
Abstract
This research investigates how listening to versus reading news alters its interpretation. A proposed theory argues that because listeners (vs. readers) are less able to regulate the rate of incoming information, they selectively attend to the more emotionally arousing elements in a story, such as those that are more negative. This selective attention leads listeners to form different interpretations of news than readers, the nature of which depend on the valence of the story. Six main experiments and three supplemental ones (N = 14,744) support the predicted effects on impression formation as well as the proposed mechanism. For example, participants who listened to (vs. read) a mixed-valence news story on the risks and benefits of a product processed its negative details more selectively, and in turn formed more pessimistic impressions of its safety. Moderators are also explored, showing that negativity biases similar to those observed for listeners arose among readers when their control over information flow was restricted, and that a positivity bias arose among listeners when the positive (vs. negative) information in a story was more surprising. Theoretical contributions to previous research on reading versus listening comprehension are discussed, as are the substantive implications for media firms and consumers.
One of the major shifts in media consumption in recent years has been the rise in popularity of streaming audio platforms (e.g., podcasts) as a source for news and information. In 2023, for example, 48% of Americans reported listening to spoken-word audio channels daily (Edison Research 2023). The appeal of listening to content (vs. reading) is easy to understand; through streaming audio on our smartphones we can consume information at virtually any time and in any place, whether on our subway commute, while working out, or while cooking at home. Advances in automated text-to-speech technologies also offer more ways for consumers to access audio content than ever before. Media outlets, for example, increasingly provide audio analogs of their printed content, giving consumers a choice between reading a news story or listening to a recording of the same content (Adgate 2019; Bullard 2020).
While the increased availability and popularity of streaming audio channels have greatly changed how we consume news, might this change also be altering how we interpret it? On one hand, decades of research spanning the fields of communication, cognitive psychology, and education suggest that readers tend to recall the details of the same narrative better than listeners do (e.g., Clinton-Lisell 2022; Daniel and Woody 2010; Furnham and Gunter 1989; Gunter, Furnham, and Geitsin 1984). Thus, as convenient as listening to the news might be, it could risk leaving consumers with shallower knowledge about emerging events. On the other hand, one might argue that what matters most in news comprehension is not one's ability to recall every detail of a story, but rather the accuracy of the interpretation one draws from it. For example, given a report from the Centers for Disease Control and Prevention saying that the benefits of a new vaccine outweigh its risks, readers and listeners might ideally form the same intention to seek vaccination—even if listeners are less able to recall the vaccine's exact composition or pharmacological name.
In this article we propose and test a theory of listening versus reading comprehension that predicts that consumers will tend to draw different interpretations of a news story depending on whether they hear or read it. In particular, we theorize that when consumers listen to (vs. read) a news story, they are more prone to selectively attend to its more emotionally arousing elements—such as details that are more negative (e.g., Baumeister et al. 2001) or surprising (e.g., Brondino et al. 2019)—which in turn alters the nature of the interpretations they draw.
We organize our presentation in four sections. We begin by reviewing prior research on how reading versus listening affects comprehension and then propose a conceptual and mathematical theory of how listening to (vs. reading) news can systematically alter consumers’ interpretations of it, as well as the mechanism that underlies these differences. We test these ideas and their predicted downstream consequences across six main experiments and three supplemental experiments reported in the “General Discussion” section.
Theoretical Background
Listening Versus Reading Comprehension
Whether reading or listening is better for comprehension is one of the oldest and most widely studied questions in educational psychology, communication, and other fields (e.g., Clinton-Lisell 2022; Witty and Sizemore 1959; see the Web Appendix for a comprehensive summary of prior comparisons). While past findings have varied, most show that when adults read a narrative at their own pace, they are better able to recall its details than when they listen to it—especially for more complex narratives (e.g., Chaiken and Eagly 1976; Furnham and Gunter 1989).
Why might reading comprehension be superior to listening comprehension? Past work points to two sets of contributing factors, one of which focuses on the inherent advantages of reading, the other on the inherent disadvantages of listening. First, evidence for the relative advantages of reading comes from work in cognitive and neuropsychology, which finds that our visual memory tends to be better than our auditory memory (e.g., Cohen, Horowitz, and Wolfe 2009). For example, we are better able to recall words from lists when they are presented in written (visual) rather than spoken (auditory) form (e.g., Janczyk, Aßmann, and Grabowski 2018). A key explanation for this difference comes from eye-tracking studies, which show that when we read, our eyes reflexively rescan and reprocess words that we encounter. In fact, it is estimated that up to 25% of our reading involves reverse saccades in which we visually rescan or reprocess textual content, such as individual words or larger passages of text (e.g., Wegner and Inhoff 2006). In contrast, when listening to content, we might be able to pause and rewind a podcast to relisten to parts we missed, but even when we exercise this option, the process is more effortful and less reflexive than visually rescanning words to reread a text, and it is not even possible in formats such as radio, where audio is ephemeral. It has also been argued that visual encoding enables us to recall spatial features of text, such as where a word or phrase appeared on a page, that could further enhance the memorability of visual inputs compared with audial ones (e.g., Hadley and MacKay 2006).
The second line of reasoning for the superiority of reading (vs. listening) comprehension is that listening is usually more cognitively taxing (e.g., Bayramova et al. 2021). Whereas we can regulate the speed with which we read, when listening we must try to rapidly encode an uninterrupted stream of words while anticipating the arrival of new ones, a demanding process that reduces the cognitive resources available for encoding (Bayramova et al. 2021; Rubin, Hafer, and Arata 2000). Moreover, this greater cognitive load tends to be exacerbated in real-world listening contexts, where we often listen to news while simultaneously engaging in other activities, such as driving or cooking (e.g., Cohen and Gordon-Salant 2017). Even without multitasking, people tend to be more susceptible to “mind wandering” while listening—another source of distraction that has been shown to degrade listening comprehension (e.g., Bonifacci et al. 2023).
Selective Processing in Listening Versus Reading
If indeed listeners tend to recall less of what they are exposed to in a narrative compared with readers, might there be a bias in the types of information they do recall? While we are aware of no prior work that has examined this question in relation to news consumption, some insights might be drawn from research on the effects of cognitive load on information processing in other contexts (e.g., Lavie et al. 2004). A major finding from this literature is that when our cognitive resources are taxed while engaging in an activity, we tend to selectively focus on the elements of the activity that are more perceptually salient (e.g., Cohen and Gordon-Salant 2017; Middlebrooks, Kerr, and Castel 2017). For example, when we are exposed to the competing sounds of voices at a cocktail party, our auditory system can become overloaded, leading us to selectively process only a subset of the auditory inputs, such as the words of the person we are speaking with (e.g., Bronkhorst 2015; Pugh et al. 1996).
We posit that an analogous process of selective encoding occurs when we listen to (vs. read) a news story. Past work suggests that when consuming information, we are naturally drawn to words or phrases that are more emotionally arousing (e.g., Citron et al. 2014; Mather 2007). Here, we follow past work (e.g., Mather and Sutherland 2009; Zsidó 2024) in defining emotional arousal as a heightened state of activation in response to a stimulus, which naturally triggers alertness and attentiveness toward that stimulus. That is, by definition, one is more likely to attend to a more (vs. less) emotionally arousing stimulus and, in turn, to subsequently recall it from memory (e.g., Hamann 2001; Kohout, Kruikemeier, and Bakker 2023). Building on this, we hypothesize that readers and listeners will differ in the degree to which they selectively process more (vs. less) arousing content; namely, because consumers experience greater cognitive load when listening to (vs. reading) news, the tendency to selectively attend to and recall the more emotionally arousing parts of a story will be amplified among listeners.
What types of words will tend to be more emotionally arousing in a news story? While different features of words have been found to trigger emotional arousal, perhaps the most widely documented is valence (e.g., Kuperman et al. 2014; Megalakaki, Ballenghein, and Baccino 2019). Specifically, words that convey either positive (e.g., “love”) or negative (e.g., “hate”) emotion have been found to be more arousing than those that are emotionally neutral (e.g., “couch”) (e.g., Hamann 2001; Kousta, Vinson, and Vigliocco 2009). Notably, however, extensive research demonstrates that negative words and phrases are particularly arousing—a phenomenon known as the negativity bias (e.g., Baumeister et al. 2001; Melumad, Meyer, and Kim 2021; Soroka, Fournier, and Nir 2019). Hence, if a news story contains positive details about the good fortunes of a lottery winner but also negative information about how lottery winnings are often squandered, this latter information will likely loom larger for consumers of the story (e.g., Soroka, Fournier, and Nir 2019). Thus, we predict that listeners and readers will be more aroused—and hence more attentive to—the negative information in a news story than the positive or neutral content, but that this differential attention will be more pronounced among listeners than readers.
Finally, while negative valence is one of the most well-documented triggers of emotional arousal, other features of text have also been shown to heighten arousal, such as content that is surprising (e.g., Brondino et al. 2019; Ranganath and Rainer 2003). Hence, although positive news tends to be less arousing than negative news in general, when the positive news is more surprising, it may be end up being more arousing than the negative news. In such cases, we expect listeners (vs. readers) to selectively process the more positive (vs. negative) elements in a story.
How Listeners (vs. Readers) Form Impressions of News
To the extent that listeners (vs. readers) indeed more selectively attend to—and thus recall—the more emotionally arousing information in a news story, how might this difference affect the overall interpretations they form of the same story? To help answer this question, we draw on literature on serial information integration, which considers the problem of how overall impressions of multiattribute stimuli are formed when they are consumed in a piecemeal fashion over time—such as impressions formed of personalities that are described one attribute at a time (e.g., Anderson 1973, 1981; Fredrickson and Kahneman 1993). Those who have investigated this topic historically have approached the problem mathematically, arguing that judgments of a stimulus often resemble a serially weighted average of the valence of its parts, where the weights reflect the relative strength of each component in memory (e.g., Anderson 1973).
We leverage these ideas to develop a set of predictions about the impressions that listeners versus readers form of a news story. We theorize that the greater cognitive load faced by listeners (vs. readers) limits the amount of information they can attend to in a story, which leads them to selectively encode the more emotionally arousing elements in lieu of the less arousing ones. This results in the formation of impressions by listeners and readers that will differ in systematic ways depending on the valence composition of the story.
To illustrate, consider the case of a mixed-valence news story that contains a similar amount of positive and negative information on a topic—such as the risks versus benefits of self-driving cars. For both readers and listeners, when encoding the story, information about the risks will likely be more salient than the benefits due to the negativity bias (e.g., Baumeister et al. 2001). However, we predict that since listeners tend to process information more selectively than readers, this negativity bias will be more acute among listeners. As a result, listeners will form more negative impressions about the safety of the cars than readers, whose impressions will be more equally informed by the positive and negative elements.
Next, consider the case where a news story has one predominant valence—such as a mostly positive story emphasizing just the benefits of self-driving cars, or a mostly negative one that focuses on the risks. In both cases we expect that readers and listeners will tend to form impressions that generally align with the primary valence of the story—for example, both readers and listeners should form generally positive impressions of self-driving cars based on a story that solely discusses its advantages. We predict, however, that because readers (vs. listeners) can encode and recall a greater number of details, their impressions of a mostly positive story will be more strongly positive, and their impressions of a mostly negative one will be more strongly negative. For example, while a reader's memory of the positive story will be rich with details on the benefits of self-driving cars, listeners will have encoded fewer positive details to draw on from memory, leading to a more tempered positive impression.
Note that our predictions of readers’ versus listeners’ impressions of different types of stories depend on specific assumptions about how they initially encode and, thus, recall those stories. To precisely articulate these ideas, we present them mathematically in the following section. Specifically, in what follows we develop a mathematical theory of how listeners versus readers encode and recall elements of a story, and how this affects the impressions they form of that story. The central ideas of the model are outlined next, with a more comprehensive treatment reported in the Web Appendix.
Formal representation of impression formation
Consider an individual who consumes (reads or listens to) a story about the risks and benefits of a new vaccine. The story is composed of i = 1, …, N semantic elements (words or sentences), some positive (benefits), some negative (risks). After reading or listening to the story, the consumer forms an overall impression of it, such as a judgment about the vaccine's safety (i.e., overall positivity judgment), which the consumer rates on a seven-point scale (1 = “extremely harmful,” and 7 = “extremely beneficial”). Let Vm represent this overall positivity rating given modality m (read or listen). If V* is the neutral midpoint of this scale (4), values of Vm > V* imply increasingly positive beliefs about the vaccine's safety, and those for which Vm < V* imply increasingly negative beliefs.
Further, assume that each element i (e.g., sentence) is associated with (1) a valence, vi (i.e., how positive the ith element is perceived to be), as measured on the same scale (1 = “extremely harmful,” and 7 = “extremely beneficial”) used for the overall positivity judgment Vm, and where v* is the scale midpoint; and (2) a probability, pim, that element i will be recalled from memory when forming the judgment. In the Web Appendix we show that the overall impression of the vaccine's positivity/safety, Vm, can then be represented by the linear-additive rule:
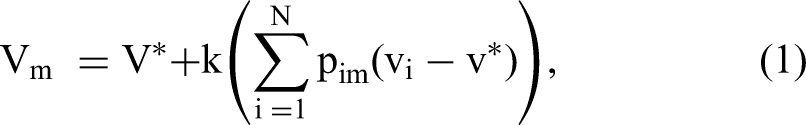
Assumed properties of recall probabilities
Because Equation 1 is quite general in form, it does not yield specific predictions about how overall impressions of the vaccine might differ between readers and listeners. To form these predictions, we need to make additional assumptions about (1) what drives the probabilities of recalling different story elements, and (2) how these probabilities might differ between readers and listeners. For what drives the probabilities, we follow past work by assuming that the probability pim that each story element will be recalled from memory increases as a function of how emotionally arousing it is (e.g., Hamann 2001), and that negative information tends to be more arousing than positive or neutral content (Baumeister et al. 2001; Megalakaki, Ballenghein, and Baccino 2019). Formally, we assume that pim will be monotonically increasing in |vi − v*| for both readers and listeners, where [pim|vi < v*] > [pim|vi > v*]. In addition, we assume that because listeners (vs. readers) face higher cognitive load that makes them more selectively encode a story, readers will recall more information overall, compared with listeners (i.e., pi_read ≥ pi_listen for all i), including the positive and negative elements of the story. At the same time, we assume readers will exhibit a negativity bias that is less acute than that exhibited by listeners. This latter idea can be described mathematically by [pi_read − pi_listen|vi < v*] < [pi_read − pi_listen|vi > v*].
In Figure 1 we illustrate these assumptions about how readers and listeners differ in their recall of various story elements as a function of their valence. As depicted in the figure, we expect to observe a general U-shaped relationship between the valence of an element and the probability of its recall, such that negative information will be more arousing—and thus more memorable—than positive information for both readers and listeners (Baumeister et al. 2001; Mattek, Wolford, and Whalen 2017). Critically, the figure depicts two of our key predictions: (1) readers (vs. listeners) will have better recall for all elements of a story regardless of valence (pi_read ≥ pi_listen for all i); and (2) the tendency to better recall negative (vs. positive) information will be more acute for listeners ([pi_read − pi_listen|vi < v*] < [pi_read − pi_listen|vi > v*]). As an example, if a story contains a mixture of positive and negative information, readers’ memory for that story will be informed by both types of information, whereas listeners’ memory would be mostly informed by the negative information.
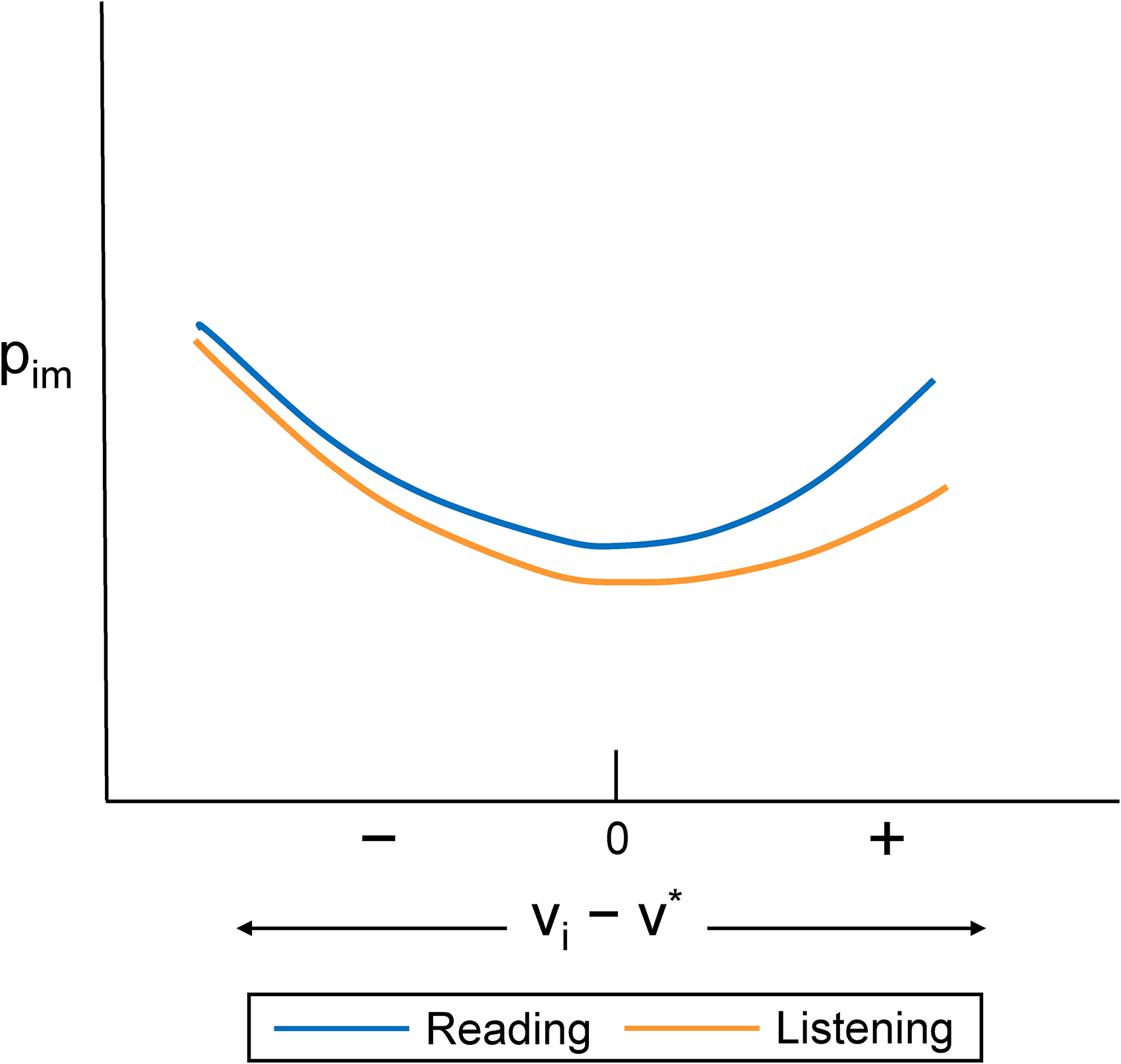
Hypothesized Relationship Between Valence (vi − v*) and Recall Probabilities (pim) for Readers and Listeners.
Formal representation of listeners’ and readers’ impressions
Our central interest is in exploring the implications of these assumptions for the overall impressions that readers versus listeners form about different news stories. As shown in the Web Appendix, when we apply to Equation 1 our preceding assumptions about the probabilities of recalling different story elements among readers and listeners (pim), we can derive a series of predictions about how their overall impressions (Vm) will differ across stories with varying distributions of valences.
Specifically, in the case where a news story contains a mixture of positive and negative elements (vi > v* for some i, vi < v* for others), Equation 1 predicts that listeners will form more negative overall interpretations of the story than will readers. This follows from the assumption that listeners more selectively recall the negative (vs. positive) elements of a story, thereby making their impressions more negatively biased than those formed by readers.
In the case where a news story is primarily positive in nature (vi > v* for all i), Equation 1 predicts that readers’ impressions will be more strongly positive than listeners’. This follows from the assumption that readers are more likely to encode and recall every type of information from a story than listeners. That is, since readers will have a larger number of the positive details to draw on from memory, they will form cumulative impressions that are more intensely positive than those formed by listeners.
Finally, in the case of a news story that is primarily negative (vi < v* for all i), we analogously predict that because readers will have encoded a larger number of negative details that they can recall from memory, they will form impressions that are more strongly negative than those formed by listeners. However, since we assume that listeners are more likely to encode negative information than positive information, here we predict that listeners will be able to recall negative information from a primarily negative story to almost the same degree as readers (see Figure 1). As a result, if readers indeed form more strongly negative impressions of a primarily negative story than listeners do, we expect this difference in intensity to be smaller than for the primarily positive story.
Extensions
The model described in Equation 1 is a relatively simple one that assumes that the probability that each element in a story will be recalled is a function only of its valence. While this assumption has grounding in prior work (e.g., Hamann 2001), other factors could influence recall probability, such as the presence of surprising details, or the serial position of positive and negative information (e.g., primacy or recency; Anderson 1973; Fredrickson and Kahneman 1993). In the Web Appendix we generalize the framework to consider such factors, noting that our key predictions across different types of stories still hold, though with varying magnitudes. Additionally, in Study 4 we test for serial-position effects directly.
Empirical Overview
We test our predictions across six main experiments as well as three supplemental experiments. In Study 1 we test for the proposed mechanism by examining whether, when consumers listen to (vs. read) a mixed-valence news story, they indeed find negative (vs. positive) information to be more arousing than do readers, suggestive of more selective encoding of its negative (vs. positive) elements. In Studies 2a–2c we seek convergent evidence for this mechanism as well as its proposed downstream effects on the impressions that listeners (vs. readers) form of news stories with different mixtures of valence (i.e., primarily positive, primarily negative, or mixed-valence news). These results include process-by-mediation evidence for the theorized mechanism (Study 2c). In Study 3 we further investigate the proposed mechanism through a process-by-moderation experiment wherein readers’ control over the rate of incoming information is restricted in a manner akin to that experienced by listeners. Finally, in Study 4 we test for a boundary condition for the effects: namely, that when the positive elements in a mixed-valence story are more surprising than the negative, listeners (vs. readers) will form impressions of the story that are more positively biased. In three supplemental experiments, reported in the “General Discussion” section, we further test for the robustness of the findings to an incentive-compatible task, as well as to more naturalistic listening tasks, such as listening to news while driving, and listening with the option to control audio playback (e.g., podcast) versus without it (e.g., radio).
All of the studies were approved by the Institutional Review Board of the University of Pennsylvania under Category 2 exemption. All study materials, recordings, data, and code are available at https://osf.io/fktyu/.
Study 1: Differences in Perceived Arousal Between Listeners and Readers
The purpose of Study 1 was to test the central thesis that listeners (vs. readers) attend to information more selectively when consuming a news story. To do this, we recruited 798 participants from the Prolific Academic panel and randomly assigned them to either read or listen to a mixed-valence fictionalized news story describing research on the risks and benefits of lauryl sulfate, an ingredient used in many shampoo products (see the Web Appendix for the survey instrument). For example, the story reported that half of the trial participants experienced benefits (e.g., increased collagen counts) from long-term exposure, while a smaller percentage experienced negative side effects (e.g., rashes). Because the audial properties of a voice can potentially affect how emotionally arousing it is (e.g., Bachorowski and Owren 1995), we randomly assigned participants in the listening condition to hear one of three different narrations of the text: a male human voice, a realistic male AI voice emulator developed by Murf AI, or a more robotic AI voice produced by the emulator Balabolka. 2 The experiment thus utilized a hierarchical design with modality (read vs. listen) as the first-level factor and listen-voice (human vs. realistic AI vs. robotic AI) as the second-level factor, resulting in four conditions.
Our theory assumes that impression formation is determined by the probability that different story elements will be recalled from memory, which strongly relates to how emotionally arousing each element was at the time it was encoded into memory (e.g., Hamann 2001). Thus, a key feature of the study design was that, rather than consuming the story all at once, participants were presented with each of the 22 sentences of the story one at a time, and after reading or listening to each sentence they were asked to rate how emotionally arousing it was. Such sentence-level ratings of arousal provided natural proxy measures for the probability that each sentence would be recalled when forming an impression of a story (pim in our formal representation).
To measure how emotionally arousing each of the 22 sentences were, participants were asked to rate each sentence on a seven-point scale (1 = “not at all arousing/attention-grabbing,” and 7 = “very arousing/attention-grabbing”). In the Web Appendix we report evidence for the convergent and construct validity of this scale, which draws on past work showing that arousal and attentiveness are closely related (e.g., Arfé, Delatorre, and Mason 2023; Kohout, Kruikemeier, and Bakker 2023; Mather 2007). If as we predict readers encode stories more comprehensively than listeners do, then they should find the sentences to be more arousing on average, compared with listeners.
Finally, we sought to test the prediction that readers (vs. listeners) not only find the sentences to be more arousing overall, but that this difference is particularly acute for positive (vs. negative) sentences (Figure 1). To do this, we collected measures of the valence of each sentence by recruiting a separate sample of 402 Prolific Academic judges and randomly assigning them to the same sentence-by-sentence reading or listening task as in the main study. Here, however, we asked them to rate the valence of each sentence on a seven-point scale (1 = “extremely negative/pessimistic,” and 7 = “extremely positive/optimistic”) after it was read or heard, with the midpoint (4) being defined as “neutral; neither negative nor positive.” In the listening condition, sentences were narrated by the realistic AI voice from the main task.
Results
First, within the listening conditions, there was no significant difference in the average arousal reported across the different voices, which confirmed that listeners’ arousal judgments were not affected by the particular voice they were exposed to (listening conditions: F(2, 590) = 2.75, p = .065, η2 = .009). Second—consistent with the idea that readers process content more comprehensively than do listeners—readers reported finding the sentences to be more arousing on average than did listeners (read vs. pooled listen across sentences: Mread = 4.20 vs. Mlisten = 3.85; F(1, 796) = 18.69, p < .001, η2 = .042; see Figure 2).
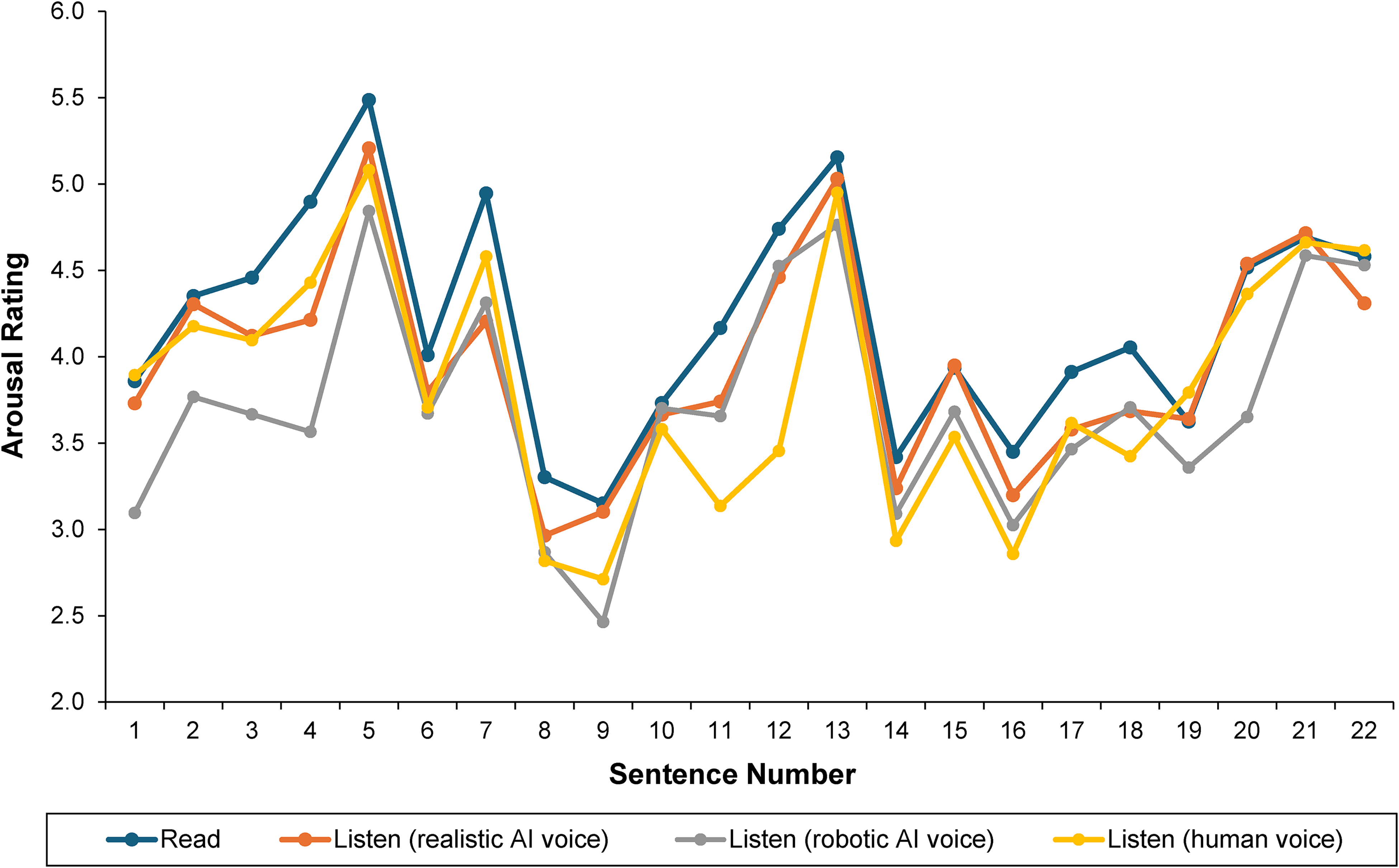
Judged Arousal of Each Sentence in the Story as a Function of Modality, Study 1.
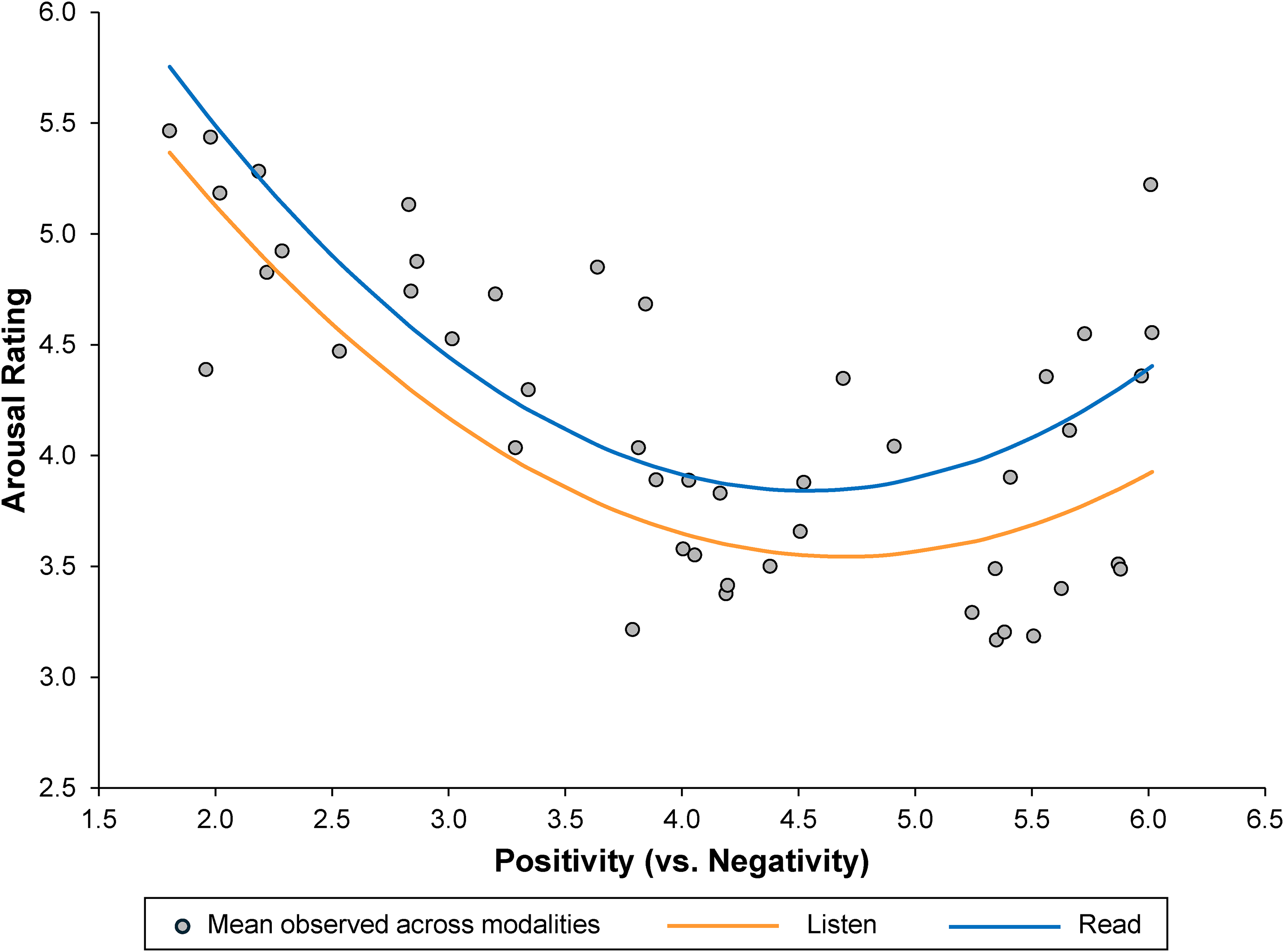
More importantly, to test our key prediction that listeners more selectively attend to negative (vs. positive) information than readers do, we analyzed the relationship between ratings of arousal and valence across sentences. Specifically, we modeled the sentences’ arousal ratings from readers and listeners as a quadratic function of their rated negativity versus positivity (from the independent sample of readers and listeners). 3 The results, which are plotted in Figure 3, yield two key insights. First, we find support for the theorized U-shaped relationship between valence and arousal (Figure 1): Across modalities, participants reported heightened arousal not just in response to highly negative information but highly positive as well. However, increases in arousal in response to greater negativity were larger than that observed for greater positivity (βlinear = −2.23, t = −19.51, p < .001; βquadratic = .25, t = 17.89, p < .001), which, as expected, points to a negativity bias for both readers and listeners.
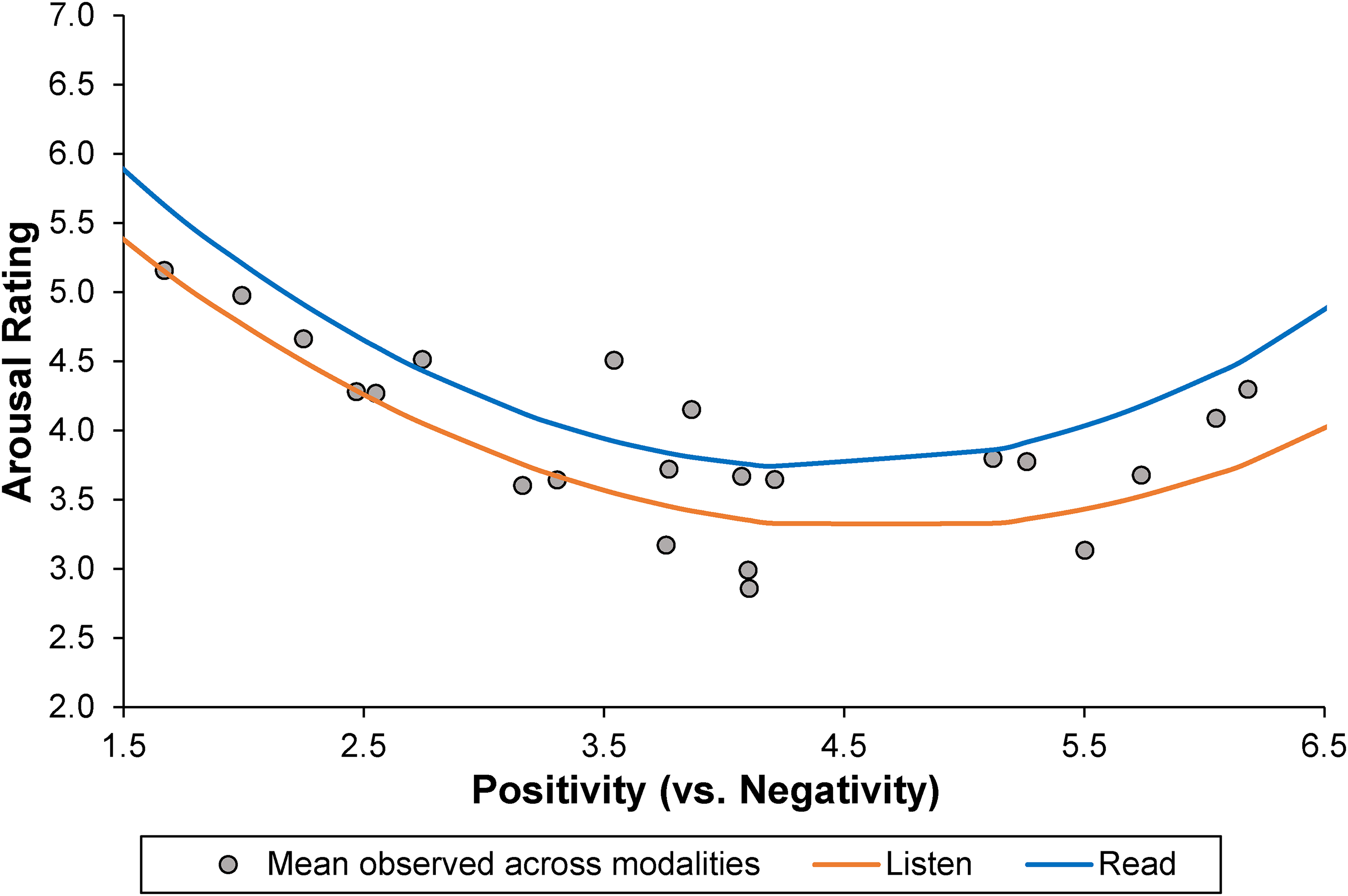
Quadratic Relationship Between Arousal Ratings (y-Axis) and Positivity (vs. Negativity) Ratings (x-Axis) Across Modalities, Study 1.
Second, and more importantly, we find evidence that this U-shaped relationship differed between readers and listeners. The results of a regression analysis reveal a significant interaction between modality and both the linear and quadratic trends that explain the relationship between valence and arousal (linear: βmode × valence = .29, t = 2.24, p = .025; quadratic: βmode × valence = −.04, t = −2.53, p = .012). Critically, as predicted, these interactions showed that whereas both readers and listeners experienced similar rates of increase in arousal when exposed to sentences that were increasingly negative in tone (less than four on the seven-point valence scale), listeners experienced less of an increase in arousal in response to sentences that were increasingly positive in tone (greater than four on the valence scale) compared with readers.
Discussion
Study 1 provided initial evidence that readers and listeners differ in how selectively they process negative (vs. positive) information. As predicted, participants assigned to listen to (vs. read) a mixed-valence news story not only were less attentive to the sentences overall, but paid more attention to those that were more negative (vs. positive). In contrast, those assigned to read showed greater attention overall, and more equitably attended to the negative and positive sentences. In Studies 2a–2c we test for convergent evidence for these processing differences, as well as for their proposed downstream effects on readers’ and listeners’ overall impressions of stories.
Studies 2a–2c
The purpose of Studies 2a–2c was twofold. The first was to test the thesis that listeners (vs. readers) form impressions of news that vary systematically depending on the distribution of valence in a story. Second, building on the findings of Study 1, we also sought to test for the proposed theoretical process: namely, that differences in readers’ and listeners’ impressions of a news story are driven by differential attention to its negative and positive information. To address the first aim, in Study 2a participants were randomly assigned to either listen to or read one of three variations of a story presented in full (rather than sentence by sentence). The variations included the same mixed-valence story from Study 1, a version that focused primarily on the positive information from the story, and a version that focused primarily on the negative information. This design enabled us to test our predictions that listeners (vs. readers) would form more negative interpretations of a mixed-valence story, less positive interpretations of an all-positive story, and slightly less negative interpretations of an all-negative story.
To address the second aim, we conducted three sets of analyses to test for the proposed mechanism: one leveraging data from Study 2a, and the others using data from two new experiments (Studies 2b and 2c). In Study 2a we asked readers and listeners a series of questions that measured the overall depth of attention they paid to the positive, negative, or mixed-valence story they consumed. In Study 2b we implemented the same sentence-level design as in Study 1 to test how arousing/attention-grabbing readers and listeners found each sentence of the positive and negative stories to be (rather than the mixed-valence story utilized in Study 1). Finally, in Study 2c we provide more direct evidence for the proposed mechanism through a process-by-mediation analysis, which tested the degree to which the different impressions of a story formed by readers versus listeners were indeed driven by differences in arousal responses to the story's positive versus negative sentences.
Study 2a: Does Listening to (vs. Reading) News Lead to Different Behavioral Intentions?
Overview
Study 2a was a preregistered 4 experiment that utilized a 2 (modality: listen vs. read) × 3 (valence: mixed vs. positive vs. negative) between-subjects design. Participants were 2,400 North American, English-speaking members of the Prolific Academic panel (52% male, 45% female, 3% nonbinary; Mage = 38.4 years) who were randomly assigned to either read or listen to one of three different versions of the news article from Study 1, this time in full (rather than sentence by sentence) (see the Web Appendix for the survey instrument). 5 All three stories described the findings of a university research study on lauryl sulfate, but in two of the articles the text was modified so that its message emphasized either just the benefits of the ingredient (positive frame) or just the risks (negative frame). The third article was the same as that in Study 1, containing a mix of positive and negative information. In the listening conditions, the story was read aloud by the realistic male AI voice emulator used in Study 1. To simulate a podcast, participants in the listening condition had the option to stop, pause, and relisten to the audio (see the Web Appendix).
After reading or listening to their assigned story, participants were asked a series of questions that captured our focal dependent variable: whether listeners and readers formed different behavioral intentions toward products with lauryl sulfate across stories. Specifically, participants were asked to rate the following statements on a seven-point scale (1 = “very unlikely,” and 7 = “very likely”): “Based on the story, how likely would you be to use a shampoo that contained lauryl sulfate?”; “How likely would you be to recommend a shampoo that contained lauryl sulfate to a friend or family member?”; and “Based on the research, how likely would you be to use other products (e.g., soaps, lotions) that use lauryl sulfate?” Responses to these items were averaged into a “behavioral intention” index (α = .96 across stories).
Finally, participants were asked a battery of questions capturing the overall depth of attention they paid to their assigned story. Specifically, participants indicated (on a seven-point scale) the extent to which they agreed with seven statements such as “I paid close attention to all parts of the story,” “I felt very immersed/engaged in the story,” and “If asked, I could accurately retell the story from memory to someone else” (see the Web Appendix). Responses to these items were averaged into an “overall attention” index (α = .84 across stories). These questions were designed to capture how the emotional arousal triggered by individual positive and negative sentences (Study 1) might manifest in the overall depth of attention they paid to each type of story (positive, negative, and mixed valence).
Results
Per the preregistered exclusion criteria, 104 participants in the listening condition were removed for having terminated the story before hearing it in its entirety, leaving a sample of 2,296 participants. We also observed that some participants in the reading condition spent less than 30 seconds on the reading task, implying a reading speed greater than 1,300 words per minute—well above the upper limit of human word comprehension abilities of 300 words per minute (Primativo et al. 2016). 6 Given that we did not preregister an exclusion criterion for participants in the reading condition who might have only superficially skimmed the article, we undertook two analyses: one that included all participants from the reading condition, and one that excluded readers whose time on the page implied a reading speed of twice or more the average reading speed of 238 words per minute for adults found by Brysbaert (2019). Because the results were generally robust to these exclusions, for brevity we report the analyses comparing listeners to the attentive readers, which is the comparison that is most relevant for our theorizing. In the Web Appendix we report the full statistical results for Study 2a with and without these exclusions.
Behavioral intentions
We first tested our focal predictions that listeners versus readers will draw different interpretations from the articles depending on their valence, as reflected by participants’ behavioral intentions to use and recommend lauryl sulfate to others. A check of the valence manipulation supported a main effect of story valence on behavioral intentions (F(2, 1,945) = 1,163.55, p < .001, η2 = .550), such that participants reported greater behavioral intentions toward the ingredient after consuming the positive story versus the mixed-valence one, and greater intentions to use the ingredient after consuming the mixed-valence story versus the negative one (Mpos = 5.15 vs. Mneg = 1.53 vs. Mmixed = 3.03; positive vs. negative: F(1, 1,945) = 2,312.74, p < .001, η2 = .537; positive vs. mixed: F(1, 1,945) = 795.99, p < .001, η2 = .185; negative vs. mixed: F(1, 1,945) = 419.34, p < .001, η2 = .098). We also observed a main effect of modality across stories, with readers having greater behavioral intentions toward the ingredient overall compared with listeners (Mread = 3.27 vs. Mlisten = 3.14; F(1, 1,945) = 8.69, p < .001, η2 = .002).
More importantly, the results confirmed a significant modality × story valence interaction on participants’ behavioral intentions (F(2, 1,945) = 6.82, p < .001, η2 = .003; see the Web Appendix). After consuming the mixed-valence article that described both the risks and benefits of lauryl sulfate, listeners reported lower behavioral intentions toward products containing the ingredient (Mread = 3.24 vs. Mlisten = 2.84; F(1, 1,945) = 15.32, p < .001, η2 = .004). Likewise, when the story focused primarily on its benefits (positive frame), we found that although participants in both conditions held positive views of the ingredient, those who read the article reported greater intentions toward products with lauryl sulfate than did those who listened (Mread = 5.30 vs. Mlisten = 5.04; F(1, 1,945) = 5.64, p = .012, η2 = .001). Finally, consistent with our prediction, when the story focused primarily on risks (negative frame), readers expressed only slightly lower behavioral intentions toward lauryl sulfate than did listeners (Mread = 1.46 vs. Mlisten = 1.58), with this difference not approaching statistical significance (F(1, 1,945) = 1.39, p = .238, η2 = .000).
Overall attention
Consistent with the findings of Study 1 as well as past work on the negativity bias (e.g., Baumeister et al. 2001), we observed a main effect of story valence on overall attention (F(2, 1,945) = 6.31, p = .002, η2 = 006; see the Web Appendix), with participants reporting that they paid closer attention to the negative story than to the positive on average (Mneg = 5.80 vs. Mpos = 5.63; F(1, 1,945) = 10.21, p < .001, η2 = .005; see the Web Appendix for all pairwise comparisons). Overall attention paid to the mixed-valence article was roughly between that for the positive and negative stories: Participants reported attending more to the negative story than to the mixed one (Mmixed = 5.67 vs. Mneg = 5.80; F(1, 1,945) = 8.56, p = .004, η2 = .004) but paying similar attention to the positive and mixed stories (Mmixed = 5.67 vs. Mpos = 5.63; F(1, 1,945) = .11, p = .737, η2 = .000).
More importantly, consistent with the thesis that readers (vs. listeners) attend to stories more comprehensively, readers reported paying greater attention to the stories on average than listeners did (Mread = 5.88 vs. Mlisten = 5.56; F(1, 1,945) = 58.32, p < .001, η2 = .029). We also observed a greater negativity bias in what listeners did attend to. Although the overall interaction between modality and story valence did not reach statistical significance (F(2, 1,945) = 2.09, p = .124, η2 = .0021), a post hoc comparison of the negative and positive articles confirmed that whereas listeners paid more attention to the negative story than to the positive one (Mneg|listen = 5.67 vs. Mpos|listen = 5.44; F(1, 1,945) = 11.31, p < .001, η2 = .006), readers paid similar degrees of attention to both (Mneg|read = 5.97 vs. Mpos|read = 5.87; F(1, 1,945) = 1.67, p = .197, η2 = .000). Taken together, these results provide a conceptual replication of Study 1, suggesting that listeners (vs. readers) indeed process news content more superficially and attend to negative (vs. positive) content more discriminatively.
Study 2b: Sentence-Level Arousal Ratings Across Story Types
Overview
A limitation of Study 2a is that by measuring participants’ overall level of attention for each story type, we could not derive insights into how readers versus listeners processed the individual elements of each story—something that the sentence-level design of Study 1 enabled us to explore with the mixed-valence news story. In Study 2b we therefore recruited an independent sample of 791 participants from Prolific and randomly assigned them to either read or listen to 7 the primarily positive or primarily negative stories from Study 2a (see the Web Appendix), with each story being presented one sentence at a time using the same method as in Study 1. After reading or hearing each sentence, participants rated how arousing it was (on the same seven-point scale as in Study 1). Finally, as in Study 1, we recruited an additional sample of 400 Prolific participants who were randomly assigned to rate each sentence of either the positive or negative story (on the same negativity-to-positivity scale used in Study 1).
Results
We first tested for the hypothesized U-shaped relationship between arousal and valence. To do this, we pooled the sentence-level ratings of arousal as well as the sentence-level ratings of valence across the negative and positive stories, and then fit the same quadratic function as in Study 1. Due to a programming error in the arousal ratings study, the 20th sentence in the positive story differed between the reading and listening conditions; 8 thus, we conducted two sets of analyses: one excluding the arousal ratings of this one sentence, and one including them. We report the analysis of the fully matched data in this section, and we report the results of the latter analysis—which yields similar results—in the Web Appendix.
As shown in Figure 4, this analysis yielded the same curvilinear relationship observed for the mixed-valence story in Study 1 (Figure 3), but here the ratings of the negative sentences came from the negative story and the ratings of the positive sentences came from the positive story. 9 Thus, as in Study 1, story elements that were more strongly negative or more strongly positive were perceived as more arousing by both listeners and readers. Next, conceptually replicating Study 1, we observed a main effect of modality on arousal (Mread = 4.36 vs. Mlisten = 4.10; F(1, 789) = 10.67, p = .001, η2 = .013), suggesting that readers found the sentences to be more arousing on average than listeners did. More importantly, the results revealed significant interactions between modality and the linear and quadratic trends in valence (linear: βmode × valence = .319, t = 2.72, p = .007; quadratic: βmode × valence = −.037, t = −2.68, p = .008)—confirming that whereas readers and listeners were both more aroused by increasingly negative sentences, listeners were relatively less aroused by increasingly positive sentences than readers were. (The Web Appendix contains a more complete reporting of this sentence-by-sentence analysis, including plots of raw sentence-by-sentence changes in arousal for the positive and negative stories.)
Quadratic Relationship Between Arousal Ratings (y-Axis) and Positivity (vs. Negativity) Ratings (x-Axis) for Readers and Listeners, Collapsed Across the Positive and Negative Stories, Study 2b.
Study 2c: Process-by-Mediation Evidence
Overview
The aim of Study 2c was to provide more direct evidence for the proposed mechanism: namely, that readers and listeners draw different impressions of news because they experience different levels of emotional arousal in response to its positive versus negative elements. To test this, we conducted a preregistered (https://osf.io/vjequ) experiment in which 1,507 participants from the Prolific Academic panel were recruited to complete the same sentence-by-sentence task as in Study 1, with the listening condition using same male human voice as in Study 1. As in Study 1, participants rated how arousing they found each sentence of the mixed-valence story to be on the same scale (1 = “not at all arousing/attention-grabbing,” and 7 = “very arousing/attention-grabbing”; see the Study 1 instrument in the Web Appendix). 10 Here, however, there was an important addition: After they completed the sentence-level rating task, participants were asked to respond to the same behavioral intention questions used in Study 2a. 11 Our goal was to test the predictions that (1) listeners (vs. readers) would form more negative impressions of the safety of lauryl sulfate and thus report lower behavioral intentions; (2) the difference in the average degree of arousal triggered by negative sentences compared with positive sentences would be larger among listeners than among readers—which is consistent with the thesis that listeners (vs. readers) show more selective attention to more emotionally arousing content; and, importantly, (3) this difference would statistically mediate the effect of listening versus reading and participants’ behavioral intentions.
To analyze the second of these three predictions, in our preregistration we operationalized differential arousal as the arithmetic difference in the average arousal ratings for the four most negative sentences in the story minus the three most positive (based on the valence ratings collected in Study 1). To ensure the robustness of this analysis, we also computed the difference in participants’ arousal ratings for all the negative and positive sentences in the story: namely, the six sentences that were rated as negative and six that were rated as positive (based on the valence ratings from Study 1). 12 For both measures, we predicted that the mean difference in arousal ratings (for negative versus positive sentences) would be positive for both readers and listeners—that is, both would exhibit a negativity bias—but, critically, this negativity bias would be larger for listeners.
Results
As in Study 2a, we observed a significant main effect of modality on behavioral intentions, with readers of the mixed-valence story having more positive impressions of the safety of lauryl sulfate compared with listeners (Mread = 3.66 vs. Mlisten = 3.38; F(1, 1,505) = 19.75, p < .001, η2 = .013). Conceptually replicating Studies 1 and 2b, we also found that listeners (vs. readers) were more differentially aroused by the negative (vs. positive) elements of the story. Specifically, across both measures, the difference in listeners’ average arousal ratings in response to negative versus positive sentences—that is, the size of their negativity bias—was larger than that observed for readers (most negative minus most positive: Mread = .18 vs. Mlisten = .76; F(1, 1,505) = 76.16, p < .001, η2 = .048; all negative minus all positive: Mread = .09 vs. Mlisten = .65; F(1, 1,505) = 112.18, p < .001, η2 = .070).
Finally, we ran a mediation analysis using the SAS procedure CAUSALMED (SAS Institute 2017). As shown in Figure 5, the results confirmed that the effect of listening (vs. reading) on decreased behavioral intentions was statistically mediated by listeners’ greater emotional arousal in response to negative (vs. positive) sentences in the story. This was supported by a significant indirect effect of modality on behavioral intentions through differential arousal, based on both measures (bootstrap bias-corrected 95% confidence intervals with 5,000 bootstrap samples—most negative minus most positive: [−.113, −.017]; all negative minus all positive: [−.113, −.021]).

Mediation Analysis Results, Study 2c.
Discussion of Studies 2a–2c
The results of Study 2c provide a conceptual replication of Study 2a, showing that readers and listeners formed systematically different impressions of news stories that varied depending on the valence of the story. The findings also offer convergent evidence for the proposed mechanism underlying these differences in interpretations: Consistent with Studies 1–2b, listeners (vs. readers) were more aroused by negative (vs. positive) elements in a news story, whereas readers had more similar arousal responses to both types of information—that is, they encoded and recalled the elements of the story more comprehensively.
Critically, our theory argues that a major driver of why listeners engage in more selective processing is that they face greater cognitive load. Specifically, whereas readers can easily regulate the pace at which they process the words in a story, listeners cannot exert the same level of control during processing, which leads them to selectively encode more emotionally arousing details that ultimately inform their impressions. If this theoretical account holds, it follows that readers’ impressions of stories should more closely resemble those of listeners when their control over the flow of information is analogously restricted. We test this idea in Study 3.
Study 3: Reducing Control over Information Flow During Reading
The purpose of Study 3 was to examine whether, like listeners, readers would more selectively process the more emotionally arousing parts of a story when their control over information flow was constrained—thus making their impressions more similar to those formed by listeners. We tested this through a process-by-moderation study wherein participants consumed the same mixed-valence story about the risks and benefits of a shampoo ingredient as in the prior studies. Here, however, they were randomly assigned to one of three conditions: the same reading or listening condition as in Study 2a, or a new reading condition in which the words of the story were presented akin to a scrolling marquee across the screen. This new condition (restricted reading) enabled us to simulate the reduced regulatory control that listeners experience when consuming a story.
After they consumed the story, we asked participants to report their beliefs about the ingredient's safety, as well as to recall the positive and negative details from the story. Participants were also asked to write a summary of the story as if they were retelling it to a friend. If, as we theorize, consumers more selectively attend to more emotionally arousing information when their regulatory control over information flow is restricted, then they should show better recall for the negative risks (vs. positive benefits) of the ingredient and be more likely to emphasize its risks in their retellings. That is, we predicted that participants in both the listening and restricted-reading conditions would exhibit greater negativity biases across these measures than those who were able to read naturally.
Method
We recruited 1,804 members of the Prolific Academic panel to participate in a single-factor between-subjects design. 13 They were randomly assigned to one of three conditions: listening, reading control, or restricted reading (see the Web Appendix for the survey instrument). The listening and reading-control conditions were similar to conditions described in the prior studies. In contrast, in the restricted-reading condition we employed a rapid serial visual presentation paradigm (e.g., Benedetto et al. 2015) in which the words of the article appeared as a scrolling marquee (akin to a stream of subtitles) that moved across the screen at a rate of 200 words per minute (see Figure 6). This rate was chosen to be slightly slower than the 238 words per minute average reading speed among adults, as reported by Brysbaert (2019). A video of the scrolling task can be viewed in the supplemental materials posted on OSF (https://osf.io/fktyu/). As in Study 2a, participants in the listening condition could control playback of the audio (simulating a podcast) and, to achieve comparability, those in the restricted-reading condition could control the playback of the scroll.

Screenshot of the Scrolling Text in the Reading-Restricted Condition, Study 3.
After consuming the story, participants were asked to write a summary of it as if they were retelling it to a friend. Next, to capture participants’ interpretations of the story, here we asked them to indicate their beliefs about the safety of lauryl sulfate along three items on a seven-point scale (1 = “very unlikely,” and 7 = “very likely”): “If you were to use a shampoo that contained lauryl sulfate, how likely do you think you would be to experience bad side effects?”; “Based on the story, how likely would you be to use a shampoo that contained lauryl sulfate?”; and “How likely would you be to recommend a shampoo that contained lauryl sulfate to a friend or family member?” These were combined to form an overall measure of the perceived safety of lauryl sulfate (α = .82), which enabled us to test for the degree of negativity bias in participants’ beliefs about the ingredient. Finally, participants responded to a cued-recall task (e.g., Furnham and Gunter 1989) that asked them to indicate whether it was true or false that each of ten details was included in the story, five describing negative information on the risks of the ingredient (e.g., some trial participants experienced hair loss) and five describing positive information about its benefits (e.g., some experienced increased collagen counts). This enabled us to test for differences in the selectivity of participants’ recall for the story's negative versus positive details.
Once the data collection was complete, we calculated the degree of negativity bias in participants’ retellings of the story. To do this, we measured the degree to which participants referenced negative versus positive information in their retellings by undertaking three approaches to content analysis, one that is reported in the main text, with the other two described in the Web Appendix. The first approach, reported subsequently, relied on two lexica that were generated based on the words participants used in their retellings to refer to the risks versus benefits of lauryl sulfate (see the Web Appendix for description of how these lexica were generated). This enabled us to calculate the difference between the proportion of risk-related and benefit-related words in the summaries. As described in the Web Appendix, we provide convergent evidence for these findings using two additional approaches to measuring degrees of negativity bias in retellings: one employed a widely used dictionary-based text analysis tool called LIWC-22 (Boyd et al. 2022) to capture relative negativity along three measures (LIWC's “tone”; “negemo”–“posemo”; and “risk”–“reward”), and the other used external human judgments of the emphasis placed on risks (vs. benefits) in the retellings.
Results
Negativity bias in beliefs
From the original pool of participants, 73 in the listening condition and 28 in the restricted-reading condition terminated the task before the story was consumed in full and were thus removed from analysis. In the reading-control condition, as in Study 2a, we excluded 88 participants who had times on the page that implied reading speeds twice the average for adults (476 words per minute or more) and above the minimum required for word comprehension (300 words per minute; Primativo et al. 2016). Thus, as in Study 2a, for brevity we report the analyses comparing listeners to attentive readers, and we report the full statistical results for Study 3 with and without these exclusions in the Web Appendix.
Conceptually replicating the prior findings, participants assigned to listen to the story formed more negative beliefs about the safety of the ingredient compared with those who read it at their own pace (Mread-control = 3.93 vs. Mlisten = 3.52; F(1, 1,612) = 24.28, p < .001, η2 = .015; see the Web Appendix). More importantly, similar to listeners, readers whose control over the flow of information was restricted were more pessimistic about the ingredient's safety than readers who read freely (Mread-control = 3.93 vs. Mrestricted-read = 3.66; F(1, 1,608) = 11.77, p < .001, η2 = .001). Finally, as expected, there was no statistical difference between listeners and restricted readers in their appraisals of safety (Mlisten = 3.52 vs. Mrestricted-read = 3.66; F(1, 1,608) = 2.63, p = .105, η2 = .000).
Negativity bias in retellings
We next tested the predictions that when listeners retell the story, they are more likely to emphasize the risks (vs. benefits) of the shampoo ingredient compared with those who read naturally, and that restricting readers’ abilities to regulate the flow of processing would make their retellings more closely resemble those of listeners. First, an omnibus ANOVA supported a significant overall effect of modality on the use of risk-related versus benefit-related words in participants’ retellings (F(2, 1,608) = 8.01, p < .001, η2 = 010; see the Web Appendix). Follow-up contrasts confirmed that, as predicted, those who listened were more likely to mention lauryl sulfate's risks (vs. benefits) in their retellings than those who read naturally (Mread-control = .31% vs. Mlisten = 1.19%; F(1, 1,608) = 15.94, p < .001, η2 = .010). Importantly, those who were constrained to read by following text that scrolled across the screen were also more likely to refer to the ingredient's risks (vs. benefits) than those who read naturally (Mread-control = .31% vs. Mrestricted-read = .81%; F(1, 1,608) = 5.33, p = .021, η2 = .003). These results, combined with those reported for the LIWC-based and human-based judgments of negativity (vs. positivity) in retellings (reported in the Web Appendix), reinforce the conclusion that reducing regulatory control leads to more negatively slanted interpretations of the story, here manifested in how it is retold.
Selective recall of negative Information
As a final analysis, we explored whether the observed differences in participants’ beliefs and retellings were mirrored in their processing selectivity—here, measured through their recall accuracy for the negative versus positive details from the story. First, consistent with work that has found higher recall accuracy for readers than listeners (e.g., Furnham and Gunter 1989), readers answered a higher percentage of the true-false questions correctly in the cued-recall task than did listeners (Mread-control = 68% vs. Mlisten = 62%; F(1, 1,608) = 38.66, p < .001, η2 = .020). In contrast, readers and restricted readers showed similar overall recall accuracy (Mread-control = 68% vs. Mrestricted-read = 67%; F(1, 1,608) = .41, p = .520, η2 = .000; see the Web Appendix).
More insightful, however, are comparisons in what was recalled across modalities. Compared with those who read freely, listeners more accurately recalled the story's negative elements relative to its positive ones (percentage of negative vs. positive details recalled accurately: Mread-control = −.097% vs. Mlisten = .209%; F(1, 1,608) = 41.28, p < .001, η2 = .024; see the Web Appendix). More importantly, participants whose regulatory control was restricted also showed better recall for negative over positive details relative to those who read freely (Mrestricted-read = .059%; F(1, 1,608) = 11.31, p = .001, η2 = .007). 14 Thus, similar to listeners, readers who consumed the story by following a scrolling marquee on the screen seemed to more deeply attend to negative details over positive ones compared with those who read freely.
Discussion
The results of Study 3 conceptually replicate Studies 2a and 2c, showing that when participants are exposed to a news story that reports a mixture of positive and negative information, listeners draw more negatively slanted interpretations than readers do. These differences in interpretation manifested both in the manner in which listeners retold the story to others and in their reported beliefs about the ingredient. More importantly, Study 3 also offers process-by-moderation evidence that when readers’ regulatory control over the flow of information is restricted, they show negativity biases similar to those observed among listeners, both in the information they attend to and the interpretations they form of the story. First, akin to listeners, readers whose regulatory control was restricted tended to recall negative (vs. positive) details more accurately compared with those who read freely, suggesting that restricted readers attended to the story's negative (vs. positive) details more selectively. Second, like listeners, readers with reduced regulatory control formed interpretations that were more pessimistic than those who read naturally.
Study 4: When Do Listeners (vs. Readers) Display a Positivity Bias?
A robust finding across Studies 2a, 2c, and 3 is that when consuming mixed-valence news, listeners (vs. readers) often show greater negativity biases in the impressions they form. We theorize that this occurs because the greater cognitive load faced by listeners leads them to discriminatively process the subset of more emotionally arousing information—which is often that which is more negative (e.g., Soroka, Fournier, and Nir 2019). Consistent with this, in Study 2a we found that when listeners consume a story containing mostly positive or mostly negative details, they walk away with relatively less positive or less negative impressions, respectively, compared with readers who encode more of the story's details.
One question that has remained unexplored to this point is as follows: In what contexts might listeners exhibit positivity biases? Here, our theory makes a clear prediction: When consuming mixed-valence news, listeners will selectively attend to positive (vs. negative) information when such content is the more surprising or unexpected in the story, since unexpectedness is another documented trigger of arousal in semantic processing (e.g., Brondino et al. 2019; Ranganath and Rainer 2003). For example, if one reads or listens to a news story in which the negative information is familiar or expected (e.g., that smoking has negative side effects), while the positive information is more surprising (e.g., that smoking might be healthier than vaping), then listeners should display a more acute positivity bias in their encoding and recall of the story. We explore this potential boundary condition in the fourth experiment by randomly assigning participants to read or listen to a primarily negative, primarily positive, or mixed-valence news story (as in Study 2a), but here, the negative details in the mixed-valence story were less surprising/unexpected than the positive ones.
An ancillary aim of Study 4 was to explore whether the order or serial position in which information is presented might alter the observed effects. Past work found evidence of “recency effects” in impression formation, whereby overall impressions are often more heavily influenced by the information that is presented last (vs. earlier) in a text (e.g., Anderson 1973; Fredrickson and Kahneman 1993). Building on this, we were interested in whether consumers might differ in their susceptibility to recency effects when consuming news through reading versus listening.
Design and Method
We recruited 3,004 participants from Prolific Academic and randomly assigned them to either read or listen to one of four articles based on real news published in Science Daily in January 2023. 15 Each article summarized research findings on the same general topic—the effects of screen time on adolescent development—but, importantly, varied in whether the arousing, attention-grabbing details in the story were negative or positive. The negative article was a 399-word summary of an investigation (by Negata et al. 2023) that reported a correlation between excessive screen time and behavioral disorders (e.g., OCD). The positive article was a 401-word summary of a more optimistic study (by Sauce et al. 2022) that found a positive association between added screen time and IQ after controlling for potential correlates (e.g., socioeconomic factors). The mixed article was a 412-word summary that synthesized both sets of findings from the positive and negative articles (see the Web Appendix for stimulus materials). 16 We chose this context because it is one in which negative information might be less arousing than positive information: Whereas the risks of screen time have been widely discussed in recent years and may thus be more expected or familiar to participants, the idea that screen time might be beneficial to one's IQ is potentially more unexpected and, thus, more emotionally arousing.
In addition, to test whether the serial position of more arousing information would differentially affect readers and listeners, participants who were assigned to consume the mixed-news article were presented with one of two versions: one in which the findings of the negative study were reported last (with those from the positive study reported first), or another with the opposite order. 17 Thus, the design was a 2 (modality: read vs. listen) × 3 (story valence: negative vs. positive vs. mixed) between-subjects hierarchical design, with a third factor—serial position of positive or negative news—nested within the mixed-valence condition.
After reading or listening to their assigned article, participants rated their agreement with five items that measured their beliefs about the findings on the benefits (vs. risks) of screen time (see the Web Appendix for the survey instrument). For example, participants were asked to rate their agreement (1 = “strongly disagree,” and 7 = “strongly agree”) with statements such as “On balance, recent science seems to suggest that playing video games is mostly good for children” and “The research indicates that while playing video games has both risks and benefits for children, the risks are more worrisome” (reverse-coded). These five items were averaged into a “positivity of beliefs” index (α = .89). We predicted that, as in Study 2a, listeners would form less intensely negative interpretations of the negative story and less intensely positive interpretations of the positive story compared with readers, but that listeners would now form more intensely positive impressions of the mixed-valence story than readers.
Finally, akin to Study 2a, to capture the overall depth of attention paid to the stories, we asked participants to rate their agreement with a set of five statements such as “I felt very immersed/engaged in the story” and “If asked, I could accurately retell the story from memory to someone else” (1 = “strongly disagree,” and 7 = “strongly agree”). Responses to these items were averaged into an index of “overall attention” (α = .83). Similar to Study 2a, these items were designed to capture how the emotional arousal triggered by a positive, negative, and mixed-valence story might manifest in the overall depth of attention paid to each story. This measure therefore enabled us to confirm that the valence manipulation worked as intended: namely, that the negative story would be less emotionally arousing on average than the positive and mixed-valence stories.
Results
Manipulation check
First, to ensure that listeners were compared with readers who actually paid attention to the stories, following the method in Study 2a we conducted two analyses: one with no exclusions, and one excluding data from 19 listeners who terminated the task before its completion and 223 readers whose time on the page implied reading speeds more than twice the average adult reading speed and above the physical visual maximum for word comprehension (Brysbaert 2019). We report the results of the latter analysis here (N = 2,762) and report the analyses with no exclusions—which yielded similar results—in the Web Appendix.
We began by examining whether the valence manipulation affected depth of attention as intended. An ANOVA revealed a main effect of story valence on reported attention (F(2, 2,756) = 9.48, p < .001, η2 = .007), whereby the negative story about how screen time heightens OCD risk was indeed perceived to be the least attention-grabbing compared with both the positive story about how it can boost IQ (Mpos = 5.52 vs. Mneg = 5.34; F(1, 756) = 14.35, p < .001, η2 = .005) and the mixed story that mentions both benefits and risks (Mmixed = 5.53 vs. Mneg = 5.34; F(1, 2,756) = 14.07, p < .001, η2 = .005; see the Web Appendix). We did not observe a statistically significant difference in the depth of attention given to the positive and mixed stories, both of which contained the surprising positive information (F(1, 2,756) = .00, p = .963, η2 = .000). 18
Positivity of beliefs
We next tested our focal prediction that after consuming the mixed-valence story—about both the familiar risks of increased screen time and its surprising potential benefits—listeners would draw more positive interpretations about the impacts of screen time compared with readers. First, the results revealed main effects on the positivity of participants’ beliefs both by modality (F(1, 2,756) = 8.01, p = .005, η2 = .001) and by valence (F(1, 2,756) = 3,000.76, p < .001, η2 = .682), which were qualified by a modality-by-valence interaction (F(1, 2,756) = 7.08, p = .001, η2 = .002; see the Web Appendix). Specifically, after consuming the negative article about how excessive screen time is associated with deleterious behavioral outcomes—which was presumably more familiar or expected—readers expressed somewhat more pessimistic beliefs than did listeners of the same content, although this difference did not reach statistical significance (Mlisten = 2.69 vs. Mread = 2.59; F(1, 2,756) = 3.32, p = .068, η2 = .000). After consuming the surprising, positive news story that screen time could boost IQ, both readers and listeners held similarly optimistic beliefs about screen time (Mlisten = 5.75 vs. Mread = 5.82; F(1, 2,756) = 1.24, p = .265, η2 = .000). These results are conceptually consistent with those observed in Study 2a.
More important, however, were the results for the mixed-valence story. As predicted, after learning about both the potential risks and benefits of screen time, listeners believed that screen time was more beneficial than did readers of the same content (Mlisten = 4.07 vs. Mread = 3.83; F(1, 2,756) = 26.29, p < .001, η2 = .009). These results provide further support for our thesis that when forming their interpretations, listeners privilege the more emotionally arousing content in the story—here, the positive (vs. negative) information—to a greater extent than readers do.
Testing for serial position effects
Finally, among participants who consumed the mixed story, we found no evidence that the order in which positive and negative information was presented affected readers and listeners differently. Consistent with a recency effect, on average beliefs about screen time were more positive when its benefits were described at the end of the story compared with the beginning (Mpos_end = 4.03 vs. Mpos_beginning = 3.87; F(1, 917) = 5.64, p = .012, η2 = .006). More importantly, we observed no interaction between order and modality (F(1, 917) = .17, p = .684, η2 = .000), implying that the order in which positive and negative information was reported affected listeners and readers similarly.
Discussion
The results of Study 4 demonstrate a boundary condition of the previously observed effects and lend further support to our theory. Whereas Studies 2a, 2c, and 3 showed that listeners’ interpretations of mixed-valence news focus more on negative (vs. positive) information, as theorized we show that this effect reverses when the more arousing content in the story is positive rather than negative.
General Discussion
Radio broadcasts of news and entertainment have existed for more than a century, and today advances in streaming audio and text-to-speech technologies are greatly expanding consumer access to spoken-word audio content (e.g., Adgate 2019). In this work we explored a question that naturally follows from this trend: Might hearing (vs. reading) the same news story alter how it is interpreted? While it has been long been known that reading allows for better recall of the details of a narrative than does listening (e.g., Furnham and Gunter 1989), in this work we offer evidence of further differences between reading and listening: namely, that readers and listeners exhibit systematic differences in the types of information they retain from a story, which in turn alter their overall impressions of its content.
We tested our predictions across six main experiments. The results confirmed that listeners and readers form different impressions of the same news story depending on the distribution of valences in the story. For example, when consuming a mixed-valence news story about the risks and benefits of a shampoo ingredient, listeners (vs. readers) drew more negatively biased interpretations—as manifest in lowered behavioral intentions to use such products (Studies 2a, 2c), more pessimistic beliefs about the ingredient's safety (Study 3), and retellings of the story that emphasized the risks over its benefits (Study 3). Importantly, we also uncovered convergent evidence for the proposed mechanism underlying the effect. We theorized that listeners and readers form different impressions of news because listeners are less able to regulate the flow of incoming information, which leads them to selectively process the more (vs. less) arousing information in a story—which is often the negative (vs. positive) details (e.g., Soroka, Fournier, and Nir 2019). Consistent with this, we found that listeners exhibited more differential arousal in response to negative (vs. positive) sentences compared with readers (Studies 1, 2b, 2c) and showed better recall for the negative (vs. positive) details from a mixed-valence story (Study 3). We also found process-by-mediation evidence for the mechanism, showing that the impressions formed by listeners (vs. readers) were statistically mediated by their more selective processing of the story (Study 2c). In Study 3 we provide process-by-moderation evidence, showing that when readers’ ability to regulate incoming information is restricted—akin to that experienced while listening—their recollections of the story, as well as the impressions they formed, more closely resembled those of listeners (vs. those who read naturally). Finally, we uncovered a boundary condition for this effect: Consistent with our theory, when the positive (vs. negative) information in a mixed-valence story was more surprising—a common trigger of high arousal—this led listeners to exhibit more acute positivity biases than readers (Study 4).
Generalizability: Additional Empirical Findings
In addition to the six experiments described previously, our research program included six more studies reported in our OSF repository (https://osf.io/fktyu/) that tested the generalizability of the effects to other contexts and explored possible moderators. We highlight three such experiments here. One was a preregistered (https://osf.io/kxb7g) experiment showing that differences between reading and listening were sustained even in an incentive-compatible setting, where both listeners and readers were rewarded with monetary incentives for closely attending to the information in the task. In the study, 792 participants from the Prolific Academic panel were first randomly assigned to either listen to or read an illustrative list of 20 possible outcomes of gambles that involved potential gains and losses. Three losses were described in the example (−$2, −$3), offset by 17 gains ($.50, $1), yielding a cumulative payoff of $4. After consuming this illustrative list of 20 gambles, participants were asked to choose between either receiving a (certain) bonus payment of $1 or the sum of 20 payoffs that were described as being potentially similar to the ones they just read or heard (see the Web Appendix for the study instrument). We predicted that because listeners would be more prone to selectively attend to the three losses than to the 17 gains, compared with readers they would be more inclined to accept the $1 over the uncertain gamble (whose expected value was assumed to be $4). This was indeed what we observed: 34.1% of listeners accepted the risk-averse (certain) $1 payoff compared with only 24.0% of readers (χ2 = 9.80, p = .002).
We also sought to investigate the possible size of these effects in real-world news-consumption settings where listeners often face added cognitive load due to multitasking (e.g., driving while listening to news). Here we predicted that the added cognitive demands of simultaneously engaging in another activity would amplify listeners’ tendency to selectively process the story. To test this, we conducted an experiment in which 1,855 participants from Prolific Academic were recruited to consume the mixed-valence story about the shampoo ingredient (Studies 1, 2a, 2c, and 3), but here we randomly assigned them to one of four conditions: either reading or listening naturally (as in the prior studies), or listening under two types of distraction (see the Web Appendix for the study instrument). Specifically, in the two new conditions listening was undertaken while engaging in a simulated drive through Rome, Italy, and in one condition participants were instructed to equally attend to both the road and the podcast (divided listening), while in the other they were asked to primarily attend to the road scene (incidental listening).
The results confirmed that the more distracted participants were when listening, the more negative their interpretations of the mixed-valence story. For example, those who were instructed to attend to both the story and the driving scene reported being more pessimistic about the safety of the ingredient compared with those who were undistracted while listening (Mlisten_undistracted = 3.35 vs. Mlisten_divided = 3.03; F(1, 1,851) = 17.91, p < .001, η2 = .009), and those for whom listening was incidental to the video were more pessimistic than those whose attention was divided while listening (Mlisten_divided = 3.03 vs. Mlisten_incidental = 2.81; F(1, 1,851) = 7.79, p = .005, η2 = .004). These results are consistent with our thesis that the cognitive load that arises while listening leads to more selective processing of more emotionally arousing information in a story.
In a third additional experiment we explored the possible effect of another feature of real-world listening contexts: whether listeners have the ability to control the audio playback (see the Web Appendix for the study instrument). For this study, we recruited 996 Amazon Mechanical Turk participants and asked them to consume to the same mixed-valence story about the shampoo ingredient as used previously, but here they were randomly assigned to one of two listening conditions: one where participants had the ability to control the playback (akin to podcast, as in our other studies), or one where they did not (akin to radio). Afterward they were asked about their behavioral intentions toward shampoos with the ingredient (on the same seven-point scale as in Studies 2a and 2c), as well as whether they had used the pause/rewind feature available to them in the podcast condition. We found no significant difference in behavioral intentions toward the ingredient between these two groups of listeners (Mpodcast = 3.64 vs. Mradio = 3.55; F(1, 994) = 1.36, p = .243), which is unsurprising given that almost 88% of those in the podcast condition elected not to use the pause/rewind feature and instead listened to the audio uninterrupted (akin to radio).
Practical Implications
A key substantive implication of our work is that the mere decision of whether to consume the same news story by listening or reading can have material downstream effects on such things as beliefs about ingredient safety and intentions to use products. Such differences also arose in how listeners versus readers retold stories through word of mouth, a finding that is especially relevant in light of past research showing that negativity can be particularly contagious or influential (e.g., Heath 1996). Thus, these results imply that a negatively biased interpretation of a story formed by a listener may propagate further or more rapidly across a network than the interpretation of a reader of the same content (e.g., Melumad, Meyer, and Kim 2021). Hence, as a story is retold from one consumer to the next, what starts as a listener's retelling of a story that places slightly more emphasis on the risks (vs. benefits) of a vaccine might, over time, transform into a retelling that strictly focuses on its risks. If true, this would suggest that the rapid rise in popularity of streaming audio platforms might yield a nefarious outcome: The more consumers choose to listen to news information rather than read it, the more diminished and biased their collective knowledge might become.
What interventions might be undertaken to ameliorate such biases among listeners (vs. readers)? Our theory argued that one of the main reasons listeners’ (vs. readers’) interpretations of stories are less comprehensive is that they are less able to regulate the rate of incoming information, which increases cognitive load when processing information. Given this, one might expect that formats such as podcasts (vs. radio)—which give users more control over pausing and relistening to content—would help mitigate this effect. However, as reported, many consumers choose to not utilize these playback features, presumably because doing so seems more effortful than simply listening without interruption. This notion is consistent with past work on self-regulated learning, which finds that people typically only benefit from having control over information flow if the advantages of implementing it outweigh its perceived costs (e.g., Ariely 2000; Klayman 1988; Meyer 1987; Xu et al. 2023). Hence, a natural intervention might be the development of audio-playback formats that make the experience of pausing and relistening to audio easier or more frictionless—akin to the regulatory control that one naturally experiences when reading information. Additionally, content producers might consider creating different versions of articles for readers versus listeners to help equate the interpretations they form. For example, given that listeners may overweigh negative elements when they are more arousing, a possible remedy is for news creators to place greater vocal emphasis on positive elements to enhance their arousal in audio versions. We leave determining how such an emphasis might be achieved when designing audio recordings (e.g., by altering pitch or speed) to future researchers.
Limitations and Future Research
While our findings provide convergent evidence for the theorized effects, they should be interpreted with a number of caveats. First, since the observed effects are theorized to arise from differences in cognitive load, we would not expect differences in interpretations to arise for short narratives that are trivial to process. Hence, for example, while readers and listeners might walk away with different interpretations of a full-length news article about luxury cars, we would not expect to see differences in how they interpret its headline or title (e.g., “BMW Voted Car of the Year”).
Moreover, there are likely additional psychological differences that arise when listening versus reading than those studied here. For example, in our theorizing we conceptualized impression formation as a “bottom-up” process, where impressions are an accumulation of the valence of the information consumers find to be most arousing. Past work on reading comprehension, however, finds that understanding language often involves “top-down” processes wherein our prior expectations about what a story might contain drive what we attend to in the story (e.g., Bransford and Johnson 1972). For example, when a listener who is generally skeptical about vaccines hears a news story about the results of a vaccine trial, they may be even more prone to selectively attend to the details that are congruent with their views than a reader with the same negative priors—akin to the adage “we hear what we want to hear.” Thus, an area for future work could be to explore the degree to which the added cognitive load associated with listening (vs. reading) might moderate the effects of prior expectations on comprehension.
Finally, another interesting question for future research is whether different features of the modalities themselves might moderate the effects. For example, prior work has shown that variations in the appearance of text, such as whether it is viewed on paper or on a computer screen, can alter the memorability of ad content (e.g., Venkatraman et al. 2021). Though we did not find that varying the nature of the male voices altered the effects (Study 1), future work could explore whether other features of a human voice (e.g., gender, pitch) might alter how listeners interpret a given news story compared with readers (e.g., Lowe and Haws 2017; Wang et al. 2021).
Supplemental Material
sj-pdf-1-mrj-10.1177_00222437241280068 - Supplemental material for How Listening Versus Reading Alters Consumers’ Interpretations of News
Supplemental material, sj-pdf-1-mrj-10.1177_00222437241280068 for How Listening Versus Reading Alters Consumers’ Interpretations of News by Shiri Melumad and Robert J. Meyer in Journal of Marketing Research
Footnotes
Coeditor
Rebecca Hamilton
Associate Editor
Nailya Ordabayeva
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded with support from the Wharton Behavioral Lab and a grant from the Wharton Dean's office.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.