
Abstract
In recent years, structural health monitoring has been increasingly applied to composite sandwich structures, as typically used in aerospace applications. In addition, machine learning approaches are increasingly popular for damage detection, localization and size estimation, due to their great advantages in pattern recognition and anomaly detection. However, a major disadvantage of machine learning techniques is that these algorithms generally require large amounts of realistic data. In general, these data are expensive or even impossible to obtain within a feasible time. In order to overcome this hindrance, this work introduces a computationally inexpensive framework for physics-driven feature generation of strain data for the training of ML-based SHM methods using sub-structuring and the concept of reanalysis. First, the global FE model is subdivided into a monitored part, i.e., a smaller submodel, and a global model. Second, the stiffness matrix of the submodel is extracted from the finite element software. Then, static condensation is performed to further reduce the computational effort. Afterwards, selected eigenvectors are derived in terms of displacements of master nodes and the corresponding strains are calculated. Finally, a statistically varied linear combination between the different characteristic eigenvector load cases is performed based on the superposition principle. This procedure enables the efficient generation of a large number of different physics-driven determined strain solutions for a subsequent training of a ML algorithms. The proposed framework is evaluated by means of a damage detection approach, based on an artificial neuronal network classifier algorithm. The applied approach utilizes strain measurements from selected positions as physical quantity and is demonstrated using a composite sandwich structure imitating an aircraft spoiler. The key principle of the damage detection algorithm is based on the fact that a change in the relationship between sensors indicates the presence of damage. Additionally, to the numerical healthy strains resulting from the framework, synthetically generated damage data are used for training the neuronal network classifier. The synthetic data are obtained by statistical modifications of the healthy strains, to avoid time-consuming and expensive damage simulations. The feature generation framework and health monitoring approach are validated using experiments and numerical simulations of a glass fiber reinforced polymer sandwich structure with a hole considered as damage. The presented numerical and the experimental results clearly show the high potential for the efficient approach for damage detection in a sandwich structure.
Keywords
Introduction
Fiber-reinforced polymers (FRP) are increasingly utilized for aerospace applications due to their beneficial strength-to-weight and stiffness-to-weight ratios compared to metal structures. However, besides their outstanding lightweight potential, FRPs exhibit disadvantages, such as high initial cost due to the expensive manufacturing of molds and the complex failure mechanisms. The latter disadvantage reduces the lightweight potential due to the high safety factors that are required because failure prediction is not reliable so far. Hence, structural health monitoring (SHM) is introduced to ensure the integrity of composite structures during operation and to increase the lightweight potential of FRP materials. According to Rytter,
2
SHM-systems can be divided into four levels, namely: 1. Detection - Existence of damage 2. Location - Position of damage 3. Extent - Severity of damage 4. Prediction - Prognosis of damage
Another way to classify SHM systems is to divide them into static and dynamic methods, depending on whether static or dynamic physical effects are evaluated.
2
The most commonly utilized static methods are strain-based methods. A popular example regarding aerospace industry and strain-based methods is the developed structural health and usage monitoring system of the aircraft Eurofighter Typhoon, which uses strain gauge (SG) fatigue damage analysis, presented by Hunt and Hebden.
3
Another possible application of SHM in the aerospace industry could be the health monitoring of an aircraft spoiler, depicted in Figure 1. One major task of this safety-related lightweight part is to control the lift and drag during take-off and landing. Composite sandwich spoiler of a civil aircraft.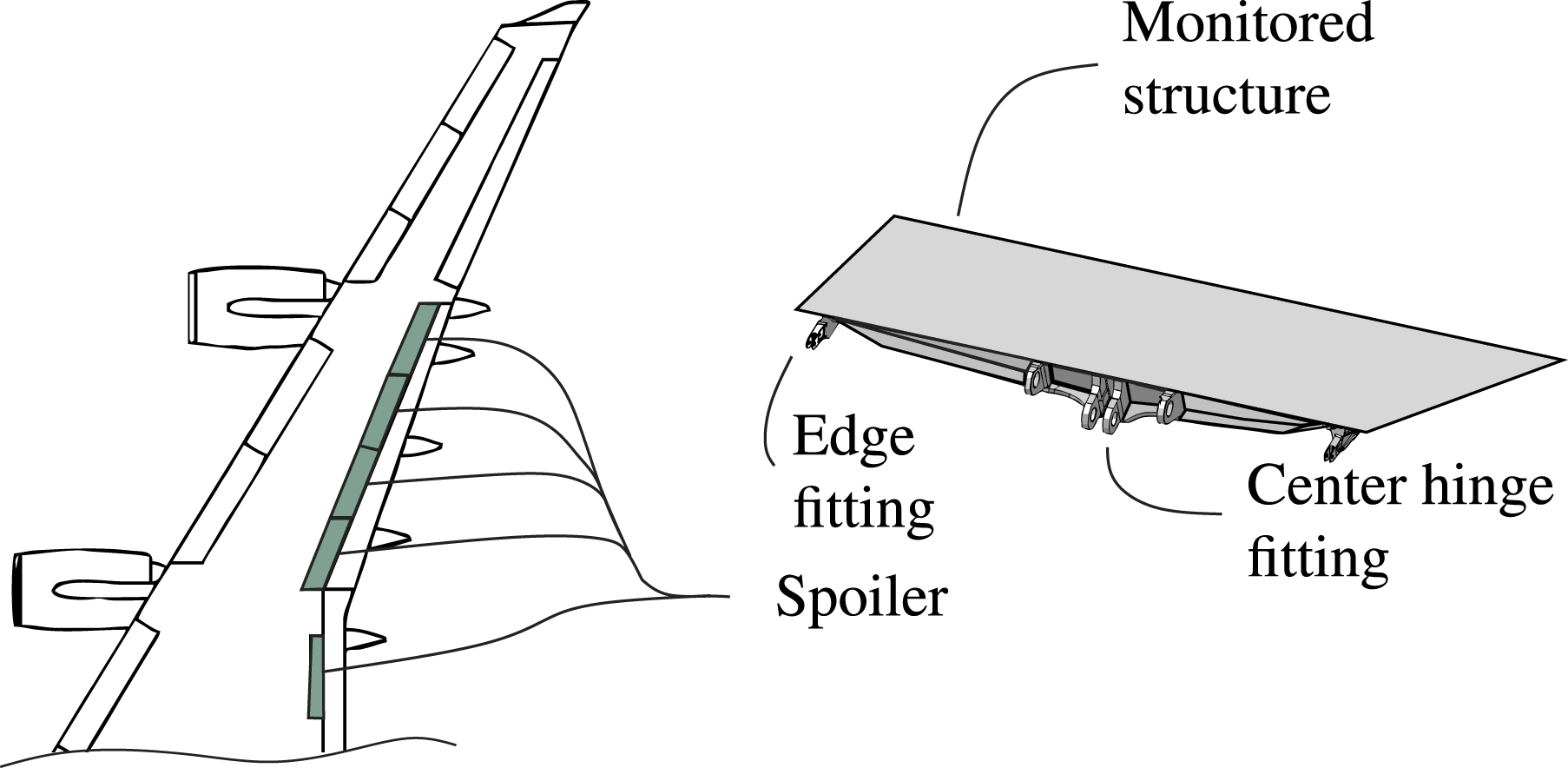
During the last decades, the possible applications of strain measurements in the field of strain-based SHM have increased significantly with the development of fiber optical sensors (FOS). These sensors have great advantages compared to commonly used SG, e.g., higher sensitivity, immunity to electromagnetic interference, the potential to be embedded in the structure and the ability to multiplex sensors, which can be discrete or continuous.4–7 Distributed FOS are one of the most commonly used types of FOS. They have the ability to monitor changes in physical and chemical parameters with spatial continuity along with the fiber. Another commonly used type of FOS is the fiber Bragg grating sensor. In comparison to distributed FOS, a fiber Bragg grating sensor is not able to monitor strains with spatial continuity. It monitors discrete strain values for selected locations and directions, if multiple sensor elements are used. Fernandez-Lopez et al. 8 presented a strain-based SHM strategy that uses the differential strain of closely connected sensors based on the assumption that sensors far from damage exhibit a linear relationship with a reference strain, whereas sensors closest to damage will exhibit nonlinear behavior. Milanoski and Loutas 6 presented a numerical study of the effect of debonds in the strain-field of T-joint single-stiffener panels and propose strain-based health indicators for damage detection. The proposed health indicator is leveraging the anti-symmetrically formed buckling mode of the structure.
Regardless of the physical effect considered for damage detection, recent research in the field of SHM has focused on ML algorithms to serve the purpose of classification, anomaly detection and correlation or pattern search for damage localization and size estimation. The most commonly utilized ML algorithms regarding SHM are tree-based algorithms, e.g., the random forest (RF) 9 or the isolation forest (IF) algorithm,10,11 support vector machines (SVM)12,13 and artificial neural networks (ANNs). The IF is commonly utilized for level 1 SHM systems, to evaluate whether the monitored structure is damaged or not. Chen et al., 14 used an IF framework for anomaly detection in different operating states of a wind turbine, and for identifying the critical behavioral attributes leading to these anomalies. However, Malekloo et al. 15 concluded, that an unsupervised approach alone cannot effectively be used on its own when dependence on external factors must be considered for the ML-based health monitoring approach. The ANNs are typically used for predicting damages in terms of damage size and location estimation (level 1–3, according to Rytter 2 ). Chakraborty, 16 used an ANN for the prediction of embedded delaminations (size, shape and location) in FRP laminates. As input parameters of the ANN, only the natural frequencies are used. The database for training the ANN was generated by simulations of finite element (FE) models. Similar to ANNs, RFs can be also used as regressor or as classifier.
Kesavan et al.17,18 proposes a ML-based health monitoring approach that uses discrete strain measurements as a health indicator. The work deals with a novel data-oriented methodology to detect debonding by means of an ANN. The methodology relies on the examination of the strain distribution of the structure and uses an ANN to predict the location and size of the disbond regardless of the magnitude and angle of the load acting on the structure. Teimouri et al. 19 demonstrated in their work that an ANN trained by dynamic signal-to-noise weighted data has higher damage prediction accuracy than an ANN trained without signal-to-noise weighted data. Unfortunately, the applicability of this method was only shown using data from FE simulations. A different very simple data-oriented method was presented by Grassia et al. 20 The proposed approach evaluates the correlations between strain sensors from different locations with ANNs in the healthy state. Deviations from the trained relationship are indicating a damage.
However, there are major challenges in using ML-based health monitoring methods as mature technology. Today, whether supervised nor unsupervised learning are used. Generally, in supervised learning, the ML algorithm is trained using data that is ‘labeled’. This means the input training data is already labeled with the correct prediction or output. In contrast, in unsupervised learning, the data is not labeled, thus, the correct prediction is not known during training. Bao and Li 21 concluded that the main challenge in supervised learning is the problem of unbalanced data and heavy dependence on sufficient data. SHM methods intended to cover the first three SHM levels commonly have to include damage data for the training of supervised ML-based methods. These data are typically very expensive or even impossible to obtain within feasible time by experiments. In particular, if different variations of damage types, sizes and quantities as well as different load cases are considered. Nevertheless, even for level 1 SHM methods, which typically use anomaly detection algorithms, a large amount of data is required to obtain a robust model. In order to minimize experimental effort, data acquisition can be often done by a large number of numerical simulations. However, data acquisition through FE simulations with varying loading or structural conditions is time-consuming and expensive due to the enormous computational effort. Hence, there exist multiple methods for reducing the computational effort in simulations of similar structures, e.g., sub-structuring, reduced-order models and the reanalysis technique.
The sub-structuring method,1,23,24 is based on the idea that the numerical model of the entire structure can be divided into smaller sub-structures. This method enables a reduction in computational effort for both static and dynamic problems. In static studies, sub-structuring is often referred to as submodeling. A typical application is the partitioning of a computationally intensive simulation, for example of a large composite structure. First, the global model represented by a shell or a coarse mesh 3D model is simulated. Subsequently, nodal displacements or forces are applied to the edges of detailed model of a subregion, which is called the local submodel. Zou et al. 24 developed an Abaqus/standard® plugin for efficient damage initiation hotspot identification for large composite structures based on the submodel technique. Akterskaia et al. 1 utilized a two-way procedure, in which the information exchange in both ways, i. e, local-global and global-local. In the study a skin-stringer debonding in composite panels was investigated. Dynamic sub-structuring allows the dynamic behavior of sub-structures to be analyzed separately and the entire dynamics to be calculated later using coupling methods. 23 The study presented by Tian et al., 25 used dynamic sub-structuring for model updating of large nonlinear structures by dividing the global structure into linear and nonlinear sub-structures.
The objective of the reduced-order modeling is intended to offer a numerical representation, which enables fast computable and accurate approximations of complex numerical models.26,27 The most commonly utilized reduced-order models are based on the proper orthogonal decomposition. This method constructs a reduced-order basis onto which the governing equations of the complex numerical model can be projected to obtain a low order approximation. 26
However, the procedures of data generation in terms of numerical simulations usually require reanalysis of the structural FE-model and repeated compilation of structural system matrices during operation. A more efficient alternative is provided by reanalysis techniques. The virtual distortion method is one of the fast structural reanalysis methods and is used in both static and dynamic methods.28,29 The principle of the method is to introduce a virtual distortion to simulate structural damage or parameter changes in the mass, damping, and/or stiffness matrices.
The main motivation of the present research is to simplify the commonly time-consuming and computationally expensive generation of large amount of data required for machine learning methods. For this purpose, a novel efficient framework for physics-driven feature generation of strain data for the training of ML-based SHM methods is developed, combining selected numerical and stochastic techniques, i.e., sub-structuring of the global structure, the concept of reanalysis, eigenvector decomposition and statistical variation. Since the focus of the paper lies on the proposed feature generation framework, the validation of it is done by means of a representative level 1 SHM approach. The damage detection approach is done by a supervised ANN classifier. On the one hand, the training is performed using data considering a healthy structural configuration obtained by the proposed feature generation framework. On the other hand, the damage data required for training is obtained synthetically by statistical modifications of the healthy strain data. However, the applicability of this method to detect damages in plate-like structures is discussed by an in-depth numerical and experimental study. A composite sandwich structure that imitates an aircraft spoiler is used as a case study. A hole in the face layer with different sizes is considered as damage.
The article is divided into three sections, starting with a description of the proposed feature generation framework and the SHM approach. The second section describes the investigated idealized spoiler model of the case study and its loading. Particularly, the description of the experimental set-up and the numerical model is presented. In the last section, the application of the presented framework for feature generation in combination with the SHM approach is presented and discussed by means of numerical and experimental results for the idealized spoiler model.
Methods
Feature generation framework
The aim of the proposed framework for advanced feature generation is to enable fast and easy creation of a large physics-driven dataset for the training of ML-algorithms, schematically depicted in Figure 2. Initially, a realistic load condition is assumed, referred to as the objective load case. Then, this condition is varied within the framework over a realistic range to generate a large amount of physically based data for a ML approach. The consideration of an objective load case enables the limitation of the theoretically possible load cases that can occur. In this study discrete strain values are used as features and fed as input of the ML-based classifier. Hence, a large amount of realistic training data is required. To accomplish this task computationally efficiently, sub-structuring and static condensation are employed. In addition, an eigenvector decomposition is proposed with subsequent selection of the best fitting eigenvector to reduce the number of FE simulations. The underlying assumption is that by superimposing these different best fitting eigenvector load cases, the objective load case can be approximated. This is feasible due to the assumption that the linear superposition is valid. Since the computations take into account a linear geometry due to the assumed small deformations. The last step involves the mathematically efficient statistical variation of the linear combination of eigenvector load cases. Schematic process diagram of the proposed framework for physics-driven feature generation.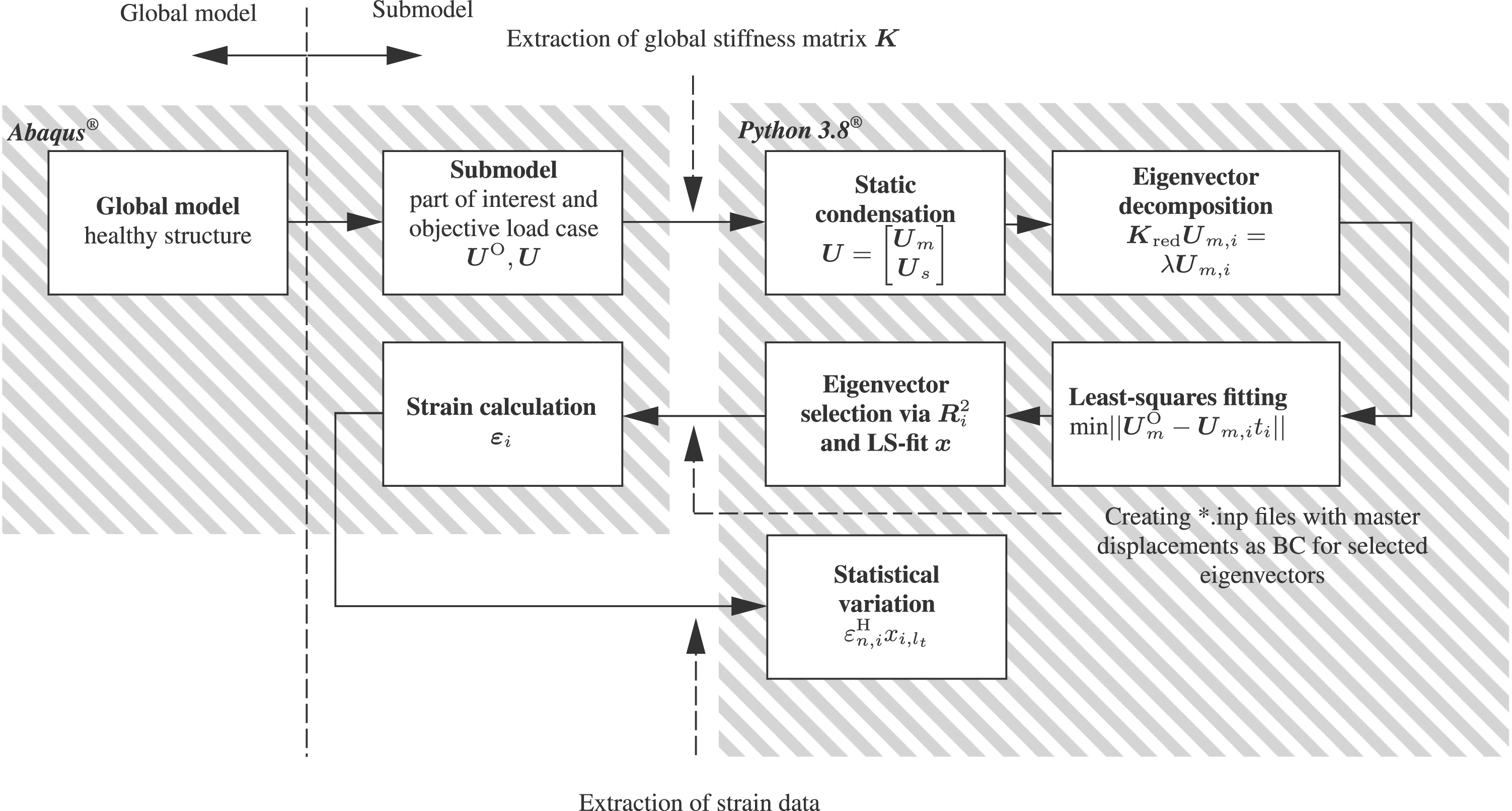
Sub-structuring
First, a part of the structure that is susceptible to damage needs to be identified. This can be done by structural risk analysis. Next, the SHM sensor grid can be defined for this part. In a subsequent step, sub-structuring of the numerical model is performed, where the global FE model is divided into a submodel (critical part) and the remaining part of the structure. In general, the computation of a global and complex sandwich structure is a time-consuming and computationally intensive task. Thus, only the submodel is considered for the generation of the training data in the further steps. This step allows avoiding a repeated simulation of the global model considering load variations. However, large lightweight structures, like in our case the investigated aircraft structure, are often loaded by aerodynamic forces. Assuming that the submodel is small compared to the whole structure and no large local forces occur, the local aerodynamic forces in the submodel are neglected in its simulation.
There are two ways for sub-structuring or often called sub-modelling a static FE model. In the first method, nodal forces resulting from the global simulation are applied to the boundary of the submodel. The second approach, applied the nodal displacements instead of the nodal forces.
24
In this work, the displacement-based sub-structuring is chosen. However, according to standard FE theory, the basic equation is given by

Static condensation
At this step only the derivation for the local submodel is shown, since the separation between the local and the global model is handled by commercial solvers, in our case Abaqus/Standard®. The resulting displacement

It is assumed that no external forces are applied at the structure. Hence, a static condensation of Equation 1 can be performed to reduce the dimensionality of the system of equations. Taking into account the splitting of the DOFs, the Equation 1, can be rewritten to

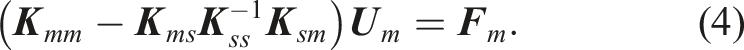
Afterwards the stiffness term can be substituted to a reduced stiffness matrix, referred as
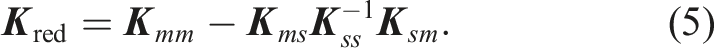

The displacement vector
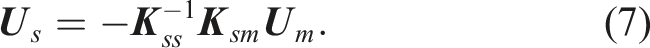
The stiffness matrix of the slave DOFs
Eigenvector decomposition
A major part of the proposed feature generation framework is an eigenvector decomposition. Due to the assumption that the displacements or loads can only be applied through the boundary of the submodel, only the master DOFs j
m
are considered for this step. Hence, the eigenvector decomposition of the reduced stiffness matrix
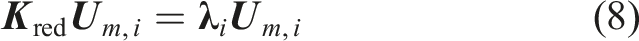
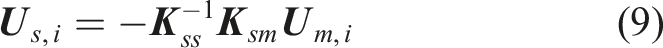
Least-squares fitting
To generate a physics-driven strain data set for a ML-based health monitoring approach in a realistic range, a realistic training load case of the global model must be considered for feature extraction. Hence, a reference load case, for example, the most critical one, has to be defined and simulated for the global model. The deformation of the selected reference load case model is defined as the objective displacement vector
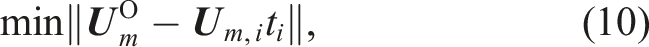
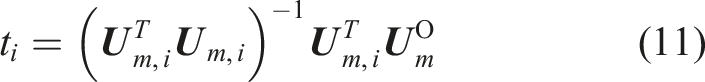
Eigenvector selection
Then, for each of these approximations, the coefficient of determination
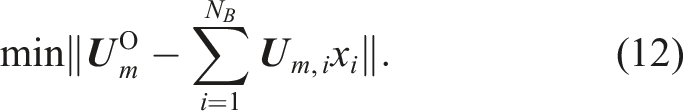
The solution for the parameter vector

Strain calculation
The next step is to compute the strains corresponding to the selected best fitting eigenvector displacements
Statistical variation
The last step involves the generation of a huge feature training database by combining strains. Realistic variations are introduced by linear combination and variation, which is computationally very inexpensive. The strain

However, for the generation of training data, the parameter vector

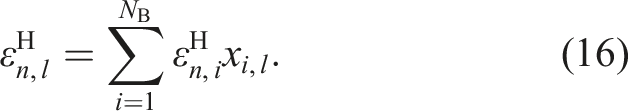
Structural health monitoring approach
In this work, the SHM of a plate-like structure is performed by an ANN approach using discrete strain values as features. The training data of the healthy structural configuration is obtained from the proposed feature generation framework. Damage strain data are generated synthetically from the physics-driven strain data of the healthy structure by means of statistical modifications. The level 1 health monitoring approach is thus divided into three steps: (i) sensor grid definition, (ii) training data generation and (iii) classifier.
Sensor grid definition
The damage detection approach requires a grid of strain sensors, e.g., fiber Bragg gratings with multiple sensor elements or SGs, to monitor the strain distribution of the structure’s surface. Hence, the first step of the proposed SHM approach is to define a sensor array. The number of applied strain sensors and their mesh size can be chosen flexibly. However, this should be done considering a structural risk analysis, e.g., damage tolerance or failure risk, of the monitored structure.
For illustration purposes a 3 × 3 sensor grid is considered, giving a total of N
n
= 9 sensors, as schematically shown in Figure 3. In the case study presented later, the same sensor grid is used. Thereby, only the strains in one direction are considered, since it is assumed that it is in principle possible to detect damages by evaluating only one direction. In addition, measurements with fiber Bragg grating grids usually monitor only one strain direction, since a complicated installed rosette is commonly omitted. Schematically sketch of the monitored part, i.e., submodel, and the applied sensor grid.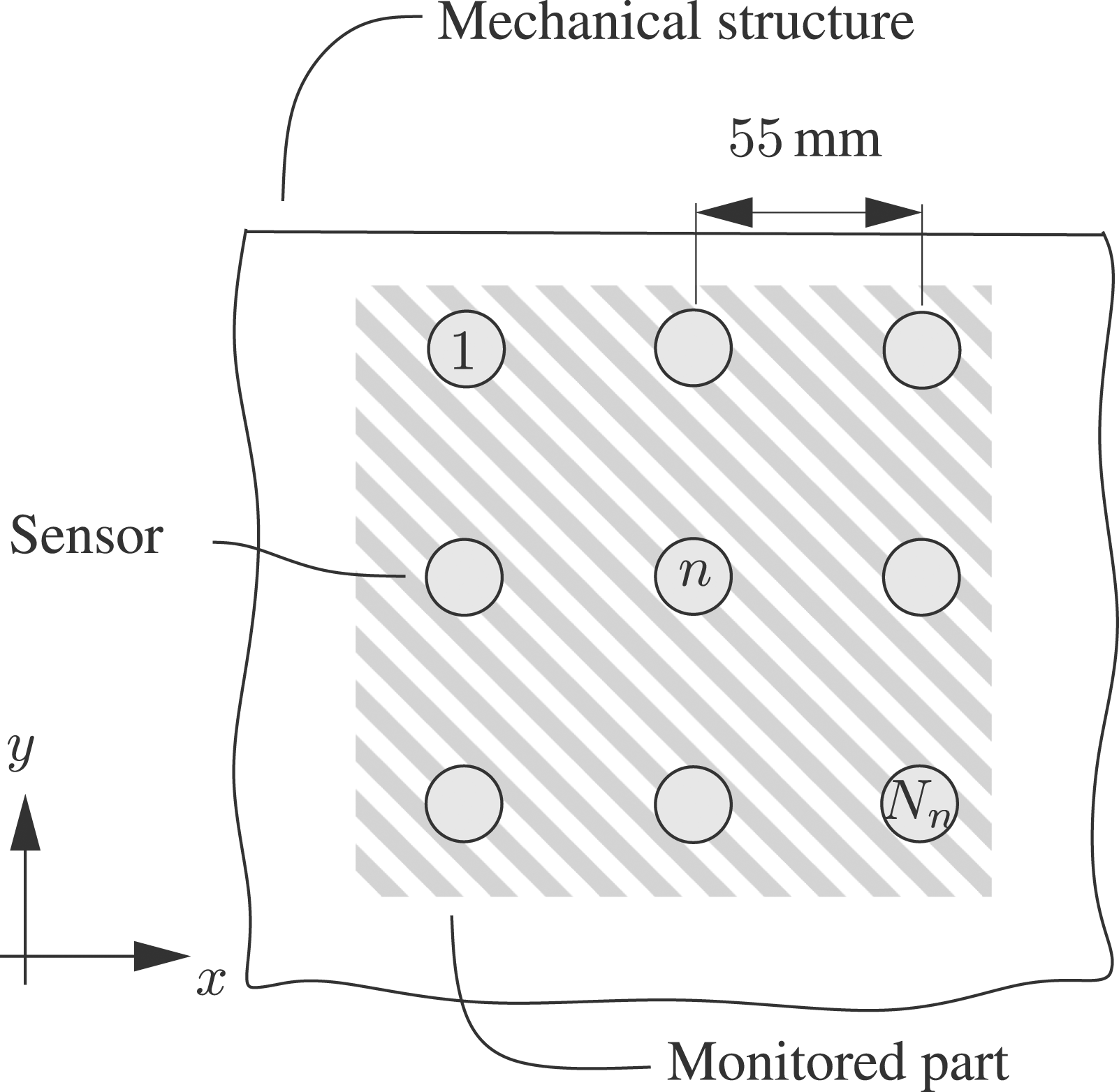
Training data generation
For the training of the supervised ML-based classifier labeled strain data of a sufficient number of different load cases are required. The strain data of the sensor array taking into account a healthy structure is defined as
Nonetheless, due to the use of a supervised learning algorithm, strain data of a damaged structure is required. The damage data required for training is obtained synthetically by statistical modifications of the healthy strain data. In general, the generation of synthetic data is not widely used, except in the field of image processing. Particularly, in the field of SHM, there is a lack of research on these techniques. Nevertheless, there exists common techniques for imitating damage data in experiments and numerical simulations, especially in the field of vibration-based SHM. For instance, Papatheou et al., 30 presents a study where an multilayer perceptron is utilized for damage detection and identification in a full-scale aircraft wing. The author used pseudo faults for the generation of damage data by adding masses to identify features suitable for the training of supervised learning algorithms. Furthermore, two separate cases of a dual-class classification problem, representing two distinct locations, and a three-class problem representing three distinct locations are used in order to test the approach of adding masses. However, the principle for generating synthetic damage data in the present paper lies on the assumption that damage leads to a local strain concentration, which can be observed by distributed strain gauges. Since, both the varying load and the unknown damage itself affect the magnitude of the local strain concentration, this approach simply assumes that significant changes of the measured strain, as a positive or negative deviation, from the healthy strain data represents damage.
For a healthy structure with typical varying loading conditions, the loads and associated strains are assumed to be approximately normal distributed. Figure 4 shows the normal distribution Schematic statistical distribution of the strain data of a healthy structural state 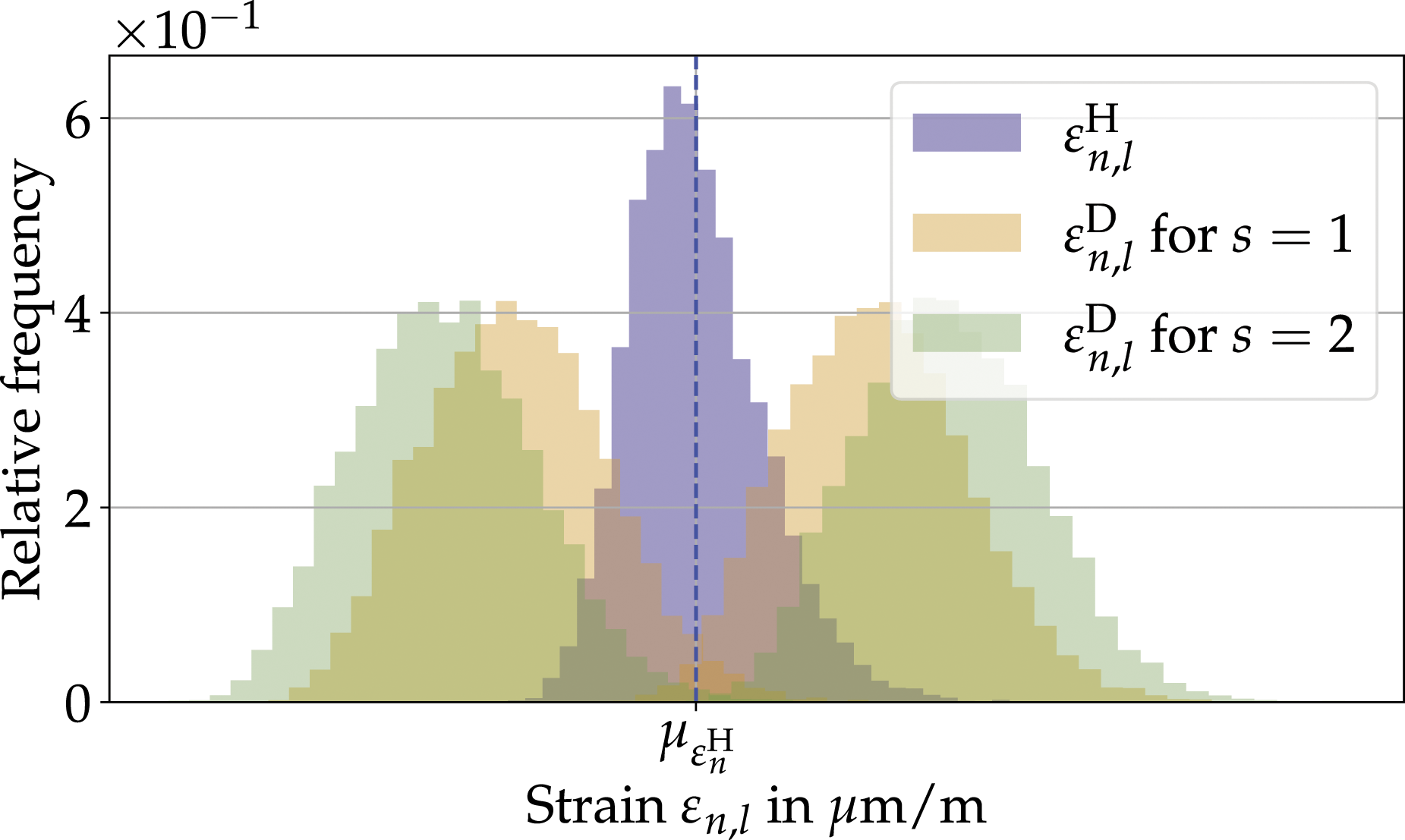
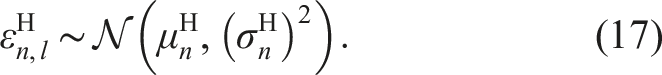
However, for the synthetic generation of damage strain data, a strain deviation following a uniform distribution
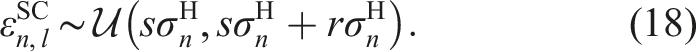
Note that the thereby defined strain concentrations are positive. The synthetic strain data of a damaged structural configuration

Figure 4 shows the distribution of the synthetically generated damage data
Classifier
For a level 1 SHM approach, unsupervised ML algorithms could be used for anomaly detection, i.e., damage detection. In such an unsupervised algorithm, healthy data alone would basically be sufficient, such as those produced by the developed framework. However, in this case, artificial neural networks were used because these methods are more easily extensible for further functions, e.g., damage location and size estimation. In addition, anomaly detection is a difficult task for unsupervised algorithms, especially in the case of overlapping nominal clusters. 31 Hence, a supervised ANN-based classifier is utilized for the evaluation of the structural state for varying loads.
An ANN represents a network of neurons inspired by the biological neural networks and is applied for different tasks, e.g., regression, classification, clustering and system identification.32,33 Networks with multiple hidden layers are commonly referred to as multilayer perceptrons (MLPs) and are widely employed in the field of SHM and load monitoring. An indirect classification by means of MLPs could be done as presented by. 34 The classification is split into two stages, whereas in the first one, an MLP is trained with acceleration input data of a healthy structure. Based on the acceleration at previous instants, the trained MLP is able to predict future accelerations. In the second stage, the structure is classified as healthy or damaged based on the prediction error. Fekrmandi et al., 35 presents a study, where the presence and the location of an applied load are classified by means of an MLP classifier. The approach was evaluated for two composite plates and uses the principle of the surface response-to-excitation method. Dworakowski et al. 36 utilizes an MLP classifier for evaluation of different damage indices obtained by ultrasonic signals considering the pitch-catch configuration.
However, in the present approach, the MLP classifier learns the relationship between the strains measured on the surface of the healthy and damaged structure. The basic assumption is that damage affects the strain distribution between these sensors, thus, a deviation to the healthy relationship indicates damage. This is similar to the approach presented by Grassia et al. 20 For evaluating the performance of the binary classifier (0=healthy, 1=damaged) receiver operating characteristic (ROC) curves are utilized. A ROC curve represents a powerful method for analyzing the false-positive and false-negative errors of a classifier. It is a two-dimensional graph (cf., applied in the case study Figure 15) in which the true-positive rate is plotted with respect to the false-positive rate. 37
In order to increase the robustness of the classifier and to reduce false alarms, majority voting of the MLP classifier prediction is considered. Therefore, the majority of MLP classifications, i.e., votes, considering randomly selected load cases, determines whether the structure is classified as healthy or damaged. The effect of the number of voters on the accuracy of the classifier and its sensitivity is investigated in the results section.
Application
The present approach is validated for damage detection in a composite sandwich structure as typically used for aerospace applications. Therefore, an idealized model of a sandwich aircraft spoiler was built and investigated. Since the method is evaluated by an experimentally validated numerical model, the following section is divided into the experimental set-up and the numerical modeling.
Experimental set-up
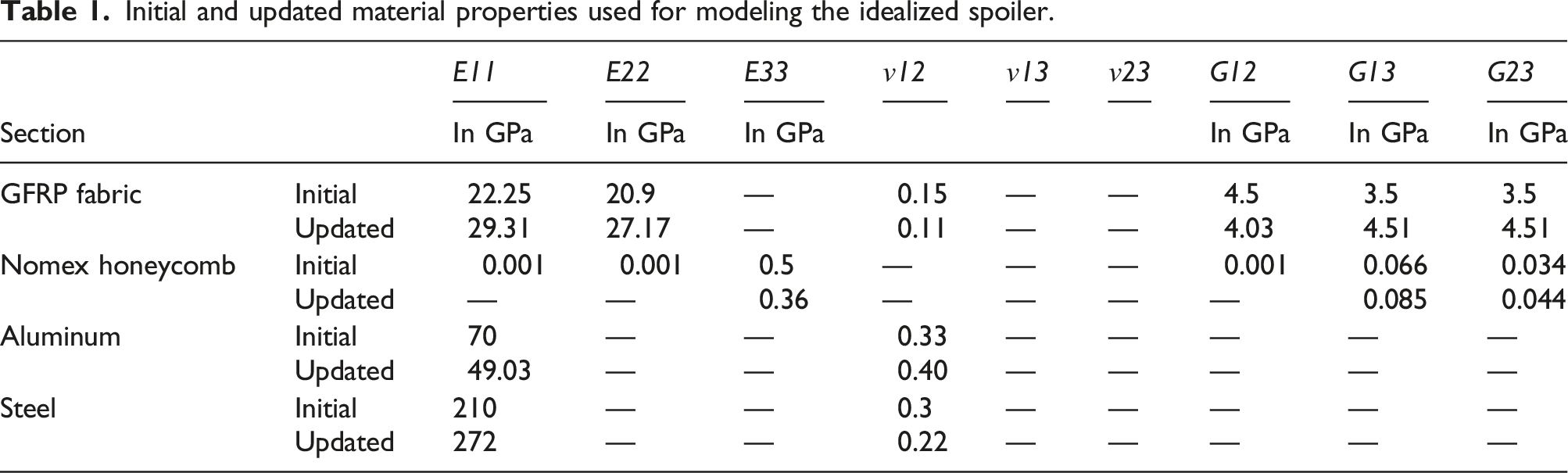
The investigated structure imitates an aircraft spoiler of a large civil aircraft (cf. Figure 1) on the scale of 1:2. The idealized spoiler is depicted in Figure 5 and has the dimensions 1000 × 380 × 16 mm3. It is composed of glass fiber reinforced plastic (GFRP) face layers, a Nomex® honeycomb core and adhesively bonded aluminum brackets (center hinge fitting and edge fitting; for mounting to the test rig). The GFRP face layer laminate is built up of four prepreg fabric plies [0, 45, −45, 0], with a total thickness of 0.5 mm. The Nomex® honeycomb core has a total thickness of 15 mm. The material stiffness properties from material data sheets are listed in Table 1. Nevertheless, the material properties according to the material data sheet are not used for the FE model, they only present the initial values for the FE model updating. This step is used to derive the real material data. The experimental set-up of the idealized spoiler test rig with the corresponding attachment via the center hinge fitting (fixed) and the edge fittings (rotational degree of freedom around x-axis). Initial and updated material properties used for modeling the idealized spoiler.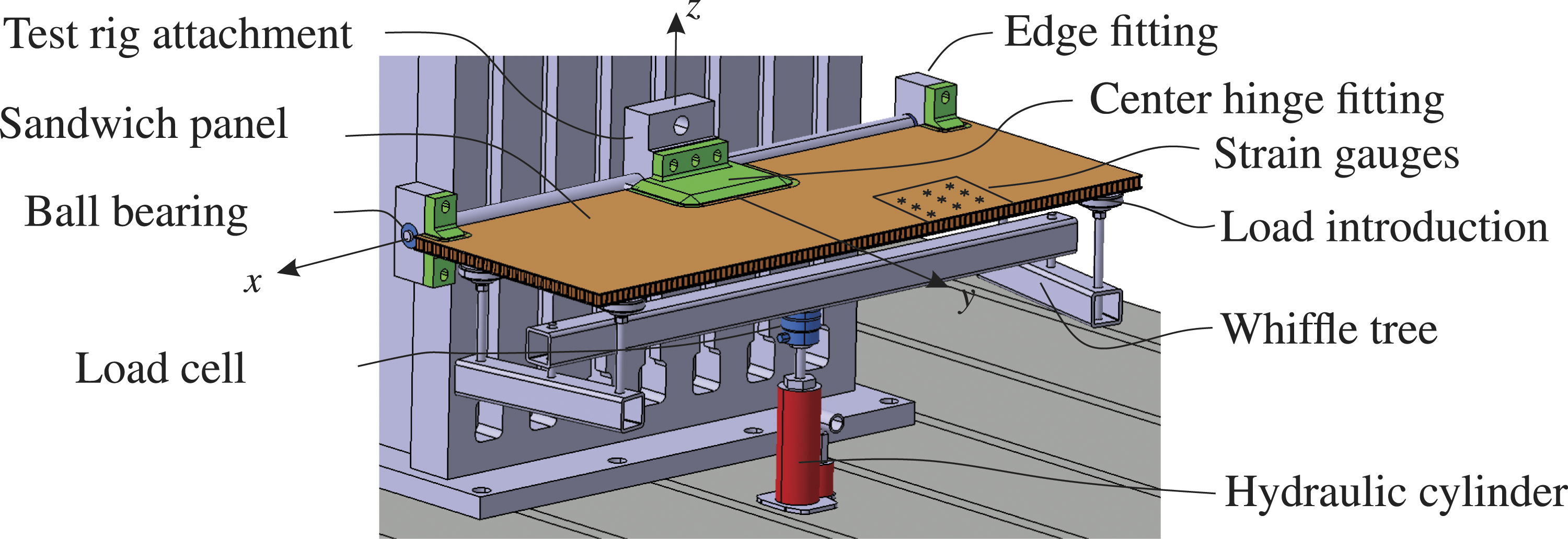
The experimental set-up, shown schematically in Figure 5 and pictured in Figure 6, consists of the load introduction mechanism, the structure under investigation, the utilized sensors, and the corresponding test rig attachments. The load introduction is done by a hydraulic cylinder and a mechanism for the defined distribution of a force through linkages, commonly referred to as whiffle tree. However, an important and frequently repeated load case of an aircraft spoiler is the application as air brake during landing (spoiler is extended typically in an 35° angle from the wing), in which the aircraft spoilers are mainly loaded by air pressure (aerodynamic loads). The representative application of distributed loads, e.g., air pressure loads, is a challenging task in mechanical testing. Thus, the utilized test rig was developed to approximate this important load case with respect to deformation and strain at the pressurized spoiler surface by only four local loads distributed via the whiffle tree.38,39 Image of the experimental set-up of the idealized spoiler model.
As schematically depicted in Figure 5, N n = 9 strain gauges (HBM RY93-6/120) with a mesh size of 55 mm were attached to the surface of the composite structure to monitor the strain distribution over the monitored face layer area (equivalent to the FE submodel). The measurement signal acquisition is done by two HBM Quantum X MX840 A.
In the experimental part of the investigation, a hole in the top face layer at the trailing edge is considered. To find the minimal detectable damage size, both the numerical simulations and the experimental strain measurements are performed for two selected damage states, i.e., a single hole with a diameter dDS1 = 12.5 mm and dDS2 = 19 mm, respectively.
Numerical modeling
The experimental set-up is modeled and solved with the commercial FE software Abaqus/Standard®. The face layers of the sandwich structure of the global and the submodel are modeled as one layer using quadrilateral shell elements with reduced integration points (S4R) and three integration points in the thickness direction. The sandwich core and the brackets are modeled with linear brick elements, with reduced integration (C3D8R). Nevertheless, the numerical analysis of this study is divided into three consecutive steps. First, the global model is simulated. Second, a model updating is performed. Third, the submodel is simulated in a healthy state and in selected damage states.
Global model
As shown in previous studies by Winklberger et al.,38,39 the deformation and strains of aircraft spoiler due to aerodynamic forces can be well approximated by an idealized model and a little number of optimized locally introduced forces. It was shown that two symmetrically applied local forces F1, F2 (i.e., four forces) are adequate to imitate the landing load case of a real spoiler (the idealized model/spoiler is assumed to be symmetrical). Location coordinates x, y and amplitude f are found by using a linear FE shell model and parametric optimization performed in Matlab R2019a®41. However, the deformation resulting of the imitated landing load case by the two symmetric applied forces, represents the objective deformation of the model
Model updating
An essential component of numerical simulations in structural engineering is the FE model updating step.
40
This step involves updating the material stiffness properties initialized with the values from the material data sheet (cf., Table 1). The optimization objective is defined as the match between numerical and experimental results. Hence, the optimization uses the experimental strain values from the strain sensors and the virtual strain measurements from the numerical simulations considering a representative load case. The exact setting of the total load and the ratios of the load amplitudes, which is determined by the change of the ratio between the lever arms of the whiffle tree is quite difficult. Thus, a general scaling factor for the total load level and the force ratio f1/f2 was implemented as a further parameter in the optimization. The material parameters and the two parameters resulting from uncertainties in the experiments are updated using a Nelder-Mead optimization procedure included in the scipy python package.41,42 To avoid unrealistic material properties, limits of ±30% are defined for all parameters. It should be noted that the updated material parameters also contain uncertainties, for example due to the not exactly modeled boundary conditions. However, the obtained material properties of the model updating are listed in Table 1. Figure 7(a) shows the evolution of the fitness, i.e. the mean-squared error (MSE) of the strain values experimental versus numerical. The resulting strains are depicted in Figure 7(b). Results of the model updating procedure. (a) Fitness with respect to the iterations. (b) Comparison of the experimental 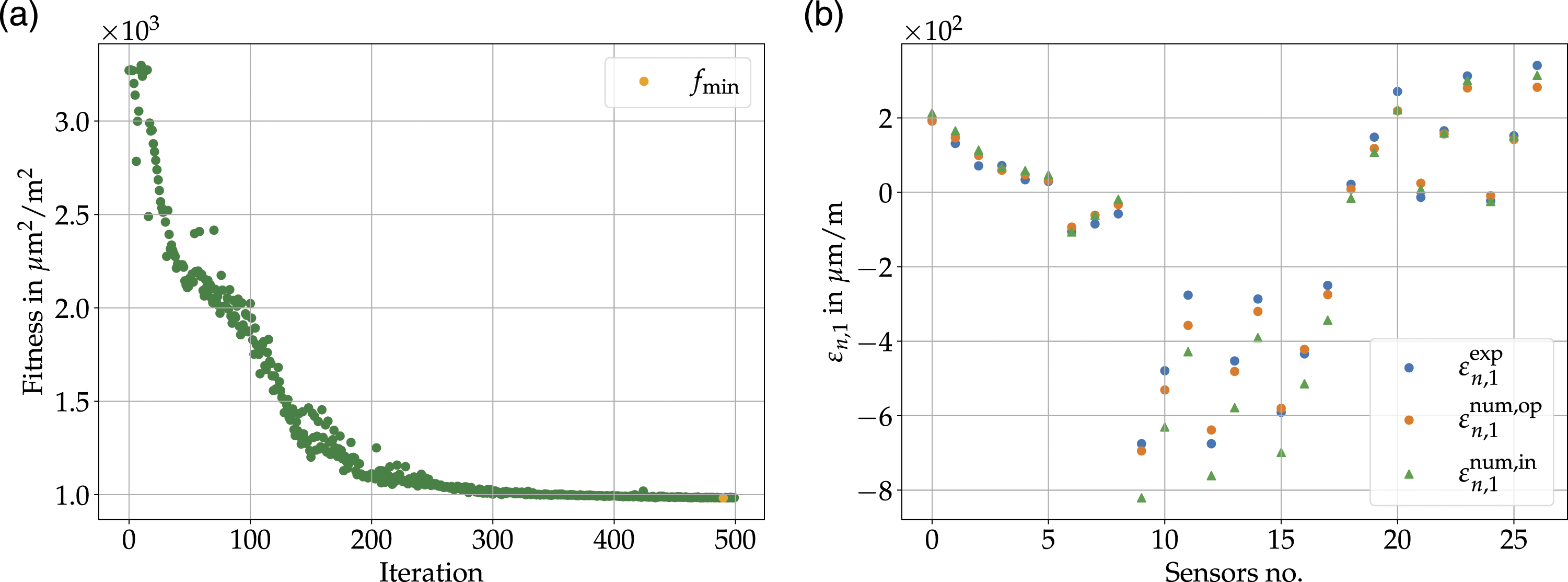
Submodel
In order to reduce the computational demand, in particular for the eigenvector decomposition step in the framework, the monitored part of the sandwich structure should be modeled as a submodel. The sandwich structure of the submodel is modeled taking into account a finer mesh with a mesh size of 8 mm compared to the global model with a mesh size of 10 mm. Since it is assumed that the considered damages affect the structure only locally, the same boundary conditions given by the global load cases are taken into account for both, the healthy and the damaged submodel. As damage, a hole is modeled in the submodel by cutting a hole into the face layer of the submodel. To investigate the sensitivity of the introduced method, two damage sizes, i.e., hole diameters dDS1 = 12.5 mm and dDS2 = 19 mm, are considered.
Feature data generation
The first step of the framework consists of the definition of the area of interest, which should be monitored. In the present study, the part of interest, i.e., submodel, is defined as an area of 192.5 × 220 mm2 located at the edge of the idealized spoiler model (cf. Figure 8). The defined mesh properties of the submodel results in a mesh with a total of 3,625 nodes. Due to the assumption that forces or displacements can only be applied at the boundaries, a static condensation is performed. This leads to a splitting of the nodes into 3,240 slave nodes and into 385 master nodes, which are located at the edges of the partial model. The assembling of the local stiffness matrix of the submodel Symmetric global FE model with the fixed support, i.e., center hinge fitting, the kinematic coupling representing the edge fitting and the submodel. The rectangles marked with the dashed lines represents the area where the load introduction points are varied for the validation data set.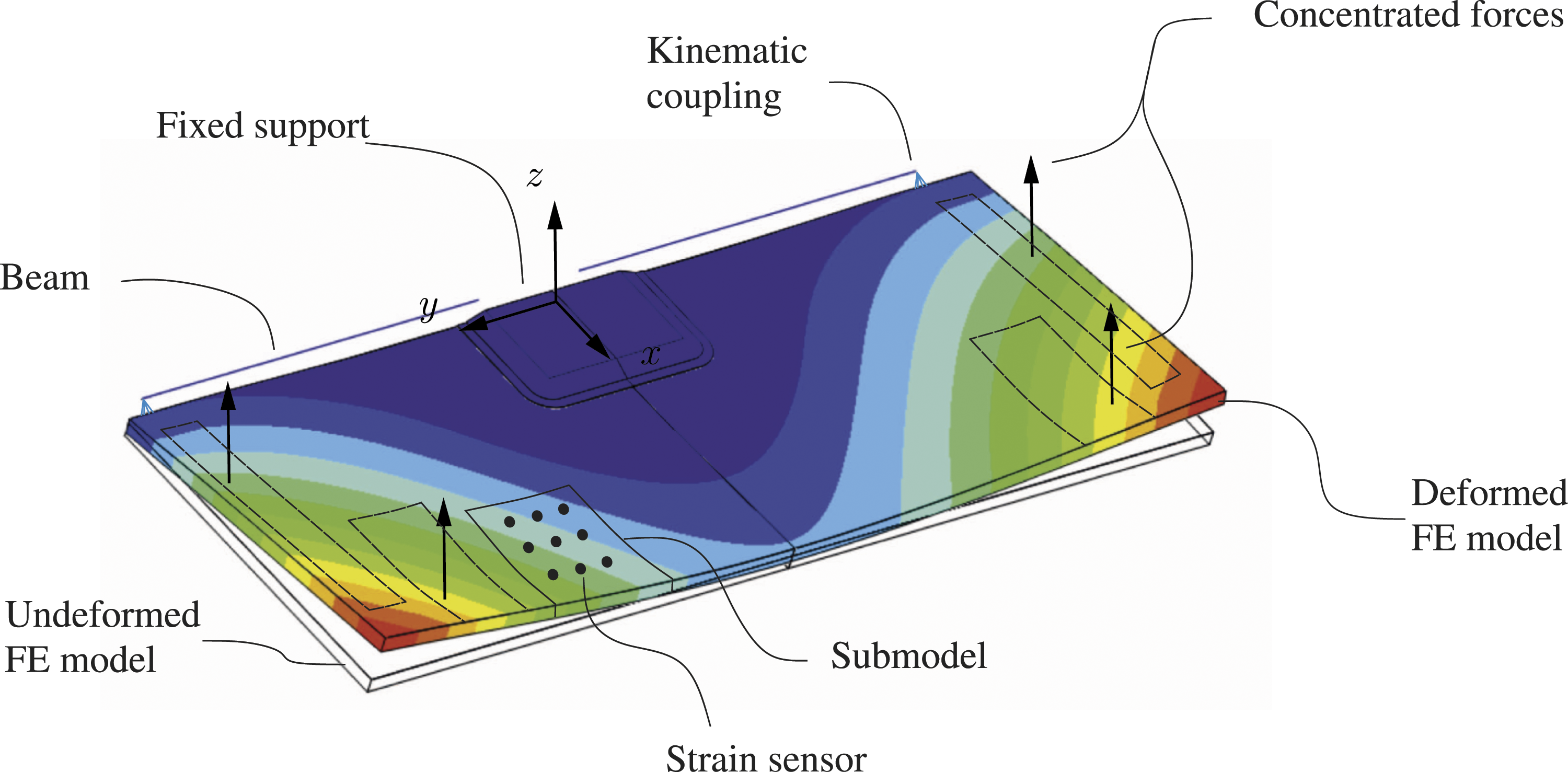
After separating the DOFs according to the static condensation the eigenvectors
The next step is the selection of the most representative eigenvectors. This step involves the computation of the coefficient of determination R2 for each fit of the eigenvector deformation Coefficient of determination R
2
with respect to the eigenvectors. The eigenvectors marked in orange are selected to approximate the objective load case.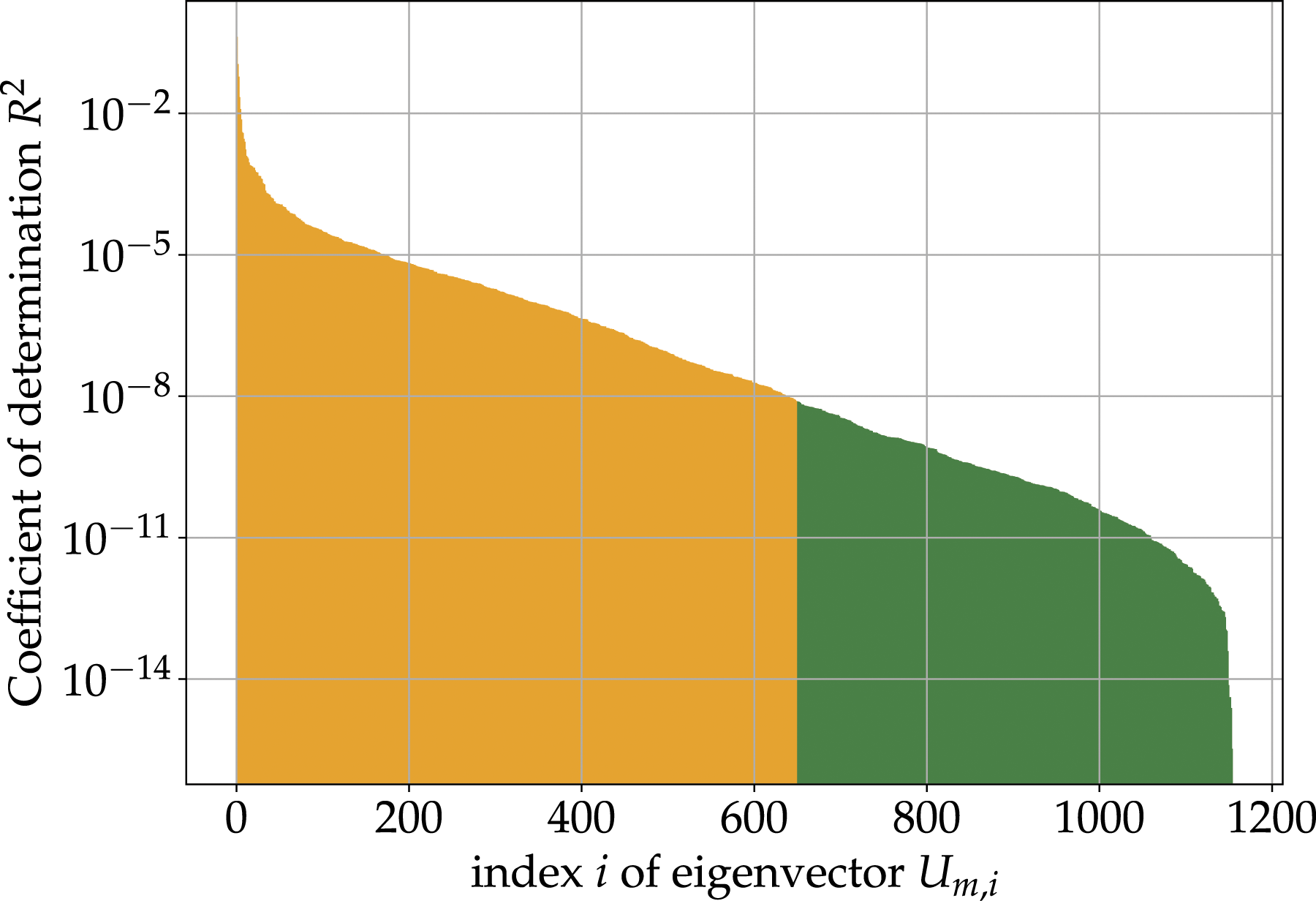
The best and the weakest fit of the eigenvector displacement vector of the top skin with respect to the z-direction, where the strain sensors are mounted, Displacement results with respect to the z-direction of the objective load case Displacement results with respect to the z-direction of the (a) best eigenvector displacement vectors and (b) the worst, i.e., lowest R2, eigenvector displacement vector.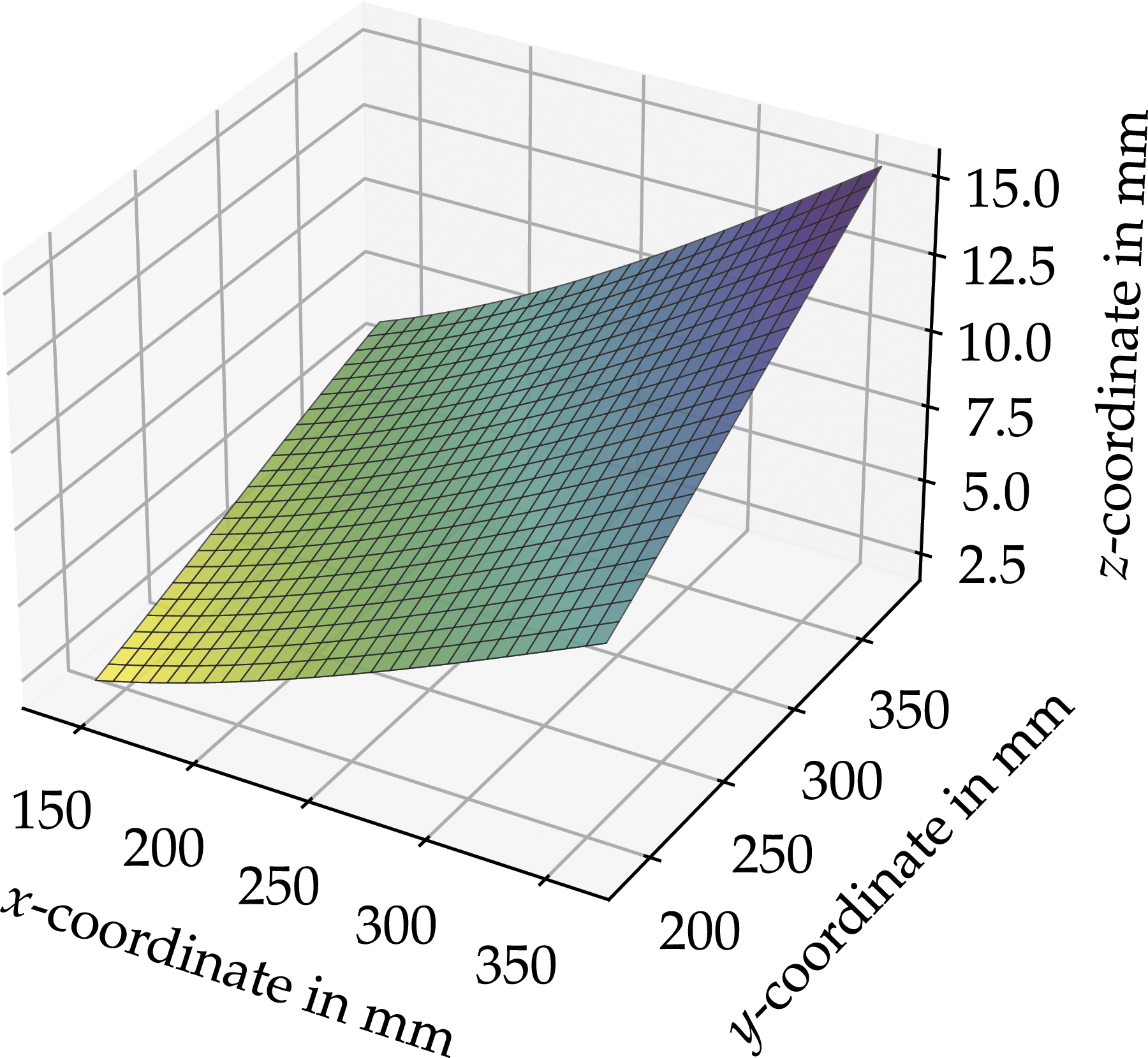
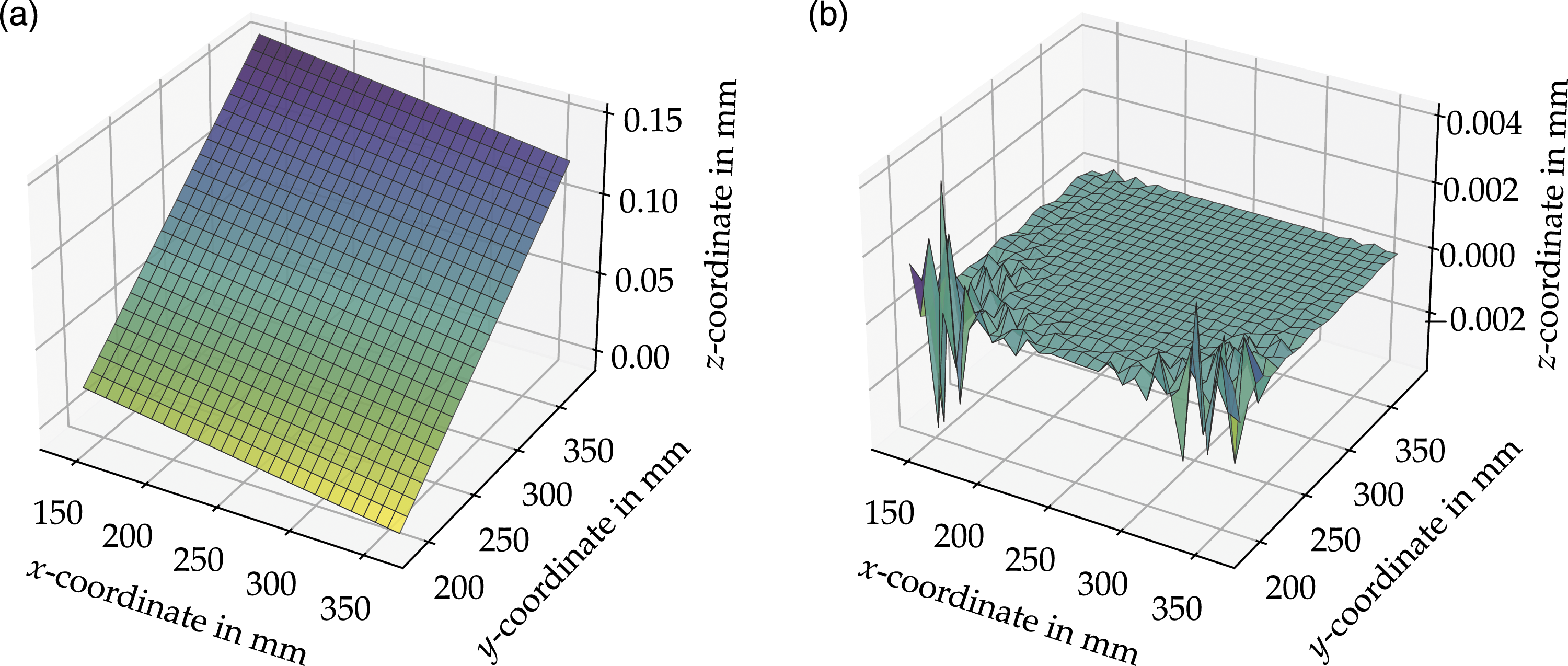
To illustrate the results of the reduction process of the introduced framework shows Figure 12 representative results of the displacement fields in x-direction. Figure 12(a) shows the objective displacement Displacement results with respect to the x-direction of the objective load case: (a) solved by Abaqus® 
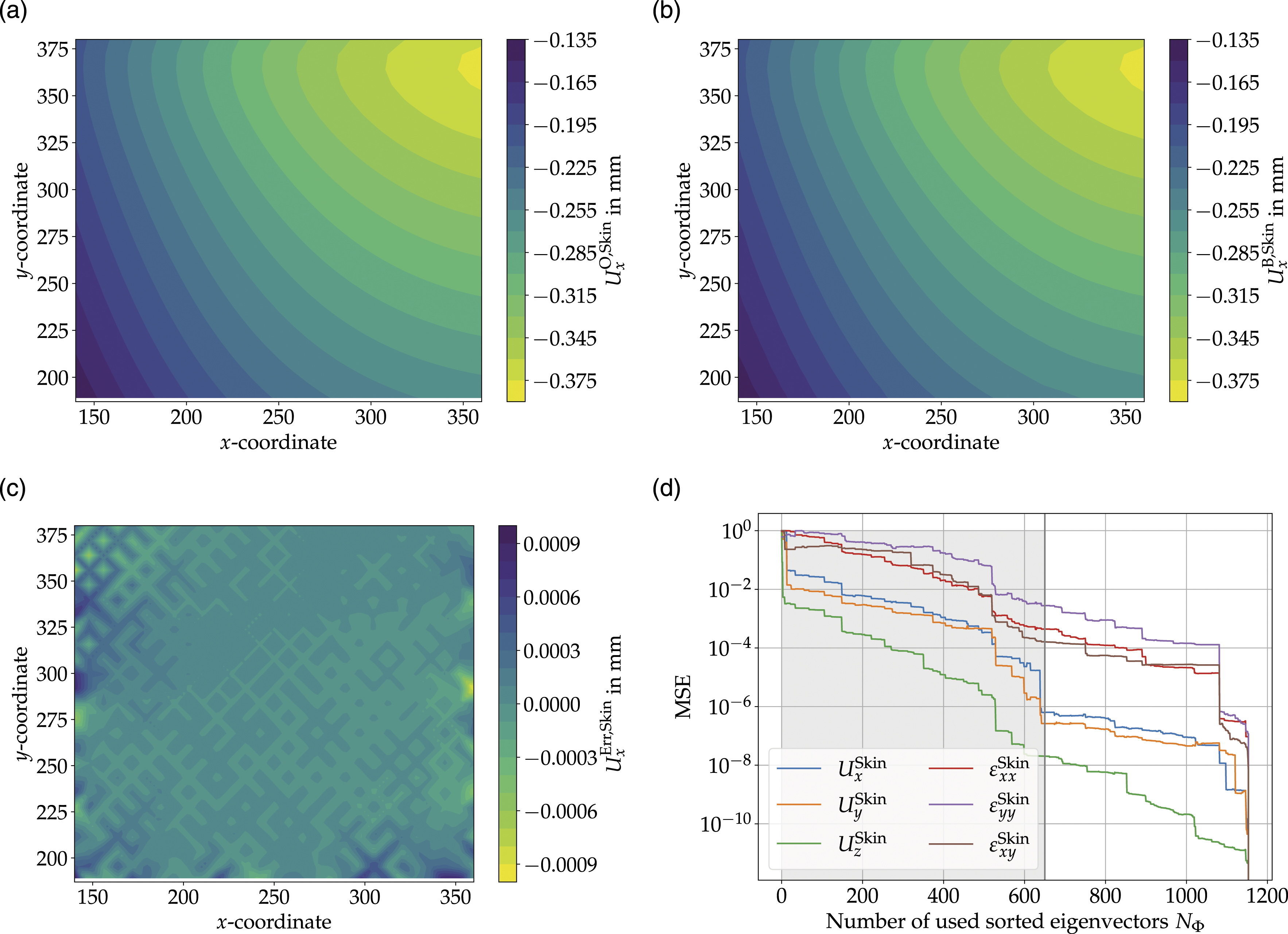
The comparison shows that there is only a slight difference between Figures 12(a) and (b). The difference is caused due to the fact that only the best eigenvector displacement vectors 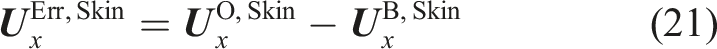
The slight difference is also shown in Figure 12(d), where the MSE between the objective displacement field
However, for the best eigenvector displacement vectors
In the last step of the framework, a statistical variation is performed to generate physics-driven training data. Hence, the parameter vector
However, for illustration purposes, the strain distributions of the approximation of the entire submodel skin are also computed. This is done by multiplying the strains Comparison of strains for the selected objective load case. Strains computed using Abaqus: (a) x-direction and (b) y-direction. Strain estimates obtained by LS-fitting of the best eigenvectors: (c) x-direction and (d) y-direction.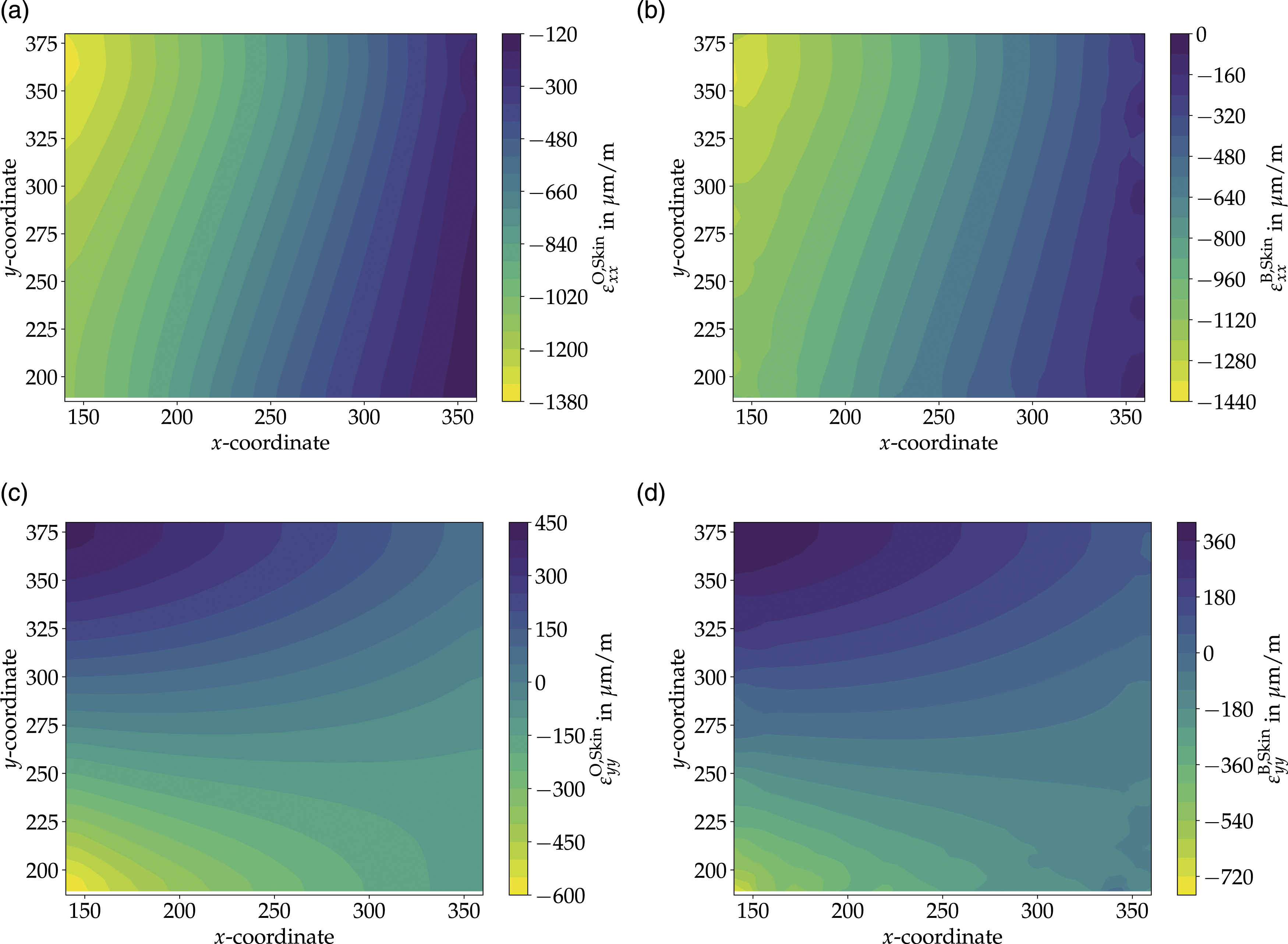
To achieve an damage detection accuracy of about 95.5% of the ML based algorithms (cf. Figure 14) a training data set of about 35,000 load cases are required. This calculated prediction accuracy considers the healthy strain data obtained from feature generation and the synthetically generated damage data. This result impressively demonstrates the benefit of the new approach for efficient training data generation. Since the classical way of training data generation by varying the loads within certain limits to generate the 35,000 load cases is very time-consuming and computationally expensive. As it requires the repeated simulation of each load case of the global model followed by the simulation of the fine-meshed submodel. In contrast, for the considered case example the proposed framework requires only a single simulation of the global model followed by 650 simulations of the selected eigenvector load cases. This comparison clearly shows the great advantage of the framework from a computational efficiency point of view. Model accuracy with respect to the training data size considering the training and the validation data set.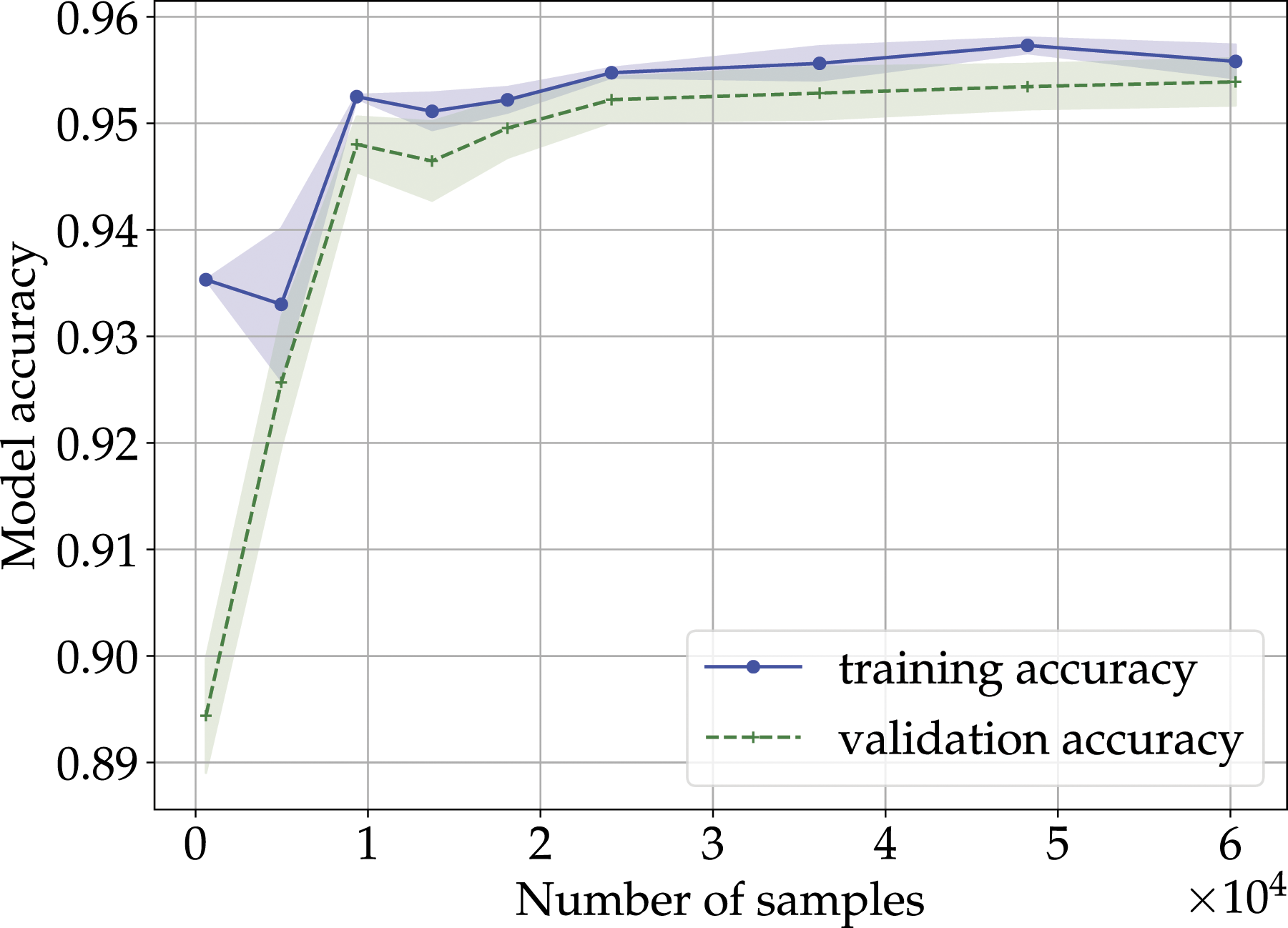
Structural health monitoring application
The first step of the presented SHM approach involves the definition of the sensor array. In this study, a 3 × 3 sensor array resulting in N n = 9 strain sensors orientated in the y-direction, is utilized. For the SHM approach, only one direction is considered because it is assumed that one direction is sufficient to correctly estimate the health state of the structure. The sensors are uniformly distributed, with a constant mesh size of 55 mm, see Figures 3 and 5.
The second step involves the feature data generation for the ML-based health monitoring approach. Initially, the healthy strain data obtained by the feature generation framework is split into two equally sized datasets. Afterwards the damage data is synthetically generated from one of these two datasets. This is done by adding strain concentrations (cf. Equation 19) uniformly distributed among the individual sensor strain values. This procedure was utilized to generate strain data for N
g
= 105 different load cases, taking into account both a healthy and a damaged structure. Subsequently, this data is divided into a training (70%), validation (15%) and test (15%) dataset. Since only the relationship between these sensors is evaluated and not the absolute values, all data sets were standardized with respect to the healthy strain data
In the last step, the training of the MLP classifier is performed, which is done in Python 3.8® using the Python package scikit-learn.43 To find an optimal neural network architecture, a grid search was performed using the function gridsearchCV, included in scikit-learn, to tune selected hyperparameters, i.e., number of neurons, activation function and the regularization term. To avoid overfitting of the model early stopping was utilized. This function stops the training if only the prediction accuracy of the training dataset increases and not the accuracy of the validation dataset. Furthermore, it should be taken into account that in the present case the synthetically generated damage data included in the training data can be varied by the shifting factor s (cf. Equation 18). The hyperparameter tuning was only performed with a shifting factor of s = 0.2 to keep the computational effort low. Hence, it cannot be excluded that there might be a better network architecture for the other training data.
Nevertheless, the grid search revealed an optimal network with five hidden layers of 50 neurons each and hyperbolic tangent as activation function. Within this optimized architecture, different MLP classifiers were trained with different training data sizes. Figure 14 shows the effect of training data size on the prediction accuracy of the MLP classifier, for the training and validation dataset. The result clearly shows that a training data size of almost 35,000 is required to achieve a model accuracy of almost 95.5% for both the training and validation datasets.
Damage detection results
This section demonstrates the applicability of the proposed strain-based SHM approach for damage detection. The section is structured as follows. First, the results of the numerical validation of the SHM method is presented considering the different validation load cases and the different structural states. An implemented hole in the surface layer with different damage size is considered as damage, i.e., damage state 1 (DS1) dDS1 = 12.5 mm and damage state 2 (DS2) dDS2 = 18 mm. Second, the experimental results are discussed and compared with the numerical ones by means of arbitrarily selected representative load cases. ROC-curve of the MLP classifier considering the training, validation, FE-based validation and experimental data set.
Numerical validation
For the evaluation of the presented strain-based approach a hole in the face layer of the sandwich structure with two different diameters is considered as damage. For better illustration, a representative load case, which is also used in the model updating step, is initially selected from the test data set. Subsequently, the strain matrices Strain difference 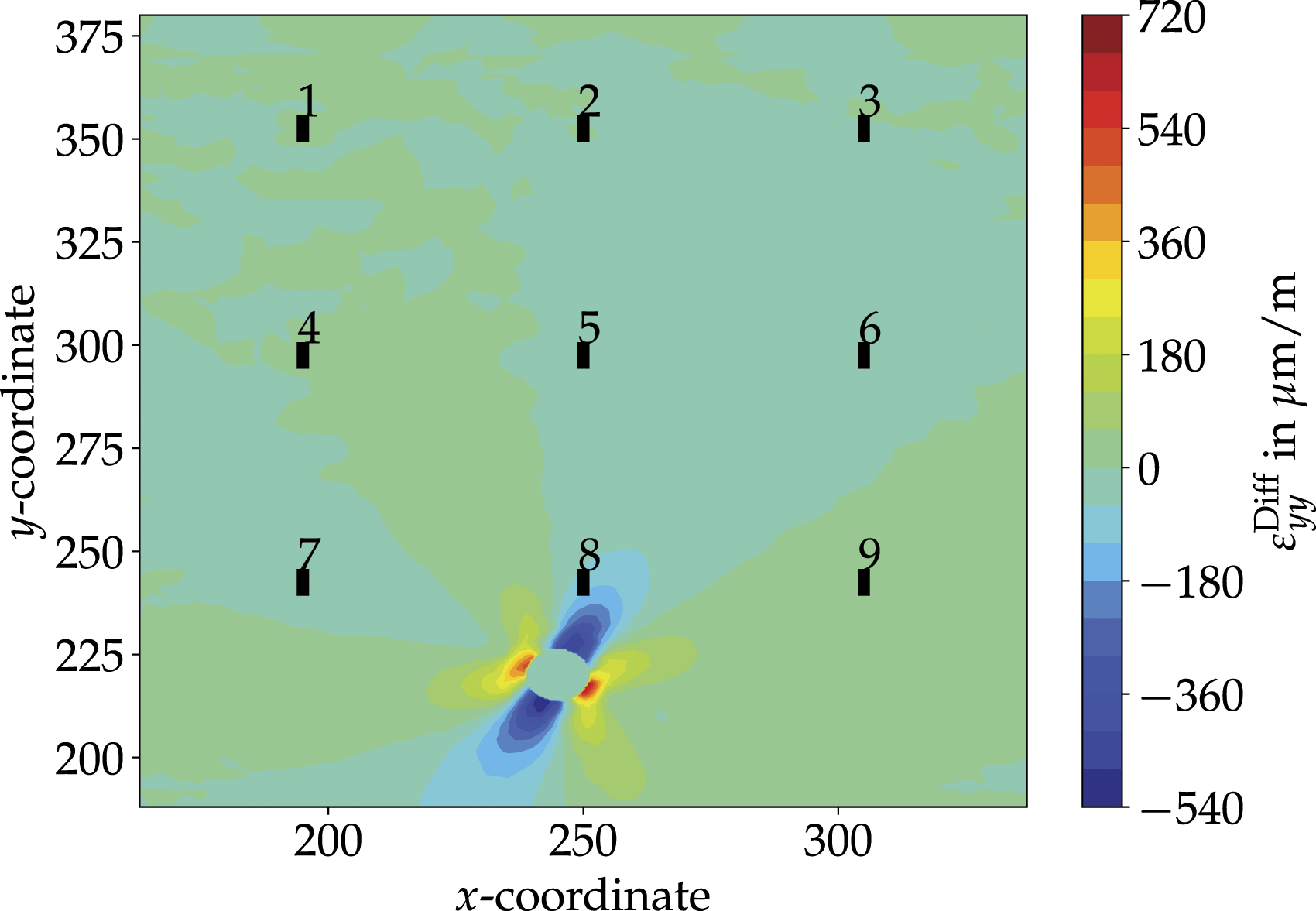
However, the performance of the SHM approach depends on the number of voters considered by the majority voting and the shifting factor s, which is used for synthetically generating the damage data. To investigate the effect of the shifting factor s on the prediction accuracy of the damage detection approach, the MLP classifier was trained by with datasets generated by different shifting factors. Furthermore, in order to determine the optimal number of voters, i.e., MLP classifications, a comparison was made with different numbers of voters (1,3,5). Figure 17 shows the detection rate with respect to the shifting factor s, the different structural states, i.e., H, DS1 and DS2, and the different numbers of voters. Generally, the detection rate is defined as the ratio between damage classified load cases to the total considered load cases in percent. The results considering the FE-based validation data set, with the 250 FE simulations, clearly show the strong influence of the shifting factor s and the number of voters on the detection rate. In general, it can be observed that as the shifting factor s increases, the detection rate is decreasing. This seems logical, since, with increasing shifting factor, the strain deviation of the synthetically generated damage data increases, and thus, the sensitivity decreases. Furthermore, the results show that the detection rate of DS2 with the larger hole diameter is higher compared DS1. This can be attributed to the higher induced strain concentration of DS2. A further reason for the higher detection rate is the smaller distance between the edge of the damage and the strain sensor n = 8. Detection rate with respect to the shifting factor s and the structural states, i.e., H, DS1 and DS2, and different numbers of voters for the majority voting.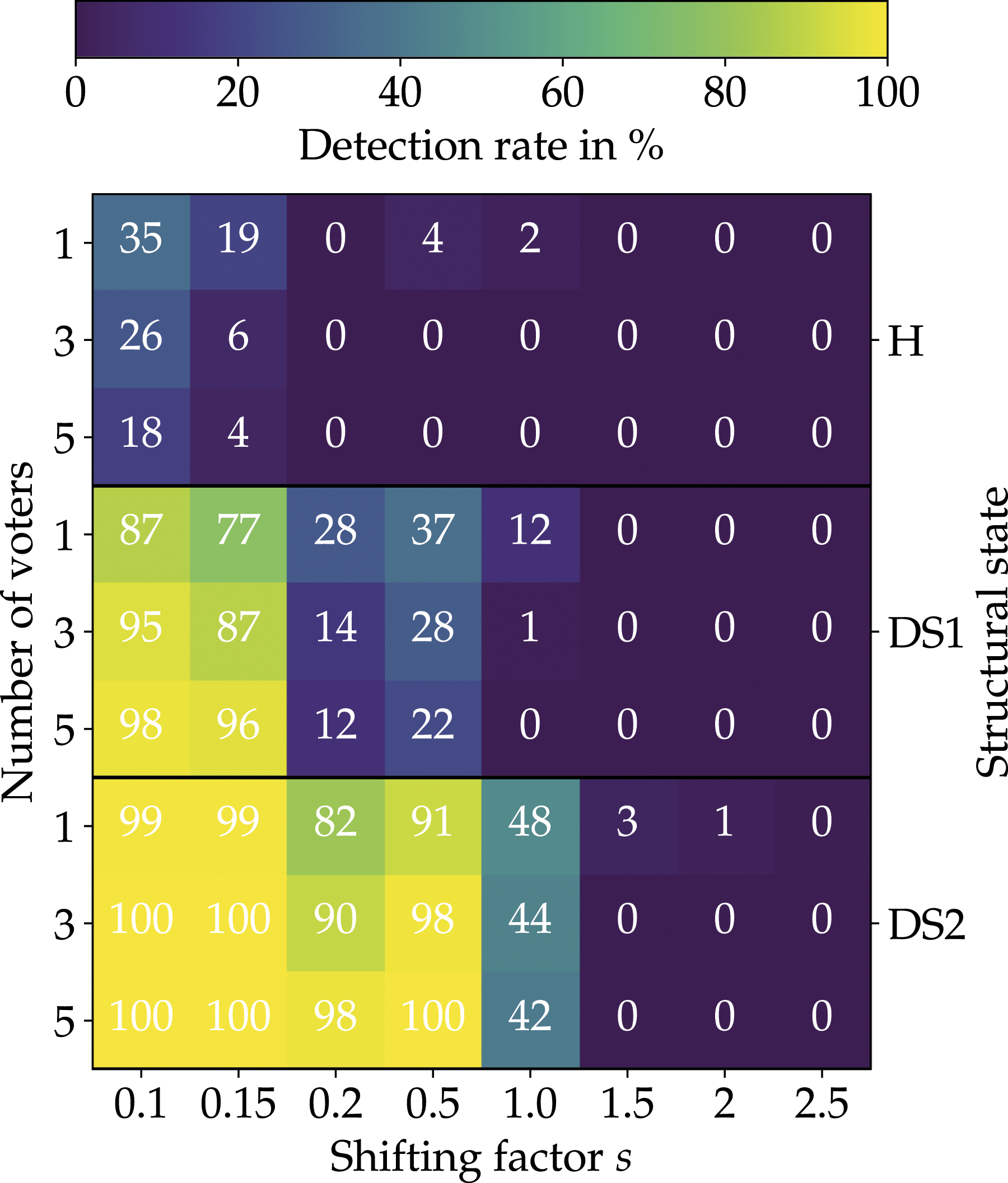
Since the detection rate considering a shifting factor of s = 0.2 represents a good compromise between false alarms and sensitivity, the model with this parameter was chosen for the analysis of the ROC curve, shown in Figure 15. The results considering the numerical validation dataset show a significantly worse performance than the training and validation dataset. A reason for this is that in many cases the damage cannot be detected in the first damage state DS1, which is already visible in the results shown in Figure 17.
Experimental validation
To evaluate the strain-based SHM approach experimentally, five load cases from the validation data set were randomly selected and replicated using the test rig. Figure 18 shows the number of damage votes for the shifting factor s and the three different structural states. Due to the small number of the experiments, the majority decision is ignored in the experimental results of the MLP classifier detection algorithm. Nevertheless, the results show that the ML-based classifier can differentiate between a healthy and damaged structure regardless of the chosen shifting factor s. In this context, it should be emphasized that due to the small sample size, no reliable statement can be made about a suitable shifting factor s. For this purpose, the FE-based validation dataset is much more suitable due to the large number of load cases. For the ROC curves analysis, the same shifting factor s = 0.2 was defined as in the FE-based validation data set. As a result of the accurate prediction, the ROC curve (cf., Figure 15) of the experimental data exhibits the perfect classifier. However, it should be stated that all these load cases have a rather high load amplitude and thus cause a large strain concentration in the vicinity of the damage. Damage votings with respect to the shifting factor s and the structural states, i.e., H, DS1 and DS2, considering the five randomly selected representative load cases.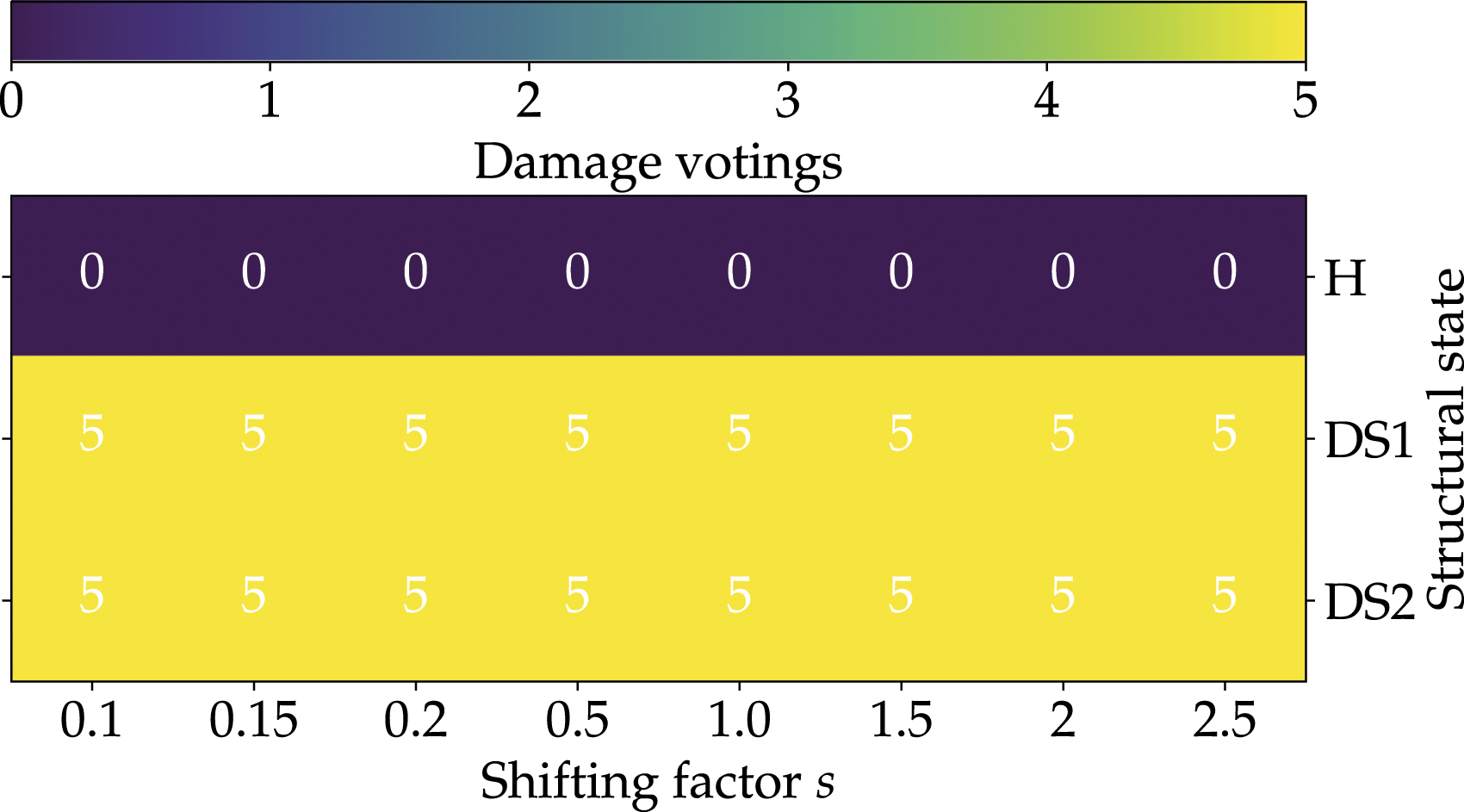
In summary, both the experimental and numerical results demonstrate the high potential of the presented MLP-classifier. Furthermore, it was successfully shown that it is possible to significantly reduce time expensive and exhausting computational costs by utilizing the proposed framework for generating healthy training data and synthetically generated damage data.
Conclusion and outlook
In this paper, a physics-driven feature data generation framework for the training of a ML based damage detection approach is presented that significantly reduces the simulation effort compared to today’s repeated simulation of the global FE model with varying loading conditions. The present approach is demonstrated by a composite sandwich structure that imitates the structural behavior of a real aircarft spoiler. This novel feature generation framework uses sub-structuring, static condensation, eigenvector decomposition and statistical variation. The applicability of the framework was discussed by means of generating strain data for the healthy structure. The results showed that the presented framework represents a fast and efficient solution. In particular, the comparison made with the conventional method, which requires the global and submodels to be simulated sequentially with different loading conditions, shows the high efficiency of the framework. Since a relatively small number of simulations of the submodel and a single global simulation were sufficient in employing the physics-driven framework. An MLP classifier for damage detection was used to validate the proposed framework. The SHM method is demonstrated on an aerospace sandwich structure, where a hole in the face layer is considered as damage with two damage states, i.e., single position but varying diameter of the hole. It was shown that the presented framework significantly reduces the computational cost for generating strain data considering a healthy structural configuration. The damage data were generated synthetically by statistical modifications of the healthy data. Numerical simulations with different damage states were used to validate the presented damage detection method. In addition, physical experiments of representative load cases considering the different structural states were performed for validation. The numerical and experimental results clearly show the high potential of the presented approach for damage detection over a wide range of different loadings.
Future research will explore the possible extension of neural networks to the determination of damage size and localization. Finally, it will be worthwhile to extend the feature generation framework to the task of generating physics-driven damage data and to consider different characteristic load cases.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research leading to this article has received funding from several institutions. We gratefully acknowledge the financial support received by (i) the Austrian Federal Ministry for Digital and Economic Affairs, the National Foundation for Research, Technology and Development and the Christian Doppler Research Association, (ii) the program Take Off of the Austrian Research Promotion Agency (FFG) within the project 881,095 AICorrSens, (iii) the EU’s Horizon 2020 program under grant agreement 101,006,952 SUSTAINair, and (iv) the LCM K2 Center within the framework of the Austrian COMET-K2 program.