
Abstract
Making good health insurance decisions is important for health outcomes and longevity, but consumers’ errors are well documented. The authors examine whether targeted choice architecture interventions can reduce these mistakes. The article examines the interaction of two choice architecture tools on improved consumer insurance decisions in online health care exchanges: (1) ordering the options from best to worst based on a high-quality user model and (2) partitioning the total set of options. Although ordering and partitioning do not always improve choices separately, the authors use one field study and three experiments to identify the conditions that allow the combination to greatly improve health insurance decisions. Findings indicate that when options are ordered such that the best options appear at the beginning of the presented list, partitioning nudges consumers to focus on the best options. However, if the best options are not at the top of the list, partitioning discourages search and can impair consumers’ discovery of the best options. Process data show that these effects are achieved by focusing consumers’ limited attention on higher-quality options. These results suggest that wise choice architecture interventions need to consider the joint effect of choice architecture tools as well as the quality of the firm's user model.
Keywords
Choice architecture affects consumers’ choice behavior, and its impact is amplified by digital technology. We investigate how choice architecture affects consumers’ health insurance choices. These decisions are important for consumers. They have strong financial consequences and determine access to potentially lifesaving health care. Health insurance coverage increases longevity (Woolhandler and Himmelstein 2017) and halves the probability of bankruptcy (Gotberg and Sousa 2019). Health insurance decisions are also important for society because they affect firms’ labor costs and raise social justice concerns.
Health insurance choices are also complex: They involve many attributes like deductibles and copayments that people often do not understand (Loewenstein et al. 2013). Because of the economics of insurance, these attributes often require complex trade-offs involving negatively correlated attributes (Abaluck and Gruber 2011; Ericson and Starc 2012). For example, large provider networks are usually more expensive, and low deductibles generate higher premiums. As a result, it is not surprising that consumers make mistakes that result in substantial overpayment for coverage (Johnson et al. 2013). Many consumers select options that are dominated, unnecessarily spending more for equivalent benefits. In a recent study, employees of a large U.S. firm paid 42% more than needed for equivalent coverage, essentially wasting a large part of their payments (Bhargava, Loewenstein, and Sydnor 2017). Improving these choices can increase health outcomes for consumers and broadly increase the efficiency of health care resources. In this article, we show that seemingly minor changes in choice architecture can have a large effect on health insurance product choice and consumer health care costs.
Ideally, choice architecture improves consumers’ choices (Sunstein 2018; Thaler and Sunstein 2008). For example, defaults can facilitate the choice of a good alternative while reducing the need for extensive contemplation (Brown and Krishna 2004; Donkers et al. 2020; Jachimowicz et al. 2019; Johnson and Goldstein 2003; Smith, Goldstein, and Johnson 2013). In parallel, recent rapid advances in large-scale data availability, artificial intelligence, and machine-learning-based algorithms suggest a new reality in which marketers can predict with greater accuracy which products best match a given consumer's needs (Chintagunta, Hanssens, and Hauser 2016; Ghose, Ipeirotis, and Li 2012). Combining these insights with choice architecture can help consumers choose the product that is best for them. It can also provide new business opportunities for firms while increasing consumer satisfaction with the chosen product. Domains such as health and consumer finance are especially promising for such interventions because they involve high-impact, infrequent consumer decisions. The complexity of these decisions combined with the limited opportunity to learn from experience makes it difficult for consumers to select the best available option on their own.
Health care exchanges offer promising opportunities for digital choice architectures to support consumer health insurance decisions. Like many websites, they use two ubiquitous choice architecture tools. First, health care exchanges can order the available options. All websites make this decision. Even an alphabetical order is a choice architecture design decision. Second, exchanges can partition the total choice set presented to consumers by determining whether a small number of initial options are presented on the first web page. Although ordering and partitioning do not always improve choices separately, we identify the conditions that allow the combination to greatly improve health insurance decisions. This is because the effects of ordering and partitioning are not independent: When options are ordered such that the best options appear at the beginning of the presented list, partitioning slightly and subtly nudges consumers to focus on the best options. However, if the best options are not at the top of the list, partitioning discourages search and can impair consumers’ discovery of the best options.
These findings can be understood in terms of fundamental decision principles. To choose a good option, consumers must pay attention to that option and avoid paying attention to poor-quality options. High-quality ordering ensures that good options are seen by consumers. However, without partitioning, consumers sometimes search too much and revise which options they consider, also including lower-quality options. Therefore, when the best options are not presented at the beginning of a choice set (e.g., with random or low-quality ordering), partitioning can be harmful by focusing consumers’ attention on options that are not truly superior.
We make three contributions in this research. First, we provide a substantive demonstration of the impact of predictive choice architecture in health care. We demonstrate that the novel combination of the existing choice architecture interventions of ordering and partitioning can improve consumer decision outcomes in the societally relevant domain of health insurance. Second, we show that the quality of a firm's predictive model or algorithm to determine the ordering of options is an essential component of choice architecture. We call this algorithm the firm's “user model.” An algorithm is a high-quality user model if there is a strong correlation between the ordering and what the consumer would like best if searching exhaustively (Alba et al. 1997). Third, we demonstrate that different choice architecture interventions interact, and the resulting effects are not simply additive. Choice architecture tools are an ensemble with complex interactive effects. This implies that choice architecture tools, like ordering and partitioning, need to be assessed jointly. Most research, in contrast, focuses on the impact of single choice architecture tools, such as defaults, on consumer choice outcomes (Cadario and Chandon 2020; Johnson et al. 2012; Szaszi et al. 2018). We illustrate this type of joint effect by looking closely at how ordering and partitioning improve consumer decision outcomes. We explain that this interaction occurs because both ordering and partitioning can shift consumers’ attention to different alternatives and that choice improvement happens when both tools steer attention to better outcomes.
Ordering and Partitioning Can Improve Consumer Health Insurance Decisions
Ordering
Ordering options in a choice set can help consumers because individuals are more likely to choose the options that are presented first. There can be an advantage of being first in an ordered list or a series of stimuli (Bar-Hillel 2015; Mantonakis et al. 2009). Therefore, presenting options that are better for consumers earlier in an ordered choice set can improve choice (Diehl, Kornish, and Lynch 2003; Häubl and Trifts 2000; Ursu 2018).
A common explanation for this effect is that consumers’ greater attention to initial options increases the probability of these options being selected (Atalay, Bodur, and Rasolofoarison 2012). If the order is well aligned with consumers’ preferences, the initially presented most attractive options will receive more attention, and later—less attractive—options will receive less attention. This effect of focusing on the best options should increase the probability that consumers choose better options, promoting higher-quality decisions (Diehl, Kornish, and Lynch 2003; Häubl and Trifts 2000; Ursu 2018).
But countervailing effects also suggest that ordering might not be as helpful to consumers as it could be. Consumers can search too much when they are presented with an ordered list because it is so easy for them to inspect more options (Diehl 2005). This increase in search with ordering can lead to worse choice outcomes when it is challenging for consumers to find the best option. Because consumers may consider more options, they may be more likely to end up focusing on inferior options presented later in an ordered list. Ordering can also increase the complexity of comparing options by bringing more similar options closer together, creating choice conflict and increasing the difficulty of selecting the best option (Dellaert and Häubl 2012). Thus, ordering may not always help choice.
Partitioning
Partitioning separates a choice set into two or more sets that can be inspected independently (Cheema and Soman 2008; Dorn, Messner, and Wänke 2016; Johnson et al. 2012). This is common in online shopping. Partitioning does not remove options but influences choice while also preserving consumer autonomy. Many websites present partitions that allow consumers to easily transition from an initial smaller selection to a second larger selection of options. For example, Google Flights first presents a small “Best Flights” subset of all possible flights, followed by a set of “Other Flights.” A recent search presented 4 best flights and 216 other flights. Partitioning focuses consumers’ attention on the initial set of presented products, and a trivial action (e.g., clicking a button) reveals the remaining options. It makes examining the initial set of alternatives slightly less effortful for the consumer than examining the remaining set. We predict that the immediate effort of having to click through to the next page with more options can overwhelm the potential returns that could occur if consumers saw better options on that page (Häubl, Dellaert, and Donkers 2010; Hogarth and Einhorn 1992; Wilson et al. 2000). Partitioning can increase consumers’ focus on a smaller set of alternatives and alleviate any tendency to search “too much” in ordered sets.
User Models and Choice Architecture
Ordering and partitioning can focus consumers’ attention on a more attractive set of options, but both assume that the choice architect can identify the best choice for the consumer. We define a “user model” as the algorithm used by the choice architect to match, probabilistically, different products to a consumer on the basis of the products’ characteristics. When the user model is accurate, there is a strong correlation between the ordering and the products that are most attractive for a consumer. In that case, choice architects can encourage consumers in the right direction, supporting better decision making (Sunstein 2018; Thaler and Sunstein 2008). But if the user model is inaccurate, choice architecture can lead to worse outcomes because it directs consumers’ attention toward inferior options.
Because user models seem important, it is surprising that choice architecture research has not systematically examined their impact. User models can be inaccurate for at least two reasons. The first reason is heterogeneity in preference. The best ordering may differ dramatically for different users, and it may not be possible for firms to make a correct prediction for each consumer. New customers present a “cold start” problem because the website does not know enough about the user to make good recommendations (Padilla and Ascarza 2021). A choice architect who is naive about a consumer's preferences cannot use preference information to order the options or to select an appropriate subset in a partition for this consumer. The second reason is that the choice architect may be misguided in their beliefs about the consumers’ needs. Policy or political considerations may arise. In health insurance decisions, government-based choice architects may be reluctant to order products in terms of a particular user model because there might be a debate on what ordering criteria should be used. Further, private-sector choice architects in health insurance may not always have the consumer's best interests in mind. Their goal may be to maximize their payments as brokers, for example. In those cases, a nudge can turn into a “sludge” and harm consumer decisions (Sunstein 2021). The accuracy of the user model determines whether ordering and partitioning are helpful, make no difference, or are potentially harmful.
Attention Mediates the Effect of Choice Architecture
How do ordering and partitioning affect choice? We hypothesize that ordering and partitioning focus consumers’ attention on a subset of options (Johnson 2021; Payne 1976). This focus can improve consumers’ decisions if it increases the attention they pay to the best options (see Figure 1). Ordering based on a high-quality user model can achieve this positive effect because it presents the better options first. Partitioning reduces the number of options that consumers examine. For both ordering and partitioning, focusing attention on a subset of options can help improve choice with a high-quality user model but hurt if user model quality is low and more attractive alternatives are ignored (Caplin and Dean 2015; De Los Santos, Hortaçsu, and Wildenbeest 2012).

The Joint Impact of High-Quality Ordering and Partitioning on Consumer Decision Quality.
Hypotheses
In summary, we suggest two choice architecture tools that can, in principle, improve consumer health insurance choice: (1) ordering the options in a choice set according to a high-quality user model, and (2) partitioning choice sets into two sets: a primary set with a small number of alternatives and a secondary set with all the other alternatives. Together, we predict that these interventions can improve consumer choice through a greater focus on a smaller number of higher-quality options. There may be reasons to be skeptical about the effects of ordering based on a high-quality user model. Consumers tend to search too much in these types of ordered sets because searching is easier (Diehl 2005). We predict that partitioning can overcome this downside and improve consumer choice by putting up a behavioral barrier to reduce searching. Of course, the effectiveness of both interventions depends on the accuracy of the user model. Therefore, we hypothesize:
We expect these tools to improve choice by changing how the consumer allocates attention. Ordering suggests that options presented at the top of the list will receive the most attention. Thus, we predict that, compared with random ordering, high-quality ordering will increase consumer focus on the best options. Similarly, we predict that partitioning will cause individuals to examine only a smaller initial set and allocate less attention to later options. When the two choice architecture tools are combined and the ordering is based on a high-quality user model, we hypothesize that the stronger focus on a small set of alternatives due to partitioning will promote greater attention to the best options. However, when ordering is based on a random user model, consumer attention to the initial options will mainly highlight average-quality options, and we predict that partitioning reduces attention to the best options. More formally, we hypothesize:
Finally, jointly, these three effects suggest a mediation process by which ordering and partitioning impact consumer choice outcomes. First, we predict that consumers’ attention to the best alternatives mediates the impact of ordering on consumer decision outcomes. Second, we predict that the main effect of partitioning on consumer decision outcomes is mediated by consumers’ examination of a smaller number of alternatives. Third, we predict that the positive impact of partitioning on the effect of high-quality ordering on consumer decision outcomes is also mediated by consumers’ attention to the best alternatives (mediated moderation).
Overview of Experiments
We present four studies that examine the joint effects of ordering and partitioning and their possible effect on consumers’ health insurance choices. We first present, as a pilot study, field data showing the positive effect of these interventions in a realistic environment, when adopted by a commercial health insurance broker. Study 1 is an incentive-compatible experiment in a setting closely modeled on the U.S. health insurance exchange websites (see Wong et al. (2016) for a descriptive survey of the U.S. health exchange marketplace). The results show the positive interactive effects of ordering and partitioning (H1 and H2), and, using a MouselabWEB data analysis, we show that this impact is mediated by consumers’ attention to the best options and the number of options examined (H3 through H6). Study 2 replicates the results for H1 and H2 and extends them to the case of a low-quality user model (i.e., generating an order that is antagonistic to the consumer's preferences). The results show that with a low-quality user model, partitioning harms consumer choices. They also show that with a random user model, partitioning may also lead to worse consumer choices, depending on the quality of the alternatives in the partitioned set. Finally, Study 3 investigates the effects of ordering and partitioning on consumer decision quality in a setting modeled on the ordering and partitioning that are most common on U.S. health insurance exchange websites. This common setting is an ordering based on health insurance premium only (“premium-based” ordering), which is often combined with a partitioning of ten options per page. We investigate whether a higher-quality ordering based on a prediction of consumers’ total health care spending (“predicted-spending-based” ordering) combined with a partitioning of three options can improve consumer decision quality, compared with current practice. The results of Study 3 show that this is indeed the case.
We adopt a framed-field experiment approach in all three studies, whereby real consumers make choices about realistic options, in a setting that mimics the actual choice environment that consumers face on the U.S. health insurance exchange websites (Harrison and List 2004). The participants are given a well-defined goal for buying insurance and instructed to find the option that is closest to that goal. Their objective is to minimize total expected costs given specified health care needs. This approach allows us to objectively define the quality of the decision made by each participant and to quantify deviations from the best choice outcome. It also eliminates unobserved preference heterogeneity between participants (Johnson et al. 2013). The materials, data, and analysis syntax for all three studies are available at https://osf.io/xvdnp/?view_only=d40fd1c9813845b6ae51b53c744eab99.
Pilot Study: The Impact of Ordering and Partitioning on Consumer Health Insurance Choice
Our pilot study explores the effects of ordering and partitioning using field data from a commercial health insurance broker in the Netherlands. The broker perceives itself to be a strong innovator in the market, and in 2010 it changed its product comparison website introducing a higher-quality ordering with partitioning aiming to improve consumers’ choice outcomes. Health insurance plans can be purchased directly through the website, and many consumers go to the site each year to switch insurance providers. The prior choice architecture provided a complete list of health insurance products screened by a consumer's prespecified criteria. These were ordered from low to high according to the plan's premium, and ten options were displayed per web page. The intervention improved the user model in two ways. First, by including quality in addition to price in the ordering, the model more closely matched user preferences, based on the broker’s market research, even though the same user model was used for every visitor. Second, by introducing a partitioning that presents a subset of the top three plans, the model potentially increases the effect of ordering. There was no change in the total number of options. Consumers could simply click to see the full list of health insurance products.
We compared the impact of this choice architecture on consumers’ choices by comparing the data from the year before the website's choice architecture redesign to the choices made after the change. Before the redesign (price-only ordering, no partitioning), 47.7% of the visitors who bought health insurance selected the first-ranked alternative (of a total of 8,581 consumer visits, 41.3% of visitors identified as female, and the average age was 36.5 years). After the redesign (price- and quality-based ordering, with partitioning), this increased to 60.7% (of a total of 34,677 consumer visits, 45.6% of visitors identified as female, and the average age was 39.2 years). To test the significance of this difference, we estimated a logistic regression model of whether or not consumers selected the first-ranked alternative (i.e., the alternative presented at the top of the list) in the years before and after the redesign was introduced. The result shows a significant positive effect of the choice architecture redesign, which suggests a strong combined impact of ordering and partitioning on consumers’ health insurance choices (βredesign = .53, SE = .02, p < .001).
However, although the website managers believed that choices were improved with the new design, as more consumers chose the first-ranked alternative, we had no way of demonstrating that choice outcomes were improved objectively. We could not know whether the first-ranked alternative in either year was indeed the best option for a consumer. In addition, since the choice architecture change occurred as part of an annual update of the site, the pilot study did not control for factors such as the properties of the health insurance policies, a prelaunch media campaign, and potential changes in the demographics of consumers.
We turned to a controlled framed-field experiment to validate these findings. In the experiment, we manipulated ordering and partitioning independently, and all conditions had identical alternatives. Participants were randomly assigned to the different conditions. The results replicated the positive synergistic effect of high-quality ordering and partitioning from the pilot study (see Web Appendix A for details).
Study 1: The Impact of Ordering and Partitioning on Consumer Decision Quality and the Mediating Processes
In Study 1, we constructed an incentive-compatible experiment with a choice task modeled on a typical consumer health insurance decision task on the U.S. health insurance exchange websites used by consumers to purchase health insurance plans. We first analyzed the U.S. health exchanges in all 50 states in 2020 (of which 14 states had set up their own exchange and 36 states were using the federal health exchange, HealthCare.gov) for a person 40 years of age with medium health care use. We found that the mean number of products offered was 38.4 (with a minimum of 5 and a maximum of 95) and that exchanges most often presented consumers with ten options on the first page. Consumers could then click to see the remaining options. To mimic this choice architecture, we presented participants with 40 health insurance products drawn from one of the U.S. health exchanges and included ten-option partitioning as one of the conditions.
Method
Experiment
Participants were given a clearly defined objective, which was to minimize total expected costs given a person's relevant health care usage. The health insurance plans differed on three key characteristics for the U.S. market: the monthly premium, the doctor visit copayment, and the annual deductible. These attributes reflect the monetary cost components of the health insurance and were used successfully in previous research (Bhargava, Loewenstein, and Sydnor 2017; Johnson et al. 2013). This information allowed participants to identify the annual expected costs of each of the health insurance products. To increase motivation, we also gave participants a monetary reward based on their performance: in addition to the $2 completion fee, they could earn an additional bonus of up to $4 depending on how closely their choices matched the assigned objective.
Participants were randomly assigned to six treatment conditions, based on a 2 (ordering: high-quality and random user model) by 3 (partitioning: three-option, ten-option, and no partitioning) between-subjects design. All conditions presented the same 40 health insurance plans. In the high-quality user model ordering condition, alternatives were ordered perfectly from best to worst (minimizing the participants’ expected costs given the decision rule; see Web Appendix B1 for ordering details). Participants were informed about the ordering as follows: “The comparison website attempts to rank the options based on the projected cost for your family in your state. However, the ordering may not be fully accurate.” The random user model ordering condition presented the same randomized order of alternatives to participants with a zero correlation between the presented ordering and the optimal ordering. Participants were informed as follows: “The comparison website does not sort the options in any particular order.” The partitioned conditions showed participants either the first three or ten listed products with the possibility to click through to see the complete list of products. Conditions without partitions showed participants the complete list of 40 products. We predicted that with high-quality ordering, the three-option partitioning would produce the best decisions, followed by the ten-option partitioning, and that the no-partitioning condition would produce the worst choices.
Process data
To observe attention, we had participants make their decisions using MouselabWEB (see www.mouselabweb.org). This technique is shown to be useful in the study of individual choice, as well as games and time preferences (Costa-Gomes and Crawford 2006; Gabaix et al. 2006; Payne, Bettman, and Johnson 1993; Willemsen and Johnson 2011). MouselabWEB presented the options as a table, consistent with displays in the state-based and national exchanges. Each row presented a different health plan, and each column presented a different plan attribute (see Web Appendix B2). In the MouselabWEB interface, when participants used a mouse to move the cursor over each cell, the values of the attribute for that option were instantly revealed. When the cursor exited the cell, the information was again hidden. This process revealed how often, for how long, and in which order participants acquired the information about the attributes of each plan. Previous research suggests a close correlation between MouselabWEB observations and eye-tracking data, an alternative way of tracing participants’ decision processes (Lohse and Johnson 1996; Reisen, Hoffrage, and Mast 2008). Following previous research (Willemsen and Johnson 2011), we eliminated all information acquisitions of less than 200 milliseconds. These are too short to be seen and probably reflect travel of the cursor through a cell in transit to another. We also eliminated outlier observations of more than 50,000 milliseconds (Willemsen and Johnson 2011).
Using the MouselabWEB process data, we constructed two variables reflecting the mediators in our hypotheses. The first variable captured consumers’ attention to the best options. It was measured by the information participants acquired on the best alternatives (i.e., the three options with the lowest total cost in the defined utility task) relative to the total number of inspections (i.e., number of information acquisitions for the best three options divided by the total number of information acquisitions). A value of 0 corresponds to no focus on the best three options, and a value of 1 means looking at only the three best options. The second process variable captured the number of options examined; that is, the total number of options for which a participant acquired information. This number could be observed directly from the process data. 1
Sample
The participants were recruited through a commercial panel (ROI Rocket) and restricted to U.S. participants. We predetermined the sample size to be 200 per treatment condition, and data collection was stopped when all the conditions contained at least this number. This provided a total of 1,324 completed responses. We eliminated 27 outlier participants who were not engaged in the task and had made extraordinarily few (i.e., less than five) information acquisitions during the decision (Willemsen and Johnson 2011). The average age of participants was 53.1 years, 67.1% identified as female, 42.9% had obtained a bachelor's or higher degree, and 76.1% were the primary insurance decision maker for their household.
Results
Decision quality
We first investigate the effects of ordering and partitioning on consumer decision quality (H1 and H2). Decision quality was measured in dollars, expressing the consumer's excess payment compared with the most cost-efficient alternative. This metric means that a smaller number reflects a higher decision quality. We tested the significance of the results using a 2 × 3 analysis of variance.
2
We find that consumers choose dramatically better health insurance plans (in other words, overpay less) with a high-quality ordering than with a random ordering (MHigh = $1,185.57 vs. MRand = $4,305.08, F(1, 1,291) = 1,709.82, p < .001,
As we predicted (H2), this effect is even stronger when the choice set is partitioned, as evidenced by the significant interaction effect of ordering and partitioning (F(2, 1,291) = 12.54, p < .001,
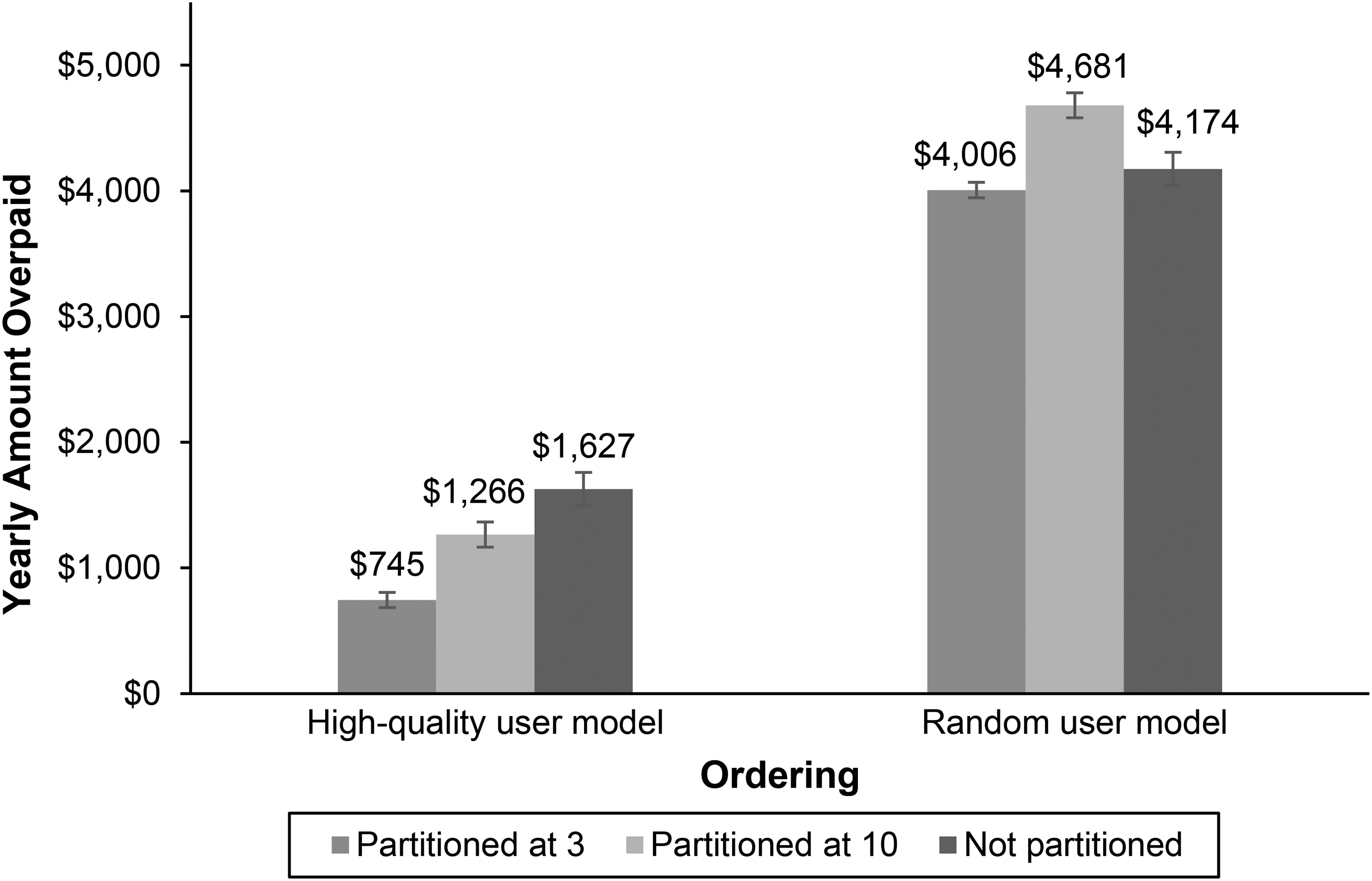
The Impact of Ordering and Partitioning on Consumer Decision Quality (Study 1).
Attention to the best options and number of options examined
We hypothesized that with a high-quality user model, consumers’ attention would be focused more on the best options (H3). Analysis of variance shows that this main effect is indeed significant in the expected direction (MHigh = .55 vs. MRand = .03, F(1, 1,291) = 3,285.12, p < .001,
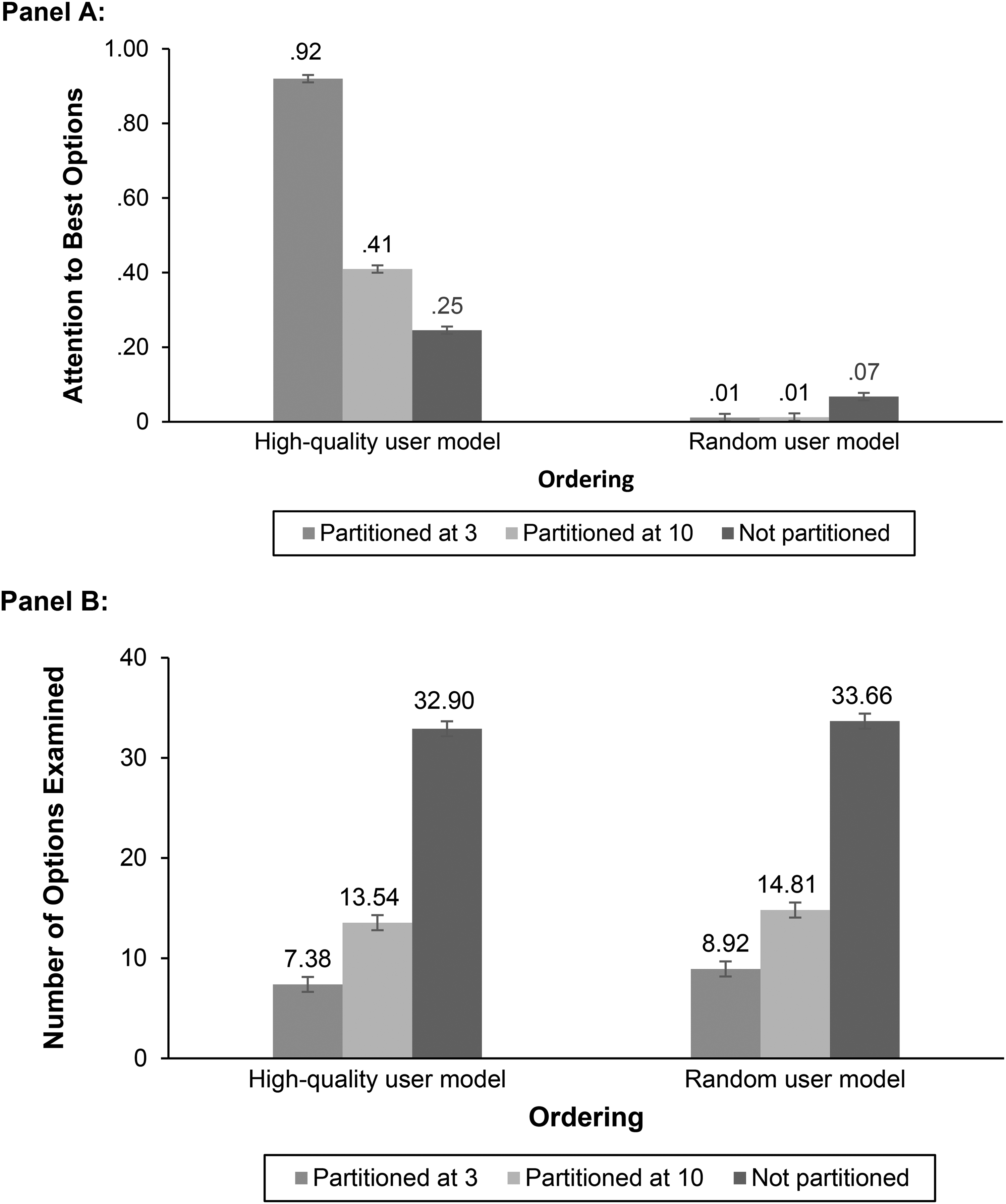
Mediation Process Measures (Study 1).
We also hypothesized that consumers would examine fewer options when partitioning is introduced (H4). We indeed find a significant negative effect of partitioning (M3Part = 8.10 vs. M10Part = 14.22 vs. MNoPart = 33.28, F(2, 1,291) = 592.70, p < .001,
Finally, we hypothesized that partitioning combined with high-quality ordering would further strengthen the attention paid to the best options (H5). We find that the interaction of partitioning and ordering is significant (F(2, 1,291) = 632.46, p < .001,
Mediation analysis
To test the hypothesized mediated moderation structure, we use Hayes’s (2013) PROCESS module (Model 8; 5,000 bootstrap samples; see Web Appendix B4). The dependent variable was the amount consumers overpaid. Ordering (high-quality user model, random user model), partitioning (three-option, ten-option, none), and their interaction were the independent variables coded as indicators. The interaction between ordering and partitioning was included, as were the two mediating process variables (i.e., attention to the best options and number of options examined).
Following the procedure outlined in Zhao, Lynch, and Chen (2010), we analyze the indirect effects of ordering and partitioning on the decision outcome via the two parallel mediating decision processes. To test H6a and H6c, we look at the mediation via attention to the best options. The results show that this variable is a significant mediator of the effect of ordering on the dependent variable for each of the three partitioning conditions (three-option, ten-option, none) (a1 × b1 = −1,012.76, 95% confidence interval [CI] = [−1,607.47, −460.96]; (a1 × b1 = −442.68, 95% CI = [−695.10, −204.62] and a1 × b1 = −198.25, 95% CI = [ − 315.91, −89.76]). This result provides support for H6a. Importantly, the differences between the conditional indirect effects for the three partitioning conditions are also significant (the indices of moderated mediation between the two partitioned conditions and the nonpartitioned conditions are −814.51, 95% CI = [−1,292.84, −371.26], and −244.44, 95% CI = [−387.99, −112.44]). This result provides support for H6c, indicating that the moderating effect of partitioning on the effect of ordering is mediated by consumers’ attention to the best options.
To test H6b, we look at the mediation via the number of options examined. The results show that this variable is indeed a significant mediator of the effect of both partitioning levels (three-option and ten-option) on the dependent variable for each of the two ordering conditions (three-option partitioning: a1 × b1 = 335.79, 95% CI = [158.56, 534.82]; a1 × b1 = 346.40, 95% CI = [165.71, 534.87], and ten-option partitioning: a1 × b1 = 255.95, 95% CI = [123.99, 401.38], a1 × b1 = 262.70, 95% CI = [125.51, 406.75]). This result provides support for H6b. Thus, partitioning leads to a lower number of options being examined, which in turn leads to more overspending (i.e., lower decision quality). Note that in the case of high-quality ordering, this negative effect is more than offset by the positive moderating impact of partitioning on the effect of ordering on decision quality (via attention to the best options), as evidenced by the support for H2 and H6c.
Discussion
The results of Study 1 provide both outcome and process-level support for the hypothesized impact of ordering and partitioning on consumer choice quality. In this incentive-compatible study closely modeled on the U.S. health insurance exchange websites, we find that ordering based on a high-quality user model with partitioning is beneficial for consumers. Thus, the results strongly support H1 and H2. Process data supported that the hypothesized change in decision process occurs, focusing attention on the better options, and that this increase in attention mediates the improvement of decisions (H3 through H6). Finally, the results indicate that the improvement in decision quality is a joint effect of ordering and partitioning. Ignoring this joint effect would be misleading.
Study 2: Can a Low-Quality User Model Harm Choice?
What happens when a user model does not reflect the preferences of the consumer? For example, a user model might reflect a platform's desire to sell higher-priced, more profitable options that may not be preferred by consumers. In Study 2, we extended our analysis to the more extreme case where ordering may decrease consumer welfare. This study also replicates Study 1 in an environment without process tracing, allowing us to examine possible reactivity to these measures.
Method
Experiment
The study was similar in structure to Study 1 with a few changes. First, we did not collect process data and presented a smaller set of health insurance products to participants. We also manipulated three levels of user model quality. The user model qualities were based on the correlation between the order of plans presented to participants according to the goal of minimizing expected costs (high-quality, low-quality, and random user model; see Web Appendix B1 for ordering details). In the high-quality user model ordering condition, alternatives were ordered approximately from best to worst, with a positive correlation of .7 between the presented and the optimal ordering. The low-quality user model ordering condition presented an order of alternatives that was opposite, with a correlation of −.7 between the presented and the optimal ordering. Both random ordering conditions had a zero correlation between the presented and optimal ordering. By necessity, the correlations constrained the way the partitioned set was constructed. The best alternatives had to be present in the partitioned set for the high-quality user model and outside the partitioned set in the low-quality user model condition. To allow us to separate this effect from the effect of correlation, we used two versions of the random order: one that included the best alternative in the partitioned set and one that did not (labeled “random (in)” and “random (out)”). Participants within each ordering condition saw the same order of alternatives. Finally, as in Study 1, we also varied whether the set was partitioned or not.
Participants were randomly assigned to one of eight treatments based on a 4 (ordering: high-quality user model, low-quality user model, and the two random orders) by 2 (partitioning: yes vs. no) between-subjects experimental design. All conditions presented the same eight health insurance plans. To control for the possible effect of variation in instructions, and in contrast to Study 1, we gave participants the same information in all ordering conditions: “The comparison website attempts to rank the options in order of attractiveness for the average family in your state. However, the ordering may not be fully accurate.” The range of pricing for the plans was similar to those of the top 50% of those found at HealthCare.gov. Participants made two choices, both in the same experimental condition, but with different alternatives.
Sample
The participants were recruited online through ROI Rocket, a U.S. market research firm. Participants received a small, fixed payment from the firm for their participation. We predetermined the sample size to be 200 per treatment condition. The assignment to treatment conditions was randomized, and the data collection was stopped after all the conditions contained at least 200 observations. The data set consisted of responses from 1,646 respondents. The average age of the participants in the sample was 50.74 years old, 62.3% identified as female, and 50.5% had obtained a bachelor's or higher degree.
Results
We tested the effects of ordering, partitioning, and their interaction (see Figure 4, Panel A) on decision quality (excess payment) using a repeated-measures analysis of variance with the two responses per participant. There is a beneficial effect of higher-quality ordering (i.e., it lowers the amount consumers overpay; MHigh = $467.52 vs. MRand = $559.33 vs. MLow = $743.99, F(2, 1,640) = 18.65, p < .001,

The Impact of Ordering and Partitioning on Consumer Decision Quality (Study 2).
Next, we conducted a close-up analysis separating the two random ordering conditions (see Figure 4, Panel B) in simple-effects repeated measures analyses of each random ordering condition. The partitioned and nonpartitioned conditions did not differ reliably when the best alternative is included in the partitioned set (MPart = $379.59 vs. MNoPart = $433.94, F(410) = .87, p = .352,
Discussion
Study 2 further supports the idea that ordering and partitioning can improve consumer decision quality (H1 and H2), and that these effects depend on the user model. We find that ordering based on a higher-quality user model improves consumers’ choice outcomes. With a high-quality user model, partitioning is beneficial for consumers; with a low-quality user model, it is harmful.
Study 3: Ordering Options by Premium Versus Predicted Spending
In Study 3, we investigated two kinds of ordering that are commonly used in practice on the health care exchanges: ordering based on annual premium and ordering based on predicted health care spending. Premium-based ordering sorts health insurance plans according to one component of their overall cost, the monthly premium. This is the default ordering on most states’ websites (see https://www.healthcare.gov/). However, because health insurance prices have multiple components, this might be misleading. Other components, like the deductible and copayment, are usually negatively correlated with the monthly premium. This means that choosing a policy with a low premium implies higher deductibles and copayments. To estimate overall cost, consumers need to predict their future health care usage and do some complex calculations (Abaluck and Gruber 2011; Ericson and Starc 2012).
When the health exchanges were introduced, there was concern that consumers would overweight the premium in their health insurance decisions, resulting in choices that would be more expensive overall (Johnson et al. 2013; Wong et al. 2016). Anecdotally, some consumers bought low-premium insurance but were faced with high deductibles and copayments that, in some cases, led them to forgo needed care.
Some exchanges, such as California and Kentucky, implemented predicted-spending-based ordering in the third enrollment period of 2015 to overcome this problem (Wong et al. 2016). This ordering is based on a prediction of a consumer's health care spending. To estimate spending, they use projected health care needs, which potentially represent a more accurate reflection of costs, compared with ordering by premium alone. More states adopted this ordering in the fourth enrollment period in 2016.
In Study 3, we compared the initial standard premium-based ordering with ordering based on a prediction of total health care spending. Although this predicted-spending-based ordering may be more informative than premium-based ordering, it is not a perfect user model. Different consumers have different usage patterns. Exchanges make some attempts at customization, asking consumers which of three prototypical health care usage patterns best describes them, but this does not capture all the details of their health care needs. This study allowed us to see the difference in impact of the two different real-world ordering types on consumer decision quality. In addition, it allowed us to examine the role of partitioning using the level currently used in exchanges and one that would be considerably smaller. In essence, Study 3 examines the impact of these contemplated design changes in choices closely resembling the actual setting.
Method
Experiment
Study 3 used the same health insurance plans and participants’ objective goal as in Study 1. Participants were randomly assigned to one of four treatments based on a 2 (ordering type: premium-based vs. predicted-spending-based) by 2 (partitioning size: ten-option vs. three-option) between-subjects experimental design. All conditions presented the same 40 health insurance plans as used in Study 1. To reflect the actual policy of the health insurance sites, we implemented two orderings (see Web Appendix B1 for ordering details). Premium-based ordering sorted the policies from low to high using premiums alone. This resulted in a correlation between the presented ordering and the optimal ordering of .48. Participants were told: “The comparison website ranks the options based on the plan's premium.” Predicted-spending-based ordering sorted the policies from lowest to most expensive using predicted total health care expenses. In reality, these predictions are not perfect, and to reflect this uncertainty, we added some noise to the ranking, producing a correlation between the presented ordering and the optimal ordering of .70. Participants were told: “The comparison website attempts to rank the options based on the projected cost for your family in your state. However, the ordering may not be fully accurate.” Participants within each ordering condition saw the same order of alternatives. We manipulated partitioning, with the initial set containing the three or ten most highly ranked products. The most common practice used on the exchanges powered by HealthCare.gov is to present ten options on the first page. We investigated whether using three options in a partition would be more helpful to consumers. In all conditions, participants could also click through to see the full list of alternatives, which was ordered the same way as the initial set. Participants received a fixed payment of $3 for their participation, and they could earn an additional bonus of up to $4 depending on how close the alternative they selected was to the best alternative. We also measured participants’ socioeconomic status (SES) using three items: education, occupational status, and income. These items were combined into one standardized SES score following current practice reported in previous research (Mrkva et al. 2021).
Sample
The participants were recruited online through ROI Rocket, a U.S. market research firm. We predetermined the sample size to be 200 per treatment condition. The study was preregistered on AsPredicted (https://aspredicted.org/i8q67.pdf). ROI Rocket delivered considerably more respondents than the number we had requested, and we included all 946 responses. They were assigned randomly to the four conditions. The average age of the participants was 53.96 years, 49.2% identified as female, 42.5% were in managerial/professional jobs (vs. 14.1% homemaker, 17.5% clerical, and 22.7% blue-collar jobs), 48.1% had a personal yearly income above $50,000, 46.6% had obtained a bachelor's or higher degree, and 79.2% were the primary insurance decision maker for their household.
Results
To test the impact of ordering and partitioning, we conducted an analysis of variance, modeling the amount consumers overpaid as a function of ordering, partitioning, and their interaction (see Figure 5). The results show that, as expected, there is a significant positive effect on decision quality of predicted-spending-based versus premium-based ordering (i.e., predicted-spending-based ordering lowers the amount consumers overpay; MSpending = $998.26 vs. MPremium = $2,673.85, F(1, 942) = 283.56, p < .001,

The Impact of Ordering and Partitioning on Consumer Decision Quality (Study 3).
We conclude that premium-based ordering is of sufficiently high quality that partitioning is not harmful, but also that it is not of high enough quality that partitioning is beneficial. In summary, in this context, ordering based on predicted spending is much better: when combined with three-option partitioning, it saves consumers $1,898 compared with premium-based ordering with ten-option partitioning. Finally, we also examined differences in the responses of participants with varying SES scores to the four treatment conditions but found no significant effects.
Discussion
Study 3 suggests that ordering and partitioning can help improve consumer decision quality in a setting similar to practice. Ordering based on predicted spending is beneficial compared with premium-based ordering, and, in that case, partitioning is also beneficial for consumers, no matter what level of SES we examine.
General Discussion
This research shows that ordering and partitioning can have a significant and beneficial impact on consumer choice outcomes, but that achieving this effect depends critically on having a good user model that accurately predicts which options are most attractive to consumers. Consumers were more likely to choose the best alternative when presented with a set that was ordered according to a high-quality user model and partitioned into a small initial set of alternatives. The process data from Study 1 show that this impact occurs because partitioning focuses consumer attention on a small set of high-quality options when combined with high-quality ordering. Yet, as shown in Study 2, the positive effect of partitioning becomes negative when the ordering is based on a low-quality user model. When this occurs, consumers are harmed by partitioning. Finally, as an application of our findings, Study 3 shows that the most common approach in health care exchanges, premium-based ordering combined with ten-option partitioning, can be improved by presenting consumers with predicted-spending-based ordering combined with three-option partitioning.
Policy Implications
One of the advantages of using simulated decisions is that we can take a closer look at welfare effects for consumers. We should take these estimates with some caution because even though the decisions are based on realistic stimuli and made by incentivized consumers, there are other factors, such as advertising, that occur in actual marketplaces but not in our studies. Still, our Study 3, which resembles actual marketplaces, provides initial estimates of the cost of ignoring these choice architecture interventions. Study 3 compares predicted-spending-based and premium-based ordering, both orderings that are currently used in exchanges. Consumers, on average, made larger mistakes, costing about $2,650 annually, when the policies were ordered by premium. This ordering, used on many exchanges, represents a user model that does not correspond to their goal. Employing a higher-quality user model that ordered the options based on total predicted spending reduced that error to about $1,000. Introducing a new choice architecture, three-option partitioning, further reduced errors to just under $800. Together, these changes result in a yearly savings of about $1,850 per consumer, compared with premium-based ordering with ten-option partitioning. Although these figures are specific to this study, they are similar to the size of errors reported in previous framed-field experiments (Johnson et al. 2013) and field studies (Bhargava, Loewenstein, and Sydnor 2017). Given that slightly over 200 million people are covered by private plans and 100 million by government health care plans, many of which involve choice, the stakes of getting health insurance choice architecture right could be measured in hundreds of billions of dollars in the United States alone. Not paying attention to choice architecture has huge costs. We would argue that by not adopting these changes, governments, firms, and consumers are creating a health insurance system that is less efficient, causing consumers, and, through subsidies, governments, to spend much more on health insurance than needed, using money that could be better spent on other priorities.
For consumer protection policy, asking whether choice architectures serve consumers’ best interests poses new challenges and research questions. Choice architecture design could become part of regulatory frameworks. Firms might be asked to store the combination of choice architecture environments, available product alternatives, and consumer decision outcomes, for example, when offering consumers (online) financial advice (Baker and Dellaert 2018). Such data would allow for post hoc validation of the quality of the advice provided and whether consumers were supported in making better decisions. Consumer protection policy makers could also bring regulatory oversight to deceptive choice architecture shown to lead to worse consumer choices. It would be valuable to study the effectiveness of such possible interventions empirically.
It is also important to develop further insights into which choice architecture ensembles are most promising to activate consumers to consider changing their health insurance in general. For example, an approach suggested to promote comparisons by consumers without the need to provide detailed personalized information is to require that different firms offer at least the same basic version of a (financial) product (Lynch 2009).
Managerial Implications
For managers, this research highlights the potential tension between the interests of consumers and the profit-maximizing interests of health insurance firms, but there is a twist. A classical dilemma facing insurers is adverse selection: consumers may know more about their health states than firms know, thus reducing firms’ profits. However, there may be situations where firms know more about some health outcomes than consumers do and can prevent consumers from making mistakes. Health insurers may have, because of their extensive data, a more accurate idea of health risks than the individual consumer has, especially when dangerous health events are both rare and potentially catastrophic. For example, the average consumer probably has an inaccurate view of the probability and financial cost of an accident or a serious disease.
Health insurers may, in the short term, exploit these informational asymmetries, but another path may lead to greater consumer satisfaction and loyalty in the long run. Firms may build choice architectures that will help consumers make better decisions. Although the economics of this strategy is an open question, it depends on the ability of health insurance firms to develop accurate user models. A requisite step would be convincing consumers that there is value in following the firm's recommendations. Future research could address consumer trust in and reactance to firm recommendations.
Another line of research could investigate how online intermediaries’ choice architecture tools can also help shape markets. For example, the new choice architecture design in the online health exchange in our pilot study not only helped consumers make more informed decisions but also led to changes in the market supply. Health insurers strengthened the consumer-satisfaction-driving aspects of their offerings in response to the greater prominence of this feature in the platform's ordering. However, the impact of choice architecture may be underappreciated in practice (Benartzi et al. 2017; Zlatev et al. 2017; but also see McKenzie, Leong, and Sher [2021] for nuances).
Theoretical Implications
Our idea of choice architecture ensembles is only a beginning. Research is needed to develop further insights into which choice architecture ensembles are the most promising to improve consumer financial decision making. Although choice architecture research has been a successful endeavor to date, better understanding the interaction of ensembles seems important. Applications that look at one tool at a time may miss important opportunities for improving choices.
Our research also makes explicit another idea long implicit in the choice architecture literature: the idea of a user model. If choice architects have access to high-quality user models (i.e., accurate prediction algorithms), they can intervene more effectively because they can identify more precisely what is the correct option for each consumer. Although we explored the impact of user model quality in the context of ordering and partitioning, it is also relevant to other choice architecture interventions, such as defaults (Goldstein et al. 2008).
An interesting question for future research is to develop a conceptual framework for helpful choice architecture depending on whether user models make strong or weak predictions. The strength of a user model can affect the implementation of a choice architecture. Partitioning offers a good example. If a health insurance firm is certain of the quality of its user model for a given consumer, the partitioned set can be small, but as uncertainty increases, the size of the partitioned set can increase as well, reflecting that uncertainty. There is, therefore, no “one size fits all” optimal partitioning size; rather, there are different optimal sizes for different markets, different consumers, and different firm modeling and data analytics capabilities. Similarly, if user model quality is low, presenting a single strong default could be harmful, while offering a partitioned set instead allows consumers greater flexibility in selecting the best option. A deeper understanding of the decision process used by consumers with different choice architecture tools also seems important for understanding when to give recommendations and when firms could use consumer input to develop better user models. One interesting question is whether allowing consumers to tailor their choice architecture improves their choices. Many websites allow consumers to sort by an attribute, and firms usually impose a default ordering that impacts consumers’ decisions. Our results lead us to speculate that the resulting ordering, chosen by either users or firms, could lead to worse choices.
Conclusion
Rapid developments in digital technologies, artificial intelligence, and machine-learning-based algorithms may allow firms to suggest options that lead consumers and patients to more satisfying outcomes than they could determine themselves. Choice architecture, wisely applied, can be a relatively inexpensive and efficient way to use firm-level knowledge to improve social welfare. Better prediction of consumer choices and choice architecture could, in contrast, also be used to increase short-term profit. For example, a health insurer who observes consumers paying too much for a dominated policy might be pleased with the increased revenue. Regulatory oversight might be used to prevent choice architectures that lead to worse consumer health insurance choices but will depend on understanding how choice architecture ensembles affect consumers’ outcomes and choice processes. We hope that managers of health care firms will choose to use their knowledge to develop new business models that deliver longer-term value and minimize waste for customers, other stakeholders, and their firms.
Supplemental Material
sj-pdf-1-jmx-10.1177_00222429221119086 - Supplemental material for Choice Architecture for Healthier Insurance Decisions: Ordering and Partitioning Together Can Improve Consumer Choice
Supplemental material, sj-pdf-1-jmx-10.1177_00222429221119086 for Choice Architecture for Healthier Insurance Decisions: Ordering and Partitioning Together Can Improve Consumer Choice by Benedict G.C. Dellaert, Eric J. Johnson, Shannon Duncan and Tom Baker in Journal of Marketing
Footnotes
Acknowledgments
The authors would like to thank Mieke van Os at Independer.nl for providing the data used in the pilot study of this research and for practical insights on the website's structure, Nathaniel Posner for assistance in data collection, Martijn Willemsen for feedback and support in analyzing the MouselabWEB data, and Nuno Camacho and Kellen Mrkva for valuable feedback. The first author would like to thank Netspar for financial support of part of this research. The second and fourth authors would like to thank the Alfred P. Sloan Foundation for financial support of part of the research.
Special Issue Editor
Christine Moorman
Associate Editor
John Lynch
Declaration of Conflicting Interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Benedict Dellaert formerly was a member of the independent board of supervisors of Independer, and Tom Baker and Eric Johnson were affiliated with Picwell.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Network for Studies on Pensions, Aging and Retirement and the Alfred P. Sloan Foundation.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.