
Abstract
Listeners adjust their perception to match that of presented speech through shifting and relaxation of categorical boundaries. This allows for processing of speech variation, but may be detrimental to processing efficiency. Bilingual children are exposed to many types of speech in their linguistic environment, including native and non-native speech. This study examined how first language (L1) Spanish/second language (L2) English bilingual children shifted and relaxed phoneme categorization along the cue of voice onset time (VOT) during English speech processing after three types of language exposure: native English exposure, native Spanish exposure, and Spanish-accented English exposure. After exposure to Spanish-accented English speech, bilingual children shifted categorical boundaries in the direction of native English speech boundaries. After exposure to native Spanish speech, children shifted to a smaller extent in the same direction and relaxed boundaries leading to weaker differentiation between categories. These results suggest that prior exposure can affect processing of a second language in bilingual children, but different mechanisms are used when adapting to different types of speech variation.
1 Introduction
In the United States, many bilingual children acquire their first language (L1) at home and begin hearing their second language (L2) regularly upon school entry. In addition, bilingual children are often exposed to both native and non-native speakers of their languages (Place & Hoff, 2016). In the long-term, language input shapes the developing phonological systems of the bilingual child, but the exact mechanisms that children use to adapt to variability in speech are not well documented. This study aims to examine the real-time fine-grained changes that take place in a child’s phonological system as a result of various types of common language exposure in bilingual environments.
1.1 Adapting to speech variability
Listeners comprehending unfamiliar speech, such as foreign-accented speech, tend to do so more slowly and less accurately than when comprehending speech they are familiar with (Adank et al., 2009; Atagi & Bent, 2015; Bent, 2014, 2015; Creel et al., 2016; Floccia et al., 2009; Hanulíková & Weber, 2012; Holt & Bent, 2017; Munro & Derwing, 1995; Nathan et al., 1998; Newton & Ridgway, 2016). Yet, adaptation to variability in the speech input allows listeners to improve in their comprehension of unfamiliar speech even after a small amount of input (Bradlow & Bent, 2008; Clarke & Garrett, 2004; Maye et al., 2008; Schmale et al., 2012; White & Aslin, 2011; Witteman et al., 2013). This ability develops throughout childhood, with 8- to 9-year olds outperforming 5- to 6-year olds; however, even 15-year olds do not yet perform at adult-like levels (Bent, 2018; Bent & Atagi, 2015). The mechanism by which listeners respond to variability in the speech stream has many names, such as perceptual learning, adaptation, recalibration, and retuning (Dahan et al., 2008; Eisner & McQueen, 2005, 2006; Kraljic & Samuel, 2005, 2006, 2007; McQueen et al., 2006, 2012; Norris et al., 2003; Reinisch et al., 2013; Reinisch & Holt, 2014). In this work, we use the term “perceptual retuning” to broadly refer to changes in perceptual categorization including shifting and relaxing of phoneme categories.
Research using perceptual learning paradigms demonstrates that listeners can use lexical context to retune to unfamiliar speech (Norris et al., 2003). This phenomenon is known as lexically guided retuning. For example, if an atypical sound [?] is presented instead of [f] as the last sound of giraffe in English (e.g., gira[?]), there is only one phoneme that the ambiguous sound can be interpreted as to create a real word—[f]. Therefore, the listener can use context to determine that for the speaker, a [?] sound is most similar to the listener’s own [f] phoneme. Eisner and McQueen (2006) presented Dutch native speaking adults with a 4-minute-long story which included exactly 78 instances of [f] and 78 instances of [s]. In one version of the story, all 78 instances of [f] were replaced with an ambiguous fricative, and in the other version all 78 instances of [s] were replaced with the same ambiguous sound. Prior to and immediately after being presented with one of the two stories, participants performed a forced-choice phoneme categorization task on a continuum of five [f]–[s] sounds. The authors found that while all participants had similar categorization of the 5-step pre-exposure, those that were exposed to the ambiguous sound in [f] contexts were more likely to categorize the most ambiguous sounds in the continuum as [f], whereas the [s] exposure group was more likely to categorize ambiguous sounds as [s]. This indicates that exposure can retune the perception of individual phonemes to more efficiently process input that deviates from the listener’s norm.
A similar study with [f] and [s] perception was conducted in children, but instead of an exposure story, ambiguous sounds were presented in single word contexts (McQueen et al., 2012). The study revealed that 6-year olds, 12-year olds, and adults all adapted to perceiving the ambiguous sounds according to how the speaker had used them. Therefore, lexical context can provide children and adults with the necessary information to determine what an ambiguous fricative is most analogous to in their own systems. This retuning of phoneme categories has been proposed to be one of the mechanisms that helps listeners adapt to variability encountered in the speech stream, such as accented speech (Reinisch & Holt, 2014; Zheng & Samuel, 2020).
1.2 Generalizing retuning
While the ability to adapt to speech variability has been widely examined, the persistence of such effects, both duration of the effect and whether it generalizes to other sounds, has not been examined as extensively. In a study which examined dynamic perception, Kraljic and Samuel (2005) asked whether there would be a return to normal after retuning. They found that even after doing a distraction task for 25 minutes post-exposure, retuning was still strong. Only when the distraction task was an unlearning task, where non-ambiguous tokens (e.g., a good [s]) were presented by the same speaker as the exposure speaker, did categorical perception return to pre-exposure levels. It has further been shown that effects of retuning can last up to 12 hours after exposure takes places (Eisner & McQueen, 2006). Therefore, effects of retuning are long-lasting, and seemingly speaker-specific.
Examinations of speaker specificity in perceptual retuning and generalization suggest that retuning generalizes differently for different kinds of phonemes. First, it was found that retuning using stops was generalizable to a new speaker (Kraljic & Samuel, 2005), while fricatives retuned only when the exposure and test speaker were the same (Kraljic & Samuel, 2007). It was hypothesized that speaker-specific frequency cues in fricatives make it easier to identify speaker-specific productions, but Reinisch and Holt (2014) further showed that if the fricatives are produced within a similar acoustic range, they could lead to cross-speaker retuning, even from female to male speakers. Reinisch and Holt (2014) suggested that this may be the reason why exposure to multiple talkers facilitates adaptation to accented speech more so than exposure to a single talker. Multiple speakers are more likely to cover a wider acoustic range, increasing the likelihood of encountering phonemes in a similar acoustic range of a novel test speaker.
Perceptual retuning may be useful when processing an ambiguous sound with supporting lexical context, but may be more difficult to implement if the ambiguous sound is actually a valid phoneme for the listener, as could be the case with bilingual listeners. Examination of perceptual retuning in bilinguals is complex because the phonetic realization of many phonemes is not the same for bilinguals as for their monolingual counterparts in each of their languages (e.g., Flege & Eefting, 1987). Both languages of early bilinguals tend to influence each other. For example, in English and Spanish, the phoneme categories /d/ and /t/ can be differentiated along the cue of voice onset time (VOT). Flege and Eefting (1987) found that the perceptual category boundary between /d/ and /t/ for English monolingual adults was around 43 ms, for Spanish monolinguals was around 23 ms, and for early Spanish–English bilingual speakers was around 27 ms indicating that their category boundary fell in between the prototypical values of both of their languages. Similarly, in production, Spanish–English bilinguals produce stop-initial words with VOTs ranging from prototypical English to prototypical Spanish values. The VOT values of an individual are affected by linguistic variables such as the age of L2 acquisition (Thornburgh & Ryalls, 1998) and correlate with strength of their foreign accent (Major, 1987). Therefore, bilingual speech adaption is different from monolingual speech adaptation due to differences in the linguistic systems even before adaptation has taken place.
There is evidence that bilingual adults can retune phoneme categories in both their L1 and L2, and in response to exposure to both native and accented speech (Cooper & Bradlow, 2018; Cutler et al., 2018; Reinisch et al., 2013; Schertz et al., 2016; Weber et al., 2014). Furthermore, retuning across languages is also possible. In a study with Dutch native/English L2 listeners, Reinisch et al. (2013) showed that after exposure to Dutch-accented English (their L2), listeners retuned categories in Dutch (their L1). However, little is known about how flexible perceptual retuning is in bilingual children. It has been shown that children do not reach adult native-like perception of phonological categories even by age 12 (Hazan & Barrett, 2000), although the very idea that setting native-like perception as the “ideal” outcome has been questioned (Kutlu et al., 2022). Children are not able to accommodate to accented speech as accurately as adults (Bent, 2014; Bent & Atagi, 2015). For example, Bent and Atagi (2015) asked 5- to 8-year-old children and adults to repeat sentences spoken by native and accented speakers. Adults were more accurate at identifying key words within the sentences than children, and this effect was stronger when listening to the accented than the native speaker. However, the improvement in accented speech comprehension is gradient across age. Although they are not yet adult-like, 12-year olds still outperform younger children on accent comprehension tasks (Bent, 2018). As perception of categories prior to adaptation taking place is affected by the developmental stage and language knowledge of children, it is likely that bilingual children adapt to speech sounds differently than bilingual adults or monolingual children. In fact, on a semantic judgment task at the sentence level, simultaneous Spanish–English bilingual children between ages 5 and 6 showed less of a difference in comprehension accuracy between a native English and a Spanish-accented English speaker than monolingual children of the same age (McDonald et al., 2018). Therefore, bilingual experience clearly creates a different perceptual environment than the monolingual experience prior to any perceptual retuning.
The current study examined how Spanish–English bilingual children respond to exposure to native English, native Spanish, and Spanish-accented English speech. We investigated this question within the framework provided by two hypothesized mechanisms to account for responses to speech variability.
1.3 Mechanisms to account for speech variability
A visual depiction of the two hypothesized mechanisms for responding to speech variability is found in Figure 1. The first, boundary shifting (Llanos & Francis, 2017; Zheng & Samuel, 2020), is a method by which a listener shifts their category boundary to be closer to the category boundary of a presented speaker to facilitate speech processing. For example, as mentioned previously, the place along the VOT continuum at which /d/-/t/ boundary falls is different in prototypical Spanish and English speech. In general, at word onset, the Spanish category boundary falls at about 23 ms, while in English it falls at 43 ms (Flege & Eefting, 1987). Therefore, when comprehending Spanish-accented English speech, an English listener may shift their category boundary between /d/ and /t/ from the typical English 43 ms to a lower value to compensate for the fact that Spanish-accented English speech often has category boundaries closer to Spanish norms. Shifting is often tested in artificial language conditions (such as perception of [f] and [s] following an artificially ambiguous [?]), and there has not been extensive testing of shifting as a mechanism for comprehending variability in natural speech. Nonetheless, shifting is one of the leading mechanisms proposed by researchers to explain how listeners deal with variability (e.g., Reinisch & Holt, 2014). Zheng and Samuel (2020) addressed the necessity to link findings from perceptual shifting to broader level comprehension of accented speech. They tested whether magnitude of shifts in perceptual retuning correlated with improvements of comprehension of accented words and found no correlation between the two. They instead suggested that relaxation may better explain accent accommodation.
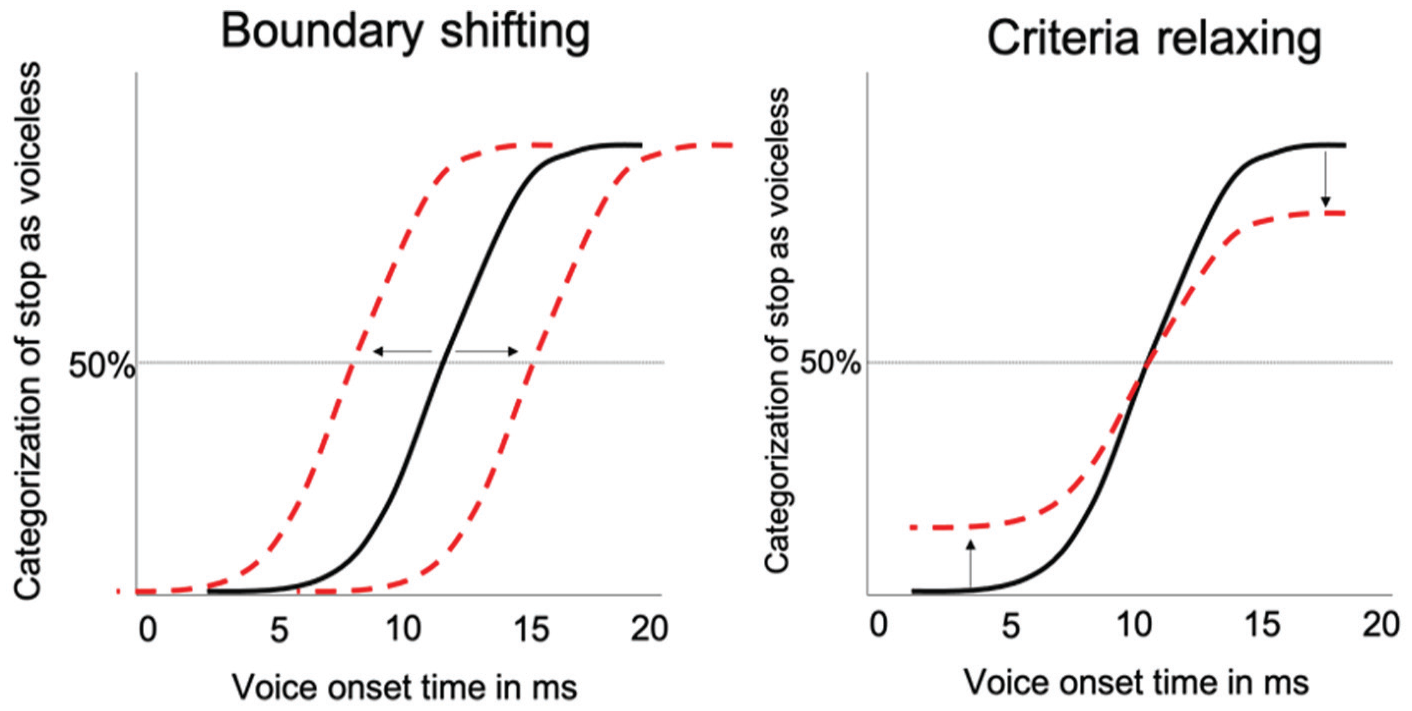
Demonstration of boundary shifting (left) and criteria relaxing (right). The solid curve represents pre-retuning categorization of a stop continuum based on voice onset time (VOT). The dotted curves represent how categorization may change after retuning. The point where the curves cross the 50% vertical line represents the category boundary.
The other method for responding to speech variability, known as criteria relaxing, phonetic relaxation, or general expansion (Llanos & Francis, 2017; Schmale et al., 2012; Zheng & Samuel, 2020), is a method by which a listener relaxes the strictness of what productions to accept as a specific phoneme. As the perceptual space of both phonemic categories expands, this leads to more overlap between the two categories and a weakening of the strength (or steepness in Figure 1) of the boundary. An alveolar stop sound with a VOT of 10 ms would likely be categorized as a /d/ by an English speaker but as a /t/ by a Spanish speaker. To facilitate processing of accented speech, a listener may relax their typical classification of a 10-ms VOT sound to allow for it to be classified as the non-dominant category more often. For an English speaker, this would mean accepting a 10-ms VOT as a /t/ at a higher rate than they normally would. Relaxing can be examined at the category boundary by testing how steep the slope at the boundary is to index overall amount of relaxing, but it can also be examined at the tails of each category. Relaxation may especially affect the tails for ranges that fall in ambiguous range cross-linguistically such as the 0–10 ms range for Spanish and English stimuli. Whereas a listener may need to relax categorization for sounds where categorization differs between languages (e.g., English /d/ and Spanish /t/ in the lower VOT values), there would be less need to relax the classification of a 70-ms VOT, which would fall to the right of the category boundary in both languages. Relaxing has been proposed as a general mechanism to support accented speech comprehension because it allows the listener to be less strict in what is accepted as a “correct” phoneme, therefore making it more likely that they can comprehend accented speech (Llanos & Francis, 2017; Tao & Taft, 2016; Zheng & Samuel, 2020).
Both mechanisms could be applied when using lexical context to guide retuning. A crucial element of lexically guided retuning is the presence of a lexical item to guide the top–down retuning process. Without the lexical context, the listener would have no cue as to how to shift or whether to relax their categorization. However, there are indications that the lexical context is not always necessary for perceptual changes to take place. Instead, bottom–up perceptual learning is possible through distributional or statistical learning. This has been a driving force behind explanations of infants’ acquisition of native phoneme perception before exhibiting detailed knowledge of words (Maye et al., 2002 but see Cristia, 2018) and it is an ability still present in adults (Maye & Gerken, 2000). Spanish–English bilingual children, who are the focus of the present study, are well-suited to test the role of lexically guided retuning, because they hear similar distributions of phonemes with and without lexical context that could guide retuning of English. Spanish-accented English input includes phoneme distributions more in-line with Spanish phonetics, but includes English lexical context to guide retuning. Native Spanish input, on the contrary, provides Spanish phoneme distributions in Spanish word contexts which would not be useful for lexically retuning in English. However, if bottom–up phoneme distributions are tracked by listeners, then retuning may be possible regardless of the lexical context of exposure and should happen similarly for Spanish and Spanish-accented English.
1.4 Current study
Linking perceptual learning to accent accommodation has been attempted with adults, but it is not clear whether and how children adapt to accented speech. This study aimed to examine how phoneme categorization in school-aged children who acquired Spanish before English was affected by the common types of speech exposure they receive in their environment: native English, native Spanish, and Spanish-accented English speech. Exposure was provided through listening to short clips of stories read by a speaker of one of the three types of speech. At testing, children’s perception of phoneme categories produced by a new native English speaker was examined. We were specifically interested in how perception of English plosives along the cue of VOT would be affected by each of the three exposure types. This was tested by having children classify plosive minimal pairs (e.g., gold–cold) from a continuum of VOTs across typical English ranges (e.g., 10–60 ms) after exposure to each type of speech. The English exposure condition served as a baseline for comparison to the other two exposure conditions. Crucially, both the native Spanish and Spanish-accented English speech conditions provided exposure to phonemes with Spanish-like VOT distributions; however, only the Spanish-accented English condition provided exposure in the context of English lexical items which may allow for the use of lexically guided retuning. Without lexical context to give the listener a hint to which phoneme a sound was meant to be, changes in categorization may not take place.
Two possible mechanisms behind accent adaptation were examined: boundary shifting and category relaxation. We predicted that if lexically guided retuning was used, then exposure to Spanish-accented English would cause a shift to a lower, more Spanish-like category boundary and more boundary relaxation as compared with exposure to native English speech. However when using lexically guided retuning, native Spanish exposure should not lead to any shifting or relaxing as the lexical context at exposure is not English. However, if retuning occurs from the bottom up, then we may find shifts to more Spanish-like boundaries and boundary relaxation after exposure to both Spanish-accented and Spanish speech. Importantly, the experimental design provides a strict test of retuning such that any adaption to the exposure speaker would have to be generalized to the new test speaker. Therefore, it is also possible that cross-speaker differences would lead to no changes regardless of exposure type.
2 Method
2.1 Participants
Sixty-eight participants between ages 6 and 9 years who were exposed to Spanish from birth and English as an L2 participated in this experiment as part of a larger study. At the time of testing, children were growing up in an English-dominant, metropolitan area in the Midwest US. Exclusionary criteria included exposure to English from birth (3 participants excluded), extensive exposure to a third language (defined as more than 5% weekly exposure), parental concern or a formal diagnosis of a language disorder, failure to pass a hearing screening, standardized receptive vocabulary scores in both languages more than 1.5 SD below the mean (3 participants excluded), and standardized nonverbal intelligence quotient (IQ) scores more than 1.5 SD below the mean (4 participants excluded). Following exclusion of these participants, and those excluded due to data cleaning procedures (1 participant), 57 participants were included in the final dataset. Participant characteristics for the final sample are available in Table 1.
Participant Characteristics.
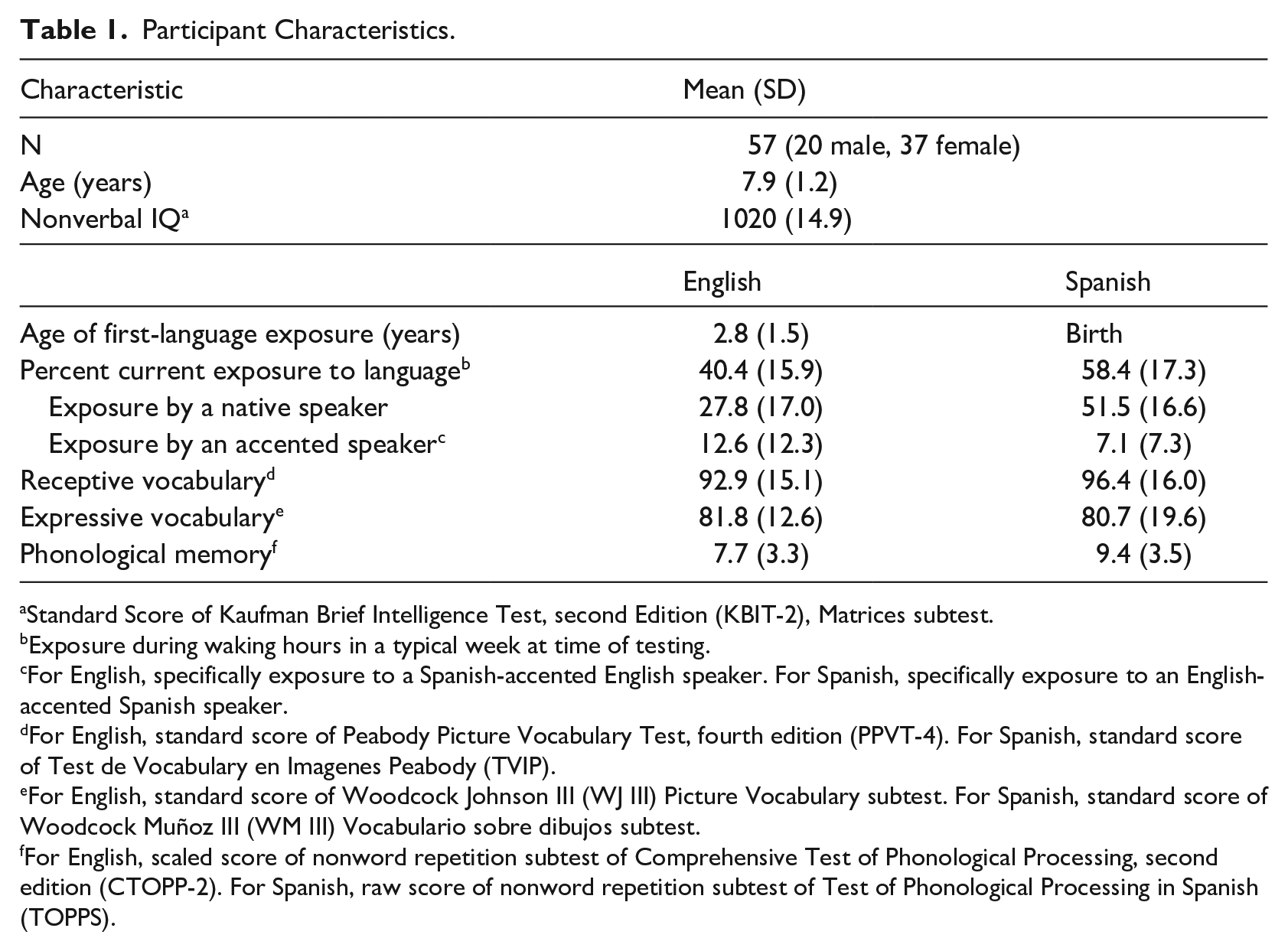
Standard Score of Kaufman Brief Intelligence Test, second Edition (KBIT-2), Matrices subtest.
Exposure during waking hours in a typical week at time of testing.
For English, specifically exposure to a Spanish-accented English speaker. For Spanish, specifically exposure to an English-accented Spanish speaker.
For English, standard score of Peabody Picture Vocabulary Test, fourth edition (PPVT-4). For Spanish, standard score of Test de Vocabulary en Imagenes Peabody (TVIP).
For English, standard score of Woodcock Johnson III (WJ III) Picture Vocabulary subtest. For Spanish, standard score of Woodcock Muñoz III (WM III) Vocabulario sobre dibujos subtest.
For English, scaled score of nonword repetition subtest of Comprehensive Test of Phonological Processing, second edition (CTOPP-2). For Spanish, raw score of nonword repetition subtest of Test of Phonological Processing in Spanish (TOPPS).
Children were administered standardized language tests in both English and Spanish. Expressive vocabulary in English was assessed with the Woodcock-Johnson III (WJ III; Woodcock et al., 2001) Picture Vocabulary subtest and expressive vocabulary in Spanish was assessed with the Woodcock-Muñoz III (WM III; Muñoz-Sandoval et al., 2005) Vocabulario sobre dibujos subtest. Receptive vocabulary in English was measured with the Peabody Picture Vocabulary Test-4 (PPVT-4; Dunn & Dunn, 2007) and receptive vocabulary in Spanish was measured with the Test de Vocabulary en Imagenes Peabody (TVIP; Dunn et al., 1986). Although overall receptive scores were slightly higher in Spanish than English, neither receptive, t(55) = 1.5, p = .15, nor expressive scores, t(55) = 0.3, p = .75, significantly differed between languages. The nonword repetition subtest of the Comprehensive Test of Phonological Processing-Second Edition (CTOPP-2; Wagner et al., 1999) was used to index English phonological memory and the nonword repetition subtest of the Test of Phonological Processing in Spanish (TOPPS; Francis et al., 2001) was used to index Spanish phonological memory. All participants also completed the Visual Matrices subtest of the Kaufman Brief Intelligence Test, Second Edition (KBIT-2; Kaufman & Kaufman, 2004) as a measure of nonverbal IQ. Finally, caregivers completed questionnaires about their child’s current language and accent exposure and language history.
Fifty-five caregivers provided answers to the background questionnaire related to schooling and language acquisition. Of these families, 62% reported their child was enrolled in Headstart, a program that provides early education services for families falling below federal poverty guidelines, when they were younger. Almost all families reported children receiving their first English exposure in an educational setting. At the time of testing, 65% of children were attending Spanish–English dual immersion schools and the majority of them received 50% English and 50% Spanish exposure in school. Overall, the children had more weekly exposure to Spanish than English. When further categorized into exposure to both native and accented speech in the two languages, Native Spanish exposure was the most common type of speech heard, followed by native English, then Spanish-accented English, and finally English-accented Spanish was the least common type of language exposure. Individual level data along with supplemental material and detailed explanations of analyses are available in the OSF repository: osf.io/bu8p4.
2.2 Stimuli
2.2.1 Exposure stories
Two child-friendly stories, each with three parts, were constructed in English and then professionally translated into Spanish. These stories were used to provide participants with exposure to the conditions of interest and to stop-initial words. Participants only heard one of the two stories. Each part of the stories was designed to include minimally a set of 18 stop-initial, early acquired nouns. These 18 words were placed in positions that would ensure that they would be produced as stop-initial words in both languages. In Spanish, it is common for stop-initial words in specific positions (e.g., after vowels or fricatives) to be spirantized such that there is no full closure and VOT cannot be measured (Fabiano-Smith et al., 2015). The careful placing of the 18 words after nasals or after a pause (such as in a list) ensured that the child would receive minimally 3 exposures to each of the targeted phonemes (i.e., /p, t, k, b, d, g/) in each condition; however, in reality, they received many more exposures to stop-initial words that naturally occurred throughout the story. The 18 words were chosen because they were stop-initial words in both English and Spanish (e.g., /d/ from dog in English but /p/ from perro in Spanish), but they were not cognates nor did they start orthographically with the same letter (e.g., gloves in English and guantes in Spanish was not part of the set). In both languages, the set of 18 words included an equal number of words from each extreme of the VOT continuum (9 voiced, 9 voiceless) and an equal number from each place of articulation (6 bilabial, 6 alveolar, 6 velar).
In addition to the 18 words in positions where they must be produced with full closures, in each English part of the story there were on average 52 other words that could potentially be produced as voiced stop-initial words and 45 potential voiceless stop-initial words. In Spanish, there were 71 potential voiced-stop initial words and 113 potential voiceless-stop initial words (and the high number of Spanish voiceless-stop initial words was in part due to 15% of the words in this set being “que”). Each part of the two stories had on average 523 words in English (range: 517–528) and 526 words in Spanish (range: 513–546). The full list of chosen 18 stop-initial words (which differed between stories) and full stories in English and Spanish are available in the OSF repository.
Stories were normed on a set of 8 native English-speaking adult listeners. They rated each part of the story for how interesting it was on a scale of 0 (not interesting)–10 (very interesting). They also rated stories as a whole. A paired samples t-test revealed that there were no differences on ratings of interest between the two stories for Part 1, t(7) = 2.0, p = .09; Part 2, t(7) = 1.8, p = .14; or Part 3, t(7) = 0.2, p = .84, of the stories. Stories were revealed to be comparable in overall ratings of interest as well, t(7) = 0.9, p = .40. Assignment of story was counterbalanced between participants to maximize the effects of the language-of-exposure manipulation and to minimize the effects of any idiosyncrasies associated with a particular story, or story part.
All stories were recorded in Audacity (Audacity Team, 2018) by females in their thirties in a sound attenuated booth using a Logitech USB microphone. This age was targeted to parallel the maternal input that school-aged children receive. Speakers were all residing in the Midwest US at the time of recording. From the set of story recordings gathered, which included 2 native English speakers and 3 native Spanish speakers, who also recorded Spanish-accented English stories, one speaker was chosen for each exposure category: a native English speaker, a native Spanish speaker, and a different Spanish-accented English speaker. Speaker characteristics of the 3 chosen speakers are available in Table 2. Following recording, the story parts were edited to remove any long pauses, non-speech sounds, and to normalize the intensity to the same level. Stop-initial words were further edited to ensure that for the English-speaker, the stop sounds had a VOT that fell within ranges of English (i.e., voiced: 0–30 ms; voiceless: 70–100 ms) and for the accented and Spanish speaker that they fell within the ranges of Spanish (i.e., voiced: 100–0 ms; voiceless: 0–30 ms). Although this range is on the extreme end for Spanish-accented English speaker, the values do represent natural variability, especially of a speaker with a strong accent (Thornburgh & Ryalls, 1998). Manipulation was implemented for short and long lag stops by either cutting or copying and inserting short portions of the recording between the burst release and voicing onset. Where necessary, prevoicing was added by inserting an instance of prevoicing from a different instance of a matching phoneme of the same speaker.
Speaker Characteristics.
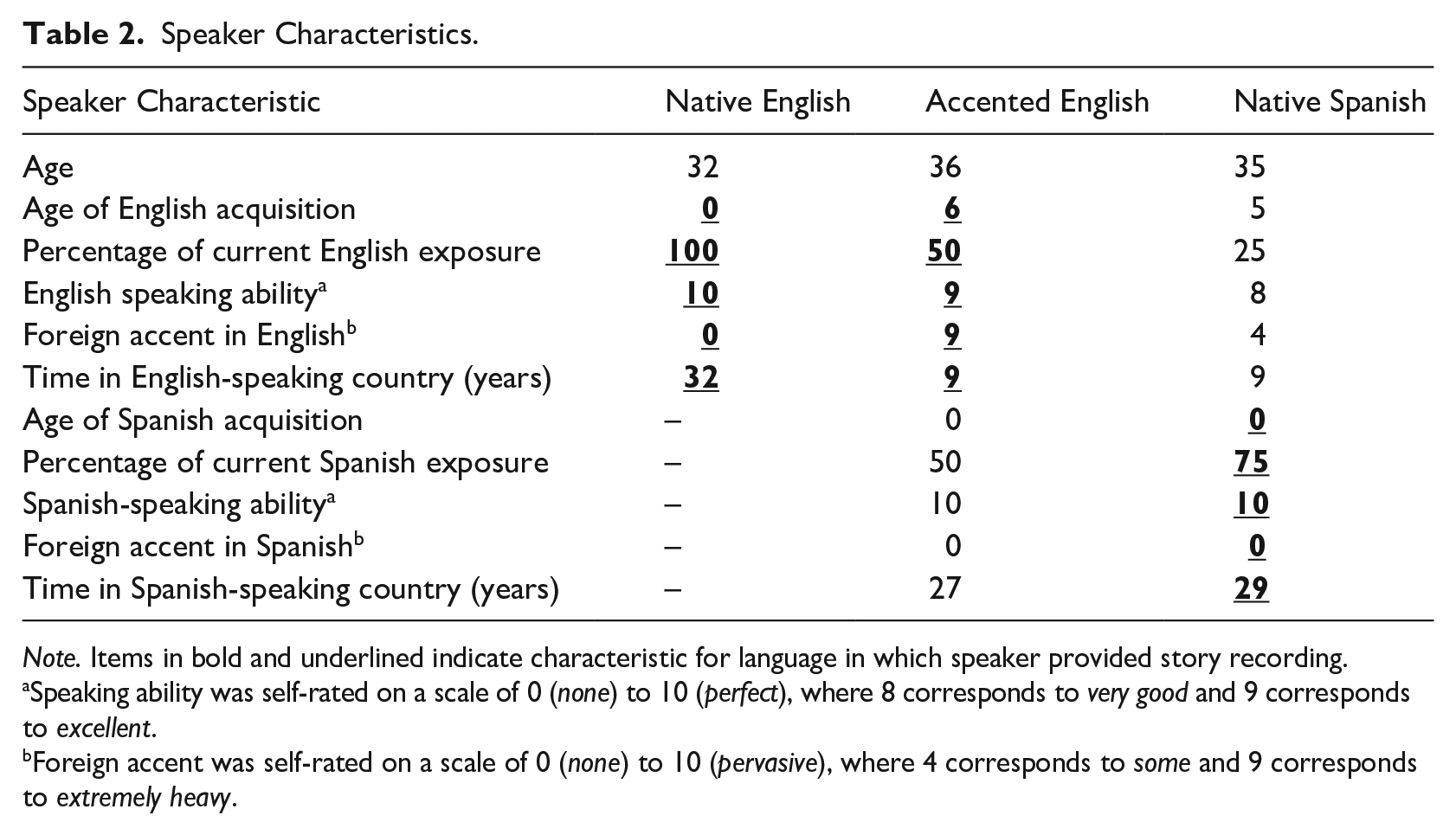
Note. Items in bold and underlined indicate characteristic for language in which speaker provided story recording.
Speaking ability was self-rated on a scale of 0 (none) to 10 (perfect), where 8 corresponds to very good and 9 corresponds to excellent.
Foreign accent was self-rated on a scale of 0 (none) to 10 (pervasive), where 4 corresponds to some and 9 corresponds to extremely heavy.
Stop-initial words that were approximated naturally by the speaker were not manipulated. This included 2% of voiced-stop initial words produced by the native English speaker, 5% of voiced-stop initial words produced by the accented speaker, and 57% of voiced-stop initial words produced by the Spanish speaker. The natural VOTs for each phoneme produced by each speaker before manipulation are available in Table 3. Values were adjusted to yield an absolute average change (i.e., measuring both lengthening and shortening with positive values) of 11.6 ms for the native English speaker, 63.6 ms for the accented speaker, and 19.6 ms for the Spanish speaker. For the accented speaker, the largest absolute changes were made by the addition of prevoicing; however, both voicing categories for the accented speaker’s productions underwent significant changes. The average VOT of each phoneme by each speaker after manipulation is available in Table 4. All other aspects of production associated with native and accented speech were allowed to vary naturally based on how the speakers normally read child-directed stories.
VOT (ms) of Stops Produced by Each Speaker and Phoneme Before Manipulation of the Stories.
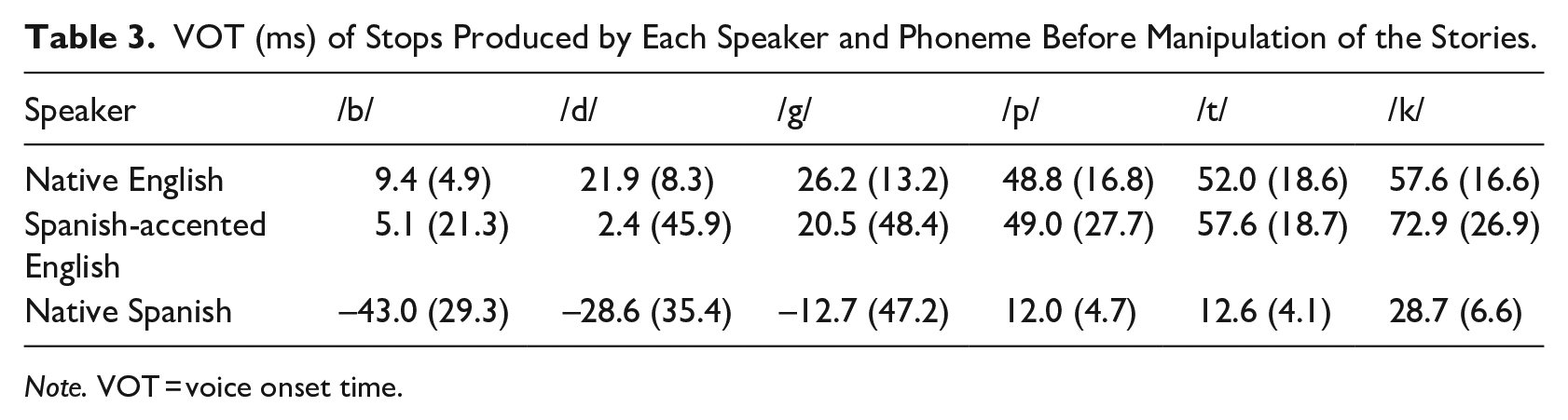
Note. VOT = voice onset time.
VOT (ms) of Stops Produced by Each Speaker and Phoneme After Manipulation of the Stories.
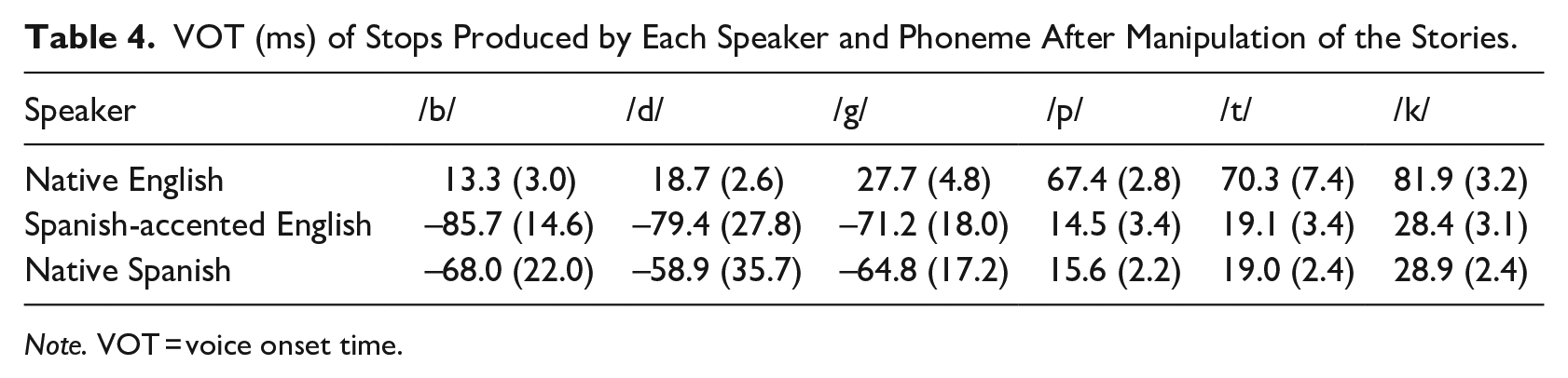
Note. VOT = voice onset time.
Children were exposed to the first part of the stories always in native English. This was done to ensure a similar starting point in exposure for all children. The language exposure prior to visiting the lab could not be controlled and starting with the same exposure condition allowed for some degree of control. The order of the second and third parts was counterbalanced between participants such that they were presented either in native Spanish second and Spanish-accented English third, or vice versa. The native English speaker read the first part of each story with an average duration of 2.6 minutes or speech rate of 4.7 syllables/second (3.3 words/second). The Spanish-native speaker had an average reading duration per story part of 3.9 minutes or a speech rate of 4.1 syllables/second (2.2 words/second). Finally, the Spanish-accented English speaker had an average reading duration of 3.7 minutes per story part or a speech rate of 3.3 syllables/second (2.34 words/second).
2.2.2 Minimal pair VOT continua
Three stop-initial minimal pair continua were created to test perceptual categorization. The targeted VOT range was 0–60 ms since this includes the range in which English category boundaries usually fall for stop sounds by Spanish-English bilingual and monolingual English children (Williams, 1979). One continuum was created for each of the three English places of stop articulation: bees–peas, dough–toe, gold–cold. These were chosen for similarity of word frequency across the two words, imageability, and early age of acquisition such that the children would be able to easily recognize them. None of the words were cognates in Spanish. Images are available in OSF.
The minimal pairs were recorded by a native English female speaker in her twenties in a sound attenuated booth. The recordings were manipulated in Praat using a script to create a VOT continuum (Winn, 2020), which included a word at every 10-ms increment. Because of restrictions associated with children’s attention, only 6 steps of each continuum were used in testing. The category boundary of bilabial stops is generally at a shorter VOT than other stops and velar stops tend to have category boundaries at higher VOTs. In order to accurately capture the most ambiguous VOT steps for each type of stop continuum, the bees–peas continuum was tested between 0 and 50 ms while the dough–toe and gold–cold continuums were tested between 10 and 60 ms. These ranges were confirmed to capture the category boundary (VOT at which classification was at 50% for all words) during piloting with Spanish–English bilingual child listeners, Spanish–English bilingual adult listeners, and native English adult listeners.
2.3 Procedure
The experimental task involved a two-alternative forced-choice paradigm. Children sat in front of a Tobii Prop T60XL eye-tracker and completed 5-point calibration. They eye-tracker was used to trigger the beginning of trials to ensure children were paying attention, and not to examine eye-gaze data. In front of children was a button box used to record responses. Children were first familiarized with the six pictures used to represent the minimal pairs of each of the 3 VOT continua (bees, peas, dough, toe, gold, cold). Children were asked to name the images and any images that were not labeled with the intended name were corrected. Following the familiarization with the image labels, the task was explained to the children. They were told that they would hear a story with three parts. No mention of the language in which the task would be presented was included. Children were told that following each part of the story, they would play a game that involved seeing two pictures, one on the left and one on the right side of the screen. Children were instructed to look at the fixation video in the middle of the screen, listen, and choose the image that matched the target word by pressing the corresponding left or right button on the button box. Participants performed six practice trials to understand the task and the necessity to look to the fixation video in order for the task to move forward. The six trials were the extremes of the 3 minimal pair continua to further ensure that the children knew the labels of the words. If the child did not answer correctly (e.g., chose bees when the word presented was peas) they were given corrective feedback. During practice trials, 88% of participants identified all 6 or 5 of 6 words on their first try. Five participants identified 4 words, one participant identified 3 words and one participant identified 2 words on their first try. During data cleaning steps, the 3 continua of each participant were examined to ensure that even children who did not give all correct answers at practice gave reasonable answers at test and any child who clearly confused labels was excluded. Finally, children were given a chance to ask questions before the first part of the story began.
During the exposure stories and the testing blocks, the experimenter sat behind participants and interacted as little as possible with them while keeping them focused on the task. When intervention was necessary to assure that children were attentive, the experimenter provided nonverbal cues such as pointing to the screen or tapping them on the shoulder to encourage them to sit up. This was done in order to not give the children any exposure to a voice other than the exposure story speaker and test item speaker.
During testing blocks, the timing of the trial included 500 ms of the 2 pictures being presented before the fixation video appeared. The fixation video disappeared when the child made a fixation of at least 100 ms to the video or after 2,500 ms passed without a fixation to the center of the screen. The fixation video disappeared as the target word played, and the two images disappeared when the child made a button push or if 5,000 ms passed without an answer. There was a 200 ms interstimulus interval between trials. The location of the two images was counterbalanced across trials (e.g., bees was on the left for half of the bees-peas trials and on the right for the other half). Each of the 6 steps of the VOT continua was repeated 5 times for each of the 3 different continua for a total of 90 categorization trials following each story part. There were also 30 filler trials within each testing block which required children to identify words that were not stop-initial (e.g., flower). All 120 trials were randomized within a test block. Children were able to choose a sticker and take a break after completing each test block. The experimenter spoke to the child in their preferred language during this time, and the majority spoke English with the experimenter.
2.4 Analyses
All data cleaning steps and analyses are available in the OSF repository. The dataset was first assessed for any children that did not understand the task or were answering at random. In order to exclude these children, the data were checked for those who selected the same item for more than 90% of trials (i.e., always chose the bees image) and those who answered near chance at both extremes of the VOT continuum. No children were identified from these steps. To ensure that children who did not know the test words (e.g., bees, peas) even after practice were not included, the 3 continua for each participant were examined separately. If at the extremes of the continuum, a child’s answers did not indicate accurate categorical perception, the continuum was excluded for that child. Accurate categorical perception was defined as selecting voiceless stops more at the higher extreme (e.g., at 50 ms for beas–peas continuum) than at the lower extreme of the continuums (e.g., at 0 ms for beas–peas continuum). This led to the exclusion of 7 continua from 5 children. Following data cleaning, the number of trials provided for each continuum in each condition for each participant was examined, and when a participant provided less than a third of the possible trials (less than 10) for a specific continuum in a specific condition, the continuum was removed. Finally, any continuum for a specific participant for which there were no data available in more than one condition was removed.
A total of 13,484 trials were available for the final analysis. Three separate analyses were conducted to examine how exposure affected phoneme categorization. The first analysis examined boundary shifting on the VOT continuum, the second examined the change in slope of the category boundary, and the third involved categorization of the words at the extremes of the VOT continua. The second two analyses indexed criteria relaxing. Post hoc analyses to examine effects of block order were run as well. Analyses were run in R using the lme4 (v1.1.26; Bates et al., 2015), afex (v0.28.1; Singmann et al., 2017), car (v3.0.10; Fox & Weisberg, 2019), emmeans (v1.5.4; Lenth, 2019), lattice (v0.20.41; Sarkar, 2008), HLMdiag (v0.4.0; Loy & Hofmann, 2014), MuMIn (v1.43.17; Bartoń, 2020), and DHARMa (v0.4.1; Hartig, 2021) packages.
2.4.1 Category boundary shifting
The category boundary between the pair of phonemes for each continuum was calculated for each participant in each exposure condition. Each boundary was calculated using the maximum available trials from the 30 possible trials in each exposure condition (5 repetitions of 6-step continuum) based on a logistic regression model. The logistic regression model created a curve similar to that in Figure 1 and was represented by an intercept (α) and beta value (β) which can be entered into the logistic equation
A linear mixed effect model was created with category boundary as the outcome variable and fixed effects of exposure (English, accent, Spanish), continuum (/b–p/, /d–t/, /g–k/), and their interaction. Exposure was reference coded with English as the reference group. Continuum was sum coded. Random effects included a by-participant intercept, a by-participant slope for exposure, and a by-participant slope for continuum. Following model fitting, model assumptions were checked, and 6 data points were identified as regression outliers (more than 2.5 SD from mean residual) and removed. The final model included 429 category boundaries. Follow-up analyses on any significant effects were conducted using pairwise Tukey least significant difference (LSD) tests.
2.4.2 Slope at category boundary
Using the same 429 continua that remained after exclusion for unreasonable category boundary values, the slopes of the curve at the category boundary were calculated. This was done by taking the derivative of each logistic equation, setting x to the median effective level (or the location where the curve crossed chance level), and then solving the equation to find the slope at this point. The equation simplifies to 0.25 * β, where β represents the beta value of the model created for each curve (Agresti, 2018). One slope that was negative was removed from analysis. Owing to the fact that the curve had to be predicted with a limited number of data points (30 or less) in each condition for each participant, slopes fell into three main categories ([0,0.08], [0.5,0.55], [1.1,1.2]) with large gaps in between them. Upon inspection, the rank order of slopes was correct—high numbers indicated a steeper slope and more differentiation between categories; however, to account for the lack of constant variance, the ranked slopes were inverse normal transformed (i.e., rankit, Bishara & Hittner, 2012) before being entered into the linear mixed effect model. The same model that was fitted for the category boundary analysis was applied to the transformed slopes. The full random effects structure led to convergence problems, so the model was simplified until it converged. The final model included a by-participant random intercept. Model assumptions were checked for this model, and 5 regression outliers were removed for a total of 423 data points used in this analysis. Follow-up tests were carried out similarly as above.
2.4.3 Categorization at extremes
Accuracy at the extremes of the VOT continua was examined by checking the choice of the dominant category at the two extremes of the continuum—voiced stops for the first two steps and voiceless stops for the last two steps. The data were not aggregated by participant for this analysis, and the outcome variable was binomial, coded 1 for dominant and 0 for non-dominant category. The full dataset with all 57 participants was used for this analysis. A logistic mixed effect model was created with the binary outcome variable, fixed effects of exposure, continuum, and voicing [voiced stop (Steps 1 and 2), voiceless stop (Steps 5 and 6)], and all higher order interactions between the three variables. Voicing was deviation coded (−0.5, 0.5) and other variables were coded the same as the previous models. The full random structure did not converge, and instead, the final model included a random by-participant intercept. Model comparisons were used to determine significance of predictors. A check of model assumptions did not reveal any problems. Means are reported as proportions, and comparisons as odds ratios.
3 Results
3.1 Category boundary shifting
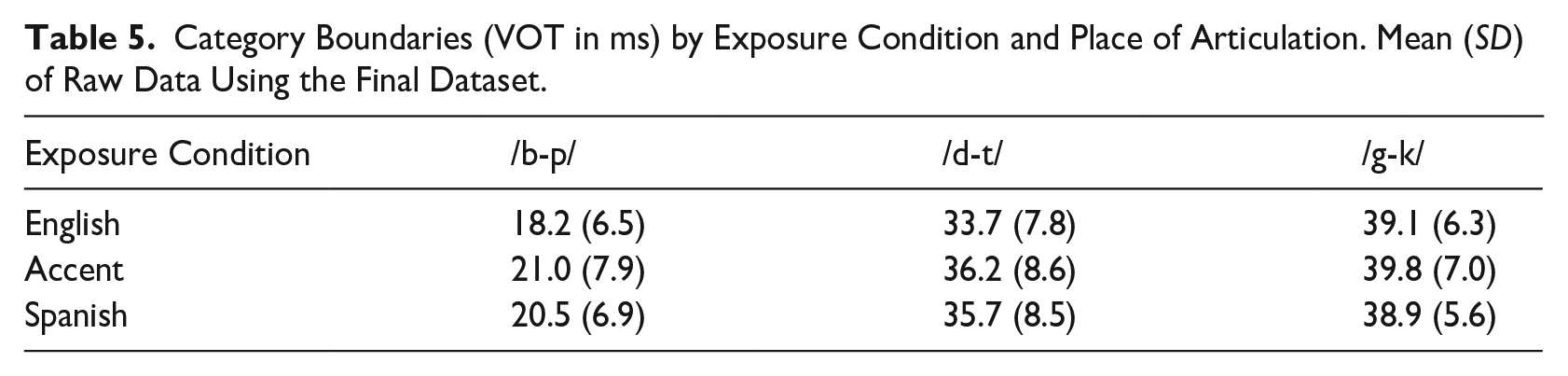
See Figure 2 for a depiction of identification curves. There was a significant effect of exposure, F(2, 49) = 13.7, p < .001, on category boundary such that the estimated category boundary in the accent condition, M = 32.5, SE = 0.7, was significantly higher than in the English condition, M = 30.2, SE = 0.6; β = −2.3, SE = 0.4, p < .001. The estimated Spanish category boundary, M = 31.8, SE = 0.7, fell in between the other two boundaries and was significantly higher than the English condition, β = −1.6, SE = 0.6, p = .03, but did not differ from the accent condition, β = 0.7, SE = 0.6, p = .42. The effect of continuum was also significant, F(2, 75) = 121.1, p < .001, such that the /b-p/ continuum had the lowest category boundary, M = 20.5, SE = 1.0, which significantly differed from the category boundary for /d-t/, M = 34.5, SE = 1.1; β = −14.0, SE = 1.6, p < .001, and /g-k/, (M = 39.4, SE = 0.8; β = −19.0, SE = 1.2, p < .001. The category boundary for /d-t/ and /g-k/ also significantly differed, β = −5.0, SE = 1.2, p < .001. Finally the interaction of exposure and continuum was not significant, F(4, 182) = 2.1, p = .08. Average boundaries of each continuum in each condition based on the raw data can be found in Table 5. The full model summary can be found in supplementary materials.
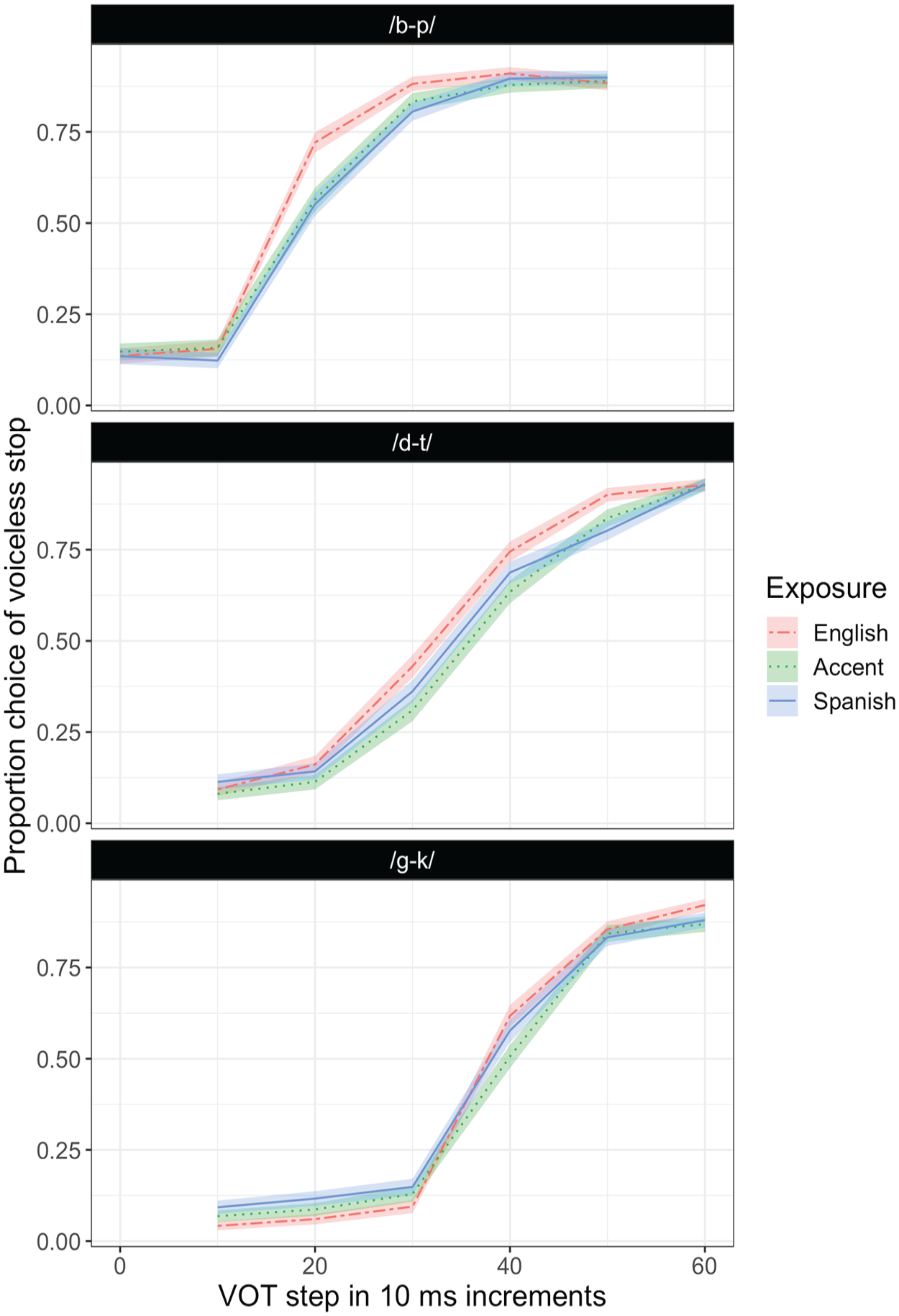
Raw performance for categorization of stops on VOT continua by exposure type.
Category Boundaries (VOT in ms) by Exposure Condition and Place of Articulation. Mean (SD) of Raw Data Using the Final Dataset.
3.2 Slope at category boundary
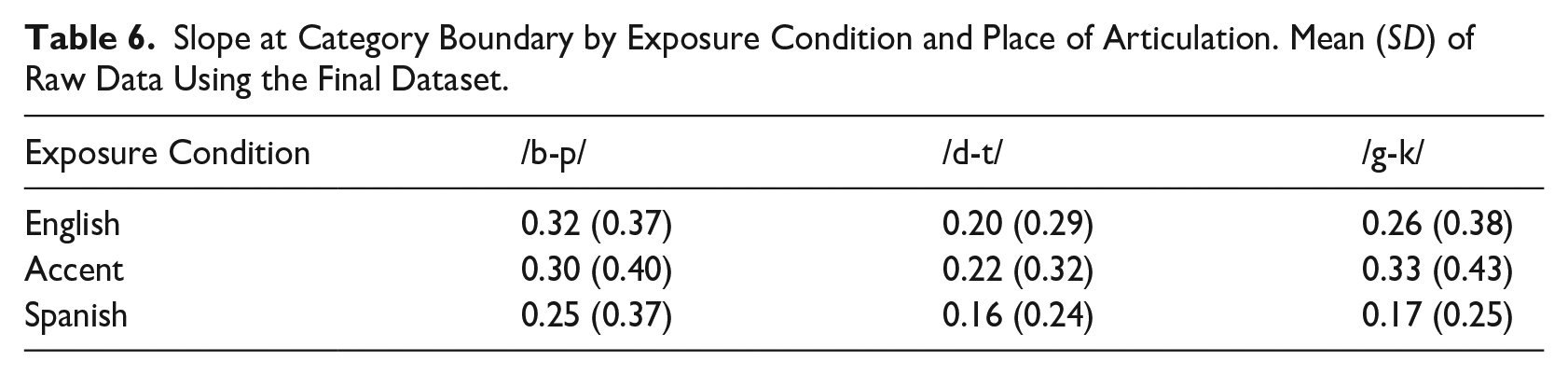
There was a significant main effect of exposure, F (2, 362) = 3.5, p = .03, on the transformed slope at the category boundary such that the predicted slope was significantly more shallow in the Spanish condition, Mtransformed = −0.27, SE = 0.12, than in the English condition, Mtransformed = −0.06 SE = 0.12, β = 0.22, SE = 0.08, p = .03. The slope was also more shallow in the Spanish than the accent condition, Mtransformed = −0.14, SE = 0.12, but this difference was not significant, β = 0.14, SE = 0.08, p = .23. There was no difference in slope of the accent and English condition, β = 0.08, SE = 0.08, p = .60. The effect of continuum, F (2, 362) = 1.3, p = .27, and the interaction between exposure and continuum were not significant, F (4, 361) = 0.9, p = .48. Average slope at the category boundary for each continuum in each condition can be found in Table 6.
Slope at Category Boundary by Exposure Condition and Place of Articulation. Mean (SD) of Raw Data Using the Final Dataset.
3.3 Categorization at extremes
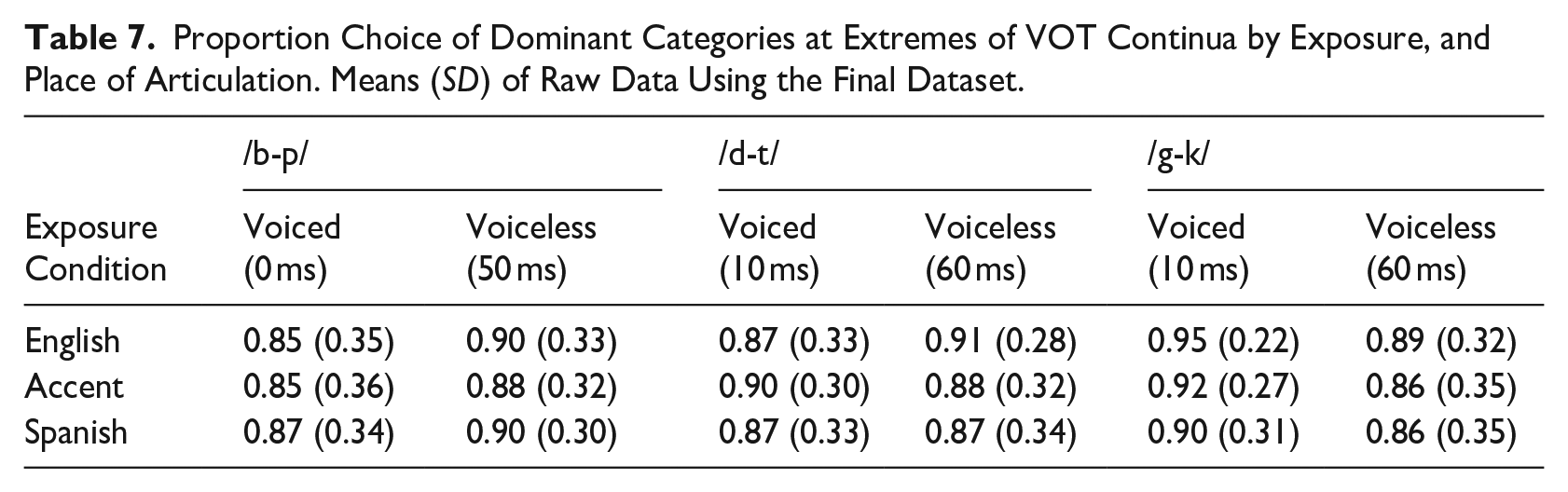
There was a significant effect of exposure, χ2 (2) = 13.9, p < .001; continuum, χ2 (2) = 9.9, p = .01; and a significant interaction between exposure and continuum, χ2 (4) = 10.0, p = .04, on categorization at the extremes. The interaction indicated that a significant difference between exposure conditions was only present for the /g-k/ continuum and the difference was such that predicted accuracy on the continuum for the English condition, M = .95, SE = 0.01, was significantly higher than the accent, M = .92, SE = 0.01; OR = 1.6, SE = 0.3, p = .01, and the Spanish condition, M = .91, SE = 0.02; OR = 1.9, SE = 0.3, p < .001. The accent and Spanish conditions did not significantly differ from each other for the /g-k/ continuum, OR = 1.2, SE = 0.2, p = .51. Finally, there was also a significant interaction between continuum and voicing, χ2 (2) = 39.3, p < .001, such that accuracy at both voicing extremes did not differ for /d/, M = .91, SE = 0.02, and /t/, M = .91, SE = 0.01; OR = 0.9, SE = 0.1, p = .58, but did for the other two continuums. Participants were more accurate for /p/, M = .92, SE = 0.01, than /b/, M = .89, SE = 0.02; OR = 0.7, SE = 0.1, p < .002, but were more accurate for /g/, M = .95, SE = 0.01, than /k/, M = .90, SE = 0.02; OR = 2.0, SE = 0.3, p < .001. This interaction between continuum and voicing does not involve the exposure variable, and therefore is not of interest here. Further nonsignificant effects included that of voicing, χ2 (1) = 1.5, p = .22; the interaction between exposure and voicing, χ2 (2) = 1.5, p = .47; and the three-way interaction between exposure, continuum, and voicing, χ2 (4) = 6.8, p = .15. The full model summary is available in supplementary materials. Average choice of the dominant category for the extremes of each continuum in each condition can be found in Table 7.
Proportion Choice of Dominant Categories at Extremes of VOT Continua by Exposure, and Place of Articulation. Means (SD) of Raw Data Using the Final Dataset.
3.4 Block order effects
Since all participants received exposure to the native English speaker first, post hoc analyses examined how order of presentation may have driven results due to fatigue, acclimation to the task, or the test speaker’s voice. Full analyses and visualizations are available in supplementary analyses on OSF. First, the English exposure block was examined on its own. To examine if children adapted to the test speaker’s voice, performance during the first 45 versus the last 45 trials of testing following English exposure was examined. Category boundary and slope did not significantly differ between the first versus the last trials. This effect also did not significantly interact with place of articulation for category boundary and slope. Therefore, the lower category boundary found after native English exposure is likely not due to the fact that it was the first time participants heard the test speaker’s voice.
Another post hoc analysis examined block effects in the counterbalanced second and third blocks. The variables order (2nd or 3rd) and non-English exposure conditions (Spanish or Accent) were used. One set of models included the three-way interaction among order, exposure, and continuum with the same random effects as in the analyses for boundary and slope above. Another set of models did not include the effect of continuum to simplify the model. In all models run, the effect of order and its interaction with other effects were not significant.
4 Discussion
The effects of exposure to native Spanish, native English, and Spanish-accented English speech on school-aged Spanish-English bilingual children’s categorization of English voiced and voiceless stops was examined in this study. Bilingual children presented with different patterns of adaption to the different types of speech. Contrary to our hypothesis, following exposure to Spanish-accented English speech, the category boundary between voiced and voiceless stops when processing English words was shifted to a higher, more English-like category boundary as compared with the boundary following native English exposure. Categorization at the extremes indicated that some criteria relaxation may have been taking place following accented exposure, but only for velar stops. Following native Spanish exposure, children shifted to a more English-like category boundary and also showed criteria relaxation.
The category boundary shift after exposure to the accented speaker was in a more English-like direction, contrary to our hypothesis. Rather than capturing accommodation to accented and Spanish speech, it appears that we captured the effects of returning to processing native English after exposure to speech variability. Our test speaker was a fourth, native-English speaker who differed from all of the exposure story speakers. This design allowed a strong direct comparison between exposure conditions, but hindered us from knowing how children categorized sounds during the exposure phase. The test speaker’s use of English words may have been a strong enough cue to prompt children to switch or shift to English-like processing rather than maintain boundaries used to process speech during the exposure phase. The unexpected finding that this return to English processing was more “English-like” after exposure to Spanish phonemes than after exposure to native English phonemes may have to do with the juxtaposition between the Spanish and English phonologies. Presenting the test speaker immediately after an accented or Spanish speaker may have made the differences in phonemic targets more salient, leading to the more exaggerated shift. It is clear that following exposure to native Spanish and Spanish-accented English, with both exposures providing access to Spanish category boundaries, children did not categorize English speech with lower, more Spanish-like boundaries.
Criteria relaxation, which was found following exposure to Spanish speech, aligns with our predictions that listeners would be less stringent in their acceptance of stops to each category after exposure to Spanish phonology if perceptual tuning is bottom up. However, if this was the case, we would expect exposure to accented speech to also lead to criteria relaxation, and yet, we found only modest evidence of relaxation after accented exposure for the /g-k/ continuum. Criteria relaxation was indicated in the Spanish condition as the category boundary was not as steep after native Spanish exposure as it was after native English exposure. This was the case for all contrasts, and it was especially visible at the extremes of the continuum for velar stops. However, because the test speaker was always a native speaker of English, we cannot differentiate whether the relaxation was specific to English, or generalized broadly to the whole phonological system. Whether this effect would be observed in situations where testing occurred with a Spanish or accented speaker is unclear. In adults, relaxation has generally been cited as a way to deal with accented speech rather than speech from a different language (Llanos & Francis, 2017; Maye et al., 2008; Zheng & Samuel, 2020). Rather than being a mechanism specifically for accented speech, it may be a mechanism well-suited for environments which contain multiple different types of speech (i.e., two languages or multiple accents).
Our experiment provides some hints as to why accented speech comprehension does not reach adult-like levels until well into adolescence (Bent, 2018). Children may not yet be applying the mechanisms necessary to adapt to accented speech, despite having the ability to do so. Zheng and Samuel (2020) found more evidence for criteria relaxation than boundary shifting as a mechanism for natural accent adaptation in adults. Examination of performance in the accented condition suggests that criteria relaxation may not yet be strongly used by children. However, we have evidence that children were capable of criteria relaxation, as in the Spanish condition, but they simply did not do so to a large degree after accented speech exposure. On the other hand, children shifted boundaries to a large degree after exposure to accent. It is likely that listeners both relax criteria and shift boundaries over the course of processing speech variability. It may be that the use of each mechanism has not yet been fully calibrated in children, such that they rely too much on boundary shifting and not enough on criteria relaxation during accented speech processing.
Our results show that children are capable of using the perceptual retuning mechanisms in their L2 when encountering speech variability. Past research has found that children are capable of retuning categories to accommodate artificially induced phonological deviations in their native language (e.g., [?] instead of [s] as in McQueen et al., 2012) and a separate line of research has shown that children in the school age range are capable of accommodating accented speech broadly (e.g., Bent & Atagi, 2017). Our findings indicate that similar mechanisms may be used by children, though not fully proficiently, when processing speech variability in a second language. Even in adults, perceptual retuning in an L2 has been shown to be possible (Cooper & Bradlow, 2018; Reinisch et al., 2013), but not consistent (Cutler et al., 2018; Llanos & Francis, 2017). The structure of the phonologies of the two languages being examined affects performance in adults and this point is relevant to children as well. In a study with English and Mandarin listeners, Cutler et al. (2018) found perceptual retuning of English following English exposure in native English listeners, but not in L2 English listeners. Cutler and colleagues (2018) posit that the skill of perceptual retuning may not occur in an L2 if the L2 (English) has a larger phonemic inventory, or lacks critical cues to a contrast as compared with the L1 (Mandarin). In our study, L2 English had both a larger phonemic inventory than Spanish and lacked the critical prevoicing cue specific to the contrast we targeted. This lack of symmetry may make it more difficult to apply perceptual learning in L2 English, but would not preclude it from being captured in the other direction—if we had tested adaptation in Spanish with L1 English bilinguals.
Our findings indicate that while effects of exposure to native English differed from the other exposure types, effects of exposure to accented and Spanish speech never significantly differed from each other. Therefore, lexically guided retuning did not play a strong role in driving adaptation. When exposed to Spanish-accented speech, the Spanish phonemes were embedded in English words and this was expected to aid in children’s shifting of perceptual boundaries. When exposed to Spanish speech, Spanish phonemes were embedded in words, but as the words were Spanish, it was not expected that the lexical context would drive adaptation in English. Yet, as performance in the accent and native Spanish conditions did not differ, it is likely that lexically guided retuning was not at play. Rather, differences between the English condition and the other two conditions may have been due to exposure to different distributions of phonemes across the VOT cue. While lexically guided retuning is often construed as a top–down process, it has also been suggested that retuning can happen as a bottom-up process simply due to statistical learning of the phonetic distribution (Idemaru & Holt, 2014; Schertz et al., 2016). If children in this experiment adjusted their perception based simply on phoneme distributions, then similar performance in the Spanish and Spanish-accented English condition would be expected as the distribution of voiced and voiceless stops along the cue of VOT were almost the same in these two conditions. Therefore, bottom–up learning could be the mechanism driving differences between the English condition and the other two conditions in our experiment. This explanation does require the presupposition that distributional learning is language-independent, that is, that distributional learning of Spanish can affect perception in English. This idea has received some support in the bilingualism literature where the perceptual space is increasingly considered to be nonindependent in children (Persici et al., 2019) and adults (e.g., Marian & Spivey, 2003).
We must take care when interpreting the findings of this study because it is possible that the first exposure condition being always fixed to native English affected the results. Despite a lack of evidence of this from post hoc analyses, future studies would need to confirm that these results hold with a different order of testing. A further point to consider is that we manipulated the VOT for each condition to be within an absolute range, which may have led to unnatural productions. The range of VOT for the accented speaker specifically, incurred the most manipulations to add prevoicing to some items that were not prevoiced as well as to shorten the VOT of some voiceless stops. The speaker naturally produced VOTs that were within the range of typical Spanish–English bilinguals, but they were not as extreme as the ones associated with strongly accented speech. This speaker was chosen because they had a perceptible accent and yet were highly intelligible. We aimed to only manipulate the phonetic and phonological elements of accented speech and not additionally have differences in how reliably children might perceive the speaker’s speech. The outcome of this choices is that the manipulated VOTs may have seemed less natural. This may have contributed to the unexpected direction of the shift in category boundary after accented speech exposure. Examining performance after exposure to different strengths of accents, including those with VOT values naturally more similar to Spanish and those naturally more similar to English would also be an informative follow-up experiment. The manipulation to absolute ranges also did not take into account how speech rate may affect VOT (e.g., Magloire & Green, 1999). The English speaker naturally read stories faster than the other two speakers, which could lead to her VOTs being perceived to be exaggeratedly long. However, this is still in line with the manipulation to have the English speaker have longer VOTs than the other two speakers. Altogether, although we maintained control of VOT values themselves, some of the natural variability present in the different speakers was not fully accounted for. Follow-up studies with other speakers would help confirm whether effects are voice-specific or generalize to other speakers. In addition, as we only focused on a single cue, we did not capture adaptation to other cues or reweighting of cue reliance. Future studies should examine more than a single cue to form the full picture of how children adapt to accented speech.
5 Conclusion
We have demonstrated that comprehension of an L2 in bilingual children is affected by the natural language environments to which bilinguals are exposed in their day-to-day life. School-aged bilingual children made subtle changes to phoneme classification in English in response to the 3-minute language exposure they had encountered. When exposed to Spanish-accented English speech, they were more likely to shift their category boundary to be more English-like than after exposure to native English speech. When exposed to native Spanish speech, they shifted to a smaller extent, and relaxed category boundaries as compared with exposure to native English speech. We have demonstrated that phonological shifting and relaxing are both used by bilingual children to accommodate to different types of language exposure, and that bottom up retuning broadly explains our results better than lexically guided retuning. Future work would need to consider how these mechanisms are applied to a variety of phonemic contrasts during accent processing to determine if relaxation and boundary shifting are generalized mechanisms or if they are contrast-specific.
Footnotes
Acknowledgements
The authors thank all the children and caregivers who participated in the study, and the members of the Language Acquisition and Bilingualism Lab and Centre for Child Language Research for assistance in data collection, coding, and manuscript review. They especially thank Tania Zamuner for helpful comments on the manuscript.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Institutes of Health National Institute on Deafness and Other Communication Disorders (grant nos. R01 DC016015 and P30 HD003352) and the National Science Foundation (grant no. BCS-1749378).
Supplemental material
Supplemental material for this article is available online.