
Abstract
Musical abilities, both in the pitch and temporal dimension, have been shown to be positively associated with phonological awareness and reading abilities in both children and adults. There is increasing evidence that the relationship between music and language relies primarily on the temporal dimension, including both meter and rhythm. It remains unclear to what extent skill level in these temporal aspects of music may uniquely contribute to the prediction of reading outcomes. A longitudinal design was used to test a group-administered musical sequence transcription task (MSTT). This task was designed to preferentially engage sequence processing skills while controlling for fine-grained pitch discrimination and rhythm in terms of temporal grouping. Forty-five children, native speakers of Portuguese (Mage = 7.4 years), completed the MSTT and a cognitive-linguistic protocol that included visual and auditory working memory tasks, as well as phonological awareness and reading tasks in second grade. Participants then completed reading assessments in third and fifth grades. Longitudinal regression models showed that MSTT and phonological awareness had comparable power to predict reading. The MSTT showed an overall classification accuracy for identifying low-achievement readers in Grades 2, 3, and 5 that was analogous to a comprehensive model including core predictors of reading disability. In addition, MSTT was the variable with the highest loading and the most discriminatory indicator of a phonological factor. These findings carry implications for the role of temporal sequence processing in contributing to the relationship between music and language and the potential use of MSTT as a language-independent, time- and cost-effective tool for the early identification of children at risk of reading disability.
Across most cultures, learning to read is essential for long-term educational, vocational, and economic potential (Irwin et al., 2007; Riddick et al., 1999). Children who experience difficulty learning to read are susceptible to feelings of frustration, low self-esteem, and helplessness. Individuals with learning disabilities are more likely to develop internalizing or externalizing behaviors and are more likely to receive a diagnosis of depression or anxiety (Lawrence, 2006; Riddick, 2009). Yet, an alarming rate of adolescents and adults worldwide have not acquired proficient reading skills according to the UNESCO report (Huebler & Lu, 2013). Literacy levels are especially low in developing countries where schools have limited resources and/or when families come from a background of low socioeconomic status (SES; Ball et al., 2014). Brazil has one of the lowest levels of reading internationally (Organisation for Economic Co-operation and Development, 2016). Approximately 54.73% of students are below grade level in reading proficiency by third grade, according to the National Literacy Assessment (National Institute for Educational Research and Studies “Anisio Teixeira”, 2018). Critical factors for low literacy attainment in Brazil include reduced access to literacy at home and very limited resources at schools (Enricone & Salles, 2011). Furthermore, standardized assessments for assessing the various components of reading, as well as screening protocols for early precursors of reading disability, are rare. Therefore, receiving a formal diagnosis of a reading disability or intervention/remediation for reading difficulties is improbable in Brazil (Andrade et al., 2015; Navas, 2013).
Longitudinal studies have shown that children classified as poor readers at the end of first grade rarely reach grade-level reading ability by the end of elementary school without intensive intervention (Francis et al., 1996; Juel, 1988; Torgesen & Burgess, 1998). This can lead to a downward cascading spiral, in which persistent difficulty with reading results in reduced reading exposure and engagement among poor readers, thereby hindering vocabulary growth in missing the opportunity to learn new words and content from text (Stanovich et al., 1986). By contrast, research has shown that when children are identified as at-risk for reading disability at the start of formal reading instruction and provided timely, targeted intervention, the majority of these children achieve grade-level reading-related skills by the beginning of first grade (Catts et al., 2015; Wanzek et al., 2013; Wanzek & Vaughn, 2007).
Emerging research has demonstrated substantial progress in the ability to screen children at risk for subsequently developing reading disabilities as early as preschool (e.g., Catts, 2017). Early screening at the onset of formal reading instruction can help determine which children are at-risk to subsequently struggle and can further inform instruction and early intervention, which significantly improves outcomes (e.g., Catts et al., 2001; Gaab & Petscher, 2022). It is important to note that screening for dyslexia differs from a diagnostic evaluation intended to formally identify or diagnose a child with developmental dyslexia. Risk factors assessed in a screening instrument do not determine whether a child will subsequently develop dyslexia. Rather, they assess the probability that a child will develop dyslexia (Catts & Petscher, 2022). Unfortunately, studies to date have primarily focused their efforts within high-resource countries, resulting in proposed screening methods that do not necessarily effectively apply to children in countries with fewer or very limited resources.
Need for Global Screening Tools for Identification of Children at Risk for Learning Disabilities
A global screening tool with the potential to reach communities with limited resources needs to fulfill a number of important criteria: cultural-appropriateness, easy access, promotion of equity in the screening process, and developmentally appropriate. Furthermore, it needs to be easy to administer in settings with limited resources, require minimal training, and exhibit high levels of both specificity and sensitivity to minimize the rate of false negatives (at-risk children who were not identified) and false positives (children inaccurately identified as at-risk, e.g., Catts, 2017; Petscher et al., 2019). Other essential criteria include appropriate reliability, validity, sample representativeness, and classification accuracy (Gaab & Petscher, 2022). However, fulfilling these criteria has proven to be difficult. Longitudinal, multifactorial screening designs assessing key preliteracy skills starting in preschool and utilizing computer-adaptive testing to shorten administration time and increase engagement and effort are considered an optimal solution (Catts & Petscher, 2018; McBride et al., 2010). However, this poses several issues for schools and/or families in low-resource countries that may not have access to the monetary and personnel resources (including “data-literacy”) necessary for implementing, updating, and interpreting this form of assessment (Mitchell et al., 2015). While effective advances in screening tools rapidly progress in high-resource countries, the requirement for one-on-one administration and length of administration (associated with high costs), as well as language-specific content, pose persistent problems for universal screening batteries (Adlof et al., 2017; Compton et al., 2010). This makes large-scale screening in educational settings difficult. An effective global screener calls for minimal training necessary for implementation and interpretation and should allow for administration in classroom settings across different languages and cultures.
Relationship Between Auditory Processing Skills, Speech Sound Perception, and Phonological Awareness and Its Importance for Reading Development
One key preliteracy skill that has repeatedly been shown to be a reliable predictor of subsequent reading outcomes is phonological/phonemic awareness. This term describes the ability to manipulate speech sounds comprising words at the level of syllables, onset-rhymes, and phonemes (e.g., Georgiou et al., 2008; Scarborough, 1998; Schatschneider et al., 2004; Ziegler & Goswami, 2005). The foundational skills that give rise to phonological awareness (PA) have yet to be fully understood, but it has been hypothesized that broad auditory processing deficits could play a causal role in developing poor phonological processing skills. Weaknesses in basic auditory processing have been reported in individuals with dyslexia, including discrimination of pitch and frequency modulation in quiet and in noise (Ahissar et al., 2000; Amitay et al., 2002; Lorusso et al., 2014; Wright & Conlon, 2009; Ziegler et al., 2009) and in slow (Goswami et al., 2002) as well as fast temporal transitions (e.g., Tallal & Piercy, 1973). However, numerous other studies failed to replicate these findings (for a review, see Goswami, 2015a; Hämäläinen et al., 2013). Furthermore, differences in the discrimination of speech sounds and/or categorical perception of speech sounds have been reported, but it is unclear whether this may play a causal role in the development of phonological/phonemic processing deficits (Hämäläinen et al., 2013). However, when focusing on the first few years of development, the ability to perceive differences between speech sounds at 7 months of age has been positively associated with subsequent PA in preschool (Cardillo, 2010). Additionally, event-related potential studies have demonstrated that neural responses to speech in newborns are associated with their later reading outcomes (Molfese, 2000; Molfese et al., 2002). To date, it remains unclear whether basic auditory processing may serve as a reliable early indicator of risk for subsequent reading difficulty.
Relationships Between Music, Speech, and Language Skills
Interestingly, music encompasses acoustic properties that overlap with those inherent in speech, which suggests that music is one domain involving basic auditory discrimination skills that has in-turn been linked with PA, albeit inconsistently (Patel, 2012, 2014). Specifically, music and speech inherently share overlapping spectral (frequency/pitch) and temporal (timing/rhythm) properties, which suggest that the basic auditory processing necessary for music perception may also be associated with speech perception abilities (Chandrasekaran & Kraus, 2010; Chobert et al., 2012; Parbery-Clark et al., 2009; Patel, 2012). Moreover, music and language can arguably share some cognitive mechanisms that go beyond basic auditory processing. Both domains are based on patterned sound sequences hierarchically structured generating inherent structural relations (Koelsch, 2011; Patel, 2012) whose analysis may depend at first on the domain-general, mid-level cognitive mechanism of auditory sequence processing (e.g., Fedorenko et al., 2009; Janata & Grafton, 2003; Osterhout et al., 2012; Shain et al., 2020).
Advanced musical skills, acquired through engagement in musical training, have been associated with advantages in perceiving pitch inflections within spoken language (Koelsch et al., 1999; Micheyl et al., 2006; Schön et al., 2004; Spiegel & Watson, 1984). In the temporal domain, perception of differences in rhythm/meter and sequencing in music and/or musical experience have been positively associated with speech-specific syllable discrimination and detection of segmental structure (François et al., 2013; Magne et al., 2016; Marie et al., 2011; Moreno et al., 2009; Zuk et al., 2013). These associations between music and speech may carry significance for PA since the ability to manipulate individual speech sounds within words draws upon spectral and temporal acoustics, such as distinguishing between certain phonemes and word boundaries through syllable duration patterns (Cutler, 2012; Greenberg, 2005; Ozernov-Palchik et al., 2018).
Musicality, defined as the potential for music perception and production independent of formal training (Gingras et al., 2015), has been positively associated with PA in preschool children (Anvari et al., 2002; Degé et al., 2020; Degé & Schwarzer, 2011; Douglas & Willatts, 1994; Forgeard et al., 2008; Lamb & Gregory, 1993; Moritz et al., 2013; Overy et al., 2003; Peynircioglu et al., 2002). Moreover, studies have shown that musicality differs between typical readers and individuals with reading deficits in adults (Thomson et al., 2006) and children (Bhide et al., 2013; Corriveau & Goswami, 2009; Forgeard et al., 2008; Huss et al., 2011; Overy, 2000; Overy et al., 2003). Furthermore, musical training, as well as music-based interventions from the preschool age onwards, has been linked with improvements in phonological skills (e.g., Bolduc, 2009; Degé & Schwarzer, 2011; Moritz et al., 2013; Patscheke et al., 2019), as well as attention and working memory (Barbaroux et al., 2019), and long-term memory effects for learning novel words (Dittinger et al., 2021). These findings bring forth consideration of the extent to which putative relationships between musicality and PA may carry implications for reading development and what aspects of musicality could be underlying this relationship.
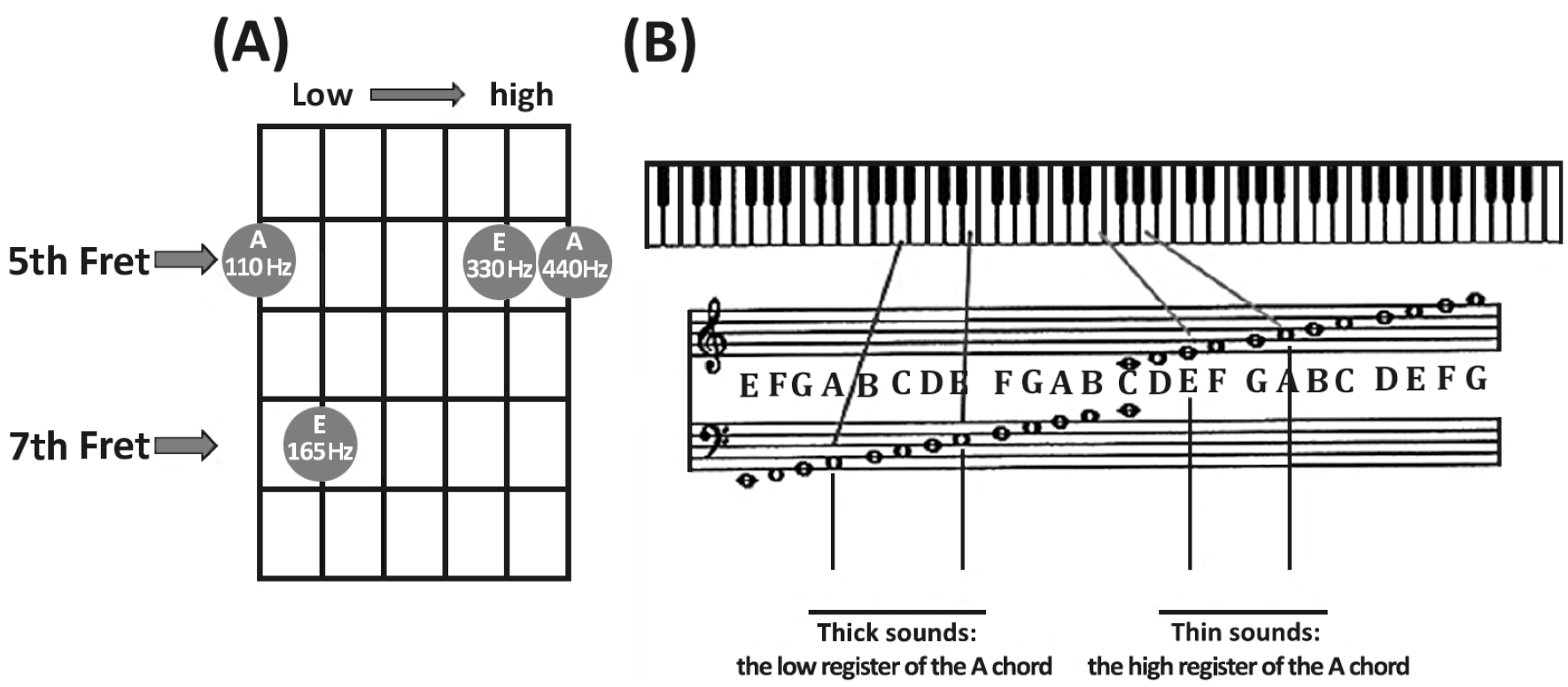
Few studies to date have investigated the relationship between auditory processing/music skills and early literacy skills in low-resource countries. One previous study identified positive links between a short, music-based assessment and emerging literacy skills among second-grade children in Brazil (Zuk, Andrade, et al., 2013). Zuk, Andrade, et al. (2013) targeted the overlap between linguistic and musical sequence processing through the design of a custom musical sequence transcription task (MSTT). This MSTT consists of isochronous 4-chord sequences, which include combinations of only two different 2-note chords, one in the low register and the other in the high register of the same A chord on the guitar. The low 2-note chord and the high two 2-note chord are separated by large intervals of one or more octaves. Children are asked to recall the sequence by writing it down on an answer sheet using two symbols (one for each chord; see task and procedure details in the Method section). This task was designed to preferentially engage perceptual and cognitive mechanisms important for “auditory pattern sequencing,” one of several mechanisms that may be shared between music and language (e.g., Fedorenko et al., 2009; Grube et al., 2012; Koelsch, 2011; Osterhout et al., 2012; Shain et al., 2020).
Additionally, converging evidence supports the hypothesis that both deficits associated with dyslexia may be partially explained by difficulties in sequence processing, which may stem from more basic temporal processing deficits (Archer et al., 2020; Goswami, 2015b, 2018; Stein, 2018, 2019; Vidyasagar, 2019). Interestingly, Grube et al. (2012) reported that sound-sequence analysis appears more relevant to the relation between auditory processing and phonological skills than the analysis of single sounds. Discrimination between short sequences, for example, indicating whether two four-tone sequences were “the same or different” in terms of pitch detection (global or local pitch changes) or temporal changes (deviation from isochronicity), but not between tone pairs, was significantly correlated to phonological skills (Grube et al., 2012). Moreover, MSTT allows for a fast, ecologically valid way to assess this temporal auditory processing skill in a classroom setting that is not contingent on a specific language, which has the potential to facilitate comparative studies and global use. However, it remains unclear whether MSTT performance is prospectively associated with subsequent reading skills. Using a cross-sectional design, Zuk, Andrade, et al. (2013) reported significant positive associations between the MSTT and several linguistic tasks (reading speed, accuracy, completion, and word spelling) in primary school children. Another positive aspect of the MSTT is that it is culture/language-independent and can be administered regardless of language background and literacy skills. Moreover, as a musical activity, MSTT is inherently engaging and motivating to children (Goswami, 2012; Hallam, 2010).
The Current Study
The Zuk, Andrade, et al. (2013) study identified an expedient, classroom-based, and ecologically feasible music-based assessment appropriate for implementation in developing countries and linked with key preliteracy skills. However, it remains unclear to what extent the MSTT may predict long-term literacy outcomes. To address this gap in our understanding, the present study builds on these previous findings by carrying out a longitudinal follow-up of these participants to examine how the MSTT predicts longitudinal reading outcomes. The present study aims to expand on the findings from Zuk, Andrade, and colleagues (2013) by determining whether the MSTT is prospectively associated with subsequent reading outcomes over a 3-year period. Specifically, we hypothesize that MSTT, assessed in the second grade, will significantly predict subsequent word reading in fifth grade. This work offers the first attempt to assess the potential for MSTT to serve as an early indication of risk for reading disability. If so, it may serve as a quick, classroom-based, ecologically feasible task that could assist with identifying children at risk for reading difficulties in conjunction with traditional early screening tools. This would be especially effective in settings where standardized tests are not available in the language of instruction or where resources for the development and purchase of standardized assessments are lacking.
Finally, an exploratory factor analysis with the behavioral measures as assessed in Grade 2 and the MSTT was performed to examine the underlying mechanism and related construct of the MSTT. The MSTT requires a motor component during the output/production phase and involves executive functioning skills including inhibition and working memory. Examining the cognitive underpinnings of the MSTT can guide the development of future screening instruments and can give insights into the development of atypical reading skills in Brazilian Portuguese.
Method
Participants
The current study is a longitudinal follow-up of Zuk, Andrade, et al. (2013). Forty-five children (29 males; 16 females; 4 with left handedness) initially participated from “Colégio Criativo,” Marília, an elementary school in São Paulo, Brazil. Legal guardians provided informed written consent prior to second-grade testing. All testing occurred on school premises during school hours with permission from the school administration, principal, and teachers. Students initially enrolled in the study were in the second grade of primary school, as per grade distinctions in the Brazilian education system. The study protocol was approved by the “Júlio de Mesquita Filho”—Faculdade de Filosofia e Ciências/Universidade Estadual Paulista (Ethics Committee from the Faculty of Science and Philosophy of São Paulo State University), Marília, São Paulo, Brazil.
Age was calculated at the onset of testing, at which time children ranged in age from 6 to 8 years (Mage: 7 years 4 months, SD: 4 months). Forty out of 45 children were right-handed (based on reports from parents, classroom teachers, and physical education teachers). All participants had normal hearing. This was assessed via school screening and parent interviews. Furthermore, no speech deficits were reported, which was assessed by a pedagogical coordinator who carefully monitored the speech and language development of all children starting in preschool. Also, these children had no formal musical training outside of general primary school curricula. Starting in second grade, this group of children participated in group music classes, which involved singing, listening to music, and music perception games but did not involve learning to read music or learning a musical instrument. Pedagogical approaches to teaching music adopted by the music teacher were based on group lessons, including attentive listening to different dimensions of musical materials (e.g., melody, harmony, rhythm, and emotions) through several activities (such as drawing and painting the images brought by instrumental music) and musical games involving singing, reproduction, comparison, and predictions of musical elements as well as further discussion of these musical dimensions. Therefore, the music lessons reflected the view that a central aim of the music curriculum should involve the construction of musical meaning and mental representations of fundamental organizing structures of music through attentive listening and singing, which should be a basis for subsequent music learning in more formal settings (Bamberger, 2006; Barret, 2007; Gordon, 2011; Wiggins, 2007) and even precede it (Gordon, 2011). It is worthy of note that it is very unlikely that the music lessons played a relevant role in the children’s MSTT performance since all tests, including MSTT, were administered during the four first weeks after the start of the second-grade school year (see procedure section).
All participants were native speakers of Brazilian Portuguese, the language in which all testing occurred. Furthermore, all students came from upper-middle class families, and most had at least one parent who was a working professional. Forty-one of the 45 original children (25 males; 16 females) assessed in the second grade were reassessed in the third (mean age: 8 years 11 months, SD: 4 months) and fifth grade as well (mean age: 10 years 11 months, SD: 4 months).
Behavioral Measures
Cognitive and Linguistic Measures
Cognitive and linguistic abilities (including reading) were assessed by administering tasks from the cognitive-linguistic protocol (CLP, Capellini & Smythe, 2008), which are described briefly here (for a detailed description of all measures, see Zuk, Andrade, et al., 2013). The CLP was designed in Brazilian Portuguese. The alphabet task was a test of letter knowledge in which participants were required to write the 26 letters of the alphabet from memory. Reading abilities were measured by assessing reading rate (number of correctly pronounced words per minute), reading word accuracy, and pseudoword reading accuracy tasks. The PA tasks consisted of alliteration detection, rhyme detection, and syllable segmentation. In the alliteration and rhyme detection tasks, participants had to correctly identify, from three words spoken by the examiner, the two words with the same initial sound and the two words with the same final sound, respectively. The syllable segmentation task consisted of students repeating words spoken by the examiner while tapping each syllable. Participants also completed two tasks measuring the time (in seconds) to rapid naming of objects and digits and three tasks measuring verbal working memory, namely, word sequence, nonword repetition, and verbal backward digit span. Additionally, participants engaged in a word discrimination task (i.e., identifying whether two words spoken by the examiner were the same or different), and also completed a rhythm production task. In this task, they had to reproduce rhythmic items demonstrated by the examiner by tapping out the rhythm on their desk. Participants also engaged in visual short-term memory tasks.
Musical Sequence Transcription Task
In second grade, participants completed the MSTT. The task was designed to preferentially engage perceptual and cognitive mechanisms important for “auditory pattern sequencing,” including auditory working memory. However, MSTT also contains a sound-to-symbol mapping component and requires both a motor output during the output/production phase and may engage attention and executive functions, particularly inhibition (since children have to wait for four beats until the examiner allows them to start recalling the sequence). The musical task involved a sequence of four two-note chords played isochronally on the guitar in a predetermined arrangement. All four-chord sequences consisted of only two different two-note chords, one in the low register and the other one in the high register of the same A chord on the guitar (see Figure 1A). In each sequence, the two-note chords were combined in order to originate a four-element sequence. As can be seen in the piano of Figure 1B, the two notes of the low two-note chord, that is, A (110 Hz) and E (165 Hz), form a perfect fifth interval (7 semitones), and the two notes of the high two-note chord, that is, E (330 Hz) and A (440 Hz) form a perfect fourth interval (5 semitones). Both two-note chords included the same pitches, A and E, but spanned one octave between the low E of the “thick sound” and the high E of the “thin sound” and two octaves between the low A of the “thick sound” and the high A of the “thin sound.” Children were then taught to code the two chords with two respective symbols. The thin sound (higher pitched fourth) was marked with a vertical line “
MSTT 2-Note Chords Based on the A Chord on Both Guitar (A) and Piano (B)

Examples of MSTT Sequences and How Students Recalled Them Using a Circle “O” for the Low Chords and a Vertical Line “I” for the High Chords (Delmolin et al., 2017)
The design of the MSTT deliberately does not require the perception of fine pitch variations. This ensured that low performance on MSTT could not be explained by a possible low-level deficit in perception of fine-grained pitch. Moreover, because the sequences consisted of the same two-note intervals in two different registers and were presented isochronally, the MSTT was designed to be devoid of both harmonic variation (e.g., musical syntax) and rhythm (in terms of temporal grouping).
The MSTT was administered collectively to the 45 children at the first time point (in second grade). Children were introduced to the MSTT as the “Smart Ear Game.” All students were given the same amount of instruction time, training trials (sequences), and exposure to the two chords. Initially, in a learning phase, children were presented with either the low or the high two-note chords and were asked which of the two symbols, a vertical line “I” or a circle “O,” best represented these chords. Most of them agreed that the vertical line was a better fit to represent the “thin sound” (high two-note chord) and the circle to represent the “thick sound” (low two-note chord). In both training and task phases, the sequences of the MSTT were presented to participants in a slow, isochronous manner, consistent in tempo throughout the entire task (approximately 88 beats per minute). After a short pause equal to the length of the sequence, students received a signal from the examiner allowing them to take the pencil and start recalling the chords in the order that they were presented using the symbols for the “thin” and “thick” sounds/chords. Although all experimental trials consisted of four-element sequences, training also included simple five-element sequences. However, children were never explicitly informed about the number of chords in each sequence throughout the experiment, and the inclusion of five-element sequences in the training trials was intended to prevent the a priori conclusion that all sequences would consist of just four elements. Students were not permitted to write anything before they received a signal from the administrator. The entire task consisted of 20 trials consisting of nine unique sequences, each presented twice with an additional two repetitions of the first sequence presented at equally spaced intervals across the series of trials. A correct recall of all four chords in the right order of the individual sequence was considered a correct response, leading to a maximum score of 20 on the task. If students recalled more or less than four chords, the trial was scored as incorrect. The duration of each sequence is 11 seconds including the four preparation beats, the four two-note chords, and the last four beats. The overall duration of the collective administration of the task, including instruction and training examples, was around 35 minutes.
Procedure
During the first 4 weeks of the second-grade school year, participants were assessed on the MSTT and all behavioral subtests of the CLP by Capellini and Smythe. The MSTT was administered to all participants concurrently in the music classroom, followed by individual and group administration of the linguistic and cognitive tests over 6 weeks. The following assessments were administered individually: reading speed, reading accuracy, reading completion, reading pseudowords, alliteration, rhyme, syllable segmentation, auditory word discrimination, rhythm production, word sequence, nonword repetition, verbal number sequence backwards, rapid object naming, rapid number naming, figure order, and figure rotation error. In contrast, the following subtests were administered in the classroom: the alphabet task, writing words, and writing pseudowords. Since all assessments took place during school hours, whole-classroom administration was implemented for time efficiency on assessments that did not require one-on-one administration. Testing began at the beginning of the academic calendar year and concluded within 6 weeks.
Due to time constraints, only a subset of measures was administered in third grade, which included reading rate/fluency, reading accuracy, reading pseudowords, phonological processing tasks, the rhythm production task, verbal working memory tasks, and rapid automatized naming (RAN) tasks. In fifth grade, all tasks from the third-grade assessment battery were re-administered, as well as the following measures: the alphabet task, the writing tasks (spelling of words and pseudowords), the visual short-term memory tasks, and the shapes copying task. The time elapsed between the initial MSTT testing at the second grade and third- and fifth-grade tests was 1 and 3 years, respectively. Even though interventions were recommended and available to all struggling readers from second to fifth grade, some children did not receive interventions because parents opted-out (see info in Andrade et al., 2015).
Data Preprocessing
An initial inspection indicated that scores from the tasks assessing three aspects of reading ability (word accuracy, pseudoword reading accuracy, and reading rate) were significantly correlated (Pearson’s r-values from .4 to .56, all p values < .001), suggesting the aggregation of scores by factor analysis. All three tasks showed high loadings (range of loadings: .63–.88; range communalities: .39–.78) on the single factor of the minimum residual factor analysis model (see Note 1). The factor model explained 52% of the variance of the raw scores and the multiple R2 between estimated factor scores and factors was .83. Subsequently, students’ scores were extracted by regression from the latent factor and termed reading ability, which was thereby used as the dependent variable in subsequent analyses. Note that combining scores of reading accuracy (words and/or pseudowords) and reading rate to obtain a composite score is commonly employed in related literature (Babayiğit & Stainthorp, 2011; Catts et al., 2001, 2015; Compton et al., 2010; Torgesen et al., 2001; Vellutino et al., 2008; Wagner et al., 1994).
Similarly, scores from the three tasks measuring aspects of PA (alliteration, rhyme, and syllable segmentation) showed significant correlations (Pearson’s r-values .35–.6, all p values < .001) and were subjected to a minimum residual factor analysis, which explained 49% of the variance in the raw scores and the multiple R2 between estimated factor scores and factors was .8. All three tasks loaded highly (range loadings: .51–.86; range communalities: .26–.74) on a single factor. Latent scores of this factor, labeled as PA, were extracted through regression and used as a predictor in the subsequent analyses.
In addition, we computed a composite score from the two RAN subtasks from a principal component analysis which scales the resulting component scores to have a mean of 0 and unit variance. The scores from the two subtasks (rapid object naming and rapid digit naming) were correlated very highly (r = .79, p < .001), which would lead to multicollinearity issues when using both scores simultaneously in a regression model.
Finally, a binary variable was created from the reading ability factor scores (see above) for indicating children who were at risk for reading disability (at-risk status). In accordance with the study by Andrade et al. (2015) and Fuchs et al. (2012), we defined all children scoring at least one standard deviation or more below the mean of their grade group as being at risk. For Grades 2 and 3, this resulted in six students being defined as being at-risk for reading disabilities, but seven students for Grade 5. Accordingly, 39, 35, and 34 were defined as not being at-risk for Grades 2, 3, and 5, respectively. We computed the at-risk variable separately for each grade.
Statistical Analysis
The statistical analyses of the data collected in second, third, and fifth grades were performed in three different steps, each targeting a different aspect of reading development and musical ability. All analyses were carried out using the statistical software environment R, version 3.4.1.
Longitudinal Mixed Effects Models of Reading Ability
In the first step, we constructed longitudinal mixed effects models of reading ability. We followed the recommendations for the construction and evaluation of longitudinal models provided in Long (2012). The reference model included reading ability as a dependent variable, the timepoints of data collection as the only fixed effects predictor variable, and participant ID as a random intercept effect. This null model was compared to models that also included the PA and RAN aggregate scores as well as the MSTT scores from second grade as predictor variables. The choice of predictor variables was informed by previous literature (McBride-Chang & Kail, 2002; Torgesen et al., 2001; Wagner et al., 1994) indicating that phonological processing and RAN are two main predictors of reading acquisition. Consistently with this literature, the principal component analysis presented in Zuk, Andrade, et al. (2013) also showed that MSTT, rhyme, alliteration, and RAN measures as well as word sequence all loaded very highly on the same component, thus demonstrating their strong associations. Because of the robust empirical support for the predictive value of PA and RAN combined with our goal to test the predictive power of MSTT, we have chosen MSTT, RAN, and PA as the predictor variables for reading abilities in the present study. Predictor variables were employed to predict the overall level of the reading ability (intercept model) or the overall level as well as the increase in reading ability over time (intercept and slope model). We employed a model-selection strategy that started with the full model including main effects and interaction effects with time of all three predictors (PA, RAN, MSTT). Nonsignificant terms were removed from the full model, and the model fit of the resulting reduced model was compared to the full model and the null model. Model fit was assessed on the Bayesian Information Criterion (BIC) and on likelihood ratio tests.
Prediction of Low-Achievement Readers
In a second step, we computed a series of logistic regression models for the prediction of low-achievement readers. The binary variables at risk for reading disability for each grade (2, 3, 5) were used as dependent variables. With each of these three dependent variables, we computed two variants, one variant used the MSTT as the only predictor and the other variant used MSTT, RAN, and PA as predictor variables. Both variants were compared by assessing their accuracy (i.e., proportion of students correctly classified), sensitivity, specificity, and by computing the area under the receiver operating characteristic (ROC) curve (AUC). Generally, on all four measures, higher values indicate a better prediction and discrimination of the model. The AUC method is a widely employed statistic to assess the discriminatory power of logistic regression models. The ROC curve is usually a convex curve generated by plotting sensitivity (percentage of true positives) in the y-axis against 1-specificity (percentage of false positives) in the x-axis across all possible cutoff points. The AUC provides a nonparametric estimate of how closely predicted probabilities are linked to the low-achievement group of readers and representing a discriminatory power of identification (Swets, 1988). By definition, AUC values range from .5 (chance level) to 1 (perfect association). If the AUC has a value of .5 it means that the ROC curve falls in the diagonal and that discrimination power of the prediction model is at the chance level, whereas AUC values over .5 indicate discriminatory capacity of the evaluated model. According to Hosmer and Lemeshow (2000), AUC values from .7 to .8 are considered acceptable, from .8 to .9 excellent, and above .9 outstanding.
Locating the MSTT in the Factor Structure of the Assessment Measures Battery
In the third and final step, we explored through an exploratory factor analysis the location of the MSTT in the factor structure of the assessment measures battery. The MSTT has both a motor component during the output/production phase and requires executive functions and attention skills. Therefore, we also performed an exploratory factor analysis on the data from all cognitive-linguistic measures and MSTT taken in Grade 2 in order to examine the likely cognitive underpinnings of the MSTT task. Exploratory factor analysis allows us to explore how variables correlate to each other and, thus, cluster together to represent potential cognitive dimensions or factors. Investigating the specific and salient loadings of measures onto each factor (commonalities) will enable us to (a) infer what these potential cognitive factors/dimensions are and name them and (b) to infer the level of shared cognitive mechanisms between a given measure and a cognitive factor through its communality, which represents the total amount of variance this measure shares with other measures that form the factor.
Results
Descriptive statistics of all variables employed in the subsequent analysis are given in Table 1. Investigation of the extent to which MSTT contributes to the prediction of subsequent reading outcomes, while accounting for additional contributing factors, is outlined via two approaches as follows: (a) longitudinal mixed models with reading ability scores across Years 2, 3, and 5 as the repeated measures outcome variable and scores from the MSTT, PA, and RAN tasks (assessed in Year 2) as predictors and (b) logistic regression to examine the potential for MSTT to predict low-achievement reader status at each longitudinal timepoint.
Means and Standard Deviations for the Administered Measures.
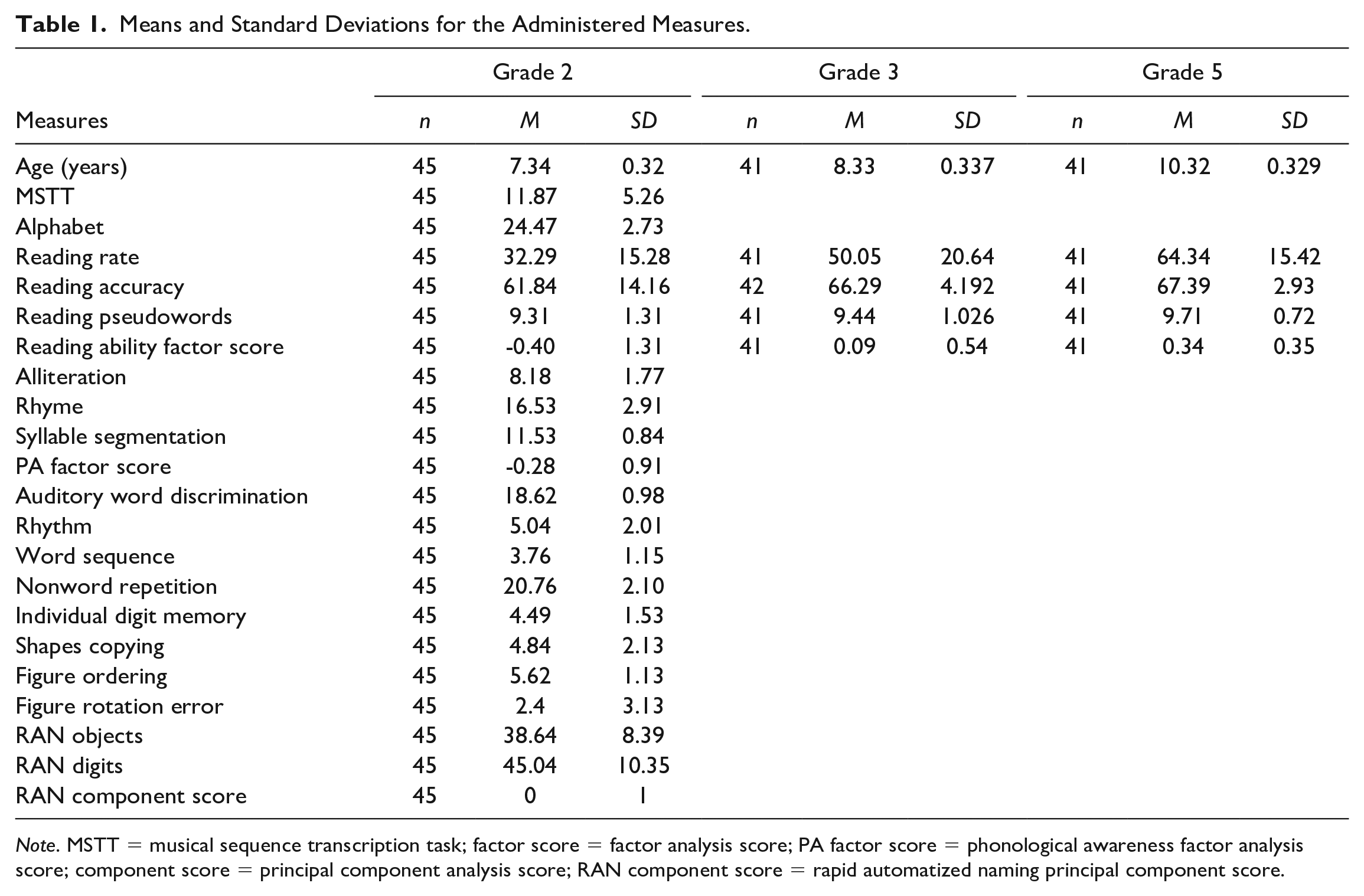
Note. MSTT = musical sequence transcription task; factor score = factor analysis score; PA factor score = phonological awareness factor analysis score; component score = principal component analysis score; RAN component score = rapid automatized naming principal component score.
Longitudinal Mixed Effects Models of Reading Ability
In a first step, a full mixed effects model was fitted to the longitudinal data, including main effects of timepoint (grade of testing) and of all three predictors of interest (MSTT, RAN, PA). The full model also included three interaction effects of timepoint with each of the three predictor variables. All main and interaction effects of the full model were significant at the p < .05 level with the exception of the interaction effects time × PA and time × MSTT. Removing these two nonsignificant terms gave rise to a reduced model, which showed a better fit to the data than the full model, and a null model that only included time but none of the other predictor variables. Model fit indices (BIC, p values from likelihood ratio tests) of the null model, the full model, and the reduced model are given in Table 2. The reduced model for the development of reading abilities is summarized in Table 3.
Evaluation of Longitudinal Models of Reading Development.
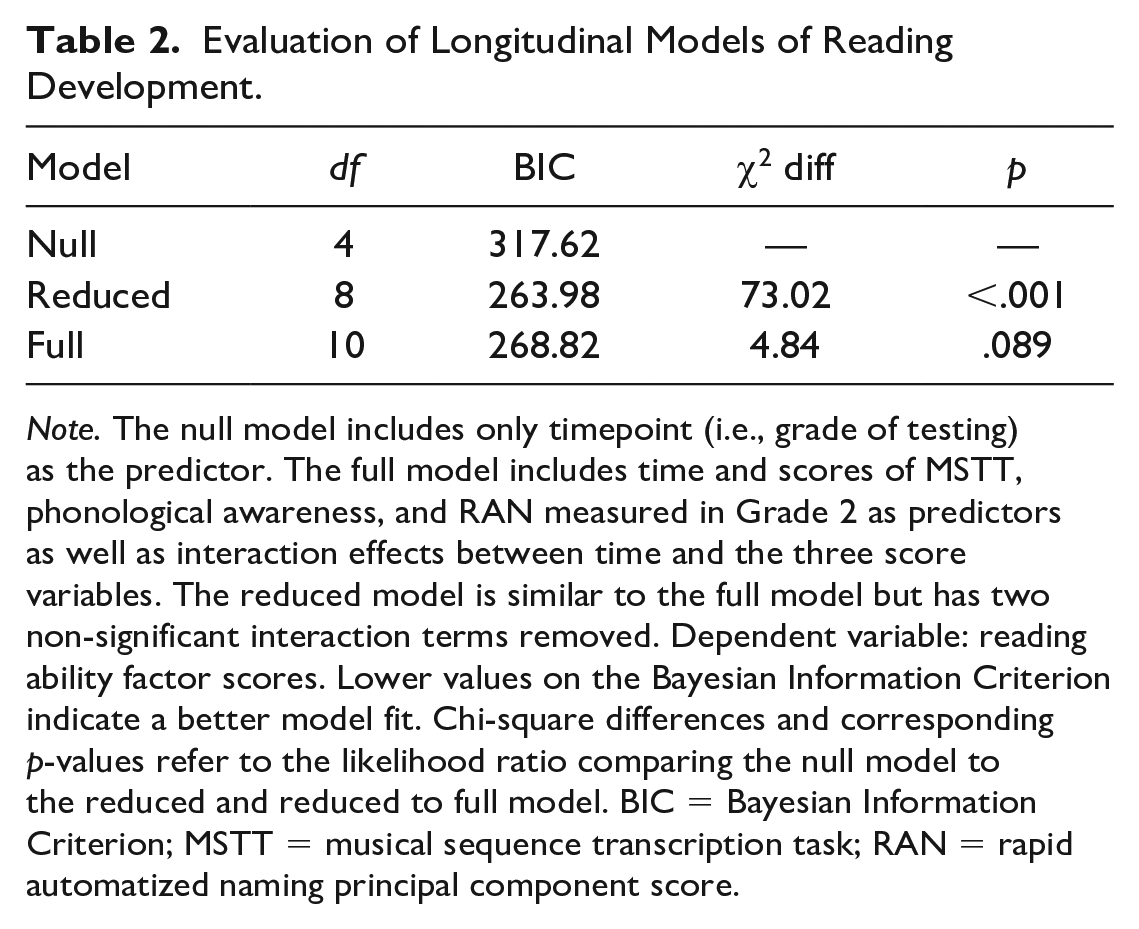
Note. The null model includes only timepoint (i.e., grade of testing) as the predictor. The full model includes time and scores of MSTT, phonological awareness, and RAN measured in Grade 2 as predictors as well as interaction effects between time and the three score variables. The reduced model is similar to the full model but has two non-significant interaction terms removed. Dependent variable: reading ability factor scores. Lower values on the Bayesian Information Criterion indicate a better model fit. Chi-square differences and corresponding p-values refer to the likelihood ratio comparing the null model to the reduced and reduced to full model. BIC = Bayesian Information Criterion; MSTT = musical sequence transcription task; RAN = rapid automatized naming principal component score.
Longitudinal Regression Model for Reading Abilities Including MSTT, Phonological Awareness, and RAN as Predictors.
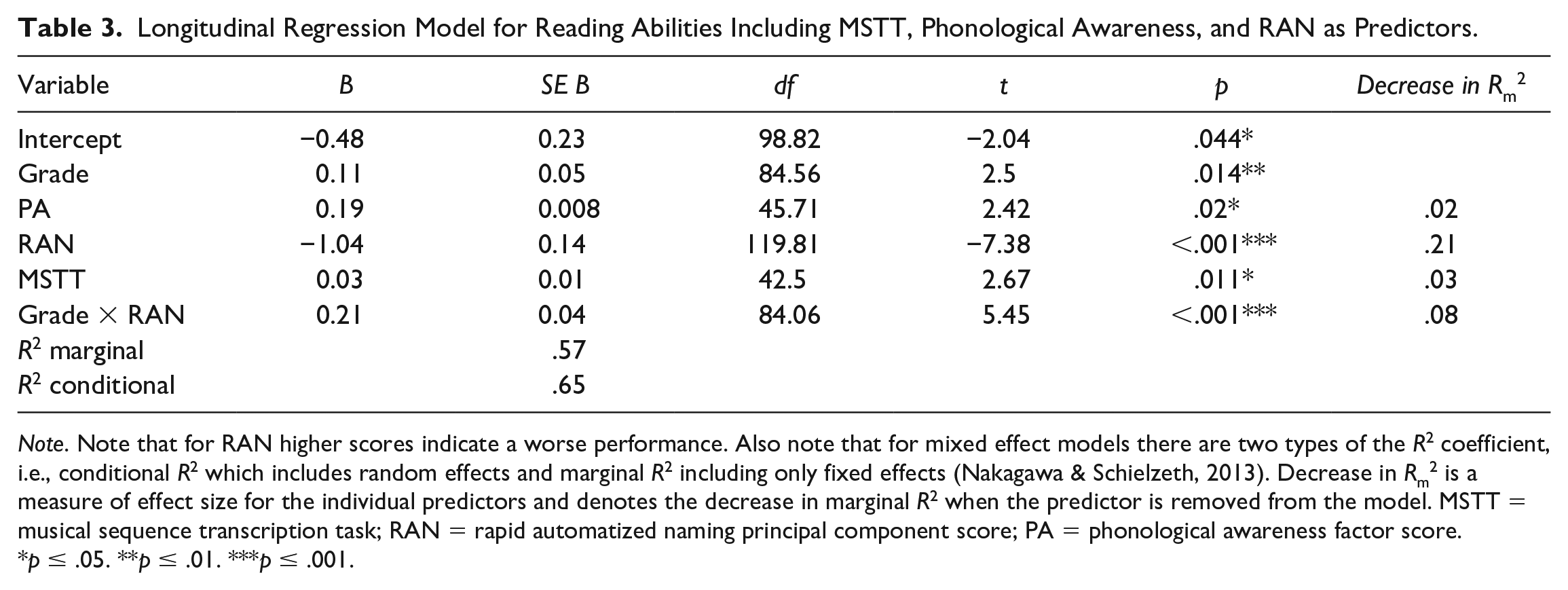
Note. Note that for RAN higher scores indicate a worse performance. Also note that for mixed effect models there are two types of the R2 coefficient, i.e., conditional R2 which includes random effects and marginal R2 including only fixed effects (Nakagawa & Schielzeth, 2013). Decrease in Rm2 is a measure of effect size for the individual predictors and denotes the decrease in marginal R2 when the predictor is removed from the model. MSTT = musical sequence transcription task; RAN = rapid automatized naming principal component score; PA = phonological awareness factor score.
p ≤ .05. **p ≤ .01. ***p ≤ .001.
The model in Table 3 shows a significant positive effect for grade of assessment (p = .044), which simply indicates that children become better readers over time. The RAN task is a time-based measure (the faster the children name the objects, the lower the score) which has previously been shown to be negatively correlated to reading ability (e.g., Denckla & Cutting, 1999; Wolf & Bowers, 1999). Here, we observe that RAN shows the strongest main effect on reading ability (p < .001, decrease in marginal R2 = .22). Therefore, as hypothesized, shorter naming times on the RAN tasks assessed in Grade 2 were observed to significantly contribute to the prediction of fifth grade reading abilities.
The interaction between RAN and grade of testing is also significant (p < .001, decrease in Rm2 = .08), suggesting that the influence of the RAN speed assessed in Grade 2 decreases over time. In addition, MSTT scores had a significant positive effect (p = .011, decrease in Rm2 = .03), meaning that children with higher MSTT scores in second grade tend to show better reading abilities. Similarly, PA was also positively related to reading abilities (p = .02, decrease in Rm2 = .02). Because interactions for time × PA and time × MSTT were nonsignificant (i.e., the importance of PA and MSTT remained consistent over time), they were not included in the model.
In sum, reading ability increases over time from Grade 2 to 5 and MSTT, PA, and RAN aggregate scores taken in Grade 2 are all significant predictors of reading ability across the primary school years.
Prediction of Low-Achievement Readers
The longitudinal mixed effects models above have shown that performance scores from the MSTT as well as PA and RAN composite scores are associated with the overall level of reading outcomes in the full sample of children. In practice, it is furthermore important to effectively identify whether children present with an early risk for reading disability (low achievers at second and third grades) will subsequently develop reading disabilities (low achievers at fifth grade). To address this, we used the binary variable, low-achievement reader status, for each grade (Grade 2: six children with low reading achievement status, i.e., 1 SD below the mean; Grade 3: six children; Grade 5: seven children) as the dependent variable in a series of logistic regression models. To assess the contribution of MSTT to prediction of low-achievement reader status, we compared two models, one using only the MSTT score and a model with all three predictor variables (MSTT, PA, RAN) from Grade 2 as predictors. For all models, overall classification accuracy (child low-achievement readers/non-low-achievement readers) as well as sensitivity and specificity of the logistic regression model were recorded. Results are summarized in Table 4 and show that the classification accuracy of all models is in the range of 83% to 91%. This means that between four and seven children (depending on the sample) were misclassified. Absolute misclassification numbers were generally balanced with respect to the low- and high-achieving groups. Because the low-achievement group was substantially smaller due to the definition criterion, this resulted in substantially lower sensitivity than specificity rates. In contrast to Fuchs et al. (2012) and Andrade et al. (2015), this represents a conservative approach for logistic regression modeling (i.e., producing almost no false positives but affording several misses).
Classification Accuracy Indices for Predicting Reading Low-Achievement Reader Status at the Beginning of Second and Third Grades and at the End of Fifth Grade.
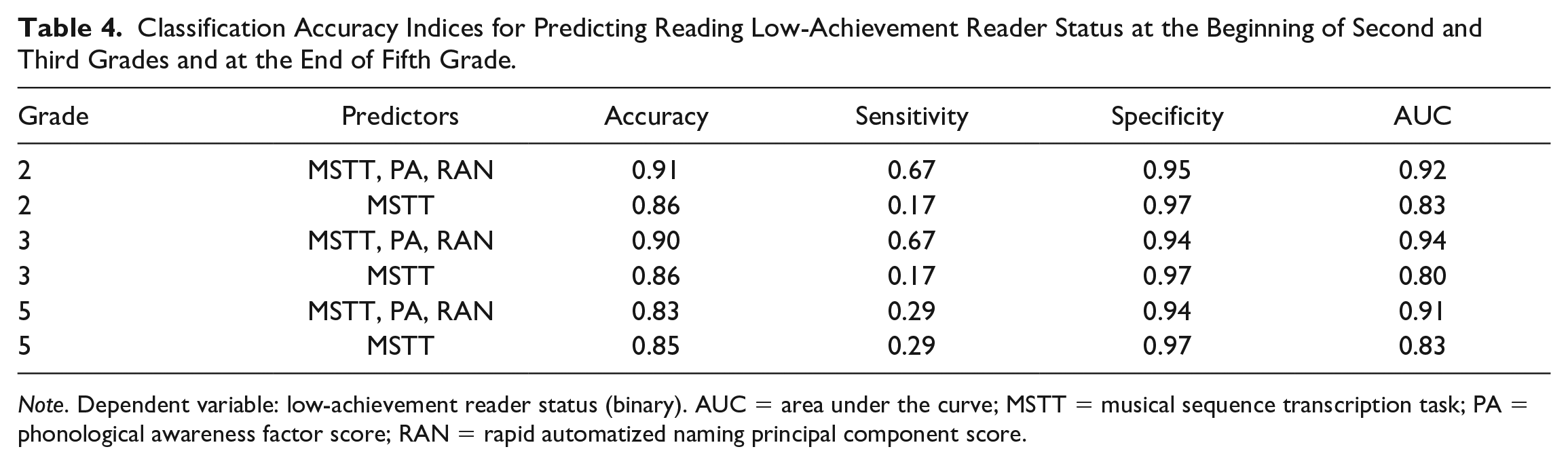
Note. Dependent variable: low-achievement reader status (binary). AUC = area under the curve; MSTT = musical sequence transcription task; PA = phonological awareness factor score; RAN = rapid automatized naming principal component score.
For the prediction of low-achievement readers, assessed in Grade 5, the model including MSTT, PA, and RAN assessed in Grade 2 as predictors classifies 83% of all participants accurately. The model using only the MSTT model achieves a comparable classification rate of 85%. Performances of typical and low-achievement readers on MSTT and cognitive-linguistic tasks are provided in the Supplemental Table 1.
Table 4 also shows the association of the binary low-achievement/non-low-achievement variables and the model predictions on the continuous probability scale by computing the area under the ROC curve (AUC).
Additionally, Table 4 shows that across all grades, the AUC values of the combined predictor models are superior compared to the corresponding models that contain only the MSTT as a predictor. This superiority is linked to a higher sensitivity of the combined predictor models. In contrast, the specificity of all MSTT models is higher than that of the combined predictor models. Hence, using the MSTT as a single predictor produces slightly fewer false positives, but this comes at the price of a slightly lower overall accuracy.
In sum, identifying low-achievement readers solely on the basis of MSTT achieves an overall classification accuracy that is only slightly lower than models that also include PA and RAN scores. The relatively good performance of the model using only the MSTT as a predictor is particularly true for long-term predictions (i.e., reading abilities in Grade 5 predicted by scores from Grade 2).
Locating the MSTT in the Factor Structure of Assessment Measures
In order to examine cognitive underpinnings of the MSTT task, we performed an exploratory factor analysis with a descriptive aim on the data from all 21 measures taken in Grade 2. An initial parallel analysis based on randomly re-sampled correlation matrices suggested the presence of a strong first factor and the high value of MacDonald’s coefficient omega (omega = 0.7) indicated the presence of a general factor common to all items. Therefore, we subsequently performed a series of hierarchical factor analyses, always including a general factor and between three and seven secondary group factors (i.e., so-called Schmid-Leiman factor models). We used principal axis factoring with oblimin rotation and compared different solutions on the Bayes Information Criterion. The solution with three group factors achieved the smallest BIC value and was considered the most adequate solution for the data. Supplemental Table 2 shows the factor loadings of all items. The general factor has high loadings from almost all measures and can, therefore, be considered a factor of general cognitive ability or “g” factor. The items measuring reading abilities load most strongly on the first group factor. The second group factor has high loadings from the auditory measures (auditory discrimination, rhythm production) as well as from the phonological measures (alliteration, rhyming, syllable segmentation, RAN of objects and digits), working memory (word sequence, figure ordering), and the MSTT. In fact, the MSTT has the highest loading on this factor and can, therefore, be considered the most discriminating indicator of this phonological-working memory factor. The third group factor was characterized by highest loadings from figure rotation and nonword repetition. A potential interpretation of this factor structure with regard to the MSTT might suggest that, for performing well on the MSTT, a combination of auditory discrimination, working memory, or phonological abilities is required, which distinguishes this test from other tests loading on the same latent factor. However, the parameter estimates of the bifactor solution given in Supplemental Table 2 should only be interpreted with care and from a descriptive perspective as they are unlikely to represent the true bifactor model parameters form the population (see Mansolf & Reise, 2016).
Discussion
The present study investigated the extent to which MSTT, a musical task collectively administered in the classroom, predicts subsequent reading outcomes among children in Brazil. The MSTT consists of isochronous four-chord sequences made of different combinations of only two different two-note chords, one in the low register and the other in the high register of the same A chord on the guitar. However, MSTT also contains a sound-to-symbol mapping component and requires both a motor output during the output/production phase and may engage executive functions, particularly inhibition (since children have to wait for four beats until the examiner allows them to start recalling the sequence) and working memory skills to recall the sequence. The present study carried out a longitudinal follow-up of Zuk, Andrade, et al. (2013) participants to examine how the MSTT predicts longitudinal reading outcomes. We hypothesized that MSTT, assessed in second grade, would significantly predict subsequent word reading in fifth grade.
Replicating Zuk, Andrade, et al. (2013) Findings in a Longitudinal Study
As expected, reading ability increases over time (from Grade 2–5), and multiple regression analysis reveals that MSTT, PA, and RAN are all significant predictors of the outcome variable, reading ability (determined by a composite of reading fluency, reading accuracy, and reading pseudowords). In a longitudinal regression model with the outcome variable of reading ability and the MSTT, PA, and RAN as predictors, the RAN tasks were found to be the strongest predictors, followed by PA and MSTT both showing comparable effects. Interestingly, the interaction between RAN and grade of testing was significant (which was not the case for PA and MSTT), suggesting that the strength of the effect of RAN on reading ability decreases over time.
These findings are consistent with evidence suggesting that both domains can share cognitive mechanisms at the midlevel of auditory sequence processing (Janata & Grafton, 2003; Osterhout et al., 2012; Shain et al., 2020). Second, these findings are in line with the growing body of evidence suggesting positive relationships of musicality with both PA and reading abilities in both typical (Anvari et al., 2002; Degé & Schwarzer, 2011; Douglas & Willatts, 1994; Forgeard et al., 2008; Lamb & Gregory, 1993; Moritz et al., 2013; Overy et al., 2003; Peynircioglu et al., 2002) and atypical readers (Thomson et al., 2006) and children (Bhide et al., 2013; Corriveau & Goswami, 2009; Foregard et al., 2008; Huss et al., 2011; Overy, 2000; Overy et al., 2003).
MSTT Identifying Low-Achievement Readers
A subsequent analysis recoded reading outcome scores for each grade (2, 3, and 5) into low versus high achievement to examine the degree to which the MSTT, PA, and RAN can contribute to classify children as low- versus high-achievement readers. Two prediction models were used to assess how much MSTT contributes toward prediction of poor reader status: the MSTT-only model and the whole model based on all three predictor variables (MSTT, PA factor score, RAN component score). For identifying low-achievement readers, we decided to use an evaluation method known as the area under the ROC curve (AUC), which is a widely employed statistic to assess the discriminatory power of logistic regression models (Adlof et al., 2017; Fuchs et al., 2012; Hendricks et al., 2019; Petscher et al., 2019).
For identifying low-achievement readers on its own, MSTT achieved an overall accuracy for Grades 2 and 3 (AUC = 0.86) that is lower than the identification accuracy of the whole model, that is, MSTT, PA, and RAN as predictors (AUCyear 2 = 0.91, AUCyear 3 = 0.90), and in Grade 5, the performance of the model including only MSTT was comparable to the full model.
It is worth mentioning that, even though the MSTT performed worse than the full model across all grades according to the AUC criterion, it still has the best specificity across all years. Overall, the AUC values of all models fall within the range of excellent to outstanding according to the classification provided by Hosmer and Lemeshow (2000). It is also interesting that the models using the MSTT as the only predictor reached an identification accuracy similar to levels reported in earlier studies with much larger samples that investigated the effectiveness of either univariate (only one screener) or multivariate screening (multiple screeners) models where AUC values range from .85 to .86 (see Petscher et al., 2019). Adding multiple indicators to the screening measures (e.g., progress monitoring or teacher ratings) has been shown to improve identification accuracy. Similar to the present findings, Compton et al. (2012) report an increase in AUC from .88 (single indicator model) to .92 (multiple indicator model). A recent study found that adding a group-administered word reading task to a group-administered listening comprehension task increased AUC value in the prediction of risk of language impairment from .699 to .792 (Adlof et al., 2017). However, the word reading task alone in the dyslexia screener reached an AUC of .85 and did not improve by including the listening comprehension task (Adlof et al., 2017). Taken together, these results point to a promising perspective for the use of the MSTT as a complementary screening tool in multivariate screening models, especially for group-administered tasks.
Potential Cognitive Mechanisms Underlying Performance in the MSTT Task
While the MSTT is a music-based tool assessing auditory sequence processing, it is important to consider additional cognitive constructs that may underlie this task. One consideration pertains to the extent to which children may be engaging verbal working memory resources to recode and memorize the chord sequences verbally, such as using “low” or “thick” vs. “high” or “thin.” Second, it could be asked whether MSTT might be measuring the visual processing involved in sound-symbol correspondence or, third, whether children could be memorizing the chord sequences verbally. To address this question, an exploratory factor analysis was performed on all 21 measures taken in Grade 2 (including MSTT) to gain some insight into related constructs and potential underlying cognitive mechanisms of the MSTT task. The most adequate solution for the data yielded three group factors. The items measuring reading abilities loaded most strongly on the first group factor, whereas MSTT loaded most strongly on the second factor, labeled as phonological factor because its highest loadings were from the phonological and auditory memory measures. By having the highest loading on this second factor, MSTT can be considered the most discriminating indicator of this phonological factor. The third group factor, labeled as short-term working memory factor, was characterized by highest loadings from figure rotation and nonword repetition.
The results from the factor analysis indicate that the subtests word sequence repetition and nonword repetition loaded differentially on the phonological and working-memory factors. This result is intriguing because both tasks can be regarded as indexing verbal short-term memory. This suggests that the MSTT is highly related to auditory and phonological processing abilities. The MSTT was designed to preferentially engage auditory sequence processing but does not require fine-grained pitch perception (two-note chords are separated by large intervals: one octave or more) and being devoid of both harmonic syntax (no chord changes) and rhythm in terms of temporal grouping as well (isochronous sequences). It, therefore, seems to be a measure of sequencing skills of larger auditory chunks similar to sequences of syllables or a measure of verbal working memory of larger auditory “objects” such as syllables, onsets, rhymes, or whole words. Therefore, it seems to be measuring different skills than those underlying nonword repetition wherein the emphasis is primarily on the accurate repetition of phonemes and their sequence from phonological working memory. Future studies that systematically vary specific components of the MTSS are needed to further investigate which aspects of the task are most predictive of subsequent reading outcomes and to further investigate the underlying perceptual and cognitive mechanisms of the MSTT.
Limitations and Future Directions
The present findings are to be interpreted in the context of some notable limitations. First, the modest sample size drawn from only one school imposes strong restrictions regarding the generalization to the larger population of primary school children in Brazil, let alone in other countries. Therefore, it is necessary to replicate this work with a larger and more heterogeneous sample of primary school children.
Second, the present study was conducted with a sample of children from upper-middle class families, suggesting that the observed reading and writing difficulties are not primarily the result of lower family SES, a relevant variable in Brazil (Enricone & Salles, 2011). Hence, there is a need to address the role of SES for the development of reading abilities more explicitly in future studies.
In order to understand the association between MSTT scores taken at an early age and the subsequent development of reading and writing abilities, more longitudinal observations are needed, for example, assessing reading and writing abilities at 6 months intervals ranging from first to fifth grade. Another future direction concerns the implementation of the MSTT in countries other than Brazil to test its cross-linguistic and cross-cultural applicability. The MSTT is nonverbal in nature and uses very basic rhythmic structures that are not biased toward any particular musical culture (at least within the broad spectrum of Western musical cultures). These characteristics make it very much plausible that the MSTT should work equally well in European countries with more transparent (e.g., German, Finish, Italian, Spanish) or even less transparent orthographies such as English when compared to Portuguese (see Ziegler & Goswami, 2005). Therefore, future research is necessary to evaluate the feasibility of implementing MSTT in other languages and cultures.
Conclusion
The preliminary findings of this study carry implications for the role of temporal sequence processing in contributing to the relation between music and language while suggesting that the MSTT may be helpful as an expedient, ecologically valid approach to assess auditory sequence processing skills in a classroom setting without the need for a costly or language-specific measure. Moreover, these preliminary findings also indicate the potential use of MSTT as a language-independent, time- and cost-effective tool for the early identification of children at-risk for reading disability. Finally, MSTT carries the potential for its use in comparative studies across different language regions. However, the present results are not intended as a form of proof that the MSTT is a valid screening tool given the small sample size and the lack of a well-designed psychometric validation study. Instead, these results should be interpreted as preliminary evidence that a group-administered musical activity designed to engage auditory sequence processing has the potential to predict subsequent reading abilities 1 to 3 years after its administration. Although the MSTT does not require fine-grained pitch perception, syntax, or rhythm processing (in terms of temporal grouping), it is still a musical task. The musical nature of the MSTT makes it very pleasurable and motivating for children (Goswami, 2012; Hallam, 2010). Because the MSTT can be run with groups of children and requires only minimal training for its implementation and interpretation, it is suitable for administration in classroom settings. Hence, this study contributes to the scarce evidence on the accuracy as well as time and cost-effectiveness of collectively administered screening procedure for children (Adlof et al., 2017; Andrade et al., 2015; Hendricks et al., 2019; Petscher et al., 2019). Because of the nonverbal nature of the MSTT and its very basic rhythmic structures which are not biased toward any particular Western musical culture, it has the potential of providing a relatively time- and cost-effective mean of early identification of children at-risk for reading disability in different languages.
Supplemental Material
sj-docx-1-ldx-10.1177_00222194231157722 – Supplemental material for Sequence Processing in Music Predicts Reading Skills in Young Readers: A Longitudinal Study
Supplemental material, sj-docx-1-ldx-10.1177_00222194231157722 for Sequence Processing in Music Predicts Reading Skills in Young Readers: A Longitudinal Study by Paulo E. Andrade, Daniel Müllensiefen, Olga V. C. A. Andrade, Jade Dunstan, Jennifer Zuk and Nadine Gaab in Journal of Learning Disabilities
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.