
Abstract
Previous research has shown that native listeners benefit from clearly produced speech, as well as from predictable semantic context when these enhancements are delivered in native speech. However, it is unclear whether native listeners benefit from acoustic and semantic enhancements differently when listening to other varieties of speech, including non-native speech. The current study examines to what extent native English listeners benefit from acoustic and semantic cues present in native and non-native English speech. Native English listeners transcribed sentence final words that were of different levels of semantic predictability, produced in plain- or clear-speaking styles by Native English talkers and by native Mandarin talkers of higher- and lower-proficiency in English. The perception results demonstrated that listeners benefited from semantic cues in higher- and lower-proficiency talkers’ speech (i.e., transcribed speech more accurately), but not from acoustic cues, even though higher-proficiency talkers did make substantial acoustic enhancements from plain to clear speech. The current results suggest that native listeners benefit more robustly from semantic cues than from acoustic cues when those cues are embedded in non-native speech.
1 Introduction
A variety of factors impact how listeners perceive speech. Some factors can make understanding speech more difficult (e.g., listening to an unfamiliar talker or someone from an unfamiliar language background, or in a noisy environment). Particularly, communication breakdowns can occur when speakers do not share a native language background, including when native listeners have difficulty understanding speech produced by non-native speakers of the language (e.g., Rogers et al., 2004). This problem can be further exacerbated for listeners who are older adults (e.g., Bieber & Gordon-Salant, 2017; Burda et al., 2003; Gordon-Salant et al., 2013; Janse & Adank, 2012) and listeners with hearing impairment (e.g., Hau et al., 2020).
Difficulty understanding speech could be mitigated by factors related to semantic content as well as acoustic characteristics of the delivery of the speech. For example, utterances that are semantically predictable are typically better understood than utterances that are not (Kalikow et al., 1977). Furthermore, talkers can also enhance the clarity of their speech by shifting their speaking style, which results in acoustic enhancements in the speech signal (Picheny et al., 1986). However, the bulk of the prior work investigating semantic and acoustic enhancements in speech has largely focused on the perception of native speakers’ speech by other native speakers. Thus, to better understand the benefits of semantic and acoustic enhancements in broader speech communication contexts than previously known, we investigate how native listeners perceive non-native speech that includes acoustic and/or semantic enhancements. Below, we review relevant previous literature about both types of enhancements.
1.1 Perceptual benefits associated with acoustic enhancements
Previous studies have demonstrated that when talkers are aware of the difficulty that listeners experience understanding speech, they engage in a speaking style, described as clear speech, to enhance acoustic-phonetic properties of their speech (e.g., Smiljanić & Bradlow, 2009; Uchanski, 2005). Such clear speech enhancements are manifested as various types of acoustic modifications. For example, to increase the overall salience of the speech signal (Bradlow & Bent, 2002), native English talkers speak with higher fundamental frequency (F0), wider F0 range, increased intensity, as well as increased energy in the 1000- to 3000-Hz range of long-term spectra (e.g., Bradlow et al., 2003; Liu et al., 2004; Picheny et al., 1986; Smiljanić & Bradlow, 2005). Furthermore, talkers slow down their speech by lengthening segments, as well as by inserting more frequent pauses (e.g., Bradlow et al., 2003; Ferguson & Kewley-Port, 2002; Krause & Braida, 2004; Picheny et al., 1986; Smiljanić & Bradlow, 2005). Studies have reported robust intelligibility gains resulting from such clear speech enhancements for listeners from various populations, including hearing-impaired listeners and non-native listeners (e.g., Bradlow & Alexander, 2007; Bradlow & Bent, 2002; Ferguson, 2004; Krause & Braida, 2002; Liu et al., 2004; Picheny et al., 1985; Schum, 1996; Uchanski et al., 1996). A similar clear speech intelligibility benefit has also been reported for native talkers and native listeners of languages other than English, including Croatian and French (Gagné et al., 2002; Smiljanić & Bradlow, 2005).
While clear speech enhancements made in talkers’ native languages have been shown to result in robust intelligibility gains for a variety of listeners, much less is known about how clear speech enhancements made in a non-native language are perceived by native listeners. Specifically, existing literature regarding intelligibility gains resulting from non-native talkers’ clear speech enhancements is mostly limited to those produced by highly proficient non-native talkers. For example, acoustic enhancements made by highly proficient non-native talkers can be as effective as those made by native talkers. This is shown in the comparable size of intelligibility gains resulting from clear speech enhancements made by native talkers and by highly proficient speakers or those who acquire the second language early (Rogers et al., 2010; Smiljanić & Bradlow, 2005, 2011), as well as in the types of acoustic modifications made by native talkers and by proficient non-native talkers (Granlund et al., 2012). However, data from non-native talkers of lower proficiency are relatively scarce. One study demonstrated that late second-language learners of English were much less effective at enhancing the intelligibility of English vowels than learners who acquire the language early and native English talkers (Rogers et al., 2010). Specifically, clear speech enhancements of English vowels in /bVd/ syllables produced by monolingual native English talkers and early learners of English whose native language is Spanish resulted in similar intelligibility gains, whereas those produced by late learners of English with the same native language background resulted in much smaller intelligibility gains. In fact, the late learners’ clear speech enhancements sometimes resulted in a decrease in intelligibility.
These studies suggest that the perceptual benefits that native listeners receive from non-native talkers’ clear speech enhancements may be impacted by the talkers’ target language proficiency level. Specifically, for native listeners, the size of intelligibility improvement resulting from higher-proficiency talkers’ clear speech enhancements may be larger than those of lower-proficiency talkers. However, such investigation has been limited to the perception experiments using materials which have limited semantic context (e.g., semantically anomalous sentences: Smiljanić & Bradlow, 2011; bVd syllables: Rogers et al., 2010), while listeners’ understanding of speech in everyday communication is impacted by factors beyond just the bottom-up processing of the acoustic signal. Specifically, listeners employ top-down processing to make use of the semantic context when processing speech (e.g., Mayo et al., 1997). Thus, investigating listeners’ perception using materials with both variation in semantic context and variation in acoustic-phonetic characteristics of speech may help us better understand how native listeners benefit from non-native talkers’ attempt to speak more clearly.
1.2 Perceptual benefits associated with semantic context
As mentioned above, listeners’ perception is also impacted by the semantic context available. That is, listeners use the semantic context to understand and predict the upcoming content of speech. For example, lexical competition between phonologically similar nouns is reduced if the preceding verb makes one of the competitors an unlikely referent (Dahan & Tanenhaus, 2004). In a phoneme-monitoring task, listeners are faster at detecting a phoneme (e.g., /b/) in more predictable words than in less predictable words (e.g., branch vs. bed in A sparrow sat on the branch/bed whistling a few shrill notes to welcome the dawn; Morton & Long, 1976). Semantic context also helps listeners understand speech better in a challenging listening condition. For example, after listening to sentences with noise, native English speakers repeat the sentence more accurately for semantically well-integrated sentences (e.g., The actor played the part) as compared with semantically poorly integrated sentences (e.g., The lawyer named the road; Rosenberg & Jarvella, 1970). Furthermore, Mayo et al. (1997) demonstrated that, when listening to speech in noise, listeners’ recognition of sentence final words was more accurate in high-predictability (HP) sentences (e.g., The road sailed across the
While the role of semantic context in the perception of non-native speech has been much less explored compared to the perception of native speech, several studies have demonstrated that native listeners use the available semantic context to understand and evaluate non-native speech. For example, a set of sentences produced by non-native talkers were transcribed more accurately by native English listeners who had been familiarized with the topic of the sentences, as compared with listeners who had not (Gass & Varonis, 1984). Similarly, native English listeners’ transcription accuracy of non-native speech was the highest for true versus false sentences (e.g., Most children like to eat cookies; where listeners could use their real-world knowledge), followed by semantically meaningful sentences (e.g., A new plan makes John nervous; where listeners were unfamiliar with the semantic context) and by semantically anomalous sentences (e.g., A dark nail zaps a ready reason; Kennedy & Trofimovich, 2008). Furthermore, Schmid and Yeni-Komshian (1999) demonstrated that native English listeners detected mispronunciation of a target word in non-native speech faster and more accurately when the target word was more predictable given the preceding context (e.g., blast mispronounced as plast in The bomb exploded with a blast) compared with when the target word was less predictable (e.g., cake mispronounced as gake in Tom wants to know about the gake). Thus, these studies have demonstrated that listeners make use of semantic context available when processing native and non-native speech, as manifested in listeners’ overall understanding of speech, and monitoring of specific features of speech (e.g., detection of a specific phoneme or mispronunciation).
1.3 Current study
Taken together, the previous studies have demonstrated that listeners’ understanding of speech is influenced by both bottom-up factors (acoustic properties of the speech signal) and top-down factors (semantic context available). Native listeners benefit from bottom-up as well as top-down enhancements in non-native speech when either one type of these enhancements is available. However, it is unknown whether native listeners benefit from acoustic enhancements (plain or clear speech) and semantic enhancements (more or less predictable context) to similar extents when these types of enhancements are both available in non-native speech, or whether they benefit from one type of enhancements more than the other when trying to understand non-native speech. Specifically, while previous work has shown that native listeners benefit from both acoustic enhancements and semantic enhancements when evaluating native speech (Bradlow & Alexander, 2007), it remains unclear to what extent these types of enhancements benefit native listeners’ understanding of non-native speech.
Thus, the goal of the current study is to directly investigate perceptual benefits resulting from acoustic and semantic enhancements when listening to native and non-native speech. Given that native English listeners benefited from both clear speech enhancements (acoustic enhancements) and HP of sentence final words (semantic enhancements) when listening to native English speech (Bradlow & Alexander, 2007), we expect similar patterns in the current study for the perception of native English speech.
We additionally examine whether native listeners benefit from acoustic and semantic enhancements differently depending on the proficiency of the non-native talker. Given the previous results that acoustic enhancements in clear speech produced by highly proficient non-native talkers result in significant intelligibility gains for native listeners (Smiljanić & Bradlow, 2011), it is possible that we will observe an improvement in listeners’ recognition accuracy of final words in the sentences produced by higher-proficiency talkers in clear-speaking style as compared with plain-speaking style. However, this clear speech intelligibility benefit may be smaller for speech produced by lower-proficiency talkers (Rogers et al., 2010). To further explore whether the degree of perceptual benefits resulting from clear speech enhancements could be characterized by acoustic features of clear speech enhancements, we compare acoustic characteristics of plain- versus clear-speaking style for native talkers’ and higher- and lower-proficiency non-native talkers’ speech. This will allow us to compare acoustic characteristics of clear speech enhancements and the intelligibility benefit that native listeners receive from those enhancements. For example, highly proficient non-native talkers may make acoustic enhancements that are similar to native English talkers’ speech (e.g., Granlund et al., 2012); though it is unknown whether such acoustic enhancements would result in intelligibility benefits in non-native speech when other types of support, such as semantic enhancements, are also present in speech materials (discussed further later in this section).
In the case of semantic enhancements, it is possible that the extent to which listeners are able to build expectations based on the semantic context of the sentence differs depending on the general intelligibility or accentedness of speech. It has been shown that speech produced by less experienced non-native talkers is less intelligible and is also perceived to be more accented compared with that produced by more experienced non-native talkers (van Wijngaarden et al., 2002). The degree of accent is shown to impact speech processing in various ways. For example, when evaluating more heavily accented speech, listeners are less accurate at detecting mispronunciation (Schmid & Yeni-Komshian, 1999), and make less use of a prime in a lexical decision task (Porretta et al., 2016; Witteman et al., 2013), compared with when evaluating less accented speech. Given these results, it is possible that the influence of semantic enhancements on speech intelligibility will be reduced for talkers of lower proficiency levels. That is, higher-proficiency talkers’ speech may be generally more intelligible and less accented than lower-proficiency talkers’ speech, and this may make it easier for listeners to make use of the semantic context provided by the sentence to build their expectations for sentence final words. However, Schmid and Yeni-Komshian (1999) also demonstrated that the effect of semantic predictability on listeners’ accuracy of detecting mispronunciation did not differ for speech produced by mildly-accented talkers versus heavily accented talkers. Given this result, it is possible that native listeners are able to take advantage of semantic enhancements from lower-proficiency talkers’ speech when their speech is sufficiently intelligible (e.g., recognizing a keyword in a sentence may be enough to make a prediction about a sentence-final word). Thus, we may observe that native English listeners benefit from semantic enhancements to a similar extent when evaluating higher-versus lower-proficiency talkers’ speech.
A final question is how these types of enhancements interact to benefit listeners’ understanding of speech. That is, when both acoustic and semantic enhancements are available, do native listeners make use of both sources of enhancements to a similar extent, or do they benefit from one source of enhancement more than the other? This question is particularly important in the case of unfamiliar accents because some previous work has shown that semantic and acoustic information interact differently in different listening conditions. For example, when listening to native talkers, clear-speaking styles are more beneficial to listeners in audiovisual conditions than audio-only conditions and more beneficial in cases of semantically anomalous sentences than semantically meaningful ones (Van Engen et al., 2014). If it is difficult for native listeners to take advantage of the acoustic enhancements made in non-native clear speech (e.g., due to a smaller size of acoustic modifications compared with native speech or the presence of a foreign accent), they may benefit more from the top-down semantic enhancements than from the bottom-up acoustic enhancements. It is also possible that the effects of acoustic enhancements are facilitated by semantic enhancements (i.e., the plain- versus clear-speaking style difference may be larger in sentence final words of HP compared with those of LP).
We examine these questions in a perception experiment with two conditions: listening to speech in quiet and with noise. Though clear speech intelligibility experiments typically involve having participants listen to speech with noise to prevent ceiling effects on performance in transcription (e.g., Bradlow & Alexander, 2007; Bradlow & Bent, 2002; Rogers et al., 2010; Smiljanić & Bradlow, 2011), it can be difficult to determine whether the noise is actually preventing ceiling effects without knowing the level of listeners’ best performance for transcribing different types of speech. That is, the level of listeners’ best transcription performance could differ when listening to native talkers and non-native talkers of different proficiency levels (e.g., listeners’ best performance for lower-proficiency talkers’ speech might be lower than that for higher-proficiency talkers’ speech: Rogers et al., 2004). This may make it difficult to determine whether a certain level of noise is limiting the transcription performance to a similar extent for different talkers’ speech. Thus, we include a quiet listening condition to assess native listeners’ best performance for transcribing native and non-native talkers’ speech. This helps ensure that any clear speech intelligibility improvement, when listeners are transcribing speech with noise, is not limited by their best transcription performance.
2 Method
2.1 Materials
Materials were 28 pairs (56 sentences) of HP and LP sentences from Bradlow and Alexander (2007; e.g., Red and green are
Four native English talkers (age range = 19–22 years, M = 20) and 8 non-native English talkers whose native language was Mandarin Chinese (age range = 20–31 years, M = 25.3) recorded the sentences. All talkers identified themselves as female, and reported no history of speech or hearing impairment. Native English talkers were recruited from the University of Oregon Psychology and Linguistics human subject pool, and they received partial course credit for their participation. We recruited non-native English talkers from two different instructional settings. Specifically, we recruited four higher-level non-native talkers from the graduate student population at the University of Oregon, and four lower-level non-native talkers from an intensive English program, who were international students hoping to enter the university as matriculated students. Table 1 shows the information regarding non-native talkers’ English learning background and proficiency. As shown in the table, lower-proficiency native Mandarin (Native Mandarin-Low) talkers and higher-proficiency native Mandarin (Native Mandarin-High) talkers have different characteristics, particularly in terms of length of US residence and the Test of English as a Foreign Language (TOEFL) score. 1
Non-Native English (Native Mandarin) Talkers’ English Learning Background and Proficiency.
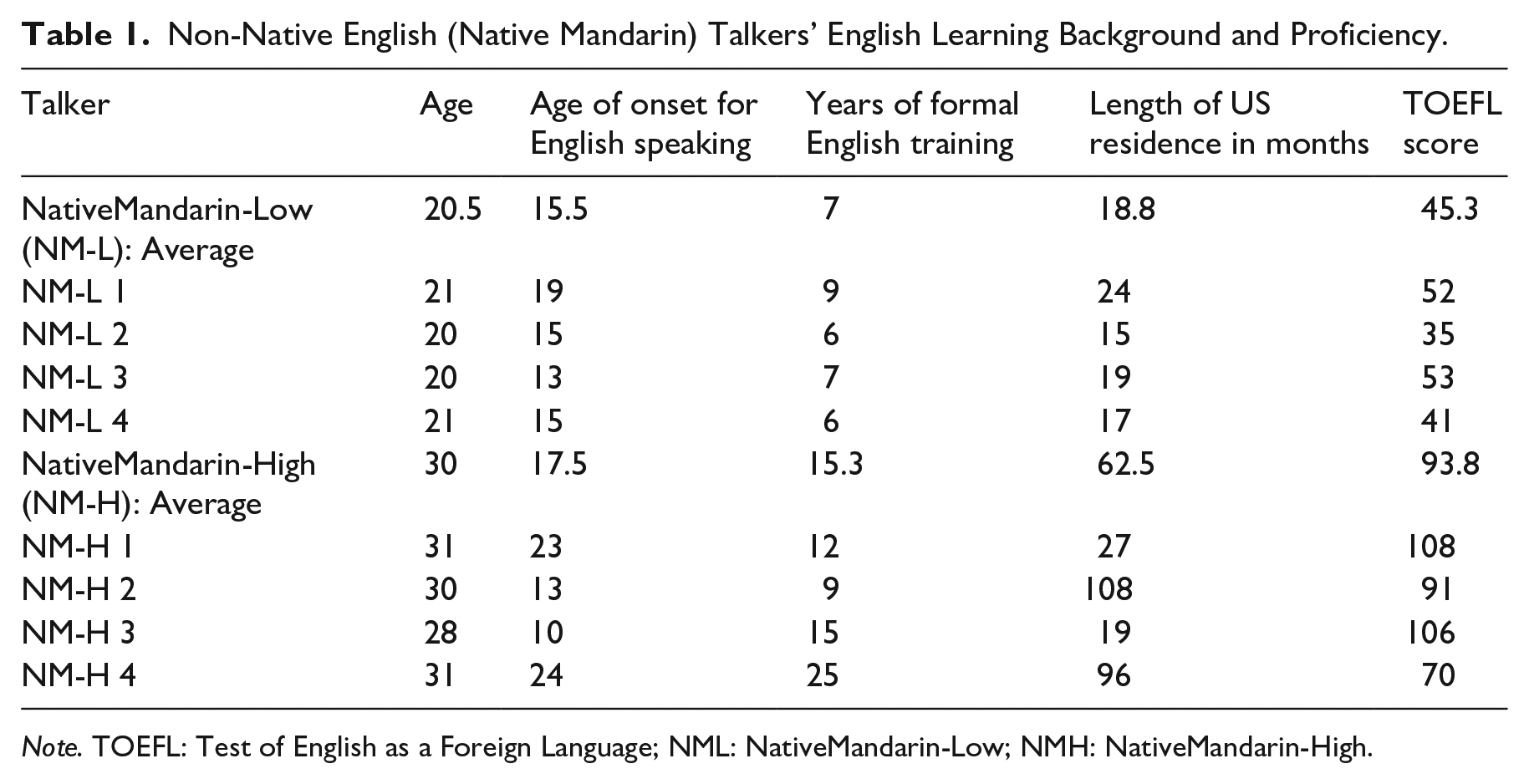
Note. TOEFL: Test of English as a Foreign Language; NML: NativeMandarin-Low; NMH: NativeMandarin-High.
All talkers were recorded in a single-walled IAC sound booth. The sentences were displayed on the computer screen one at a time; the presentation of each sentence was self-paced. The talkers read into a microphone that fed directly into a desktop computer. Recording was done on a single channel at a sampling rate of 44,100 Hz (16 bit) using the Praat speech analysis software package (Boersma & Weenink, 2001). The talkers first recorded the practice sentences. They were instructed to practice reading the sentences to the microphone. Then, they were instructed to read the test sentences in a plain-speaking style first, followed by the second recording in a clear-speaking style. For the recordings in the plain-speaking style, the talkers were instructed to read as if they were talking to someone who is familiar with their voice and speech patterns. For the recordings in the clear-speaking style, the talkers were instructed to read as if they were talking to a listener who has a hearing loss (Smiljanić & Bradlow, 2011). After the recording, talkers completed a language background questionnaire and other proficiency-measuring tasks. All speech files were segmented into individual sentence-length files.
There were 1344 unique sound files: 56 sentences (28 HP sentences + 28 LP sentences) × 2 speaking styles (Plain and Clear) × 12 talkers (4 Native English talkers + 4 Native Mandarin-High talkers + 4 Native Mandarin-Low talkers). These files were RMS normalized to 65 dB SPL to ensure that no file was significantly louder or quieter than any other file. Silence of 500 ms was then added at the beginning and end of each sound file. Furthermore, to create materials for speech-in-noise intelligibility task, we mixed each file with speech-shaped noise 2 (Bradlow & Alexander, 2007; Quené & Van Delft, 2010) at a signal-to-noise ratio (SNR) of −6 dB for native talkers’ items and −2 dB for non-native talkers’ items. These SNRs were determined based on a series of pilot testing, where we examined the noise level that would prevent ceiling or floor effects on listeners’ performance for native and non-native talkers’ speech. The same noise level was used for Native Mandarin-High and Native Mandarin-Low talkers’ speech so that we could examine the effect of talkers’ English proficiency level on native listeners’ understanding of their speech in general, as well as the intelligibility improvement based on clear speech and semantic predictability at a constant SNR.
For the intelligibility task under the Noise condition, each stimulus file consisted of 500 ms header of noise, followed by the speech-plus-noise portion, and ending with a 500-ms noise-only tail (following Bradlow & Alexander, 2007). The noise in the 500 ms header and tail was always at the same level as the noise in the speech-plus-noise portion of the stimulus file. For the intelligibility task under the Quiet condition, each stimulus file consisted of 500 ms of silence, followed by speech in quiet, and ending with a 500 ms of silence.
2.2 Talkers’ perceived foreign accentedness
To characterize non-native (native Mandarin) talkers’ English proficiency, the recordings of the practice sentences were evaluated for foreign accentedness by native English listeners. The sentence-length files of the practice sentences were RMS normalized to 65 dB SPL. Forty native English listeners (13 females, 27 males; age range = 23–67 years, M = 35.8), recruited using Amazon Mechanical Turk (www.mturk.com), participated in the foreign accent rating task. None of the listeners reported a history of speech or hearing impairment. None of the listeners reported experience with Mandarin Chinese. In the accent rating task, conducted via Qualtrics (www.qualtrics.com/), the listeners were told that they would listen to English sentences and evaluate the foreign accent of the speech. In each trial, listeners heard an English sentence without noise and were instructed to rate the accentedness of the speech on a scale of 1 (“a native speaker of English”) through 9 (“an extremely strong foreign accent”; similar to Munro & Derwing, 1995). To prevent the accentedness ratings from being influenced by the intelligibility of the speech, the transcript of the sentence was displayed while the listeners were evaluating the speech (Gittleman & Van Engen, 2018). Each sentence could not be played more than once, but there was no time limit for responding. Twenty listeners evaluated 6 talkers (i.e., 2 Native English, 2 Native Mandarin-High talkers, 2 Native Mandarin-Low talkers) and another set of 20 listeners evaluated the other 6 talkers. Thus, each listener evaluated 60 sentences (i.e., 10 unique sentences × 6 talkers). The presentation of the sentences was randomized for each listener.
Foreign accent ratings were z-score normalized for each listener to account for variation in the listeners’ use of the nine-point rating scale. Figure 1 shows accent ratings by talker group (Native English, Native Mandarin-High, and Native Mandarin-Low). To examine whether the accent ratings differed for different talker groups, one-way repeated-measures ANOVA (talker group as a within-subject variable) was carried out with z-scored ratings as the dependent variable. The results indicated that the ratings differed significantly by the talker group, F(2, 9) = 128.29, p < .001, η2 = .97. The post hoc Tukey comparisons confirmed that all the group comparisons were significant: Native English versus Native Mandarin-High, Native English versus Native Mandarin-Low, and Native Mandarin-High versus Native Mandarin-Low (p < .0001 for all). These results demonstrated that there was a clear difference in the perceived accentedness of the talkers. That is, Native English talkers were perceived to be less accented than Native Mandarin talkers, and Native Mandarin-High talkers were perceived to be less accented than Native Mandarin-Low talkers.
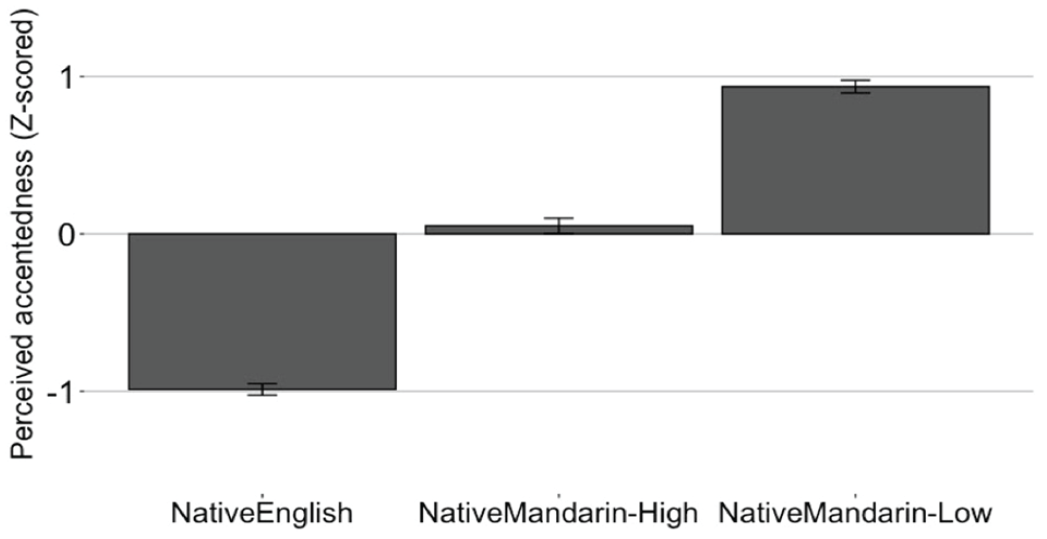
Z-score normalized accentedness ratings plotted by talker group. Error bars represent 95% confidence interval of the mean.
2.3 Participants
Participants were 379 Native English listeners (183 females, 194 males, 2 declined to provide a gender; age range = 18–69 years, 3 M = 38.2). They were recruited using Mechanical Turk, and participated in the sentence transcription task. None of the listeners reported a history of speech or hearing impairment. All participants resided in the United States, and self-reported to be native speakers of American English. None of the participants reported experience with Mandarin Chinese.
2.4 Procedure
The intelligibility perception experiment was conducted remotely with Qualtrics. They were told that they would listen to English sentences and transcribe them. They were instructed to be in a quiet room, and use headphones to complete the task. 4 The experiment began with a consent procedure as well as a sound check to ensure that participants could listen to the audio files at their comfortable volume. After that, participants read the instructions; in each trial, they were asked to listen to an English sentence and type the final word (following Bradlow & Alexander, 2007). They could listen to the sentence only once but could take as much time as needed to type their answer. They also completed two practice trials with the talkers and sentences that were different from the following 28 test sentences.
During the test trials, each participant listened to 28 unique sentences produced by one talker. The 28 sentences included 7 HP sentences in Plain-speaking style, 7 LP sentences in Plain-speaking style, 7 HP sentences in Clear-speaking style, and 7 LP sentences in Clear-speaking style. During the test trials, each participant heard each of the 28 target words only once. To counterbalance the combination of the sentences (HP vs. LP) and speaking styles (Plain- vs. Clear-speaking style), we created four conditions for each talker’s materials. For example, the materials from Native English talker 1’s speech (28 HP sentences and 28 LP sentences in Plain- and Clear-speaking styles) were presented in four conditions (Conditions A–D). Each talker’s materials were evaluated by approximately 16 listeners; thus, there were an average of four listeners in each of the four counterbalancing conditions (Conditions A–D). The presentation order of the 28 test sentences was randomized for each participant. After the experimental trials were completed, each participant completed a post-test demographic survey.
2.5 Analysis
To analyze the perception data, sentence final words were scored as correct (1 was given) or incorrect (0 was given). Words correct were defined as those that matched the intended target exactly, as well as homophones and/or common misspellings (e.g., scents for cents in the sentence He pointed at the cents). However, words with incorrect, added, or deleted morphemes were scored as incorrect (e.g., hand for hands in the sentence She looked at her hands). In terms of the number of the data points, there were 193 participants who listened to the materials under the Quiet condition (66 participants listened to Native English speech, 57 participants listened to Native Mandarin-High speech, 70 participants listened to Native Mandarin-Low speech), and 186 participants who listened to the materials under the Noise condition (60 participants listened to Native English speech, 63 participants listened to Native Mandarin-High speech, 63 participants listened to Native Mandarin-Low speech). As each listener evaluated 28 items, there were a total of 10,612 data points (i.e., 379 listeners × 28 items). Each item was scored by two raters. When there was a disagreement (74 instances out of 10,612 instances), the two raters discussed discrepancies until they reached agreement.
To complement the intelligibility perception data, we examined the characteristics of the materials in acoustic analyses. For each test sentence in each of the plain- and clear-speaking styles for each talker, we examined speaking rate, mean F0, and F0 range, which are the acoustic features typically examined in previous studies (e.g., Bradlow et al., 2003; Granlund et al., 2012; Picheny et al., 1986; Smiljanić & Bradlow, 2005). The speaking rate was computed by dividing the number of syllables of the sentence by the sentence duration (in seconds). Furthermore, because it is possible that any difference in speaking rate (e.g., slower speaking rate for the clear-speaking style than for the plain-speaking style) could be characterized by the frequency or duration of pauses (e.g., Smiljanić & Bradlow, 2005), we also examined whether the difference in speaking rate could partly be characterized by longer segment durations. Specifically, we examined whether vowel durations are longer in clear-speaking style compared with plain-speaking style. To measure vowel durations in test sentences, phone-level alignment between sound files and transcripts of the sentence was automated using Montreal Forced Aligner (McAuliffe et al., 2017). Then, automated vowel duration extraction was carried out using Forced Alignment and Vowel Extraction (Rosenfelder et al., 2014). The vowels measured were /ɑ, æ, ə, ɔ, aʊ, aɪ, ɛ, ɝ, eɪ, ɪ, i, oʊ, ɔɪ, ʊ, u/, and only stressed vowels were included in the analysis following previous studies (e.g., Scarborough et al., 2007). To measure mean F0 and F0 range, a Praat script was run to calculate mean F0, maximum F0, and minimum F0 (in Hertz) for each sentence. The F0 range was obtained by subtracting the minimum F0 value from the maximum F0 value for each sentence. To account for individual variability (e.g., some talkers have higher F0 than others), mean F0 and F0 range values were transformed using the min-max scaling procedure (Gerstman, 1968; Kallay & Redford, 2018). That is, the mean F0 and F0 range for a particular sentence was normalized using the talker’s minimum and maximum values of those measurements, so that all the values are within the range of 0 (minimum value of that talker) to 1 (maximum value of that talker).
3 Results
3.1 Perception results
In this section, we present the results of the analysis where we examined whether listeners’ final word recognition accuracy was higher under the Quiet listening condition than the condition with Noise. We examined this effect of condition for HP and LP sentences produced by Native English, Native Mandarin-High, and Native Mandarin-Low talkers. We also examined whether listeners’ final word recognition accuracy was higher for HP sentences than in LP sentences, whether it was higher for the sentences produced in Clear-speaking style than those produced in Plain-speaking style, as well as whether these effects of Semantic Predictability and Style interacted with one another for different talker groups and Quiet versus Noise conditions.
Figure 2 shows the proportion correct of final word recognition accuracy in HP and LP sentences (HP and LP in the figure) spoken in Plain- and Clear-speaking style by 3 Talker Groups (Native English, Native Mandarin-High, Native Mandarin-Low), evaluated in two listening conditions (Quiet and Noise). We analyzed the data via logistic mixed-effects regression models using the R package lme4 (Bates et al., 2015). The dependent variable was the final word recognition, scored as a 0 for incorrect and 1 for correct for each final word in the sentence; the binary-response variable was used here (as opposed to the mean proportion correct shown in the graphic visualization in Figure 2) to include item-level variance in the model. As fixed-effects, Condition (Quiet or Noise; across participants), Semantic Predictability (HP or LP; within participants), Talker Group (Native English, Native Mandarin-High, Native Mandarin-Low; across participants), Style (Plain or Clear; within participants), and interaction of these factors were included. Condition was contrast-coded to compare between Noise (−0.5) and Quiet (0.5) conditions. Semantic Predictability was contrast-coded to compare between HP (0.5) and LP (−0.5) sentences. Style was contrast-coded to compare between Plain- (−0.5) and Clear (0.5)-speaking styles. Talker Group was also contrast-coded to compare between Native English and Native Mandarin (Native Mandarin-High and Native Mandarin-Low combined) groups (TalkerGroup1: 0.5, −0.25, −0.25), and between Native Mandarin-High and Native Mandarin-Low group (TalkerGroup2: 0, 0.5, −0.5). To allow for the model to converge with maximal random slopes, we simplified the model by uncorrelating the random effects (Barr et al., 2013); see the model syntax in the table in Appendix B. The random effects structure included random intercepts for talker, listener, and item. The random effects structure also included by-talker random slopes for Style, Condition, and Semantic Predictability, and by-item slopes for Condition, Talker Group, Style, and their interactions. In the model, the random effects that did not account for any variance (e.g., by-listener random slope for Semantic Predictability) were not included in the model to avoid overfitting of the model; see the model syntax for the final random-effect structure.
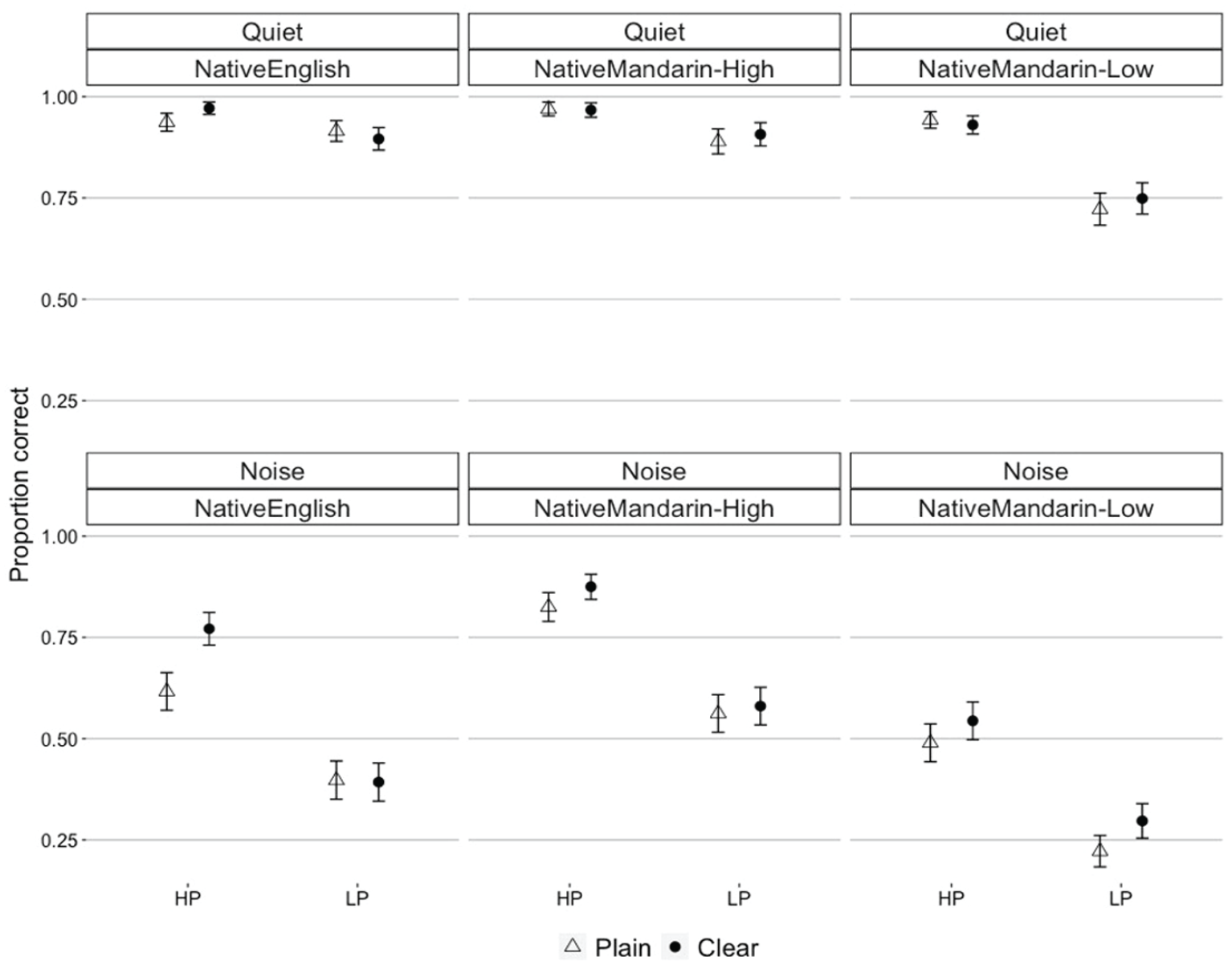
Proportion correct of final word recognition in two listening conditions (Quiet and Noise) for high- and low-predictability sentences (HP and LP) produced by each Talker Group (Native English, Native Mandarin-High, Native Mandarin-Low) in Plain- and Clear-speaking styles. Error bars represent 95% confidence interval of the mean.
The results of the mixed-effects logistic regression model, which includes significance levels using the Wald z statistic, are summarized in Appendix B. The model showed that final word recognition accuracy was significantly higher under the Quiet condition than under the Noise condition (β = 3.1, z = 12.48, p < .001). This effect of Condition did not differ across sentences of HP and LP (β = −.37, z = −1.29, p = .2), across sentences spoken in Plain and Clear styles (β = −.13, z = −0.67, p = .5), across sentences produced by Native English and Native Mandarin (High- and Low-proficiency combined) talkers (β = .82, z = 1.78, p = .076), or across sentences produced by Native Mandarin-High and Native Mandarin-Low talkers (β = −.9, z = −1.73, p = .084). Furthermore, we examined the effect of Condition in a post hoc Tukey test using R package lsmeans (Lenth, 2016), and the test confirmed that the effect of Condition (Quiet vs. Noise) was significant in both Plain- and Clear-speaking styles of Native English talkers’ HP and LP sentences, Native Mandarin-High talkers’ HP and LP sentences, and Native Mandarin-Low talkers’ HP and LP sentence (p < .001 for all combinations; see Appendix B for a summary of the results). This confirmed that listeners’ final word recognition accuracy under the Noise condition was lower than that under the Quiet condition.
Furthermore, the significant effect of the Native Mandarin-High versus Low comparison (β = 1.68, z = 5.31, p < .001) indicates that final word recognition was generally higher for the sentences produced by Native Mandarin-High talkers than those produced by Native Mandarin-Low talkers. However, the three-way interaction among the Native Mandarin-High versus Low comparison, Condition (Quiet or Noise), and Semantic Predictability (HP or LP; β = −1.24, z = −3.09, p < .01) indicates that the effect of Semantic Predictability (HP or LP) differed for the perception of Native Mandarin-High versus Native Mandarin-Low talkers’ items under Noise versus Quiet conditions. The nature of this interaction was further examined in the post-hoc Tukey test (see Appendix B for the summary of the results). It revealed that the effect of Semantic Predictability (HP or LP) was significant under both Noise and Quiet conditions for all talker groups’ sentences. However, under the Quiet condition, the effect of Semantic Predictability was numerically larger for Native Mandarin-Low talkers’ sentences than Native Mandarin-High talkers’ sentences, although this pattern did not persist under the Noise condition. This was likely because the easy listening condition (the Quiet condition) did not lower the final word recognition accuracy for LP sentences as compared with HP sentences for Native Mandarin-High talkers’ speech, although it did for Native Mandarin-Low talkers’ speech.
The results also showed a significant effect of Semantic Predictability (HP or LP sentence; β = 1.63, z = 6.15, p < .001), indicating that listeners generally recognized final words correctly more often for HP sentences than for LP sentences. HP sentences improved recognition accuracy (as compared with LP sentences) to a similar extent across Native English versus Native Mandarin (High- and Low-proficiency combined) talkers’ speech (β = −.3, z = −1.02, p = .31), and across Native Mandarin-High versus Native Mandarin-Low talkers’ speech (β = −.2, z = −0.66, p = .51). The effect of Style was also significant (Plain- or Clear-speaking style; β = .33, z = 2.56, p < .05), indicating that final words were better recognized in Clear-style sentences than in Plain-style sentences, and the effect of Style did not significantly differ for Native English versus Native Mandarin comparison (β = .27, z = 0.95, p = .34), or for the Native Mandarin-High versus Native Mandarin-Low comparison (β = .09, z = 0.3, p = .76). However, the effect of Semantic Predictability and Style interacted with one another (β = .36, z = 2.3, p < .05). This indicates that the difference in final word recognition accuracy between Plain- and Clear-style sentences was larger for the HP sentences than that for LP sentences. There was also a significant three-way interaction among the Native English versus Native Mandarin (High- and Low-proficiency combined) comparison, Style, and Semantic Predictability (β = 1.2, z = 3.21, p < .01). This indicates that the effect of style (Plain vs. Clear) differed for the perception of Native English versus Native Mandarin talkers’ items across different Semantic Predictability types (HP vs. LP). The nature of this interaction was further examined in the post hoc Tukey test (see Appendix B for the summary of the results). It revealed that, for Native English talkers’ items, listeners’ recognition accuracy was significantly higher in clear-style than in plain-style for HP sentences, but this style-based difference was not significant for LP sentences, and this pattern persisted across Noise and Quiet conditions. The effect of style was not significant for Native Mandarin (High- and Low-proficiency) talkers’ HP and LP sentences under Noise and Quiet conditions.
Together, these results demonstrated that across different listening conditions (Quiet and Noise), there was a robust effect of non-native talkers’ proficiency level on listeners’ final word recognition. That is, listeners recognized final words in Native Mandarin-High talkers’ speech better than those in Native Mandarin-Low talkers’ speech. Semantic predictability (HP vs. LP) improved recognition accuracy significantly in all talker groups’ speech under both Quiet and Noise conditions. Despite such a robust effect of Semantic Predictability, non-native talkers’ clear speech enhancements did not improve final word recognition accuracy (in either HP or LP sentences across Quiet and Noise conditions). Native English talkers’ clear speech did improve perception accuracy, but only for HP sentences. These results suggest that Native English listeners benefited from Semantic Predictability to a larger extent than they did from acoustic enhancements when listening to non-native speech. When listening to native speech, listeners generally benefited from Semantic Predictability (under both Quiet and Noise conditions). However, listeners only benefited from clear speech enhancements in HP sentences but not in LP sentences.
3.2 Production results
To complement the perception results, we examined the acoustic characteristics of the materials.
3.2.1 Speaking rate
Figure 3 shows the raw speaking rate (i.e., number of syllables divided by the sentence duration in seconds) for Native English, Native Mandarin-high, and Native Mandarin-low talkers’ productions of HP and LP sentences (HP and LP in the figure) in Plain- and Clear-speaking styles. To examine whether Native Mandarin (High- and Low-proficiency combined) talkers spoke slower than Native English talkers in general, and whether these talkers varied their speaking rate for Plain versus Clear-speaking styles, we implemented a linear mixed-effects regression model with the number of syllables per second as the dependent variable. This model and all the subsequent production models have the same structure; the fixed effects were Semantic Predictability (HP vs. LP sentences), Style (Plain- vs. Clear-speaking style), Talker Group (Native English, Native Mandarin-high, Native Mandarin-low), and interaction among them. All the factors were contrast coded as specified above. The random effects structure included random intercepts for talker and item. The random effects structure also included by-talker random slopes for Style, Semantic Predictability, and their interaction, and by-item slopes for Style, Talker Group and their interaction. In the model, the random effects that did not account for any variance (e.g., by-talker random slope for Semantic Predictability) were not included in the model to avoid overfitting of the model; see the model syntax in each table in Appendix B for the final random effect structure. p values were calculated based on Satterthwaite approximations (Luke, 2017), using the lmerTest package for R (Kuznetsova et al., 2016).
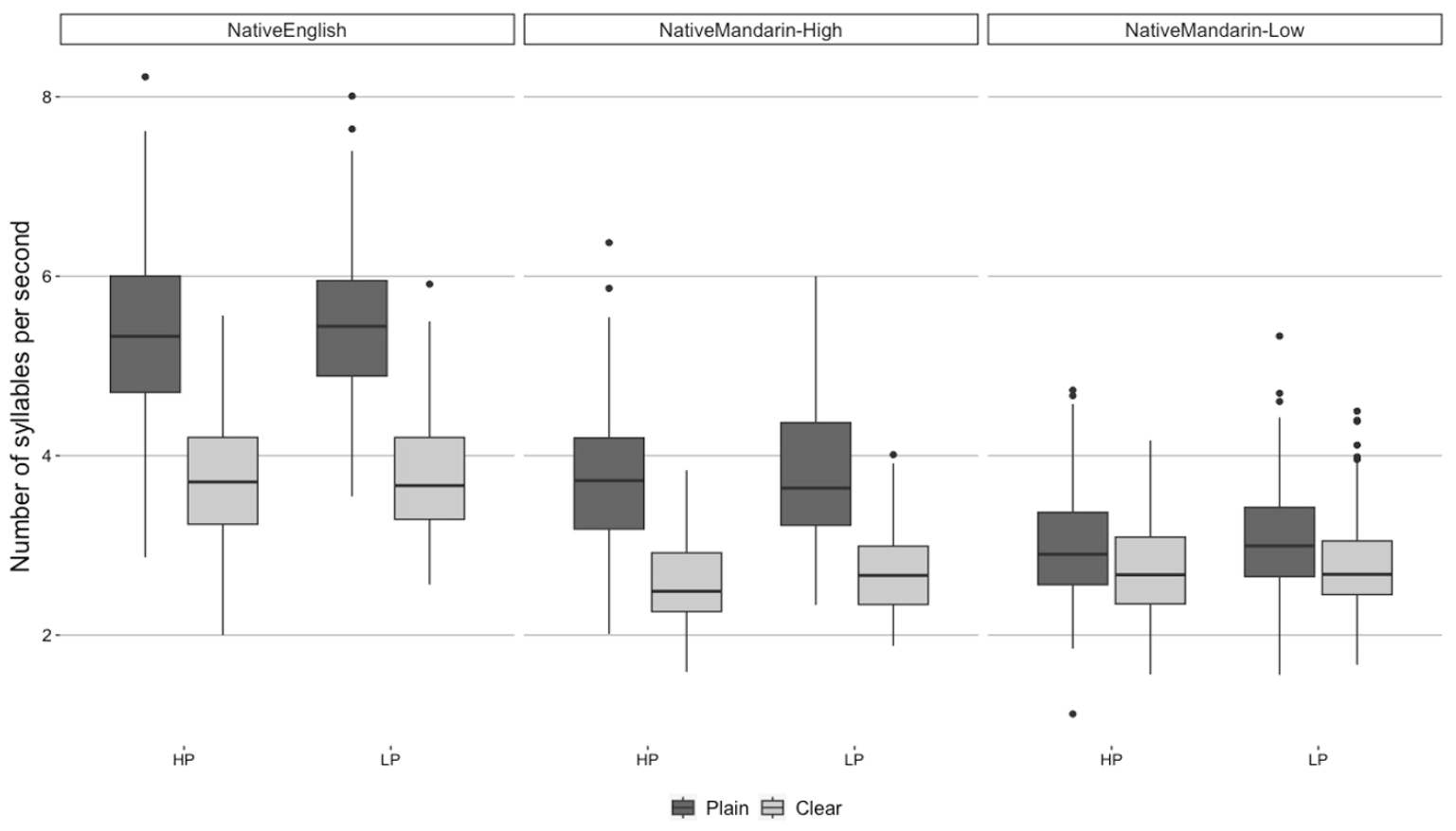
Raw speaking rate for Native English, Native Mandarin-High, Native Mandarin-Low talkers’ productions of High- and Low-predictability sentences (HP and LP) in two speaking styles (Plain and Clear).
The results showed that Native Mandarin (High- and Low-proficiency combined) talkers spoke more slowly than Native English talkers (β = 1.53, t = 9.47, p < .001). However, the difference between Native Mandarin-High and Low talkers was not significant (β = .32, z = 1.7, p = .12), indicating that Native Mandarin-High talkers did not speak faster than Native Mandarin-Low talkers. In terms of the effect of Style, talkers generally spoke more slowly in Clear-speaking style than in Plain-speaking style (β = −.1.01, t = −7.81, p < .001). This effect of Style was larger for Native English talkers’ productions than for Native Mandarin (High- and Low-proficiency combined) talkers’ productions (β = −.94, t = −3.41, p < .01), and for Native Mandarin-High talkers’ productions than for Native Mandarin-Low talkers’ productions (β = −.9, t = −2.82, p < .05). The effect of Style did not differ across HP and LP sentences (β = .2, t = 0.42, p = .67). Semantic Predictability (HP vs. LP) did not make a significant difference in speaking rate, either (β = −.09, t = −0.67, p = .5). A post hoc Tukey test revealed that the effect of Style was significant in Native English and Native Mandarin-High talkers’ productions (p < .0001 for both), although not for Native Mandarin-Low talkers’ productions (p = .1); see the summary of results in Appendix B.
3.2.2 Vowel duration
To explore whether the speaking rate results (e.g., slower speaking rate in Clear-speaking style than Plain-speaking style) were partly characterized by longer segment durations, we examined vowel durations. Because the vowel duration data were positively skewed, we log-transformed the data. 5 Figure 4 shows the log-transformed vowel duration for Native English, Native Mandarin-High, and Native Mandarin-Low talkers’ productions of HP and LP sentences (HP and LP in the figure) in Plain- and Clear-speaking styles. The results of the linear mixed-effect regression model (summarized in Appendix B) indicated that vowel durations were significantly longer in Native Mandarin (High- and Low-proficiency) talkers’ productions than in Native English talkers’ productions (β = −.27, t = −5.81, p < .001). Further, talkers produced speech in Clear-speaking style with longer vowel durations compared to Plain-speaking style (β = .27, t = 10.6, p < .001). This effect of Style was larger in Native Mandarin-High talkers’ productions than in Native Mandarin-Low talkers’ productions (β = .27, t = 4.43, p < .001). Semantic Predictability (HP vs. LP sentences) did not influence vowel durations (β = −.03, t = −1.17, p = .25). A post hoc Tukey test indicated that the effect of Style (Plain vs. Clear) was significant for all combinations of Talker Groups and Semantic Predictability, except for Native Mandarin-Low talkers’ productions of LP sentences (p = .057; see the summary of results in Appendix B).
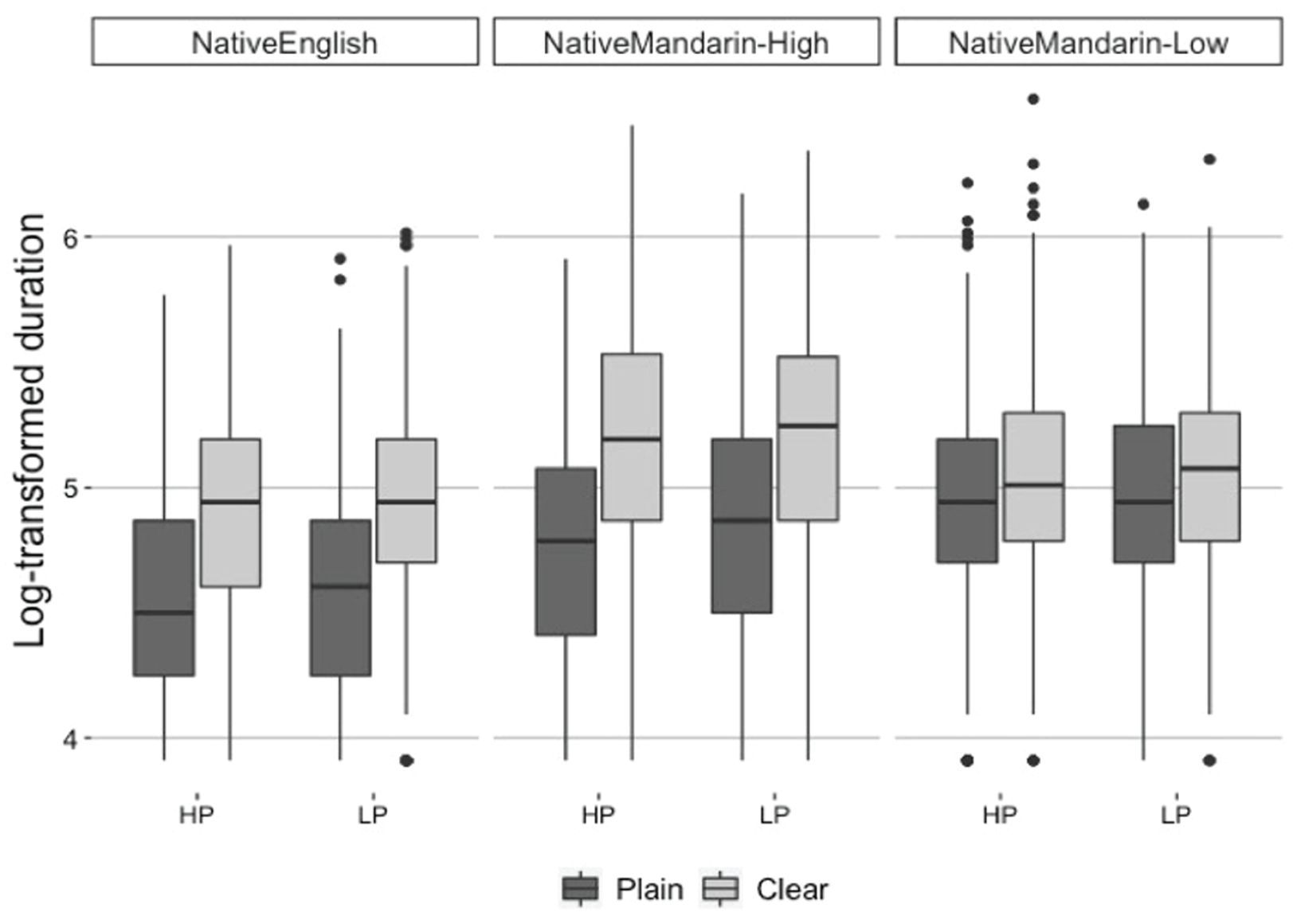
Log-transformed vowel duration for Native English, Native Mandarin-High, Native Mandarin-Low talkers’ productions of High- and Low-predictability sentences (HP and LP) in two speaking styles (Plain and Clear).
3.2.3 Fundamental frequency
In terms of fundamental frequency (F0), we examined F0 range and mean F0. 6 Figure 5 illustrates scaled values of F0 range (left panel) and mean F0 (right panel) for Native English, Native Mandarin-High, and Native Mandarin-Low talkers’ productions of HP and LP sentences (HP and LP in the figure) in Plain- and Clear-speaking styles. For F0 range, the results of the linear mixed-effects regression model (see Appendix B for the summary of the results) indicated that talkers generally spoke with a wider F0 range in Clear-speaking style than in Plain-speaking style (β = .11, t = 7.43, p < .001). This effect of Style was larger in Native Mandarin-High talkers’ productions than in Native Mandarin-Low talkers’ productions (β = .19, t = 5.15, p < .001). There was also a significant effect of Semantic Predictability (HP vs. LP; β = .08, t = 4.31, p < .001). This indicates that talkers generally spoke with a wider F0 range for HP sentences than for LP sentences. A post hoc Tukey test (see Appendix B for the full results) indicated that the effect of Style (Plain vs. Clear) was significant for both HP and LP sentences produced by Native Mandarin-High talkers (p < .0001 for both), though not for either HP (p = .6) or LP (p = .55) sentences produced by Native Mandarin-Low talkers. For Native English talkers’ productions, the effect of Style was significant for HP sentences (p = .001) but not for LP sentences (p = .09).
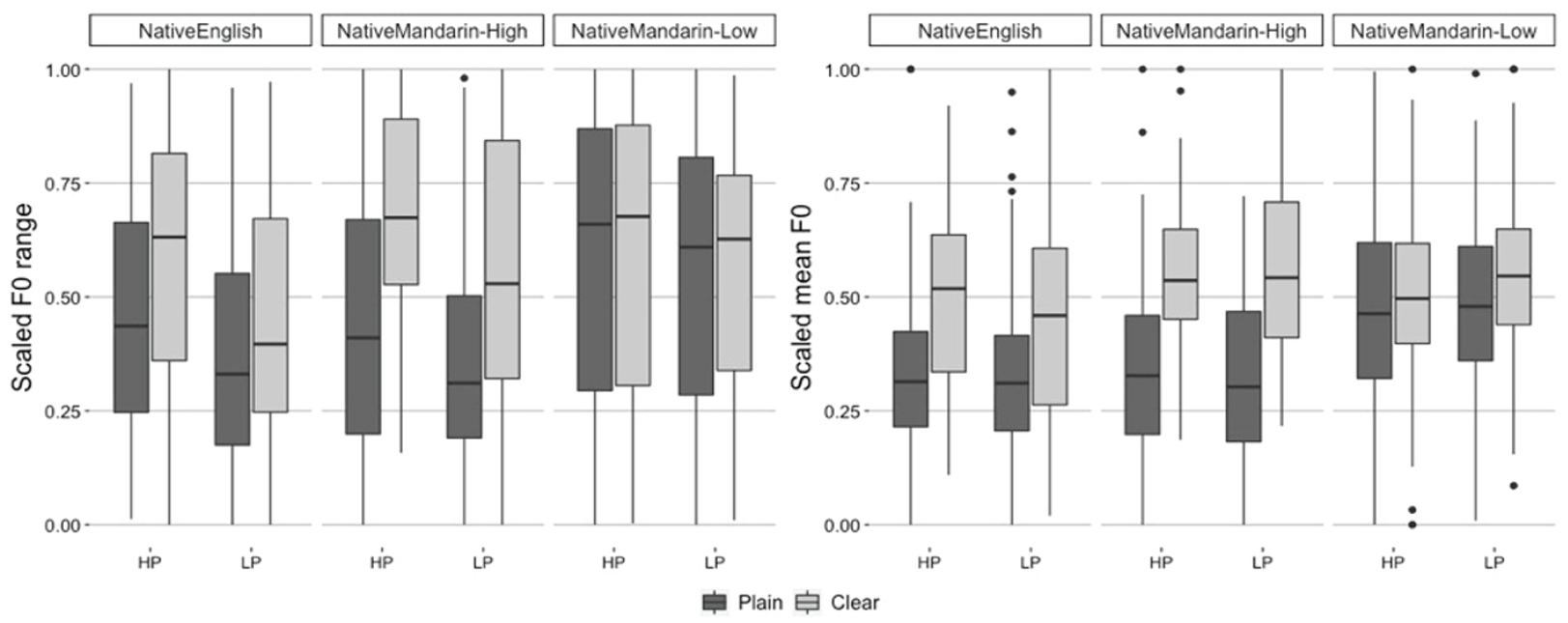
Scaled F0 range (left panel) and scaled F0 mean (right panel) for Native English, Native Mandarin-High, Native Mandarin-Low talkers’ productions of High- and Low-predictability sentences (HP and LP) in two speaking styles (Plain and Clear).
For mean F0, the results of the linear mixed-effects regression model (see Appendix B for the summary of the results) indicated that talkers generally spoke with higher F0 in Clear-speaking style than in Plain-speaking style (β = .14, t = 5.53, p < .001). This effect of Style was larger in Native Mandarin-High talkers’ productions than in Native Mandarin-Low talkers’ productions (β = .18, t = 2.89, p < .05). There was also a significant interaction between Semantic Predictability (HP vs. LP sentence) and the Native English versus Native Mandarin (High- and Low-proficiency combined) comparison (β = .04, t = 2.18, p < .05). This indicates that Native English talkers spoke with higher mean F0 for HP sentences compared with LP sentences, but this was not the case for Native Mandarin talkers’ productions. Furthermore, there was a three-way interaction among the Native English versus Native Mandarin (High- and Low-proficiency) comparison, Style, and Semantic Predictability (β = .07, t = 2.18, p < .05). This indicates that Native English talkers increased mean F0 from Plain- to Clear-speaking style to a larger extent for HP sentences as compared with LP sentences, but this was not the case for Native Mandarin talkers’ productions. A post hoc Tukey test indicated that the effect of Style (Plain vs. Clear) was significant for Native English and Native Mandarin-High talkers’ productions of HP and LP sentences, but not for Native Mandarin-Low talkers’ productions (see the test results in Appendix B).
3.2.4 Production results summary
Overall, these production results demonstrated a robust effect of non-native talkers’ target language proficiency level on clear speech enhancements. That is, Native Mandarin-High talkers made larger differences between plain and clear speech than Native Mandarin-Low talkers across different acoustic features (i.e., speaking rate, vowel duration, F0 range, mean F0). For these acoustic features examined here, Native Mandarin-High talkers made significant differences between plain and clear speech for both HP and LP sentences. Native English talkers also made significant differences between plain and clear speech for speaking rate and vowel durations, but they showed somewhat different patterns for F0. That is, for F0 range, Native English talkers made a significant plain-to-clear speech difference for HP sentences but not for LP sentences. Similarly, for mean F0, Native English talkers made a larger plain-to-clear speech difference for HP sentences than for LP sentences. These results indicate that Native English talkers implemented larger F0 clear speech enhancements for HP sentences than for LP sentences. The acoustic characteristics of talkers’ productions also differed for HP versus LP sentences in terms of F0 characteristics in general. Specifically, HP sentences were produced with a wider F0 range (by both native and non-native talkers), and with a higher mean F0 (by native talkers) as compared with LP sentences. It is possible that the length of the sentence influenced the F0 range in general. That is, as HP sentences were generally longer than LP sentences (the average number of syllables for HP sentences = 8.4; for LP sentences = 6.6), there may have been more room for F0 to vary for HP sentences than for LP sentences. It is also possible that Native English talkers produced HP sentences with higher mean F0 than LP sentences because the talkers were aware of the increased semantic content in HP sentences than in LP sentences. How these acoustic characteristics may have impacted listeners’ perception are discussed in the next section.
4 Discussion
The results of the study demonstrate that native English listeners are able to take advantage of both semantic and acoustic modifications in perception, but the extent to which they are able to do so depends on both the talker’s native language background and their proficiency level in the target language. Specifically, under both quiet and noisy listening conditions, listeners demonstrated better perception of speech for non-native talkers who have higher proficiency in English than talkers who have lower proficiency. However, listeners are also able to take advantage of semantic modifications, regardless of talker proficiency. That is, final words in HP sentences are better recognized than final words in LP sentences regardless of the talker proficiency level. Interestingly, acoustic modifications (i.e., changes from plain to clear speech) only benefited listeners when produced by native English talkers. This finding could lead one to ask whether the non-native talkers simply do not make differences between clear and plain speech, and thus, listeners do not have any acoustic modifications to take into consideration when listening to clear versus plain speech. Interestingly, our acoustic analysis suggests that this is not the case. Higher-proficiency non-native talkers demonstrate significant differences between clear and plain speech on a variety of acoustic dimensions, suggesting that listeners may utilize acoustic modifications differently depending on the talker producing these modifications. 7 Below, we discuss the implications of these results.
As described above, lower-proficiency talkers do not make large acoustic enhancements when differentiating clear speech from plain speech. Therefore, it is unsurprising that listeners do not make use of acoustic modifications, if no such modifications exist. 8 One outstanding question, however, is why this lack of acoustic enhancement occurs. One hypothesis is that lower-proficiency talkers may be in a “clear speech” mode at all times when producing speech in their non-native language. That is, the difficulty for these talkers may not be in producing clear speech but may rather be in producing plain speech. It is well-known that reduction patterns are difficult to acquire in a non-native language and even relatively proficient non-native English talkers do not show the same patterns of vowel reduction, for example, that native talkers demonstrate (Baker et al., 2011). This explanation seems feasible as non-native talkers typically produce slower speech than native talkers (see Guion et al., 2000 and Figure 3 in the present study). Furthermore, in the present study, lower-proficiency non-native talkers produce speech that has a relatively high F0 and a relatively wide F0 range (within the range of mean F0 and F0 range for each individual talker) in both plain and clear speech, compared with the higher-proficiency non-native talkers and the native talkers. This suggests that lower-proficiency talkers generally try hard to speak clearly (i.e., across plain and clear speech).
The question remains, however, as to why native English listeners did not benefit from higher-proficiency talkers’ acoustic modifications. These talkers made clear speech enhancements, as is evidenced by our acoustic analysis, but listeners fail to take advantage of these modifications. It should be noted that it is not the case that listeners were at ceiling performance for the higher-proficiency non-native talkers in noise; their “best” performance for these talkers (i.e., under the quiet condition) was significantly higher than their performance under the noise condition. There are several possible ways to interpret this result. One explanation is that non-native talkers’ acoustic enhancements were simply ineffective, causing listeners to rely more on semantic than acoustic enhancements. It is also possible that listeners were biased to rely more on top-down semantic cues than bottom-up acoustic cues when listening to non-native speech. Specifically, detecting a foreign accent in non-native speech may have encouraged listeners to shift their reliance to top-down cues, rather than solely relying on the acoustic signal.
This may be particularly interesting when considering its implications for processing of non-native speech in general. Previous work in word segmentation suggests that there is an underlying hierarchy for native listeners’ processing of native speech; they inherently rely more on lexical cues (e.g., semantic and lexical knowledge) than sublexical cues (e.g., coarticulation and word stress) when all cues are equally available and are in conflict (Mattys et al., 2005), and when listeners are under an increased cognitive load, processing multiple sources of competing information (Mattys et al., 2009). It is possible that when listening to non-native speech, native listeners’ tendency to rely on lexical cues more heavily than sublexical cues becomes even stronger, as suggested in some other previous studies that native listeners may be less sensitive to the details in the speech signal when trying to understand a non-native talker compared with a native talker (Hanulíková et al., 2012; Lev-Ari & Keysar, 2012). Because processing the acoustic signal of non-native speech can be effortful (e.g., Munro & Derwing, 1995), native listeners may be even more biased toward the use of semantic knowledge to predict the upcoming speech rather than interpreting the acoustic signal itself. Given these results, it is possible that when a native listener does not understand non-native speech, modifying linguistic features (e.g., using different words or syntactic structures) could be more helpful than modifying acoustic features of the same utterance; clarifying the semantic content of the message could help native listeners understand the acoustic signal in non-native speech better.
In future work, it would also be beneficial to investigate how other listener populations (e.g., older adults or individuals with hearing loss) may be impacted by acoustic and semantic modifications when listening to non-native speech. Previous work has demonstrated that these groups have difficulty understanding unfamiliar speech (e.g., Bieber & Gordon-Salant, 2017; Burda et al., 2003; Gordon-Salant et al., 2013; Hau et al., 2020; Janse & Adank, 2012), but it is not yet clear how they may or may not benefit from such modifications when listening to non-native speech. This is particularly important because it is also clear that non-native speech is also impacted by listening effort (Brown et al., 2020; McLaughlin & Van Engen, 2020; Van Engen & Peelle, 2014) and other cognitive factors (Ingvalson et al., 2017), which may differently impact the role of top-down and bottom-up processing during perception for varying listener populations.
One potential concern in the current study may be that the listening situation was doubly difficult for non-native speech in noise. That is, by making speech more ambiguous by masking the acoustic signal, listeners are required to attend more to top-down information. However, if this were the case, we would expect that under the quiet condition listeners may be able to take better advantage of acoustic modifications. Even in cases where listener performance is not at ceiling and talkers do make acoustic modifications (e.g., LP sentences spoken by higher-proficiency talkers), listeners still fail to take advantage of these modifications. This suggests that the particular task of listening to speech in noise cannot fully account for why we fail to see listeners take advantage of acoustic modifications as readily as they take advantage of semantic modifications.
Indeed, when investigating acoustic enhancements produced by native talkers, we also see a divergence such that acoustic modifications do not occur with equal probability and are not taken advantage of in equal measure. For example, native English listeners better utilize acoustic enhancements when listening to HP sentences as compared with LP sentences. We should first note that this pattern is similar to a pattern observed by Bradlow and Alexander (2007). Intelligibility improvement from plain to clear speech was much larger for HP sentences than for LP sentences.
There are two possible explanations for this result in the present study. First, the acoustic analysis demonstrates differences between the plain-clear difference for HP versus LP sentences produced by native English talkers. That is, talkers demonstrate a greater plain-clear difference in F0 range and mean F0 for HP sentences than for LP sentences. This increased acoustic differentiation could be attributed to features of the stimuli. HP sentences are generally longer than LP sentences, which may give talkers more leeway to vary the F0 across a longer sentence, or more incentive to vary the F0 given the greater variation in semantic content for the HP sentences. That is, while HP sentences are more predictable in the final word, they also vary more in syntactic structure, content, and lexical items across sentences than the LP sentences, possibly leading to more variance in F0.
However, it is also possible that this finding is not driven by properties of the stimuli and is more driven by properties of the listeners. Listeners have more semantic support for the target sentence in the case of HP sentences, and such support may allow them to even further take advantage of acoustic enhancements (plain vs. clear speech). This interplay between talker- and listener-related factors seems particularly likely because native talkers did still make acoustic modifications, even for the lower-predictability sentences. It is important to remember that in cases where we investigate how listeners perceive different varieties of speech (e.g., native and non-native speech), we must take into consideration both talker-related factors (e.g., the types of acoustic modifications made in speech) and listener-related factors (e.g., how listeners may differentially use these modifications depending on the listening scenario). Future work should more directly address issues of talker-listener interactions in perception of non-native speech (see, e.g., Baese-Berk et al., 2020).
This result may also be seen as contradictory to some previous findings that clear speech benefits perception of semantically anomalous sentences more than semantically meaningful ones (e.g., Van Engen et al., 2014). That is, clear speech benefits sentences with less semantic context in their study but sentences with more semantic context here. It is important to note, though, some large differences between the present study and that study. First, our LP sentences do still provide some semantic information. That is, while LP sentences can be thought of as containing less semantic information than the HP sentences here, it is not the case that they provide no semantic information, as in the case of anomalous sentences. Therefore, it is possible that this is not an effect of a continuum of semantic context, but rather a binary issue of whether or not context is present. Second, in this study, we are specifically investigating non-native speech, and it is possible that the relative weighting of semantic and acoustic information differs for this type of speech compared with the babble-masked speech in the van Engen et al. study. Future work could more directly compare these two types of listening conditions.
Finally, some limitations of this study should be mentioned. First, while we hoped to investigate speech of higher- and lower-proficiency non-native talkers and how listeners may utilize acoustic and semantic modifications produced by these talkers, it is important to note that these stimuli were strictly controlled. That is, they do not include many other features that may vary across these two populations (e.g., differences in syntactic structure or lexical choice). Therefore, the extent to which these findings can translate to real-world communication between native and non-native talkers of a variety of proficiency levels may be limited. Furthermore, while our results are suggestive of the role of talker proficiency in using acoustic and semantic modifications during perception for native English listeners, it is possible that these results may not generalize beyond the specific talkers (or accents) used in our present study. For example, while the current study examines native Mandarin learners of English, talkers whose native language is more similar to English (or a specific target language used in a study) may be able to make more robust acoustic enhancements that could result in greater enhancement of perception from plain to clear English speech. Furthermore, these findings may not generalize to listeners in languages other than English. That is, listeners from other languages may benefit differently from acoustic and semantic enhancements than English listeners.
Another point of caution is that the acoustic analyses we conducted here likely do not accurately capture the full constellation of potential acoustic modifications talkers make when producing clear speech. We acknowledge that we did not measure all possible acoustic modifications, but rather chose “global” measures (F0 mean, F0 range, and speaking rate) as we anticipated that these measures would shift during production of clear speech. However, given the specific properties of our stimuli, we did not measure a variety of other segmental characteristics that have been previously demonstrated to shift from plain to clear speech (e.g., vowel space; Kato & Baese-Berk, 2022; Smiljanić & Bradlow, 2005). Simply put, our stimuli were designed to investigate perceptual benefits of clear and plain speech within HP and LP sentences, but were not designed for more detailed acoustic comparisons. That said, we believe it is likely that when listeners demonstrate perceptual benefits for clear speech as compared to plain speech, they are responding to a combination of acoustic modifications rather than single acoustic cue changes. Future work in this area could examine the perceptual impacts of multiple co-varying acoustic cues. This is particularly critical because it is possible, and perhaps even likely, that non-native speakers may enhance both cues we expect them to enhance (e.g., speaking rate or F0), but also “non-native” cues to clear speech, or factors that we may not initially anticipate would be manipulated. Some previous work has used a technique of investigating multiple cues simultaneously when examining production of non-native contrasts (e.g., linear discriminant analyses; Jaggers & Baese-Berk, 2019), but this is also an approach that could be scaled up to larger stretches of speech. We believe that this approach is likely to be more enlightening about what specific collection of acoustic cues is likely to impact perception.
Finally, our design choices may also have impacted our results. In this study, we use different SNRs for our native and non-native talkers. This was done to prevent potential ceiling and/or floor effects for some talker groups, and follows precedent from other work (Kato & Baese-Berk, 2022; Rogers et al., 2010). However, this does introduce a potential confound. Specifically, when comparing the native talkers to non-native talkers, it is possible that differences are not driven specifically by talker group, but rather by signal-to-noise ratio. We believe our approach is the “lesser of two evils” in that it allowed us to avoid ceiling and floor effects which were very likely to distort our results; however, we do appreciate that it is possible that the differences between native- and non-native-talker groups may be less reliable than they would be were the SNRs perfectly matched across groups and do not make strong claims based on comparison of native and non-native talker groups. Furthermore, to alleviate some of these concerns, we have included an analysis of just the two non-native groups in Appendix C, and demonstrate that even when just comparing these groups we see similar patterns as those reported in the broader data, namely that we see large differences between the two proficiency groups and between HP and LP sentences, but no significant differences between clear and plain speech. Therefore, we believe that the most important results of this study hold despite this design decision, which is that native listeners utilize semantic cues more robustly than acoustic cues when trying to understand non-native speech produced by both higher- and lower-proficiency talkers.
5 Conclusion
Despite the limitations described above, we believe our findings are informative to better understand how native English listeners make use of semantic and acoustic cues when processing native and non-native speech. It appears that listeners are able to take advantage of semantic enhancements under a variety of listening circumstances and for a variety of talker populations. Use of acoustic enhancements in perception, however, appears to be more limited. This may be in part due to the nature of the acoustic enhancements produced by native and non-native talkers or due to the properties of the listeners, and how they weigh information during perception. We propose that it is likely a combination of these two factors, and suggest that future research more seriously consider interactions between properties of talkers and listeners when examining perception of non-native speech.
Footnotes
Appendix A
List of 56 test sentences (Bradlow & Alexander, 2007) and 10 practice BKB sentences (Bamford & Wilson, 1979) recorded by native and non-native English talkers.
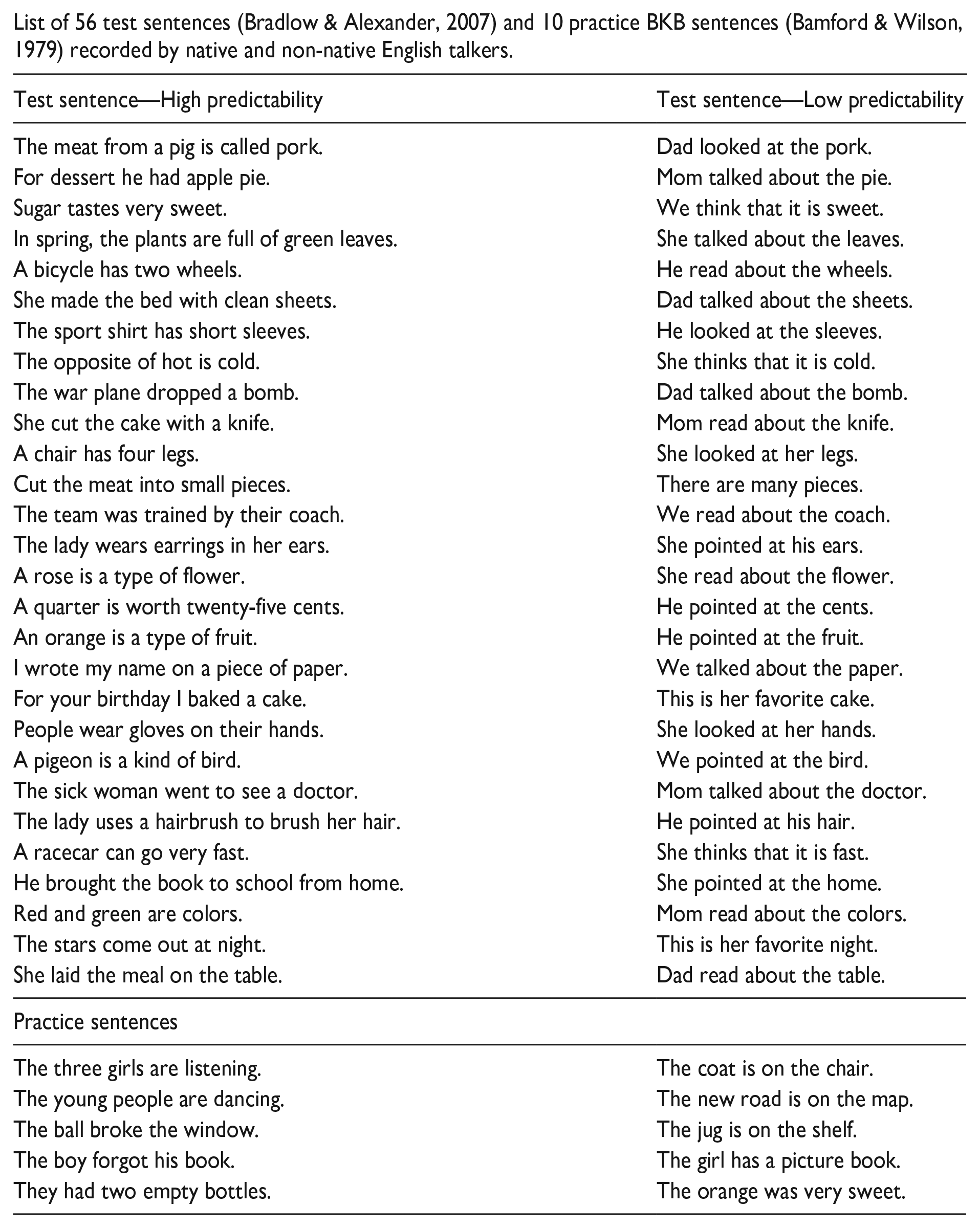
| Test sentence—High predictability | Test sentence—Low predictability |
|---|---|
| The meat from a pig is called pork. | Dad looked at the pork. |
| For dessert he had apple pie. | Mom talked about the pie. |
| Sugar tastes very sweet. | We think that it is sweet. |
| In spring, the plants are full of green leaves. | She talked about the leaves. |
| A bicycle has two wheels. | He read about the wheels. |
| She made the bed with clean sheets. | Dad talked about the sheets. |
| The sport shirt has short sleeves. | He looked at the sleeves. |
| The opposite of hot is cold. | She thinks that it is cold. |
| The war plane dropped a bomb. | Dad talked about the bomb. |
| She cut the cake with a knife. | Mom read about the knife. |
| A chair has four legs. | She looked at her legs. |
| Cut the meat into small pieces. | There are many pieces. |
| The team was trained by their coach. | We read about the coach. |
| The lady wears earrings in her ears. | She pointed at his ears. |
| A rose is a type of flower. | She read about the flower. |
| A quarter is worth twenty-five cents. | He pointed at the cents. |
| An orange is a type of fruit. | He pointed at the fruit. |
| I wrote my name on a piece of paper. | We talked about the paper. |
| For your birthday I baked a cake. | This is her favorite cake. |
| People wear gloves on their hands. | She looked at her hands. |
| A pigeon is a kind of bird. | We pointed at the bird. |
| The sick woman went to see a doctor. | Mom talked about the doctor. |
| The lady uses a hairbrush to brush her hair. | He pointed at his hair. |
| A racecar can go very fast. | She thinks that it is fast. |
| He brought the book to school from home. | She pointed at the home. |
| Red and green are colors. | Mom read about the colors. |
| The stars come out at night. | This is her favorite night. |
| She laid the meal on the table. | Dad read about the table. |
| Practice sentences | |
| The three girls are listening. | The coat is on the chair. |
| The young people are dancing. | The new road is on the map. |
| The ball broke the window. | The jug is on the shelf. |
| The boy forgot his book. | The girl has a picture book. |
| They had two empty bottles. | The orange was very sweet. |
Appendix B
Appendix C
( |
||||
| Fixed Effects | Estimate | S.E. | z-val. | Pr(>|z|) |
|---|---|---|---|---|
| (Intercept) | .34 | .25 | 1.36 | .17 |
| Style (Plain vs. Clear) | .3 | .2 | 1.47 | .14 |
| Type (High vs. Low predictability) | 1.65 | .24 | 6.74 | < .001*** |
| Native Mandarin High vs. Low | 1.94 | .45 | 4.27 | < .001*** |
| Style: Type | .04 | .28 | .14 | .89 |
| Style: Native Mandarin High vs. Low | −.1 | .38 | -.26 | .8 |
| Type: Native Mandarin High vs. Low | .45 | .18 | 2.53 | .01* |
| Style: Type: Native Mandarin High vs. Low | .55 | .49 | 1.14 | .25 |
| Post-hoc Tukey test comparing the effect of Type (High vs. Low predictability) | ||||
| Talker Group | Estimate | S.E. | z-val. | Pr(>|z|) |
| Native Mandarin-Low | −1.42 | .26 | -5.56 | < .001*** |
| Native Mandarin-High | −1.87 | .27 | -7.06 | < .001*** |
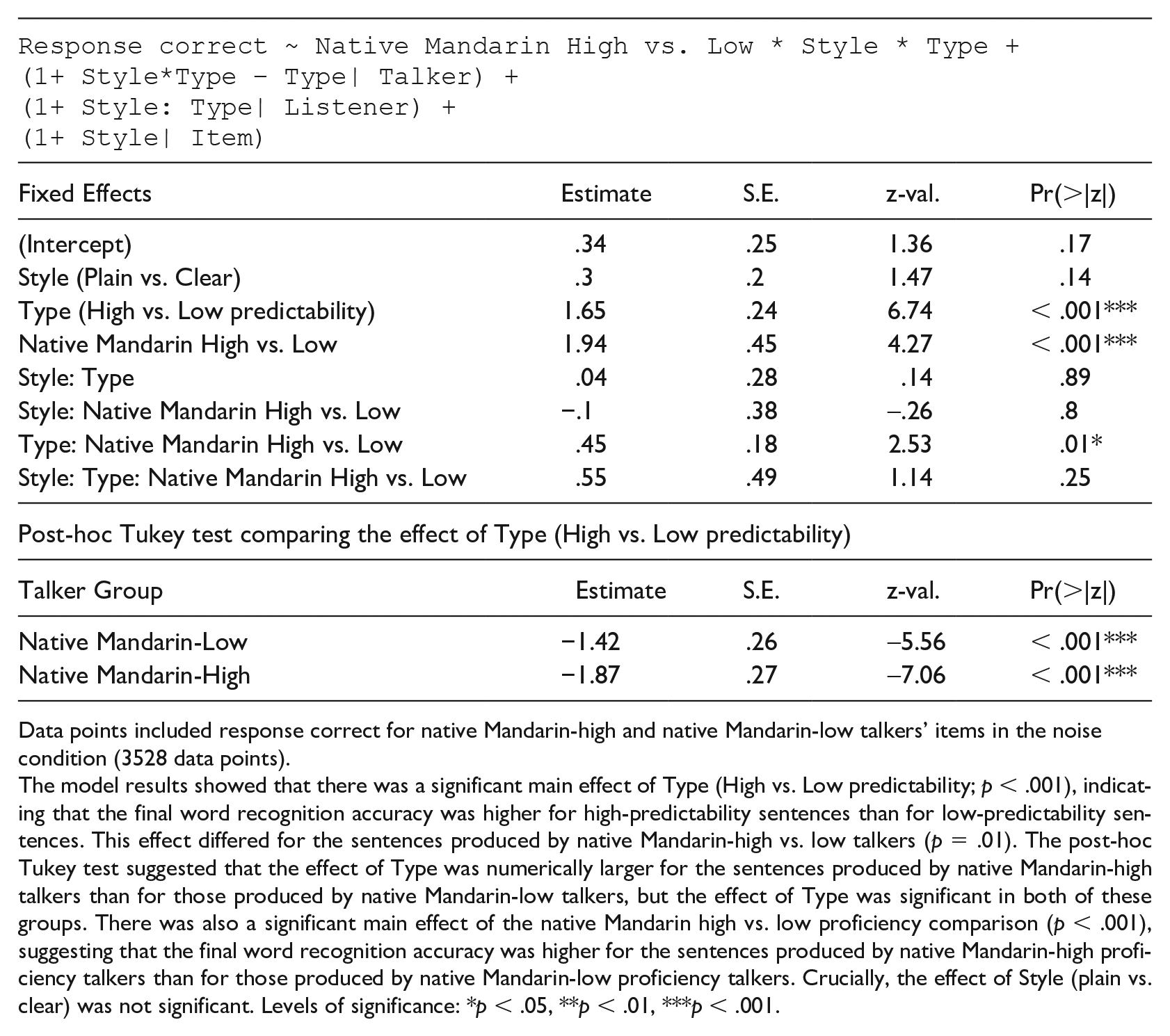
Data points included response correct for native Mandarin-high and native Mandarin-low talkers’ items in the noise condition (3528 data points).
The model results showed that there was a significant main effect of Type (High vs. Low predictability; p < .001), indicating that the final word recognition accuracy was higher for high-predictability sentences than for low-predictability sentences. This effect differed for the sentences produced by native Mandarin-high vs. low talkers (p = .01). The post-hoc Tukey test suggested that the effect of Type was numerically larger for the sentences produced by native Mandarin-high talkers than for those produced by native Mandarin-low talkers, but the effect of Type was significant in both of these groups. There was also a significant main effect of the native Mandarin high vs. low proficiency comparison (p < .001), suggesting that the final word recognition accuracy was higher for the sentences produced by native Mandarin-high proficiency talkers than for those produced by native Mandarin-low proficiency talkers. Crucially, the effect of Style (plain vs. clear) was not significant. Levels of significance: *p < .05, **p < .01, ***p < .001.
Acknowledgements
We would like to thank Brandon Lasala and Sarah Steindorf for their help with data analysis. We also would like to thank Alyssa Brown, Cydnie Davenport, Zachary Houghton, Joanna Kraski, Karlie Scott, and Kayla Walker for their assistance with data collection and analysis for an earlier version of the manuscript.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by National Science Foundation (NSF) Doctoral Dissertation Research Improvement Grant (BCS-1941739) to MMBB (PI) and MK (Co-PI).