
Abstract
The success of customer relationship management programs ultimately depends on the firm's ability to identify and leverage differences across customers—a difficult task when firms attempt to manage new customers, for whom only the first purchase has been observed. The lack of repeated observations for these customers poses a structural challenge for firms to infer unobserved differences across them. This is what the authors call the “cold start” problem of customer relationship management, whereby companies have difficulties leveraging existing data when they attempt to make inferences about customers at the beginning of their relationship. The authors propose a solution to the cold start problem by developing a probabilistic machine learning modeling framework that leverages the information collected at the moment of acquisition. The main aspect of the model is that it flexibly captures latent dimensions that govern the behaviors observed at acquisition as well as future propensities to buy and to respond to marketing actions using deep exponential families. The model can be integrated with a variety of demand specifications and is flexible enough to capture a wide range of heterogeneity structures. The authors validate their approach in a retail context and empirically demonstrate the model's ability to identify high-value customers as well as those most sensitive to marketing actions right after their first purchase.
Keywords
Customers differ not only in their preferences for products and services but also in the way they respond to marketing actions. Understanding customer heterogeneity is at the heart of customer relationship management (CRM) programs—from obtaining accurate estimates of the value of current and future customers to deciding which individual customers should be targeted in the next marketing campaign. Over the last three decades, the marketing literature has provided researchers and analysts with methods to empirically estimate unobserved differences across customers using their past history. These methods allow firms to identify customers with higher versus lower expected lifetime value (e.g., Fader, Hardie, and Lee 2005; Fader, Hardie, and Shang 2010; Schmittlein, Morrison, and Colombo 1987), those who are less sensitive to a price increase (e.g., Allenby and Rossi 1998; Rossi, McCulloch, and Allenby 1996), or those who are more receptive to marketing communications (e.g., Ansari and Mela 2003). However, when firms attempt to implement CRM programs on customers who have been acquired recently, they only observe these customers’ first purchase. This lack of repeated observations presents a structural challenge for estimating unobserved differences across recently acquired customers, precluding firms from leveraging such heterogeneity. 1 We call this the “cold start” problem of CRM—that is, the challenge that firms face when trying to make inferences about customers at the outset of the relationship, when data are limited.
Firms have traditionally relied on demographics (e.g., age, gender) and/or recency metrics (e.g., how many weeks since the last transaction) to target marketing efforts with limited data (Shaffer and Zhang 1995). These approaches, however, face practical limitations: recency metrics, for example, do not differentiate among recently acquired customers (as they all were acquired at the same time), and relevant personal information is generally difficult to collect or poses data privacy challenges. However, thanks to technological advances, firms can now increasingly observe a wider range of behaviors on each customer touch. What in the past might have been considered simply a transaction added to a customer base is now a collection of behaviors that a customer incurs while making a first purchase (e.g., Did the transaction occur online or offline?, Did the customer buy any new products or old bestsellers in the transaction?, Did they buy any products on discount?). While some of these characteristics may merely coincide with the moment in which the customer made their first purchase, others may carry important information, as they reflect latent customer preferences/attitudes. Thus, although firms observe a newly acquired customer on only one occasion, they now have many more cues to form a “first impression” of this customer, which can be used to understand heterogeneity across recently acquired customers.
We present a solution to the cold start problem that is flexible, scalable, and general. Specifically, we augment transactional data with information collected when a customer makes their first purchase—information already available in the firm's database—and propose a probabilistic machine learning (ML) modeling framework that extracts information relevant to making inferences about the customer's future behavior. The model, which we term the “First-Impression Model” (FIM), reflects the premise that behaviors and choices observed in newly acquired customers can be informative about underlying traits that are, in turn, predictive of their future behavior. We operationalize these customer traits via a finite set of latent factors that enable the model to reduce the dimensionality of, while extracting relevant signals from, the data, and we assume those traits to drive (at least partially) customer behaviors observed both at the moment of acquisition and in the future.
In essence, the FIM is a deep probabilistic model of demand (main outcome of interest to the firm) and acquisition characteristics (customer outcomes that are observed by the firm at the moment of acquisition) where the individual-level parameters of each of these submodels are projected into a lower-dimension space using a two-layered deep exponential family (DEF) component. The lower layer of the DEF component captures the relevant interrelations among the individual-level parameters. We incorporate automatic relevance determination (ARD) priors for this layer, enforcing sparsity and automatically reducing the dimensionality of the individual-level parameters, similarly as in a Bayesian principal component analysis (PCA) model and modern applications of “supervised” factor models. The model departs from the aforementioned models by allowing nonlinear relationships among the factors in the lower layer through the upper layer.
First among four notable aspects of the proposed modeling approach is that the model can capture a wide range of relationships between observed behaviors and variables of interest—for example, the interaction effects between two (or more) acquisition variables and the outcomes of interest. Because the model will recover them from the data, those (linear or nonlinear) relationships do not need to be prespecified. Second, unlike traditional dimensionality-reduction methods, the number of latent factors do not need to be specified a priori. The model infers the number of relevant dimensions from the data through ARD. Third, the model is scalable, being applicable to data sets with large numbers of customers and many acquisition characteristics, some of which might contain missing observations. When present, these missing observations are easily handled by the FIM, which models them as outcomes using a Bayesian estimation framework. Lastly, the proposed modeling framework is general in the sense that can be integrated with any demand specification, from simple linear specifications to more complex model structures that incorporate a latent attrition component (i.e., “buy-till-you-die” models) or other forms of customer dynamics (e.g., hidden Markov models). This desirable feature implies that marketers across business settings, contractual and noncontractual, can use this framework by making minor adjustments to the demand/transactional model.
Using a set of simulation analyses, we demonstrate that the FIM inferences for newly acquired customers are more accurate than those generated by multiple tested benchmarks. Unlike other models, our approach accommodates flexible relationships among relevant behaviors, enabling the model to make accurate inferences about newly acquired customers when the relationships between acquisition characteristics and demand parameters are unknown to the firm or researcher.
We then apply the FIM to a retail context and demonstrate how the focal firm can overcome the cold start problem by augmenting the (thin) historical data using its transactional database and employing the proposed modeling framework that extracts the relevant information from the augmented customer data. First, we use the transactional data to extract the characteristics of every customer's first purchase (e.g., price paid, number of products purchased) as well as observed product characteristics (e.g., category purchased, package size). Second, we leverage the transactional data from customers outside our sample to create a continuous multidimensional representation of products (or product embeddings). Specifically, we use the word2vec algorithm—an ML approach originally developed to analyze textual data—to model the co-occurrence of products in customer baskets. This yields a set of product embeddings that can be used to augment data on customers’ first transactions on the basis of the specific products they bought. We then estimate the FIM to the augmented cold start data and make individual-level predictions for newly acquired customers outside the calibration sample.
We empirically demonstrate the superiority of the FIM at distinguishing heavy spenders from those expected to yield less value, immediately after they make their first purchase. The model can also be used to highlight the set of acquisition characteristics most predictive of future behavior. For example, we find the predicted top 10% heavy spenders to be less likely to be acquired during the holiday period and more likely to be acquired offline, and their first purchases to tend to include expensive and discounted products. The model also captures differences in customer responsiveness to marketing actions, enabling firms to identify and characterize those most (or least) sensitive to specific marketing communications. For example, we find that customers most sensitive to email marketing are more likely to be acquired online and buy less expensive products, and their first purchases are likely to include fewer units. We also find nonlinear relationships between acquisition characteristics and customer responsiveness to marketing actions. For example, the differences in email sensitivities across customers who received discounts on their first purchase exist only for those who also purchased a recently introduced product.
The present research develops a modeling framework that overcomes the cold start problem by linking customers’ early observed behaviors and choices with future purchase behavior, enabling firms to make meaningful predictions about newly acquired customers. Methodologically, our article contributes to the CRM literature by being the first to incorporate—in a general, flexible, and scalable way—information obtained at the moment of acquisition, which is generally discarded due to an inability to use it effectively. Substantively, our research is relevant to marketers faced with the challenge of managing customers soon after acquisition. We show how the proposed modeling framework enables firms to identify and characterize, from information collected at the moment of acquisition, high-value customers and those most sensitive to marketing communications. From a practical perspective, our research guides firms in the use of cold start data to augment information already in their databases. To that end, we employ developments in ML and natural language processing to create a matrix of product “embeddings” that enable firms to characterize (even recently acquired) customers on the basis of the products they purchase. We believe this approach to customer segmentation to be highly promising, enabling firms to obtain rich information about individual customers without recourse to customer-provided data or external sources that might pose privacy concerns.
The remainder of the article is organized as follows. Following a brief review of the literature related to our work, we introduce the cold start problem and illustrate the main challenges to solving it in practice. We next present our modeling framework, discuss its components, and evaluate its performance relative to existing approaches that could be used to solve the cold start problem. We then apply our model in the context of an international beauty and cosmetic retailer. We conclude with a discussion of the implications, managerial relevance, and future directions of our research.
Previous Literature
Our research relates to the broad literature on customer-base analysis that has provided managers and analysts with tools for understanding, forecasting, and managing the (heterogeneous) behavior of customers. It relates particularly to work that has incorporated the effect of marketing variables or, more generally, time-varying covariates in customer lifetime value (CLV) models. Notable work in this area includes Schweidel and Knox (2013) and Schweidel, Park, and Jamal (2014), who, building on the foundations of the Beta-Geometric/Beta-Binomial model (Fader, Hardie, and Shang 2010), incorporate the effect of direct marketing activity and past customer activity on the latent attrition process and the customer's purchase propensity. In addition, Knox and Van Oest (2014) and Braun, Schweidel, and Stein (2015) incorporate the effect of the customer service experience and customer complaints on the latent attrition process of the Beta-Geometric/Negative Binomial Distribution model (Fader, Hardie, and Lee 2005). Our research and methodological objectives differ in two main ways. Whereas the main purpose of the aforementioned studies is to capture the effect of time-varying marketing variables (e.g., direct marketing activities, customer complaints) on customer behavior, we extract as much information as possible from cold start data. Although the referenced models could be used to incorporate a handful of prespecified acquisition variables, they are not well-suited to extract relevant information from noisy and redundant variables, as is the case with cold start data. Second, we do not build on a specific demand specification tied to a business context but, rather, provide a modeling framework that can incorporate any of the models of behavior presented in previous research.
On a substantive level, our work relates to Gopalakrishnan, Bradlow, and Fader (2016), who propose a framework for multicohort data able to predict the behavior of new cohorts of customers for whom little transactional data are available. These authors build a model that allows customers to be inherently different depending on when they were acquired (i.e., which cohort they belong to) while capturing the underlying dynamics across cohorts. We posit that such inherent heterogeneity can be explained (at least partially) by individual-level observed characteristics collected when customers make their first purchase. This is consistent with Anderson et al. (2021), who document the existence of “harbinger products.” These are products that, when purchased by a customer in their first transaction, are an indicator of the customer being less likely to purchase again and, thus, provide less value to the firm. Our work also relates to Loupos, Nathan, and Cerf (2019), who use social network data for recently acquired customers to explain heterogeneity in their future value to the firm. To the best of our knowledge, our approach is the first to integrate several types of information collected at the moment of acquisition and to differentiate responsiveness to marketing actions—not only individual propensity to transact—on the basis of customers’ first purchases. The latter aspect is crucial in cases in which targeting occurs soon after the customer is acquired or when it is challenging to secure a second purchase.
The premise that behaviors observed at the moment of acquisition can help firms explain heterogeneity in future behavior is consistent with empirical findings in the CRM literature (e.g., Fader, Hardie, and Jerath 2007; Voigt and Hinz 2016), specifically, work on customer acquisition that has investigated the relationship between acquisition-related information (e.g., channel of acquisition) and subsequent CLV (e.g., Chan, Wu, and Xie 2011; Datta, Foubert, and Van Heerde 2015; Lewis 2006; Schmitt, Skiera, and Van den Bulte 2011; Steffes, Murthi, and Rao 2011; Uncles, East, and Lomax 2013; Verhoef and Donkers 2005; Villanueva, Yoo, and Hanssens 2008). Although our work investigates relationships between acquisition-related variables and subsequent customer behavior, it differs in two important ways. First, our end goal is to inform decisions related to the management of already-acquired customers (e.g., whom to target in the next campaign) rather than the design of optimal strategies for customer acquisition (e.g., free trials to increase customer acquisition). The goal of our modeling framework is to extract as much observed heterogeneity as possible from initial behaviors while controlling for firms’ acquisition activities rather than estimate the causal impact of these acquisition variables on future behavior. Second, this literature suggests that customers are inherently different depending on how they have been acquired. We broaden the range of acquisition-related behaviors by examining not only how a customer was acquired (e.g., online vs. offline, trial vs. regular) but also what they did when they were acquired (e.g., What kind of product did they buy?, How much did they pay?), thus extracting more information from the initial transaction. The latter is especially relevant for managers and analysts in large retail and hospitality businesses, among others, given that such information is not only easily observed but also typically already in their databases.
From a methodological perspective, we contribute to the literature on applying probabilistic ML methods to marketing (Dew and Ansari 2018; Dew, Ansari, and Li 2020; Jacobs, Donkers, and Fok 2016). More specifically, our work relates to the literature on applying DEFs (Ranganath et al. 2015) as building blocks of more complex models (Ranganath et al. 2016; Wang and Blei 2019) and other generative models such as Bayesian PCA (Bishop 1999; Mohamed, Ghahramani, and Heller 2008).
The “Cold Start” Problem: An Example from a Retail Setting
We turn to a retail context to illustrate the cold start problem and to motivate and validate our modeling framework. Retail is a good context to examine this phenomenon for several reasons. First, firms in this sector increasingly collect transactional data and rely on analytics to better manage their customers (Marr 2015). Second, retail represents a large proportion of the total economy, with revenues accounting for 31% for the global gross domestic product (Research and Markets 2016). Finally, the data structure in most retail settings—in particular, the one used in this research—resembles that in many other industries (e.g., hospitality, entertainment business, nonprofit organizations) that face similar data challenges when implementing CRM programs.
The Cold Start Problem
Consider a retailer that sells cosmetic/beauty products via both online and offline channels. 2 Like most other companies, it records the transactions of all individual customers since the moment they were acquired, including the time of purchase, the products purchased in each particular transaction, their price and discounts (if any), along with information about the CRM activities that the company engaged in (e.g., email marketing activities). With these transactional data at hand, the focal company could apply some of the aforementioned models and be able to predict, with a good degree of accuracy, the number of transactions that customers with different transaction patterns would make in future periods (e.g., Fader, Hardie, and Shang 2010). The marketer can also incorporate the historical marketing actions to capture how those variables affected transaction propensities and customer value (e.g., Schweidel and Knox 2013; Schweidel, Park, and Jamal 2014). However, when making these types of inferences for recently acquired customers, for whom the firm has no transactional history or past marketing interventions, the “best guess” that the marketer can get is the population average. This is what we call the “cold start problem of CRM,” whereby firms cannot make individual-level inferences about newly acquired customers to differentiate them, therefore diminishing the effectiveness of future CRM activities.
The premise of this research is that, while it is the lack of (historical) data that causes the cold start problem, firms now have access to other data sources that, properly leveraged, can help them overcome the cold start problem. Granted, if firms observed only that the customer made a transaction, it would be very difficult to overcome this problem. However, most firms not only know when a customer made their first transaction but also record details such as the channel/store used, the exact product the customer purchased, the price paid, whether they used a discount, the time of the day, and so forth. 3 We propose leveraging those existing data and extract what we call “acquisition characteristics” from each customer's first transaction. 4 We contend that these acquisition characteristics/choices can be informative about underlying customer differences that can predict customers’ future behavior. Because these data are also available for customers with longer tenure with the company, the firm would be able to uncover the (subtle) relationships between the choices observed at the moment of acquisition and customer behavior down the road.
Augmenting Cold Start Data with Acquisition Characteristics
Consider our focal retailer, which is trying to make inferences about its customers right after they have been acquired. A natural first step for the analyst would be to select a handful of variables collected at the acquisition moment (e.g., channel of acquisition) and use existing models to relate those characteristics to future demand (e.g., Chan, Wu, and Xie 2011). The caveat of doing so is that so few variables might not fully capture the richness of the acquisition data, and the level of personalization would likely be limited, as these few variables capture only a coarse representation of customers’ heterogeneity. We aim to fully augment the acquisition data to broaden the amount of information that would (potentially) be linked to future behavior, therefore increasing marketers’ ability to solve the cold start problem.
Specifically, using the (existing) data from each first transaction, we propose augmenting cold start data with three types of acquisition variables: (1) transaction characteristics (e.g., channel, price paid, holiday season) and (2) product characteristics 5 (e.g., product category, package size), which are easily extracted from the transactional database, and (3) shopping basket (latent) representation. The latter type of data aims to capture the “nature” of products that the customer purchased, beyond what the standard (observed) product categories represent. Our premise is that the nature of products purchased can signal the type of customer who purchases those. For example, in the cosmetics market, certain ingredients or aromas characterize lines of products. It is possible that customers who discover the brand by buying products of a certain nature are similar in the way they behave in the future. Because such information is not readily available from the firm's database, we need a method to encode the information embedded in each product and then aggregate it at the basket level. 6
Previous literature has used different methods to encode such information, from human coding based on full description of the product to ML approaches that apply textual analyses to the description of products or that leverage co-occurrence of products in basket data to create measures of similarity across products (e.g., Chen et al. 2020; Jacobs, Donkers, and Fok 2016; Kumar, Eckles, and Aral 2020; Ruiz, Athey, and Blei 2017). We take the latter approach and leverage the transaction data from anonymous customers to create continuous multidimensional representations of products, called “product embeddings,” that capture the nature of the product. Specifically, we create a co-occurrence matrix based on the composition of shopping baskets (i.e., which SKUs are purchased together?) and implement word2vec (Mikolov et al. 2013), an ML approach widely used for natural language processing, to map each item to a multidimensional vector that captures similarities across products. This exercise is similar to creating a perceptual map from association data (Netzer et al. 2012) in which the co-occurrence of products in a basket is used as proxy of association between two products. (For details about how we process the transaction data and create the product embeddings using the word2vec algorithm, see Web Appendix A.) Once we represent each product by a continuous vector, we can easily characterize the first purchase of any customer by computing moments of the product vectors in that basket.
In summary, using the transactional data already collected by the firm, one can easily augment each customer's data with a high-dimensional vector that captures a wide variety of acquisition characteristics, including details about the first transaction and the type of products purchased. 7
Predictive Power of Augmented Data
A natural question to ask is: Do acquisition characteristics carry information about future behavior? While this is an empirical question, we present preliminary evidence from our empirical application that these augmented acquisition characteristics in turn explain differences in subsequent demand behavior across customers. To do so, we select customers who have been with the company for at least 15 months and relate their total number of repeat purchases during those 15 months with their (augmented) acquisition characteristics. We explore the relationship between individual acquisition characteristics and future transactions (Figure 1) as well as possible interactions among acquisition variables in their association with future demand (Figure 2).

Observed (mean) repeated transactions as a function of a sample of augmented acquisition characteristics.

Observed (mean) repeated transactions as a function of interactions among acquisition characteristics.
Indeed, acquisition characteristics are predictive of customers’ future transactions. Consistent with common belief in the industry (e.g., Artun 2014; RJMetrics 2016), customers who were acquired during the holiday season are less valuable to the firm, as we find that they are less likely to purchase in the future. In contrast, customers who bought using discounts on their first transaction generally buy more during the next 15 months than customers who did not. A similar pattern exists for customers who bought a recently introduced product on their first transaction and for those who purchased products from the hair care category. Interestingly, this model-free analysis also suggests that some of these relationships are likely to be nonlinear. For example, looking at average price paid per item, customers in the lowest quartile (Q1) tend to buy less frequently in their first 15 periods than all other customers. Similar nonlinear relationships appear for the number of units and the total amount of the ticket.
Interesting patterns also emerge in Figure 2. On the left, we group customers depending on whether they were acquired during the winter holiday season, coupled with whether they purchased travel-size products. We find that purchasing travel-size products moderates the relationship between being acquired during the holidays and the future number of transactions. In the panel on the right, we observe that purchasing a discounted product in the first transaction signals lower value only if the purchase did not include a new product. Taken together, these results present evidence of a relationship between acquisition characteristics and future transactions, confirming that augmenting cold start data with acquisition characteristics incorporates relevant information to infer customers’ differences.
Nevertheless, this simple analysis is insufficient for solving the cold start problem of CRM, as we would likely miss useful information from the data. First, it can be performed for only a subsample of customers—those we observe for a relatively long period of time (e.g., 15 months)—to have a fair comparison across customers over the same number of periods. Second, this type of analysis examines each variable independently (Figure 1), at most allowing for single interactions (Figure 2). Given that the goal is to extract relevant interrelations in high-dimension cold start data, it will be more effective (and efficient) to examine these interrelations collectively, while allowing for flexible relationships among the variables. Furthermore, the model-free analysis does not shed light on customers’ response to marketing actions. These results indicate that “holiday” customers are less likely to transact again. However, are they more/less sensitive to the firm's communication? How strongly will they react product introductions? A model is necessary to effectively extract the information from the acquisition characteristics to predict differences in transaction propensities as well as in responsiveness to marketing actions. Before presenting our modeling framework, we describe the methodological challenges that such a model should overcome.
Modeling Challenges
Our solution to overcome the cold start problem ultimately depends on the model’s ability to extract the information hidden in the augmented data that is predictive of future behavior. Naturally, increasing the dimensionality of the acquisition data increases the chances of adding (at least potentially) information that will be relevant to infer customer differences down the road. However, expanding the dimensionality of the acquisition data also adds methodological challenges.
First, several of those augmented variables are likely to be irrelevant. Many of the behaviors observed in the first purchase are likely to be random and not systematically related to how customers will behave in the future. Second, some of these augmented data are multiple signals from the same underlying behaviors, implying that much of the data would be redundant. For example, a price-conscious customer may purchase a set of travel-sized, cheap products that are discounted. Although the price and discount variables capture different types of information (e.g., a discounted product may still be an expensive one), these variables are clearly correlated as they are both signals of the customer's preference for inexpensive products. Moreover, if one also were to include latent representations of the products bought, these representations would likely correlate with prices and with how frequently they are discounted, adding to the redundancy already present among augmented variables. Taken together, these characteristics suggest that it is likely that cold start data would have low “signal-to-noise” ratio, increasing the difficulty of recovering the relationships between acquisition characteristics and future behavior.
Importantly, the underlying relationships between acquisition variables and future demand is unknown. As indicated by the early exploration of the data (Figures 1 and 2), those relationships are unlikely to be linear. It is unrealistic to recommend that a firm would explore all possible interactions and nonlinear specifications among their augmented acquisition characteristics, and is especially cumbersome when also interested in customers’ response to marketing actions. Moreover, increasing the dimensionality of the augmented data only emphasizes this challenge as it would increase the number of potential nonlinear relationships and interactions among acquisition variables. Another potential limitation of increasing the dimensionality of the acquisition variables is that some variables might be missing for some customers. Missing observations present challenges to estimate models that use those missing variables as covariates because they require imputation methods—cumbersome for high-dimensional spaces—or deletion of customers (or variables) from the data, which directly reduces the amount of information, defeating the purpose of the data augmentation step.
In this research, we propose a modeling framework that overcomes all these issues. We combine a flexible demand specification (that can be applied to a wide range of marketing contexts) with state-of-the-art ML methods (addressing nonlinearities and data redundancy) within a Bayesian framework (that extracts signals from the acquisition characteristics while handling missing data). The resulting modeling framework is a flexible probabilistic ML model that links the individual-level parameters governing a customer's future behavior (e.g., transaction propensities, sensitivity to marketing actions) with a latent representation of the behaviors/choices observed at the moment of acquisition. This modeling approach seamlessly captures flexible relationships among variables (linear and nonlinear) without the need to prespecify those relationships a priori. Moreover, the model explicitly accounts for interrelations among acquisition data, which helps regularize the flexible model and avoid overfitting.
These benefits will become clear as we build and validate the model in the next section, where we also show how this approach dominates existing alternatives that address some (but not all) modeling challenges. For example, we compare it with a standard hierarchical Bayesian (HB) model with acquisition characteristics included as covariates, a fully hierarchical model where acquisition characteristics and demand are jointly correlated using a multivariate Gaussian distribution, and a (supervised) Bayesian PCA that aims to reduce dimensionality of acquisition characteristics as well as demand parameters.
Finally, we show in our empirical application that, if we simplify the task and only consider the model's ability to predict future transactions, our modeling approach performs at the level of traditional ML approaches such as a random forest (RF) and a deep neural network (DNN; proven to capture nonlinear relationships very well). Our model stands out from these ML benchmarks in two main ways. Methodologically, it can be easily be combined with multiple demand specifications and allows for missing observations in acquisition characteristics without relying on data imputation. Practically, our model provides inferences beyond predictions of future transactions, enabling marketers to get insights about customer heterogeneity in preferences and in sensitivity to marketing actions.
Modeling Framework
Model Development
Our modeling framework, the FIM, comprises three main components: (1) the demand model, the main outcome of interest to the firm, which could include customers’ transactions, purchase volume, and so on; (2) the acquisition model, which captures all customer outcomes that are observed to the firm at the moment of acquisition; and (3) the probabilistic model, which links the underlying customer parameters influencing these two types of behaviors through hidden traits.
Demand model
We start by assuming a general model for demand, suitable for different specifications, and parametrized using individual-level parameters and population-level parameters. Specifically, for customer i at period

Acquisition model
We denote
Modeling the acquisition characteristics as an output not only enables us to control for the time-varying factors that shift demand at the moment of acquisition but also allows for a flexible modeling specification of the latent traits that overcome challenges such as redundancy, irrelevance of variables, and missing data commonly encountered in the firm's database. (We discuss these challenges in the “Linking Acquisition and Future Demand: Deep Probabilistic Model” subsection.) Specifically, we denote

The term


All of these types of variables are easily incorporated by adjusting the acquisition model accordingly. We define
Note that we have only one observation per individual and behavior. Thus, in theory, having an individual-level parameter
Finally, the term
Linking acquisition and future demand: deep probabilistic model
We use a DEF component (Ranganath et al. 2015) to relate demand and acquisition parameters hierarchically, through hidden layers. We chose this specification because of its hierarchical nature, which allows the model to identify/extract individual-level traits that affect both acquisition and future demand, and because the presence of multiple layers facilitates the reduction of dimensionality while accommodating a wide range of possible relationships between acquisition and demand variables. Furthermore, one important characteristic of DEFs is that the latent variables are distributed according to distributions that belong to the exponential family (e.g., Gaussian, Poisson, Gamma), making them a good candidate to model the wide range of data types encountered in the firm's database. Finally, DEFs also have the flexibility of probabilistic models, allowing them to be easily incorporated in more complex model structures, as we do in this research. (For details on DEFs, see Web Appendix B.)
Turning our attention to our modeling challenge, the primary goal of our model is to infer the individual-level parameters


We assume that each component k of the lower layer,


Dimensionality of the DEF component
At first glance, the choice of the layers dimensions
Similar to other latent-space models, one could test all possible combinations of
Therefore, our approach to specifying the dimensionality of the model is to set a large-enough number of traits to ensure that all relevant traits are recovered while using sparse priors to ensure that the model activates only the relevant traits, thus avoiding overfitting the data. Specifically, we use sparse Gamma priors for
The added benefit of inducing regularization through the priors is that we can look at the posterior estimates of the variances of the weights (
These insights are further developed in Web Appendix D.7, where we explore the dimensionality of the DEF component by analyzing the results of estimating the FIM on simulated data for which we know how many traits are needed. There, we show how the model’s performance remains largely unchanged by the additional dimensions (on either
In summary, we take a hybrid approach to model selection, in which we ensure that the number of prespecified dimensions is large enough—a phenomenon that can be validated from the model parameters—while we rely on the priors of the model to ensure regularization.
Bringing it all together
We briefly discuss how each part of the model contributes to the desired goals and how the FIM compares with alternative approaches to overcome the cold start problem. In essence, the model comprises a demand and an acquisition model, whose individual-level parameters are projected into a lower-dimensional space through a two-layered DEF component. The lower layer of the DEF captures the relevant associations among the individual-level parameters while reducing the dimensionality of those vectors. An alternative approach to link the acquisition and demand parameters could be through using traditional full HB priors (e.g., multivariate Gaussian). Such an approach would assume that all individual-level parameters (
The upper layer of the DEF—and in particular, the nonlinear link function
Finally, a different approach to overcome the cold start problem could be to simply specify the individual-level demand parameters (
In conclusion, Figure 3 shows the graphical model for the FIM, connecting all the individual components. We propose a model of demand and acquisition characteristics where the individual-level parameters of each of these submodels are projected into a lower-dimension space via a DEF component. The specification of the demand submodel is general such that the modeling framework can be applied to a wide range of business contexts. The submodel for acquisition characteristics enables the model to control for market conditions or firm-initiated actions that can potentially shift the type of customers that are acquired over time. If these shifts were not captured, the model would not be able to differentiate market conditions from customers’ underlying preferences. Regarding the DEF component, there are three main benefits of using a two-layered DEF to connect both types of individual-level parameters. First, the model provides dimensionality reduction, avoiding the curse of redundancy and irrelevance of acquisition variables. Second, the model allows for flexible relationships (e.g., nonlinear relationships) among the model components. Third, the model can incorporate acquisition characteristics with missing observations, as these are modeled as outcomes that are easily handled using a Bayesian estimation framework. These benefits will become clearer in the “Model Performance” subsection and “Empirical Application” section, when we compare the predictive accuracy of the FIM with that of several alternative specifications.

Graphical model of first impressions.
Estimation and Identification
We estimate the model using full Bayesian statistical inference with Markov chain Monte Carlo sampling. We sample the parameters from the posterior distribution, which is proportional to the joint,
16

Regarding the identification of the model parameters, the demand and acquisition parameters (
Lower layer
The parameters that link the lower layer of the DEF with
Top layer
The top layer of the DEF and the parameters that link the top and lower layer are not identified. This is similar to DNNs, in which the lower layer is a combination of the values of the upper layer and the weights linking them. In our model specification, this translates to the value of the top layer (
Model Inferences for Newly Acquired Customers
Recall that the main purpose of the model is to assist firms in the task of making inferences about how individual customers will behave in the future (e.g., how they will respond to marketing interventions), based on the observed behaviors at the moment of acquisition. Intuitively, that process would works as follows: a new customer is acquired and the firm observes their behaviors at the moment of acquisition. At that point, and given the firms’ prior knowledge of the market (i.e., the model parameters and market conditions), the firm makes an inference about that particular customer's latent traits, which are then used to infer the individual-level parameters that will determine their demand (e.g., likelihood that the customer will purchase in the future, their responsiveness to marketing interventions).
More formally, we want to infer

Model Performance
Before applying the new modeling framework to the empirical context, we need to demonstrate the model’s accuracy at inferring the individual-level parameters for newly acquired customers. Because individual-level parameters are, by definition, unobserved, we perform this task using a simulation analysis in which we know the exact values of
We generate three scenarios for the underlying relationship between acquisition variables and demand parameters. In each scenario, customers are “endowed” with a set of demand parameters that follow a specific relationship with their observed acquisition characteristics, namely (1) linear, (2) quadratic/interactions (allowing the relationship between one acquisition variable and the demand parameters to vary depending on the value of other acquisition characteristics), and (3) positive part (forcing the relationship between acquisition characteristics and demand parameters to be zero for low values of the acquisition characteristic). Given those individual-level demand parameters, customer transaction history is simulated for 2,200 customers. We use 2,000 customers to estimate the model and the remaining 200 customers to evaluate the accuracy of the model at inferring demand parameters for newly acquired customers. Specifically, only using the acquisition characteristics for these 200 customers, we use the model to infer their individual-level demand parameters and compare those estimates with the true values.
We compare the performance of the FIM with that of three other specifications: (1) a HB-linear model, where individual demand parameters are specified as a linear function of the acquisition characteristics (this corresponds to the simulated data under the linear scenario); (2) a full hierarchical model, where demand and acquisition parameters are jointly distributed according to a multivariate Gaussian distribution with a flexible covariance matrix; and (3) a Bayesian PCA model. As discussed in the “Bringing It All Together” subsection, the Bayesian PCA model is a nested specification of the proposed FIM (in which the second layer does not exist), whereas the full hierarchical model and HB-linear specifications reflect alternative (simpler) ways in which previous research has modeled these types of data. To measure the accuracy of each model, we compare the predicted posterior mean with the actual values for the demand parameters (both the intercept and the effect of the covariates) of the 200 out-of-sample customers. Table 1 includes the results for all models across all scenarios. 19 We also include the results of estimating an HB demand-only model in which acquisition characteristics are not incorporated to have a reference of how much error one would obtain by simply predicting the population mean.
Accuracy of Predictions of Demand Parameters for (Out-of-Sample) Customers.
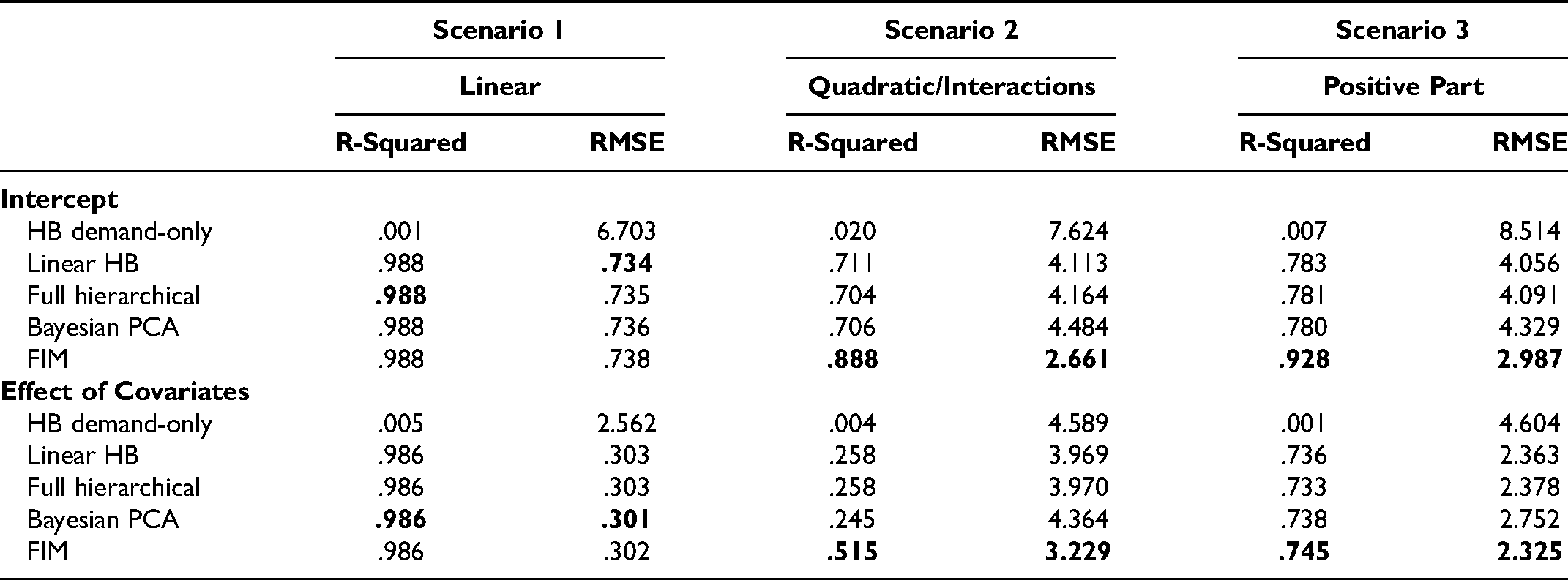
First, under a true linear relationship (Scenario 1), the FIM predicts the individual parameters as accurately as the benchmark models. The root mean square error (RMSE) of the FIM is comparable to the benchmark models, and the R-squared is equal to the benchmark models. This result verifies that the FIM does not overfit the training data or, in other words, that the additional model complexity—even when not needed—does not hurt the accuracy of predictions for customers outside the calibration sample. Second, when the relationship among the model parameters is not perfectly linear (Scenarios 2 and 3), the FIM significantly outperforms the benchmark models in all dimensions. In particular, the R-squared of the FIM is higher than that of the benchmarks, demonstrating that the model is superior at sorting customers on the basis of their demand parameters. Moreover, the RMSE for the FIM is substantially lower than that of the benchmarks, indicating that the proposed model predicts the exact magnitude of customer parameters (e.g., purchase probability, sensitivity to marketing actions) more accurately than any of the benchmarks. These results hold when we examine the model “at scale,” when we significantly increase the amount of data collected by the firm and also add standard regularization techniques (e.g., LASSO) to the benchmark models. (For details, see Web Appendix D.8.)
To help understand what drives the greater accuracy of these predictions, we further explore the results for Scenario 3 (when the true relationship is positive part). The first row of Figure 4 shows the scatter plot of the predicted (
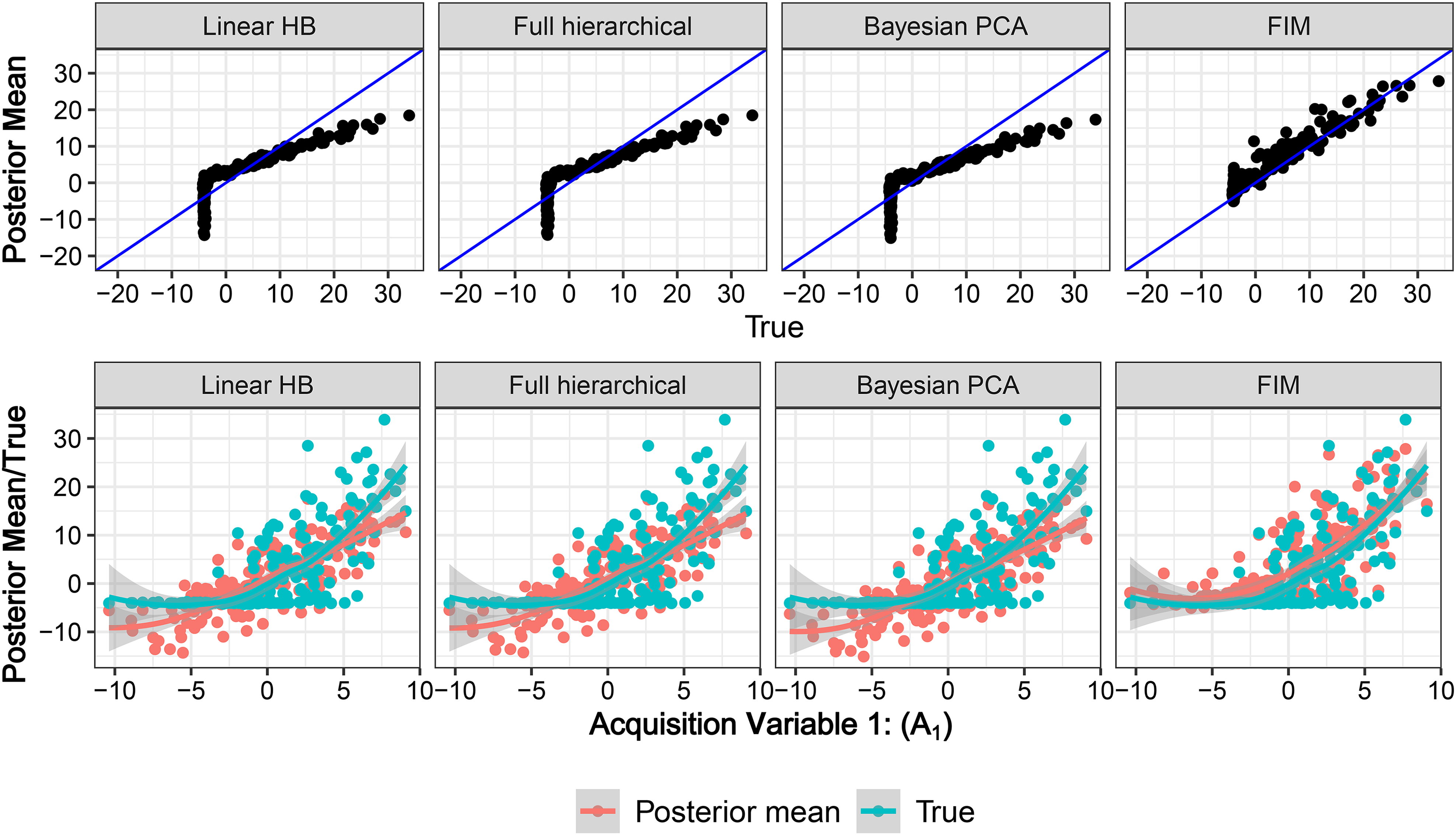
Visualization of model performance for Scenario 3: positive-part individual results of intercept.
Finally, to better understand which aspect of the model is responsible for this accuracy of predictions, we compare the BPCA and the FIM model more closely, allowing both specifications to vary the dimensionality of their latent components. Such an analysis indicates that the presence of the second layer of the DEF component is contributing significantly to the improvement in accuracy for scenarios where the relationship is not linear. The results suggest that incorporating that second layer, even if specified with low dimensionality, allows the model to flexibly capture the nonlinear relationship between acquisition and demand parameters. (See full details in Web Appendix D.6.)
In summary, these analyses demonstrate the effectiveness of the FIM at overcoming the cold start problem. We have shown that the FIM can accurately infer customer parameters using only acquisition data, even when such a model is not used to simulate the true parameters. While the benchmark models fail to form accurate inferences of newly acquired customers when the underlying relationships among variables are not perfectly linear, the FIM is flexible enough to reasonably recover those parameters. This latter point is of great importance because, in reality, the researcher/analyst never knows the underlying relationships among variables. Therefore, having a flexible model able to accommodate multiple forms of relationships is crucial to accurately infer customers’ parameters.
Empirical Application
Data and Model Specification
Our focal firm is an international retailer that sells its own brand of beauty and cosmetic products (e.g., skincare, fragrance, haircare). 21 Customers can purchase the company's products only via owned stores, either offline (the company owns brick-and-mortar stores across many countries) or online (with one online store per country). Although the company is present in many countries, most marketing functions (e.g., promotional campaigns, product introductions) are centralized, and therefore operations are very consistent across markets. Like most other companies, the focal firm records the transactions of all individual customers, along with other information about the CRM activities, such as direct marketing campaigns and email marketing activities.
Transactional data
We obtain individual-level transactions for registered customers in the six major markets—the United States, the United Kingdom, Germany, France, Italy, and Spain. We observe customers from the moment they make their first purchase (starting in November 2010). At the point of purchase, customers are asked to provide their name, email, and address so that they can receive promotions and other marketing communications from the firm. We track their behavior up to four years after that date (ending in November 2014). We have
We specify demand as a logistic regression where 
Marketing actions
The firm regularly sends emails and direct marketing to registered customers. The content of these promotional activities is set globally (i.e., the same promotional materials are used across countries, translated to the local language), though their intensity is set by market (e.g., the United States tends to send more emails than France). 24 In addition to promotional activity, the company uses product innovation as a marketing tool. Like other major brands in this category, the focal retailer regularly adds extensions and/or replacements to their product lines. The sense among the company managers is that such an activity not only helps in acquiring new customers but also keeps current customers more engaged with the brand. When the company introduces a new product, it does so in all markets simultaneously. There is, however, some variation across markets regarding when new products were introduced. Conversations with the company confirmed that such variation is due to differences (and random shocks) in the local distribution channels.
Although direct marketing and email marketing are observed at the individual level (we denote them by DM and Email, respectively), the availability of new products is not observed at a granular level. We create a new product introduction variable (Introd) by combining point-of-sale data (at the SKU level) with a firm-provided SKU list of new products. Specifically, we obtain the list of all new products introduced during the period of our study. We identify the SKUs for all products in that list and infer availability in each market from all purchases observed in that particular market (including all 304,497 transactions from “anonymous” customers). We assume that a new product was introduced in a market at the time the first unit of that SKU was sold. We then create a period-/market-level variable representing the number of new products that were introduced in each market in each time period.
Table 2 shows the summary statistics for the marketing actions summarized across observations and across individuals. For the latter, we summarize individual average, individual standard deviation, and the individual coefficient of variation. The variation in these data is very rich both across and within customers.
Summary of Time-Varying Marketing Actions.

We define the vector of demand time-variant covariates 
Given the business nature of our application, the information provided by the firm about how the managers conduct their marketing actions, the rich longitudinal and cross-sectional variation in our data (Table 2), and our model specification, we argue that the potential endogenous nature of the marketing actions is not a main concern in this research (for details, see Web Appendix G.1). Nevertheless, in situations where these conditions do not hold (due to different strategic behavior by the firm or for data limitations), the demand model should be adjusted to account for the firm's targeting decisions. Given the flexibility of our modeling framework, those adjustments would merely involve extending the demand model to capture unobserved shocks between firm's actions and individual-level responsiveness (Manchanda, Rossi, and Chintagunta 2004) or adding correlations between firm decisions and unobserved demand shocks through copulas (Park and Gupta 2012), depending on how these actions are determined by the firm. Those changes would only affect the demand (sub)model and not the overall specification of the FIM.
(Augmented) acquisition characteristics
Transaction characteristics: We compute Avg.Price as the total amount (in euros) of the ticket divided by the number of units bought at the first transaction; Quantity is the total number of units bought at the first transaction; Amount is the total amount (in euros) of the ticket at the first transaction 26 ; Discount is a dummy variable that equals 1 if the customer received discounts in the first transaction, and 0 otherwise; and Online is a dummy variable that equals 1 if the first transaction was made online, and 0 otherwise. We also create a Holiday dummy variable that equals 1 if customer made their first transaction during the winter holiday period and 0 otherwise (analogously as the time-varying covariate Season).
Product characteristics: Directly from the observed product characteristics, we create a ten-dimensional vector that indicates whether the basket includes a product from a Category, including Body Care, Face Care, Hair Care, Toiletries, and so on, as defined by the focal company. Moreover, given that product innovation is very important in markets of beauty and cosmetic products, we create a NewProduct dummy variable that equals 1 if the customer bought a product that had been introduced in the 30 days prior to the purchase, and 0 otherwise. We also include the average Size of the packages in the basket, operationalized as relative size with respect to other products in the same subcategory, and a Travel dummy that equals 1 if the basket includes products on travel size, and 0 otherwise.
Latent representation of shopping baskets: As described previously, we characterize each customer's first purchase by computing moments of the products included in their shopping basket. The resulting product embeddings in our empirical application is a six-dimensional vector that represents the position of each product in a similarity space, which we call the “nature” of a product. Once those product embeddings are created, we create BasketNature, computed as the “average” product purchased, and BasketDispersion, computed as the element-wise standard deviation across products in the same basket, with missing values when the first purchase includes only one product. 27
Formally, the vector of acquisition characteristics is specified as follows:
Summary Statistics of Selected Acquisition Characteristics.

Notes: For the sake of simplicity, we omit the descriptive statistics for the six BasketNature variables and eight remaining product categories. We also aggregate the BasketDispersion variables by averaging across all dimensions of the word2vec representations. Missing values correspond to first purchases that include products with missing information (and, in the case of BasketDispersion, those with only one item in the basket).
Consistent with the challenges mentioned in the “Modeling Challenges” subsection, some acquisition characteristics are correlated with each other (Table 4)—for example, customers who purchased many items paid less per item (correlation = −.330)—and those who bought on discount also paid slightly less than those who paid full price when they were first acquired (correlation = −.200). Online first purchases tend to include more items in the basket (correlation = .411) and contain products in the face care category (correlation = .483). While it is to be expected that some of these variables will be correlated, as they capture different behaviors incurred by the same customer, some of these correlations might also arise from the market conditions at the moment when a customer was acquired (e.g., if the company introduces all of its new products during the holiday, customers with Holiday = 1 will also have NewProduct = 1, and vice versa).
28
As discussed in the “Acquisition Model” subsection, our modeling framework separates these two types of correlations by incorporating firm's market-level actions,
Correlations Among Selected Acquisition Characteristics.
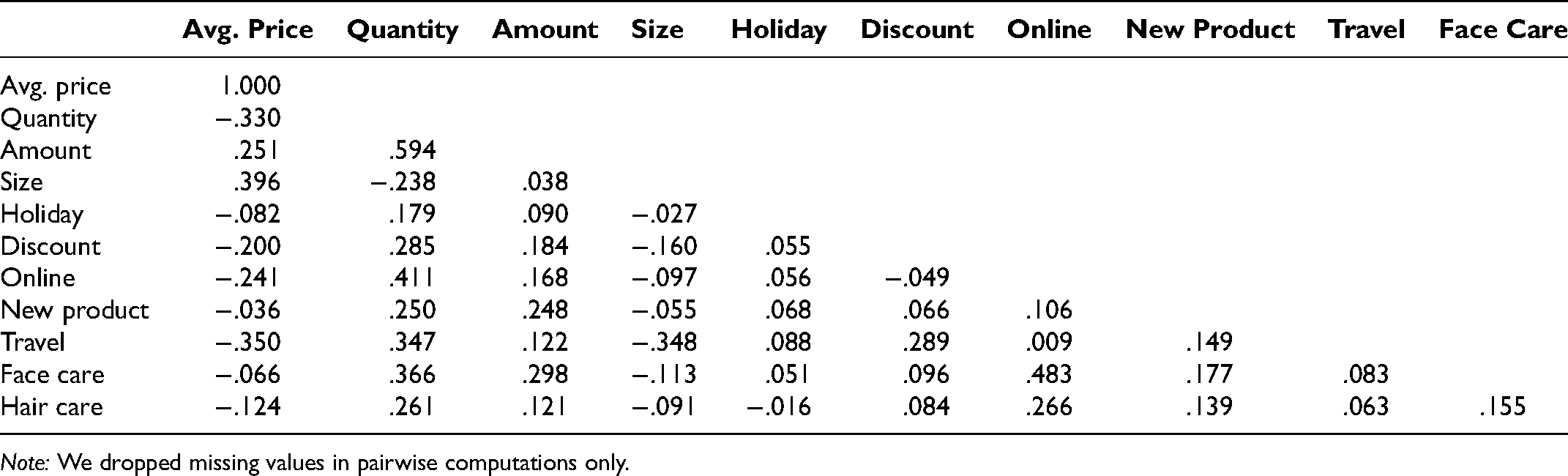
Note: We dropped missing values in pairwise computations only.
Specifically, we include market-level CRM activities such as number of emails (MarketEmail), direct marketing actions (MarketDM),
29
and the number of products introduced by the firm (Introd) in that period.
30
That is,
Estimation
We apply our modeling framework to this retail context to show how a firm can make meaningful inferences about newly acquired customers. The firm would do so by calibrating the FIM using historical data from its existing customers and making inferences about newly acquired customers for whom only the acquisition characteristics are observed.
We restrict our analysis to periods in which the firm was engaging in marketing activities, which span from October 2012 to November 2014 (
We also select another set of customers acquired during the same period for our Validation sample, which we will use to compare the predictive accuracy of the models at estimating demand (
Similarly as in the “Model Performance” subsection, we estimate all models (linear HB, Bayesian PCA, and FIM) using No U-Turn Sampling in Stan. 34 We also estimate a set of probability models (also estimated with Stan) that have been proposed in the literature to model these types of data because they explicitly account for latent attrition (e.g., Chan, Wu, and Xie 2011; Schweidel and Knox 2013; Schweidel, Park, and Jamal 2014). For completeness, we test multiple specifications varying the inclusion of time-varying covariates in the transaction process and time-invariant covariates in the attrition process, namely (1) linear model with marketing actions + logistic attrition process (without acquisition covariates), (2) linear model (without marketing actions) + logistic attrition with acquisition covariates, and (3) linear model with marketing actions + logistic attrition with acquisition covariates (see details in Web Appendix G.3). Finally, we estimate two ML methods widely used for supervised learning (i.e., whether a customer transacts)—namely, a feed-forward DNN and an RF. Both ML models include time-varying covariates, acquisition characteristics, and market-conditions at the moment of acquisition. (For details about the packages used for estimation of the ML methods and related model specifications, see Web Appendix G.4.)
Results
Parameter estimates
Table 5 shows the population mean and standard deviation of each of the demand parameters. Customers in the sample have a low propensity to transact, on average (
Parameter Estimates of FIM.

Another set of interpretable parameters of the FIM are the posterior estimates of the lower layer of the DEF component. Properly rotated, these parameters could be used to interpret the latent factors that connect acquisition characteristics and demand parameters. For the sake of brevity, in this section we focus on the model performance at solving the cold start problem and include those interpretable results in Web Appendix G.5.
Comparison with the benchmark models
Unlike the simulation exercise, in the empirical application we do not know the true value of the demand parameters (
Comparison with Benchmark Models (Validation Sample).

Notes: Log-like corresponds to the log expected posterior predictive density. Boldfaced cells represent the best model for each metric.
These analyses demonstrate that the FIM outperforms the benchmark models at accurately inferring individual-level demand parameters when only acquisition characteristics are available. The benefits of the proposed model are most salient when the underlying relationship between the acquisition characteristics and the parameters governing future demand are not linear, as is the case for many empirical applications. Next, we illustrate the managerial value of these predictions and discuss other insights (provided by the model) that are of managerial relevance.
Overcoming the Cold Start Problem
First, we investigate how accurately the firm can identify “heavy spenders” using only the data from their first transaction. We do so by leveraging the information from customers in the Test sample. Specifically, we combine the estimates of the models (calibrated with the Training sample) and the acquisition characteristics observed for customers in the Test sample and infer their individual-level demand parameters (see Web Appendix G.7) to predict each individual's expected number of transactions. We then compare these inferences with customers’ actual behavior using two sets of prediction metrics (Table 7). First, we compute the RMSE on the individual-level average number of transactions per period. 36 Second, drawing on each individual's expected number of transactions, we flag whether a customer belongs to the top 10% and top 20% of highest average number of transactions and report the proportion of customers correctly identified/classified in each group. 37 For reference, we compare those figures with what a random classifier would predict (shown in the last row).
Identifying Valuable Customers Using Test Customers.

Notes: The proportion of top spenders is computed by predicting over the observed periods, computing the average number of transactions per period, and selecting customers with highest predicted values. Boldfaced cells represent the best model for each metric.
As Table 7 shows, the FIM can predict the value of customers reasonably well: the FIM has a lower RMSE than the linear HB and the Bayesian PCA models and is outperformed only by the RF and the DNN. Moreover, linear HB and Bayesian PCA models are significantly better than the baseline at identifying valuable customers, which proves that acquisition characteristics carry valuable information to predict the value of customers. Nevertheless, the FIM significantly improves the identification of valuable customers over the benchmark models, including the DNN, correctly identifying 40.5% of customers in the Top 10% and 47.7% of customers in the Top 20%. These results are consistent with the notion that because the FIM captures the nonlinearities in the relationship between acquisition characteristics and future demand parameters, it does an excellent job—significantly better than the benchmarks—at sorting customers on the basis of their expected value inferred from their acquisition characteristics.
Similarly, a firm would use the FIM to identify which customers are the most sensitive (or least sensitive) to marketing interventions—information that would be instrumental in increasing the effectiveness of its marketing actions (e.g., Ascarza 2018). Unfortunately, our data does not enable us to quantify the exact value that the focal firm could extract from a FIM-based targeting approach; ideally, one would run a field experiment to test the effectiveness of targeting policies based on the predictions of the FIM. Nevertheless, combining the results from the “Model Performance” subsection, where we demonstrate the model's ability to predict the (individual-level) demand intercept as well as the sensitivity to the covariates, with the results in Table 7, where we corroborate some of those findings in our empirical application, we are confident that implementing targeting policies based on predictions of the FIM would generate incremental revenues to the firm. We trust that future research will be able to quantify these benefits empirically.
Second, we use the FIM results to explore the acquisition variables that better characterize “heavy spenders” (separately from light users), customers with “high sensitivity to email” (from those who are better left out in the email campaigns), and those who are “most sensitive to direct marketing” campaigns. From the model predictions, we split customers from the Test sample in three groups—top 10%, middle 80%, and bottom 10%—for each of the three categories and summarize the average value of each of the (standardized) variables observed at the moment of acquisition. Figure 5 shows the results when sorting customers on the basis of expected future value. Several interesting findings emerge: Consistent with the patterns we observed when exploring the predictive power of the acquisition variables (Figure 1), we find that the top 10% heavy spenders are less likely to be acquired during the holiday period, more likely to being acquired offline, and tend to buy expensive and discounted products in their first purchase, compared with those in the bottom 10%. They are also characterized to buy certain types of products, as indicated by the high likelihood of including Perfume and Hair products in their first transaction (lower likelihood of including products in the Body Care, Home, and Services categories) as well as by a high score in dimension 4 of the product embeddings. 38
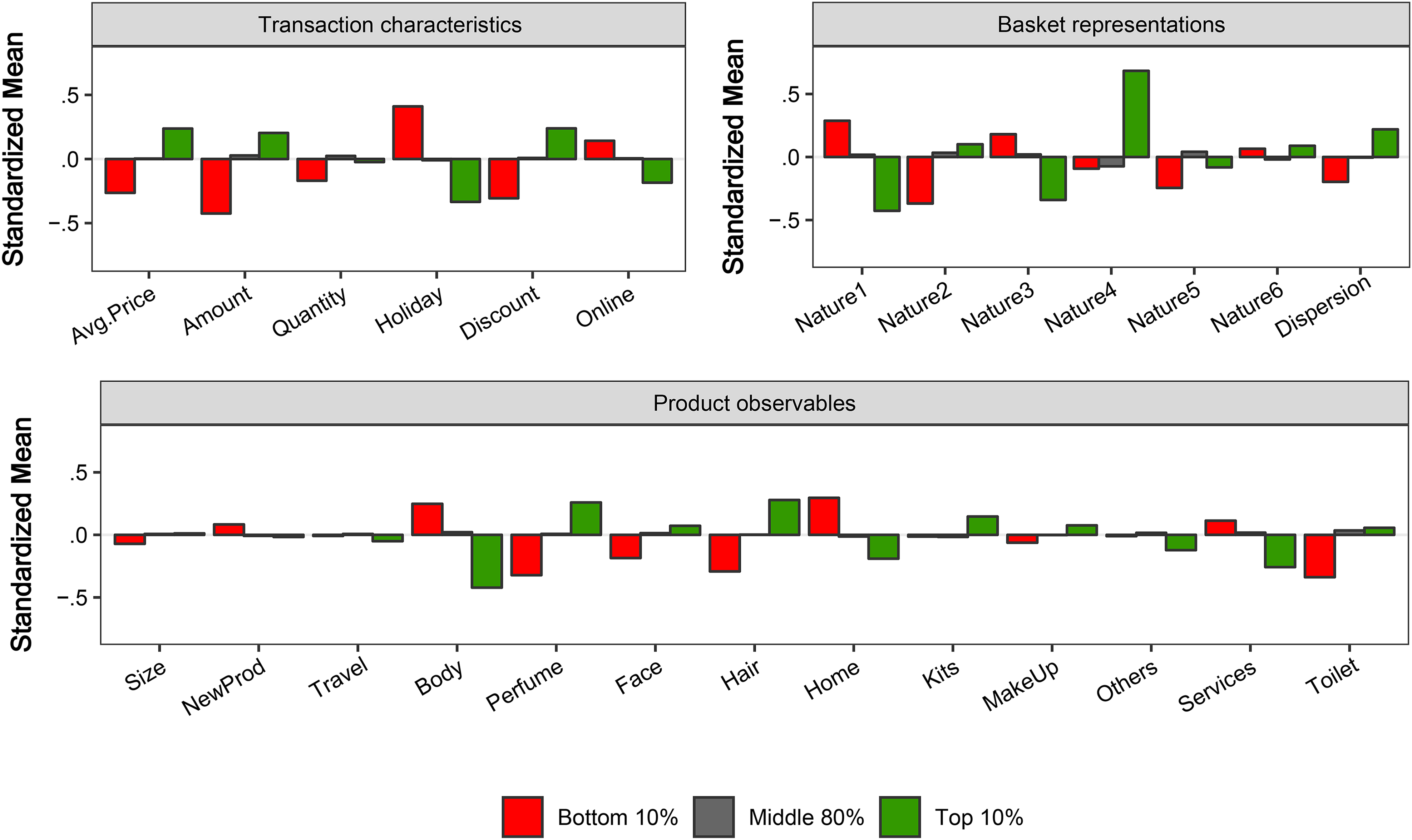
Acquisition characteristics for customers with top/middle/low CLV.
We repeat the analysis now sorting customers on the basis of their predicted sensitivity to email (Figure 6) and predicted sensitivity to DM (Figure 7). Consistent with the previous findings, several acquisition characteristics exhibit a nonlinear relationship with the sensitivities to marketing actions. Both the top 10% and bottom 10% email sensitivity groups are less likely to buy in the Body Care category during their first transaction, compared with the remaining 80% of customers in between. Customers who are the most sensitive to email marketing are more likely to be acquired online, buy less expensive products, and buy fewer units in their first purchase. With respect to DM, less sensitive customers buy fewer units and more expensive products in their first transaction, while high-sensitive customers are more likely to buy relatively small-sized products, recently introduced products, and products in the Perfume Category at their first purchase.

Acquisition characteristics for customers with top/middle/low sensitivity to email.
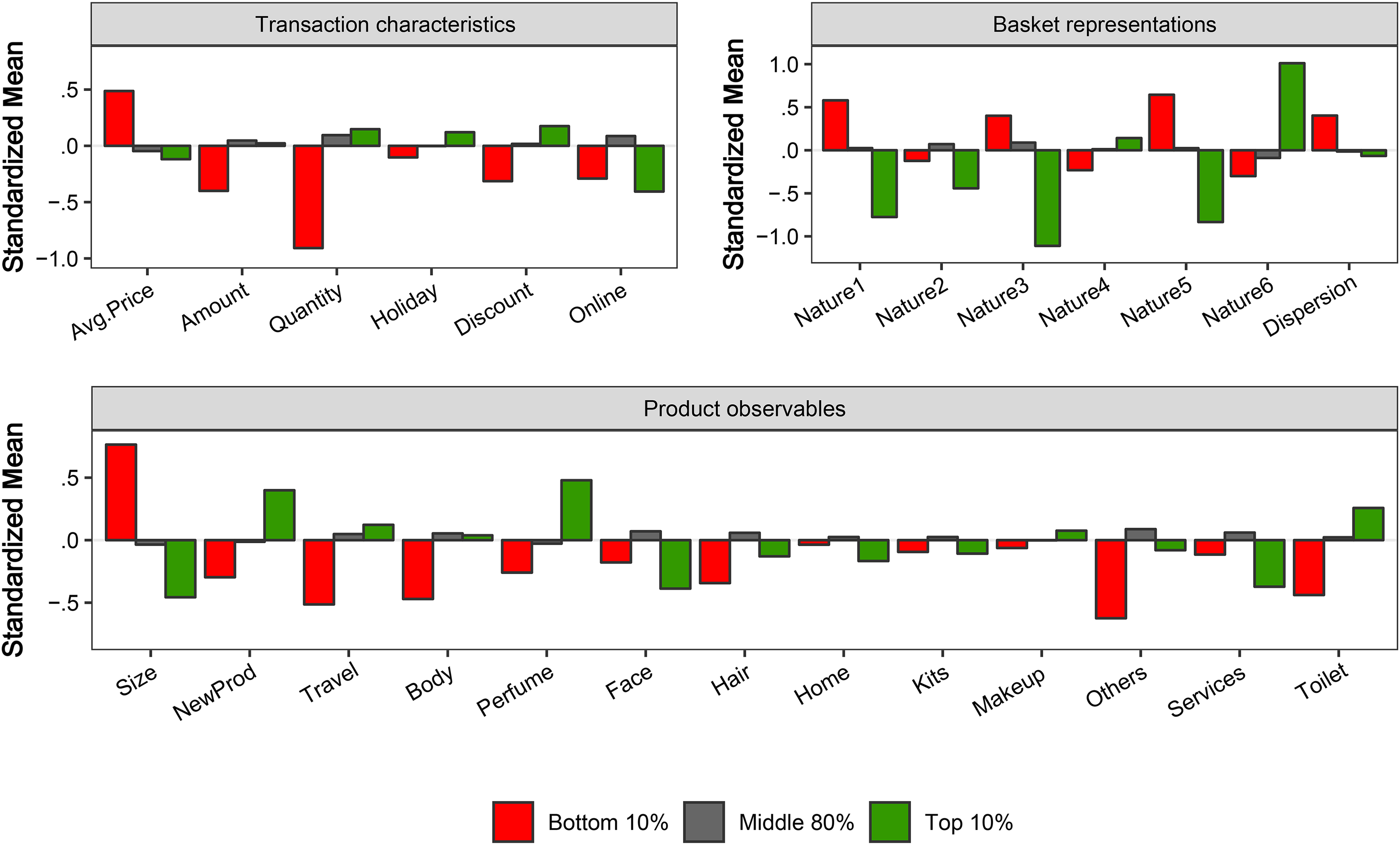
Acquisition characteristics for customers with top/middle/low sensitivity to DM.
Finally, we use the inferred demand parameters from these test customers to explore the relationships between the magnitude of the demand parameters and the acquisition characteristics. Figure 8 shows the individual-level posterior mean of the demand parameter versus the acquisition characteristics for a set of demand parameters and acquisition characteristics. In particular, we find that these plots corroborate that there are nonlinear relationships that the model can uncover. 39 Figure 9 explores possible interactions by presenting box plots of individual-level posterior mean demand parameters and pairs of discrete acquisition characteristics. The model replicates the model-free insights shown in Figure 2: (1) the relationship between the intercept and whether the customer was acquired during the winter holiday season (Holiday) depends on whether the customer purchased a travel-sized product (Travel Size), and (2) the relationship between the intercept and whether the customer purchased discounted products at acquisition (Discount) depends on whether the customer purchased a recently introduced product (New Product). Moreover, the model captures these relationships not only for the intercept but also for other demand parameters. For instance, the holiday season lift is higher for customers who were acquired during a previous holiday season compared with those who were not, but this difference is considerably larger for those who did not purchase a travel-sized product when acquired. In addition, the differences in email sensitivities across customers who received discounts on their first purchase exist only for those who purchased a recently introduced product at acquisition.
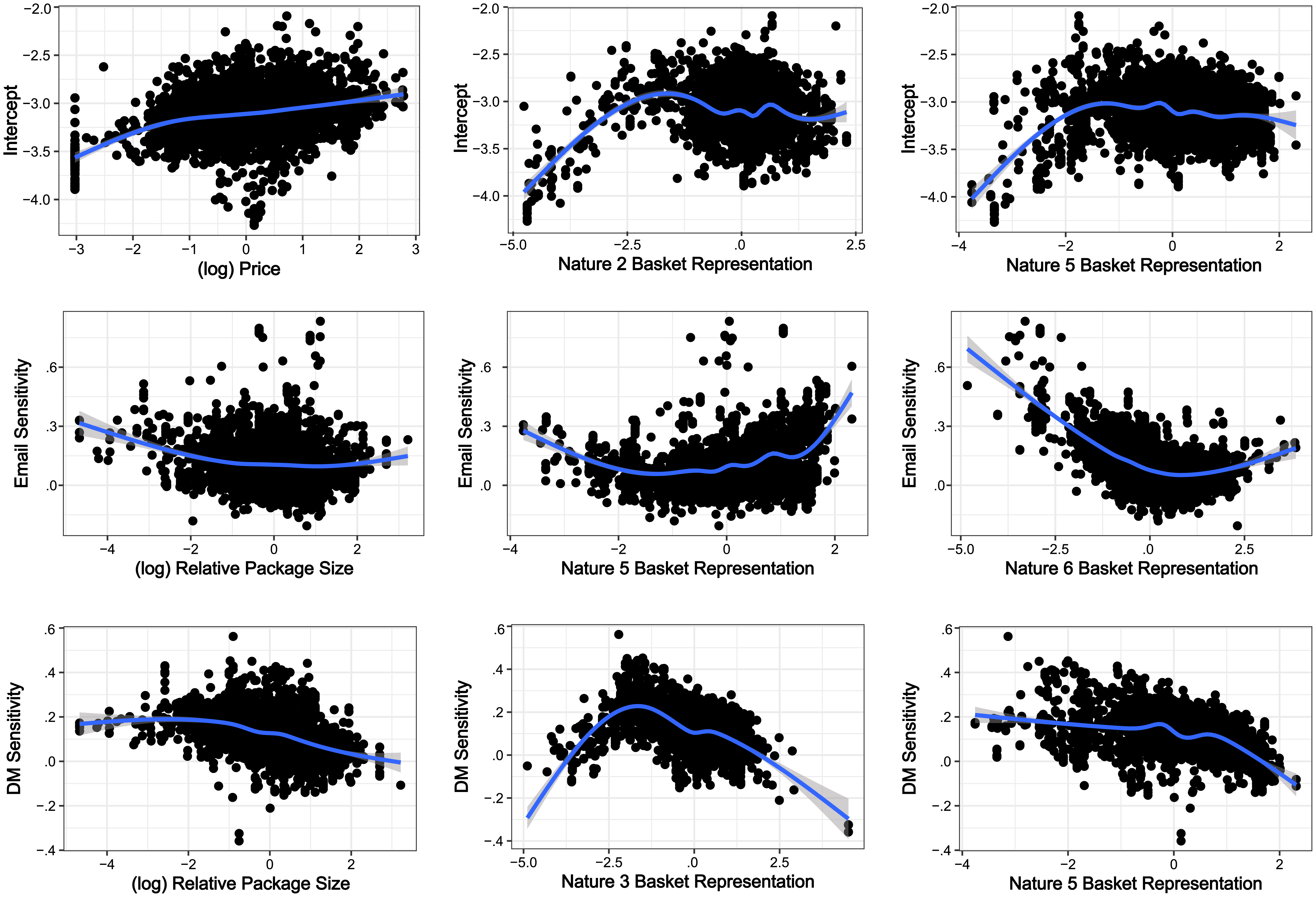
Empirical relationship between the posterior mean and some (continuous) acquisition characteristics.

Empirical relationship between the posterior mean and some of the (binary) acquisition characteristics.
Conclusion
We have developed a modeling framework (FIM) that, leveraging information collected when customers are acquired, enables firms to overcome the cold start problem of CRM. Using a probabilistic ML approach, the model connects underlying acquisition and demand parameters using a set of hidden factors modeled via DEFs. The multilayer structure with flexible relationships among layers enables the researcher or analyst to be agnostic about the (assumed) underlying relationship among variables. The hidden factors automatically extract relevant information from existing data (i.e., identify the traits that relate acquisition characteristics with future outcomes), overcoming the challenge (commonly faced by firms) of maintaining significant amounts of redundant and irrelevant data in their customer databases.
We have illustrated the benefits of using the FIM in a retail setting. First, we have shown how the focal firm can further leverage its existing database to augment the cold start data using readily available techniques. We have further demonstrated how subtle signals extracted from the augmented data by the FIM enables the focal firm to make individual-level inferences about just-acquired customers (e.g., distinguish high-value customers from those unlikely to purchase again) and those most and least sensitive to marketing interventions (e.g., email campaigns, DM). We leverage the model predictions to identify characteristics of first transactions that are predictive of customer behavior in future periods. For example, compared with the rest, top 10% heavy spenders are more likely to be acquired online and their first purchases are more likely to be expensive and contain discounted products; customers identified as most sensitive to email marketing are more likely to be acquired online but buy less expensive products, and their first purchases are more likely to contain fewer units.
These findings suggest that firms can meaningfully categorize customers by drawing on characteristics of their first transactions. We believe this approach to customer segmentation to be promising in that it relies on neither customer-provided data, which is sometimes difficult to obtain (Dubé and Misra 2017), nor external sources of data that could pose privacy concerns. The resulting insights can be used both to prune acquisition data and to inform decisions about the types of variables worth collecting from customers who make a first transaction or first visit a company's website. Our research shows that firms leave value on the table by not fully leveraging the multiple behaviors observed when a customer makes a first transaction, and it provides a general framework for extracting meaningful but hard-to-pinpoint relationships imprinted in subtle ways in “cold start” data.
While this research highlights the value of using the FIM to tackle the cold start problem of CRM, it is also important to acknowledge some limitations of the present research. The simulation analyses enabled us to validate the accuracy of the model at inferring individual-level parameters, but doing so in an empirical setting, in which only realized purchases are observed, is more difficult. We leave it to future research to examine and quantify the effectiveness of targeting policies based on the predictions of the FIM. Regarding the model specification, we investigated model performance using linear and logistic specifications for the demand and acquisition models. Although the proposed FIM is extremely flexible so as to be adaptable to other modeling frameworks, we have not empirically tested the model's performance in more complex structures. The current model estimation is computationally feasible for data sets with thousands of customers, dozens of time periods, and a handful of variables (as in our empirical application). Although the model scales readily to situations with more acquisition variables (and the model does not need to be fully trained when making inferences on new customers), increasing the sample size to, for example, millions of customers will increase estimation time substantially, constraining the ability to gauge customers’ first impressions in a timely manner. For such cases, variational inference implemented in recent deep probabilistic programming languages that allow for black-box variational inference methods (e.g., Pyro) might be a better way to estimate and use the model. We look forward to reading about and exploring such approaches in future research.
A natural extension to this research would be to investigate a wider range of acquisition characteristics and the relevance thereof to customers’ first impressions in different contexts. The results of our empirical application could be built on to further augment the data from first purchases and incorporate other acquisition characteristics that, although not currently collected (e.g., whether the customer visited the store alone or with family), could be valuable in identifying which marketing actions are most likely to increase future sales. We encourage further research to investigate these research settings and identify additional drivers and methods that might help companies overcome the cold start problem.
Because the main goal of this work is to provide a flexible model that overcomes the cold start problem, we have not formally investigated the latent traits that drive all the observed behaviors. It would be relevant for researchers and marketers to identify individual traits that characterize shopper behavior, to which end customer behavior in a variety of contexts could be measured and estimated in a unifying FIM framework. We hope that this research opens up new avenues for understanding “universal” shopping traits and identifies the behaviors that best relate to those generalizable findings.
Footnotes
Acknowledgments
The authors are grateful to the Wharton Customer Analytics Initiative (WCAI) for providing the data used in the empirical application. The authors thank Bruce Hardie, Donald Lehmann, Daniel McCarthy, and Oded Netzer for very useful comments and suggestions, the participants of the seminars at Harvard Business School, McCombs School of Business, Rotterdam School of Management, Tilburg University, Tuck School of Business, Questrom School of Business, Rady School of Management at UCSD, The Wharton School, and the audiences of the 2018 Marketing Science conference, the WCAI symposium and the 2020 Virtual Quantitative Marketing Seminar for their comments. The authors are grateful to Hengyu Kuang for excellent research assistantship.
Associate Editor
Fred Feinberg
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.