments to match proportions within the syllable. Note, however, that this response is not corrective in the sense that it is counteracting the direction of perturbation.
Responses to temporal feedback manipulations have not been completely consistent over the speech material and languages investigated to date. A variety of different factors that could have an impact on adaptation to temporal perturbations have been considered. Oschkinat and Hoole (2020) perturbed the German words “Pfannkuchen” (/pfankuːxən/, pancakes) and “Napfkuchen” (/napfkuːxən/, ring cake), stretching the onset /pf/ and compressing the vowel /a/ in /pfan/ and stretching the vowel /a/ and compressing the coda /pf/ in /napf/. They found opposing responses to perturbations of both vowels and the coda, but not in the onset of the syllable. Based on this they suggested that in temporal control, syllable onsets might be less sensitive to errors in the auditory feedback, rely more on feedforward production and are hence less malleable in production than other parts of syllables. However, Karlin and Parrell (2022) did find adaptive responses to stretched VOT in onset consonants. Specifically, Karlin and Parrell (2022) investigated the role of temporal perturbation either crossing a phonemic category boundary or not in word-initial English consonants. In their cross-category condition, they stretched a previous segment before compressing the VOT in a word-initial /t/ (where duration can be considered the primary cue) or the duration in /s/ toward /z/ (where duration can be considered the secondary cue). Hence, the word tapper sounded closer to the word dapper, and the word sapper sounded closer to the word zapper. Thereby, the compression in both words caused a shift in phonemic (and lexical) identity. In the within-category condition, stretching the VOT of the word-initial /k/ in the real word copper or frication duration of /ʃ/ in the real word shopper could not possibly result in other phonemes (or words). Their results showed that speakers did adapt for the manipulations for both words in the cross-category condition by lengthening the VOT in tapper or fricative duration in sapper. In the within-category condition, speakers also counteracted the manipulation in copper by shortening VOT in production (but lengthening the closure duration). No reaction was found for manipulations of shopper. The learning effect (adaptation) when perturbation was removed was equally strong for all words that showed an effect (tapper, sapper, and copper). While this study provides evidence that onsets can indeed be updated, it does not unconditionally support the assumption that phoneme category crossing is the primary source to drive adaptive responses in manipulations of speech timing. Rather, the authors suggest, it seems that speakers respond to temporal shifts that cause either highly untypical tokens of the intended segment, independent of the change toward another category (phoneme and word, in this case) or to shifts that lie outside a typical phoneme but with no adjacent other phoneme (and thus word). Note that this assumption is also plausible for the findings in Oschkinat and Hoole (2020): By stretching the vowel /a/ in “Napfkuchen” in the auditory feedback, the shift pushed near/across the phoneme boundary toward the phoneme /a:/. Although there is no word (or compound with) /na:pf/ in German, (moreover, the long vowel before a coda cluster is phonotactically illegal), speakers adaptively shortened their productions of /a/ in “Napfkuchen.”
While Karlin and Parrell (2022) provide first evidence that phonemic identification might play a different role in speech timing than it does for spectral information, their experimental paradigm leaves unsettled issues to investigate: Previous temporal auditory feedback perturbation studies agreed on the suggestion that there is a bias for lengthening responses being more easily produced than shortening responses (Karlin & Parrell, 2022; Oschkinat & Hoole, 2020). By comparing two conditions that used different perturbation directions, whereby one condition additionally delayed the target while the other did not, the paradigm in Karlin and Parrell (2022) might have biased their outcome and affected the comparability of the conditions. Furthermore, as noted previously for spectral perturbation studies, in this case, too, crossing of a phonemic boundary was always closely tied to the crossing of a lexical boundary from one lexical identification to another. Hence, the influence of phonemic vs. lexical status remains unclear.
This study is concerned with the role of phonemic vs. lexical identity along the temporal dimension. We compare responses to phonemic shifts that do not cause a shift in lexical status (e.g., shifting a real word toward another real word) with responses to phonemic shifts that also cause a shift in lexical status (from a real word toward a non-word) using the same perturbation setup across the compared conditions. Although the collection of our data had already started prior to the publication of Karlin and Parrell (2022, see Section 2.1 for details), it complements this previous study well due to its different methodology.
In English, duration as a primary cue for establishing phoneme boundaries is not as ubiquitous as formant frequencies are for delineating vowels. In German, however, the vowels /a/ and /a:/ differ almost exclusively in duration without remarkable differences in spectral properties (Jessen, 1993; Pätzold & Simpson, 1997). Hence, it can be assumed that minimal pairs such as /ʃta:t/ and /ʃtat/ differ predominantly in vowel duration. Similar to the study by Bourguignon et al. (2014), the segmental perturbation of the vowels /a/ and /a:/ in this study pushed the vowel percepts near/across phoneme boundaries. The manipulation involved two perturbation conditions: one where the critical vowel was compressed and one where it was stretched. In addition, each condition comprised two target words: One where the perturbation led to a shift in lexical status from real word to non-word, and the other one without a shift in lexical status (from one real word to another real word). Consequently, the applied perturbation (stretching and compressing of segments) was balanced over the two lexical conditions.
If speakers respond similarly in both lexical conditions (i.e., lexical status does not matter), we may conclude that speakers attend to phonemic identification more than to lexical status. If speakers respond more strongly in the condition that shifts a real word toward another real word than a real word toward a non-word, it can be concluded that lexical status plays an additional role in the control of speech timing, further indicating that word productions on a word—non-word continuum are more flexible toward the non-word boundary (lexical bias effect). Accordingly, with this study, we aim to shed light on the mechanisms for controlling speech timing focusing on phonemic and lexical status.
2 Methods
In the following, we report the characteristics of the tested sample (Section 2.1) and the implementation of the experimental procedure (Sections 2.2 and 2.3). Section 2.4 reviews the reliability of the procedure, including an issue with a malfunction at a technical level that led to testing of additional participants before analyses. Section 2.5 outlines data preparation and exclusion; Section 2.6 then outlines the analytical strategy for the main analyses of the vowels (Section 3) and the additional analyses of the consonants (Section 4) and further gives a visual overview of the response data (Figure 4). We report how we determined the measures of interest along with the R version and R packages used for the reported analyses (Section 3). The study’s design and the analyses were not pre-registered. We used the STROBE cross-sectional reporting guidelines (Von Elm et al., 2007). This study was approved by the ethics committee of the medical faculty of the Ludwig Maximilian University of Munich on August 10, 2017.
2.1 Participants
Initially, 51 participants were tested in 2018/2019. After post-processing the data and verifying the fit of the perturbation to each participant’s speech, another set of 10 participants was tested with improved implementation of the perturbation procedure (see Section 2.4), resulting in a total number of 61 tested participants (51 females, 10 males). We considered the sample size adequate to large compared with previous auditory feedback perturbation studies, which commonly used 15 to 20 speakers per group (see Caudrelier & Rochet-Capellan, 2019 for an overview). The exact implementation as well as participant exclusion rules will be outlined further below. All participants were native speakers of German recruited in the Munich area, between 18 and 34 years of age (mean age 23 years), and none of the participants claimed to have any speech or hearing impairments. All participants gave informed written consent to participate in this study.
2.2 Experimental setup
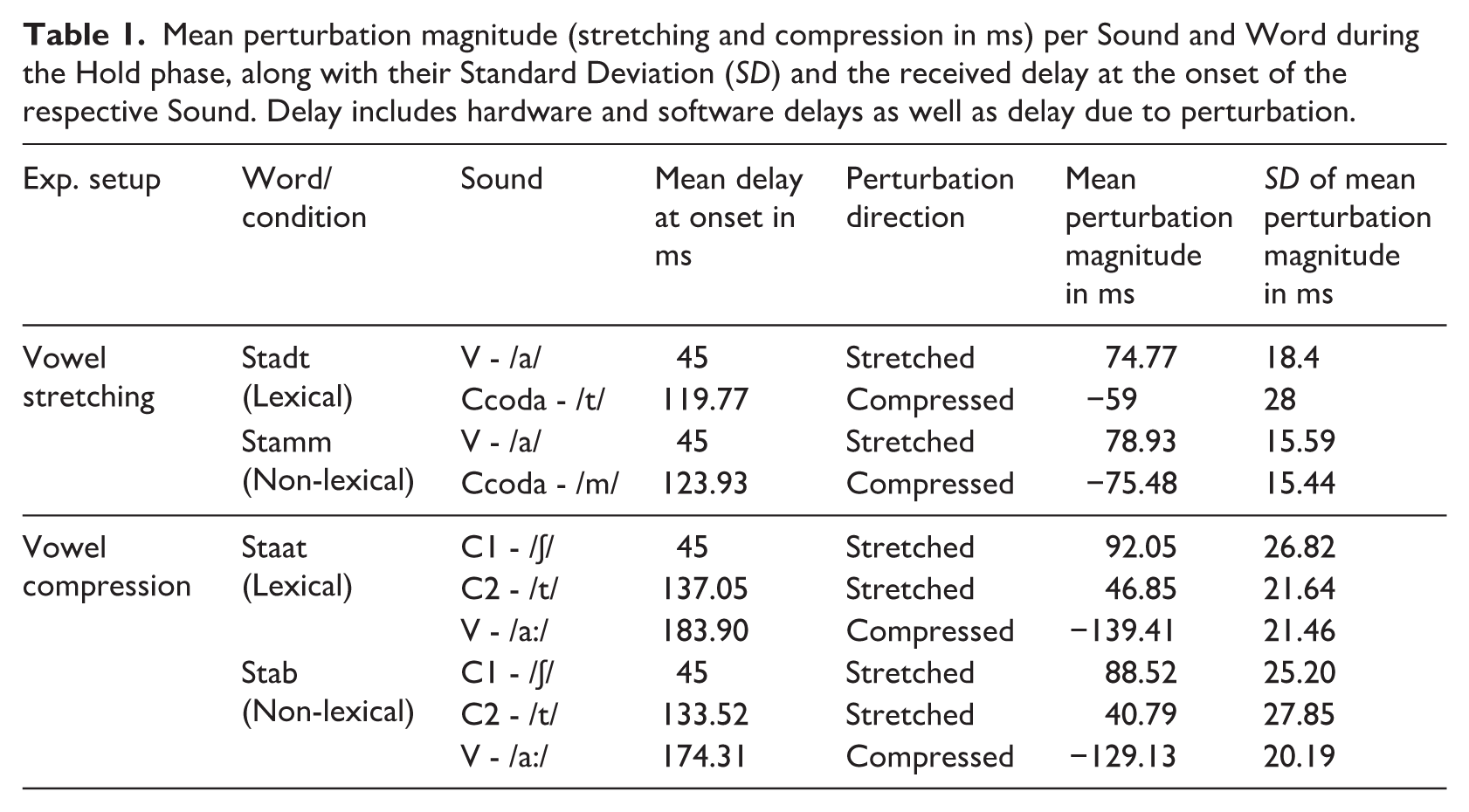
Real-time temporal auditory feedback perturbation was implemented in Matlab using the time-warping function of Audapter (Cai et al., 2008, 2011) with similar setups as in Oschkinat and Hoole (2020, 2022). Participants spoke into a Beyerdynamic TG H74 headset microphone (Heilbronn, Germany) placed 3 cm from the corner of the mouth. The spoken signal was fed into the computer and sent back via E-A-RTone 3A in-ear earphones with foam eartips (3M, Saint Paul, MN, USA) which minimize airborne sound transmission. Feedback was sent back to the participant with a total delay of around 45 ms. This delay is the sum of the buffering and processing delays in the Audapter software plus the hardware delay from the MOTU Microbook II soundcard (estimated at 12–13 ms, cf. Kim et al., 2020) 1 . Note, however, that this delay was already received during the Baseline, and did not cause any visible trends or effects of DAF during the Baseline. In real-time temporal auditory feedback perturbation, it is necessary to first stretch one part of the signal before a subsequent part can be compressed, otherwise the signal that should serve as feedback would not yet have been produced after the received compression. Therefore, in this study the stretched part in the signal always preceded the compressed part. The perturbation was implemented in two experimental setups focusing on the German vowel length contrast between the vowels /a/ and /a:/: One setup stretching the vowel /a/ (Vowel stretching setup) and one setup compressing the vowel /a:/ (Vowel compression setup), each of them comprising two words/conditions. In one condition the perturbation did not change lexical status (real word to another real word). This condition will be termed lexical condition. The other word was perturbed toward a change in lexical status from real word to non-word, hence not toward another lexical item. This condition will be termed non-lexical condition. In the Vowel stretching setup, the short vowels /a/ in the target words Stadt (/ʃtat/, city) and Stamm (/ʃtam/, trunk) were stretched toward /aː/ and the following coda consonants /t/ or /m/ were compressed, respectively. In doing so, Stadt was perturbed toward the real word Staat (/ʃtaːt/, state, lexical condition), while Stamm was perturbed toward a non-word (/ʃtaːm/, non-lexical condition). In the Vowel compression setup, the onset consonants /ʃ/ and /t/ in the target words Staat (/ʃtaːt/, state) and Stab /ʃtaːp/, pole) were stretched, and the long vowels /aː/ were compressed to result in the real word Stadt (/ʃtat/, city, lexical condition) and the non-word /ʃtap/, (non-lexical condition, see Table 1 for an overview). Note that with this implementation the compressed sounds were not only compressed, but also delayed by the amount of stretching of the previous segment. Table 1 summarizes the delays during the Hold phase and provides an overview of which sounds were stretched and which were compressed.
Mean perturbation magnitude (stretching and compression in ms) per Sound and Word during the Hold phase, along with their Standard Deviation (SD) and the received delay at the onset of the respective Sound. Delay includes hardware and software delays as well as delay due to perturbation.
Each participant performed either both conditions/target words of the Vowel stretching setup or both conditions/target words of the Vowel compression setup (23 participants performed the Vowel stretching setup Stadt/Stamm, 38 participants in total performed the Vowel compression setup Staat/Stab). The order of tested words within the perturbation setup was counterbalanced between participants, and participants had a short break in which they read a wordlist before being tested in the second condition. Participants read the lexically presented German phrase “besser [target word]” (/bɛsɐ/, better [target word]) from a computer screen in front of them in 110 trials per condition/word. Perturbation was applied in a classical adaptation paradigm, whereby the first 20 trials served as a reference where normal feedback was provided (Baseline). In the following 30 trials (Ramp phase), perturbation was incrementally increased for each trial up to maximum perturbation. The maximum perturbation was held for another 30 trials (Hold phase) before normal feedback was abruptly restored and continued for another 30 trials (After-Effect phase, see Figure 1 for visualization). The carrier word besser was chosen to provide a larger prosodic context (an utterance) and additionally facilitated detection of the part in the target word that should be affected by the perturbation, this being achieved with Audapter’s online status tracking (OST, see Section 2.3).
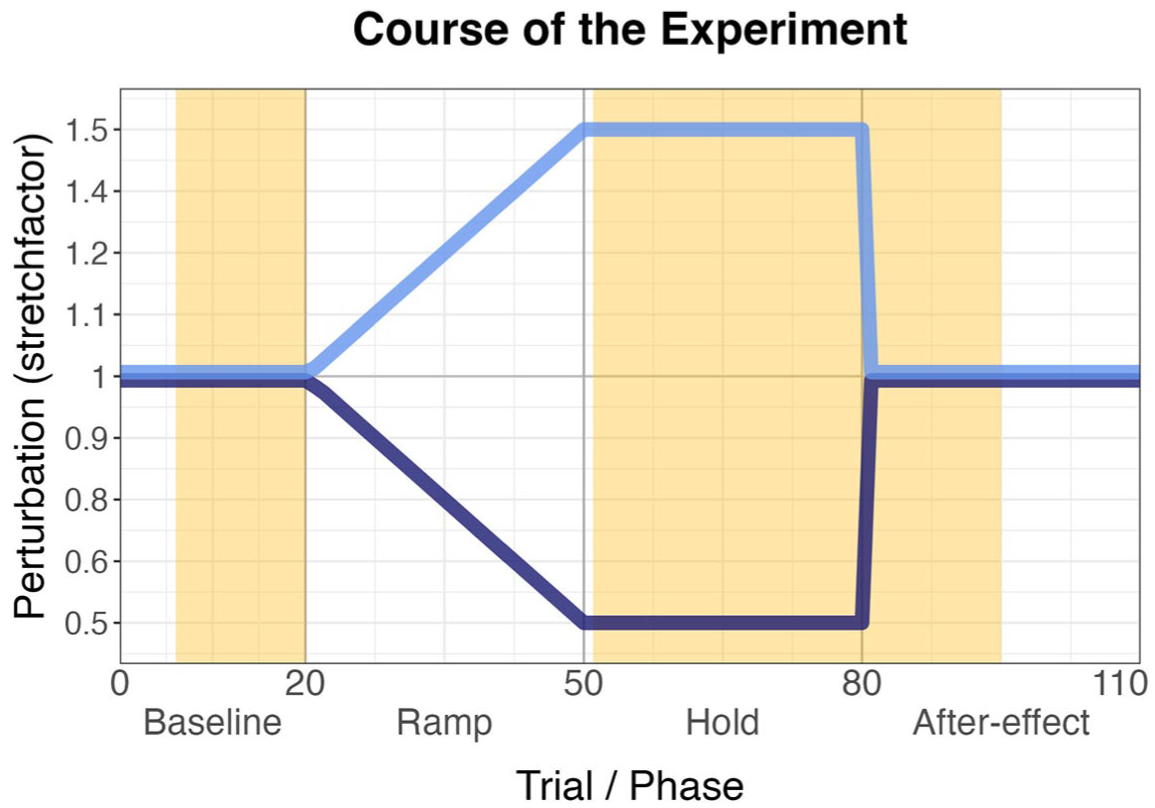
Course of the experiment with trial number/phase on the x-axis and the amount of perturbation (stretch factor) on the y-axis. 1 indicates that the signal was played back as produced; the other numbers indicate the proportion of compression or stretching (stretching in light blue, compression in dark blue). The yellow part marks the trials used for statistical comparison between Baseline (Trials 6–20) Hold phase (Trials 51–80) and early After-effect phase (81–95).
For each of the tested target words, the participant performed a pretest which consisted of 10 to 15 trials of the experiment with no perturbation; this served to adjust the microphone level and to analyze individual duration patterns in the produced speech for implementation into the main testing protocol (see Section 2.3). It further served to get the participant used to the procedure and establish a stable speaking rate and volume.
2.3 Implementation
The implementation of the temporal real-time perturbation required two main parts: First, the start of the perturbation needed to be detected in the ongoing speech signal with Audapter’s OST, which was generically pre-defined for all participants per experimental setup (i.e., Vowel stretching vs. Vowel compression). Second, the OST had to be complemented with participant-specific information about the duration of the part in the signal that should be perturbed (perturbation section). The latter was established in the pretest and determined for each participant and word individually.
The OST is a part of the Audapter software package and is a tool for detecting high- and low-frequency weighted intensity thresholds based on the speech signal’s short-time root-mean-square (RMS) amplitude. This OST finds user-configured pre-defined thresholds as landmarks in the acoustic signal to identify the temporal progress of the utterance being spoken. In due course, the OST activates the perturbation at a certain landmark for a predefined time (duration of the perturbation section). For the Vowel stretching setup (Stadt and Stamm), the OST was programmed to find several acoustic events before detecting the onset of the vowel /a/ in the target word and then directly trigger the perturbation (stretching the /a/, compressing the coda, see Figure 2(a)). In the Vowel compression setup, the initial OST implementation detected the offset of the /s/ in besser, after which an individual duration per participant was implemented. This duration corresponded to the duration of the vowel /ɐ/ − the typical pronunciation of -er in German—before both Staat or Stab to then trigger the stretching at the beginning of the /ʃ/. This individual duration was measured by the experimenter in the pretest trials and was subsequently implemented as their final (fixed) OST state duration (“elapsed time” command) into the testing protocol. To then determine the part in the signal that should be stretched and compressed in both setups, the experimenter measured the mean duration of the perturbation section (/am/ or /at/ in the Vowel stretching setup, /ʃta:/ in the Vowel compression setup) in the 10 to 15 pretest trials and implemented the mean duration into the test protocol (see Figure 2, segment “Perturbation”).
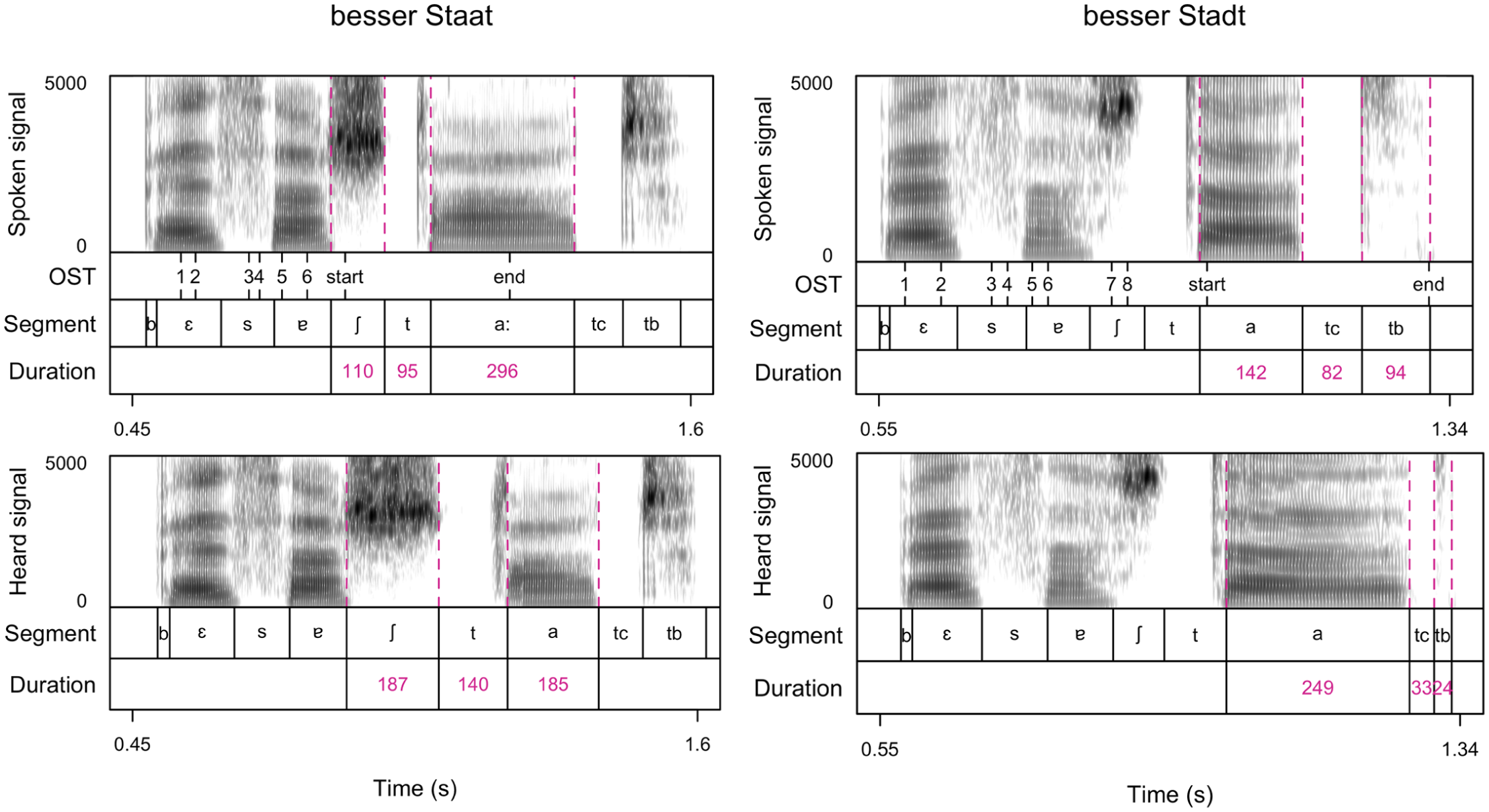
Visualizations (spectrograms and annotations) of the spoken signal (upper panels) and the heard/perturbed signal (lower panels) of one Hold phase trial for Staat (Vowel compression setup, improved tracking, left panels) and one for Stadt (Vowel stretching setup, right panels). The displayed heard signal includes the software delay of ~32 ms (but not the additional hardware delay). The “OST” tier shows the real-time OST tracking, marking each predefined acoustic landmark with numbers; start and end mark the extent of the perturbation section (of which the first half is stretched, and the second half compressed). Segmentation of the carrier word besser and the target word in the “Segment” tier, and durations (in milliseconds) for the perturbed segments of the target word in the “Duration” tier. tc stands for /t/ closure, tb for /t/ burst and aspiration. Time (in seconds) on the x-axis, and frequency (in Hz) on the y-axis. Figures generated in RStudio with praatpicture (Puggaard-Rode, 2024).
The perturbation section was coded as two halves, whereby the first half was always stretched, and the second half compressed. In maximum perturbation (during the Hold phase), the signal in the first half of the perturbation section was stretched by an amount of 1.5, whereas the second half was compressed by a factor of 0.5 (see Figure 1, light blue and dark blue lines, respectively). Due to this approach, the absolute duration of the perturbation section (and thus of the stretching and compression) varied between participants, ensuring a perturbation that is relative to the produced segments rather than an absolute amount in milliseconds. Given the shorter duration of /a/ compared with /a:/, the absolute amount of stretching for /a/ was smaller than the amount of compression for /a:/.
2.4 Corrections to the initial implementation and additional testing of participants
In post-processing, every speaker’s data was scanned for the correct triggering of the intended perturbation section (onset + vowel in the Vowel compression setup or vowel + coda in the Vowel stretching setup). The implementation worked very reliably in the Vowel stretching setup (Stadt/Stamm). For the Vowel compression setup (Staat/Stab), in many cases, the perturbation triggered too early leading to a perceptually stretched vowel /ɐ/ from the end of the carrier word besser, especially for participants with slower speech rates. This stretching of the vowel /ɐ/ was not intended and hence the affected participants were excluded from the main analyses. Handling of this participant group and data exclusion for all participants will be outlined in the following section (Section 2.5).
Due to this malfunction in triggering the intended part in the utterance, 10 new participants were tested with the Vowel stretching setup and an improved OST implementation that directly triggered perturbation at the onset of /ʃ/ of the target word without customized elapsed time (The left panels of Figure 2 show an example where the start of perturbation is triggered by the new OST implementation). Post-processing confirmed a reliable triggering of the intended part in the utterance for the retested participants.
Figure 3 shows the vowel durations in the Baseline for both setups with indication about the OST implementation in the Vowel compression setup (gray: new OST, black: old OST, participants with perturbed vowel /ɐ/ excluded). The Figure indicates that the additionally tested participants for the Vowel compression setup had longer vowel durations (a slower speech rate) in the Baseline. However, the whole batch of tested participants forms a homogeneous group, and the difference in Baseline duration rather indicates that the new OST implementation did work better for speakers with a slower speech rate. This was confirmed by statistic modeling (see Appendix A). In summary, there was no systematic difference in response patterns of participants tested with the initial implementation but a good fit of the perturbation, and the response data of the new participants with the improved tracking, hence they were treated as one group in the main analyses.
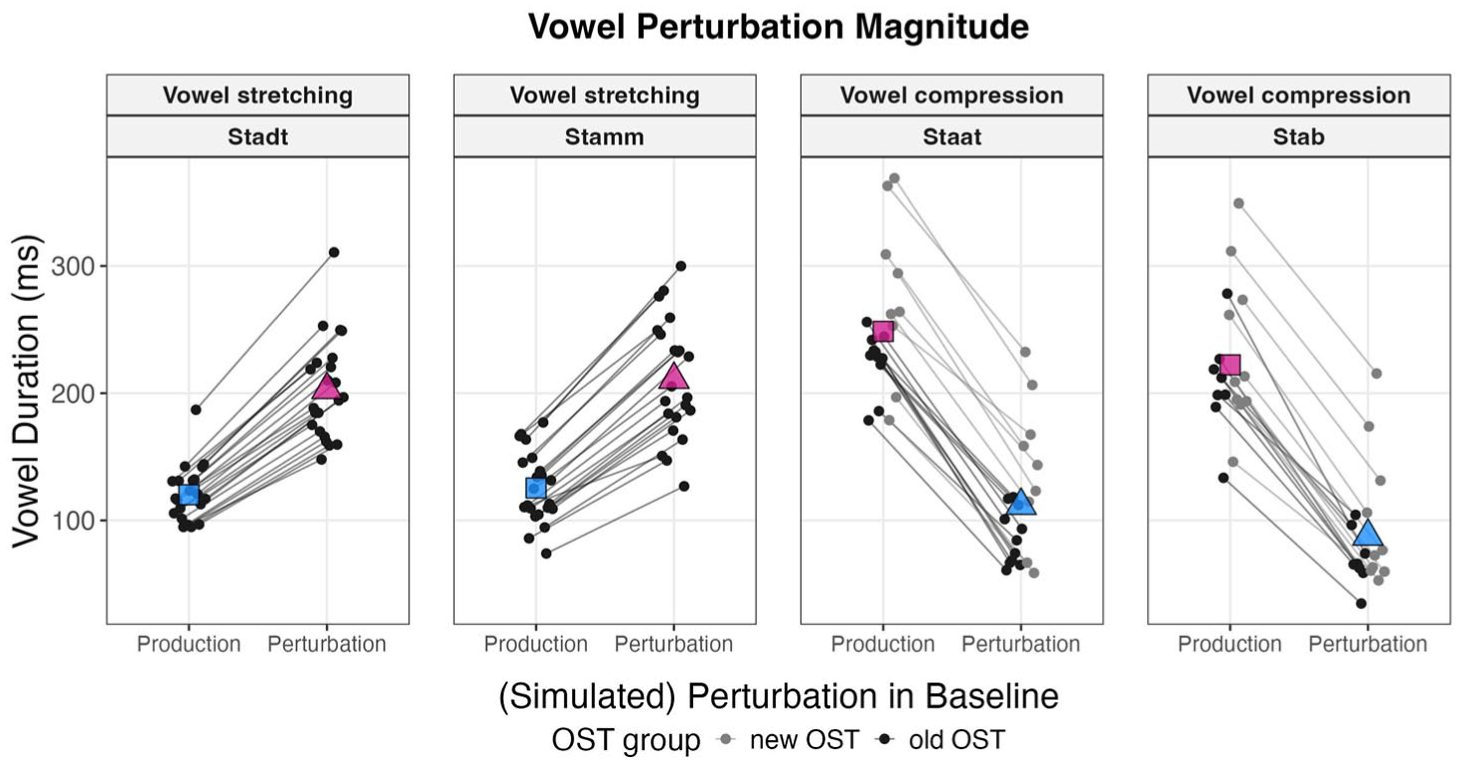
Mean vowel durations produced during the Baseline (Production) and simulated received perturbation (Perturbation). Dots mark single participants linked by lines (Staat: n = 20, Stab: n = 18, Stamm: n = 22, Stadt: n = 22). Black dots show participants tested with the original OST implementation; gray dots (in the Vowel compression panels) show participants with the updated OST. Colored symbols show group means for produced durations (squares) and perturbed durations (triangles) for long/lengthened vowels (magenta), and short/shortened vowels (blue).
2.5 Data preparation
For all participants (new and old OST tracking), single trials in which the perturbation did not work as intended were marked with an automated Matlab script. This script included rules about the minimal portion of stretching and compression that the intended segments should have received. Furthermore, incomplete trials or trials with yawning were removed from the data set. Participants with either fewer than 20 functioning Ramp phase trials or 20 functioning Hold phase, and fewer than nine Baseline or After-effect phase trials were removed completely from further analyses for the respective target word, since adequate perturbation throughout the experiment could not be ensured. Based on these criteria, one participant was removed for Stamm, one participant for Stadt, eight participants for Staat, and 10 participants for Stab. One additional participant for Stab was excluded from the beginning due to errors in implementation during testing. The remaining participants (with at least 20 trials per Ramp/Hold phase and nine per Baseline/After-effect phase) in the Vowel compression setup (Staat and Stab) were divided into groups based on the functionality of perturbation: the first group included the participants where the previous vowel /ɐ/ was not stretched in perturbation, as intended (Staat: 20 participants, Stab: 18 participants). This dataset was used in the main analyses reported below. The second group comprised the subset of participants of the old OST group, for which the preceding vowel /ɐ/ was accidentally stretched (by at least 25 ms mean perturbation in the Hold phase), due to a too short customized elapsed time (Staat: 10 participants, Stab: nine participants). The analysis of the systematic differences in response to the previous stretched vowel would distract from the main goal of this study. However, this analysis could nevertheless contribute to our understanding of timing mechanisms and will therefore be presented in Appendix B.
To summarize, based on these exclusion rules, for the analyses reported below data from 22 participants for Stamm and 22 participants for Stadt were included, as well as data from 20 participants for Staat and 18 participants for Stab. The final dataset comprised 46 different participants (mean age 22.9 years, five male, 41 female). Data for both lexical conditions/words per experimental setup were available for 21 participants in the Vowel stretching setup (Stadt and Stamm) and 15 participants in the Vowel compression setup (Staat and Stab). The imbalance in tested male vs. female participants arose from the fact that more female participants were willing to participate in the study. Since we do not expect nor have any scientific evidence for different auditory-motor integration based on gender or sex, this imbalance should not affect the conclusions of this study.
Figure 3 visualizes the perturbation magnitude as implemented, that is, how perturbation would be received without any corrective responses. The key aim of this figure is to indicate the durational region that the perturbation pushed into. For visualization, for each participant and condition, the maximum stretch factor (1.5 for vowel stretching/0.5 for vowel compression) was applied to the perturbation section covering the vowel in the baseline trials (excluding the first five trials) as a simulated received maximum feedback shift. This simulation on baseline trials provides the intended shift magnitude as implemented without any interference by possible counteracting responses to the perturbation in the Hold phase. In the Vowel stretching setup, the simulated perturbed durations of /a/ (two left panels, magenta triangles) fall close to the area of mean /a:/ Baseline durations in the Vowel compression setup (two right panels, magenta squares). In the Vowel compression setup, the perturbation (blue triangles) falls well within (or even below) the mean Baseline durations of /a/ in the Vowel stretching setup (two left panels, blue squares). Figure 3 shows the intended perturbation magnitude and direction of perturbation. In the Hold phase, changes in vowel duration in response to the actual perturbation can alter the exact fit of the perturbation section and change the perceived signal in every direction. Therefore, Table 1 shows the actual received mean perturbation per Word and Sound averaged across speakers during the Hold phase, as well as the standard deviation of perturbation magnitudes across speakers and the delay that was received at the onset of the respective segment (delay = software and hardware delay of ~45 ms plus previously received stretching). Values are calculated for all participants included in the final analyses without excluding malfunctioning trials to reflect the actual perceived feedback shifts during the experiment.
2.6 Analytical strategy
For all subsequent analyses, segment durations were automatically determined by a Matlab script and then hand-corrected in Praat (Boersma & Weenink, 2024). As an overview, the response patterns throughout the experiment for all perturbed segments are shown in Figure 4 (vowels and consonants, durations in ms relative to mean Baseline durations). The main analyses focus on the perturbed vowels (Figure 4, magenta dots and Section 3), since they are the segments causing − or not causing − a shift in lexical identity. The main analysis first examines the flexibility of the perturbed vowels themselves by comparing absolute durations between Baseline, Hold phase, and After-effect phase productions (Section 3.1). The second part of the main analysis relates the responses in Hold and After-effect phases to the amount of applied maximum perturbation, as a normalized response value that allows for a direct comparison of the lexical words (Stadt, Staat) with the non-lexical words (Stamm, Stab) across experimental setups, independent of the perturbation direction (Section 3.2). In a secondary analysis, the response patterns of the other perturbed segments (the consonants) are analyzed (Section 4). Data and analyses are available on the Open Science Framework https://osf.io/rsytu/.
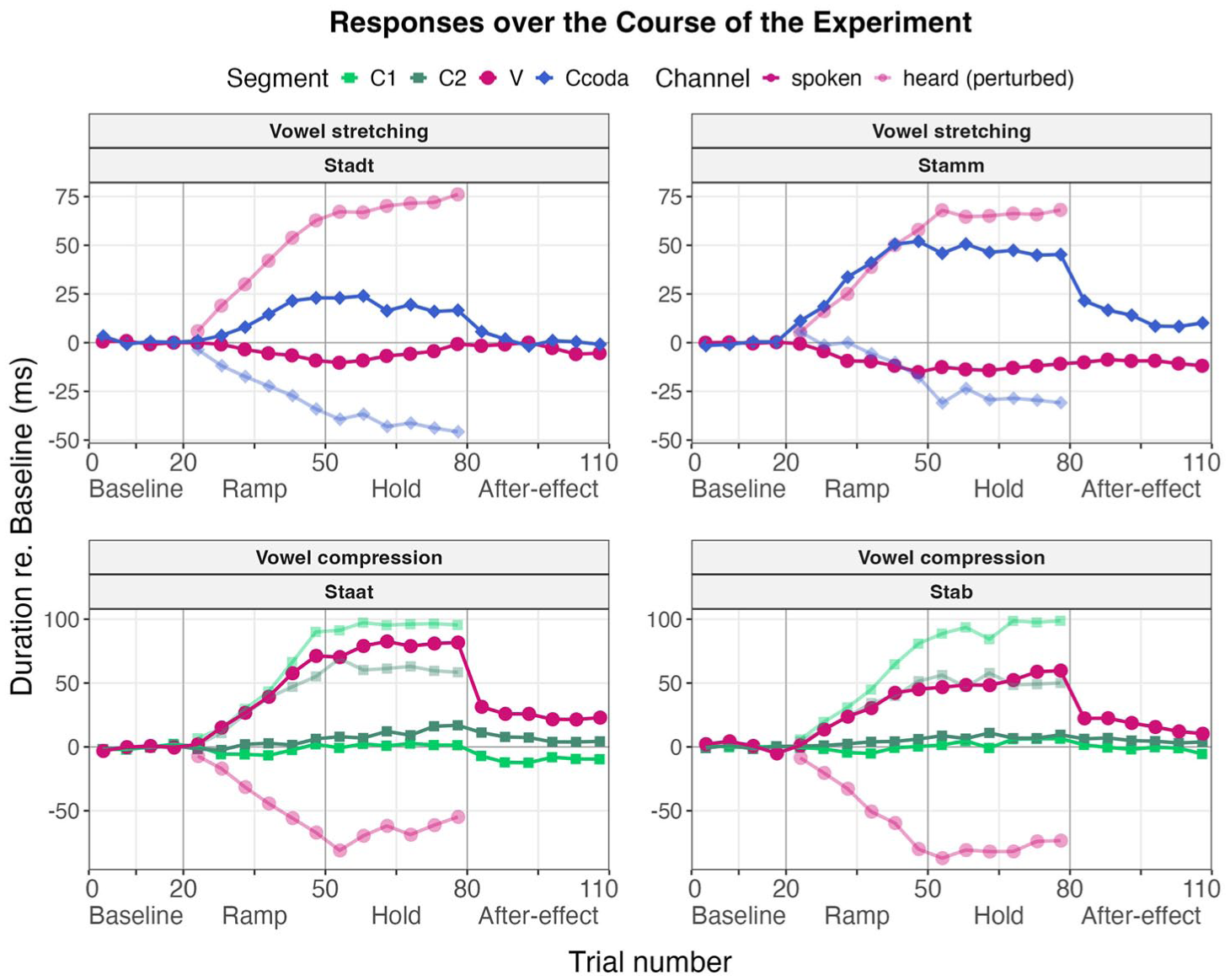
Mean durations binned over five trials of the perturbed segments for all participants over the course of the experiment. Spoken signal in solid dots/lines and heard/perturbed signal in transparent. Vowel (V) and the coda consonant (Ccoda, closure duration of /t/, or duration of /m/, respectively) of the Vowel stretching setup in the upper panels (magenta and blue, Stadt = 22 participants, Stamm = 22 participants) and the onset consonants (C1 - /ʃ/, C2 - /t/) and the vowel (V) of the Vowel compression setup in the lower panels (green and magenta, Staat = 20 participants, Stab = 18 participants). Lexical condition in the left panels, non-lexical condition in the right panels.
3 Main analyses: vowels
The primary focus of this study is to examine the responses to perturbations of /a:/ and /a/ that either shift or do not shift their target words toward another lexical identity. The following sections are organized into two main approaches, capturing first the temporal flexibility of the vowels (Section 3.1), and second the percentage of change relative to the amount of perturbation (Section 3.2). All analyses were carried out in RStudio (R version 4.2.2) using mostly packages of the tidyverse (Wickham et al., 2019). The analyses included the last 15 trials of the Baseline phase (to exclude fluctuations and inconsistencies in speaking style at the start of the experiment), all of the Hold trials (30), and the first 15 trials of the After-effect phase, since it has previously been shown that possible after-effects in vowels may fade within the first 15 trials after perturbation is removed (see Oschkinat & Hoole, 2020). All Hold trials were included to capture any response during the Hold phase that might be more pronounced at the beginning or end of the phase. In the following, references to the “Baseline” and “After-effect phase” denote the 15 late Baseline and 15 early After-Effect phase trials, respectively.
3.1 Temporal flexibility of vowels
In this section, we compare vowel durations between the Baseline, Hold phase, and After-effect phase. This analysis shows whether the vowels themselves are being flexibly adjusted in response to the applied perturbation. In general, we expect speakers to oppose the direction of perturbation during the Hold phase, thereby reducing the perceived auditory error. In the Vowel stretching setup (Stadt and Stamm), an opposing response is indicated by shorter durations relative to the Baseline. Such a response can only be adaptive in nature, meaning that there has been a learning effect and a short-term update of the motor representation from trial to trial, since shortening segments in real time in response to perceived longer durations is physically not possible.
In the Vowel compression setup (Staat and Stab) opposing responses are indicated by longer durations in the Hold phase compared with Baseline productions. This lengthening can be adaptive—in response to the consistent compression in perturbation in the preceding trials—and/or an online (within-trial) response to the delay: The stretching of the onset consonants delays the following vowel and further creates distorted segment proportions within the word, potentially causing effects of reactive feedback control.
The subsequent analyses aim at capturing responses during perturbation by comparing Baseline and Hold phase. In addition, the amount of adaptation is examined by comparing Baseline and After-effect phase productions (a significant difference would indicate learning effects, adaptation). In addition, to capture effects of reactive feedback control during the Hold phase, Hold and After-effect phase productions will be compared. Reactive feedback control is indicated by significantly larger responses in the Hold than in the After-effect phase.
3.1.1 Model selection
To examine the effects of Phase (Baseline, Hold phase, After-effect phase), Experimental Setup (Vowel stretching or Vowel compression), and Lexical Condition (lexical, non-lexical) on vowel productions, we fit a linear mixed-effects model (LMM) using the lmerTest package in R (Kuznetsova et al., 2017). Although the dependent variable (vowel duration in milliseconds) was not strongly skewed, a log10 transformation was applied to improve the normality of the residuals in the final model. The model structure was built incrementally, beginning with a null model that included only a random intercept for participant. Fixed effects were introduced stepwise, and models were compared using likelihood ratio tests via analysis of variance to determine whether additional terms significantly improved model fit. The final model included main effects for Phase (Baseline, Hold, After-effect), Lexical Condition (lexical, non-lexical), and Experimental Setup (Vowel stretching, Vowel compression), as well as their two-way and three-way interactions. The random effects structure included random intercepts for participants and a by-participant random slope for Phase to account for individual variability in this within-participant factor. Model diagnostics confirmed model convergence, normality of residuals, and stable fixed-effect estimates.
Marginal and conditional R2 values were computed using the MuMIn package (Bartoń, 2022), indicating that the model explained 77% of the variance due to fixed effects (marginal R2) and 94% when including both fixed and random effects (conditional R2).
3.1.2 Results: vowel responses during and after perturbation
The analysis revealed a significant three-way interaction between Phase, Lexical Condition, and Experimental Setup, F(2, 4638.1) = 5.35, p = .0048, indicating that the effect of Phase on vowel duration varies depending on both lexical status and experimental Setup. The interaction between Phase and Experimental Setup is expected per design: We expect vowel durations to decrease in the Vowel stretching setup but increase in the Vowel compression setup in the Hold/After-effect phases. Figure 5(b)) visualizes the three-way interaction between Condition, Phase, and Experimental Setup with mean estimates per Phase and Word. Figure 5(a)) shows individual response data on the ms scale per phases and setup.
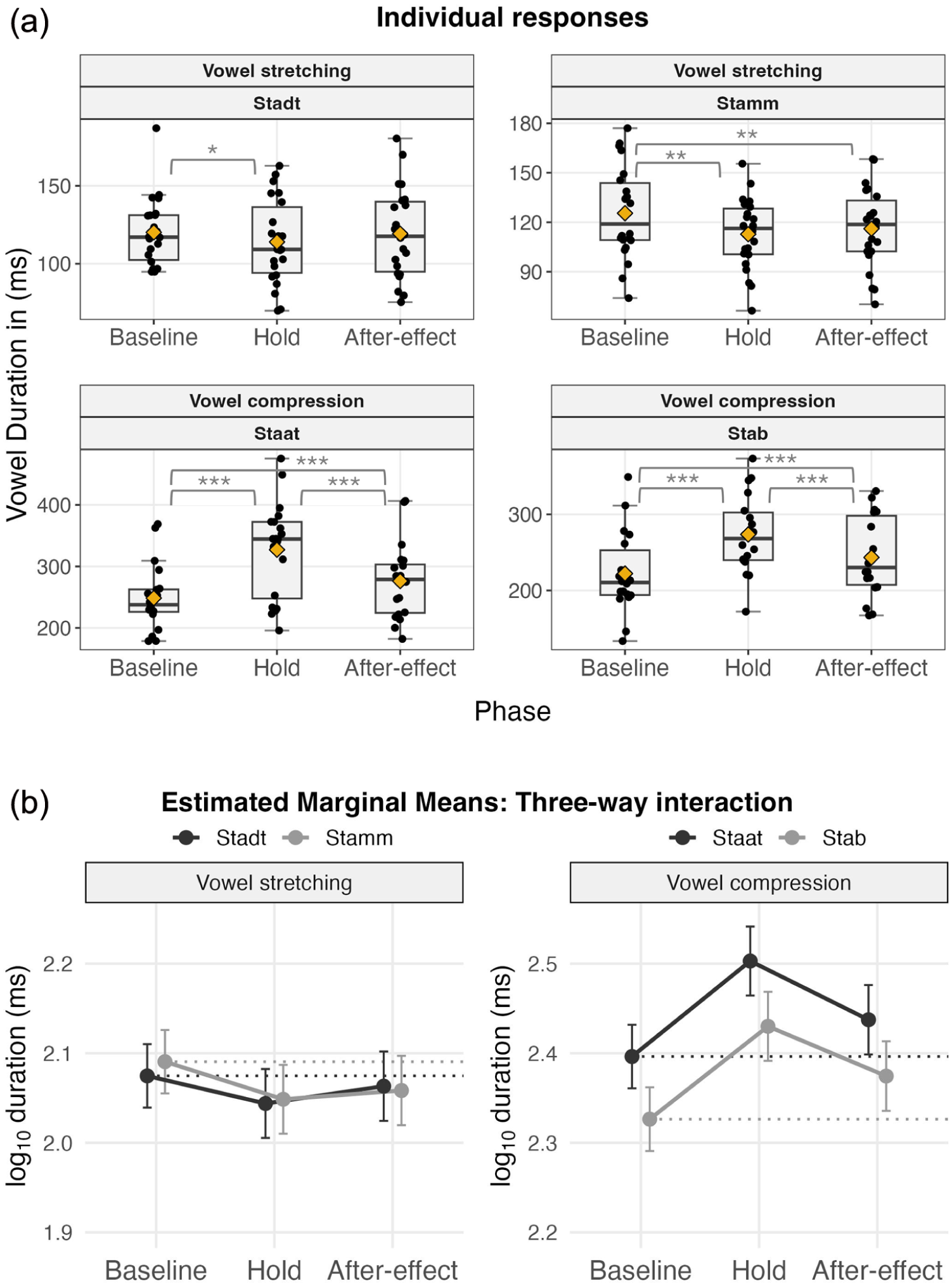
(a) Individual response data (ms) per phase and experiment. Boxes span the interquartile range (25th–75th percentiles), and whiskers extend to 1.5 × IQR beyond the quartiles (or to the most extreme value, if inside this range). Means indicated by yellow diamonds, median displayed as a horizontal line. Individual participants marked by dots, points beyond whiskers are outliers. (b) Points show estimated marginal means (log-transformed ms) with 95% confidence intervals (error bars) for the interaction between Phase, Condition, and Experimental Setup. Lexical Condition in black, non-lexical condition in gray. Dotted lines mark the baseline mean per word for visual orientation.
Given the significant three-way interaction, we conducted post hoc pairwise comparisons between Phases (Baseline, Hold, After-effect) using estimated marginal means (EMMs) with the emmeans package in R (Lenth, 2022). Comparisons were run separately for each combination of Experimental Setup (Vowel stretching, Vowel compression) and Lexcial Condition (lexical, non-lexical), with Bonferroni-adjusted p-values applied to correct for multiple testing. These comparisons were followed by second-order contrasts (i.e., contrasts of contrasts) to compare phase-related effects between lexical and non-lexical conditions within each Experimental Setup (Bonferroni-corrected).
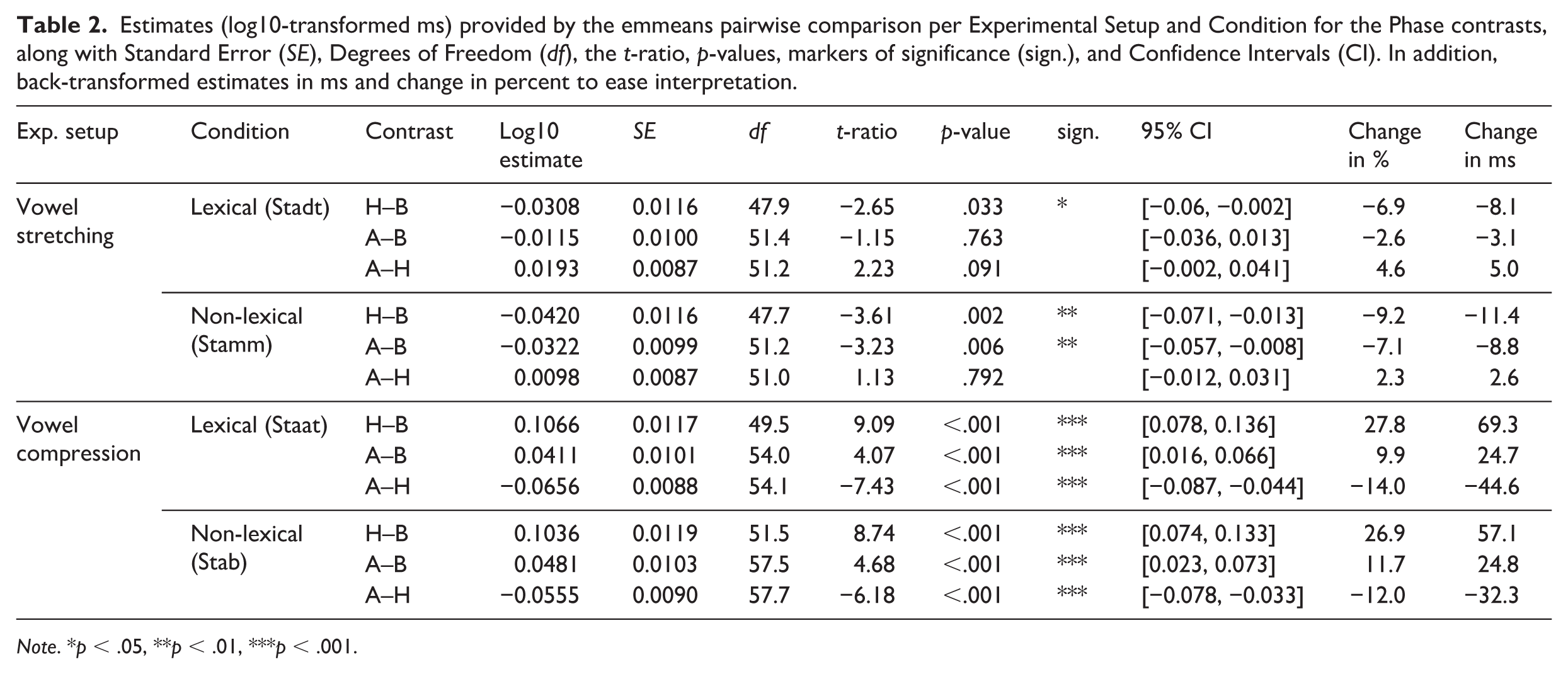
As a reminder, the pairwise comparison of the Hold−Baseline contrast indicates whether and in what direction speakers responded during exposure to the perturbation (and the delay); the After-effect−Baseline comparison reflects the magnitude of any remaining adaptive change in production after the perturbation was removed; and the After-effect−Hold comparison tests whether there was a significant reactive feedback control response (due to the delayed signal caused by the prior stretch) during the Hold phase, as indicated by a significant change in duration toward the baseline during the After-effect phase. Estimates are reported on the log-transformed scale used in the model and are supplemented with back-transformed differences in milliseconds to aid interpretation. Statistical results include log10 estimates, standard errors, degrees of freedom, t-values, and Bonferroni-adjusted p-values. All contrasts—including back-transformed estimates in milliseconds and change in percent—are presented in Table 2.
Estimates (log10-transformed ms) provided by the emmeans pairwise comparison per Experimental Setup and Condition for the Phase contrasts, along with Standard Error (SE), Degrees of Freedom (df), the t-ratio, p-values, markers of significance (sign.), and Confidence Intervals (CI). In addition, back-transformed estimates in ms and change in percent to ease interpretation.
Note. *p < .05, **p < .01, ***p < .001.
Negative estimates denote shortening responses, whereas positive estimates indicate lengthening responses. Note, however, that in the Vowel stretching setup, opposing responses result in negative estimates (shortening), whereas in the Vowel compression setup, opposing responses result in positive estimates (lengthening). To ease interpretation, we briefly note that vowel durations in the Hold and After-effect phases (H−B, A−B contrasts) consistently shifted
In the Vowel stretching setup, vowel durations shortened significantly from Baseline to Hold for both the lexical condition Stadt, b = –0.0308, SE = 0.0116, t(47.9) = –2.65, p = .033, and the non-lexical condition Stamm, b = –0.0420, SE = 0.0116, t(47.7) = –3.61, p = .002. This corresponded to a 6.9% (–8.1 ms) and 9.2% (–11.4 ms) reduction in duration, respectively. From Baseline to the After-effect phase, a significant shortening was observed only for Stamm, b = –0.0322, SE = 0.0099, t(51.2) = –3.23, p = .006, amounting to a 7.1% (–8.8 ms) reduction. For Stadt, the difference was not significant, p = .763. Durations in the After-effect phase were numerically longer than in the Hold phase for both items (Stadt: + 4.6%, + 5.0 ms; Stamm: + 2.3%, + 2.6 ms), but these differences were not statistically significant (Stadt: p = .091 and Stamm: .792).
In the Vowel compression setup, durations increased significantly from Baseline to Hold for both the lexical condition Staat, b = 0.1066, SE = 0.0117, t(49.5) = 9.09, p < .001, and the non-lexical condition Stab, b = 0.1036, SE = 0.0119, t(51.5) = 8.74, p < .001, corresponding to increases of 27.8% (+ 69.3 ms) and 26.9% (+57.1 ms), respectively. Significant increases also remained in the After-effect phase for both Staat, b = 0.0411, SE = 0.0101, t(54.0) = 4.07, p < .001, and Stab, b = 0.0481, SE = 0.0103, t(57.5) = 4.68, p < .001, amounting to increases of 9.9% (+24.7 ms) and 11.7% (+ 24.8 ms), respectively. From Hold to After-effect, durations decreased significantly for both items: Staat, b = –0.0656, SE = 0.0088, t(54.1) = –7.43, p < .001 (–14.0%, –44.6 ms), and Stab, b = –0.0555, SE = 0.0090, t(57.7) = –6.18, p < .001 (–12.0%, –32.3 ms), indicating a partial decay of the opposing response.
In summary, speakers opposed the direction of perturbation in both setups and both conditions. Shortening responses (negative estimates, Vowel stretching setup) were much less pronounced than vowel lengthening responses (positive estimates, see Figure 5(b)), which is in line with findings from previous studies (Karlin & Parrell, 2022; Oschkinat & Hoole, 2020).
3.1.3 Results: lexical differences within setup
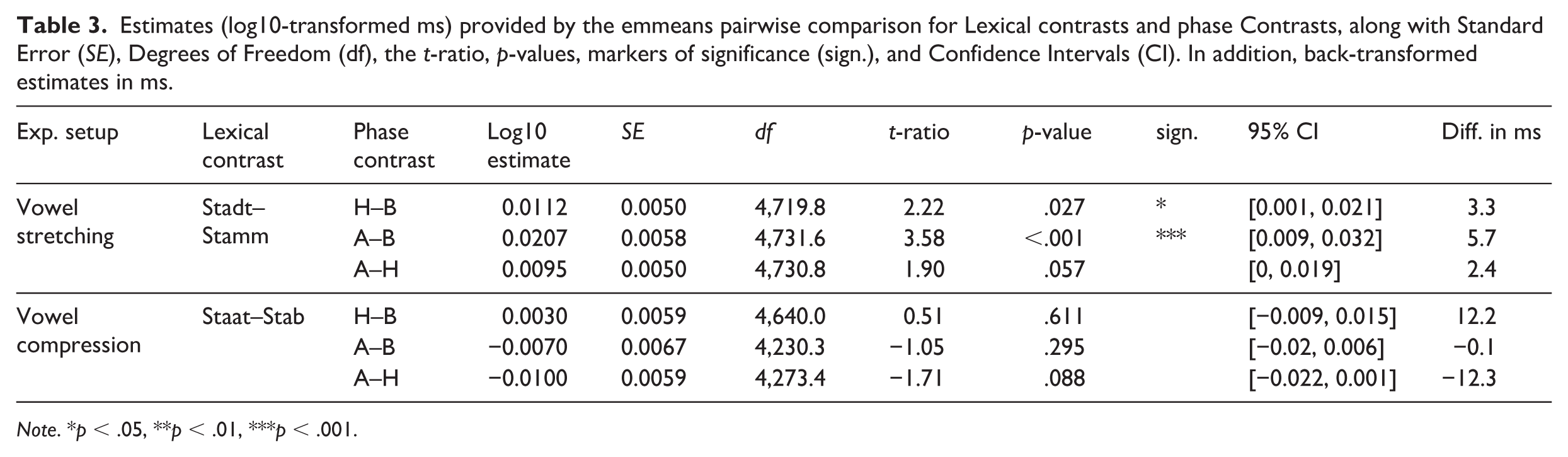
The analyses of second-order contrasts (summarized in Table 3) revealed that, in the Vowel stretching setup, the reduction in vowel duration from Baseline to Hold was significantly larger for the non-lexical condition (Stamm) than for the lexical condition (Stadt), b = 0.0112, SE = 0.0050, t(4,719.8) = 2.22, p = .027, 95% confidence interval (CI) = [0.001, 0.021], corresponding to 3.3 ms more shortening for the non-lexical condition (Stamm). Similarly, the reduction from Baseline to After-effect was also significantly larger for Stamm than for Stadt, b = 0.0207, SE = 0.0058, t(4,731.6) = 3.58, p < .001, 95% CI = [0.009, 0.032], reflecting a difference of 5.7 ms. The After-effect response relative to Hold was not significantly different for Stadt compared to Stamm (p = .057, 2.4 ms). No significant lexicality differences were found in the Vowel compression setup. Differences between lexical (Staat) and non-lexical (Stab) items in the Hold–Baseline contrast (p = .611, 12.2 ms), After-effect–Baseline contrast (p = .295, -0.1), and After-effect–Hold contrast (p = .088, -12.3) were all non-significant. Statistical output is summarized in Table 3.
Estimates (log10-transformed ms) provided by the emmeans pairwise comparison for Lexical contrasts and phase Contrasts, along with Standard Error (SE), Degrees of Freedom (df), the t-ratio, p-values, markers of significance (sign.), and Confidence Intervals (CI). In addition, back-transformed estimates in ms.
Note. *p < .05, **p < .01, ***p < .001.
3.1.4 Summary: vowel responses
Overall, the results demonstrate that speakers systematically opposed the direction of auditory perturbation for both the stretched vowel /a/ (Vowel stretching setup) and the compressed vowel /a:/ (vowel compression setup). In the Vowel stretching setup (Stadt vs. Stamm), shortening responses were observed from Baseline to Hold phase for both items. Shortening persisted only for Stamm, while no significant change between After-effect and Baseline phase was found for the lexical condition Stadt. The absence of differences between Hold phase and After-effect phase points to exclusively adaptive behavior during the Hold and/or After-effect phase, as expected. In the Vowel compression setup (Staat vs. StabStaat), lengthening responses were robust and remained: both the lexical condition and the non-lexical condition Stab showed significant increases in duration during the Hold and After-effect phases, followed by a partial decay from Hold to After-effect phase indicating both reactive feedback control and adaptation.
Second-order contrasts revealed a significant lexicality effect in the Vowel stretching setup: shortening was greater for the non-lexical condition Stamm than for the lexical condition Stadt. No such lexicality-related differences were observed in the Vowel compression setup.
3.2 Lexical effects across setups
To examine a more global impact of lexicality on the perception-production loop, we analyzed the effect of lexical condition (lexical shift or non-lexical shift) on response magnitude across experimental setups (Vowel stretching and Vowel compression). Since the direct comparison between lexical and non-lexical condition was the main interest here, only participants with data in both conditions were included in the following analyses. These included 21 participants for the Vowel stretching setup (Stadt and Stamm) and 15 participants for the Vowel compression setup (Staat and Stab).
For this purpose, we calculated a measure of response (in %) relative to the maximal applied perturbation in the Hold phase, for both the Hold and the After-effect phase. This measure accounts for different perturbation magnitudes between experimental setups and thus allows a direct comparison. Adaptation in % in the After-effect phase can then be compared between lexical conditions and across setups. The measure of adaptation in % does not only allow for a direct comparison across conditions, but also provides information about auditory-motor integration, that is, how much of the auditorily perceived perturbation is accounted for in corrective production. The comparison of adaptation in the After-effect phase between lexical conditions is the major focus here; however, since the model also retrieves the data from the Hold phase, adaptation in % during the Hold phase (which technically also includes reactive feedback control in the Vowel compression setup) between lexical conditions will be reported as well. The difference between Hold and After-effect phase will, like the phase comparison in Section 3.1.2, reveal the proportion of online response during the Hold phase.
3.2.1 Adaptation relative to the perturbation
Adaptation as percent of perturbation was determined per speaker, word, and trial. This was achieved by first calculating the mean perturbation magnitude in the Hold phase as the mean duration of the perceived (perturbed) signal minus the spoken signal during the Hold phase (see Formula 1), where n is the number of included trials and i is the respective trial number in the Hold phase.
Analogously to the procedure in Karlin and Parrell (2022), adaptation in % per speaker and word was calculated per trial as the negative difference between the produced duration (spoken signal in the Hold or After-effect phase) and the Baseline mean, divided by the mean perturbation magnitude and multiplied by 100 to yield a percentage value (see Formula 2). Here, p denotes either the Hold or After-effect phase, and i the respective trial. With this calculation, 100% adaptation is reached when the heard signal in the Hold phase matches the Baseline production. In contrast, 0% adaptation occurs when the produced signal either does not deviate from the Baseline mean or exactly matches the heard signal (i.e., when no perturbation was applied; see Figure 6 for visual examples). Positive values indicate compensatory responses, whereas negative values indicate following the perturbation.
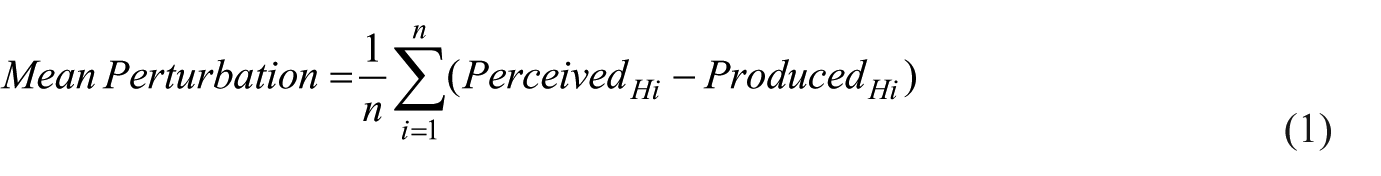
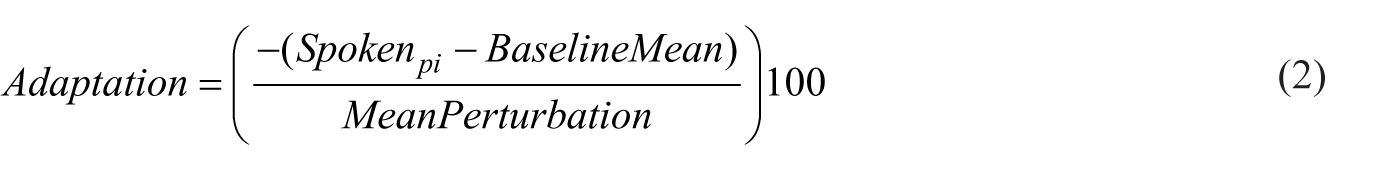
With this calculation, we capture adaptation relative to the perturbation in the Hold phase, which technically includes both adaptive and reactive feedback control. In the After-effect phase, this measure captures only the adaptive component, but does so not in relation to the Baseline (as in Section 3.1), but in relation to the applied perturbation.
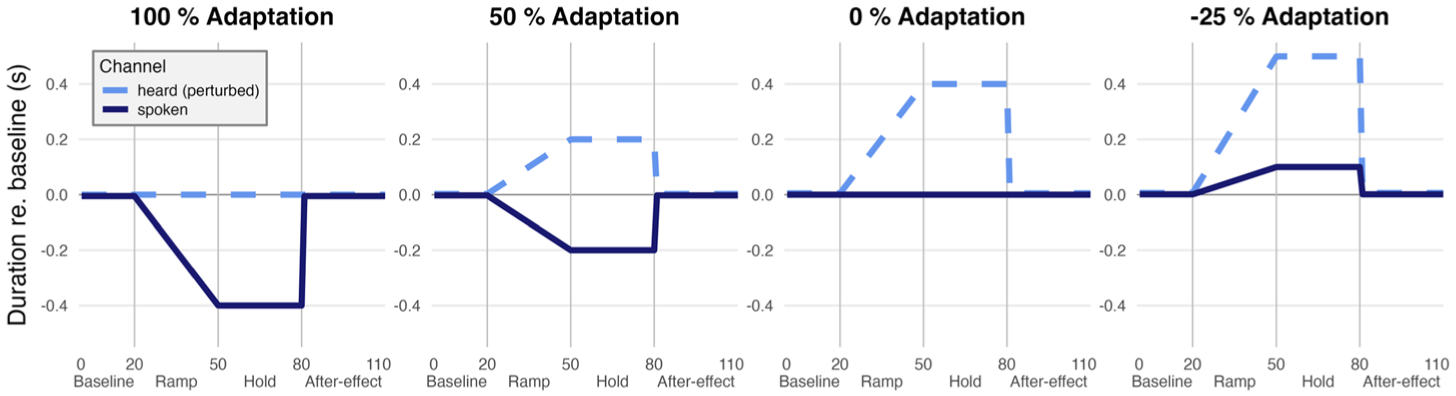
Visual examples of exemplary response patterns over the course of the experiment for a stretched segment. Titles indicate the amount of Adaptation in percent of perturbation (as calculated in formula 2) in the Hold phase (and no after-effects in the After-effect phase, for simplicity). The dark blue solid line marks the spoken signal, the light blue dashed line the heard/perturbed signal.
3.2.2 Model selection
Models were built with adaptation in % as the dependent variable, starting with a random-intercepts-only model. We then added fixed effects for Phase and Lexical Condition, followed by their interaction to test whether the Lexical Condition effect varied across Phases. Finally, Experimental Setup was included as a fixed effect to control for known baseline differences between experimental setups. Interaction terms involving Setup were not included, as our primary research question concerned Lexical Condition differences within phases, and we had no hypothesis that this effect would differ across Setups. Including Setup as a main effect allowed us to account for overall level differences without overfitting the model or introducing collinearity due to known overlap between Setup, Lexical Condition, and Word. The final LMM included fixed effects for Phase, Lexical Condition, their interaction, and Setup, along with by-subject random intercepts and random slopes for Phase. Visual inspection of residuals showed moderate deviations from normality, particularly in the tails of the Q–Q plot. Influence diagnostics indicated that several participants lay outside recommended boundaries; however, no single participant exerted a disproportionate influence on the fixed effects, including the critical Phase × Lexical Condition interaction. Attempts to transform the dependent variable (e.g., via signed square root) did not improve model fit or residual behavior. Given the large sample size, convergence of the full random effects structure, and the stability of key effects across influence analyses, we retained the untransformed outcome and reported results using standard inferential procedures. Robustness checks confirmed that the Phase × Lexical Condition interaction remained statistically significant and directionally consistent even when excluding the most influential participants.
3.2.3 Results: lexical effects across setups
The model summary revealed a significant main effect of Phase, F(1, 34.9) = 23.81, p < .001, indicating less pronounced responses in the After-effect phase compared with the Hold phase. The main effect of Lexical Condition was also significant, F(1, 3096.1) = 12.79, p < .001, and the main effect of Setup was significant as well, F(1, 34) = 13.24, p < .001. Crucially, the interaction between Phase and Lexical Condition was significant, F(1, 3096.13) = 12.9, p < .001, indicating that the effect of lexicality differed across phases. Post hoc pairwise comparisons revealed no significant difference between lexical conditions during the Hold phase: the non-lexical condition (Stab, Stamm) showed a mean adaptation of 28.71% (95% CI = [21.90, 35.50]), and the lexical condition (Staat, Stadt) showed a nearly identical mean of 28.72% (95% CI = [21.91, 35.50]). This contrast was not significant, t(3,096) = –0.01, p = .990, with a mean difference of –0.01 percentage points (95% CI = [–1.99, 1.78]).
In contrast, during the After-effect phase, adaptation was significantly larger for the non-lexical condition (Stab, Stamm), with a mean of 16.02% (95% CI = [9.09, 22.90]), compared with 9.98% (95% CI = [3.05, 16.90]) for the lexical condition (Staat, Stadt). The pairwise contrast was significant, t(3,096) = 4.41, p < .001, with a mean difference of 6.04% (95% CI = [3.45, 8.67]). This effect was primarily driven by large adaptation for the non-lexical word Stamm, whereas Stadt (lexical) showed reduced after-effects. The other two words, Staat (lexical) and Stab (non-lexical), exhibited similar adaptation levels in this phase. Figure 7 shows adaptation relative to perturbation during the Hold and After-effect phases binned per five trials for all four words (A) and the interaction between phase and lexical condition (B).
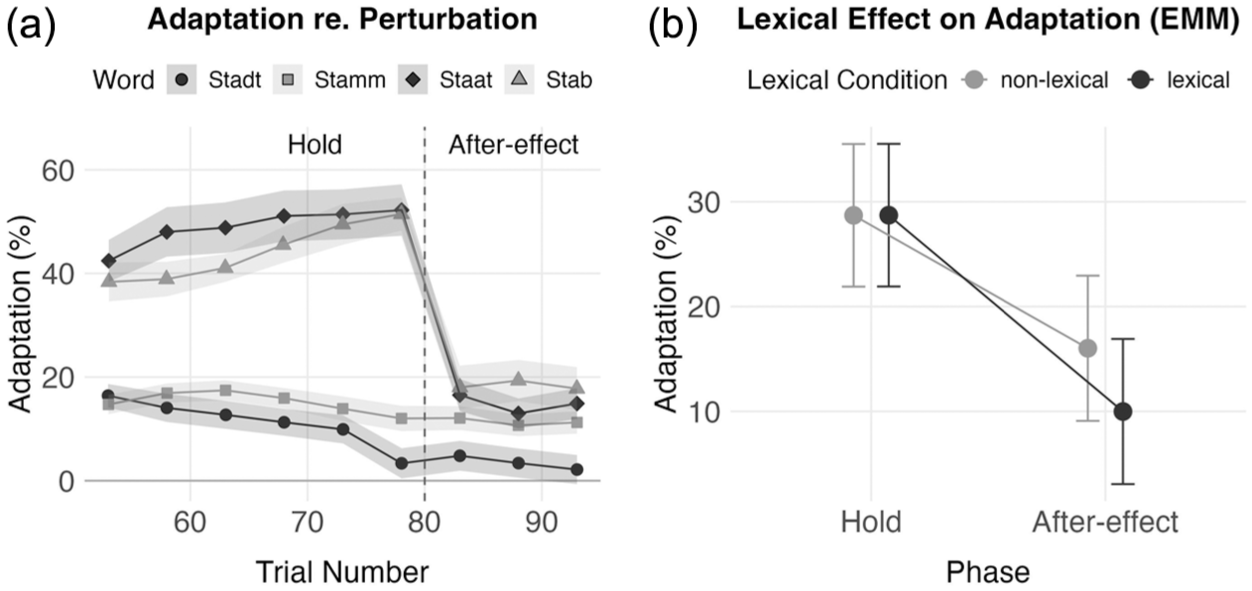
(a) Mean adaptation relative to perturbation throughout the Hold and After-effect phase by word, binned per 5 trials. Lexical condition in black (Stadt and Staat), non-lexical condition in gray (Stamm and Stab). Transparent ribbons indicate the standard error of the mean (SEM). (b) Estimated marginal means (EMMs) of adaptation relative to perturbation based on the linear mixed-effects model, showing a significant interaction between phase and lexical condition. In the After-effect phase, adaptation was significantly higher for the non-lexical condition compared with the lexical condition. Error bars indicate 95% confidence intervals.
3.2.4 Summary: lexical effect
In summary, although a significant main effect of Lexical Condition was observed, this effect appears to be driven primarily by the non-lexical condition Stamm, which showed markedly greater adaptation in the After-effect phase compared with its lexical counterpart Stadt. The other word pair (Staat and Stab) exhibited similar levels of adaptation in both Hold and After-effect phase, suggesting that the observed interaction between Phase and Lexical Condition should be interpreted with caution. As further analyses will show, this effect may reflect additional factors such as the influence of the following consonant in Stamm, rather than a consistent lexicality effect across items.
4 Other perturbed segments (consonants)
To achieve the desired manipulation of the vowels in our target words, the onset consonants preceding the compressed vowels in Staat and Stab (C1 and C2, i.e., /ʃ/ and /t/) were stretched and the coda consonants following the stretched vowel in Stadt and Stamm (Ccoda, i.e., the closure phase of the /t/ in Stadt or /m/ in Stamm) were compressed. Based on previous findings with similar paradigms (e.g., Oschkinat & Hoole, 2020, 2022), we did not expect shortening responses for the stretched onset consonants but did expect lengthening responses for the compressed and delayed coda consonants. To examine temporal flexibility of these consonants over the course of the experiment, two linear mixed-effect models were calculated. Due to the partially nested and structurally confounded design, and to avoid collinearity, separate models were fitted for each experimental setup. The first model included the compressed and delayed coda consonants /t/ or /m/ respectively, occurring in either Stadt or Stamm, whereas the second model included the onset consonants /ʃ/ and /t/, both present in Staat and Stab, which were stretched in perturbation. Models were built incrementally similar to the models reported in the previous sections. For a visualization of consonant durations over the course of the experiment, please refer back to Figure 4.
4.1 Compressed coda consonants (in Stadt and Stamm)
For the compressed coda consonants in Stadt and Stamm, the model included Phase, Word, and their interaction as fixed effects, with random intercepts and random slopes for Phase by participant. Model comparisons supported the inclusion of the interaction term, indicating that the consonant durations across phases differed between Stadt and Stamm. To examine these differences, post hoc pairwise comparisons between phases were conducted separately for each word using EMMs with Bonferroni-adjusted p-values. Table 4 summarizes the statistical outcome.
Pairwise comparisons between phases of the two models (one per Setup) per words/sounds for the respective manipulated consonants. Table content as in Table 2.
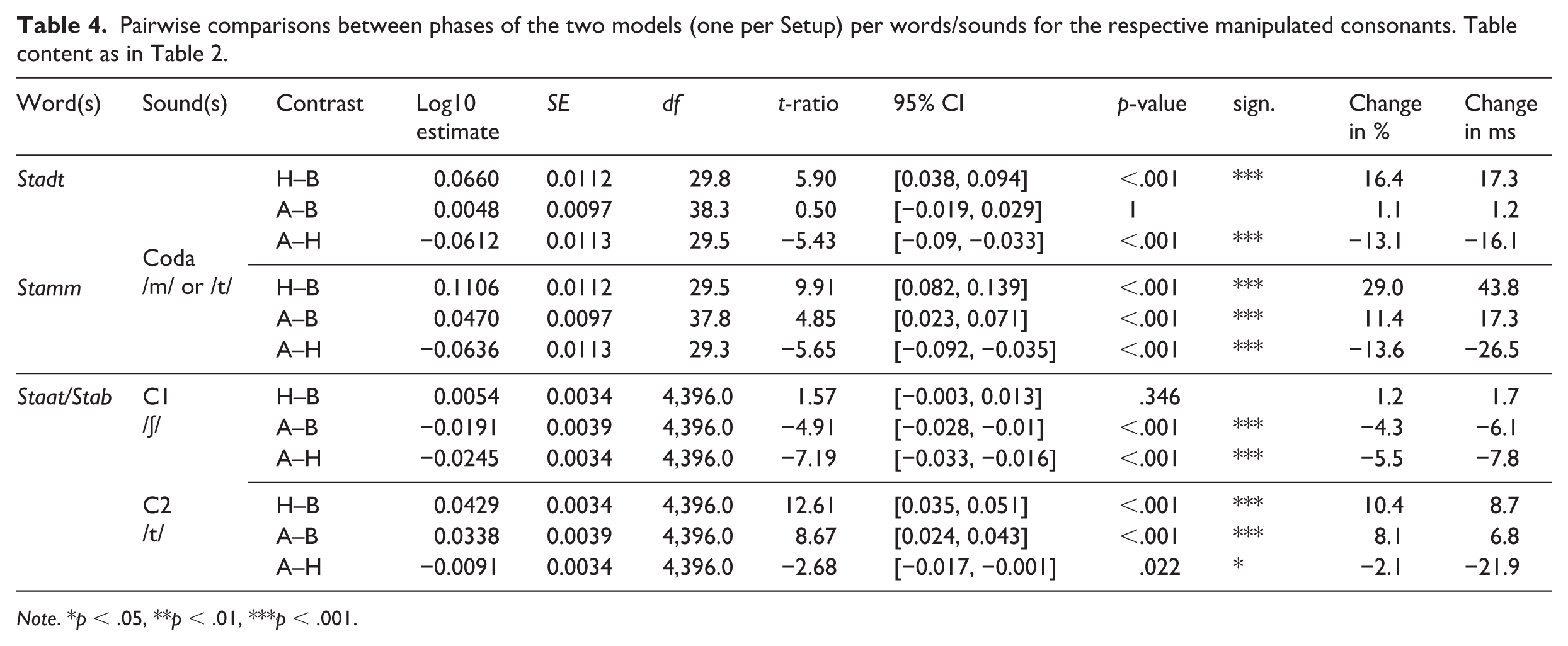
Note. *p < .05, **p < .01, ***p < .001.
In Stadt, the closure of the coda consonant increased significantly from Baseline to Hold (b = 0.066, SE = 0.011, t(29.8) = 5.90, p < .001), corresponding to an increase of approximately + 16.4% or + 17.3 ms. No significant difference was observed between Baseline and After-effect phase (b = 0.005, SE = 0.010, p = 1.000), although the estimate reflects a small increase (+1.1%, +1.2 ms). Consonant duration significantly decreased from Hold to After-effect phase (b = –0.061, SE = 0.011, t(29.5) = –5.43, p < .001), corresponding to –13.1% or –16.1 ms. In Stamm, the duration of the coda consonant /m/ increased significantly from Baseline to Hold (b = 0.111, SE = 0.011, t(29.5) = 9.91, p < .001), corresponding to an increase of +29.0% or +43.8 ms. This effect partially persisted in the After-effect phase, with significantly longer durations than in the Baseline (b = 0.047, SE = 0.010, t(37.8) = 4.85, p < .001; +11.4%, +17.3 ms). The decrease from Hold to After-effect phase was also significant (b = –0.064, SE = 0.011, t(29.3) = –5.65, p < .001), corresponding to –13.6% or –26.5 ms. These results confirm a clear increase in segment duration under compression and delay during the Hold phase, with full or partial return toward baseline levels in the After-effect phase.
4.2 Stretched onset consonants (in Staat and Stab)
For the stretched onset consonants in Staat and Stab, the model included Phase, Sound (C1 - /ʃ/ and C2 - /t/), and their interaction as fixed effects, with by-subject random intercepts and random slopes for Sound. The factor Word did not improve model fit and was therefore not included into the final model. The significant interaction term justified conducting post hoc comparisons between phases separately for each consonant using EMMs with Bonferroni-adjusted p-values. For C1, no significant difference was observed between Baseline and Hold phase (b = 0.005, p = .346) but duration decreased significantly in the After-effect phase relative to both Baseline (b = –0.019, SE = 0.004, t(4396) = –4.91, p < .001; –4.3%, –6.1 ms) and Hold phase (b = –0.025, SE = 0.003, t(4396) = –7.19, p < .001; –5.5%, –7.8 ms). C2 showed a significant increase in duration from Baseline to Hold phase (b = 0.043, SE = 0.003, t(4396) = 12.61, p < .001), corresponding to +10.4% or +8.7 ms. This increase remained statistically significant in the After-effect phase when compared with Baseline (b = 0.034, SE = 0.004, t(4396) = 8.67, p < .001; +8.1%, +6.8 ms). A small but significant decrease was observed from Hold to After-effect phase (b = –0.009, SE = 0.003, t(4396) = –2.68, p = .022), corresponding to –2.1% or –1.9 ms.
4.3 Summary: consonants
Taken together, the coda consonants /t/ (closure) and /m/ showed significant lengthening during perturbation (Hold phase), but only the /m/ in Stamm remained significantly longer after perturbation was removed, whereas the /t/-closure reverted back to Baseline in the After-effect phase. The onset consonants /ʃ/ and /t/ were not shortened in production but instead /t/ was lengthened, possibly due to the introduced delay from the first consonant. Interestingly, Figure 4 and Table 4 suggest that the individual onset consonants diverge in their response patterns in the After-effect phase (C1 - /ʃ/ −6.1 ms, C2 - /t/ +6.8 ms), causing the full onset to remain approximately the same duration as in the Baseline.
5 Discussion
This study investigated the temporal control of speech segments with a special focus on lexical status in German. In a real-time temporal auditory feedback perturbation paradigm, we compressed and stretched vowels and consonants in real words. The vowel manipulations pushed toward a phonemic boundary, either causing a shift in lexical identity but not in lexical status (word to word, lexical condition) or a shift in lexical status but not in lexical identity (word to non-word, non-lexical condition). With this setup, we tested for a lexical bias effect in speakers’ production-perception loop. The two conditions were compared in absolute duration differences (in ms) within the same implementations (stretching the vowel /a/ or compressing the vowel /a:/) to ensure comparability and to examine the flexibility of the vowels to shorten or lengthen in production. In addition, the responses were compared across implementations with response measures relative to the applied perturbation.
5.1 Vowels
The main analyses of vowel durations (Section 3.1) showed that during perturbation (in the Hold phase), all vowels of interest were significantly adjusted in the direction opposite to the direction of perturbation. This opposing response was necessarily adaptive for the vowels in Stadt and Stamm (which were stretched in perturbation and thus shortened in production), since shortening segments in response to a perturbation can only be on a trial-to-trial basis, that is, adaptive. This assumption was further supported by no significant differences (no “gap”) between Hold and After-effect phase. Visual examination of Figure 4 suggests that responses to the vowel perturbation in Stadt de-adapt already within the late Hold phase (upper left panel, magenta solid dots) and are therefore already too small at the start of the after-effect phase to be detected (leading to a non-significant change of the vowel in the After-effect phase compared with baseline productions). For Stamm, the adaptive vowel shortening during the Hold phase significantly persisted into the After-effect phase. For Staat and Stab, the vowels were significantly lengthened during the Hold phase. Part of this opposing response to the perturbation was also adaptive, as examined through persistent lengthening in the After-effect phase, whereas the other part of the response was presumably due to the stretching of the onset in perturbation and the resulting increased delay of the vowel that activated reactive feedback control responses during the Hold phase. The comparison of lexical conditions within experimental setups (in absolute durations, Section 3.1.3) showed no lexical effect for Staat vs. Stab, but overall larger responses for Stamm vs. Stadt.
Section 3.2 set the amount of response in relation to the applied perturbation during the Hold phase, and therefore allowed for a comparison of responses across the different setups (Stadt and Staat—lexical condition vs. Stamm and Stab—non-lexical condition) which experienced different magnitudes of perturbation (due to initial vowel length) and directions of perturbation (vowel stretching and vowel compression). Similar to the analysis of vowel durations in Section 3.1.3, there was no main effect for lexicality in the Hold phase—the responses between lexical conditions were equally strong. In the After-effect phase, the significant main effect indicated larger adaptive responses for the non-lexical condition. Figure 7(a) indicates that these were mostly driven by weaker responses for the vowel in Stadt, while Stamm, Stab, and Staat show almost equal amounts of response, ranging from ~16% to ~20%. This amount is comparable with other studies, for example, the amount of consonant adaptation for three out of four tested lexical items in Karlin and Parrell (2022, ranging from 13.8% to 16.8%) However, the vowel adaptation in our study should be interpreted with caution, since Stamm showed overall greater effects than Stadt, especially in the coda consonant /m/ which might have enhanced the overall adaptive response for both vowel and coda /m/ in Stamm (as compared to vowel plus coda /t/ in Stadt).
5.2 Consonants
The analyses of the consonants in Section 4 supported this assumption, showing that both coda consonants (closure of /t/ in Stadt and /m/ in Stamm) were significantly lengthened during the Hold phase (opposing the perturbation, Table 4), but only the /m/ in Stamm showed significant after-effects. The difference in response to the coda consonants /m/ and /t/ can mainly be attributed to differences in perturbed sound class; since these were the only sounds that differed in manner of articulation between conditions, with the nasal being a continuous sound while the final plosive in Stadt was merely silence (closure of the /t/). Therefore, the manipulation of the final /t/ would only be identifiable in a delayed burst. Furthermore, the duration of /m/ was longer than the duration of /t/, providing much more auditory information and thus a higher perceptibility of the perturbation. These differences emerged from the inevitable difficulty in finding more similar word pairs for perturbation.
Both onset consonants (C1 - /ʃ/ and C2 - /t/ in Staat and Stab) were not shortened in response to the stretching in perturbation, instead C2 was lengthened. This might be due to the implementation of the perturbation: If the onset segment was overall long enough, the stretching of the initial part /ʃ/ could have resulted in a delayed /t/, thus initiating effects of reactive feedback control on /t/ by lengthening it or slowing down (cf. Karlin & Parrell, 2022). This assumption is supported by the significant difference between Hold and After-effect phase for /t/, indicating that at least some part of the lengthening during the Hold phase is a reactive response to the ongoing perturbation. This finding is in line with previous studies that did not observe shortening in response to stretched onset consonants (Oschkinat & Hoole, 2020, 2022). Interestingly, however, C1 is significantly shorter in the After-effect phase compared with both Baseline and Hold phase (opposing the direction of previously received perturbation), perhaps showing some late adaptation effects when perturbation is removed and when there is no additional reactive response (which may counteract the adaptive shortening response during the Hold phase, see Figure 4, lower panels, green dots and lines). At the same time, C2 remains longer in the After-effect phase compared with Baseline durations; thus, the two consonants diverge in their temporal behavior. This in turn suggests that the full onset /ʃt/ retains approximately the same duration as in the Baseline, indicating that the complex onset might rather be timed as one unit displaying an overall constant duration, instead of timing each consonant separately, as suggested in Oschkinat and Hoole (2020).
5.3 Imbalance in shortening and lengthening responses
The data from both experimental setups indicate that lengthening responses are more pronounced than shortening responses. This effect might be naturally given, since short vowels can only be shortened by a certain extent before they are non-existent, while lengthening is theoretically limitless. This imbalance is presumably further enhanced by the fact that shortening responses most likely require higher cognitive effort due to the need to be “ahead of time” in planning and execution. On the contrary, lengthening or slowing down in response to manipulated auditory feedback can always be a generic response of taking more time to process the input. All compressed segments (the vowels in Staat and Stab and the codas in Stadt and Stamm) experienced significant effects of reactive feedback control due to the previously stretched segment (in addition to the software/hardware delays). Especially in the Vowel compression setup, the delays at the start of the vowels in Staat and Stab were between 150 and 200 ms, which are delays that are known to enhance DAF-effects and may cross the threshold for noticeable delays. Notably, Figure 5(a)) indicates that for Staat in the Hold phase (lower left panel, middle boxplot), some participants responded much more weakly than the majority. This could be driven either by perturbations that did not push toward/across the phoneme boundary or by a shorter delay that might not have crossed the boundary of ~150 ms to cause DAF-like effects, resulting in less slowing down/lengthening. However, regarding the effect of the total delay, one must keep in mind that this delay is only received for a very short period of time, that is until the start of the vowel in the heard signal, since the end of the vowel aligns again in almost real time with the spoken signal (except for the software/ hardware delay that is constantly received). Speakers were asked after the perturbation whether they noticed anything; most of them could not articulate what changed, simply observing that something was “weird.”
5.4 Lexical effects
This study provides first insights into the control of phonemic quantity contrasts when an auditory shift in phonemic category jeopardizes the lexical status or not. We found that for temporal properties in German, maintaining lexical status seems less important than maintaining phonemic identification or maintaining typical productions of the intended token, that is, overall, our data did not show strong lexical effects. This finding indicates that, in our data, lexical status is not the major force that drives adaptive and reactive responses and that the lexical bias effect may not take effect in the temporal control of self-produced speech. Given our data, it is, on the one hand, possible that either phonemic identification is of higher priority than lexical status since adaptation was found for all vowels but to a similar extent independent of lexical condition. On the other hand, it could also be the case that phonemic or lexical categories in general do not play a large role in temporal adaptations. This assumption is supported by Karlin and Parrell (2022), who concluded that the driving force of adaptive responses in their data was not a change in phonemic category but rather percepts that fell outside the typical distribution of productions of the intended segment. This assumption could further explain the large responses for /m/ in Stamm, whereby /m/ was not perturbed toward another category, but still showed large response patterns. Our findings are not fully in line with the findings of Bourguignon et al. (2014) for spectral perturbations, who found larger compensation when a real word was shifted toward another real word compared with when a real word was shifted to a pseudo-word. The similarity of our findings with the temporal perturbation study by Karlin and Parrell (2022) but not with the spectral perturbation study by Bourguignon et al. (2014) could have several implications. First, we assume temporal properties of speech to be maintained differently in fluent speech than spectral parameters. This is naturally given by the fact that adjustments on the spectral dimension can be executed within the perturbed speech attempt, while still maintaining the overall duration. On the other hand, in temporal manipulations the segment has to be fully perceived before the duration can be determined and (corrective) adjustments initiated. Second, differences in the processing of spectral and temporal perturbations might likely be enhanced by a different mismatch between auditory and somatosensory feedback. In temporal perturbations, the time lag between auditory and sensory information might constitute a greater mismatch than the quality difference between auditory and sensory information received in spectral perturbations. This might lead to differences in acceptance of the perceived auditory feedback as self-produced.
Regarding the role of timing in accepting speech tokens as self-produced, the study by Lind et al. (2014) connected self-agency in speech motor control with semantic processing in perception/production. In an auditory feedback perturbation study going beyond the phonemic level they fed back different words than those produced, challenging self-agency in semantic monitoring. In a Stroop task, participants had to name the color of an orthographically presented color word (such as the color name “red” written in the color blue) while hearing themselves over headphones. In some trials, a color name produced by the participant in previous trials, and different from the one produced in the respective trial, was fed back. Over two thirds of falsely fed back tokens (here: different words than those produced) remained undetected by participants and were still experienced as self-produced, as long as they had an ideal temporal alignment with the produced word. Thus, the temporal alignment between feedback and production was found to be more important than spectral shape, or even lexical/semantic identification. These findings, in combination with the results from this study, suggest that higher-order linguistic function plays a minor role compared with the general temporal alignment of productions and perceived auditory feedback.
5.5 Outlook and limitations
This study is to our knowledge the first examining the planning and control of temporal phonemic cues with respect to their dependence on higher-order linguistic function in speech motor control. In this study, we tested for a lexical bias effect by perturbing toward a “heard competitor” (another real word) or not. In future studies, a valuable addition would be to perturb toward “spoken competitors”; this would involve stretching the /a:/ in Staat and compressing the /a/ in Stadt, whereby opposing responses would push toward the “spoken competitors,” analogously to the spectral perturbation study by Frank (2011). This perturbation would reduce the mismatch between the sensory channels but could help to indicate whether different categories in feedforward representations might hinder adaptation to erroneous auditory feedback. For future studies it would further be relevant to investigate languages with more pronounced quantity cues, such as languages with geminates that differ in quantity, such as Italian or Finnish. For example, Finnish has segmental quantity oppositions in both consonants and vowels. Furthermore, in Finnish, there is a complex relationship between syllable and segment duration in stressed syllables depending on the moraic pattern, syllable structure, and voicing (Suomi & Ylitalo, 2004). More broadly speaking, the planning and control of cues on different linguistic levels remains a fruitful area of investigation. While most studies investigate phonemes as the distinctive factors in real word identification, another appealing approach to phonemic identification would be to use spectral or temporal alterations that violate the phonological structure of the language; this could deepen our understanding of the connection between the phonemic and phonotactic system of a language (i.e., which sounds exist and which sounds are allowed to be combined next to each other). For example, in Oschkinat and Hoole (2020), we found shortening responses to the stretching of the vowel /a/ in “Napf,” even though the shift toward another phonemic category (/a:/) resulted in a phonotactically illegal German syllable (/na:pf/). However, we did not explicitly compare this with a condition in which the perturbation would have resulted in a phonotactically legal syllable.
One limitation of the study is that it is possible that for some speakers, the perturbation might have pushed more toward the phoneme boundaries than for others, and therefore might have elicited greater responses. In future studies, the perceptual category boundaries and typically produced tokens of the vowels should be examined and monitored throughout the experiment. This approach should further take the broader context such as speech rate and typical context of sounds as well as word representation in the sense of exemplar-based approaches into account.
Further limits on generality are naturally given due to the small number of studies on the topic to date. That is, the speech material in this study (as in every similar study) is limited, and to date real-time temporal auditory feedback perturbation studies span over speech material in German and English. Since it was concluded previously that findings from temporal perturbation studies depend on the phonological structure of a language, for more generality the investigation of further languages is a clear desideratum. In addition, this study tested participants between the age of 18 and 35 to eliminate possible effects of hearing loss due to aging and reduce variability within the tested group of participants. In future studies, other age groups could be the focus of investigation to reduce this gap in our knowledge. In summary, the investigation of online processing of temporal characteristics of auditory feedback is still at quite an early stage compared with the huge body of work on the processing of spectral perturbations. Our results make it clear that results from the spectral domain cannot simply be extrapolated to the temporal domain and much work remains to be done to achieve a detailed understanding of processing in the temporal domain.
6 Conclusion
This study rejected the hypothesis that speakers respond more to temporal auditory feedback errors when the lexical identity (word to word) is jeopardized. Instead, phonemic identification and sound class were shown to be factors that enhance responses. Hence, this finding does not support the assumption that the so-called lexical bias effect plays a role in self-monitoring of temporal dimensions of speech, further indicating that self-produced speech is differently processed than not self-produced speech. The data of this study should serve as a motivation for continuing research on sensorimotor integration in speech with respect to higher-order linguistic processing, enhancing the development of linguistic and psycholinguistic models of speech perception that intertwine with existing models of speech motor control.
Footnotes
Appendix A
The following analysis examines whether the groups in the vowel compression setup (Staat and Stab) with different online status tracking (OST) implementation differ in their response patterns. A linear mixed-effects model with log-transformed durations and Phase (B, H, A), OST group (old OST, new OST), and Lexical Condition (lexical, non-lexical) as well as the interaction between OST group and Lexical Condition and a random effects structure including random intercepts for participants and a by-participant random slope for Phase revealed a significant main effect of OST group on duration: The old OST group showed shorter durations compared to the new OST group (β = −0.088, SE = 0.032, t(21.27) = −2.75, p = .012). We also found a significant interaction between OST group and Lexical Condition (β = 0.027, SE = 0.005, t(2207) = 4.97, p < .001), indicating that while both groups exhibited shorter durations for the non-lexical item (Stab), this effect was less pronounced in the old OST group compared to the new OST group. However, and crucially, an added interaction between OST group and phase did not improve model fit and was not significant, indicating that phase changes were not dependent on OST group. This was confirmed by emmeans contrast-of-contrasts per phase difference (H-B, H-A, A-B) between the OST groups from a model including the (non-significant) interaction between phase and OST group: All group differences for phase differences were non-significant. Hence, the main effects imply that the new OST implementation worked better for participants with a slower speech rate than the old OST implementation.
Appendix B
In this appendix, the participant group of the Vowel compression setup for which the perturbation accidentally stretched the previous vowel /ɐ/ in the carrier word /bεsɐ/ were analyzed similar to the analysis described in Section 3.1. This group comprised 10 participants for Staat and 9 for Stab. Figure B1 indicates that in both words (Staat and Stab), the perturbation stretched the preceding vowel (preV) /ɐ/, and the initial onset consonant (C1 - /ʃ/), while the second onset consonant (C2 - /t/) remained unaffected (probably due to equal amount of stretching and compression) while the vowel (V) /a:/ was compressed (Figure 4, opaque lines). The response patterns (Figure B1, solid lines) suggest that all affected sounds are generically lengthened during the Hold phase, indicating a slowing down in response to the stretching and to the received delay. The response data was fed into a linear mixed-effects model which was built stepwise as in the previous sections. The final model was fitted with log-transformed duration as the dependent variable and included the predictors Phase (Baseline, Hold, After-effect) and all Sounds of interest (here: preV, C1, C2, V) and the interaction of Phase and Sound. The factor Word/ Lexical Condition did not improve model fit and was therefore not included. Post hoc tests with emmeans provided Phase contrasts per sound; the detailed statistical outcome is summarized in Table B1. As shown in Table B1, preV, C1, and C2 were indeed significantly lengthened during the Hold phase and this lengthening persisted into the After-effect phase for preV and C1. The vowel did not change significantly over the course of the experiment. We therefore assume that stretching of segments not directly preceding the vowel (C2 did not change, while C1 and preV where stretched) might have induced an even stronger impression of generally delayed auditory feedback rather than focal perturbations. This is supported by the generic lengthening/no shortening of segments in production (see Figure B1, solid lines).
Acknowledgements
We thank all our participants for taking part in our study and Rosa Hufschmidt, Sebastian Böhnke, and Sishi Liao for their help in running the tests.
We would further like to thank two anonymous reviewers for their thoughtful comments on an earlier version of this manuscript. All remaining errors are our own.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by DFG; Grant No. RE 3047/1-1 and Grant No. HO 3271/6-1.