
Abstract
This paper proposes a novel LiDAR road point cloud completion algorithm (PCCA) to address the challenges in road point cloud completion due to factors such as sampling frequency and 3D object occlusion. Our algorithm utilizes Open Street Map (OSM) data as structural and semantic priori knowledge to improve the completion process. To locate missing road area and extract its boundary, PCCA first obtains semantic information from the LiDAR data, then combines the extracted semantic information with OSM data to extract the boundary. Finally, PCCA accomplishes road point cloud completion based on the nearest neighbor principle according to the missing road boundary. The PCCA method proposed in this paper achieves road point cloud completion through the data-driven approach, rather than depending on LiDAR hardware parameters. This method demonstrates its superiority over traditional algorithms by reducing the error of the average nearest neighbor distance to 0.08 m in road point cloud completion. Additionally, the PCCA algorithm exhibits better robustness and higher accuracy when completing road point cloud.
Keywords
Introduction
With the advancement of technology, autonomous vehicles have gradually come into public view in recent years. High-precision map is the key component of autonomous driving system. By matching real-time data from onboard sensors with high-precision map, autonomous vehicles can accurately determine their position and orientation. Additionally, high-precision map contains semantic information about the road, including lane marking, traffic sign, and other details, allowing the vehicles to anticipate the road conditions and make better decisions. The main difference between high-precision map and traditional navigation map lies in their detail and position accuracy. High-precision map provides centimeter-level position accuracy and specific lane information, whereas traditional navigation map only provides meter-level accuracy and general road information.
Currently, vehicle-mounted Light Detection and Ranging (LiDAR) technology is often used for high-precision map construction to acquire detailed information about road boundaries and features in complex geographical environments. However, the LiDAR point cloud faces challenges such as data missing, uneven density distribution and large data volume, which impact the integrity and accuracy of high-precision maps. 1 To enhance the integrity and accuracy of these high-precision maps, we concentrate on a novel LiDAR road point cloud completion method driven by the data itself, rather than depending on LiDAR hardware parameters.
Researches on the vehicle-mounted LiDAR data processing primarily focused on the point cloud classification, building information extraction and road facilities identification. In contrast, there are relatively less researches on the road boundary extraction and completion based on LiDAR data. Recently, researches on the road point cloud completion for high-precision map have attracted the experts’ attention and achieved some significant results. To handle the problems of road point cloud data missing and low accuracy of image vector map, Li et al. 2 use remote sensing images to generate point cloud, register them with the original missing point cloud, and complete the missing point cloud for airborne LiDAR. Van Gansbeke et al. 3 propose an accurate completion method for sparse LiDAR maps guided by RGB images. Wu et al. 4 propose a 3D point cloud completion method based on the symmetry plane, which firstly resamples original point cloud and obtains the initial symmetry plane through spatial transformation and density clustering. Then, it optimizes the initial symmetry plane using the registration relationship to perform point cloud completion. The aforementioned researches on road point cloud completion predominantly implement high-precision map construction based on multi-sensor information fusion, integrating two-dimensional image with three-dimensional point cloud. However, these methods encounter challenges such as complex data processing and low precision.
The core technology for high-precision map construction is point cloud completion. Point cloud completion methods can be broadly categorized into two major types. One is traditional data repairing algorithms, such as geometry-based methods and model matching methods. Some representative results, such as least squares data smoothing, Laplace smoothing 5 and Poisson surface reconstruction 6 are not effective in the case of complex object shape and sparse data. Therefore, shape-based completion algorithm has been developed in recent years. Sipiran et al., 7 Speciale et al., 8 and Sung et al. 9 apply the symmetry structure of 3D shapes to point cloud completion. Such completion algorithms usually require defective objects having prominent geometric properties, which are not suitable for objects with insignificant shape features. An effective method is proposed to extract road surfaces in a fixed-width environment regarding the LiDAR survey trajectory, which provides detailed information and geometry extraction with fewer parameters and requires less prior knowledge. 10
Compared to traditional point cloud completion algorithms, the algorithms based on deep learning could learn more features and semantic information under complex circumstances, significantly improving the precision and efficiency. Among voxel-based methods, Wu et al. 11 firstly propose three-dimensional convolution for completion, applying volumetric representations to the 3D ShapeNets trained on a self-built database. The 3D-EPN 12 utilizes an encoder-decoder network composed of three-dimensional convolution to predict the complete shape from partial inputs. However, the computation cost increases exponentially with the enhancement of resolution, posing significant challenges for network training. Xie et al. 13 introduce the Grid Residual Network (GRNet), which converts unordered point cloud into a regular grid representation, followed by feature extraction and intermediate data generation using 3DCNN. The VE-PCN proposed by Wang et al. 14 transform unordered point cloud to grid representation to support edge generation and point cloud reconstruction, which can generate fine-grained information. Although the features extracted by voxel-based point cloud completion algorithms can satisfy the requirement of classification and segmentation, for the completion tasks, the incomplete point cloud information requires more fine-grained semantic and geometric features for completion. Moreover, a large number of zero-value voxels occupy memory, leading to voxel space redundancy and significant memory consumption.
In the point-based methods, Qi et al. 15 pioneeringly propose PointNet, which could process unordered point cloud directly, addressing the irregularity and unordered nature of point cloud data input. FoldingNet designed by Yang et al. 16 reconstruct arbitrary point cloud from two-dimensional grids, but this network is unable to complete sharp surfaces of objects. Yuan et al. 17 introduce a deep learning network PCN (point completion network), integrating the ideas of FoldingNet and PointNet. It represents point cloud geometric information into feature vectors and complete point cloud in a coarse-to-fine manner. Huang et al. 18 propose a multi-scale hierarchical GAN network PF-Net (point fractal network), which predicts missing parts in the hierarchical network based on multi-level feature points generation. As the Transformer architecture has been widely used for sentence encoding in natural language processing, Yu et al. 19 introduce a Transformer structure PoinTR for point cloud completion, which rephrases point cloud completion as a problem of set-to-set translation and uses FoldingNet to generate point cloud. Li et al. 20 design the ProxyFormer algorithm for the geometric structure and details of the missing point cloud.
However, above methods based on deep learning face certain limitations, such as constraints in processing high-resolution 3D models due to limited GPU storage space, the insignificance of shape features, and a lack of priori knowledge. Addressing these issues, the paper proposes a novel LiDAR Road Point Cloud Completion Algorithm (PCCA), integrating Open Street Map (OSM) data as a source of structural and semantic priori knowledge. The contributions of this paper can be summarized as follows:
Accurate localization and completion: PCCA can accurately locate missing road point cloud and extract boundary curve information, which is essential for defining the edges of the missing area. By processing redundant data, the algorithm ensures the completed point cloud is not only structurally sound but also accurately represents the intended road point cloud.
Robustness and accuracy for road point cloud completion: Most current point cloud completion algorithms are not sensitive to linear and planar data due to their lack of distinct shape features and priori knowledge. PCCA is specifically designed to handle such issue, which takes advantages of structural and semantic information from OSM data to achieve robust and high-accuracy missing road point cloud completion.
Overcoming GPU storage limitations: By integrating OSM data, PCCA avoids the processing limitations of GPU storage space. This, is a common issue in deep learning algorithms because of large amounts of memory requirement for training and inference, especially when dealing with high-resolution 3D models. PCCA provides a feasible method for data completion.
Methodology
PCCA is mainly conducted by two stages: missing area boundary extraction and missing area completion. The PCCA processing flow is shown in Figure 1.

The PCCA processing flow.
Data semantic segmentation: This step involves segmenting the point cloud data into different semantic categories (e.g., road, buildings, vegetation, etc.). A deep learning network model is used to recognize and classify different objects within the point cloud.
Road information fusion: Once the semantic segmentation is done, the algorithm fuses the road information from LiDAR data and OSM data to accurately identify and locate the missing area.
Boundary information extraction: With the missing area located, the next step is to extract the boundary information by calculating the curvature defined by the radius of this outer circle the road segment.
Missing road point cloud completion: Using the boundary information extracted in the first stage, PCCA generates a completed point cloud for the missing road area using interpolation techniques.
Redundant data processing: this step removes redundant points, ensuring the integrity and accuracy of the completed point cloud.
Semantic information and boundary extraction
High-precision map is comprised of point cloud oriented to large-scale scene, which has the characteristics of large data volume, wide collection field and wide data distribution range. The captured three-dimensional scene contains a large number of diverse objects. To ensure accurate identification and analysis of specific objects, it is necessary to implement semantic segmentation, which categorizes and differentiates various elements within the point cloud.
Due to the occlusion of buildings, bridges and other obstacles during the scanning process of the LiDAR measurement system, the point cloud will inevitably be obstructed in the acquisition process, resulting in data loss.21,22 The accurate boundary extraction of the missing area is a critical prerequisite for the subsequent missing data completion, and the quality of the extraction result will directly impact the quality of the completion result.
However, the uncertainty associated with the feature points location makes it difficult to extract the boundary of point cloud completely and accurately.23–25 As illustrated in Figure 2(a), the point cloud surrounding the missing area is taken as the boundary points for the missing area. The definition of this boundary is subject to the issues of boundary uncertainty, as depicted in Figure 2(b) and (c). To address this challenge, an ideal road boundary algorithm can be extracted based on OSM map priori knowledge.
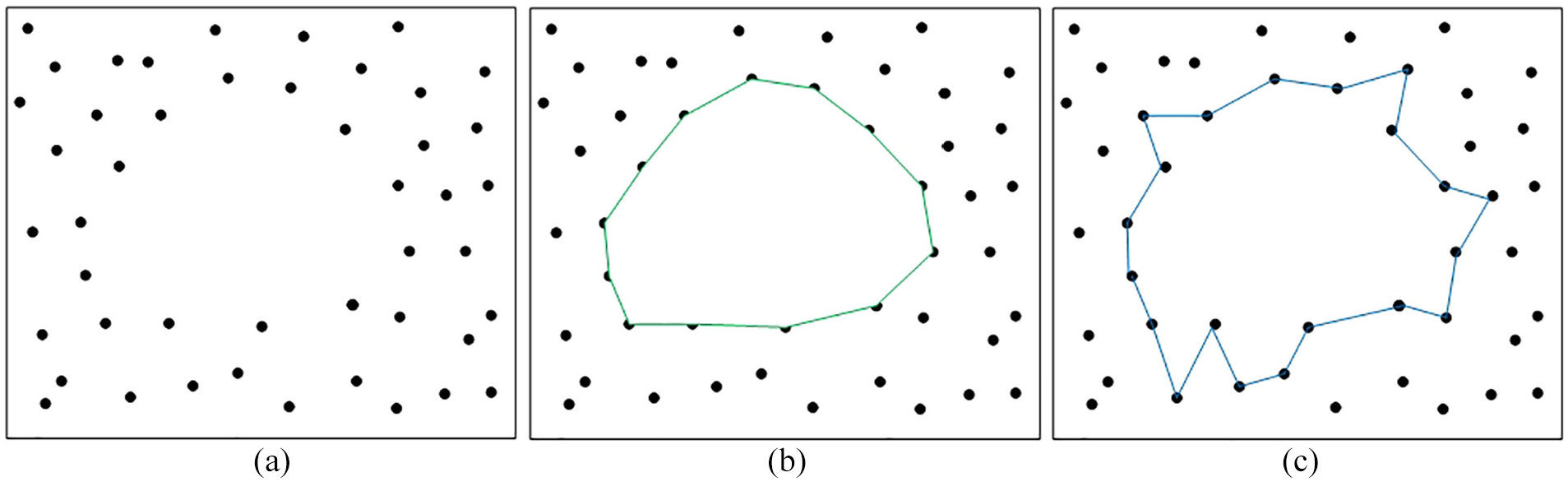
Boundary definitions: (a) original point cloud, (b) boundary definitions 1, and (c) boundary definitions 2.
OSM (OpenStreetMap) is a platform for Volunteered Geographic Information (VGI) built by public and is one of the most comprehensive vector maps available today. However, OSM vector data cannot meet the precision requirements of road boundary extraction for high-precision map and lacks three-dimensional representation. Therefore, this paper utilizes it as auxiliary information. To extract road boundaries from vehicle-mounted LiDAR point cloud. The main reasons for selecting OSM data to provide road prior knowledge in this study are as follows: (1) OSM data is easily accessible and open to the public; (2) OSM data contains sufficient geographic feature information, such as location, semantic, and topological information; (3) OSM data have a high degree of completeness among the current open-source maps.
In the geospatial data processing, the OSM represents a centerline-based cartographic dataset which result in inaccurate road curve fitting due to the uncertainty of road width threshold and center line position. Therefore, this method employs the curvature information derived from the OSM map as a priori knowledge for road boundary extraction. Here’s the detailed steps of the process.
Step 1: Locate missing area based on OSM priori knowledge. This step involves registering the geographic element from the OSM map with semantic segmentation data derived from point cloud data. By analyzing the spacing and density of adjacent point, the missing or incomplete area can be identified and located.
Step 2: Fit the boundary of missing area based on edge point cloud. Points closed to the boundary of the missing area are identified as edge points. These points are crucial to infer the shape of the missing road boundary.
Step 3: Obtain accurate boundary curve of road segment. Road boundary is extracted by fusing the boundary curve derived from the OSM data with those inferred from the point cloud data. The combination can lead to a more accurate representation of the missing road boundary. Besides, road boundary curve could infer to the redundant data for the road completion algorithm, which make the completion result accurately.
From Figure 3(a) to (d) illustrate this process, with Figure 3(a) showing the road point cloud, Figure 3(b) showing the OSM map road information, Figure 3(c) showing the missing area localization and Figure 3(d) showing the missing area boundary.
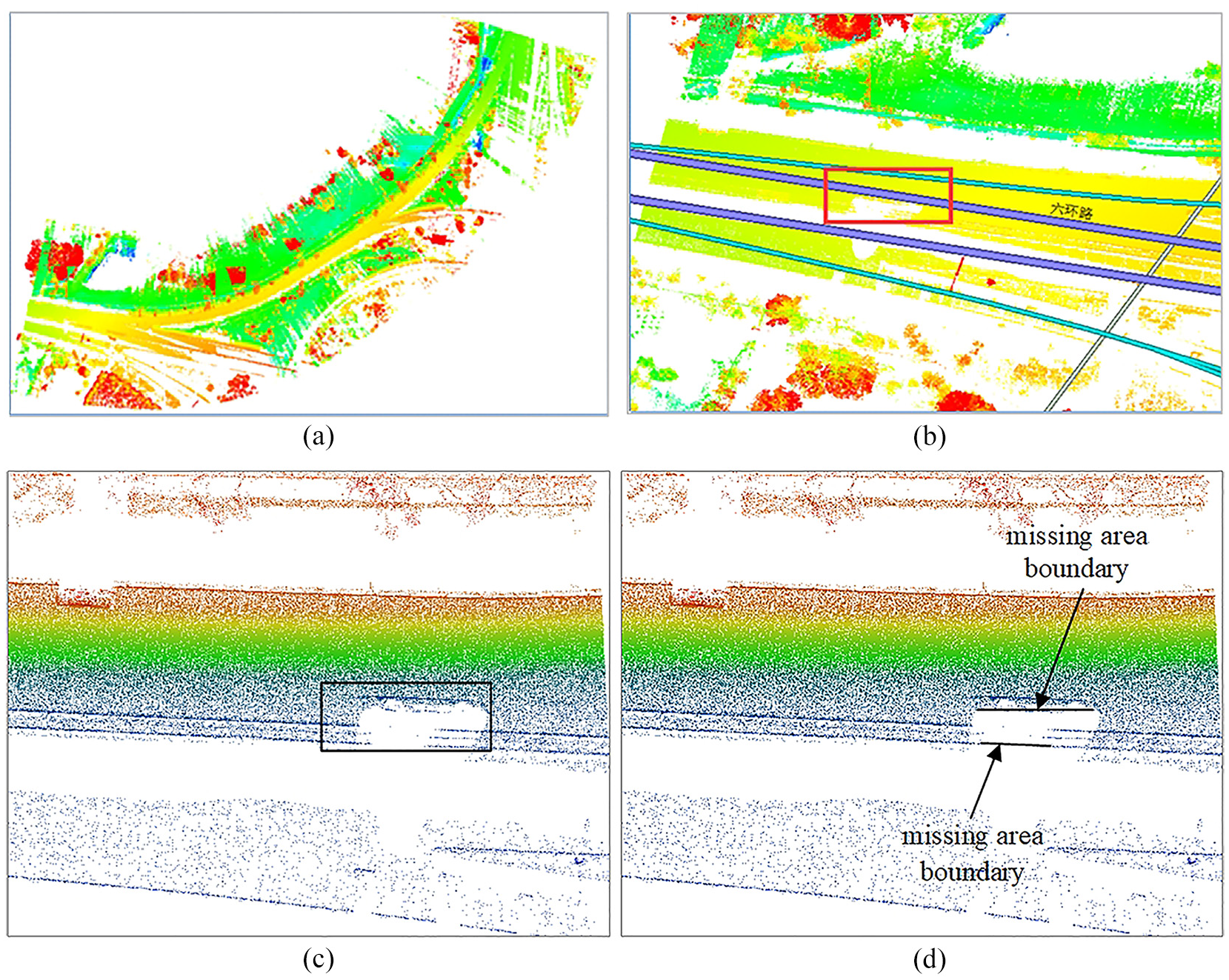
The boundary extraction of missing area: (a) road point cloud, (b) OSM map data, (c) missing area localization, and (d) missing area boundary.
This fusion of data from OSM and point cloud information is a powerful technique for improving the accuracy and completeness of road maps derived from these sources, particularly in urban environments where the complexity of the road network and the density of buildings can challenge traditional mapping methods.
Data semantic segmentation
In order to improve the accuracy of road point cloud completion, semantic segmentation is indispensable. According to the different methods of point cloud data processing, point cloud segmentation could be divided into traditional methods and methods based on deep learning. Segmentation methods based on deep learning could be further categorized into projection-based methods, voxel-based methods,26,27 and point-based methods.28–30 Depending on the segmentation scenes, point-based methods could be divided into large-scale and small-scale segmentation algorithms. This study uses a large-scale segmentation algorithm for semantic segmentation of road scenes. The point cloud segmentation algorithms oriented to large-scale scene can be broadly categorized into two groups: data segmentation based on 2D point cloud and data segmentation directly based on 3D point cloud. The former method typically involves projecting the point cloud onto a 2D plane, followed by the application of established 2D semantic segmentation networks, such as U-Net. 31 In contrast, the latter method focuses on the extraction of feature information directly from the 3D space, as RandLA-Net 32 and GRanD-Net. 33 Considering the unique attributes of road point cloud with the purpose of minimizing data loss, this paper performs semantic segmentation and extract road scene data directly from the original 3D point cloud. Inspired from the architectures of RandLA-Net and GRanD-Net, we propose a deep learning network for road segmentation in a 3D point cloud context.
This proposed network directly extracts semantic information point-by-point from cloud point in the context of large-scale scene. Through a systematic sampling process, a secondary sampling method is employed to refine the point cloud dataset. Additionally, the network incorporates dilated residual blocks (DRB) to preserve the integrity of the data features and retain the rich data features. The network structure maintains the same layer count as that of the RandLA-Net, which is visually represented in Figure 4.
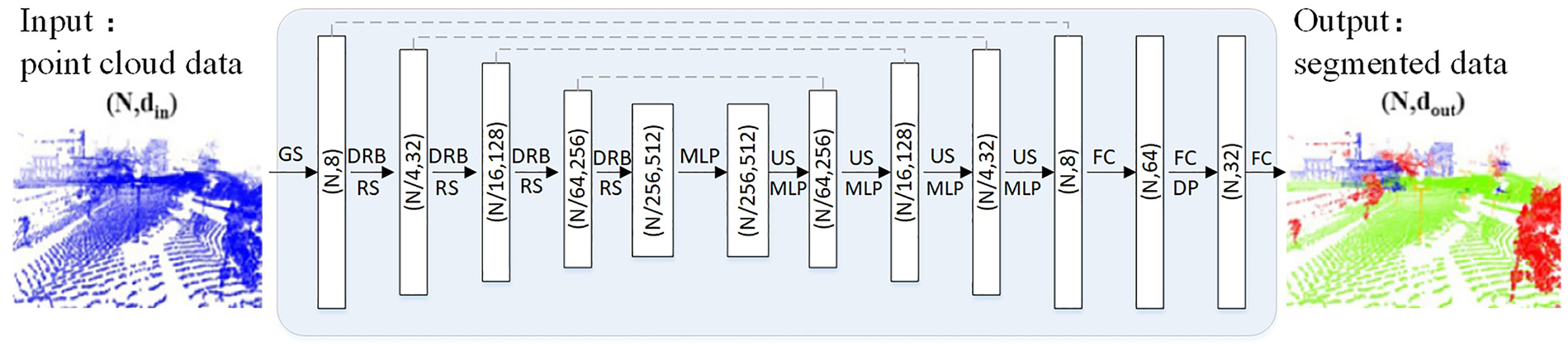
Segmentation network structure.
This point cloud segmentation network utilizes a Dilated Residual Block (DRB) to preserve data features and encodes the point cloud within the DRB by incorporating centroid information and K-nearest neighbors. The network implementation steps are as follows.
Step 1: Point cloud segmentation and road section data extraction. This module in the network mainly aims at road point cloud data in the context of large-scale scene with significant volume. It is necessary to set a certain segmentation threshold, which is determined by the maximum data volume of the file during model training. The maximum size of the dataset used for training is 100 MB, hence the data volume threshold is set to 100 MB. To ensure the integrity of road scene during data segmentation, our research proposes a road scene segmentation method based on OSM map. The road point cloud data is segmented according to the topological connectivity and road width of OSM map, that is, the nodes’ vertices are used as segmentation points. OSM map and road point cloud data are registered according to the coordinate alignment. Finally, road section data D is extracted based on priori knowledge from the OSM. This road segmentation preprocess is crucial to avoid the computation overhead and data features loss that would result from directly sampling and inputting the integrated point cloud into the network.
Step 2: Edge and elevation feature extraction from road section data D. Based on point position, edge and elevation information, the network performs semantic segmentation. Edge feature is mainly computed by ground points and non-ground points. Suppose G represents ground data and J represents non-road data.
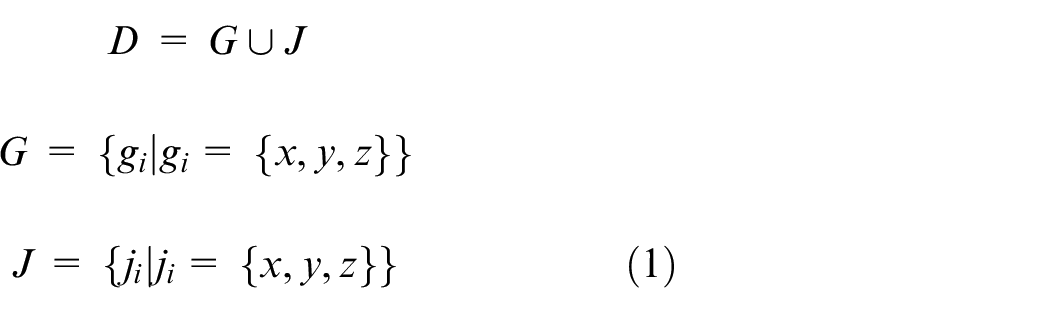
In the set G, the ground edge feature b could be calculated according to the principle that the maximum and minimum values of y are data edge points for the same x. The road scene includes various data categories such as ground, vehicles, and buildings. Based on the elevation difference between ground and non-ground data and using a hierarchical clustering approach, the data could be classified roughly and labeled to represent the elevation features h.
Step 3: Random sampling for dataset. This step is designed to enhance the segmentation rate and accuracy of feature extraction.
Step 4: Feature aggregation and semantic labeling. This module encodes the spatial positions of input point cloud firstly. For the point set
Road information fusion
In point cloud completion, priori knowledge is also crucial for accuracy. OpenStreetMap (OSM), an open-source dataset, offers comprehensive priori knowledge with four key elements: nodes, ways, relations, and tags.
Road information fusion involves integrating point cloud data with OpenStreetMap (OSM) ways elements through coordinate registration. This fusion provides priori knowledge for completing missing road point clouds. Based on OSM road data, road information fusion contributes to identify and locate the missing area, determine their curvature, and extract boundary information. In the Point Cloud Completion Algorithm (PCCA), road boundary curvature is applied to boundary extraction and the removal of redundant data. The OSM road network information is shown in Figure 5(a), and the road information fusion is shown in Figure 5(b).
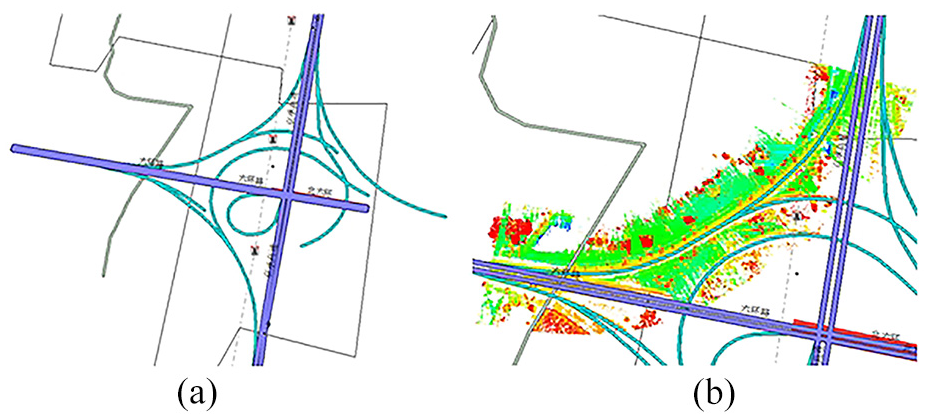
Road information fusion: (a) OSM road network information and (b) road information fusion.
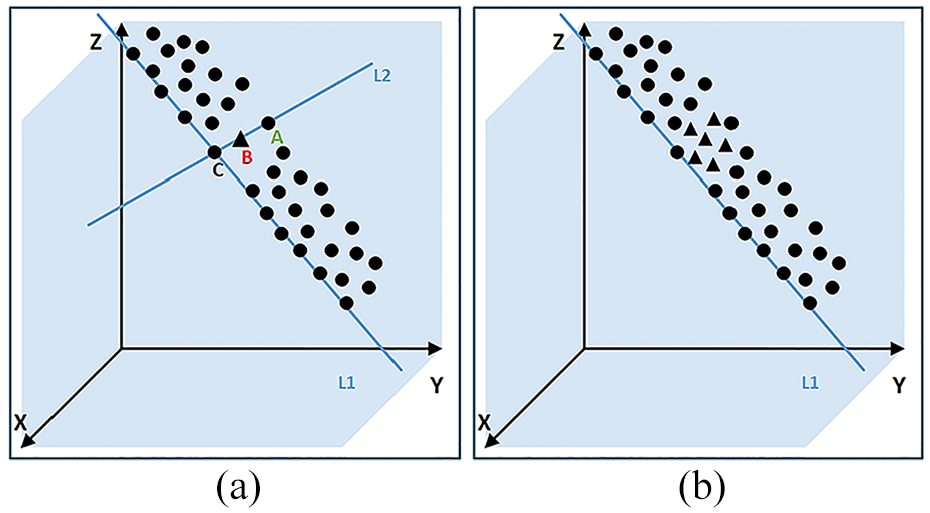
In the process of road information fusion, regular expressions are employed to extract road elements from the OSM data. Within the missing area of the road point cloud, three candidate points from the OSM data are identified, and an outer circle is constructed using these points. The radius of this outer circle is used to define the curvature information for the road segment. The road boundary is determined based on the curvature information. The curvature information extraction is illustrated in Figure 6, where the rectangular box represents the missing road area. Points A and C are the farther candidate points, B is the middle candidate point, R denotes the radius of the outer circle determined by points A, B, and C, and 1/R represents the curvature of the missing road area.
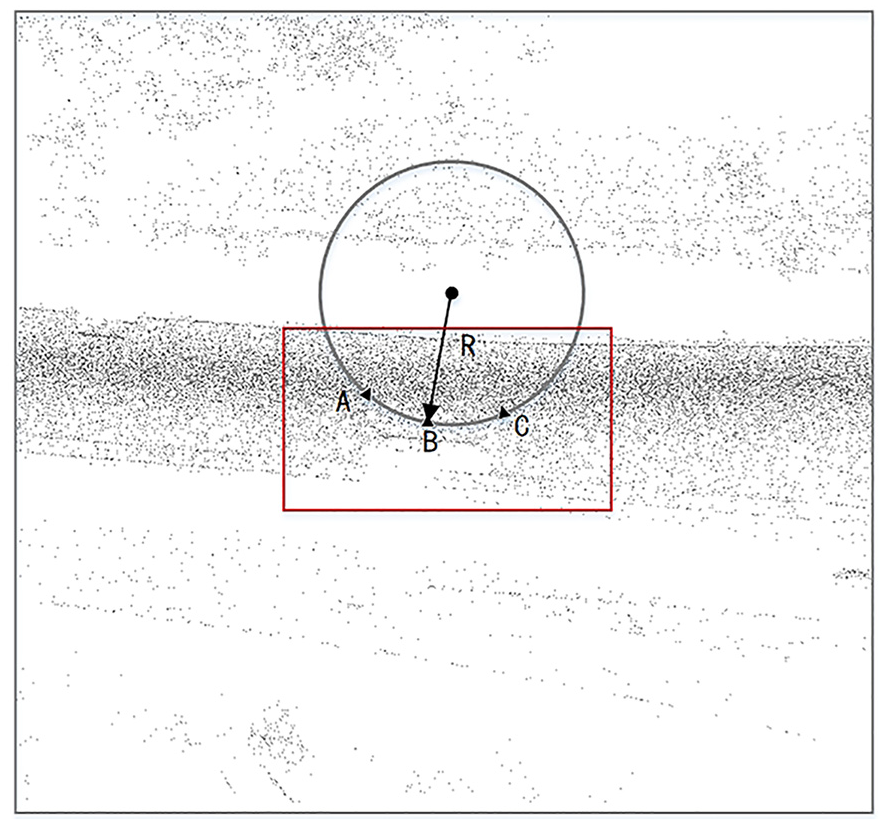
Curvature information definition.
Road point cloud completion
Existing point cloud completion algorithms often rely on object shape features and voxel features, which are effective for data with distinct shape features. However, the road point cloud is linear model with less shape features. Consequently, traditional algorithms designed for obvious shape objects are not well-suited for completing road point cloud.
Surface completion processing
The surface completion algorithm fills missing area E in point cloud by fitting a surface

Missing road area: (a) original missing area, and (b) sparsely sampled missing area.
The surface fitting process involves identifying optimal fitting points from the boundary and nearest neighbor point sets.
35
By minimizing the sum of squared errors between these points and the fitted surface, a completed point set
In the missing road area, the point cloud nearest to
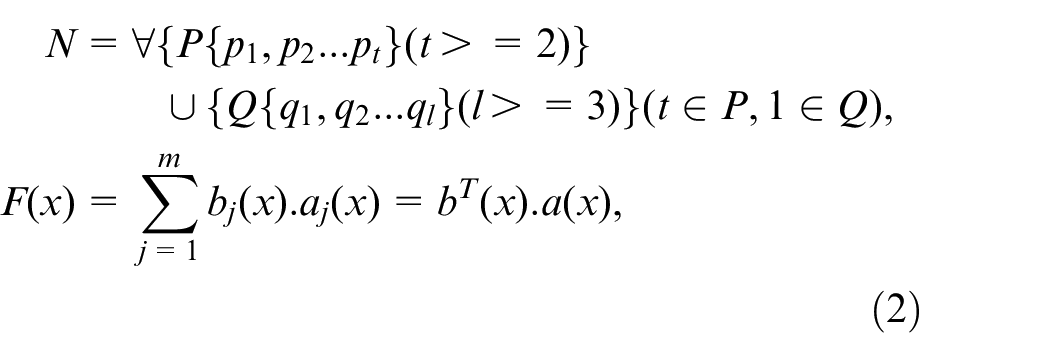
The selection of basis functions aims to fit the appropriate surface equation. Generally, two-dimensional basis functions are used. There are three common forms of two-dimensional polynomial basis functions. In this paper, quadratic polynomial basis functions are used.
Linear polynomials (linear basis):

Quadratic polynomials (quadratic basis):
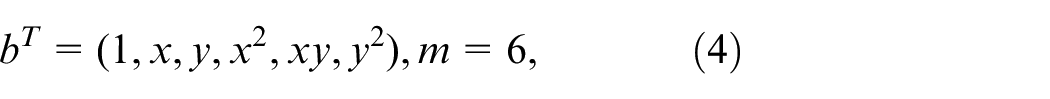
Cubic polynomials (cubic basis):
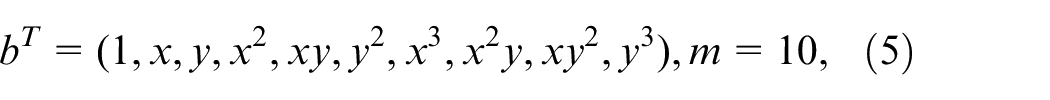
In order to make surface equation fit the point set
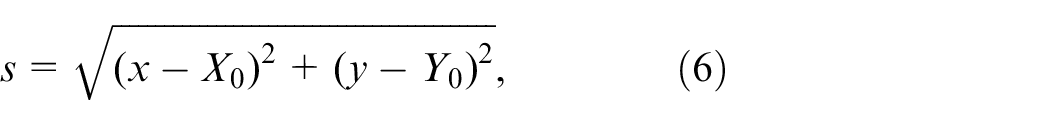
In order to minimize the sum of square errors between the set of points
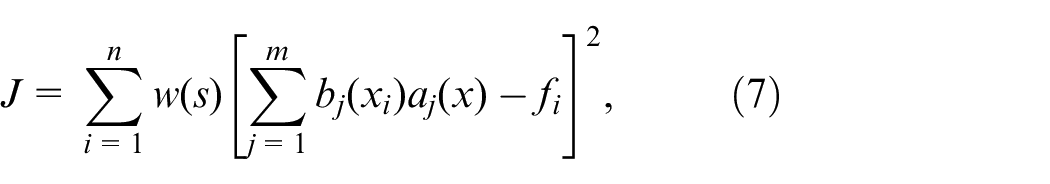
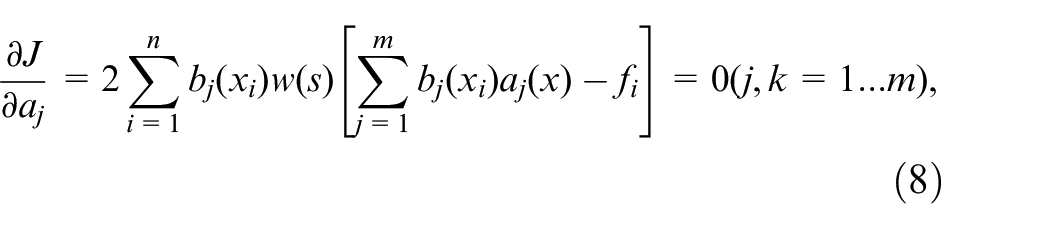
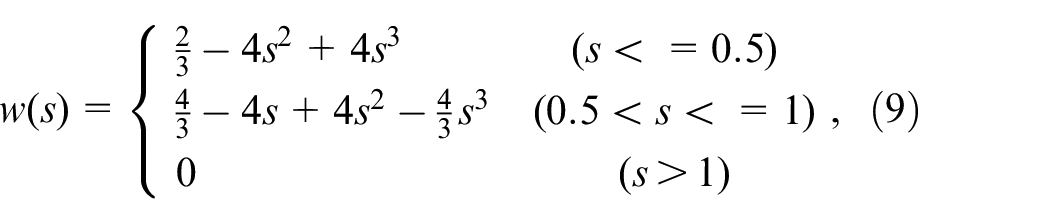
Before surface construction, compactly supported domain of the nodes in the point set
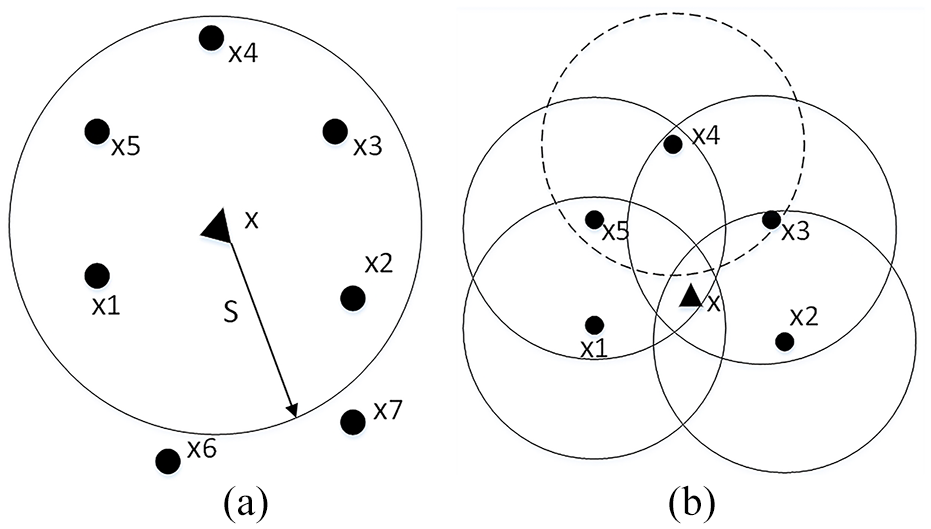
Calculation point: (a) compactly supported domain and (b) nodes involved in “calculation point” calculation.
By using equation (3), we obtain
Redundant data processing
After the point cloud surface completion, the phenomenon that the complemented data does not match the actual road boundary perfectly occurs, resulting in the appearance of redundant data. The completed point set is
The interpolation algorithm is applied to obtain the boundary curve
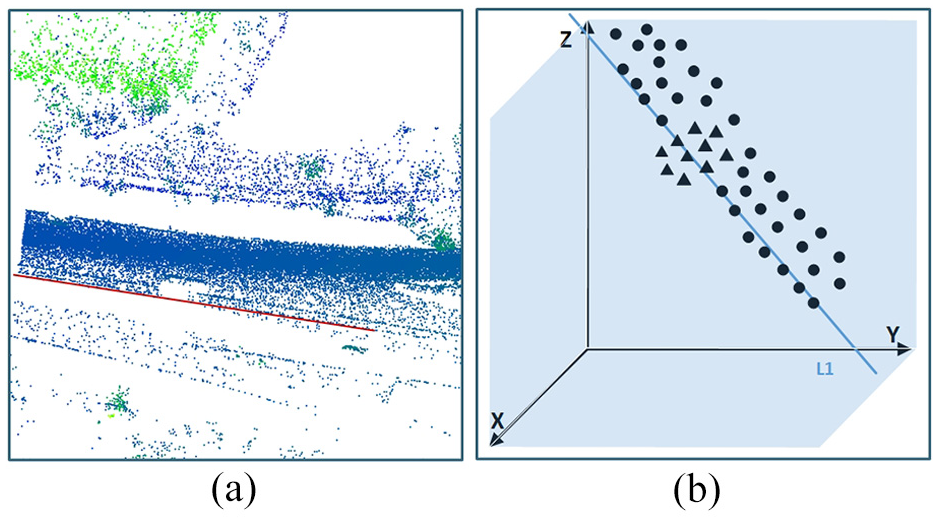
Redundant data processing: (a) boundary curve fitting and (b) completed point set.
The specific process for redundant data processing in the missing area is as follows:
Step 1: Obtain the point set
Step 2: Obtain the reference line L2:
Step 3: Obtain the intersection point C of lines L1 and L2. The intersection point
Step 4: Determine and remove the point set
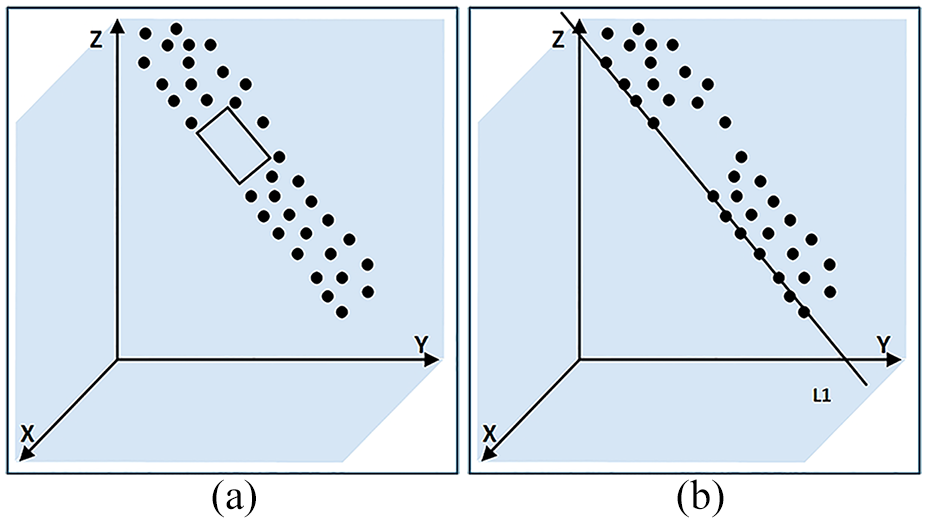
Line fitting: (a) original point cloud and (b) the line fitting boundary points.
Complementary results: (a) processing schematic and (b) graph of processing results.
If Point A is located outside of the roadway, then remove newly generated points that are on the same side as A, while keeping the points that are not on the same side as A.
If point A is located inside the edge of the roadway, then keep newly generated points that are on the same side as A, while removing points that are not on the same side as A.
Experiments and analysis
Experimental environment
Our data source is HighWay point cloud data of the sixth ring road area in Changping District, Beijing, which is collected by the RIEGL VMY-2 dual scanner mapping system with a laser emission frequency of 400 kHz, a view field of 360°, a scanning speed of 200 lines per second, and a measurement accuracy of 10 mm. The HighWay point cloud is about 3G, 111,969,986 points, including roads, vegetation, and other categories. The main experimental environment is Windows 10, Ubuntu 16.04, PyTorch 1.4, etc.
Results and analysis
Experiments on road semantic segmentation algorithm
During the training of the road semantic segmentation network, a five-layer network is used with 8, 32, 128, 256, and 512 feature values respectively, which is trained using the Adam optimizer with 0.01 learning rate. The number of nearest points K is set to 16. The number of down sampling times is 5, the batch size is 16, and the number of epochs is 100.
The experiments on semantic segmentation mainly compares the PointNet network, RandLA-Net network, and ours on HighWay data. The segmentation results are compared based on the evaluation metrics Intersection over Union (IoU) and Mean Intersection over Union (mIoU).
The receptive field of PointNet network is relatively limited, which results in better segmentation performance for indoor scene data compared with large scene data such as roads. The segmentation result on road segment is shown in Figure 12(a), where green points represent road data and purple points represent vegetation data. The segmentation result on the entire roads is shown in Figure 12(b). We can conclude that the segmentation results of road segments and entire roads are not fine-grained enough.
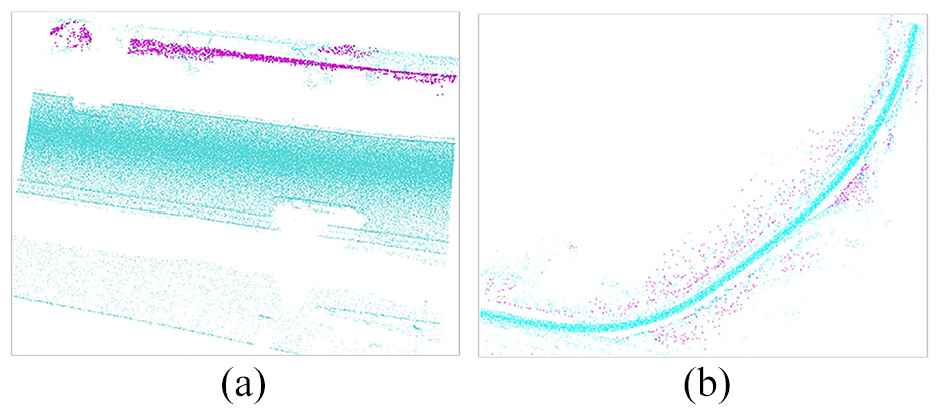
PointNet segmentation results: (a) road segment and (b) entire roads.
RandLA-Net and ours have a larger receptive field than the PointNet network, making them suitable for segmenting large scene data. But the semantic segmentation results of RandLA-Net on road data is not satisfactory with poor perception of road data edges and elevation feature information. The segmentation result of RandLA-Net is shown in Figure 13.
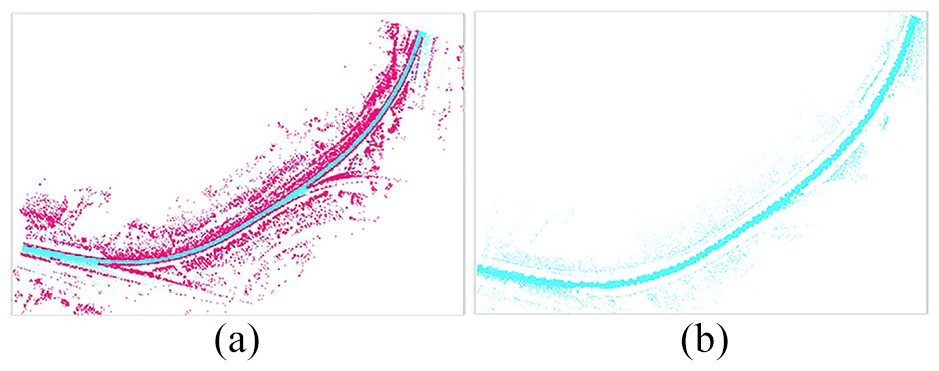
RandLA-Net segmentation results: (a) semantic segmentation result and (b) road points.
Our algorithm integrates edge and elevation features of road scene, enhancing the network’s perception of edge information, significantly improving the precision of data segmentation and leading to an overall satisfactory result. The segmentation results are illustrated in Figure 14.
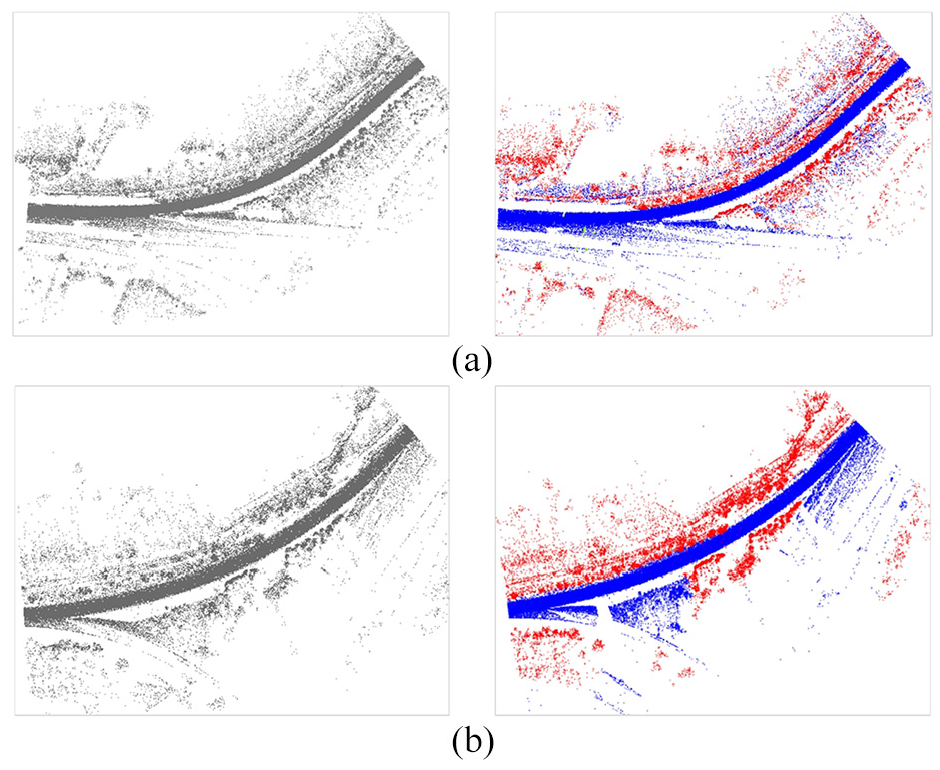
Our algorithm results: (a) segmentation result of HighWay segment 1 and (b) segmentation result of HighWay segment 2.
For these three algorithms PointNet, RandLA-Net, and the algorithm proposed in this study, the quantified results are shown in Table 1. To evaluate the segmentation performance of our network model, we choose two commonly used segmentation metrics: Intersection over Union (IoU) for each category and mean Intersection over Union (mIoU) for the average IoU value of all category data. Through a comparative analysis of the related algorithms, we found that our algorithm performs well in semantic segmentation based on point position, edge and elevation feature information of road scene. The experimental results indicate that ours has a high accuracy rate of 90.70% for segmenting road data.
Accuracy rate of road segmentation based on HighWay data (%).
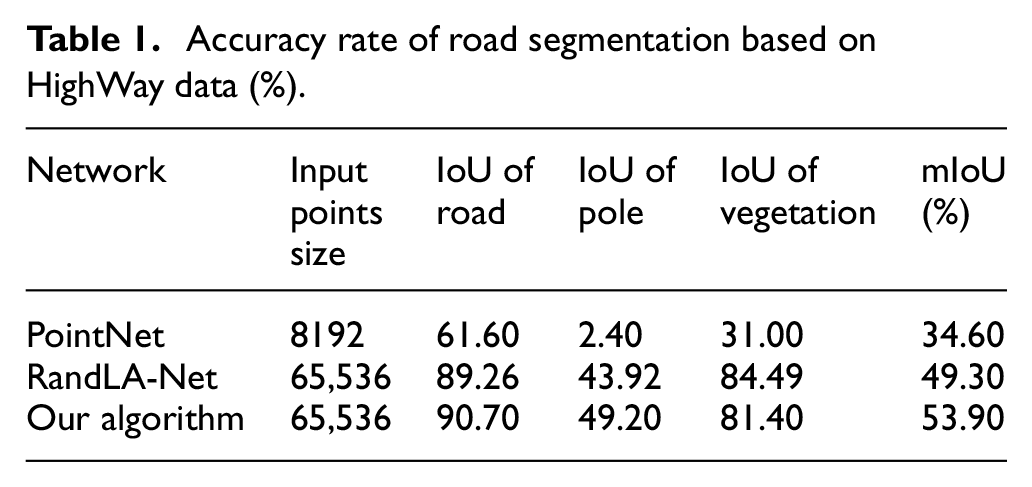
Experiments on PCCA robustness
The HighWay point cloud is cropped to about 600 M, 21,344,635 points in robustness experiments. The missing data ratio is calculated by equation
HighWay point cloud data with the missing data ratio 25%, 50%, and 75%.
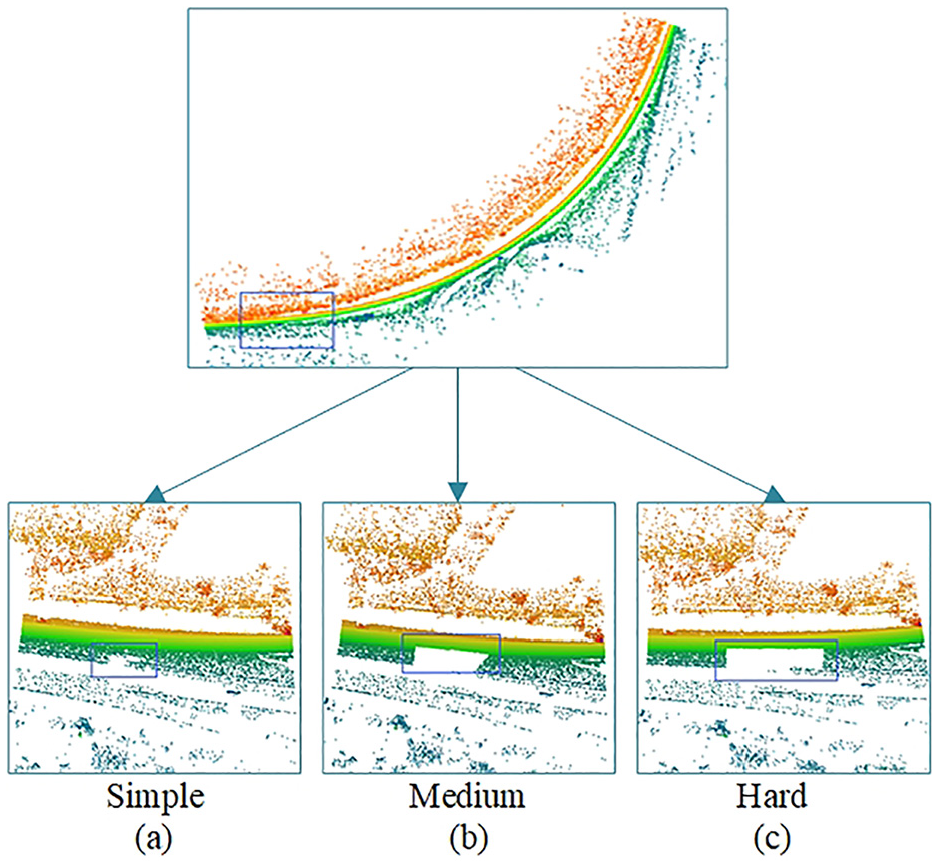
For qualitative analysis of robustness experiments, we execute PCCA using 25%, 50%, and 75% missing ratio data and display its visualization effect. The results show good adaptability to different missing data situations. The visualized completion results of PCCA are shown in Figure 16.
Completion results: (a) simple, (b) medium, and (c) hard.
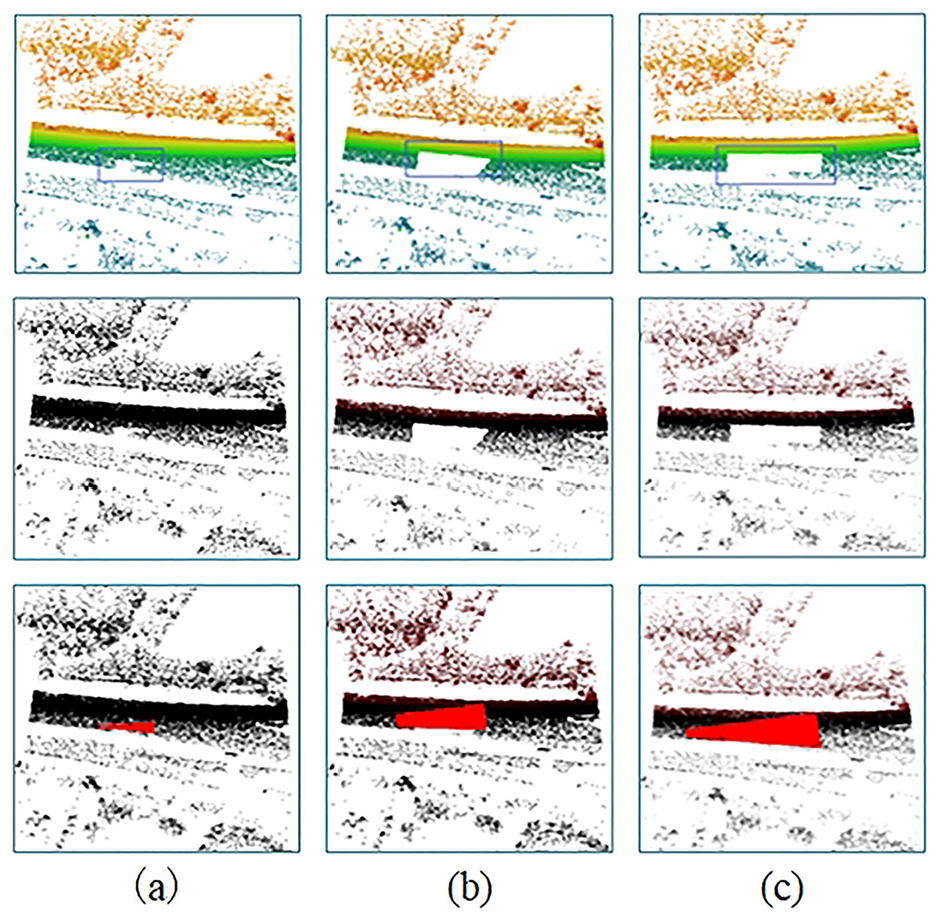
In the point distribution experiments, we take the experimental data in the hard case, compare the point distribution in the same area and test the algorithm adaptability for specific missing area based on the specific number of missing points. The point distribution experimental results are shown in Figure 17, where the original missing point cloud is shown in Figure 17(a), and the completed point cloud is shown in Figure 17(b). The missing area has obvious data completion effect and accurate data completion location, indicating the PCCA is effective for road point cloud completion in specific area.
Point distribution: (a) raw data and (b) completion data.
For the analysis of grouping data volume, the missing point cloud and the completed point cloud are divided into four groups according to the X-axis value, and the result comparison is shown in Figure 18 (X-axis represents the number of groups, and Y-axis represents the number of point). The point volume in the second, third and fourth groups is significantly increased compared to the original missing data, indicating a clear improvement and a high fitness degree in data completion
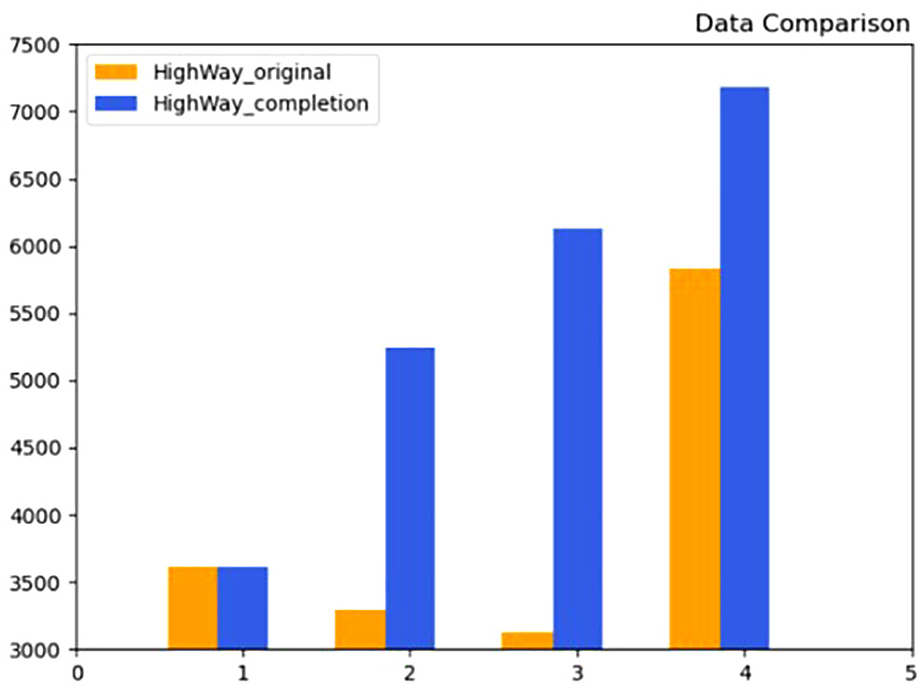
Grouping data volume.
In conclusion, from the visualization effect, point distribution and grouping data volume experiments, PCCA shows strong robustness under different missing data situations.
Comparative experiments on PCCA accuracy
The completion algorithm based on deep learning such as PCN and PF-Net have better completion effects eff for objects with distinct shape features and high missing ratio. Road point cloud has less distinct shape features and low missing ratio with relatively stable elevation information, which is suitable to be completed through more than one stages.
Comparison experiments for deep learning network PCN using HighWay road point cloud, ShapeNet dataset and KITTI road point cloud are conducted respectively. We train the PCN model on HighWay road point cloud and KITTI road point cloud, and the experimental results shows that the completion network has defects in the linear and planar data with less distinct shape features. The KITTI road point cloud completion is shown in Figure 19(b), and the HighWay road point cloud completion is shown in Figure 19(c). Then, we train the PCN model on ShapeNet dataset. A comparison of this network effect on the nonlinear data, linear and planar data completion is shown in Figure 19(a). The above experimental results show that PCN completion network has a defect in locating and completing the missing data accurately in terms of road data with less distinct shape features.
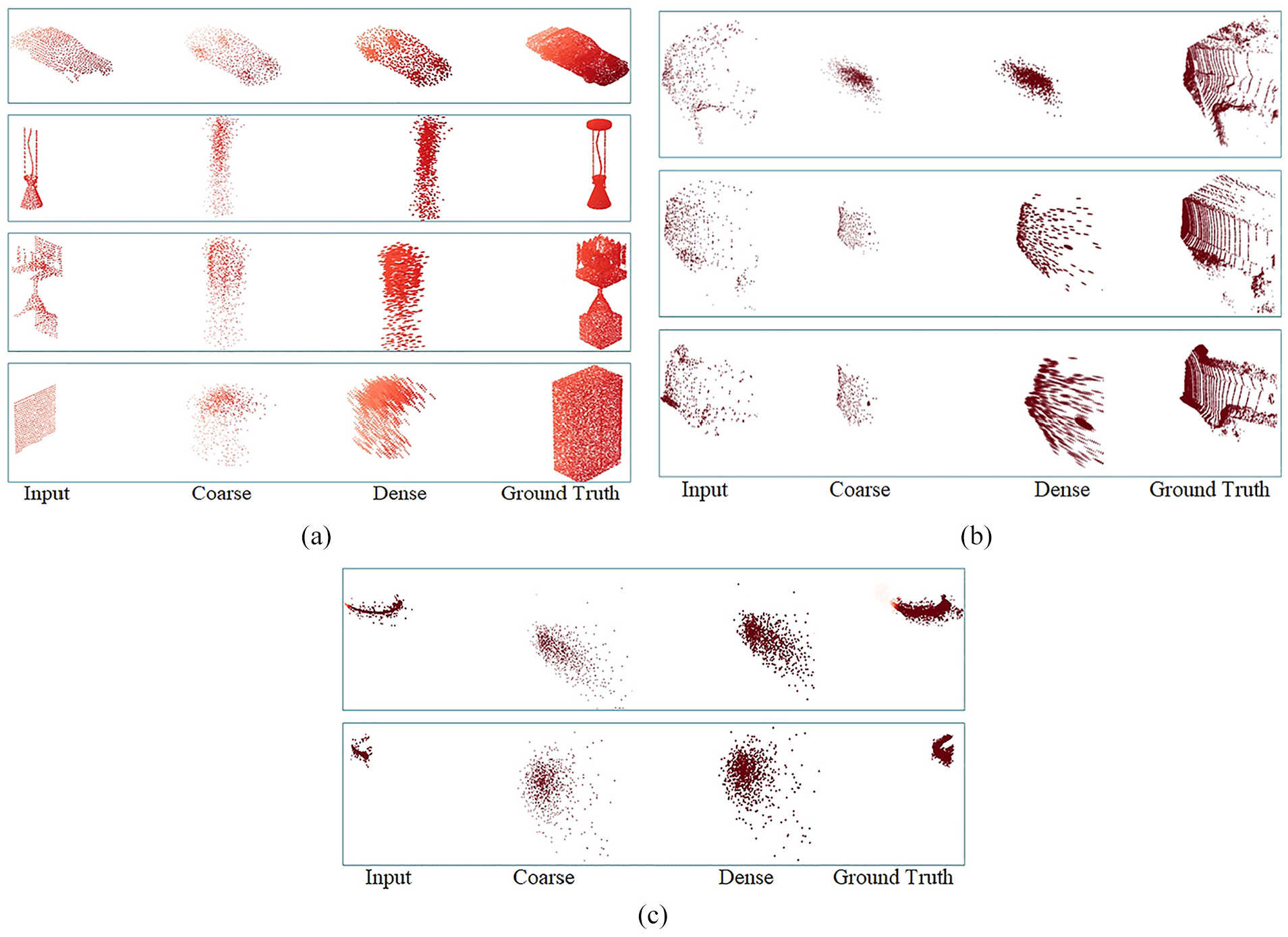
PCN completion: (a) ShapeNet data completion, (b) KITTI data completion, and (c) HighWay data completion.
Through the comparison experiments for deep learning network PF-Net using HighWay road point cloud and KITTI road point cloud respectively, PF-Net shows less sensitive to linear shapes such as roads, and is not effective in completing the hole details in the rectangular region in Figure 20. The results of KITTI road data completion and HighWay data completion are shown in Figure 20.
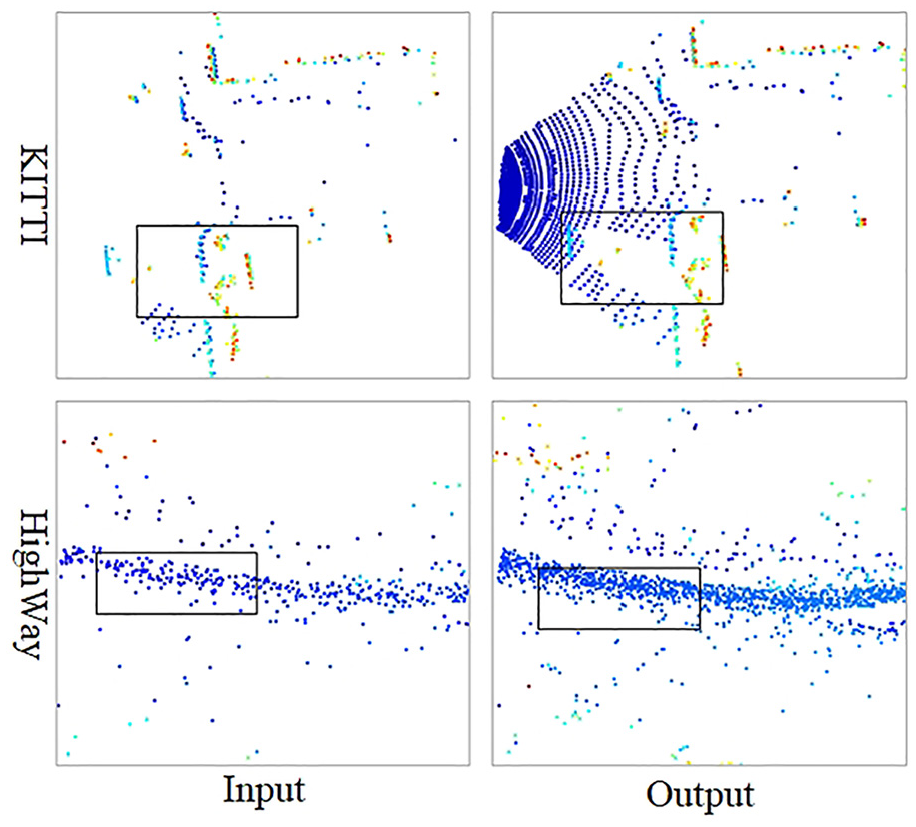
PF-Net completion.
In conclusion, both PCN and PF-Net show bad completion effect in the linear or planar data with less distinct shape features. The experiments prove that PCN and PF-Net are not adaptable for the road data model to realize missing area completion accurately.
To quantitatively evaluate the PCCA accuracy, 40,000 points are selected from HighWay point cloud as the validation point cloud and cropped into three original point sets. Three comparative experiments are conducted to obtain the average results. The original point cloud is defined as PD, the completed point cloud is defined as PR, and average nearest neighbor distance between PD and PR is calculated and defined as error Er. The three original point sets and their completion results are shown in Figure 21.

Our algorithm results: (a) original point set 1, (b) original point set 2, (c) original point set 3, (d) completion result 1, (e) completion result 2, and (f) completion result 3.
Due to the road segmentation and the point cloud sampling, the number of points may vary, leading to fluctuations in the Er values for the three sets of data. However, for the data set of 40,000 points, our experimental results are basically stabilized at 0.08. Comparison of the average point volume completed by different algorithms and their changes in average Er are shown in Table 2.
HighWay road data completion errors.
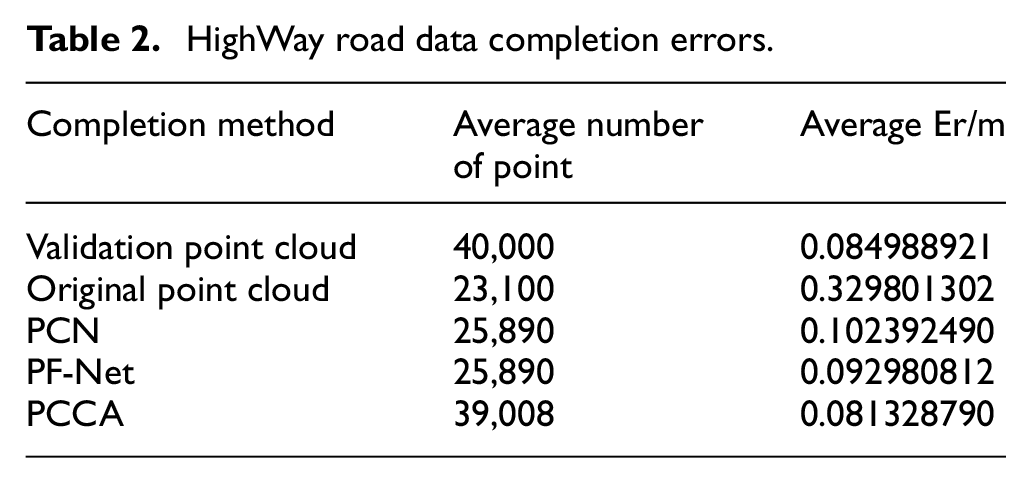
Comparison of the point volume completed by different algorithms and their changes of Er are shown in Table 2. PCCA outperforms other algorithms in terms of the number of completed points and Er index.
Discussion
The majority of existing point cloud completion algorithms are not sensitive to linear and planar data because of lacking in semantic priori knowledge. This paper proposes an OSM-based LiDAR road point cloud completion method, PCCA. Through experimental validation using HighWay data, it is proved that PCCA could complete the road missing area data with 0.08 m Er value and adapt to 25%, 50%, and 75% missing ratios. Based on semantic information and priori knowledge of road boundary curves, PCCA eliminates the constraints of hardware environment and data size, supports easy processing and implementation. Additionally, PCCA could locates the missing road area with high algorithm accuracy and strong algorithm robustness.
Deep learning network algorithms such as PCN and PF-Net are more effective in completing objects with distinct shape features and high missing ratios. Road point cloud usually has less distinct shape features and lower missing ratios, with relatively stable elevation information of the same road. Therefore, comparing these deep learning networks using HighWay point cloud, ShapeNet dataset, and KITTI road point cloud, PCN demonstrates poor completion performance on linear and planar data with less distinct shape features. These experiments confirm that PCN is not suitable for accurately completing missing road area. Similarly, PF-Net also shows less sensitiveness to linear data like roads and fails to effectively complete hole details.
From the experiments, PCCA shows better algorithm performance on road point cloud with less distinct shape features. However, there are still some limitations of PCCA:
The process of PCCA is complex, including missing area boundary extraction based on OSM priori knowledge and missing road point cloud completion. It is important to simplify the algorithm processing flow, reduce algorithm complexity, and improve calculation efficiency.
The dataset used in the current experiments is not enough to prove the general applicability of PCCA. In the future, we will apply road point cloud from different regions and terrains to conduct more extensive experiments and optimize the algorithm.
The lack of a unified standard (or benchmark) for point cloud completion makes it difficult to quantify experimental results, leading to a complex experimental comparison process. This is an issue that needs to be addressed in the future.
PCCA cannot been applied to real-time systems temporarily because of the feature aggregation method in the data semantic segmentation, which segments the data according to the OSM map and KNN (K-Nearest Neighbor) algorithm to accurately encode the positional relationship of the point cloud data and its neighborhood as position and feature. In the future, we will further optimize this algorithm that strengthening the contextual representation ability of high-level features information by constructing a deep learning network to achieve real-time processing.
Conclusion
This paper focuses on LiDAR road point cloud completion and proposes a novel LiDAR road point cloud completion algorithm (PCCA) based on OSM boundary constraint. The algorithm has been experimentally validated using HighWay point cloud. Compared to deep learning network algorithms PCN and PF-Net, the experiments proves PCCA exhibits strong robustness and high accuracy in realizing road point cloud completion. By employing the PCCA method, the Er value of the missing point cloud is reduced to 0.08 m, which contributes to enhancing the accuracy and integrity of high-precision maps. Furthermore, this research promotes the advancement in the fields of autonomous driving and unmanned aerial vehicles.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Data availability statement
The data used to support this research is included in the article. Additional data, collected as part of this project, cannot be shared due to project requirements.