
Abstract
Multimodal phonetic training with hand gestures can support L2 speech learning, but few studies have examined its generalization effects. In this between-subjects study with a pretest/post-test paradigm, 39 Japanese learners of Mandarin practiced Mandarin aspirated stops, high back rounded vowel /u/, and T3 Sandhi over four training sessions. The gesture (G) group (n = 20) received training with hand gestures illustrating the phonetic and articulatory features of the target sounds, while the no gesture (NG) group (n = 19) received the same training without gestures. Participants read trained words during the pre- and post-tests and untrained words in a generalization test. Results showed that the G group outperformed the NG group in improving the pronunciation accuracy of aspirated stops and vowels, but not T3 Sandhi. Importantly, the G group showed better generalization to untrained items across all targets. These findings highlight the robust effects of hand gestures in multimodal phonetic training and the role of embodied cognition in L2 speech acquisition.
Keywords
1 Introduction
In second language (L2) speech acquisition, adult learners often face challenges in acquiring non-native segmental and suprasegmental features. Extensive research has explored the role of multimodal phonetic training in L2 speech acquisition, which is supported by the theoretical framework of embodied cognition (Matheson & Barsalou, 2018). According to this theory, body and cognition share the same processing system (Ionescu & Vasc, 2014), and therefore, bodily movements may affect cognitive task processing (Wilson, 2002). This close link between body and cognition provides essential implications for teaching and learning (Shapiro & Stolz, 2019). More importantly, hand gestures and speech are closely tied to each other in both first language (L1) speech (Iverson & Goldin-Meadow, 2005; McNeill, 1992; Yang & Shu, 2016) and L2 speech (Kamiya, 2012; Li et al., 2024; Sato, 2020). Therefore, various hand gestures have been proposed for training L2 segmental and suprasegmental features which enhance L2 speech acquisition. However, previous studies have provided limited evidence that gestural training can facilitate generalization from trained items to untrained ones. This study, therefore, examines the generalization effects of multimodal phonetic training with hand gestures in L2 speech acquisition.
1.1 The effects of hand gestures in multimodal phonetic training in L2 acquisition
Hand gestures can express prosodic and pragmatic information through various shapes and motions, which are closely related to human cognition (Shattuck-Hufnagel & Prieto, 2019). Human cognition is a metaphorical system that conceptualizes abstract ideas in terms of embodied experiences (Lakoff & Johnson, 1980). One of the basic metaphors that relates to hand gestures is the orientational metaphor. For instance, pitch is conceptualized as a vertical metaphor in space, where high-frequency pitch is mapped to “up,” and low pitch to “down” (Casasanto et al., 2003; Connell et al., 2013; Dolscheid et al., 2014; Morett et al., 2022). Likewise, temporal duration is conceptualized as a horizontal metaphor, such that a long duration is associated with long distance and a short duration with short distance (Casasanto & Boroditsky, 2003, 2008). These metaphorical links between space and abstract concepts can be represented by hand movements (e.g., an upward hand movement can represent a high pitch). Relatedly, in spontaneous speech, the up-and-down hand beats can co-occur with speech prominence to highlight speech rhythm and may form an integral part of speech prosody (Prieto et al., 2025). Finally, there is an interaction between hands and mouth, which links articulatory gestures to hand gestures in speech production (Vainio, 2019). Empirical studies also confirmed that gesture shape and upper-limb movements can affect sound articulation in both L1 and L2 speech production (Gentilucci et al., 2001; Li et al., 2024; Pouw et al., 2020, 2021; Vainio et al., 2018). In short, there is a solid theoretical foundation for using hand gestures in L2 phonetic training, from the suprasegmental perspectives to the speech sound articulation.
Given that gestures can metaphorically represent abstract concepts, previous studies investigated how gestures help learn suprasegmental features, including rhythm, duration, and pitch. The first category is rhythmic beat gestures involving up-and-down hand movements (Gluhareva & Prieto, 2017). Beat gestures highlighting the rhythmic and informational structure of speech (Krahmer & Swerts, 2007) can improve the learners’ L2 overall oral proficiency (Gluhareva & Prieto, 2017). A second category makes the metaphorical link between sound duration and horizontal hand movements, which can improve production accuracy of L2 long and short vowels (Li et al., 2020), although it shows limited effects on perception (Hirata et al., 2014; Hirata & Kelly, 2010; Kelly et al., 2014). The most widely investigated gesture type is the pitch gesture, which involves hand movements depicting pitch contours in space. It can improve learners’ production of L2 intonation (Baills et al., 2022; Li, Baills, Baqué, et al., 2023; Yuan et al., 2019) and the perception of L2 lexical tones (Baills et al., 2019; Morett & Chang, 2015; Yu et al., 2024; Zhen et al., 2019).
Recent evidence shows that gestures can improve L2 sound production by iconically depicting the relevant articulatory features. One well-studied gesture moves from a closed fist to an open palm to represent the burst of air in aspirated stops. This fist-to-open-palm gesture improves learners’ accuracy in producing aspirated plosives (Li et al., 2021, 2024; Xi et al., 2020). Moreover, gestures can mimic or illustrate visible articulatory information, such as mouth aperture and lip roundedness. For instance, using an “o” shape gesture guides learners to round their lips correctly for rounded vowels (Hoetjes & van Maastricht, 2020). Instructors may likewise vary the distance between thumb and fingers to signal vowel height, namely, wide for open vowels, narrow for close vowels, which boosts production accuracy in vowel contrasts defined by mouth aperture (Xi et al., 2023, 2024).
The positive effects of a successful training paradigm should not only be observed on the trained items but also be generalized to untrained items, which is called the generalization effect (Logan & Pruitt, 1995). Compared with the training effects on trained items, generalization effects can better indicate the robustness of a training paradigm (Rato & Oliveira, 2023). However, most of the gesture studies showed limited generalization effects. Typically, previous studies involved a between-subject design with a pretest-training-post-test paradigm. Some studies only analyzed the learning outcome of the trained items, without considering generalization effects (Baills et al., 2019; Gluhareva & Prieto, 2017). Others involved untrained items in the tests, but failed to find significant differences between the trained and untrained items (Baills et al., 2022; Li, Baills, Baqué, et al., 2023; Li et al., 2021; Xi et al., 2020) or could not find significant improvement in untrained items from pretest to post-test (Hirata et al., 2014; Hirata & Kelly, 2010; Hoetjes & van Maastricht, 2020). Only a handful of studies revealed generalization effects of gestural training, where gestural training yielded better learning outcomes than non-gestural training in the untrained items (Hirata et al., 2024; Yuan et al., 2019).
Three factors may explain the absence of generalization in earlier gestural training studies. First, most of the studies delivered a brief, one-session training (Hoetjes & van Maastricht, 2020; Li et al., 2020), which may not have given learners sufficient time to generalize what they had learned. Second, the untrained items for testing generalization effects were repeated in pretest and post-test (Baills et al., 2022; Li, Baills, Baqué, et al., 2023; Li et al., 2021; Xi et al., 2020). The testing effects might have hindered the generalization effects (Rato & Oliveira, 2023). Third, most of the previous studies recruited novice learners without prior knowledge in the target L2 (Baills et al., 2019; Hirata & Kelly, 2010; Hoetjes & van Maastricht, 2020; Kelly et al., 2014; Li et al., 2020; Xi et al., 2020), who were unlikely to generalize from limited exposure. Therefore, it is necessary to test experienced learners across multiple sessions and assess generalization on entirely new items.
Hence, the aim of this study is twofold. First, we assess whether hand gestures can help experienced L2 learners improve L2 pronunciation on segmental and suprasegmental levels. Second, we advance the current research by examining the generalization effects of hand gestures in L2 pronunciation. We selected three types of hand gestures from the previous research: (a) the fist-to-open-palm gesture (henceforth “aspirating gesture”) to train aspirated stops (Li et al., 2021; Xi et al., 2020), (b) the “o” shape gesture (henceforth “rounding gesture”) to train rounded vowels (Hoetjes & van Maastricht, 2020), and (c) the pitch gesture to train lexical tones (Baills et al., 2019; Morett & Chang, 2015). These gestures can represent articulatory features of segments (i.e., lip roundedness and consonantal aspiration) and phonetic features of suprasegmentals (i.e., pitch contours of lexical tones). With these three representative gestures, we can draw a comprehensive picture of the effects of hand gestures in multimodal phonetic training.
To achieve this goal, we selected L1 Japanese speakers learning L2 Mandarin as our participants. We used the aspirating gesture to train /pʰ, tʰ, kʰ/, the rounding gesture for the rounded vowel /u/, and a pitch gesture for Mandarin lexical tones. All three learning targets pose phonetic challenges for Japanese speakers. The following subsection summarizes the key phonetic features of these three learning targets.
1.2 Mandarin aspirated stops, high back rounded vowel, and lexical tones
Mandarin and Japanese stops differ in laryngeal specifications, which poses challenges for Japanese learners of Mandarin. At the phonological level, Mandarin contrasts aspirated /pʰ, tʰ, kʰ/ with unaspirated /p, t, k/ (Duanmu, 2007), while Japanese shows the contrast between voiced /b, d, g/ and voiceless /p, t, k/ (Okada, 1999). At the phonetic level, voice onset time (VOT) can acoustically measure the time interval between the stop release and the glottal pulsing onset (Lisker & Abramson, 1964). Both languages include stops with short-lag VOT, but Mandarin /pʰ, tʰ, kʰ/ show a long-lag VOT, which is absent in Japanese (Riney et al., 2007). The mean VOT of Mandarin /pʰ, tʰ, kʰ/ is around 82–92 ms (Chao & Chen, 2008), whereas that for Japanese /p, t, k/ ranges from 30 to 56.7 ms (Riney et al., 2007). Therefore, L1 Japanese learners must form new phonetic categories that are characterized by long-lag VOT.
Mandarin and Japanese high back vowels differ in lip rounding and tongue position. Specifically, Mandarin /u/ is a high back rounded vowel but the Japanese /ɯ/ is not a typical rounded vowel (Kamiyama & Vaissière, 2009). Japanese speakers also retract the tongue less than speakers of Mandarin (Liu et al., 2013). The crosslinguistic differences may lead Japanese learners to produce /u/ with weaker lip rounding and a more fronted tongue position. However, we chose to train the visually salient lip rounding rather than the invisible tongue position with hand gestures for the following reasons. First, hand gestures are more effective in supporting L2 pronunciation when mimicking visible articulatory movements, such as mouth aperture, than for invisible movements like tongue position (Xi et al., 2023, 2024). Second, for the high back rounded vowel /u/, lip rounding and tongue retraction appear to have a trading relationship, with their maximum points temporally correlated (Lee, 1994; Perkell et al., 1993). Therefore, we can expect that increasing lip rounding can indirectly retract the tongue as well, which improves learners’ vowel production in a more global manner.
At the suprasegmental level, Mandarin and Japanese specify pitch on different units. Mandarin has four lexical tones to differentiate word meanings: Tone 1 (level, e.g., mā), Tone 2 (rising, e.g., má), Tone 3 (fall-rising, e.g., mǎ), and Tone 4 (falling, e.g., mà), which differ in pitch contours within a syllable. However, Japanese employs a “pitch-accent” system, where each word has a specific pitch pattern characterized by the pitch down step position (Vance, 2008). The pitch accent is marked by the relative pitch height between syllables. For instance, hashi (high-low) “chopsticks” contrast with hashi (low-high) “bridge.” In other words, Mandarin specifies pitch on the syllable level whereas Japanese does so on the word level.
Mandarin tonal patterns on word-level pose additional challenges for L2 learners. In disyllabic or polysyllabic words, the surface tone of a given syllable alters depending on the tone of the neighboring syllables. The most familiar instance appears in T3 Sandhi. That is, in a disyllabic word with two T3 syllables, the first T3 shifts to T2 (Duanmu, 2007, p. 254). For example, ma³ yi³ “ant” changes to ma² yi³. Figure 1 contrasts the T3 contours in isolation with those in T3 Sandhi. Because Japanese does not have such a contour shape, to produce T3 Sandhi, learners must reshape the surface tonal structure of each syllable to form the target T3 Sandhi contour.

The pitch contours of T3 (a) in isolation (two falling-rising contours) and (b) under T3 Sandhi (a rising followed by a falling-rising contour), as produced by an L1 Mandarin speaker.
To sum up, there are three main challenges for Japanese learners of Mandarin in speech acquisition. First, they should produce a strong air burst to reach the long-lag VOT, which marks the aspirated /pʰ, tʰ, kʰ/. Second, they should increase their lip roundedness to correctly articulate the high back rounded vowel. Finally, for the lexical tones, the challenges are twofold. They need to learn the pitch contour of each isolated syllable and then apply the sandhi rule (e.g., T3 Sandhi) to reshape those contours at the word level (Gao & Yang, 2023). These challenges can be explicitly trained with the three hand gestures, namely, the aspirating gesture, the rounding gesture, and the pitch gesture.
1.3 This study
In the multi-session training study, we trained experienced Japanese learners of Mandarin to produce aspirated stops /pʰ, tʰ, kʰ/, high back rounded vowel /u/, and the T3 Sandhi with aspirating gestures, rounding gestures, and pitch gestures. The participants held elementary to intermediate Mandarin proficiency.
We address two research questions (RQs) in this study.
Research question 1 (RQ1): Does explicit gestural training enhance fine-grained phonetic learning in experienced L2 learners? To answer RQ1, we compared the pronunciation gains from pretest to post-test on trained items between a gesture group and a no gesture group. As the three gestures have been proven effective with novice learners, we hypothesize that the same training effects should be observed in experienced learners.
Research question 2 (RQ2): Does gestural training yield generalization effects on the production of untrained words? To answer RQ2, we compared the pronunciation accuracy of the untrained items at the post-test between the two groups. Since our participants have prior knowledge of Mandarin, we hypothesize that training with gestures can help learners better generalize their knowledge to novel items than training without gestures.
2 Methods
2.1 Participants
We conducted the study at a university in Kyoto, Japan. Thirty-nine undergraduate students majoring in the Chinese language (33 females, aged 20–22 years, M = 20.46 years, standard deviation [SD] = 1.52) participated. The Department of Chinese Studies approved this experiment as an extracurricular activity for consolidating the students’ knowledge learned from class. Participation was voluntary with no monetary reward. The participants were divided into two groups: the gesture (G) group (N = 20) and the no gesture (NG) group (N = 19). All the participants started learning Chinese at the age of around 18 and had no study abroad experience in Chinese-speaking regions. They had learned Chinese for around 3 years, achieving proficiency from elementary to intermediate levels.
We conducted two independent rating tasks to justify that both groups had similar Mandarin proficiency before training. In the first task, a Chinese instructor who was blind to the grouping and had instructed all participants for 1 year rated each participant’s overall proficiency on a 100-point scale. A Mann–Whitney U test showed no significant difference (W = 195, p = .899) in the proficiency rating between the NG group (Mdn = 88, IQR = 10) and the G group (Mdn = 86.5, IQR = 11.2).
The second task assessed participants’ oral reading skills through a sentence-reading exercise. Each participant read four 8–10-word sentences, excerpted from the textbook. Three native speakers of Chinese, who were unfamiliar with the participants and the experiment, scored the participants’ read speech. They showed good inter-rater reliability, ICC = .83, 95% CI = [.71, .90], based on the intraclass correlation coefficient (Hallgren, 2012) test calculated with the irr package (Gamer et al., 2019) in R (R Core Team, 2014). We then averaged the three ratings to obtain each participant’s pronunciation score. A Mann–Whitney U test showed no significant difference between the groups (NG: Mdn = 70, IQR = 13.3; G: Mdn = 71.7, IQR = 16.7; W = 185.5, p = .910). Therefore, we concluded that the two groups of participants were comparable in L2 Mandarin proficiency.
2.2 Materials
The experiment followed a between-subjects design, incorporating a pretest, training, and post-test paradigm. This section outlines the materials used for the training sessions and the tests.
2.2.1 Teaching materials for the training sessions
The training materials included 144 Mandarin words to train the aspirated stops (N = 48), the /u/ vowel (N = 48), and T3 Sandhi (N = 48), evenly distributed across the first three training sessions. Therefore, each session included 16 words for each training target. The fourth session served as a review of all 144 items, without introducing new materials. In addition, we selected 43 short dialogues for a sentence completion exercise (see Section 2.3 for details).
The materials were presented in Chinese logographic characters rather than Romanized spelling (i.e., pinyin) for two reasons. First, logographic characters are the official writing system of Chinese and pose little difficulty for Japanese speakers. This choice also promotes actual vocabulary learning alongside pronunciation gains. Second, while pinyin uses diacritics to mark lexical tones, it does not reflect tone sandhi, which may hinder learning. For instance, ant is spelt as mǎ yǐ, rather than má yǐ, although the latter better represents the realized tonal contour 1 (see Figure 1). Therefore, avoiding pinyin reduces potential confounds from visual cues. All these materials were adapted from the participants’ textbooks. See Supplemental Material A for the full training materials.
2.2.2 Pretest and post-test materials
Participants completed a word-reading task before and after the four training sessions (pretest and post-test). We drew 36 words from the training materials, 12 words per target feature for the pre- and post-test. In the post-test, we added 18 untrained novel words (six per feature) not included in the training sessions for the generalization test. Although learners encountered each character in the untrained words individually, they had never learned these words and, therefore, needed to apply their pronunciation knowledge to read them correctly. During both tests, participants saw only Chinese characters, without tonal diacritics. The complete test word list can be found in Supplemental Material B.
2.2.3 The design of the gestures
We adapted three gestures from previous studies for the three training targets, namely aspirated stops /pʰ, tʰ, kʰ/, high back rounded vowel /u/, and T3 Sandhi (Baills et al., 2019; Hoetjes & van Maastricht, 2020; Li et al., 2021; Morett & Chang, 2015; Xi et al., 2020). Before the experiment, the instructor was trained with the three gestures, described as follows. She practiced as many times as needed until she felt comfortable with performing the hand gesture in the correct shape while simultaneously producing the target sounds.
The aspirating gesture was a fist-to-open-palm gesture (Figure 2(a)). Specifically, when pronouncing a target word containing an aspirated stop, the instructor raised her fists to shoulder height. When she articulated the aspirated stop, she abruptly opened both fists, extending her fingers outward in a forceful, forward motion toward the participants to visually stimulate the strong airburst required for Mandarin aspirated stops.

The gesture design of the G group includes (a) an aspirating gesture for Mandarin aspirated /pʰ, tʰ, kʰ/, (b) a rounding gesture for Mandarin high back rounded /u/, and (c) a pitch gesture for Mandarin T3 Sandhi.
The rounding gesture was an “o” shape gesture (Figure 2(b)). When pronouncing words containing the /u/ sound, the instructor raised her right hand to mouth level and curved her fingers inward, pressing the thumb against the tips of the other four fingers to form a circle. The circle mimicked the lip rounding required for producing Mandarin /u/. As she articulated the sound, she gently shook her hand in this rounded shape to emphasize the need for stronger lip rounding.
The pitch gesture was an “N” shape hand movement performed on a vertical plane (Figure 2(c)). The instructor started the gesture from the left side of her body followed by sweeping her hand upward toward her right shoulder. She then dropped it down to waist level on the right side and finally extended it upward and outward toward the upper right. The hand movement could depict the pitch contours of Mandarin T3 Sandhi in space, which visualized its tonal pattern.
2.3 Procedure
The entire study lasted 6 weeks. In Week 1, participants completed a pretest word-reading task consisting of 36 words. The words were presented on PowerPoint slides. Each participant entered the classroom individually and read the words aloud without prior preparation. Their speech was recorded using Praat (Boersma & Weenink, 2020).
From Week 2 to Week 4, participants took part in three pronunciation training sessions, held once per week. Each session lasted approximately 40 to 50 min and followed an identical structure. Given that the participants were experienced learners, we adopted a collective training format, which resembled a classroom environment. A native Chinese instructor with 10 years of experience teaching Mandarin as a foreign language delivered the sessions to both groups, following a standardized training protocol. In Week 5, a fourth session served as a review, during which the instructor revisited all previously trained material with the participants.
The training procedure was as follows. For the G group, the instructor wrote the target words on the blackboard and instructed the participants to read them aloud individually. The instructor then demonstrated the phonetic or articulatory properties of each word using one of the designated hand gestures while pronouncing the word aloud three times. Participants were encouraged to mimic the gesture while reading the word along with the instructor. Following this, participants were randomly selected to read through the word list individually. The instructor provided corrective feedback as needed, using one of the three designed gestures to highlight pronunciation issues. At the end of each session, participants completed a sentence completion exercise. They were given a short dialogue with one sentence missing a word and had to select a suitable word from the training word list to complete the sentence. They then read the entire dialogue aloud, with the chosen word embedded in the sentence. This task was designed to encourage the use of the training words in meaningful, contextualized speech.
The NG group was instructed in the same procedure as that of the G group, with one key difference: The three gestures for the target sounds were not used. The instructor provided reading models and corrective feedback verbally, without using any hand or body movements to illustrate phonetic or articulatory features. Participants read the materials aloud without gestures.
In Week 6, we conducted the post-test following the same procedure as the pretest. Participants completed a word-reading task that included the original 36 trained words and 18 novel items, which served as a generalization test. Their speech was recorded in the same way as the pretest.
2.4 Data coding
A total of 3,321 recordings were collected from the word-reading task at pretest and post-test, calculated as (36 trained words × 2 tests + 18 untrained words) × 39 participants − 189 missing trials. Missing trials refer to words that participants omitted or skipped, likely due to difficulty recalling the pronunciation of specific characters. To assess pronunciation accuracy, we conducted acoustic analyses for the aspirated stops and vowels and obtained perceptual ratings from native speakers for the T3 Sandhi productions. For the acoustic analyses, we recruited 14 native Mandarin speakers to read the target words as the baseline data for comparison ([18 aspirated words + 18 /u/ words] × 14 speakers = 504 recordings). A trained research assistant blind to the purpose of the study annotated all the vowels and consonants produced by L1 and L2 speakers in randomized order, which was later checked by a second annotator for the correctness of the boundaries.
2.4.1 VOT of aspirated stops /pʰ, tʰ, kʰ/
The pronunciation accuracy of Mandarin aspirated stops /pʰ, tʰ, kʰ/ was evaluated acoustically by comparing learners’ VOT to that of native speakers. VOT is a fine-grained acoustic measure that can quantify the aspiration strength of stop consonants, with longer VOT indicating stronger aspiration (Lisker & Abramson, 1964). We annotated the VOT of all aspirated stops from both groups using Praat (Boersma & Weenink, 2020) and exported the VOT values from the recordings. The VOT was annotated from the burst release onset to the onset of the first vocal fold vibration. We then averaged native speakers’ VOTs for each of the 18 items to obtain reference values. For each item produced by the learners, we calculated the absolute difference in VOT from the corresponding reference value, which is later labeled as “VOT score” for the follow-up statistical analysis. Note that smaller VOT differences indicate more native-like pronunciation.
2.4.2 Mahalanobis distance of the high back rounded vowel /u/
We conducted formant analysis to assess the production accuracy of the vowel /u/. As with the consonants, we measured how far the learners’ productions deviated from those of native speakers using Mahalanobis distance (MD). MD is a unitless, scale-invariant metric that reflects the distance between a point (i.e., a vowel token produced by a single learner) and a distribution (i.e., several vowel tokens produced by multiple native speakers) (Kartushina & Frauenfelder, 2014). Therefore, in L2 speech research, Mahalanobis distance can measure the native-likeness of the learners’ vowel production (Mora, 2021).
To calculate the MD, we included the first three formants. Initial inspection of the acoustic data indicated that F2 values showed the strongest effects. This is unsurprising, as both lip rounding and tongue retraction influence F2 (see Figure 6). However, participants also exhibited non-target F1 and F3 values across sessions and conditions. Because vowel acoustics are inherently multidimensional, we included all three formants in calculating the MD to obtain a comprehensive measure. We first annotated the steady-state portion of each vowel token and extracted F1, F2, and F3 at the midpoint of each interval. For each /u/ token produced by learners, we calculated its MD from the formant vector of the corresponding token produced by the 14 native speakers. This value was labeled as “MD score” in our data set for subsequent statistical analysis. Smaller MD scores reflect more native-like productions.
2.4.3 Rating on the production accuracy of T3 Sandhi
We assessed the production accuracy of T3 Sandhi through a perceptual rating task. Acoustic analysis was not performed for two reasons. First, Mandarin T3 is often produced with creaky voice (Kuang, 2017), which causes tracking errors in Praat and reduces the reliability of F0 analysis (Garellek, 2022). Second, unlike formant and VOT, although researchers have proposed various methods to acoustically quantify lexical tone accuracy, their validity remains debated (see Zhou & Olson, 2023 for a discussion). Therefore, following previous gestural studies on suprasegmental features (Baills et al., 2022; Li, Baills, Baqué, et al., 2023), we used perceptual rating to code the T3 Sandhi data.
The raters were three native Mandarin speakers (three females, aged 23), who were blind to the experiment. All were pre-service Chinese as Second Language instructors with at least one semester of Mandarin tutoring experience in China. Before the task, they completed a 45 min training session to familiarize themselves with the evaluation criteria and rating scale. Each rater scored the pronunciation accuracy of T3 Sandhi on a scale from 1 to 100 for each word, presented in random order, yielding 3,363 ratings in total. Inter-rater reliability was evaluated using the ICC test (Hallgren, 2012), following the same procedure as in the earlier analysis. As the raters showed good agreement, ICC = .78, 95% CI = [.75, .80], we averaged the three scores for each item produced by the learners to obtain a “T3 Sandhi score” for statistical analysis.
2.5 Statistical analyses
We conducted six linear mixed models (LMMs) in R (R Core Team, 2014) using the lme4 package (Bates et al., 2015) to assess the impact of gestural versus non-gestural training on three pronunciation measures: VOT score, MD score, and T3 Sandhi score. For each measure, one model assessed the participants’ pre- and post-test production on the trained items, and a second model tested generalization by comparing groups on untrained items.
In the trained-item models, the fixed effects included session (pretest vs. post-test), condition (G vs. NG), and their interaction. This structure can assess whether both groups improved over time and whether the gestural training yielded greater gains than the non-gestural training. In the untrained-item models, we only entered the condition as a fixed effect, since untrained items had no pretest baselines. All six models incorporated random intercepts for participant and item. We then added the maximal random-slope structure that converged without singular fit issues. While untrained-item models only allowed random intercepts, the random slopes of the trained-item models varied across training targets. Specifically, the VOT model and the tone model specified a by-participant random slope for session and by-item random slopes for session and condition. In contrast, the vowel model included a by-item random slope of condition.
For all six models, we evaluated the significance of each term via Type II Wald chi-square tests using the car package (Fox & Weisberg, 2019). For any significant main effect or interaction, we performed pairwise comparisons in the emmeans package (Lenth et al., 2020) with p values adjusted using the false discovery rate method.
3 Results
This section reports the descriptive and inferential statistics for each of the three measures. For the acoustic analysis, before reporting the statistical models, we plot the raw values of VOT and the first three formants of /u/. In each figure, we add a shaded rectangle area to indicate the native range calculated as ± 2 SD from the mean values of the native speakers (see Nagle, 2018 for a similar approach).
3.1 Analysis on the VOT score of aspirated stops /pʰ, tʰ, kʰ/
Figure 3 plots the raw VOT values produced by the participants. At pretest, the learners in general produced short VOTs outside the native range (mean ± 2SD). At post-test, the G group showed longer VOTs, with a higher proportion of the values falling within the native range than the NG group for both trained and untrained items.
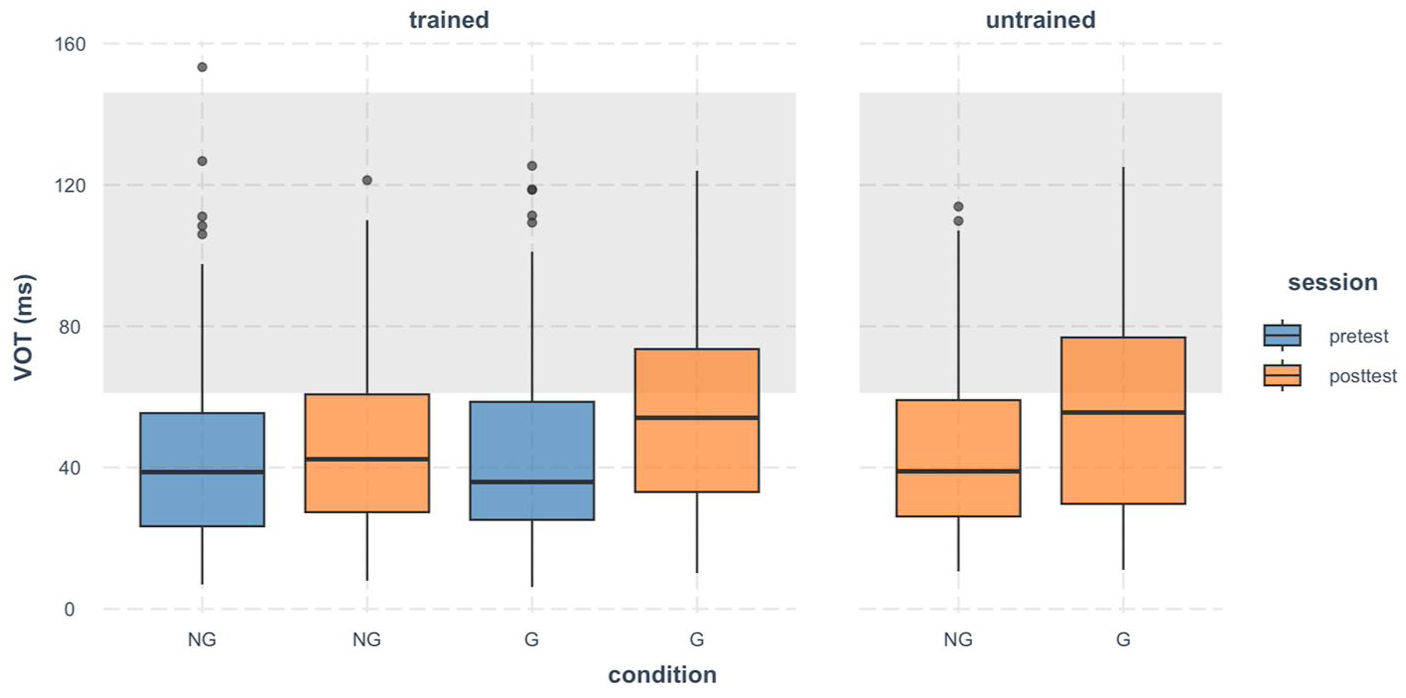
Boxplot of VOT (in milliseconds) of Mandarin aspirated stops /pʰ, tʰ, kʰ/ produced by Japanese speakers. The shaded area represents the native range which is calculated as the Mandarin native speakers’ mean value ± 2 standard deviations.
The LMM for the trained items (Figure 4, left panel) revealed a significant main effect of session, χ2 = 9.54, p = .002, and a significant session × condition interaction, χ2 = 6.12, p = .013. No significant main effect of condition was found, χ2 = 1.35, p = .246. These results indicate that VOT scores changed significantly across sessions, and the extent of change differed by condition. Post hoc comparisons revealed that only the G group showed a significant reduction in VOT scores from pretest to post-test, Δ = 11.55, SE = 2.94, t = 3.94, p = .001. The NG group showed no significant change, Δ = 3.55, SE = 2.95, t = 1.20, p = .240. These results mean that the G group improved more in approximating native-like production of aspirated stops.
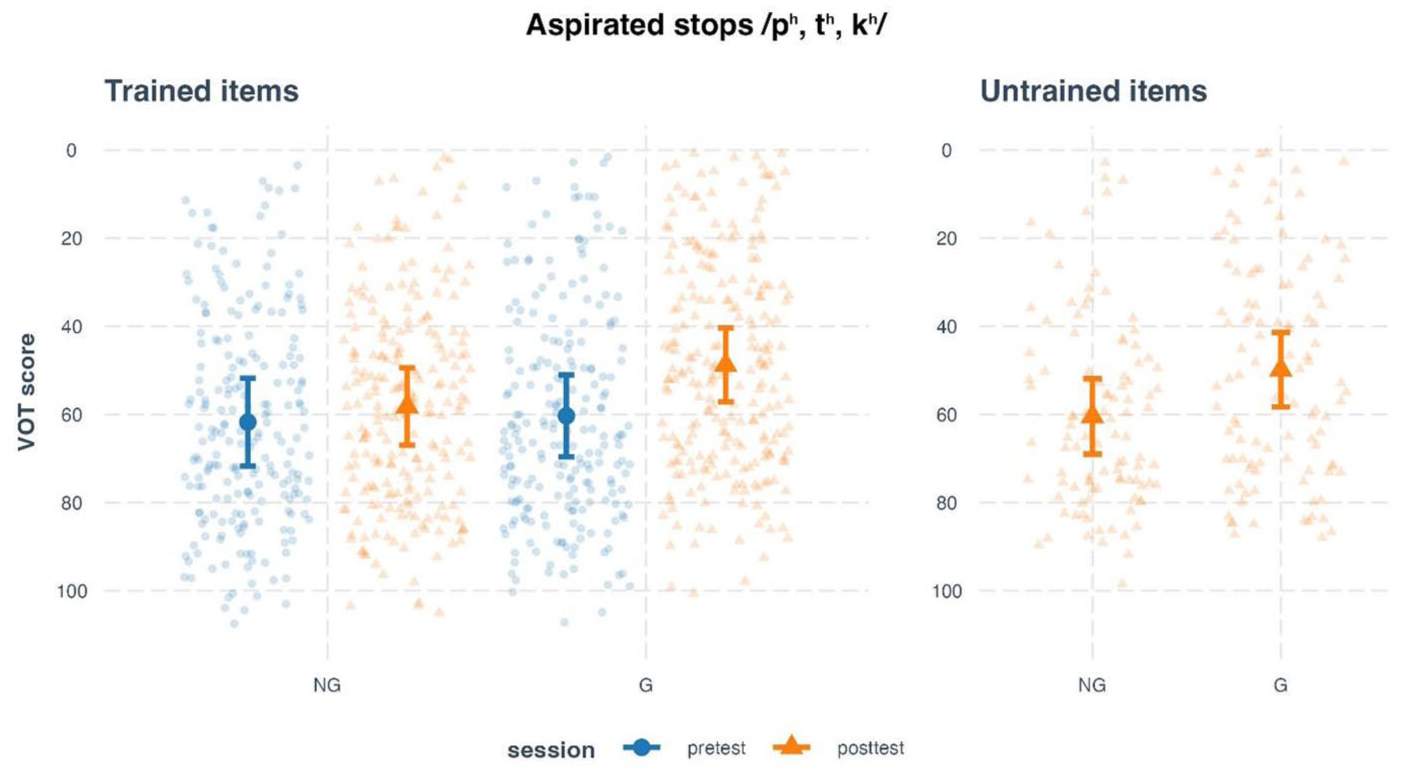
Estimated voice onset time (VOT) scores of Mandarin aspirated stops /pʰ, tʰ, kʰ/ produced by L2 learners at pretest, post-test, and generalization test, split by training condition.
For the untrained items (Figure 4, right panel), the model revealed a significant main effect of condition, χ2 = 7.09, p = .008, indicating a group difference in the generalization test. Post hoc analysis showed that the G group had significantly lower VOT scores than the NG group, Δ = 10.60, SE = 3.99, t = 2.66, p = .012. In other words, the G group outperformed the NG group on untrained items, which signals greater generalization effects.
Taken together, these findings demonstrate that aspirating gestures led to greater improvement in the production accuracy of L2 Mandarin aspirated stops than non-gestural training. Crucially, gestures also promoted generalization beyond the trained items.
3.2 Analysis of the MD score of the high back rounded vowel /u/
Figure 5 shows that most F1 values were within the native range, with some exceptions. This is unsurprising, as F1 is more closely related to vowel height, which is not a challenge for Japanese speakers producing Mandarin /u/. However, the non-native values, though a small proportion, indicate that F1 cannot be excluded from the analysis.
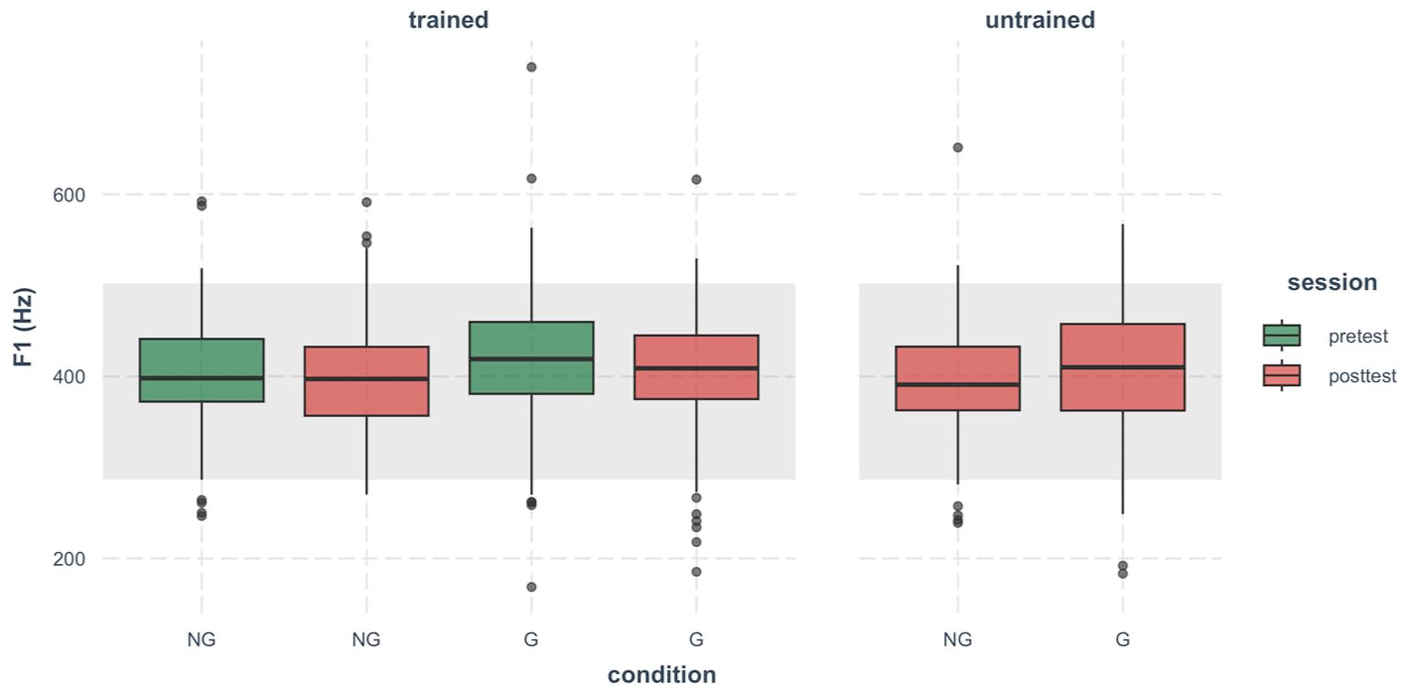
Boxplot of the first formant (in Hertz) of Mandarin high back rounded vowel /u/ produced by Japanese speakers.
As shown in Figure 6, training showed the strongest effects on F2 values. Most F2 values fell outside the native range at pretest, but the G group lowered F2 at post-test for both trained and untrained items, which increased the proportion of data within the native range.
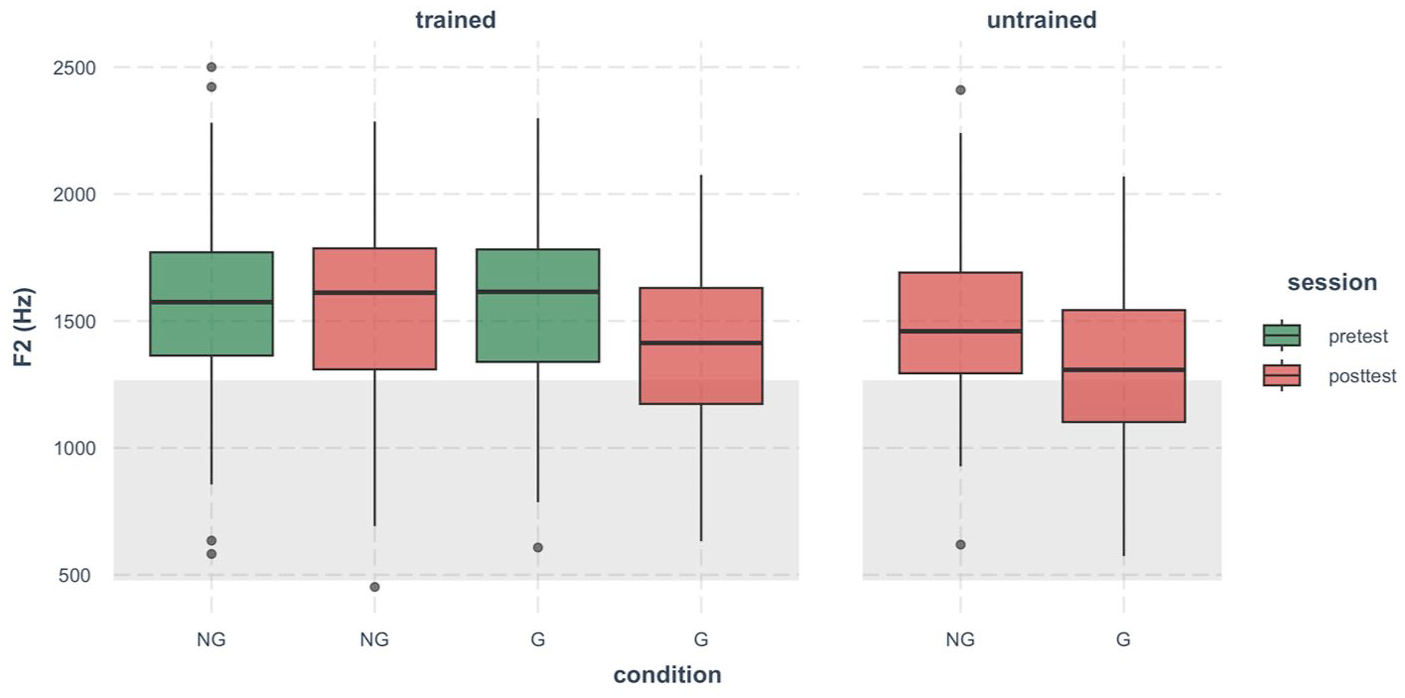
Boxplot of the second formant (in Hertz) of Mandarin high back rounded vowel /u/ produced by Japanese speakers.
Although lip rounding can affect F3, most F3 values were within the native range (Figure 7). This may reflect the inherently large variability of F3 in both L1 and L2 speech, such that differences between groups are difficult to observe.
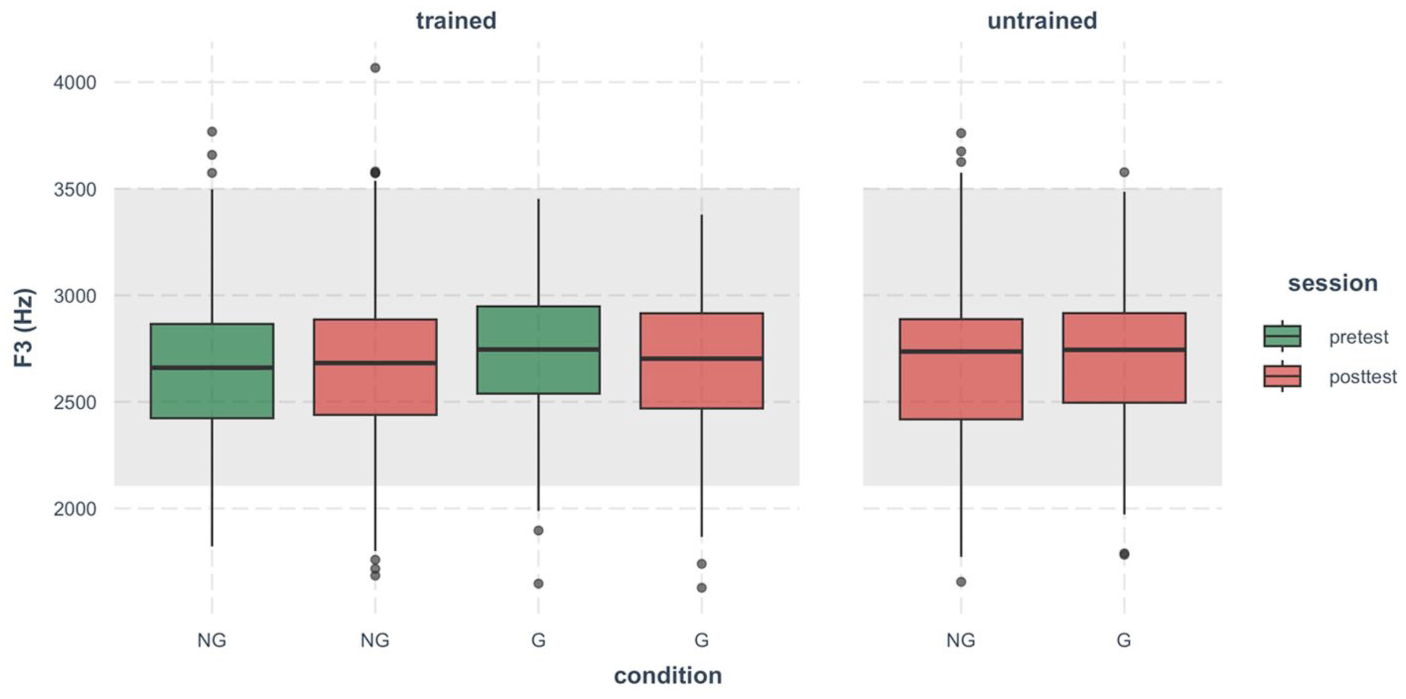
Boxplot of the third formant (in Hertz) of Mandarin high back rounded vowel /u/ produced by Japanese speakers.
In sum, the data inspection suggests that all three formants showed diverse variability across groups and sessions. Calculating the MD score using all three formants thus provides a fine-grained measure capable of capturing vowel complexity.
The LMM analysis on the trained items (Figure 8, left panel) revealed a significant main effect of session, χ2 = 8.99, p = .003, and a significant session × condition interaction, χ2 = 5.91, p = .015. No significant effect of condition was found, χ2 = 2.90, p = .088. These results indicate that the MD score changed from pretest to post-test, and the degree of change differed across conditions. Post hoc pairwise comparisons mirrored the pattern found in the analysis of aspirated stops. Concretely, the G group significantly reduced their MD score from pretest to post-test, Δ = 5.15, SE = 1.34, t = 3.84, p < .001, while the NG group showed no significant change, Δ = .48, SE = 1.38, t = .34, p = .732. These results suggest that gestural training helped learners produce /u/ more closely to native speakers than NG training.
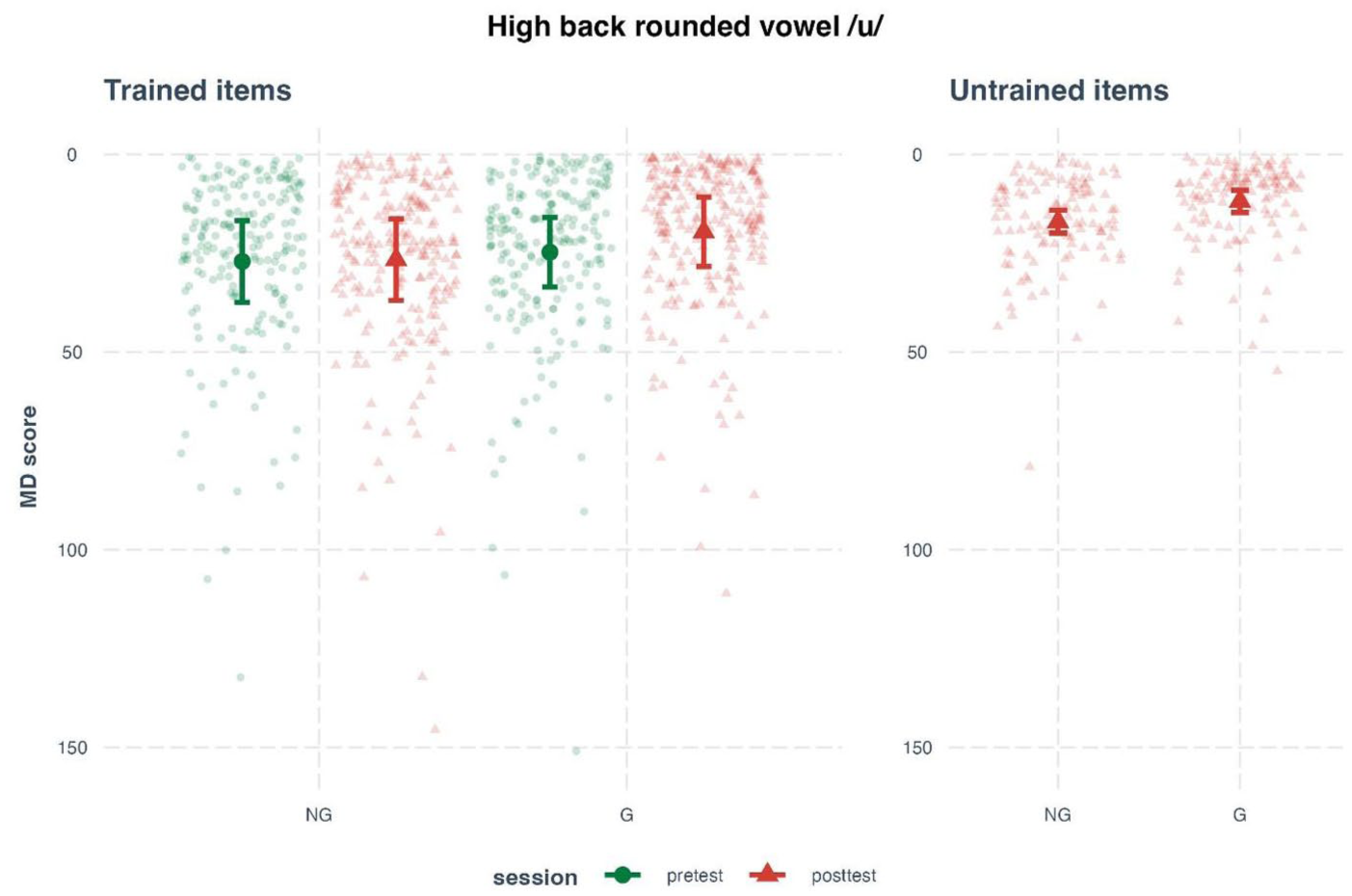
Estimated Mahalanobis distance (MD) scores for the Mandarin high back rounded vowel /u/ produced by L2 learners at pretest, post-test, and generalization test, split by training condition.
For the untrained items (Figure 8, right panel), a significant main effect of condition was obtained, χ2 = 6.84, p = .009, which suggests a group difference in the generalization test. Post hoc analysis revealed that the NG group had a significantly higher MD score than the G group, Δ = 5.13, SE = 1.96, t = 2.61, p = .013. The results suggest that the G group produced /u/ more accurately in unfamiliar words than the NG group.
Taken together, the analysis of MD scores showed that the rounding gesture improved learners’ production of /u/ in trained items. Moreover, this benefit extended to untrained items, indicating a generalization effect.
3.3 Analysis for the T3 Sandhi score of the lexical tone Sandhi
For the trained items (Figure 9, left panel), the model revealed a significant main effect of session, χ2 = 18.71, p < .001. No significant differences were found for condition, χ2 = 3.59, p = .058. No significant session × condition interaction was found either, χ2 = .006, p = .980. These results indicate that both groups improved their T3 Sandhi scores from pretest to post-test, but the extent of improvement did not significantly differ between conditions. Post hoc comparisons confirmed a general improvement from pretest to post-test, Δ = 4.34, SE = 1.00, t = 4.32, p = .001.
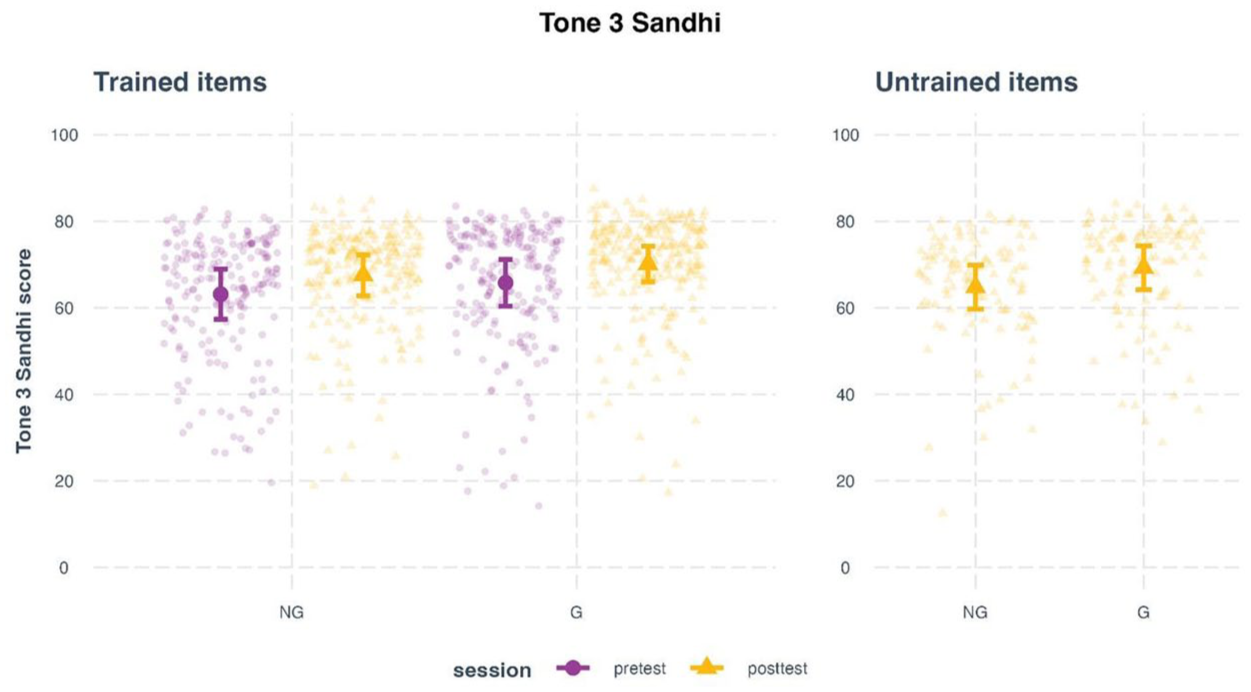
Estimated pronunciation ratings (T3 Sandhi scores) for Mandarin disyllabic words with consecutive third tones produced by L2 learners at pretest, post-test, and generalization test, split by training condition.
For the untrained items (Figure 9, right panel), the model showed a significant main effect of condition, χ2 = 7.27, p = .007, suggesting a group difference in the generalization test. Post hoc analysis indicated that the G group achieved significantly higher T3 Sandhi scores than the NG group, Δ = 4.46, SE = 1.65, t = 2.70, p = .011.
In sum, the analysis of T3 Sandhi scores suggests that both types of phonetic training improved learners’ tone sandhi production. However, pitch gestures promoted greater generalization to untrained items.
4 Discussion
In this four-session multimodal training study, 39 L1 Japanese speakers, in two groups, practiced the pronunciation of Mandarin words with aspirated stops, the high back rounded vowel, and T3 Sandhi. The G group received training with gestures, where hand gestures illustrated the relevant phonetic or articulatory features, while the NG group was trained without hand gestures. We found that gestural training yielded greater improvements in the pronunciation accuracy of vowels and stops than training without gestures, although this was not the case for T3 Sandhi. Moreover, gestural training yielded greater generalization effects than non-gestural training at post-test in the pronunciation accuracy of all three training targets.
RQ1 asked whether adding hand gestures to multi-session phonetic training would improve experienced L2 learners’ pronunciation of the trained items compared with a non-gestural condition. Our results are in line with prior work which showed that gestures enhance novice learners’ segmental production accuracy (Hoetjes & van Maastricht, 2020; Li et al., 2021; Xi et al., 2020), and extend those findings to more experienced learners. This extension matters for two reasons. First, most earlier studies relied on imitation tasks to test L2 speech production, which was necessary when learners lacked sufficient literacy ability in the L2 script, but reading tasks provide a more direct window into a learner’s phonological representations than imitation tasks (Llompart & Reinisch, 2019; Ozakin et al., 2023). Second, prior research with reading tasks has been limited to languages with transparent orthographies, such as Spanish (Hoetjes & van Maastricht, 2020). Our study demonstrates the gesture benefits in a logographic context and offers new evidence that hand gestures can support L2 segmental acquisition across both novice and experienced learner populations.
In RQ2, we examined whether gestural training produced stronger generalization to untrained items than non-gestural training. The G group consistently outperformed the NG group on consonants, vowels, and tones. This result shows that adding hand gestures to phonetic instruction supports stronger transfer than instruction without gestures. It also addresses a common gap in earlier work, which often failed to find clear generalization effects (Baills et al., 2019; Hoetjes & van Maastricht, 2020; Li et al., 2021; Morett & Chang, 2015; Xi et al., 2020). Our study differs from previous research in two respects. First, our participants are experienced L2 learners of Mandarin. Their prior knowledge of Mandarin may have enabled them to generalize what they had learned during the training to novel items, during which gestures facilitated the process. This finding aligns with previous studies where the generalization effect of gestures was revealed on L2 suprasegmental learning (Hirata et al., 2024; Yuan et al., 2019). Here, we add new evidence on the segmental level. Second, unlike previous single-session training studies, we delivered training over 4 weeks and embedded target items in meaningful contexts. By encountering each target sound multiple times and in varied materials, participants consolidated their knowledge and extended it to untrained words.
Nevertheless, for T3 Sandhi, both the NG and G groups yielded similar benefits on the trained items. The results are not consistent with previous findings on the perceptual learning of L2 lexical tones (Baills et al., 2019; Morett & Chang, 2015; Yu et al., 2024; Zhen et al., 2019). The T3 Sandhi results are also not consistent with the vowel and consonant results. Unlike acoustic analyses of VOT and formants, perceptual ratings may not be sensitive enough to detect subtle differences that could reveal group-level improvements from pretest to post-test. Despite the methodology, the differences in the nature of the three training targets may also play a role. Hirata et al. (2024) found that gestural training helped novice learners generalize their knowledge to perceive Japanese pitch accent patterns in untrained items but showed limited effects on trained items. Their finding mirrors our production data. It might be that suprasegmental features span over several syllables, which allows for longer time windows than segmental features (e.g., VOT is often lower than 150 ms) for learners to process. Perhaps, auditory input alone is salient enough for learners to acquire the trained items, and consequently, gestural information becomes irrelevant here. This time-window difference can also explain why the NG group showed limited improvement on segments but significant improvement on T3 Sandhi. Therefore, as Hirata et al. (2024) suggest, practitioners might want to explore a “just right” amount of multimodal information for L2 suprasegmental learning.
Unlike previous laboratory-based studies, our experimental setting mimicked the real-world classroom teaching context with learners from Chinese studies programs. On one hand, this design can provide more practical implications than strictly controlled laboratory studies for validating the pedagogical values of the three target gestures. Especially, in-person training can minimize the artificial effects caused by the manipulation of training materials. On the other hand, this design involves certain limitations. First, we did not videotape the training sessions to validate the instructor’s gesture use, as some learners might have been uncomfortable being filmed, which could have increased anxiety and influenced their behavior or participation. Instead, we relied on the instructor’s report. The instructor indicated that she consistently kept one hand in her pocket while using the other to point to the target words during pronunciation instruction in the NG condition. Crucially, the instructor reported using the three target gestures exclusively in the G condition. Co-speech hand gestures may alter the speech sound production in the G condition (Gentilucci et al., 2001; Li et al., 2024; Pouw et al., 2020, 2021; Vainio et al., 2018), and in both conditions, teachers may use foreigner-directed speech (FDS) for clarity which also affects speech production (Piazza et al., 2022). Our study cannot isolate the effects of gestures and FDS on the instructor’s speech production, but this situation is not unusual in teaching practice. That said, a classroom-based replication of our experiment may deliver the training with pre-recorded videos, as previous laboratory studies did, to ensure homogeneity of the speech stimuli.
Considering the findings from both RQs, this study shows that hand gestures enhance L2 pronunciation learning and, crucially, support transfer to untrained items. Because generalization from trained to novel items serves as a key indicator of effective speech training (Logan & Pruitt, 1995; Rato & Oliveira, 2023), the robust generalization effects add strong evidence that gestures play a positive role in multimodal phonetic training. Moreover, previous studies on L2 lexical tone research focused on perceptual aspects, but our data extended the benefits of gestures to the production of L2 lexical tones.
This study has both theoretical and practical implications. In the theoretical aspect, we provide direct evidence to support the role of embodied cognition (Matheson & Barsalou, 2018) in L2 phonetic training (Shapiro & Stolz, 2019). The positive effects of hand gestures in multimodal phonetic training are driven by the close link between the sensorimotor and cognitive systems (Ionescu & Vasc, 2014), through which gestures partly offload the cognitive load onto the visual and sensorimotor channels to facilitate learning (Post et al., 2013; Risko & Gilbert, 2016). Moreover, hand gestures are embodied visualizers of abstract ideas, which aligns with human’s cognitive mechanism (Lakoff & Johnson, 1980; Morett et al., 2022). Therefore, through metaphorical and iconic gestural representations of L2 phonetic features, learners can process new information more effectively. It might be that gestures enhanced learners’ perceptual accuracy of training items produced by the instructor, which later favored their production accuracy. In short, gestures provide an additional multimodal channel that consolidates phonetic knowledge and facilitates its generalization.
Our study provides a model for multimodal phonetic training practice. We designed a multi-session training with meaningful training materials, coupled with explicit corrective feedback (see also Li, Baills, Alazard-Guiu, et al., 2023 for more teaching recommendations). In practice, instructors can use gestures to provide corrective feedback and encourage students to adjust their pronunciation immediately. At the same time, instructors can observe students’ gestural performance to diagnose their readiness to learn (Shapiro & Stolz, 2019). Furthermore, embedding target words in communicative tasks, such as a sentence completion exercise, can encourage learners to apply the acquired knowledge in various contexts, which may be a source of generalization as well.
Finally, this study has certain limitations that point to directions of future research. First, due to the testing tradition in the participants’ university, we could not elicit speech samples using a spontaneous speech task. As a result, it remains unclear whether the current findings can be generalized to spontaneous speech. Second, we assessed T3 Sandhi using isolated words rather than sentences, because tone–intonation interactions alter surface tonal patterns at the sentence level. Future research should investigate how pitch gestures affect L2 intonation in connected speech and explore whether gesture-based training enhances learners’ spontaneous pronunciation. Third, together with the generalization effects, the retention effects can also validate the robustness of a training method (Logan & Pruitt, 1995; Rato & Oliveira, 2023). As the retention effects of multimodal training have been documented in previous studies (Baills et al., 2022; Li, Baills, Baqué, et al., 2023; Li et al., 2021; Xi et al., 2024), our study focused on the less conclusive generalization effects. Given the positive results of the current and previous studies, future studies can include a delayed post-test to assess both generalization and retention within a single experiment.
In conclusion, despite these limitations, our study is the first to demonstrate that gestures showing L2 phonetic and articulatory features can lead to generalization effects in multi-session pronunciation training with experienced learners. These findings suggest that L2 instructors should actively integrate hands into their teaching practice, especially when teaching complex phonetic concepts.
Supplemental Material
sj-docx-1-las-10.1177_00238309251399140 – Supplemental material for Revisiting the Benefits of Hand Gestures in L2 Pronunciation: Generalization Effects in Multi-Session Multimodal Phonetic Training
Supplemental material, sj-docx-1-las-10.1177_00238309251399140 for Revisiting the Benefits of Hand Gestures in L2 Pronunciation: Generalization Effects in Multi-Session Multimodal Phonetic Training by Sichang Gao, Xiaotong Xi and Peng Li in Language and Speech
Footnotes
Author contributions
Sichang Gao: conceptualization (supporting); investigation (lead); methodology (equal); writing—original draft (equal); writing—review and editing (equal).
Xiaotong Xi: conceptualization (supporting); methodology (equal); writing—original draft (equal); writing—review and editing (equal); formal analysis (supporting).
Peng Li: conceptualization (lead); methodology (equal); writing—original draft (equal); writing—review and editing (equal); formal analysis (lead); supervision (lead).
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the National Social Science Fund of China (Project title: 二语语音习得中多模态训练的效应与机制研究 [The Study on the Effects and Mechanisms of Multimodal Training in Second Language Pronunciation Acquisition]; Project identifier: 24CYY082).
Ethical considerations
The Review Board of Kyoto University of Foreign Studies, where the experiment and data collection took place, approved this study.
Consent to participate
Informed consent was obtained from all individuals included in this study in written form.
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.