
Abstract
Timely detection of early pavement distress is crucial for effective pavement maintenance. A promising approach involves the segmenting the road surface cracks area from its images. However, the previously employed full-resolution residual network (FRRN), when employing a large number of full-resolution residual units (FRRUs), is susceptible to challenges such as exploding and vanishing gradients. Addressing these issues, this paper has introduced a depth supervision mechanism into FRRN, leading to the development of the Depth Supervision FRRN (DSFRRN) model, designed specifically for accurate segmentation of cracks in road images. This model enhances nonlinear expressiveness while retaining essential features, achieving high precision in pavement crack segmentation. Through experimental validation using a dataset comprising 1565 images of damaged pavements, the result demonstrate that DSFRRN outperforms the original FRRN in terms of both F1 score and Jaccard index, accurately delineating cracks. Consequently, the automated pavement damage detection method presented herein facilitates cost-effective and efficient pavement inspection, contributing to the safeguarding of roadway surfaces and transportation infrastructure.
Introduction
Road transportation is an essential method of land transportation worldwide, playing an important role in the collection and distribution of materials at ports, stations, and airports. Due to rain erosion 1 and the increase of heavy vehicles, the load-bearing capacity of the road decrease. Most roads have encountered the problem of insufficient load-bearing capacity, resulting in pavement damages of varying shapes and sizes. If such road damage is not treated at the initial stage, the appearance, load-bearing capacity, and service life of the road will be reduced. 2 Untreated early road damage will also lead to more serious degradation, which will require greater maintenance investment. In the worst case, road damage will significantly affect existing highways’ life cycle and structural safety and cause serious economic losses, traffic accidents and casualties. Therefore, automated road detection algorithms are attracting increasing attention from researchers due to the rising difficulty and cost of highway maintenance and management. 3 Traditionally, Road maintenance inspection was based on manual on-site investigations, with inspectors driving vehicles to observe and record the road surface. This method lacks efficiency and requires excessive investment time, manpower, and material resources costs. The results are also significantly affected by subjective factors. 4 Most road maintenance management systems established in many countries rely on hardware equipment, which is time-consuming and labor-intensive to use. Such inspection equipment impedes traffic, and some even destroy the integrity of the road structure. 5
In response to the low work efficiency of manual field surveys and the high cost of manpower and material resources, researchers have proposed automatic segmentation algorithms based on pixel thresholds to improve work efficiency. Amhaz et al. 6 divided images into sub-blocks, selected the smallest path to extract the fracture skeleton, and set the pixel weights on a skeleton to determine the threshold and complete segmentation. This algorithm was only suitable for images with single cracks without crossover and had low applicability. Huang and Xu 7 proposed a cell image crack detection algorithm. The algorithm divided the pavement crack image into grids, calculated the crack grayscale contrast value to determine the crack pixel, and obtained crack segmentation by setting the grayscale contrast value threshold. Fujita and Hamamoto 8 propose the use of median filtering combined with the removal of image shadow through subtraction of the original image to identify cracks. Yamaguchi and Hashimoto 9 employ a percolation algorithm for rapid identification of cracks in large-sized images. Tang and Gu 10 employed the difference of cracks and gray road information to segment cracks. However, even though the aforementioned algorithms are simple to operate, there nonetheless remain many fundamental drawbacks about the poor segmentation performance and the low detection accuracy when the noise produced by uneven illumination, stains, and road lane lines, exists in images. To overcome the negative influence of noise, Dinh et al. 11 used Hessian Matrix to preprocess the image to alleviate the influence of noise and thus achieve a better segmentation result. This method eliminates the destructive influence of image noise to a certain extent but ignores the correlation of crack pixels, resulting in poor detection ability for mesh cracks with a complex structure. Hence, based on the edge characteristics of cracks, researchers in great number applied Laplace, Sobel, and Canny edge detection operators 12 to segment cracks in images. Ayenu-Prah et al.13,14 utilized the Sobel operator to extract the gradient features of the degradation and segment the crack edges. But the crack detection method based on edge detection operators can only identify the edge of cracks and has no way to quantitatively study the width information of cracks.
Road damage detection methods based on deep learning have emerged more recently, facilitated by the continued evolution of computer technology and the performance of equipment. These methods can achieve feature learning and classification, with high accuracy and fast detection speed. A promising approach involves Zhang et al. 15 used a convolutional neural network to determine whether a single image was a crack based on the local block information of the image. Cha et al. 16 used a sliding window to divide the image into blocks and then applied a convolutional neural network to extract the characteristics of cracks and classify them. Mei et al. 17 introduce a novel deep learning-based pavement crack detection method that considers pixel connectivity by employing a depth neural network that integrates multi-level features through the use of transposed convolutional layers. Liu et al. 18 proposed an improved U-net to segment cracks. The encoder was replaced by pre-trained ResNet-34, and space and channel compression modules were added to the up-sampling part to conduct experiments on road crack data sets under different conditions. Simulation results showed that the algorithm improved segmentation efficiency and accuracy. Billah et al. 19 used a deep convolutional neural network to segment cracks and proposed a crack segmentation framework containing feature modules, which eliminated non-discriminatory feature mapping from the network. However, the accuracy of the segmentation framework was not high.
Fully convolutional neural network 20 has been successfully applied in image segmentation. U-Net incorporates dense or residual connections to enable short patch connections for feature fusion within different channels. Moreover, the full-resolution residual network (FRRN) outperforms the residual network (ResNet) in passing full-resolution features to the different layers of the model. FRRU is the basic module of FRRN. The FRRU structure is used to enable the model to couple the information carried in the two processing streams. FRRU references the design method of the residual unit, which makes the network have a good gradient conduction property and can acquire both low-level and high-level features. The special design of FRRU enables the network to achieve precise semantic segmentation in street scenarios without pre-training models and post-processing. These enhancements have yielded high performance in street image segmentation. But the loss function of the FRRN network cannot take global pixels into account, it cannot provide direct supervision for the training of low and mid-tier network. Further, it will cause gradient explosion and gradient disappearance problems.
In this article, a deep supervision module is introduced to different levels of FRRN, and the deep supervised FRRN (DSFRRN) is proposed to segment pavement crack images. DSFRRN adds a supervisory mechanism that retains the overall network structure of the FRRN. In addition, 1 × 1 convolution and Dice loss are added to the four decoding layers of the FRRN to establish a road crack area segmentation model based on DSFRRN that can reduce the loss of effective feature information and improve the nonlinear expression ability of the model. The deep supervision mechanism was first proposed in DSN (Deeply Supervised Nets) 21 as a training skill for large training samples and the deep network structure. The so-called deep supervision mechanism refers to that auxiliary classifiers or loss functions being added to some hidden layers of a deep neural network as its branches to provide supervisory signals for the training of the main trunk network. 22
Methodology
Design of pavement crack detection framework based on DSFRRN
The road crack samples are involved in the initial step of the experimental process. Initially, 1565 images containing cracks from various road environments, representing different types and complexities of cracks, were collected. Next, the dataset was divided into training, validation, and testing sets in a 7:2:1 ratio to ensure comprehensive and reliable model training, parameter tuning, and performance evaluation. After the division, the crack areas in the samples were accurately annotated using the LabelMe program, an open-source image annotation tool. Through manual labeling, high-quality label data for each crack sample was generated for model training. Once the model parameters were set, the DSFRRN model was trained. During training, hyperparameters like batch size and learning rate were tuned to ensure effective learning and extraction of crack features by the model. Upon completion of training, the weights of the crack segmentation model were obtained. With these trained weights, the test images were segmented. This process specifically involved inputting the test images into the model, which subsequently output the predicted crack areas. To assess the model’s performance, the predicted results were compared with the true labels of the test samples. The evaluation encompassed recall, accuracy, and F1-score, comprehensively reflecting the model’s detection performance and robustness. Recall quantifies the proportion of actual cracks detected, accuracy measures the proportion of correctly predicted crack areas, and F1-score, the harmonic mean of precision and recall, offers an overall performance measure. The entire crack detection framework, depicted in Figure 1, encompasses data collection, annotation, model training, prediction, and evaluation, with each step meticulously designed and optimized to guarantee the final model’s reliability and effectiveness in practical applications.
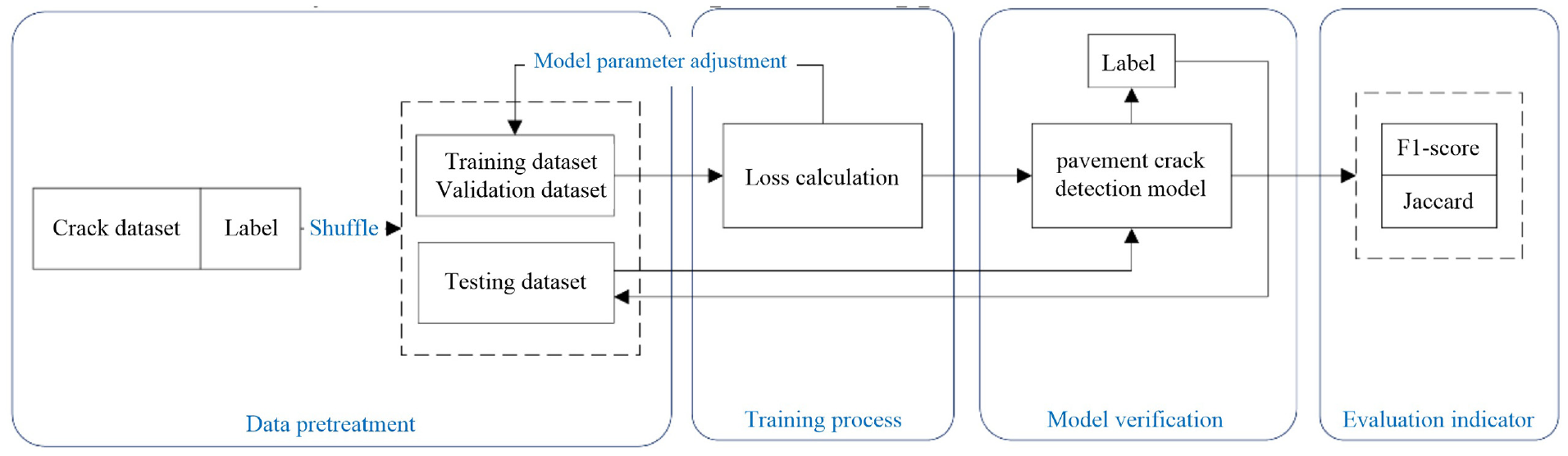
Road crack detection framework based on the deep supervised full-resolution residual network (DSFRRN).
FRRN
With the increasing development of computer vision technology, excellent image semantic segmentation networks have emerged one after another. The encoder-decoder structure is innovatively proposed in the U-net. The encoder gradually reduces the spatial dimension of the image, whereas the decoder gradually repairs the details of the object and recovers the spatial dimension of the image. Meanwhile, a skip connection structure is set up between the encoder and decoder to better repair the details of the target. The residual network structure is proposed in the ResNet, resulting in solving the problem that the model training effect is too poor due to the network structure being too deep.
Nowadays, traditional image semantic segmentation networks mostly rely on pre-training models to improve their recognition accuracy, but a lot of spatial information is lost due to its pooling operation, which further leads to poor positioning accuracy. To alleviate the above-mentioned problem, a full-resolution residual network (FRRN) captures the idea of the U-Net and ResNet model, and a network model with two processing streams is proposed, which combines multi-scale context information with pixel position accuracy and thus both the recognition accuracy and positioning accuracy of the FRRN are considered. 23 The structure of the FRRN model is shown in Figure 2, in which one processing flow carries full-resolution features throughout the whole network to achieve accurate boundary segmentation; the other processing flow uses a classic U-shaped structure, applying convolution, pooling, and concatenate operations to obtain high-level semantic information. Beyond this, fully-resolution residual units (FRRUs) are proposed in FRRN to couple the information carried in the two processing flows.
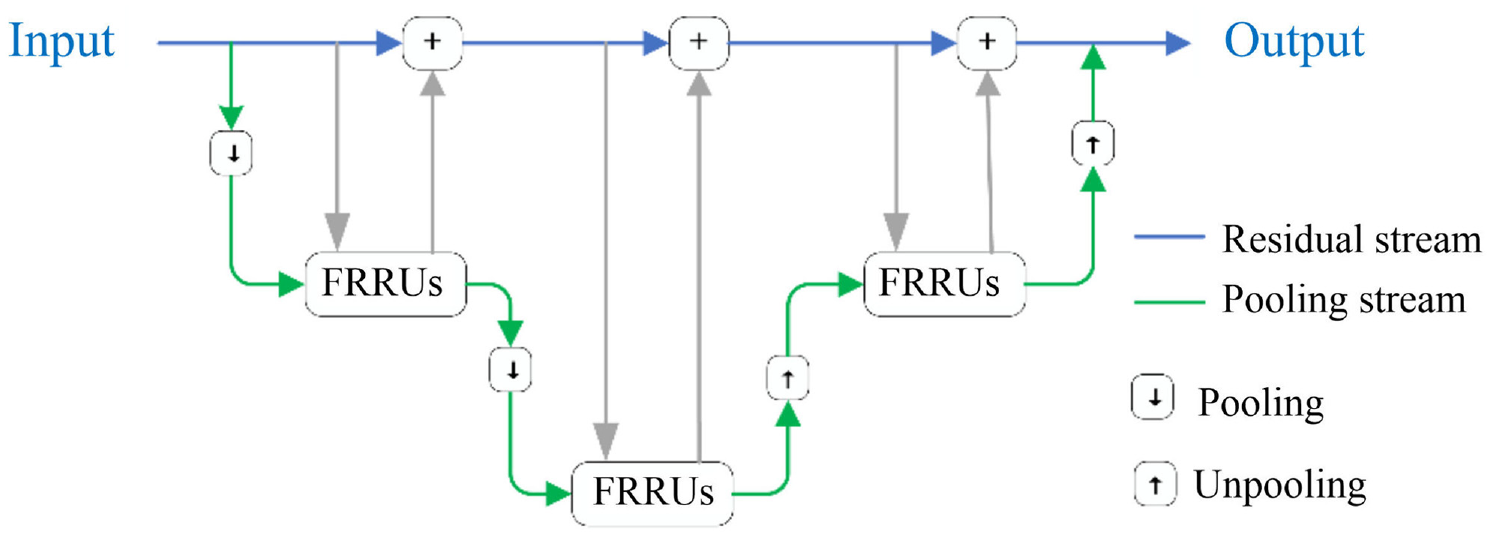
The structure of FRRN.
Full-resolution residual unit (FRRU)
FRRN draws on the structure of the feedforward network and the residual network. 24 It designs a full-resolution residual unit so that the network has similar gradient transfer advantages to the residual network. The residual network was proposed by He et al. to solve the problems of gradient disappearance and gradient explosion. It can train a deeper network while ensuring good performance. The mathematical operation of the FRRU is shown in Figure 3.
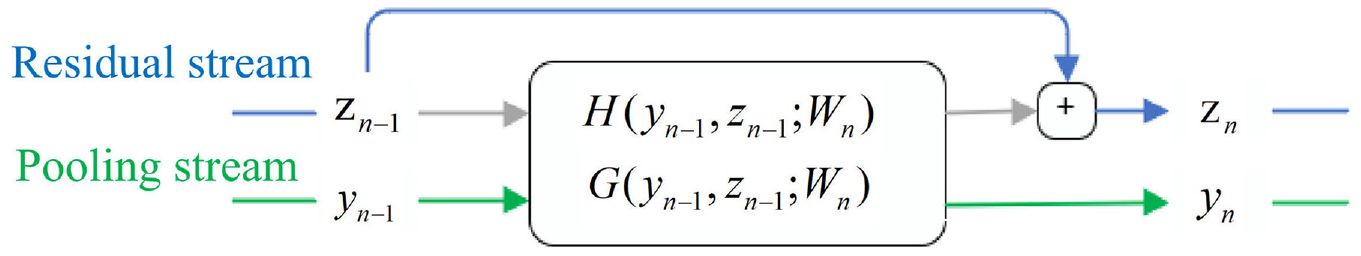
Full resolution residual unit (FRRU).
The FRRU has two inputs and two outputs that process data from the two processing streams and return the processed data to the two streams. In Figure 3,

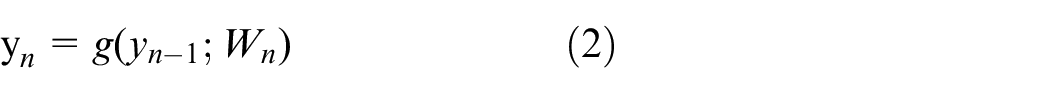
where
The structure of the FRRU is shown in Figure 3, where each FRRU includes a pooled stream operation G and a residual stream operation H. FRRU first reduces the size of the residual flow feature map by pooling the stream operation G and then uses the concatenate operation to connect the two input streams. The feature map after the stacking operation needs to pass through two convolution units. Each convolution unit consists of a 3 × 3 convolution (conv3 × 3), a batch normalization (BN) layer, and a ReLU activation function. The second convolution unit has two outputs; one stream is used as the input of the pooling stream of the next FRRU, and the other is reclassified into the residual stream after the H function. The residual flow operation H adjusts the number of channels of the feature map through a 1 × 1 convolution and offset operation and then enlarges the spatial size of the feature map through an up-sampling operation. As illustrated in Figure 3, the H function includes the G function. This design can provide a good gradient flow for the weight unit of the network.
Set deep supervision signals
In this study, the depth and size of the network will increase as the number of FRRUs increases. FRRN uses a large number of down-sampling and up-sampling operations in the pooled stream channel to transfer multi-scale context information to the higher-resolution network layer. These network layers carry a large amount of information. If only the top-level loss is used to supervise the training of the middle-level network, it will cause problems, including loss of information or non-convergence of training due to gradient disappearance and other issues. To solve this problem, this paper adds additional loss as a supervision signal to the decoding layer of FRRN, which can better promote the learning characteristics of the middle-level network and improve the recognition and segmentation performance of the network.
The FRRN network only uses bootstrapped cross-entropy loss to supervise training in the last top-level network. Where
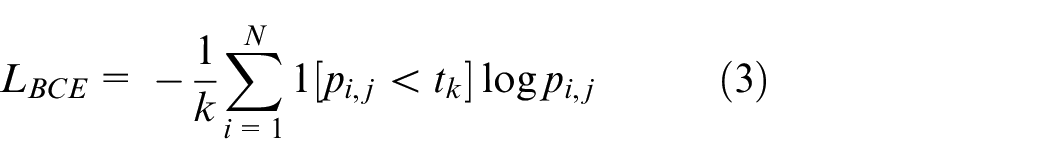
Among them, if x is true, then 1[x] = 1; otherwise, 1[x] = 0. The threshold
The loss function focuses on the edge pixels of the object during training. As the number of pixels considered by this function relative to the number of pixels in the entire picture is too small, the classification accuracy of pixels in the entire picture tends to be low.
To further improve the accuracy of network pixel classification, 1 × 1 convolution and Dice loss are added to the network layer decoder part (behind the four FRRU modules). The bootstrapped cross-entropy loss and Dice loss are used as supervision signals to supervise the decoding process in network training. Dice loss is used to evaluate the similarity of two samples and can better consider the classification accuracy of the pixels of the entire image. Referring to Dice loss as DSC, the calculation process is as follows:
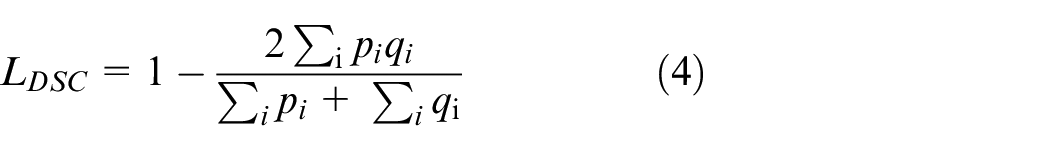
where
Therefore, the total loss of the FRRN model based on the deep supervision proposed in this paper includes one bootstrapped cross-entropy loss and four Dice losses. The total loss of the network is denoted as L and calculated as follows:

To optimize the FRRN model based on deep supervision, the training process must continuously iterate the parameters to minimize all network losses and improve the segmentation performance of the model.
DSFRRN
The structure of the DSFRRN proposed in this study is illustrated in Figure 4. This innovative model builds upon the FRRN (Full-Resolution Residual Network) as its backbone and introduces a novel deep supervision mechanism into the decoder part of FRRN’s U-shaped architecture. Specifically, this mechanism is integrated into the four up-sampling layers, creating a deeply supervised FRRN model. The DSFRRN model comprises four main components: the residual flow structure, encoder-decoder structure, FRRU structure, and deep supervised structure.
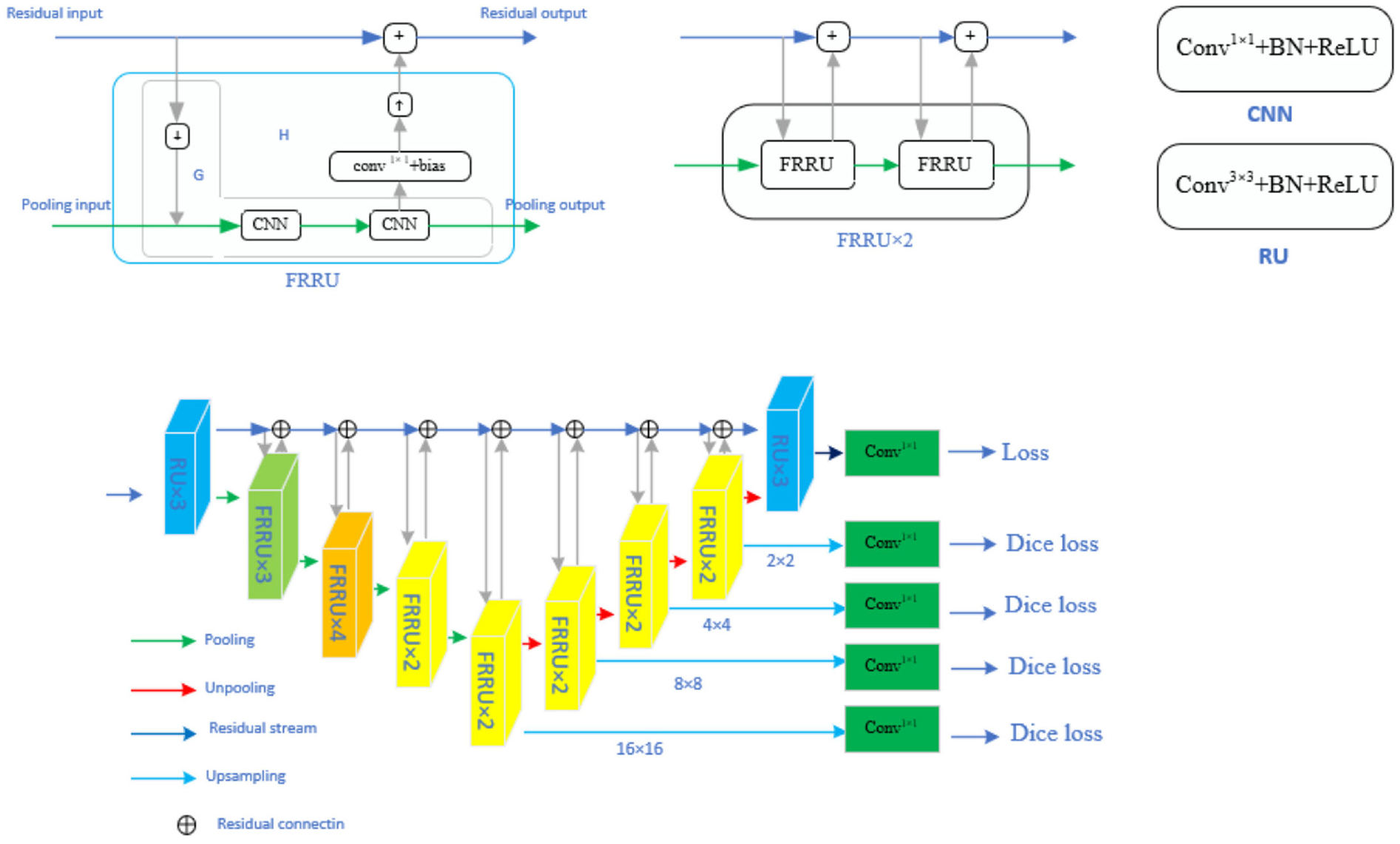
The deep supervised full-resolution residual network (DSFRRN) model.
The residual flow structure, represented by the blue arrows in Figure 4, transmits full-resolution information and refines boundary segmentation. This ensures that high-resolution details are preserved throughout the network, which is crucial for accurate boundary detection in crack segmentation. The encoder-decoder structure, illustrated by the green arrows, extracts high-level features from images to improve recognition accuracy. This dual ability to capture both low-level and high-level features enhances the model’s capability to recognize complex patterns within image data. The FRRU (Full-Resolution Residual Units) structure forms the foundational architecture that allows for full-resolution processing, maintaining high resolution throughout the network, which is critical for detailed segmentation tasks.
The deep supervised structure adds a supervision mechanism at multiple layers of the decoder. Specifically, after the 12th, 14th, 16th, and 18th FRRU, the model includes a 1 × 1 convolution followed by Dice loss at the 16 × 16, 8 × 8, 4 × 4, and 2 × 2 up-sampling layers. The 1 × 1 convolution operation adjusts the number of channels in the output features, reducing the computational complexity of the Dice loss. The combination of four Dice losses and one bootstrapped cross-entropy loss provides comprehensive supervision during training. This multi-level supervision enables the model to constantly adjust the weights and biases of each network layer according to the change in each loss value during the training process, resulting in an excellent image segmentation model.
Overall, the DSFRRN model represents a significant advancement in pavement crack segmentation. The deep supervision mechanism allows DSFRRN to leverage fine-grained feedback at multiple scales, helping the model learn more robust features and improving overall segmentation accuracy. The residual flow structure ensures that full-resolution information is preserved, which is critical for precise boundary segmentation, especially in intricate and detailed crack detection. Additionally, the use of 1 × 1 convolutions before Dice loss calculations reduces computational overhead, making the training process more efficient without compromising performance. This innovative architecture and deep supervision mechanism significantly enhance the model’s accuracy and robustness, offering a superior solution for practical pavement crack detection scenarios.
Experimental data collection and model comparison analysis
Experimental data collection
The experimental data in this article is collected from the Internet public data collection and personal mobile phone shooting collection methods. After cutting and screening, 1565 pixels of 320 × 320, 24-bit RGB road crack PNG images are finally obtained. These images are divided into training dataset, validation dataset and testing dataset. Table 1 shows the number of the three types of dataset, and Figure 5 shows some examples of crack images. The crack images are marked by the LabelMe tool, and the segmentation data contains 1565 crack and labeled RGB images.
Experimental data.


Image sample of pavement cracks. The first and second rows show the original crack images and their ground truth segmention.
Training and testing experiments
In this paper, DSFRRN and other comparison models are implemented in Keras opensource deep learning framework, and NVIDIA TITAN RTX GPU is used for training experiments. The initial learning rate of DSFRRN is set to 0.0001, the learning rate decay strategy is reduced by 0.1 times every 10 rounds, and the minimum number of image samples is set to 8. The trained model is tested on the testing dataset, and then a comparative analysis is performed.
Compared methods
U-Net
U-Net 25 is a neural network suitable for training small-scale dataset, and there are 23 layers in the entire network structure. At present, it is commonly used for medical image segmentation, such as for images of the liver, breast, etc.
Deconvolution network (DeconvNet)
DeconvNet 26 is an improved network based on the convolution part of VGG16. 27 The network is composed of a series of deconvolution layers and unpooling layers. A dense pixel segmentation probability map is realized by continuous unpooling, deconvolution, and ReLU. 28
DeepLabv3+
The latest generation of the DeepLab model is combined with the lightweight network Xception, 29 which is a deeply separable convolution. The models are used as a backbone network for initial feature extraction, and a decoder module is added. This process solves the problem of the DeepLabv3+ model, in which a large amount of detailed information is lost by the feature map being directly upsampled to restore the original image resolution size. Advanced semantic segmentation performance is thus achieved.
Dual Attention Network (DANet)
DANet 26 includes the addition of two types of attention modules to the traditional fully convolutional network, which can learn the spatial and channel characteristics and capture the interdependence of spatial features. It is often used for scene segmentation. 30
FRRN
The FRRN is the basic network of the proposed method. It uses two independent streams (the residual stream and pooling stream) to complete multi-scale processing.
Evaluation index
This paper uses Jaccard and F1 coefficients as evaluation indicators to evaluate the effects of model segmentation.
As important parameters of the two-class problem, precision and recall are important indicators to evaluate the effectiveness of model segmentation. Precision indicates how many of the samples that are predicted to be positive are true positive samples. For a single picture, it refers to the percentage of the predicted correct positive pixels in all the predicted positive pixels (prediction is correct + prediction is wrong); recall indicates how many positive examples in the sample are correctly predicted. For a single picture, it refers to the percentage of positive pixels of the prediction pair in all pixels of the prediction pair (including the correct prediction positive examples and the correct prediction negative examples). The calculation expressions of the two are as follows:
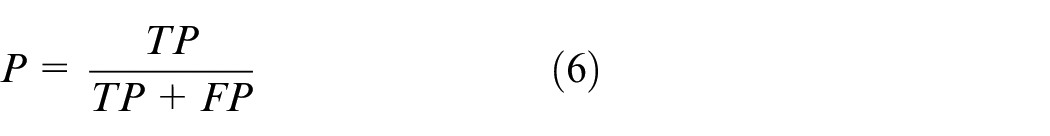
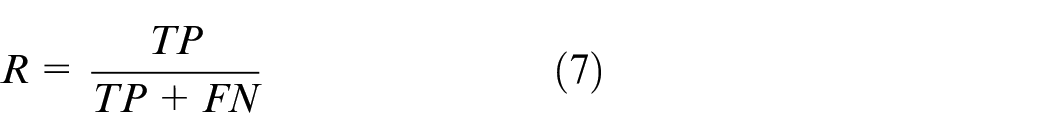
where
Due to the characteristics of the definition itself, the recall rate is often low when the precision rate is high. Therefore, the
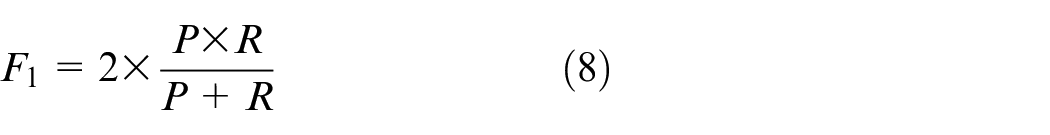
The Jaccard coefficient characterizes the similarity between the sample set predicted by the model and the real sample set and is used to evaluate the accuracy of image segmentation. The value ranges from 0 to 1. The larger the value, the better the image segmentation effect. Its expression is as follows:

Test results
Loss of the DSFRRN and other models
Figure 6 shows the loss variation of the validation dataset by using the proposed and previous networks during the training. As shown in the figure, DSFRRN has the lowest loss in validation dataset. At the same time, DANet achieves the largest valuation loss after training; FRRN have validation losses lower than that of U-Net but higher than those of U-Net, DANet, and DeepLav3+.
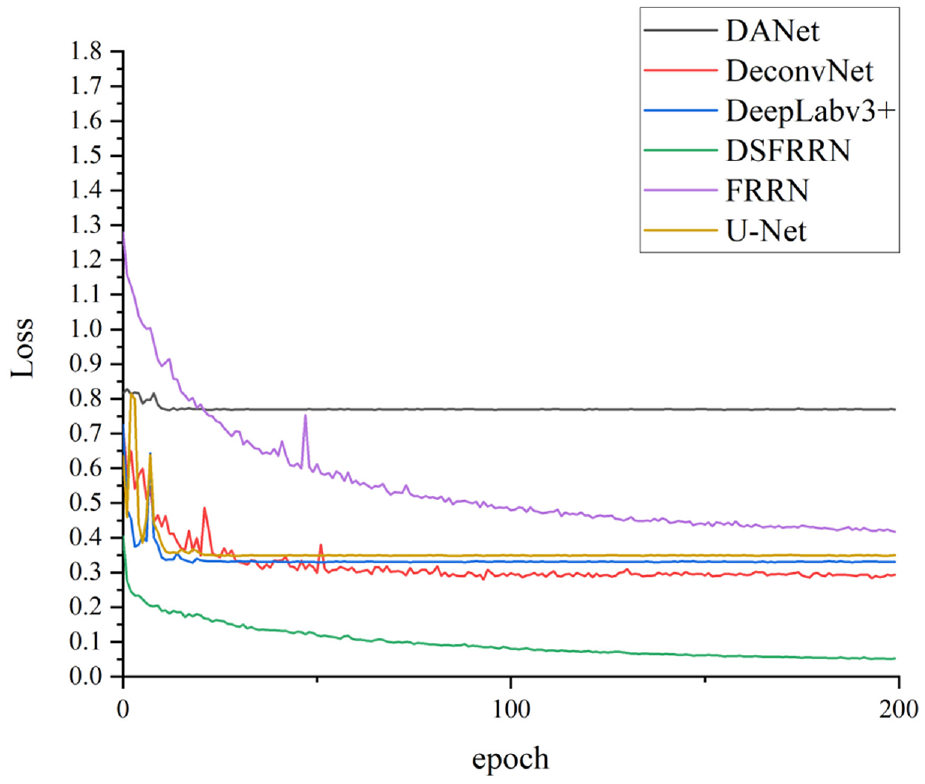
Loss variation of the validation dataset.
Evaluation indicators of DSFRRN and other models
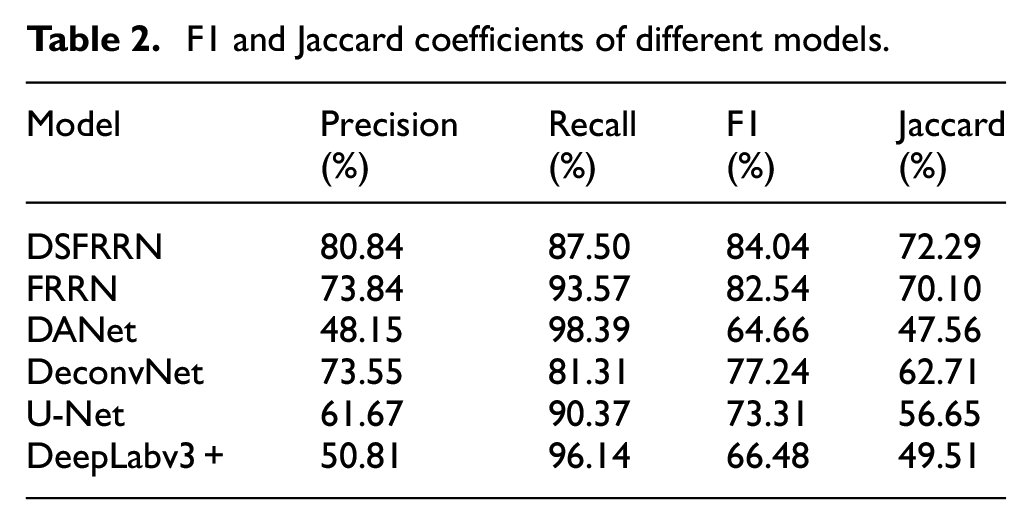
This paper uses 1319 images as the training dataset (1074 images) and validation dataset (245 images) to train DSFRRN, FRRN, DANet, DeconvNet, U-Net, and DeepLabv3+ models, and conducts a prediction segmentation test on a testing dataset composed of 246 images. The average F1 and Jaccard coefficients of the testing dataset are provided in Table 2.
F1 and Jaccard coefficients of different models.
By comparing these metrics, the DSFRRN model demonstrates the highest overall effectiveness, confirming its robustness and precision in segmenting pavement cracks.
From Table 2, it is evident that among the six types of models, the DSFRRN model achieves the highest performance in both F1 and Jaccard coefficients, indicating superior image segmentation performance, accuracy, and similarity. Specifically, the DSFRRN model achieves an F1 score of 84.04% and a Jaccard coefficient of 72.29%. These results highlight the effectiveness of the deep supervision mechanism integrated within the DSFRRN model, which enhances feature learning and segmentation accuracy.
In contrast, the DANet and DeepLabv3+ models exhibit significantly lower performance, with F1 scores of 64.66% and 66.48%, respectively, and Jaccard coefficients of 47.56% and 49.51%. The lower performance of these models may be attributed to their inability to preserve high-resolution details and accurately capture the complex crack patterns present in the dataset.
The FRRN model, while also based on a full-resolution approach, achieves slightly lower performance than DSFRRN with an F1 score of 82.54% and a Jaccard coefficient of 70.10%. This suggests that while FRRN is effective, the addition of deep supervision in DSFRRN provides a notable improvement.
DeconvNet and U-Net models fall in the middle range, with F1 scores of 77.24% and 73.31%, and Jaccard coefficients of 62.71% and 56.65%, respectively. These models perform better than DANet and DeepLabv3+ but are outperformed by DSFRRN and FRRN. The moderate performance of DeconvNet and U-Net can be linked to their encoder-decoder structures, which, while effective, may not fully capture the intricate details required for precise crack segmentation.
Overall, the results clearly indicate that the DSFRRN model, with its innovative deep supervision mechanism and ability to maintain high-resolution details, outperforms other models in pavement crack segmentation tasks. This highlights the importance of advanced supervision techniques and detailed feature preservation in improving segmentation accuracy and robustness.
Model segmentation effect
The segmentation ability of each model is further analyzed through the test results of the six models on the road crack testing dataset. This paper randomly selects three test pictures with different crack characteristics from the testing dataset and employs the corresponding prediction pictures from the prediction pictures of the six models for comparative analysis. The yellow line represents the real boundary (label boundary) and the red box represents the real boundary (model prediction boundary). The specific results are shown in Figure 7.

Test results of pavement cracks under different models.
It can be seen from the model segmentation comparison graph in Figure 7 that the actual segmentation effect is consistent with the evaluation index results. Compared with DSFRRN, the FRRN model exhibits obvious mis-segmentation phenomena, with imprecise segmentation edges that fail to accurately delineate the real boundaries of cracks. This highlights the limitations of FRRN in maintaining high-resolution details, making it inferior to the DSFRRN model. The DSFRRN model, by contrast, excels in retaining boundary segmentation details, offering higher positioning accuracy and better segmentation continuity. The DANet model has the poorest performance among the evaluated models, as evidenced by serious segmentation issues such as overly large segmentation areas and discontinuous segments. These problems indicate that DANet struggles to accurately segment crack-like images, especially when dealing with a limited number of images. This suggests a potential weakness in DANet’s ability to generalize from small datasets, which is critical in practical applications where comprehensive datasets may not always be available. The segmentation performance of the U-Net model is slightly better than DANet but still exhibits false detection phenomena. U-Net’s performance, while an improvement over DANet, is hindered by its tendency to incorrectly classify non-crack regions as cracks, which reduces its overall accuracy. This underscores the challenge of achieving high precision in segmentation tasks, where distinguishing between subtle features is essential. DeconvNet, on the other hand, shows significant missed detections, failing to identify several crack regions entirely. This indicates a shortfall in DeconvNet’s ability to capture and segment fine details, which is crucial for accurate crack detection. The frequent missed detections suggest that DeconvNet’s architecture may not be well-suited for tasks requiring detailed segmentation at high resolution.
Discussion
In this study, DSFRRN was proposed to segment pavement crack. A self-constructed dataset of 1565 pavement crack was used to evaluate and compare the proposed model with other comparative models. Figure 6 shows that the proposed method has the fastest loss reduction and also the smallest loss at convergence. Table 2 provides a quantitative analysis for DSFRRN and the comparison model, and the proposed model has the highest F1 and Jaccard. Figure 7 provides the results of the qualitative analysis, and the proposed method has the best segmentation, outperforming the other models.
In addition to these findings, future work could explore the integration of DSFRRN with real-time detection systems, aiming to enhance the model’s operational efficiency without compromising accuracy. Further studies could also investigate the model’s performance on larger and more diverse datasets, to validate its scalability and adaptability across different pavement conditions and environments. In the future, further analysis will be conducted by comparing with other deep learning models (e.g. YOLO and Faster R-CNN). Besides Jaccard and F1 coefficients as evaluation indicators, more evaluation indicators need to be considered. IoU, the recognition speed and efficiency of the models should also be considered.
In the future, image data of the entire road with different types of cracks and different road conditions (such as flat roads, pits, etc.) should be further collected and crack detection should be performed using the DSFRRN model. In particular, the interference of other factors (such as pits, water stains, shadows, etc.) on the detection results, and pre-processing and post-processing strategies are used to reduce the impact of these interferences on the detection accuracy. It is expected that even in complex road environments, the DSFRRN model can still accurately detect cracks and show good robustness and generalization capabilities.
With the continuous development of computer vision and deep learning technology, the DSFRRN model is expected to play an important role in a wider range of road detection and maintenance tasks31,32. At the same time, future research may involve directions such as combining multi-source data (such as lidar, GPS, etc.) for more comprehensive road condition assessment, and developing more intelligent and automated road maintenance systems33,34.
Conclusion
This paper presented a DSFRRN model that integrated FRRN with a depth supervision mechanism for road crack segmentation. By employing F1 and Jaccard scores as quantitative evaluation metrics, the model achieved the highest values among the six models, namely 0.8404 and 0.7229, respectively. Based on the test results of the test set, DSFRRN outperformed FRRN, DANet, DeconvNet, U-Net, and DeepLabv3+ models in terms of road crack segmentation accuracy and exhibited distinct advantages. Therefore, the road crack detection method based on the DSFRRN model can effectively improve the detection accuracy and provide a reference for road maintenance.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research was sponsored by the National Key R&D Program of China (No. 2021YFB2601000), the National Science Foundation of China (No. 52178409), the Inner Mongolia Transportation Research Project (No. NJ-2021-17), Natural Science Foundation of Shaanxi Province (No. 2022JQ-547), the Fundamental Research Funds for the Central Universities, CHD (No. 300102212210). Their support and assistance are gratefully acknowledged.
Data availability
The data used to support the findings of this study are included within the article.