
Abstract
This article presents ViEWS – a political violence early-warning system that seeks to be maximally transparent, publicly available, and have uniform coverage, and sketches the methodological innovations required to achieve these objectives. ViEWS produces monthly forecasts at the country and subnational level for 36 months into the future and all three UCDP types of organized violence: state-based conflict, non-state conflict, and one-sided violence in Africa. The article presents the methodology and data behind these forecasts, evaluates their predictive performance, provides selected forecasts for October 2018 through October 2021, and indicates future extensions. ViEWS is built as an ensemble of constituent models designed to optimize its predictions. Each of these represents a theme that the conflict research literature suggests is relevant, or implements a specific statistical/machine-learning approach. Current forecasts indicate a persistence of conflict in regions in Africa with a recent history of political violence but also alert to new conflicts such as in Southern Cameroon and Northern Mozambique. The subsequent evaluation additionally shows that ViEWS is able to accurately capture the long-term behavior of established political violence, as well as diffusion processes such as the spread of violence in Cameroon. The performance demonstrated here indicates that ViEWS can be a useful complement to non-public conflict-warning systems, and also serves as a reference against which future improvements can be evaluated.
Keywords
ViEWS: Guiding principles
Large-scale political violence kills thousands every month across the globe and forces many more to relocate within countries and across borders. Armed conflicts have disastrous economic consequences, undermine the functioning of political systems, prevent countries from escaping dire poverty, and hinder humanitarian assistance where most needed.
The challenges of preventing, mitigating, and adapting to large-scale political violence are particularly daunting when it escalates in locations and at times where it is not expected. Policymakers and first responders would benefit greatly from a system that systematically monitors all locations at risk of conflict and assesses the probability of conflict onset, escalation, continuation, and geographic diffusion. This article presents ViEWS – a political violence early-warning system — which seeks to address this need. We outline the methodological framework and evaluate the predictive performance of the system as of 1 October 2018.
The forecasting task ViEWS has set out is multidimensional. ViEWS provides forecasts 36 months into the future for three types of political violence: armed conflict involving states and rebel groups, armed conflict between non-state actors, and violence against civilians (Pettersson & Eck, 2018). The probability that political violence occurs in a given month is forecasted for both countries and subnational geographical units. This means that ViEWS provides forecasts for continued conflict as well as new conflicts. To be useful as an early-warning system, ViEWS has since June 2018 published monthly updated forecasts for Africa at http://views.pcr.uu.se/. 1 This is made possible by the monthly release of candidate events from the Uppsala Conflict Data Program (UCDP; see Hegre et al., 2018).
The ViEWS forecasts build on a number of constituent models drawing on insights from decades of quantitative peace and conflict research. Some of the models are thematic, concentrating on topics such as conflict history, the economy, political institutions, and geography. Others are more general, combining multiple themes or using information at the country and the subnational level to generate forecasts. We subsequently combine the forecasts from these individual models to ensembles. Our evaluation shows that the ViEWS ensembles improve forecasting of political violence at both the country and the subnational level compared to multiple tough baseline models.
The forecasts from October 2018 indicate that conflict will persist up to and beyond 2021 in several countries that have a recent history of political violence, such as Burundi, Nigeria, and DR Congo. The system also alerts to new conflicts in Southern Cameroon and Northern Mozambique.
The aims of ViEWS are maximal transparency, uniform coverage, and public availability. Transparency requires that the risk assessments can be traced back to a fully specified argument and accessible information, allowing readers and potential users to evaluate what lies behind the forecasts. ViEWS is therefore exclusively based on publicly available data. Moreover, its results, input data, and procedures are available to researchers and the international community. Uniform coverage of the regions at risk helps to alert observers to locations that receive insufficient attention. In principle, ViEWS seeks to be able to issue a warning with equal probability for any location independent of its geo-strategic importance, past conflict history, or current humanitarian situation. Public availability of the results is useful for domestic actors and small international NGOs, and essential to ensure transparency regarding decisions they might make based on these results.
In the following, we first briefly review the literature that has informed ViEWS. Second, we outline the methodological framework. Third, we evaluate the performance of the system and present the ViEWS forecasts from October 2018 to October 2021. Finally, we discuss future extensions of the system and conclude.
Literature review
Prediction has long been considered a core task for peace research (Singer, 1973), and a comprehensive literature review is beyond the scope of this article (rather, see Schneider, Gleditsch & Carey, 2010; Hegre et al., 2017). Conflict forecasting has taken a number of methodological approaches, for example game theory (Bueno de Mesquita, 2010), machine-learning tools such as neural networks (Schrodt, 1991), and algorithms for automatic coding of event data (Schrodt, Davis & Weddle, 1994). Ward, Greenhill & Bakke (2010) arguably represents a turning point, bringing prediction into the mainstream of peace research.
ViEWS builds on innovations in the academic early-warning systems for conflict that have been proposed since the 1970s (Andriole & Young, 1977). The State Failure/Political Instability Task Force (PITF) aimed to forecast political crises two years in advance (Esty et al., 1995; Gurr et al., 1999; Goldstone et al., 2010). A key insight from PITF is that simplistic models with a few powerful variables performed as well as complex models, at least at the country-year level. The Integrated Crisis Early Warning System (ICEWS) focused on a range of domestic and international crises (O’Brien, 2010). Valuable insights from ICEWS include separate modelling of conflict phases (onset, continuation, termination) and the utility of a multimethod approach to forecasting.
As the literature has matured, real-time forecasts have become increasingly common (Brandt, Freeman & Schrodt, 2011; Ward & Beger, 2017). Some of these are publicly available. For instance, the US Holocaust Memorial Museum has a regular updated early-warning system for mass atrocities (https://www.ushmm.org/confront-genocide/how-to-prevent-genocide/early-warning-project), and One Earth Future publishes monthly forecasts for military coups (CoupCast; http://oefresearch.org/activities/coup-cast).
Some contributions have been particularly important for ViEWS. We build on the pioneering work of Michael Ward and his team (Montgomery, Hollenbach & Ward, 2012; Ward & Beger, 2017) using ensemble methods to combine forecasts from unique thematic models. We also adapt efforts to integrate structural factors with temporally and spatially disaggregated event data that change more swiftly (Weidmann & Ward, 2010; Chiba & Gleditsch, 2017). Our evaluation builds on the introduction of ROC curves to peace research (Ward, Greenhill & Bakke, 2010), PR curves (O’Brien, 2002), Brier scores (Brandt, Schrodt & Freeman, 2014), and separation plots (Greenhill, Ward & Sacks, 2011; Colaresi & Mahmood, 2017). We also use the random forest algorithm (Breiman, 2001) which has been shown to be effective in our domain (Colaresi & Mahmood, 2017).
Finally, ViEWS would not have been possible without the extensive substantive research on armed conflict (see Buhaug, Levy & Urdal, 2014; Gleditsch, Metternich & Ruggeri, 2014; Hegre & Sambanis, 2006, for reviews). ViEWS has greatly benefited from civil war studies conducted at the country level (e.g. Muller & Weede, 1990; Fearon & Laitin, 2003), but also from the geographically disaggregated studies initiated in the early 2000s (Buhaug & Gates, 2002; Buhaug, Cederman & Red, 2008; Cederman & Gleditsch, 2009), made possible by the geo-coded events data (Raleigh et al., 2010; Sundberg & Melander, 2013).
Methodology
To address its forecasting task, ViEWS is organized into smaller subtasks following a ‘divide and conquer’ strategy detailed in this section. We describe how we analyze three outcomes separately at two levels of analysis, and eventually combine all models using ensembles to produce the ViEWS forecast. The workflow for each monthly update is sketched in Figure 1. All steps in this process are automatized as a set of SQL and Python 3.x scripts. Data are handled on a dedicated server, whereas most model training and simulation is run on a high-performance computing cluster. Further methodological details and additional results are in an Online appendix, the sections of which are referred to as ‘Appendix [no.]’.
Levels of analysis
ViEWS generates forecasts at two levels of analysis: country-months (Gleditsch & Ward, 1999, abbreviated cm), and subnational geographical location months (pgm). The cm level is useful for predictions of new conflicts where no known actors exist, and to model processes at the government level. The set of countries is defined as in Gleditsch & Ward (1999), and the geographical extent of countries by CShapes (Weidmann, Kuse & Gleditsch, 2010). For the subnational forecasts, ViEWS relies on the PRIO-GRID (version 2.0; Tollefsen, Strand & Buhaug, 2012), a standardized structure consisting of quadratic grid cells that cover all areas of the world at a resolution of 0.5 x 0.5 decimal degrees. More details on the levels of analysis are in Appendix B.1.
The outcomes we predict: Conflict data
ViEWS generates predictions for the three forms of organized violence coded by the UCDP (Melander, Pettersson & Themnér, 2016): state-based conflict (
We focus primarily on state-based conflicts here to simplify presentation.
Conflict data are obtained from UCDP-GED and take the form of events (Sundberg & Melander, 2013). Historical data covering 1989–2017 are extracted from the UCDP GED version 18.1 (Croicu & Sundberg, 2013; Allansson, Melander & Themnér, 2017; The ViEWS system and monthly process flow in six steps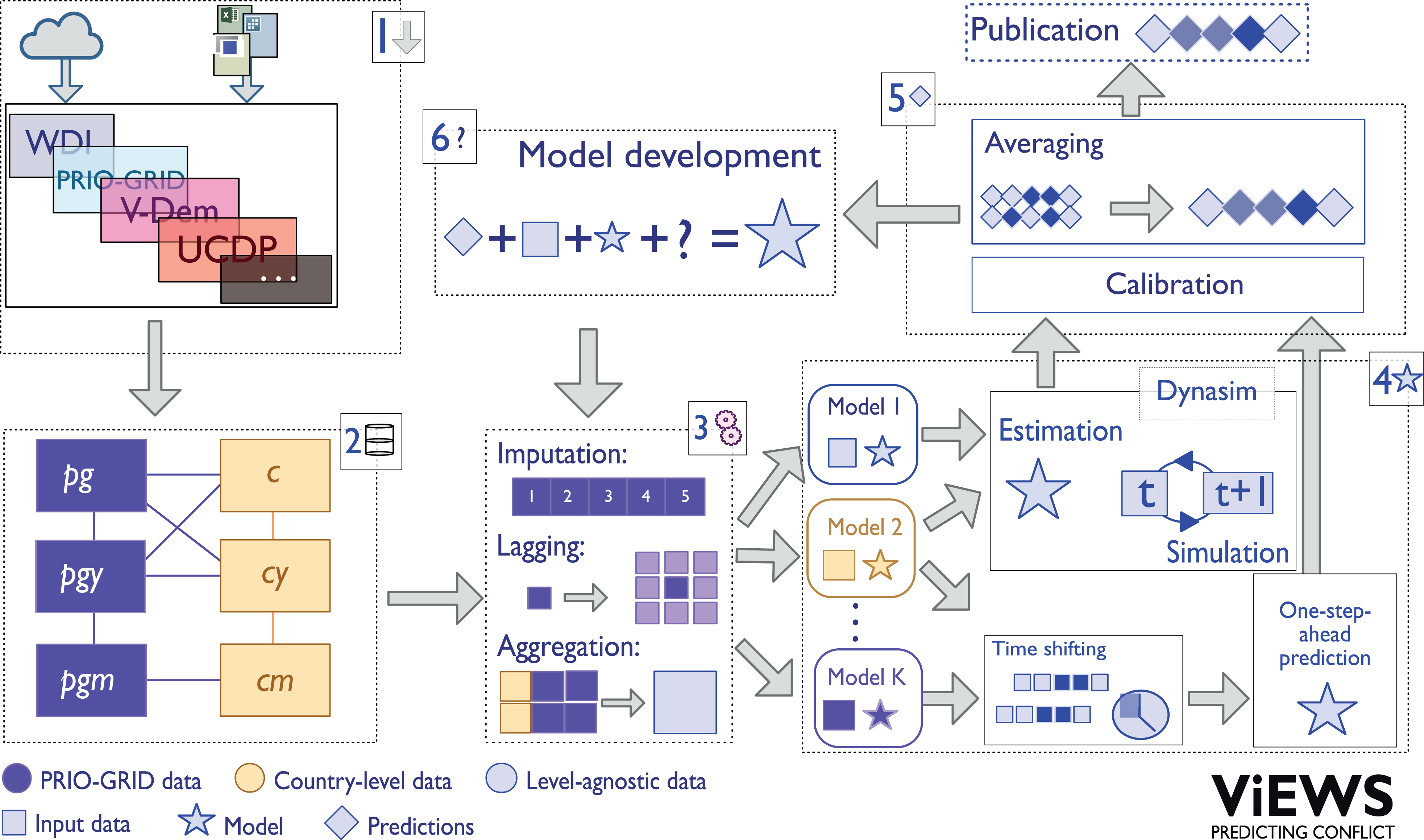
The statistical models constituting ViEWS
The models in ViEWS (summarized in Table I) are designed to complement each other. As of October 2018, ViEWS has specified two extensive and six thematic core models at the cm level. At the pgm level there are ten core models – five thematic, two combined themes, and three with country-level predictors. We use three different estimation strategies for each of these core models. We combine these models in ensembles to produce the ViEWS forecasts – 24 models in the cm ensembles, and 30 in pgm. We estimate the same ensembles of models for each of the three outcomes (
Overview of models, and abbreviations, used in the ViEWS ensemble
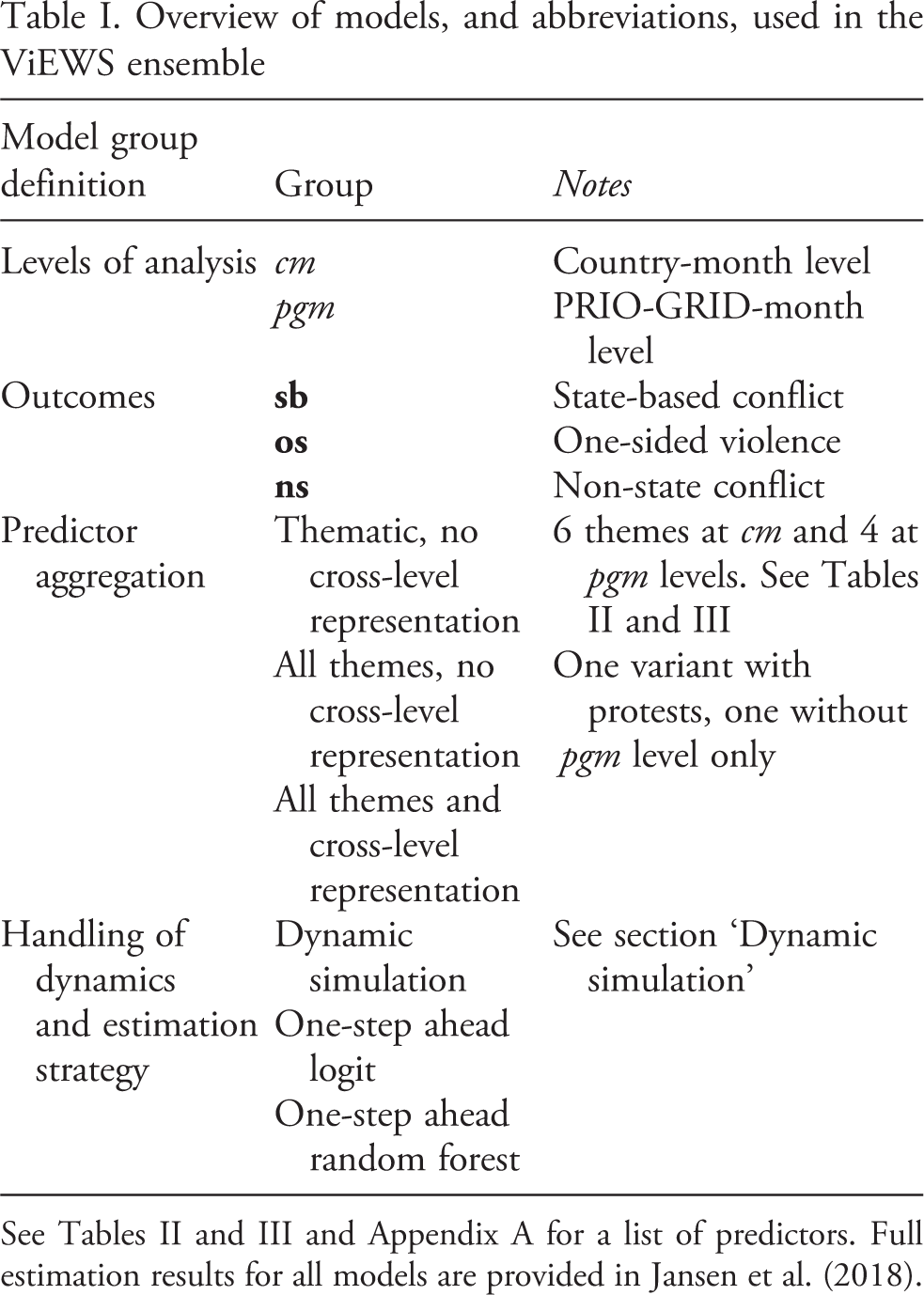
See Tables II and III and Appendix A for a list of predictors. Full estimation results for all models are provided in Jansen et al. (2018).
cm (country-level) models

‘All themes’ and ‘All themes + protest’ specifications are separated because protest data only exist for a limited time period.
Country-level
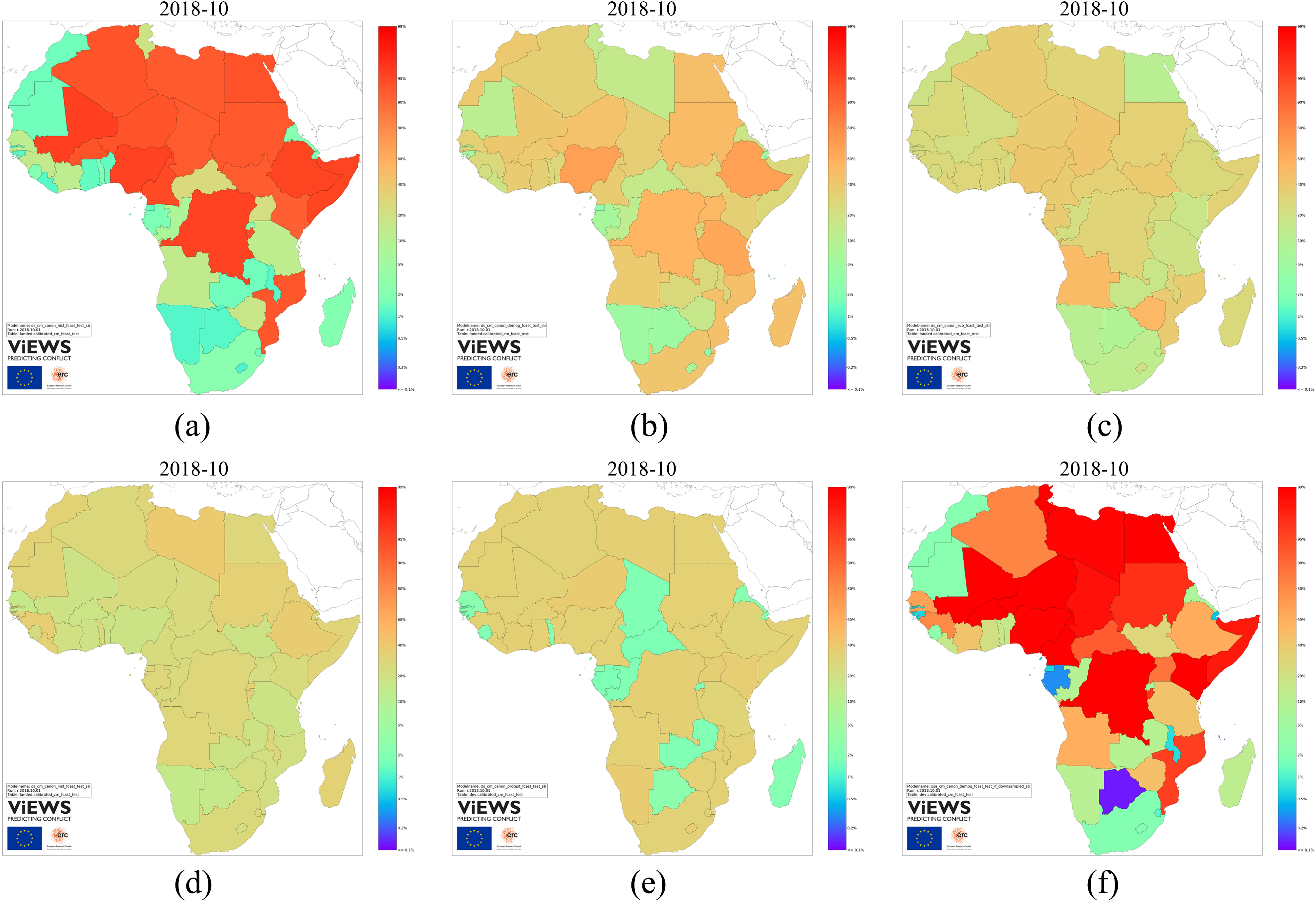
Table III summarizes the ViEWS models at the pgm level, and their prediction maps are shown in Figure 3. As for the cm level, the
We have defined two themes with relatively static geographical predictors, one for natural features and one for social ones. Figure 3b shows that the
We have also specified a number of large models that include all the thematic predictors. Figure 3e shows the predictions from a model including history, natural geography, and social geography as well as cm level predictors. This large model pulls up the predicted probabilities for locations in countries that the cm models indicate are relatively high risk (e.g. Angola and Zimbabwe), and pulls down probabilities for countries like Namibia and Botswana.
Finally, Figure 3f shows a model containing the same predictors as 3e but modelled using one-step-ahead random forests instead of dynamic simulation. When PRIO-GRID level 
Data sources for predictors
Complete references to the data sources are in Appendix A. The most important sources are PRIO-GRID (Tollefsen, Strand & Buhaug, 2012), the World Development Indicators (World Bank, 2015), data on politically excluded ethnic groups (Cederman, Wimmer & Min, 2010), demographic factors (Lutz et al., 2007), protests from ACLED (Raleigh et al., 2010), and data on institutions from V-Dem (Coppedge et al., 2011).
Model estimation
ViEWS relies on logistic regression and random forest models. The logit model is a generalized linear model (GLM) that performs well compared to many machine-learning techniques (Géron, 2017). The random forest model (Breiman, 2001; Muchlinski et al., 2016) is a machine-learning technique based on a combination of classification and regression trees (CART), bootstrap-aggregating (bagging), and random feature selection. Because random forest models are computationally intensive, we estimate them using a ‘downsampled’ dataset which includes all conflict events and a random sample of non-events. See Appendixes C.1 and D.1 for more details.
Handling forecasting dynamics
ViEWS employs two alternative strategies to compute forecasts for each of
Dynamic simulation
pgm (PRIO-GRID level) models

‘All themes, without cm’ and ‘All themes, without cm + protest’ specifications are separated because protest data only exist for a limited time period.
If we are interested in forecasting two months into the forecasting period, we first train the constituent models, estimate the weights, and produce our ensemble one-month-ahead forecast. To produce forecasts for the next month, we need the input predictor matrices
The predictions for the three outcomes are obtained simultaneously within each time step. For each of these, we compute the predicted probability at t + 1 as a function of information available at t, including the status for the other two outcomes. This procedure repeats for every month to the end of the forecasting window.
‘One-step-ahead’ modeling
In the one-step-ahead modeling, we predict each step into the future (t + 1, (…), t + 12, (…) t + 36) independently, as opposed to dynamic simulation which moves forward sequentially. We do this by estimating a set of models of the form
Partitioning of data for forecasting, evaluation, and estimating model weights

Data partitioning and calibration
Table IV summarizes how we partition the data in ViEWS. When evaluating our models, we need a held-out test set for which we have observed conflict. We call this the ‘evaluation periodization’. We use the three most recent years for which we have final UCDP-GED data as the test period – currently, 2015–17. When forecasting, the future is the test set. In this case, we use all of our available data to train and calibrate the forecasting models. We call this the ‘forecasting periodization’. 5 For each of these two periodizations, we partition our data into three periods: one for estimating or training statistical models, one for calibrating predicted probabilities from the models, and one for testing and forecasting.
All our models are initially estimated on the training period. Based on this estimation, we generate predictions for each of the constituent models for the calibration period. We use these to calibrate predicted probabilities, and compute thresholds for cost-function based metrics. 6 Calibration of predicted probabilities is especially useful as input to the ensembles we describe in the next section. This entails obtaining parameters that rescale predicted probabilities so that the mean of predicted probability is similar to the relative frequency of conflict in the data. The details of the calibration procedure are described in Appendix E.2.
With these hyper-parameters in hand, we retrain the models using both the training and calibration periods and generate predictions for the test period. 7 These predictions are calibrated using the scaling parameters obtained in the previous step.
Ensembles
The ViEWS forecasts are combinations of the constituent models in Tables II and III. Model combinations are commonly referred to as ensembles, and have recently been successfully applied to conflict forecasting (Montgomery, Hollenbach & Ward, 2012; Ward & Beger, 2017). Importantly, by drawing on the ‘wisdom of the crowds’ of multiple models, they consistently produce more robust forecasts than individual models. In addition, ensembles often improve overall predictive performance by incorporating more information in forecasts (Armstrong, 2001), and pooling indicators in thematic models improves interpretability.
In ViEWS, the ensemble forecast probability
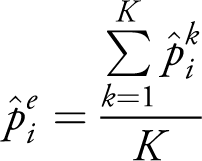
The cm ensemble consists of the 8x3 models listed in Table II (8 models estimated using dynamic simulation, one-step-ahead logits, and random forests). Moreover, the pgm ensemble includes the 10x3 models listed in Table III, again estimated in three different ways. The full list of models and evaluation of each model included in the ensembles is shown in Appendix sections G, H, and I.
Cross-level representation: Combining two levels of analysis
The risk of conflict in a given location is influenced by local factors as well as country-level factors. ViEWS aims to make the two levels of analysis inform each other. Our pgm model ensemble currently combines three approaches. The first approach is to ignore cm factors. The second is to add core cm variables to the pgm model specification. This approach may be suboptimal, however, since it tends to spread the country-level risk evenly out across the country’s territory. This may lead the model to over-predict in low-risk locations even when our pgm models are able to differentiate between the local risk levels. To counter this, we also include as a third approach some models that are based on the product of the predicted probabilities at the cm and pgm levels.
Handling of missing or incomplete data
Dependent variables
In about 15% of the cases, UCDP-GED is unable to precisely identify the location of conflict. ViEWS has developed a method for multiple imputation of imprecise conflict locations that considerably improves the predictive performance of the system. The method employs the locations of precisely known events within the same conflict and within close temporal proximity to determine a spatial probability distribution of latent conflict propensity for each uncertain event. See Croicu & Hegre (2018) and Appendix F.1 for details.
Predictor variables
The methods in ViEWS require that the input data used for the simulations and predictions are complete. Dropping observations with missing values would make it impossible to make predictions for those observations. If the data cannot be assumed to be missing completely at random, dropping them creates bias in parameter estimates and standard errors of the models (Allison, 2009), and presumably also in forecasts. To counter this issue, we perform multiple imputation to replace the missing data using the Amelia II package in R (Honaker, King & Blackwell, 2011). We provide more details in Appendix F.2.
Projections
To generate forecasts for the future, the system requires that the input predictor matrix
The first is to use our dynamic forecasting system (see the ‘Dynamic simulation’ section). The forecasts we generate for state-based conflict or any other endogenous variable at t are used as projected inputs in each relevant equation at t + 1. A similar approach can be used for other events. For instance, dynamic simulations of ACLED protest events (Raleigh et al., 2010) are used as projections in models that include protest variables. The second is to use information from external sources. This is often straightforward: most countries, for instance, have scheduled dates for elections over the next few years. We will also search for projections for other predictors such as droughts in a given location, or expected growth rates for a given country. The third is to make very simple assumptions, for example that a predictor is unchanged over the forecasting window. This approach is the one we use for most predictors in the system.
How well do we predict? Evaluation of models
To evaluate the out-of-sample predictive performance of the ViEWS forecasting system, we use the ‘evaluation periodization’ (Table IV). We evaluate by comparing predictions based on data from the training and calibration periods with what the UCDP observed in the testing period. 9
Principles and metrics for model evaluation
We evaluate our models using four metrics: area under the curve of the receiver operating characteristic (AUROC), area under the precision-recall curve (AUPR), Brier score, and accuracy. The AUROC and AUPR metrics range from 0 to 1, with high values signifying good predictive performance. AUROC is based on the ROC curve, which plots the true positive rate
10
(
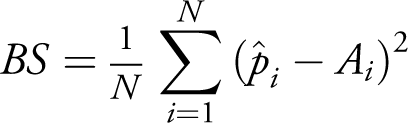
Evaluation of constituent models and ensembles, cm level, state-based conflict, 36 months January 2015–December 2017
We use multiple performance metrics because model performance is multidimensional. In many model comparisons, one model outperforms others in terms of all measures, so we can safely conclude on the best. In other situations, the picture is less consistent and multiple metrics reflect this. In particular, while the Brier score favors sharp, accurate probabilistic predictions (near 0 or 1), the relative ordering of the forecasts are used for AUROC and AUPR. Moreover, since the AUROC captures the trade-off between producing a large number of true positives versus the expense of many false alarms, the metric favors models that are good at correctly predicting no-conflict cases. The AUPR, on the other hand, focuses on the positive cases, since it captures the trade-off between maximizing the proportion of positive predictions that are correct versus identifying as many of the actual conflicts as possible. Consequently, the AUPR does not reward models that only excel at predicting non-conflict cases. Since we are more interested in predicting instances of political violence than the absence of such, we give priority to the AUPR over the AUROC, as the former rewards models more for accurately predicting conflict rather than non-conflict.
Overall performance
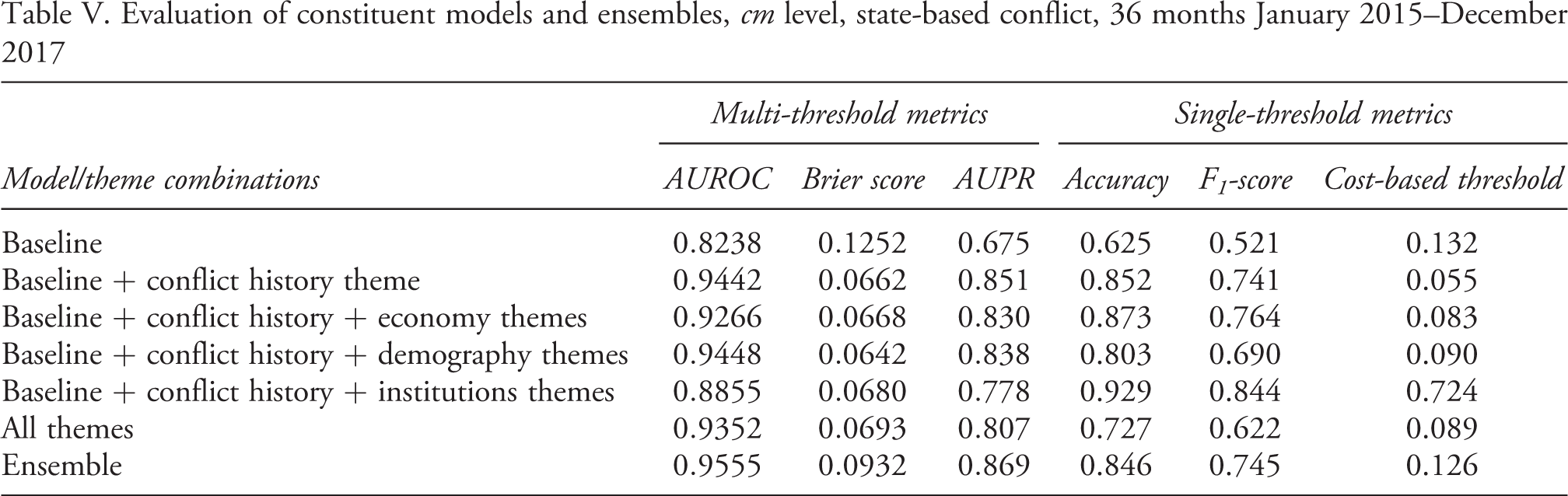
Table V shows summary statistics of the predictive performance of the ViEWS forecasts for state-based conflict at the cm level aggregated over the test period (2015–17). 13 Since the metrics introduced above depend on the data they are applied to, they are most informative when compared to a baseline prediction for the same forecasting problem. The top line reports our metrics for the baseline model defined above (Table II). The following lines report the same for a set of reference models that include an increasing number of themes from Table II. Note that our final ensemble does not include all these models – they are only used here to demonstrate the relative importance of the themes. 14
The second line in Table V combines the baseline and the conflict history theme predictors. Adding conflict history to the baseline model increases AUROC from 0.824 to 0.944, AUPR from 0.675 to 0.851, and reduces the Brier score from 0.125 to 0.066. Accuracy and F1 score given the optimal threshold also increases. The three middle lines in the table show the relative contribution of the three main cm-level themes: economics, demography, and institutions. In isolation, they have ambiguous contributions to the baseline + conflict history model: the precision-recall curve deteriorates for all models, and the other metrics improve only for the demography model.
Finally, we turn to the evaluation of the cm ensemble, displayed in the final row in Table V. The metrics show that the ensemble increases the predictive performance considerably in comparison to the baseline models. Compared to the model including the demography theme, there is an increase in AUROC from .9448 to .9555 and in AUPR from .838 to .869. The Brier score, on the other hand, worsens from 0.0642 to 0.0932. This may be because the ensemble model yields more high-probability predictions than the simpler models, and these are punished excessively by the Brier score.
Evaluation of constituent models and ensembles, pgm level, state-based conflict, 36 months January 2015–December 2017
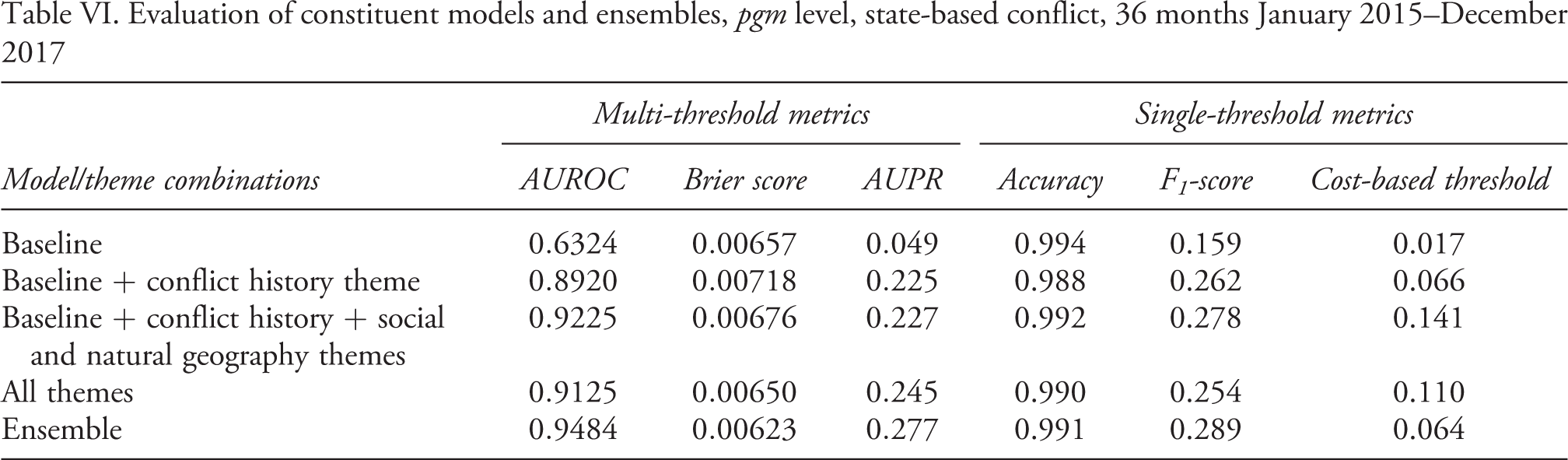
The evaluation for the pgm level is summarized in Table VI. Adding the conflict history theme to the baseline model represents a huge improvement in terms of both AUROC and AUPR, but not so in terms of Brier scores. Adding the two geographical themes improves performance in terms of all metrics. When we add the cm predictors to the models, the AUROC deteriorates whereas the other two improve. This indicates that cm-level predictors are important also at the fine-grained geographical level, but involves a certain ‘smearing’ cost – this model simply lifts the pgm-level probabilities up uniformly within high-risk countries, partly ignoring the local information in the simpler models.
The ensemble, again, performs much better than the constituent parts across all metrics. Compared to the conflict history model, the ensemble improves AUROC from 0.892 to 0.948, AUPR from 0.225 to 0.277, and Brier score from 0.00718 to 0.00623. These improvements are considerable. The ensemble successfully sorts observations into higher and lower probability and thus improves AUROC and AUPR. At the same time, the modest improvement in the Brier score shows that the value of the ensemble predicted probabilities for true positives is still quite far from 1. In other words, compared to the baseline models, the ensemble is not making sharper predictions that clearly separate the classes.
Overall, however, these evaluations show that the current system does well relative to the baseline models. As ViEWS moves forward, the metrics reported here for the ensemble models will constitute the baselines for future comparisons. These numbers also constitute a new frame of reference for other research aiming to gauge the performance of similar conflict early-warning systems.
Performance over time
The results above implicitly assume that the uncertainty of the forecasts for 2021 is similar to those for 2018, which may be unreasonable. Figure 4 shows how the predictive performance of the ViEWS forecasts change depending on how far into the future we move. As before, forecasts for, say, January 2016 are compared with actual outcomes in January 2016, but here we look at the metrics computed for individual months. These evaluations enable us to gauge the feasibility of forecasting up to 36 months into the future. The top row shows performance for the conflict outcomes at the cm level, the bottom row the same for pgm. In the plots in the left column, the y axis shows AUROC for each month and the right column AUPR. Since the predictive performance differs between the models, the y axis varies from plot to plot. The x axis shows the month of the forecast, moving from one to 36 months into the future. The lines are smoothed using a loess function. 15
At the cm level, both AUROC and AUPR decline over time. As we move further into the future, it becomes increasingly difficult to predict accurately. The deterioration is substantial, especially for AUPR. In the top left figure, AUROC decreases from about 0.98 in the first six months to around 0.95 in the second and third years. Top right, we also see a decrease in AUPR. In the first six months, AUPR is well over 0.90. In the second and third years, it is closer to 0.80 on average. More strikingly, AUROC and AUPR at the pgm change much less over time. In the third year of the forecasting window, the system still retains an AUPR at about 0.25. This is probably because of the quite static conflict picture across Africa. In Appendix B.3 we show how persistent the patterns have been throughout the later training and calibration periods and up to today. The results Performance for model ensembles over time, cm (top) and pgm (bottom)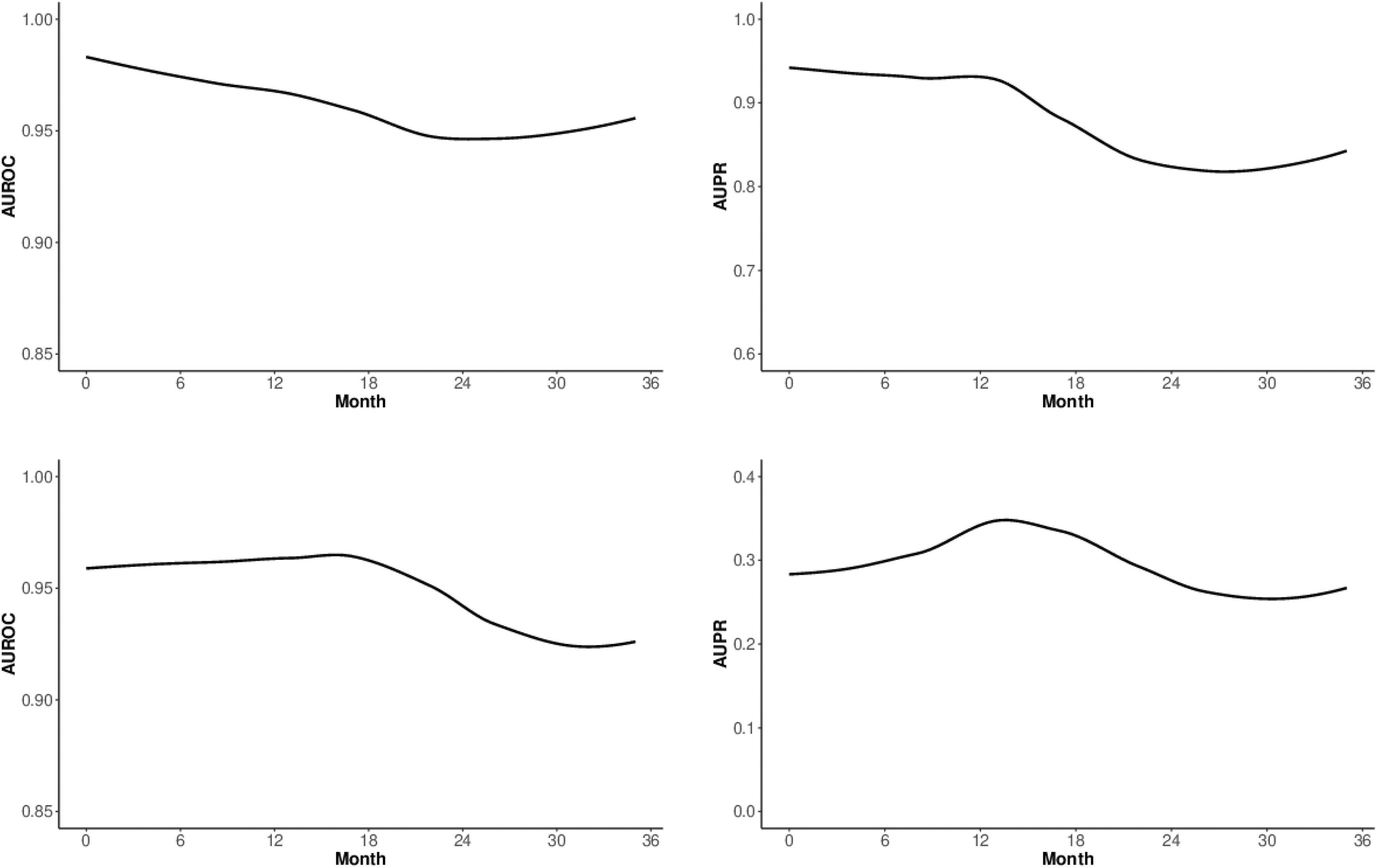
Current forecasts
Here, we present the ViEWS forecasts as of 1 October 2018. These are the first set of results using the model setup described in the previous sections. Since June 2018, we have published updated forecasts for the coming 36 months at http://views.pcr.uu.se/ and are continuously updating. 16
State-based conflict sb
Figure 5 shows the current ensemble forecasts for
Comparing Figure 5 with the observed conflict history reproduced in Appendix B.2, it is clear how a recent history of conflict translates into a high probability of conflict. In Mali, Nigeria, and DR Congo conflict is almost certain. We also forecast a high probability of state-based conflict (
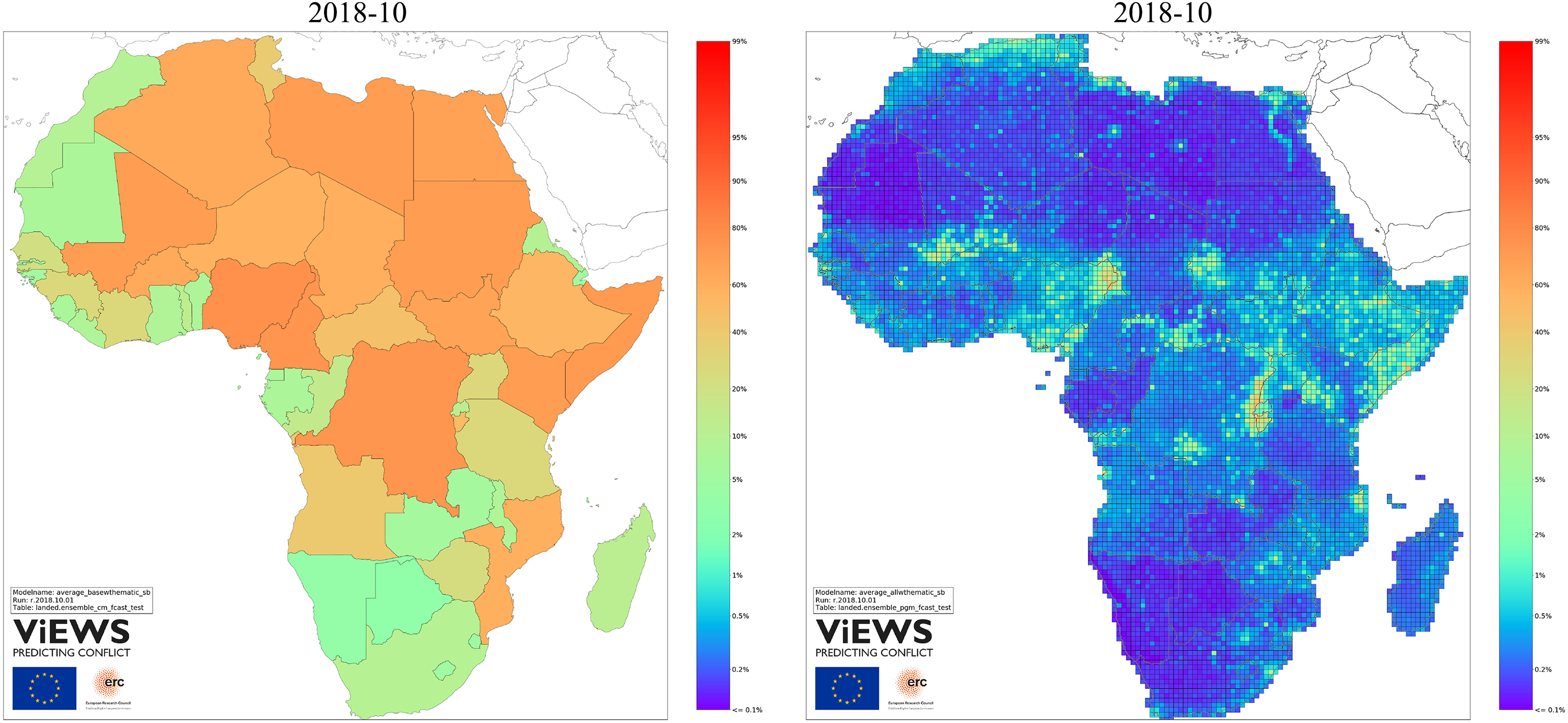
ViEWS forecasts for state-based conflict, October 2018
The rightmost map in Figure 5 shows ViEWS forecasts for statebased conflict at the pgm level. The color mapping is the same as for the cm forecasts. The densest risk clusters for state-based conflict are in northern Nigeria, the Kivu provinces in DRC, Somalia, and Darfur. All of these regions have been ravaged with violence for years. These maps reflect that countries’ recent conflict history is the strongest predictor of future violence. The 2017 re-activation of armed conflict between the government and Renamo de-escalated markedly as talks moved forward during the spring and summer of 2018 (Crisis Watch, 2018b). At the same time, we also see a surge in conflict in the north east where government forces clashed with suspected Islamist militants during the summer of 2018. The militants also increased their attacks against civilians during the summer (allAfrica, 2018).
Beyond history, our natural and social geography features are also important. The low population concentration in Sahara translates into a low risk of conflict, and conflicts are more likely in border regions than close to countries’ capitals. The maps also show how country-level risk assessments influence the geographical forecasts. Zambia, Botswana, and Tanzania, for instance, have markedly lower probability of future conflict than neighboring countries.
All forecasts shown so far have been for October 2018, the second month after the most recent data available. Figure 6 indicates how the forecasts change over time. The color mapping is roughly the same as above, but here corresponds to the forecasted proportion of PRIO-GRID cells in
Our models reflect that forecasted violence in these clusters change little over time – most countries have the same color throughout the period. 18 This reflects that our projections for the exogenous variables change little, which may artificially inflate the impression of constant future conflict. But the predicted persistence is also reflecting patterns that are very real. The ViEWS models contain information about conflict events many years into the past, and the underlying estimates indicate that African conflicts in general are very persistent (see Appendix B.3). Consequently, most of the variation in Figure 6 is between countries, not across time, and there is only a very slight tendency of a ‘regression to the mean’.
There are a couple of exceptions to this static picture. For example, compared to our forecasts a few months ago, we now predict a lower danger of conflict in Togo as the impact of violent events in 2017 recedes (Zodzi, 2017). On the other hand, there is an increasing danger of conflict in DRC and Burundi spilling over into Rwanda. The forecasted proportion of pgms with conflict in Rwanda increases from 0.063 in October 2018 to 0.112 in late 2021. 19
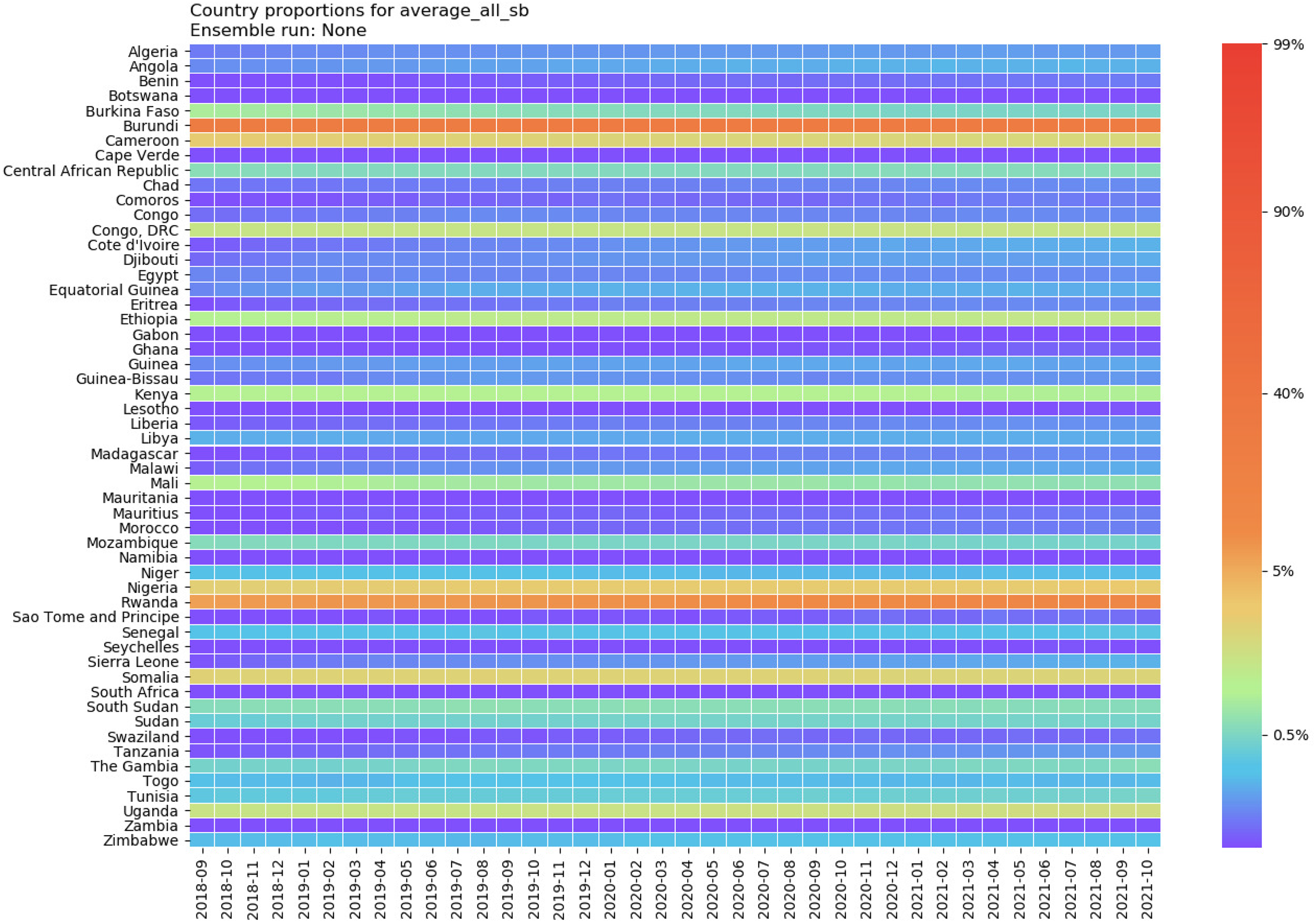
Forecasted proportion of pgm cells with conflict events, by country, September/October 2018–October 2021
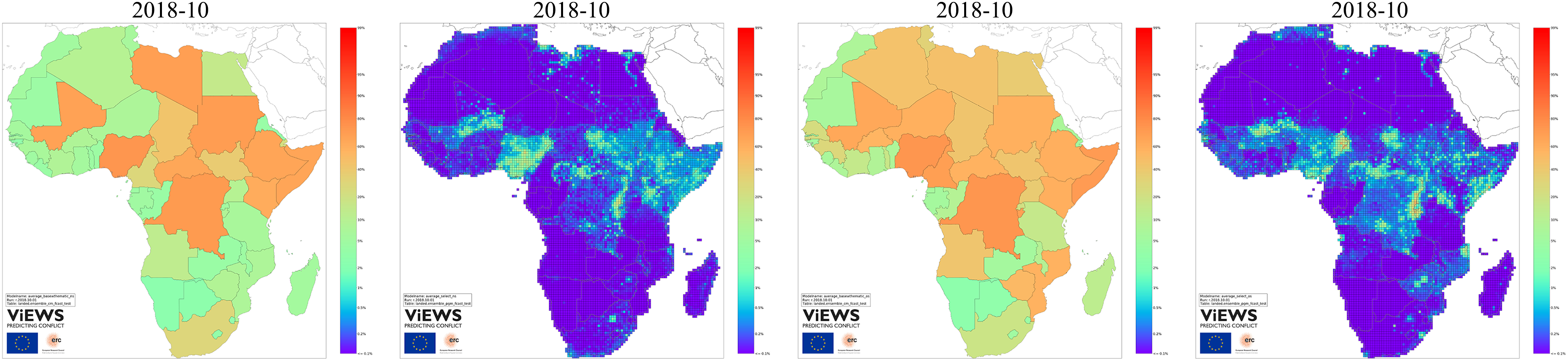
ViEWS forecasts, non-state conflict (left) and one-sided violence (right)
The other two types of outcomes
Figure 7 shows the forecast maps for non-state conflict (
The forecasts for
Conclusions
This article has presented initial results from the ViEWS forecasting system and summarized the methodology behind these forecasts. We have accounted for the evaluation procedures of ViEWS and established a frame of reference and a baseline that we can compare future extensions to. The evaluation indicates that the system generates very accurate forecasts for conflict-prone regions in Africa.
ViEWS is being developed according to four guiding principles: public availability, uniform coverage, transparency, and methodological innovation. Public availability is ensured by the complete release of all data and procedures on the ViEWS website. This means that ViEWS is restricted to using data that are publicly available, even if predictive performance could be improved by the inclusion of other data. ViEWS safeguards uniform coverage by relying on the UCDP suite of datasets, which consistently applies a clearly articulated definition and procedures that minimize the risk of overseeing conflict.
Transparency and replicability are essential objectives for ViEWS. They are also challenging given the complexity of the system. The system is primarily documented in this article and the accompanying Online appendix. Interested readers can find additional details and updates to the system in auxiliary documentation available on our website. The ViEWS source code is available at https://github.com/UppsalaConflictDataProgram/OpenViEWS. The ViEWS team welcomes any interested party to use the replication material and compare it to their own forecasts.
As we continue to develop ViEWS, we will follow the guidelines of Colaresi & Mahmood (2017), iteratively evaluate the current system, and use this to inform the next generation. We will work to strengthen the ‘early-warning’ component by defining a useful definition of ‘onset’ and partially optimize the system for forecasting such onsets, add assessments of the likely severity of the violence, introduce actors as units of analysis, solicit qualititative input from country experts, and add more predictors that we find can strengthen the forecasting performance. 21 To document this, we are making change logs avaliable at https://github.com/UppsalaConflictDataProgram/OpenViEWS/blob/master/CHANGELOG.md.
How useful is the current system? Currently, the main strength of ViEWS is not its ability to forecast entirely new conflicts. Still, the system models geographical diffusion quite well. Because of its vicinity to the various conflicts in Nigeria, the recent tensions in Cameroon are reflected as a high predicted probability of further violence. Moreover, the models show how persistent organized violence is in Africa. Our results indicate that the major conflict clusters in Africa will continue to be very violent over the coming three-year period.
Many governments have their own intelligence systems upon which they act in response to threats of organized violence. Such intelligence is never publicly available. If an open-source early-warning system such as ViEWS can be made sufficiently accurate, critical voices may in some cases use this to challenge the assessments government actions are based on. Moreover, outside observers that lack such inside information may use high-quality forecasts to closely monitor a situation, engage in public debate around the risks involved, and possibly take action. NGOs can apply pressure on conflict actors or prepare for humanitarian assistance. Large organizations such as the UN may use the forecasts when they decide on whether to deploy peacekeeping operations (Hegre, Hultman & Nygård, 2019).
Can the system be misused? A government that sees our risk assessment for a location inside the territory it governs might conceivably be led to violently pre-empt the conflict. We do not believe this is a great danger. Local governments have much better information about what is going on than any system based on open-source data can deliver.
ViEWS is currently restricted to Africa, and all models have been trained on Africa-only data. We believe the system can easily be scaled up to global coverage. Most of the results for the country-level thematic models are consistent with previous research done with global data. Some of the geographical features, on the other hand (e.g. distance to diamond deposits), are more specific to Africa. Our intuition is that most of the models specified here translate well outside Africa, but such an extension would probably accentuate the need for more context-sensitive models (e.g. random-slope models). We have, for instance, noted the very persistent and localized conflict patterns in Africa. Other regions may display other patterns, and a global ViEWS would probably benefit from modeling them as conditional either on the regions they take place in or some predictor that affects the dynamics (e.g. general income levels).
We see ViEWS as a step towards a future where high-resolution forecasts of conflict at practically useful spatial and temporal scales are publicly available. While any such system for violence will necessarily be less precise than those for physical systems, the goal is to improve outcomes relative to a world where these forecasts do not exist. Even an imperfect future system has the potential to inform the placement of peacekeepers, the deployment of NGO resources, and even the decisions of private citizens. Making it more difficult to hide behind a cover of ignorance may potentially save lives. Attaining this goal will take a community of researchers collaborating across domain specialties to identify mistakes, suggest innovations, and incorporate successful new ideas into a computational infrastructure. We believe ViEWS is a start towards bringing this vision to fruition.
Footnotes
Replication data and source code
Replication data, the Online appendix, and datasets with detailed predictions are available at http://views.pcr.uu.se/downloads/. Full source code is available at ![]() .
.
Acknowledgements
Funding
ViEWS receives funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement no. 694640) as well as from Uppsala University. ViEWS computations are performed on resources provided by the Swedish National Infrastructure for Computing (SNIC) at Uppsala Multidisciplinary Center for Advanced Computational Science (UPPMAX).