
Abstract
In many English varieties, /l/ is produced differently in onsets and codas. Compared with “light” syllable-initial realizations, “dark” syllable-final variants involve reduced tongue tip-alveolar ridge contact and a raised/retracted tongue dorsum. We investigate whether native French and Spanish speakers whose L1 lacks such positionally conditioned variation can acquire English-/l/ allophony, testing the hypotheses that (1) the allophonic pattern will be acquired by both groups but (2) learners will differ from native speakers in their phonetic implementation, particularly in codas; and (3) French-speaking learners will outperform their Spanish-speaking counterparts. The production of syllable-initial and -final /l/ (singletons and clusters) in words read in isolation and a carrier sentence by 4 French- and 3 Spanish-speaking learners as well as three native English speakers was analyzed via electropalatography and acoustic analysis. While some learners produced distinct onset and coda variants and all learners had moved away to some extent from their L1 production, they differed from the native speakers in certain ways. Moreover, between- and within-group variability was observed including greater target-like anterior and posterior contact reduction in codas in the L1 French versus L1 Spanish group and generally higher F2 values in both learner groups compared with their native speaker peers. A comparison of the learners’ L1 and L2 production revealed L1-based patterns of positional reduction of the tongue tip and dorsum gestures. We conclude by addressing the contributions of EPG to our understanding of L2 speech and highlight avenues for future research including the study of both linguistic and speaker variables.
1 Introduction
Within any language, the articulation of a given consonant varies, conditioned by factors including position in the syllable and flanking vowels and consonants. Such differences in phonetic realization vary in degree and, when sufficiently large, result in perceptible allophonic variation. One of the most studied of these processes in experimental phonetic research is English-/l/ allophony (e.g., Bladon & Al-Bamerni, 1976; Lehman & Swartz, 2000; Narayanan et al., 1997; Turton, 2017). In many varieties including Canadian English that is the target language here, syllable-initial laterals are characterized as “lighter”, produced with firm tongue tip-alveolar ridge contact and little-to-no tongue dorsum raising. In contrast, “dark” syllable-final laterals are realized with reduced tongue tip contact and vowel-like tongue dorsum raising or retraction (e.g., lap [læp], pal [pʰæɫ]). In other languages like French and Spanish, the first languages (L1s) of the participants in the current study, no such allophonic variation in laterals exists. Consequently, learners of these latter languages must acquire positionally conditioned variants when acquiring English.
To date, relatively little experimental phonetic work has investigated this particular learning challenge. The few studies that exist (Barlow, 2014; King & Ferragne, 2015, 2017; Nagamine, 2022) have shown that, while L2 learners may move toward English-like allophonic variation, they differ from native speakers in various ways. Moreover, such studies have focused first and foremost on the place of articulation/degree of anteriority. At present, we know little to nothing about learners’ acquisition of other L1-L2 differences in the articulation of /l/. The present study seeks to fill this lacuna via a study of L1 French and Spanish speakers’ acquisition of English-/l/ allophony measured both via electropalatography (EPG) and acoustically, the former allowing for the study of learners’ acquisition of L1-L2 differences in tongue contact. Seven L2 learners (4 of L1 French and 3 of L1 Spanish) and three native English speakers read words involving initial and final laterals (e.g.,
In the remainder of this article, we first provide a detailed overview of the production of the English, French, and Spanish laterals including the degree of allophonic variation attested (§2.1) followed by a review of experimental phonetic studies having examined the L2 acquisition of English-/l/ allophonic variation (§2.2). We then turn to the present study (§3) that tests three hypotheses related to the degree of target-likeness of learners’ mastery of English-/l/ allophony including potential differences in both onset versus codas and tongue tip contact versus tongue dorsum retraction as potentially shaped by individuals’ L1. This is followed by a review of our methodology including a detailed overview of the use of EPG for the study of consonant articulation. Results are then presented, beginning with an EPG analysis of degree of tongue contact (§4.1), followed by an acoustic analysis to study learners’ acquisition of lingual positional reduction (§4.2). We conclude with an evaluation of the three hypotheses and discussion of the ways in which the present study as well as EPG research more generally contribute to the study of L2 speech.
2 Background
2.1 English, French, and Spanish laterals including allophonic variation
English, French, and Spanish all have a lateral approximant /l/ that can appear in both simple and complex onsets (English: lake, replace; French: lapin ‘rabbit,’ conflict ‘conflict’; Spanish: lana ‘wool,’ blanco ‘white,’ respectively) and codas (English: tell, wild; French: final ‘final,’ film ‘film’; Spanish: sal ‘salt,’ caldo ‘broth’). While the distribution of the lateral is similar in the three languages, 1 there are differences in phonetic realization. The one that is the primary focus of the present study involves positionally conditioned differences in place of articulation and degree of constriction. The English lateral, in many dialects including the Canadian variety that is the target here, has two principal allophonic variants. 2 The first is a clear(er), lightly velarized [l] in syllable onsets. Articulatory studies reveal this pre-vocalic variant to be realized with firm tongue tip-alveolar (Giles & Moll, 1975; Proctor et al., 2019), lateral contact (Lehman & Swartz, 2000; Narayanan et al., 1997), and a dorsal gesture (King & Ferragne, 2015). The second variant encountered in codas is a dark or strongly velarized variant [ɫ] (e.g., peel [pʰiɫ], help [hɛɫp]). Syllable finally, /l/ is produced with relatively reduced/no (Chaves, 2019; Giles & Moll, 1975; Lehman & Swartz, 2000; Proctor et al., 2019; Turton, 2017) and/or retracted tongue tip contact, a relatively retracted and lowered tongue dorsum (Giles & Moll, 1975; Proctor et al., 2019; Sproat & Fujimura, 1993; Turton, 2017), and little to no lateral contact (Lehman & Swartz, 2000). With some speakers or realizations, this lenition may lead to vocalization (Sproat & Fujimura, 1993; Turton, 2017). The two English lateral variants also differ in the timing of the tongue tip and dorsum gestures. In (word-initial) onsets, the tongue tip extremum is reached before that of the tongue dorsum, whereas syllable finally, the opposite sequencing occurs (e.g., Sproat & Fujimura, 1993 for American English; Gick et al., 2006 for Western Canadian English). Note that differing degrees of inter-speaker variation have been observed for many if not most/all of the onset-coda patterns described here (see, e.g., Narayanan et al., 1997 for variation in the degree of apicality/laminality; Proctor et al., 2019 for differences in degree of tongue tip closure; Gick et al., 2006 for differences in tongue tip/dorsum extremum sequencing) that may be sociolinguistically conditioned (e.g., King & Ferragne, 2015 for the effects of variety; De Decker & Mackenzie, 2017 for the effects of variety, sex, and age).
Both flanking vowels and consonants may shape English-/l/ articulation. As concerns the former, Bladon and Al-Bamerni’s (1976) acoustic study of Standard British/RP English found the nuclear vowel in both /lV/ and /Vl/ sequences to affect anteriority, although with a greater effect on syllable-initial laterals. Proctor et al. (2019) also found an onset-coda asymmetry in the effect of the tautosyllabic vowel, however, in their real-time MRI study, it was coda and not onset /l/ that was more affected in terms of the degree of middorsal displacement. As concerns the effects of particular vowels, these authors also found a lesser degree of tongue-back retraction in back-vowel contexts. Chaves’ (2019) EPG study of American English found vowels to influence the degree of anterior contact in syllable-final but not -initial /l/ and that the effect differed by task, namely, greater anterior activation following low back /ɑ/ in citation forms versus after high front /i/ in sentences. As concerns degree of contact, Lehman and Swartz (2000) found greater linguopalatal contact in pre-vocalic /l/, with this tendency being more substantial in the context of high versus low vowels; no similar effect of vowels was found for syllable-final laterals. Finally, alongside coarticulation, partial devoicing of /l/ occurs following voiceless obstruents, both within and across syllable boundaries (e.g., play [pʰl̥e], fresh lemon [fɹ̥ɛʃl̥ɛmən]; Bladon & Al-Bamerni, 1976).
The French and Spanish /l/s do not participate in syllable position-conditioned allophonic variation; indeed, both descriptive characterizations and acoustic studies report a universally “light” realization of both languages’ lateral (e.g., French: O’Shaughnessy, 1982; Tranel, 1987; Spanish: Navarro Tomás, 1972; Recasens, 2012). However, our previous EPG investigation of /l/ produced by four French and seven Spanish speakers (Colantoni et al., 2023b) revealed some positional reduction in codas compared with onsets: weaker tongue tip and tongue body side contact for two Quebec French speakers, and weaker tongue body contact for all Spanish speakers. As in English, the lateral’s articulation is influenced by flanking vowels and, to a lesser extent for French, consonants. French /l/ is produced with greater anteriority before a high front vowel or next to denti-alveolar /t d n/ (Dart, 1998; O’Shaughnessy, 1982; Recasens, 2012; Rochette, 1973). Spanish /l/ fully assimilates to a following consonant resulting in gemination in Caribbean dialects (e.g., caldo [ka
Articulatory differences between light and dark realizations are reflected in the acoustics, particularly in F2 values that are lower for darker realizations. Table 1 provides the mean F1 and F2 values for word-initial and -final /l/ in the context of /i/ and /a/ reported in Recasens (2012) for American English as well as European French and Spanish.
Mean F1 and F2 Values for American English, European French, and Peninsular Spanish /l/ Produced by Male Speakers (Recasens, 2012).
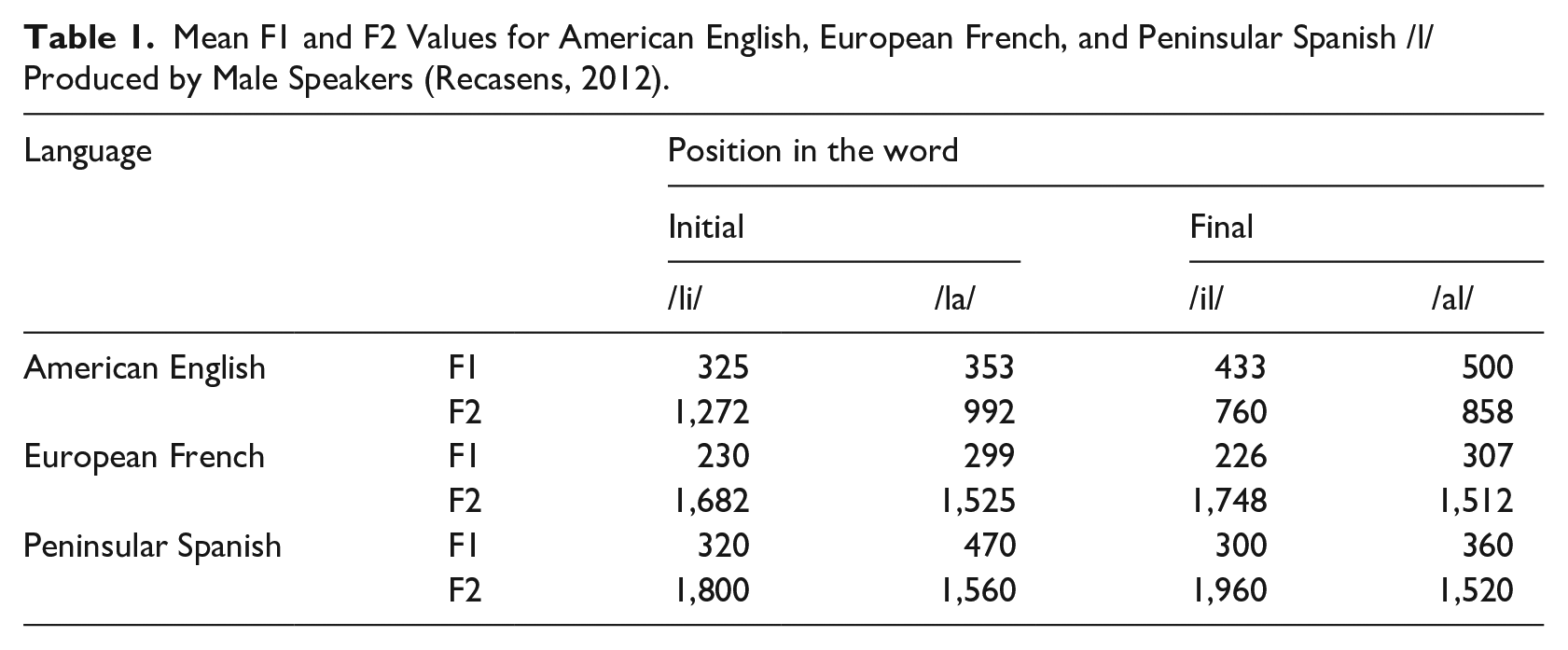
The allophonic variation present in English /l/ is evident in the context of front /i/ where F1 is higher and F2 is lower in codas (word-initial: F1 325 Hz, F2 1272 Hz; word-final: F1 433 Hz, F2 760 Hz). In both French and Spanish, in contrast, word-initial and -final F2 values are relatively similar (with /i/: 1682 Hz vs. 1748 Hz and 1800 Hz vs. 1960 Hz, respectively), and there are hardly any differences in F1. The acoustic values in Table 1 also demonstrate the effects of flanking vowels. In English, the positional differences between word-initial and -final /l/ are greater with /i/ than with /a/. In French and Spanish, where both word-initial and -final realizations are relatively light, /l/ is nonetheless more fronted with /i/ (word-initial: French F2 1682 Hz vs. 1525 Hz, Spanish F2 1800 Hz vs. 1560 Hz; word-final: French F2 1748 Hz vs. 1512 Hz, Spanish F2 1960 Hz vs. 1520 Hz).
In summary, English, French, and Spanish /l/ have similar phonotactics but differ in various ways in their phonetic realization and the resulting acoustic (primarily F2) patterns including in the absence of perceptible allophonic variation. Given the existence of a phonemic lateral approximant with similar phonotactic distribution in all three languages, the acquisition of English /l/ by L1 French and Spanish speakers primarily involves acquiring positionally conditioned differences in place of articulation and degree of contact conditioned by flanking vowels and consonants. In the following section, we review studies having investigated this particular learning challenge.
2.2 L2 acquisition of English lateral allophonic variation
Compared with the large number of studies on the L2 acquisition of phonemic contrasts including English /l/-/ɹ/ (e.g., Aoyama et al., 2004; Brown, 1998; Ingvalson et al., 2011; Sheldon & Strange, 1992), there is relatively little experimental research on non-native speakers’ production of allophony with the exception of Spanish voiced stop approximantization (e.g., Cabrelli Amaro, 2017; Face & Menke, 2009; Nagle, 2017; Regan, 2022; Shea & Curtin, 2010; Zampini, 1994). Very few phonetic studies have examined L2 learners’ production of English-/l/ onset and coda variants. 3 Barlow’s (2014) acoustic study examined the production of L1 Spanish speakers enrolled as undergraduates in an English-speaking university in California. Her fourteen learners had begun to acquire English on average toward 8 years, had a mean age of twenty years, and reported slightly greater English use at the time of testing. Although these late bilinguals produced statistically significant F2 and F2-F1 differences between English word-initial and -final /l/, the mean values for their onset laterals were higher than those of the monolingual English controls. King and Ferragne (2015) examined ten intermediate proficiency French-speaking learners’ production using ultrasound. Whereas their learners produced a relatively more posterior allophone syllable-finally as measured at the highest point of the tongue, their coda-/l/ was not distinct from the American and British native speaker controls’ light onset-/l/ (i.e., both of the L2 variants were relatively more fronted). In a follow-up study with 14 French-speaking learners of overall similar proficiency designed to test the effects of visual ultrasound training on the production and perception of English /l/ and /ɹ/ (King & Ferragne, 2017), all of the Francophone participants produced onset and coda-/l/ variants similarly before training. 4 However, following training, all seven learners in the experimental group, which received visual ultrasound feedback of their own production as well as a visual-and-auditory native speaker model through pre-recorded videos, and two participants in the native speaker model-only feedback (control) group produced lowered or retracted coda variants characterized by statistically significant lower F2. Finally, Nagamine (2022) conducted an acoustic and ultrasound study of five high-proficiency Japanese-speaking learners’ production of the English lateral alternation in monosyllabic CVC words in which the vowel was either /i/ or /a/ and /l/ appeared in either onset or coda position (e.g., leap, peal; lap, pal). Although it is not possible to determine to what extent the learners’ production was target-like as an L1 English control group was not included for comparison, all learners produced statistically significant higher F2-F1 differences syllable-initially than syllable-finally. For one speaker, this was true in all vowel contexts, whereas for the four other speakers, a reliable contrast was observed only in two of the four contexts with the particular contexts varying among speakers. In contrast to the acoustic analysis, the ultrasound data targeting midsagittal tongue shape revealed almost no articulatory differences between onset and coda-/l/ variants except for one speaker for whom consistent tongue shape differences existed in the anterior-posterior regions.
In summary, although all studies but King and Ferragne (2017) revealed that intermediate and advanced French, Japanese, and Spanish-speaking learners can come to produce distinct onset and coda variants (but not in all vowel contexts in Nagamine, 2022), the particular implementation of the two variants may not be target-like in terms of anteriority (onsets in Barlow, 2014; both onsets and codas in King & Ferragne, 2015) and learners may not use tongue shape to realize the distinction (Nagamine, 2022). Interestingly for our study, previous work focusing on French- (King & Ferragne, 2015, 2017) and Spanish-speaking (Barlow, 2014) learners of English, revealed that speakers of these two Romance languages, which have been described as having similarly articulated laterals, differ in their L2 productions, with French learners approaching the native speaker controls versus Spanish learners differing from the controls, at least in onset position. In the present study, we expand upon our understanding of the L2 acquisition of English lateral allophonic variation by coupling an EPG study of a second, previously unstudied articulatory parameter, degree of contact, with acoustic analysis. More importantly, the use of a similar corpus and technique will, thus, allow us to determine whether learners of similar languages differ in the production of L2 English laterals. Given the importance of EPG to the present research, before presenting the experimental study, we first provide an overview of this articulatory method including the particular contributions that it can make to the study of L2 speech production.
2.3 Electropalatography
EPG is a common method for investigating contact patterns in consonants involving contact with the palate including coronals (Gibbon & Nicolaidis, 1999; Kochetov, 2020). This method registers the contact between the tongue and the roof of the mouth using an artificial palate with built-in electrodes. The most widely used system, WinEPG by Articulate Instruments (Wrench, 2007), employs an acrylic palate with 62 electrodes, custom-made for each participant. As shown in Figure 1 (bottom left panel), the electrodes are organized into eight columns (C1-8) and eight rows (R1-8), ranging from the denti-alveolar (R1) to pre-velar regions (R8). The palate is connected to a scanner unit, a serial port interface (SPI), and a multiplexer (Figure 1, right panel). This allows the system to track the tongue-palate contact (as “on” or “off” for each electrode) dynamically every 10 ms, showing the results live on the computer screen.

An articulate instruments artificial palate and its schematic zoning (left) and a WinEPG system setup (right).
Among lingual consonants, laterals in particular have been studied using EPG in a wide range of languages including Arrernte (Tabain, 2009, 2011; Tabain et al., 2011), Catalan (Recasens, 2012; Recasens & Espinosa, 2005; Recasens et al., 2004), English (Narayanan et al., 1997; Scobbie & Pouplier, 2010), French (Colantoni et al., 2023b; Fougeron, 2001), German (Bombien et al., 2010), Greek (Nicolaidis, 2001), Hindi (Dixit, 2003), Italian (Payne, 2006), Russian (Hacking et al., 2016), and Spanish (Colantoni et al., 2023b; Kochetov & Colantoni, 2011; Ramsammy, 2023). As with other anterior coronals, dental or alveolar lateral /l/ has been found to be typically realized with contact in the first few rows of the palate. Unlike other coronals, however, the posterior side contact for /l/ is often limited given the need to produce lateral airflow. That contact may be absent altogether for laterals that are strongly velarized or vocalized, as is often the case for English /l/ in coda (e.g., Scobbie & Pouplier, 2010). The use of EPG to study positional variation in laterals is particularly revealing, as partial or complete reduction of lingual gestures is notoriously difficult to detect using standard acoustic analysis. Similarly, acoustic examinations of laterals in clusters are not very informative in cases when the /l/-constriction is partly or fully coproduced with (overlapped by) the other consonant’s constriction, and thus acoustically masked or fully hidden. The articulation of the lateral and its relative timing in such cases, however, are fully accessible to EPG analysis, making the method a valuable tool for studying clusters (see e.g., Bombien et al., 2010 on German consonant + /l/ clusters). Other commonly used methods of articulatory analysis are electromagnetic articulometry (EMA) and ultrasound tongue imaging (see Kochetov, 2020 for a review). EMA tracks sensors attached to several fleshpoints on the tongue, the lips, and the jaw of the participant. While it provides researchers with fairly accurate dynamic information concerning fully or partially reduced lingual gestures (e.g., Honorof et al., 2011 on /l/ allophones in American English), the information about lingual constrictions is limited to only a few sensors along (typically) the central line of the tongue. Unlike EMA, ultrasound provides a more complete view of the tongue surface and thus can capture overall shapes corresponding to laterals with secondary articulations (e.g., De Decker & Mackenzie, 2017 on /l/ in Newfoundland English; Lin et al., 2014 on /l/ in American English; Strycharczuk & Scobbie, 2017 on /l/ in Southern British English). However, the tongue tip is not reliably imaged using this method, and the lingual contact with the palate can only be inferred indirectly. This, together with the generally poorer temporal resolution of most ultrasound systems, makes the method less appropriate for studying linguopalatal constrictions. As such, EPG is a particularly useful technique for understanding how laterals are produced by monolingual and bilingual speakers and for uncovering different strategies that learners may use when acquiring L2 allophony. As with any articulatory method, EPG does have its limitations, among which are the lack of information provided about overall tongue shape and contact beyond the palate (e.g., with interdental and post-velar constrictions) as well as the relatively high cost of manufacturing artificial palates (see Kochetov, 2020 for discussion).
3 Present study
The present analysis sought to expand our understanding of the L2 acquisition of English-/l/ allophonic variation, testing the following three hypotheses with learners immersed in and using the target language daily:
The data analyzed here come from a larger study, all of which can be found in the University of Toronto Cross-language Articulatory Database (CLAD; https://clad.chass.utoronto.ca). Ethics approval for this study was received from the University of Toronto Social Sciences, Humanities and Education Research Ethics Board. In what follows, we outline the particulars of the participants, stimuli, and tasks chosen for the current analysis.
3.1 Participants
Data from 10 speakers are analyzed here, including four L1 French, three L1 Spanish, and three native English speakers. 5 Table 2 provides biodemographic information for all individuals:
Participant Profiles.
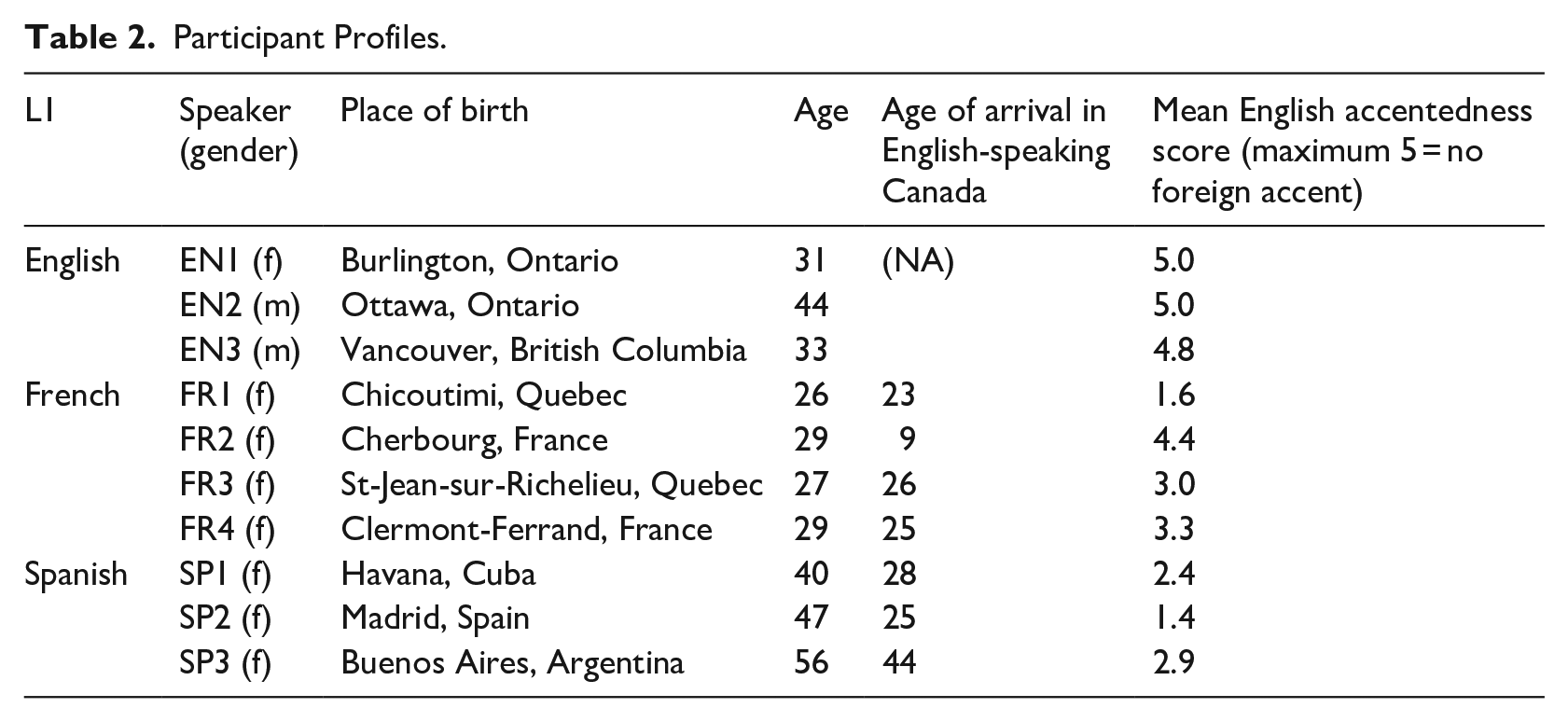
All participants were female except two of the native English speakers (EN2, EN3). The English speakers were essentially monolingual having minimal French proficiency from the relatively little French instruction that they had received in middle and high school. The French-speaking learners were from both Quebec, Canada, and France; the Spanish-speaking learners were from Cuba, Spain, and Argentina. Out of a larger data set of Spanish speakers, we selected one female speaker representative of three different varieties. Since our larger corpus includes only one Peninsular speaker, we chose speakers of the other dialects that matched her in age and L2 English proficiency. It is important to keep in mind that the participant from Cuba, as opposed to the other two participants, may exhibit deletion and/or assimilation of coda laterals to the following consonants. Although the majority of participants had arrived in English-speaking Canada in their 20s, on average, given that the French-speaking participants were considerably younger than their Spanish-speaking counterparts when the data were collected, the latter group had more years of English immersion experience. Perhaps surprisingly then, the Spanish-speaking learners’ accentedness scores, used as a measure of general English-speaking ability, were not higher. These scores were obtained as follows. During the study, each participant read the fable “The Northwind and the Sun” on multiple occasions (see §3.3). All 10 participants’ readings of the passage, approximately 1 minute of speech each, were intermixed with those of 7 other L2 learners of different L1s (three Japanese; two Korean; one each of Punjabi and Russian). The 17 recordings were randomized and presented to 10 native speakers of Canadian English in one of five randomized orders. The judges were asked to rate the accent of each of the speech samples using a five-point scale, ranging from “1—The speaker that you have just heard has a very strong accent and is definitely not a native speaker of English” to “5—The speaker has no foreign accent at all and is without a question a native speaker of English.” Two of the judges’ scores were not used because they failed to assign scores of “5” to two of the three English native speakers. The accentedness scores in Table 2 correspond to the mean of the remaining eight judges. There are arguably three oral proficiency-based subgroups: two low intermediates with mean scores between 1 and 2 “The speaker has a strong accent” (FR1, SP2); four high intermediate learners with mean scores between 2 and 3 “The speaker has a medium accent” (FR3, FR4, SP1, SP3); and one advanced learner with a mean score between 4 “The speaker has a slight accent” and 5 “The speaker has no foreign accent at all and is without a question a native speaker of English” (FR2). Perhaps not surprisingly, this latter learner was the sole individual to have arrived in English-speaking Canada as a child at 9 years of age.
3.2 Stimuli and task
The stimuli analyzed here include onset and coda /l/ produced in both singletons and clusters (Table 3). These included 13 onset singletons (e.g.,
Lateral Containing Stimuli by Position (Onset, Coda) and Structure (Singleton, Cluster).
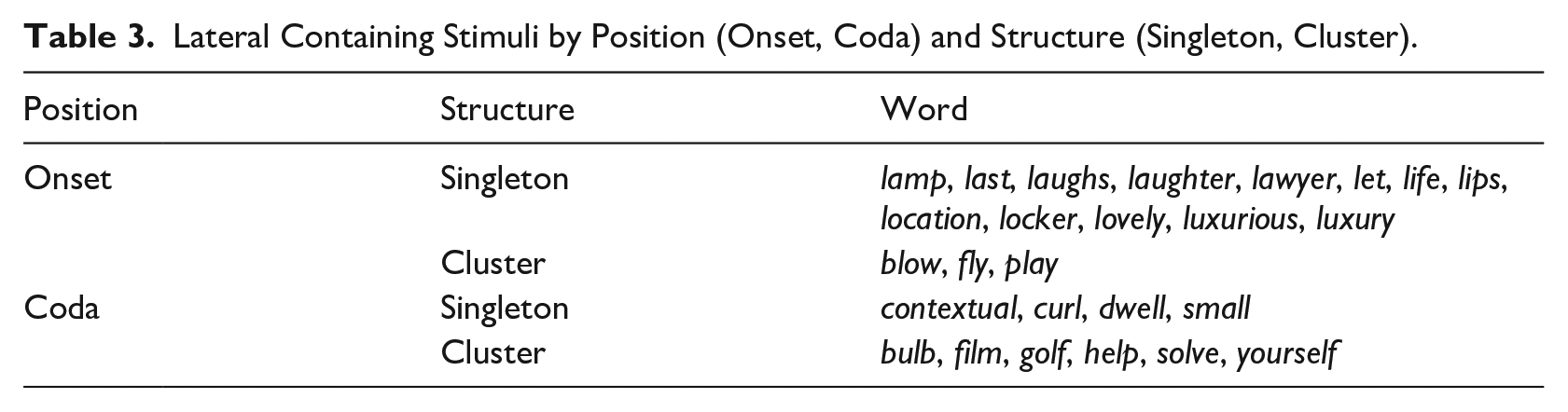
All stimuli were read both in isolation and in the carrier sentence “I say___again,” intermixed with 202 other stimuli. Four repetitions of each utterance were elicited from all speakers, except for EN1, EN3, and SP3, who produced two repetitions each and FR1 who produced five repetitions. With a few omissions due to technical errors, this resulted in a total of 1,871 tokens (or on average 187 tokens per speaker).
3.3 Experimental protocol
As highlighted earlier, the data analyzed here are drawn from the CLAD database, which contains EPG as well as acoustic data for English, French, Japanese, Serbian, and Spanish representing both read (wordlist, carrier phrase, text) and—for French and Spanish—narrative speech. All of the French- and Spanish-speaking participants participated first in data collection in their L1; as such, by the time that the English data collection took place, they were very familiar with speaking with the artificial palate.
Data collection for a given language took place over 5 or 6 sessions for each participant, each session approximately 1.5 hours in length, conducted exclusively in English. The data analyzed here were collected over multiple sessions. At the beginning of each session, the experimenters—one responsible for monitoring the EPG system, the other a native speaker who led participants through the tasks—interacted with them informally for approximately 5 minutes to allow participants to (re)adjust to speaking with the palate. Data collection then began with multiple readings of the “Northwind and the Sun” passage in the language being tested that served as a warm-up followed by one or more of the elicitation tasks. When a pronunciation error was made, participants were invited to repeat the item in question.
3.4 EPG data preparation and analysis
A custom-made palate with 62 electrodes was made for each participant. Those for two of the English speakers (EN2, EN3) and the French participants were of the Articulate model (Wrench, 2007; see Figure 1), whereas those for EN1 and the Spanish participants were of the older Reading-style. Although the former palate can have somewhat better coverage of dental and velar places, both devices are similar in measuring contact differences within places (Kochetov et al., 2017; Tabain, 2011). Both artificial palates have the same grid of 62 electrodes as described earlier in Figure 1. The first four rows correspond to the denti-alveolar and alveolar regions where /l/ is typically produced (Gibbon & Nicolaidis, 1999). The recordings were made using the WinEPG system (Wrench et al., 2002) at a sampling rate of 100 Hz (i.e., 10 ms per frame). The audio data were collected using an Audiotechnica cardioid microphone connected via a pre-amp to the WinEPG system, which automatically synchronizes the audio and EPG streams using an internal beep.
The data were annotated based on the waveform and spectrogram using the Articulate Assistant software (version 1.18; Wrench et al., 2002). Boundaries for singleton /l/ were marked at the onset and offset of the acoustic closure, as often manifested by an abrupt reduction in intensity and changes in formant patterns. In some cases, particularly for (partly) vocalized tokens of coda /l/, discontinuities in intensity and/or formants were less obvious. Lateral intervals were still marked in such cases, based on auditory impressions. As /l/ in clusters can be partly overlapped with the preceding (and, less commonly, following) consonant, we chose to include the articulatory closure of the lateral in the annotated interval, regardless of whether it was acoustically present or partly absent. This is shown in Figure 2, where the denti-alveolar constriction for /l/ begins during the bilabial closure for /b/.
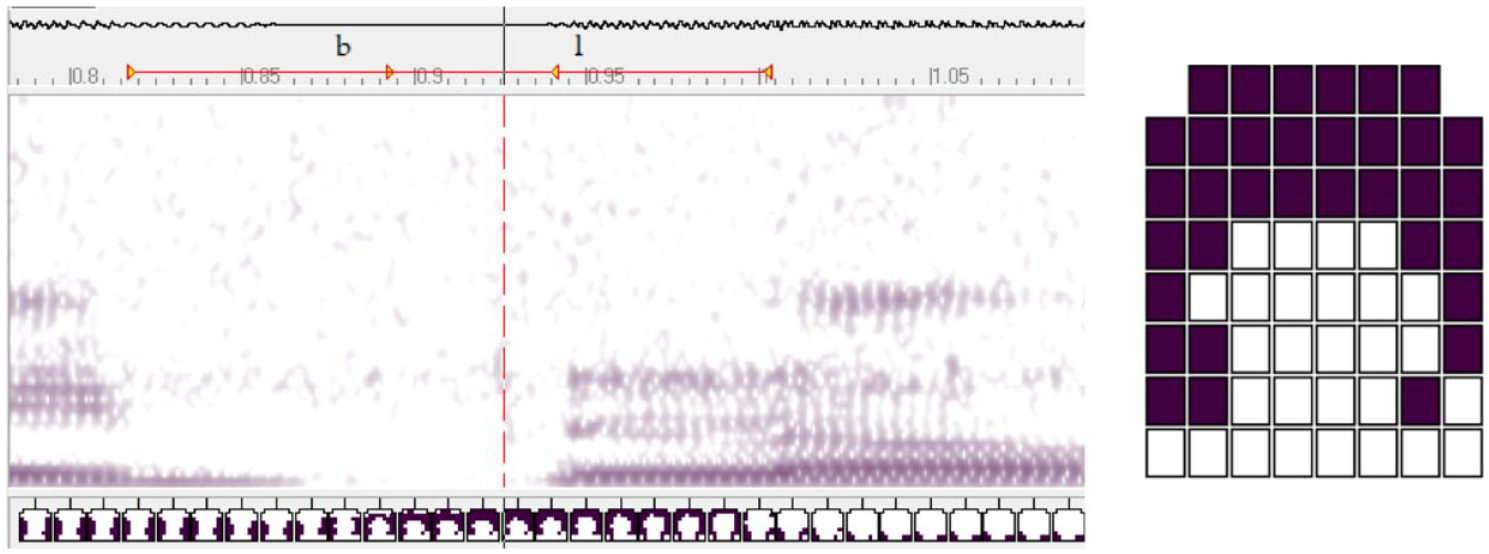
Sample annotation of /l/ in Say b
The interval where the two closures (labels “b” and “l” below the waveform and above the spectrogam) overlap is acoustically silent, with the lateral formants being realized only after the release of /b/. The frame of the maximum contact for /l/ (indicated with the vertical red line), however, occurs during the overlapped period, and thus would have been missed if the annotation was based solely on the acoustic realization of /l/.
For each token, linguopalatal contact values (“1” or “0” for each electrode) were automatically extracted from the frame of maximum contact. Following Ramsammy (2023), we examined two variables, namely, the amount of contact in the first four and last four rows of the palate, Qa4 and Qp4 (Quotient of maximum activation over the anterior or posterior region of the palate). Values range from 0.00 to 1.00, calculated by dividing the number of contacts activated by the total number of contacts in the region (30 and 32, respectively). Note that the frame shown in Figure 2 has Qa4 and Qp4 values of .87 (26/30) and .25 (8/32), respectively.
The data were analyzed using linear mixed-effects regression (LMER) models implemented with the lme4 package (Bates et al., 2015) using R (R Core Team, 2014) separately for Qa4 and Qp4 (§4.1.2 and §4.1.3). For full models, fixed factors were L1 (English, French, Spanish), Position (onset, coda), and Structure (singleton, cluster), included as interactions; random intercepts were included for Speaker (random intercepts and slopes) as well as for Utterance Type (isolated word, carrier sentence), and Word (random intercepts). 6 Treatment contrast coding was used for categorical variables, with the baseline condition being the singleton onset /l/ produced by L1 English speakers. For each analysis, likelihood ratio tests were used to compare the full model to a nested model excluding the factor of interest, employing the Anova() function of the lmerTest package (Kuznetsova et al., 2017). Pairwise comparisons and post hoc tests (with a Bonferroni correction for multiple comparisons) were performed using the phia package (De Rosario-Martinez, 2015). Further details of the analysis are presented in each subsection.
3.5 Acoustic annotation and analysis
Audio files accompanying the EPG recordings were exported from the Articulate Assistant software and annotated automatically using The Montreal Forced Aligner (McAuliffe et al., 2017), with models specifically designed for English, French, and Spanish. The produced annotations were checked manually in Praat (Boersma & Weenink, 2023) and adjusted where needed. Some files had to be discarded, either because of quality issues (L1 English: N = 1: L1 French: N = 2; L1 Spanish: N = 27) or, in clusters, because the lateral was apparently deleted or fully devoiced (L1 English: N = 7; L1 French: N = 53; L1 Spanish: N = 40). A Praat script was used to extract formants F1 and F2 (Hz) at five equally distributed time points during the lateral interval, with the default window settings (a 25-ms Gaussian window with a 5-ms step) and the maximum formant value used in the Burg analysis set by gender (5000 Hz for males, 5500 Hz for females). Values for time point 3 (midpoint) were used for the analysis. The same LME models were employed for F1 and F2 as for the EPG data analysis, with the exception of the addition of another fixed factor, Gender. 7 The two formants were analyzed separately, rather than as a single variable F2-F1 (e.g., Barlow, 2014; Nagamine, 2022), as they were expected to better correspond to the articulatory variables (as being indicative of primary and secondary constrictions for the lateral).
3.6 Comparison to L1 French and Spanish data
The L2 English articulatory data for our French and Spanish speakers were further compared with the speakers’ native productions of /l/ reported in Colantoni et al. (2023b). The L1 French and Spanish data sets in this other study were collected as part of the same project using the same methodology and parallel to those for the speakers’ L2 English reported here. The L1 data contained /l/ in various French and Spanish words, as singleton consonants and in clusters with labials, read both in isolation and in a carrier phrase (see Appendix A for the complete French and Spanish stimuli sets). The purpose of this comparison was to determine whether speakers in the current study had adapted their production of the lateral to the positional reduction pattern expected of L1 English or rather continued to use (in part) their native patterns.
4 Results
To test our three hypotheses, the learners’ /l/ production was analyzed both via EPG for tongue contact and then acoustically to assess the place of articulation/degree of tongue anteriority.
4.1 EPG analysis: Tongue contact
4.1.1 Overview
We begin by providing examples of linguopalatal contact profiles for selected words and speakers. These are shown in Figure 3, with images presenting averages of lateral closures over multiple repetitions. English native speaker EN2 produced the syllable-initial /l/ in life and let with clear denti-alveolar contact (rows 1–3) and side contact extending through most of the palate’s length (rows 1 and 8). His realization of words with onset /l/ in the clusters in fly and play involved similar denti-alveolar contact with the exception of the lack of contact in row 1 for fly, yet without any side contact behind the closure. Words with /l/ in coda exhibited denti-alveolar contact that is further reduced compared with onsets, with many cells in rows 1–3 lacking contact. This is particularly evident in the word help, where the contact is absent most of the time.
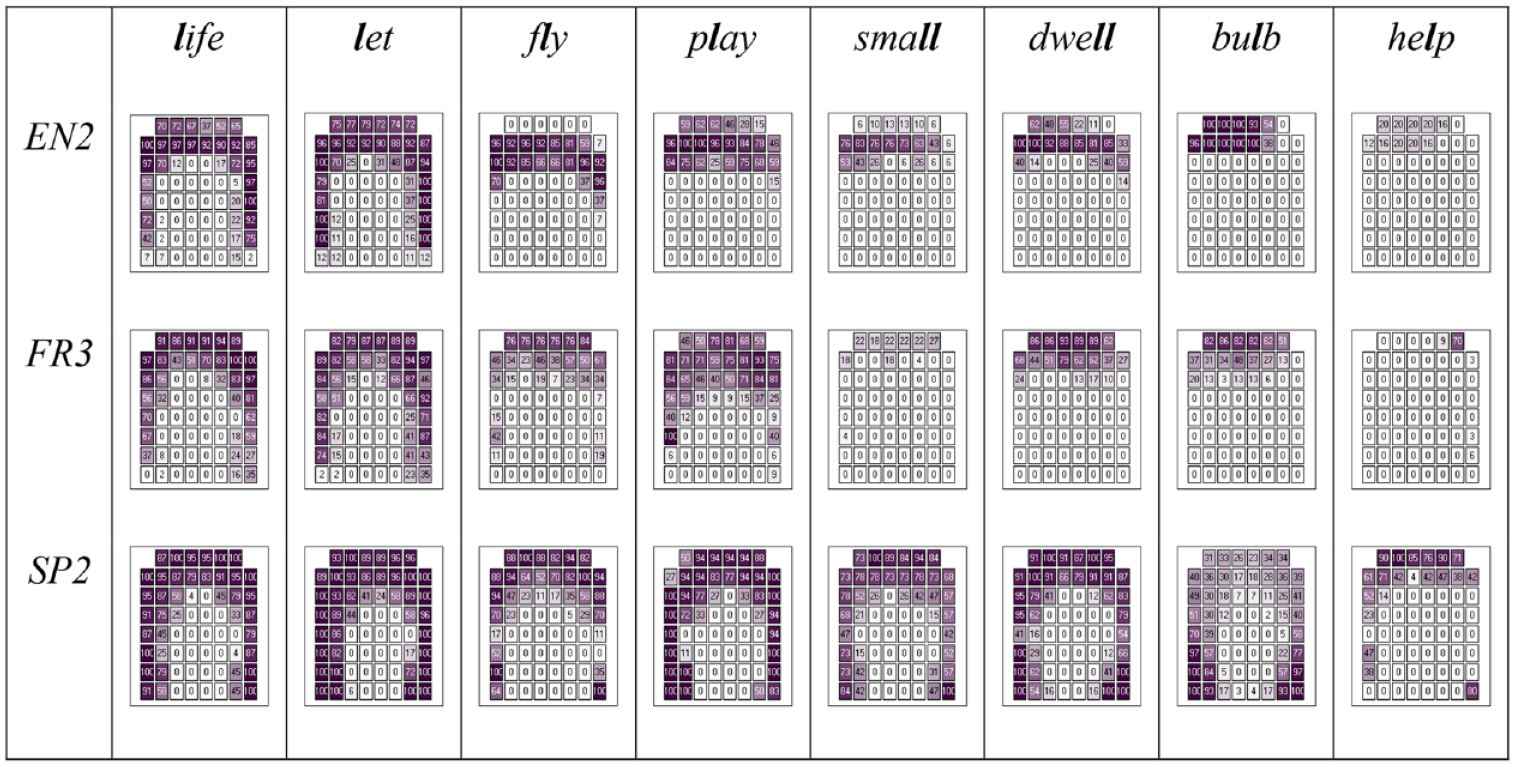
Average linguopalatal contact profiles for selected words produced in a carrier sentence by speakers EN2, FR3, and SP2, based on 4 tokens per word per speaker; numbers represent average contact for each electrode, from no contact at all (0) to contact occurring 100% of the time (100).
Linguopalatal contact patterns for L1 French speaker FR3 showed an overall similar progression in contact reduction: lesser posterior contact in onset clusters compared with singleton onset consonants, as well as overall lesser contact in codas, with some words (small, help) showing hardly any contact at all. Spanish speaker SP2, in contrast, showed relatively stable contact profiles, with small-scale anterior and/or posterior reduction in contact, more obvious in some coda-/l/ words (bulb, help) than others. In terms of our variables, high linguopalatal contact in the anterior part of the palate corresponds to high Qa4 values. Based on the averages in Figure 3, we would therefore see overall higher Qa4 values for /l/ in onset than in coda position as well as for singleton /l/ than the same consonant in clusters. Largely similar differences would be expected for Qp4, which tracks posterior contact. In fact, values for this variable would be at zero for EN2 in all cases except singleton onset /l/ and, for FR3, in all cases except onsets.
In the following sections, we will examine patterns of reduction in more detail, separately for anterior and posterior contact, followed by a by-speaker comparison of positional differences in L1 and L2 data for the learners.
4.1.2 Positional differences in anterior contact (Qa4)
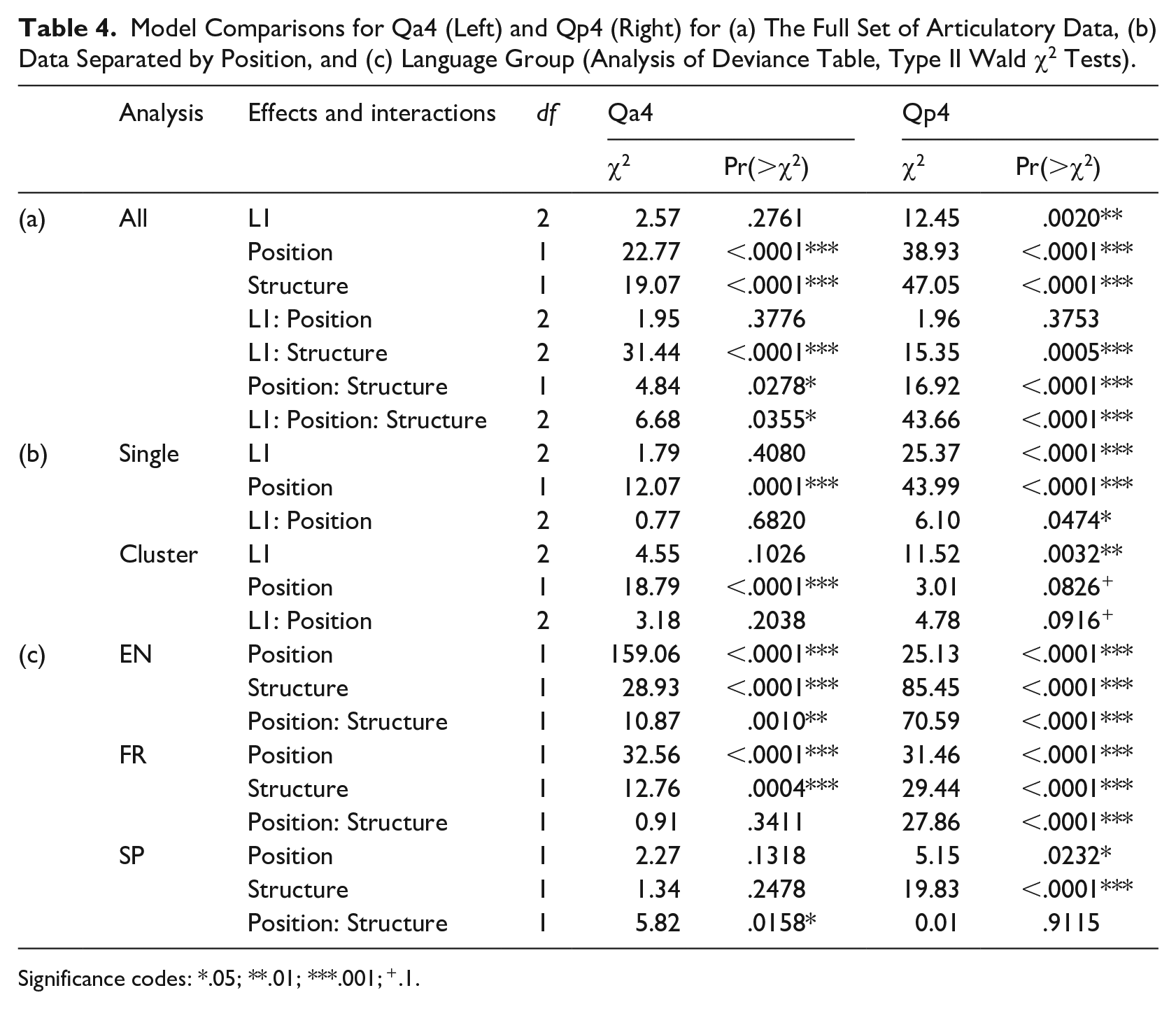
Results of a linear mixed effect model (see §3.4 for details) produced significant effects of Position, χ2(1) = 22.77, p < .0001, and Structure, χ2(1) = 19.07, p < .0001, but not L1. There were, however, significant interactions of L1 and Structure, χ2(2) = 31.44, p < .0001, and Position, χ2(2) = 4.84, p < .05, as well as L1, Position, and Structure, χ2(2) = 6.68, p < .05. The three-way interaction can be observed in Figure 4. Full model comparisons are presented in Table 4a (left; see also Table S1 in the Supplementary Materials file for model estimates).
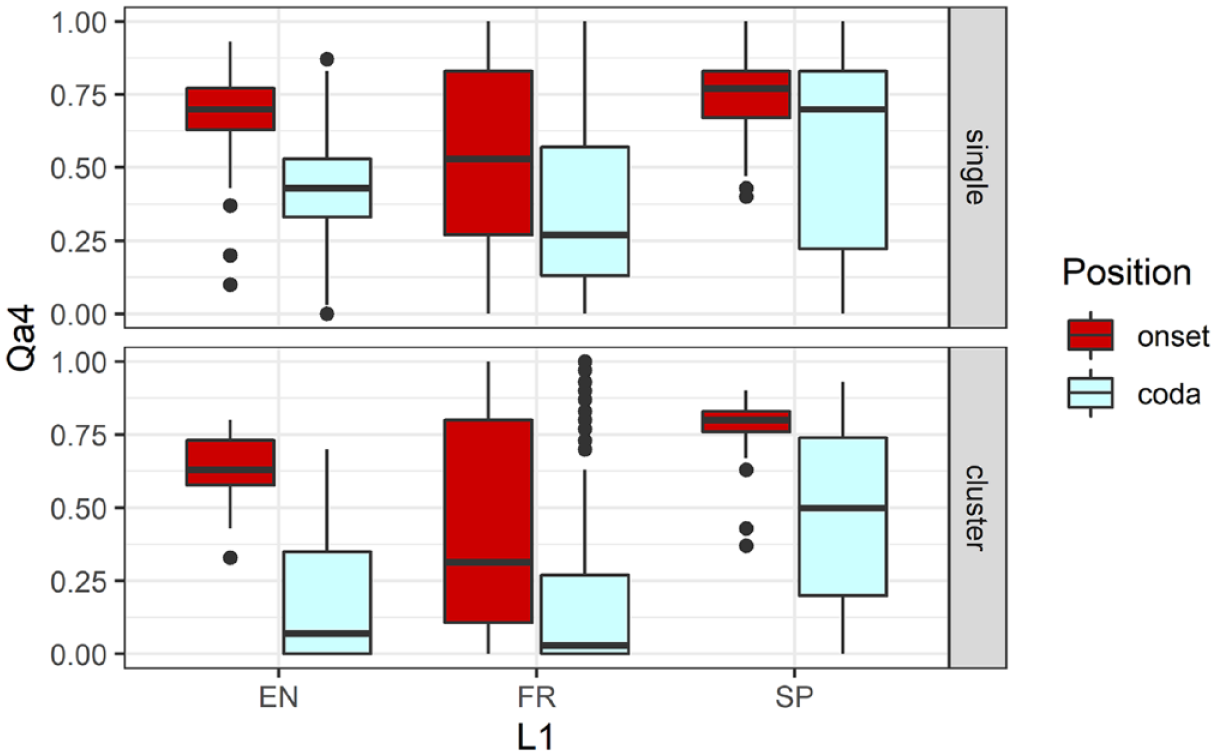
Boxplot of anterior contact (Qa4) by position (onset, coda), structure (singleton, cluster), and language group (EN = English, FR = French, SP = Spanish).
Model Comparisons for Qa4 (Left) and Qp4 (Right) for (a) The Full Set of Articulatory Data, (b) Data Separated by Position, and (c) Language Group (Analysis of Deviance Table, Type II Wald χ2 Tests).
Significance codes: *.05; **.01; ***.001; +.1.
Note that all three groups showed lower Qa4 values in codas compared with onsets, albeit with much greater variation within the L2 groups. Notably, values for the French group were on average lower, whereas values for the Spanish group were higher than for the English group—either for the singleton or cluster conditions or for both conditions. Note also that Qa4 values were lower for /l/ in clusters than for singleton /l/, but generally only in codas.
It can be observed in Figure 4 that some of the Qa4 values were as low as zero, meaning that some lateral tokens were produced without any anterior contact. In total, there were 229 such tokens (13% of all tokens), with the English and French groups producing most of the cases (14% and 18% of their total tokens, respectively, compared with 2% for L1 Spanish speakers). Most of these tokens involved codas (e.g., contextual), especially coda clusters (e.g., yourself), and thus can be considered as instances of full reduction of the anterior lingual gesture. In addition, some zero-Qa4 values were observed for onset clusters and singletons (e.g., play, lawyer) produced by two of the French speakers (FR1, FR2). In these cases, it is possible that the realization of the /l/ closure was (inter-)dental and therefore not captured by the artificial palate.
Given the significant 3-way interaction described above, we performed two separate analyses by Structure (for words with a singleton /l/ and /l/ in clusters) as well as three separate analyses by L1. The model for singleton /l/ produced a significant effect of Position, χ2(1) = 12.07, p < .001 but no significant effect of L1 or its interaction with Position. The model for /l/ in clusters produced similar results: a significant effect of Position, χ2(1) = 18.79, p < .0001, and no significant effect of L1 or its interaction with Position. Altogether, these results show that all three language groups exhibited a positional reduction in anterior contact in codas, both for singleton /l/ and /l/ in clusters (as evident in Figure 4; see Table 4(b) (left) and Supplemental Tables S2 and S3 for more details).
Language-particular analyses with Position and Structure, however, gave more variable results. An analysis for the English group produced significant effects of Position, χ2(1) = 159.06, p < .0001 and Structure, χ2(1) = 28.93, p < .0001 as well as a significant interaction of the two, χ2(1) = 10.87, p < .01. Post hoc tests revealed that Qa4 was significantly lower in codas than onsets for both Structure conditions and was significantly lower in clusters than for singleton /l/, however, only in codas. This can be seen in Figure 4 for the English group, where a considerable singleton-cluster difference was found in coda but not in onset position. An analysis for the French group produced significant effects of Position, χ2(1) = 32.56, p < .0001 and Structure, χ2(1) = 12.76, p < .001 but no significant interaction of the two. Qa4 values were lower in codas than onsets as well as lower in clusters than for singleton /l/ regardless the position. An analysis for the Spanish group produced no significant effects of Position or Structure, yet a significant interaction of the two, χ2(1) = 5.82, p < .05. This interaction was due to the lower amount of contact in coda clusters than for singleton coda /l/. There were no significant differences in Structure in onsets and no significant differences in Position (see Table 4(c) (left) and Supplemental Tables S4 to S6 for more details).
Overall, the results attest to robust anterior contact differences conditioned by syllable position, with contact being more reduced in codas than onsets. While significant in the combined data set, it was not significant for the Spanish group examined in isolation. This contradiction appears to be due to some inter-speaker variability within this group. As can be observed in Figure B1 (top panel) in Appendix B, one of the Spanish speakers, SP1, showed a substantial positional reduction in Qa4, which was very similar to the English controls and different from the relatively small-scale reduction observed for the other two Spanish speakers. Note also that there was considerable variation within the French group (see Figure B1, top panel), yet the inter-speaker differences mostly involved absolute values (cf. onset /l/ for FR1 and FR2 versus FR3 and FR4) and not the general positional patterns. The results of the analyses presented above also showed that the amount of anterior contact was dependent on syllable structure. Specifically, /l/ in clusters was found to be produced with lesser anterior contact than singleton /l/. For the English and Spanish groups, this difference, however, was limited to codas, while occurring across the board with the French group.
4.1.3 Positional differences in posterior contact (Qp4)
The amount of contact in the posterior region of the palate (Qp4) was also examined employing an LMER model with the full set of fixed factors (L1, Position, Structure). The model produced significant effects of L1, χ2(2) = 12.45, p < .01, Position, χ2(1) = 38.93, p < .001, and Structure, χ2(1) = 47.05, p < .001. There were also significant interactions of L1 and Structure, χ2(2) = 15.35, p < .001, Position and Structure, χ2(1) = 16.92, p < .0001, and L1, Position, and Structure, χ2(2) = 43.66, p < .001. The three-way interaction can be observed in Figure 5. The full model comparison is shown in Table 4(a) (right; see also Supplemental Table S7 for model estimates).
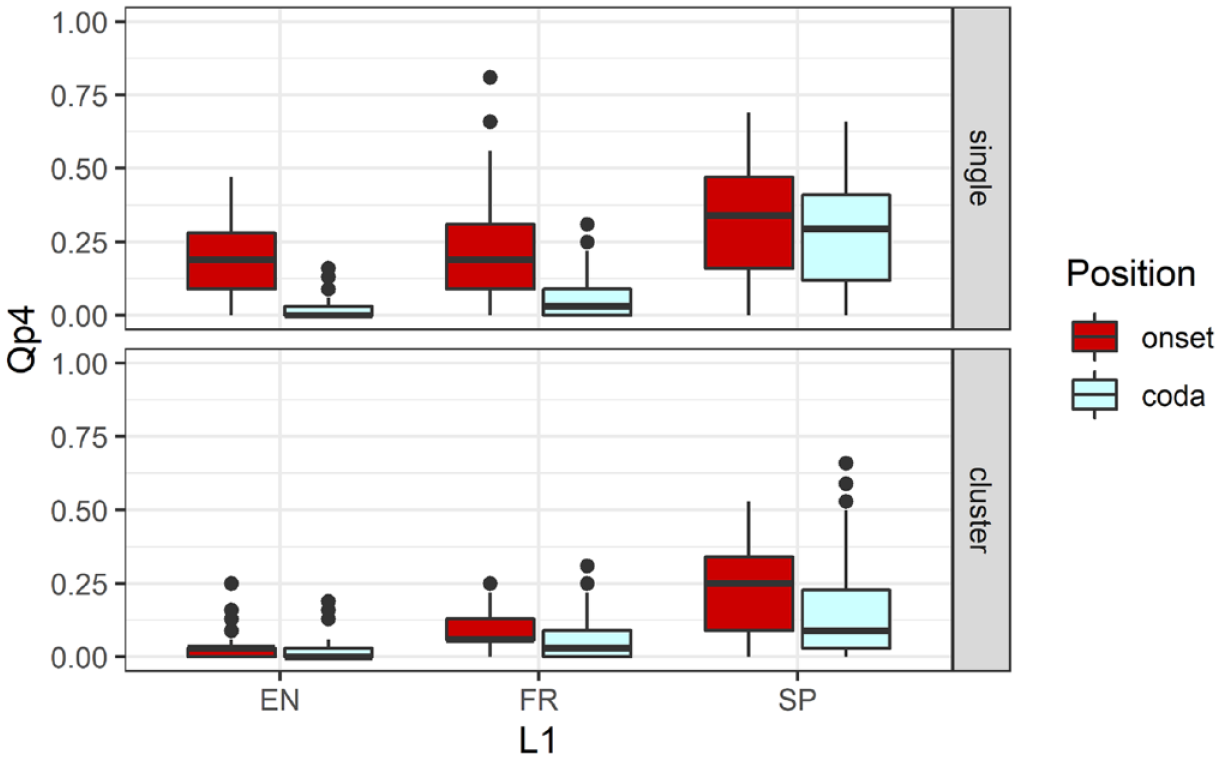
Boxplot of posterior contact (Qp4) by position (onset, coda) and structure (singleton, cluster) by language group (EN = English, FR = French, SP = Spanish).
Note that Qp4 values for codas were on average lower than in onsets for singleton /l/ produced by the English and French groups (but only marginally so for the L1 Spanish speakers); the values were lower for codas than onsets in clusters for the Spanish and French groups (but not for the English group for whom both mean values approached 0). Qp4 values were lower in clusters than for singleton /l/ but not in the codas produced by the English and French speakers (where they were near zero). Note also that values for the Spanish group tended to be higher than for the other two groups.
As seen in Figure 5, there were many cases of Qp4 being equal to zero, corresponding to lateral tokens being produced without any posterior contact (see, e.g., Figure 3). In total, there were 327 (18%) tokens with no posterior contact, overwhelmingly found either in coda or in clusters. All three groups showed such cases of complete reduction, however, to different degrees: 29% for English, 17% for French, and 8% for Spanish.
Given the significant 3-way interaction described above, we performed two separate analyses by Structure (for words with a singleton /l/ and /l/ in clusters) as well as three separate analyses by L1. The model for singleton /l/ produced a significant effect of L1, χ2(2) = 25.37, p < .0001, and Position, χ2(1) = 43.99, p < .0001, as well as a significant interaction of L1 and Position, χ2(2) = 6.10, p < .05. Post hoc tests revealed that Qp4 was significantly lower in codas than in onsets for the English and French groups (p < .001) but not for the Spanish group. The tests also showed that the contact in codas (but not onsets) was lower for the English and French groups compared with the Spanish group (p < .001). The model for /l/ in clusters produced a significant effect of L1, χ2(2) = 11.52, p < .01, yet no other significant effects or interactions. A post hoc test revealed that Qp4 was significantly lower for the English than the Spanish group (p < .05); the French group showed a similar difference to the Spanish speakers, albeit failing to reach significance (p = .082). These results indicate that two of the three groups (English and French) exhibited the expected positional reduction in posterior contact. However, this effect was limited to singleton /l/. These two groups also showed lesser contact in codas than the Spanish group, which is related to the positional reduction or lack of it mentioned above (see Table 4(b) (right) and Supplemental Tables S8 and S9 for more details).
Turning to the language-specific analyses, the model for the English group produced significant effects of Position, χ2(1) = 25.13, p < .0001, and Structure, χ2(1) = 85.45, p < .0001, and a significant interaction of the two, χ2(1) = 70.59, p < .0001. Post hoc tests revealed that Qp4 was significantly lower in codas than onsets for singleton /l/ (p < .001) but not for /l/ in clusters. The latter finding was not surprising, given the near-zero values in clusters (see Figure 5). The tests also revealed that the amount of posterior contact was greater for singleton /l/ than for /l/ in clusters (p < .001), yet only in onset position. The analysis for the French group produced very similar results: positional reduction for singleton /l/ and lesser contact in clusters occurring in onset position, given the significant effects for both factors, Position χ2(1) = 31.46, p < .0001, Structure χ2(1) = 29.44, p < .0001, and their significant interaction, χ2(1) = 27.86, p < .0001. The analysis for the Spanish group produced significant effects of Position, χ2(1) = 5.15, p < .05, and Structure, χ2(1) = 19.83, p < .0001, and no significant interaction of the two. These effects indicated that posterior contact was somewhat lower in coda than onset position, as well as considerably lower in clusters than in singleton /l/ (see Table 4(c) (right) and Supplemental Tables S10 to S12 for more details).
In sum, the results showed the expected positional differences, yet only under certain conditions: for singleton /l/ as produced by the English and French groups and for both the singleton and cluster conditions by the Spanish group. Notably, the latter effect held in the language-particular analysis but not in the cross-language analysis. This, again, points to some inter-speaker variability in the Spanish group. As can be seen in Figure B1 (bottom panel) in Appendix B, particularly high Qp4 values were exhibited by Spanish speakers SP2 and SP3, while SP1’s values for both onset and coda /l/ were more in line with those of the English speakers. Recall that the greater posterior contact for /l/ can be attributed to the lack of velarization (and the presence of palatalization). This interpretation, however, should be made with caution, as the overall amount of linguopalatal contact is partly speaker-specific, affected by the relative size of an individual’s oral cavity and palate morphology (Brunner et al., 2009). The results of the Qp4 analyses also showed less posterior contact in clusters compared with singleton /l/, yet mostly in the onset position. Finally, the results revealed an overall greater amount of posterior contact for the Spanish group than for the other two groups (for individual differences in Qp4, see the bottom panel of Figure B1 in Appendix B).
4.2 Acoustic Analysis
We now turn to the examination of acoustic differences in the realization of /l/. To this end, LMER models were performed separately for F1 and F2 as expected correlates of the primary and secondary constrictions (tongue tip and dorsum), respectively. The models contained interactions of the fixed factors L1, Position, and Structure as well as the factor Gender. The random factors were Type, Item (both random intercepts), and Speaker (random intercepts and slopes). Given the lack of balance for Gender in our data (with males being limited to the English group), between-group results should be interpreted with caution.
The model for F1 produced significant effects of Position, χ2(1) = 26.75, p < .0001, and Structure, χ2(1) = 4.33, p < .05, but not L1 or Gender. Overall, F1 was higher in codas than in onsets, and higher for singleton /l/ than in clusters, as illustrated in Figure 6 (top panel). There was, however, a significant interaction of Position and Structure, χ2(2) = 85.45, p < .05. Post hoc tests showed that the interaction was due to the lack of the Structure effect in codas as well as the greater positional difference for singleton /l/ than in clusters.
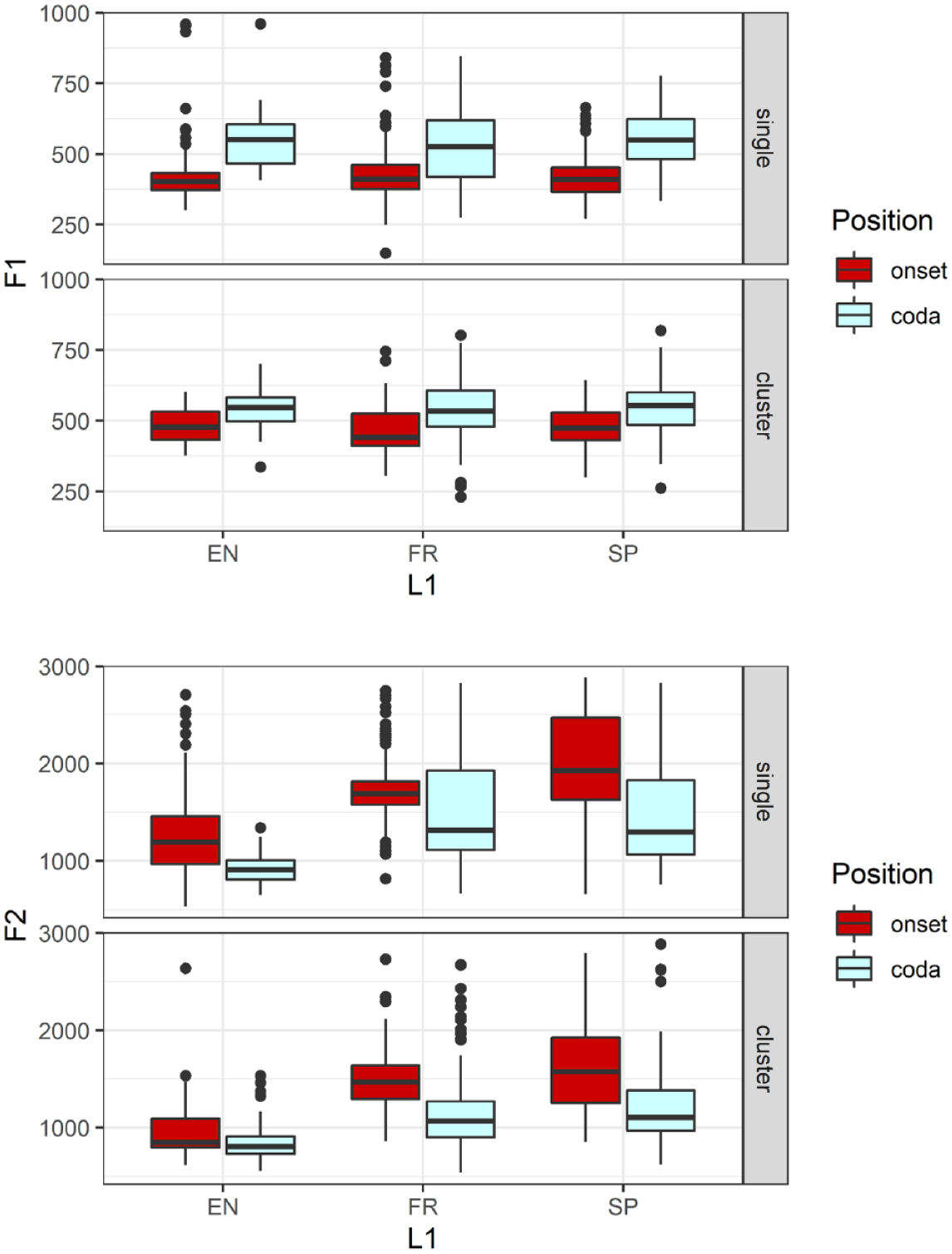
Boxplots for F1 (Hz, top panel) and F2 (Hz, bottom panel) at /l/ midpoint by position (onset, coda), structure (singleton, cluster), and language group (EN = English, FR = French, SP = Spanish).
The model for F2 produced significant effects of L1, χ2(2) = 12.09, p < .01, Position, χ2(1) = 16.45, p < .001, Structure, χ2(1) = 31.26, p < .0001, and Gender, χ2(1) = 5.40, p < .05. It also produced a significant interaction of L1, Position, and Structure, χ2(2) = 9.79, p < .01 (see Supplemental Tables S27 to S28 for more details). Sources of this interaction, as illustrated in Figure 6 (bottom panel), were further examined using separate analyses for the singleton lateral and /l/ in clusters, as well as separately for each language. See Table 5(a) for full F1 and F2 model comparisons and Tables S13 and S14 in the Supplementary Materials for model estimates.
Model Comparisons for F1 (Hz, Left) and F2 (Hz, Right) for (a) The Full Set of Articulatory Data, (b) Data Separated by Position, and (c) Language Group (Analysis of Deviance Table, Type II Wald χ2 Tests).
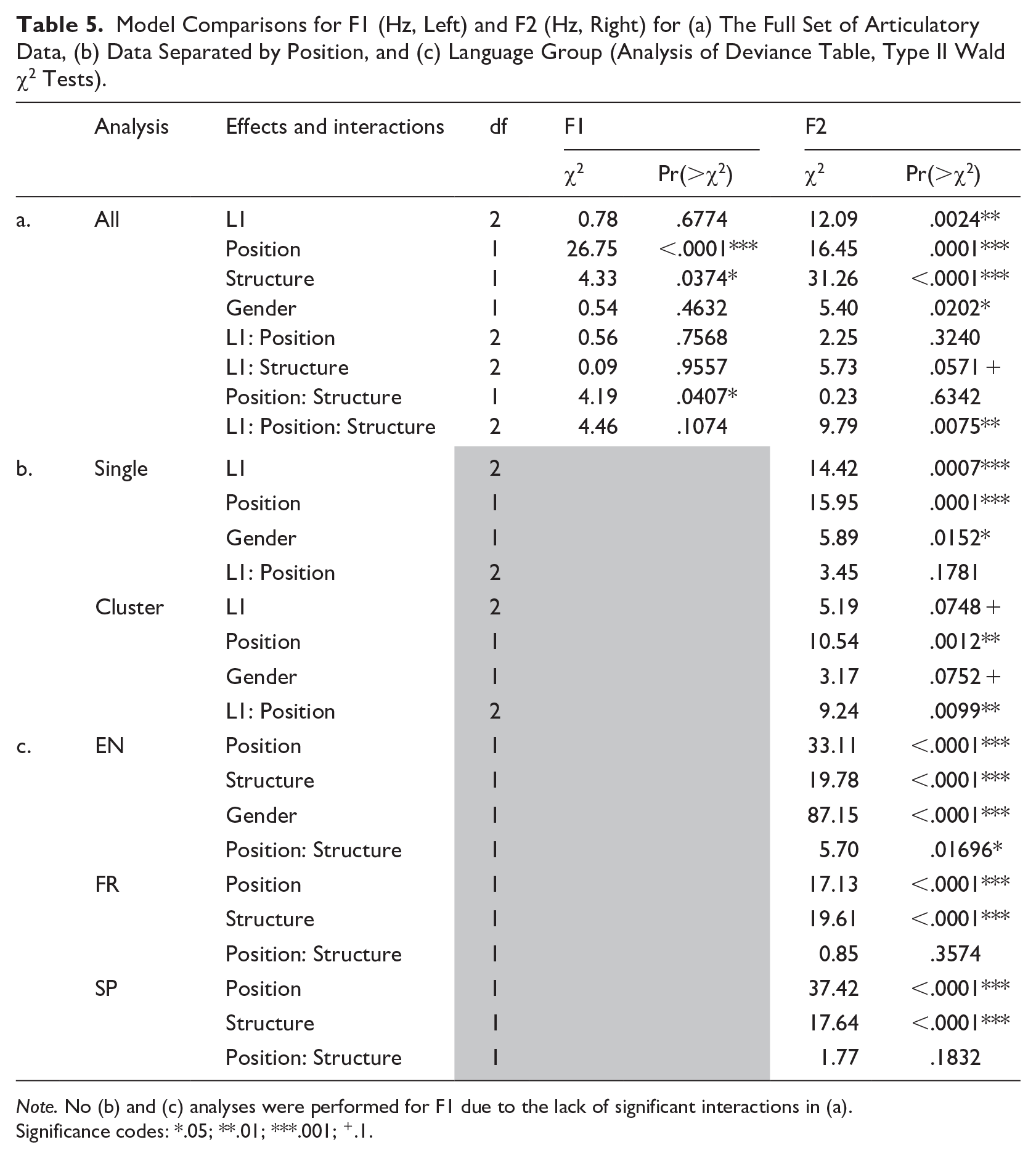
Note. No (b) and (c) analyses were performed for F1 due to the lack of significant interactions in (a).
Significance codes: *.05; **.01; ***.001; +.1.
The model for singleton /l/ produced a significant effect of L1, χ2(2) = 14.42, p < .001, Position, χ2(1) = 15.95, p < .001, and Gender, χ2(1) = 5.89, p < .05. There were no significant interactions. The effect of Position showed that F2 was lower in codas than in onsets (regardless of the language group). It was also higher for the French and Spanish than the English speakers, as well as—expectedly—higher for females than males. The language differences could therefore be attributed to gender differences. It should be noted, however, that the female English speaker’s F2 values for singleton /l/ (on average 1444 Hz) were still lower than for the French and Spanish speakers (on average 1665 and 1923 Hz, respectively). The model for /l/ in clusters produced a significant effect of Position, χ2(1) = 10.54, p < .01, and a significant L1 * Position interaction, χ2(2) = 9.24, p < .01. Post hoc tests revealed that the interaction was due to the greater F2 values for Spanish than English, but only in onset position, as well the lack of positional difference for English but not for the other languages (see Table 5(b) (right) and Supplemental Tables S15 and S16 for more details).
The model for the English group produced significant effects of Position, χ2(1) = 3.11, p < .0001, Structure, χ2(1) = 19.78, p < .0001, and Gender, χ2(1) = 87.15, p < .0001, as well a significant interaction of the first two factors, χ2(1) = 5.70, p < .05. Post hoc tests revealed that the F2 positional effect was limited to the singleton lateral, and the cluster effect was limited to onsets. As expected, F2 was higher for the female speaker than for the males. The results for the French and Spanish groups were similar to each other, both showing significant effects of Position, χ2(1) = 17.13, p < .0001; χ2(1) = 37.42, p < .0001, and Structure, χ2(1) = 19.61, p < .0001; χ2(1) = 17.64, p < .0001, and no significant interaction of these; gender was not included in the models. F2 was lower in codas than in onsets and lower in clusters than for singleton /l/ (see Table 5(c) (right) and Supplemental Tables S18 and S19 for more details).
To summarize, positional differences were manifested in both F1 and F2, and were exhibited by all three groups. A notable exception to this was F2 for /l/ in clusters produced by the English group (where even onset /l/ showed relatively low values). There was a clear L1 difference in F2, with the /l/ produced by the English group being characterized by lower values. As noted above, this difference is partly due to the gender of the speakers, while also reflecting language-specific differences in the realization of the lateral (as is evident in the individual results; see Figure B2 in Appendix B). A close examination of the individual results also showed that F2 values in onsets were the highest for SP2 and SP3, the speakers who were noted to show the highest posterior contact values (see §4.1.3).
Finally, the results of our analysis showed that Structure differences were also manifested by F1 and F2, with /l/ in clusters showing higher F1 and lower F2. This can be reasonably attributed to the coarticulation of the lateral with the preceding or following labial consonant. 8 Yet another source of these differences was the overall lesser anterior and posterior contact for /l/ in clusters (see §§4.1.2 and 4.1.3).
4.3 Positional L1-L2 differences in articulation
In this section, we will compare articulatory results for our L2 English speakers to those for the lateral produced in their native languages based on Colantoni et al. (2023b), to assess to what extent, if any, the learners’ /l/ production was influenced by their native language. Table 6 presents mean Qa4 and Qp4 values for onset and coda /l/ as produced by the same speakers in their L1 and L2 (with L1 French and Spanish data coming from Colantoni et al., 2023b). The data for English speakers are given for reference. Of interest here is the difference between onset and coda for each speaker’s L1 and L2 (italicized) and the average difference for each language group (bolded). A positive difference of this kind is indicative of syllable-final reduction in anterior (Qa4), posterior (Qp4) or both contacts. The English speakers showed a robust positional reduction in Qa4 (.39–.49, on average .42) and a moderate reduction in Qp4 (.12–.18, on average .14). The French speakers showed apparent variety-specific variability in Qa4 in their L1: moderate reduction by the two Quebec speakers (FR1: .21; FR3: .15) and the absence (and in fact the reverse) for the two European French speakers (FR2: −.03; FR4: −.08). Notably, all four speakers showed moderate to large positional reduction in Qa4 in their L2 English (.17–.40; mean .26). The patterns were somewhat different with Qp4: all four speakers showed a moderate positional reduction in both their L1 and L2, and the overall magnitude was similar between the two conditions (mean .16 for both). Like the European French speakers, our Spanish speakers showed no positional reduction of Qa4 (.00–.05, mean .02), whereas—with the exception of SP3— they showed moderate to large reduction in L2 (SP2: .15; SP1: .51). All three speakers exhibited moderate reduction in Qp4 in both their L1 (mean .10) and L2 (.11).
Individual Means for Articulatory Variables (Qa4 and Qp4) by Position and Positional Differences (Onset Minus Coda) as Produced by English Speakers (Their L1), as well as by French, and Spanish Speakers in Their Native Language (From Colantoni et al., 2023b) and L2 English.
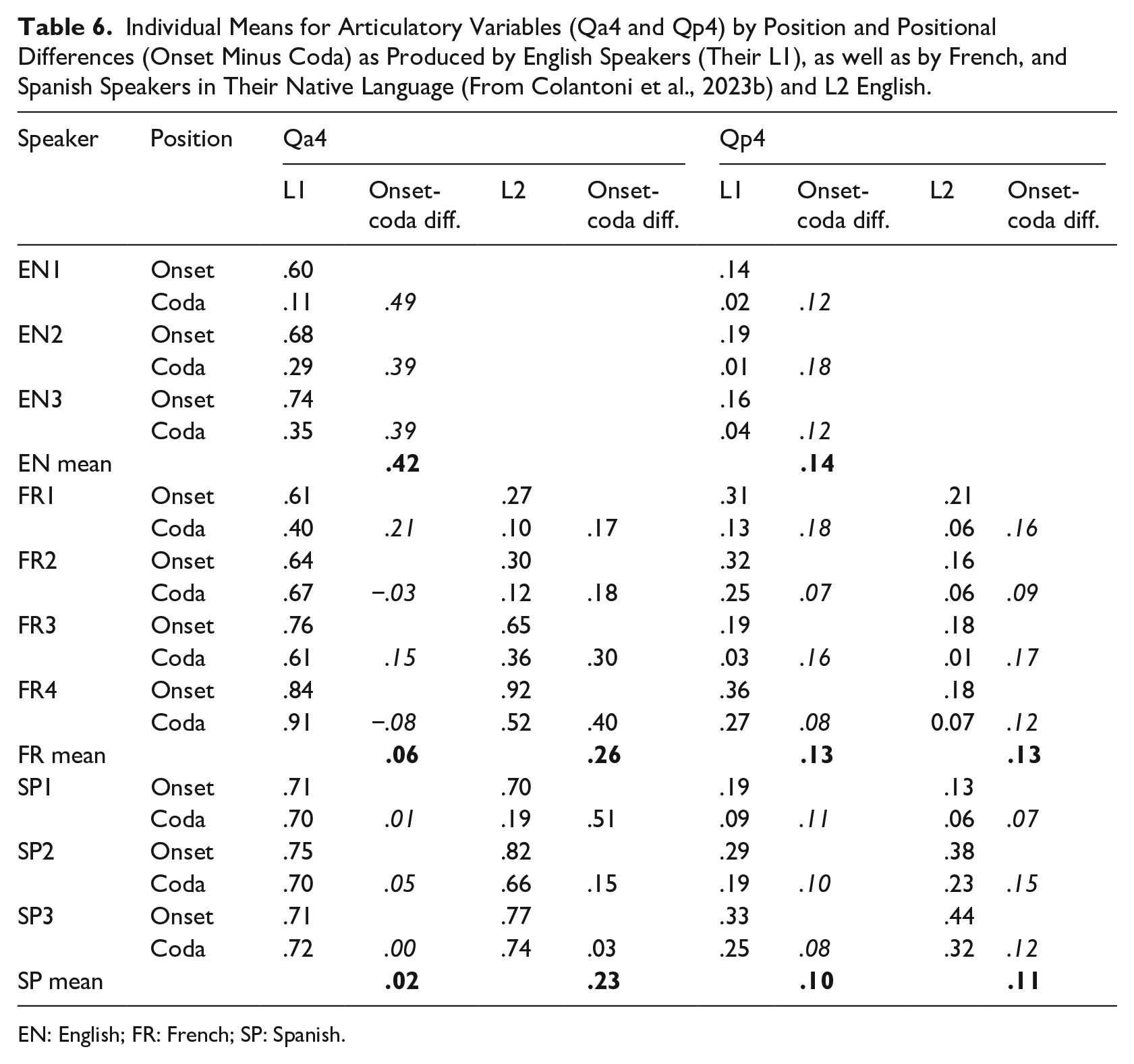
EN: English; FR: French; SP: Spanish.
In summary, the L1 results for our French and Spanish speakers indicate that positional reduction of the tongue tip constriction is not characteristic of European French and Spanish (while it seems to be for Quebec French), at least as produced by our speakers. This was indeed the conclusion reached by Colantoni et al. (2023b) based on a statistical evaluation of individual results for these plus three additional Spanish speakers. In contrast, both languages are characterized by a small-scale positional reduction of the tongue body. The comparison of L1 and L2 results reveals that most speakers have increased their reduction of the tongue tip gesture, while keeping essentially the same amount of reduction for the tongue body gesture. Exceptions to this generalization are the Quebec French speakers (who already had Qa4 reduction in their L1) and SP3 (who showed essentially no adaptation). Finally, it is worth noting that, although the amount of tongue tip reduction had increased for most speakers, it was still on average lower than for the English speakers.
5 Discussion
In this study, we investigated the acquisition of positional differences in the realization of English /l/ by native speakers of French and Spanish. Specifically, we examined linguopalatal contact and acoustic realizations of this sound in simple and complex onsets and codas produced in isolation and a carrier sentence. The L2 speakers’ data were compared with native English speakers producing the same materials. Finally, we compared L2 productions by French and Spanish speakers with their L1 productions from an earlier study (Colantoni et al., 2023b).
5.1 Hypothesis evaluation and the L2 acquisition of English-/l/ allophony
Our first hypothesis predicted that learners would produce a statistically significant difference in onset versus coda-/l/ realization but that they might still differ from the native speaker controls in the degree of anterior contact in both onsets and codas. EPG results for the contact patterns in the anterior part of the palate (Qa4) revealed that L1 French speakers’ realizations were significantly different in onsets versus codas, providing partial support for this hypothesis. As also predicted, their contact patterns differed from those of target English in that anteriority contact values were overall lower than those obtained for the native speaker controls. The individual results shown in Table 4 revealed that, with the exception of FR1, the L1 French participants had a larger difference in the onset-coda contact patterns in English than in their L1, which is indicative of learning the L2 allophonic patterns. Despite differences being smaller, even this speaker displays clearly lower L2 values compared to the patterns found in her L1. L1 Spanish speakers as a group did not show the expected onset-coda asymmetry as revealed by the model run on Qa4 values for this L1 group. These nonsignificant results were largely attributed to the behavior of two of the three L1 Spanish speakers, SP2 and SP3, who did not produce a significant difference in the contact patterns in the front of the palate (see also Table 4), in contrast to SP1 whose values were in the expected direction. Although differences in Qa4 were not significant, as seen in Table 4, all participants exhibited the expected tendency to depart from their L1 values, that is, to have a lower degree of contact in codas. Finally, despite this tendency toward the acquisition of the allophonic pattern, L1 Spanish speakers showed higher Qa4 values than their English-speaking peers. Moreover, all Spanish speakers, in contrast to FR1 and FR3, showed identical Qa4 values for onset laterals in their L1 and L2, which suggests that they have modified the articulation of their coda but not onset laterals.
As concerns patterns of contact in the posterior part of the palate (Qp4), all groups exhibited the expected differences, albeit results were marginally significant for the L1 Spanish group since participants showed higher values in onsets and codas. In addition, L1 French speakers resembled the English controls in showing more contact in onsets than in codas but only for singleton /l/. L1 Spanish speakers, instead, displayed significant differences with both structures. The individual results displayed in Table 4 are very revealing in terms of the articulatory adjustments (or the lack thereof) observed in the L1-L2 comparison. Although results for Qa4 indicated that participants showed the expected trend of producing less anterior contact in codas versus onsets in their L2 compared with their L1, very little change in the contact patterns in the posterior part of the palate was apparent. Indeed, the patterns observed were consistent with the weakening reported in their L1 in Colantoni et al. (2023b). Thus, Qp4 results support the hypothesis that French learners have acquired the asymmetry, while still showing some differences in the implementation of the alternation. As concerns the Spanish learners, we see the transfer of weakening patterns observed in their L1, with extreme cases such as SP1 who produced almost no contact in either language—recall that weakening including vocalization of laterals is witnessed in Cuban Spanish—which suggests that the implementation of the L2 allophonic alternation primarily involves modifying the anterior contact patterns.
The acoustic results revealed that all groups had significantly higher F1 values in codas than in onsets; differences across groups were not significant. Values obtained for F2 did show significant differences when learners were compared with the controls since the former had higher values in codas indicative of more fronted articulations. L1 Spanish speakers also had higher values than the other groups in onsets. Our EPG and acoustic findings, thus, reveal that the learners have acquired or are on the path to acquiring the allophonic alternation in the production of /l/ in onsets versus codas. Our EPG findings alone suggest that a possible articulatory path involves changes in the degree of contact between the tongue and the front of the palate rather than changes in the degree of contact in the posterior region of the palate, as evidenced in the values displayed in Table 4 for our Spanish participants. Although not considered in the formulation of the hypothesis, the current study provides interesting new results for L1 English: /l/ in onset and coda clusters behaves differently from singletons in not showing the asymmetry in contact patterns, probably due to the already low contact values in clusters obtained in onsets (also recall the high proportion of complete reductions observed in the data).
Our second hypothesis predicted that learners would resemble native English speakers more closely in onsets than in codas. The results do not fully support this hypothesis with group-level differences modulated by factors such as L1 and type of structure. As concerns Qa4 values, there were no significant group differences in onsets, but we argued that this was due to the L1 French speakers having consistently lower values than their English-speaking peers and the L1 Spanish speakers having higher values. As we noted earlier, the lesser anterior contact shown by some of the French speakers is possibly due to an (inter)dental realization of the English /l/, which is not fully captured by the EPG palate. We also highlighted the existence of individual differences within each group. As concerns Qa4, the overall tendency was for French speakers to lower their L2 values compared with those of their L1 (i.e., to reduce anterior contact), whereas Spanish speakers displayed almost identical values in onset position in both languages. When looking at Qp4 values, L1 differences were significant but were not only restricted to codas, particularly for the L1 Spanish group who, once again, displayed a higher degree of contact across positions. Although not predicted by the hypothesis, within-language analyses revealed different patterns of contact in singleton versus cluster /l/ interacting with position. The L1 English and Spanish speakers showed a higher degree of contact in singletons versus clusters but only in coda position, whereas L1 French speakers had more contact overall in singletons than in clusters, independent of the position. Although the articulatory results did not support our second hypothesis, we observed interesting and opposing tendencies in our two groups of learners. When we compare L1-L2 patterns (see Table 4), L1 French participants appeared to adopt the strategy of decreasing the amount of anterior contact in their L2, both in onsets and codas, when compared with the target language, English. Spanish speakers, instead, transferred their contact patterns in onsets (thus, apparently being closer to the native speaker controls than their French counterparts), and at least one of them (SP1) lowered the degree of L2 anterior contact. Our acoustic results do not support Hypothesis 2 either. F1 values did not differ significantly across language groups in either position, and F2 values were higher for the learners and controls both in onsets and in codas. The across-the-board higher F2 for the L2 speakers is partly due to gender differences and partly due to the influence of their L1s in which /l/ is overall clearer than in English.
This, in turn, leads us to evaluate our third hypothesis which predicted that, were differences to exist between the two learner groups, L1 French speakers would be more target-like once any English proficiency differences were accounted for. Given the number of participants per group and given the within- and between-group variability in accentedness scores (see Table 1), we proceed with some caution in evaluating this hypothesis. Indeed, in our sample, there may be a confound between the factor L1 and L2 English proficiency. It is important to highlight that, despite being perceived as less native-like, the Spanish participants had spent more time in an English-speaking context than their French counterparts. If we look at group results for the two articulatory indices, the French-speaking learners seem to be closer to the native speaker target. For example, whereas nonsignificant differences in the degree of contact in the front of the palate were obtained for L1 Spanish speakers, the L1 French group showed significant differences. Yet, these apparent group effects may indeed be the result of the patterns displayed by some individuals within the group. If we return to Table 4, we see that large differences in Qa4 values were not only observed within the L1 Spanish group but also within the L1 French group, where FR3 and FR4 showed differences in values that were approximately twice as large as the differences obtained for the other two francophone participants. What was interesting to observe was that the articulatory results offered us greater insights into the differences displayed by the two learner groups than the acoustic results, which pointed to generalized fronting as revealed by the F2 analysis. With EPG, we were able to observe differences in (1) cross-linguistic and possible cross-dialectal patterns; (2) interactions between L1 and structure (singleton versus clusters); and (3) differences in the realization of singleton laterals versus /l/ in clusters interacting with position in the native speakers, which made it more difficult to establish similarities between the L1 and L2 speakers. As concerns (1), the L1 Spanish speakers displayed overall a higher degree of anterior and posterior contact, which additionally manifested in a very low proportion of tokens involving no lingual contact when compared with the other two groups. This raises the question of whether the Spanish lateral is overall more different compared with French than the English lateral and that more phonetic adjustments are required by the former group to achieve target-like English /l/ production. The L1 data collected from these same speakers do not seem to support this hypothesis (Table 4) since the contact patterns in the anterior part of the palate appear to be very similar in both Romance languages, whereas Spanish shows a slightly lower degree of tongue-palate contact in the back of the palate when compared with French. Data obtained from L1 French speakers also suggested some possible dialectal effects, since we observed that the Quebec and European French speakers showed different Qa4 patterns with the latter displaying higher values than the former. The variety of positions and contexts incorporated in this study allowed us to see that the L1 French speakers resembled the controls more closely than their Spanish counterparts, at least in some contexts, as evidenced by statistically similar Qp4 values obtained for /l/ in singleton codas by both groups of speakers, as opposed to L1 Spanish speakers, who showed higher contact values. Finally, hypotheses for future studies need to be refined to incorporate the findings regarding differences in the articulation of /l/ in singleton and clusters by our L1 Canadian English speakers.
5.2 Contributions of EPG studies to our understanding of L2 speech
Our findings are overall consistent with the few existing studies on the acquisition of English lateral allophony by L1 Spanish (Barlow, 2014) and L1 French speakers (King & Ferragne, 2015; 2017), which found that L2 learners can acquire the allophonic pattern at a broad level. In parallel to previous studies, we observed differences in the phonetic implementation of the alternation. Such studies had reported higher F2 values in onset laterals for L1 Spanish speakers (Barlow, 2014) and overall more fronted values in onsets and codas for L1 French speakers (King & Ferragne, 2015). Our acoustic results are in line with these findings since both our L1 French and L1 Spanish speakers had higher F2 values than controls.
Our articulatory results, however, offer a more complex picture. Although we found group-level differences, these were modulated by a series of factors including position in the syllable (onsets vs. codas), syllable structure (singletons vs. clusters), speaker L1 (French vs. Spanish), and possibly L1 dialect (French alone). We believe that the differences found are the result of the larger variety of stimuli types included here compared with previous studies, and more importantly, for the present volume, the technique used to measure and compare the production of these populations. The use of EPG allowed us to capture the degree of contact between the tongue and the front palate (Qa4) and the back palate (Qp4). We observed first some systematic and not previously reported differences in the native English group in the production of /l/ in singletons versus clusters. For example, Qp4 values for /l/ in clusters were not significantly different in onsets compared with codas, as opposed to what has been consistently documented (and also observed here) for singleton /l/. This was largely due to the relatively high proportion of tokens that showed no contact between the tongue and the palate in onset and coda clusters. We also found interesting phonetic differences when we compared our learners’ patterns. L1 French speakers displayed less contact than their English-speaking peers in the anterior part of the palate, and this was particularly true for the two participants from Quebec, which is suggestive of dialectal differences in the contact patterns for the lateral. L1 Spanish speakers displayed the opposite pattern, namely, higher contact values both in the anterior and posterior parts of the palate across positions. A comparison of the L2 and L1 data obtained from the same speakers (Table 6) allows us to formulate a hypothesis regarding the learning of this allophonic pattern. Table 6 shows that participants diverge more from their L1 patterns in anterior contact than in posterior contact values, which suggests that the acquisition of tongue-tip/blade gestures precedes the acquisition of tongue-back gestures when acquiring English-/l/ allophony. In summary, the combined articulatory and acoustic analysis of the same data set confirms that similar F2 values (in our case higher F2 values in L2 speakers than in the controls) are due to different articulatory gestures, speaking to the complexity of articulatory-to-acoustic mappings reported in previous studies (see, e.g., Lawson et al., 2019).
Finally, the individual analysis of the EPG data better captures the magnitude of individual differences. A comparison of Figures B1 and B2 (Appendix B) reveals that Qa4 and Qp4 values better reflect the differences between Quebec and European French speakers than the F1 and F2 values. This was also the case for SP1 since Qa4 values clearly indicate that this participant, as opposed to the other L1 Spanish participants, had acquired the onset-coda asymmetry.
5.3 Future directions
The present work has added to previous studies by including a new dimension of /l/ production, namely, the degree of tongue constriction. Light and dark-/l/ variants also differ in the relative timing of the tongue tip and dorsum gestures with earlier retraction of the tongue dorsum in dark variants (e.g., Gick et al., 2006; Sproat & Fujimura, 1993); whether and how L2 learners acquire this timing pattern should be explored in future studies. It is also worth exploring dialectal effects in the acquisition of lateral allophony and expanding the contexts analyzed by controlling for preceding and following vowels and stress. The individual differences found also call for the need for developmental and perception studies, since our results do not clearly allow us to understand whether inter-speaker variability could be attributed to factors such as differences in perceptual acuity or the amount of exposure to English. For example, the results obtained for this group do not allow us to determine if factors such as Age of Arrival play a role, since FR2, who arrived in Canada at a very young age, did not outperform her peers. In the Spanish group, SP1 performed better than SP2, who arrived in Canada at a similar age. Finally, in addition to including techniques that allow us to capture tongue movement such as ultrasound, we need to supplement the present learning scenario with the reverse scenario (L1 English/L2 French or Spanish) to understand better not only the relative difficulty of suppressing versus acquiring allophonic patterns in laterals but also whether this proceeds by modifying first contact patterns in the anterior versus the posterior portion of the palate as observed here in the acquisition of /l/ allophony.
6 Conclusion
The present study investigated the acquisition of English lateral allophony by learners whose first language was either French or Spanish. The data elicited, which included a wide array of contexts (onsets and codas; singletons and clusters), were subjected to articulatory (EPG) and acoustic analyses. Consistent with previous studies, results showed that learners were able to acquire the English lateral allophony but differed from the native speakers in many ways in the phonetic implementation of the alternation. The inclusion of EPG data allowed us to capture fine-grained differences that were not apparent in the acoustic analysis of the same data set, such as possible dialectal differences in the L1 French group and the systematically higher degree of anterior and posterior contact in the L1 Spanish group. We also found previously unreported differences in native English-/l/ production, such as the lack of difference in the degree of contact with laterals in onset and coda clusters, due to the absence of tongue-palate contact in many tokens of laterals in onset and coda clusters.
Supplemental Material
sj-docx-1-las-10.1177_00238309231200629 – Supplemental material for Articulatory Insights into the L2 Acquisition of English-/l/ Allophony
Supplemental material, sj-docx-1-las-10.1177_00238309231200629 for Articulatory Insights into the L2 Acquisition of English-/l/ Allophony by Laura Colantoni, Alexei Kochetov and Jeffrey Steele in Language and Speech
Footnotes
Appendix A
French and Spanish Stimuli from Colantoni et al. (2023b).
| Onset | Coda | |||
|---|---|---|---|---|
| Singleton | Cluster | Singleton | Cluster | |
| French |
collègue
i là-dedans lapin lessive logement lundi syllabe zélé |
bloquer
éblouir flocon meubler plateau plateforme pleurer |
capsule
final Noël |
illisi |
| Spanish |
absoluto
deshielo helada hielo laca pelo pulió reloj sale |
Biblia
blasón bledo flaco floté plan plato plegó |
actual
animal hiel miel sal |
alba
álbum calmante olfato |
Appendix B
Acknowledgements
The authors thank all of our participants. They also thank Zhanao Fu for his assistance with the automatic annotation of acoustic data.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partly funded by an Insight Grant from the Social Sciences and Humanities Research Council of Canada (grant no. #435-2015-2013) to Alexei Kochetov and a University of Toronto Faculty of Arts & Science Advancing Teaching and Learning in Arts and Science (ATLAS) grant to the three authors.
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.