
Abstract
Internet news and search sites often excerpt content from and link to competing news outlets. On the one hand, providing outbound links can make the linking site more attractive, even to the point of stealing traffic from the linked sites. Regulatory policy, such as the European Union’s Copyright Directive Article 15 taxing links, is predicated in part on this idea. On the other hand, receiving inbound links can increase a linked site’s audience by informing readers about its news content that day. To explore these opposing perspectives, the authors develop a dynamic learning model and fit it to browsing and link data from celebrity news sites. They then simulate how banning links affects consumer browsing and find that linking increases celebrity news consumption, especially among consumers who browse the least. On average, linking benefits both the linking and linked sites. The authors estimate that exposure to a link increases the likelihood of visiting the linked site by .14%. This increase is approximately three times the commonly reported click-through rate for paid display advertisements.
Keywords
On October 2, 2009, celebrity news website The Superficial reported about homophobic comments rapper 50 Cent had made about Kanye West. The Superficial’s article excerpted content from and linked back to another news article—also about West and 50 Cent—that was published at Celebuzz, another celebrity news site. Thus, anyone who read The Superficial’s article but had not yet visited Celebuzz would have learned something about Celebuzz’s content that day. Importantly, this knowledge might have affected what these readers chose to do next. Fans of rap music, for example, might have been more likely to visit Celebuzz that day, whereas others might have been less likely. 1
Although this example comes from celebrity news (the empirical context for this article), linking among news sites is a key feature of internet news—of all types—that sets it apart from print news. Links to other news sites provide information about the linked sites’ content that consumers would otherwise not observe. Thus, links play an important role in online news consumption by helping readers locate interesting content (and avoid uninteresting content) more efficiently.
The purpose of this study is to gain a better understanding of how linking among internet news sites affects demand for online news. We aim to measure how much the likelihood of visiting a linked celebrity news site changes after encountering a particular link, while accounting for the possibility that consumers anticipate and value outbound links when choosing which sites to visit. Motivated by recent regulatory initiatives, such as Article 15 of the European Union (EU) Copyright Directive—the so-called “link tax”—and legislation that led to the withdrawal of Google News from Spain, we consider the implications of a policy of banning links on the consumption of online news. Implicit in these regulations is the belief that links and excerpts are mostly harmful to news publishers. The idea is that by appropriating content from linked sites, linking sites steal audience share from the sites they link to, thereby decreasing the linked sites’ traffic and advertising revenues. However, because excerpts inform readers about the linked sites’ content, they can potentially increase the linked site’s audience and revenues. Google estimates that news excerpts in search results drive 8 billion clicks per month to European publishers (Gingras 2019). We consider both perspectives about the effect of links on traffic and find evidence that links to news sites can be more beneficial to the linked sites than harmful. Quantification of these link effects is an important first step in measuring the welfare effects of link taxes.
Throughout this study, we make a distinction between two effects of linking on consumer demand for online news. One effect arises after a consumer encounters a specific link and learns about the linked site’s content on that particular day. We refer to this learning as the “within-session” effect of linking, as its influence on the consumer’s choices is confined to the remainder of that day’s browsing session. The other effect arises when a consumer, before visiting a site, assigns it a higher value because the site tends to provide useful links. We refer to this enhanced value as the “across-session” effect, because the higher value (1) depends on the consumer’s knowledge of sites’ long-run average content and linking behaviors and (2) affects which sites consumers tend to visit in the early steps of all browsing sessions.
We measure both of these effects and further assess the net impact of banning links on (1) total traffic at the linking and linked sites, (2) the frequency with which consumers browse for news, and (3) the number of sites consumers visit in each session. These insights are relevant to (1) content producers, who need to know how linking affects their traffic (and, thus, advertising revenue); (2) policy makers such as the EU, who need to understand how excerpting affects consumer demand for news; and (3) advertisers, who need to know how changes in linking affect the reach and frequency of ads running on multiple sites.
We consider the effects of linking on consumers and news sites by developing and estimating a structural model of demand for online news. The structural approach enables us to assess a counterfactual policy of banning links prospectively, rather than waiting to observe such a policy in data. The structural approach also facilitates a decomposition of linking effects into the within- and across-session effects just described. The combination of these effects can be either positive or negative for the linked sites. Thus, this decomposition of link effects both motivates and enriches the counterfactual policy analysis.
At its core, our model describes sequential news consumption with learning among consumers with heterogeneous opportunity costs from browsing and horizontal tastes for news (the latter means, for example, that some readers might enjoy reading about Kanye West, but others might not). A consumer’s utility from reading a site’s content depends on the consumer’s match with what the site published that day. Due to the nature of news, consumers are ex ante uncertain about what each site has published each day. Therefore, at the start of each browsing session, consumers are uncertain about their horizontal match with each site that day.
Each link provides a signal about consumers’ (heterogeneous) horizontal match utilities with the linked site’s content on that day. Because these links are informative about daily variation in horizontal match, their within-session effect can be to increase the likelihood of visiting the linked site for some consumers and decrease it for others. In both cases, encountering a link lowers uncertainty and, thus, (on average) leads to better browsing choices later in the session. We consider a model with forward-looking individuals and contrast this model with one in which consumers are not forward looking. Forward-looking consumers anticipate that encountering links will decrease their uncertainty about their daily match with the linked sites. This anticipation is the source of the across-session effect, whereby forward-looking consumers place a higher expected value on sites that frequently link to others. We show that this higher valuation can lead to higher traffic for the linking site, but either higher or lower traffic at the linked site.
Because the net impact of linking on site traffic depends crucially on the particulars of a news ecosystem, the question of whether links are beneficial or not is fundamentally empirical. We conduct such an empirical analysis using internet panel data describing browsing at five celebrity news sites, which we augment with data describing the daily news content and links published at those sites. Preliminary analysis of the raw browsing and link data shows that for more than half of the panelists, the likelihood of visiting a site is lower after encountering a link to that site. This outcome is consistent with our modeling framework, which allows the within-session effect of observing a link to either increase or a decrease this likelihood. When the baseline probability of visiting a site is already low, this probability can increase much more than it can decrease due to a floor effect. For this reason, the aggregate effect of encountering a link (averaged across panelists) in the raw data is positive.
To assess how banning links affects browsing, we first fit the data to our structural model, and subsequently use the estimates for counterfactual simulations. The model estimates provide a view into how these celebrity news sites differentiate from one another, both vertically and horizontally. The results also underscore the importance of links to the consumers who visit these news sites. In this empirical setting, encountering a link lowers consumers’ uncertainty about their daily match with the excerpted site by approximately 6%. The results further show that consumers value this reduced uncertainty and thus find sites that provide outbound links more attractive. In total, linking raises the value of reading celebrity news.
Although the data reflect choices made on days when sites both linked and did not link to each other, browsing on days without links occurred in a world where linking was allowed (meaning consumers could anticipate the possibility of finding links). Estimating a structural model thus allows us to consider a counterfactual policy of banning links that is not observed in the data. These results show that among these news sites, the total effect of linking is positive for both consumers and the sites. Compared with a counterfactual without linking, the median consumer visits
The remainder of this study is organized as follows. First, we discuss our study’s contribution in the context of the prior literature. Next, we present the structural model and discuss its main behavioral implications. We then describe our data, and discuss issues related to estimation and model identification. Finally, we present the model estimates and results of the counterfactual simulations, before summarizing the implications and limits of this study.
Contribution and Related Literature
This study builds on previous work in marketing and economics that has modeled internet browsing both at the aggregate (Danaher 2007; Park and Fader 2004) and individual levels (Goldfarb 2002; Johnson et al. 2004; Lee, Zufryden, and Drèze 2003). Among these studies, our model is most similar to that of Goldfarb (2002). We describe utility-maximizing individuals choosing which site to visit next, in consideration of their past browsing decisions and any outbound links they expect to encounter. In our model, however, encountering outbound links does not generate utility per se. Instead, such a link provides the consumer with a positive or negative signal about the linked site’s content. Thus, in our model, outbound links make the linking site more attractive because they help consumers make better browsing choices later in the session. Moreover, the extent of this increased attractiveness varies across consumers depending on (1) the set of sites that are typically linked and (2) consumers’ average preferences for those sites.
Although our study focuses on the demand implications of linking, this study is also related to previous theoretical work that has considered the process by which sites link to one another (Dellarocas, Katona, and Rand 2013; Jeon and Nasr 2016; Katona and Sarvary 2008; Mayzlin and Yoganarasimhan 2012). This work shows how links can play an important role in helping uninformed consumers discover new sites and learn about their typical news content. In equilibrium, sites end up serving a mix of experienced consumers—those who already know about the sites’ typical content and outbound linking decisions—and inexperienced consumers—those who are as of yet uninformed about these. We do not model such a process of site discovery. Rather, we condition on its outcome—the content and links observed in our data—and estimate their effects on experienced consumers’ demand for news sites.
Our model is grounded in the consumer learning literature in marketing (Ching, Erdem, and Keane 2013; Ching, Erdem, and Keane 2017; Erdem and Keane 1996). In our model, consumers sequentially choose which site to visit next in the current browsing session. This choice is made with uncertainty about the news content at each site. However, with each site visit, there is the potential to observe outbound links, and thereby obtain signals about the consumption utility from other sites. Our study is therefore related to previous work that has modeled consumer learning about a good via advertising or information spillovers from consuming related goods. Because our empirical setting involves individuals consuming news content that changes every day, we observe, for each consumer, multiple repetitions of a learning process that starts with the same initial condition (not having read the news yet).
We make two methodological contributions to the Bayesian learning literature. The first of these is related to our model. Although the main focus of our model is on consumers learning about horizontally differentiated site content after observing outbound links—and the Bayesian learning model we use to capture these dynamics is standard in the literature (Ching, Erdem, and Keane 2013)—there are other dynamics, also relevant in a news consumption setting, that motivate a second Bayesian learning process. Specifically, different news outlets can publish the same basic news facts, but consumers only gain utility from their first encounter with those facts. Thus, if two sites publish many of the same news facts, the marginal utility from the second site’s content will be lower after visiting the first. Because the utilities from the two sites’ news content are correlated, after visiting the first site, there is the potential for Bayesian updating about the amount of unknown content that remains at the second site. Thus, we augment the main model (horizontal differentiation and linking) to include a vertical dimension of utility with Bayesian learning based on the daily volume of basic news facts published at each site. We first conceptualize these news facts as distinct bits, each of which represents a unique piece of information capable of generating utility when first encountered (Allen 1983, 1986, 1990). Using this foundation, we then consider how these bits are consumed under uncertainty. The resulting Bayesian learning model is novel to the consumer learning literature. We believe this approach could be a useful basis for studying consumption utility in the context of news and other information goods. Moreover, this approach is general enough to be used to study sequential choices over alternatives with correlated utilities in other settings (e.g., retail store visits).
The second methodological contribution pertains to our estimation procedure, which combines two advances from the econometrics and statistics literatures, and provides a template for efficient Bayesian estimation of single-agent dynamic discrete choice models. Our approach to estimation is based primarily on that of Imai, Jain, and Ching (2009, hereinafter IJC). Compared with the standard nested fixed-point algorithm for estimating dynamic discrete choice models (Aguirregabiria and Mira 2010), IJC’s method requires significantly fewer computational resources (Ching, Imai, et al. 2012). Although IJC’s computational advantages are great, the method still produces samples that can be highly autocorrelated. Thus, we further improve efficiency by using Girolami and Calderhead’s (2011) full manifold Metropolis adjusted Langevin algorithm (MMALA) to construct high-quality proposal distributions for the Metropolis–Hastings accept/reject steps in the IJC algorithm. This approach decreases autocorrelation in the resulting sample chains and improves the rate of convergence to the posterior distribution.
Finally, although limited in scope to the empirical setting of celebrity news, our findings contribute to an emerging empirical literature that seeks to understand how the internet affects news consumption (Flaxman, Goel, and Rao 2016; Gentzkow and Shapiro 2008, 2011; Gentzkow, Shapiro, and Sinkinson 2011). Some of this work has looked at how large news aggregators—Google News in particular—affect the amount of traffic going to linked news sites (Athey, Mobius, and Pál 2017; Calzada and Gil 2018; Chiou and Tucker 2017; George and Hogendorn 2019; Majó-Vázquez, Cardenal, and González-Bailón 2017; Posado de la Concha, García, and Cobos 2015). Studies in this literature typically exploit sudden changes in Google News’s linking behavior due to market entry, copyright lawsuits, or legislation. These studies have shown that the aggregator’s outbound links can increase traffic to smaller or more horizontally differentiated news publishers, while having a less positive, or possibly negative, total effect on larger or more mainstream news sites. As a pure news aggregator, Google News does not create any news content of its own. By contrast, the sites we consider primarily publish original celebrity news while also excerpting from and linking back to one another. Sites such as these generate a substantial portion, if not the majority, of the links and excerpts most readers will encounter when consuming news. We contribute to this literature by considering the impact of links originating from sites that publish original news content, studying individual consumers rather than aggregate traffic, structurally modeling the entire news browsing sequence, assessing the separate effects of linking within and across sessions, assessing how links affect demand at different steps of the browsing session, and simulating a counterfactual policy of banning links.
Modeling Framework
A defining characteristic of news, whether online or offline, is its uncertainty. Consumers do not know exactly what a news site has published until after they visit the site and see its content (otherwise, the content is not news to the consumer). The importance of this point for understanding how links affect news consumption is illustrated by the previous example of the link to Celebuzz’s coverage of 50 Cent and Kanye West. A consumer who likes reading about rap artists might have experienced higher-than-normal utility from visiting Celebuzz that day, while a reader who dislikes rap artists might have experienced lower-than-normal utility. In either case, the consumer could not have anticipated this difference in utility unless they knew something about Celebuzz’s coverage ahead of time.
Links provide consumers with this type of knowledge. Anyone who saw The Superficial’s article, which excerpted and linked back to Celebuzz, would have learned something about Celebuzz’s coverage that day. Thus, consumers who like reading about rap artists might have been more likely to visit Celebuzz after seeing the link. At the same time, not all consumers want to read the same type of news. Thus, consumers who dislike rap might have grown less likely to visit Celebuzz after seeing the link.
This example highlights the core of our model. Consumers have heterogeneous horizontal preferences for differentiated news content, meaning that consumers differ in the type of content they like to read. Every day, sites publish new content, leading to variation in and uncertainty about the horizontal utility their readers will receive from reading that content. At the start of each browsing session, consumers are initially unaware of what each site has published. Yet as consumers encounter links to sites they have not visited yet, that uncertainty is reduced. This learning process takes place over the course of a single browsing session and repeats each day starting with the same initial information state (not knowing the news).
The model describes the choices made by experienced consumers of online news. These consumers are certain about the type of content sites tend to publish on average, but uncertain about what those sites publish on any given day. We assume that based on their past browsing, these experienced consumers already know the sites’ stable, long-run average content behaviors. Specifically, they know which topics the sites typically cover, as well as the frequency with which the sites link to each other.
Previous studies have considered the processes by which sites arrive at these stable, average content and linking behaviors, and consumers come to know them (Dellarocas, Katona, and Rand 2013; Katona and Sarvary 2008; Mayzlin and Yoganarasimhan 2012). We do not model such a process but, rather, assume it has already taken place. We condition on sites’ supply of content and links to model experienced consumers’ demand for these (we detail our identification strategy later).
To focus attention on the role of links, we first present a model in which sites are only horizontally differentiated in their news coverage. One site, for example, might focus on news about the film industry, and another site on news about reality television. Consumers who like films but dislike reality TV would probably prefer the former over the latter, on average. We subsequently extend the model so that news sites are vertically differentiated according to the amount of news facts they publish.
Notation, Timing, and Period Utility
We present the model from the perspective of a single consumer, bearing in mind that different consumers have different preferences for news. Every day, the consumer engages in a browsing session, which is indexed d. By a “browsing session,” we refer to the process of sequentially visiting zero or more sites within a day (visiting zero sites means not browsing that day). Figure 1 depicts the sequence of events within each browsing session (Figure 1 includes notation that we explain subsequently).

Schematic representation of steps in browsing sessions.
At each step of the browsing session, t = 1,…, Td, the consumer decides which site to visit next, if any (Figure 1, °3). Visiting a site and viewing its content does two things: (1) it provides utility to the consumer and (2) it changes the consumer’s information set (Figure 1, °4). Consumers are indexed with i and the sites with j. When discussing linking, we sometimes refer to the linking site by the index j = L, and the site receiving the link by the index j = R. The option j = 0 denotes the option to end the browsing session. The set
We follow the literature on sequential browsing online and assume that the consumer sees all available content at each site visited, and therefore visits each at most once per session (Kim, Albuquerque, and Bronnenberg 2010). This assumption matches both the empirical context of celebrity news sites (whose home pages display all content posted each day), and choices observed in the estimation data (which we describe subsequently). Thus, the consumer’s choice set, which is initially
The utility from visiting site j at step t of browsing session d comprises three parts.

The first is
Apart from
Horizontal Match Utility from Content
The horizontal component of utility,
In these examples, as well as in our model, we make an important distinction between a site’s long-run average match with the consumer, and daily deviations from that average. The consumer’s long-run average match with a site depends on the type of content the site publishes on average. This long-run average is therefore the same for every browsing session. On the basis of a potentially long history of browsing, an experienced consumer knows their own long-run average match with each site. By contrast, daily deviations from that average arise due to news events and the sites’ choices about what to publish. These daily deviations are therefore unknown at the start of each session (Figure 1, °1 and °7). We model the horizontal match utility consumer i receives from site j’s content on day d as a function of (1) site j’s long-run average position in a horizontal attribute space, zj; (2) site j’s deviation from this average position on day d, νjd; and (3) the consumer’s preferences, vi.

This formulation implies that consumers, on average, prefer sites for which

Like the zjs, we assume that consumers know the value of
Signals of Horizontal Match Utility from Links
If the consumer visits site L during session d, and if site L has linked to site R that day, then the consumer will learn something about their horizontal match with site R that day. Site R, for example, might rarely report on rap artists. Site L’s link to R’s coverage of Kanye West thus signals that R’s coverage leans more in the direction of rap artists that day. If site L links to site R on day d, we say

Although horizontal position
This setup highlights the informative role of linking among news sites. Links help consumers ascertain whether a site’s content is more or less congruent with their preferences that day. Importantly, because different values of ν jd imply higher or lower levels of match utility (relative to the site’s long-run average), links can signal lower-than-average match (in which case they make the consumer less likely to visit the linked site). Furthermore, because consumers have different horizontal preferences, vi, the same link from L to R might make some of L’s readers more likely to visit R, and others less likely.
Updated Beliefs About Horizontal Match Utility
Let nijd t–1 denote the number of links to site j that consumer i has seen prior to choosing what to do at step t of session d, and

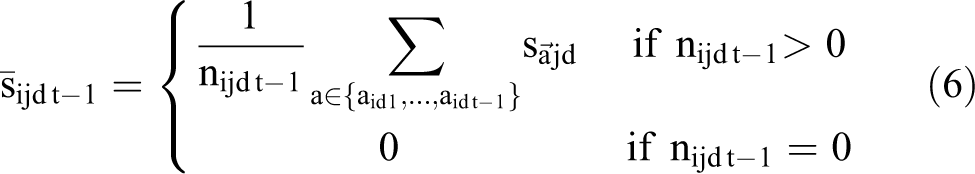
Before the consumer sees any links (

Expected match utility at site j is thus a weighted average of the consumer’s long-run average match, zjvi, and the match signaled by previously seen links to j,
Summary of Bayesian Updating for

Value Function for Present and Future Browsing
When consumers visit a site, they not only gain utility but also may update their beliefs about match utility at other sites if they see outbound links (Figure 1, °4). As we show subsequently, forward-looking consumers anticipate this updating and thus face the standard exploitation–exploration trade-off when choosing which site to visit next. A consumer, for example, might decide to visit a site that frequently links to many others, expecting any links encountered to increase (decrease) their chance of visiting (avoiding) sites with higher (lower) daily match. For such consumers, sites that provide many outbound links provide value, in part, by raising the expected utility of the remainder of the browsing session.
The following value function corresponds with consumer i’s utility function and beliefs about match utility at step t of session d.

Equation 8 introduces the following notation:
We describe the latter two bulleted terms next.
Consumer Information Set
The consumer’s information set, Iidt, includes three variables.
4
The first two, the number of links to each site encountered,
First, and most simply, given the choice to visit site j, the set of sites visited, hidt, will evolve deterministically to reflect this choice. Second, if site j has not linked to any other sites, then neither nidt nor
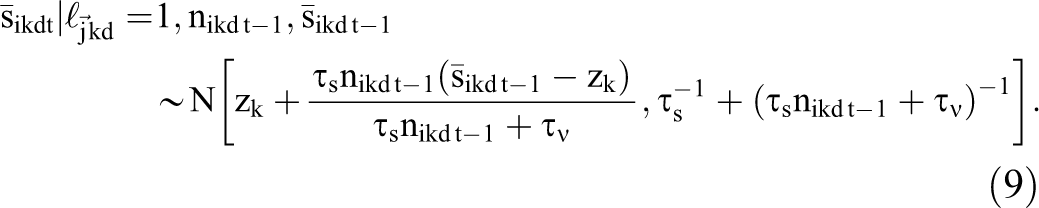
Prior to visiting site j, however, the consumer does not know if site j has linked to any other sites. Because links are a priori unobserved by consumers, the transition function also reflects consumer i’s uncertainty about whether they will see links to other sites. We assume these probabilistic beliefs are rational, to the extent that experienced consumers know the average frequency with which each site j links to every other site k. We denote this long-run average linking frequency

This link probability does not imply that site j links to site k at random. Importantly, why site j chose to link to site k on day d does not matter as long as the consumer’s expectations about links are based on their knowledge of
Effects of Linking on Choice
The value function in Equation 8 encapsulates two routes through which linking can affect choice. The first is the within-session effect described in Equations 2
–7. This effect operates through Bayesian updating of expected horizontal match utility as consumers are exposed to the set of available links,
The second route through which linking can affect choice is the across-session effect. This effect is a consequence of consumers’ forward-looking behavior (Equations 8
–10), and in particular, consumers’ rational expectations about the sites’ long-run average link frequencies,
To illustrate these implications, we use our model to simulate browsing in a stylized setting with two news sites and one consumer. Site L sometimes links to site R, but R never links to L (thus,
Linking can increase traffic to the linked site through the within-session effect
If the probability of visiting R is below 50% at the start of the session—as is typical for most sites consumers visit—then links from L to R increase the number of L’s visitors who subsequently visit R within the same session. Moreover, this increase arises even though half of L’s links signal lower-than-average match at R. This increase in visits is due to a floor effect on the likelihood of visiting R. If the chance of visiting R is already low, a signal indicating lower than normal match utility can do little to lower the visit likelihood further. By contrast, a signal indicating higher match can raise the chance of visiting the linked site considerably. Importantly, the increase in R’s traffic arises in cases when the consumer, if not for the link, would have ended the session after visiting L. Thus, exposure to links increases overall news consumption on average. Note also that the increase in traffic at site R is due to the consumer’s exposure to specific realizations of links,
Providing links can increase the linking site’s traffic at the start of the session through the across-session effect
Recall that in this example, the zjs for sites L and R are the same and that L may link to R with probability
The increased attractiveness of L has two effects on browsing. First, it makes the option of not browsing relatively less attractive, thus increasing the number of browsing sessions. Second, the increased attractiveness of L means R is relatively less attractive at the start of the session. Thus, by linking to R, site L may end up “stealing” traffic that would have otherwise gone to R (Dellarocas, Katona, and Rand 2013; Jeon and Nasr 2016). Importantly, both of these effects depend on the forward-looking behavior of the consumer, as a consumer who discounts the future completely (
The combined within- and across-session effects can either increase or decrease traffic at the linked site
The within-session effect increases the number of L’s visitors who might subsequently visit R. This positive effect is further amplified by the across-session effect—if L attracts more visitors early in the session, there will be more people seeing its links to R. But linking to R can also lower R’s traffic. The across-session effect allows L to attract visitors who, in the absence of linking, would otherwise have visited R. Depending on the size of this effect, R may lose more traffic to L at the start of the session than R gains from L’s links later in the session.
Whether the total impact of linking is positive or negative for the linked site is thus an empirical question. The sign depends on a variety of factors, including (1) how often sites link to each other, (2) how informative links are, (3) the extent of horizontal differentiation among the linking sites, (4) the overall popularity of the sites, and (5) the extent to which future benefits from browsing affect previous decisions.
Vertical Differentiation in News Volume
The period utility function in Equation 1 includes a horizontal match utility term,
In most empirical contexts, including ours, sites are also differentiated vertically. In a news setting, vertical differentiation can be based on the volume of basic news facts sites publish, and consumers may differ in the value they place on greater news coverage. Extending the model to include a vertical dimension of utility has two implications for how it can rationalize browsing data. First, differences in news volume can help explain why some sites are more popular among all consumers. Second, in a setting where there is redundancy in news coverage across sites, differences in news volume can also help to explain why we rarely observe consumers visiting more than a few news sites in the same browsing session. In other words, vertical quality also helps to explain session length.
To illustrate the connection between news volume and session length, consider two sites that partially overlap in their coverage of basic news facts—such as the fact that an actor has been admitted to a drug rehab program, or the fact that a singer has released a new music video. After the consumer has visited the first site, some of the news facts at the second site will no longer be news, as they will already be known to the consumer. In the extreme, if two sites published every available news fact each day, their coverage would necessarily be identical. In such a case, a reader could obtain all of the day’s news by visiting one site or the other, leaving nothing remaining at the second. Publishing a higher volume of news facts thus implies a higher degree of redundancy with other high-volume news sites.
From the perspective of modeling vertical differentiation in news volume, the main implication is that the vertical utility provided by a news site not only depends on how much news the site publishes, but also on (1) which sites were visited previously in the same session and (2) how much news those sites published. The vertical component of utility is thus state dependent in this setting, as both expected and experienced vertical utility change after each site visit.
Utility from Vertically Differentiated News Sites
To account for vertical differentiation in the volume of news facts sites publish, we update the consumer’s utility function (Equation 1) to the following:

The term
We follow Allen (1983, 1986, 1990) by representing news facts as a collection of unique and indivisible “bits” that are observed by consumers, but not by the researcher. These bits correspond with the smallest units of news content that can generate a vertical component of utility (e.g., “Actor X will star in movie Y”). A new set of no more than N bits is available each day. Some of these bits are distributed heterogeneously across sites. A bit might appear at more than one site, or the bit might appear at none of the sites. If some bit b appears at site j on day d, we write
The number of distinct bits that have been seen, prior to choosing what to do at step t, is denoted

The consumer knows
Distribution of Bits and Consumer Learning
The number of bits at each site is obtained from a stylized model of information availability. On each day, there are at most


The parameter
Given their past browsing, experienced consumers know sites’ long-run, average daily number of bits—that is, they know the sites’
We assume consumers’ prior beliefs about the availability of bits at each site are consistent with Equations 13 and 14). An application of Bayes’ rule then leads to the following (binomial) posterior distribution for


Recall that the state variable
It follows from Equation 15 that the expected vertical utility from the next site j is

The expected level of vertical utility in Equation 17 is the expected number of new bits found at site j from Equation 15, multiplied by the consumer’s preference for them,
Implications for Browsing
Here we briefly comment on the implications of this part of the model for browsing. Equation 17 reflects how the expected vertical utility is (1) higher at sites that publish more news facts on average,
Because each bit can potentially be published by more than one site, the volume of news published each day is correlated across sites. This correlation in news volume affects the consumers’ browsing choices at steps t > 1 of each browsing session—that is, after the consumer has visited one or more sites and learned something about the day’s news coverage. The number of bits at one site thus provides the basis for learning about the number of bits at other sites. We assume that the presence or absence of links is not directly informative about the number of bits at the linked site. The presence of links, however, can be indirectly informative about bits. This is because links can affect the order of visits, and the ordering of site visits determines which bits are encountered. In this way, links can affect the consumer’s beliefs about the bits available at the remaining sites. 8
This stylized specification of the vertical component of utility achieves two main objectives. First, the specification captures a long-run average component of utility that all consumers value in absolute terms, and thus, it cannot be reflected in the model of horizontal match utility. Second, and relatedly, the specification accounts for the impact of daily variation in news volumes and redundant coverage on traffic to news sites.
Data
We estimate the model using data that describe browsing and content at five celebrity news sites between October 1, 2009, and December 31, 2009—a period of 92 days. We assemble these data from two sources: (1) comScore panel data describing consumers’ browsing at the URL level and (2) links and content scraped from the sites. We describe both of these data sources before concluding with preliminary evidence that links can either encourage or discourage visits to linked sites—a central feature of this model.
Consumer Data
The browsing data were provided by comScore as part of a larger data set describing visits by a rolling panel of U.S. consumers to more than 3,000 sites (all of which are members of the same blog-oriented advertising network). We focus on celebrity news sites in this study because (1) these sites cover a limited range of news items each day, (2) they frequently excerpt from each other, and (3) they format their home pages like blogs (i.e., as scrolling lists of news stories). We limit our attention to the five most visited celebrity news sites among the panel: Celebuzz, Dlisted, Egotastic!, Perez Hilton, and The Superficial. 9
Panelists
Most panelists visit only a fraction of the total available sites and therefore are largely inconsequential for assessing the impact of links on traffic. We thus limit attention to the most active panelists (Flaxman, Goel, and Rao 2016). These are panelists who (1) visited one or more of the 3,000 sites on at least 16 occasions in Q4 2009, (2) had at least five of those visits occur in each of the three calendar months, and (3) visited at least two of the five sites used for this study. Browsing and demographic data for the 127 consumers who fit this profile make up the estimation panel. In Q4 2009, these 127 consumers comprised 10.8% of browsing sessions involving any of the five sites, and 13.3% of those sites’ traffic, even though they represent about 1% of the unique visitors to these sites. The sample thus comprises individuals who are relatively experienced and frequent readers of celebrity news, who would plausibly know (1) the long-run average horizontal position of the five sites, zj; (2) the typical news volume for each site,
Most consumers in the estimation panel are female (65%), with the majority (60%) between 25 and 55 years of age (35% are younger, 5% older). Income is reported categorically, with a median of $55,000–$65,000 per year. Most panelists have children living with them (57%), and the average household size is 2.7 people. Five panelists listed their race as African American. We code binary variables as {−.5, .5}, scale the seven income categories between 0 and 1 using the center of the category range, and scale household size by subtracting the median (two people) and dividing by two standard deviations (2.89). We denote by Di the row vector of demographic variables for consumer i. In the Web Appendix, we contrast the demographics of the estimation sample with a larger set of comScore panelists. Compared with the larger comScore panel, the estimation sample has a higher proportion of consumers who are female, are aged 25–55 years, and have higher incomes.
Browsing data
A consumer’s browsing session includes all of their site visits occurring on the same day (as celebrity news sites operate under the same 24-hour news cycle as other media; Leskovec, Backstrom, and Kleinberg 2009). Thus, for each panelist, we compile the order in which any of the five sites were visited each day (the step t choices, aidt, in the model). During Q4 2009, the 127 panelists in our estimation sample made 19,130 such choices over the course of 5,757 browsing sessions (where a session might comprise the choice not to browse that day).
Recall that visiting the same site more than once within the same browsing session is not feasible in our model framework. For the median consumer in our sample, 96.9% of sessions generated data consistent with this no-revisit assumption (for a graphical depiction of this distribution, see the Web Appendix). Furthermore, 96.9% might be a lower bound, because internet panel data contain false positives for site/page visits due to web browsers refreshing pages in open tabs (without any action taken by the consumer). Modeling revisits would add significant computational burden in exchange for limited insights. Thus, consistent with the online browsing literature (e.g., Kim, Albuquerque, and Bronnenberg 2010), we do not model revisits. The aidts thus reflect the daily rank order of the earliest page request for each of the five sites.
Panelists differ in the subset of sites they visited most, as well as in the typical order of those visits within the session. Table 2 shows that Perez Hilton was the most popular site among both male and female consumers and was visited earliest in the session on average. Although panelists vary in the order of site visits across sessions, their typical ordering is stable over time (i.e., they are not learning which site is their favorite on average). The audiences of the other four sites differ noticeably by gender: male panelists visited Egotastic! and The Superficial relatively more, and female panelists visited Dlisted and Celebuzz relatively more.
Summary of Browsing Behavior by Site and Gender.

Notes: Means and bootstrapped 95% CIs based on 19,130 observed choices over the course of 5,757 browsing sessions. There are 127 consumers in the estimation panel (45 male and 82 female). “Visitors per Day” indicates the average number of male or female panelists visiting each site per day. “Step in Session” indicates the average time index t across visits; thus, lower values indicate visits that occurred earlier in the browsing session.
Men make up 35% of the panel but browsed more often than women. The median man browsed on 46 (out of 92) days, averaging 1.12 site visits per session, and the median woman browsed on 44.5 days, averaging 1.05 site visits per session. Variation within each group exceeds these cross-group differences.
Website Data
We created an automated web crawler to collect the full text from all news posts published at each of the five sites in Q4 2009. We use the text scraped from each site to determine, for each day, which other sites the linking site linked to and how many words each site published. We describe each of these next.
Link data
Links that appear within the text of posts are typically accompanied by an excerpt from the linked site or a brief description of the linked content (Dellarocas, Katona, and Rand 2013). Thus, even though we use the shorter term “link” to refer to both the link and excerpt, the excerpted content, and not the link per se, signals consumers’ match with the linked site. We therefore ignore static sidebar links that may be part of a site’s navigation but are never accompanied by an excerpt. After determining which (if any) of the other sites were linked each day (the
We derive the
Empirical Link Frequencies (%).
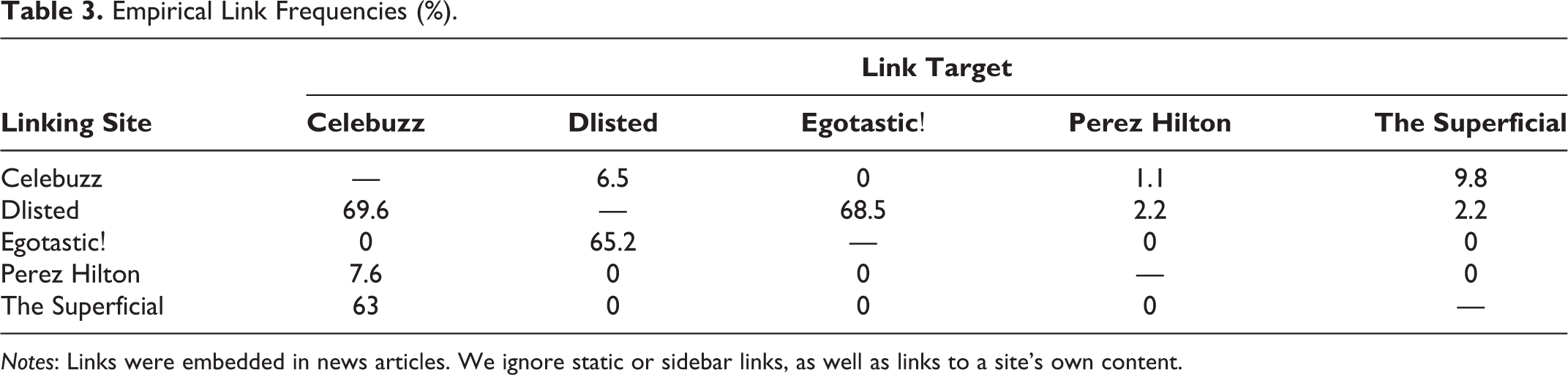
Notes: Links were embedded in news articles. We ignore static or sidebar links, as well as links to a site’s own content.
The model assumes consumers know these average link frequencies,
Word counts
Recall that the vertical component of utility is motivated in part by potentially large differences in the amount of news facts the sites publish each day. We use the number of words that sites have published each day as a measure for the unobserved quantity of news facts. As discussed in the model section, a consumer who has just visited a site with a large amount of news facts that are potentially redundant with content at the remaining sites might be more likely to end the session (and vice versa after visiting a site with very little news information). By using word counts as proxies for sites’ unobserved daily quantities of news information, we can measure more precisely the extent of this state dependence due to redundancy. For each site, we calculate the number of words in all posts published that day (including the text of hyperlinks to other sites, if any). Sites’ word counts are summarized in Table 4. We transform the daily word counts to define
Summary of Daily Word Counts by Site.
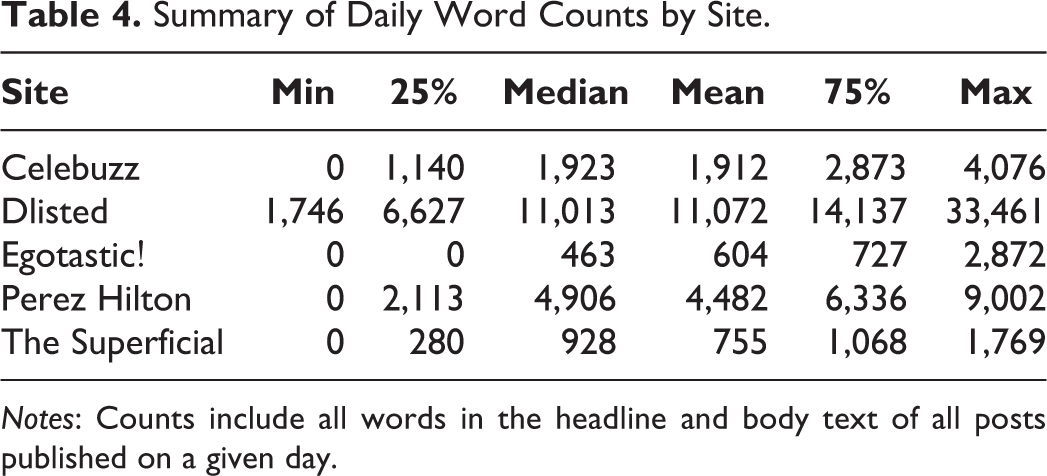
Notes: Counts include all words in the headline and body text of all posts published on a given day.
Recall that the vertical component of utility described in the previous section is defined in terms of the amount of news facts (bits) available at each site, but not the number of words. We relate the two as follows. First, after visiting the first site in any session, the consumer will have seen all of the bits published at that site. Thus, the state variable for the number of bits seen after visiting the first site,
Preliminary Analysis
Recall that an excerpt in our model can signal either higher or lower horizontal match utility, thereby increasing or decreasing the likelihood of visiting the linked site. To understand whether variation in the data is consistent with the model, we conduct a preliminary analysis at the level of individual consumers. We first define two empirical choice probabilities for each consumer i at each site j. The first is the probability that consumer i visits site j after seeing one or more links to j at a previous site:

The second is the probability that consumer i visits j without previously seeing a link to site j:

We next calculate, for each consumer i, the frequency-weighted average of each of these probabilities (i.e., averaging across all five sites). Thus,
Because observed links only affect choices at steps t = 2 and later (they are seen only after visiting a site), we compute these statistics using a subset of the full sample that excludes choices at step t = 1. We also repeat the analysis using only the subset of choices made at step t = 2. Figure 2 plots the empirical cumulative distribution of the difference in visit probabilities with and without links,
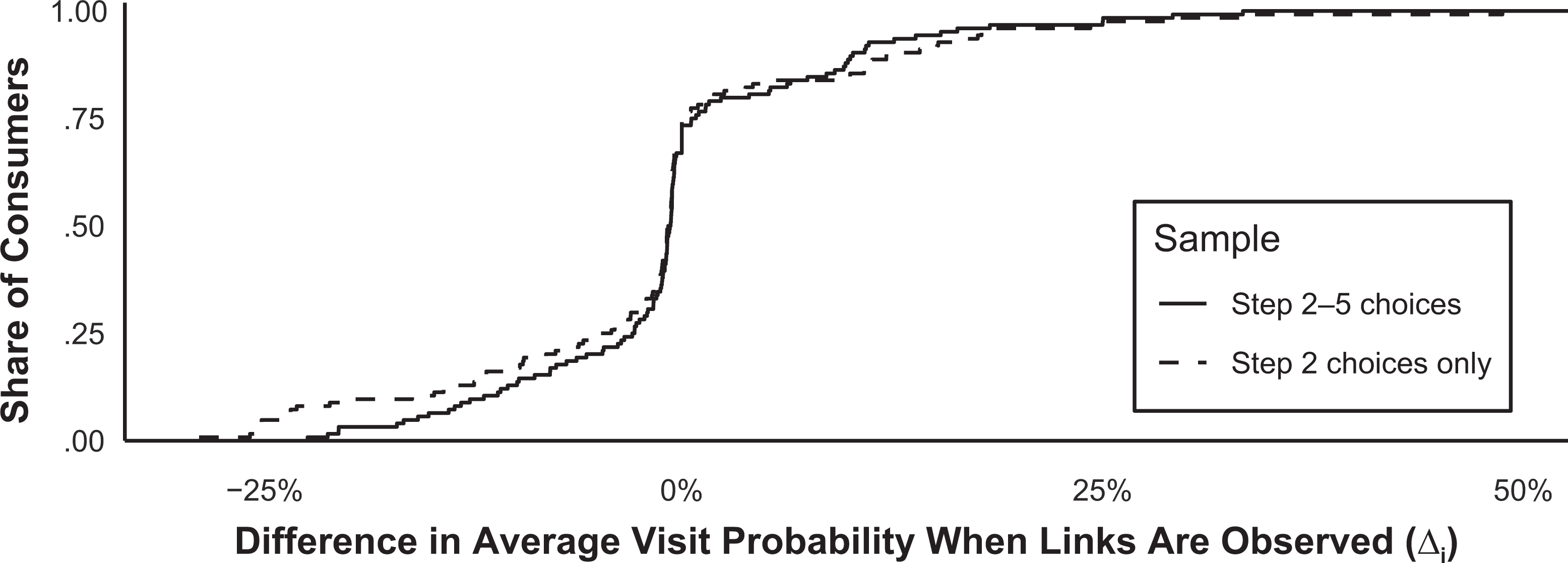
Average effect of exposure to links on consumers’ probability of visiting the linked site.
This analysis provides preliminary support for our modeling approach, whereby individual links encountered during a browsing session can either increase or decrease the chance of visiting the linked site. The relative prevalence of negative values of
Although this result indicates that for many individuals encountering links might be detrimental to the linked site, recall that the average effect (over all consumers) on site traffic might still be positive, because there is a floor on the probability of visiting the excerpted site. We see evidence for this positive outcome in Figure 2, as the magnitudes of increases in choice probability (the right tail) are greater than the magnitudes of decreases (the left tail). To understand if the overall effect is positive, we also calculate frequency-weighted averages of the probabilities in Equations 18 and 19 for each site—meaning we average across choice occasions to derive
The preliminary analysis exploits variation in consumer choices on days when sites linked or did not link to one other. However, this data is not enough to determine what would be the result of a policy that bans links completely, because the choices recorded in the data occurred in a world in which linking, as a practice, was allowed. Consumers did not know which links would appear at any given site, but they knew the appearance of a link was possible (and might occur with a known average frequency,
Model Specification, Identification, and Estimation
Here we complete the empirical model and describe alternative specifications, model identification, and our MCMC sampling procedure.
Model Specification
Consumer parameters
Consumers are heterogeneous with respect to horizontal match preferences, vi, their vertical utility from bits of news information,
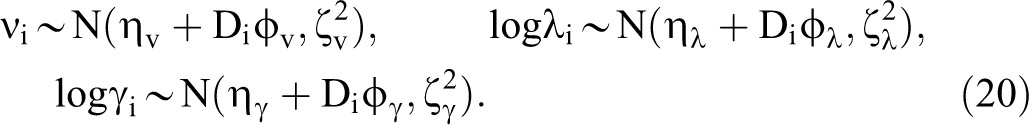
Although this prior distribution assumes conditional independence among these parameters, they may be dependent in the joint posterior distribution.
Model likelihood
Following the literature on single agent, dynamic discrete choice models, we assume that the unobserved utility shocks,

The choice-specific value function comprises two parts: (1) the expected period utility from visiting site j at step t and (2) the expected maximum utility from the remainder of the session, after visiting site j. The latter is an expectation taken with respect to the consumer’s information set,
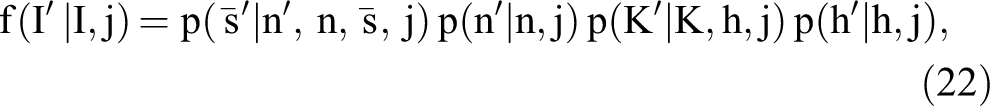
where (1)
Integrating over the unobserved utility shocks,

Parameter normalizations
Several parameter normalizations are necessary for estimation. First, recall the term N in Equation 17 represents an upper limit on values of
Summary of Estimated Parameters.

Notes: Parameters that are integrated out of the posterior distribution through data augmentation are not listed.
Bayesian posterior distribution
We assume the following prior distributions for the model parameters:

The likelihood function in Equation 23 depends on the state variables, Iidt. The state variables
Alternative specifications
We compare the full model specification to two nested specifications. The first restricts the discount parameter
Identification
Model parameters
The model includes multiple parameters defined at the level of individual consumers and sites. These are separately identified due to observing sequential choices within a single browsing session, many sessions over time, and different realizations of state variables for both of these. For many parameters, identification arguments are analogous to those for standard choice models using panel data, in which a person’s choices are observed over multiple periods. Consumers’ cost parameters,
Identification of the remaining structural parameters arises due to differences in choice shares between step t = 1 and subsequent steps t > 1 of browsing sessions. The covariance of these differences in choice share, when different numbers of links have been encountered, identifies the link informativeness parameter,
Linking effects
Links do not have a direct effect on utility but, instead, affect browsing through consumers’ information sets and expectations. Accordingly, there are several parameters that govern the effect of linking on site traffic. These parameters are defined at the daily and step level (observed links, n, and their average signals,
Sites may link to each other for many reasons. However, even if linking is strategic, estimates of the model primitives are statistically consistent. First, consider the choice to visit a potentially linking site L. In this or any other news setting, the consumer does not see site L’s links on day d until after visiting site L. 13 Thus, even though the consumer knows how often L links to R on average, L’s daily outbound links are a priori unknown in the current session and thus exogenous to the choice to visit L. 14
Next, consider the choice to visit site R after encountering a link to it at site L. Sites obviously do not link to each other at random each day. In particular, site L might choose to link (or not link) to site R on day d for reasons that we do not observe in the data. For example, say that site L only links to R on days when R’s content is a better match with L’s audience’s preferences. Due to selection, the unobserved horizontal match signaled by the link from L to R,
Estimation
We use the IJC method to sample from the data-augmented posterior distribution of the model parameters. This method is based on the random walk Metropolis–Hastings (MH) algorithm, but augmented with a method for approximating the forward-looking component of the choice-specific value function (Equation 21). The computational gains from IJC are substantial, but may still produce sample chains with high autocorrelation. We alleviate some of this autocorrelation by using Girolami and Calderhead’s (2011) MMALA procedure to construct high-quality MH proposal distributions. These proposal distributions have two important features. First, they are centered over points lying in the direction of higher density regions of the parameter space (relative to the current parameter vector). Second, the covariance of the proposal distribution approximates the local curvature of the target distribution.
These features greatly improve the rate of convergence and reduce autocorrelation. Figure 3 illustrates this improved efficiency. The figure plots the first 1,000 draws from the full model estimated with random walk and MMALA proposal distributions. The MMALA chain reaches the maximum log density attained by the random walk chain with less than a third as many iterations. The benefits of MMALA proposal distributions are not limited to models estimated using IJC. When we estimate the myopic model using MMALA, lag-1, -5, and -50 autocorrelations are 19%, 36%, and 56% lower, respectively, compared with random walk, and effective sample sizes are 13 times higher.

Illustration of IJC’s faster rate of convergence with MMALA proposal distributions.
Constructing the MMALA proposal distribution requires the first, second, and third partial derivatives of the target log-density function with respect to the parameters. For single-agent dynamic discrete choice models, these derivatives are not available in closed form. Thus, we obtain their values through automatic differentiation (AD). 15 The MH proposal distributions we construct are based on derivatives of the model posterior distribution while ignoring the IJC approximation to the forward-looking component of the value function. Performing AD on the IJC approximation reduces the numerical stability of the derivative calculations and increases the computational expense. Estimation code is written in MATLAB and C++ using the CppAD library for automatic differentiation (Bell 2007) and is tested using the method of posterior quantiles (Cook, Gelman, and Rubin 2006). The Web Appendix provides additional details about the sampling algorithm.
Results
We first compare the alternative specifications. We then present and discuss parameter estimates from the full model.
Model Fit
We compare model specifications using two measures of fit. First is the median absolute percentage error (MAPE) of the posterior predictive distribution of the total visits to each site across all consumers and days in the sample, which provides a broad measure of fit with the sample data. Second is the expected deviance, which provides a measure of predictive accuracy (Gelman et al. 2004). Table 6 shows the full specification performs best for both measures, and the differences in fit are substantial. Because models with more parameters may have lower expected deviance due to overfitting, Table 6 also presents the Akaike and Bayesian information criteria. These penalize expected deviance by 2p and
Model Fit Statistics.

Notes: MAPE = the median absolute percentage error of posterior predicted browsing at each of the five sites; AIC = Akaike information criterion; BIC = Bayesian information criterion.
The model comparisons suggest not only that links provide useful information that enables consumers to find better matching content but also that consumers anticipate these benefits and use them in the way suggested by the full model. First, accounting for exposure to links to other sites in the model helps rationalize consumers’ choices within the current session. Second, accounting for the anticipated value of links to other sites helps to rationalize consumers’ choices across all sessions.
Table 7 reports the MAPE of total traffic across all consumers and days in the sample for each site. All specifications fit total traffic at Perez Hilton and Egotastic! better than at the other three sites. The full model performs relatively worse at Perez Hilton in terms of prediction error (perhaps because Perez Hilton does not provide or receive as many outbound and inbound links as the other four sites). In terms of overall fit, the full model has the lowest prediction error, and we present results from this specification next.
MAPE of Posterior Predictive Distribution of Total Site Visits.

Parameter Estimates
Horizontal match utility
Recall that average horizontal match utility is factored into a site-specific location, zj, and consumer-specific preference, vi. Posterior means and standard deviations for sites’ average match locations (zj) are shown in Table 8, and posterior densities are depicted along the x-axis in Figure 4. Drawing on an informal sampling of site content, our post hoc, qualitative interpretation is that sites are horizontally differentiated depending on whether they emphasize content that is more or less sexual (e.g., pictorials of attractive female entertainers and models). Two sites have negative values of zj, Egotastic! (−2.72) and Dlisted (−.89); the other three sites are positive: The Superficial (.45), Celebuzz (.95) and Perez Hilton (2.20). This ordering is consistent with what we see as a relatively greater amount of salacious content at Egotastic!, Dlisted, and The Superficial. Although Celebuzz and Perez Hilton also publish sexually oriented content, they do so less frequently and feature attractive male celebrities more than the other three sites. Moreover, reporting at Celebuzz and Perez Hilton aligns more closely with traditional tabloid celebrity gossip compared with the other three sites.

Joint posterior distribution of sites’ average vertical quality (
Horizontal (

Notes: Estimates are posterior means with standard deviations in parentheses.
Consumers’ horizontal match preferences (vi) are highly heterogeneous, as shown in column 1 of Table 9. This heterogeneity is partly explained by two demographic variables. The most important of these is gender. The match preference coefficient for gender is positive, with a 95% Bayesian credible interval (CI) that excludes zero. This implies a higher preference among men (on average) for sites with zj < 0 (i.e., the more salacious content of Egotastic! and Dlisted) and higher preference among women for sites with zj > 0 (i.e., the more gossipy content of Celebuzz and Perez Hilton). The other demographic match preference coefficient with a 95% CI excluding zero is African American: these consumers receive higher match utility at Egotastic! and Dlisted, although we note that this estimate reflects the preferences of just five panelists. In total, demographic variables account for 12.7% of the heterogeneity in horizontal match preferences.
Consumer Heterogeneity Parameter Estimates.

* For observed heterogeneity parameters, indicates that the estimates with 95% CIs exclude zero.
Notes: Estimates are posterior means with standard deviations in parentheses.
Link informativeness
Horizontal match utility from each site varies each day, and links signal these deviations to consumers. The informativeness of links, relative to daily variation in horizontal match, is reflected in the parameter

Links reduce uncertainty about match utility.
Overall, we find compelling evidence that links provide informative signals about content at other sites, inasmuch as after seeing a link, consumers are less uncertain about match utility at the linked site. The counterfactual simulations further demonstrate that the information provided by links can have a meaningful impact on browsing.
Vertical utility from news volume
Sites are differentiated according to the volume of news published on average. Posterior means and standard deviations for sites’ vertical qualities (
Consumers are heterogeneous in their preference for this vertical component of utility,
Opportunity costs of browsing
The opportunity cost of browsing,
Discount rate
The parameter
The discount rate is high when compared to those estimated from purchase data. In models of consumer purchases, utilities are measured relative to money costs, which permits a monetary interpretation of the discount rate. Here, utilities are measured relative to the value of an outside option that corresponds with “not browsing.” This lack of a dollar metric limits our ability to interpret the magnitude of the discount rate. However, the fact that this parameter takes on a nonzero value suggests that the value of future browsing has an impact on the choice of which site to visit.
Average Linking Frequency and Site Differentiation
Next, we comment briefly on how the frequency of links between competing sites affects how sites are differentiated in the eyes of consumers. Sites are differentiated by their average horizontal match locations, zj, average news volumes,

Summary of link frequencies and site heterogeneity.
Figure 6 shows that sites tend to link to competitors with similar values of zj (i.e., their closest neighbors along the x-axis). 16 Because links provide signals about daily match locations, sites that frequently link to their closest competitors provide value by informing their audiences about sites with similar levels of match utility. If instead, links tended to point to sites with very different match locations—if Egotastic! were to link to Perez Hilton, for example—then consumers would find links to be less useful, because the links would be telling consumers about sites they are highly unlikely to visit anyway. As we demonstrate next through counterfactual simulation, a meaningful portion of some sites’ value to consumers stems from their tendency to link to other sites.
Counterfactual Analysis
How much do the within-session, across-session, and combined effects of linking affect consumer demand for online news? In this section, we use estimates from the structural model to answer that question in the empirical context we study—consumption of celebrity news in Q4 of 2009. We use estimates from the structural model because they enable us to compare browsing not only in the presence or absence of links (as in the preliminary analysis) but also in the presence or absence of consumers’ expectations about links. This structural approach makes it possible to consider policies not reflected in the data, such as outright or de facto bans on linking to news sites (similar to ones previously enacted within the EU). We first describe the approach and then discuss the main insights.
Procedure
We measure the impact of linking in terms of the amount of browsing, the flow of traffic between sites, and total traffic at each site, by comparing demand simulated under two scenarios. In the baseline scenario, we simulate demand using all links that are observed in the data (see Table 3 and Figure 6). In the counterfactual scenario, we remove these links and update consumers’ expectations about linking frequencies. In other words, we set all of the
We simulate the full 92-day sequence of browsing S times for every consumer under the baseline and counterfactual scenarios. Each of the S simulations corresponds with a sample from the data-augmented posterior distribution of the model parameters. For each simulation, we calculate a quantity of interest (e.g., the change in a site’s traffic particular site), then take the average over all S simulations (i.e., we integrate over the posterior distribution). Because consumers’ expectations about the links they will encounter depend on the
We present the results in two stages. First, we discuss the total effect of links on consumers and sites at the aggregate level. Second, we decompose this total effect into two theoretically distinct effects of linking on choice: (1) the within-session effect due to observing a particular link on a given day (as a result of the
Total Effect of Links
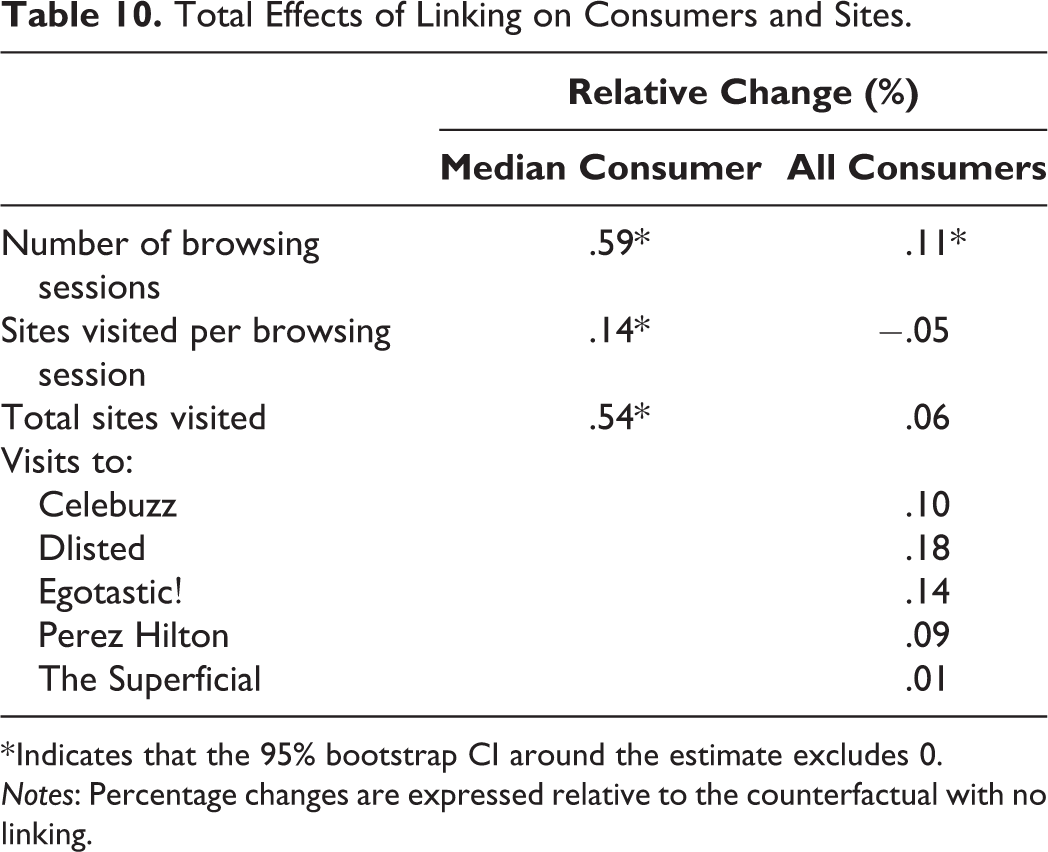
Among these sites, links positively affect browsing, as shown in Table 10. When we compare the baseline with linking to a counterfactual without, the total number of browsing sessions increases .11%. For the median consumer, the number of browsing sessions increases by .59%, the number of sites visited per session by .14%, and the total number of site visits increases by .54%. The impact of linking on the median consumer is more positive than the average effect across all consumers. This is because the increases in browsing and site visits due to linking are greatest among consumers who browse relatively less. Put another way, links provide less of an incentive to browse for those who would browse anyway, and more of an incentive for the marginal consumer. Turning to the site-specific browsing results, Table 10 shows that links also increase sites’ traffic to varying degrees. The greatest gains in total visits are found at Dlisted (.18%) and Egotastic! (.14%), sites that give and receive relatively greater numbers of links.
Total Effects of Linking on Consumers and Sites.
* Indicates that the 95% bootstrap CI around the estimate excludes 0.
Notes: Percentage changes are expressed relative to the counterfactual with no linking.
The total effects reported in Table 10 reflect both the within- and across-session effects and are averaged across conditions in which links affect browsing decisions to different degrees. At the start of a browsing session, for instance, only forward-looking consumers’ expectations about links influence choice. Later in the session, choices are also affected by the actual links they might encounter. Because sites do not always provide outbound links, and because consumers do not visit every site, we interpret the results in Table 10 as the total effect of a broader policy of allowing links, with the understanding that some consumers may see few or even none of those links. To understand how exposure to any particular link affects consumers’ choices, we decompose the total effect into its constituent parts.
Decomposition of the Total Effect of Links
The across-session effect due to changes in beliefs about linking frequencies
Linking has a different effect on decisions at step t = 1 of a session, compared with later steps. At step t = 1 (prior to observing any links), only the across-session effect (due to
Relative Change in Total Visitors by Step of Browsing Session (%).

* Indicates that the 95% bootstrap CI around the estimate excludes 0.
Notes: Percentage changes are expressed relative to the counterfactual with no linking. Consumers are included in either the core audience or noncore audience segments based on how many times they visited each site in the raw data. The top 30 consumers comprise the core audience and the remainder the noncore audience.
The difference between the within-session and across-session effects for Egotastic! provide a useful illustration. Egotastic! gains little traffic at step t = 1 (.03% in total) due to the cross-session effect. This suggests that Egotastic!’s outbound links do not make it more attractive. But Egotastic! does gain substantially more traffic at later steps t > 1 (1.32% in total) due mostly to the within-session effect. This result shows how the across-session effect depends on both sites’ horizontal positions and the other sites to which they link. Specifically, Egotastic! creates and receives a large number of links, but only in exchange with Dlisted. Dlisted, in contrast, links to all other sites. Because a substantial portion of Egotastic!’s audience frequently visits Dlisted as well (even in the absence of links), the information value of Egotastic!’s links is lower than Dlisted’s in expectation. Accordingly, when linking is allowed, Egotastic! actually loses a portion of its audience to Dlisted at step t = 1 (and Dlisted gains 1.18% in traffic from its noncore audience). The loss in some of Egotastic!’s traffic to Dlisted at step t = 1 thus offsets any gains that might have accrued to Egotastic! from its own outbound links. Accordingly, the increase in traffic at step t = 1 (due to the across-session effect) is greater for Dlisted (.21%) than for Egotastic! (.03%). At the same time, the within-session effect for Egotastic! is substantial. When linking is allowed, the number of visitors to Egotastic! at later browsing steps is
The within-session effect due to exposure to a link
Although the increase in traffic at later stages is relatively large for Egotastic!, this increase is defined as an average over cases in which some consumers encounter a link and others do not. We are also interested in comparing consumers’ choices when they have been exposed to a link against counterfactual choices in which the link has been removed. The challenge with making this comparison is that, as Figure 6 shows, sites often link to their closest neighbors in terms of match location. Thus, the propensity to visit a linked site, conditional on having already visited the linking site, is a priori high.
To deal with this challenge, we introduce the concept of a “removed link,” meaning a link that a consumer would have seen, had we not removed that link under the counterfactual of no linking. 17 We compare baseline choices, in which a link was observed, against counterfactual choices, in which a removed link would have been observed had the link not been deleted. Thus, the measured effect is almost entirely due to the exogenous presence or absence of the link itself. These differences in consumers’ propensities to visit a linked site are somewhat analogous to click-through rates for (untargeted) internet ads, in the sense that their measurement is predicated on exposure to a particular link (or ad).
Table 12 summarizes the results of this analysis. The third column of Table 12 compares consumers’ baseline choices after exposure to links with their counterfactual choices after “exposure” to removed links. For example, the probability of visiting Dlisted after exposure to a link is .26% higher than the visitation probability would be without the link. This result represents a 3.8% increase in the amount of Dlisted’s traffic originating from linking sites. The changes in visit probabilities differ in magnitude among sites’ core and noncore audiences. Links to Dlisted from other sites have a greater impact on visits to Dlisted among its noncore audience than among its core audience. Links to Dlisted thus increase its traffic relatively more on the extensive margin. By contrast, links to Egotastic! (all of which come from Dlisted) have a greater impact on visits to Egotastic! among its core audience than among its noncore audience. Links to Egotastic! thus increase its traffic relatively more on the intensive margin.
Difference in Choice Probability by Prior Exposure to Link (%).
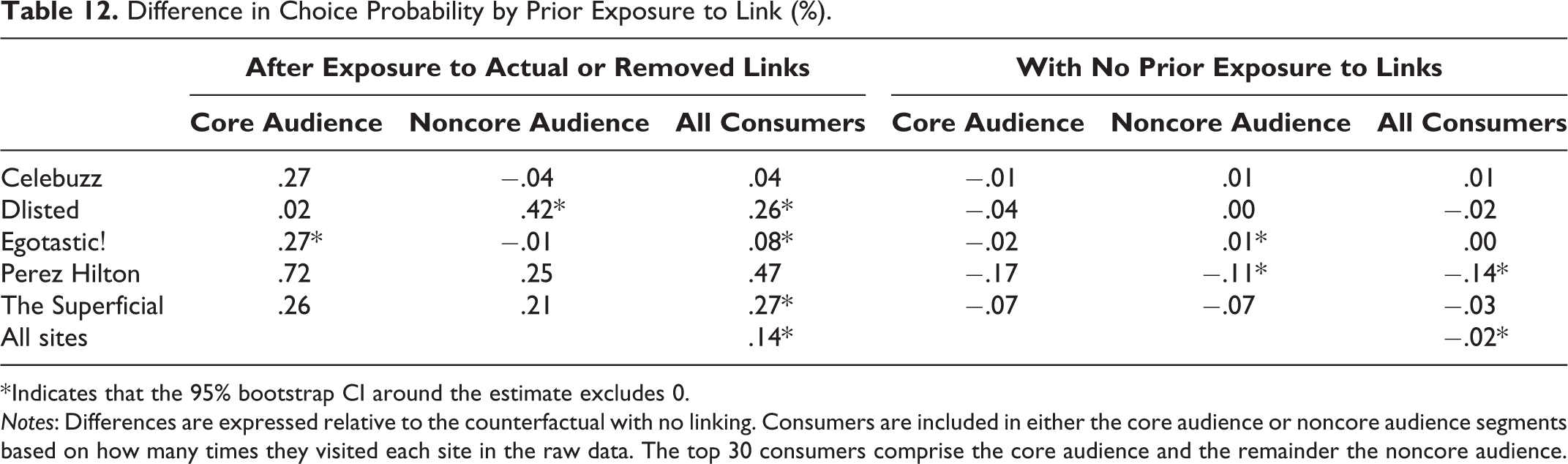
* Indicates that the 95% bootstrap CI around the estimate excludes 0.
Notes: Differences are expressed relative to the counterfactual with no linking. Consumers are included in either the core audience or noncore audience segments based on how many times they visited each site in the raw data. The top 30 consumers comprise the core audience and the remainder the noncore audience.
The difference in how links affect traffic among Dlisted and Egotastic!’s core and noncore audiences is related to the order in which these sites are typically visited when linking is allowed or banned. When linking is allowed, a substantial portion of Egotastic!’s core audience is made up of individuals who prefer to visit Dlisted first because of its outbound links. This result thus demonstrates another way in which the across-session effect moderates the within-session effect—it determines in part which consumers are (or are not) exposed to links.
The overall frequency-weighted average increase in the probability of visiting a linked site due to prior exposure to a link is .14%, a 2.3% increase. A relevant baseline for comparison is paid forms of links, such as display advertising. These typically have click-through rates less than .05% (Chaffey 2017; Lambrecht and Tucker 2013; Lewis, Rao, and Reiley 2011), and the effect we measure is large by comparison. 18
Contribution and Opportunities for Further Study
Linking between news sites is a distinguishing feature of internet news, and one with the potential to change the way individuals stay informed. By providing information to consumers of online news, links make it easier to seek out more interesting content and to avoid less interesting content. When consumers value news links, sites that provide them become more attractive to consumers, even to the point that the linking site might be more popular than the sites it links to (e.g., Google News). The potential for a linking site to benefit more than the sites it links to has been the catalyst for both lawsuits (both the Associated Press and Agence France-Presse news services previously sued Google News) and regulatory actions (legislation in Germany, Spain, and the EU have narrowed the legal basis for linking to news sites). The reasoning behind these legal actions is often predicated on a presumption of harm to the news sites that receive inbound links. Yet, to date, there has been little academic work seeking to understand the impact of links on demand for news sites, and what work has been done has mostly been limited to the context of Google News.
We offer a new perspective on this issue by studying the impact of linking among news publishers—that is, sites that both publish original news and link to other news sites. We show that it is possible to measure the effects of links on consumers and news sites instead of presuming they are harmful. In the empirical setting we study, celebrity news, we find that links change the way experienced consumers browse for news to the benefit of both consumers and news sites. Compared with a counterfactual policy in which links are banned, consumers browse more under the baseline scenario with linking. In the sample we consider, the median consumer is both more likely to start browsing and more likely to continue browsing when linking is allowed. These differences are greatest among consumers who browse for news relatively less, which suggests that linking plays an important role in increasing news consumption at the extensive margin. Individuals who encounter links have, on average, a .14% higher probability of visiting the linked site, a 2.3% increase over the counterfactual without links. The size of this effect is approximately three times larger than typically reported increases from display ads.
We also make several methodological contributions. First, we present a model in which links signal consumers’ daily horizontal match with the linked site’s news content, thus allowing the within-session effect of encountering a link to either increase or decrease the chance of a visit. We show that even when links signal lower-than-average match, the aggregate effect on the linked site can be positive. Second, we also develop a novel Bayesian learning model based on bits of news information that are redundantly distributed across multiple news sites. We developed this model in the context of studying internet news consumption, but the approach can be applied to study the consumption of offline news or, more generally, sequential choices in other settings where alternatives have correlated utilities due to redundancy. Third, we demonstrate the value of combining adaptive MMALA proposal distributions with IJC’s method for sampling from dynamic discrete choice models. Compared with the standard IJC method using random walk proposal distributions, the gains from our approach are significant: autocorrelations using our approach are substantially lower, and effective sample sizes are many times larger.
This study also has limitations that bear on how we interpret the results but that also point in potentially useful directions for future studies. The first of these is related to our focus on steady-state demand among experienced consumers of celebrity news (as opposed to the more transient behaviors of new consumers). That is, we study within-session learning about daily variation in content among experienced consumers who encounter links to sites they are already familiar with. Owing to the complexity involved in understanding this within-session learning process, this study does not consider the process by which inexperienced consumers eventually become experienced over the course of many sessions. Yet understanding this process of site discovery is important, and links certainly play a role in how this process unfolds. The total value of linking depends not only on the value a site’s outbound links provide for its readers but also on whether the site’s links inform readers about the availability of new and potentially superior alternatives. Previous work has considered how sites may choose their content and links strategically to attract and sustain interest among both types of consumers (e.g., Mayzlin and Yoganarasimhan 2012). Empirically studying how sites balance these two forces will be a critical step forward in our understanding of how linking affects news consumption in a competitive setting.
The inclusion of both horizontal and vertical dimensions of utility in our model allows it to flexibly represent how interactions between consumer preferences and site content determine consumers’ choices. At the same time, the available data and the need to model forward-looking consumers constrain the degree to which these aspects can be further developed. We use word counts as proxies for the amount of news facts sites publish each day and model the horizontal component of utility in a one-dimensional latent space. These word count and dimensionality choices allow for model estimation but limit our ability to extrapolate from the parameter estimates to other empirical settings (e.g., making out-of-sample predictions for traffic at other sites). By applying recent advances in image and text analysis, we might overcome these limitations and further gain a clearer understanding of how news sites differentiate from one another. Such an approach might enable us to measure the signals embedded in individual links more precisely. Better measurement of link content would lead to richer models in which links could influence learning on both the horizontal and vertical dimensions (e.g., by allowing the absence of a link to signal lower vertical quality at the not-linked site). Previous studies have considered links as signals of sites’ short- and long-run vertical qualities (Dellarocas, Katona, and Rand 2013; Mayzlin and Yoganarasimhan 2012). There is room for a unifying theory of linking in both the horizontal and vertical dimensions and for further empirical work in this area.
A final limitation pertains to the generalizability of the empirical results. The results we obtain apply to the limited context of celebrity news at a particular point in time and are predicated on the behavior of more frequent (and knowledgeable) readers. These results are valid for this setting, but this setting may not be typical of most news consumption. Our modeling framework suggests that each news ecosystem might have a different answer to the question of how linking affects consumers and news sites. Accumulating more evidence about how links affect news consumption might lead to generalizations about the conditions under which linking is beneficial or harmful. This study is a step in this direction, and one that we hope stimulates further work on the important topic of news consumption.
Supplemental Material
Supplemental Material, jmr.18.0164-File003 - The Effect of Links and Excerpts on Internet News Consumption
Supplemental Material, jmr.18.0164-File003 for The Effect of Links and Excerpts on Internet News Consumption by Jason M.T. Roos, Carl F. Mela and Ron Shachar in Journal of Marketing Research
Footnotes
Appendix
Acknowledgments
The authors would like to thank comScore for the data used in this study as well as Peter Arcidiacono, Andrew Ching, Andres Musalem, Ken Wilbur, Marshall Van Alstyne, Hema Yoganarasimhan, and seminar participants at Duke (Fuqua, Dept. of Economics), Erasmus (RSM, ESE), Ohio State University, Yale University, Washington University in St. Louis, Georgia Tech, Tilburg University, University of North Carolina Chapel Hill, University of San Diego, University of Michigan, INSEAD, University of Frankfurt, University of Houston, University of Pennsylvania, University of Toronto, University of Rochester, the 34th ISMS Marketing Science Conference, the 2012 HEC Marketing Camp, the 11th ZEW Conference on the Economics of ICT, the 2015 Marketing in Israel Conference, the 13th Marketing Dynamics Conference, and the 2016 Summer Institute in Competitive Strategy for their comments. This work was carried out on the Dutch national e-infrastructure with the support of SURF Cooperative. This article stems from the first author’s dissertation.
Associate Editor
S. Sriram
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.