
Abstract
As AI-powered negotiations spread, their psychological and relational impact remains unclear. The authors propose a novel generative adversarial network framework that trains a bot to aim for superior economic outcomes while appearing “human” (“algorithmic anthropomorphization”). In a bargaining game experiment, they compare this “superhuman” bot with two simpler alternatives: a bot that mimics human behavior and a purely efficient bot. The results show that (1) superficial anthropomorphization can make a bot seem human but does not improve subjective evaluations, (2) the efficient bot is so rational that it is easily exploited, undercutting its performance, and (3) the superhuman bot achieves superior economic results while appearing more human than actual humans. Yet even when bots act indistinguishably from humans, they may trigger an “uncanny valley” effect, lowering subjective evaluations regardless of performance. Because subjective evaluations predict future negotiation outcomes, these findings highlight the potential negative impact that AI bargaining algorithms can have on long-term customer relationships. The authors urge firms to measure more than objective outcomes when assessing AI negotiators.
To concede that one's intelligence and skills are being surpassed by a machine's can be a disturbing experience, and with the rise of artificial intelligence, humankind will likely experience that feeling more and more frequently.
After playing AlphaGo and losing four of five games, Lee Sedol, a professional Go player, demonstrated an extreme case of “algorithm aversion” (Dietvorst, Simmons, and Massey 2015) and announced that he would retire from professional play, stating that “even if I become the number one, there is an entity that cannot be defeated,” that is, artificial intelligence (Yoo 2019). The chess community was similarly surprised when presented with the latest DeepMind development, AlphaZero. The AI taught itself how to play chess in less than four hours and developed a style that did not resemble anything experts had seen before. Grandmaster Peter H. Nielsen said: “I always wondered how it would be if a superior species landed on earth and showed us how they play chess. I feel now I know” (Klein 2017).
Marketing is rarely interested in such direct, face-to-face adversarial contexts. However, even when human interests align with an AI's objectives and users could benefit from collaborating with AI, they still tend to suffer from algorithm aversion (Dietvorst, Simmons, and Massey 2015). Nascent literature suggests several ways to attenuate such aversion, such as giving users control over the AI's output (Dietvorst, Simmons, and Massey 2018; Kawaguchi 2020), making the algorithm's decision-making process more transparent and understandable to its users (Yeomans et al. 2019), or anthropomorphizing the AI to foster a feeling of trust (De Visser et al. 2016; Waytz, Heafner, and Epley 2014). However, anthropomorphizing an AI to a point where it resembles a human being, but not quite, can also backfire. It may generate unease, discomfort, and even disgust, a phenomenon dubbed the “uncanny valley” (Mathur and Reichling 2016).
Bargaining is another essential human activity that has seen an uptick in AI applications. However, contrary to the domains in which AI is typically deployed, bargaining is neither purely adversarial nor purely collaborative; it stands in a gray area. To be successful, bargaining partners need to collaborate to reach an agreement. Yet, there is always a zero-sum-game component in any negotiation, where negotiators’ interests are partly misaligned, and one bargainer's gains may be the other bargainer's losses.
Despite this peculiarity, intelligent machines are increasingly being used to automate negotiations, and “AI has already begun to dramatically reshape the negotiation landscape” (Falcão Filho 2024b). An automated AI bargainer overcomes many of the shortcomings of human bargainers. A firm can perform one-on-one negotiations on a larger scale with a multitude of customers while maintaining consistent behavior across all its negotiations. Furthermore, an AI bargainer will not be affected by cognitive or emotional biases that could result in economic inefficiencies (Johnson et al. 2002). As a result:
Companies that provide autonomous negotiation products, such as Negobot, Aerchain, Pactum, or Lindy, are becoming popular for sale, procurement, or salary negotiations. Major corporations like Walmart increasingly use AI agents to negotiate terms with suppliers (Van Hoek et al. 2022). In 2023, Luminance demonstrated an AI that negotiated a nondisclosure agreement without human involvement (Brown 2023). In an online interview, JLL's global CMO, Siddharth Taparia, described how the firm's in-house large language model enabled a real estate contract negotiation process to be completed in hours rather than months (Hood and Wei 2024). Platforms like Retrograde act as “AI talent agents,” managing the initial rounds of negotiation with brands on behalf of social media influencers (McDowell 2024).
Unfortunately, research on the psychological and relational aspects of negotiation between humans and AI is not progressing at a pace that corresponds with the rate at which AI is being deployed in practice. We find this trend worrisome for two reasons.
First, the success of a good negotiation cannot be measured by its short-term financial result alone. To paraphrase previous examples, no customer wants to “negotiate with an alien” or be “defeated” by the firm they negotiate with. An AI that exclusively focuses on its economic outcomes and develops unorthodox bargaining tactics to gain an advantage may be perceived as unpleasant to negotiate with, unfair, or even exploitative; consequently, it may be poorly evaluated by customers. Subjective evaluations of negotiations are crucial for firms as they impact the relationship with the customers they bargain with and are directly proportional to the economic efficiency of any future negotiation (Curhan, Elfenbein, and Kilduff 2009). A firm deploying a ruthless bargaining AI may inadvertently sacrifice long-term customer relationships.
Second, while algorithm aversion appears to be of great concern in bargaining situations (as it is both likely to occur and detrimental to the firm's long-term profits), classic solutions do not apply. Because of the adversarial nature of bargaining, one cannot alleviate algorithm aversion by simply giving control over the AI's outputs (Dietvorst, Simmons, and Massey 2018; Kawaguchi 2020) or making the decision-making process more transparent (Yeomans et al. 2019) as both tactics would go against the firm's interests. Likewise, it is doubtful that giving the AI a human name and a smiling avatar (a process we label “superficial anthropomorphism”) would solve algorithm aversion altogether.
In this article, we examine whether it would be possible to develop an AI that behaves like a human (to reduce algorithm aversion) yet remains efficient enough to be of value to the firm. We develop the notion of “algorithmic anthropomorphism,” which we define as an agent that optimizes its objective outcomes while appearing humanlike in its behavior. We develop a novel generative adversarial network (GAN) framework to develop a bargaining bot that optimizes its economic outcomes while retaining human traits in the way it negotiates (a trade-off we control with a single parameter). We call it a
We then asked 1,019 participants to play 20,380 unstructured, continuous-time bargaining games with asymmetric information (Camerer, Nave, and Smith 2019), representing many real-world bargaining scenarios (Karagözoğlu and Kocher 2019). They were paired either with one of the bargaining bots or with another human being for the experiment, and the bots were either depicted as such or portrayed as other human beings. We compare the objective performance of the bots as well as the subjective evaluations of the negotiations by the participants.
In the limiting context of our small-stakes bargaining game, we find that the
However, even though participants could not distinguish the
We organize the article as follows. After conducting a literature review, we present the mechanics and design of the game that serves as an initial test bed for our bot development. We then describe the development of the three bot versions (
Literature Review
Subjective Value Inventory
In negotiations, subjective evaluations matter. A bargainer can be psychologically affected by a negotiation, including, but not limited to, effects on their self-esteem, their satisfaction with the bargaining process, and their willingness to negotiate with their counterpart in the future (Curhan, Elfenbein, and Xu 2006). These subjective evaluations not only impact the long-term relationship between bargainers but also predict future negotiation outcomes (Curhan, Elfenbein, and Kilduff 2009).
In the literature, subjective evaluations of negotiation are typically measured using the Subjective Value Inventory, or SVI (Curhan, Elfenbein, and Xu 2006). The SVI has four subconstructs: feelings about the outcome, the self, the process, and the relationship. We report the survey items in Web Appendix A.
The SVI is a widely accepted measure for subjective evaluations of negotiations. Some examples of its use include research on how subjective evaluations are affected by negotiator creativity (De Pauw, Venter, and Neethling 2011) and negotiator deception (Van Zant, Kennedy, and Kray 2023). It has also been used in longitudinal studies to show that the subjective evaluations of an initial negotiation can negatively impact the objective outcomes of a subsequent negotiation due to a spillover of incidental anger and pride (Becker and Curhan 2018). The SVI has also been modified and used outside the domain of negotiation, such as to operationalize procedural justice and determine how it is affected by status and power (Blader and Chen 2012).
Algorithm Aversion
Algorithm aversion is a “biased assessment of an algorithm which manifests in negative behaviors and attitudes toward the algorithm compared to a human agent” (Jussupow, Benbasat, and Heinzl 2020, p. 4). It can manifest in people's distrust or reluctance to rely on advice from an automated system, whereas they would accept the same advice from another human being. Algorithm aversion has been observed in a variety of AI applications, including medical diagnostics (Dai and Singh 2020; Longoni, Bonezzi, and Morewedge 2019), forecasting (Dietvorst, Simmons, and Massey 2015, 2018), product assortment determination (Kawaguchi 2020), and selling through chatbots (Luo et al. 2019).
Given how widespread algorithm aversion appears to be, one can only wonder how it could manifest in a bargaining situation. If people generally distrust algorithms, the same negotiation outcome might be more negatively evaluated if it is obtained by negotiating with an AI than with a human being, with known adverse long-term consequences on relationships and future negotiation outcomes. Consequently, we conjecture:
Anthropomorphization
Prior research on human–AI interactions has examined possible ways to attenuate the effects of algorithm aversion. In forecasting, this can be accomplished by giving people some control over the forecasts (Dietvorst, Simmons, and Massey 2018; Kawaguchi 2020). For recommender systems, algorithm aversion can be reduced by making the algorithm's decision-making process more understandable to its users (Yeomans et al. 2019). However, for strategic interactions like bargaining, neither of these approaches is applicable as they would at least partially divulge the algorithm's strategy, thereby hurting the firm's profits.
In this article, we explore another way discussed in the literature to mitigate algorithm aversion, namely superficial anthropomorphization, which we define as giving superficial human characteristics, such as a name or physical appearance, to an AI. Anthropomorphizing an autonomous agent can foster a feeling of trust in its users (De Visser et al. 2016; Waytz, Heafner, and Epley 2014) and does not compromise the fundamental objective of the firm, hence making it ideally suited for alleviating the effects of algorithm aversion in bargaining situations. In the literature, human characteristics have usually been conveyed through avatars, audio, or textual communication (Aggarwal and McGill 2007; Crolic et al. 2022; Kwak, Puzakova, and Rocereto 2015; Wan, Chen, and Jin 2017) and have been shown to be quite effective. Hence, we expect:
Some recent work has examined anthropomorphizing the strategies of AI in specific games (Jacob et al. 2022; McIlroy-Young et al. 2022), but these studies focus primarily on the strategic or algorithmic advantages of doing so rather than on their psychological consequences. They also concentrate on structured, turn-based games like Diplomacy and chess. They cannot be easily extended to unstructured bargaining games where any player can make an offer at any time. We address these gaps in the literature by building various AI bots specifically catered to unstructured bargaining games using deep learning techniques. We discuss the bargaining game mechanics in the next section.
Game Mechanics
We base our research on the game design proposed by Camerer, Nave, and Smith (2019). It is an unstructured bargaining game, played in continuous time, with a fixed deadline and one-sided private information about the pie size. Each game proceeds as follows:
A pie size is randomly selected from {1, 2, 3, 4, 5, 6} and assigned to the game. Two players enter the game, with the pie size known to only one (the informed player). Before the bargaining game begins, both players have 5 seconds to select their first offer. At this stage, neither player has information about what the other player is doing. Once the game begins, each player bargains over the uninformed player's payoff. An offer of x from either player implies that the uninformed player will receive x, and the informed player will receive (pie size − x). Players can click on the upper part of their screen at any moment (see Figure 1) and as often as they please to make a proposal or counterproposal, between $0 and $6, in 10-cent increments. They do not need to wait for the other bargainer's response and can make multiple proposals in a row. Any change in the other player's current proposal is displayed in real time in the lower part of the screen. If both players agree on the same amount, a green bar appears, indicating that they are in agreement (see Figure 1). The game ends when both players remain in agreement for 1.5 seconds—in which case the pie is split accordingly between the two players—or automatically after 10 seconds of bargaining, in which case neither player receives any payoff. Hence, the latest time for reaching a successful agreement is 8.5 seconds. In the end, both players are informed of the game's outcome. At that time, the uninformed player is also informed of the size of the pie they were negotiating over.
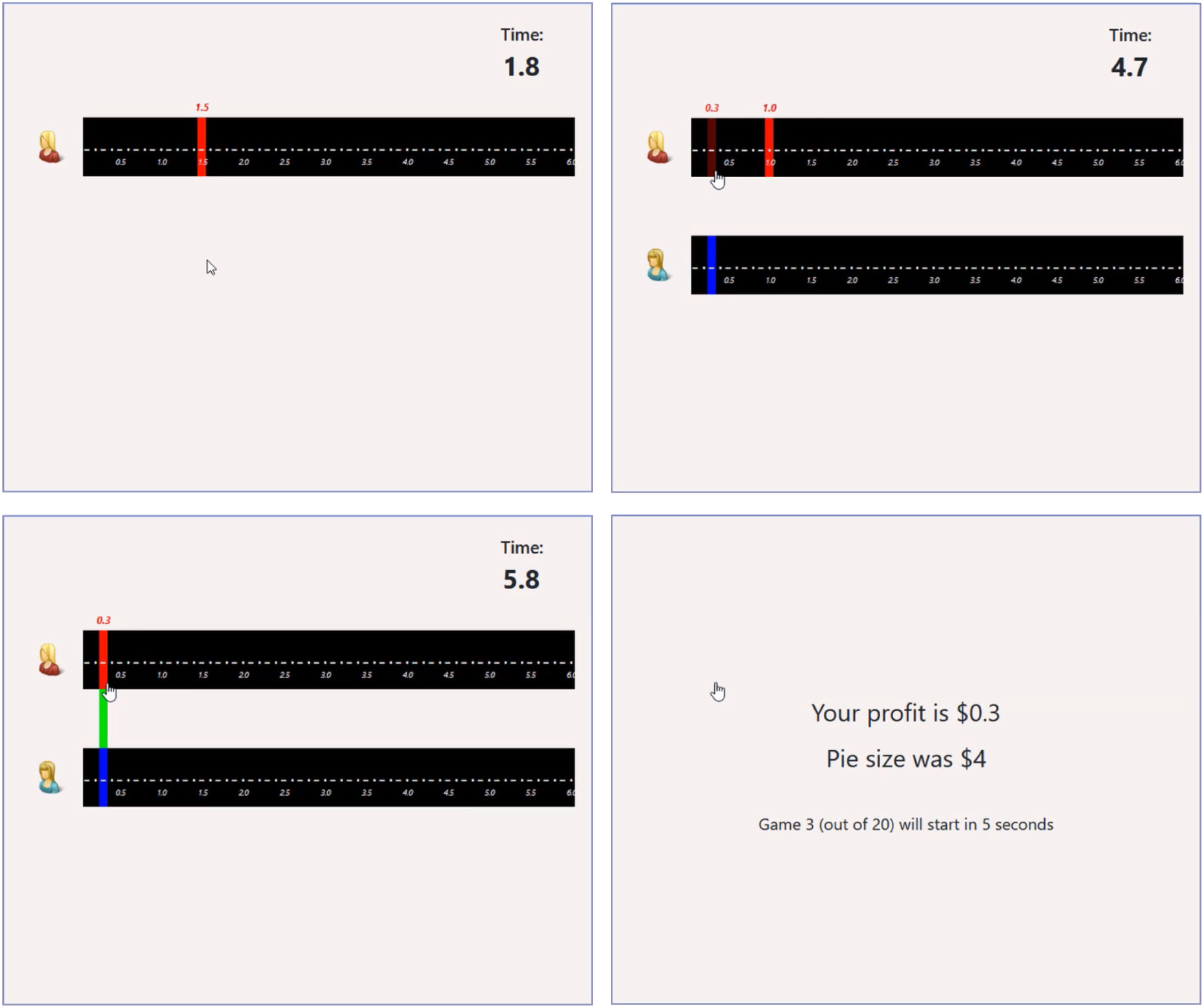
Game Interface.
While this game format is a stylized form of negotiation, the literature reckons that it is representative of many real-world bargaining scenarios (Karagözoğlu and Kocher 2019).
An important aspect of this game is the information asymmetry. Asymmetric information is representative of many consumer-versus-firm bargaining scenarios, as firms tend to have more information regarding a product than a consumer (e.g., stock availability, current demand, actual production costs, part quality). Therefore, in the context of this research, we focus on human players assuming the role of uninformed players.
Methodology
Overview
We build three distinct AI bots operating with different degrees of anthropomorphization and efficiency:
Notice that we expect the
The
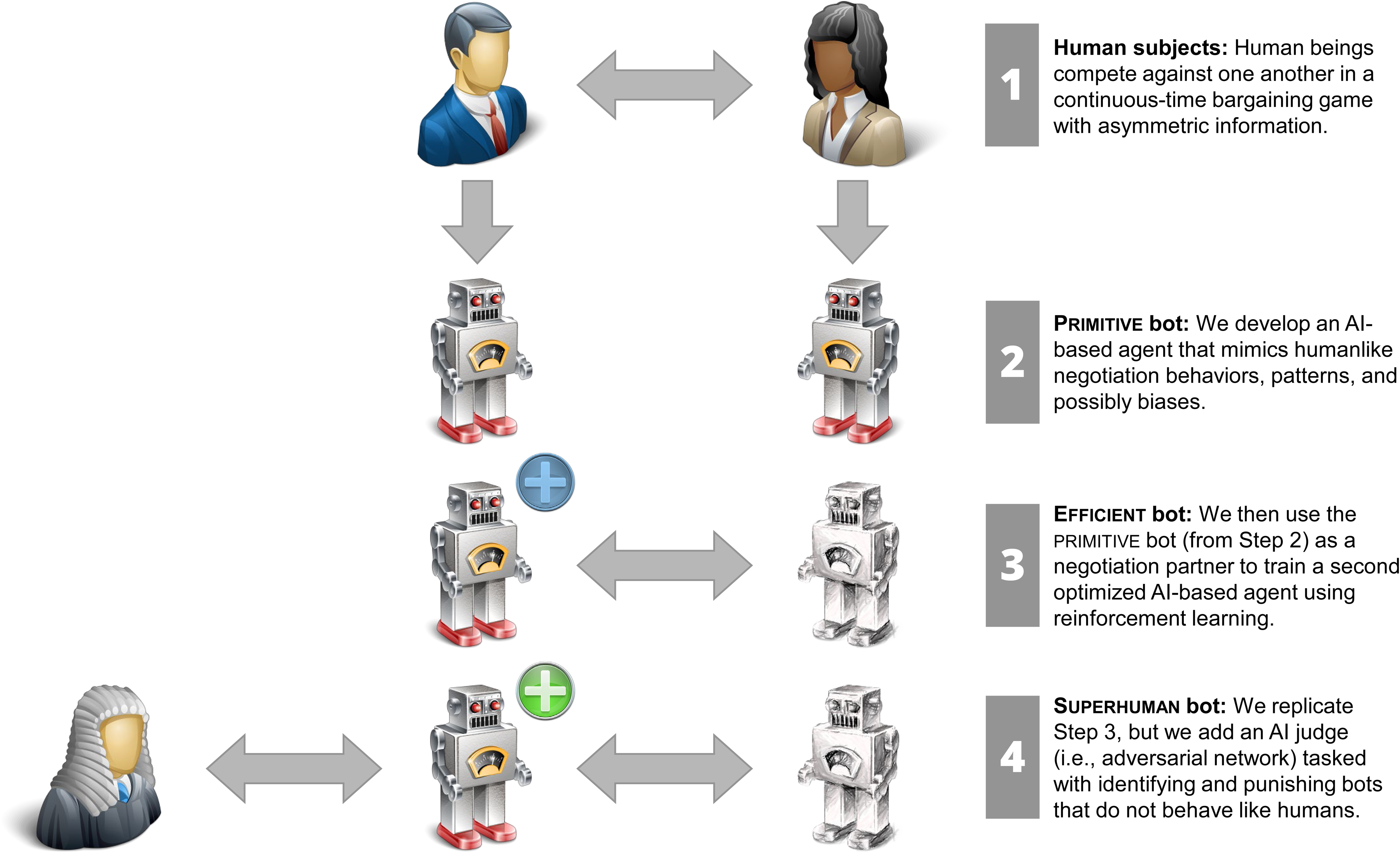
Overview of the Development Phases of the
We first explain the intuition behind the four-stage development of these three bots (Figure 1) and develop the technical aspects and formal hypotheses in subsequent sections.
First, we obtain the dataset from Camerer, Nave, and Smith (2019), where 110 participants collectively played 6,432 games designed according to the game mechanics described previously. The participant pool was divided into 55 pairs of one informed and one uninformed player, and each pair bargained for 120 rounds (after completing 15 rounds of practice).
Second, using supervised learning and calibrating the models on the dataset available from Camerer, Nave, and Smith (2019), we develop two
Third, using the
Fourth, we repeat the previous step but train in parallel an additional deep learning model (a
Deep Learning Model
It is difficult to explicitly model humanlike behavior in bargaining games with a finite set of equations, especially in continuous time. Therefore, we use deep learning techniques that allow models to learn complex patterns from data without any elaborate theoretical specification. We use a similar sequential deep learning architecture to model all AI bots. From a prediction perspective, these architectures lend well to applications like bargaining games, where each action in a game is dependent on all other actions that precede it. Specifically, we use a long short-term memory (LSTM) neural network (Hochreiter and Schmidhuber 1997). LSTM models perform well in prediction tasks that deal with sequential data and have been used in marketing applications (Sarkar and De Bruyn 2021; Valendin et al. 2022; Wang et al. 2022). The modeling process can be broken down into three distinct tasks, which we discuss in turn: feature engineering, policy formulation, and objective function specification.
Feature Engineering
We use feature engineering to extract input features at each step, defined as either (a) the beginning of the initial five-second period where players enter their initial offer, (b) the beginning of the up-to-ten-second bargaining game, (c) any offer or counteroffer observed during the bargaining session, or (d) the end of the game. Therefore, each sequence has a minimum of three steps (a, b, d) and an unspecified maximum length (a, b, c, c, c, …, d). Each input fully represents the state of the game at each step. We list the features in Table 1.
Features of the LSTM Model Used to Describe the State of the Game at Each Step of the Bargaining Process.

Notes: These features have been refined through trial and error to help the model learn as efficiently as possible. For instance, we found that specifying the feature “fairness” as a separate component (even though it could be inferred from “offer” and “pie size”) helps the model converge faster.
Policy Formulation
We use the parameters from the LSTM as inputs to a function that defines the effective action space of a bargainer. We refer to this as a policy likelihood function since it tells us the likelihood of any action that can be taken by an AI at each step of the game.
At each step i, the player can follow three distinct actions: make a counteroffer (c), accept the offer of the other player (a), or wait indefinitely until the next event, such as the other player's action or the end of the game (w). We note the probabilities of each action as pc, pa, and pw, with pc, pa, pw > 0 and pc + pa + pw = 1 (for simplicity, we do not specify the index i).
If the player makes a counteroffer, the model needs to predict two additional quantities: how long the player will wait to make the offer (between zero and ten seconds) and what that counteroffer will be (between $0 and $6). Because predictions are probabilistic and will subsequently be used to generate behaviors stochastically, we model each quantity (time and amount) as a distribution rather than a scalar. In addition, we reckon that no standard distribution (e.g., normal, lognormal, or beta) will fully capture the complexity of patterns observed in real-life data. Hence, we model each distribution as a mixture of truncated Gaussian distributions (truncated to 0–10 seconds for time and $0–$6 for amounts). The exact number of components (i.e., the number of truncated Gaussian distributions) will subsequently be determined as hyperparameters of the model. Each truncated Gaussian component has three parameters: a mean (bounded within the acceptable interval), a standard deviation (>0), and a weight (a percentage indicating how much that component contributes to the overall distribution). Each of these parameters is, itself, an output of the LSTM model, and will be predicted based on the sequence of events observed up to this point in the game. We collectively denote Φc and φc as the cumulative distribution function (CDF) and probability density function (PDF) of the mixture of truncated Gaussian distributions used to predict the timing of the counteroffer and Φx and φx as the CDF and PDF of the mixture that captures the amount of that counteroffer.
If the player accepts the other player's current offer, we only model the time they wait until they accept, denoted as Φa and φa. We use the same modeling approach as used previously.
If the player decides to wait indefinitely, no other quantity needs to be predicted.
The LSTM model will take the entire sequence of events observed in the game so far (described by the features listed previously at each step) and predict pc, pa, pw, φc, φx, and φa. The number of outputs of the model will depend on the number of components in each mixture of truncated Gaussian distributions, 1 which are themselves hyperparameters of the model.
Not all predictions are used at each step. For instance, if a player accepts the other player's offer, φc are φx are predicted but unused.
Objective Functions
While the LSTM architecture is identical for all bot versions, their strategic prerogatives are codified through their respective objective functions, which we describe next.
primitive bot
The objective of the
Suppose that, at step i of the game, a player is observed to make a counteroffer of amount x at time t. The probability of such an event can be denoted as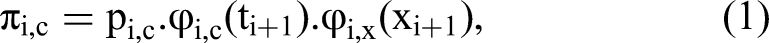
If the player accepts the other player's offer, the likelihood simplifies to
However, if the player's opponent is the first to make a move instead, the likelihood needs to capture three distinct possibilities: (1) the focal player had decided to wait, (2) the focal player was about to accept the current proposal, but their opponent acted before they could, or (3) the focal player was about to make a counterproposal but did not have time to act before their opponent made a move. The likelihood then becomes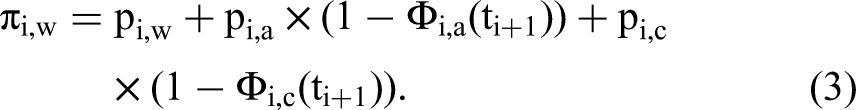
Note the use of the CDF (Φ) rather than the PDF (φ) of the distributions here. The same logic applies if the game reaches the ten-second limit (i.e., the player planned to let the game end without acting or was about to accept the proposal but poorly managed their time).
Figure 3 summarizes the various components of the likelihood function that are activated based on the specific event observed at time ti + 1.
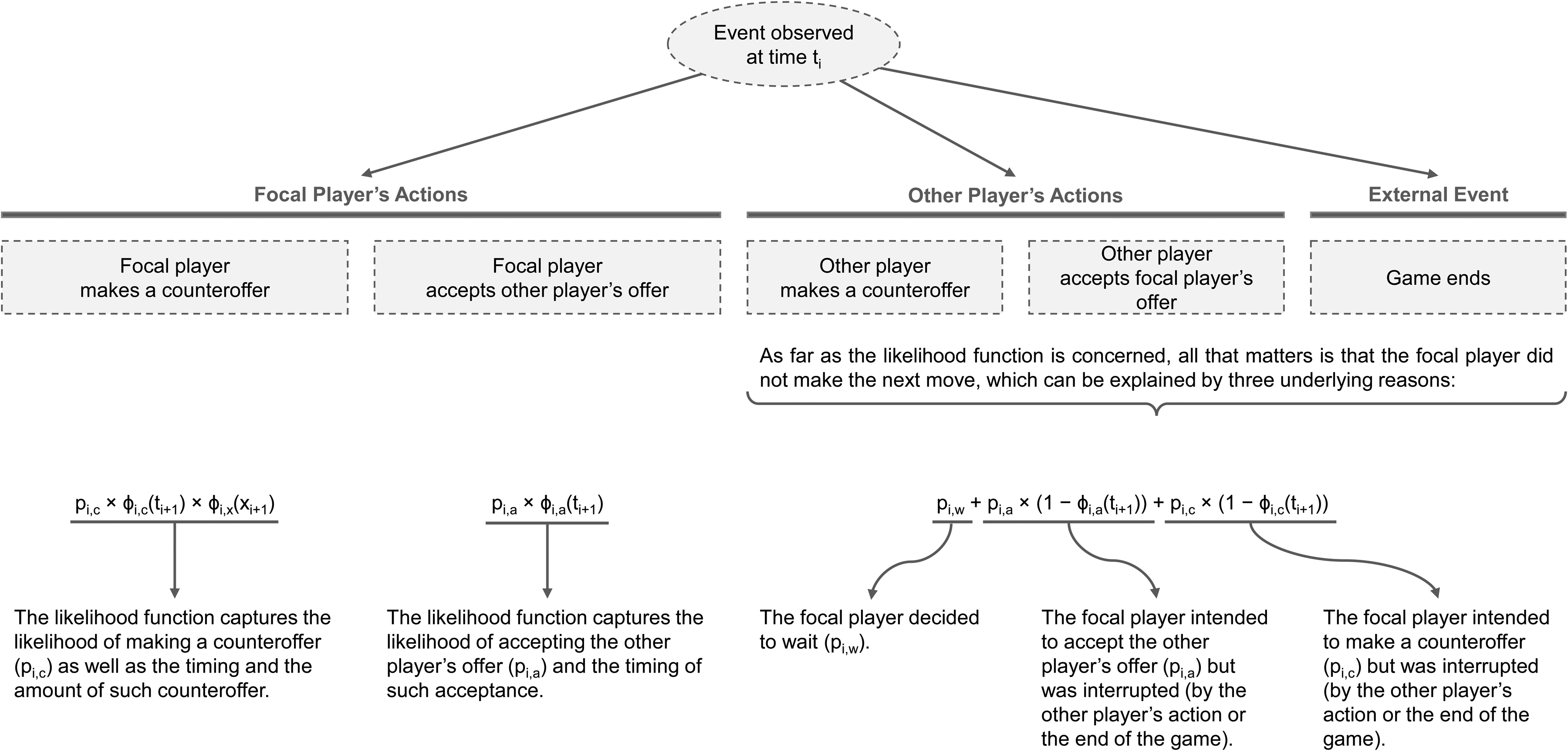
Components of the Likelihood Function Based on the Event (i.e., Focal Player's Action, Other Player's Action, End of Game) Observed at Time ti.
By letting 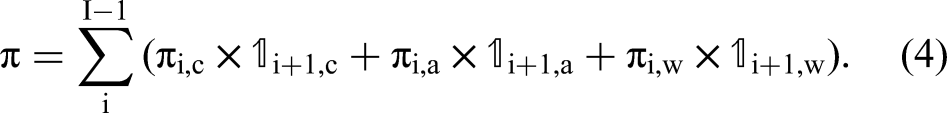
We train the 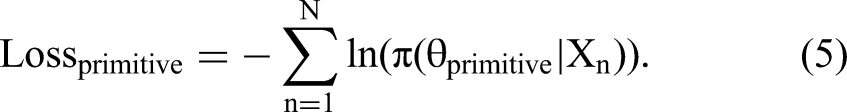
Because the sole objective of the primitive bot is to appear humanlike, and deep learning models are exceptional function approximators, we expect:
efficient bot
The 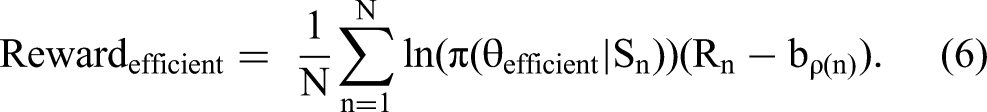
The term ln(π(θefficient | Sn)) is the log-likelihood of observing a game sequence (Sn) from a policy parameterized by θefficient. The incremental reward is given by (Rn − bp(n)), where n is the game index (∈[1, N]), Rn is the end-of-game payoff, and bp(n) is the average reward 2 observed for a game with that particular pie size. Introducing a baseline is important in the policy gradient algorithm as it ensures the variance of rewards is manageable during the calibration process, thereby facilitating convergence (Williams 1992). Since the average expected reward evolves continuously (with learning), it is updated after each epoch using exponential smoothing.
Reinforcement learning requires thousands upon thousands of games to learn, and it is neither economically nor practically feasible to use humans as sparring partners during the training phase. Therefore, we train the

Reinforcement Learning Algorithm for the
The reinforcement learning algorithm will train the
superhuman bot
The third bot is built on the concept of algorithmic anthropomorphization. We refer to it as a
In our context, the training of the
For the 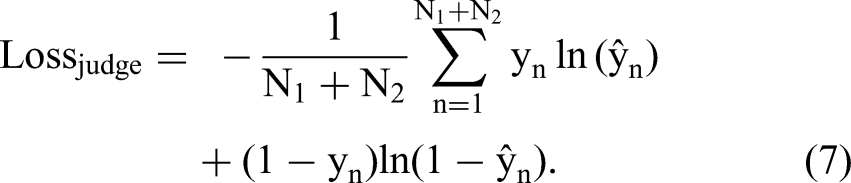
Here, the 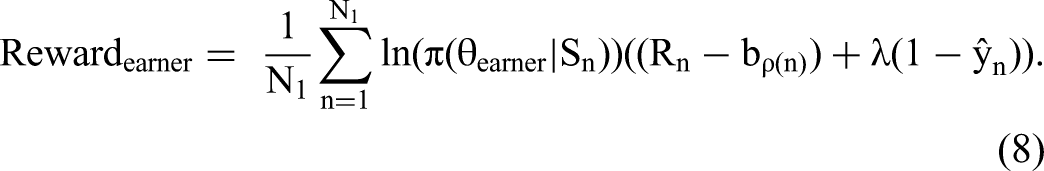
Importantly, in traditional GAN algorithms, the
But what is a blessing in most contexts is a curse in ours. If a
Alternatively, if the penalty for not behaving like humans is small, the
To achieve our balanced objective, we develop an innovative GAN algorithm in which the
Traditionally, both the

GAN Algorithm for the
In the first step of the main loop, the
Training Details
We train all our models using the Adam optimizer (Kingma and Ba 2014). We prevent overfitting by using L2 regularization (weight decay). We tune hyperparameters of learning rate, weight decay, number of nodes in each neural network, and number of mixtures in each truncated Gaussian mixture model distribution by using the Bayesian optimization technique (Snoek, Larochelle, and Adams 2012). Details of hyperparameter tuning are provided in Web Appendix C.
Simulations
We conduct a simulation study to evaluate the performance of five bot versions: the
The idea behind this study is to generate synthetic bargaining games using our models against an uninformed
We summarize the economic performance of each bot in Table 2, which reports key statistics across all simulations. We observe that the
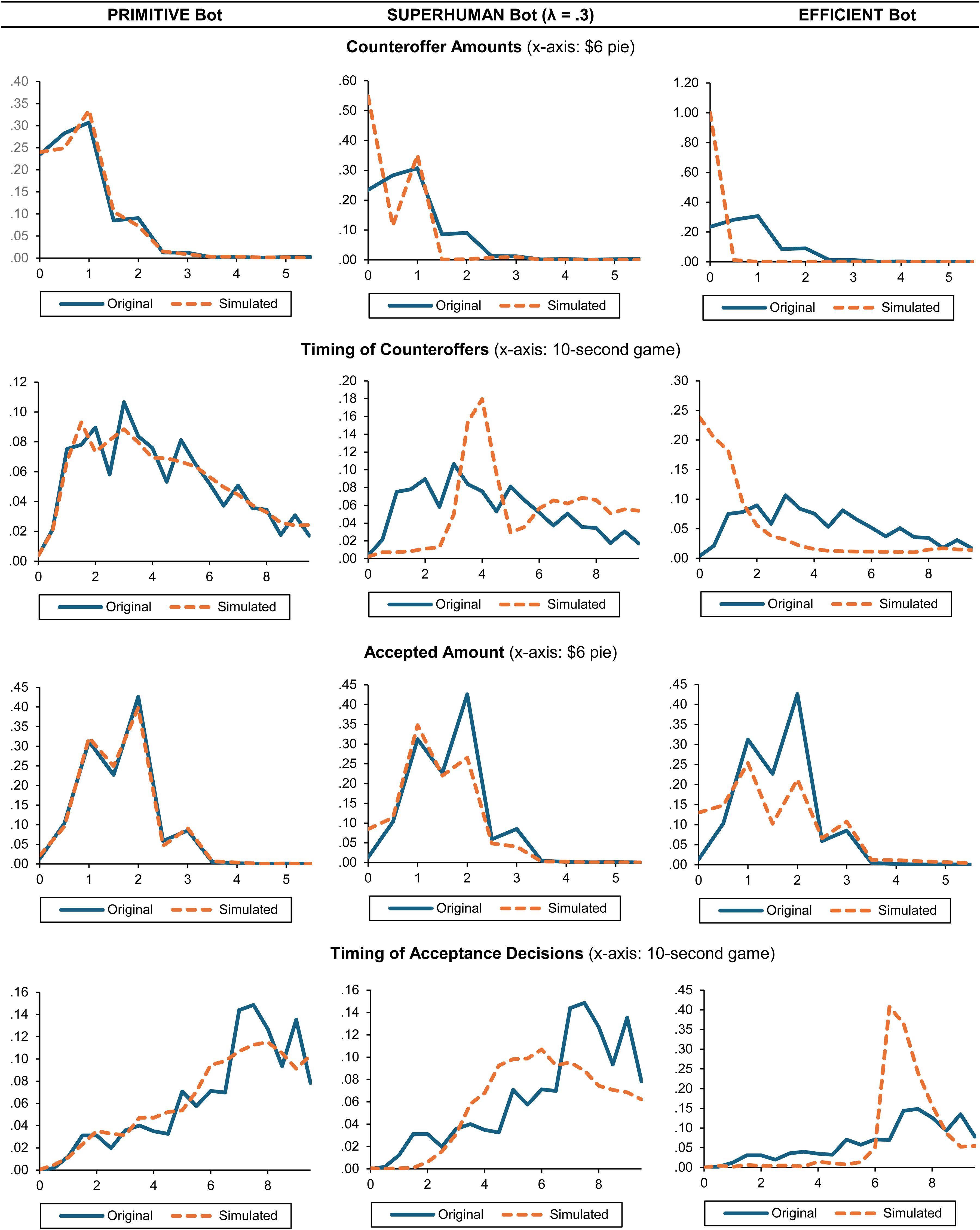
Distribution of Key Behavioral Indicators from the Informed Players.
Key Statistics for the Simulations.
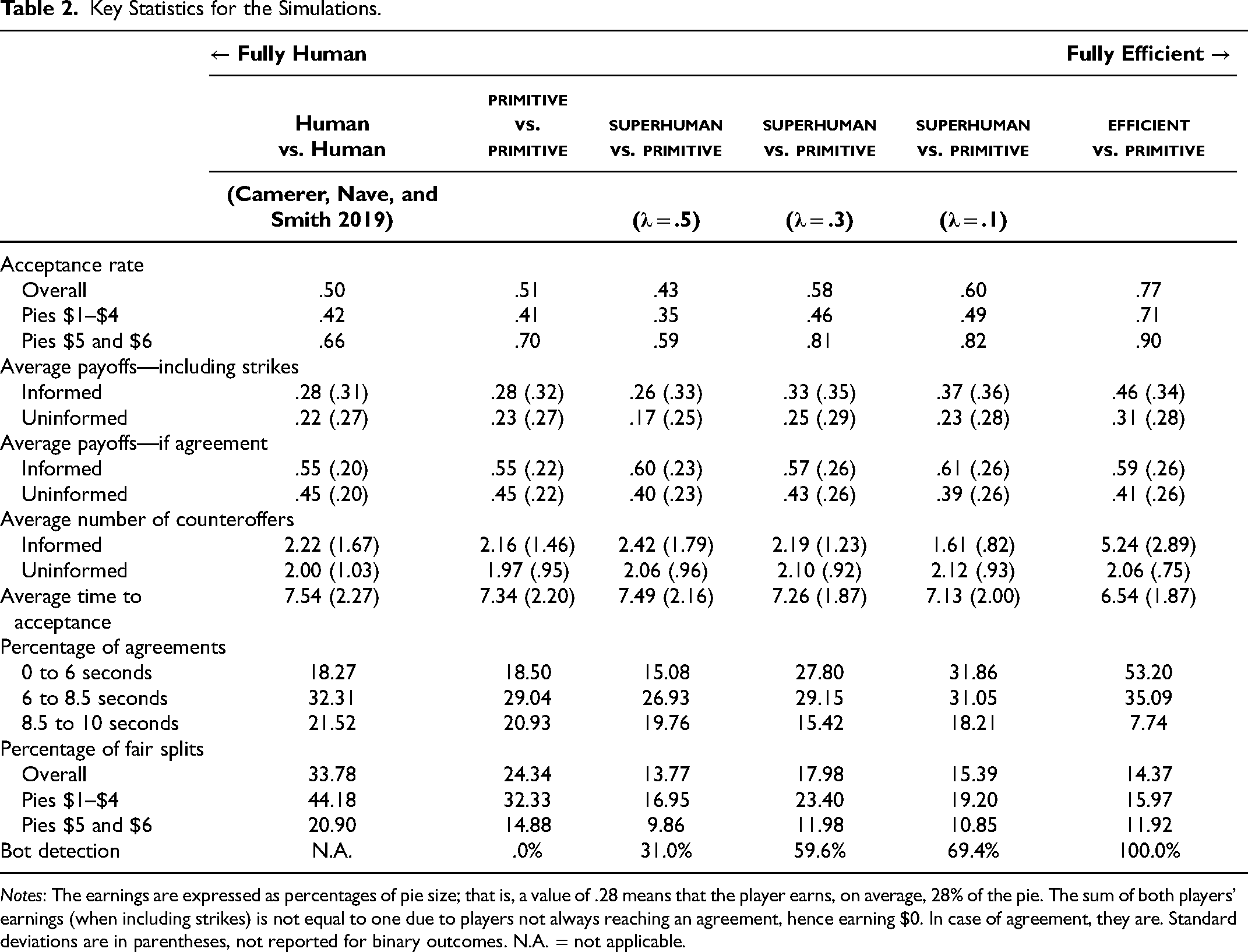
Notes: The earnings are expressed as percentages of pie size; that is, a value of .28 means that the player earns, on average, 28% of the pie. The sum of both players’ earnings (when including strikes) is not equal to one due to players not always reaching an agreement, hence earning $0. In case of agreement, they are. Standard deviations are in parentheses, not reported for binary outcomes. N.A. = not applicable.
The It cares far less about fairness. The number of fair splits (defined as when each player gets between 45% and 55% of the pie) drops from 24.34% to 14.37%. The number of agreements within the last 1.5 seconds drops from 20.93% to 7.74%. An agreement reached in the last 1.5 seconds leads to a strike. The The optimal strategy in this game is to secure as many deals as possible, and the The
As expected, the
We report in Figure 6 the distributions of four key behavioral indicators: counteroffer amounts, timings of counteroffers, acceptance offer amounts, and timings of deal acceptance. We plot those distributions against the baseline of human behavior observed by Camerer, Nave, and Smith (2019). The distributions of the
Next, we test all five bot versions against actual human players in a controlled experiment setting.
Experiment
Experimental Design
In this controlled experiment, we want to measure the impact of algorithmic and superficial anthropomorphization on both objective bargaining outcomes and subjective bargaining evaluations. Algorithmic anthropomorphization is manipulated at five levels, each corresponding to one of the bot versions:
For completeness, in addition to the 5 × 2 experimental design, we also add a control condition in which humans bargain against humans.
Within each condition, participants were recruited from Prolific Academic and asked to play 20 rounds of a bargaining game and then respond to a questionnaire. For all 20 rounds, they played the role of the uninformed player, whereas their opponent (human or bot) played the role of the informed player.
At the beginning of the experiment, participants were asked to select a human avatar (out of 20 available) and enter their first name. They were then shown a two-minute tutorial video (with subtitles), which they could not skip and could replay at will. Then, they were directed to an online waiting room, where they were paired against a randomly assigned opponent. This opponent could be another human player (also recruited from Prolific) or a bot from one of the 5 × 2 main experimental conditions. If a player was paired with a bot, we replicated the waiting room experience as though they were paired with a human (i.e., half of the participants were paired immediately as if their opponent was already waiting, while the other half were asked to wait a random length of time while waiting for their opponent to “arrive”).
From a technical point of view, the AI models were deployed on the same GPU-optimized server as the one where the experiment took place, using a flask web framework, hence ensuring minimal latency (less than 1/50 second on average) between any change in the game status and the AI's response.
As discussed previously, the design of each game was identical to that of Camerer, Nave, and Smith (2019), with the exception that participants only played 20 rounds, instead of the 100 or more rounds played in Camerer, Nave, and Smith. Since our respondents are more representative of the general population—unlike economics students in a university lab—they could not be expected to play the same game for an extended period without losing interest or dropping out.
Once the 20 rounds concluded, respondents were invited to complete an online questionnaire, including subjective evaluations of their bargaining experience using the SVI (Curhan, Elfenbein, and Xu 2006). The SVI scale comprises 16 items categorized into four underlying subconstructs: feelings about the outcome, the self, the process, and the relationship. The questionnaire also included a Turing test administered using a single item: “Regardless of what you have been told, your counterpart in the negotiations may have been either an artificial-intelligence bargaining bot or an actual human being. Do you think you have negotiated with a human partner or a bargaining bot?” (1 = “Definitely a bot,” and 7 = “Definitely a human player”). The detailed questionnaire is provided in Web Appendix A.
The experiment was incentive-aligned. In addition to a show-up fee, participants were paid $.02 for every experimental dollar they earned. We consider the first five games for each participant to be a learning period and exclude them from our analysis. We collected data for 1,019 uninformed players, resulting in 15,285 games.
Results
Analyses
We report the descriptive statistics of all the variables of interest (objective outcomes and subjective evaluations) in Table 3 (superficial anthropomorphization with human avatar and name) and Table 4 (full identity disclosure with a bot avatar and “BargainBot” name). In addition, in Table 5, we use regression analyses to analyze the extent to which uninformed players realize they have bargained against a human player or a bot (i.e., the Turing test) and how they subjectively judged their negotiation experiences (i.e., SVI; Curhan, Elfenbein, and Xu 2006). We expect the Turing test and the SVI to be influenced by our experimental manipulations, namely, the kind of bot they bargained against (
Descriptive Statistics (Experiment on Prolific) for the Objective Outcomes and Subjective Evaluations When the Bots (Playing the Informed Players) Are Portrayed with a Human Avatar and Name.
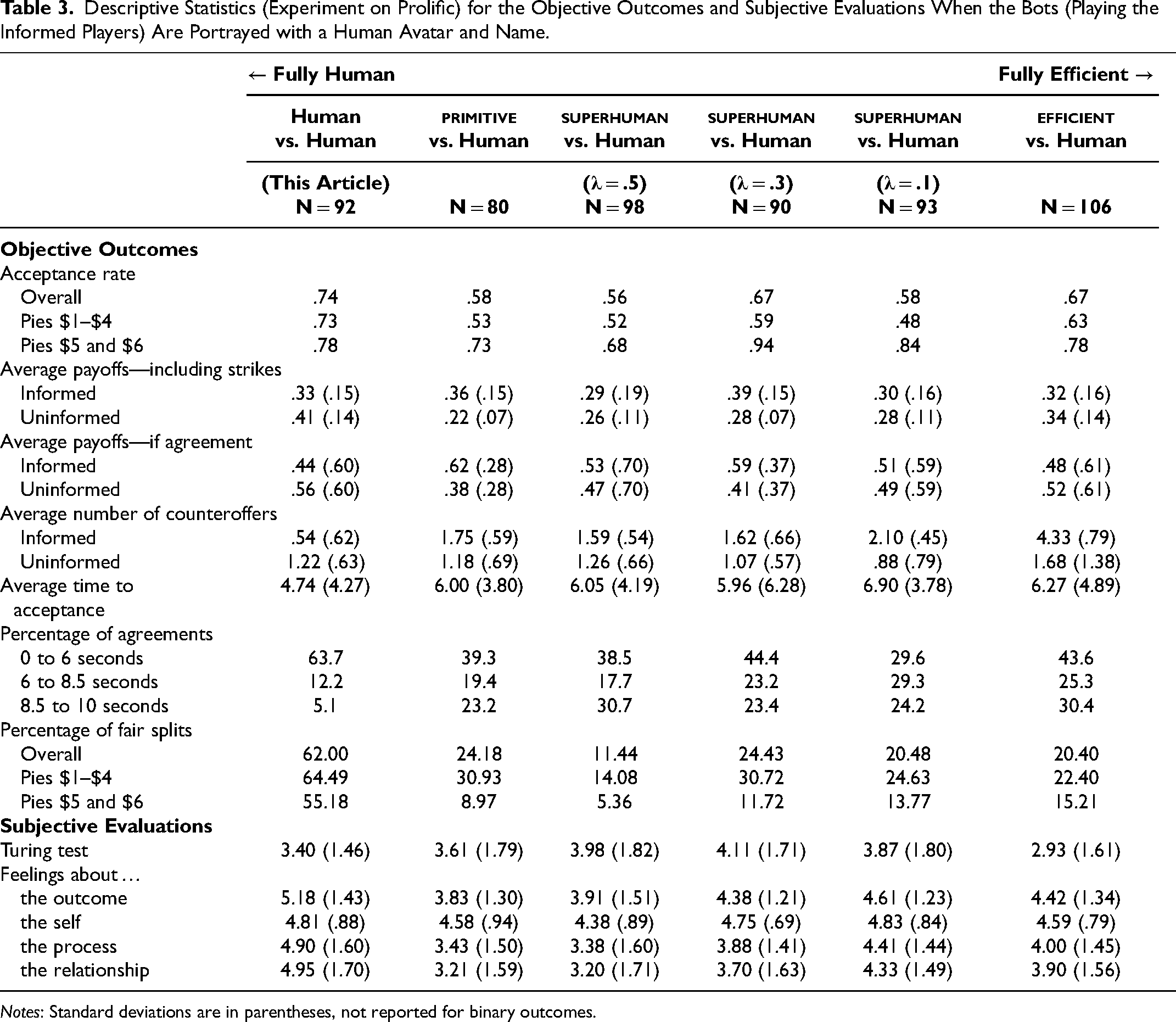
Notes: Standard deviations are in parentheses, not reported for binary outcomes.
Descriptive Statistics (Experiment on Prolific) for the Objective Outcomes and Subjective Evaluations When the Bots (Playing the Informed Players) Are Portrayed with a Bot Avatar and the Name “BargainBot.”
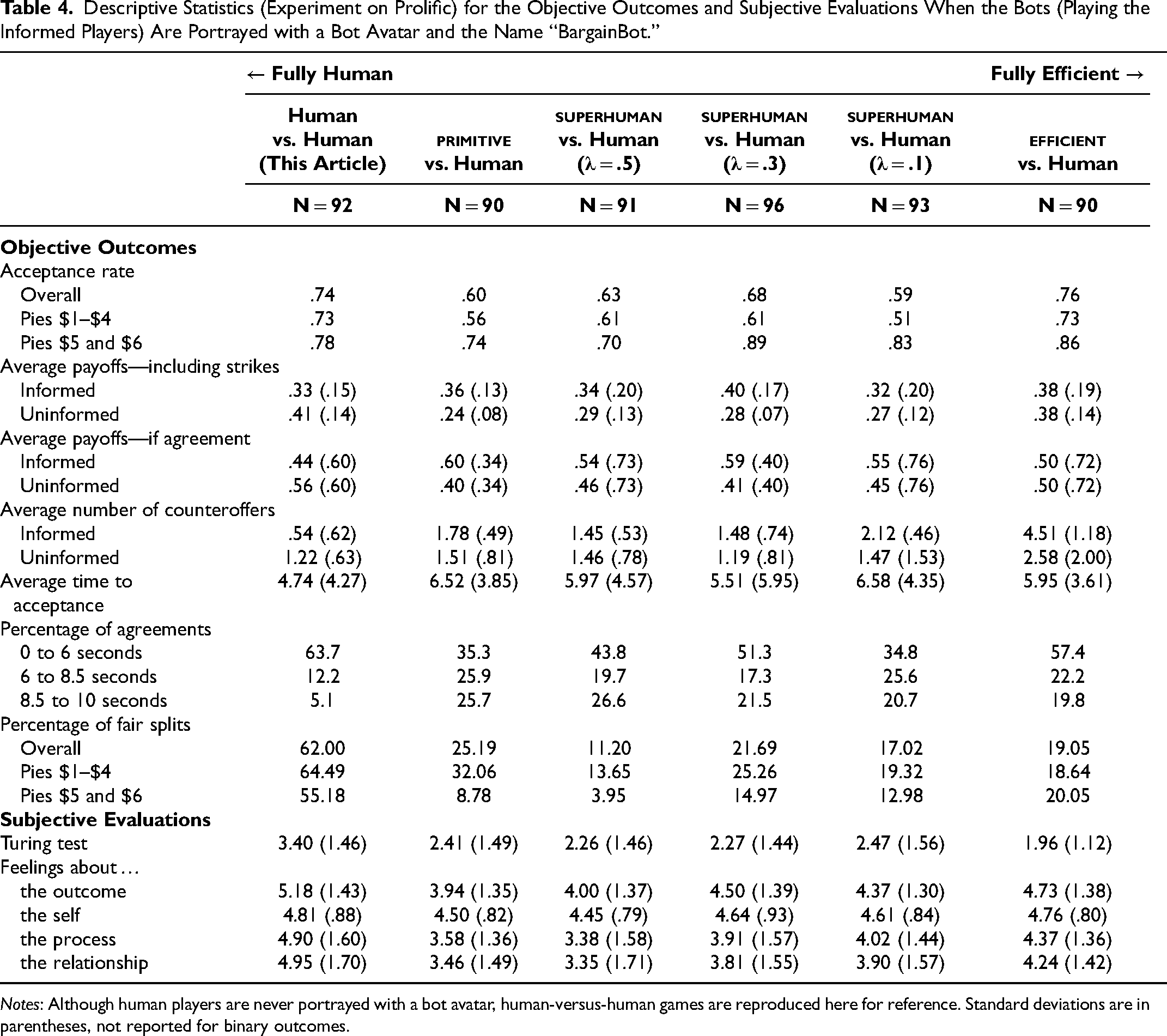
Notes: Although human players are never portrayed with a bot avatar, human-versus-human games are reproduced here for reference. Standard deviations are in parentheses, not reported for binary outcomes.
Results of Regression Analyses.
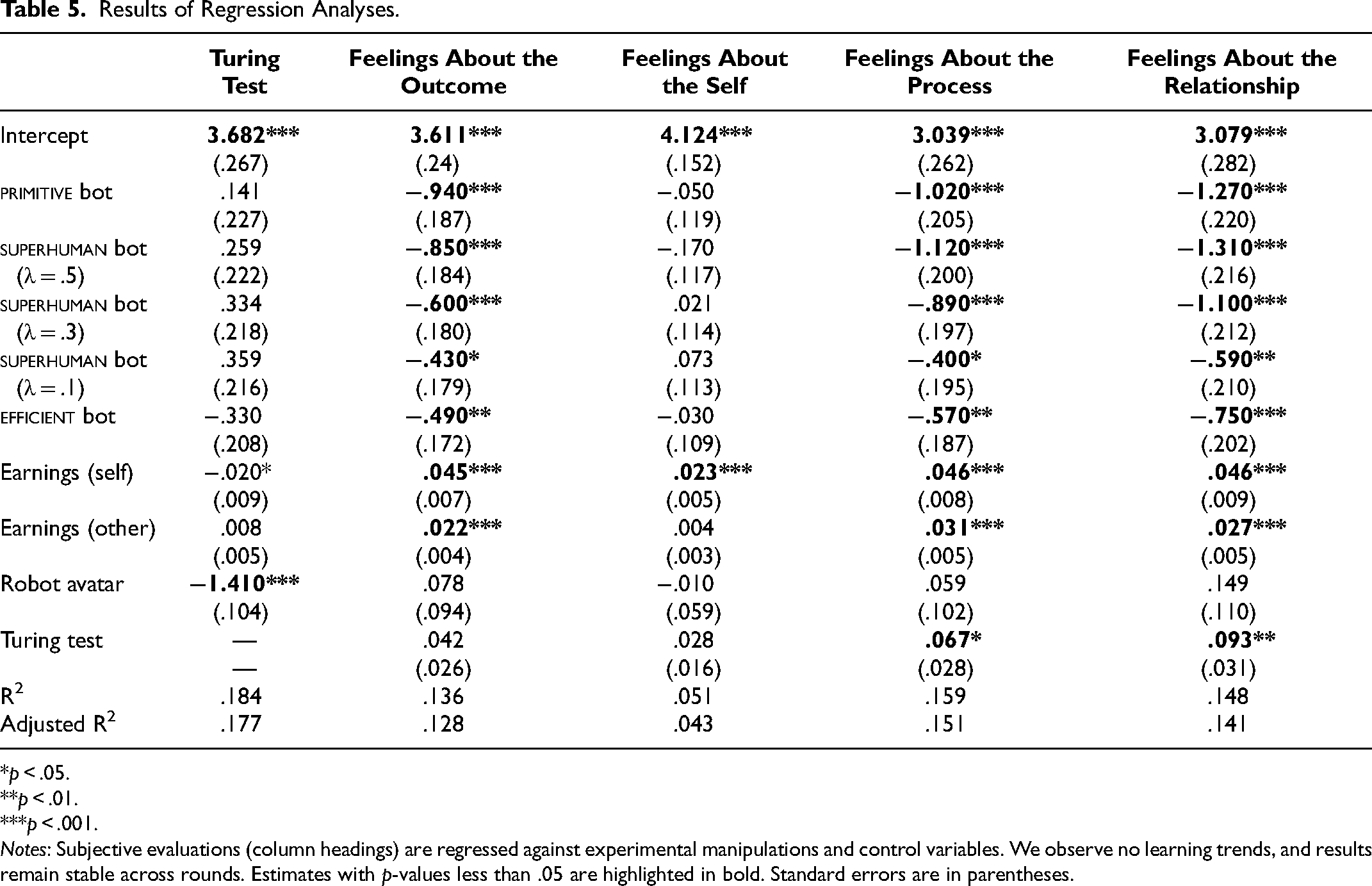
*p < .05.
**p < .01.
***p < .001.
Notes: Subjective evaluations (column headings) are regressed against experimental manipulations and control variables. We observe no learning trends, and results remain stable across rounds. Estimates with p-values less than .05 are highlighted in bold. Standard errors are in parentheses.
Regarding the SVI, we run a confirmatory factor analysis (see Web Appendix D) that shows that items corresponding to each subgroup have significant loadings on the latent constructs they represent. In line with Curhan, Elfenbein, and Xu (2006), we define each construct as an average of the items that load onto it, per the authors’ recommendations.
Algorithm aversion and anthropomorphization (H1–H3)
Identity disclosure has a strong negative effect (Table 5; β = −1.410, p < .001) on the Turing test. Superficial anthropomorphism (i.e., not revealing the AI's identity) significantly impacts the players’ perceptions that they are, indeed, playing against a fellow human being. While this effect is fairly obvious, it implies that superficial anthropomorphization effectively hides the identity of AI bots in bargaining, at least partly, which strongly supports H2.
In terms of subjective evaluations, feelings about the self are the only component of the SVI where only the uninformed (self) player’s earnings have a significant impact on the regression analysis (β = .023, p < .001). It is fairly intuitive; the more one earns, the more one feels good about one's abilities and, eventually, oneself. The three other components of the SVI (feelings about the outcome, process, and relationship) display similar patterns. First, uninformed and informed player earnings positively influence subjective evaluations, although self-earnings have a greater impact than other-earnings. Second, all bots negatively affect subjective evaluations, offering strong support for H1. Surprisingly, however, superficial anthropomorphization (i.e., robot avatar) has no significant effect in any of the regression analyses. Neither feelings about the outcome, the self, the process, or the relationship are affected by whether bargainers are told they are bargaining against a bot or a human being. This is interesting because, in the literature, superficial anthropomorphization has been shown to be effective in improving subjective evaluations and reducing algorithm aversion. Yet, we find no evidence of algorithmic aversion in this bargaining context. In other words, H1 is confirmed, but not for the reasons we anticipated (more on this subsequently).
Consequently, because negotiators do not seem to care whether they are told they are bargaining against another human being or an AI, portraying an AI as a human being using superficial anthropomorphization does not improve anything (thus, H3 is rejected). Superficial anthropomorphization can help portray bots as humans, but ultimately, this does not change how human beings judge their interactions with the bot. Algorithm aversion has been demonstrated many times over in collaborative environments. The fact that we fail to replicate it in a bargaining (i.e., partly adversarial) environment is noteworthy.
Interestingly, while being told they are bargaining against a human being is inconsequential for participants (contrary to predictions from the algorithmic aversion literature), believing they are bargaining against a fellow human is not. The Turing test influences feelings about the outcome (β = .042, p < .1), the process (β = .067, p < .05), and the relationship (β = .093, p < .001).
primitive bot (H4)
In the simulations, we showed that the
While being judged “humanlike” in its behaviors, the
efficient bot (H5 and H6)
In the simulations, the
While the
In terms of anthropomorphism, the
superhuman bot (H7 and H8)
For clarity, we will focus on the
In the simulations, the
The same patterns occur in the experiment. Compared with the
While improving all performance metrics, the
Astoundingly, the
Understanding the efficient bot’s underperformance
On the one hand, the simulations predicted a highly performing
The
The
In Table 6, we report the results of a regression analysis where we explain how often a bot is “exploited” by the uninformed player, that is, how often the agreement gives more than half of the pie to the latter—who is, in theory, at a marked disadvantage. It appears that the more “economically rational” a bot is, the more often it is exploited. The parameter goes from β = −.904 (p < .001) for the
Regression Analysis.

*p < .05.
**p < .01.
***p < .001.
Notes: The dependent variable is the number of rounds (out of 15) where the informed player (played by a bot) conceded more than half of the pie to the uninformed player (played by a human being). Estimates with p-values less than .05 are highlighted in bold. Standard errors are in parentheses.
In theory, the unpredictability and irrationality of humanlike behaviors should make them less profitable, and our simulations predicted that the
We summarize all the key results of this research in Table 7.
Summary Results of the Seven Hypotheses, as Assessed in Our Simulation Study and Controlled Experiment.

Notes: N.A. = not applicable.
Conclusions
Summary
Companies are increasingly using AI to automate their negotiation processes. While there are considerable benefits for firms to rely on AI (e.g., automation, cost-cutting, consistency), little attention has been paid to the psychological and relational impact of negotiating against AI. We posited that using AI bots may lead to unfavorable subjective evaluations, which have been shown to impact the outcomes and profitability of future negotiations. Hence, the use of AI in bargaining may be beneficial in the short term but detrimental in the long term, and no research to date has addressed that question.
On the one hand, many solutions have been proposed to assuage algorithm aversion (e.g., explaining the AI reasoning or giving control over the AI's output), but they have been suggested in contexts where humans’ and AI's objectives are perfectly aligned. They do not transpose easily to an adversarial context such as bargaining.
On the other hand, research has shown that superficial anthropomorphization (e.g., portraying the AI as being human in its appearance) could help foster trust and familiarity and, hence, may possibly prove beneficial in a bargaining context. Still, we posit that it might not be sufficient. We propose the concept of algorithmic anthropomorphization, namely, a novel GAN framework to train an AI to improve on its quantitative objectives while appearing humanlike in doing so, and test three versions of a
During our initial exploration of the phenomenon, and in the specific context of a low-stakes, sequential bargaining game, we show that bargaining against a bot, indeed, negatively affects participants’ subjective evaluations of the negotiations’ outcome, process, and relationship, even after controlling for the objective outcomes of the game. More importantly—and maybe more surprisingly—this effect also holds after controlling for identity disclosure (i.e., superficial anthropomorphism) and the results of the Turing test. In other words, it does not matter whether participants are told or believe they are bargaining against an AI. The fact that they are bargaining against an AI is sufficient to affect subjective evaluations negatively, which may affect their willingness to engage in future negotiations with the firm.
The
This result is confirmed by anecdotal evidence. One participant who bargained against the
Uncanny Valley?
Despite their superior anthropomorphism, the
In our deep learning framework, the unit of analysis to train all bots (whether to replicate human behaviors or improve on them) is a single bargaining sequence. In other words, no bot is trained to consider (or even be aware of) the outcomes from previous rounds with the same player, as doing so would increase the model complexity (and training data requirements) by several orders of magnitude. If it were possible to circumvent this limitation, we would expect the performance of all models to improve significantly.
Still, human players do not start each bargaining game from a blank slate. Game after game, they form a mental model of their bargaining partners, build trust or distrust, and even may “invest” in the relationship, hoping to reap the benefits in later rounds. If human bargainers signal their intentions across games, and the bot blatantly ignores them, it might create an uneasy feeling of one-way communication and the absence of reciprocity. Of the four subconstructs constituting the SVI, all bots perform the worst on feelings about the relationship, which is consistent with our conjecture. Interestingly, human participants do not even need to perceive they are bargaining against a bot to feel uneasy.
If confirmed beyond the limited context of our experimental setting (i.e., small-stakes, sequential bargaining), this would be a significant warning call for firms considering replacing human negotiators with automated AI solutions. Our research suggests that even an AI that is economically efficient, hard to exploit, and perceived as more humanlike than actual human beings may still behave in a way that, unbeknownst to all, could hurt the relationship between parties (e.g., loss of reciprocity, lowered mutual understanding and commitment).
Sample Differences
The sample used to train our models (Camerer, Nave, and Smith 2019) exclusively consisted of young students (μ = 21.3, σ = 2.4) at premier educational institutions in the United States (Caltech and UCLA) and possibly primed with relevant game-theory coursework. They also played 135 games instead of 20, likely generating boredom and inattention. The incentive-alignment mechanism was based on a lottery rather than directly proportional to their economic performance. The large number of games they played may also have diluted the incentive alignment of the experiment and made the outcome of each game far less economically relevant. Comparatively, our sample is much more diverse, and the outcome of each game matters proportionally more. It is, therefore, not surprising that the behaviors of both samples diverge significantly 4 (i.e., the student sample is more greedy and less likely to reach an agreement).
While such sample divergence might be considered an issue, it is typical of AI development challenges that companies face in real life. It is quite common for data used to calibrate an AI model not to be perfectly representative of the circumstances in which the model will be used. For instance, research has shown that state-of-the-art object detection systems are more likely to correctly identify pedestrians when they are light-skinned than when they are dark-skinned (Wilson, Hoffman, and Morgenstern 2019), leading to a flurry of articles claiming that self-driving cars relying on these systems were “racist” and might pose a greater danger to dark-skinned pedestrians than to light-skinned ones (e.g., Makoni 2022). The original study's authors correctly identified that the source of the problem was the underrepresentation of dark-skinned pedestrians in the training data (barely 22%) and that it could be corrected by reweighting the sample. In the same vein, digital assistants recognize white American accents better than any other (Rangarajan 2021) and thus are not well adapted to many real-life usage situations, most likely for similar reasons. Several researchers have highlighted the risks of such biases, such as creating cultural barriers or safety risks, or violating cultural values (Prabhakaran, Qadri, and Hutchinson 2022). In data labeling, a fastidious and time-consuming but essential step in many AI applications, Google and Microsoft largely rely on human coders located in Africa due to their cheap labor force (Hale 2019), with underinvestigated consequences (e.g., would a customer email be equally labeled “angry” by an African, Asian, or American coder?).
The fewer differences between the training data and the actual context in which an AI model will be deployed, the better the latter should perform. Our models likely suffer from a mismatch between the students in Camerer, Nave, and Smith (2019) and the Prolific respondents in our study. Still, it is reassuring to observe that the bots could develop excellent bargaining strategies from the Camerer, Nave, and Smith sample and that such strategies remained effective against a markedly different population. For instance, the informed
Key Takeaways
Our research is a preliminary exploration of the impact of using AI on the subjective evaluations of negotiations. While the context (a single, small-stakes, unstructured bargaining game) might limit the generalizability of our results, we highlight three takeaways: methodological, substantive, and managerial.
Methodological
We build and test a novel GAN framework that simultaneously pursues objective payoffs and anthropomorphization. In settings of strategic interactions, work has been done on developing AI that finds optimal solutions (Lewis et al. 2017) or that is anthropomorphized in its behavior (Jacob et al. 2022; McIlroy-Young et al. 2022). To the best of our knowledge, however, no work has been done on building AI that can find optimal solutions while being rewarded to behave like humans in the process. In the specific context of a low-stakes, unstructured bargaining game, our preliminary results show that the resulting
Substantive
We contribute to the human–AI interaction literature by highlighting both the importance and shortcomings of the anthropomorphization of strategies (rather than appearances). While superficial anthropomorphization contributes to portraying a bot as human, algorithmic anthropomorphization is equally crucial to pass the Turing test since the bot strategy may reveal its nonhuman nature. In stark contrast with predictions from the algorithm aversion literature, however, in our small-stakes bargaining game, neither form of anthropomorphization alleviates the detrimental effects of AI on subjective evaluations. While our empirical focus is on a specific bargaining context, we speculate that outcome differences across bargaining situations—especially those involving AI—are primarily driven by negotiators’ perceptions of fairness, predictability, mutual understanding, and exploitation. While AI negotiators’ ability to replicate humanlike unpredictability seems to help, it still fails to manage relational signals over multiple interactions: The AI negotiator does not signal its intentions or dispositions, and is oblivious to the signals it receives from its human counterpart. This inability likely moderates the differences we observe across conditions, influencing both economic outcomes and subjective evaluations. This theoretical perspective, which emphasizes the interplay between algorithmic predictability and perceived relational intent, offers valuable directions for future research in improving human–AI interactions.
Managerial
We urge companies that rely on AI negotiators to consider going beyond short-term objective outcomes to measure success. Although our initial exploration of the phenomenon relies on a simple, low-stakes bargaining game, our preliminary results suggest that AI negotiators may hurt subjective evaluations and, consequently, long-term relationships, even when the AI is objectively good and indistinguishable from human beings.
Future Research
Beyond this research, bargaining with AI still poses many questions that have yet to be answered. How do human beings adapt their behavior to AI bots? Are there certain traits that make humans better (or worse) bargainers against AI bots? Can we cross the uncanny valley by building an AI model that goes beyond optimizing one bargaining game at a time but also models the long-term relationship with the other party across bargaining rounds?
Based on discussions with managers and researchers at Pactum AI, the industry also seems to be concerned with how AI (1) could better account for cultural differences, (2) anticipate the other party's priorities as quickly as possible to better “calibrate” the negotiations, and (3) adapt one's strategy on the spot based on subtle signals sent by the other party—qualities that professional human negotiators excel at compared with AI systems. Recent literature also mentions that (4) “AI-powered negotiation agents are likely to develop biases and create unfair deals or unethical interactions, especially when trained or given rules that make them purely utilitarian” (Falcão Filho 2024a, p. 53). Interestingly, including a penalty for being humanlike in the response function partly mitigates this latter concern.
With the rapid diffusion of AI in society, we can expect strategic interactions with AI to be increasingly normalized, and expanding our understanding of the psychological aspect of this phenomenon becomes imperative. Our work aims to build knowledge in this nascent area.
Supplemental Material
sj-pdf-1-mrj-10.1177_00222437251375323 - Supplemental material for Bots Bargaining with Humans: Building AI Super-Bargainers with Algorithmic Anthropomorphization
Supplemental material, sj-pdf-1-mrj-10.1177_00222437251375323 for Bots Bargaining with Humans: Building AI Super-Bargainers with Algorithmic Anthropomorphization by Sumon Chaudhuri and Arnaud De Bruyn in Journal of Marketing Research
Footnotes
Coeditor
Brett R. Gordon
Associate Editor
Eric T. Bradlow
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors acknowledge the financial support of the Research Center at the ESSEC Business School.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.