
Abstract
Listeners adjust their perception of sound categories when confronted with variations in speech. Previous research on speech recalibration has primarily focused on segmental variation, demonstrating that recalibration tends to be specific to individual speakers and situations and often persists over time. In this study, we present findings on the perceptual learning of lexical tone in Standard Chinese, a suprasegmental feature signaled primarily through pitch variations to distinguish morpheme/word meanings. Native speakers of Standard Chinese showed a recalibration of tone category boundaries immediately following exposure to ambiguous tonal pitch contours. However, this recalibration effect significantly weakened after 12 hours. Furthermore, participants trained at night did not exhibit delayed stabilization, a phenomenon commonly observed during sleep-induced consolidation. Our results replicate previous findings and provide new evidence suggesting that while our perceptual system can flexibly adapt to real-time sensory inputs, subsequent consolidation processes, such as those occurring during sleep, may exhibit selectivity and, under certain conditions, may be ineffective.
1 Introduction
A well-recognized challenge in speech perception is the ubiquitous variation that listeners encounter when decoding the speech signal. No two utterances are the same, no two voices are identical, and words in connected speech are often realized in ways different from their canonical forms. Coping with variability in speech, which seems natural and effortless during daily speech communication, has been argued to instantiate two functional capacities of our perceptual system (e.g., see Kleinschmidt & Jaeger, 2015 for a review). One is the system’s stability in categorizing and recognizing phonetic sound units in terms of category. Within a sound category, listeners are sensitive to the fine-grained acoustic details but can also interpret these variations as instances of the same category. The other is that the system needs to be flexible, actively taking advantage of certain phonetic variations to recalibrate relevant sound categories as needed. This perceptual learning process enhances the system’s capacity to make better inferences about the situational specificity of a sound category (e.g., due to speaker attributes or situational factors). Ultimately, our speech perceptual system must continuously balance the stability and flexibility of sound categories.
The existing literature provides ample evidence for spontaneous and effective perceptual learning with long-lasting effects in different domains. There are nevertheless cases, although limited in number, that suggest that adaptation to acoustic variations can be selective and short-lived (e.g., see studies by Kraljic, et al., 2008; Kraljic & Samuel, 2011; Kraljic, et al., 2008 for sensitivity to preceding exposure context; Maye, et al., 2008 for sensitivity to vowel height; Zäske, et al., 2013 for sensitivity to spatial attention; and Earle & Myers, 2015b for short-term adaptation). The current study provides further evidence of the instability of sound category recalibration over time from a much-less-studied empirical domain: the perceptual recalibration of lexical tone.
Lexical tone is a suprasegmental feature that distinguishes morpheme/word meanings in 60%–70% of the world’s languages (Yip, 2002). While various cues, such as duration and phonation, contribute to encoding tonal contrasts, pitch variation is the primary cue in most tonal languages. For example, in Standard Chinese, the identical segmental syllable ma denotes “horse” with a dipping pitch contour but signifies “mother” with a level pitch contour. Lexical tone plays a vital role in spoken word recognition (Malins & Joanisse, 2010; Yang & Chen, 2022). However, significant questions remain open concerning (a) the degree of automaticity with which listeners of tone languages adjust to pitch variations in the speech signal to efficiently process lexical tones and recognize words and (b) the time scale over which such perceptual retuning is generalized and consolidated beyond immediate processing contexts. With data from Standard Chinese, this project presents novel evidence concerning the flexibility and stability of perceptual adaptation of lexical tonal features. Moreover, it underscores the need for further investigation into perceptual learning, generalization, and consolidation within the realm of suprasegmental speech, as discussed below.
1.1 Flexibility in speech perception and categorization
Speech signals vary along the continuum of different acoustic properties. Listeners can integrate multi-dimensional acoustic cues (Repp, Liberman, Eccardt, & Pesetsky, 1978) and process the variations (semi-)categorically (Delattre, et al., 1955; Hallé, et al., 2004; Liberman, et al., 1957). It is important to note that while listeners may categorically interpret speech signals, they may remain sensitive to within-category variations, as demonstrated by McMurray, et al., (2002). Furthermore, perception is context-dependent (Lotto & Holt, 2016), with exposure to speech stimuli in specific contexts influencing subsequent perception through processes known as “phonetic retuning” or “perceptual recalibration” (Norris, et al., 2003; Samuel & Kraljic, 2009).
Perceptual recalibration has been observed across various phonetic features, including vowels (Huang & Holt, 2012; Maye, et al., 2008), consonants such as fricatives (Eisner & McQueen, 2005, 2006; Newman, et al., 2001), stops (Allen & Miller, 2004; Clayards et al., 2008; Holt, 2006; Kraljic & Samuel, 2006; Mitterer et al., 2016), and liquids (Mitterer et al., 2013), as well as suprasegmental features such as lexical tones (Mitterer et al., 2011), lexical stress (Bosker, 2022; Severijnen et al., 2023), and intonation (Kurumada et al., 2018). The perceptual retuning of sound category boundaries/internal structures has been shown to generalize to novel words with a similar effect size as those trained words (McQueen et al., 2006; Mitterer et al., 2011), which has been attributed to recalibration that occurs in relation to abstraction at the pre-lexical level.
Many models of speech perception have been motivated to account for such flexibility of the perceptual system (e.g., see the studies by Goldinger, 1998; Johnson, 1997; McClelland & Elman, 1986; Norris & McQueen, 2008). By now, one widely accepted view is that perceptual learning is one form of distributional learning across multiple levels (Kleinschmidt & Jaeger, 2015). By instantly employing various information, listeners can update their beliefs about the distribution of acoustic cues that leads to category/internal structure recalibration.
1.2 Stability of perceptual recalibration over time
The substantial evidence of quick recalibration in speech perception raises questions concerning the stability of such perceptual adjustments and possible factors that condition them. There has been mixed evidence concerning whether, and if so, how long exposure-induced rapid recalibration is stabilized via memory consolidation (Walker et al., 2003). For instance, Eisner and McQueen (2006) showed an equivalent extent of category boundary change in a test performed immediately after training compared to that after 12 hours. Moreover, their study examined the impact of learning time by comparing participants who attended sessions with a daytime interval to those with a regular sleep interval. Interestingly, no significant difference was found between the two groups, suggesting sustained fine-tuning in phonetic categorization regardless of sleep. Roth et al. (2005) similarly showed that participants achieved comparable identification accuracy for consonant place of articulation (i.e., /da/ and /ga/) after hours of sleep or wakefulness.
In contrast, Gaskell and Dumay (2003) reported a sleep effect on lexical competition after learning nonwords, which emerged after a 12-hour interval with sleep but not after the same time interval during the day. This finding is consistent with an earlier study (Fenn et al., 2003) investigating how listeners adapt to (low-quality) synthetic speech, where learning was stronger after participants slept between training and test. Strikingly, for participants trained in the morning with two post-tests, one on the same day in the evening and one in the following morning, performance increased overnight despite no training between these two tests. Similar results were also found for non-segmental musical tone feature learning (Gaab et al., 2004; Gottselig et al., 2004), suggesting that sleep promotes auditory learning by reducing interferences typically experienced during waking hours (although Gottselig et al. (2004) did observe a similar learning effect for noon sleep and resting while awake in the same period).
The effect of sleep on the sustainability of perceptual learning can be selective. Talker-specific adaptation appears to be long-lasting, even after intervals of 12 hours, 1 week, or longer (Witteman et al., 2015; Xie, et al., 2018), but generalization across talkers seems to rely heavily on sleep consolidation, as shown in the study by Earle and Myers (2015a). In their study, native English speakers learned the contrast between Hindi dental and retroflex stops produced by one speaker and exhibited a generalization effect to stimuli produced by a different talker. However, sleep only benefited the learning of the untrained talker. Earle and Myers (2015b) also reported an interesting interference effect in sleep-mediated learning consolidation. After exposure to Hindi sounds, American-English participants encountered native sounds similar or dissimilar to those newly learned from Hindi. Sleep-mediated consolidation was significantly disrupted when participants heard similar sounds from their native language but remained intact when different native sounds were heard. In short, these studies suggest that sleep consolidation is selective and typically beneficial “in storing salient acoustic-phonetic features abstracted away from the training experience, and in protecting listeners from interference coming from the speech communication outside the laboratory” (Xie, et al., 2018).
A recent study systematically analyzed the time course of lexically driven recalibration with two segmental contrasts in American English, that is, S versus TH and S versus SH (Zheng & Samuel, 2023). Participants were initially exposed to ambiguous sounds in wordlists while performing a lexical decision task and then completed a phoneme categorization task after a specified delay. The findings of this study extended Eisner and McQueen’s (2006) work, revealing that the recalibration did not significantly degrade in the 24-hour delayed test and remained reliable even after a 1-week interval. However, consistent with previous findings (Liu & Jaeger, 2018), this study confirmed a substantial loss of recalibration during the test phase regardless of the delay interval, suggesting little resistance to the test-retuning effect from sleep-induced consolidation.
1.3 The current study: The flexibility and stability of lexical tone perceptual learning
Despite our increasing understanding of the flexibility of speech perception and the stability of perceptual recalibration, particularly concerning the effects of sleep consolidation, it is important to note that most existing studies have drawn evidence from segmental aspects of speech. We know that sound systems across world languages are not just defined by consonants and vowels; suprasegmental cues such as fundamental frequency (F0), duration, and intensity are equally significant. Here, we focus on the F0 information in speech signals, which is perceived as pitch patterns.
Pitch is a fundamental cue to distinguish word meanings in more than half of the world’s languages, referred to as lexical tone languages (Yip, 2002). In addition, in virtually all languages, pitch is the primary cue for conveying intonation which signals meaning contrasts at the level of utterances (Gussenhoven, 2004). Beyond its linguistic functions, pitch also conveys a wealth of information about the talker, including gender, dialect background, emotional state, and attitude (e.g., see the article by Y. Chen, 2022 for a review of the multiplexing of pitch variation for different functions in Standard Chinese). Importantly, the temporal domain of segmental variation differs from pitch variation; while the former is typically localized within a short segment of the acoustic signal, the latter spans a much longer duration, often encompassing the entire syllable, if not even longer stretches.
There is some (but limited) evidence that the adaption effect of suprasegmental pitch variation is comparable to that of consonants and vowels: exposure to pitch variation patterns can effectively bias the listeners in perceiving pitch accent for contrastive focus (Kurumada et al., 2018), intonation contours of statement versus question (Xie et al., 2021), lexical stress (Bosker, 2022; Severijnen et al., 2023), and lexical tones (Mitterer et al., 2011). These studies suggest that the perceptual system is likely to remain flexible similarly for segmental and suprasegmental prosodic features in terms of probabilistic learning (Xie et al., 2021).
To our knowledge, no study has examined the stability of the perceptual learning of suprasegmental pitch variations for lexical tone. Given the pervasive nature of pitch cues in speech, the multifunctional role of pitch variation in conveying both linguistic and paralinguistic speaker information, alongside the temporal domain of pitch cues, it is crucial to investigate whether recalibration in suprasegmental pitch features is effectively consolidated and can persist for long. The current study aimed to fill this knowledge gap with perceptual learning of lexical tones in Standard Chinese.
In Standard Chinese, there are four different lexical tones: high-level tone (tone1), mid-rising tone (tone2), low(-falling-rising) tone (tone3), and high-falling tone (tone4). Although cues such as duration, intensity, and phonation can be informative, the critical cue for tonal identification on a single syllable is F0 (Whalen & Xu, 1992), mainly in terms of pitch height and pitch change direction (Gandour, 1984). As mentioned earlier, lexical tone in Standard Chinese plays a crucial role in distinguishing monosyllabic morphemes and words, with a considerable portion of monosyllables in the lexicon being differentiated solely by tone. While there are different proposals on the exact timing of tonal information utilization in spoken word recognition compared to segmental information (Cutler & Chen, 1997; Sereno & Lee, 2015; Ye & Connine, 1999 and references therein), recent eye-tracking studies, offering better insights into the temporal dynamics of speech perception, indicate that tones are processed incrementally, just like segments (Malins & Joanisse, 2010; Yang & Chen, 2022). Notably, Liu and Samuel (2007) highlighted a shift in the relative importance of segmental and tonal cues during spoken word processing, with evidence suggesting that larger (bisyllabic) tonal context and noisy listening conditions may enhance the use of lexical tones for lexical decision, echoing the proposals of Ye and Connine (1999) and Mattys et al. (2005).
Worth noting is that in connected speech, the F0 patterns of different lexical tones are highly variable across utterances and speakers. Excised out of context, tones may become much less distinct, as contours are relatively flattened and vary depending on the tones of adjacent syllables, as well as utterance-level intonational contours (Chen & Gussenhoven, 2008; A. Li, 2015; Xu, 1994, 1997; see also reviews by Y. Chen, 2012, 2022). Take tone1 (high-level) and tone2 (mid-rising), for example. When a mid-rising and high-level tone are preceded by a lexical tone that ends with a low pitch level (e.g., tone3), both are realized with a rising F0 contour. (Notably, the production of lexical tones manifests talker-specific variations and can vary significantly due to the speaker’s dialectal background; e.g., see the studies by J. Chen, 2004; Xiang, 2010; Y. Zhang & Zhu, 2013). Predominant results have been found regarding the influence of phonetic context on Mandarin lexical tone perception, although most of the studies are not easily comparable due to their differences in tonal stimuli and experimental designs (e.g., Huang & Holt, 2009; Leather, 1983; T. Lin & Wang, 1985; Moore & Jongman, 1997 on tone categorization; but see the work by Fox & Qi, 1990 for a marginal effect). From the perspective of speech recalibration, Mitterer et al. (2011), however, reported a lack of significant tonal context effect on the generalization of the tonal perceptual-learning effect.
The goal of this project was to delve deeper into the phenomena of tonal recalibration (or perceptual learning) in context and explore the potential consolidation of this learning effect over time. One straightforward and plausible hypothesis (hereafter referred to as the Consolidation Hypothesis) is that lexical tone perceptual learning follows a general memory consolidation process. Once the learning occurs, the adapted tone categories are stored and can be reactivated later when cued. Setting aside the specifics of the actual mechanism, the expected outcome of this hypothesis for tonal perceptual learning over time is predicted to align with findings on the stability of perceptual learning of segmental features over extended periods. However, it would not be entirely surprising if lexical tone recalibration shows quick decay rather than consolidation after a certain time interval (hereafter referred to as the Dynamic Hypothesis). This could be, in part, attributed to the dynamic normalization process of F0 information in a local context to estimate the acoustic distributions of tones systematically and constantly for perception (e.g., Sjerps et al., 2018). In addition, given the multiplexing of pitch in speech for both linguistic and paralinguistic information (Chen, 2022), tonal perception for word identification is likely to demand a much more dynamic adjustment to various factors that affect the pitch pattern of a lexical tone. Again, setting aside the specifics of the actual mechanism, a possible outcome of the Dynamic Hypothesis is that when an incoming tonal variant represented in working memory is regarded as having no immediate future utility, it would lead to its weakened representation and non-automatic storage in long-term memory. Consequently, we will not observe a consolidation effect after a certain time interval from the exposure.
More specifically, this project aimed to replicate the findings of Mitterer et al. (2011) with a 12-hour delay between the exposure phase (where listeners are provided with a context that may lead to a recalibration of their lexical tonal categories) and test phase (in which the potential effect of such recalibration is investigated). Furthermore, we aimed to gather empirical evidence to ascertain whether we observe long-term retention and sleep-mediated consolidation of lexical tone perceptual learning. Briefly speaking, during the exposure phase, participants in one group were trained to interpret an ambiguous F0 contour as tone 1 (high-level tone) within the semantic context of a bisyllabic (lexical) collocation presented in a framed sentence. Another group, however, was given a semantic context to interpret the ambiguous contour as tone2 (mid-rising tone). Subsequently, a post-training test was conducted to verify the learning effect on ambiguous tone contours within a neutral semantic context. Participants engaged in a forced-choice task of spoken word recognition to assess the learning effect induced during the exposure phase. As depicted in Figure 1, two experiments were carried out. Within each experiment, participants underwent the exposure and test sessions at varying times of the day (i.e., morning vs. evening), with differing intervals between them (i.e., immediate vs. with a 12-hour delay).
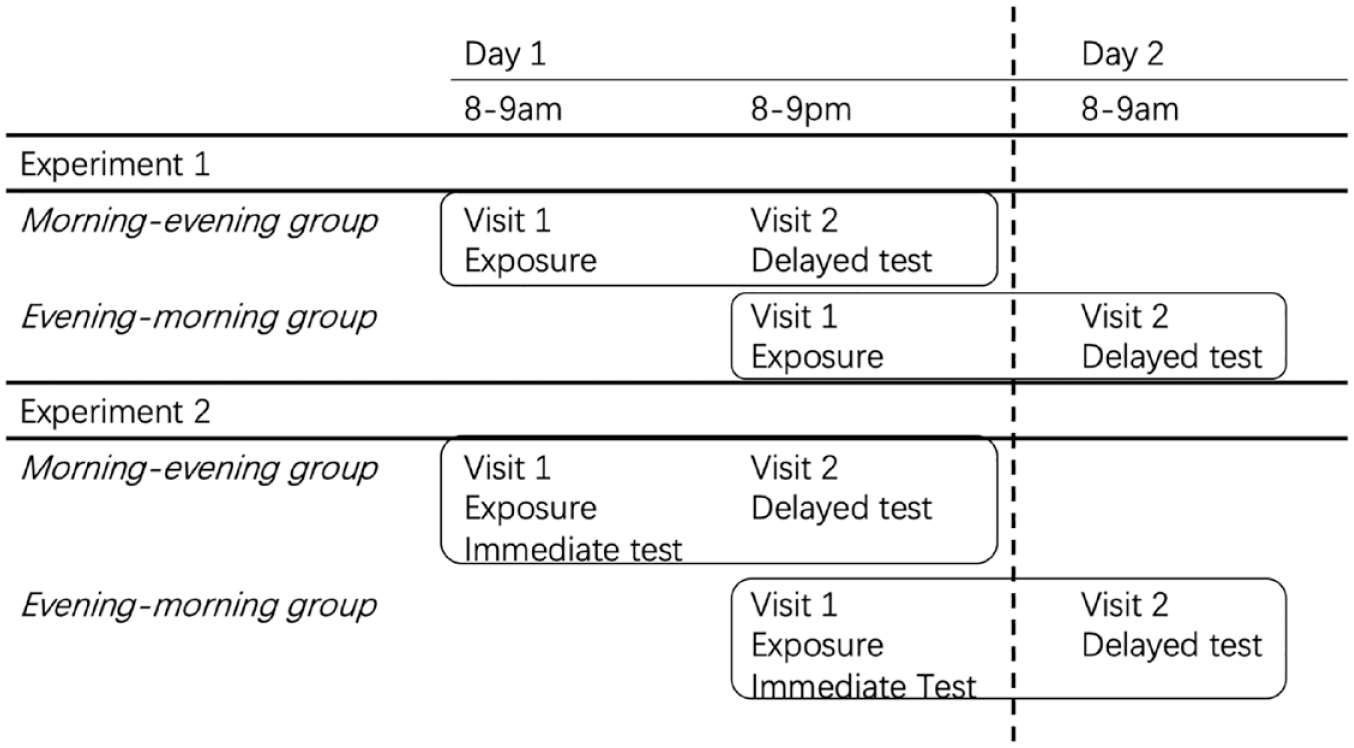
The time schedule of the procedure.
In Experiment 1, participants were assigned to two groups, with the first lab visit scheduled in either the morning or evening. Their second lab visit occurred in the evening of the same day or the following morning. The exposure to ambiguous tone learning took place during the first lab visit. During this visit, participants were divided into two sub-groups. One sub-group heard the ambiguous contours in a T1-biasing context, and the other heard them in a T2-biasing context. They all took the same forced-choice task (i.e., the test) during the second visit, 12 hours later. Aiming to find the stability of perceptual learning, we focused on two key effects: (a) the learning effect (after a delay), assessing whether exposure resulted in a difference in tone judgments in the delayed test after a 12-hour interval; and (b) the generalization effect (after a delay), assessing whether despite the delay, the learning effect was comparable across test words encountered during the exposure (i.e., previously encountered) and those encountered for the first time during the test (i.e., newly encountered).
In Experiment 2, we required participants to take part in two forced-choice tasks, one right after the exposure (comparable to that in Mitterer et al., 2011) and the other after 12 hours (comparable to Experiment 1). By conducting both an immediate test and a delayed test, we aimed to investigate further (a) the potential influence of the circadian rythm in perceptual learning, to ascertain the extent to which perceptual learning was influenced by the time of learning; (b) the consolidation effect, assessing whether the recalibration effect observed in the immediate test persisted, strengthened, or diminished over a 12-hour interval as reflected in the delayed test; and (c) the sleep effect, exploring whether a nighttime interval yielded a more robust consolidation effect compared to a daytime interval.
Note that in the task instructions given to the participants, it was explicitly stated that the second test, scheduled 12 hours later, would be a separate experiment irrelevant to their first visit. Participants were instructed not to discuss or recall the first visit during the interval outside the lab. This measure was intended to mitigate the possible impact of conscious recall upon the relatively implicit consolidation process under investigation.
According to the Consolidation Hypothesis, it is anticipated that the lexical tone recalibration effect will stabilize over time. Consequently, in Experiment 1, we hypothesized both learning and generalization effects. In Experiment 2, we hypothesized a consolidation effect in the delayed test, particularly following a night of sleep. In contrast, following the Dynamic Hypothesis, we anticipated the tonal recalibration effect to diminish in the delayed tests of Experiments 1 and 2 after a 12-hour interval. Furthermore, we expected a possible absence of consolidation effect even after a night of sleep in Experiment 2, as sleep might not yield additional gain or reduced decay of the learning effect, due to the possible selective nature of sleep-dependent consolidation.
2 Experiment 1
The primary goal of Experiment 1 was to examine whether the perceptual-learning effect of lexical tone categories, as reported by Mitterer et al. (2011), could still be observed after a 12-hour interval, during which participants engaged in their usual daytime activities or slept during the night. If the tone recalibration effect mirrors the perceptual learning observed in segments (e.g., Eisner & McQueen, 2006), we anticipated observing a learning effect even with a delay. We adhered to the design of Mitterer et al. (2011), so, in the following sections, we only provide the essential information from this study for readers’ convenience.
2.1 Methods
2.1.1 Participants
Eighty-one native speakers of Standard Chinese (aged between 19 and 28 years, 75 females and 6 males) participated in this experiment for a monetary reward. They all reported being born and grown up in Beijing. Participants gave their written informed consent before the experiment, which conformed to the tenets of the Declaration of Helsinki. The data of five participants were excluded due to the malfunction of the devices. Therefore, data from the remaining 76 participants (37 for the morning-evening group and 39 for the evening-morning group) were included for further analysis.
2.1.2 Stimuli
Identical stimuli from Mitterer et al. (2011) were used in this study. Forty segmental syllables (e.g., qin) were included. Half were used only in the exposure phase, and in the test phase, all were included. All segmental syllables could be pronounced with either the high-level tone (i.e., tone1) or the mid-rising tone (i.e., tone2) in Standard Chinese, each constituting a different morpheme. Either of the paired syllables could be preceded by another syllable with T3 to form a two-character word/phrase collocation. Because T3 ends with a low F0 in connected speech, the F0 contours of its following T1 and T2 would surface with a rising contour (albeit with different rising trajectories; Chen & Gussenhoven, 2008). In such tonal contexts (i.e., T3 T1 and T3 T2), the lexical tone of the target syllables, when synthesized to have a non-prototypical F0 contour ambiguous between T1 and T2 (hereafter Tx), could be semantically biased easily and interpreted as either T1 or T2. For example, qin (Tx) with mu (T3) can be potentially interpreted as the lexical item muqin (tone3–tone1) meaning “mother” while qin (Tx) with gu (T3) as guqin (tone3–tone2) meaning “ancient zithern.” In other words, qin (Tx), with an ambiguous F0 contour (between tone1 and tone2), is likely interpreted as tone1 in the context of muqin and tone2 in the context of guqin.
All auditory stimuli were recorded by a male native speaker of Standard Chinese who did not participate in the experiment. For all pairs of target syllables, new F0 contours were generated in PRAAT (Boersma, 2001) by interpolating (in 10 equal steps on a semitone scale) between the tone1 and tone2 F0 contours. This gave rise to a total of 11 contours (100% tone1–0% tone2, 90% tone1–10% tone2, . . ., 0% tone1–100% tone2). The segmental syllables with an original tone1 contour were used as the base for resynthesis with the Pitch-Synchronous-Overlap-and-Add (PSOLA) method. For each tone1–tone2 minimal pair, the original contours were replaced with the 11 newly generated f0 contours.
In the exposure phase, 20 segmental syllables were used. Each target syllable utilized a single interval F0 contour (hereafter referred to as the ambiguous F0 tone contour; Tx), selected from one of the interval contours created for each tone1–tone2 pair. The ambiguous tone contour for each pair varied in terms of the specific interval contour chosen. For example, some items featured a contour with 50% T1 and 50% T2 along the continuum, while others included a contour with 60% T1 and 40% T2 along the continuum or one with 40% T1 and 60% T2. The selection of stimuli followed that of Mitterer et al. (2011), where a pre-test determined the interval contour for each tone1–tone2 pair, which was most significantly influenced by the semantic context and, therefore, interpreted as most ambiguous. In addition to the 40 critical syllables, 160 fillers with bisyllabic collocations with only T3 and T4 were included, together with the same frame sentence as the targets.
In the exposure, the chosen ambiguous contours (Tx) were played, with a preceding T3 syllable as a bisyllabic lexical/phrasal collocation, in the carrier sentence “he wrote the word/phrase . . .” (他写X这个词 ta1 xie3. . .zhe4 ge4 ci2). Note that each ambiguous contour could be combined with two different preceding T3 syllables, and the specific T3Tx collocation could bias the perception of Tx as more likely to be T1 or more likely to be T2.
For the test, all 40 segmental syllables were included. Furthermore, we included five steps of the interval contours along the T1 T2 continuum (i.e., Step 1 with 80% T1 and 20% T2, Step 2 with 60% T1 and 40% T2, Step 3 with 50% T1 and 50% T2; Step 4 with 40% T1 and 60% T2; and Step 5 with 20% T1 and 80% T2). The presentation of the target syllables with their interval contours was embedded in the carrier sentence “he said the character . . . (他说. . .这个字 ta1 shuo1. . .zhe4 ge4 zi4)”), with the target syllable preceded by a high-level tone (tone1), providing a different phonetic context from the Exposure phase. In total, 200 sentences were played auditorily during the test phase.
For the lexical decision task, Chinese characters were visually presented on the screen. Each character was approximately 50 × 50 pixels wide and presented on a white rectangle of 189 × 113 pixels.
2.1.3 Apparatus and procedures
The presentation of stimuli was controlled by MATLAB using Psychtoolbox (Brainard & Vision, 1997). As mentioned earlier, participants came to the laboratory twice for two different tasks. They were randomly assigned to one of the two groups differing in experiment time (Figure 1): one group paid the first visit in the morning at around 8–9 am, and the second visit in the evening around 8–9 pm (i.e., the morning-evening group); the other group first came at around 8–9 pm, and then returned 12 hours later the following morning (i.e., the evening-morning group).
In the exposure phase during their first visit, participants completed 200 trials (40 critical trials and 160 fillers). They monitored sentences to check for a visually presented target character, clicking the mouse if the sentence contained the target. Each sentence started 600 ms after the visual target appeared, and participants had up to 1.5 seconds after the sentence ended to respond. After a reaction or a time-out, there was a 400-ms interval before the next trial started.
The 40 critical trials involved semantically biased segmental syllables that could be interpreted either as a T1 or T2. Half of the participants heard the original tone2 over the segmental syllables, while the tone1 collocations they heard featured an ambiguous F0 contour, creating a T1 bias. The other half heard the original tone1 over the segmental syllables, while the tone2 collocations they heard featured an ambiguous contour, creating T2 bias.
All critical trials included the visual target and required a click. In addition, there were 50 filler trials with a clear tone1 (for the sub-group with T2-bias syllables) or a clear tone2 (for the sub-group with ambiguous T1-bias syllables). For these 50 filler trials, five were accompanied by a correct character. The remaining 110 trials had either tone3 or tone4 words, with half having a correct character.
The 200 trials of the exposure phase were presented in a different random order for each participant, with no critical target items in the first 10 trials. After the exposure phase, participants were instructed to participate in a different experiment 12 hours later and not to recall the experiment they had taken or talk about it to others.
During the second visit, the participants performed the post-training forced-choice spoken word recognition task. They heard monosyllables which have the tone1-to-tone2 F0 continuum steps. These syllables were embedded in the semantically neutral sentence frame (“he said the character. . . 他说. . .这个字 ta1 shuo1. . .zhe4 ge4 zi4”). On each trial, two characters were presented on the screen, representing the tone1 and tone2 interpretations of the target monosyllable for that trial. The frame sentence started 0.2 seconds after the onset of the two visual characters. Participants had to move the mouse to one of the characters and click on it within 5 seconds from the start of the sentence. Clicks on other parts of the screen were ignored. During the test phase, each of the 40 target syllables was presented five times, each time with one of the five F0 continuum steps used for testing. A different random order was used for each participant.
2.1.4 Design and analysis
We were interested in whether, after a 12-hour delay, we could observe that participants exposed to T1-biasing ambiguous F0 contours would be more likely to respond to the interval contours in the test phase as tone1 while those to T2-biasing ambiguous contours were more likely to response as tone2, as the findings reported in Mitterer et al. (2011) which had an immediate test to investigate perceptual recalibration. The dependent variable was the binary response to T1 or T2. Trials that were not responded to with these two options were excluded from further analysis. Two between-subject independent variables were included: Time (morning-evening or evening-morning) and Exposure (ambiguous F0 contour presented in the T1-biasing or T2-biasing context in the exposure phase). In addition, there were three within-subject variables: Continuum Steps of the T1-to- T2 F0 continuum (5 levels); Old versus New critical segmental syllables, with Old items included in both the exposure and test phases (i.e., previously encountered) while New items only present in the test phase (i.e., newly encountered); and Trial Sequence, referring to the trial’s position in the presentation sequence.
Estimates were from generalized linear mixed models (GLMM) via the lmer program of the lme4 package. The fixed factors included in the models were (a) Continuum Steps, (b) Time, (c) Exposure, (d) Old/New, and (e) Trial Sequence. The variable Continuum Steps was treated as an additive to the other factors (since its effect is reportedly non-linear) and centered to [−2, 2] (0 representing the level of 50% tone1–50% tone2) as a numerical variable. The variable Trial Sequence was also numerical and centered. Sum coding was used for the other factors. With the interactions, there was a total of 16 fixed terms. We started with a model with a fully parameterized variance-covariance matrix for subjects and items and then a random-intercept-and-slope model, which, due to convergence issues, was simplified to a random-intercept-only model, capturing the variability in the baseline tone judgment for subjects and items.
Responses during the exposure phase were also analyzed with GLMM. The dependent variable was the accuracy of each trial, which was binary data; the predictors were Time, Exposure, and their interaction, and the random factor were subject and item.
2.2 Results
2.2.1 Lexical identification in the exposure phase
All participants correctly responded to over 90% of the critical trials in the exposure phase (M = 97%, SD = 2.8%), showing that they followed the training carefully. As shown in Table 1, participants were able to identify the spoken syllable/character according to the semantic context equally accurately and efficiently, regardless of (a) the tone exposure type (i.e., ambiguous F0 contour for tone1 or tone2) and (b) the time of day when they attended the experiment. This observation was confirmed by statistical analysis (no significant result; z < 1.2).
Experiment 1: Accuracy of Lexical Identification in the Exposure Phase, with Subject Means and Standard Deviations Reported.

Evening-morning: participants learned in the evening time and performed the test the following morning. Morning-evening: participants learned in the morning and performed the test in the evening. T1-bias: participants learned ambiguous tones aurally presented in a tone1 context. T2-bias: participants learned ambiguous tones aurally presented in tone2 context.
2.2.2 Tone judgment in the test phase with a 12-hour delay
Results of the final model are provided in the Appendix. As shown in Figure 2, the more the F0 contour was tone2-like, the more likely the syllable was identified to have tone2. This is supported by the significant effect of Continuum Steps (b = 1.469, SE = .025, z = 59.176, p < .001). The effect of Trial Sequence was also significant (b = .394, SE = .084, z = 4.688, p < .001) as tone2 responses generally increased over testing time. Trial Sequence interacted significantly with Exposure (b = .719, SE = .168, z = 4.279, p < .001), Time (b = −.503, SE = .168, z = −3.001, p = .003), and Old/new (p = .026), respectively, although these factors’ main effects were not significant (ps > .18). To further examine how Trial Sequence modulated the effect of Exposure, we looked at the exposure effects in the first and second halves of the trials, but neither reached a significant level (ps > .1). No exposure effect was observed for either learned or newly encountered words (ps > .20), although the interaction between Exposure and Old/new was significant (b = −.233, SE = .096, z = −2.434, p = .015).
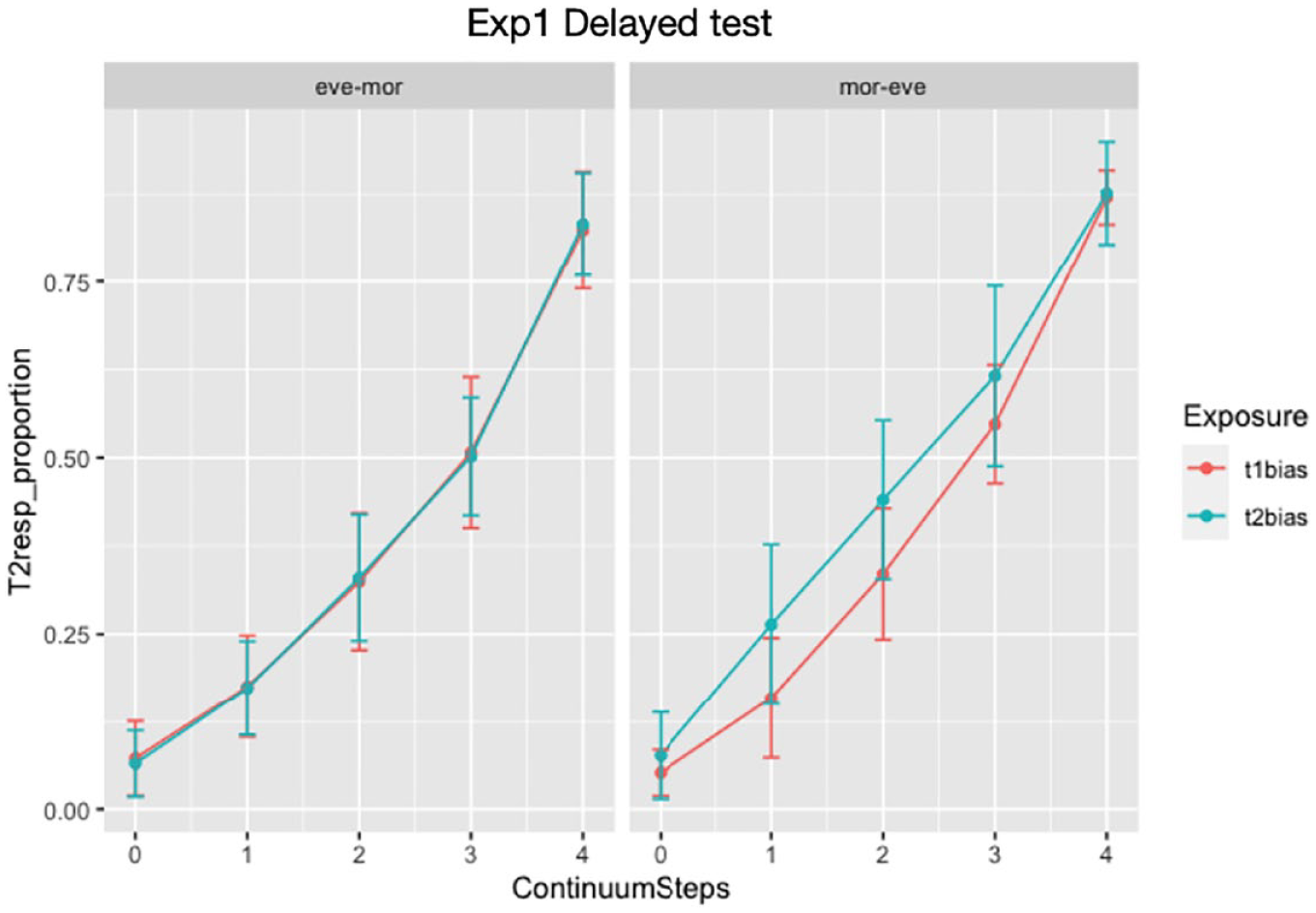
The proportion of tone2 responses by participants attending at different times in Experiment 1. The y-axis represents the mean proportion of tone 2 responses, and the error bars reflect 95% confidence intervals.
Interestingly, there was no significant interaction between Exposure and Time (b = −.440, SE = .570, z = −.772, p = .44). Provided that the exposure-induced lexical tone recalibration occurred similarly to the findings reported by Mitterer et al. (2011) and was consolidated more effectively by night sleep rather than wakefulness, we would anticipate a more salient exposure effect in the evening-morning group than in the morning-evening group. However, this expectation was not upheld due to the absence of exposure effect in both groups.
2.3 Discussion
Experiment 1 aimed to examine the stability of the lexical tone recalibration effect induced by exposure to semantically biased yet phonetically ambiguous F0 contours. Although a significant learning effect was reported when tested right after the training (Mitterer et al., 2011), in the delayed test conducted after a 12-hour interval, we did not observe a clear impact of exposure, regardless of whether the tone-carrying syllable had been encountered during the exposure (i.e., Old) or was presented only during the test phase (i.e., New). Moreover, as illustrated in Figure 2, the evening-morning group showed no trace of learning, as participants with different exposures showed similar performance patterns in the post-training test. In comparison, there seemed to be slight retention of tone recalibration among participants from the morning-evening group, although this difference did not reach statistical significance. While it was possible that the exposure effect was modulated by factors such as the trial position in the sequence or whether the word had been learned, further analyses did not reveal any significant exposure effects in the sub-datasets. Notably, a subsequent Bayesian analysis indicated that the confidence interval for the Exposure*Trial Sequence interaction just excludes zero, with the effect in the opposite direction from what was previously observed (see further discussion in Experiment 2). In sum, the perceptual learning of ambiguous tones, which was reported by Mitterer et al. (2011) as an immediate effect, was not observed after a 12-hour interval.
These results contrast with the prediction of the Consolidation Hypothesis, which posits that the perceptual recalibration effect of tone categories should be stable and long-lasting. However, they are consistent with the Dynamic Hypothesis, which predicts ineffective consolidation for tone recalibration. Before discussing the potential implications of our findings, it is important to note that the null effect of exposure in the delayed test could also be the consequence of unsuccessful perceptual learning during the exposure phase for the participants of Experiment 1, in contrast to those in the study by Mitterer et al. (2011). While individual variations in perceptual learning are not frequently reported, they are far from unlikely. In addition, the result could have also been confounded by the circadian rhythm effects, as different times of learning may lead to asymmetrical recalibration effects (e.g., Eisner & McQueen, 2006; Fenn et al., 2003).
To investigate these possibilities further, Experiment 2 aimed to replicate the findings of Mitterer et al. (2011) and those from Experiment 1 by adding another post-training test immediately after the exposure phase. This setup would enable us to compare the tone recalibration effect immediately after training (i.e., immediate test) versus after a 12-hour interval (i.e., delayed test). Significant learning differences between the immediate and delayed tests would illuminate whether the tone recalibration effect is consolidated or degraded in the delayed test phase. In addition, questionnaires were implemented in Experiment 2 to gather participants’ self-reports of their arousal state during the experiment (Honma et al., 2015), aiming to take into consideration potential individual differences in perceptual learning.
3 Experiment 2
Experiment 2 differed from Experiment 1 by adding a post-training test immediately after the exposure phase. The predictions for this experiment were as follows. First, we expected a possible circadian effect on learning in this perceptual-learning paradigm. Young adults are typically at the peak of their circadian cycle (Colquhoun, 1981; Monk et al., 1983), but so far, no stable circadian effect has been reported on the perceptual learning of speech. Second, we predicted a robust immediate effect, consistent with the findings reported by Mitterer et al. (2011), but a significantly attenuated delayed learning effect for both the daytime and overnight intervals, as observed in Experiment 1.
3.1 Methods
3.1.1 Participants
Eighty-five native speakers of Standard Chinese (aged between 18 and 33 years, 62 females and 23 males) participated in this experiment. They were all born and grew up in Beijing. Participants gave their written informed consent prior to the experiment, which conformed to the tenets of the Declaration of Helsinki. Eight participants’ data were excluded due to the malfunction of the devices. In total, data from 77 participants (39 for the morning-evening group and 38 for the evening-morning group) were included for further analysis.
3.1.2 Materials and procedures
The materials for the exposure and test phases were identical to those in Experiment 1. The procedures were also similar to those in Experiment 1, except that a forced-choice spoken word recognition test was added immediately following the exposure phase. Thus, the entire procedure of Experiment 2 included an exposure phase, an immediate test (Test1) during the first visit, and a delayed test 12 hours later (Test2) during the second visit (see Figure 1).
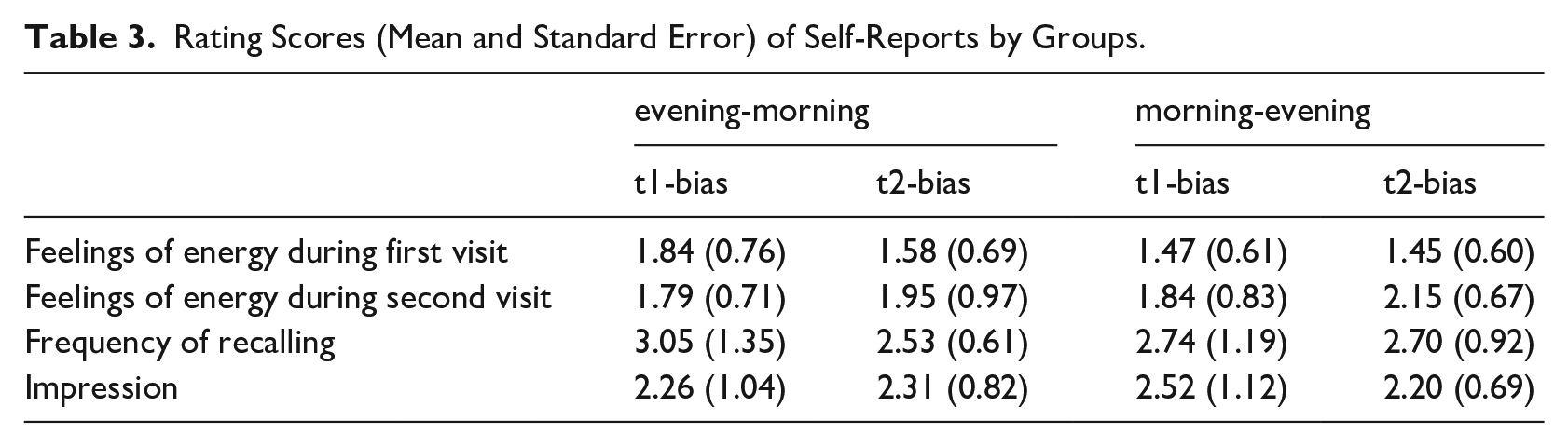
At the end of the first visit, after completing Test1, participants were instructed not to intentionally recall the first visit and were informed that they would return for a different experiment 12 hours later. During the second visit, participants were given the same items as in Test1, but with a different trial sequence. After completing the second test, participants rated the following on respective scales: (a) their feeling of energy level during the first visit (1 = energetic, 4 = fatigued), (b) their feeling of energy level during the second visit (1 = energetic, 4 = fatigued), (c) the frequency of recalling the first visit during the 12-hour interval (1 = always, 5 = never), and (d) the strength of their impression of the first visit (1 = very strong, 5 = no impression). The rating scores are summarized in Table 3. Finally, the experimenter explained the relationship between the two visits and answered the participant’s questions if they had any.
3.1.3 Design and analysis
Similar to Experiment 1, tone1/tone2 judgment (based on forced-choice spoken word recognition) was the critical measurement. In addition to the variables in Experiment 1, the round of Test (Test1 vs. Test2) was identified as a key factor. Statistical analyses were conducted similarly to those in Experiment 1. The regressions included (a) Continuum Steps and (b) Old/New, Time, Exposure, Trial Sequence, Test, and their full interactions as predictors.
3.2 Results
3.2.1 Lexical identification in the exposure phase
All but two participants performed well in the exposure phase with an accuracy rate of over 90% (M = 96%, SD = 1.6%). The other two (with an accuracy of 82.5% and 87.5%, respectively) reported that they missed some trials because the pronunciations sounded odd although they were able to identify the spoken words. As shown in Table 2, there was no significant distinction between participants of different conditions,|ts| < 1.3.
Experiment 2: Accuracy of Lexical Identification in the Exposure Phase with Subject Means and Standard Deviations Reported.

Evening-morning: participants learned in the evening time and performed the test the following morning. Morning-evening: participants learned in the morning and performed the test in the evening. T1-bias: participants learned ambiguous tones aurally presented in a tone1 context. T2-bias: participants learned ambiguous tones aurally presented in a tone2 context.
3.2.2 Self-report questionnaires
All evening-morning group participants reported having had a regular night’s sleep during the interval, with an average of 7.76 hours for tone1-biased participants and 7.37 hours for tone2-biased participants. For the morning-evening group, 30% (i.e., six participants) of the tone1-biased and 20% participants (four participants) of the tone2-biased reported that they had a nap during the daytime, on average of 55 minutes and 111 minutes, respectively.
We analyzed participants’ ratings on the four self-reported questions using linear regressions. Again, no group differences reached significance, all|ts| < 1.7 (see Table 3), suggesting little difference between the two groups. In other words, these conscious-level factors were unlikely to be the main resources of any potential differences in the perceptual learning of the two groups during or after the exposure phase, if there were any.
Rating Scores (Mean and Standard Error) of Self-Reports by Groups.
3.2.3 Tone judgment in the test phase
Results of the final model are provided in the Appendix. Similar to the findings of Experiment 1, a significant main effect was observed for Continuum Steps (b = 1.724, SE = .020, z = 84.532, p < .001), with increasing tone2 responses when the continuum steps had a larger proportion of tone2 properties (Figure 3). The main effect Trial Sequence was also significant (b = .462, SE = .062, z = 7.399, p < .001), showing more tone2 responses over the testing time. In addition, there was a significant difference between the immediate and delayed tests (i.e., Test), b = .399, SE = .036, z = 11.109, p < .001, reflecting an overall tendency of the participants to choose more tone2 choices in Test2 than in Test1.
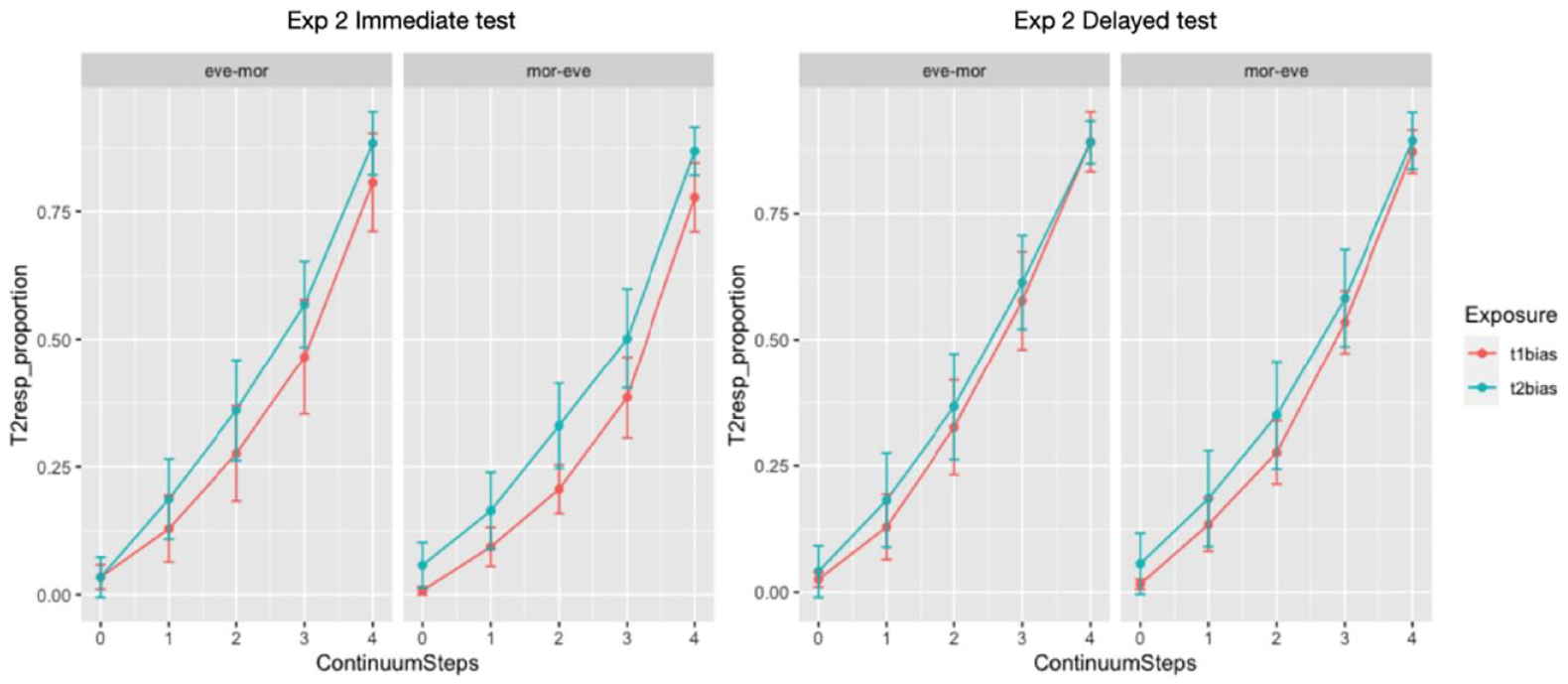
The proportion of tone2 responses by participants attending at different time periods in Experiment 2.
Moreover, Figure 3 and Figure A2 (in Appendix) show the pattern of exposure effect, which is observed to be larger in the immediate test than in the delayed test, and in the earlier trials than in the latter trials. The statistical results indicate that, with the inclusion of data from both the immediate and the delayed tests, the main effect of Exposure became significant, b = .566, SE = .263, z = 2.151, p = .031. This suggests that the training of perceiving ambiguous F0 contours as belonging to one particular tone category in the exposure phase was generally effective in inducing changes in lexical tone categorization, replicating the findings in Mitterer et al. (2011). However, the interpretation of the effect of Exposure must consider its significant interaction with the factor Test (b = −.397, SE = .071, z = −5.551, p < .001), which suggests differences in the exposure effects between the immediate and delayed tests. The two-way interaction Exposure*Trial Sequence and the three-way interaction Exposure*Test*Trial Sequence were also significant (b = −1.252, SE = .125, z = −9.991, p < .001, and b = 1.199, SE = .248, z = 4.823, p < .001, respectively), suggest the impact of trial sequence on participants’ tone judgments. In addition, Time and Test significantly interacted (b = −.204, SE = .071, z = −2.852, p = .004).
The following section will focus on specific issues of our interest and provide relevant statistical results and interpretations. Additional analyses using sub-datasets were conducted as hypothesis-driven tests.
3.2.3.1 Circadian effect on learning
Using data from the immediate test (Test1), we examined whether the exposure effect differed in time right after training. Continuum Steps, Time, Exposure, Old/new and Trial Sequence were included as fixed factors, and subject and syllable as random factors in the model. Results showed the main effects of Exposure, Trial Sequence, and Continuum Steps, as well as a significant interaction between Exposure and Trial Sequence (ps < .005). Crucially, no significant effect of Time was detected, p > .25. These results do not support the hypothesis that circadian rhythm significantly influenced lexical tone recalibration.
3.2.3.2 Consolidation effect on recalibration
As mentioned earlier, there was a significant two-way interaction of Exposure by Test. Separate models evaluated the exposure effect in the two tests, respectively, revealing that the exposure effect was significant in the immediate test (p < .005), but not in the delayed test (p > .20). Thus, one possible interpretation for the lack of exposure effect in Experiment 1 is that the training effect degraded after a 12-hour interval, rather than enhanced or maintained, in the delayed test.
3.2.3.3 Sleep effect
The sleep effect refers to the difference in the change (decay) over time between a daytime interval and an overnight interval. If waking time had a detrimental effect on learning whereas sleep facilitated consolidation, a significant interaction of Time*Test*Exposure would be expected. However, no such pattern was observed. Instead, we observed a significant interaction of Time by Test, suggesting both the morning-evening and the evening-morning groups showed that, on average, they gave more tone1 responses (i.e., fewer tone2 responses) in the immediate test than in the delayed test (ps < .001). One possible interpretation is that the recalibration decay that occurred between the immediate test and the delayed test was more pronounced in the evening-morning group than in the morning-evening group. This further challenges the idea that sleep consolidates the perceptual learning of lexical tone.
3.3 Discussion
The results of Experiment 2 confirmed that tone category-biased training induced an immediate effect on the perception of F0 continuum steps, suggesting that listeners recalibrated their perceptual tone categories to adapt to the immediately preceding auditory context. The lack of any effect on the variable Old/new suggests that such recalibration generalized to newly encountered words. Our results replicate the exposure effect reported by Mitterer et al. (2011). However, unlike Mitterer et al., who observed slightly stronger learning for words heard during exposure compared to newly encountered words during the test phrase, this effect was not replicated in the current study. Note that the effect was small in Mitterer et al. (2011), which led the authors to interpret the findings as evidence for perceptual learning at a pre-lexical level (to explain the fact that learning was observed for new words) with additional episodic storage of phonetic details at the lexical level (as proposed by Goldinger, 1998). The current data support the notion that learning can occur at a pre-lexical level (McQueen et al., 2006; Sjerps & McQueen, 2010) but raise questions about the robustness of episodic storage of phonetic details at the lexical level.
With regard to the stability of learning, the delayed test in Experiment 2 showed a decay rather than maintenance of the tone recalibration effect for both the morning-evening and evening-morning groups. Moreover, no evidence for sleep-dependent benefit was found in our data. We suggest that the decay of the tone recalibration effect over time may be interpreted as due to the selective nature of our speech perceptual system, which we will discuss in more detail in the General Discussion section.
Consistent with Experiment 1, the variable Trial Sequence emerged as a strong predictor of the overall response patterns in all tests, contributing to both a main effect and significant interactions with Exposure and Test. The main effect observed in both experiments indicates that participants were increasingly likely to respond with tone2 as the task progressed, confirming findings reported by Mitterer et al. (2011). One plausible explanation is the asymmetry of the categorization norm of the tone1–tone2 continuum, where tone2 has a broader distribution in terms of its tonal space along the T1 T2 continuum manipulated in the experiment, compared to tone1 (Rong et al., 2015). It is worth noting that Mitterer et al. (2011) used two semantically neutral sentence frames (“he said the character. . . 他说. . .这个字 ta1 shuo1. . .zhe4 ge4 zi4” and “he wrote the character. . . 他写. . .这个字 ta1 write3. . .zhe4 ge4 zi4”). In our study, we only utilized the frame “he said the character. . . ta1 shuo1. . .zhe4 ge4 zi4,” where the preceding lexical tone remained a high-level T1. Listeners can be very sensitive to the phonetic details in tonal coarticulation for online tone processing (Hasanah et al., 2024). Our choice of the preceding tone in the frame sentence may have further limited the tonal space listeners expected for T1 in our experimental conditions.
Zheng and Samuel (2023) reported that as participants progressed through their test in which an even distribution of tokens across the continuum was provided, they might “unlearn” the exposure-induced recalibration effect and return to the norm. However, our findings are more nuanced. Specifically, the coefficient for the Exposure*Trial Sequence interaction in Experiment 2 was negative, contrasting with the effect observed in Experiment 1 but consistent with previous findings. In the Appendix, Figure A1 and Figure A2 illustrate how the two exposure types influenced tone judgments during the immediate and delayed tests as the task progressed.
In Experiment 1 (Figure A1), the two lines representing the proportion of tone2 responses for each exposure type barely differed in the initial trials, yet a more pronounced divergence was observed in the second half for the morning-evening group. This trend suggests an increase in of the learning effect during the test phase, even though the exposure effect in both halves failed to reach statistical significance. In contrast, in Experiment 2 (Figure A2), both the immediate and the delayed tests showed the opposite pattern, resembling the diminishing recalibration effect as the task progressed (Liu & Jeager, 2018; Mitterer et al., 2011; Zheng & Samuel, 2023).
It should be noted that there is a difference between the categorization tasks used in this study and those in previous recalibration research. In studies focusing on segmental features, participants are typically presented with phonemes in posttests without lexical context (e.g., sounds between /asi/-/a∫i/ in Kraljic & Samuel, 2005; sounds between /θae/-/sae/ in Zheng & Samuel, 2020). In the current study, participants judged tone by distinguishing between pairs of meaningful monosyllabic words with identical segmental syllables (e.g., “亲 vs. 琴” /qin1/-/qin2/). Such a lexical categorization task requires a larger number of trials to ensure adequate coverage of a wide range of syllables, thereby globally controlling the segmental context biases. Although the trials were randomized for each participant, the requirement for sequence balance was not fully achieved. An inspection of the overall data for each test revealed that some syllables appeared more frequently in one half of the test than in the other. Therefore, the observed trial sequence effect in this study should be interpreted with caution, as it may have been influenced by potential segmental context biases.
Furthermore, our results ruled out the possibility that unstable recalibration of tone categories could be attributed to circadian rhythm, which was a confounding factor for the delayed consolidation process after learning in Test 1 (Honma et al., 2015). In our study, the main effect of Time was not salient, indicating that the time of learning was independent of the decay. Both the morning-learning and evening-learning groups showed comparable decay tendencies. In addition, we also monitored learners’ physical/mental states through self-reports, and observed little difference in participants’ energetic states at different times of the day. Thus, neither circadian rhythms nor mental states were dominant factors contributing to the observed deterioration in learning effects.
4 Bayesian analyses of the different test phases
To further substantiate our findings, we performed a Bayesian mixed-model analysis in R (v4.2.2) using the arms function from the brm package (Wang et al., 2020). Since the large number of fixed factors was problematic for the Bayesian analysis (with no convergence after 4,000 runs), we simplified the model for all three test phases (Experiment 1 delayed, Experiment 2 immediate, Experiment 2 delayed) as follows: Continuum was included as a single fixed factor without interaction with other factors. This implication was justified because an interaction would imply that the identification functions vary in steepness across continuum steps, and no hypothesis in this study predicts such effects. For Exposure, Time, Trial Sequence, and Old/New word, we modeled the main effects as well as interactions. These included Exposure with two variables related to timing, that is, Time and Trial Sequence (including the three-way interaction) and the interaction of Exposure with Old/New word. The latter was particularly relevant for addressing the theoretical question of the locus of learning (lexical vs. pre-lexical), a central focus of Mitterer et al. (2011). As in the frequentist analyses reported above, all predictors were sum-contrast coded, so that regression weights for simple effects reflected the main effects of fixed factors and that interactions and simple effects remained independent. The models used uninformed prior centered around zero for all effects. For the intercept, the prior had a standard deviation of two logit units; for fixed effects, a standard deviation of 1.5 (so that effects of larger than 3 logit units are unlikely) and a standard deviation of 1 for random slopes. The model output indicated that the models converged (Rhat = 1). Table 4 indicates the 95% credible intervals for all effects in all three analyses.
Results of Bayesian Analyses.
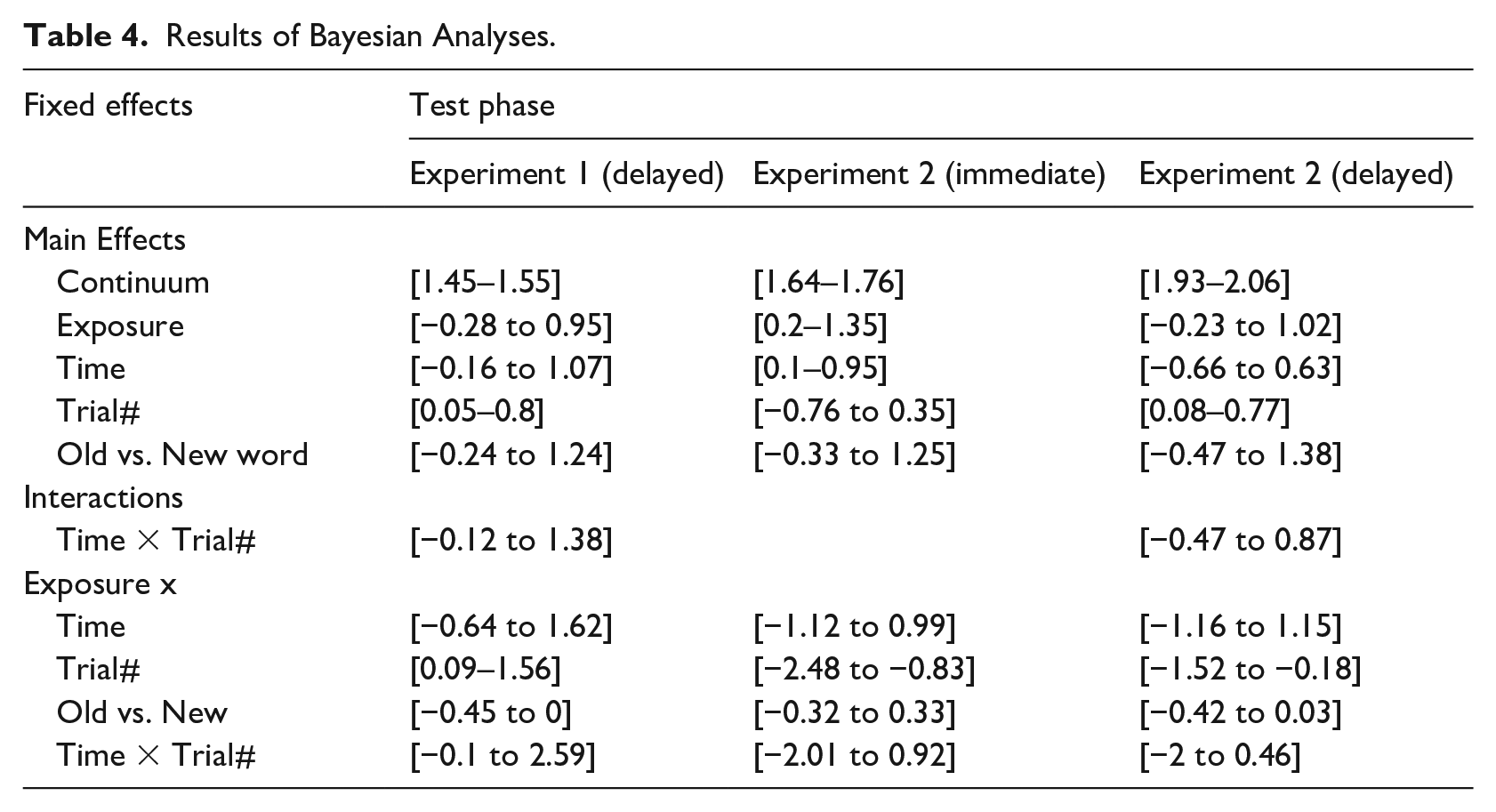
The results largely aligned with the frequentist analysis presented above and provided some additional insights. For both delayed tests, the exposure effect had a credible interval that included zero and included values close to a full logit unit, which suggests a shift of more than 20% in response rates around the midpoint of the continuum, a result often observed in perceptual-learning studies. Moreover, we see that the interaction of Exposure with Trial Sequence had a credible interval that excluded zero, but the effects were not consistent across the three tests.
5 General discussion
With two experiments, we investigated the flexibility of the speech perceptual system and the stability of generalized phonological recalibration with lexical tones in Standard Chinese. Native speakers demonstrated rapid adaptations to ambiguous F0 contours based on semantic context, as shown in the immediate test in Experiment 2. Such recalibration generalized to newly encountered words, replicating findings from Mitterer et al. (2011). However, unlike Mitterer et al. (2011), we found no significant difference in the learning effect between old stimuli that listeners encountered during the exposure phase and new stimuli that they only encountered during the test phase. If this finding is robust, it suggests that perceptual learning occurs mainly at the pre-lexical level, with little evidence for additional learning at the lexical level via exemplar storage. It is worth noting that no significant differences were observed between the two groups of participants who participated in the study at different times (i.e., morning-evening vs. evening-morning). This leads to the conclusion that the recalibration process is minimally affected by circadian rhythm.
Furthermore, the perceptual recalibration effect observed immediately after exposure degraded over a 12-hour interval, as evidenced by the delayed tests in Experiment 1 and Experiment 2. This decline occurred regardless of whether participants remained (mostly) awake during the day or slept overnight during the interval. Therefore, our study provides novel evidence against the general Consolidation Hypothesis, which posits that sleep facilitates the stabilization and maintenance of learning. In contrast, our results suggest that the recalibration of lexical tone categories, unlike other segmental features, may not be effectively consolidated over time, even after sleep, which typically enhances learning through sleep-induced consolidation. Instead, our results align more closely with the Dynamic Hypothesis, which predicts ineffective consolidation in speech perception. Specifically, the maintenance of perceptual recalibration appears to depend on various factors, including the acoustic characteristics and functional nature of the learned speech features.
When considering the results of our post hoc Bayesian analyses, it is important to note that our findings should not be interpreted as indicating that the recalibration of lexical tone categories is completely forgotten (as the frequentist analyses might imply). In both delayed tests, the credible intervals show compatibility with a significant learning effect of nearly a full logit unit, an effect size comparable to other recalibration effects. In Experiment 2, recalibration was still detectable at the start of the test phase, as indicated by the interaction of Exposure and Trial Sequence, which had a credible interval excluding zero. While our results suggest that the recalibration of lexical tone categories is more prone to decay over time—contrary to Eisner and McQueen (2006), who observed undiminished delayed effects of exposure after 12 hours— our results indicate that the the recalibration of lexical tones may not be entirely gone after this interval. Given that the interaction of Exposure and Trial Sequence shows different patterns in the two delayed tests of Experiment 1 and Experiment 2, further research is needed to replicate the findings.
There is compelling evidence from the literature against automatic perceptual learning following exposure to ambiguous stimuli. For instance, studies on the perceptual learning of the s-sh (/s/-/∫/) continuum have shown no recalibration effects when the target variation was preceded by exposure to normal speech or paired with incidental behaviors that could temporarily or contextually change the way of speaking (Kraljic et al., 2008; Kraljic & Samuel, 2011; Kraljic et al., 2008). Liu and Jaeger (2018) argue that adaptation to atypical pronunciations depends on whether listeners infer the sounds to be characteristic or incidental, rather than ignoring causally ambiguous evidence. Qin et al. (2021) investigated the perceptual learning of level-tone contrasts by second-language learners with experience of a contour-tone system and found weak evidence of learning. In addition, factors such as variance distribution and cross-modal attention mediate adaptation effects (Sumner, 2011; Zäske et al., 2013). These findings suggest that the formation of representations of phonetic feature variations depends not only on the perceptual acoustic-phonetic context but also on the evaluation of the situational context in which the variation is experienced. A related point has been made by Babel et al. (2021), who proposed an evaluation stage during perceptual learning where listeners assess whether to update a representation.
Our results further suggest that, even when temporarily recalibrated, adjusted representations can be re-tuned in subsequent phases, regardless of whether these phases occur during the day or overnight with sleep, the latter of which is commonly believed to enhance learning. During this extended phase, which is considerably longer than the exposure phase, the impact of exposure may decay. However, a non-trivial amount of learning obtained during exposure may persist (though unstably), as brought out by the Bayesian results. These findings lend further support to the idea that adjustments in lexical tone category representations are better explained as part of a dynamic process rather than as memory traces consolidated after exposure.
What factors contribute to the rapid decay of lexical tone recalibration during the day and the absence of learning consolidation during sleep? In the introduction, we posited the Dynamic Hypothesis, based on the distinct acoustic-phonetic and functional properties of Mandarin tones compared to segmental features. Here, we delve further into the potential cognitive mechanisms underlying this phenomenon, which are partly related to these properties of pitch variations in Mandarin Chinese.
One plausible explanation is that while the system may initiate general consolidation for lexical tone recalibration, this process could be disrupted by interference. Previous research has highlighted unspecified interference as a factor in studies that show degraded perceptual-learning effects over waking periods, with some restoration after sleep (Fenn et al., 2013; Gottselig et al., 2004; Walker et al., 2003). Earle and Myers (2015b) specifically tested the role of acoustic similarity in interfering with the sleep consolidation of non-native segmental adaptation. They reported that a mere 15 minutes of passive listening to native sounds acoustically similar to the learning target after training could alter the enhancement typically induced by subsequent sleep. This suggests that exposure to stimuli with overlapping acoustic-phonetic features after training may destabilize the activation pathways for trained stimuli, acting as a source of interference.
In our study, we did not observe a consolidated learning effect after a 12-hour interval, including sleep. Instead, our pattern reflects a complete lack of sleep-dependent consolidation, consistent with the results of Earle and Myers’ (2015b). We speculate that potential interference, although not explicitly manipulated in our experiment but likely encountered by participants outside the lab, may arise from similar F0 features that are pervasive in Mandarin speech signals.
Specifically, pitch in Mandarin Chinese serves a multiplexing function, playing a crucial role not only in distinguishing lexical meanings but also in encoding a range of linguistic and paralinguistic information at the utterance level (Chen, 2022). While our target stimuli relied heavily on F0 variations between the high-level tone (tone1) and the mid-rising tone (tone2), a rising F0 contour in Standard Chinese is also closely associated with question intonation. This intonation is typically signaled with a raised F0 level or a steeper F0 rising slope at the final position of an utterance (M. Lin, 2004; Liu et al., 2021). It is plausible that our participants were exposed to substantial instances of question intonation outside the testing sessions. Such exposure may have interfered with the stabilization and potential sleep-induced consolidation of lexical tone recalibration observed in the immediate test.
Another possible explanation may be found in the dynamic nature of lexical tone perception compared to segments. First, we know that the normalization process of F0 information to estimate the acoustic distribution and categorize lexical tones is influenced by various factors. For instance, studies have shown neural distinctions of how contextual F0 and first formant (F1) cues affect the perception of identical syllables, suggesting different processes for normalizing of lexical tones and vowels (K. Zhang et al., 2021). When it comes to vowel quality transitions (e.g., from /u/ to /o/), perception of the target is primarily influenced by F1 cues in the preceding speech context (Sjerps et al., 2018), as indicated by early event-related potential (ERP) effects (Sjerps et al., 2019; K. Zhang et al., 2021). In contrast, lexical tone perception and categorization seem to be a different process. Sjerps et al. (2018) showed, with data from Cantonese, another Sinitic variety with lexical tone, the significance of F0 cues not only in the immediately preceding but also in the subsequent tonal contexts. This influence is evident in a later and more sustained ERP effect (K. Zhang et al., 2021). Studies have also shown that Mandarin listeners are sensitive to both carryover (preceding tone influence) and anticipatory (following tone influence) tonal coarticulation cues, utilizing them for online speech processing (Hasanah et al., 2023, 2024). Due to the reliance on contextual F0 cues for perceptual normalization and processing, lexical tone variants may be represented with more contextual details. Consequently, the learning and retention of pitch variations for lexical tones are more susceptible to being disrupted by changes in the context in which speakers experience the tones.
Furthermore, native listeners’ reliance on lexical tone cues for Mandarin speech recognition can be context-dependent. Evidence shows that tonal information becomes significantly more important when words are presented in context than in isolation, and when interpretive conditions are altered, for example, in the presence of noise (Liu & Samuel, 2007; Ye & Connine, 1999). In our study, participants might have adopted a tone-focused strategy during the exposure task, prioritizing tonal information as crucial for word recognition and retaining it in working memory. This strategy allowed for the rapid reactivation of these representations during the immediate test. However, once outside the lab, this strategy could dynamically adjust, potentially shifting to assign less weight to tonal cues in speech recognition. Consequently, the recalibration effect of tonal categories becomes less stable due to decreased attention to lexical tone. Future research is needed to verify this possibility.
Results of our study also shed light on the mechanism of sleep-dependent memory consolidation, highlighting its selectivity through evidence from speech perceptual learning. Early research on motor-skill training memories, which are classified as “non-hippocampus-dependent” (Klinzing et al., 2019), similar to acoustic memories, has implied sleep consolidation is conditional upon motivational factors and potential future utility (Diekelmann et al., 2009; van Dongen et al., 2012). Recent neural-biological advancements have provided deeper insights into how the brain consolidates some information into long-term storage while forgetting others (Andrillon et al., 2017; Sakai, 2023). This “housekeeping” mechanism clears out less-important information, ensuring the brain works efficiently.
It is worth noting that in the literature on perceptual learning and consolidation, little attention has been given to initial participant instructions regarding the relationship between multiple lab visits. Without clear guidelines, participants may expect similar tasks upon return and consequently (and frequently) recall previous encounters between visits. Such explicit retrieval could lead to additional memory consolidation. Sleep enhances explicitly encoded memories more than implicitly encoded ones (Diekelmann et al., 2009). Therefore, participants’ assumptions about the task could amplify the sleep-induced consolidation of the learning benefits. To control this, we explicitly told our participants that their two visits were unrelated. While we do not wish to assert that sleep consolidation in perceptual learning is specific to experiment conditions or task instructions, this possibility warrants further investigation.
To sum up, the current study provides evidence for a new case of unstable phonetic recalibration: the non-consolidated perceptual recalibration of lexical tone, a feature within the suprasegmental domain. Across two experiments, native speakers of Standard Chinese were exposed to ambiguous lexical tones in semantically biased contexts. The results consistently showed that the exposure-induced tone recalibration decayed significantly after 12 hours, regardless of the timing of exposure, though it did not completely vanish. Surprisingly, participants trained at night showed no benefits of sleep-induced consolidation in stabilizing these adjustments. The rapid recalibration of lexical tone observed immediately after exposure reaffirms the flexibility of the speech perceptual system. The decay of this perceptual adjustment highlights the selectivity of the speech perceptual system in adaptation and consolidation, likely influenced by the unique acoustic properties and functional roles of pitch variations in Mandarin, which serve as the primary cues for lexical tones. Such properties, in turn, make tonal processing more dynamic and context or task-dependent. Overall, our findings support the view that sleep-induced memory consolidation is selective, optimizing the utility of memories for only robust and functional variations.
Supplemental Material
sj-docx-1-las-10.1177_00238309241291536 – Supplemental material for Flexibility and Stability in Lexical Tone Recalibration: Evidence from Tone Perceptual Learning
Supplemental material, sj-docx-1-las-10.1177_00238309241291536 for Flexibility and Stability in Lexical Tone Recalibration: Evidence from Tone Perceptual Learning by Yingyi Luo, Holger Mitterer, Xiaolin Zhou and Yiya Chen in Language and Speech
Footnotes
Acknowledgements
The authors thank Yunyan Duan for assistance with data collection and Ludovica Onofri for helpful discussions and editing. We gratefully acknowledge the financial support of the Key Laboratory of Linguistics, Chinese Academy of Social Sciences (2024SYZH001), and the Netherlands Organization for Scientific Research (NWO-VI.C.181.040).
Author contributions
All authors contributed to the study’s conception and design. Yingyi Luo performed data collection. Yingyi Luo and Holger Mitterer conducted data analysis and collaborative discussions with Yiya Chen. Yingyi Luo and Yiya Chen wrote the first draft of the manuscript. All authors commented on previous versions of the manuscript. All authors read and approved the final manuscript. Data and analysis code will be available at ![]() upon the submission’s publication and can be provided upon request before then.
upon the submission’s publication and can be provided upon request before then.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Key Laboratory of Linguistics, Chinese Academy of Social Sciences (2024SYZH001), and the Netherlands Organization for Scientific Research (NWO-VI.C.181.040).
Supplemental material
Supplemental material for this article is available online
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.