
Abstract
Native speakers generally outperform non-native speakers in identifying and discriminating speech sounds. Yet, the categorical perception of native speech sounds can sometimes impede the discrimination of sounds within the same phonemic category. It remains unclear whether different linguistic features show similar patterns in cross-linguistic comparisons. Therefore, we studied the categorization and discrimination of vowel duration and lexical tone—two features that differ fundamentally. Vowel duration (short vs. long) typically requires phonemic context for categorization, while tone (rising vs. falling) can be recognized directly from acoustics. Participants were native Finnish and Mandarin Chinese speakers, and native Mandarin Chinese speakers exposed to Finnish. As expected, Mandarin speakers demonstrated a steeper category boundary for tonal stimuli than Finnish speakers. In contrast, no group difference was found for categorization slope for duration. In discrimination, native speakers outperformed non-native speakers for between-category pairs, as anticipated. For within-category pairs, however, native speakers performed worse than non-native speakers—but only for the tone feature. Mandarin speakers exposed to Finnish showed differences in categorization of vowel duration and in associated reaction times compared with the other groups. The results suggest that native language does not influence vowel perception uniformly across tone and duration features. Moreover, exposure to a foreign language in adulthood may, at least initially, lead to categorization preferences that diverge from, rather than align with, those of native speakers. These findings provide a basis for future theoretical models of how native language and late exposure shape speech perception across different phonetic features.
1 Introduction
1.1 Categorical perception of phonetic features
Infants exhibit the ability to discern distinctions among phonetic units across a wide array of languages (Eimas, 1985; Trehub, 1976; Werker et al., 1981). Within the first year of life, children develop perceptual skills specific to their native language (Jusczyk et al., 1994), including a notable enhancement in the capacity to differentiate between native phonemes (Kuhl, 2004; Kuhl et al., 2008). However, the acquisition of proficiency in one’s native language comes at a cost of diminished ability to represent and discriminate speech sound features in foreign languages that differ from the native language (Elsabbagh et al., 2013; Werker & Tees, 1984). A classic example of this is the difficulty that Japanese speakers encounter when attempting to distinguish between the /r/ and /l/ sounds in English, because these sounds do not form two different categories in their native language (Aoyama et al., 2004; Miyawaki et al., 1975).
Categorical perception refers to a phenomenon in which individuals perceive stimuli as discrete entities belonging to non-overlapping categories, even though the underlying physical dimensions vary continuously (Goldstone & Hendrickson, 2010; Liberman et al., 1957; Repp, 1984). This phenomenon is often greater for consonants than for vowels (Altmann et al., 2014). Experimentally, categorical perception is typically investigated through a combination of identification (or categorization) and discrimination tasks. In identification tasks, participants classify stimuli into predefined categories, revealing both the location and the sharpness of category boundaries (Macmillan et al., 1977). Evidence for categorical perception is provided by discrimination tasks that show higher accuracy for stimulus pairs crossing category boundaries compared with pairs drawn from within a category—a pattern often referred to as the phoneme boundary effect (Goldstone & Hendrickson, 2010; Iverson & Kuhl, 2000; Liberman et al., 1957). This effect has been linked to the “perceptual magnet effect,” which refers to the reduced discriminability of stimuli located near the prototypical exemplar of a phonetic category (Aaltonen et al., 1997; Kuhl & Iverson, 1995).
1.2 Categorization and discrimination of speech sound duration by native and non-native speakers
Categorical perception is typically more robust for speech sound features that are phonemic in a listener’s native language, whereas non-native features often elicit more gradient perception. For example, speakers of languages with phonemic vowel duration, such as Finnish and Estonian, perceive short–long contrasts categorically, showing sharp boundaries and clear discrimination peaks, whereas Russian speakers, whose language lacks such contrasts, perceive vowel duration more gradient, with broader boundaries (Meister & Meister, 2011; Ylinen et al., 2005).
Native language can influence also the discrimination of speech sounds. For example, a cross-linguistic study examined Swedish language vowel duration discrimination in learners from different language backgrounds (McAllister et al., 2002). Estonian speakers were most successful in acquiring the Swedish duration contrast, Spanish speakers the least, and English speakers performed in between. This pattern suggests that learners’ perceptual accuracy depends on how prominently a given phonetic feature is used in their native language. Interestingly, however, no differences were found between German and Italian speakers in vowel discrimination, even though only German uses vowel duration phonemically (Altmann et al., 2012). Since Italian uses consonant duration phonemically, it is possible that Italian listeners’ sensitivity to non-native vowel-length contrasts benefits from their experience with durational contrasts in their native language. In contrast, native speakers of Arabic and Japanese were less accurate at discriminating vowel-length contrasts in the other language (Japanese for Arabic speakers, Arabic for Japanese speakers, Tsukada, 2012a), indicating that native language experience with vowel length does not automatically transfer to another language with similar contrasts.
In general, research on duration-based contrasts in foreign-language perception remains limited, particularly cross-linguistic studies of categorization and discrimination of more than one type of speech sound feature within the same study. Examining different speech sound features is crucial, because their perception may differentially engage acoustic and phonological information. Notably, vowel duration has no absolute definition in terms of length; rather, its phonemic status (e.g., short vs. long) is determined relative to language-specific categories. Consequently, categorization of speech sound duration depends on the distribution of durations within a language, but also speech rate, word context, and the listener’s experience with relevant contrasts (Engstrand & Krull, 1994). By contrast, certain other features can be categorized on the basis of acoustic cues alone. One such feature is lexical tone.
1.3 Categorization and discrimination of lexical tones by native and non-native speakers
Lexical tones are pitch patterns that distinguish word meaning in tonal languages such as Thai and Mandarin Chinese. Lexical tones vary across tonal languages in the number of distinct tones and their pitch contours (e.g., level, rising, falling, or dipping in Mandarin Chinese). Behavioral studies show that speakers of tonal languages typically exhibit more robust categorical perception of tonal contrasts than speakers without tone in their native language. For example, Trique speakers, Mandarin Chinese speakers, and other tonal-language speakers demonstrate sharper categorical boundaries than French and Dutch speakers, who do not have a tonal feature in their native language (DiCanio, 2012; Hallé et al., 2004; Liu et al., 2017). Native speakers of non-tonal languages seem to perceive tonal speech sounds based on their psychoacoustical features, resulting in a more linearly aligned categorization curve (e.g., Wang, 1976). Brain activity studies using change detection paradigms have also suggested that native speakers represent tones more categorically than non-native speakers (Yang et al., 2024).
Similar to categorization, native speakers of tonal languages typically outperform non-native speakers in discriminating their native tones. For instance, Mandarin, Thai, and Cantonese speakers demonstrate higher discrimination accuracy for their respective native tones than speakers of non-tonal or other tonal languages (Hallé et al., 2004; Huang & Johnson, 2010; Lee et al., 1996; Tsukada & Kondo, 2019; Wayland & Guion, 2004; Zhu et al., 2023). However, sounds within the same category can be more difficult for native than non-native speakers to discriminate (DiCanio, 2012; Liu et al., 2017) due to previously mentioned perceptual magnet effect.
1.4 Effects of language acquisition and immersion on categorization and discrimination
Developing language proficiency is closely linked to categorization ability, as increased experience with a language enhances the formation of stable phonological categories and sharpens perceptual boundaries between them (Best et al., 2007; Flege, 1995). Although identification and discrimination of foreign speech sounds are often difficult at first, they can improve in adulthood with sufficient exposure or training (Georgiou, 2021; Giannakopoulou et al., 2013; Liu et al., 2022; Wang et al., 1999). Such improvements have been documented for both tone (e.g., Tsukada & Han, 2019; Wayland & Guion, 2003) and duration contrasts (e.g., Tsukada, 2012b; Tsukada & Hajek, 2023).
Foreign speech learning can also occur through immersion, that is, adapting to a foreign language by living in an environment where it is spoken. In relation to the present study, which examines the effects of immersion, evidence suggests that extended exposure to a foreign language through immersion can enhance the development of categorical perception for the relevant speech features. Learners with more than 5 years of exposure were able to form phonological duration categories closely aligned with native Finnish speakers (Ylinen et al., 2005), whereas those with shorter exposure did not. However, critical perceptual adaptation may occur much earlier, within the first 6 to 12 months of experience (Best et al., 2007). In addition, intensive laboratory training studies have demonstrated that perceptual changes can occur rapidly: for example, intensive high-variability training with Mandarin tones led American English speakers to improve their identification accuracy by over 20% within just 2 weeks, with the gains generalizing to new talkers and stimuli and persisting for at least 6 months (e.g., Wang et al., 1999). Nevertheless, compared with lexical tone, experimental evidence on how training or immersion shapes vowel duration perception remains limited.
1.5 Present study
Here, we conducted a fully balanced cross-linguistic study comparing native Finnish and native Mandarin Chinese speakers in terms of their ability to discriminate and categorize duration (a native feature for Finnish speakers) and tone (a native feature for Mandarin Chinese speakers) in the vowel /a/. This is a fruitful group comparison, as the Finnish language lacks tonal variation for lexical meaning, whereas Mandarin Chinese does not utilize duration as a lexically distinguishing phonetic feature. We chose to use an isolated vowel, which carries no independent lexical meaning in either Finnish or Chinese, to avoid word and sentence-level intonation patterns that could introduce pragmatic interpretations (e.g., questions, emphasis). Although categorical perception is typically more distinct for consonants than vowels (e.g., Eimas, 1963), which seems to be related to their differences in spectro-temporal features (Mirman et al., 2004), we wanted to use vowels in this study, because both duration and tone can be varied in vowels. We employed both categorization and discrimination tasks, as underlying categorical representations can influence discrimination performance. However, it remains unclear whether these effects operate similarly for different types of speech sound features, such as tone and duration. In addition to cross-linguistic comparisons, we also investigate how immersion in a Finnish language environment affects the perception of native and non-native speech sounds of Mandarin Chinese speakers living in Finland. We compare their categorization and discrimination results with those of Mandarin Chinese speakers who have not been exposed to Finnish and with native Finnish speakers.
We hypothesize, for categorization, that the category boundary is steeper in the group for which the feature is native. Due to categorical perception in native speakers, but not necessarily in non-native speakers, group differences in reaction time of categorization are expected to be most pronounced at the category boundary stimulus, with the native group exhibiting longer reaction times at the boundary than at the endpoints of the stimulus continuum. For discrimination ability, we predict that native speakers have a higher accuracy in discriminating pairs of stimuli located at category boundaries (e.g., Hallé et al., 2004), and non-native speakers may have higher accuracy than native speakers when discriminating within-category stimuli (DiCanio, 2012). Due to their exposure to the Finnish language, native Mandarin Chinese speakers living in Finland are expected to show changes in their categorization preference and/or discrimination for the duration feature in comparison with Mandarin Chinese speakers naïve for this feature.
2 Method
2.1 Participants
The participants were recruited for three groups: (1) Native Finnish speakers living in Finland and having no exposure to tonal languages (FIN); (2) Native Mandarin Chinese speakers living in China with no exposure to quantity languages—that is, languages that use phonemic duration contrasts in vowels or consonants (CHN); and (3) Native Mandarin Chinese speakers who had lived in Finland for at least 6 months and had thus been exposed to Finnish—a language with phonemic duration contrasts (CHF). The participants in the FIN group were recruited through announcements on social media and through the University of Jyväskylä’s email lists. Participants in the CHF group were recruited through bulletin board advertisements and social media at the University of Jyväskylä and the University of Helsinki, whereas participants in the CHN group were recruited through an advertisement in the WeChat groups of Sichuan Normal University. Written informed consent was obtained from all participants before their participation. The experiment was undertaken in accordance with the Declaration of Helsinki. The ethical committee of the University of Jyväskylä and Sichuan Normal University approved the research protocol.
For all three groups, the inclusion criteria were age of 18–40 years and good general health. Exclusion criteria were language deficits, learning disabilities, hearing problems, or other sensory deficits (vision corrected with eyeglasses was allowed), neurological disorders/injuries, and motor dysfunctions that could affect the reaction time tasks. Professional musicians and people who have practiced singing or playing an instrument for more than 2 years extensively (more than 2 hr per week) within the last 5 years were also excluded from the study. All participants included in the three groups had an education level of at least high school.
Due to the lack of similar studies, adequate statistical power for group-level comparisons was ensured by an a priori power analysis, assuming a medium effect size (
Forty-three participants initially volunteered for the CHN group; however, three did not meet the inclusion/exclusion criteria, leaving 40 participants included in the study (21 female, 19 male, mean age = 20.33 years, SD = 2.54, age range 18–29 years). Forty-six participants volunteered for CHF group, but three of them did not meet the inclusion/exclusion criteria. Therefore, the final sample for CHF group was 43 (31 female, 12 male, mean age = 27.86 years, SD = 3.94, age range 20–37 years). Forty-one Finnish-speaking participants volunteered for the study. Six of them did not meet the inclusion/exclusion criteria, leaving 35 participants for FIN group (29 female, 6 male, mean age = 24.69 years, SD = 4.44, age range = 20–35 years).
Use of different languages was evaluated by using the short version of the Language Experience and Proficiency Questionnaire (LEAP-Q) (Marian et al., 2007). Two CHN participants reported using only Mandarin Chinese. All the other CHN participants used English as a second language, but its use was limited only to the study context. The amount of daily English use they reported ranged from 1% to 30% (M = 13.37%, SD = 9.22%). Only one CHN participant had learned a third language (Spanish) and used it less than 5% of the time.
The participants in the CHF group had lived in Finland for an average of 29.59 months (SD = 25.81, range 6–96 months, missing information from four participants); among them, 25 CHF participants had been actively learning Finnish in an online Finnish language course or another type of course. All included CHF participants spoke English as their second language, and they were exposed to the English language environment 5% to 80% of the time every day (M = 33.72%, SD = 17.76%). Nineteen participants reported daily exposure to a Finnish language environment, with exposure levels ranging from 2% to 35% (M = 13.74%, SD = 10.20%). In addition, participants reported speaking Japanese (1 participant, 5%), Korean (1 participant, 10%), Spanish (1 participant, 5%), German (1 participant, 10%), and French (2 participants, 5%) in their daily lives.
All participants in the FIN group spoke English. Thirty-five reported using English 4% to 50% of the time each day (M = 20.49%, SD = 12.11%). Thirty-one participants spoke Swedish, using it 0% to 10% daily (M = 3.48%, SD = 3.49%). Ten participants spoke German, using it 0% to 13% daily (M = 4.00%, SD = 4.97%). Seven spoke Spanish, using it 1% to 4% daily (M = 1.43%, SD = 1.13%). Five spoke French, using it 0% to 4% daily (M = 2.00%, SD = 1.87%). Two spoke Japanese but did not use it daily. Two spoke Russian, using it 10% and 20% daily. One participant spoke Italian and used it 2% of the time daily. Eight Finnish participants had stayed abroad for more than 6 months, but none had lived in a tonal-language environment.
2.2 Stimuli
The experiment employed the speech sound /a/ as the stimulus. Tonal stimuli were prepared by having a female native Mandarin Chinese speaker articulate the initial phoneme /a/ with rising (Chinese lexical tone 2) and falling (Chinese lexical tone 4) pitch contours. Duration stimuli were based on a female native speaker of Finnish who articulated the vowel /a/. All recordings were conducted at a sampling rate of 44.1 kHz. For tonal stimuli, sounds from a Mandarin Chinese female speaker were digitally edited using SoundForge software (SoundForge 9, Sony Corporation, Japan) to ensure a duration of 200 ms. To isolate the lexical tones while maintaining the constancy of other acoustic features, pitch tier transfer was performed using Praat software (version 5.4.06, University of Amsterdam). This process produced a rising tone and a falling tone, identical except for their fundamental frequency (F0) pitch contour. These two tones served as the endpoint stimuli to create a continuum of lexical tones with 10 interval steps (as in: Xi et al., 2010), but only the vowel part was used here. Six stimuli (Tone tokens 1, 3, 5, 7, 9, and 11) were applied in this study (Figure 1(a)). The duration stimuli were digitally edited from recordings of a Finnish female speaker using SoundForge Pro 10.0 (MAGIX Software GmbH, Germany). The 200 ms speech sound was digitally shortened in 10 ms increments, as described in (Lipponen et al., 2019). Five sounds with durations of 110, 130, 150, 170, and 190 ms, which were used as stimuli in this experiment (Figure 1(b)). To ensure consistency, all stimuli were normalized to have the same root mean square intensity. Prior to data collection, the nativelikeness of both tonal and duration stimuli was confirmed by native speakers of the respective languages, none of whom participated in the study.
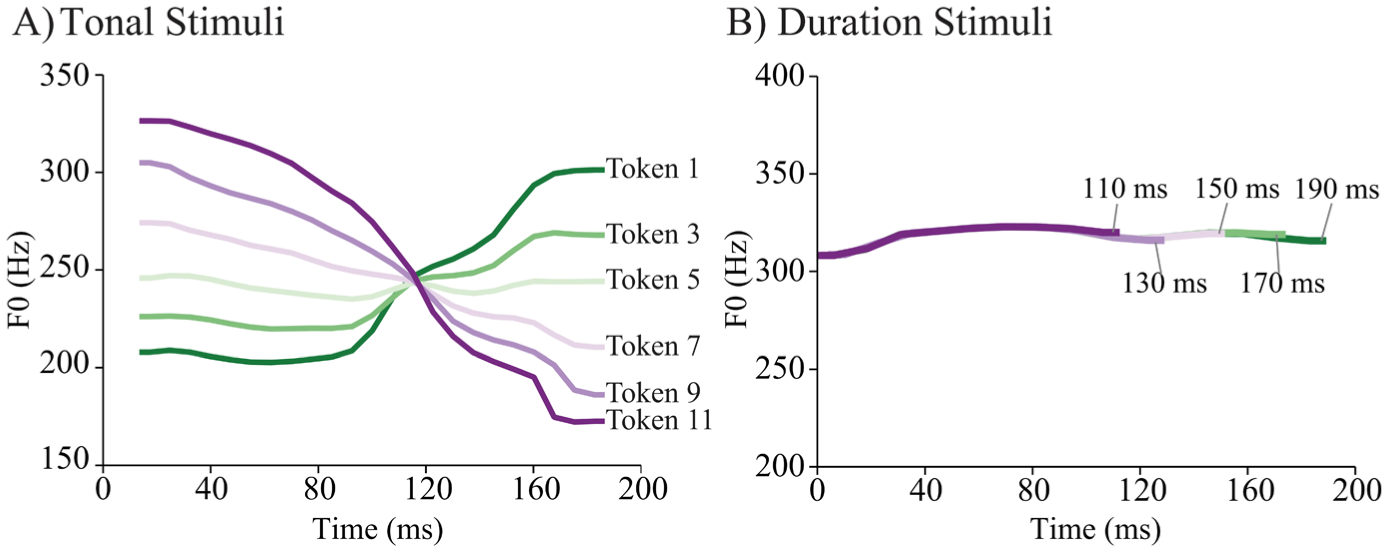
Illustration of the (a) tonal stimuli and (b) duration stimuli.
2.3 Procedure
Participants completed the behavioral tests in quiet laboratory rooms on university premises, either in China (CHN group) or in Finland (CHF and FIN groups). The experimental setup was identical across sites, and the participants used the same model of laptop and earphones (over-ear headphones, Sony MDR-XD150), under the control of PsychoPy v2021.2.3 (Peirce et al., 2019). The same native Mandarin Chinese-speaking experimenter conducted data collection for both the CHN group in China and the CHF group in Finland, ensuring consistency in experimental procedures and instructions. In Finland, data collection for the FIN group was carried out by a native Finnish-speaking experimenter. The procedure and task instructions were carefully matched across the two countries. All participants received identical task instructions, presented in their respective native languages. Instructions were standardized: they were pre-planned and agreed upon by the experiment leaders in Finland and China and delivered in the participants’ native language. The same instructions were also displayed on the computer screen. Participants could request clarification of the instruction if needed. All participants received the same amount of practice before the experiments started. Both accuracy and response speed were emphasized in the instructions. The tasks were administered sequentially: all participants completed the discrimination task first, followed by the categorization task. Within each task type, the order of tone and duration conditions was counterbalanced across participants.
The discrimination task was a so-called AX task, where the speech sounds were presented in pairs. After each sound pair, the participants indicated whether the sounds in a pair were the same or different by pressing the “F” key or “J” key; the key assignment was counterbalanced between the participants. In the discrimination tasks, the pairs of sounds were divided into two blocks, each with 60 trials, and participants took a brief break after completing the first block. There were four tasks for the participants (categorization and discrimination of tone and duration). The discrimination task was longer in duration than categorization and was therefore conducted in two blocks. For the tone discrimination task, the interval between the sounds within each pair was 300 ms, and for the duration discrimination task, it was 340 ms. Each condition (tone and duration) included 60 trials with the same sound pairs and 60 trials with different sound pairs. A new trial was presented 1000 ms after the participant’s response in the tone task and 1040 ms after the response in the duration task. The small differences in inter-stimulus intervals between the tone and duration tasks were unintentional and resulted from differences in the sound files (with or without silent periods).
In discrimination tasks, “same stimulus pairs” and “different stimulus pairs” were presented. For duration, 12 trials of each same stimulus pairs were presented (pairs: 110–110 ms, 130–130 ms, 150–150 ms, 170–170 ms, and 190–190 ms). For tones, 10 same stimulus pairs were presented (pairs: Token 1–Token 1, Token 3–Token 3, Token 5–Token 5, Token 7–Token 7, Token 9–Token 9, and Token 11–Token 11). Different stimulus pairs for duration, with 10 trials for each, were paired as follows: 110–130 ms, 130–150 ms, 150–170 ms, 170–190 ms, 110–150 ms, and 130–170 ms. Different stimulus pairs for tones with 12 trials for each were: Token 1–Token 3, Token 3–Token 5, Token 5–Token 7, Token 7–Token 9, and Token 9–Token 11. The presentation order of the sound pairs within each task was randomized. Accuracy and response time were recorded.
In the categorization task, the speech sounds were presented one after the other. In the beginning, the participants were first presented with the extremes of the stimuli (the most rising and most falling; shortest and longest), and these were labeled for them once (e.g., “This is a short sound.”). Subsequently, the sounds were presented in a randomized order with the possibility of an immediate repetition of the same sound. After each sound, the participants indicated the category of a sound: in the tone block, whether the tone of the vowel was rising or falling, and in the duration block, whether the duration of the vowel was short or long. The participants were instructed to indicate the category by pressing either the “F” key or the “J” key; the key assignment was counterbalanced across participants. The duration categorization task had a total of 60 trials, with 12 trials for each category (110, 130, 150, 170, and 190 ms). The tone categorization task had a total of 60 trials, with 10 trials for each category (Token 1, Token 3, Token 5, Token 7, Token 9, and Token 11). Categorical preference and response time were recorded for both tone and duration categorization.
2.4 Preprocessing of the data and statistical analysis
Trials with response times shorter than 200 ms were excluded from the analysis to avoid the influence of accidental button presses on the results. After this filtering, for categorization of duration, the average percentage of included trials was 97.88% (SD = 0.05, range 78.33%–100%) for CHN, 97.05% (SD = 0.09, range 41.67%–100%) for CHF, and 99.90% (SD = 0.004, range 98.33%–100%) for FIN. For categorization of tone, the average percentage of included trials was 95.42% (SD = 0.06, range 71.67%–100%) for CHN, 95.43% (SD = 0.06, range 75.00%–100%) for CHF, and 99.76% (SD = 0.01, range 93.33%–100%) for FIN. For discrimination of different durations, the average percentage of included trials was 96.50% (SD = 0.08, range 68.33%–100%) for CHN, 98.45% (SD = 0.05, range 70.00%–100%) for CHF, and 99.81% (SD = 0.01, range 93.33%–100%) for FIN. For discrimination of same durations, the average percentage of included trials was 96.50% (SD = 0.08, range 66.67%–100%) for CHN, 98.26% (SD = 0.06, range 71.67%–100%) for CHF, and 100% for FIN. For discrimination of different tones, the average percentage of included trials was 98.29% (SD = 0.03, range 86.67%–100%) for CHN, 98.06% (SD = 0.05, range 70.00%–100%) for CHF, and 100% for FIN. For discrimination of same tones, the average percentage of included trials was 97.38% (SD = 0.04, range 83.33%–100%) for CHN, 97.60% (SD = 0.05, range 76.67%–100%) for CHF, and 100% for FIN.
Response times were calculated across all included trials in both the categorization and discrimination tasks. Although tone stimuli can be characterized as rising or falling based on their physical features (frequency), the duration feature does not allow for an objective distinction between “short” and “long” categories, and therefore, responses could not be divided into correct and incorrect responses. Discrimination performance was analyzed separately for “different” and “same” pair trials due to their marked difference in accuracy and potential response biases.
Statistical analyses of the filtered categorization preference and response time, as well as discrimination accuracy and response time in the discrimination task, were conducted on trial-level data using R (version 4.4.3) in RStudio (version 2024.12.1 + 563). Generalized linear mixed-effects models (GLMMs) were fitted using the lme4 package (version 1.1-36). A GLMM with a binomial link function was applied to examine the effects of categorization preference and discrimination accuracy, as both outcomes were binary. For response time, which was positively skewed, a GLMM with a gamma distribution and a log link function was used, as this approach has been recommended for modeling positively skewed reaction time data (Lo & Andrews, 2015). Type III Wald chi-square tests were conducted using the analysis of variance (ANOVA) function from the car package (version 3.1-3) to assess the significance of fixed effects and their interactions. Sum-to-zero contrasts (contr.sum) were set in R to ensure appropriate Type III Wald chi-square tests. To further explore significant interactions, pairwise comparisons of estimated marginal means were performed using the emmeans package (version 1.10.7) with Bonferroni correction. Wald z-tests were used to evaluate the pairwise contrasts, with the estimated differences between groups (β), standard errors (SE), and z-values reported for each comparison.
For category boundary location and slope, a one-way ANOVA was performed to investigate the effect of Group separately for these variables. The calculation of category boundary location and slope followed the methodology outlined in a previous study (Carter & Bidelman, 2023). Identification scores (P), representing the proportion of trials identified as a rising vowel or longer duration in the categorization task, are characterized by a sigmoid function (P = 1 / [1 + e^(-β1(x-β0))]). The values of β0 (location) and β1 (slope) are derived through nonlinear least-squares regression. Here, x represents the step number along the continuum. β0 (location) represents the horizontal position of the sigmoid curve (indicating the point where the perceptual transition occurs and the location of the categorical boundary), and β1 (slope) determines the steepness of the curve (reflecting the rate at which P changes, indicating the steepness of the categorical boundary). If one-way ANOVA indicated a group difference, post hoc t-tests with Bonferroni correction (as implemented in IBM SPSS Statistics 28.0.1.1, equal variances assumed) were used to investigate the effect of group in each condition. Mean difference (MD) and standard error of mean difference (SE) are reported for the pairwise comparisons. Eta square (η2) and Cohen’s d are used as indices of the effect size estimate. Degrees of freedom (df) are presented as uncorrected. For all the tests, a p-value smaller than .050 was considered significant.
3 Results
3.1 Categorization of duration
Table 1 describes the results of the GLMM analyses. Table 2 shows the results of the pairwise comparisons of estimated marginal means, investigating significant group differences in categorization preference and response time for the duration feature. Figure 2 depicts the main findings related to vowel duration categorization, including categorization preference, response time, category boundary location, and category boundary slope.
Results of the Type III Wald χ2 test on the categorization of vowel duration.

Note. df = degrees of freedom.
Significant (p < .050) results are in bold.
Pairwise comparisons of estimated marginal means with Bonferroni correction to examine the Stimulus × Group interaction effect for categorizing vowel duration.
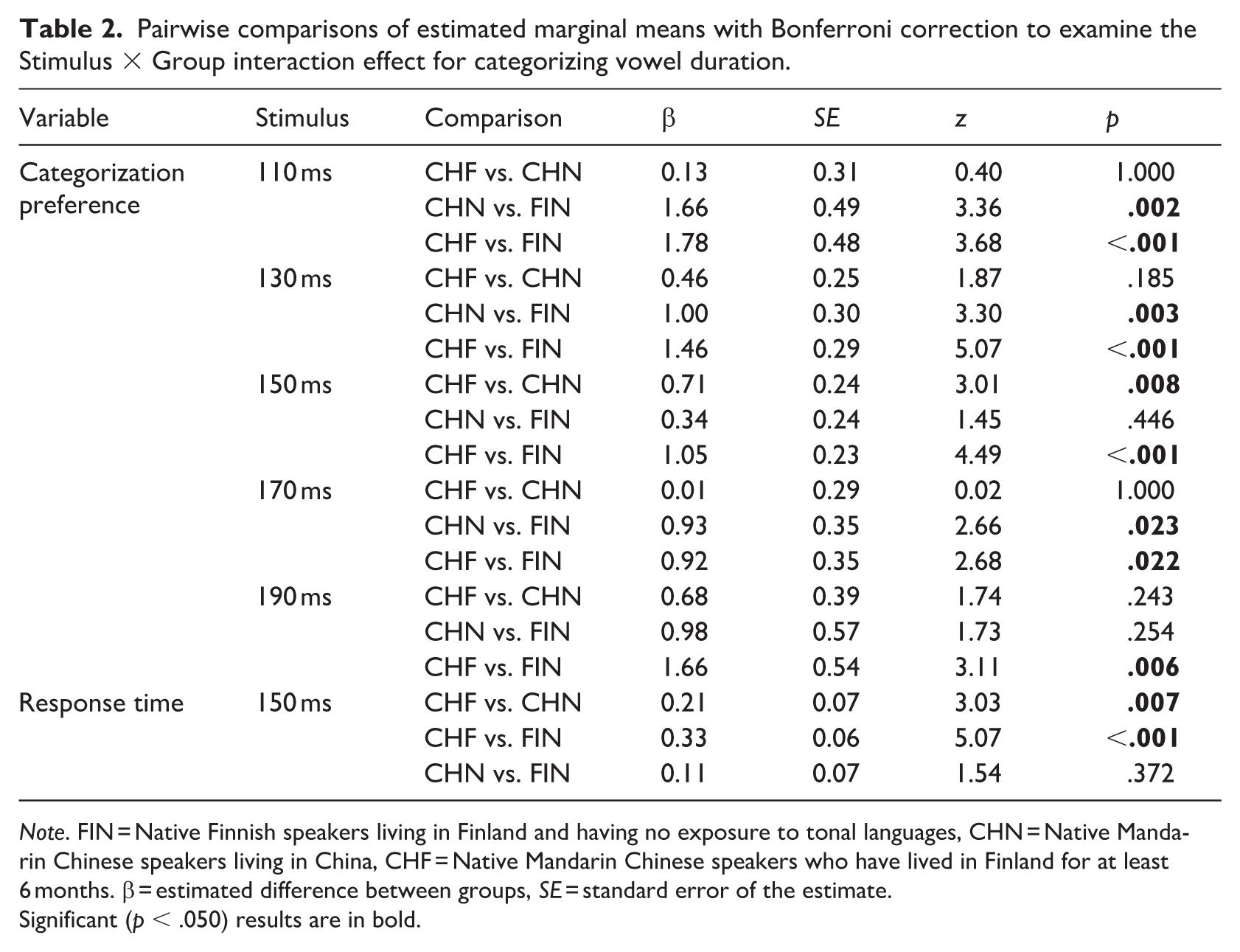
Note. FIN = Native Finnish speakers living in Finland and having no exposure to tonal languages, CHN = Native Mandarin Chinese speakers living in China, CHF = Native Mandarin Chinese speakers who have lived in Finland for at least 6 months. β = estimated difference between groups, SE = standard error of the estimate.
Significant (p < .050) results are in bold.
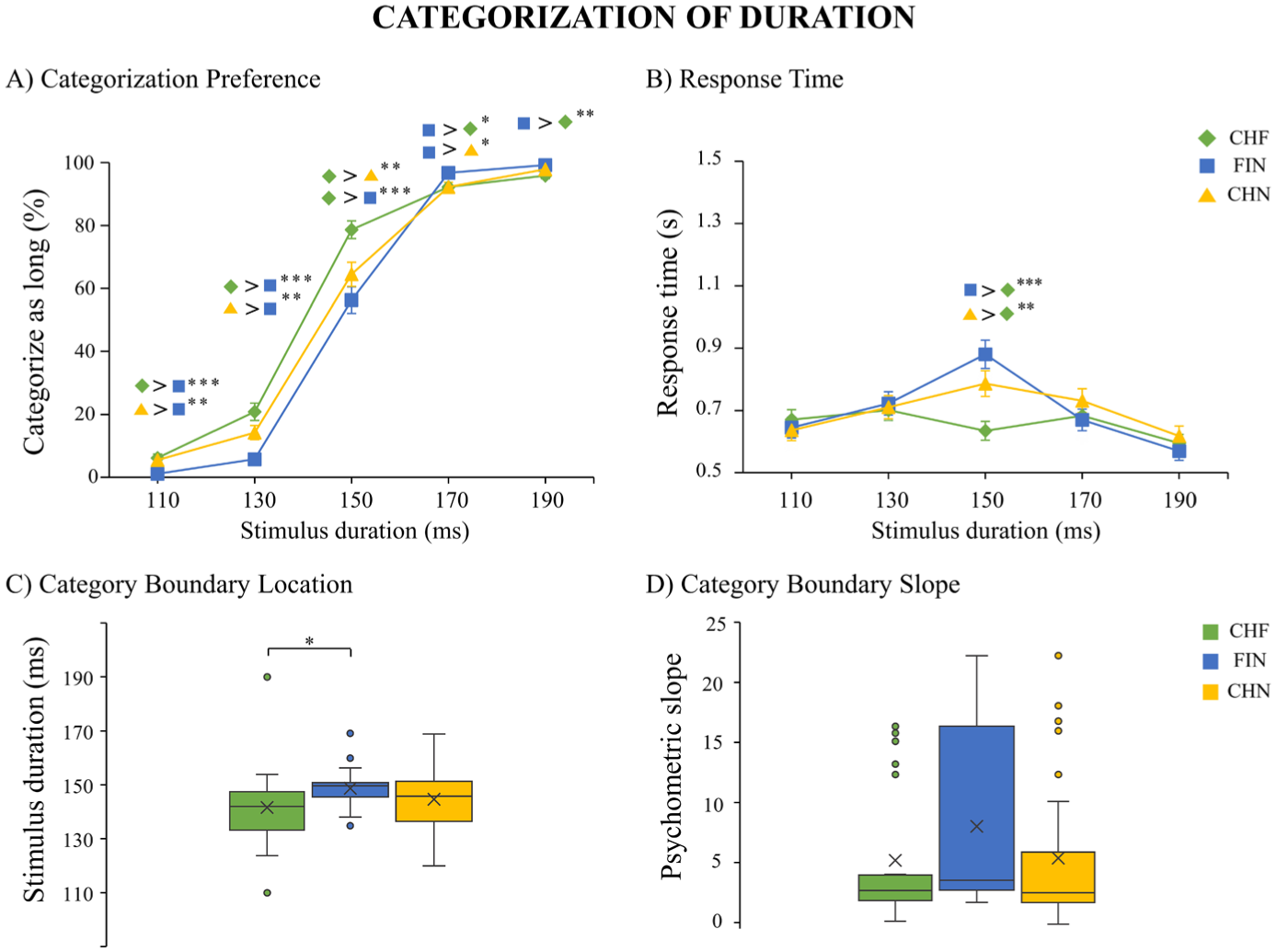
Results for the categorization of vowel duration: (a) categorization preference, (b) response time, (c) category boundary location, and (d) category boundary slope.
3.1.1 Categorization preference
A GLMM with a binomial link function was applied, and a Type III Wald χ2 test was used to evaluate the effects. The model included Group (CHF, CHN, and FIN) and Stimulus (110, 130, 150, 170, and 190 ms) as fixed effects, with Participant as a random effect. The analysis revealed a main effect of Stimulus and an interaction effect of Stimulus × Group.
To further explore the interaction effect, pairwise comparisons of estimated marginal means were conducted with Bonferroni correction. The analysis showed that both groups of Mandarin Chinese speakers were more likely than the FIN group to categorize the 110 and 130 ms sounds as long in duration. For the 150 ms sounds, CHF showed a higher tendency to categorize them as long compared with both CHN and FIN. FIN was more likely to categorize the 170 ms sounds as long compared with the Mandarin Chinese groups. FIN was also more likely to categorize the 190 ms sounds as longer than CHF.
3.1.2 Response time
A GLMM with a gamma distribution and log link function was applied, and a Type III Wald χ2 test was used to evaluate the effects. The model included Group (CHF, CHN, and FIN) and Stimulus (110, 130, 150, 170, and 190 ms) as fixed effects, with Participant as a random effect. The analysis revealed a main effect of Stimulus and an interaction effect of Stimulus × Group.
To further explore the interaction effect, pairwise comparisons of estimated marginal means were conducted with Bonferroni correction. Participants in the CHF group responded faster than those in the CHN and FIN groups when categorizing the 150 ms sound.
3.1.3 Category boundary location
A significant difference was found between the groups in the location of the category boundary for vowel duration as determined by one-way ANOVA, F (2, 115) = 3.653, p = .029, η2 = 0.06. Post hoc t-tests indicated that FIN required a longer duration to perceive a vowel as categorically “long” than CHF (df = 76, MD = 0.35, SE = 0.13, p = .024, Cohen’s d = 0.617).
3.1.4 Category boundary slope
One-way ANOVA indicated no significant differences in the category boundary slope for vowel duration between the groups, F (2, 115) = 2.504, p = .086, η2 = 0.043.
3.2 Categorization of tone
Table 3 presents the GLMM results. Table 4 shows the results of pairwise comparisons of estimated marginal means, investigating significant group differences in preference and response time for tone categorization. Figure 3 depicts the main results related to tone categorization, including categorization preference, response time, category boundary location, and category boundary slope.
Results of the Type III Wald χ2 test on the categorization of tone.

Note. df = degrees of freedom.
Significant (p < .050) results are in bold.
Pairwise comparisons of estimated marginal means with Bonferroni correction to examine the Stimulus × Group interaction effect for the categorization of tone.
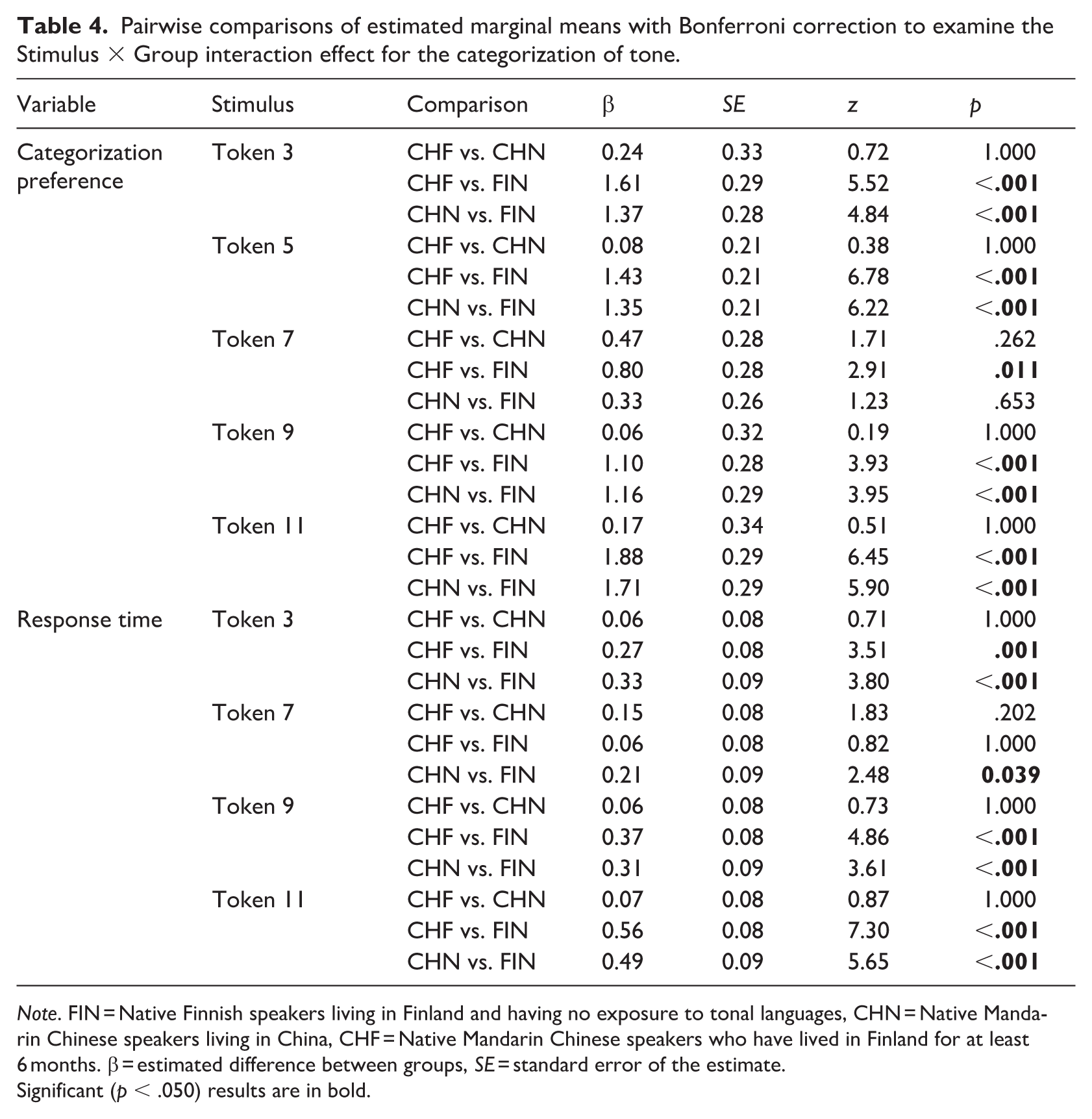
Note. FIN = Native Finnish speakers living in Finland and having no exposure to tonal languages, CHN = Native Mandarin Chinese speakers living in China, CHF = Native Mandarin Chinese speakers who have lived in Finland for at least 6 months. β = estimated difference between groups, SE = standard error of the estimate.
Significant (p < .050) results are in bold.
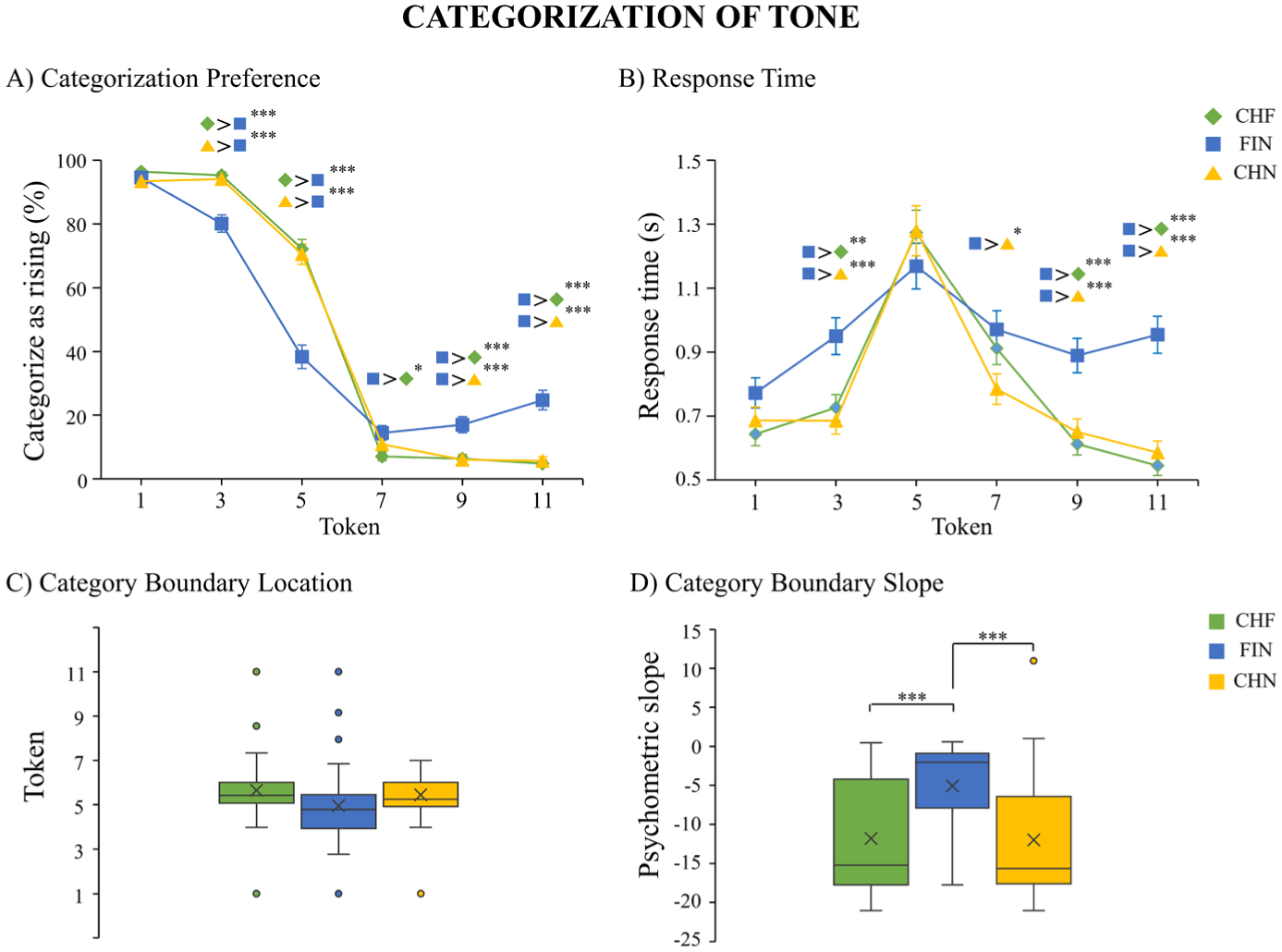
Categorization results for tone: (a) categorization preference, (b) response time, (c) category boundary location, and (d) category boundary slope.
3.2.1 Categorization preference
A GLMM with a binomial link function was applied, and a Type III Wald χ2 test was used to evaluate the effects. The model included Group (CHF, CHN, and FIN) and Stimulus (Token 1, Token 3, Token 5, Token 7, Token 9, Token 11) as fixed effects, with Participant as a random effect. The analysis revealed a main effect of Stimulus and an interaction effect of Stimulus × Group, as shown in Table 5.
Results of the Type III Wald χ2 test on the discrimination of vowel duration.

Note. df = degrees of freedom.
Significant (p < .050) results are in bold.
To further explore the interaction effect, pairwise comparisons of estimated marginal means were conducted with Bonferroni correction. The analysis indicated that both native Mandarin Chinese groups (CHF and CHN) were more likely than the Finnish group (FIN) to categorize Token 3 and Token 5 as rising tones. For Token 7, FIN categorized it as a rising tone more often than CHF. FIN also categorized Token 9 and Token 11 more often as rising tones than both CHF and CHN.
3.2.2 Response time
A GLMM with a gamma distribution and log link function was applied, and a Type III Wald χ2 test was used to evaluate the effects. The model included Group (CHF, CHN, and FIN) and Stimulus (Token 1, Token 3, Token 5, Token 7, Token 9, Token 11) as fixed effects, with Participant as a random effect. The analysis revealed a main effect of Group, a main effect of Stimulus, and an interaction effect of Stimulus × Group.
To further explore the interaction effect, pairwise comparisons of estimated marginal means were conducted with Bonferroni correction. Participants in the CHF and CHN groups responded faster than those in the FIN group when categorizing Token 3, Token 9, and Token 11. Participants in the CHN group responded faster than those in the FIN group when categorizing Token 7.
3.2.3 Category boundary location
The one-way ANOVA indicated no significant differences in the category boundary location between the groups, F(2, 115) = 2.159, p = .120, η2 = 0.036.
3.2.4 Category boundary slope
A significant difference was found between groups as determined by one-way ANOVA, F(2, 115) = 11.829, p < .001, η2 = 0.171. Post hoc tests with Bonferroni correction indicated that the category boundary slope of FIN was less steep than that of CHF (df = 76, MD = 6.89, SE = 1.60, p < .001, Cohen’s d = 1.025) and CHN group (df = 73, MD = 6.92, SE = 1.63, p < .001, Cohen’s d = 1.008).
3.3 Discrimination of duration
Table 5 presents the GLMM results for discrimination accuracy and response time for the duration feature. Table 6 presents the results of pairwise comparisons of estimated marginal means, examining significant group differences in accuracy and response time for duration discrimination. Figure 4 depicts the main results for discrimination of duration.
Pairwise comparisons of estimated marginal means with Bonferroni correction to examine the Stimulus × Group interaction effect for duration discrimination.
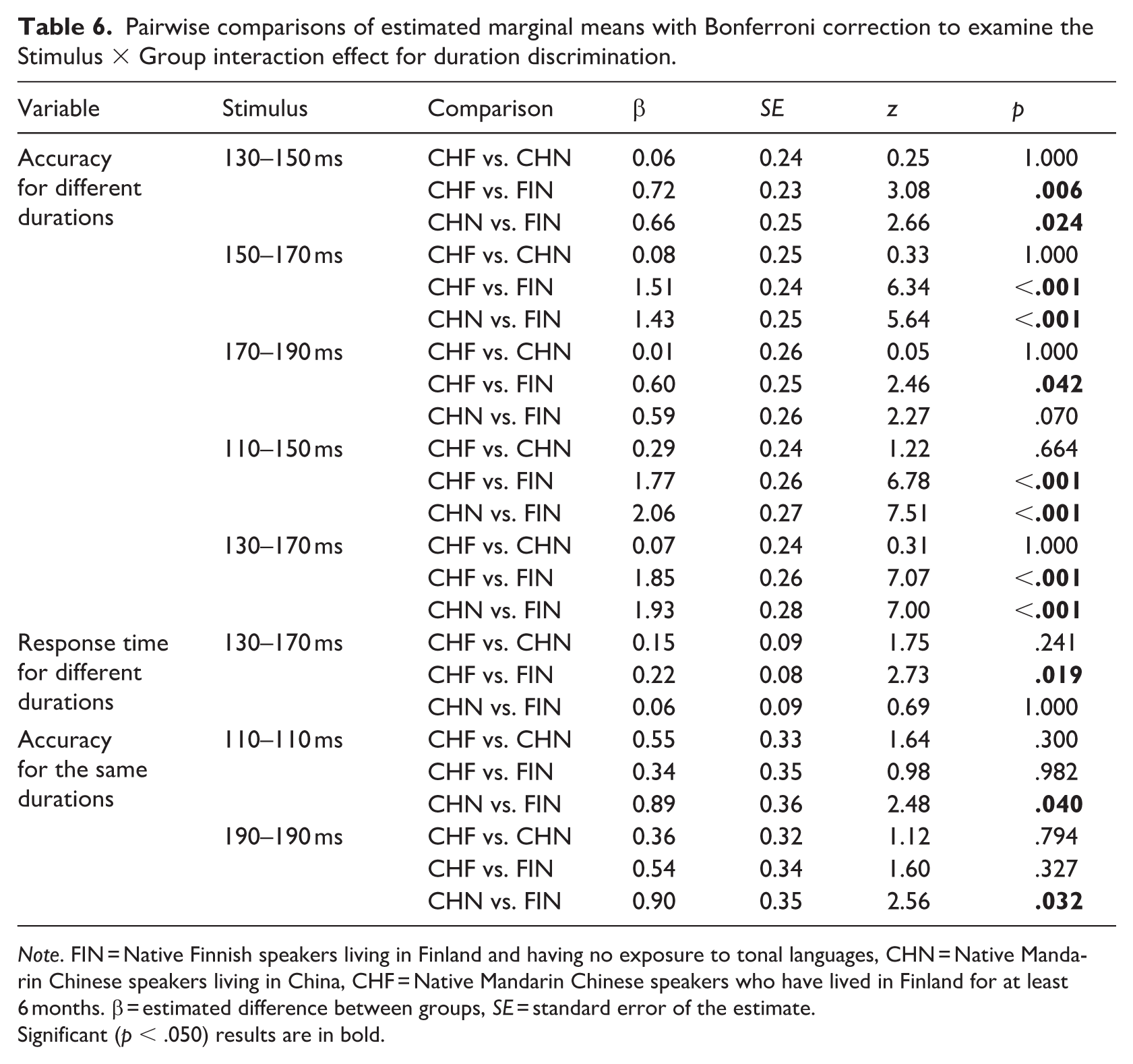
Note. FIN = Native Finnish speakers living in Finland and having no exposure to tonal languages, CHN = Native Mandarin Chinese speakers living in China, CHF = Native Mandarin Chinese speakers who have lived in Finland for at least 6 months. β = estimated difference between groups, SE = standard error of the estimate.
Significant (p < .050) results are in bold.
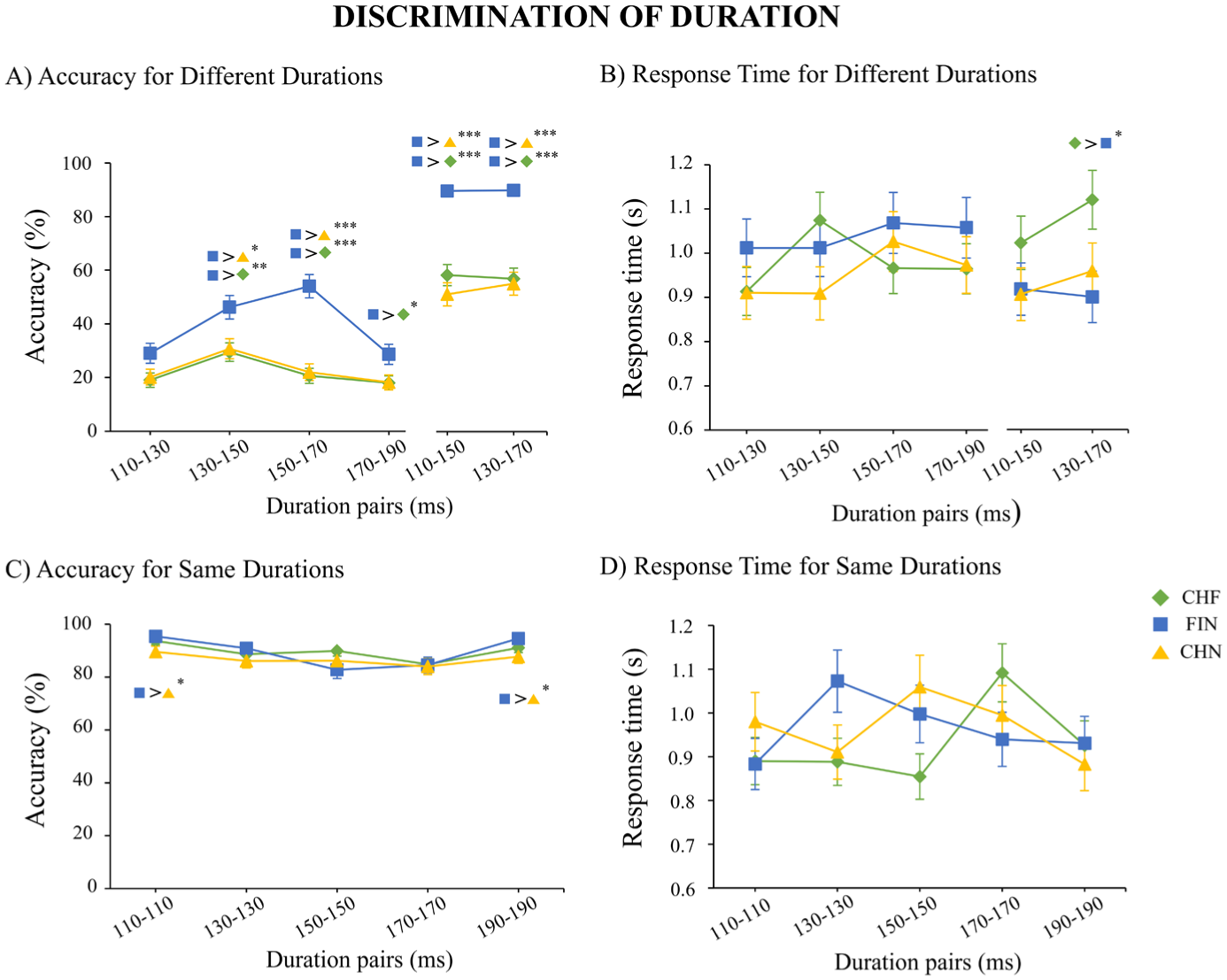
Discrimination results for vowel duration: (a) accuracy for different durations, (b) response time for different durations, (c) accuracy for same durations, and (d) response time for same durations.
3.3.1 Discrimination accuracy for different durations
A GLMM with a binomial link function was applied, and a Type III Wald χ2 test was used to evaluate the effects. The model included Group (CHF, CHN, and FIN) and Stimulus (110–130 ms, 130–150 ms, 150–170 ms, 170–190 ms, 110–150 ms, and 130–170 ms) as fixed effects, with Participant as a random effect. The analysis revealed a main effect of Group, a main effect of Stimulus, and an interaction effect of Stimulus × Group.
To further explore the interaction effect, pairwise comparisons of estimated marginal means were conducted with Bonferroni correction. The analysis showed that for the pairs 130–150 ms, 150–170 ms, 110–150 ms, and 130–170 ms, FIN demonstrated higher accuracy than both Mandarin Chinese groups. For the pairs 170–190 ms, FIN showed higher accuracy than CHF.
3.3.2 Response time for different durations
A GLMM with a gamma distribution and log link function was applied, and a Type III Wald χ2 test was used to evaluate the effects. The model included Group (CHF, CHN, and FIN) and Stimulus (110–130 ms, 130–150 ms, 150–170 ms, 170–190 ms, 110–150 ms, and 130–170 ms) as fixed effects, with Participant as a random effect. The analysis revealed a main effect of Stimulus and an interaction effect of Stimulus × Group.
To further explore the interaction effect, pairwise comparisons of estimated marginal means were conducted with Bonferroni correction. The analysis showed that for the pairs 130–170 ms, FIN responded faster than CHF.
3.3.3 Discrimination accuracy for same durations
A GLMM with a binomial link function was applied, and a Type III Wald χ2 test was used to evaluate the effects. The model included Group (CHF, CHN, and FIN) and Stimulus (110–110 ms, 130–130 ms, 150–150 ms, 170–170 ms, and 190–190 ms) as fixed effects, with Participant as a random effect. The analysis revealed a main effect of Stimulus and an interaction effect of Stimulus × Group.
To further explore the interaction effect, pairwise comparisons of estimated marginal means were conducted with Bonferroni correction. The analysis showed that the accuracy of FIN was higher than that of CHN for the discrimination of 110–110 ms and 190–190 ms pairs.
3.3.4 Response time for same durations
A GLMM with a gamma distribution and log link function was applied, and a Type III Wald χ2 test was used to evaluate the effects. The model included Group (CHF, CHN, and FIN) and Stimulus (110–110 ms, 130–130 ms, 150–150 ms, 170–170 ms, and 190–190 ms) as fixed effects, with Participant as a random effect. The analysis revealed a main effect of Stimulus and an interaction effect of Stimulus × Group.
To further explore the interaction effect, pairwise comparisons of estimated marginal means were conducted with Bonferroni correction. No significant differences were found between the groups.
3.4 Discrimination of tone
Table 7 describes the GLMM results for accuracy and response time for tone discrimination. Table 8 indicates the results of pairwise comparisons of estimated marginal means, investigating significant group differences in accuracy and response time for tone discrimination. Figure 5 depicts the main results for the discrimination of tones.
Results of the Type III Wald χ2 test on the discrimination of tones.

Note. df = degrees of freedom.
Significant (p < .050) results are in bold.
Pairwise comparisons of estimated marginal means with Bonferroni correction to examine the Stimulus × Group interaction effect for discrimination of different tones.
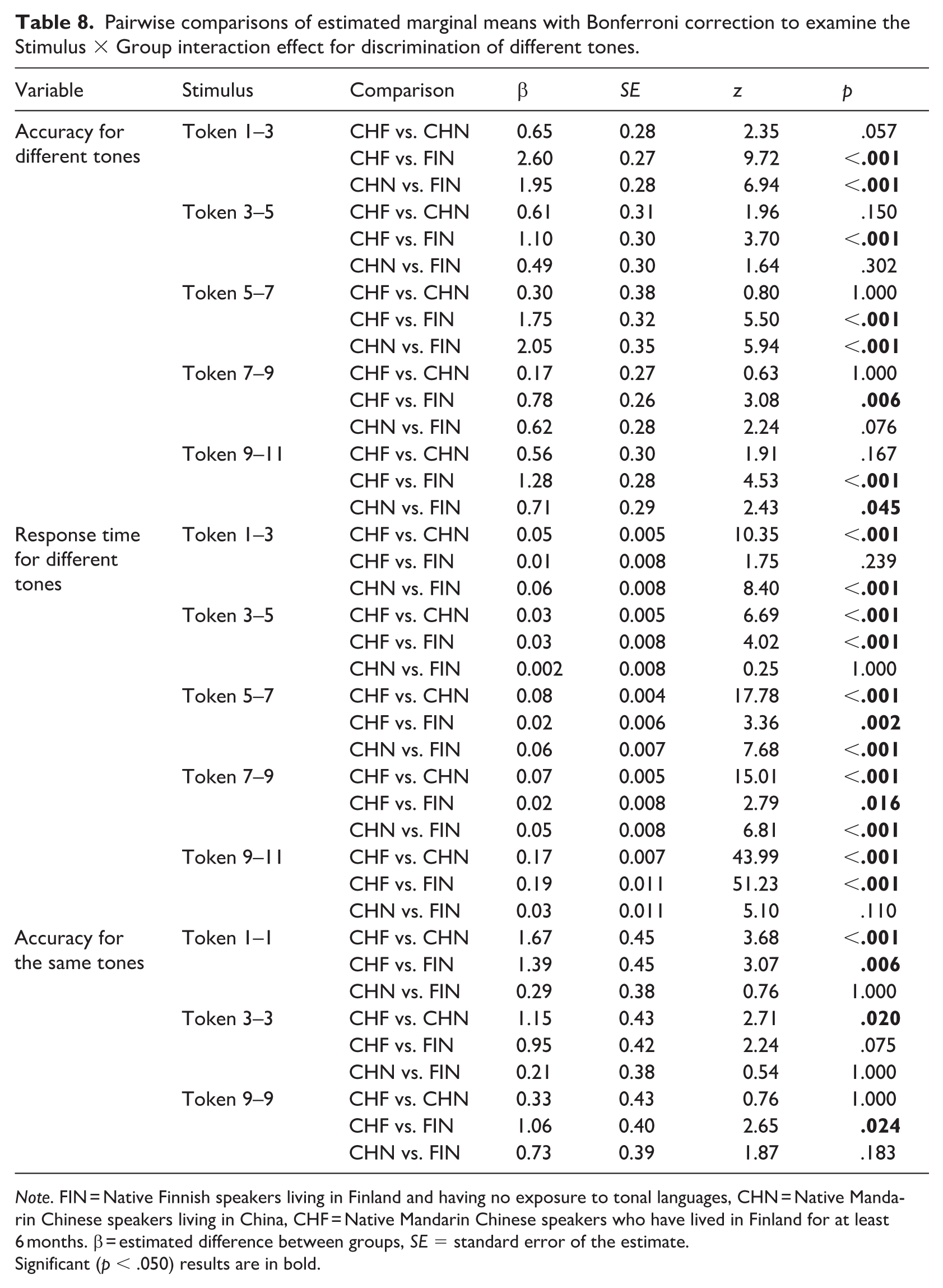
Note. FIN = Native Finnish speakers living in Finland and having no exposure to tonal languages, CHN = Native Mandarin Chinese speakers living in China, CHF = Native Mandarin Chinese speakers who have lived in Finland for at least 6 months. β = estimated difference between groups, SE = standard error of the estimate.
Significant (p < .050) results are in bold.
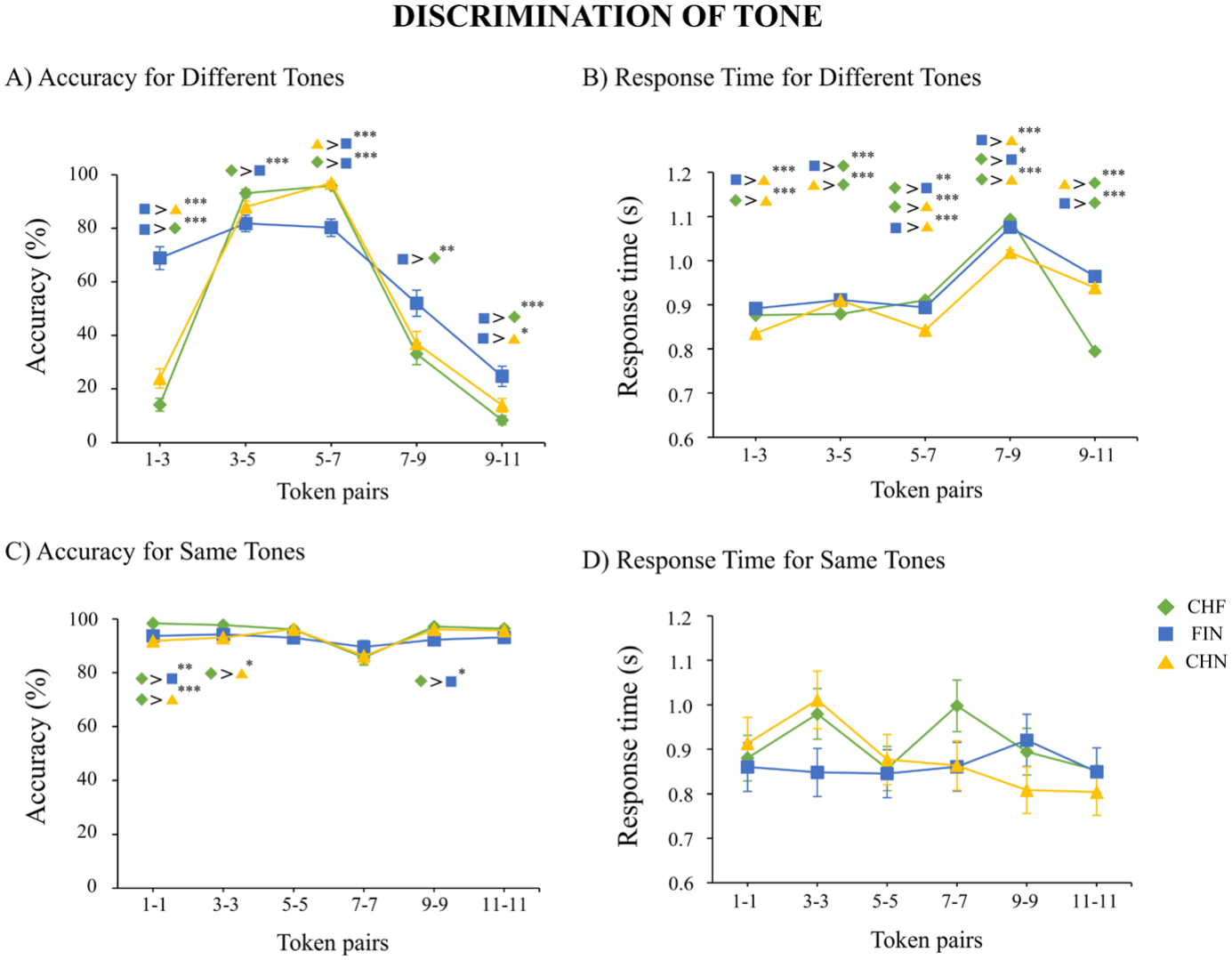
Discrimination results for tone: (a) accuracy for different tones, (b) response time for different tones, (c) accuracy for same tones, and (d) response time for same tones.
3.4.1 Discrimination accuracy for different tones
A GLMM with a binomial link function was applied, and a Type III Wald χ2 test was used to evaluate the effects. The model included Group (CHF, CHN, and FIN) and Stimulus (Token 1–Token 3, Token 3–Token 5, Token 5–Token 7, Token 7–Token 9, Token 9–Token 11) as fixed effects, with Participant as a random effect. The analysis revealed a main effect of Stimulus and an interaction effect of Stimulus × Group.
To further explore the interaction effect, pairwise comparisons of estimated marginal means were conducted with Bonferroni correction. The analysis indicated that FIN had higher accuracy in the discrimination of Token 1–Token 3 than the CHN and CHF groups. For Tokens 3–Token 5, CHF had higher accuracy than for the FIN group. For Token 5–Token 7, CHN and CHF had higher accuracy than the FIN group. For Token 7–Token 9, FIN had higher accuracy than the CHF group. For Token 9–Token 11, FIN had higher accuracy than the CHN and CHF groups.
3.4.2 Response time for different tones
A GLMM with a gamma distribution and log link function was applied, and a Type III Wald χ2 test was used to evaluate the effects. The model included Group (CHF, CHN, and FIN) and Stimulus (Token 1–Token 3, Token 3–Token 5, Token 5–Token 7, Token 7–Token 9, Token 9–Token 11) as fixed effects, with Participant as a random effect.
The analysis revealed a main effect of Group, a main effect of Stimulus, and an interaction effect of Stimulus × Group.
To further explore the interaction effect, pairwise comparisons of estimated marginal means were conducted with Bonferroni correction. The analysis showed that for Token 1–Token 3, CHN responded faster than CHF and FIN. For Token 3–Token 5, CHF responded faster than CHN and FIN. For Token 5–Token 7, CHN responded faster than CHF and FIN, whereas FIN was faster than CHF. For Token 7–Token 9, CHN again responded faster than CHF and FIN, and FIN was faster than CHF. For Token 9–Token 11, CHF responded faster than FIN and CHN.
3.4.3 Discrimination accuracy for same tones
A GLMM with a binomial link function was applied, and a Type III Wald χ2 test was used to evaluate the effects. The model included Group (CHF, CHN, and FIN) and Stimulus (Token 1–Token 1, Token 3–Token 3, Token 5–Token 5, Token 7–Token 7, Token 9–Token 9, Token 11–Token 11) as fixed effects, with Participant as a random effect.
The analysis revealed a main effect of Group, a main effect of Stimulus, and an interaction effect of Stimulus × Group.
To further explore the interaction effect, pairwise comparisons of estimated marginal means were conducted with Bonferroni correction. The analysis showed that for discrimination of the Token 1–Token 1 pair, CHF had higher accuracy than CHN and FIN groups; for discrimination of the Token 3–Token 3 pair, CHF had higher accuracy than the CHN group; for discrimination of the Token 9–Token 9 pair, CHF had higher accuracy than FIN.
3.4.4 Response time for same tones
A GLMM with a gamma distribution and log link function was applied, and a Type III Wald χ2 test was used to evaluate the effects. The model included Group (CHF, CHN, and FIN) and Stimulus (Token 1–Token 3, Token 3–Token 5, Token 5–Token 7, Token 7–Token 9, Token 9–Token 11) as fixed effects, with Participant as a random effect. The analysis revealed a main effect of Stimulus and an interaction effect of Stimulus × Group. To further explore the interaction effect, pairwise comparisons of estimated marginal means were conducted with Bonferroni correction. No significant differences were found between the groups.
4 Discussion
We investigated the categorization and discrimination of tone and duration features embedded in isolated /a/ vowels in native Mandarin Chinese and Finnish speakers, to examine potential cross-language differences in the processing of these two fundamentally different speech sound features. In addition, we explored the effects of foreign-language immersion by including a group of native Mandarin Chinese participants who had resided in Finland for more than 6 months. The findings revealed distinct patterns of native language influence on tone and duration perception, as well as changes in duration categorization preferences among Mandarin Chinese speakers living in Finland.
4.1 Cross-language differences
To explain the results indicating differences in how native and non-native speakers perceive duration and tone features, we focus on comparing the responses of native Finnish speakers with those of native Mandarin Chinese speakers residing in China. The two groups differed significantly in both categorization and discrimination performance. Specifically, Mandarin speakers more often judged the shortest 110 and 130 ms sounds as long, and the 170 ms sound as short, compared with Finnish speakers. However, there were no other group differences between Finnish speakers and Chinese speakers who were naïve to Finnish in other variables (reaction time, category boundary, slope) in the categorization of duration. Both groups showed the category boundary approximately at 150 ms. The observed high variability in boundary slopes for duration among Finnish speakers suggests individual differences in categorical perception. This variability may reflect differences in processing strategies: some participants may have adopted a more phonemic-based approach, relying on the well-established vowel length categories of Finnish, whereas others may have depended more on auditory or acoustic cues. Alternatively, the variability could also be influenced by broader individual differences in cognitive processing styles.
The categorization results for tone revealed pronounced group differences between native and non-native speakers. The Mandarin speakers were more inclined than the Finnish speakers to categorize Tokens 3 and 5 as rising tone, and Tokens 9 and 11 as falling tone. Of these, Token 3 had a physically rising pitch contour, Token 9 and Token 11 had a falling contour, whereas Token 5 had almost a flat pitch (see Figure 1). The results suggest a clear advantage associated with native language experience in identifying falling tones (Tokens 9 and 11) among Mandarin Chinese speakers. In contrast, no group differences were observed for the most rising tone (Token 1). This finding may be related to the fact that rising pitch is also used to signal intonation and questions in English and other languages familiar to the Finnish participants. Thus, sensitivity to rising pitch contours might partly reflect general auditory or prosodic processing mechanisms rather than tone-specific linguistic experience. Overall, Finnish speakers categorized the tone stimuli in a manner that more closely reflected their physical properties, whereas Mandarin Chinese speakers showed a stronger influence of categorical perception. The category boundary slope was, indeed, steeper in the Mandarin Chinese speakers than in the Finnish speakers for tone categorization. In this sense, the results differ from those for the duration feature, which did not show group differences in the slope of the category boundary. No significant group differences were observed between Finnish speakers and native Mandarin Chinese speakers in the location of the category boundary for the tone feature, which repeated the null finding for the duration feature. Reaction time showed a group difference, indicating a native language advantage in Mandarin Chinese speakers in the form of shorter reaction times for categorization of Tokens 3, 9, and 11.
The partly different result patterns observed for the categorization of duration and tone features may stem from fundamental differences between these auditory dimensions. Duration does not naturally form distinct auditory categories for short and long vowels, whereas tone can be more clearly defined by pitch contour, such as rising or falling patterns. The clearer group differences observed for tones may therefore reflect non-native listeners’ ability to rely on salient acoustic cues when performing the categorization task. In contrast, for duration, long-term memory traces of native phonological categories may have guided the responses of Finnish speakers, although the effects on categorization preferences were relatively subtle. The categorization of duration for isolated vowels may have been challenging even for native Finnish speakers, as contextual cues in words typically provide important information for distinguishing short and long vowels in natural speech. In our study, we tested only isolated vowels, whereas a previous study (Meister & Meister, 2011) reported differences between native and non-native speakers in both isolated vowels and (pseudo)word contexts. This pattern suggests that native language experience can influence vowel duration perception even in isolated stimuli.
In discrimination, the Finnish group showed a native language advantage for the duration feature. Although both groups performed near chance level when discriminating the smaller (20 ms) duration differences at the ends of the stimulus continuum for different-pair trials, Finnish speakers were more accurate than Mandarin Chinese speakers for pairs that included the category-boundary stimulus (150 ms)—specifically, the 130–150 ms and 150–170 ms pairs. Larger differences (40 ms) were clearly easier for Finnish speakers, whereas the Mandarin Chinese speakers still performed at chance level. No group differences were observed in reaction times. For same-duration pairs, accuracy was generally very high, but Finnish participants were more accurate than Mandarin Chinese speakers in identifying the end-of-continuum stimuli (110 and 190 ms) as identical. Overall, these results demonstrate a clear native language advantage for Finnish speakers in discriminating vowel duration, likely reflecting well-established categorical representations of vowel length in the native language.
In tone discrimination, the Mandarin Chinese group outperformed the Finnish-speaking group when the stimulus pair included the category boundary stimulus (Token 5–Token 7). Conversely, Finnish-speaking participants were more accurate than Mandarin Chinese speakers in discriminating between Token 1–Token 3 and Token 9–Token 11, most likely because these pairs contained tones that belonged to the same category in Mandarin Chinese (see also Xi et al., 2010, which used the same stimuli as the present study). In this respect, the results differed for the tone and duration features: Mandarin Chinese native speakers did not outperform Finnish speakers in discriminating any of the duration stimulus pairs. Another difference from duration discrimination was that Mandarin Chinese speakers were faster than Finnish speakers for almost all different-pair stimulus comparisons, whereas no group differences were observed for same-pair discrimination accuracy or response times among Finnish speakers and Mandarin Chinese participants living in Finland.
The overall pattern of results from the cross-language comparisons suggests a feature-specific influence of native language experience. For duration, categorization showed no differences in category boundary position or slope, yet discrimination revealed clear native language advantages for Finnish speakers. In contrast, for tone, categorization revealed differences in both categorization preferences and category slope, while discrimination advantages for Mandarin Chinese speakers were observed primarily for cross-category stimulus pairs, while Finnish speakers were actually better in discriminating within-pair stimuli. These findings indicate that native language experience shapes both categorization and discrimination, but the effects manifest differently depending on whether the speech feature is tonal or durational.
4.2 Impact of Finnish language immersion on Mandarin speakers’ speech perception
Exposure to the Finnish language among Mandarin Chinese participants residing in Finland resulted in differences between this group and their counterparts without Finnish language experience, especially in duration categorization preferences and associated reaction times. The group difference was evident in the categorization of vowel duration at the category boundary, as Mandarin Chinese speakers living in Finland categorized the 150 ms stimulus as a long duration when compared with Mandarin Chinese speakers naïve to the Finnish language. The response time of categorization also differed from that of the other groups in the Mandarin Chinese speakers exposed to Finnish, as they did not exhibit the typical increase in response time to the category boundary stimulus, whereas the other two groups did. The results thus suggest that exposure to Finnish did not alter the responses of Mandarin Chinese speakers in the categorization task to become more like those of native Finnish speakers. Instead, their responses were more divergent from those of Finnish speakers compared with the other Mandarin Chinese-speaking group. It can be speculated that the differences in categorization preference and decreased reaction time reflect a process where exposure has started to affect the perceptual strategies for the duration feature, although the participants’ categorical perception had not yet formed like that of native speakers. Mandarin Chinese living in Finland also differed from Finnish speakers by showing a significantly different category boundary (toward shorter duration in Mandarin Chinese living in Finland). Since the Mandarin Chinese living in Finland did not differ in their responses from the native Mandarin Chinese group, this result may be more associated with cross-language differences than with exposure to Finnish.
Discrimination task for the duration showed no exposure-related differences between the Mandarin Chinese groups. Observable effects of discrimination may take longer to appear or require more intensive exposure. Notably, differences in categorization seem to precede those in discrimination. This is understandable because discrimination may pose challenges when two sounds are both categorized as instances of a single category. The duration feature may be particularly difficult to learn, because without linguistic experience, it does not form absolute categories that can be detected based on acoustic features (for brain activity study, see Lyu et al., 2024).
Unexpectedly, tone discrimination also differed between the two Mandarin-speaking groups. Mandarin speakers exposed to Finnish were slower in their responses for almost all different-tone pairs but more accurate for rising same-tone pairs. This pattern may reflect cross-linguistic transfer or perceptual recalibration: immersion in a new language environment could temporarily modulate native language tone processing, leading to slower responses while simultaneously enhancing sensitivity to certain tonal contrasts, possibly due to increased attention to pitch patterns in a foreign-language context.
The neural mechanisms underlying the effects of language exposure and immersion are not yet fully understood. One theoretical framework that may also provide insight into immersion-based phonetic learning is the neural commitment hypothesis (Kuhl et al., 2008; Zhang et al., 2005). This hypothesis proposes that early exposure to a language shapes the formation of neural representations for speech sounds, and that adults face challenges in acquiring new phonetic categories due to prior commitment to their native language representations. Empirical evidence indicates that neural changes can occur rapidly: memory traces of foreign speech sounds can form after as little as in couple of hours of passive exposure (Kurkela et al., 2019; Li et al., 2025). At the same time, other aspects of neural adaptation may require prolonged immersion. In the present study, Mandarin speakers had widely varying durations of exposure to Finnish, ranging from 6 months to over 20 years, which may contribute to variability in perceptual abilities across individuals. Adult phonetic learning also appears to differ from infant learning, which shows rapid formation of new language maps (Cheour et al., 2002; see also White et al., 2013).
4.3 Limitations
Our study had some limitations. First, we were unable to directly compare the tone and duration features or to link the categorization and discrimination results, as the number of test stimuli and the physical differences between stimulus pairs differed across the two feature sets and tasks. Future studies should standardize the number of stimuli and the magnitude of stimulus differences across all conditions, enabling a more direct examination of the relationship between categorization and discrimination, particularly in a cross-linguistic context. Second, we could not accurately assess the extent of passive environmental exposure and active training in the Finnish language among Mandarin Chinese speakers residing in Finland. Although we asked the participants how long they had lived in Finland, we did not ask them to evaluate the amount of time they had spent listening to the Finnish language. The data were collected in 2021–2023; therefore, COVID-19 may have still affected the behavior of Mandarin Chinese speakers living in Finland, resulting in a limited number of social contacts and relatively little exposure to the Finnish language. Previous studies demonstrated that for adult foreign-language learners, their learning increased over time, but only if they received an adequate amount of input from native speakers (Flege & Liu, 2001). Last, we need to consider the effect of the Swedish and English languages on native Finnish speakers’ performance. Swedish is an official language in Finland, and it is taught in school for all children. However, in the region of Central Finland, the proportion of Swedish-speaking residents is very small. For example, in Jyväskylä, where the data of Finnish-speaking participants were collected, the proportion of Swedish speakers in the population was 0.2% at the end of 2024 (Statistics Finland, 2025). In addition, although the syntax and vocabulary of Finnish Swedish largely correspond to that of Swedish, there are significant differences in phonology (Reuter, 1992). Finnish Swedish lacks tonal word accents (Huhtamäki et al., 2020; Riad, 2014). Presumably, the impact of Swedish on the FIN group’s perception is smaller than, for example, the impact of English, which is more widely used in Finland, and to which one is inevitably exposed in the media. It is possible that the rising intonation of English is reflected in our results in that the discrimination of rising tones (Tokens 1 vs. 3) was better than that of falling tones (Tokens 9 vs. 11). Also, in the categorization, the extreme tones were asymmetrically categorized, that is, Token 1 was more often perceived as rising than Token 11 as falling.
5 Conclusion
Cross-language comparisons revealed native language effects in both vowel categorization and discrimination, though the patterns differed for duration and tone. Mandarin Chinese speakers showed a steeper category boundary and better between-category tone discrimination than Finnish speakers, whereas only Mandarin speakers living in Finland differed from Finnish speakers in their duration category boundary. Finnish speakers demonstrated a native language advantage in vowel-duration discrimination and also outperformed Mandarin Chinese speakers in within-category tone discrimination. Exposure to Finnish influenced duration categorization among Mandarin speakers, with exposed participants showing patterns that diverged more from those of native Finnish speakers than did the patterns of non-exposed participants. Overall, the results highlight feature-specific mechanisms for tone and duration and demonstrate how native language experience and exposure to a new language through immersion shape speech perception.
Footnotes
Acknowledgements
We thank Ira Nurmela for her help with data collection.
Author contributions
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The study was supported by the Research Council of Finland (grant number 351009 for Piia Astikainen and grant number 355369 for Chaoxiong Ye) and the National Natural Science Foundation of China (grant number 31700948 for Chaoxiong Ye), and the Ellen and Artturi Nyyssönen Foundation (personal grant for Kaijun Jiang).
Ethical considerations
The ethical committee of the University of Jyväskylä and the ethical committee of Sichuan Normal University approved the research protocol. The experiment was conducted in accordance with the Declaration of Helsinki.
Consent to participate
Written informed consent was obtained from all participants before their participation.
Consent for publication
Authors have no permission to publish anonymized data.
Data availability
The dataset used is available from the corresponding authors upon reasonable request for academic and research purposes.