
Abstract
This meta-analysis examines when three types of automated agents (AAs)—robots, chatbots, and algorithms—are equivalent to human agents (HAs) in marketing roles. An analysis of 943 effect sizes from 327 studies provides novel insights. First, customers may be skeptical of AAs; however, they value their performance and eventually choose or buy from them as if they were interacting with HAs. Second, each of the three AA types has a unique set of contingencies that affect its human equivalence; previously identified contingencies do not generalize and can even have opposing effects across AA types. This study also identifies novel contingencies, such as the multifaceted concept of artificial intelligence required to fulfill a task. Third, some contingencies make AAs more humanlike, while others make their machine characteristics salient. These findings enrich the concept of automated social presence (ASP), suggesting that AAs are hybrid beings with a social presence (i.e., the feeling of interacting with a humanlike entity) and an automated presence (i.e., the feeling of interacting with a machine entity). The authors provide recommendations on when AAs can replace HAs in marketing roles to release capacity and alleviate labor shortages. They also suggest a future research agenda.
Keywords
Automated agents (AAs) are system-based autonomous interfaces that interact with customers in the physical or digital realm to perform certain tasks (Wirtz et al. 2018). 1 They can perform human agents’ (HAs) roles, such as serving coffee (Choi et al. 2023), responding to inquiries (Yalcin et al. 2022), and recommending products (Longoni and Cian 2022). Given AAs’ high efficiency (Xiao and Kumar 2021), their market value is expected to reach $210.7 billion by 2033 (Saha 2023). Still, AAs lack human skills, often prompting customers to respond more negatively to them than to HAs (Longoni, Bonezzi, and Morewedge 2019). Thus, managers need to know: When do customers view AAs as equivalent substitutes for HAs? This will help them decide when to leverage AAs as an alternative to the default choice of human staff.
Prior studies have addressed this question, revealing contingencies that weaken the negative effect of AAs (vs. HAs) on customer responses (e.g., a utilitarian context; Longoni and Cian 2022). Drawing conclusions about these contingencies is difficult for two reasons. First, studies refer to different AA types: robots (physically embodied machines that interact with customers via actuators or sensors; Joshi 2022), chatbots (digital interfaces that engage customers in natural conversations; Sands et al. 2021), and algorithms (software programs that provide information by transforming an input into an output; Clegg et al. 2023). Second, studies use a variety of customer responses. Sometimes these are behaviors (e.g., choosing an AA; Holthöwer and Van Doorn 2023), but they are mostly upstream variables (e.g., trust; Wang et al. 2023). Some responses relate to the agent (e.g., perceived warmth; Frank and Otterbring 2023) and others to the firm (e.g., attitude toward the brand; Srinivasan and Sarial-Abi 2021). Hence, there is heterogeneity in which AA type is rated on which success criterion (i.e., which customer response), making it difficult to assess when AAs keep pace with HAs; this calls for consolidated research (Table 1).
This Study Fills a Void in Prior Meta-Analyses of Customer Responses to AAs.
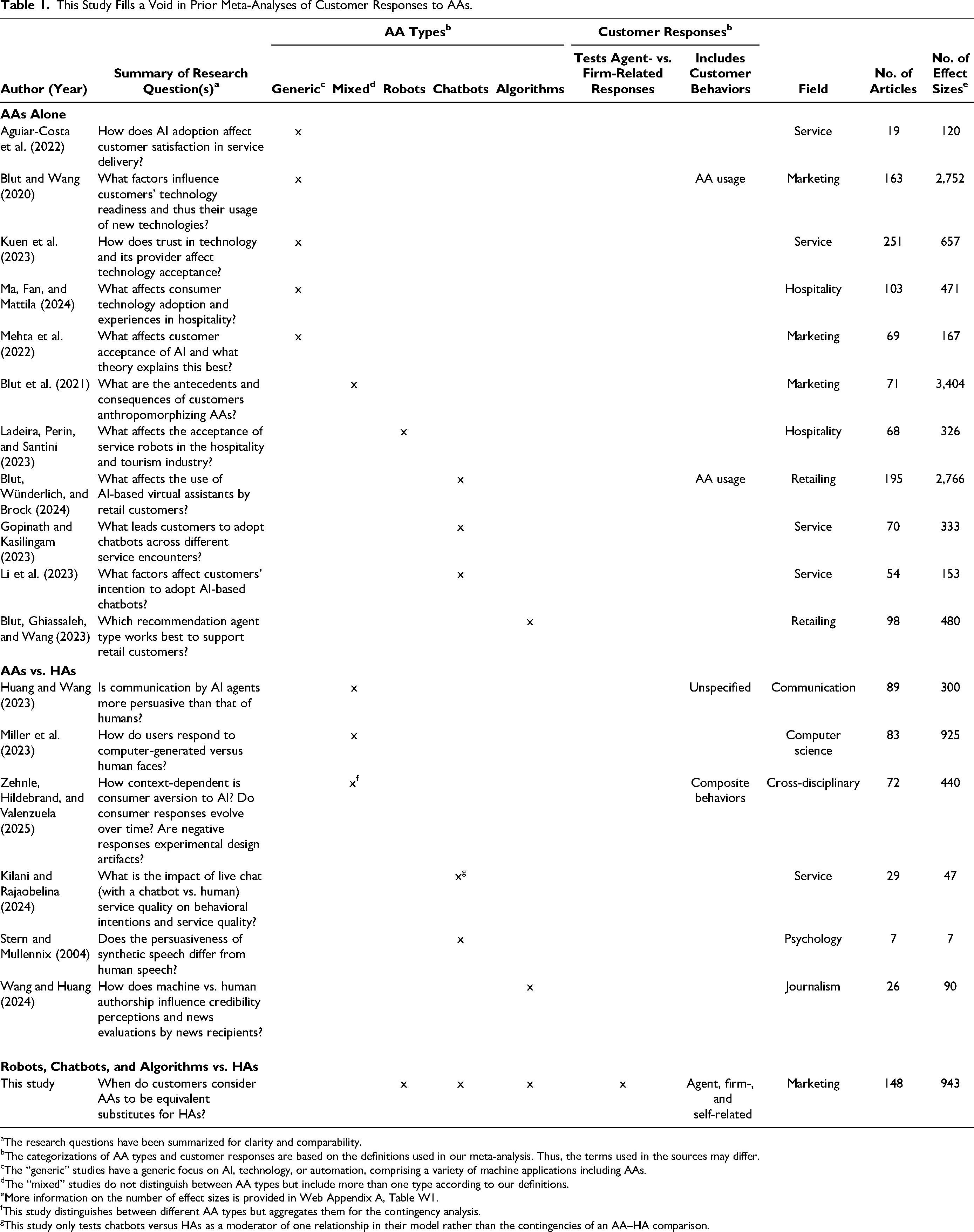
The research questions have been summarized for clarity and comparability.
The categorizations of AA types and customer responses are based on the definitions used in our meta-analysis. Thus, the terms used in the sources may differ.
The “generic” studies have a generic focus on AI, technology, or automation, comprising a variety of machine applications including AAs.
The “mixed” studies do not distinguish between AA types but include more than one type according to our definitions.
More information on the number of effect sizes is provided in Web Appendix A, Table W1.
This study distinguishes between different AA types but aggregates them for the contingency analysis.
This study only tests chatbots versus HAs as a moderator of one relationship in their model rather than the contingencies of an AA–HA comparison.
The meta-analyses listed in Table 1 have consolidated variables that affect customer responses to AAs, but two gaps limit insights into their human equivalence. First, benchmarking is missing, incomplete, or often poorly suited to a marketing context. The meta-analyses on AAs alone do not use HAs as a benchmark. However, benchmarking is necessary to delineate contingencies that cause AAs to become more equivalent to HAs, and not just benefit both agents equally, yielding a null effect. For example, Blut, Wünderlich, and Brock (2024) suggest that a name can benefit AAs because it provides them with a human touch. However, customers also respond more positively to human employees using their names as part of a personalized service (Roschk and Gelbrich 2017). In contrast, the meta-analyses on AAs versus HAs use a human benchmark, which is crucial to gauge the relative effectiveness of AAs and address the substitution question. However, these studies only consider facets of AAs (e.g., face, speech) or mainly stem from communication, computer science, psychology, and journalism contexts; thus, the outcomes and contingencies do not apply to marketing. 2
Second, no meta-analysis in Table 1 crosses the three AA types with multiple contingencies. Some of them generically focus on technology (e.g., Blut and Wang 2020) or artificial intelligence (AI) (e.g., Aguiar-Costa et al. 2022), which comprises a variety of machine applications (including AAs). Others use mixed AA samples, distinguishing between embodied (i.e., robots) and disembodied (i.e., collapsing chatbots and algorithms) AAs (Blut et al. 2021), different AI communicator roles (e.g., curator; Huang and Wang 2023), or different AI labels (e.g., AI assistants; Zehnle, Hildebrand, and Valenzuela 2025). As a result, it is difficult to assign contingencies to an AA type. Other meta-analyses examine a single AA type, but they either do not test contingencies at all (e.g., Kilani and Rajaobelina 2024) or do not assess whether the results generalize to the other two types. Generalizability is further limited in terms of customer responses. No meta-analysis tests how AAs perform across agent-related (e.g., trust in the agent) versus firm-related (e.g., attitude toward the brand) customer responses; firm-related behaviors (e.g., consumption) as such are not considered at all.
In summary, prior research cannot answer the question of when customers consider the three AA types to be equivalent to HAs in the marketing context. We conducted a comprehensive meta-analysis of multiple customer responses to robots, chatbots, and algorithms compared with human employees. Our study is based on 943 effect sizes retrieved from 327 studies with 281,954 respondents in 148 articles (Table 1). It makes three contributions to research on AAs in marketing.
First, we compare the pooled effect sizes of the three AA types (vs. HAs) for a wide range of customer responses. These are agent- or firm-related and upstream (i.e., perceptions, appraisals, intentions) or downstream (i.e., behaviors). For downstream responses, we add self-related behaviors, which occur in single studies (e.g., Desideri et al. 2019). Hence, we are the first to provide a consolidated test of customer responses with lower (i.e., agent-related, upstream) versus higher managerial relevance (i.e., firm-related, downstream). The results show that AAs tend to be less equivalent for agent-related upstream responses but equivalent for all downstream responses whether agent-, firm-, or self-related. These results challenge the belief that AAs will remain inferior to human employees in the near future (Xiao and Kumar 2021). Customers may be skeptical of AAs, but from a management perspective, this is a minor issue: Customers value AAs’ performance and choose or buy from them as if they were interacting with HAs.
Second, we test contingencies for the equivalence of robots, chatbots, and algorithms (vs. HAs). The novelty of our framework lies in carving out the particularities of the three AA types and revealing idiosyncratic contingencies for their human equivalence. This overcomes the limitations of prior meta-analyses that do not distinguish between the three AA types or are restricted to one AA type, calling for systematic research on AA-type-specific contingencies. Our results put prior findings into perspective. They show that generalizing single contingencies to all AAs is undue, refuting the idea that one size fits all. We also uncover novel contingencies, such as the AI types required for a certain task (Pantano and Scarpi 2022). This disentangles the fuzziness arising from prior meta-analyses that use AI as a generic label for AAs (Aguiar-Costa et al. 2022) or intelligence as a broad contingency (Blut, Wünderlich, and Brock 2024). AI is the ability to mimic the functions of the human mind, such as problem-solving or reasoning (Longoni, Bonezzi, and Morewedge 2019). AAs may or may not be AI-enabled (Joshi 2022), and this ability has multiple facets, such as verbal-linguistic or social intelligence (Pantano and Scarpi 2022). Our study reveals tasks in which specific types of AI benefit single AA types.
Third, we observe an overarching pattern: Some contingencies make AAs more humanlike, while others make their machine characteristics salient. These findings enrich the concept of automated social presence (ASP), an emerging paradigm in marketing (Flavián et al. 2024). ASP proposes that AAs can make customers feel that they are interacting with another social entity (Van Doorn et al. 2017). This implies that AAs’ humanlike nature is valued and overlays their machine nature, which suggests that engaging customers socially is key to success. We abandon this idea and posit that AAs are hybrid beings with a social presence (i.e., the feeling of interacting with a humanlike entity) and an automated presence (i.e., the feeling of interacting with a machine entity). Social presence only clearly benefits one AA type; it can be irrelevant to or even harm others. Automated presence benefits all AA types, which can leverage both advantageous and presumed disadvantageous machine characteristics. Hence, AAs do not need to be humanlike but can be equivalent substitutes for HAs just because they are perceived as machines.
The structure of this article follows a guided test of AA-type-specific contingencies. We describe the properties of robots, chatbots, and algorithms; use them to develop hypotheses; test these hypotheses; and use the results to inform theory. Since AA research lacks an overarching theory (De Keyser and Kunz 2022), this approach is suitable. A guided test, rather than an empirics-first approach (Golder et al. 2023), is chosen because the three AA types’ particularities allow for systematic reasoning on specific contingencies for them. We use the results to predict when AAs will keep pace with HAs. This helps marketers decide when to consider robots, chatbots, or algorithms as alternatives to HAs, or when it is not advisable to do so. We also provide a research agenda to further develop ASP.
Conceptual Development
Properties of Robots, Chatbots, and Algorithms
All AA types have a common technological nature with disadvantages and advantages over HAs (Table 2). Disadvantages relate to affective abilities: AAs (vs. HAs) lack empathy; they cannot experience emotions and often do not recognize them (Zhou et al. 2023). AAs also fall short in their cognitive abilities, particularly in cognitive flexibility (Longoni, Bonezzi, and Morewedge 2019), as they cannot think outside the box due to their reliance on past interactions (Wirtz et al. 2018). They also lack agency in that they have no opinions, cannot judge (i.e., cannot distinguish right from wrong), and do not feel responsible (Holthöwer and Van Doorn 2023). However, AAs have cognitive advantages related to speed and reliability. They can quickly process big data, react instantly, are always receptive, and replicate stable results (Larkin, Drummond Otten, and Árvai 2022).
The Three AA Types Have Commonalities and Particularities.

All AA types also carry particularities that relate to their mode of communication and form of existence (Table 2). AAs’ mode of communication can be conversational, characterized by dynamic mimicry of natural human speech. This applies to robots, which can simulate highly interactive conversations with customers (Pitardi et al. 2022). These are mostly voice-based but can also be text-based (i.e., holding a screen) (Castelo et al. 2023). Chatbots’ mode of communication also simulates highly interactive human speech (Luo et al. 2019), which is mostly text-based (Ruan and Mezei 2022) but can also be voice-based (Ruiz-Equihua et al. 2023). The communication mode can also be informational, characterized by static responses to commands. This applies to algorithms that provide information but do not engage in sophisticated conversations. They transform a one-time input into a requested output (Clegg et al. 2023) via sophisticated data-processing techniques (Schoeffer, Machowski, and Kuehl 2021).
AAs’ form of existence can be physical, with a tangible body whose motor skills enable interactions with customers in real space. This applies to robots; their materialized bodies are imbued with electronic components (Joshi 2022), allowing for skillful interactions with customers in their natural environment (Čaić et al. 2020). Robots can touch, move, and process items for customers (e.g., clean a car) or perform services on customers’ bodies (e.g., cut hair) (Wirtz et al. 2018). AAs can also have a digital form of existence, with an intangible “body” that can be visualized with icons or avatars. This applies to chatbots (Crolic et al. 2022) and algorithms (Wien and Peluso 2021). Such digital agents exist only in virtual space.
Conceptual Framework
Figure 1 depicts our conceptual framework. The independent variable refers to automated (vs. human) agents. Given the idiosyncratic properties of each AA type, we compare robots, chatbots, and algorithms with HAs separately. As a baseline, we examine the pooled effect size of these three AA types (vs. HAs) on customer responses as the dependent variable. The customer responses from single studies are organized into four categories. One category captures the perceptions of the agent. These are perceived humanlikeness—the degree to which the agent is ascribed humanlike emotions, characteristics, or motivations (Epley, Waytz, and Cacioppo 2007); perceived warmth—the degree to which the agent is perceived as having positive intentions; and perceived competence—the degree to which the agent is perceived as being capable (Fiske, Cuddy, and Glick 2007). The other three categories are responses from the general marketing literature: customer appraisals, intentions, and behaviors (Hoyer, MacInnis, and Pieters 2024). They can relate to the agent or firm (Ryoo, Jeon, and Kim 2024), for example, rapport with the agent or satisfaction with the firm as agent- or firm-related customer appraisals. For behaviors, our framework also covers self-related responses because they occur in several studies (e.g., customers’ task accuracy; Desideri et al. 2019). Web Appendix B provides details.
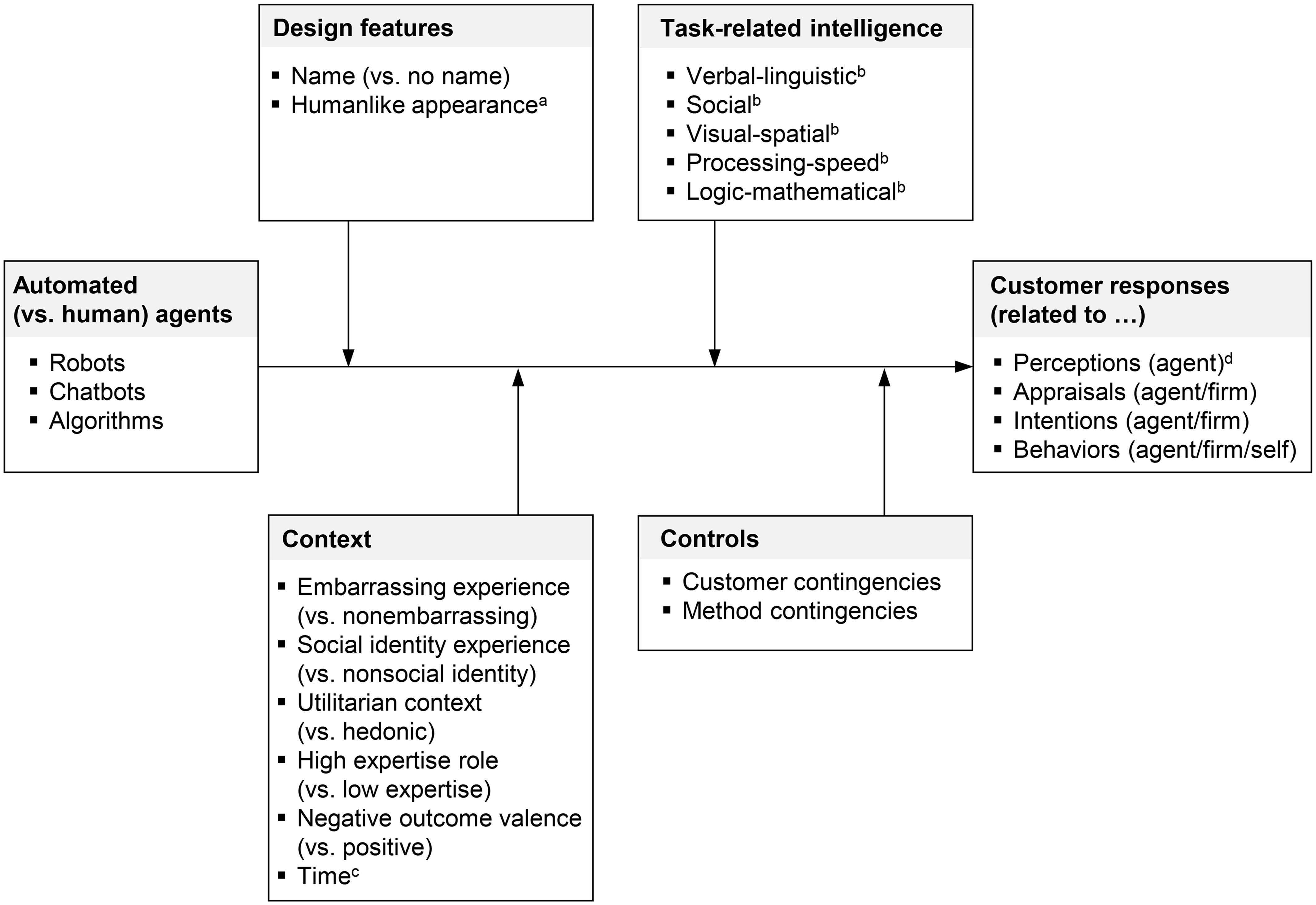
Meta-Analytic Framework for Customer Responses to AAs Versus HAs.
Our framework includes four categories of contingencies for the assumed negative effect of the three AA types (vs. HAs) on customer responses. Three categories contain substantive contingencies. The choice of these categories is guided by their alleged ability to affect the human equivalence of AAs. We include design features, which relate to the external characteristics of AAs. Design features may be relevant for the equivalence question because they represent easily accessible cues that may make AAs appear more like HAs (Go and Sundar 2019). We include task-related intelligence, defined as the degree to which AAs require a specific form of AI to fulfill a task (Pantano and Scarpi 2022). This contingency category may be relevant because it refers to internal characteristics of AAs that may make them akin to HAs, which become accessible to customers during interactions. We also consider context, which refers to the circumstances of an interaction. It is included because AAs’ (dis)advantages over HAs may matter in certain circumstances, making AAs perform as well as, or even worse than, HAs. Control contingencies represent the fourth category, with variables regarding customers and methods. Controls are included as covariates without setting up hypotheses for them (Melnyk, Carrillat, and Melnyk 2022).
Contingencies for the Human Equivalence of AAs
Overview
For the substantive contingencies (i.e., design features, task-related intelligence, and context), we follow a guided test of hypotheses. The idea is that these contingencies are AA-type-specific because each AA type has a certain mode of communication (conversational vs. informational) and form of existence (physical vs. digital) (Table 2). Thus, we first justify the choice of a contingency by explaining why it is relevant for AAs with a specific mode of communication or form of existence. Then, we argue why we expect this contingency to increase or further decrease the human equivalence of these very AAs—that is, whether it may weaken or further strengthen their presumed negative effect on customer responses.
Design Features
A name (vs. no name) refers to whether the AAs are assigned a distinctive designation (El Halabi and Trendel 2024). This variable may matter for AAs with a conversational mode of communication (i.e., robots and chatbots; Table 2). This is because conversational AAs are made for highly interactive exchanges in which information between two parties is exchanged (Luo et al. 2019). Hence, customers need to address and engage with these AAs, as in human-to-human talk. We expect that a name will help them do this by providing their machine interlocutor with an identity label (Go and Sundar 2019). This label is likely to facilitate conversations with AAs and make customers feel connected to them (McLean, Osei-Frimpong, and Barhorst 2021). This may be even more true given that conversational AAs are also able to address customers by name during dialogs (Čaić et al. 2020). Thus, we hypothesize that a name will increase the human equivalence of conversational AAs:
A humanlike appearance is the degree to which AAs look humanlike (Mende et al. 2019). This variable may matter for AAs with a physical form of existence (i.e., robots; Table 2) because physical AAs’ tangible bodies make their appearance a conspicuous quality. We expect that a visual cue, such as a humanlike appearance, will dampen the perception of physical AAs as machines (Dootson et al. 2023). Making their bodies more humanlike may lead customers to attribute human qualities to them, such as more personalized treatment and a better experience (Belanche et al. 2021), thereby improving the quality of the interaction (Wirtz et al. 2018). In addition, customers may associate physical AAs with a humanlike appearance with cutting-edge technology (Belanche et al. 2021). Prior research has also questioned these positive effects, suggesting that humanoid physical AAs may appear creepy (Mende et al. 2019). However, this phenomenon, known as the uncanny valley hypothesis (Mori, MacDorman, and Kageki 2012), refers to near-perfect humanoid machine bodies (Wirtz et al. 2018) and could not to be universally validated by consolidating research (Kätsyri et al. 2015). Thus, in acknowledging an overall positive tendency, we hypothesize that a humanlike appearance will increase the human equivalence of physical AAs:
Task-Related Intelligence
Regarding the form of AI required to fulfill a task, different taxonomies exist. Huang and Rust (2018) posit that AAs can reach successive intelligence levels during their development. Pantano and Scarpi (2022) suggest different types of AI: verbal-linguistic, social, visual-spatial, processing-speed, and logic-mathematical intelligence. These AI types are more instrumental because they allow for a more effective mapping of the AAs to the tasks they have to perform. Therefore, we use this taxonomy.
Verbal-linguistic intelligence is the degree to which a task requires the ability to understand and mimic human language (Pantano and Scarpi 2022). This variable may matter for AAs with a conversational mode of communication (i.e., robots and chatbots; Table 2) because conversational AAs engage customers in natural, one-on-one talk (Luo et al. 2019). As such, customers should be able to assess the verbal skills of these AAs during interactions. We expect that conversational AAs will benefit from their talent in this regard. Their interfaces rely on speech recognition and language processing (Pitardi et al. 2022). They are designed for the very purpose of understanding and mimicking human language (Luo et al. 2019). Like humans, conversational AAs can use idioms and phrases of politeness (Pitardi et al. 2022) as well as emojis in written conversations (Beattie, Edwards, and Edwards 2020). Hence, the more a task requires this type of intelligence, such as explaining nutritional details of food, the more conversational AAs can leverage their linguistic skills. Prior research shows that hotel guests feel attracted by conversational AAs mimicking verbal human demeanor, such as proactively greeting guests and asking if they need help (Pan et al. 2015). Similarly, conversational AAs that apologize for a long wait at a hotel check-in are perceived as sincere (Zhang et al. 2023). Thus, we hypothesize that increasing requirements for verbal-linguistic intelligence will increase the human equivalence of conversational AAs:
Social intelligence is the degree to which a task requires the ability to interact with humans; it includes understanding emotions and responding to social cues and is associated with empathy (Pantano and Scarpi 2022). Social intelligence may matter for AAs with a conversational mode of communication (i.e., robots and chatbots; Table 2). This is because employee–customer talks are highly interactive exchanges that go beyond verbal intercourse and incorporate a social component: Customers can gauge whether employees display the expected empathetic concern for their needs (Wieseke, Geigenmüller, and Kraus 2012). We expect conversational AAs to suffer from AAs’ shortcomings in this regard, particularly from their lack of empathy (Zhou et al. 2023; Table 2). Even for conversational AAs, this ability is difficult to imitate, supporting customers’ prejudice that even verbally fluent AAs still lack empathy (Luo et al. 2019). Even more, they may not believe that machines can feel at all, and perceive conversational AAs that show emotions as creepy (Appel et al. 2020). Hence, the more a task requires empathy, such as discussing customers’ health, the more conversational AAs’ lack of empathy may become salient. Thus, we hypothesize that increasing requirements for social intelligence will decrease the human equivalence of conversational AAs:
In our context, visual-spatial intelligence can be defined as the degree to which a task requires the ability to understand space and identify patterns (Pantano and Scarpi 2022). This variable may matter for AAs with a physical form of existence (i.e., robots; Table 2). This is because physical AAs have tangible bodies with interactive motor skills that move in real space. This gives customers a touch-and-feel experience of whether these agents are moving skillfully in their environment. We expect that physical AAs are likely to benefit from AAs’ outstanding abilities in this regard, namely their speed and reliability (Larkin, Drummond Otten, and Árvai 2022; Table 2). They allow physical AAs to move skillfully (Sanders et al. 2019) and enable them to quickly identify obstacles by scanning their surfaces and dimensions to navigate around them (Čaić et al. 2020). Using sensors, physical AAs are increasingly able to assess spatial proximity and respond to stimuli, making them almost as dexterous as humans (Joshi 2022). Hence, the more a task requires visual-spatial intelligence, such as giving directions at the airport, the more physical AAs may leverage their speed and reliability. Accordingly, we hypothesize that increasing requirements for visual-spatial intelligence will increase the human equivalence of physical AAs:
Processing-speed intelligence is the degree to which a task requires the ability to perform repetitive functions rapidly and fluently (Pantano and Scarpi 2022). This variable may matter for AAs with a physical form of existence (i.e., robots; Table 2). Again, this is because these AAs are embodied machines operating in real space. Unlike in digital space, customers get a touch-and-feel experience. They can see and feel the embodied AAs moving around, and gauge whether they are performing repetitive jobs quickly and accurately. We expect that physical AAs will benefit from AAs’ advantageous speed and reliability (Table 2) in tasks that directly refer to these abilities. Examples are retrieving items from a warehouse (Sanders et al. 2019) or bringing guests’ luggage to their rooms (Wirtz et al. 2018). Therefore, the more a task requires processing-speed intelligence, the more physical AAs can demonstrate their superior speed and reliability. We hypothesize that increasing requirements for processing-speed intelligence will increase the human equivalence of physical AAs:
Logic-mathematical intelligence is the degree to which the task performed by an agent requires the ability to logically analyze situations and find solutions (Pantano and Scarpi 2022). This variable may matter for AAs with an informational mode of communication (i.e., algorithms; Table 2). These AAs take a command, analyze data, and transform it into an output (Table 2). Logical-analytical skills are crucial for this process (Clegg et al. 2023). We expect that informational AAs will benefit from machine agents’ superior abilities in this regard, namely from their speed and reliability (Table 2). Both skills help them succeed at “number crunching.” Informational AAs run complex calculations with dependable output, helping customers make informed decisions (Schoeffer, Machowski, and Kuehl 2021). Hence, the more a task requires logic-mathematical intelligence, such as providing financial advice for a retirement portfolio, the more informational AAs may be able to demonstrate their speed and reliability. Accordingly, we hypothesize that increasing requirements for logic-mathematical intelligence will increase the human equivalence of informational AAs:
Context
An embarrassing (vs. nonembarrassing) experience makes customers feel uncomfortable because they fear that others will judge them negatively (Dahl, Manchanda, and Argo 2001). This variable may matter for AAs with a conversational mode of communication (i.e., robots and chatbots; Table 2). Conversational AAs are made for highly interactive settings where customers tend to expose themselves to their conversation partner (Jin, Walker, and Reczek 2024)—an aspect that holds even more true because customers cannot prepare for unexpected questions in dynamic exchanges (Holthöwer and Van Doorn 2023). We expect that in embarrassing situations, conversational AAs will benefit from one of the alleged disadvantages of AAs: their lack of agency (Table 2). Since customers believe that machines cannot form their own opinions (Pitardi et al. 2022), they trust that such mindless entities will not judge them for buying embarrassing products, which reduces shame (Holthöwer and Van Doorn 2023). Hence, in awkward situations, such as when buying an antifungal treatment, conversational AAs can leverage their lack of agency. Thus, we hypothesize that an embarrassing experience will increase the human equivalence of conversational AAs:
A social identity (vs. nonsocial identity) experience refers to whether the interaction stimulates customers’ wish for self-improvement, driven by the desire to be perceived positively by others (Schmitt 1999). This variable may matter for AAs with a physical form of existence (i.e., robots; Table 2). Physical AAs interact with customers in real space. These natural environments are often public settings (Mende et al. 2019), where others can observe interactions (e.g., a classroom). This public exposure may be relevant when customers seek to self-improve because it affects their image (Allard and White 2015). We expect that physical AAs will suffer in these contexts because of AAs’ general lack of empathy (Pitardi et al. 2022; Table 2). Customers seeking self-improvement work on their ideal self (Schmitt 1999); they may expect compassionate feedback from the agents that are helping them overcome their deficits. In public settings, nonempathetic feedback may harm customers’ image and denigrate them in front of bystanders. Hence, in contexts involving a social identity experience (e.g., when learning a new skill; Li et al. 2016), physical AAs may suffer from their lack of empathy. Accordingly, we hypothesize that a social-identity experience will decrease the human equivalence of conversational-physical AAs:
Utilitarian (vs. hedonic) context refers to cognitive decisions based on functional benefits; a hedonic context involves affective decisions based on experiential pleasure (Khan, Dhar, and Wertenbroch 2005). This variable may matter for AAs with an informational mode of communication (i.e., algorithms; Table 2). The function of informational AAs is to provide output (Table 2) that helps customers make decisions (Schoeffer, Machowski, and Kuehl 2021). Thus, whether a decision is cognitively or affectively driven should play a role in this type of AA. We expect that informational AAs will benefit in utilitarian contexts because of the speed and reliability of AAs (Table 2). In utilitarian contexts, customers’ decisions are driven by rationality (Khan, Dhar, and Wertenbroch 2005), which helps them achieve instrumental goals such as healthy nutrition (Longoni and Cian 2022) or financial yields (Larkin, Drummond Otten, and Árvai 2022). Hence, receiving a quick, reliable output may be appreciated. In contrast, informational AAs may perform poorly in hedonic contexts, such as recommending a concert. Here, customers expect experiential pleasure (Longoni and Cian 2022); speed and reliability seem less crucial. Thus, we hypothesize that a utilitarian (vs. hedonic) context will increase the human equivalence of informational AAs:
A high-expertise (vs. low-expertise) role refers to AAs replacing HAs in roles that require a rather high (vs. low) level of qualification (Xie et al. 2022) and knowledge (Önkal et al. 2009). This context variable may matter for AAs with an informational mode of communication (i.e., algorithms; Table 2). These AAs provide requested outputs (Clegg et al. 2023), raising the question of whether this static communication meets the requirements of highly qualified agents. We expect that this AA type will suffer in high-expertise roles because these roles make one of AAs’ disadvantages salient: their lack of cognitive flexibility (Table 2). AAs perform generally badly at thinking outside the box (Wirtz et al. 2018), but informational AAs’ rigid communication style is particularly limited. In contrast to the dynamic communication style of conversational AAs, they only transform a one-time input into a requested output. Hence, informational AAs are unable to be creative, improvise, or explain unforeseen results to customers. Since these are typical requirements of experts (Önkal et al. 2009; Zhang, Pentina, and Fan 2021), informational AAs may suffer from their lack of cognitive flexibility in high-expertise roles (e.g., doctors). In contrast, customers may accept informational AAs’ static communication in low-expertise roles (e.g., recommending the right clothing sizes). Thus, we hypothesize that a high-expertise (vs. low-expertise) role will decrease the human equivalence of informational AAs:
The two remaining context contingencies from our framework (Figure 1) are included as empirical examinations because they may affect the human equivalence of all AA types. A negative (vs. positive) outcome valence refers to whether the result of an interaction is unfavorable (vs. favorable), including worse-than-expected outcomes (Garvey, Kim, and Duhachek 2022), service failures (Srinivasan and Sarial-Abi 2021), and denial of service (Yalcin et al. 2022). This variable is included because customers tend to engage in attribution processes about the causer of negative events and evaluate mindless machines differently than humans (Srinivasan and Sarial-Abi 2021). We expect that a negative outcome valence will increase the human equivalence of AAs due to their lack of cognitive flexibility (Table 2). This may make customers feel that AAs follow standardized procedures (Yu, Xiong, and Shen 2022) and neglect their uniqueness (Longoni, Bonezzi, and Morewedge 2019). Thus, customers tend to take a negative outcome (e.g., being denied a loan) from AAs less personally than from human employees (Yalcin et al. 2022). This mechanism may apply to all AA types, as it is easier to accept an unfavorable outcome from any kind of machine.
Time refers to the studies’ chronological age. We included this variable because technology changes over time. We expect that AAs will move toward equivalence to HAs over time because customers are increasingly exposed to AAs in their daily lives (De Keyser and Kunz 2022) and may get used to them. Furthermore, AAs should become more capable over time because newer AAs are connected to cloud-based systems (Wirtz et al. 2018) and imbued with AI (Huang and Rust 2021). We assume a positive effect for all AA types because increased exposure and technological improvements apply to all of them.
Nonlinear Effects
Nonlinear effects are conceivable for continuous contingencies, such as humanlike appearance, task-related intelligence, and time. We focus on humanlike appearance because it is the only contingency with a theoretical rationale for potential nonlinear effects. Prior research suggests the possibility of an uncanny valley for physical AAs (i.e., robots) with an almost humanlike appearance (Mori, MacDorman, and Kageki 2012). Hence, in addition to the proposed positive, linear effect of a humanlike appearance for this AA type (H2), we explore nonlinear patterns. While uncanny valley research focuses on physical AAs (Kim, De Visser, and Phillips 2022), we also explore nonlinear effects for digital AAs (i.e., chatbots and algorithms) because they can be visualized.
Method
Data Collection
Literature search
We used five search strategies to identify relevant studies on the effects of AAs (vs. HAs) on customer responses. First, we searched electronic databases (EBSCO, ScienceDirect, and Web of Science) for articles in relevant fields (e.g., marketing, psychology, and computer science) using search terms such as robot, chatbot, algorithm digital agent, voice assistant, and AI in combination with replace/comparison and human/employee. Second, we manually reviewed relevant journals in the fields of marketing, service, psychology, and human–machine interaction (e.g., Computers in Human Behavior, Journal of Consumer Psychology, Journal of Consumer Research, Journal of Marketing, Journal of Marketing Research, Journal of Service Research, Psychological Science) covering the period from January 2000 (when the first studies appeared) through March 2022; a second search covered the period through June 2023 to update the dataset. Third, we searched the internet (e.g., SSRN, PsyArXiv, Google Scholar) for gray literature (i.e., dissertations, preprints, and conference proceedings) to minimize publication bias (Harrer et al. 2021). Fourth, we used the retrieved articles for a backward citation search and Google Scholar for a forward citation search. Fifth, we screened the references available at the time of our study from related meta-analyses in Table 1. Throughout the process, we asked the authors of the identified articles for additional data to retrieve effect sizes (when necessary) and any unpublished work.
Four inclusion criteria were applied. First, the studies had to compare an AA with an HA. Second, they had to address an employee–customer interaction (e.g., selling products, providing services). To account for related fields, we also included implicit employee–customer interactions in which the agents’ demeanor could be associated with a marketing context (e.g., people making decisions based on given information or chatting for social support). Third, the studies had to use at least one of the customer responses in our framework (Figure 1). Fourth, we included only studies for which we could extract or calculate the effect size. As exclusion criteria, we omitted studies (1) in which an AA supported rather than replaced an HA or in which an AA replaced an employee's colleague, (2) that referred to contexts too distant from marketing (e.g., preschools, mine clearance), or (3) that compared HAs with self-service technologies (e.g., ATMs), given that they are not AAs owing to their low level of autonomy (Holthöwer and Van Doorn 2023).
Database
The final database consisted of 148 articles, including 327 independent experimental studies 3 published from January 2000 to June 2023. Overall, 29.7% of the studies were real interactions (vs. scenarios); of these, 67.0% were field (vs. lab) experiments. Participants’ mean age was 32.8 years, and the average proportion of female participants was 48.9%. In the studies that specified their sample, participants were from North America (47.9%), Europe (15.6%), Asia (33.8%), and other regions (2.5%). Web Appendices C and D list the included studies and articles, respectively. We excluded two outliers with values more than three times the standard deviation (Liadeli, Sotgiu, and Verlegh 2023), resulting in a dataset of 943 effect sizes. The results of the hypothesis testing, as well as the relative comparisons of effect sizes across AA types and customer responses, remained stable when these outliers were included.
Calculation of effect sizes
We first calculated the standardized mean differences (Cohen's d) between the AA and HA groups. When the means and SDs were not given, we calculated Cohen's d from the reported statistics (e.g., χ2, F, t, p-values) via Lipsey and Wilson's (2001) formulas. Next, we converted d into the Pearson correlation coefficient r (Lipsey and Wilson 2001), which is a widely used metric for meta-analyses in marketing (e.g., Melnyk, Carrillat, and Melnyk 2022). A positive (negative) r value indicates that AAs generate more positive (negative) customer responses than HAs do.
Coding scheme
Table 3 shows the coding scheme for the contingencies from our framework (Figure 1). Two independent nonauthors, unaware of the hypotheses, used this scheme to code the contingencies (Melnyk, Carrillat, and Melnyk 2022) and the three AA types (robots, chatbots, and algorithms) based on their definitions. Most variables were subjective and required high-inference coding, using the operationalizations rather than the labels in the studies. We added examples of scale values from the studies to the coding scheme to increase the validity of the coding (Cooper 2017). Furthermore, most variables were dichotomous. For the continuous contingencies humanlike appearance and the intelligence types, we used a 1–9 scale. Krippendorff's alpha values for intercoder agreement exceeded the .60 threshold, with 12 of 17 codings exceeding .80, indicating substantial agreement. Inconsistencies were discussed with the research team until a solution was found. Objective contingencies were coded by the authors: time, percentage of female participants, mean age, control variables, published work, and top-tier journal.
Coding Scheme and Statistical Properties of Contingencies.
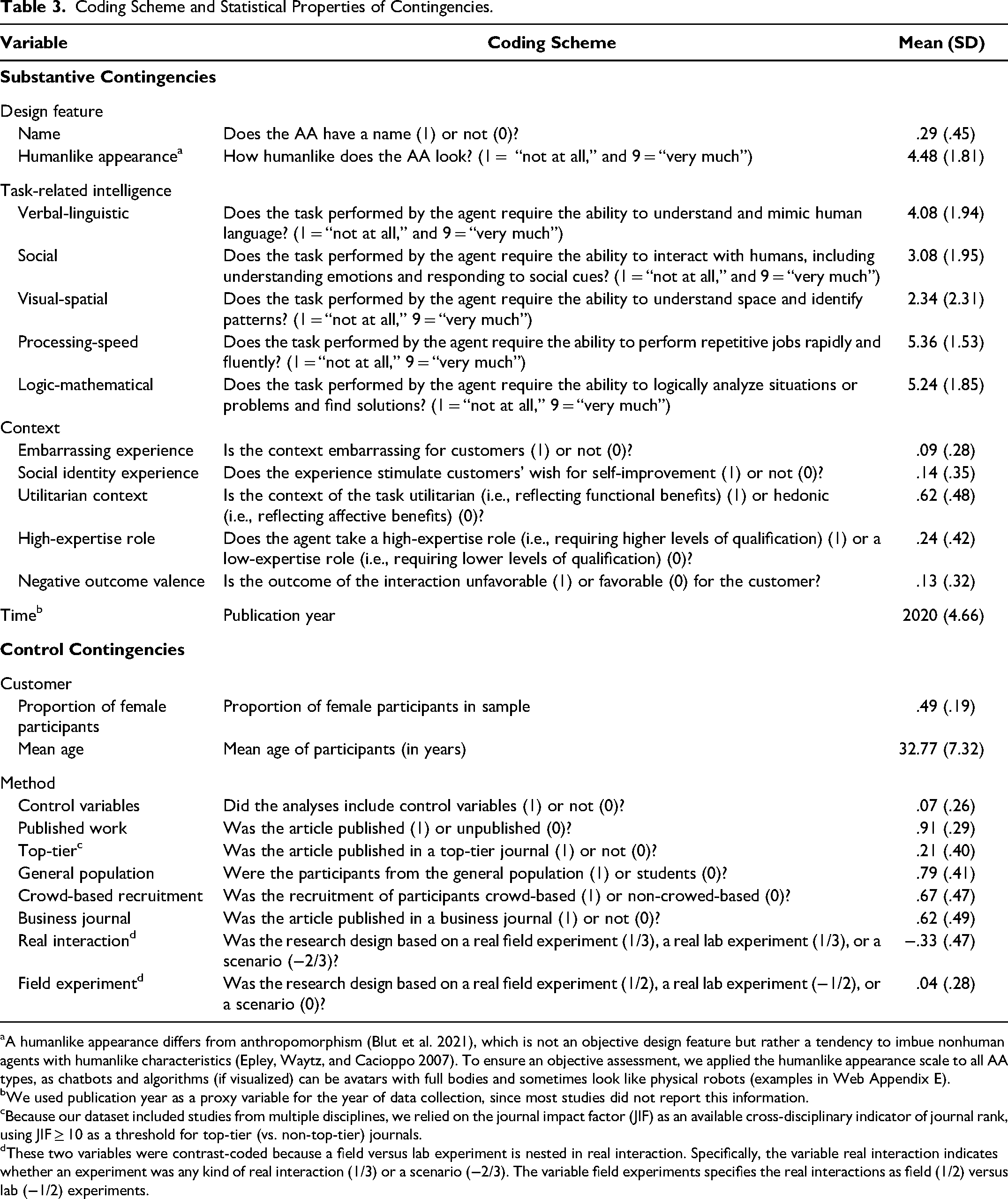
A humanlike appearance differs from anthropomorphism (Blut et al. 2021), which is not an objective design feature but rather a tendency to imbue nonhuman agents with humanlike characteristics (Epley, Waytz, and Cacioppo 2007). To ensure an objective assessment, we applied the humanlike appearance scale to all AA types, as chatbots and algorithms (if visualized) can be avatars with full bodies and sometimes look like physical robots (examples in Web Appendix E).
We used publication year as a proxy variable for the year of data collection, since most studies did not report this information.
Because our dataset included studies from multiple disciplines, we relied on the journal impact factor (JIF) as an available cross-disciplinary indicator of journal rank, using JIF ≥ 10 as a threshold for top-tier (vs. non-top-tier) journals.
These two variables were contrast-coded because a field versus lab experiment is nested in real interaction. Specifically, the variable real interaction indicates whether an experiment was any kind of real interaction (1/3) or a scenario (−2/3). The variable field experiments specifies the real interactions as field (1/2) versus lab (−1/2) experiments.
Data Analysis
Pooling effect sizes
The extracted effect sizes r were corrected for reliability to account for attenuation from random measurement error, rc (Hunter and Schmidt 2004). Missing reliability values were replaced by the mean reliability for each variable across studies. We performed a Fisher's z transformation for rc to reduce range restrictions and to account for biased standard error estimates in small samples (Alexander, Scozzaro, and Borodkin 1989). Next, we calculated the pooled effect size r̅ for each customer response across robots, chatbots, algorithms, and AAs overall. Here, we weighted effect sizes by their inverse variance, giving greater weight to more precise effects. We used a random-effects model to account for expected heterogeneity in the effect sizes and a multilevel approach because the effect sizes are nested within studies (Harrer et al. 2021). Web Appendix F shows the formulas for these calculations. Models were estimated with the metafor package for R and the rma.mv function (Viechtbauer 2010).
Meta-regressions
The contingencies were tested via meta-regressions with the same weighting, random effects, and multilevel specifications used for pooling effect sizes. This approach was justified by the I2 values for robots, chatbots, algorithms, and AAs overall (see Web Appendix G), indicating a high percentage of effect size variability that cannot be explained by mere sampling error (Higgins and Thompson 2002). We performed multiple meta-regressions, regressing the Fisher's z-transformed effect sizes on the contingency variables. Specifically, we estimated a robot (k = 264), a chatbot (k = 261), and an algorithm (k = 418) model in the respective subsamples. The models accounted for the customer responses (see Web Appendix B) with dummy variables and included the substantive and control contingencies from our framework (Table 3). We also estimated an AAs overall model (k = 943) with the full dataset, accounting for the AA types (robots, chatbots, and algorithms) with two dummy variables. Web Appendix H provides the models’ formulas.
Multicollinearity
In the meta-regressions, we accounted for multicollinearity by removing contingencies with high variance inflation factors (VIFs) in two steps. First, to obtain a consistent set of control contingencies, we removed general population and crowd-based recruitment from all models (as they had VIFs ≥ 3.0). In addition, we had to remove time from the chatbot and algorithm models because it also caused VIFs ≥ 3.0 in the control contingencies. We tested the removed contingencies separately in ex post analyses. Second, we removed nonsignificant substantive contingencies with VIFs ≥ 3.0 one by one, starting with the highest VIF, until all VIFs were < 3.0. The resulting maximum VIFs were then 2.84 (robots), 2.96 (chatbots), 2.79 (algorithms), and 2.87 (AAs overall), which are below those reported in other meta-analyses (e.g., Melnyk, Carrillat, and Melnyk 2022). Likelihood ratio tests (Harrer et al. 2021) revealed that removing variables with high VIFs did not reduce model fit (robots: p = .982, chatbots: p = .435, algorithms: p = .520). The removed variables were social intelligence and high-expertise role (robots), visual-spatial intelligence (chatbots), and verbal-linguistic intelligence (algorithms). We tested those variables in ex post analyses, retaining the formerly removed substantive contingencies and dropping those with the next-highest VIF until all VIFs were < 3.0. Web Appendix I presents details and correlation tables.
Publication bias
We checked for publication bias (i.e., unpublished nonsignificant effects; Harrer et al. 2021). The fail-safe N-values for the pooled effect sizes and the funnel plots did not provide evidence of publication bias. We also included effect size precision as an independent variable in our meta-regression models (Melnyk, Carrillat, and Melnyk 2022). It had no effect in the robot (b = .001, p = .692), chatbot (b = −.001, p = .805), algorithm (b = .001, p = .513), or AAs overall (b = .002, p = .214) models, further indicating that publication bias is not a severe problem. Web Appendix J provides details.
Results
Pooled Effect Sizes
Table 4 depicts the pooled effect sizes for the AA types (i.e., robots, chatbots, algorithms, and AAs overall) and customer responses (i.e., perceptions, appraisals, intentions, behaviors, and responses overall). The overall pooled effect size r̅ (i.e., AAs and responses overall) is −.127 (p < .001), which is a small negative effect according to Cohen (1988). For AAs overall, the pooled effects sizes for perceptions, appraisals, and intentions range between −.380 (p < .001) and −.074 (p < .001). Those for behaviors range between −.038 (p = .680) and −.014 (p = .788).
Pooled Effect Sizes Vary by AA Type and Customer Response.
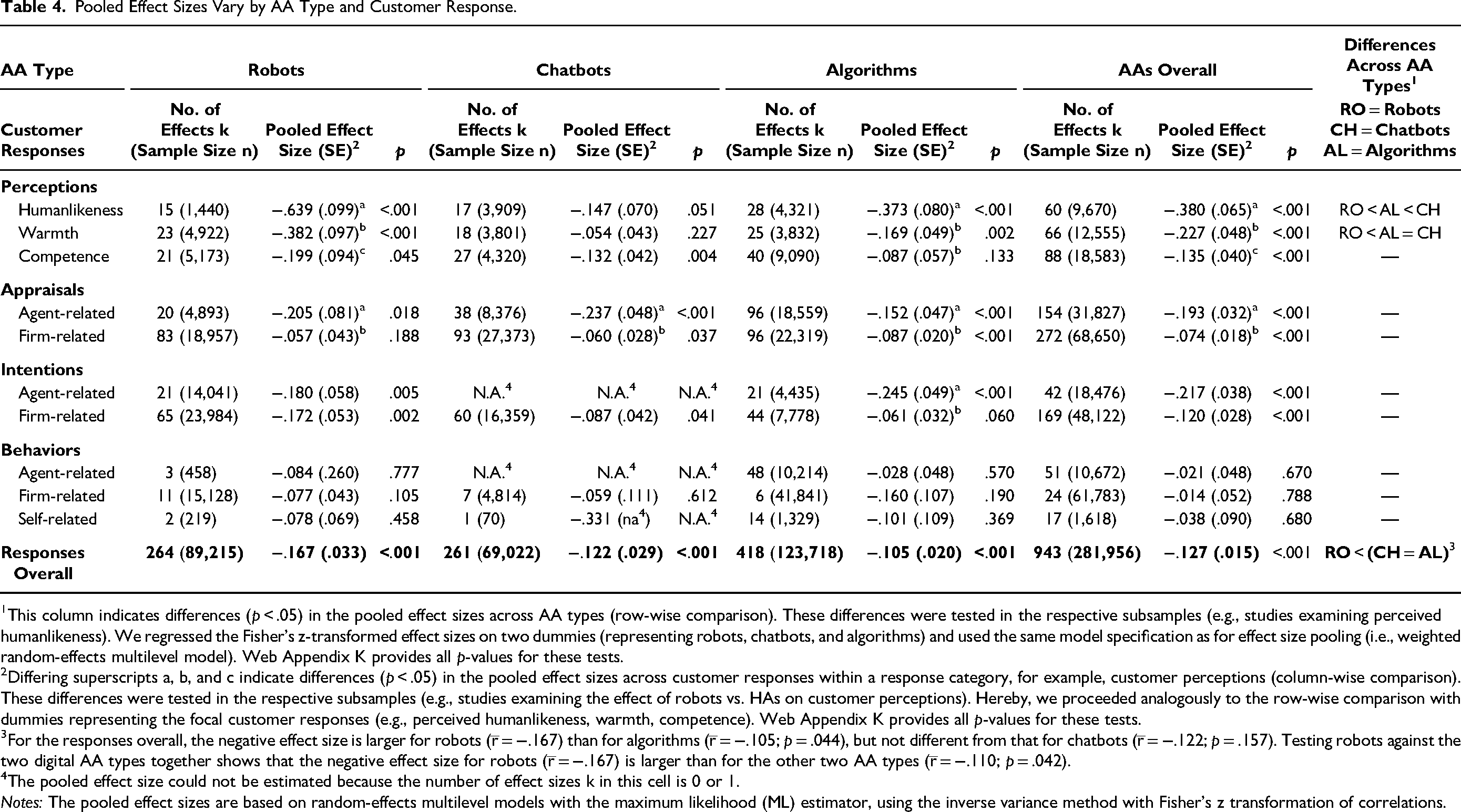
This column indicates differences (p < .05) in the pooled effect sizes across AA types (row-wise comparison). These differences were tested in the respective subsamples (e.g., studies examining perceived humanlikeness). We regressed the Fisher's z-transformed effect sizes on two dummies (representing robots, chatbots, and algorithms) and used the same model specification as for effect size pooling (i.e., weighted random-effects multilevel model). Web Appendix K provides all p-values for these tests.
Differing superscripts a, b, and c indicate differences (p < .05) in the pooled effect sizes across customer responses within a response category, for example, customer perceptions (column-wise comparison). These differences were tested in the respective subsamples (e.g., studies examining the effect of robots vs. HAs on customer perceptions). Hereby, we proceeded analogously to the row-wise comparison with dummies representing the focal customer responses (e.g., perceived humanlikeness, warmth, competence). Web Appendix K provides all p-values for these tests.
For the responses overall, the negative effect size is larger for robots (r̅ = −.167) than for algorithms (r̅ = −.105; p = .044), but not different from that for chatbots (r̅ = −.122; p = .157). Testing robots against the two digital AA types together shows that the negative effect size for robots (r̅ = −.167) is larger than for the other two AA types (r̅ = −.110; p = .042).
The pooled effect size could not be estimated because the number of effect sizes k in this cell is 0 or 1.
Notes: The pooled effect sizes are based on random-effects multilevel models with the maximum likelihood (ML) estimator, using the inverse variance method with Fisher's z transformation of correlations.
A row-wise comparison of the AA types reveals some differences (Table 4, last column). For the responses overall, the negative effect size is larger for robots (r̅ = −.167) than for the two digital agents (algorithms: r̅ = −.105 and chatbots: r̅ = −.122; p = .042). Robots’ negative effect size is larger than that of chatbots and algorithms in terms of perceived warmth (robots: r̅ = −.382; algorithms: r̅ = −.169, p = .023; chatbots: r̅ = −.054, p < .001) and perceived humanlikeness (robots: r̅ = −.639; algorithms: r̅ = −.373, p = .015; chatbots: r̅ = −.147, p < .001), with the exception that chatbots also outperform algorithms in terms of perceived humanlikeness (p = .032). Web Appendix K provides all p-values for these tests.
A column-wise comparison of the customer responses reveals some differences within customer perceptions and appraisals (Table 4, superscripts a, b, and c). For AAs overall, the negative effect size is smaller for perceived competence (r̅ = −.135), followed by perceived warmth (r̅ = −.227, p = .014) and then by perceived humanlikeness (r̅ = −.380, p = .008). Furthermore, the negative effect size is smaller for firm-related appraisals (r̅ = −.074) than for agent-related appraisals (r̅ = −.193, p < .001). These patterns apply to all AA types except for chatbots, where the three perceptions do not differ from each other. Web Appendix K provides all p-values for these tests.
Robot, Chatbot, Algorithm, and Overall Models
Table 5 shows the meta-regression results for robots, chatbots, algorithms, and AAs overall, explaining 51.1%, 33.9%, 33.1%, and 29.8% of the variance in the effect sizes, respectively. Web Appendix L provides the results for the control contingencies.
Meta-Regression Results with Unique Contingency Effects Across Robots, Chatbots, and Algorithms.
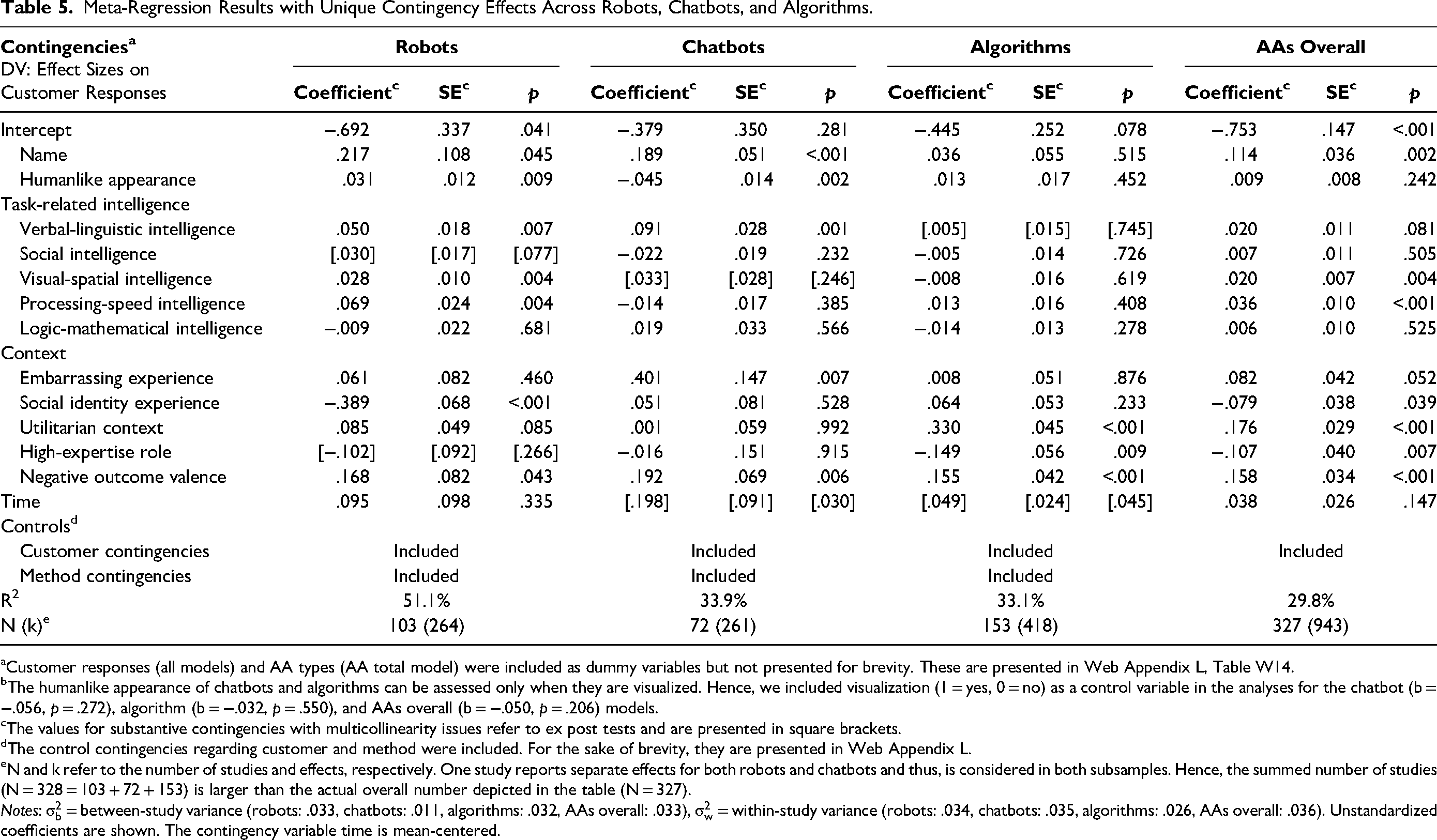
Customer responses (all models) and AA types (AA total model) were included as dummy variables but not presented for brevity. These are presented in Web Appendix L, Table W14.
The humanlike appearance of chatbots and algorithms can be assessed only when they are visualized. Hence, we included visualization (1 = yes, 0 = no) as a control variable in the analyses for the chatbot (b = −.056, p = .272), algorithm (b = −.032, p = .550), and AAs overall (b = −.050, p = .206) models.
The values for substantive contingencies with multicollinearity issues refer to ex post tests and are presented in square brackets.
The control contingencies regarding customer and method were included. For the sake of brevity, they are presented in Web Appendix L.
N and k refer to the number of studies and effects, respectively. One study reports separate effects for both robots and chatbots and thus, is considered in both subsamples. Hence, the summed number of studies (N = 328 = 103 + 72 + 153) is larger than the actual overall number depicted in the table (N = 327).
Notes:
Robot model
The results support that name (b = .217, p = .045; H1a), humanlike appearance (b = .031, p = .009; H2), verbal-linguistic intelligence (b = .050, p = .007; H3a), visual-spatial intelligence (b = .028, p = .004; H5), and processing-speed intelligence (b = .069, p = .004; H6) weaken the negative effect sizes of robots, whereas a social identity experience strengthens their negative effect sizes (b = −.389, p < .001; H9). Unexpectedly, social intelligence (b = .030, p = .077; H4a) and embarrassing experience (b = .061, p = .460; H8a) have no effect.
Chatbot model
The results support that name (b = .189, p < .001; H1b), verbal-linguistic intelligence (b = .091, p < .001; H3b), and embarrassing experience (b = .401, p = .007; H8b) weaken the negative effect sizes of chatbots. Unexpectedly, social intelligence has no effect (b = −.022, p = .232; H4b). Although not hypothesized, humanlike appearance strengthens the negative effect sizes of chatbots (b = −.045, p = .002).
Algorithm model
The results support that utilitarian context weakens (b = .330, p < .001; H10) and high-expertise role strengthens (b = −.149, p = .008; H11) the negative effect sizes of algorithms. Unexpectedly, logic-mathematical intelligence has no effect (b = −.014, p = .278; H7).
All AA type models
Regarding AA-type-independent contingencies, a negative outcome valence weakens the negative effect sizes of robots (b = .168, p = .043), chatbots (b = .192, p = .006), and algorithms (b = .155, p < .001). Time weakens the negative effect sizes of chatbots (b = .198, p = .030) and algorithms (b = .049, p = .045) but has no effect for robots (b = .095, p = .335).
Prediction of Effect Sizes
Using the estimated regression functions for the three AA types, we predict the effect sizes ȓ for two levels of the relevant (p < .05) substantive contingencies (binary variables at their coded levels, continuous variables at ±1 SD of the variable's mean), freezing the nonfocal contingencies at their means (Melnyk, Carrillat, and Melnyk 2022). Figure 2 depicts the predicted values. Using Cohen's (1988) value of ȓ = |.1| a threshold for a small effect, an AA is equivalent when ȓ ≥ −.1 (i.e., when the AA is disfavored by .1 or less).
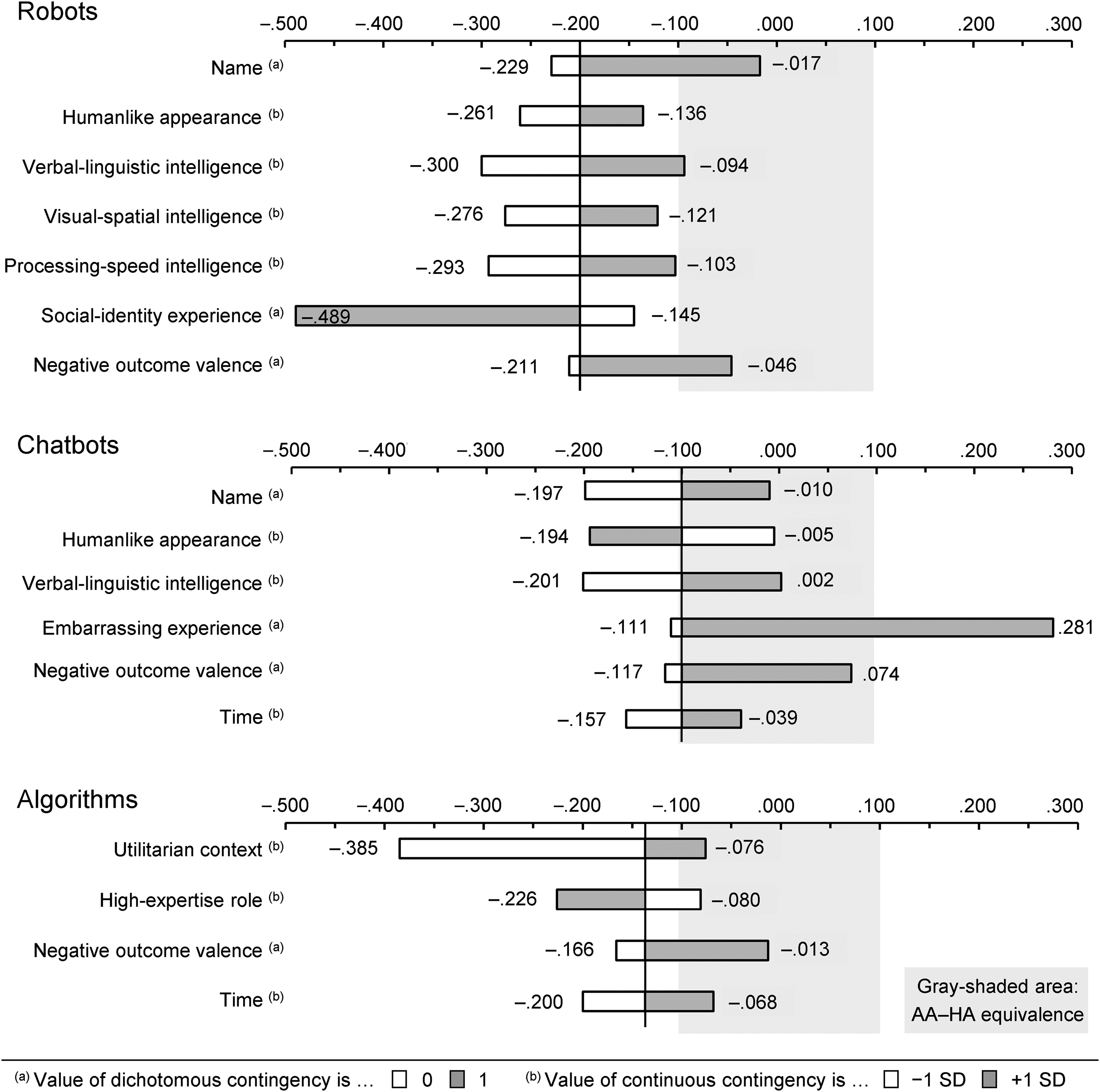
AAs Are Equivalent to HAs Under Several Conditions.
The results show that robots are equivalent to HAs if they have a name (ȓ = −.017), if the task requires verbal-linguistic intelligence (ȓ = −.094), and if the outcome valence is negative (ȓ = −.046); they are essentially equivalent if a task requires processing-speed intelligence (ȓ = −.103). Chatbots are equivalent to HAs if they have a name (ȓ = −.010), if their humanlike appearance is low (ȓ = −.005), if the task requires verbal-linguistic intelligence (ȓ = .002), if the outcome valence is negative (ȓ = .074), and if they were used more recently (ȓ = −.039). In embarrassing contexts, chatbots are even superior to HAs (ȓ = .281). Algorithms are equivalent to HAs in utilitarian contexts (ȓ = −.076), in low-expertise roles (ȓ = −.080), if the outcome valence is negative (ȓ = −.013), and if they were used more recently (ȓ = −.068).
Nonlinear Effects of Humanlike Appearance
We explore the nonlinear effects of humanlike appearance by specifying a quadratic function for it in the models for the three AA types. The results for robots (b = −.027, p = .598; c = .005, p = .241) and algorithms (b = −.013, p = .846; c = .003, p = .693) show no effects, but they do for chatbots (b = −.209, p < .001; c = .018, p < .001), with the linear term indicated by b and the quadratic term by c. Figure 3 shows the predicted curves for chatbots. They indicate that the linear model (Panel A) is qualified by the quadratic model (Panel B), such that the overall negative slope shows a U-shaped curve. Web Appendix M provides further details (i.e., model-free evidence).
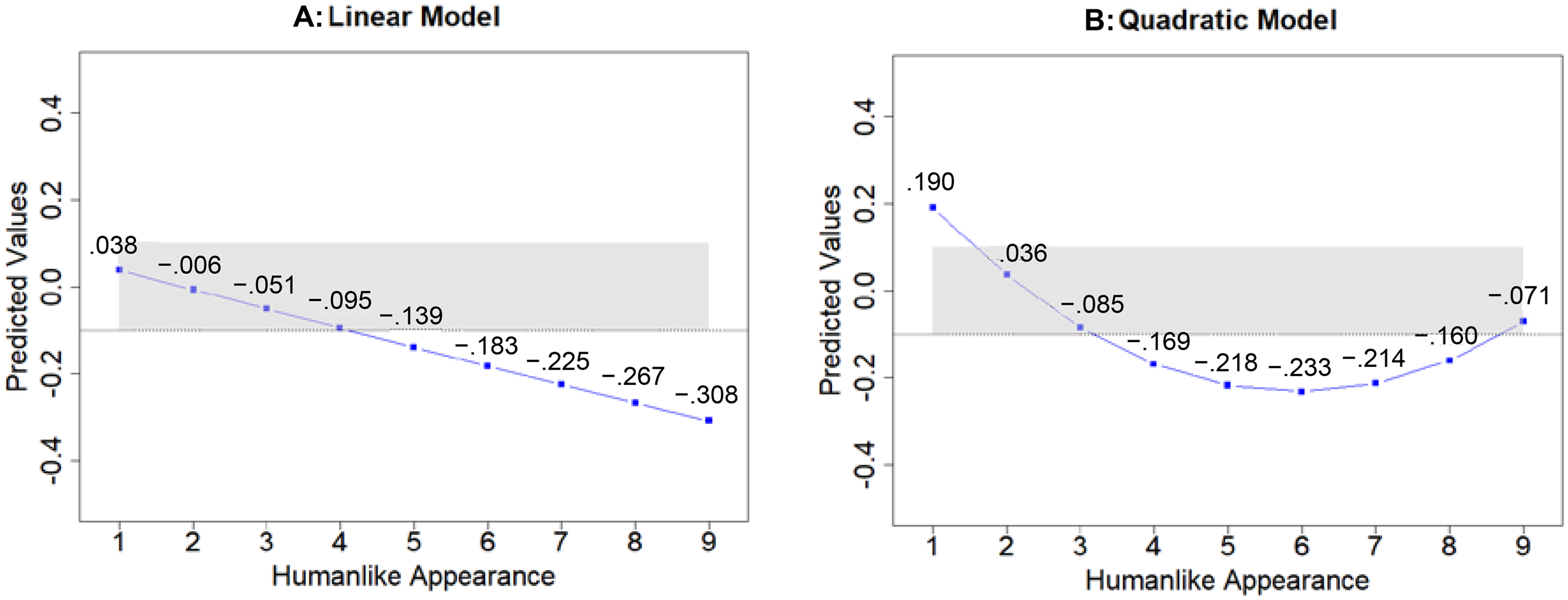
A U-Curve Qualifies the Negative Effect of a Humanlike Appearance for Chatbots.
Discussion and Theoretical Implications
Consolidated knowledge about the human equivalence of the three AA types in marketing roles, as well as the contingencies of their human equivalence, is limited, leaving it unclear whether the findings apply equally to robots, chatbots, and algorithms (Table 1). We provide the first comprehensive assessment, offering several new insights.
Human Equivalence of Robots, Chatbots, and Algorithms
As a baseline, AAs are inferior to HAs (r̅ = −.127) in the overall view but are near the equivalence threshold. Comparing the AA types reveals that robots fall short of HAs the most (Table 4, row-wise comparison). These findings are in line with Zehnle, Hildebrand, and Valenzuela (2025), but our nuanced view of single customer responses reveals that robots’ relative inferiority relates only to perceived humanlikeness and warmth. Presumably, due to their physical form of existence, it can be seen that robots are machines and therefore not humanlike or warm. Chatbots and algorithms equally outperform robots in the overall view. The relative parity of the digital AAs is surprising, as chatbots’ conversational mode of communication mimics an online talk with a real human, which makes them appear more humanlike than algorithms. However, algorithms provide information on command and are well received when serving this purpose. A general algorithm aversion, often described in the literature (Dietvorst, Simmons, and Massey 2015), is thus not supported.
Comparing customer responses reveals an overarching pattern (Table 4, column-wise comparison): (1) AAs are most inferior for agent-related perceptions, (2) they are more inferior for agent- than for firm-related appraisals, and (3) they are equivalent to HAs for behaviors, be they agent-, firm-, or self-related. This pattern challenges the common assumption that AAs will remain inferior to human employees in the near future (Xiao and Kumar 2021). It also enriches prior meta-analyses, which do not distinguish between agent- and firm-related responses (Table 1). AAs are only inferior with respect to agent-related upstream responses, supporting the idea that customers harbor reservations about AAs. However, when it comes to assessing the firm and engaging in managerially relevant downstream responses (i.e., behaviors), customers value the output of AAs and choose or buy from them as if they were interacting with HAs.
Contingencies That Affect Equivalence
Our findings reveal idiosyncratic contingencies for the human equivalence of each AA type, with minor overlaps only (Table 5). They provide the following new insights.
Contingencies are AA-type-specific and not generalizable across AAs
This insight refutes the idea of generic or mixed-sample meta-analyses implying that “one size fits all.” For example, the negative effect of a high-expertise role (Zehnle, Hildebrand, and Valenzuela 2025) applies only to algorithms, not to conversational AA types. We also qualify conflicting meta-analytic results (e.g., on the effect of a utilitarian vs. hedonic context; Blut and Wang 2020; Ma, Fan, and Mattila 2024), because they may veil AA-type-specific effects. The results also challenge two of our expectations about generalizability. First, an embarrassing context only benefits chatbots. The null effect for robots is surprising and contradicts single-study results (e.g., Holthöwer and Van Doorn 2023). One explanation is that robots are physical AAs acting in real space. Customers may feel less ashamed around them but will feel so while near human bystanders. The respective studies may have not aimed to account for such conceivable effects. Second, time only benefits chatbots and algorithms, not robots, which qualifies the positive effect of time in a mixed AA sample meta-analysis (Zehnle, Hildebrand, and Valenzuela 2025). Robots are difficult to design, and the period covered for them (from 2016 in our data) may be too short to see improvements. Hence, robots may still be somewhat unfamiliar to consumers (Van Doorn, Odekerken-Schröder, and Spohrer 2025).
The same contingency can have opposite effects in different AA types
A humanlike appearance increases the human equivalence of robots but shows a U-curve with a negative tendency for chatbots. Prior meta-analyses could not unveil such effects because many captured humanlikeness as perceived by customers rather than as an actual design feature (e.g., Blut et al. 2021; Blut, Wünderlich, and Brock 2024; Li et al. 2023). Even when testing a humanlike design, they mixed several facets (e.g., virtual face, character, name; Zehnle, Hildebrand, and Valenzuela 2025) or treated it as a categorical construct with equivocal results (Kilani and Rajaobelina 2024; Ma, Fan, and Mattila 2024). Examining nonlinear effects across AA types enriches the discussion of an uncanny valley (e.g., Mende et al. 2019), which does not seem to exist for robots and comes with a negative tendency and an earlier drop for chatbots. Chatbots’ core purpose is to talk to customers in a virtual space. Visualizing them with an icon as a placeholder may best serve this purpose. A more humanlike look, especially a cartoonish or stylized one (i.e., a medium level), is distracting.
Generalizing AI is undue
This insight bears two facets. First, some prior meta-analyses generalize AAs as AI (e.g., Aguiar-Costa et al. 2022), although AAs may or may not be AI-enabled. We show that the AI required for a task is a contingency for AAs’ equivalence with HAs, and this contingency may be more or less relevant. Second, the few meta-analyses that use AI as a contingency draw on a general, dichotomous concept of higher versus lower intelligence (Blut, Wünderlich, and Brock 2024; Ladeira, Perin, and Santini 2023). By considering Pantano and Scarpi's (2022) taxonomy of different AI types required for a task, we reveal that increasing AAs’ general intelligence is not beneficial per se. Instead, different types of intelligence benefit different types of AAs. Robots can benefit the most because they engage in conversations (where increasing verbal-linguistic intelligence is helpful) and move in real space (where increasing visual-spatial and processing-speed intelligence is helpful).
Implications for Theory Building
The meta-regression results (Table 5) reveal two overarching patterns (Table 6). First, equivalence is affected by contingencies that can make AAs more humanlike. They represent verbal human cues (name and verbal-linguistic intelligence), which benefit robots and chatbots, and visual human cues (humanlike appearance), which benefit robots and harm chatbots. Second, equivalence is affected by contingencies that can make AAs’ machine characteristics salient. These characteristics refer to the advantages and disadvantages of AAs over HAs (Table 2). Speed and reliability can benefit robots (in tasks related to visual-spatial or processing-speed intelligence) and algorithms (in utilitarian contexts). A lack of cognitive flexibility can benefit all AA types (for a negative outcome valence) but also harm algorithms (in a high-expertise role). A lack of agency can benefit chatbots (for an embarrassing experience). A lack of empathy can harm robots (for a social identity experience).
The Key Findings for the Contingencies Enrich the Concept of ASP.
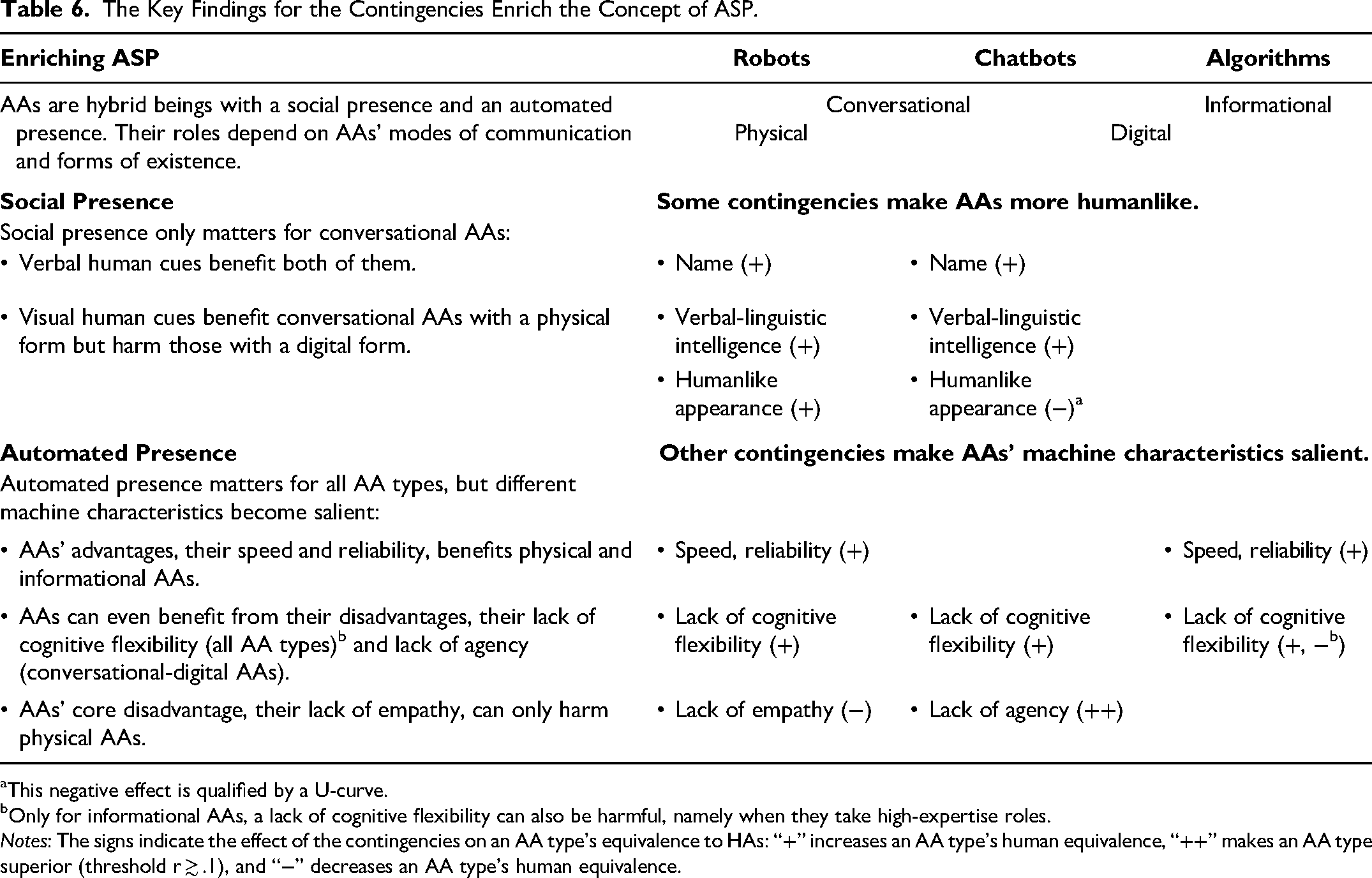
This negative effect is qualified by a U-curve.
Only for informational AAs, a lack of cognitive flexibility can also be harmful, namely when they take high-expertise roles.
Notes: The signs indicate the effect of the contingencies on an AA type's equivalence to HAs: “+” increases an AA type's human equivalence, “++” makes an AA type superior (threshold r ≳ .1), and “−” decreases an AA type's human equivalence.
These patterns provide novel insights that enrich the ASP concept (Table 6). The core idea of this concept is that customers exposed to an AA feel the presence of a social entity (Van Doorn et al. 2017). This feeling can be triggered by verbal or nonverbal human cues (Short, Williams, and Christie 1976). Such cues cause customers to perceive AAs as human, despite their better knowledge (Holthöwer and Van Doorn 2023). This concept presumes that the humanlike nature of AAs overlays their machine nature. However, the two-partite configuration of contingencies suggests that customers may value both making AAs more humanlike and making their machine characteristics salient. Following this logic, we posit that customers perceive AAs as hybrid beings that bear a coexisting social presence (i.e., the feeling of interacting with a humanlike entity) and an automated presence (i.e., the feeling of interacting with a machine entity). The relevance of both dimensions depends on AA type.
Social presence only clearly benefits one AA type; for others, it can be irrelevant or even harmful (Table 6). This insight suggests that the merits of social presence assumed in ASP are not generalizable across AA types. It also puts into perspective meta-analytic findings, which suggest that social presence has positive effects on various customer responses (Blut et al. 2021; Blut, Wünderlich, and Brock 2024). The respective meta-analyses lack a human benchmark, overlooking the fact that HAs can also benefit from a higher social presence, for example, through facial expressions (Short, Williams, and Christie 1976). Hence, when using HAs as a benchmark, the relevance of social presence looms smaller than currently assumed.
Automated presence is relevant for all AAs. Single AA types can benefit from AAs’ advantageous machine characteristics. Disadvantageous machine characteristics are less harmful than presumed and can benefit all AAs or even make one AA type superior to HAs; only a lack of empathy remains problematic in one case (Table 6). These results enrich the ASP concept, which downplays the role of AAs’ machine presence as a means to create a social presence (Van Doorn et al. 2017). Accordingly, recent meta-analyses have included AAs’ social presence, but not their automated presence (e.g., Blut et al. 2021). Our results suggest that AAs’ automated presence is an independent construct with multiple positive effects, depending on AA type and the task or context where it replaces a human employee.
In summary, our findings challenge the implicit assumption in the concept of ASP that AAs’ social presence is key to success. Technological advancements may have led to an overrating of the need to make AAs more humanlike. This may not always be necessary, but AAs can be appropriate substitutes for HAs just because they are perceived as machines.
Managerial Implications
When should marketers consider AAs as an alternative to HAs? AAs alleviate labor shortages (Song et al. 2022) and increase efficiency (Xiao and Kumar 2021), calling for substitution when customer responses are equivalent (Figure 2). Our recommendations in Table 7 relate to design features and the tasks and contexts in which the use of AAs is desirable, as customers consider them equivalent (ȓ ≳ −.1). We add the tasks and contexts in which the use of AAs is acceptable, as efficiency gains may compensate for slightly lower customer receptivity (−.2 ≲ ȓ ≲ −.1). Since replacing human staff raises ethical concerns, firms should prioritize cases in which AAs relieve employees from physical or mental loads.
The Use of the Three AA Types Is Recommended in Various Marketing Roles.
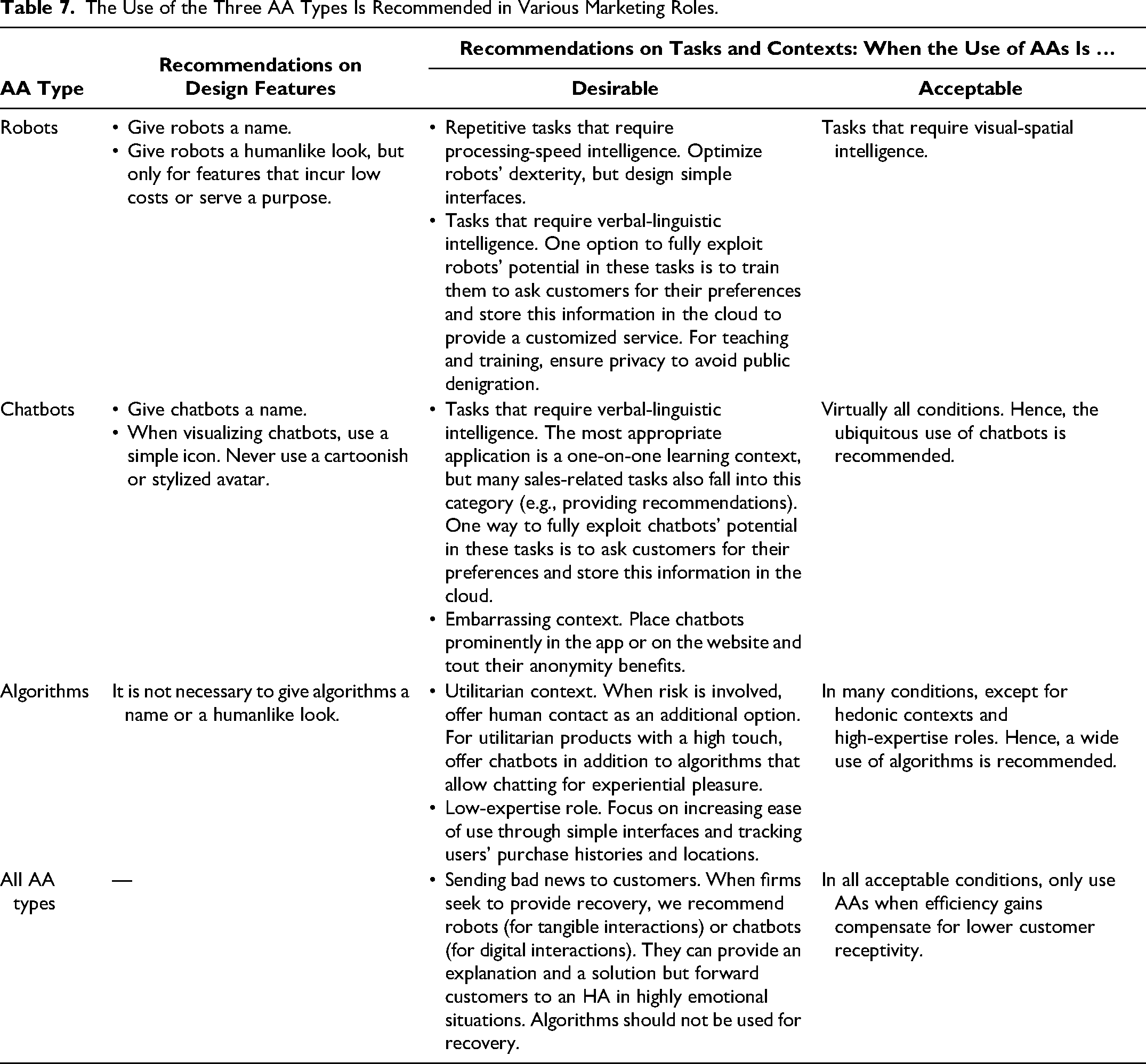
Robots
We recommend humanlike design features that incur low costs or strictly serve a given task. A useful low-cost feature is to give robots a name that helps customers engage them in conversations. Robots should also look humanlike, but this measure alone does not bring them on par with HAs and may be costly. Thus, designers should add low-cost humanlike elements (e.g., hair) and otherwise focus on elements necessary to fulfill a task. For example, wheels help robots move around, but fully functional legs are not necessary.
The use of robots is desirable when a task requires processing-speed intelligence or verbal-linguistic intelligence. Processing-speed intelligence is key for repetitive jobs that need to be performed rapidly, where robots can relieve HAs from physical loads. Examples include room service in hotels, taking standardized orders, preparing coffee, or clearing dishes. To ensure speed in repetitive jobs, developers should optimize robots’ dexterity, for example, always holding the cup at the correct angle when frothing milk. Long conversations are neither required nor expected for these tasks. Hence, we recommend simple interfaces, limited to basic conversations related to robots’ duties. For room service, this could be a touchscreen in the room to place a predetermined set of orders and another touchscreen on the robot to send the robot out. For tasks requiring verbal-linguistic intelligence, one option to fully exploit robots’ potential is to train them to ask customers about their preferences and combine this information with knowledge retrieved from the cloud. This could help customize the conversation. One example is an intelligent robotic waiter (Wang et al. 2022), which not only knows the nutritional details of the menu (Collins 2020) but also remembers a regular guest's intolerance and proactively recommends a particular dish. The tasks that require the highest verbal skills are teaching and training, such as giving a lecture (Li et al. 2016) or playing exergames with elderly people (Čaić et al. 2020). However, since customers may fear public denigration, we recommend robotic instructors only in private settings (e.g., at home or in single booths).
The use of robots is acceptable for tasks that require visual-spatial intelligence, such as cleaning or ironing at home (Kim, Schmitt, and Thalmann 2019) and guiding travelers at airports (Hwang et al. 2022). However, firms should assess whether efficiency gains compensate for lower customer acceptance and whether robots can relieve employees’ physical or mental load, which may be greater for cleaning than for ironing.
Chatbots
We recommend only one humanlike design feature that incurs low costs. Firms should give chatbots a name to facilitate conversations. Furthermore, when visualizing chatbots, they should use a simple icon, as in the case of ChatGPT. A very humanlike avatar is a second-best option and requires more design resources. In any case, firms should avoid stylized avatars with cartoon-like human features, such as Microsoft's Clippy.
The use of chatbots is desirable when a task requires verbal-linguistic intelligence or in embarrassing contexts. The highest verbal fluency is required for one-on-one learning contexts, such as improving English grammar skills or providing online lectures. However, many sales-related tasks also fall into this category (e.g., discussing recommendations for leisure time activities, the pros and cons of a product, personal food preferences). As with robots, one way to fully exploit chatbots’ potential is to train them to ask customers for their preferences, store them in the cloud, and retrieve them when necessary (e.g., remember color preferences for apparel). When customers buy embarrassing products, such as diarrhea pills or incontinence diapers, chatbots outperform HAs. Hence, firms selling embarrassing products should place chatbots prominently on their apps or websites, presenting them as a way to ensure anonymity.
The use of chatbots is acceptable even when none of the desirable conditions apply. This is because chatbots never fall below the −.2 threshold for ȓ (Figure 2). These results call for ubiquitous use whenever the expected efficiency gains of up to 30% (Xiao and Kumar 2021) compensate for lower acceptance, specifically when HAs are relieved of mental stress (e.g., handling multiple inquiries at the same time).
Algorithms
Algorithms do not need humanlike design features. Their use is desirable in utilitarian contexts or low-expertise roles. Algorithms lend themselves to utilitarian contexts, such as calculating a distance or forecasting wait times. Nevertheless, even in these contexts, emotions can be involved. This applies to decisions that entail risk, such as protecting one's home (insurance), deciding on a retirement plan (banking), and buying baby food (grocery shopping). In these contexts, HAs should be in place as an option, such as a live chat or a hotline, to convey warmth and reduce fear. Some people also seek experiential pleasure even when buying utilitarian products (e.g., high-tech/high-touch products such as laptops). Hence, an algorithm should provide basic information (e.g., on prices and features), but customers should have the option to connect with a chatbot for exploration purposes (e.g., “Explore playful features of our laptops”). This is because chatbots that follow an entertaining script can provide experiential pleasure (Sands et al. 2021).
Examples of algorithms in low-expertise roles include determining the right clothing sizes in online shops, selling tickets, and giving advice on how to protect oneself from bad weather. Since these tasks involve standard inquiries and simple requests, firms should focus on increasing the ease of use of algorithms for customers. An interface that takes commands easily and provides simple outputs, for example, through a one-click repeat order or an autofill function, can serve this purpose. Ease of use can also be increased by tracking users’ purchase history (e.g., to suggest an appropriate outfit and clothing size) and location (e.g., to provide location-based advice on how to be protected from bad weather).
The use of algorithms is generally acceptable, except for hedonic contexts or high-expertise roles, where they fall below the −.2 threshold for ȓ. Except for these cases, we recommend the wide use of algorithms if efficiency gains compensate for lower customer acceptance, specifically when HAs are relieved of mental stress (e.g., repetitive inquiries).
All AA Types
The use of all AAs is desirable for communicating bad news to customers. It prevents HAs from mental stress (e.g., when algorithms or chatbots deny a loan application or a club membership) and even physical harm from aggressive customers (e.g., when robots hand out parking tickets or deny guests without tickets access to a festival). In these examples, firms do not seek to recover customers, and AAs’ work is done.
In other cases—for example, when informing customers about problems (i.e., a service failure)—firms should recover customers. These efforts require verbal skills, particularly when exploring solutions for customers. Firms can exploit the verbal talents of robots (for tangible interactions) and chatbots (for digital interactions) to explain situations and offer solutions. For example, robots could clarify that access to theme park rides is controlled based on crowding and that, for safety reasons, ten guests are admitted every five minutes. Chatbots can explain why a check-in failed (Zhang et al. 2023), for example, by informing a guest that their code expired and that a new one is being sent. Nevertheless, negative outcomes differ in severity (McQuilken 2010), and customers vary in their levels of anger during incidents (Gelbrich 2010). Hence, robots or chatbots should be trained to recognize highly emotional situations (Huang and Rust 2024) and forward customers to an HA to prevent escalation. As algorithms lack verbal skills, we do not recommend them for service recovery.
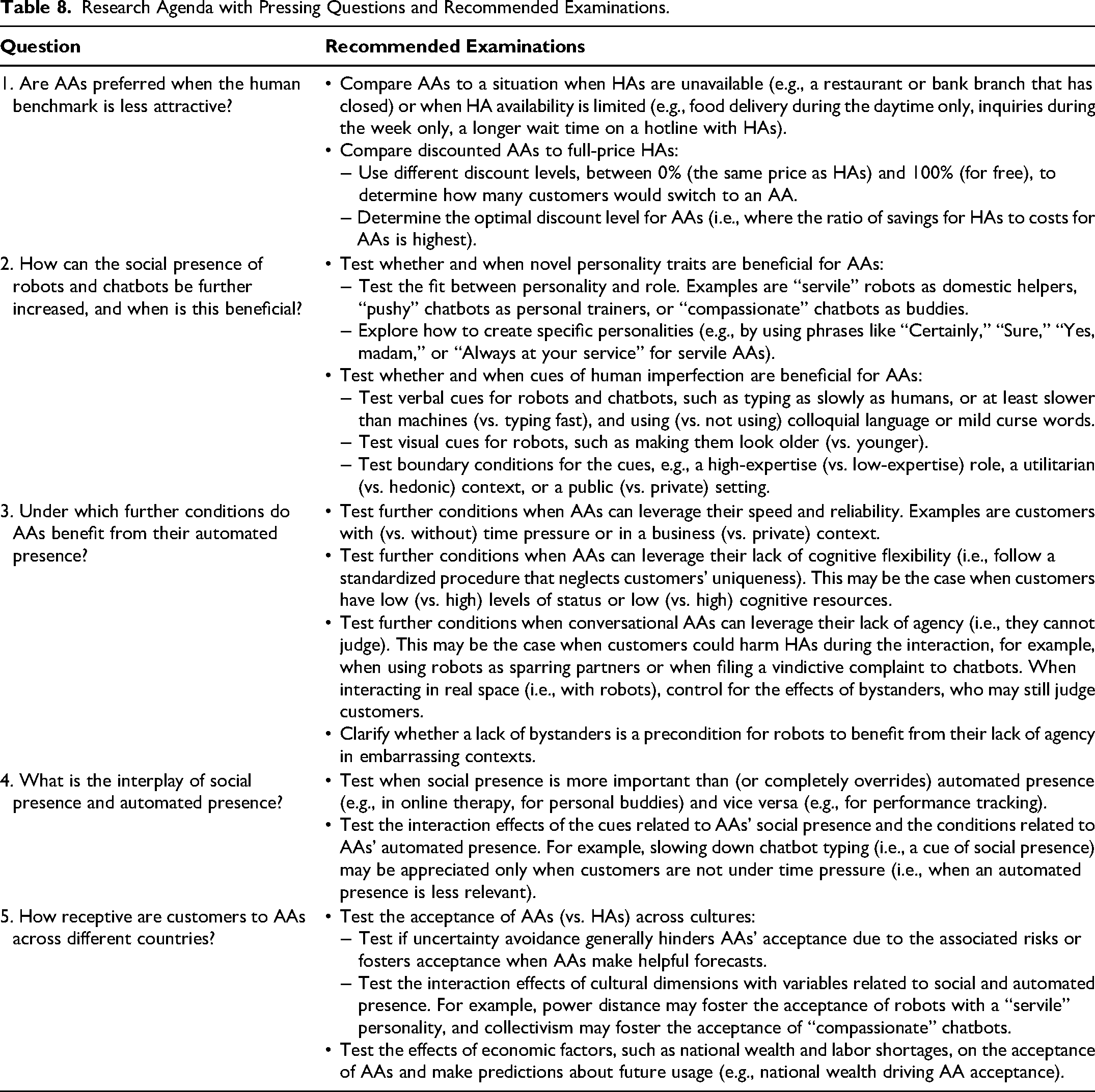
Research Agenda
This meta-analysis is a starting point for answering further pressing questions regarding AA–HA comparisons. Our research agenda comprises five key questions, based on this current study's findings, its limitations, and managerial considerations (Table 8). First, this study used comparable HAs as a control condition for AAs. Future research should examine whether AAs are preferred when this human benchmark is less attractive, either by making HAs unavailable or by discounting AAs. Second, our results suggest that increasing social presence plays a role in conversational AAs. Recent research shows beneficial effects of social presence. Specifically, robots with a conscientious (vs. extraverted) personality enhance customer engagement in a banking (vs. restaurant) context (Balaji et al. 2024). In contrast, chatbots that use conversational fillers—signs of humans’ imperfection (Lee and Yi 2025)—are shown to decrease purchase intentions when used by for-profit (vs. nonprofit) firms (Liu, Liu, and Zhu 2024). Future research should examine novel human cues (e.g., other personality traits, imperfection) to increase AAs’ social presence and test when they are beneficial. Third, our results suggest that automated presence can play a role in each AA type. Future research could identify further conditions under which AAs benefit from their machine characteristics. Fourth, we suggest that AAs are hybrid beings with a social and an automated presence. Future research could further contribute to theory building by examining the interplay between the two dimensions. The fifth recommendation relates to examining country differences in the receptiveness of AAs (vs. HAs). Only 60% of the included studies reported participants’ nationalities. Half of these studies were conducted in North America, limiting cultural variety. Research has shown that cultural differences affect consumers’ reactions to AAs (Pitardi et al. 2023); thus, the acceptance of AAs across cultural dimensions and other country-level factors requires further study.
Research Agenda with Pressing Questions and Recommended Examinations.
Supplemental Material
sj-pdf-1-jmx-10.1177_00222429251344139 - Supplemental material for Automated Versus Human Agents: A Meta-Analysis of Customer Responses to Robots, Chatbots, and Algorithms and Their Contingencies
Supplemental material, sj-pdf-1-jmx-10.1177_00222429251344139 for Automated Versus Human Agents: A Meta-Analysis of Customer Responses to Robots, Chatbots, and Algorithms and Their Contingencies by Katja Gelbrich, Holger Roschk, Sandra Miederer and Alina Kerath in Journal of Marketing
Footnotes
Acknowledgments
The authors would like to thank Chiara Orsingher for providing valuable input early in the research process. The authors would also like to thank the JM review team for their fruitful feedback and for helping develop this manuscript throughout the revision process.
Coeditor
Detelina Marinova
Associate Editor
Dhruv Grewal
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.