
Abstract
In this study, we investigate whether two structurally distinct languages, Norwegian and Russian, influence the use of Estonian morphosyntax by bilingual 5 to 7-year-olds. Using a sentence-repetition task, we tested the acquisition and use of Estonian morphosyntax by children acquiring Estonian alongside Norwegian and Russian, which differ in their use of morphological marking. We tested 69 children aged 4;9 to 7;10 (24 Estonian-Norwegian and 24 Russian-Estonian bilinguals, 21 Estonian monolinguals), using three sentence structures that vary across the languages (copula clauses, experiencer clauses, and complex conditional sentences). Quantitative results showed no significant differences between the bilingual groups. Both groups were at ceiling for copula clauses, but they performed in opposite directions with the other two structures, suggesting possible effects of the other language. An error analysis revealed small differences in children’s use of experiencer and conditional constructions. Contrary to expectations, Norwegian-speaking bilinguals did not produce more errors of omission than of commission in either sentence type. Rather, they used a wider array of cases in the experiencer clauses than Russian-speaking children. In the conditional items, both groups exhibited a tendency to use indicative past in place of conditional present, transferring the use of past forms for conditional meanings from Norwegian or Russian. Other differences are discussed in light of language structure, Estonian exposure, and study design.
1 Introduction
The factors affecting first language acquisition are numerous and characterized by great variation in both monolingual and multilingual populations. Child-internal factors such as phonological memory and working memory span intertwine with environmental factors such as amount and diversity of language exposure (Paradis, 2023). A multilingual environment increases the possible degrees of variation: as the languages in the input are increased, the quantity of input in each is decreased, and the languages may be expected to interact (Place & Hoff, 2016; Serratrice, 2013). An unanswered question is the degree to which multilingual acquisition is affected by cross-linguistic influence (CLI).
CLI is broadly defined as overuse or acceptance of linguistic properties in one language because of influence from another language (Van Dijk et al., 2022). CLI has been found across various linguistic domains, such as phonetics, phonology (Mayr & Montanari, 2015), and morphosyntax (Meir et al., 2017; Unsworth, 2025). Although the notion that the languages stored in the brain interact with each other is neither new nor controversial (see, e.g., Kroll & Bialystok, 2013; Serratrice, 2013), there is much variation in how CLI is defined and operationalized in bilingualism research (Van Dijk et al., 2022). In this paper, we ask whether morphosyntactic differences between the language pairs are manifested in the way the language is acquired and used by the child.
This study investigates bilingual acquisition with Estonian, in which the grammar relies heavily on inflectional morphology. Participants in the study are Estonian-Norwegian bilinguals in Norway and Russian-Estonian bilinguals in Estonia. The children are acquiring Estonian alongside two structurally divergent languages, as Norwegian makes much less use of inflectional morphology, while Russian has rich nominal and verbal morphology. In addition, the children are in different sociolinguistic contexts, with the Estonian-Norwegian bilinguals acquiring Estonian as a heritage language, and the Russian-Estonian bilinguals acquiring Estonian as a societal language. Using a sentence-repetition task (SRT), we tested bilingual children in Estonian, in order to probe for differences in the acquisition of Estonian morphosyntax, depending on whether the child is bilingual with Norwegian or Russian alongside Estonian.
In section 2, we discuss the previous research motivating our study, introduce the languages and structures examined and the task used, and present our research questions. Section 3 provides details regarding the method used, including participants and procedure; section 4 presents both quantitative results and a qualitative error analysis; and section 5 concludes with a discussion of the implications in the light of earlier research and possible further directions.
2 Background
2.1 Bilingual acquisition and CLI
Despite decades of research, debate is still ongoing regarding the degree to which the languages of a bilingual child interact (e.g., Van Dijk et al., 2022, for a review of children over 3; Vihman & Vihman, in press, on children under 3). Factors specifically related to bilingual development, such as age of onset and length of exposure (Unsworth et al., 2011), relative amount of input (Thordardottir, 2015), language dominance (Hamann et al., 2019), and the environment in which each language is learned (Poeste et al., 2019), interact with the individual variation observed even in monolingual acquisition (Paradis, 2023). Inevitably, then, bilingual development involves heterogeneity. Moreover, the dynamic changes with emerging proficiency and competence in each language over the course of development also complicate the interpretation of observed effects. Any differences in proficiency may then derive from the combined effect of various factors: the reduced input a bilingual child is typically exposed to for each language, in comparison with monolinguals; a learning trajectory which may be different than that of monolingual counterparts; or CLI from the child’s other language.
Van Dijk et al. (2022) provide a meta-analysis of experimental findings regarding CLI in bilingual children aged 3 years or older. Noting that results of previous work have been mixed, they report that findings from most studies were compatible with CLI, with a significant effect and a small-to-moderate average effect size. This effect was stronger when children were tested in a non-societal language, but no effect was found for language domain, age, or surface overlap (i.e., structural similarity of the linguistic structures, see Hulk & Müller, 2000).
Studies investigating the question of CLI in spontaneous or experimental data often involve language pairs with sparse inflection, such as English and Spanish (e.g., Deuchar & Quay, 2000), or one language with rich morphology (e.g., Polish, Haman et al., 2017; Russian, Janssen et al., 2015; Meir et al., 2017; Estonian, Baird, 2022; Vihman, 2018; Welsh, Phillips & Deuchar, 2022; Russian, German and Polish, Gaskins et al., 2021). Studies including languages with varying degrees of morphology (e.g., German, Italian, French, and Spanish, Eichler et al., 2013; Greek and Albanian, Kaltsa et al., 2020; Portuguese, German, Spanish, and Catalan, Rinke & Flores, 2018; Russian with various majority languages, Rodina et al., 2020) do not often address the question of whether the global morphological richness of one of the languages facilitates morphological acquisition in the other. 1
Studies investigating acquisition of specific (partially) overlapping structures present a complex picture of bilingual acquisition. Some find plausible CLI effects in either delay or acceleration of, for instance, gender marking or determiners (Eichler et al., 2013; Kupisch, 2005; Meir et al., 2017; Meir & Janssen, 2021; Schwartz et al., 2014). Others find no effect of the other language when comparing bilinguals with the same L1 and different L2s (Rinke & Flores, 2018; Rodina et al., 2020) or different L1s and the same L2 (Kaltsa et al., 2020). In recent years, several studies have underlined the inevitably intertwined nature of CLI and language-external factors (Daskalaki et al., 2020; Meir & Janssen, 2021; Van Dijk et al., 2022).
We know that morphology is acquired later in English, with its sparse morphology, than languages in which morphology plays a key role, such as Polish, Estonian, or Finnish (Argus, 2009; Granlund et al., 2019; Smoczyńska, 1985). In early stages of bilingual development, it is not always clear whether production errors involving omission of inflection arise from CLI (e.g., from a language which makes less use of inflection) or from gaps in the emerging system. Pairs of more richly inflected languages studied so far include Russian and Hebrew, where child bilinguals have exhibited bidirectional CLI (Meir et al., 2017). A comparison with Russian-Dutch bilinguals (Meir & Janssen, 2021) revealed CLI in intricate interplay with other factors, such as exposure and proficiency level. As Meir and Janssen (2021, p. 16) conclude, further studies with different bilingual groups are necessary to better understand the roles of different predictors in bilingual acquisition.
This study attempts to shed further light on these issues by considering the acquisition of Estonian, a language with rich inflectional morphology, by children learning either Norwegian or Russian alongside Estonian. Both languages make use of morphological inflection, but the inflectional system of Russian is much more complex than Norwegian, as discussed in the following section.
2.2 The languages
The three languages in our study differ in their genetic affiliation and typological structure. Estonian is a Finno-Ugric language characterized by nominative-accusative alignment, rich inflectional morphology, and relatively flexible word order. It has a complex system of nominal and verbal inflection with many declension classes (see Blevins, 2007, 2008; Viht & Habicht, 2019), 14 nominal cases and 2 numbers, but no grammatical gender or articles. Russian and Norwegian are both Indo-European.
Norwegian is a West Scandinavian language with rigid word order, gendered nouns, and limited inflectional morphology. Nouns and adjectives are marked for number and definiteness, with salient, early-acquired suffixes expressing definiteness on nouns (Anderssen, 2010). Depending on the dialect, two or three opaquely marked genders are used, and adjectives are inflected for gender as well as definiteness and number (Faarlund et al., 1997). Russian is an East Slavic language with flexible word order and rich inflectional morphology operating on different principles than Estonian (Metslang, 2009). Its noun declension system involves six cases, two numbers, and three genders. Hence, Russian nominal morphology is similarly complex to Estonian but involves different morphosyntactic features.
Children acquiring morphologically rich languages have been shown to have an early command of the morphological system, making few errors (Dressler, 2010; Xanthos et al., 2011) with frequent lexemes and forms (Aguado-Orea & Pine, 2015; Krajewski et al., 2012). Elicitation studies have found lower accuracy with less frequent lexemes and grammatical categories (e.g., Granlund et al., 2019; Räsänen et al., 2016). Less attention has been given to the effects of acquiring two languages with rich morphology, and how the morphological system of one language can support or hinder the acquisition of the other. However, some findings suggest that the presence of a grammatical feature in the societal language (SL) supports its acquisition in a heritage language, even when it is mapped differently in the two languages (e.g., accusative marking in Hebrew and Russian, Meir & Janssen, 2021, or heritage Russian gender marking across various SLs, Schwartz et al., 2014).
An exploratory study on Estonian-Norwegian bilinguals in the same age range (Vaks & Vihman, 2022) showed bidirectional CLI in the use of nominal phrases. In addition to structural transfer, seen, e.g., in overuse of the determiners üks “one” and see “this” as articles in Estonian and the omission of articles in required contexts in Norwegian, one of the more prominent features of CLI was the overuse of partitive and the unmarked nominative case in Estonian. For case usage, CLI (from the lack of cases in Norwegian) seems to combine with frequency effects (nominative being both unmarked and frequent, and partitive being the most frequently used object case in the Estonian differential object marking system, see Miljan & Vihman, 2023, p. 24; Vihman et al., 2020). These findings, in part, motivated the current study’s comparisons with Russian bilinguals. Assuming that the frequency and distribution of word forms in the children’s Estonian input is comparable, comparing their use of Estonian, affected by two typologically different languages, allows us to explore the role of the influence of the other language, all else being equal.
However, since all else is rarely equal, we must note at the outset that the two bilingual groups investigated here are also acquiring Estonian in differing sociolinguistic contexts, with the Estonian-Norwegian children (henceforth NOR) acquiring Estonian as a heritage language in Norway, and the Russian-Estonian children (henceforth RUS) acquiring Estonian as a societal language in Estonia. The Estonian population in Norway includes approximately 5,000–6,000 first- and second-generation immigrants (Integratsiooni Sihtasutus, 2022; Statistisk Sentralbyrå, 2023), and the community is spread out across the country. In larger cities like Oslo, Trondheim, and Stavanger, the community organizes Estonian Sunday schools and choirs, meeting once or twice a month. The Russian-speaking population in Estonia numbers 379,000 (Statistikaamet, 2021), constituting the largest ethnic and linguistic minority in the country. While there are regions with dominant Russian populations, the participants in this study come from predominantly Estonian-speaking areas. Thanks to the large Russian-speaking population, the RUS children have access to a fair amount of Russian exposure outside pre-school via extended family, neighbors, and playmates. An overview of the two participant groups is presented in section 3.1. We return to this, and the limitations it imposes on interpreting our results, in section 5. Considering these differences, this study provides an investigation into whether two such groups can be compared when it comes to language-internal factors.
2.3 Task and target structures
We use an expansion of the Estonian LITMUS SRT, developed for assessing bilingual children’s language usage, in order to target three constructions that differ in structural similarity across the languages, discussed at more length below, in sections 2.3.1–2.3.3. Copula clauses (COP) have a similar structure in Norwegian and Estonian but differ in Russian from the other two. Experiencer/possessor clauses (EXP) are similar in Estonian and Russian but differ in Norwegian. Conditional constructions (CON) are more similar in Norwegian and Russian, differing in Estonian. In this and the following sections, we first describe the SRT and then introduce each structure with examples from the Estonian task, compared with equivalent sentences in Norwegian and Russian. The full set of target sentences is in Appendix Table A1; the numbers in Appendix Table A1 will be used to refer to the sentences hereafter.
SRTs have been shown to be useful for tapping into both processing ability and morphosyntactic skills. Although accuracy relies on the familiarity of the grammatical structure (Polišenská et al., 2015), SRT and nonword repetition (NWR) have been identified as useful tools in the bilingual assessment of language disorder because these tasks crucially involve language-processing abilities, rather than focusing solely on language proficiency (Armon-Lotem et al., 2015; Conti-Ramsden et al., 2001). While knowledge of both vocabulary and grammar is necessary for successful repetition of sentences, these tasks place less of a burden on lexical and morphosyntactic access, as the forms to be produced are heard before the child says them. This also allows for targeting structures that are less frequent in naturalistic speech or more difficult to elicit in a production experiment.
The SRT paradigm has been tested across various language pairs and in various countries (e.g., France, Germany, Israel) for its ability to distinguish between typically developing (TD) children and children with developmental language disorder (DLD) in bilingual populations. Language-specific properties leading to CLI, as well as the effects of language dominance and age of onset of exposure, have all been shown to affect the performance of bilingual children on tasks like these (Marinis & Armon-Lotem, 2015; Thordardottir, 2015). Before the tests can be used for assessment, it is crucial to investigate the degree to which the effects of CLI, dominance, or age of onset can be seen in different groups of bilingual children. As noted by Chilla et al. (2021, p. 4), detailed analyses comparing different L1 groups on substructures of the LITMUS tasks are rare, with relevant variables including (i) L1 influence on the language dependent (LD) and language independent (LI) items of the LITMUS−NWR task, and (ii) transfer effects on specific syntactic constructions in the LITMUS−SR task.
Hence, the SRT needs to be tested for the degree to which it is impervious to CLI.
On the other hand, SRTs have also been used to investigate CLI. Meir et al. (2017) tested Russian-Hebrew bilingual children aged 5–6 years in both of their languages, targeting four phenomena: definiteness (marked in Hebrew, but not Russian), aspect (marked in Russian, but not Hebrew), accusative case, and subject-verb (S-V) agreement (marked in both languages, S-V agreement mapped more similarly across languages than accusative). Regardless of the age of onset of L2 Hebrew, heritage L1 Russian bilinguals had lower accuracy on items testing definiteness than their monolingual Hebrew peers. With S-V agreement, however, all bilinguals performed comparably to monolinguals, something that the authors interpret as a facilitative effect from L1 Russian, which also marks S-V agreement, albeit the features marked on verbs are bundled differently in the two languages. In the Russian task, bilinguals performed significantly lower than monolinguals on aspect, as well as accusative items, which are mapped differently in the two languages. There is thus evidence for influence in both directions, from L1 to L2 and from L2 to L1 in the non-overlapping structures (definiteness and aspect), as well as the overlapping structures (S-V agreement and accusative), where a facilitative effect was found only in the structure with more similar mappings across languages (i.e., S-V agreement). The authors interpret these results in light of Lardiere’s (2007, 2008) Feature Reassembly Hypothesis, expanding the hypothesis to apply not only to the L1 > L2 transfer but also to the L2 > L1 transfer. While no facilitative effect was found in comparison to monolinguals for accusative marking in L1 Russian, a later study (Meir & Janssen, 2021) using an elicitation experiment found Russian-Hebrew bilinguals outperformed Russian-Dutch bilinguals, suggesting a facilitative effect from L2 Hebrew compared to L2 Dutch.
Chilla et al. (2021) used SRTs to test children with three different first languages (Arabic, Portuguese, and Turkish) and two different L2s (French and German). Although several structures might have elicited similar transfer effects from L1 in both L2 languages, no significant differences between language groups emerged. The Turkish L1 groups showed several error patterns explicable by L1 influence in French, but not in German. The authors interpret this as a possible effect of differences in length of exposure or in the type of Turkish input received (predominantly Standard Turkish in France and predominantly Immigrant Turkish in Germany). These results further support the finding of Van Dijk et al. (2022) that language dominance, rather than structural overlap between L1 and L2, significantly predicts CLI. When comparing those two studies, it is important to note that while Meir et al. (2017) focused on structures specifically chosen to gauge CLI, the tasks in the study by Chilla et al. (2021) were developed to avoid any L1-specific hindrances, focusing on L2 structures that are challenging across different L1s. While children in the study by Chilla et al. (2021) did produce error types possibly explained by CLI, just like children in the work by Meir et al. (2017), the differences between error rates were not significant across groups with different L1s. A gap left unresolved by these studies, then, is whether differential effects are found in particular structures with or without a structural overlap in the same target language, depending on the child’s other language.
The Estonian SRT (Padrik et al., 2022) was developed according to the LITMUS project guidelines (Marinis & Armon-Lotem, 2015), similar to the tasks used by Meir et al. (2017) and Chilla et al. (2021). Padrik et al. (2022) and Sirel and Tuunas (2023) report on the piloting of the Estonian SRT with 5-year-olds, noting that it is at an appropriate level of difficulty to identify differences between TD and DLD children among monolinguals and bilinguals. The short version of the SRT, used for this study, includes 33 sentences representing 11 sentence structures. Scores from this “main SRT,” along with a vocabulary test, are presented as a proxy of the children’s general Estonian proficiency.
The present analysis includes 18 items: seven in both COP and EXP conditions and four in the CON condition. Six sentences that suit the COP and EXP categories were included from the Estonian SRT, and 12 sentences were added specifically for this study, four sentences per structure (cf. Appendix Table A1). The target structures are described in the following sections.
2.3.1 Copula clauses
Example (1) represents the items used to investigate copula provision (items 1–7 in Appendix Table A1). The copula is in the third-person singular form (on “is”) in every test item. Examples 1–3 compare the structure in three languages.
Estonian 2
Õpetaja on väga sõbralik. teacher.
[The] teacher is very friendly.
2. Russian: Zero copula
Uchitelʹ teacher.
[The] teacher [is] very friendly.
3. Norwegian
Lærer-en Teacher The teacher is very friendly.
The COP is similar in Estonian (1) and Norwegian (3), which both use an overt copula, while the same present-tense clauses in Russian (2) are verbless. In present tense, the Estonian copula bears regular inflection (e.g., ole-n “I am,” ole-d “you are,” ole-me “we are”), with the exception of third-person forms, which are short and stem-changing, with syncretic singular and plural forms in present tense (on “is/are”). The Norwegian verb å være “to be” has short, irregular forms in both present (er “be.
Modern Standard Russian does not generally use the present-tense copula. All our COP sentences have verbless equivalents in Russian, as exemplified in example (2).
COP clauses are highly frequent, as well as being semantically and syntactically simple. Hence, this structure is likely to be acquired early; if copula usage is already acquired and in frequent use, then we would expect high accuracy in both groups and no cross-linguistic effects of Russian zero copula. However, the copula is optionally omitted in Estonian (Kehayov, 2008); this optionality may increase the likelihood of omission (cf Müller & Hulk, 2001). The most frequent contexts for omission in Estonian are subordinate clauses, compound verbs (auxiliary usage), and EXP, none of which were used in the COP sentences in our task, but the optional use of zero copulas in Estonian may lead bilingual Russian-Estonian children to transfer the Russian zero copula more freely to Estonian and overuse copula omission.
2.3.2 Experiencer/possessor clauses
Seven items (8–14 in Appendix Table A1) were used to elicit EXP clauses in this study. Because the experiencer clauses follow a possessive clause structure in Estonian (Erelt et al., 2017, pp. 243–244), we included three possessive clauses from the main SRT in our analysis (Appendix Table A1, 12–14), in addition to four added items specific to this study (Appendix Table A1, 8–11). The contrast in the EXP structure is shown in examples (5–7).
4. Estonian
little-
[The] little squirrel is cold in [the] winter. (Lit: To-the-little squirrel is cold in winter)
5. Russian
Malen’k-oj belochk-e holodno zim-oj little-
[The] little squirrel [is] cold in the winter. (Lit: To-the-little squirrel is cold in winter)
6. a. Norwegian (experiencer with be)
Den lille ekorn-en er kald om vinter-en.
The little squirrel is cold in the winter.
7. b. Norwegian (experiencer with have)
All-e barn ha-r det morsom-t i dyrepark-en. all-
All children are having fun in the zoo.
Estonian marks the Experiencer argument with adessive, 3 a locative case expressing “at” and used in grammaticalized contexts similar to the dative case (see Seržant, 2015). Productive adessive use is reported in Estonian child language between ages 1;9 and 2;1 (Argus & Bauer, 2020, p. 30). The adessive Experiencer is accompanied by a copula verb and an adjective or adverbial (as in külm “cold,” ex. 5) or the nominative possessee (in possessor clauses, e.g., “red schoolbag” in Appendix Table A1, sentence 11). Experiencer and Possessor as semantic roles can be difficult to distinguish (Aigro, 2022, p. 136). We refer to the target items containing both Experiencer and Possessor clauses as Experiencer (EXP) clauses. EXP arguments are similarly marked with oblique cases in Russian. Experiencers are expressed in dative (as in 6), while Possessors are marked with genitive and the preposition u, also used to express the locative meanings “by,” “near,” and “at.”
In Norwegian, Experiencers take the form of nominative subjects, and Experiencer clauses are formed as transitive clauses, with either å være “to be” (7a) or the auxiliary å ha “to have” (7b), with the latter also used in Possessor clauses. Norwegian nouns are not inflected for case. The subject in Norwegian equivalents of the target EXP clauses is always in the unmarked form, even with pronominal subjects. Hence, in the EXP structure, there are greater similarities between Russian and Estonian.
2.3.3 Conditional constructions
The third target structure involves unreal (irrealis or counterfactual) (CON, as in example (8). Since CON were not included in the main test, the CON structure consisted of only four target sentences. Examples (8–10) show the contrast in the conditional sentence structure across the languages.
8. Estonian
Kui poisi-l if boy-
If [the] boy had money with him, he would buy ice cream.
9. Russian
Esli by u mal’chik-a by-li s sob-oj den’g-i, if on by kupi-l morozhenoe he
If the boy had money with him, he would buy ice cream.
10. Norwegian
Hvis gutt-en ha-dde penge-r, ville han kjøp-e is. if boy-
If the boy had money, he would buy ice cream.
Estonian marks conditional on the finite verbs in the main and subordinate clauses with the same distinct conditional affix -ks in irrealis conditional mood (Holvoet et al., 2021; Plado, 2013). Although the symmetrical marking of both clauses in complex conditionals may provide a simple and transparently marked target system to acquire, the conditional has complex semantic and pragmatic conditions of use and is acquired later than indicative and imperative, appearing around 2 years of age (Argus & Bauer, 2020, p. 38). All the CON items in our extended SRT have
The overt conditional marking in Estonian contrasts with both the other languages, which use past-tense forms, albeit with different strategies. In Russian, counterfactual conditionals are expressed with the subjunctive mood. As in Estonian, conditional verbs are marked symmetrically in the main and subordinate clause. In contrast to Estonian, however, there is no morphologically distinct form for the subjunctive, which is expressed by the particle by or its short form b, and the past-tense form of the verb, as in example (9). Moreover, Russian verbs are inflected for gender and number in the past tense, as shown in example (9) by the different past suffixes for plural agreement (-li) in the main clause and masculine (-l) in the subordinate clause. The form of the verb in conditional is identical to the past-tense form, which may lead Russian bilinguals to replace the suffixed conditional in Estonian with the past tense.
Norwegian lacks a grammatically marked conditional or subjunctive mood. Counterfactual conditionals can be expressed with various past forms, including past simple (10), past perfect, preterite future, or preterite future perfect. Conditionals are often marked by complementizers and prepositional phrases conveying conditionality, such as hvis “if,” om “if,” and i tilfelle “in case.” In addition, conditional meaning can be conveyed by word order (Faarlund et al., 1997, pp. 633–635; Theil, 2023) or by using a participle and omitting the auxiliary ha “to have” (Eide, 2011). Tenses, participles, and modal verbs that are used to convey conditionality and hypotheticality can also be used for politeness and other pragmatic features. Hence, the array of linguistic resources expressing conditionality in Norwegian is broad and not distinctive for conditional marking. To our knowledge, conditional acquisition as such by Norwegian children has not been researched. Auxiliary verbs necessary for building unreal conditionals have been attested in Norwegian children’s speech around the age of two (Ringstad Larsen, 2014), placing the age of acquisition close to the Estonian conditional form. However, preterite forms and expected word order also have to be mastered to productively use conditional forms. Combined with the relatively low frequency of irrealis conditionals, we expect this to result in Norwegian bilinguals substituting the conditional form with realis forms, in either present or past tense.
Similarities between Norwegian and Russian conditional expression include the use of past tense and conditional subordinating conjunctions (esli, hvis “if”), while it may be argued that Russian has a more transparent means of marking conditionals with the particle by.
2.4 Research questions
Based on the previous research and language-specific differences outlined earlier, the questions motivating our study were threefold:
Research Question 1 (RQ1). Do we find differential effects between the two groups of participants?
We expected to find differential effects based on different patterns of CLI from Norwegian and Russian. We predicted:
lower accuracy in COP constructions among RUS than NOR because of the lack of overt copula in Russian.
lower accuracy in EXP among NOR than RUS because of the structural similarity between Russian and Estonian and the use of dative in Russian experiencer clauses.
similar accuracy in CON items among both groups because of the lack of structural similarity with Estonian. Differences between the groups will be examined in an error analysis.
Research Question 2 (RQ2). Does the overall morphological richness of a bilingual child’s two languages affect the errors made?
We expected the Norwegian group (NOR) to produce more errors of omission than the Russian group (RUS), and the RUS group to produce more errors of commission than the NOR group, considering the typological character of their language pairs.
Research Question 3 (RQ3). Does the SRT reveal effects of CLI?
This is important both for task effects in investigating CLI, as well as for the assessment of how vulnerable the SRT is to differences between the non-societal languages of bilingual children, particularly in cases where it is not feasible to assess the child in both of their languages. We expected to find some evidence of CLI.
3 Method
3.1 Participants
Participants in the study included 24 Estonian-Norwegian simultaneous bilinguals (NOR) and 24 Russian-Estonian successive bilinguals (RUS), as well as 21 monolingual Estonians (EST). Monolingual children were included to identify any traits unique to bilinguals. An overview of the groups is presented in Table 1.
Overview of the Participants.
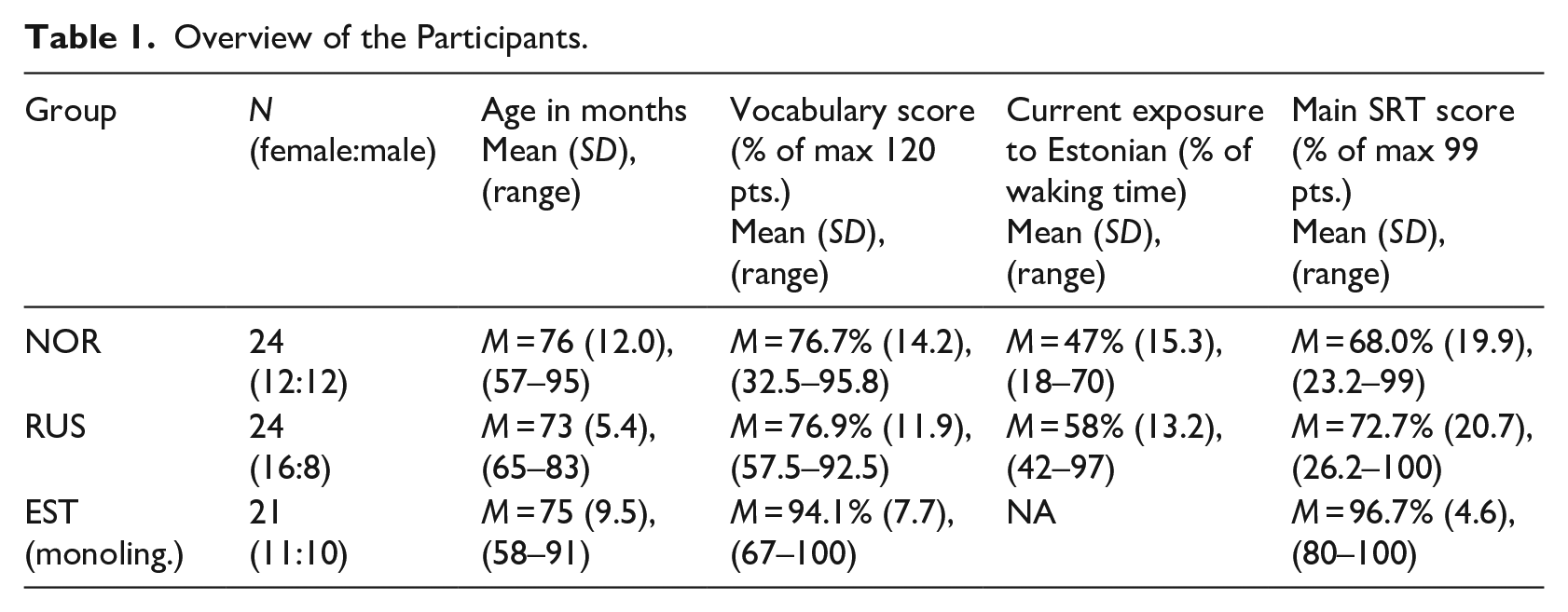
The Estonian-Norwegian (NOR) data were collected as part of PhD research on the use of Estonian morphosyntax by bilingual NOR children, whereas the RUS and EST data were collected during pilot studies testing the suitability of an Estonian adaptation of three LITMUS tests for identifying DLD in bilingual children (Armon-Lotem et al., 2015; Padrik et al., 2022; Sirel & Tuunas, 2023). This study includes data only from the TD group. Since the Estonian-Norwegian population is much smaller than the Russian-Estonian population, the NOR sample was opportunistic, resulting in a somewhat more heterogeneous group. All children lived in Norway at the time of testing. They had been exposed to Estonian at birth and to Norwegian before their second birthday. Eight children lived with one Estonian-speaking and one Norwegian-speaking parent, and 16 lived with only Estonian-speaking parents.
The RUS participants were recruited from pre-schools in predominantly Estonian-speaking areas. All children were reported to speak Russian at home, with two Russian-speaking parents, and Estonian during full-time pre-school attendance. All children were exposed to Russian at birth, and to Estonian before their fourth birthday (mean 2;2). However, all the RUS children can be considered successive bilinguals, as early exposure to Estonian was limited and they acquired primarily Russian before beginning pre-school.
As an additional measure of the children’s Estonian proficiency, scores from a vocabulary test were used. All participants completed the pilot version of Estonian Cross-Linguistic Lexical Tasks (Labent, 2023) or CLT, measuring comprehension and production of nouns and verbs through picture selection and naming tasks. The test has been developed in accordance with the LITMUS project guidelines, allowing comparison with CLTs developed in other languages (Haman et al., 2015). A pilot study has found the Estonian task to be suitable for use with both monolingual and bilingual children (Labent, 2023). The responses for the CLT comprehension tasks were automatically saved by an online interface; responses for production tasks were audio-recorded and later transcribed.
To assess the children’s exposure to Estonian, parents of each child were asked to fill in a questionnaire about their language use over the previous year. For the NOR group, a customized Q-Bex questionnaire (De Cat et al., 2022) was filled out over a Zoom call with a researcher. For the RUS group, a shorter questionnaire was distributed via the pre-school to parents, who filled it out independently (Padrik et al., 2022). Both questionnaires yielded scores for the children’s current exposure to Estonian, which are reported in Table 1, but the differences between them must be noted. The Q-Bex questionnaire tallies more indicators of language exposure than the shorter version used for measuring the RUS children’s exposure. The Q-Bex calculation of Estonian exposure is based on Estonian use reported for parents, siblings, friends, teachers, and others in various contexts. The shorter questionnaire based the percentage on two measures only: the parents’ assessment of time spent in an Estonian environment outside pre-school, and the assumption that children spend, on average, 40 hours a week at pre-school.
In Norway, children start school the year they turn five, and many stay in after-school programs after the end of their classes. In Estonia, children typically start school at age seven, with the last year of pre-school following a curriculum including reading and mathematics, as well as music, sports, crafts, and playtime. Hence, although the NOR group consists of both school and pre-school pupils, and the RUS group only of pre-school pupils, their daily schedules are fairly similar in terms of the balance between more structured learning time (including language-focused lessons) and freer playtime.
Exact Wilcoxon rank sum tests were run to explore possible differences in the background variables presented in Table 1. No significant differences were found in age, vocabulary scores, or main SRT scores. The RUS group has significantly more exposure to Estonian than the NOR group (W = 384, p = .02), with mean exposure at 58% for the RUS group and 47% for the NOR group. This might be expected, seeing that the RUS group has broader access to Estonian, including Estonian-medium daycare. It is important to keep in mind that the language dominance measure used here indicates current Estonian exposure, since this was the only language exposure quantity measure recorded for the RUS group. The dataset does not reflect other possibly significant dimensions of language exposure, such as cumulative exposure (cf. Unsworth, 2013). Note, however, that the NOR group’s earlier age of onset may be partly offset by the RUS group’s greater current exposure.
Exact Wilcoxon rank-sum tests between the monolingual EST measures and the two bilingual groups revealed no significant group differences in age. The monolingual EST group had significantly higher scores than both bilingual groups on the SRT (RUS-EST W = 48.5, p < .001; NOR-EST W = 31.5, p < .001) and CLT (RUS-EST W = 36, p = .002; NOR-EST W = 44, p = .003).
3.2 Procedure
The study was approved by the University of Tartu Research Ethics Committee (protocols no. 364/T-17 and 368/T-5); parents gave written, informed consent. The researcher asked for verbal assent from the child, and those over 7;0 gave written consent as well.
The SRT (see section 2.3) was administered to all children as part of a larger test battery. In Norway, the researcher met the children in their homes or a public space like a library. One (Estonian-speaking) parent was optionally present in the room. In Estonia, the RUS and EST children were tested during the day at their pre-school in a quiet room where only the child and the researcher were present.
Before beginning the task, the researcher explained the procedure and led the child through two practice items. The child was shown pictures of a bear paired with audio clips with a recording of each sentence. The child was asked to repeat each sentence as precisely as possible. After each trial, the bear took a step forward until arriving at a cave with a honey pot. All main SRT items and additional sentences were administered as a single test on a laptop to the NOR group. The RUS and EST groups completed the main SRT using an online interface; the pictures and audio target sentences were identical to the ones shown to the NOR group. The additional target sentences were presented with a picture puzzle revealing a drawing.
All children’s spoken responses were recorded, transcribed, and coded. SRT responses were scored using the 0–3 grammaticality scoring scheme from Marinis and Armon-Lotem (2015), which is based on Clinical Evaluation of Language Fundamentals 3 (CELF-3; Semel et al., 1995). A response was scored with 3 points if no errors were made, 2 points in case of one error, 1 point in case of two to three errors, and 0 if four or more errors were made. Any substitution, omission, or addition of a word or inflection form was generally regarded as an error, as well as changes in the word order that affected the meaning or grammaticality of the sentence. Allowances were made for colloquialisms and consistent phonological divergences. COP, EXP, and CON target items were additionally given a binary accuracy code for the relevant target structure (1 if all elements were present, 0 if any of the crucial target elements were missing or inaccurate). For the qualitative analysis, the sentences were additionally coded for the presence of the following relevant features:
EXP: presence of adessive marking on each element of the experiencer argument; in non-target like responses, the form used with the modifier and the noun (e.g. adessive endings on both adjective and noun in väikse-l orava-l ‘little-ADE.SG squirrel-ADE.SG’)
CON: presence of conditional marking, mood and tense for each verb, any additional forms used (e.g., negation or modal verb), provision of the complementizer
All responses were scored by one of the authors, a native Estonian speaker.
4 Results
We first present quantitative results, overall and for each sentence type, in section 4.1, followed by a closer look at the errors in section 4.2. Data and analysis scripts can be found at https://osf.io/n6jph/. Section 4.1 addresses the first research question, whether we find differential effects based on differences in the three languages. We ran logistic regression models in R (R Core Team, 2023) using the glmer function in lme4 package (Bates et al., 2015) to analyze the effects of language group, age, gender, CLT score, and language dominance on the accuracy of participants’ responses in each targeted structure. The Wilcoxon exact rank sum test was used with the wilcoxon.exact function.
In section 4.2, we analyze the participants’ sentence-repetition errors in the EXP and CON sentence types, aiming to establish whether any differential effects can be attributed to CLI or other factors. In addition, we examine whether errors of omission and commission differ across the language groups (RQ2).
4.1 Analysis of participants’ scores
Figure 1 gives an overview of the groups’ mean scores on each of the targeted sentence types and the main SRT task (rightmost bars, “Main”). Mean scores presented in Figure 1 are percentages of the maximum possible score (7, 7, 4, and 99 points, respectively).
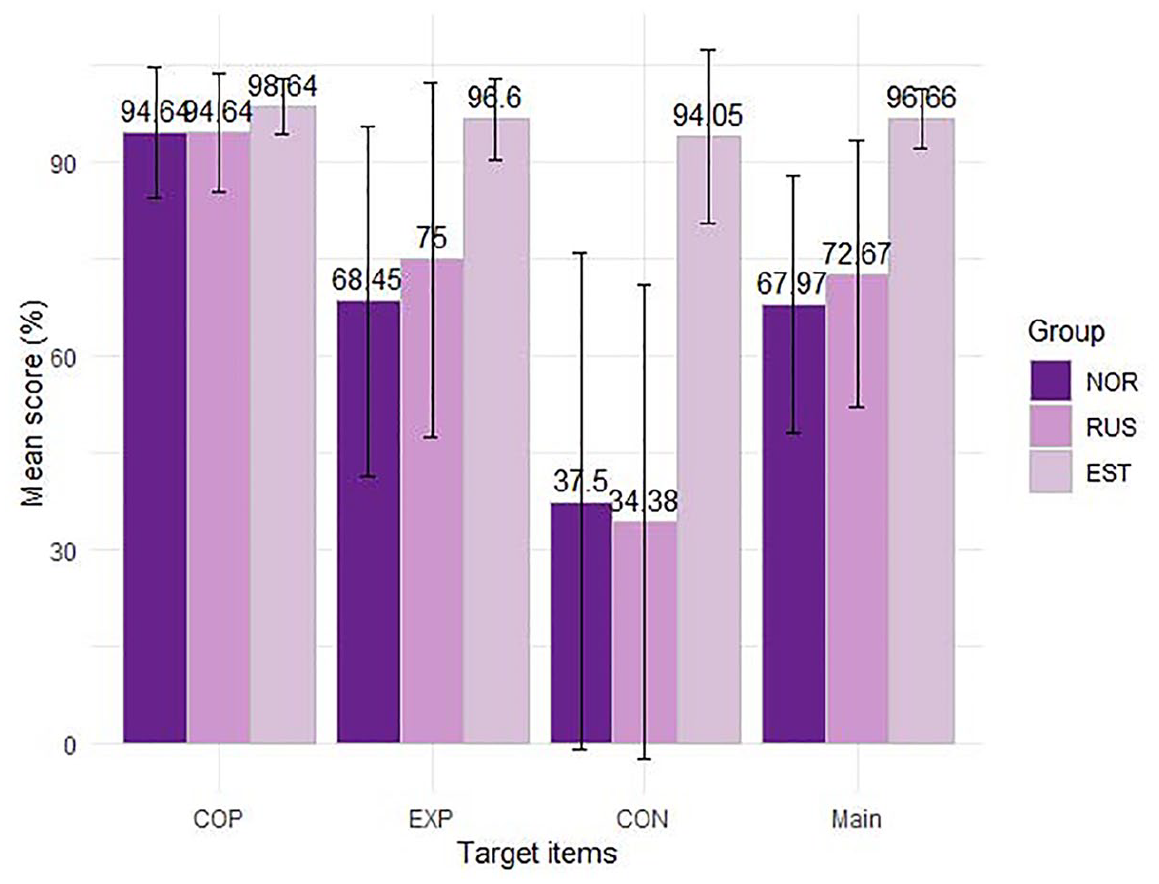
Mean scores (with standard errors) on targeted structures and the main SRT, by participant group.
All three groups show similar patterns across the three structures, with the highest accuracy and small standard errors (SE) on COP items, and the lowest accuracy and greatest SE on CON items. The greatest difference between the bilingual groups is in EXP items, where the mean accuracy is 6.6% higher for the RUS group. Across groups, EXP scores were most similar to the group’s main SRT scores, from which we infer that this structure is the closest in difficulty to the main SRT.
The only structure in which bilinguals do not differ significantly from monolinguals (according to a Wilcoxon’s exact test) is COP (NOR p = .1, RUS p = .1), which is less challenging for all groups. The bilinguals differed significantly from monolinguals in EXP (NOR: p = .02, RUS: p < .001), CON (p < .01, both groups), and the main SRT (p < .01, both groups). Differences between the bilingual groups’ scores are not statistically significant for any of the structures (COP p = .9; EXP p = .4; CON p = .7), nor the main SRT (p = .6). Within all groups, the main SRT scores differed significantly from both COP (p < .01, bilinguals, p = .03) and CON (NOR and monolinguals: p < .01, RUS: p < .001), COP scores being significantly higher and CON scores significantly lower than the main SRT. No difference was found between EXP scores and main scores for the bilinguals (NOR: p = .7, RUS: p = .4), but the difference was significant for monolinguals (p = .02).
The similar patterning of scores across groups and significant differences between monolinguals and bilinguals indicate an overall advantage for monolinguals, but no language- or structure-based advantage within the bilingual groups. To further test the effects of the predictors, we ran a mixed-effects logistic regression model comparing the two bilingual groups, with target structure score (0 or 1) as the dependent variable. To build the model, we started with group, sentence type, age, gender, CLT score, and Estonian exposure as fixed effects, and participant and item as random effects. The vifcor function in the usdm package (Naimi et al., 2014) was first used to detect any collinearity between the numerical covariates. As no collinearity issues were detected, all covariates were included in model building. Because the ranges of CLT score (0–120), Estonian dominance (0–1), and age (57–95 months) varied considerably, the scale function was employed. The final model was built stepwise, starting from a baseline model including only the intercept, participant, and item as random effects. Fixed effects were added one by one and kept in the next model only if they improved model fit (as judged by the Akaike Information Criterion, AIC, and Bayesian Information criterion, BIC). Neither gender nor Estonian dominance improved the model fit and were thus excluded from the model. One-way interactions between group and the remaining predictors were tested, and the interaction between age and group proved near-significant. An analysis of variance (ANOVA) of the models with and without the interaction suggested the interaction model is a better fit, judging by AIC (670 vs. 672), log-likelihood (−326 vs. −328), and deviance (652 vs. 656). A chi-square test indicated a near-significant (p = .057) improvement in model fit by including the interaction. The final model was: glmer(target_struct_score~Group+sentence_type+scale(CLT)+scale(Age_in_months)+(1|ChildID)+(1|Target)+Group*scale(Age_in_months), data = add_sentences, family = “binomial,” contrasts = list(Group=“contr.sum,”sentence_type=“contr.sum,” target_struct_score=“contr.sum”),control = glmerControl(optimizer = “bobyqa”))
The model output is shown in Table 2. For the categorical variables, intercept levels were NOR (Group) and COP (Sentence type). As sum contrasts were used, the model output shows effects of specific group and sentence type compared to the mean of all sentence types and groups. Statistics for CON sentences were calculated on the basis of COP and EXP statistics in the output. The final model shows main effects of CLT score (β = 1.060, SE = 0.195, p < .001) and sentence type as the statistically significant predictors of target structure score. COP (β = 2.295, SE = 0.256, p = .002) had a significantly higher likelihood of a positive score than the mean of all sentence types, while CON (β = −2.239, SE = 0.248, p < .001) had a significantly lower likelihood of a positive score than the mean of all sentence types. The negative interaction between group and age, although non-significant, shows a clear directional difference, as shown in Figure 2. Additional plots showing the marginal effects of CLT scores on target structure accuracy can be found in the Appendix (Figure A1).
Results of the Mixed-Effects Logistic Regression.
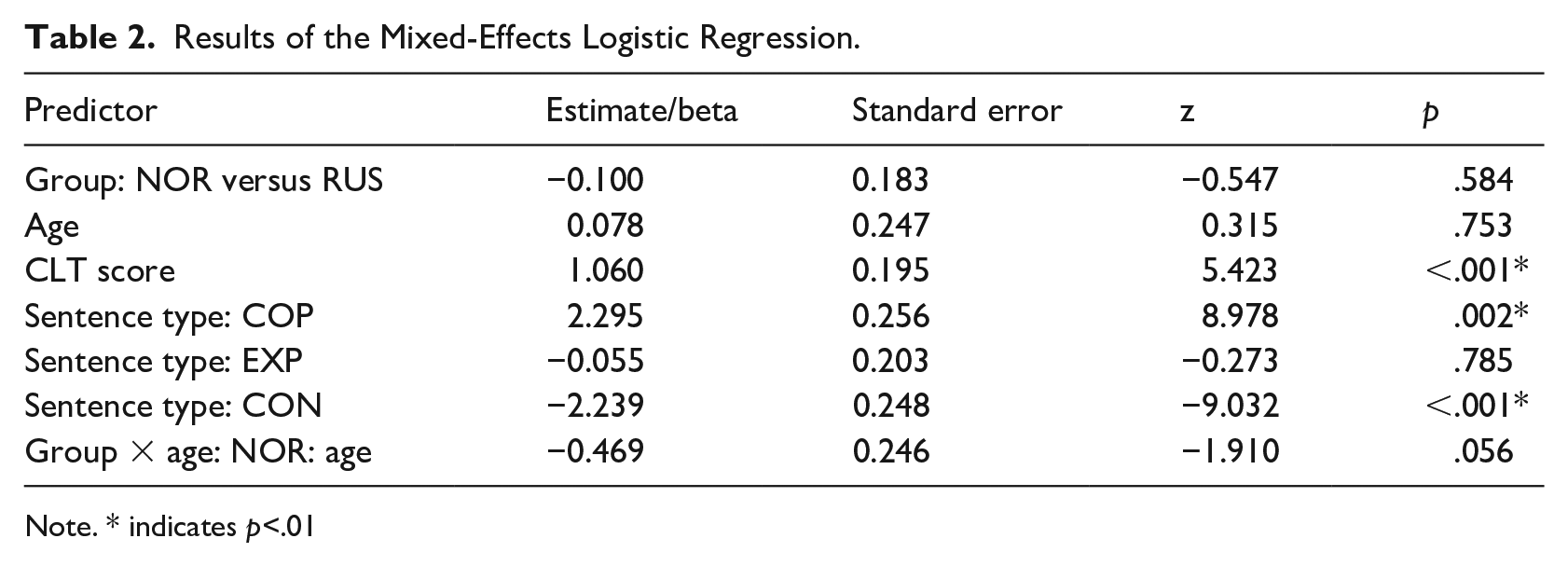
Note. * indicates p<.01
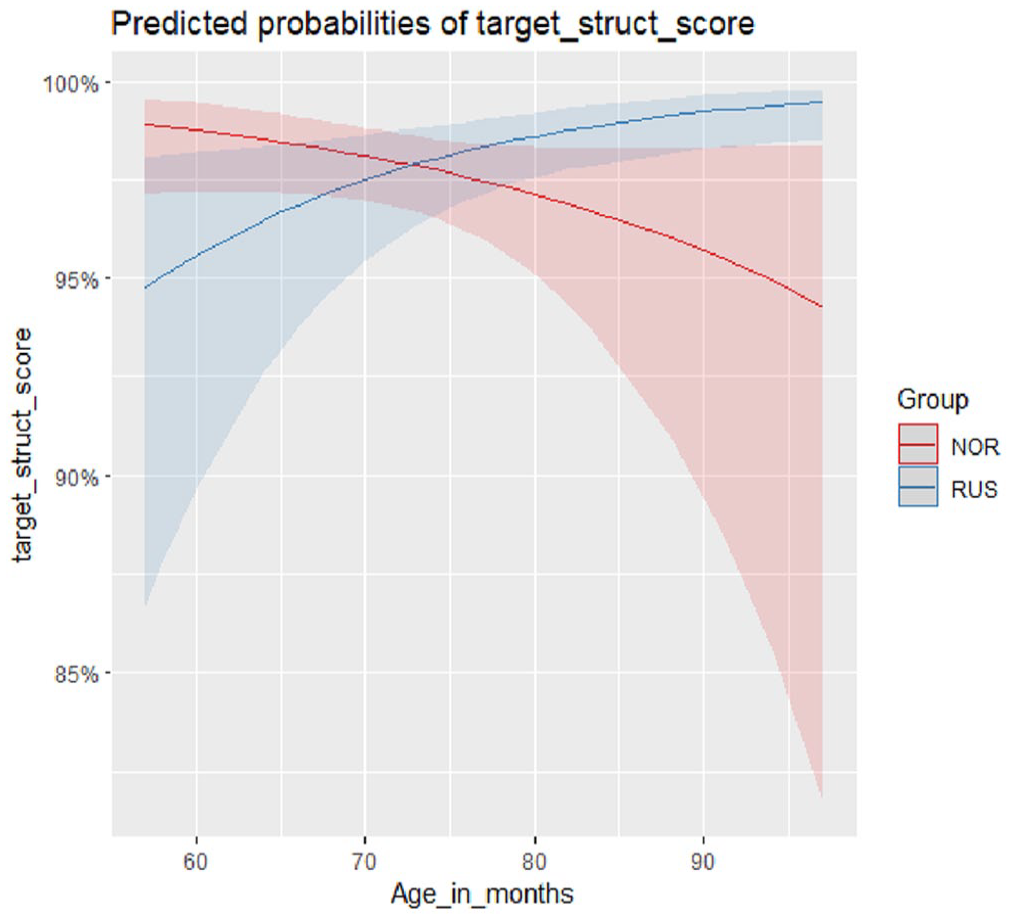
Predicted probabilities of an accurate response, by group and age.
Although it did not improve the overall model fit, adding an interaction between group and sentence type to the regression model proved beneficial for visualizing the relationship between the two. The predicted probabilities of an accurate response reflect the differences in raw scores (Figure 3): both groups have high probabilities of scoring positively on COP items, while the RUS group has a higher probability of scoring positively on EXP items and a lower probability of scoring positively on CON items.
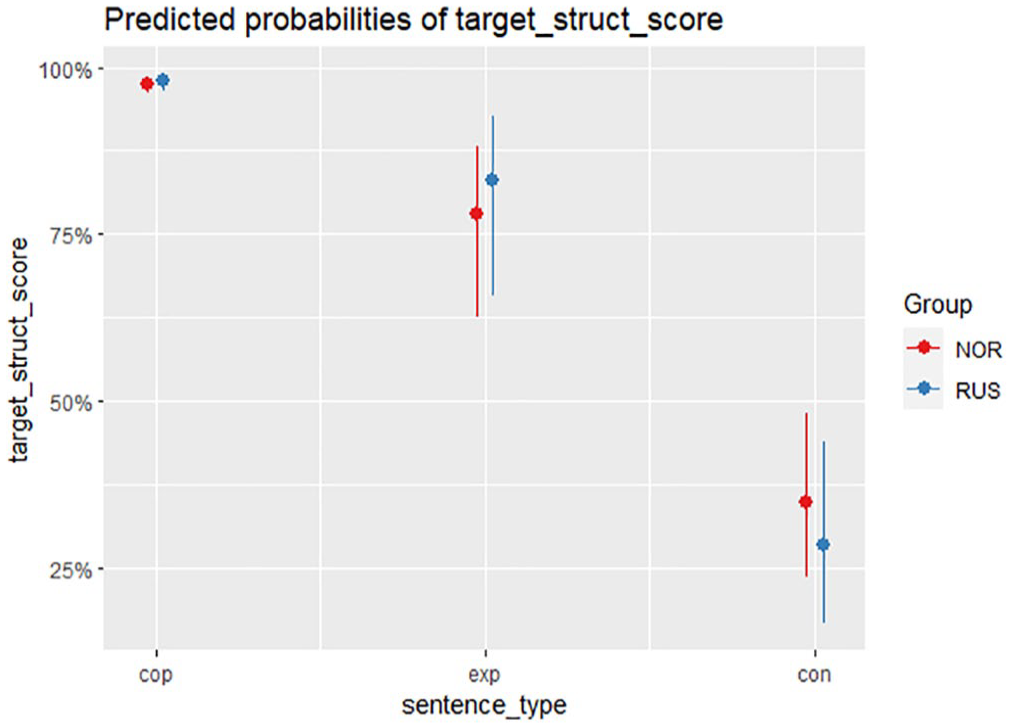
Predicted probabilities of an accurate response, by group and sentence type.
In summary, the logistic regression model did not show a main effect of group on the target structure scores. We found a significant effect of Estonian vocabulary (CLT scores), which is in line with previous research showing moderate, significant correlations between CLT and SRT scores in Estonian (Vaks et al., 2025) and in other languages (Van Wonderen & Unsworth, 2021). The interaction between group and age is approaching significance, with the probability of a positive score decreasing with age for the NOR group and increasing with age for the RUS group. This probably reflects the difference in sociolinguistic context, where the children in Norway are likely to have reduced exposure to Estonian as they grow older, while the Russian-speaking children are likely to have increased exposure, as each becomes more embedded in school and the social circles it provides.
Sentence type also had a significant effect on the scores, and this effect differed somewhat by group, although not reaching statistical significance. The difference in EXP scores is in the predicted direction of group effect, but the difference between groups is not significant, and a larger sample would be needed to test whether there is a true effect. From the mean scores shown in Figure 1, the EXP items are best matched to the overall difficulty of the SRT, and hence best able to capture the children’s abilities. COP scores were at ceiling, and hence are unrevealing. The bilingual children had much more difficulty with CON items, but the RUS group had higher scores for EXP items and lower scores for CON items than NOR children. In both the EXP and CON items, all items but one showed similar differences between group mean scores. 4 Hence, considering the small number of items and the small participant sample sizes, it is imperative to examine the children’s errors more closely.
4.2 Error analysis
The quantitative analysis revealed no group differences. This may indicate no effect of CLI, but we cannot say to what degree it reflects the combined result of too few items and great differences in difficulty across sentence types, which played a greater role than group differences. However, the (non-significant, but attested) differences between the two groups in the EXP and CON structures were in opposite directions in the two structures, meaning that these differences cannot only be due to differing levels of proficiency. In this section, we examine the errors more closely.
4.2.1 Experiencer clauses
The task included seven target items with EXP clauses, yielding 621 responses in total from the three groups. Seven responses where the child did not repeat the clause at all were excluded from the analysis. The Experiencer is always a noun phrase in adessive case: in three items, this was a noun (269 responses), and in four items, it was a noun and modifier, both marked in adessive case (354 responses). Figure 4(a) and (b) summarizes the children’s use of adessive marking in their responses. We analyze the provision of adessive case on each element of the Experiencer and then examine the substitutions in non-target-like responses.
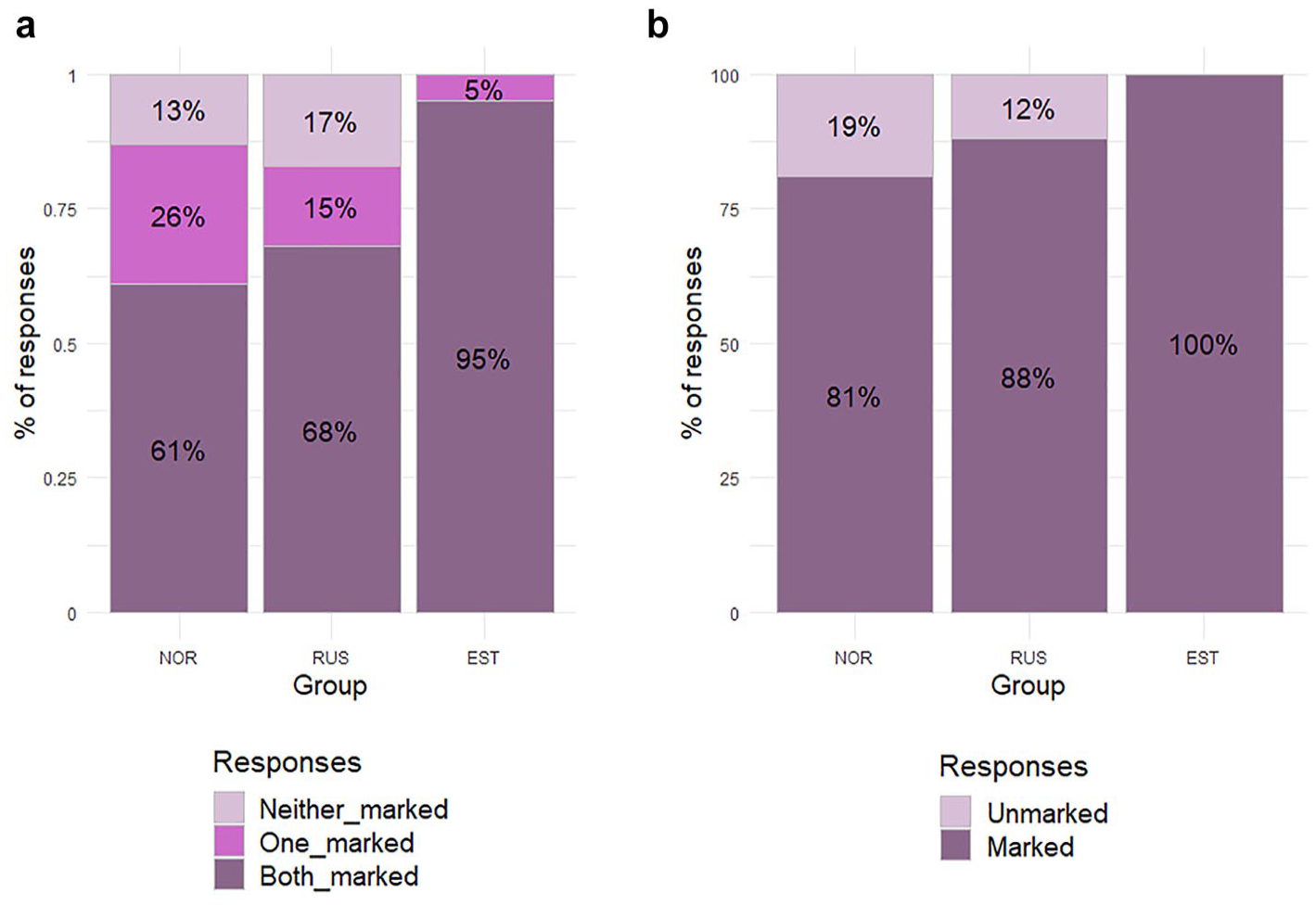
Provision of adessive marking on Experiencer in responses, in targets with modifier and noun (a, NOR: N = 95; RUS: N = 93; EST: N = 83) and in targets with only noun in adessive (b, NOR: N = 69; RUS: N = 72; EST: N = 63).
Accuracy rates are higher for target items with only an adessive noun (Figure 4(b)). The RUS group has higher accuracy than NOR participants across both target types. For target items with both modifier and noun in adessive (Figure 4(a)), the NOR group more often marked one or the other with adessive (26% had one element marked compared to 15% for RUS), while the RUS group tended to mark either both (68%) or neither (17%). While partial marking (of just the modifier or just the noun) was attested in monolinguals (5% of responses), there were no examples of omitting case marking in the targets with just the noun with adessive marking.
Table 3 gives an overview of omission and commission in non-target-like responses. In addition to the cases presented in the table (nominative, genitive, and three locative cases: inessive, elative, and allative), the adessive target was either absent or replaced with a non-word in one response in noun-only targets (NOR), and 14 nouns (7 NOR, 6 RUS, 1 EST) and 13 modifiers (10 NOR, 3 RUS) in modifier + noun targets. We consider both genitive and nominative to be examples of omission, since the genitive forms serve as the stem for the target adessive case forms: hence, the genitive form is equivalent to omitting the adessive ending from the target form (e.g., väikse-l orava-l “little-
Non-Target Responses to Experiencer Items: Omission of Adessive Marking and Substitution With Other Case Forms.
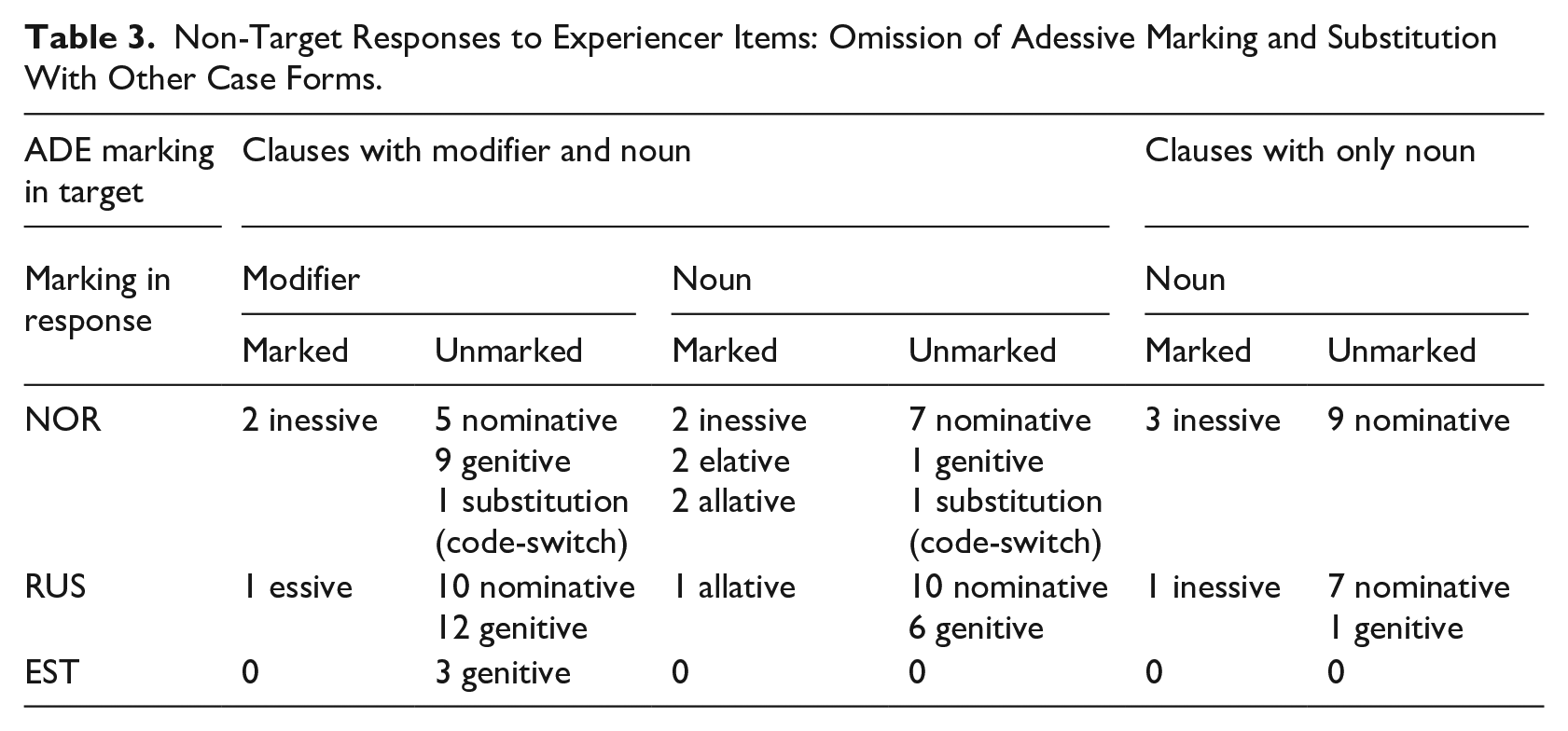
Commission, or using another marked case form instead of adessive, is very rare and occurs more in the NOR group, contrary to our expectations. Interestingly, there is no case agreement between the modifier and the noun in any of the examples of commission (e.g., 11a–b, both of which have two different locative cases on the modifier and noun). Agreement is also rare among the examples of omission (see example 11c–d), with only one response with genitive concord on modifier and noun (RUS), and four examples with nominative modifier and noun (2 NOR, 2 RUS). Contrary to our prediction for RQ2, the RUS group produced fewer errors of commission, and both groups made a similar number of omission errors. Among those, genitive was used most frequently on modifiers and nominative on nouns. Genitive modifiers were attested also in the monolingual group, while there were no examples of case commission among the monolinguals. Genitive responses by monolinguals included a lexical change with a genitive modifier and adessive noun, resulting in a grammatical sentence with a different meaning (e.g., suure-l õe-l “big-
11. a. * big- [In] big sister has [a] red schoolbag. (NORm 6;7, T11)
5
b. All It’s interesting for all the children at the zoo. (NORf 6;10, T9 ) c. Little- Little squirrel is cold in the winter (RUSf 5;6, T8) d. Little. Little squirrel’s is winter cold. (RUSf 5;7, T8)
4.2.2 Conditional structures
Conditionals were the most challenging for bilingual groups. In addition to the dissimilarity from Estonian of the relevant constructions in both other languages of the participants, these are complex clauses with complex semantics. Even in the monolingual group, conditional items yielded lower accuracy (94.0%) than the main SRT (96.6%). This underlines the complexity of the biclausal structure, but seeing that the monolingual group is still above 90%, and conditional verb forms are attested as regular and frequent in monolingual Estonian child speech as early as 2;6 (Pajusalu et al., 2011), it is reasonable to expect children between 5 and 7 years of age to be able to produce the forms.
All the conditional items consist of two clauses: a subordinate clause beginning with the complementizer kui “if,” and a main clause (see example 8). Two of the four conditional items have a sentence-initial subordinate kui-clause (subordinate-main order), and two have sentence-final subordinate clauses (main-subordinate order). Each target item has two predicates; hence, there were eight suffixed verb forms. Because neither Norwegian nor Russian uses a dedicated grammatical marker for irrealis conditionals, we wished to establish (a) to what extent children use the suffixed conditional form at all, and (b) what they use when they fail to repeat the target form.
4.2.2.1 Conditional marking on verbs
Excluding the responses where a child did not repeat the target sentence (deemed unscorable), the target items yielded 274 responses: 96 from NOR, 94 from RUS, and 84 from EST, with a total of 548 targeted verbs (two verbs per response). Figure 5 shows rates of conditional affix provision on targeted verbs for each participant groups (cf. Figure 1, which shows lower rates of item accuracy). The verbs not marked with a conditional affix were mostly in indicative form, but there were also examples of participles and verb omission. In cases of suffix omission, the most common pattern was omitting the suffix from both clauses (27 NOR, 40 RUS, 1 EST).
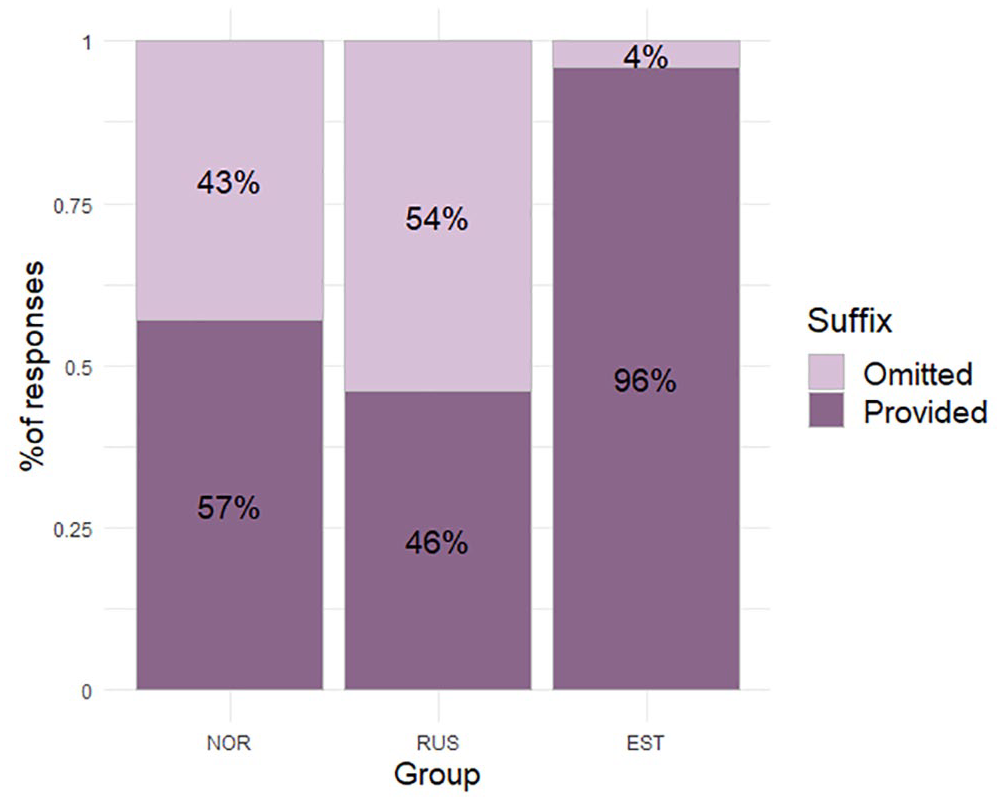
The use of conditional affixes for each verb in responses (NOR: N = 192, RUS: N = 188, EST: N = 168).
As shown in Figure 5, the RUS group had slightly fewer instances of suffix provision (46%) than omission. The NOR participants provided the suffix at a higher rate (57% of items).
Next, we investigated whether the presence of the overt conditional complementizer kui “if” in the subordinate clause supports affix use in the same clause. Both Norwegian and Russian have an equivalent of “if” that is conditional in meaning, and the contextual conditional semantics of kui may strengthen the likelihood of using overt conditional marking. All subordinate clauses in target items included kui.
Figure 6 shows the groups patterning similarly in their ways of combining kui and the conditional suffix, with one exception. Among NOR, the most common was the provision of both kui and the conditional suffix, while for RUS, it was providing kui but omitting the suffix. Providing the suffix without kui was rare in both groups. Omitting both kui and the suffix was attested in both bilingual groups, but not in EST.
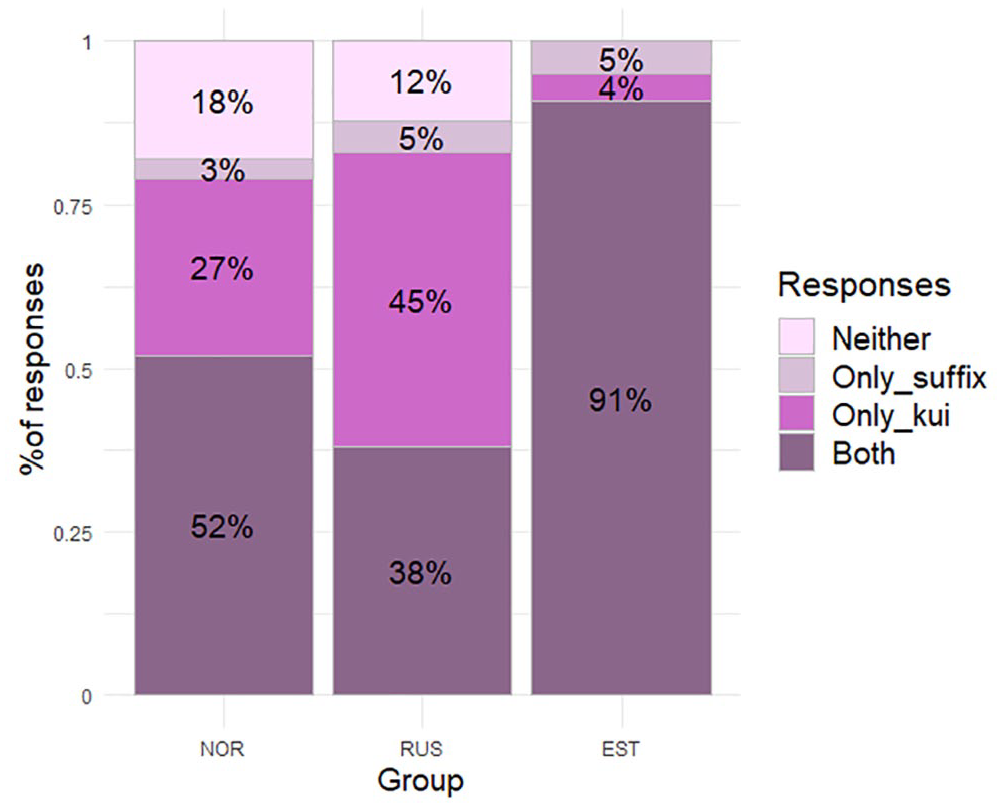
The use of complementizer kui and conditional suffix in subordinate clauses (percentage of all responses for group, NOR: N = 96, RUS: N = 94, EST: N = 84).
Example (12a) shows a response with both verbs marked for conditional, but no complementizer. Conditional suffix omission is seen in example (12b), with an explicit complementizer.
12. a. Conditional suffix present, kui omitted: Hiir Mouse. Mouse would eat cheese, no one would see (RUSf 5;9, T17) b. Conditional suffix omitted, kui present: Hiir Mouse. Mouse eats cheese if no one sees (NORf 7;4, T17)
There were also examples of code-switching in complementizer use. The child who produced example 13 used the Norwegian hvis “if” in all her responses to conditional items; in three of them, this was combined with English then as in example (13). Note also her use of the infinitive form of the verb in the sentence-final main clause. Another NOR participant (f, 6;10) used Norwegian når “when” in T17—possibly an erroneous interpretation of the Estonian kui as temporal instead of conditional, resulting in a kind of a double transfer, using a Norwegian word, semantically extended under Estonian influence.
13. If [NOR] boy- ta jäätis-t. 3sg.nom ice cream-par.sg If [the] boy had money on him then buy he ice cream. (NORf 6;10, T15)
Code-switching occurred exclusively in the NOR group’s responses. Of the total SRT responses, 2.1% included code-switching, mostly in conjunctions, relative pronouns, or complementizers, as in example (13). Most of the children who code-switched had lower rates of Estonian exposure, so the use of Norwegian function words stems either from Norwegian being more activated and easier to retrieve or the Estonian counterpart being only passively acquired. This kind of code-switching is an example of children being able to comprehend the target sentence but using non-target means to express the same meaning themselves.
4.2.2.2 Use of tense instead of mood
Our second question regarding CLI in CON items was whether the children would use past instead of present tense to convey conditional mood. All the target conditional items used present tense. Since both Norwegian and Russian utilize past forms to express counterfactuals, we expected to find some use of past instead of present in the conditionals. Bilinguals used past-tense verbs in 71 items, in at least one of the clauses (compared to 288 present-tense forms), making up 20% of all finite verb forms. In addition, some cases of infinitive, imperative, and participial forms were recorded, as well as nonwords and verbless clauses. Figure 7 shows the verb tenses used in responses (non-finite forms are grouped under “Other”).
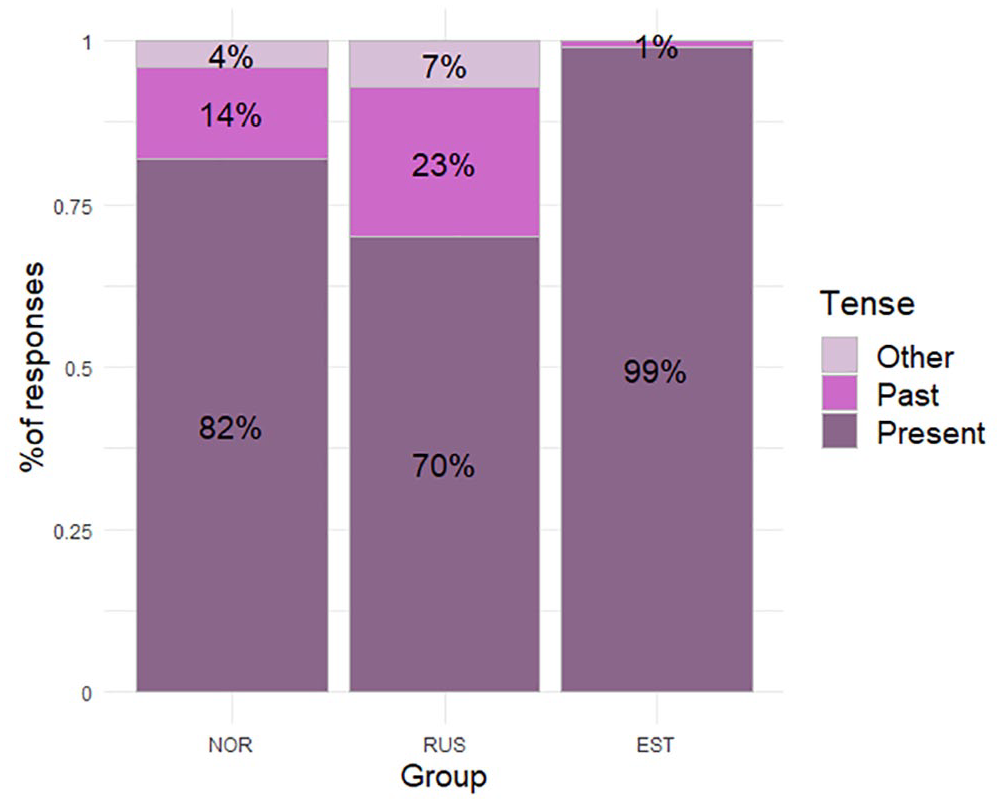
Verb tense in conditional sentence responses (NOR: N = 192, RUS: N = 188, EST: N = 168).
The use of past tense was attested in both bilingual groups, with higher proportions of past-tense use in the RUS group’s responses, while it occurred in only 1% of the monolinguals’ responses. Most frequently, these responses involved substituting both present conditional forms with past indicative forms (NOR: 5; RUS: 13); see example (14a). Participants also gave responses with a past-tense verb in only the main clause (as in 14b; NOR: 9, RUS: 8) or only the subordinate clause (as in 14c; NOR: 7, RUS: 10). In a target-like past-tense clause, the copula in example (14a) and (14c) would agree in number with the subject (“wings”), unlike the conditional, which is unmarked for number.
14. a. Laps child. The child was able to fly if/when s/he had wings (NORm 6;7, T18) b. Laps Child. The child was able to fly if s/he would have wings (RUSf 6;5, T18) c. Laps Child. The child would be able to fly if/when s/he had wings (RUSf 6;5, T18)
Substituting present forms with past tense was expected in both bilingual groups, but some differences in the patterns of tense use emerge between the groups. The NOR group produced five responses with both verbs in past tense (example 14a) and 16 responses with past tense in just one of the clauses (example 14b and c). The RUS group produced 13 responses with both verbs in past tense and 18 with past in just one of the clauses. A response almost unique to the NOR group was the use of verbs in the conditional past, which is a more complex, periphrastic construction (as in 15). Four children produced five examples in total, all of which included one verb in present conditional and the other in past conditional (as in 15). Only two responses from the EST group used past tense, following the same conditional + past pattern, both produced by one child.
15. Kui täna ole-ks pühapäev siis isa If today be make- If today were Sunday, dad would have made pancakes (NORf 7;7, T16)
One of the RUS participants used the fusional 3
In summary, the Russian-speaking children omitted morphological marking more often than the Norwegian-speaking participants. The use of past indicative was unique to bilinguals, showing that this is a strategy transferred from their other language.
5 Discussion and conclusion
This study aimed to investigate CLI through testing the effect of structural differences on bilingual children’s acquisition of Estonian morphosyntax. For this, we tested two groups of bilingual children, acquiring Estonian and either Norwegian or Russian, and a monolingual Estonian group, with an Estonian SRT which included three structures differing across the three languages. Quantitatively, the bilingual groups differed from the monolingual group, but not from each other. Language group did not prove to be a significant predictor of morphosyntactic accuracy in the structures analyzed among Russian-Estonian and Estonian-Norwegian children. The error analysis did not indicate any role for morphological richness of the child’s other language being predictive of their use of morphology in Estonian.
Our first research question was: Do we find differential effects between the two groups of bilinguals, and if so, are they related to structural similarity across the languages? We failed to find significant differences between the two bilingual groups in the target structures. COP items had high accuracy across all groups, and the bilingual groups had identical results. No significant differences were found in the other two structures (Experiencers and conditionals, EXP and CON), but the mean scores for the two structures diverged for the two groups. NOR performed with lower accuracy on EXP items than RUS participants, although this difference, at 7%, was not statistically significant. In CON items, the NOR group’s mean scores were 3% higher. As the group differences in mean scores for EXP and CON lie in opposite directions, they are likely to reflect differences connected to the languages they speak, rather than differences in proficiency, but this would need to be tested with a larger sample size and greater power.
Second, we asked whether the overall morphological richness of a bilingual child’s two languages affects the errors made. The results were contrary to our expectations: the NOR group did not produce more errors of omission than commission, nor did they make more errors of omission than the RUS group. Instead, in EXP clauses, only the NOR participants used marked cases substituting for adessive (errors of commission), although the NOR group overall had lower accuracy for experiencer clauses than RUS. Likewise in conditional structures, the NOR group produced the conditional suffix more often than the RUS group: 57% NOR compared to 46% RUS. Hence, based on the data from this study, we cannot claim that morphological richness in a bilingual child’s other language will lead to more errors of commission than of omission. It remains to be investigated in future studies whether the exposure measures not included here might influence the children’s performance beyond CLI, for example, whether there are significant between-group differences in the quality of the Estonian exposure that might lead to the NOR group being more familiar with other, less frequent locative cases that they used in place of adessive, even while the RUS group has greater current exposure scores. Another question for further study is whether the complex, infrequent conditional structures are more affected by cumulative rather than current input. This could explain the NOR group’s better performance with the least frequent and most difficult construction, the counterfactual conditional structures. If this is the case, then the fact that the RUS group outperformed the NOR group in experiencer items needs to be explained: CLI would explain these tendencies, although the differences are not significant with these samples.
Finally, we posed the question of whether the SRT can be used to investigate CLI found in other tasks. Based on the current study, we can only speculate on whether it might reveal effects of CLI with a larger group and a larger set of items. Of the three sentence types used in our study, only one represented the same level of difficulty as the main SRT, namely the EXP clauses. As this item type showed a proportional difference between participant groups, in the predicted direction, it is possible that a difference might be found with a larger group, such as that found by Meir et al. (2017) using the SRT. However, based on the present results, which indicate similar accuracy among these two distinct groups of bilinguals, as was found by Chilla et al. (2021), we may suggest that the SRT is more suitable as a tool for assessing bilingual children regardless of their language background than for teasing out features affected by CLI. Although this is promising, it should be further investigated before generalizing the test for assessment of bilinguals in Estonia.
5.1 CLI in error types
The error analysis showed only some indication of potential CLI. For EXP, when the target included a simple Experiencer phrase including just a noun, the RUS group marked it with nearly 90% accuracy, compared to 81% for NOR. When the target included Experiencers with both modifier and noun, the accuracy dropped, but RUS still marked adessive on 68% of items, compared to 62% NOR. In accuracy of morphological marking, the RUS group seems to have an advantage in the EXP items.
However, for inaccurately repeated items, the RUS group omitted marking more often than NOR. The prevalence of nominative and genitive instead of adessive echoed the results of an earlier exploratory study analyzing spontaneous speech, where Norwegian-Estonian bilingual children often replaced locative cases with (unmarked) nominative or genitive (Vaks & Vihman, 2022). This can be interpreted as the omission of case-marking, as discussed in section 4.2.1 (cf. Kaiser et al., 2020), but it may also reflect the substitution of a less frequent and more morphologically complex case with a more frequent, simpler one (Vihman et al., 2020). Since nominative and genitive are both more frequent and morphologically simpler than adessive case (Granlund et al., 2019, p. 186), the three effects (frequency, complexity, and CLI) may combine for NOR: nominative and genitive are used both because they are more readily available due to their frequency and simplicity, and because the unmarked Norwegian forms influence omission of case-marking. However, the RUS group also produced far more examples of case omission than case substitution, which suggests that the general effects of frequency and complexity may play a more significant role than CLI in this case. Examining the errors made by the RUS group, we can only appeal to the frequency or simplicity accounts to explain the lack of case-marking by Russian children. We expected the structural similarity in Experiencer marking, along with the overall greater use of case morphology in Russian, to facilitate the use of adessive in Estonian, and it did lead to higher accuracy. As the multifunctional Russian dative may be mapped to the Estonian allative, adessive, and elative cases, depending on the context, we expected to find commission errors specifically with these cases, but we did not. At the same time, the Russian genitive Possessor may have influenced the children’s use of Estonian genitive case. With the Russian case forms typically being more fusional than the Estonian semantic cases, the children may also associate the Russian dative with Estonian grammatical cases rather than the suffixed locative forms. It remains to be explored whether this contributes to case omission among RUS.
For verbs in the more difficult CON items, both groups displayed a tendency to omit conditional marking, using indicative forms instead, although RUS participants provided the conditional suffix in only 46% of verbs, compared to the NOR group’s 57%. Moreover, both groups used indicative past (as used in Norwegian and Russian) instead of conditional present, and both omitted the conditional suffix more often from the subordinate than the main clause. These errors might be explained by CLI, as they differ from monolinguals, but CLI has the same effect in both language groups. In Estonian, kui is polysemous, meaning both if and when, and it is the conditional verb suffix that gives the clause its conditional semantics, not the complementizer. This contrasts with both Russian and Norwegian, where the use of hvis/esli is enough to make a clause conditional. Equivalents to the complementizer kui in Norwegian and Russian carry an inherently conditional meaning. Hence, these items provide us with a structural contrast between Estonian and the other languages: both groups showing similar effects of possible CLI.
Yet differences were also seen between the two groups. The most frequent response for the NOR group was to provide both the complementizer kui and conditional marking (in 52% of responses), whereas the RUS group most frequently produced the complementizer but omitted the suffix (45%). Moreover, RUS children used past indicative instead of conditional forms more consistently than the NOR group, in both main and subordinate clauses. This can be due to the greater variety of means for expressing conditional semantics in Norwegian. In Russian, conditional mood is expressed more consistently with past tense, and the past forms themselves are invariant. Hence, the use of past for conditional meaning is more transparent and may be more robustly acquired in Russian than in Norwegian. This would also lead to a greater likelihood of cross-linguistic transfer, which intertwines with language-external factors, in this case, likely cumulative amount of exposure. The effect of exposure is underscored by the small group × age interaction (just below the significance threshold) illustrated in Figure 2.
Both groups, then, show some influence from the equivalent structures in their other language when faced with the more complex CON. Several studies with various bilingual groups have found similar structural transfer effects (e.g., Anderssen & Bentzen, 2013; Kolb, 2014; Kubota et al., 2020). The discussion as to where these effects stem from is still open, including studies that point more to the factors of dominance (e.g., Van Dijk et al., 2022), age of onset, and length of exposure (e.g., Kolb, 2014; Unsworth et al., 2011) or the interface between syntax and other language domains being more open to influence (see, e.g., Hulk & Müller, 2000; Sorace, 2011).
Cross-language influence has been found in multiple studies of morphosyntactic acquisition, such as Schwartz et al. (2014), who found differential effects on gender agreement depending on the children’s L1, and Meir et al. (2017), who used the SRT to identify bidirectional CLI in Hebrew-Russian bilingual children. As shown by Van Dijk et al., CLI is “part and parcel of being bilingual” (2022, p. 902) and is found across many different pairs of languages and various methods. However, it is not found ubiquitously, and it interacts with other factors, such as language dominance, but not with age. Meir et al. (2017) found CLI effects when comparing bilinguals to monolinguals. When comparing two groups of bilinguals (Meir & Janssen, 2021), both groups performed worse than monolinguals, but although L2-based CLI effects were attested, language-external factors proved crucial to understanding the different performance of the groups. Seeing that even the same structures in the same language have been found to be affected by CLI in some studies but not others (Rodina et al., 2020; Schwartz et al., 2014), it seems that although CLI is often present in bilingual language use, its effect is mediated by language-external factors and thus might be overshadowed by them.
Our study identified two populations speaking Estonian and other languages differing in their morphological richness. We expected to find differences in morphological acquisition facilitated by the richness of Russian and hindered by the morphological sparsity of Norwegian. The quantitative results indicate no difference between the groups. An error analysis also indicates that the groups’ performance, although not identical, was very similar. Some probabilistic differences emerged, but no categorical differences between the groups were found. Both groups showed knowledge of the morphology in the target structures, and overall, both omitted the morphological marking to similar degrees. Differences between target structures could be explored further, but based on the results of this study, it is impossible to tell whether a larger sample would reveal differences based on CLI, or rather similarities across the bilingual groups. Limitations of the study which may underlie this failure to confirm hypotheses are discussed below.
5.2 Limitations of the study
Various limitations make it difficult to draw clear conclusions. First and foremost, the study is underpowered, with sample sizes being too small. This is conditioned by resources as well as the inherent difficulty of accessing sufficient numbers of participants, meaning the restrictions of reaching bilingual children of the target age spread throughout Norway, with limited resources. The aim was to include a larger number of children, but considering a sample of 48 bilingual children altogether, the sentence structures would ideally have had many more items in them. Because the target structures were added to an already lengthy test battery, this was not considered in the early stages of the study.
Second, the two bilingual groups in the study have different language learning contexts: the NOR group speaking Estonian as a heritage language and the RUS group as a societal language, mostly having learned it as a second language in a pre-school setting. Although efforts were made to use the exposure measures to take this difference into account, it is problematic that the difference in language context is aligned with the different language pairs, creating a confound in the study design. Moreover, the measures we used for exposure seem not to be fine-grained enough to assess the differences between the two groups, at least not with a sample as small as ours. The Estonian exposure measure did not ultimately contribute to statistically explaining any differences in the two groups’ results. According to our measures, the NOR group had 11% less Estonian exposure than the Russian group, and a somewhat larger SD. These scores do not include information about the children’s cumulative exposure, nor do they account for differences in language-learning contexts. Although we set out to use the Estonian exposure scores to mitigate these differences in our model, the quantitative measures fail to capture the significance and the subtleties of this difference. For instance, it is unlikely that the rough figure of 8 hours to represent time in pre-school truly captures each of the RUS children’s experience; equally, the input the NOR group is exposed to is less varied in terms of speakers but differs in quality, as it is more often experienced in one-to-one interaction. Possible differences in input quality go some way toward explaining the NOR group’s greater mean accuracy for CON items than RUS, a finding that otherwise contradicts the findings of Van Dijk et al.’s (2022) meta-analysis where language dominance, operationalized as societal language, was found to be a significant predictor of CLI in the heritage language. Rodina et al. (2020) compared children speaking Russian as a heritage language in five different majority language settings and found family type (i.e., minority or mixed language use at home), age, and exposure to Russian instruction to be the most significant predictors of gender assignment accuracy, while the structure of the majority language did not have a significant effect.
Finally, the study design, allowing differences in difficulty between the three types of items used to test CLI, affected the results. With responses to COP clauses nearly at ceiling, and CON clauses significantly below the mean, differences between the bilingual participant groups were difficult to detect and would require a larger participant sample or a greater number of items. Although the adessive case (used in the experiencer constructions) and the conditional are acquired at a similar age by monolinguals (Argus & Bauer, 2020), the hypothetical nature and assumed lower input frequency of the counterfactual conditionals make this structure the most difficult, while the copula structure is the easiest.
To conclude, while our study revealed no statistically significant differences between the two participant groups, this finding would need to be confirmed with a larger sample size. The bilingual children, while performing less accurately than monolinguals, nevertheless showed sophisticated use of Estonian morphology. The difference in sociolinguistic contexts of the two groups cannot be controlled for by including our simplified measures of language exposure, and the test items need to be matched for the SRT difficulty level. The error analysis gives us no evidence for overall morphological richness being facilitative in acquiring another morphologically rich language. However, minor differences emerged between the two groups’ errors. A larger sample of participants and items, structures better matched for difficulty, and items more specifically targeting contrasts across the languages should be tested in further research.
Footnotes
Appendix
List of target sentences by structure.

| Copula clauses | |
|---|---|
| 1 | Loomaaia karu on suur ja pruun. Zoo. The zoo’s bear is big and brown. |
| 2 | Vanaema põll on pesumasina-s. Grandma. Grandma’s apron is in the washing machine. |
| 3 | Sõbra isa on kooli-s õpetaja. Friend. [The] friend’s father is a teacher at school. |
| 4 | Õpetaja on väga sõbralik. teacher. [The] teacher is very friendly. |
| 5 | See on kirju kass, kes This. püüdi-s rott-i. catch- This is the colorful cat that was chasing the rat. |
| 6 | Kui tuba on korra-s, siis võib When room. õu-e minna. outside When the room is tidy, [we] can go outside. |
| 7 | Toas on tugitool, mis läks Room. eile katki. yesterday. There’s an armchair in the room that broke yesterday. |
| Experiencer constructions | |
| 8 | Väikese-l orava-l on talve-l külm. Small- [The] small squirrel is cold in the winter. |
| 9 | Kõigi-l laste-l on loomaaia-s huvitav. all- It’s interesting for all [the] children in the zoo. |
| 10 | Karvase-l koera-l on päikese käes palav. furry- The furry dog is hot in the sun. |
| 11 | Suure-l õe-l on punane koolikott. big- Big sister has a red schoolbag. |
| 12 | Täna on isa-l jala-s uue-d kinga-d. today. Father is wearing new shoes today. |
| 13 | Jänese-l on halli-d kõrva-d ja valge Hare- saba tail. [The] rabbit has gray ears and a white tail. |
| 14 | Rongi-l on pehme-d sinise-d istme-d. train- [The] train has soft blue seats. |
| Conditional constructions | |
| 15 | Kui poisi-l ole-ks raha kaasas, osta-ks If boy- ta jäätis-t. If [the] boy had money along, he would buy ice cream. |
| 16 | Kui täna ole-ks pühapäev, tee-ks If today. isa pannkook-e. father. If it was Sunday today, father would make pancakes. |
| 17 | Hiir söö-ks juust-u, kui keegi ei mouse. näe-ks. see- [The] mouse would eat cheese if no one saw [him]. |
| 18 | Laps saa-ks lenna-ta, kui ta-l ole-ks child. tiiva-d. wing [The] child could fly if s/he had wings. |
Acknowledgements
We are grateful to three reviewers, and to Ghada Khattab, for very useful feedback which helped improve the paper. Remaining weaknesses are our own. We thank Eline Clausdatter Kleppenes, Chris Franz Langøen, Ulrik Vikestad Thorsen, Elisabet Kirch, Annika Labent, and Ljudmila their Liivamägi for help with data collection. Our deepest gratitude belongs to all the participants, their families, and pre-schools.
Abbreviations
NOM: nominative; GEN: genitive; PAR: partitive; ILL: illative; INE: inessive; ELA: elative; ALL: allative; ADE: adessive; ABL: ablative; SG: singular; PL: plural; PRS: present; PST: past; PRET: preterite; M: masculine; F: feminine; N: neuter; ART: article; DEF: definite; INDF: indefinite; PREP: prepostional; DAT: dative; INST: Instrumental; PRF: perfective aspect; 3: third person; SJV: subjunctive; CON: conditional; CNV: Converb; INF: Infinitive; PCP: participle.
Funding
Data collection for the Estonian-Norwegian sample was funded by a Dora Pluss mobility grant from the Estonian Youth and Education Board as well as support from the Nikolai, Kadri and Gerda Rõuk Research Fund at the University of Tartu. Data collection from the Russian-Estonian sample was funded by the Estonian Youth and Education Board, grant no. 1.2-2/21/3349.