
Abstract
Porosity severely reduces the mechanical performance of composite laminates and methods for automatic segmentation of void phases are growing. This study investigates porosity in composite materials that take the form of interlaminar voids and dry tow areas. Deep Learning was used for the segmentation of X-ray micrographs via the implementation of eight state-of-the-art Convolutional Neural Network (CNN) architectures trained with data sets containing twenty-five, fifty, and one-hundred images. The combination of hyperparameters providing the highest accuracy for each architecture and training set size was achieved through the optimisation of six relevant hyperparameters, including the cut-off probability applied to output probability maps. Additionally, the properties of the CNN architectures (e.g., layer typology, connections, density…) were found to play a determining role, not only in the segmentation results but also in the associated computing effort. U-Net and FCDenseNet outperformed the FCN-8s, FCN-16, SegNet, LinkNet, ResNet18 and Xception CNN architectures. However, the CNNs generally outperformed the standard thresholding approaches, especially in sub-volumes containing low porosity (1.07%) where the influence on strength is very sensitive in high-performance composites. In low porosity samples, U-Net and FCDenseNet consistently segmented voids to 85% + accuracy, whereas thresholding was only half as accurate, at around 40%. The results provide a strong motivation to replace thresholding as a segmentation method for composite X-ray micrographs. In terms of efficiency, the reduced complexity of the U-Net network allowed for an average reduction of the training time (−36%) and prediction time (−17%) when compared to FCDenseNet.
Introduction
Carbon Fibre Reinforced Polymer (CFRP) composites are hybrid materials consisting of a fibre reinforcement and a polymer matrix. The binding of the fibres by the polymer matrix confers the unique final material properties, such as high specific stiffness, i.e., rigidity, and specific strength, also known as the strength-to-weight ratio. Because of these advantageous properties, composite materials are widely used in sectors where the weight reduction and a high mechanical performance are essential, such as the aerospace, wind energy, and automotive industries. 1
The detection of micro-structural features and characterisation of composite materials has benefited from the ability of Deep Learning to provide accurate segmentations, and therefore, has positively impacted the quality of the results derived from them. Image segmentation using Deep Learning removes many of the pre-processing steps required for standard segmentation approaches, such as thresholding. Deep Learning refers to the computational models that learn complex abstract concepts via the identification and association of simpler ones. 2 Convolutional Neural Networks (CNN) are one of the current methods to implement Deep Learning models, and consist in the definition of a sequence of layers of various types (e.g., fully connected, pooling,…), where at least one of them performs a convolution operation. 3 CNNs are especially well suited for the processing of array-type data, such as time-series data, images (2D data) or volumes (3D data), 3 and have become an attractive alternative to segment objects of interest in a wide range of areas such as civil engineering, 4 biology, 5 medicine 6,7 or additive manufacturing. 8
In the composites field, Deep Learning has been successfully applied to a range of applications, such as the analysis of multiclass damage,9,10 the characterisation of woven composites from low-contrast and low-resolution X-Ray images, 11 and the generation of high-fidelity digital twins. 12 Furthermore, Deep Learning has shown a superior performance to thresholding in the phase segmentation of uncured composite samples in the presence of moderate levels of noise 13 and has enabled an accurate assessment of the porosity content in optical microscopy images of composite samples displaying a significant image quality variability. 14 However, as Deep Learning is increasingly gaining attention, questions arising around which CNN to use to segment the features of interest in composite images, and which combination of user-defined parameters, also known as hyperparameters will provide optimum segmentation results. While U-Net 15 is a common choice to segment composite images,11,13,14 other networks such as FCDenseNet 16,17 or DeepLabv3+ 12,18 have also been applied in previous studies.
As a consequence of the ample choice of CNN networks, authors have compared the performance of a selection of architectures for different segmentation tasks, such as wrinkle detection in digital images 19 or fibre segmentation in ceramic-matrix composites from high-resolution X-Ray micrographs. 20 The decision process regarding selecting the hyperparameters has been documented in only a couple of studies investigating composite,10,21 but both lack a formal justification of the choice of hyperparameters, or followed previously reported recommendations.19,20
The primary objective of this current study was to investigate the relationship between the annotation effort, computing cost and segmentation performance of Deep Learning models. For this reason, a range of state-of-the-art CNN architectures were used to segment the interlaminar voids and dry areas of CT Scan micrographs of uncured composite laminates. A strategy aiming to optimise the main hyperparameters at the training and prediction stages of each CNN model is also presented. Finally, since the selection and preparation of the training set of the Deep Learning models is a critical but time-consuming task to achieve satisfactory segmentation results, the effect of the training set size on the performance of such models is also investigated.
Methodology
A common technique to produce parts made of composite materials involves stacking uncured layers or plies, known as prepregs, where the fibres are partially pre-impregnated with a thermosetting polymer resin.13,22 This uncured preform is then moulded into a composite part at elevated temperature and with an applied pressure. The processing parameters lead to polymer flow in the gaps between the plies, i.e., interlaminar voids, and in the unsaturated fibre bundles, also called dry areas. A fully saturated and low voidage laminate is desired before the resin chemical cross-linking process converts the polymer into an immovable glassy solid. In the aerospace industry, the typical permitted voidage is a maximum of 2%, with 1% being desirable to maximise part performance.
The following sections describe the sample preparation, scanning by X-ray CT, and phase segmentation using eight Deep Learning models.
Sample preparation
The prepreg material selected for this study was HexPly® M56 epoxy matrix, reinforced with unidirectional IM7 carbon fibres. This prepreg is representative of the out-of-autoclave processable composite materials used by the aerospace industry. Specifically, this prepreg has a resin content of 35% by weight and a fibre areal weight of 268 g/m2. An initial 30-ply 100 × 100 mm laminate was prepared by stacking all layers in the same direction. After lay-up, the laminate was consolidated by vacuum pressure for 10 minutes at room temperature, after which three test samples (6 × 100 mm) were cut from the central part of the laminate. No further processing was carried out on the test samples. These samples were used in a previous study. 13
In the following sections, the three samples will be referred to as Training Sample 1, Training Sample 2, and Validation Sample.
X-Ray CT and image pre-processing
X-ray CT (XCT) scanning has become a powerful tool to visualise the 3D microstructure of composite laminates. XCT has been applied to observe crack growth during mechanical loading, 23 defect characterisation,24,25 and even in situ observation of manufacturing processes.26,27 XCT generates a greyscale image where the intensity of each voxel (3D pixel) is related to the density of the material through the Linear Attenuation Coefficient (LAC). 28 In the case of uncured composite samples, three phases are present, having each a characteristic greyscale intensity linked to the density of their constituents: 1) Interlaminar voids, formed by the entrapped air between two consecutive plies, are represented by dark pixels due to the low density of the air, 2) Fibres and resin-saturated areas have high density and therefore are displayed with brighter grey values, 3) Dry areas represent the unsaturated fibre bed and feature a mixture of air and fibres, as the spaces between fibres have yet to be filled with resin. If a voxel represents a dry area, the grey value will be determined by the volume fraction of each phase. For example, a voxel capturing a dry area with a high fibre volume fraction will be brighter than voxels containing dry areas with a high volume of air.
The three samples were individually scanned in a lab-based Nikon XTH-320 CT Scanner. Voltage, power, and resolution were set at 103 kV, 9.5 W and 8.24 µm, respectively. For each scan, 2000 projections were taken with an exposure time of 500 ms and 4 frames per projection, resulting in a scan time of 1h06 min. Following the XCT data acquisition, the scans were reconstructed using the Nikon CT Pro software. The reconstructed scans were pre-processed using Fiji (ImageJ). 29 The pre-processing steps before phase identification included: cropping each sample tomogram, 8-bit conversion, and histogram normalisation. This process was performed for each tomogram independently to increase the range of greyscale contrast included in further image sets. Although similar quantitative image properties are expected, the same settings were used for each of the three samples. No de-noising filter was applied during the image pre-processing routine. The three full-size tomograms are available through the link at the end of the paper.
Deep Learning semantic segmentation and CNN selection
Summary of the selected CNN for the interlaminar voids and dry areas segmentation.

aApplication in the field of composite materials.
All architectures were implemented in Python 3.6 from scratch using Tensorflow 2.5 30 following the instructions indicated at their original publications. Publicly available code was used as inspiration for the implementation of the SegNet, 31 LinkNet 32 and DeepLabv3+ (Xception). 33 Deeplabv3+ (ResNet18) was translated to Python from the Matlab version described in. 34 The implementation of the unpooling layer, typical of the SegNet architecture, was obtained from the TensorFlow-Addons package. 35 FCN-32s, which is the parent architecture of FCN-16s, 36 was initially included in the study, but poor segmentation performance was observed in preliminary trials, therefore it was excluded from the final set of architectures. DeconvNet 37 was also considered in preliminary trials, but was omitted here because it is very similar to SegNet.
Training strategy
The image set previously generated in 13 and consisting of 120 patches with dimensions 128 × 128 pixels was used in this study. The patches were selected from the raw scans of Training Sample 1 and Sample 2. From each scan, an average of 3.77 ± 1.5 patches per slice were manually selected from sixteen slices located the across the full tomogram in a supervised approach, i.e.,, ensuring that a high level of variability in terms of voids and dry areas shapes and sizes were included, in both the slices and patches. This method pursued a three-fold aim: 1) According to, 59 training a CNN model with patches instead of full-size images was found to provide a better performance since the variability is reduced when using a single patch, compared to using a full-sized slice, which facilitates the learning by the weights of the model. 2) A common training strategy consists of selecting a fixed number of slices from the scan used for training, annotating the full-size slices and then sub-dividing them into smaller patches that are fed to the model.4,11,20 This strategy was initially considered as it allows for a high volume of training images, but it was rejected due to lengthy annotation time. It is worth noting that manually annotating a single patch took approximately 10 minutes, and therefore annotating a full-size slice would take ∼8 hours (forty-nine patches are contained in a 900 × 900 pixels slice taken from the Training Sample 1 and 2 scans). The strategy proposed in this study sought to optimise the annotation effort. Fifty patches selected across different slices and including a wider typology of features could be annotated within a standard working day of 8h. 3) The slices, from which patches were later extracted, were randomly chosen based on the typology of voids and dry areas they contained, in order to ensure that a high variability was included. This procedure was preferred over selecting slices at specific intervals as it increased the control over the images defining the training set and reduced the risk of oversampling a certain type of feature typology. 60 A link to access the full set of patches used for training, as well as their location in the scans is provided at the end of the paper.
The associated ground truth masks for the interlaminar voids and dry areas were generated using the Pixel Annotation Tool, 61 and VIA Annotator Software, 62 respectively. The former software is a semi-automatic method based on the use of an annotation brush and the watershed algorithm to reduce the annotation effort.63,64 The latter relies on the use of bounding boxes, such as the polygon region shapes used in this study, to annotate the objects of interest in the image. Each greyscale image has three associated binary images, one for each feature, and an additional image for representing the background, i.e., pixels that were not annotated as voids or dry areas. The annotation process took approximately 20 hours. These binary masks contain two types of pixels: white pixels (positive labels) representing the phase of interest (either interlaminar voids or dry areas) and black pixels (negative labels) representing the background.
Three independent training sets consisting of 25, 50, and 100 images were randomly generated from the initial image set. This selection was used to investigate the effect of increasing and decreasing the typical annotation output of a working day (fifty patches) by a factor of two, and therefore allowing the identification of the optimum annotation effort, i.e., obtaining the highest segmentation performance with the lowest annotation time, for the type of images, features and resolution presented in this study. The three sets will be referred to as TS-25, TS-50 and TS-100. In addition, 20 images were selected to act as a control set, i.e., unknown data to the model parameters, therefore allowing the generalisation and evaluation of the model performance during training. The same control set was used across the three training sets to ensure a fair comparison of the training performance. No data augmentation techniques were applied to the training sets. The binary masks generated in 13 were used in this study after implementing minor improvements in two of the ground truths images to avoid the multiclass case in which a pixel is assigned to more than one category during the annotation process. Details about the changes are provided in the supplementary information (Appendix A).
During training the models learn to segment the features of interest following an iterative process. In each iteration, also called an epoch, the models are fed the training set in batches of N images together with the associated binary masks. Therefore, M/B steps are needed to complete an epoch, where M is the size of the training set and B is the batch size. For each greyscale image, the models receive three binary masks: one for each phase, i.e., interlaminar voids and dry areas, and an additional mask for the background, representing the pixels not belonging to either of the previous classes. At the end of each step within the epoch, the model generates a probability map for each greyscale image contained in the batch via the Softmax function, where each pixel contains the probability of belonging to each class. These probability maps are compared to the ground truth masks and generate an error, which is measured through the Categorical Cross-Entropy Loss function (1) in this study. The loss is backpropagated through the network and the trainable parameters, also called weights, are updated with the aim of reducing the loss in the following step.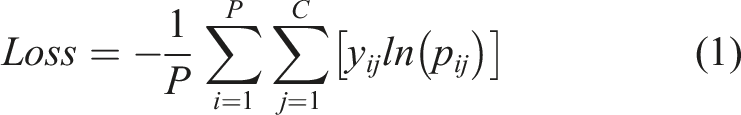
CNN hyperparameters selection
Optimising CNN performance requires selecting a set of user-defined variables, also known as hyperparameters. These non-trainable variables define the architecture properties, such as the number and typology of the layers integrating the network, and the training and inference process. Tuning the values of the hyperparameters to achieve an optimum performance of the models is a costly activity from a computing effort and time standpoint.10,20 In this study, a set of the most relevant hyperparameters was optimised using a grid-search approach, consisting of the evaluation of all possible combinations of the selected hyperparameters values. The following set of hyperparameters was chosen due to their reported contribution to the model performance: • Learning rate (LR): This hyperparameter defines the amount by which the model weights are updated during backpropagation and control the speed of the learning process; it is recognised as one of the hyperparameters having the greatest impact on the model performance.3,65 Considering the recommendations in the literature 3,66,67 and the range of values used in the studies presented in Table 1, three learning rates were evaluated: 10−2, 10−3, and 10−4. • Learning rate reduction factor: As the training progresses, the model may benefit from reducing the learning rate in order to find further optimal states that would have been overlooked by larger learning rates.
19
To account for this observation, the learning rate was automatically reduced by a user-defined factor if the control set loss did not improve during five consecutive epochs. Two reduction factors, previously reported in the literature,8,13 were studied: 0.5 and 0.9. • Optimiser: It defines the algorithm used for updating the network weights during training. Two optimisation algorithms were evaluated: Stochastic Gradient Descent (SGD)
68
and ADAM.
67
SGD was developed as an improvement of a previous gradient-based optimisation algorithm called “Vanilla” by computing the gradient in just a selection of samples, hence the term stochastic, reducing the computing complexity. In 2015, ADAM was proposed as a more efficient implementation of stochastic gradient-based algorithms by incorporating adaptative learning rates of different parameters, and combining the virtues of other optimisers such as AdaGrad
69
and RMSProp.
70
SGD and ADAM are frequently regarded as two of the most popular state-of the-art methods
3
and are widely used in the studies included in Table 1. • Batch normalisation: This technique was introduced by Ioffe et al.
71
and consists of the normalisation of the output of the layer L before being fed to the layer L + 1. It has been claimed to reduce the training effort as well as minimising the risk of overfitting, which appears when the model fails to generalise in unknown data despite achieving a high performance in the training set.21,71 Two options were considered regarding the batch normalisation layers, whether they were included in the architecture (True) or not (False).
Final hyperparameter selection and elapsed training and prediction times.
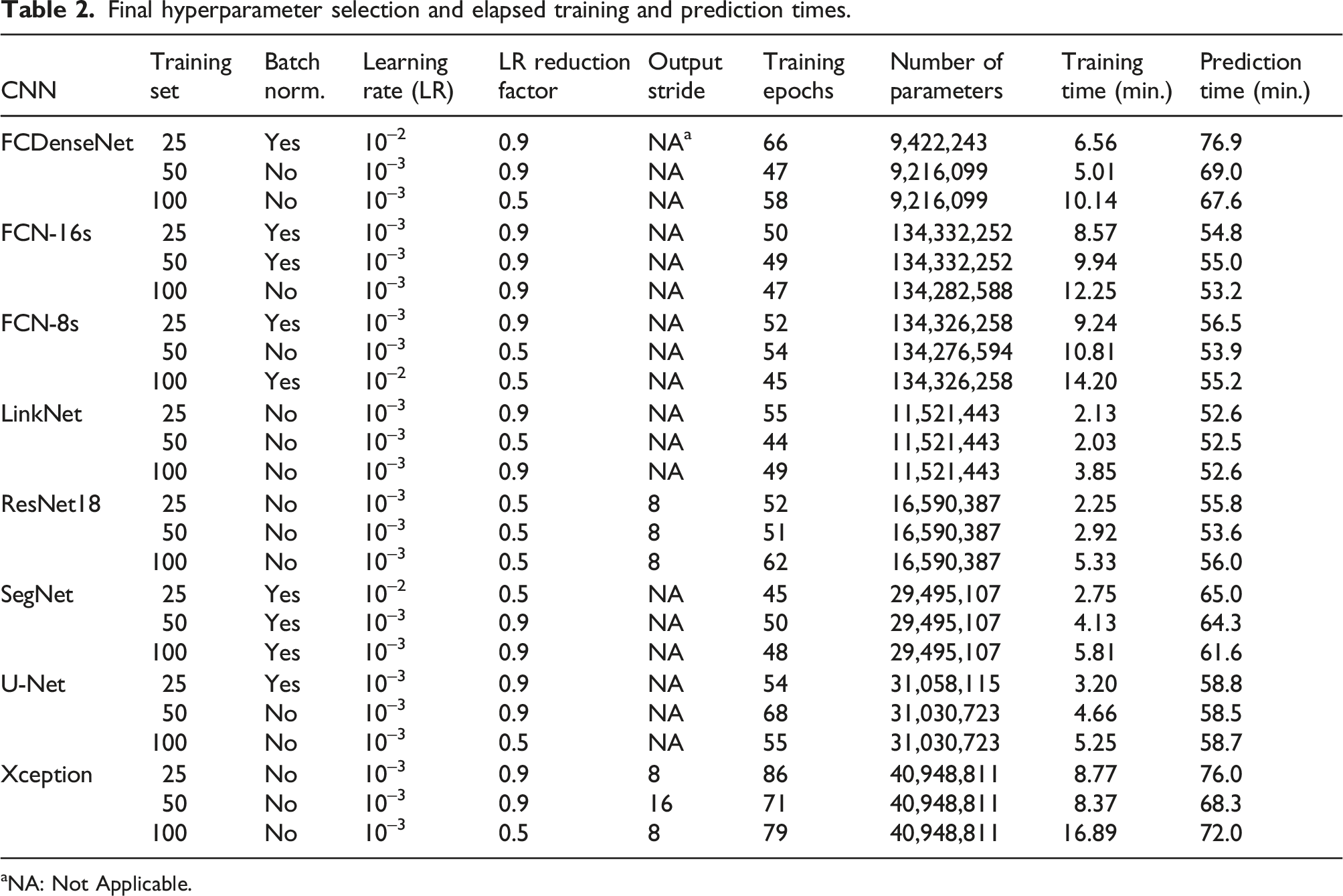
aNA: Not Applicable.
For each architecture 72 models were generated (2 optimisers × 3 LRs × 2 LR reduction factors × 2 batch normalisation × 3 training sets), with 72 additional models for each DeepLabv3 + architecture to account for the output stride, which controls the ratio between the shapes of the input image and the output of the feature extractor. Following the recommendations proposed in the original paper, 54 the output stride was set to either 8 or 16. In total, 720 models were evaluated over 115 hours in a GPU Nvidia RTX 3080. It is worth noting that certain hyperparameter combinations resulted in the non convergence (NC) of 165 models. This effect was frequent in both Deeplabv3+ (Xception: 73 NCs, ResNet18: 84 NCs) architectures, particularly when the batch normalisation layer was included in the architecture.
The U-Net models presented in this study differed from those included in 13 in the following aspects: 1) Correction of mislabelled pixels contained in the training set, 2) Training has been carried out in a GPU, as opposed of the CPU-based training used in the previous study, 3) A hyperparameter optimisation step has been included in the present analysis. Due to the aforementioned changes, the performance results included here may differ from the ones discussed in. 13
Following the training, the models are used to generate the probability maps corresponding to the interlaminar void and dry area phases in the Validation Sample scan containing a thousand 2D-slices of 700 × 700 pixels. Detailed information about the strategy followed to obtain the phase predictions in a scan whose dimensions exceed the dimensions of the images used in the training of the deep learning models can be found in. 13 The 3D probability maps for each phase are subsequently converted to binary 3D images upon the application of a cut-off probability (p t ). If the corresponding greyscale pixel receives a probability equal to or greater than p t belonging to the phase of interest, the pixel is assigned a value of 255 in the binary 3D image, and a value of 0 if the probability is below p t . For each model, the combination of both cut-off probabilities (interlaminar voids and dry areas) was calculated so that the average segmentation performance (MCC), considering each phase and ROI was maximised. Additional information describing the methodology followed for the selection of the cut-off probabilities as well as the detailed list of final cut-off probabilities for each phase and model is included in the supplementary information (Appendix B).
Finally, the plugin BoneJ
73
is used for the characterisation of the phases. Average values are expressed as mean ± standard deviation (µ ± σ). The complete flowchart regarding the model training and scan segmentation is provided in Figure 1. Deep Learning segmentation flowchart. Following the generation of the CT micrographs for the three samples (a), an image set is created after randomly selecting and manually annotating 120 patches from the scans of Training Sample 1 and 2 (b). This image set is subsequently split into two categories: training set, with three different sizes, and control set (c). These two sets are used for the training of eight CNN architectures, involving an hyperparameters optimisation step (d). After training, the models segment the interlaminar voids and dry areas in the Validation Sample allowing the phase characterisation and the assessment of the models performance in the selected ROIs, whose exact location was described in
13
(e).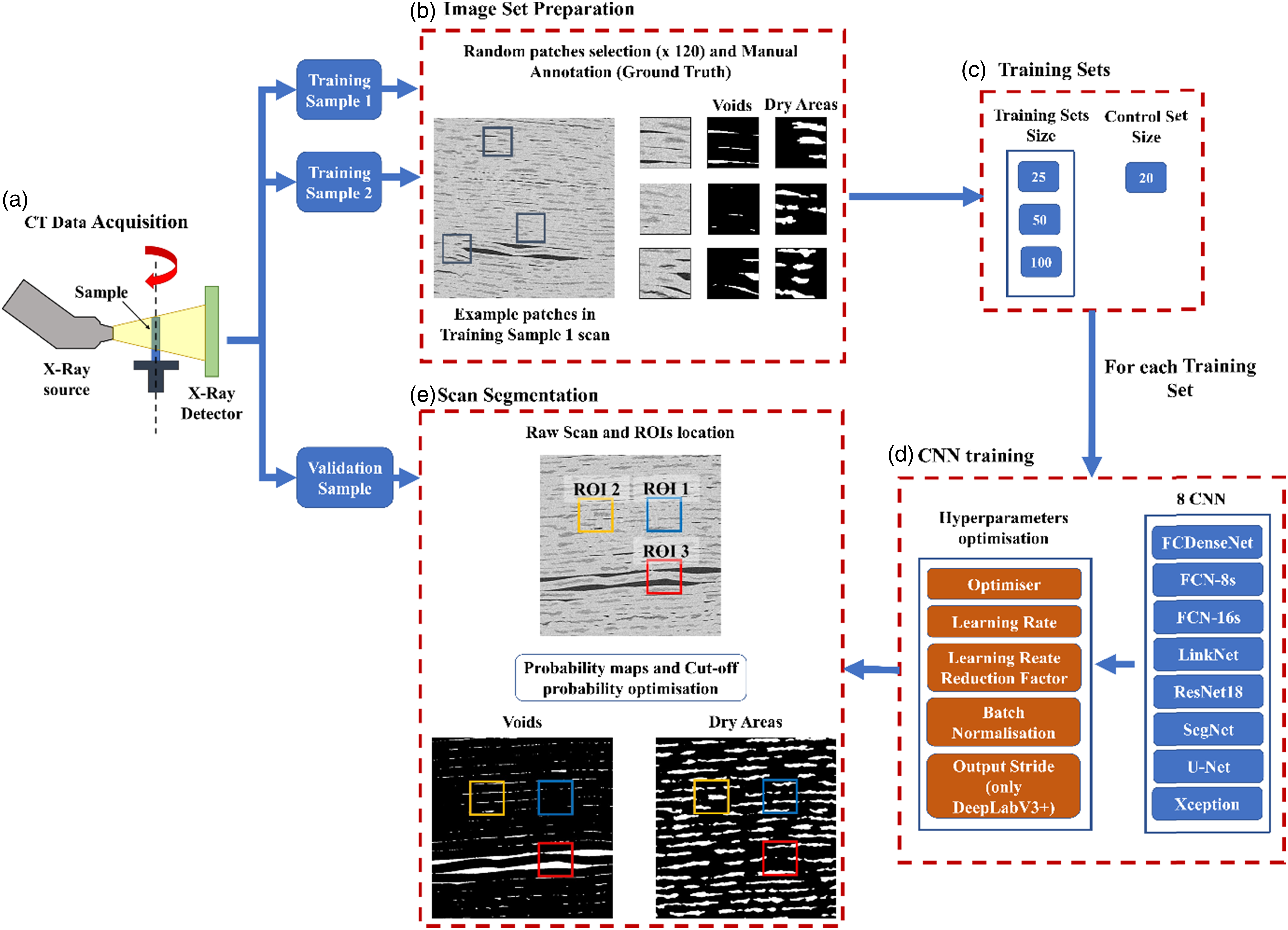
Performance evaluation
Three regions of interest (ROI) having twenty 2D consecutive slices of 128 × 128 pixels and located in its central volume, slices 491–510, were selected at different locations and containing different levels of interlaminar porosity after visual assessment (Figure 1). The ROI locations and dimensions are the same as used in.
13
This selection will provide information about the ability of the different models and training set sizes to segment different levels of porosity. The ground truth masks of the ROIs representing the interlaminar voids and dry areas were manually generated in a previous study
13
in the same fashion as the training and control set ground truths. The same ROIs were then selected in the segmented scan provided by the eight models trained with each of the training set sizes. The interlaminar voids and dry areas ground truth masks are compared to their segmented counterparts, and each pixel is assigned a category depending on the correctness of the prediction: positively labelled and positively predicted (True Positive or TP), positively labelled but negatively predicted (False Negative or FN), negatively labelled and negatively predicted (True Negative or TN) or negatively labelled but positively predicted (False Positive or FP). These four categories within each of the binary masks, allow the definition of the following segmentation performance metrics: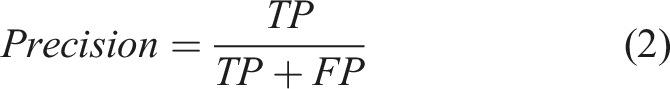

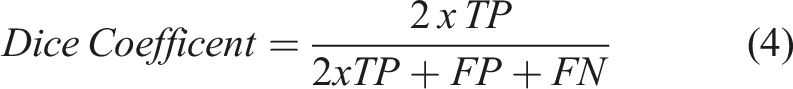
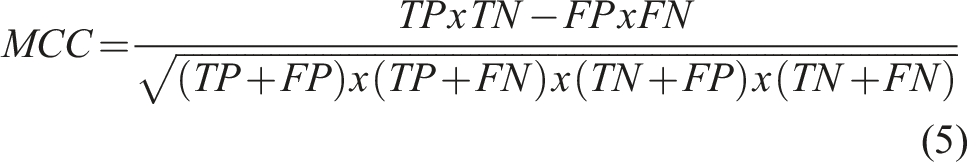
Precision (Equation (2)) informs about the level of noise (false positives) present in the prediction, whereas recall (Equation (3)) provides information about the ability of the model to capture the true labels existing in the ground truth. The Dice Coefficient (Equation (4)), also called F1-Score, 74,75 and the Matthews Correlation Coefficient (MCC) (Equation (5)) 76 integrate the four categories into one formula and provide and overall indicator of the segmentation performance for each phase provided by each of the models.
Precision, Recall, and Dice Coefficient are defined in the interval [0, 1], where a value closer to 1 meaning better performance compared to the ground truth. The MCC is defined in the interval [-1, 1], where a value closer to −1 indicates a poor segmentation performance, 0 means that the segmentation provided by the model is not better than a random segmentation, and 1 is a perfect correlation between the model segmentation and the ground truth mask.
Results
Network training and prediction
The overall aim for model training is to achieve the minimum control set loss in the shortest time, indicating a fast convergence to the optimum state of the weights for each model. The combination of the hyperparameter values minimising the control set loss is presented in Table 2. All models benefited from the use of ADAM as the optimisation algorithm. Additionally, an initial learning rate of 10−3 was the preferred option in 87% of models, whereas none of the models benefitted from a reduction of an order of magnitude in the initial value in the learning rate. The batch normalisation layer was found in nine models. LinkNet, ResNet18, and Xception minimised their respective control set loss without featuring such layers when trained with any of the three training set sizes. An output stride = 8 showed an improvement in performance during training for all DeepLabv3 + models, except for the Xception architecture trained with 50 images.
The total number of parameters notably differed from one architecture to other due to the differences in number and size of convolutional layers. FCDenseNet models accounted for just 9 million parameters, whereas FCN-8s and FCN-16s contained 134 million.
According to Figure 2, increasing the training set size has a positive effect on reducing the control set loss for all architectures. U-Net was found to provide the lowest control set loss regardless of the training set size, reaching a minimum of 0.13 when trained with 100 images. The highest control set loss was found in the three models featuring the FCN-16s architecture (TS-25: 0.3, TS-50: 0.26, TS-100: 0.23). SegNet most benefited from increasing the training set size from 25 to 50, with a decrease of 26% of the control set loss, whereas FCN-16s had a reduction of 12% in the control set loss when increasing from 50 to 100 training images. It is worth noting that the reduction in the control set loss is more acute after doubling the initial 25 training images to 50, than when doubling from 50 to 100 images (−13.25 ± 5.48% vs. −8.97 ± 2.85%). Training time generally increased with training set size. LinkNet models converged the fastest to their respective minimum control loss, due to a light and simple architecture. In contrast, heavier architectures (FCN-8s, FCN-16s) and denser architectures (DeepLabv3+ (Xception) and FCDenseNet) took between 2–6 times longer to reach their optimum state. All models converged to the optimal state before reaching 100 epochs and their control set loss increased after passing this point, thus confirming the suitability of the user-defined 300 epochs limit during training. A similar trend was observed during the prediction step. The DeepLabv3+ (Xception) models took on average 72.1 ± 3.89 minutes to generate the full set of probability maps, a 37% increase with respect to the fastest model (LinkNet: 52.56 ± 0.07 minutes). Training and prediction time for each CNN and training set size.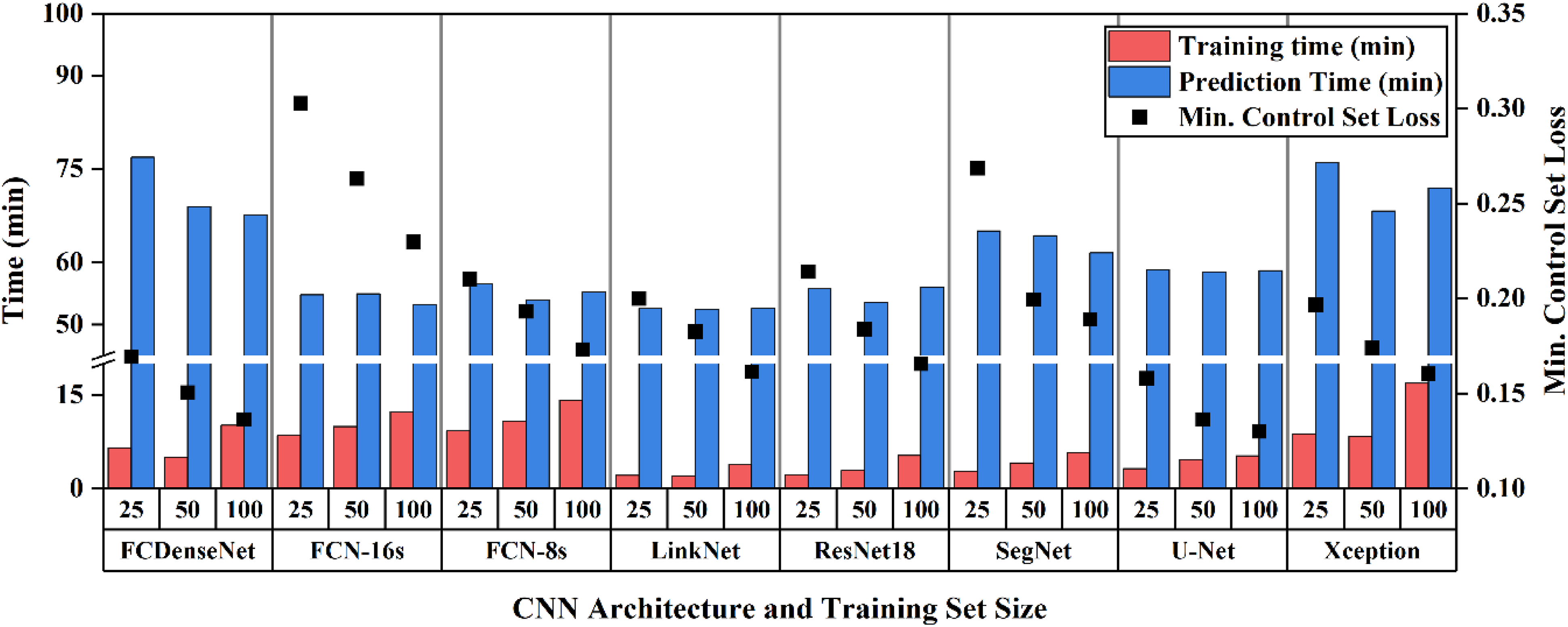
Entire scan segmentation
Figure 3 compares and contrasts the most and least suitable models to segment the interlaminar voids or dry areas. It can be observed that initially some dry areas, which contain dark pixels due to a high content of air, are initially either misclassified or completely missed by the two networks. However, as the training set increases, U-Net achieves a perfect classification and FCN-16s also increases their detectability. From visual assessment, U-Net provides the highest accuracy in the segmentation of both interlaminar voids and dry areas, regardless of the training set size. Segmentation of interlaminar voids (blue) and dry areas (red) of a full-sized slice located at the centre of the entire scan, after training with 25 and 100 images, for the best performing network (U-Net) and the networks providing the lowest MCC score for voids and dry areas (FCN-16s). The black arrow points at a dry area displaying a grey intensity characteristic of the interlaminar voids and its segmentation by the different models.
From a quantitative standpoint, it has been observed that increasing the training set size impacts the distribution of the interlaminar voids and dry areas (Figure 4). On the one hand, the computed average porosity is comparable across the three training set sizes (TS-25:5.75 ± 0.4%, TS-50: 5.51± 0.16%, TS-100: 5.61 ± 0.2%), but the dispersion in the average interlaminar void volume and individual void counts were notably reduced after a four-fold increase of the training set size (TS-25: 8.07 × 105 ± 5.42 × 105 µm3/void and 2.75 × 104 ± 1.84 × 104 counts, TS-100: 8.39 × 105 ± 1.86 × 105 µm3/void and 1.92× 104 ± 4.72 × 103 counts). ResNet18 segments the large voids effectively, but misses the smaller voids when compared to the average void count of the models trained with twenty-five and fifty images. On the other hand, FCN-16s captures a higher portion of smaller voids. The behaviour observed in the segmentation produced by FCN-16s implies that this model captures less noise as the training set size increases, which is usually characterised by small but numerous conglomerates of mislabelled pixels that lower the average volume and increase the counts. The segmentation provided by both architectures converge to the values obtained by the other networks when a larger training set is used. Quantitative assessment regarding the segmentation of the interlaminar voids and dry ares provided by each network for each training set size (25, 50 and 100).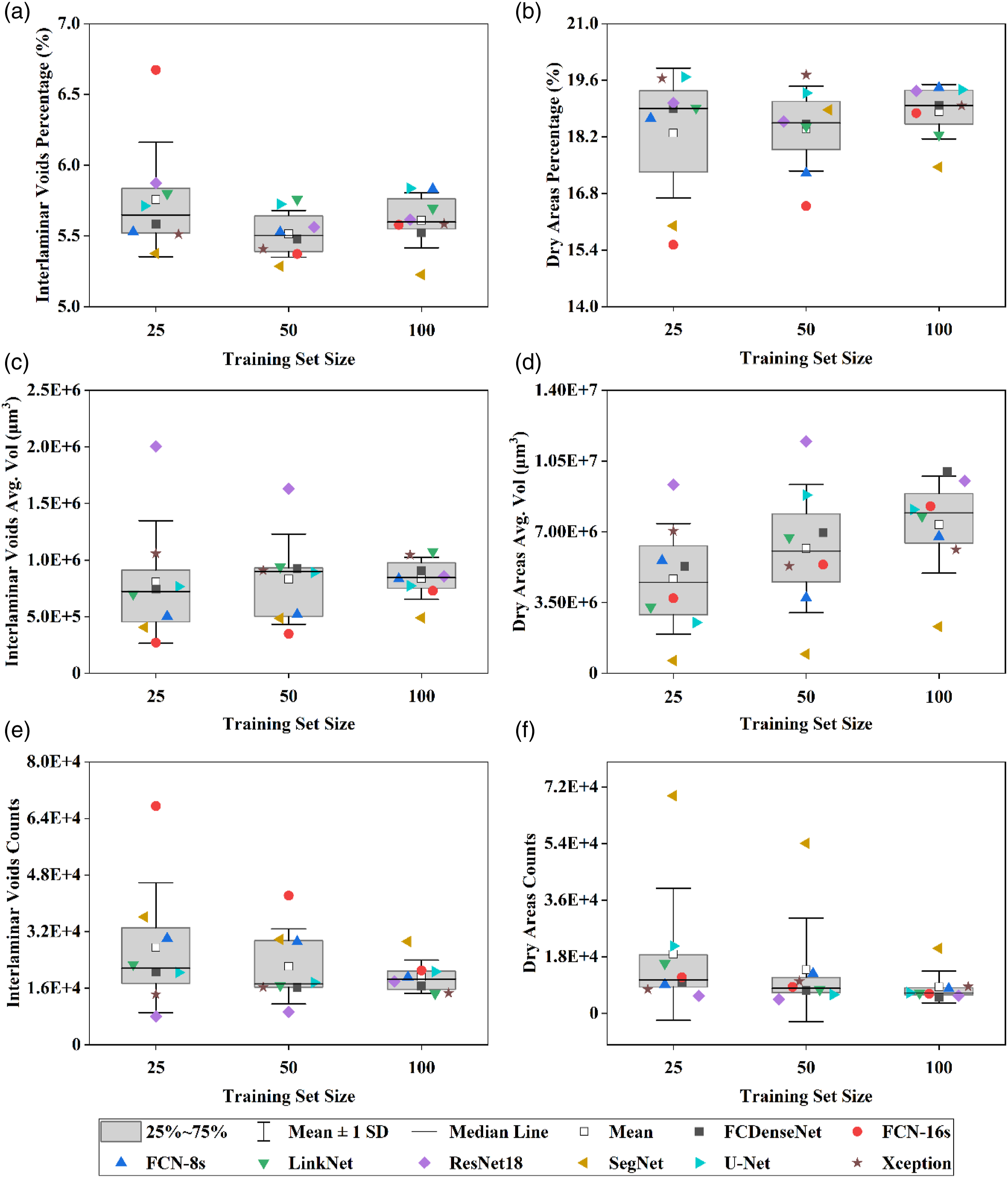
The average dry areas percentage remains approximately constant but also accounts for a reduction of the dispersion (TS-25:18.29 ± 1.61%, TS-50: 18.4 ± 1.05%, TS-100: 18.82 ± 0.67%), along with an increase of the average dry area volume and a decrease of the dry area counts as the training set size increases as the segmentation noise and mislabelling is reduced. The segmentation of dry areas produced by the ResNet18 produces the same effect as previously described in the segmentation of interlaminar voids since this architecture segments the largest dry area but accounting for the lowest counts when trained with twenty-five and fifty images. On the other hand, SegNet provides the lowest dry area average volume across the three training set sizes, due to the high number of dry area counts for a comparable porosity estimation to the rest of the models.
Performance evaluation
Voids
ROI 1
Interlaminar voids segmentation results for ROI 1.
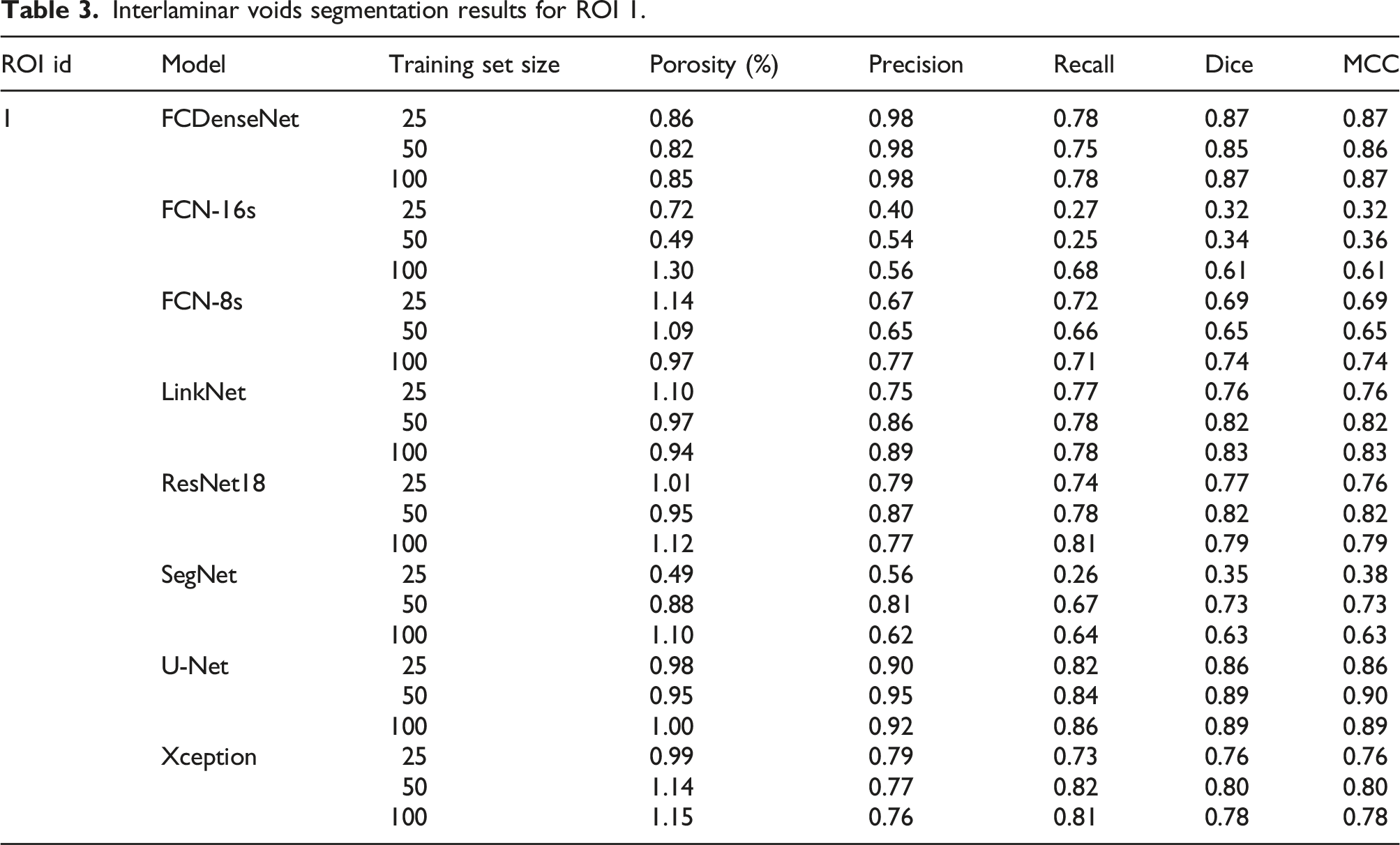
Regarding the porosity estimation, FCN-16s provides the highest porosity estimation (1.3%) after training with 100 images. However, this value does not imply a high segmentation performance. On the contrary, it comes at the expense of a low precision (0.56) and relatively high recall (0.68), meaning that a high portion of false positives and a low number of false negatives are captured. FCN-16s (TS-50) and SegNet (TS-25) account for the lowest porosity estimation (0.49), mainly driven by the fact that both models also provide the lowest recall (0.25 and 0.26). These two models also exhibit the biggest increase in their recall value after doubling the size of the training set (172% and 159% improvement).
ROI 2
Interlaminar voids segmentation results for ROI 2.
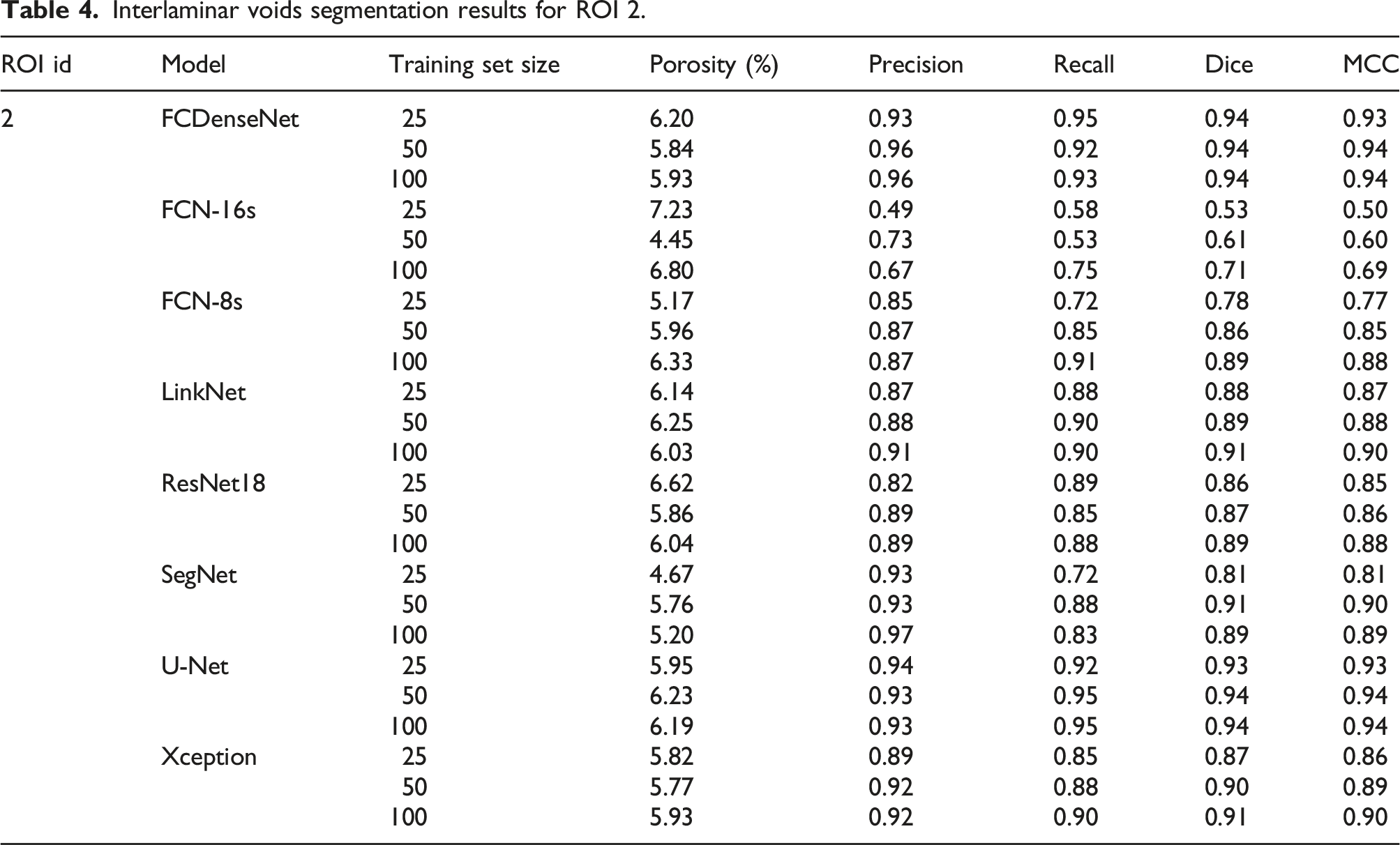
The biggest deviation with respect to the ground truth interlaminar porosity is provided by FCN-16s when trained with 50 images (4.45%) as it accounts for the lowest recall (0.53), which implies a low number of true positives and a relatively high precision (0.73). LinkNet (TS-25) and ResNet18 (TS-100), on the other hand, provide the smallest deviation with respect to the ground truth porosity. This is a consequence of registering a similar level of false positives and false negatives, which cancels out when computing the sub-volume porosity.
ROI 3
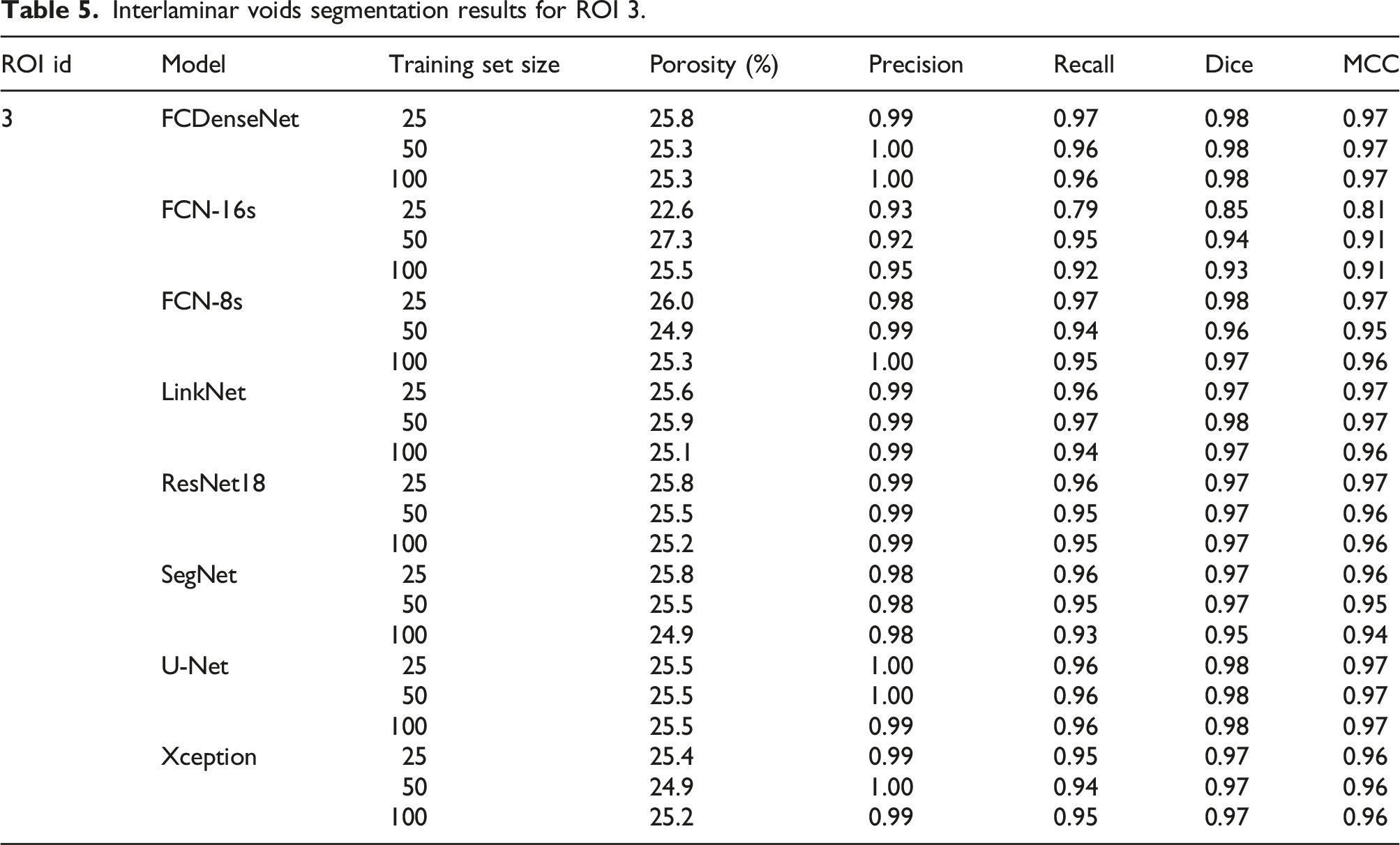
Interlaminar voids segmentation results for ROI 3.
Dry areas
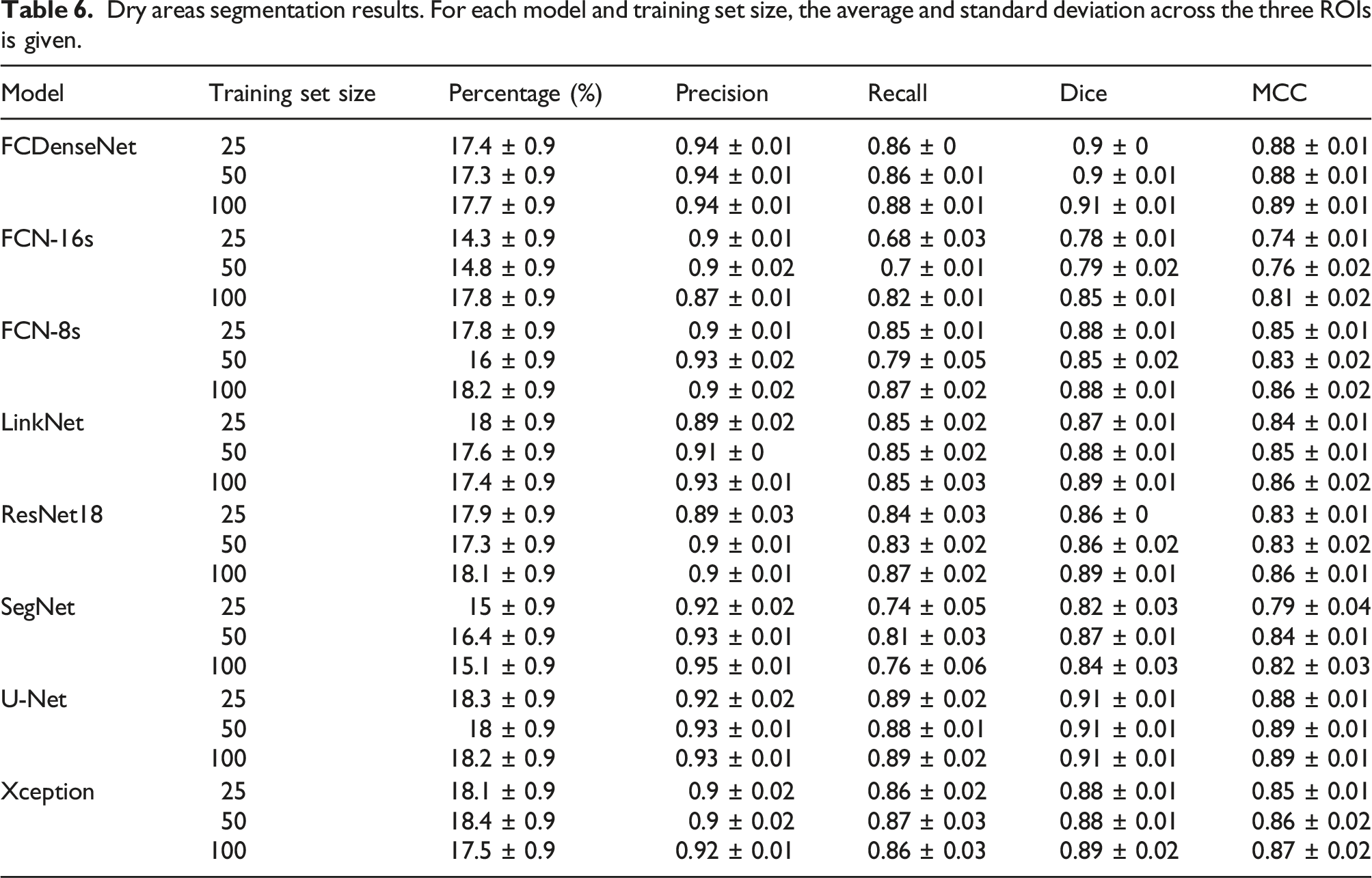
Dry areas segmentation results. For each model and training set size, the average and standard deviation across the three ROIs is given.
Discussion
Deep Learning has shown its ability to segment interlaminar voids and dry areas in X-Ray micrographs of composite laminates. However, the CNN architecture and the training set size selection have an impact on the scan characterisation and segmentation performance.
The optimisation of the set of hyperparameters for each model revealed that all architectures minimised the control set loss when ADAM was chosen over SGD as the optimiser. This was an expected result since ADAM was developed as an improvement of the existing stochastic methods. Most of the models benefited from the combination of ADAM with an initial learning rate of 10−3, which was the learning rate proposed in the original paper. 67 Furthermore, the use of batch normalisation introduced was found to introduce instability in some specific architectures (Xception and ResNet18) and prevented their convergence. Although nine models benefited from the introduction of the extra batch normalisation layer, this effect might be motivated by the small batch size used during training. 77 Overall, increasing the training set size involved an increase in the duration of the model training and prediction. However, the typology and connection between the layers significantly affected the computing effort and performance of the models during training. For example, the FCDenseNet model trained with just 25 images but featuring the batch normalisation layer was found to take longer to train and generate the predictions than the other two models trained with a larger set but not including this normalisation layer, due to the additional calculations that needed to be performed. FCDenseNet also accounts for the lowest number of parameters (9M), but due to the depth of the architecture, which contains 103 convolutional layers and features numerous connections between them, produces a computationally expensive training and prediction process. 43 A similar effect was also observed with DeepLabv3+ (Xception). Despite Xception featuring depthwise separable convolution aiming to reduce the number of trainable parameters, the density of the feature extractor (41M parameters, 132 convolutional layers) increased the training and prediction time by a factor of three, compared to using a simpler and less dense feature extractor based in ResNet18 (16M parameters, 20 convolutions), with a marginal improvement of the control set loss during training and equivalent MCC score for both phases across the three ROIs. Lighter networks such as LinkNet (11M parameters, 34 convolutional layers) and U-Net (31M parameters, 23 convolutional layers), including connections in the form of additions or concatenation operations between the encoder and the decoder to re-use information from earlier layers and therefore facilitating backpropagation and gradient flow, also performed better than models with a lower number of convolutional layers but lacking such information recovery mechanisms, despite including a higher number of parameters, such as FCN-16s (134M parameters, 19 convolutional layers) and FCN-8s (134M parameters, 21 convolutional layers). It is worth noting that increasing the number of parameters also increased the time needed to training the network, since more parameters need to be updated at each epoch.
Both phases benefit from increasing the training set size for all CNN architectures studied here. An increase in the training set size up to 100 images resulted in a convergence of all models towards a similar interlaminar void and dry areas percentage, average void volume and counts. A higher detection rate of interlaminar voids in low porosity regions was also noted as the training set size increased. Regarding the segmentation of dry areas, it was observed that fewer but bigger dry areas are captured due to the reduction of false positives and negatives when the networks were trained with the largest training set size. As the training set size increases, the models learn to better differentiate between dry areas and interlaminar voids, especially in those scenarios with a high degree of ambiguity (grey intensity, position, context…) as they are exposed to a larger number of examples of correct segmentations during training. Furthermore, the high performance exhibited by all models in the segmentation of a wide variety of voids and dry areas typologies indicate the suitability of the proposed strategy regarding the selection of the patches defining the training and control sets, as they account for the variability subsequently encountered by the models when applied to unknown data.
U-Net and FCDenseNet architectures showed the best performance in the segmentation of both phases, and they consistently achieved a high Dice coefficient (> 0.85) and MCC scores (> 0.86) for all interlaminar porosity ranges and training set sizes (Figure 5). These two architectures were able to provide a high accuracy in the segmentation of voids and dry areas when trained with the smallest training set, while further increasing the training set to 50 or 100 images only produced marginal improvements. FCN-16s and SegNet were found to be the most sensitive architectures to an increase of the training set size, and also provide the lowest performance when trained the smallest training sets. These architectures were among the first networks proposed for the image segmentation task, and therefore they lack of the developments, such as concatenation layers (found in U-Net) or dense blocks (found in FCDenseNet). These developments have helped improve the architecture efficiency and allow for a reduction of the training dataset. SegNet includes an adapted pooling layer and more balance distribution of the parameters between the encoder and decoder sections that allows a significant reduction of the computing effort compared to FCN-16s. It is worth noting that FCN-8s arises from a FCN-16s in which an additional skip connection between the encoder and decoder was introduced. This simple modification allows the FCN-8s models to notably outperform their parent architecture, regardless of the phase and the training set size. Evolution of MCC score achieved by Deep Learning and thresholding for training set sizes of (a) TS-25, (b) TS-50 and (c) TS-100.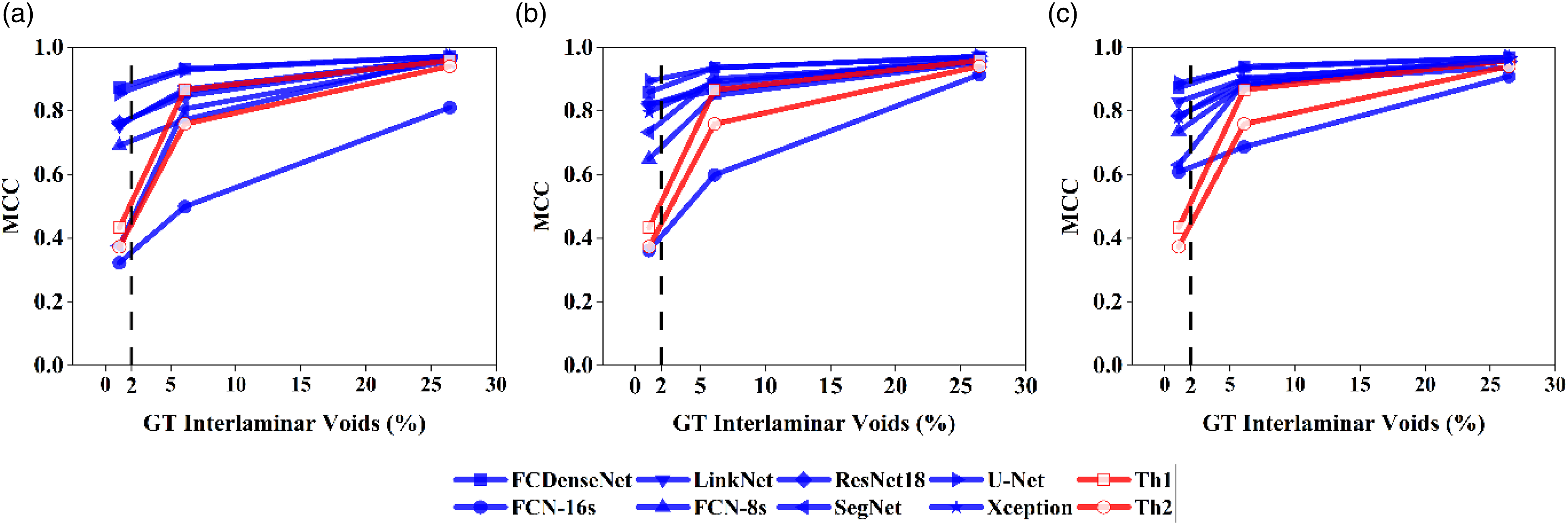
The Deep Learning models were compared to conventional thresholding approaches in Figure 5. Segmentation of the same ROIs was done using the ISO-50% (Th1) and local minimum (Th2) techniques according to the methods outlined in. 13 Thresholding performance converges towards the Deep Learning segmentation score as the porosity increases, driven by a rise in the precision and recall values. FCN-16s is the only architecture consistently underperforming thresholding in the three regions, regardless of the training set size, except in ROI 1 when using the largest training set. SegNet initially provides a similar MCC score as thresholding but increasing the training set allows the architecture to significantly overperform thresholding methods in ROI 1. U-Net and FCDenseNet are the only Deep Learning models outperforming thresholding in all conditions.
After assessing the location of the mislabelled pixels produced in the segmentation of interlaminar voids in ROI 2 (Figure 6), two observations can be made. On the one hand, the results shown in Table 3 can be visually verified as most of the misabelling occured in the form of false negatives, leading to a decrease of the recall value. On the other hand, the majority of the mislabelled pixels appear around the edges of the voids, i.e., at the interface of two phases. These areas, containing ambiguous grey values, are a challenge in terms of the manual annotation of the ground truth as they lack a high-contrast limit between the two phases. This effect was also mentioned in the Deep Learning phase segmentation of glass-fiber reinforced polyamide 66.
21
Visual location of the false positives (red) and false negatives (blue) generated in the segmentation of interlaminar voids in ROI 2 by the eight models and three training set sizes.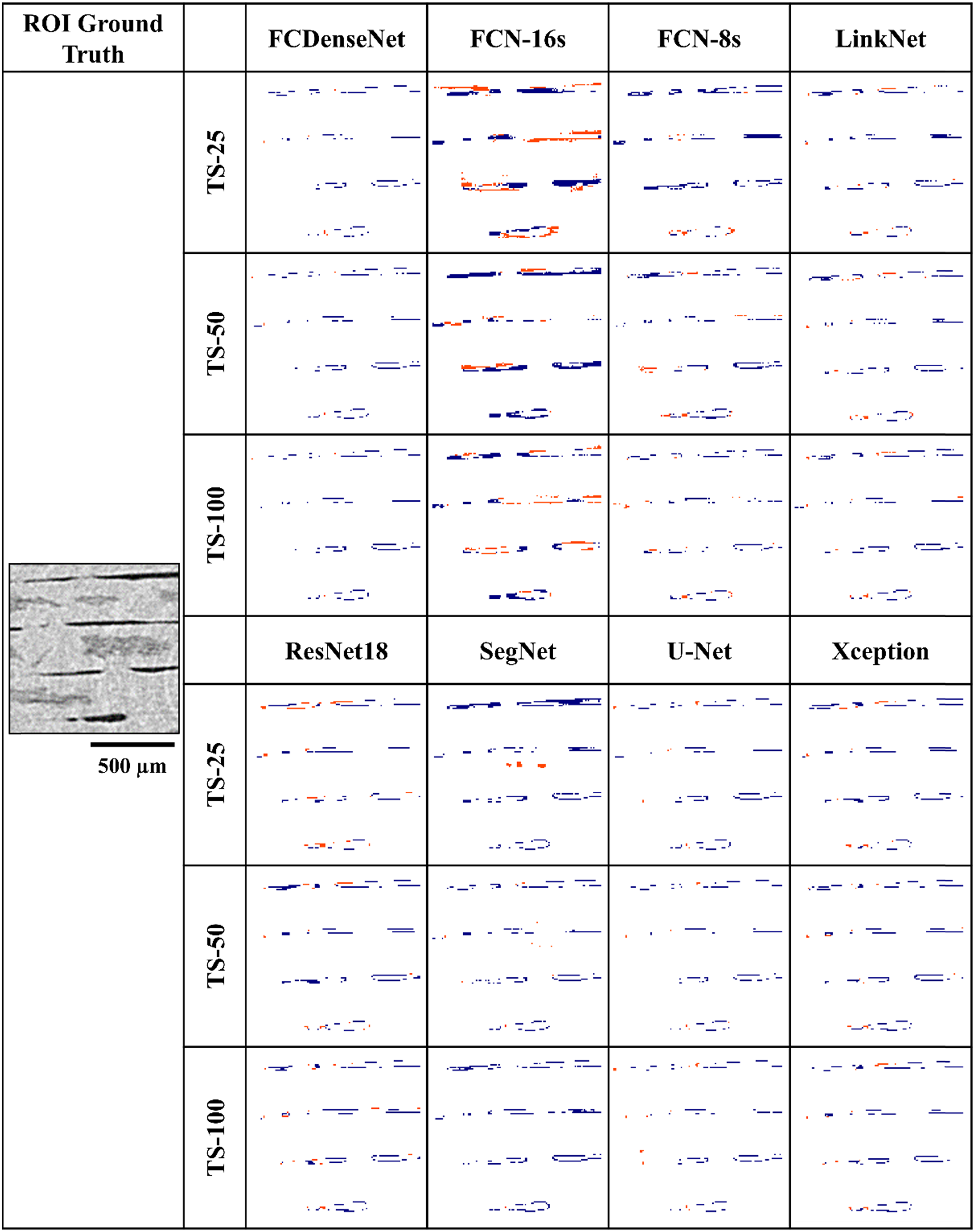
The segmentation performance for the dry areas with increasing training set size is shown in Figure 7. U-Net and FCDenseNet architectures provide the best segmentation, on average, regardless of the training set size. The other six architectures showed a consistent and robust performance in the segmentation of dry areas. All models, except SegNet, showed the strongest results when 100 images were used for training. Overall, the CNNs consistently outperform the thresholding approach, which notably struggles in the correct segmentation of dry areas containing darker pixels.
13
Average MCC score achieved by each architecture with respect to the training set size (25, 50 and 100) and thresholding approach for the segmentation of dry areas and calculated across the three ROIs. The error bars represent the standard deviation of the MCC across the three ROIs.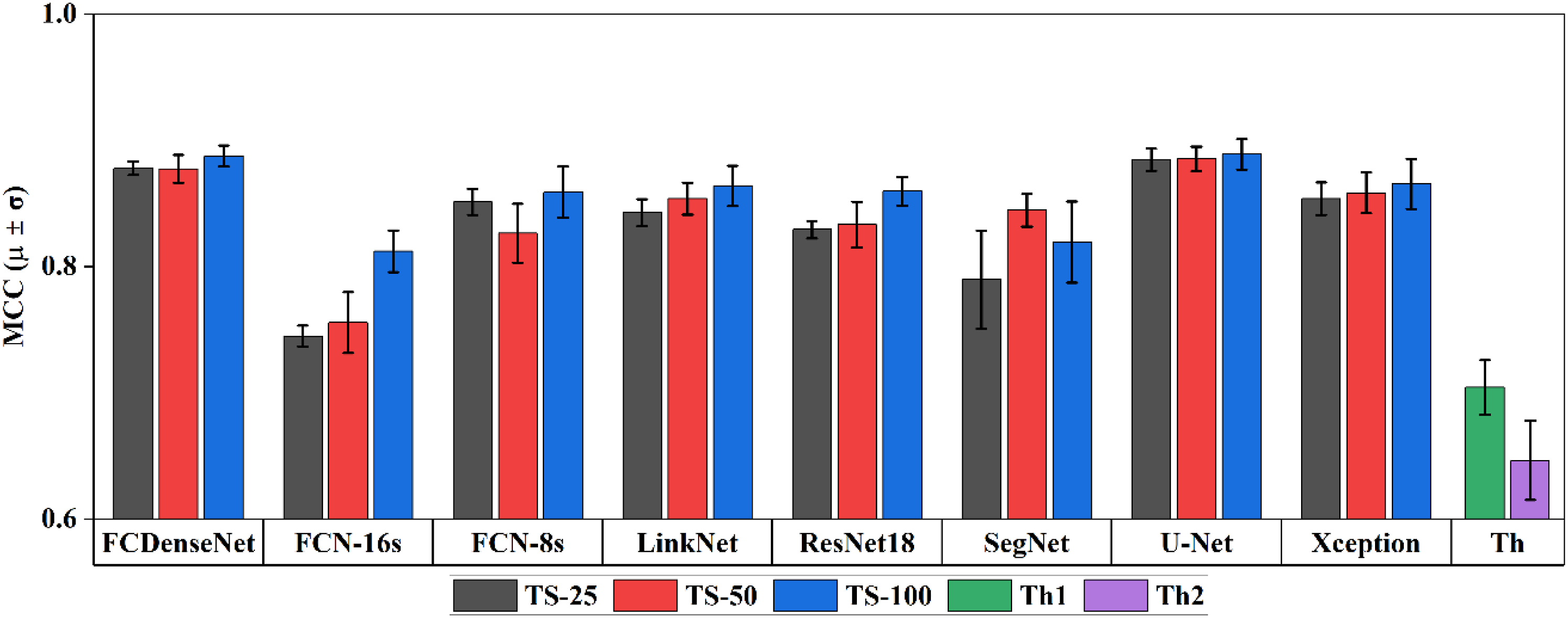
From Figure 8, it was observed that part of the mislabelling is produced by an approximately equal number of false positives and false negatives, which steadily decreases as the training set was increased. It is worth noting that U-Net (TS-25) is the only model to fully segment an unusual thin and diagonal dry area in ROI 2. Most dry areas are orientated horizontally. Further increasing the number of training images caused the U-Net (TS-25) to overlook this feature, in line with the segmentation behaviour showed by the other models. Some models either partially segmented it or produced a full mislabelling in the form of false negatives. A hypothesis derived from this observation is that the ratio of examples of such types of dry areas diminishes as the training set increases, also known as intra-class imbalance,
60
thus hampering the model learning of such specific typology of dry area. Visual location of the false positives (red) and false negatives (blue) generated in the segmentation of dry areas in ROI 2 by the eight models and three training set sizes. The red arow in the greyscale image points to an unusually diagonal and thin dry area.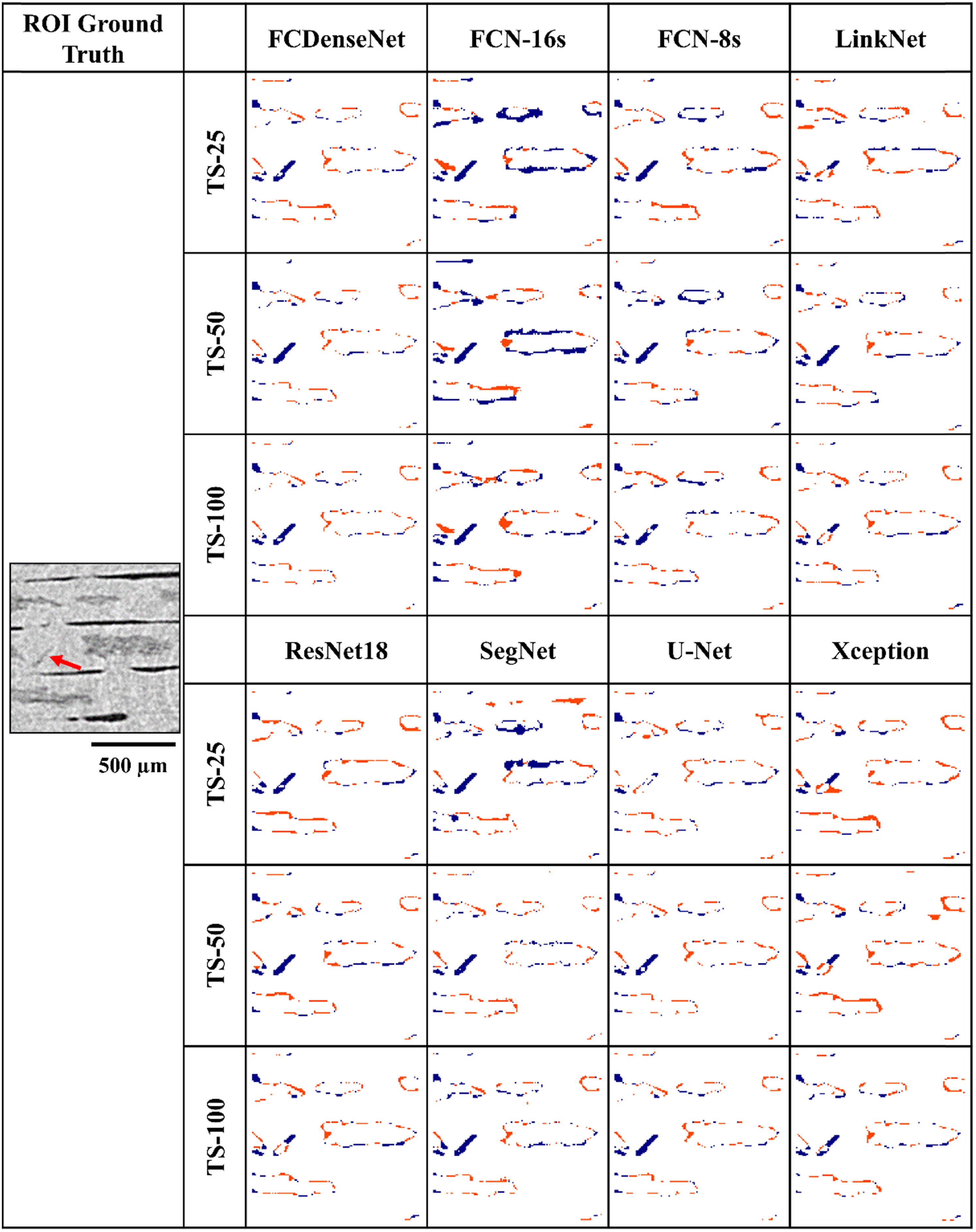
Finally, it was noted that all models were able to identify the noise and artefacts inherent to X-ray imaging and avoid mislabelling voids as dry areas, or vice-versa. This showcases the ability of Deep Learning to handle moderate levels of noise and artefacts and therefore, eliminating the need of applying de-noising filters that involve information loss.
Conclusion
The two main porosity phases (interlaminar voids and dry areas) of an uncured composite laminate were characterised using eight state-of-the-art CNN architectures. Each CNN was trained with three independent training sets containing twenty-five, fifty and one-hundred X-ray micrograph images. The segmentation performance of each model was optimised via a tailored selection of the main set of hyperparameters.
The typology of the CNN architecture and the training set size were found to play a key role in the segmentation accuracy. It was observed that increasing the number of parameters did not necessarily lead to a higher segmentation performance, as was the case for FCN-8s and FCN-16. Additionally, the high performance showed by the U-Net architecture points to the fact that reducing the number of parameters combined with specific strategies aiming to recover feature maps from early stages in the network allows a reduction in the training and prediction time. FCDenseNet provided a comparable segmentation performance as U-Net, with a further reduction of the number of training parameters, but due to the density of the network, the average training and prediction times were significantly increased (+68.5% training time and +21.3% prediction time).
The performance of the models in the segmentation of both porosity phases increased as the ground truth and the training set size increased. In general, the CNN models reached their peak MCC and Dice Coefficient values when a training set size of one hundred images was used. Notably, U-Net and FCDenseNet provided the highest performance in the segmentation of the interlaminar voids, when trained with the smallest image set (25 in this study), achieving only marginal improvements after doubling and quadrupling the number of training images. Similarly, these two architectures also achieve the highest MCC score in the segmentation of dry areas.
Deep learning was found to consistently outperform the established thresholding approach in the segmentation of dry areas because of the wider range of pixel greyscale values. The greyscale value distribution of voids is more pronounced, therefore thresholding fairs somewhat better at segmenting higher porosity (>5%) micrograph images. At low porosity levels (<2%) expected in high-performance composites, most deep learning architectures are superior, with U-Net and FCDenseNet leading the way.
This study has contributed to defining which state-of-the-art CNN architectures achieve the highest performance segmentation of X-ray micrographs, as well as providing guidance on the selection of hyperparameters that produce the best segmentation results. Furthermore, the trade-off between annotation effort, training and prediction time, and segmentation performance was analysed. The U-Net architecture trained with twenty-five images, at the analysed image size and resolution, appears to be a sensible starting point for characterisation of the interlaminar porosity and dry areas of composite materials, while also ensuring a reduction in the training and prediction time. This is needed in quality control processes for high-value composite manufacturing, involving batch-to-batch analysis of incoming prepreg materials or intra-batch variability analysis.
Supplemental Material
Supplemental Material - The effect of convolutional neural network architectures on phase segmentation of composite material X-ray micrographs
Supplemental Material for The effect of convolutional neural network architectures on phase segmentation of composite material X-ray micrographs by Pedro Galvez-Hernandez and James Kratz in Journal of Composite Materials
Footnotes
Acknowledgements
The authors would like to acknowledge the Engineering and Physical Sciences Research Council (EPSRC) for their support of this research through Investigation of Fine-Scale Flows in Composites Processing [EP/S016996/1]. A PhD studentship for P. Galvez-Hernandez was supported through the Rolls-Royce Composites University Technology Centre at the University of Bristol.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study is supported by Engineering and Physical Sciences Research Council (EP/S016996/1).
Data Availability
The raw CT data underlying this article are not available by agreement with our industrial partners to protect their commercial confidentiality.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.