
Abstract
Two prominent statistical laws in language and other complex systems are Zipf’s law and Heaps’ law. We investigate the extent to which these two laws apply to the linguistic domain of phonotactics—that is, to sequences of sounds. We analyze phonotactic sequences with different lengths within words and across word boundaries taken from a corpus of spoken English (Buckeye). We demonstrate that the expected relationship between the two scaling laws can only be attested when boundary spanning phonotactic sequences are also taken into account. Furthermore, it is shown that Zipf’s law exhibits both high goodness-of-fit and a high scaling coefficient if sequences of more than two sounds are considered. Our results support the notion that phonotactic cognition employs information about boundary spanning phonotactic sequences.
1 Introduction
Naturally emerging complex systems typically obey characteristic statistical laws. For instance, preferential attachment in emerging networks (“the rich get richer” principle) leads to a link distribution that follows a decreasing power law (Barabási & Pósfai, 2016). One of the most prominent statistical laws ubiquitous in complex systems is Zipf’s law (Zipf, 1949). It accounts for distributional patterns in demographics, economy, bibliometrics, and language (Corominas-Murtra & Solé, 2010; Ferrer-i-Cancho, 2016; Li, 2002). In linguistics, it models the skewed distribution of frequency of occurrence in a population of types (e.g., words) or equivalently the inverse relationship between token frequency f and rank r, that is, f ∝ r−α with exponent α. Similarly, Zipf’s law describes the inverse relationship between the complexity of a given type (e.g., in terms of its length, size, or duration) and its frequency. Another widely attested statistical scaling law, related to Zipf’s law, is Heaps’ law (also known as Herdan’s law; Heaps, 1978; Lü et al., 2010). It is a model of a system’s complexity (typically the number of types) depending on the number of tokens in it, that is, the sample size. According to Heaps’ law, complexity grows with the number of tokens in a sample in a sublinear fashion.
Most linguistic accounts of Zipf’s law and Heaps’ law operate on the lexical level: that is, they address the relationship between a word’s frequency and its rank, and the relationship between corpus size and the number of word types in it. Its validity has been demonstrated cross-linguistically (Baayen, 2001). The picture seems to be less straightforward with regard to the phonological level. For 95 languages it has been shown that the relationship between phoneme frequency and phoneme rank only roughly follows Zipf’s law (Tambovtsev & Martindale, 2007).
In this study, we focus on the domain of phonotactics, being systems of sound sequences also referred to as n-phones (where n stands for the number of phonological constituents in the sequence). We test to what extent Heaps’ law and Zipf’s law apply in phonotactics by analyzing n-phones (for a range of different lengths n) within words and across word boundaries.
Many mechanisms have been proposed to explain Zipf’s law and Heaps’ law in linguistics, and most of them can arguably be transferred to the phonotactic level as well. First, just like any linguistic subsystem, systems of sound sequences can be conceived of as complex systems which have evolved over time (e.g., Barabási & Pósfai, 2016). If this process is driven by preferential attachment, so that the choice of a sound sequence depends on how established (or “entrenched”) it is already, this entails a skewed distribution of token frequencies of n-phone types. The extent to which preferential attachment applies is then reflected in the degree to which this distribution is skewed and translates into the power-law exponent α in f ∝ r−α. No preferential attachment corresponds to a vanishing exponent (Baek et al., 2011).
A second hypothetical driving force, in fact brought into play by Zipf and colleagues (Newman & Zipf, 1936), is the principle of least effort, which has been suggested to explain the characteristic distributional properties on the phonological level. Some sounds are easier to produce, being for instance less complex and more well-formed, than others, and the more complex a sound is, the less frequently it is used (e.g., Deng, 2016). Similarly, sequences of sounds differ as to their complexity. For example, sequences of consonants and vowels are generally considered articulatorily and perceptually less complex than sequences of consonants (Levelt & Van De Vijver, 2004). Related to this, using graphemics as a proxy for phonotactics, Mahowald et al. (2018) have demonstrated a positive correlation between phonotactic probability as a measure of well-formedness and lexical frequency.
Third, it was argued that Zipf’s law may be a consequence of multiple underlying and interacting processes, which in isolation would not necessarily give rise to power-law distributions (Aitchison et al., 2016). On the lexical level, it was argued by Lestrade (2017) on computational grounds that an interaction of syntactic and semantic factors provides a better explanation of Zipf’s law in the lexicon than each of these two domains in isolation. Clearly, phonotactics is influenced by various linguistic domains as well: sound sequences are brought about through concatenating phonemes within morphemes (i.e., lexical phonotactics in the narrow sense), through morphology (e.g., affixation, ablaut), or through syntax (across word boundaries).
With regard to Heaps’ law it was shown rigorously by Lü et al. (2010) that in evolving complex systems with finite size, Zipf’s law entails Heaps’ law. In that sense, they argue Zipf’s law to be the more fundamental one of the two. Furthermore, they derive the interesting relationships that Heaps’ exponent is positively correlated with system size and non-negatively correlated with Zipf’s exponent. So, if a grown linguistic subsystem—such as phonotactics—obeys Zipf’s law, these relationships are expected to hold.
Although the applicability of scaling laws to phonotactics is not implausible, as argued above, phonotactic scaling laws are rather understudied. Ha et al. (2009) investigate Zipf’s law in systems of n-phones of length 2 up to 13, but they limit their analysis to word-internal phonotactics. Excluding word-boundary spanning n-phones from phonotactic research is potentially problematic for several reasons.
To begin with, this is because low-probability and/or complex phonotactic sequences have been suggested to fulfill the function of signaling word boundaries (Daland & Pierrehumbert 2011), and thus assist the listener in the decomposition of the speech stream into words.
Similarly, low-frequency diphones can signal morpheme boundaries or the boundaries between the individual parts of compound words (Finley & Newport, 2011). For example, in English, the 2-phone consonant cluster /kf/ does not occur word-internally and therefore strikes listeners as being ill-formed when they encounter it within a word. In contrast, the same sequence occurs frequently and sounds perfectly fine across word boundaries (e.g., “pink flamingo”) or across the boundaries of the parts of compound words (e.g., “workflow”, cf. Daland & Pierrehumbert 2011). Likewise, in English, the word-final cluster /ts/ does only rarely surface word internally (as in “blitz”) but mostly occurs across morpheme boundaries (e.g., “cats” or “hits”). Thus, when listeners hear such sequences, they can interpret them as boundary signals (Jusczyk, 1999; Mattys & Jusczyk, 2001; Saffran et al., 1996).
In a similar vein, the “naïve discriminative learning” approach (Baayen et al., 2016; Milin et al., 2017) argues that lexical structure can arise as the result of phonotactic distribution frequencies, so that actual morphemes, words and phrases indeed emerge from phonotactics (Divjak, 2019).
Taking this research into account, across-word phonotactics seem to fulfill a non-negligible role in the interface between phonology, morphology, syntax and the lexicon. As a consequence, accounts for scaling laws in phonotactics should not exclude boundary-spanning phonotactic items per se. Furthermore, if analyses are limited to word-internal phonotactics it cannot be ruled out that potential scaling laws in phonotactics are mere epiphenomena of corresponding scaling laws in the lexicon.
Finally, and relevant from a methodological perspective, the notion of what counts as a word (at least in corpus linguistics) is biased by graphemics among other factors (Haspelmath, 2011) so that word boundaries are usually equated with whitespaces in written text. This creates a multitude of problems: compounds are graphemically realized differently across languages; some writing systems do not show clear word boundaries; words are not the primary building blocks in polysynthetic and incorporating languages.
The goal of this study is to provide an empirical analysis of Heaps’ law and Zipf’s law in phonotactics and to test whether they indeed hold in this domain. We compare phonotactics within word boundaries (“within-word phonotactics”) to phonotactic systems that also allow for boundary-spanning n-phones (“within-and-across-word phonotactics”). We analyze n-phones of phonotactic length 2 to 6 in a corpus of spoken American English and test to what extent scaling-law characteristics (exponents) are related with phonotactic length and system size.
We demonstrate (a) that measures of phonotactic complexity taking frequency into account are more reliable than complexity measures only based on inventory size (see Rama, 2013, and discussion below) and (b) that within-and-across-word phonotactics (but not so much within-word phonotactics) shows behavior typical of emerging complex systems, indicating that phonotactic cognition also covers information about boundary spanning n-phones. Finally, we argue that (c) cognitively plausible phonotactic systems consist of sequences with more than two sounds and (d) we highlight differences between scaling laws in phonotactics and the lexicon.
2 Data and methods
We used the Buckeye Speech Corpus (Pitt et al., 2005), which contains about 300,000 phonologically transcribed word tokens produced by a total of 40 speakers of American English. We extracted 10 nested sub-corpora from the corpus so that the smallest sub-corpus counts about 10,000 tokens, and each subsequent sub-corpus is a superset of and about 10,000 tokens larger than its predecessor.
From each sub-corpus, we extracted all n-phones with different length n from 2 to 6. In theory, (across-word) n-phones can be arbitrarily long, but for practical considerations, we had to set an upper limit for our investigations. Our choice is motivated by results from research on the human working memory, which has been argued to be limited to processing 3 to 5 segments at a time (Green, 2017; Mathy & Feldman, 2012). Applying this notion to phonotactics, we set our limit slightly above this cognitively grounded figure and analyzed n-phones up to a length of 6. In addition, this limit ensures that we do not consider sequences which are much longer than the average number of phonemes in a word, which is about 7±2 (a cross-linguistic estimate, for example as reported by Nettle, 1995; a similar mean length in the lexicon can be derived from English spoken frequencies in the CELEX database, namely 7.25 phonemes; Baayen et al., 1995).
The extraction of n-phones was done in two different ways: (1) In the within-word condition, all n-phones (for a given n) occurring within word forms (i.e., word tokens separated by whitespaces) were extracted. For instance, the sequence Heaps’ law features four within-word 2-phones /hi, ip, ps, lɔ/, two within-word 3-phones /hip, ips/, and a single within-word 4-phone /hips/. For each n-phone type i, the overall frequency of occurrence fi was computed; (2) In the within-and-across-word condition, word (and sentence) boundaries were ignored, so that the sequence Heaps’ law shows five 2-phones /hi, ip, ps, sl, lɔ/, four 3-phones /hip, ips, psl, slɔ/, etc.
Next, we computed two complexity measures for each sub-corpus and each n. First, we retrieved phonotactic inventory size d0, that is, the number of n-phone types. Second, we computed phonotactic diversity as d1 = expH, where
Both sizes are special cases of the more general diversity number of order q, defined as
To measure system size, we determined the number of n-phone types t in the overall corpus for each n respectively.
Heaps’ law describes the sublinear growth of complexity dq (usually the number of types) as a function of corpus size s, given by
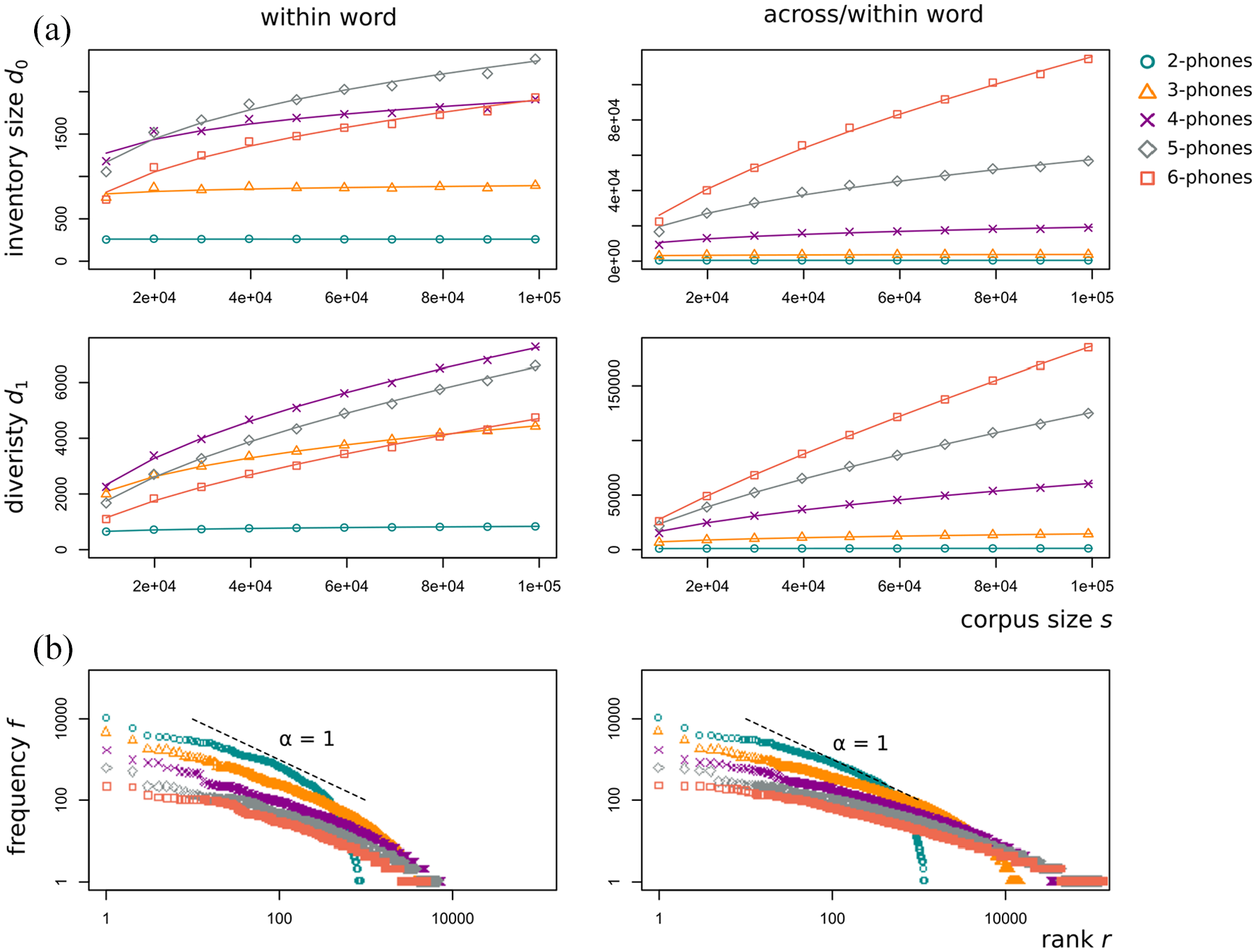
Heaps’ law (a) and Zipf’s law (b) for within-word phonotactics (left) and within-and-across-word phonotactics (right). (a) Phonotactic complexity (d0, d1) depending on corpus size for different phonotactic lengths (see legend in the upper-right corner). Lines represent non-linear least-squares regression models of Heaps’ law. (b) Token frequency by rank for different phonotactic lengths. Dashed line represents Zipf’s law with exponent α = 1 (i.e., a slope of 1 on a log-log scale).
Zipf’s law can be formalized as
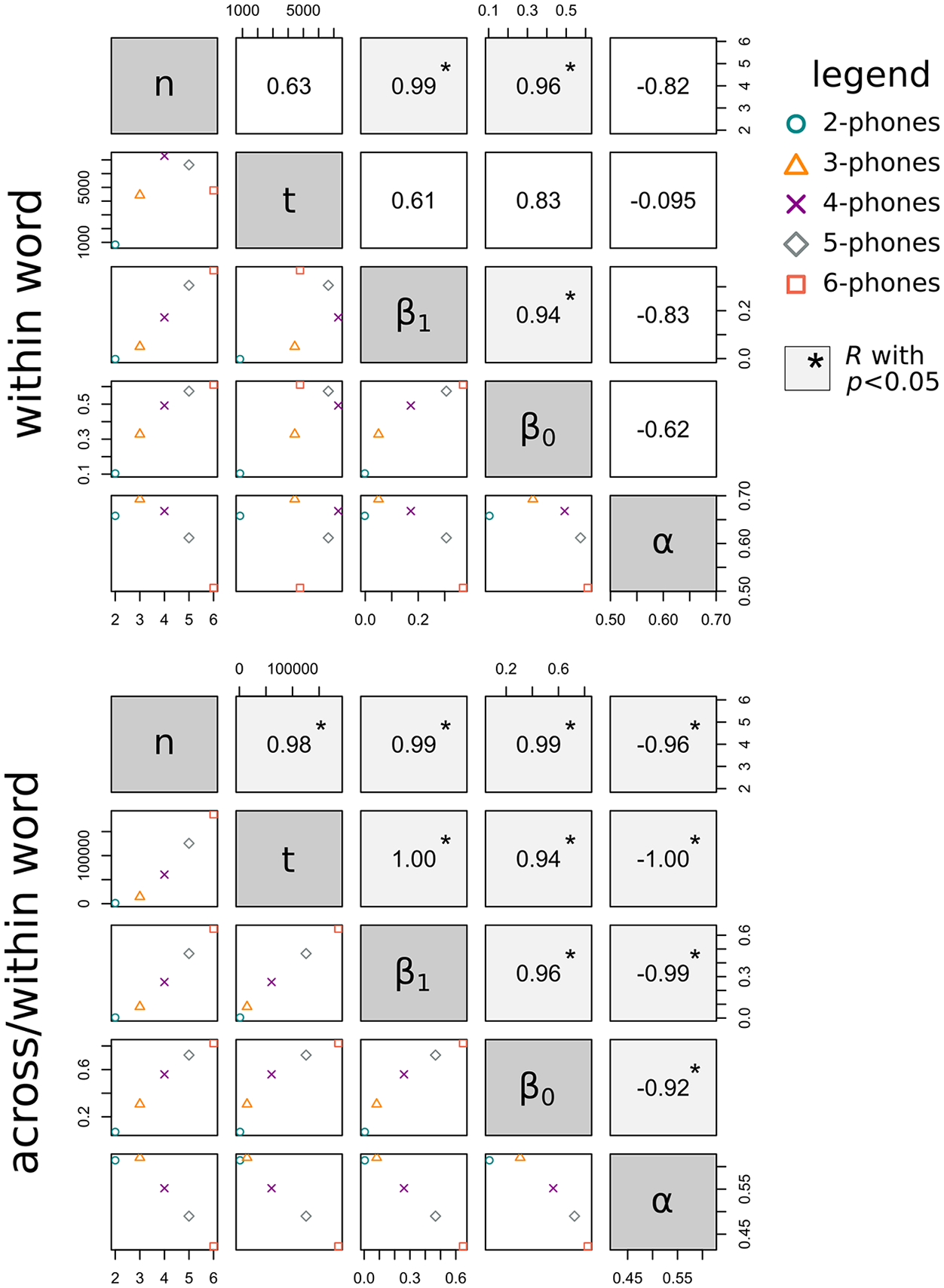
Since we consider n-phones with length 2 to 6, this resulted in a series of 5 estimates for each of the variables (number of tokens; number of types; exponents β0; β1; α) and each condition (within, within-and-across). We computed pairwise correlation coefficients (Pearson’s R) for all combinations of two variables (Figure 2). All computations were done in R (R Development Core Team, 2017).
3 Results
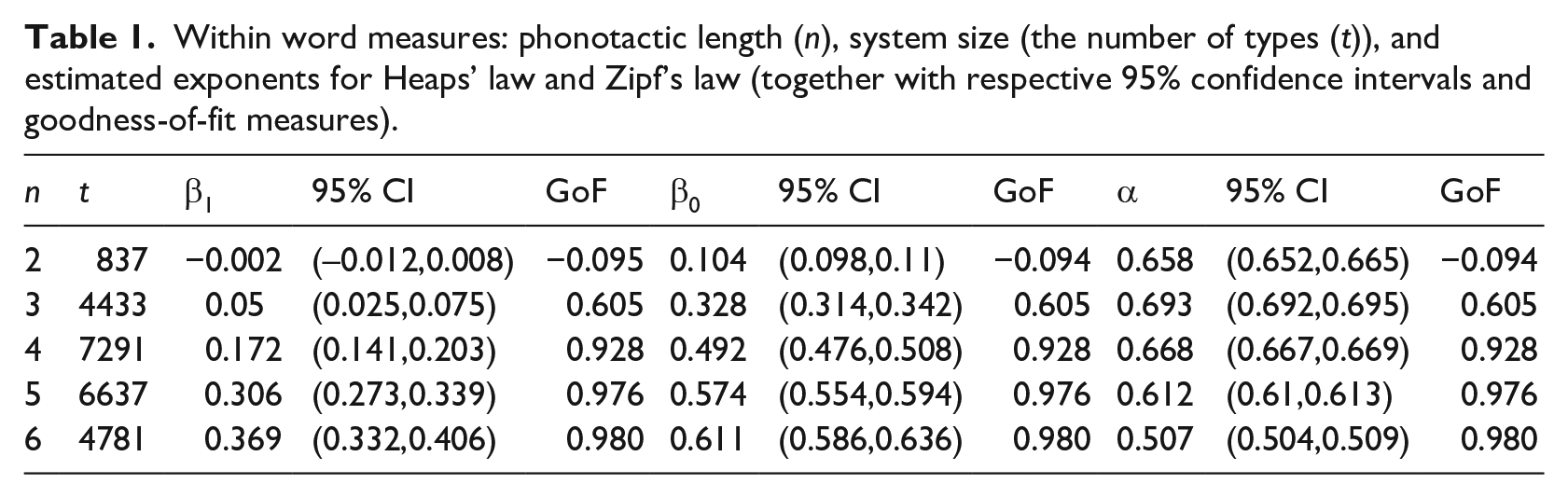
The computed values for number of tokens, number of types, and the exponents β0, β1, and α for all lengths n are shown in Tables 1 and 2, respectively.
Within word measures: phonotactic length (n), system size (the number of types (t)), and estimated exponents for Heaps’ law and Zipf’s law (together with respective 95% confidence intervals and goodness-of-fit measures).
Across/within word measures: phonotactic length (n), system size (the number of types (t)), and estimated exponents for Heaps’ law and Zipf’s law (together with respective 95% confidence intervals and goodness-of-fit measures).
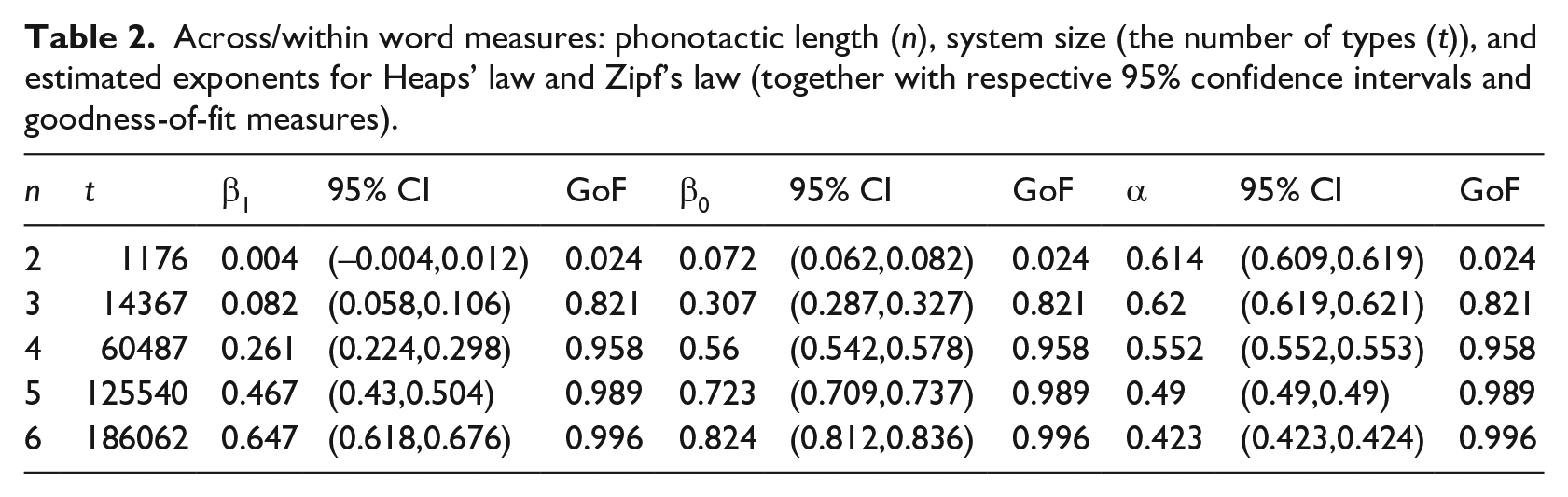
Growth curves for Heaps’ law are shown in Figure 1(a). The curves flatten more slowly as n gets larger. This is reflected in the exponent estimates, which increase with n. Similarly, it is evident that the growth curves of inventory size d0 flatten more slowly than the growth curves of diversity d1 indicating that diversity is less susceptible to changes in sample size than it is the case for inventory size. It can be seen from Table 1- that growth exponents are on average higher in the within-and-across-word condition than in the case of exclusively lexical phonotactics (within word condition), which may be attributed to larger system size in within-and-across phonotactics. Thus, phonotactics is more sensitive to changes in sample size if boundary spanning n-phones are admitted, in particular for high n. Interestingly, β0 approaches estimates of Heaps’ exponent for lexical items. In the case of 6-phones, β0 = 0.82, which comes close to the range for lexical estimates for β0 reported, for example by Torre et al. (2017). Note that lexical items have—cross-linguistically—on average about 7 ± 2 phonemes (Nettle, 1995).
The relationship between frequency and rank, as described by Zipf’s law, can be seen in Figure 1b. In contrast to Heaps’ exponent, there is no clear relationship between α and phonotactic length n (neither for the within nor the within-and-across-word condition). It is remarkable that Zipf’s coefficients measured for phonotactic items are considerably lower than estimates in the lexical regime which is about α = 1 (Zipf, 1949). This entails that phonotactic frequency distributions are less skewed than lexical ones.
Figure 2 shows pairwise correlations for all combinations of variables under investigation. The measures for system size show interesting interactions with n. While the number of types t is positively correlated with n in within-and-across-word phonotactics, this is not the case in within-word phonotactics. Similarly, both Heaps’ coefficients increase with the number of types in within-and-across-word phonotactics, but not in the within-word condition. Zipf’s exponent correlates negatively with all other measures in the within-and-across-word condition, a relationship which cannot be observed in within-word phonotactics. What both conditions have in common is that both Heaps’ exponents correlate positively with n and that Zipf’s exponent peaks at n = 3. Finally, goodness-of-fit is low for n = 2 in both conditions but reasonably high for n > 2.
4 Discussion
In this study, we investigated scaling laws of phonotactic complexity in a phonologically transcribed corpus. We considered n-phones—that is, phonotactic constituents—with different length n under two different conditions: within-word phonotactics and unconstrained phonotactics where n-phones may span word boundaries. In our analysis, we focused on Heaps’ law and Zipf’s law. For the former, we operationalized phonotactic complexity by means of two different measures, inventory size and (frequency sensitive) diversity. For each phonotactic length n, and each condition Heaps’ and Zipf’s exponents were estimated.
A number of observations can be made which have implications for our understanding and analysis of phonotactic systems. These concern (a) different ways of measuring phonotactic complexity, (b) the difference between within-word phonotactics and within-and-across-word, that is, unconstrained, phonotactics, (c) the relationship between the inspected scaling laws and phonotactic length n, and (d) the difference between scaling laws in phonotactics and the lexicon. In what follows, we discuss these observations (a—d) in more detail.
First (observation 1), a comparison of the two measures of complexity d0 and d1 reveals that frequency dependent diversity is much less strongly dependent on sample size than is phonotactic inventory size in the sense that the Heaps’ coefficients corresponding to phonotactic inventory size are considerably higher. This implies that complexity measures which also take token frequency into account are much more robust with respect to comparisons across corpora and small sample sizes. Measuring differences in phonotactic inventory size (for 2-phones and 3-phones) was suggested as a way of estimating linguistic time depth (Rama, 2013). We argue that frequency-based measures are potentially more reliable tools for these matters (although they require more fine-grained quantitative analyses).
In order to assess the difference between word-internal and unconstrained phonotactics (observation 2) with respect to Heaps’ and Zipf’s law, let us first consider what would be expected based on formal evidence. Lü et al. (2010) have demonstrated on computational grounds that in emerging complex systems which obey Zipf’s law, (a) Heaps’ law is also supposed to hold, (b) Zipf’s exponent shows a non-positive monotone relationship with Heap’s exponent, and (c) that Heaps’ exponent increases with system size. If we see (a)–(c) as indicators for how well-behaved a complex system, such as the system of n-phones, is, we find that only unconstrained phonotactic systems behave like typical complex systems.
This is because although both laws can be argued to hold in both conditions (based on the estimated coefficients and goodness-of-fit values), we do not find statistically robust support for (b) and (c) in the within-word condition (cf. Figure 2). We argue that it is a reflex of the fact that phonotactic system size decreases with phonotactic length since word length obviously constrains the number of possible word-internal phonotactic items, in particular if phonotactic length is high.
Because it is rather within-and-across-word phonotactics—as opposed to phonotactics restricted to word-internal sequences—which shows the behavior expected for emerging complex systems, this indicates that phonotactic cognition is organized in such a way that it also covers information about boundary spanning items (e.g., conceptualized as phonotactic representations or transition probabilities; Ernestus, 2014). This supports results from research on phonotactically driven speech segmentation, which suggest that listeners infer morpheme and word boundaries from phonotactic information (Daland & Pierrehumbert, 2011; Dressler & Dziubalska-Kołaczyk, 2006; Jusczyk, 1999; Saffran et al., 1996). Clearly, this requires listeners to have access to information on boundary spanning phonotactic sequences.
Going further, word boundaries can be considered as artifacts imposed by the lexical domain in a top-down manner, which should a priori not be taken for granted in phonotactic research. For example, in naïve discriminative learning approaches (Baayen et al., 2016; Milin et al., 2017) words are effectively epiphenomena of distributional properties of phonotactics rather than phonotactics being defined by what is allowed within words. In this model, n-phones are input cues and the learning process consists of finding weights to predict outcomes (i.e., lexical items). So, during learning a system of phonotactic sequences emerges which consists of predictive (discriminative) and less predictive cues. Crucially, it is the boundary spanning sequences with low transition probabilities which have high predictive power. This goes in line with our conclusion that these items represent integral parts of phonotactic cognition.
Lastly (observation 3), we can evaluate the relationship between phonotactic length n and the two scaling laws. A pattern that we find in the within-and-across condition is that while Heaps’ exponent increases and Zipf’s exponent decreases with n, respectively, goodness-of-fit is generally better for long phonotactic sequences (for
The significantly increasing relationship between Heaps’ exponent and phonotactic length
As to our final observation (observation 4), we find that Zipf’s exponent in phonotactics is much lower than on the lexical level. This suggests that phonotactics is affected less by factors which are thought to give rise to Zipf’s law than this is the case in the lexical domain. One reason might be that cognitive constraints related to memory and semantic organization (Piantadosi, 2014) are much weaker in phonotactics than in the lexicon. Clearly, phonotactic sequences carry less meaning than lexical items do (but see Topolinski et al., 2015, and Dressler & Dziubalska-Kołaczyk, 2006, for sound-symbolic and functional properties, respectively).
In addition, we found that Heaps’ exponent in phonotactics is generally lower than its lexical counterpart. An important methodological consequence of this is that phonotactic studies do not require the same amount of linguistic data as lexical studies do. This is because a relatively large share of the complexity of the phonotactic system is covered already in small samples. This difference between phonotactics and the lexicon holds particularly true for short within-word phonotactic sequences, such as word-internal 2-phones, but vanishes as phonotactic length approaches the average length of words.
5 Conclusion
We have shown that phonotactic systems obey well-established scaling laws that can be found in many complex systems. This implies—not quite surprisingly—that the architecture of phonotactics is far from random but must rather be governed by similar laws of self-organization as other complex systems in linguistics (such as multiple interacting processes, preferential attachment, or the principle of least effort).
In particular, phonotactics exhibits behavior typical of complex systems following Zipf’s law if phonotactic items spanning word boundaries are also considered. One advantage of the latter operationalization is that it does not require word boundaries and hence no top-down conceptualization of what linguistic unit counts as a word (which in turn requires a notion of semantics). In that sense, the present paper aligns with the acoustic study by Torre et al. (2017). Consequently, the method used here can be applied to languages with various morphosyntactic structures (such as incorporating or polysynthetic languages). Likewise, it would be interesting to study phonotactic scaling laws in animal vocalizations for which segmented data is available (Kershenbaum et al., 2016).
Moreover, our results tentatively suggest that cognitively plausible phonotactic systems consist of sequences with more than two sounds and that differences between processes operating in phonotactics and the lexicon, respectively, are reflected in properties of their respective scaling laws (coefficients; goodness-of-fit). This, however, needs to be validated on experimental and computational grounds in order to draw robust conclusions.
Supplemental Material
analysis – Supplemental material for Scaling Laws for Phonotactic Complexity in Spoken English Language Data
Supplemental material, analysis for Scaling Laws for Phonotactic Complexity in Spoken English Language Data by Andreas Baumann, Kamil Kaźmierski and Theresa Matzinger in Language and Speech
Supplemental Material
data – Supplemental material for Scaling Laws for Phonotactic Complexity in Spoken English Language Data
Supplemental material, data for Scaling Laws for Phonotactic Complexity in Spoken English Language Data by Andreas Baumann, Kamil Kaźmierski and Theresa Matzinger in Language and Speech
Supplemental Material
utils – Supplemental material for Scaling Laws for Phonotactic Complexity in Spoken English Language Data
Supplemental material, utils for Scaling Laws for Phonotactic Complexity in Spoken English Language Data by Andreas Baumann, Kamil Kaźmierski and Theresa Matzinger in Language and Speech
Footnotes
Acknowledgements
We would like to thank three anonymous reviewers for various valuable comments that helped to improve our manuscript, analysis, and code.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
The R code for doing all analyses in this contribution can be found in the script “analysis.R.” It requires the script “utils.R” comprising a set of helper functions. All data are collected in the binary “data.RData.” Run “analysis.R” to run the computation and to generate human readable data files. The scripts were created under R version 3.4.3. All code and data can be found in the following GitLab project: ![]()
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.