
Abstract
This study proposes a method of autonomous navigation UAV for oil and gas pipeline (OGP) dial detection based on the improved YOLOv7 model. The canny edge detection algorithm is applied in identifying the edges of the pipeline, and the Hough transform algorithm is used to detect the pipeline in a straight line. The intelligent UAV P600 is guided to patrol the oil and gas dials (OGD) along the pipeline, and the trained improved YOLOv7-based model is adopted to identify the OGD data. Dial recognition is divided into two stages, that is, dial contour detection and dial reading recognition. For the dial recognition rate (RR), the Levenstein distance, a commonly used method, is introduced, thereby calculating the distance between two character sequences. Meanwhile, an integrated global attention mechanism (GAM) is proposed based on the YOLOv7 model, aiming at extracting more informative features. With this mechanism, the channel and spatial aspects of the features are effectively captured, and the importance of cross-dimensional interactions is increased. By introducing GAM attention mechanism in the backbone and head of YOLOv7, the network’s ability in efficiently extracting depth and primary features is enhanced. ACmix (a hybrid model combining the advantages of self-attentiveness and convolution) is also included, with ACmix module improved. The improved ACmix module has the objectives of enhancing feature extraction capability of backbone network and accelerating network convergence. By substituting 3 × 3 convolutional block with 3 × 3 ACmixBlock and adding a jump connection and a 1 × 1 convolutional structure between the ACmixBlock modules, E-ELAN module in YOLOv7 network is also improved, thus optimizing E-ELAN network, enriching features extracted by E-ELAN network, and reducing inference time of YOLOv7 model. As indicated by comparing the experimental results of the six model algorithms (improved YOLOv7, YOLOv7, YOLOX, YOLOv5, YOLOv6 and Faster R-CNN), the improved YOLOv7 model has higher mAP, faster RR, faster network convergence, and higher IOU. In addition, a generic real dataset, called custom dial reading dataset, is presented. With well-defined evaluation protocol, this dataset allows for a fair comparison of various methods in future work.
Introduction
Pipeline is a basic material for the transportation of raw products. Especially in the oil and gas sector, pipeline, as an indispensable part and the most critical infrastructure, is mainly applied in transporting crude oil, flammable and toxic petroleum products from the production place to the petroleum processing plant. Once it is failure to conduct adequate inspections, disasters may be caused to humans and the environment, resulting in the cessation of transport process and even causing great economic loss. 1 Nonetheless, it is an expensive and dangerous operation to manually inspect pipeline components. Hence, there is a great need for automatic monitoring and identification of pipelines, thereby preventing intruders, pipeline leaks, and explosions. UAV-based autonomous detection mechanism is a charming solution. 2 With various fault detection sensors, high-definition cameras, and communication equipment, UAVs are fully capable of performing real-time status monitoring of pipelines. Compared with the general monitoring means, UAVs are accompanied with low cost, strong promptness, and liberation of labor.
Hausamann et al., 3 by considering two scenarios with different flight altitudes and sensor systems for the tasks of regular inspections of gas pipelines, pointed out the key issues restricting the development of UAV. Based on the existing UAV technology and the inspection requirements of oil and gas pipeline (OGP), Gómez and Green 4 developed corresponding schemes for the inspection of infrastructure, the detection and monitoring of leakage, and the monitoring of environmental conditions of pipelines, with the feasibility of such schemes demonstrated in practice. Nevertheless, the study above only mentioned the application of UAVs in OGP, while failing to plan a specific inspection path for the complicated pipeline network. Chen et al. 5 presented a multi-objective optimization model aiming at the wireless sensor network mobile agent problem, and applied the improved Dijkstra algorithm in solving the model. Consequently, the optimal mobile agent route between random two nodes might be acquired in accordance with the network environment. However, this model ignored the constraints of UAV such as endurance and the maximum turning angle, not suitable for the actual scene.
Sometimes, UAVs must hover at a certain point, thereby collecting status information of higher quality devices. For oil and gas dials (OGD), data detection is a typical application. To detect dials on each image, it needs to explore deep networks for object detection. With regard to gas cyclometers reading, Nodari and Gallo 6 presented a method, named MultiNOD. This method is composed of a neural network tree, thereby sharing and resizing features and further performing counter detection and digit segmentation. Tesseract was applied in handling the digit recognition stage, which was further improved in 7 by adding a Fourier analysis to the segmented image, aiming at avoiding false positives. Ultimately, SVM was used in digit classification. Tsai et al., 8 by employing Single Shot MultiBox Detector (SSD), 9 a deep learning object detector, located the counter region in energy meters, with an accuracy rate of 100% reported regarding their experiments, but not addressing the recognition stage. Gmez et al. 10 adopted a segmentation-free approach, aiming at performing meter reading. By training a Convolutional Neural Network (CNN), they acquired readings directly from the input images, not needing to detect the counter region. Despite the promising results, their approach adopted a private dataset in the experiments, and comparison was merely performed with the traditional algorithms relying on handcrafted features, thus easily being influenced by noise and not being robust to images obtained in adverse conditions. 11 Laroca et al. 11 developed a two-stage approach for AMR. Fast-YOLOv2 model 12 was adopted for counter detection, and three CNN-based models were assessed at the counter recognition stage. By employing data augmentation technologies, recognition results of the authors were greatly promoted during training set balancing in the aspect of digit classes.
In the present study, an autonomous pipeline inspection technology of UAV is proposed, combining the improved YOLOv7 model and Canny edge detection algorithm. Canny edge algorithm is applied in recognizing the edge of pipeline, and improved YOLOv7 model is adopted to detect and recognize the upper dial of the pipeline, thereby realizing the autonomous navigation and dial automatic reading based on the pipeline route.
1. As there is no open dataset for the dial data of OGP, and there is small number of datasets, the Custom Dial Reading datasets are re-created, thus enhancing the influence of model training.
2. By integrating strategies including extended effective layer aggregation network (E-ELAN), cascade-based model scaling, and model reparameterization, the selected YOLOv7 model achieves a good balance between detection speed and accuracy. Based on original YOLOv7 model, original YOLOv7 is improved in the following aspects. i. To extract more informative features, an integrated global attention mechanism (GAM) is developed, thus effectively capturing the channel and spatial aspects of features and increasing the importance of cross-dimensional interactions. By adding GAM attention mechanism to backbone and head of original YOLOv7, the network’s ability in efficiently extracting depth and important features is enhanced. ii. For further improvement of the network performance, ResNet-ACmix, an improved module of ACmix (a hybrid module combining advantages of self-attention and convolution), is introduced, and the improved ACmix is called ResNet-ACmix. The ResNet-ACmix module is designed to promote backbone network by capturing more information-rich features and strengthening feature extraction capability, and to accelerate the convergence of network. iii. E-ELAN module in original YOLOv 7 network is improved by replacing 3 × 3 convolutional blocks with 3 × 3 ACmixBlocks, and E-ELAN network is optimized by adding jump connections and 1 × 1 convolutional structures between ACmixBlock modules.
The improved YOLOv7 network is aimed at enhancing the ability of network model in focusing on valuable contents and locations of input image samples, enriching the features extracted by network, and reducing the inference time of model. It exhibits better performance compared with the original YOLOv7, 13 YOLOv6, 14 YOLOv5, 15 Faster R-CNN 16 and YOLOX 17 in terms of Prec, Recall, F-score, AP, mAP and IOU.
3. During model projection, the three indexes of dialing recognition rate (RR), meter RR, and mean absolute error are presented, thereby evaluating the model precision. Moreover, detailed error analysis is performed for important problems.
Materials and methods
Overall study framework
The proposed improved YOLOv7 model algorithm and canny edge detection algorithm both are trained on three target objects, namely pipes, digital-based dashboards, and dial-based dashboards. Deployed in the smart UAV P600, the canny edge detection algorithm is firstly applied in identifying the edges of pipes, and then the Hough transform algorithm is adopted to recognize the “straight line”-like pipes. With regard to the tracking command, the matching time of detected category with pipe category is determined. By confirming the distance and position of the detected object, the tracking algorithm can be used in estimating the height, roll, pitch, and yaw values. UAV moves forward while receiving these calculated values and tracking the pipeline on the road. With the improved YOLOv7 model, UAV detects and identifies the contours of OGD along the pipeline. Besides, when the detection type is considered in digital-based meter reading and dial meter-based meter reading, the detected dial reading data should be sent to the server by matching with the Wi-Fi or 5G applied. Figures 1 and 2 exhibit the flowchart and architecture of the proposed system in detail.
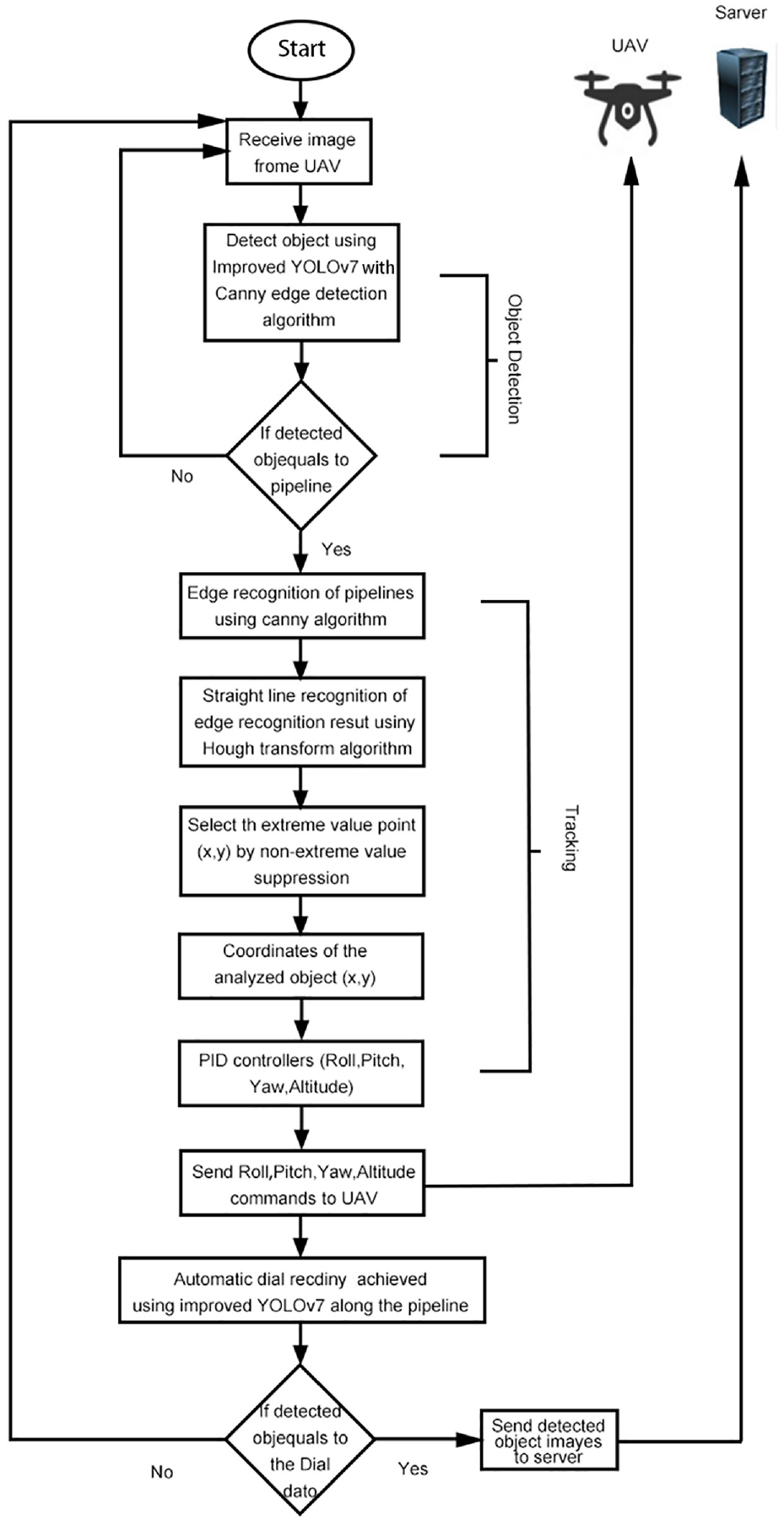
Flowchart of the system proposed.
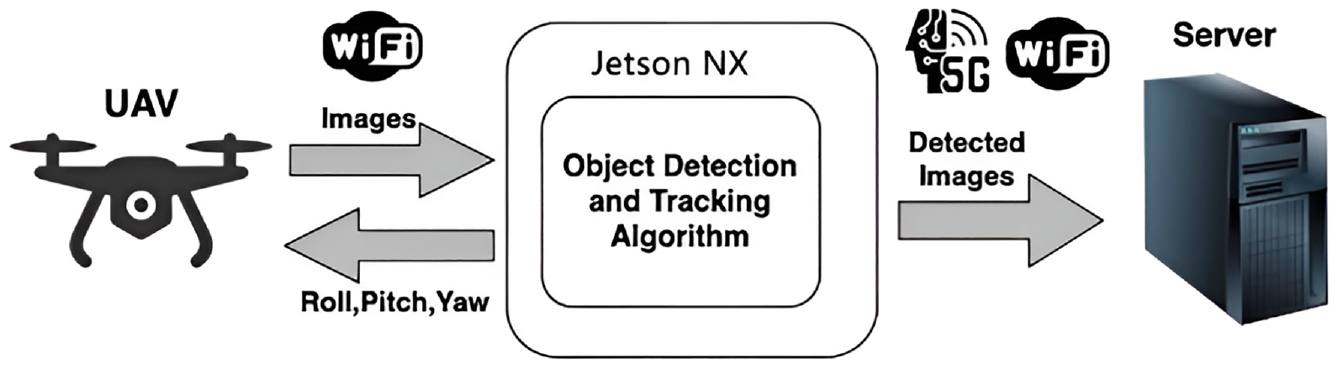
Architecture of the system proposed.
UAV hardware and communication architecture
The video acquisition is achieved by virtue of P600 smart UAV (Figure 3(a)) manufactured by Chengdu Bobei Technology Co., Ltd., Chengdu, China, with photoelectric pod (Figure 3(b)) taken by P600. As a medium-sized UAV development platform, Prometheus 600 (P600 for short) has the features of long endurance, large load, and scalability. P600 is furnished with smart equipment including onboard computer, laser radar, RTK, and three-axis photoelectric pod, thereby achieving pod frame selection and tracking, UAV location and speed guidance flight, and laser radar obstacle avoidance. In this study, P600 is provided with a Q10F 10x zoom single light pod with USB interface, and special Robot Operating System (ROS) driver is developed, thereby ensuring timely pod images in air-borne computer. Besides, by placing Jetson AGX Xavier on P600, the trained model can be operated, as exhibited in Figure 3.
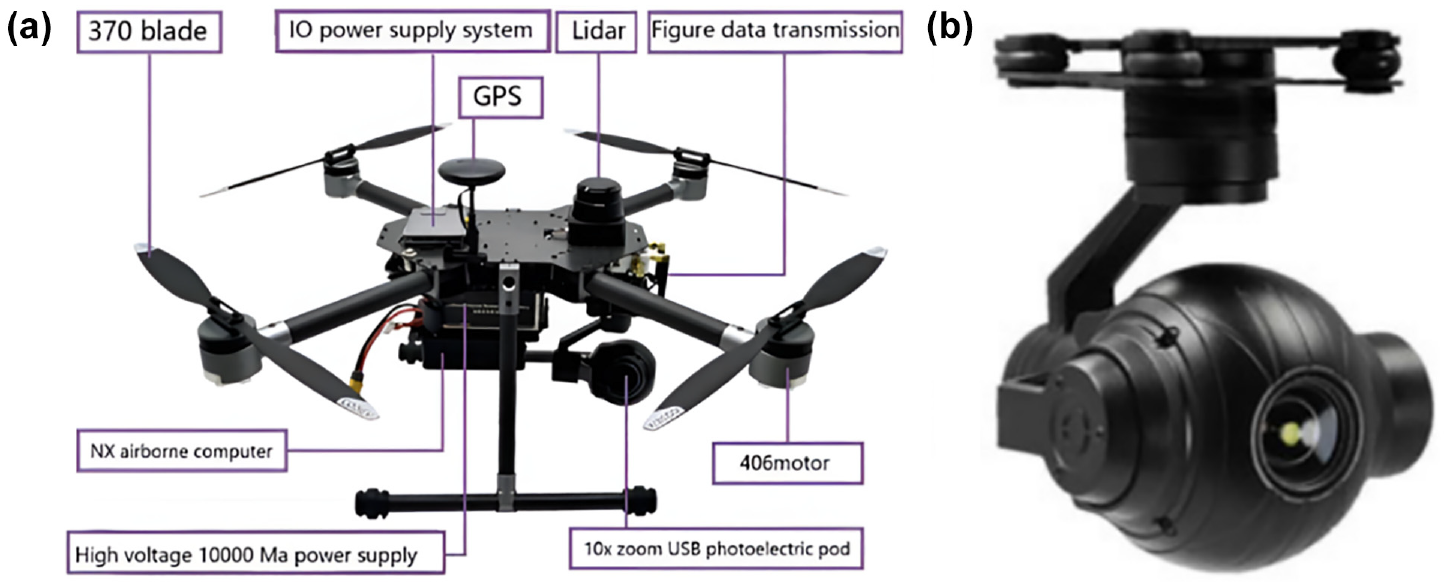
Data acquisition equipment for this study: (a) P600 smart UAV and (b) smart photoelectric pod.
Overall communication architecture of the P600 is exhibited in Figure 4. With the design of full fuselage internal wiring + built-in flight control, total three layers of expansion space is left for developers. The flight control expansion interface on the top layer of UAV fuselage is combined with the onboard computer on the bottom layer, thus realizing free addition of the sensors applicable to Px4 flight control or ROS.
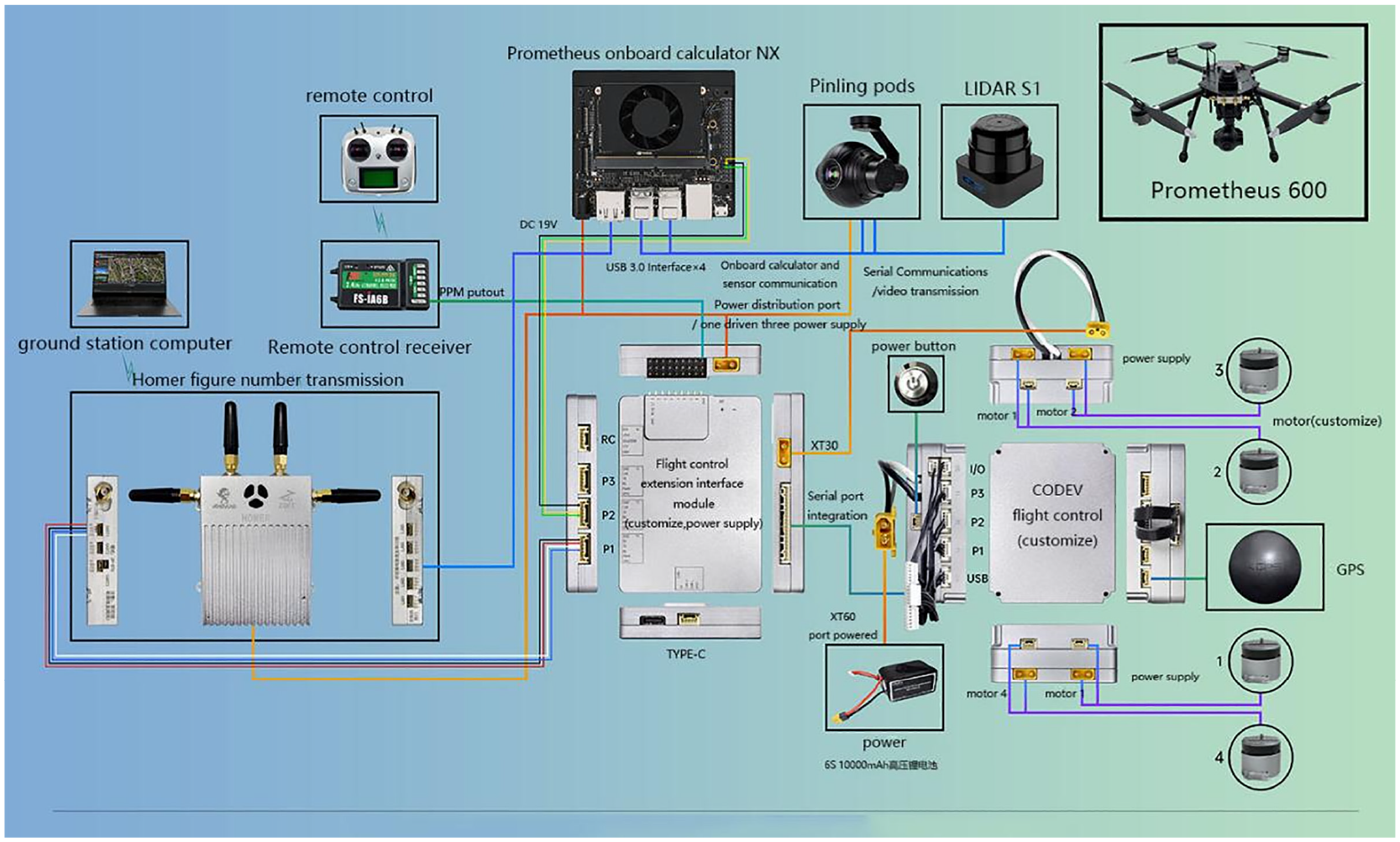
Hardware communication architecture for this study.
With a serial port connection, the communication of on-board computer NX with Codev flight control is realized. The former sends any desired commands to Mavros-based flight control, such as desired speed, desired position, and desired attitude. The on-board computer NX acquires images of electro-optical pod via USB port, operates the improved YOLOv7 algorithm and canny edge monitoring to detect and track the OGD data and dials, and calculates the relevant control commands for the pod and UAV control commands. The pod control commands are delivered to optoelectronic pod via a serial port with connection to NX, thereby realizing rotation of pod lens with moving object. UAV control commands are delivered to the Codev flight control by virtue of Mavros via the serial port, thereby ensuring control of UAV and tracking of moving object. From the NX side of airborne computer, ground station computer can realize remote accessing and viewing of desktop images through Homer image data transfer, as well as viewing of the electro-optical pod camera images acquired by NX side of airborne computer.
Navigation based on pipeline contour
The contours of pipeline are identified by employing canny edge detection algorithm (Gaussian gradient), 18 and straight line identification such as “pipeline” detection is performed mainly by UAV angle correction and pipeline contour marking, as well as visual navigation based on straight line. The overall structure of UAV autonomous navigation for pipeline detection is presented in Figure 5. The diagram (b) in Figure 5 exhibits the structure of the object tracking detected by PID controller. The four control commands in the figure take charge of the motion of P600. Among them, roll command is designed for left and right navigation of UAV, pitch command enables upward or downward motion, yaw command is responsible for clockwise or counterclockwise rotation of UAV, and altitude command take charge of left and right motion. Canny edge detection algorithm is mainly aimed to provide accurate planning of pipeline routes. NX sets UAV to automatic flight mode, obtains color pipeline route pictures taken by photoelectric pods via USB, employs Canny edge detection algorithm to grayscale processing and edge recognition, and adopts Hough transform algorithm for line recognition.
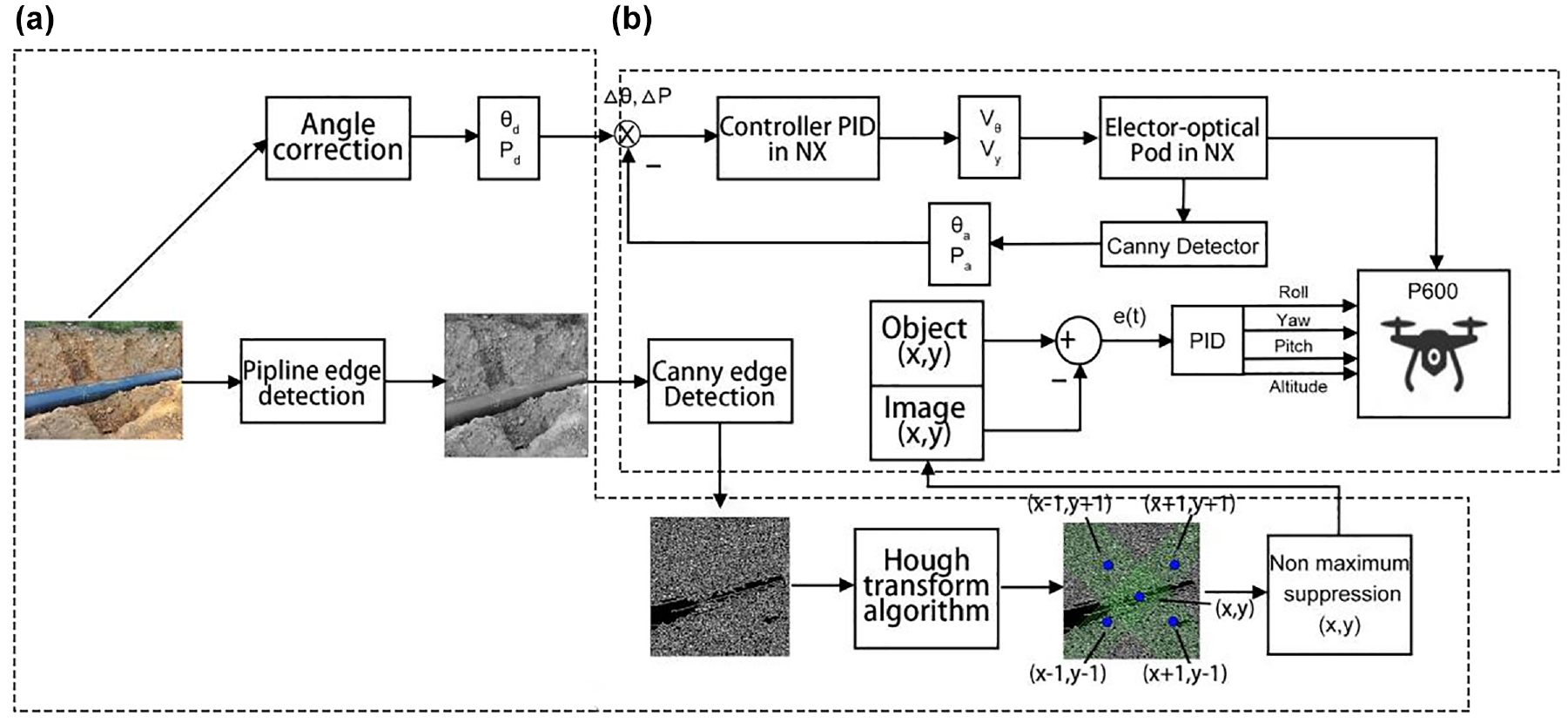
Overall structure of the UAV autonomous navigation inspection pipeline: (a) bounding box location with detected object and (b) control scheme for target tracking detection.
UAV angle correction
To track “linear” structure of a pipeline, the perfect alignment of UAV’s forward navigation direction and longitudinal axis of ground structure needs to be realized. Once UAV’s forward navigation direction is not aligned with the detected straight line, vertical axis of UAV must be rotated for alignment, thereby minimizing angular error. The Hough transform calculates two parameters, aiming at uniquely defining each detected straight line. The two parameters are the angular position relative to axis and the length of its normal from the origin, as exhibited in Figure 6. The desired angular position
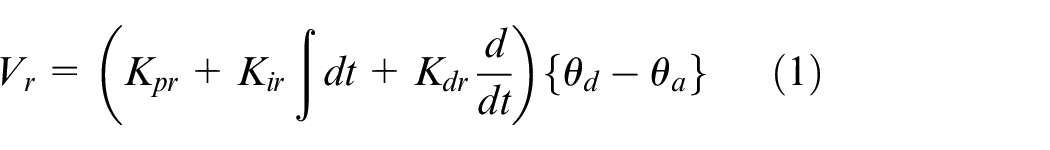
Representation of straight line in polar coordinate and Hough transformation algorithm.
Pipeline contour identification
Pipeline contours are recognized using the Canny edge detection algorithm, which is roughly divided into five steps: smoothing, intensity gradient, non-maximum suppression, normal thresholding and hysteresis thresholding. The specific threshold setting of the algorithm, we use the Canny edge detection algorithm in Shukla et al. 19 to perform edge detection of OGP by setting and adjusting these five thresholds to complete the contour identification of OGP.
Visual navigation based on straight lines
This study adopts Hough transform algorithm to extract shape features from an image as straight lines in image. 20 Expression of straight lines in polar coordinates is as follows.

where
Improved Deep Learning Models (DLM) for dial recognition
In this study, the improved YOLOv7 model was selected for detection and identification of OGD, with comparison to other model algorithms (original YOLOv7, YOLOv6, YOLOv5, YOLOX, and Faster R-CNN). Data readings from OGD are deemed as a detection problem, the reason lies in the former successful approaches adopting AMR of detection network.11,21 The Faster R-CNN gives exact results on some detection and identification problems, while YOLOv7 has faster convergence and greater detection accuracy under higher FPS conditions. The original YOLOv7 is improved, and the improved YOLOv7 model exhibits better performance compared to the original YOLOv7, Faster R-CNN, YOLOv6, YOLOv5, and YOLOX with better performance. Reasonable results have also been acquired in the relevant literature, 22 thereby improving the feasibility of mobile applications. According to Figure 7, the proposed detection and recognition of OGP dial data contains image acquisition and enhancement, dial detection and recognition, and dial data reading.
Main dial meter reading steps.
Dial detection
Dial detection is directly performed in the input image. That is, it is not needed to firstly test ROI. Taking into account of the experimental results in the next section, this method obtains the optimum F-Score value. In other words, the results are not notably affected by the small errors in detection phase. ROI test can be prevented in testing phase.
Dial recognition
Since OGPs and OGDs are infrastructures for the transportation of crude oil, flammable and toxic petroleum products, failure to carry out adequate inspections can be disastrous for human beings and the environment, leading to the cessation of the transportation process and even to huge economic losses. 1 In addition, OGD and OGP are located in remote areas and harsh environments, and manual inspections cannot meet the accuracy requirements of industry. Therefore, this article chooses to deploy the improved YOLOv7 model, Canny edge detection algorithm, and Hough transform algorithm on the intelligent unmanned aerial vehicle platform. During the process of unmanned aerial vehicle inspection of OGP, automatic real-time reading recognition of OGD is carried out along the OGP. The main reason why YOLOv7 is chosen as the core algorithm is that YOLOv7 performs better in terms of integrated detection accuracy, detection rate and network convergence speed performance compared to the YOLOv1-YOLOv6 model. Compared to the YOLOv8 model, although YOLOv7 performance is not as good as the performance of YOLOv8 in terms of detection rate and detection accuracy, it is lighter than YOLOv8 in terms of model complexity, and is able to be deployed on UAV platforms with limited computational power.
As a newly developed deep learning network, YOLOv7 model was proposed by Chien-Yao Wang and Alexey Bochkovskiy et al. in 2022, integrating strategies including extended effective layer aggregation network (E-ELAN), 23 cascade-based model scaling, 24 and model re-parameterization, 25 thereby achieving a good balance between detection efficiency and precision. According to Figure 8, YOLOv7 network is composed of four different modules, namely input module, backbone network, head network, and prediction network. Below is a detailed introduction to these four modules.
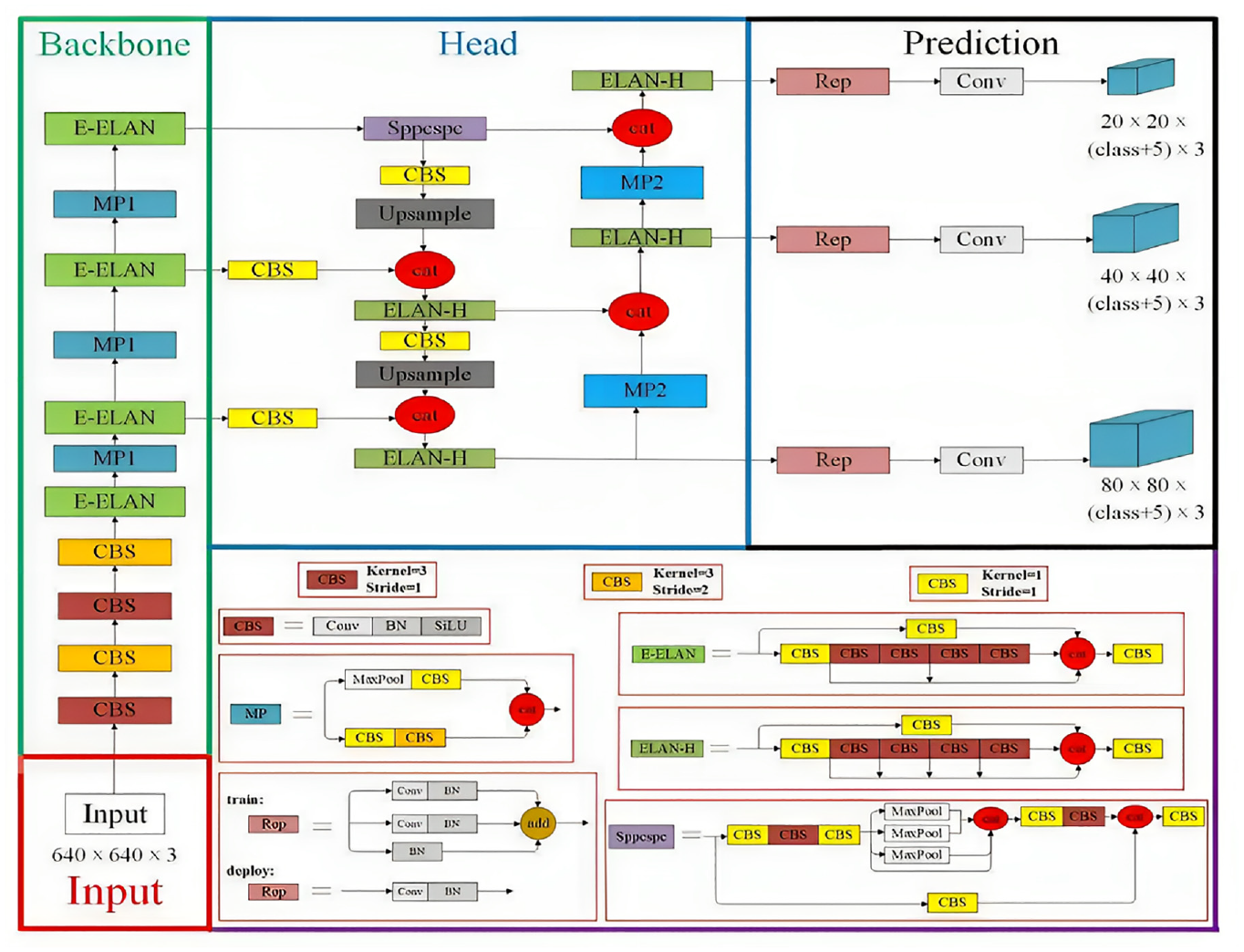
Structure of YOLOv7 network.
Input module: The pre-processing stage of the YOLOv7 model employs both mosaic and hybrid data enhancement techniques and leverages the adaptive anchor frame calculation method established by YOLOv5 to ensure that the input color images are uniformly scaled to a 640 × 640 size, thereby meeting the requirements for the input size of the backbone network.
Backbone network: The Backbone network comprises three main components: CBS, E-ELAN, and MP1. The CBS module is composed of convolution, batch normalization, and SiLU activation functions. The E-ELAN module maintains the original ELAN design architecture and enhances the network’s learning ability by guiding different feature group computational blocks to learn more diverse features, preserving the original gradient path. MP1 is composed of CBS and MaxPool and is divided into upper and lower branches. The upper branch uses MaxPool to halve the image’s length and width and CBS with 128 output channels to halve the image channels. The lower branch halves the image channels through a CBS with a 1 × 1 kernel and stride, halves the image length and width with a CBS of 3x3 kernel and 2 × 2 stride, and finally fuses the features extracted from both branches through the concatenation (Cat) operation. MaxPool extracts the maximum value information of small local areas while CBS extracts all value information of small local areas, thereby improving the network’s feature extraction ability.
Head network: The Head network of YOLOv7 is structured using the Feature Pyramid Network (FPN) architecture, which employs the PANet design. This network comprises several Convolutional, Batch Normalization and SiLU activation (CBS) blocks, along with the introduction of a Spatial Pyramid Pooling and Convolutional Spatial Pyramid Pooling (Sppcspc) structure, the extended efficient layer aggregation network (E-ELAN), and MaxPool-2 (MP2). The Sppcspc structure improves the network’s perceptual field through the incorporation of a Convolutional Spatial Pyramid (CSP) structure within the Spatial Pyramid Pooling (SPP) structure, along with a large residual edge to aid optimization and feature extraction. The ELAN-H layer, which is a fusion of several feature layers based on E-ELAN, further enhances feature extraction. The MP2 block has a similar structure to the MP1 block, with a slight modification to the number of output channels.
Prediction network: The Prediction network of YOLOv7 employs a Rep structure to adjust the number of image channels for the features output from the head network, followed by the application of 1 × 1 convolution for the prediction of confidence, category, and anchor frame. The Rep structure, inspired by RepVGG, introduces a special residual design to aid in the training process. This unique residual structure can be reduced to a simple convolution in practical predictions, resulting in a decrease in network complexity without sacrificing its predictive performance.
Output network: the output network of YOLOv7 is connected to the prediction network, the prediction network uses RepVGG block and conv for the three layers of feature maps of different size output from the head network to predict the three types of tasks of the image: classification, front and back view classification, and border regression, and finally the prediction results will be output by the output layer as the YOLOv7 output results.
In the present study, the improved YOLOv7 model is adopted for reading recognition of OGD data images. On the basis of original YOLOv7 network, the original E-ELAN network in YOLOv7 is improved. The 3 × 3 convolutional blocks are substituted by 3 × 3 ACmixBlocks, and the jump connection and 1 × 1 convolutional structure are added between ACmixBlock blocks, thereby enhancing the ability of network model in concentrating on the valuable contents and locations of the input image samples, enriching the features extracted by network, and reducing the inference time of model. Furthermore, the improved ACmix module (called ResNet-ACmix module) is integrated into the backbone module and located behind the fourth CBS and at the bottom of backbone, thereby efficiently preserving the features collected by backbone and facilitating the extraction of feature information of small targets and complex background targets, while speeding up the convergence speed of network and improving the detection accuracy. By adding GAM in backbone and head of YOLOv7, the network’s ability of efficiently extracting depth and important features can be enhanced. The model structure of the improved YOLOv7 is presented in Figure 9.
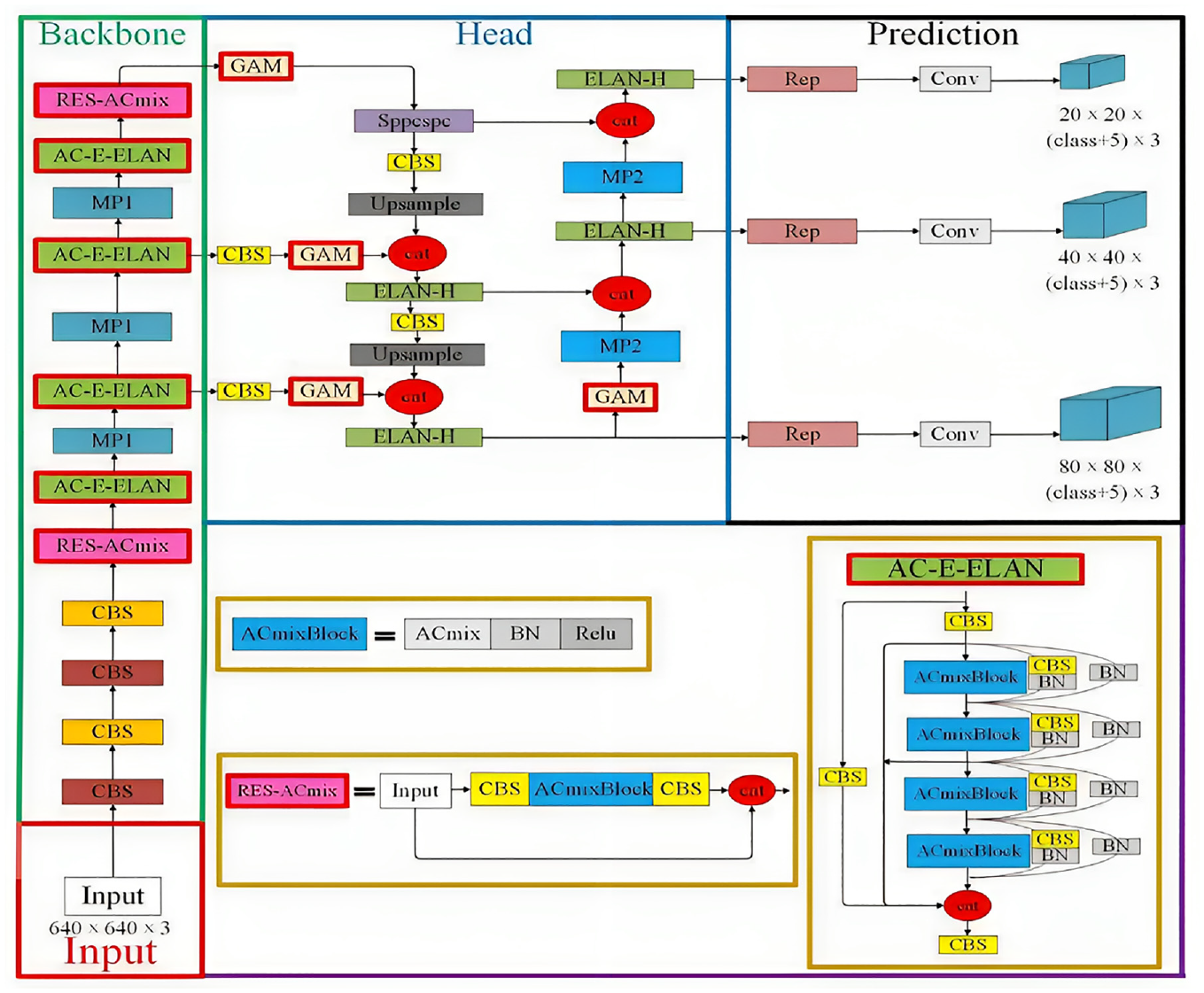
Structure of the improved YOLOv7 model.
ACmix model and ResNet-ACmix module
Due to the remote location of the OGD, the surrounding environment is very harsh, the acquired image data of the OGD is less and blurrier, and the backbone network of the original YOLOv7 captures less target information features, which leads to a lower model detection accuracy. In addition, both the self-attention mechanism and convolution of the model rely more on the 1 × 1 convolution operation, 26 as well as the UAV platform has very limited computational resources. To solve these problems, we introduced the AC-mix module 27 into the backbone network of the original YOLOv7, which combines self-attention and convolution to capture more and richer informative features of the OGD, reduce the computational power of the model, enhance the feature extraction capability, and accelerate the convergence speed of the backbone network. The Network model structure of ACmix is exhibited in Figure 10.
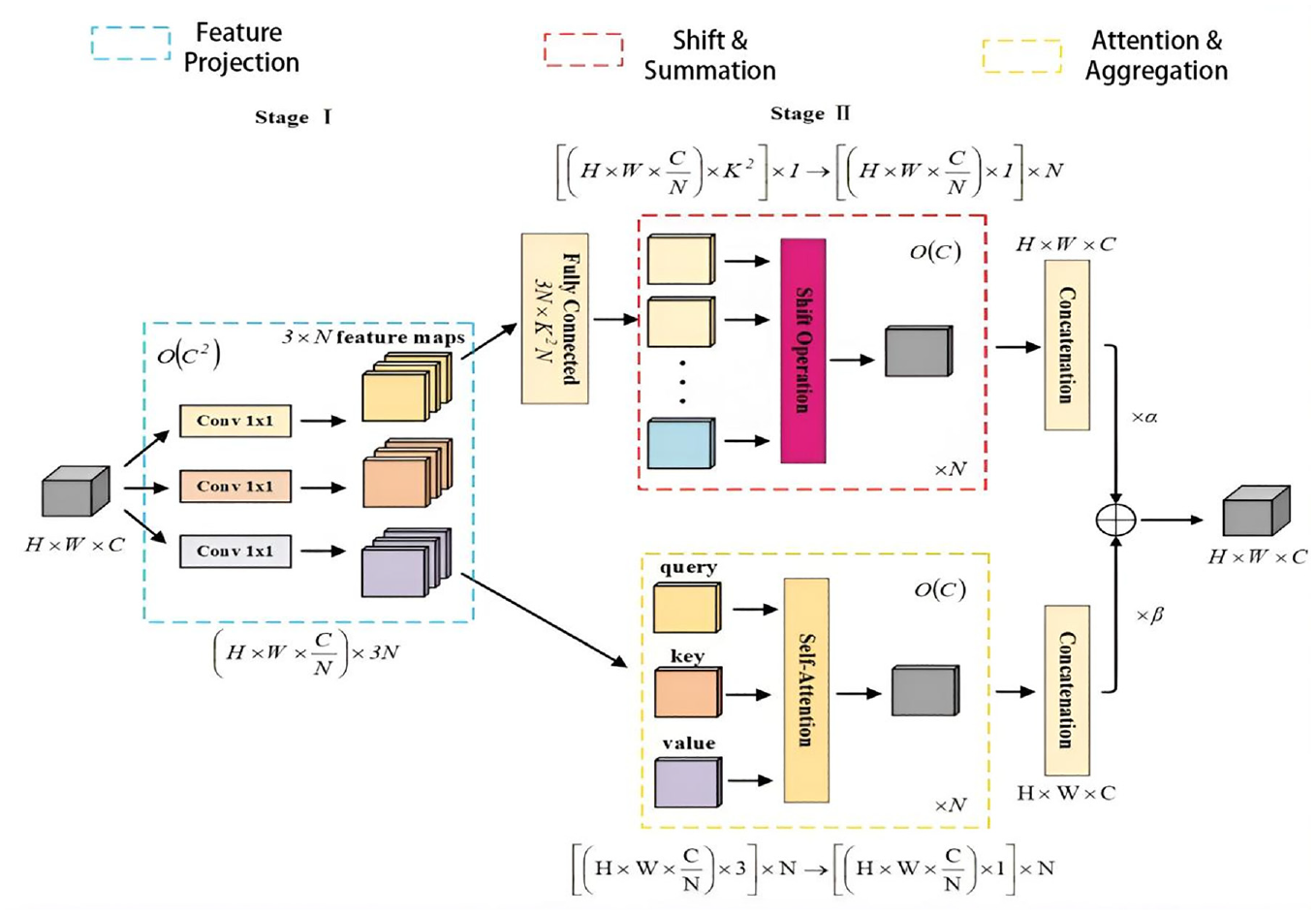
Structural diagram of ACmix module. 28
In this study, our improvement of AC-mix module is on the basis of bottleneck structure of ResNet, 28 where 3 × 3 convolution is replaced by ACmix module, thus ensuring adaptive concentration on different regions and collecting more informative features, as exhibited in Figure 11. By dividing the inputs into main and residual inputs, information loss can be prevented at the same time of reducing the number of parameters and computational requirements. The improved ACmix module, called ResNet-ACmix, was introduced into backbone component of YOLOv7, thereby efficiently maintaining consistency of the extracted feature information. Moreover, with ResNet-ACmix, the network can reach deeper depths while not encountering gradient disappearance, and learning results are susceptible to fluctuations in network weights.
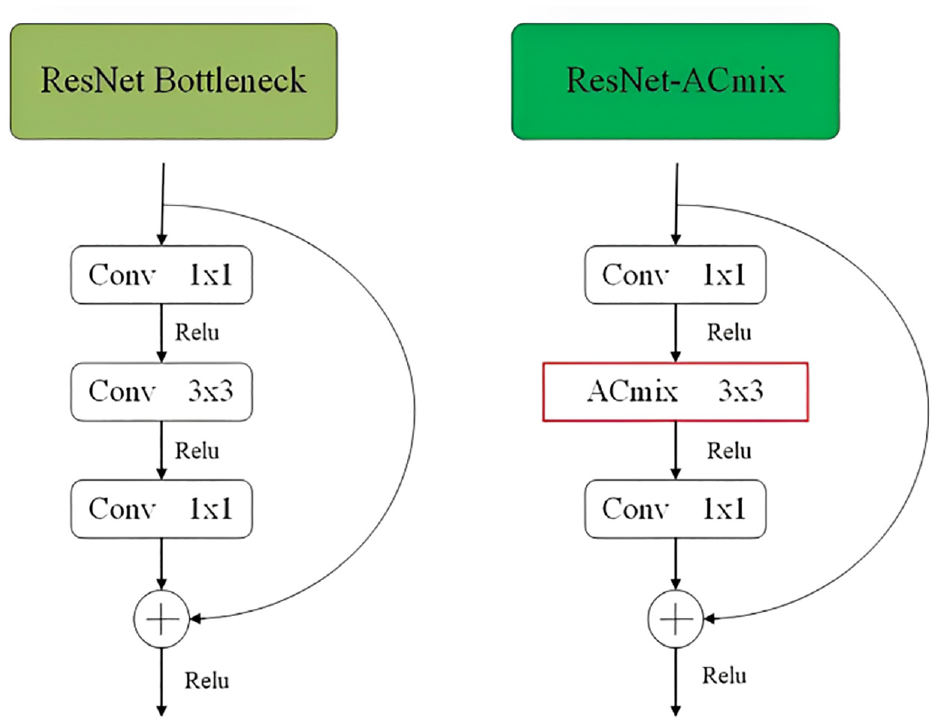
Structural diagram of ResNet-ACmix module (left: ResNet; right: ResNet-ACmix).
Improved E-ELAN module
Improvements in E-ELAN component of YOLOv7 are on the basis of advanced ELAN architecture. 29 Different from the traditional ELAN network, the extended E-ELAN adopts an extended, blended wash and merged basis approach, continuously enhancing the learning capability of network while not destroying the original gradient stream, thus improving parameter utilization and computational efficiency. Feature extraction of the E-ELAN component in the original YOLOv7, by incorporating residual structure (namely 1 × 1 convolutional branches and jump-connected branches) from RepVgg architecture, has indirectly guided the development of extended E-ELAN network architecture, 30 as presented in Figure 9, integrating ACmixBlock and consisting of 3 × 3 convolutional blocks, ACmixBlock, and jump connections and 1 × 1 convolutional structures between them. Due to this combination, the network can benefit from the rich features acquired during the training of the multi-branch model and of the fast and memory-efficient inference capabilities obtained from single-path model.
GAM module
Attention mechanism is a method applied in improving feature extraction in complex contexts, with different weights being assigned to different parts of the input in a neural network. With this approach, the model can concentrate on correlated information and ignore uncorrelated information, thereby enhancing performance. Cases of attention mechanisms contain pixel attention, channel attention, and multi-order attention. 31 With regard to attention mechanism, the improved YOLOv7 model introduces GAM module in the head, thereby endowing a deeper network depth and stronger feature extraction capability to the improved YOLOv7 network.
GAM, 32 by reducing information dispersion and amplifying global interaction representation, can improve the performance of deep neural networks. The module structure is exhibited in Figure 12. GAM module is composed of a channel attention sub-module and a spatial attention sub-module. Channel attention sub-module is developed as a 3D transformation for retention of input 3D information. It has two layers of multilayer perception (MLP), serving to amplify the inter-dimensional dependencies in channel space, thereby ensuring network focusing on valuable foreground regions of the image, as presented in Figure 13.
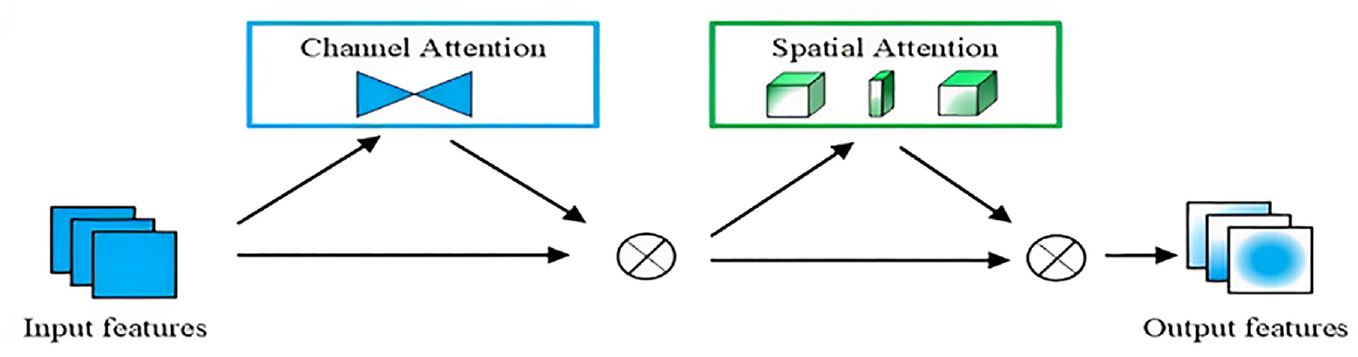
Structural diagram of GAM module.

Structure of the channel attention sub-module in GAM.
The spatial attention sub-module combines two convolutional layers, thus efficiently integrating spatial information, ensuring the network focusing on contextually meaningful regions throughout the image, as exhibited in Figure 14.
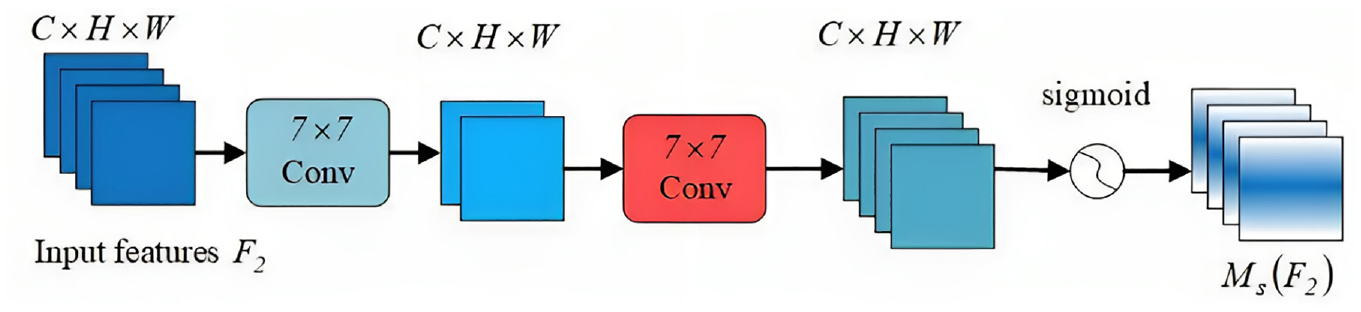
The structure diagram of spatial attention submodule in GAM module.
Final reading
The final OGD reading is generated based on the position of the scale detected by the improved YOLOv7 model on the real-time image obtained by the intelligent drone P600 (from the left digital scale to the right digital scale in each OGD). When interpreting OGD readings, the improved YOLOv7 model generates a large number of detection boxes due to the detection of OGD. Many duplicate boxes detect the same target, and non maximum suppression is used to remove these duplicate boxes to obtain the true detection box. In non maximum suppression, it is mainly achieved by setting the intersection to union ratio threshold (IoU). The IOU is the overlap rate between the target border generated by the model and the original labeled border. The intersection of the Detection Result and Ground Truth divided by their union is the accuracy of the detection, and the specific calculation process is shown in equation (10).
Considering that there are many digital scales in the OGD on each image, in this study, we set the threshold of IOU to 0.5 (In target detection, the IOU threshold of the YOLO model is usually set to 0.5.). If the IOU value between the calculated detection result and the reference standard exceeds 0.5, the detection result is considered true positive (TP), indicating accurate target recognition. On the contrary, if the IOU value is below 0.5, the detection result is considered false positive (FP), indicating incorrect recognition. In the calculation, the number of undetected targets (referred to as false negative (FN)) is considered as the number of true standard instances that do not match the detection results.
Results
Canny edge detection algorithm based on “linear” pipe vision tracking results
In this study, the study scenario selected was the pipeline project of Zheng ‘an Wuchuan Natural Gas Branch of China National Petroleum Corporation (CNPC) located in Qiandongnan County, Guizhou Province. When using the intelligent unmanned aerial vehicle P600 for inspection of OGP, the Canny edge detection algorithm is first used for edge detection and recognition of OGP, and then the Hough transform algorithm is used to detect the straightness of OGP, making it similar to a “straight line.” The experimental results are shown in Figure 15.

Plot of edge detection and straight line recognition results for OGP: (a) UAV acquisition of real-time OGP images, (b) OGP after gray value processing, (c) Canny edge detection results, and (d) Hough Linear Recognition Result Plot.
In Figure 15, the on-board computer (NX) in the UAV will set the UAV to automatic flight mode so that it is in the inspection state, and then obtain the real-time image of the optoelectronic module OGP via USB, and then use the Canny edge detection algorithm to perform grayscale processing and edge recognition (the results are shown in Figure 15(b) and (c)), and then finally the Hough transform algorithm for straight line recognition (the results see Figure 15(d)).
In addition, since the navigation direction in front of the UAV needs to be aligned with the detected straight line direction, this paper carries out the angular correction of the UAV through equation (1) to assist the UAV in accomplishing the OGP inspection task. The results of the specific tracking pipeline and angle correction error are shown in Figure 16.
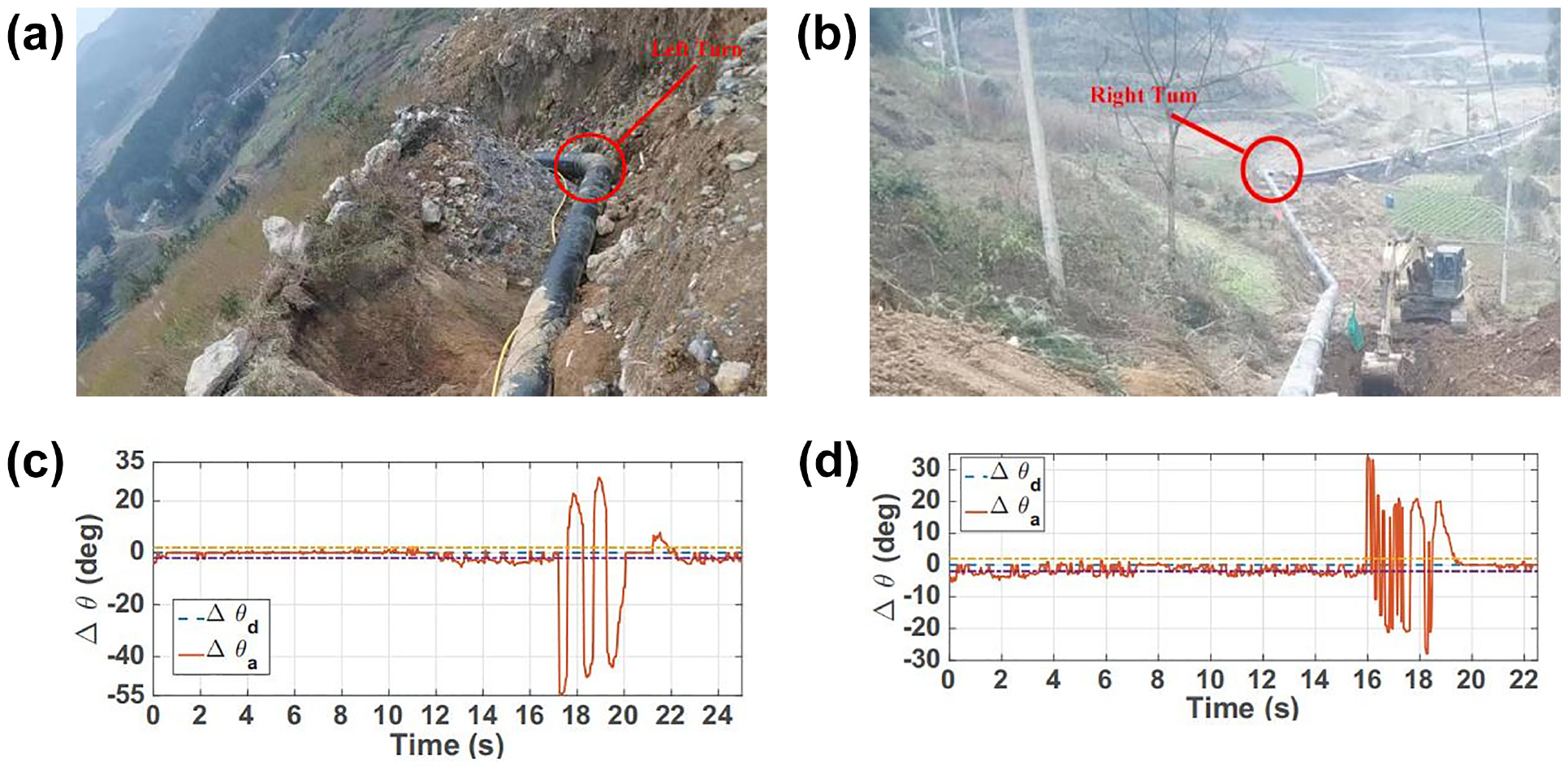
Autonomous tracking of left-turn and right-turn pipelines (a and b), with angular corrections (c and d), respectively, where dotted lines denote desired angular
To track a given pipe during the first UAV take off, it is needed to start from the right- side corner of the image where the pipe is straight, followed by going further down the pipe (as presented in Figure 16(a)) where the pipe has a left-side bending of 55° from its longitudinal direction. The on-board computer NX acquires a real-time image of the pipeline from the photoelectric chamber via the USB interface, and then the UAV is set in autonomous tracking mode. The UAV is flown at an altitude of 2–3.5 m above the pipeline, and it lands safely when completing tracking. During flight, the pipeline is regarded as a collection of straight lines in a real-time streaming 2D image by employing a Canny edge detector and a Hough transform. The parameter
Dataset specifications
Total 5000 data images were collected from the OGP dial, including 2000 pipeline data images and 3000 dial data images (containing1500 dial instrument images and 1500 digital instrument images). Considering establishment of a custom dial reading dataset, 2100 images (including 700 pipe images, 700 dial images, and 700 digital meter images) were selected. These images all were acquired in an uncontrolled environment. Therefore, in many cases, it is difficult to obtain a correct reading (Figure 17).

Aerial data image of dial in some complex environments: (a) pipeline in the bright light, (b) pipeline in the dark light, (c) fuzzy digital dial, and (d) digital dial in shadow.
Regarding each image, the location (x, y) is marked manually for every corner of irregular quadrilateral with dial. Corner comments are used in correcting image patches with dials. Figure 18 exhibits images chosen for dataset, accompanied with annotated explanations.

Example diagram of the dataset, with blue referring to the bounding box of dial and red referring to the dial in the bounding box.
To enhance the training model stability, dataset enhancement is performed on 2000 Custom Dial Reading datasets. By changing the initial dataset images slightly, new images can be obtained, so as to enhance the network generalization ability. In this study, the following transformations are casually selected for every image, namely casual scaling (from −20% to 20%), arbitrary translation (from −20% to 20%), freewill rotation (from −15° to 15°), and discretionary shearing (from −12% to 12%). With respect to initial size and location of image, the values are casually selected at determined intervals. By image enhancement, five times of the number of training images (10,000 initial and enhanced images) are obtained. Among the 10,000 images, 7000 are adopted for training set, 2000 for verification set, and 1000 for test set regarding improvement of recognition performance of DLM, the datasets are divided with a ratio of 7:2:1.
Performance metrics for evaluation
In terms of performance evaluation of the model proposed in the detection task (Figure 7), Six metrics, Prec, Recall, IOU, AP, mAP, and F-score, are given and described in detail below.
The metric of IOU is used in measuring the degree of overlap between the system predicted bounding box and the ground truth bounding box in the original image. The intersection and connectivity ratio of the detection results to the real data is calculated as follows.
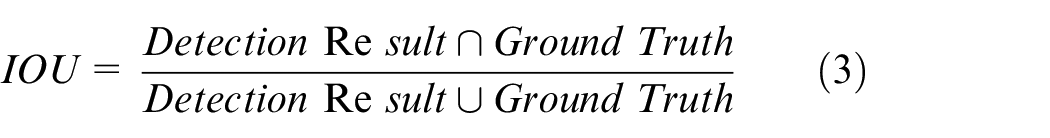
In the experiment, IOU is set with a threshold value. If the calculated IOU value between the detection result and the reference standard exceeds the threshold value, the detection result is considered as a true positive (TP), indicating accurate target identification. Conversely, if the IOU value is lower than the threshold value, the detection result is deemed as a false positive (FP), suggesting an incorrect identification. In the calculation, the number of undetected targets (called false negatives (FN)) is deemed as that of true standard instances not matching the detection result.
As defined, precision is believed as the proportion of true positives in the recognition image, represented as a percentage, and is used to describe the accuracy of finding the target object, and is calculated as follows.
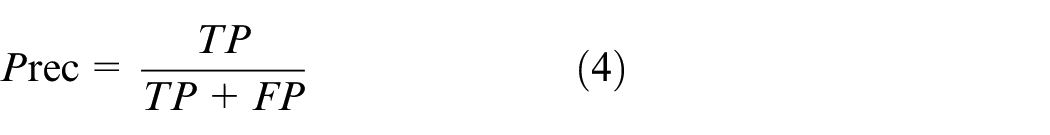
The recall rate refers to the proportion of all positive samples in the assay set with correct targets identified, as presented in equation (5).

A Precision-Recall (PR) curve plots precision along the vertical axis and recall along the horizontal axis, thereby illuminating the interplay between the accuracy of the classifier in identifying positive instances and its ability to encompass all positive instances. The Average Precision (AP) is a scalar representation of the area under the PR curve, with higher values indicating superior performance of the classifier.
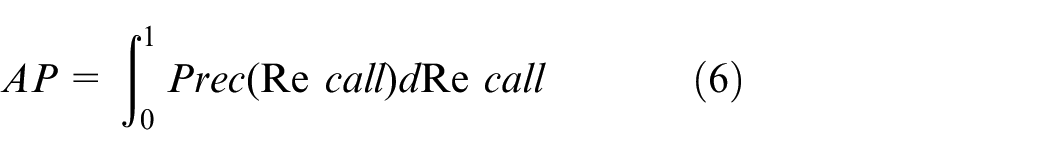
In target detection, the model usually detects many classes of targets, and each class can plot a PR curve, which in turn calculates an AP value. mAP represents the average of the APs of all classes.
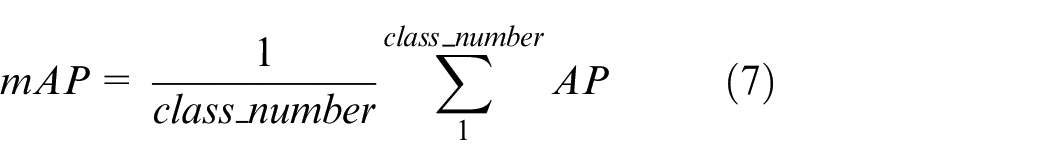
F-score is deemed as weighted mean of model accuracy and recall, with the maximal value of 1 and the minimal value of 0. If the value is larger, the model shall be better. Calculation is shown in the equation below.
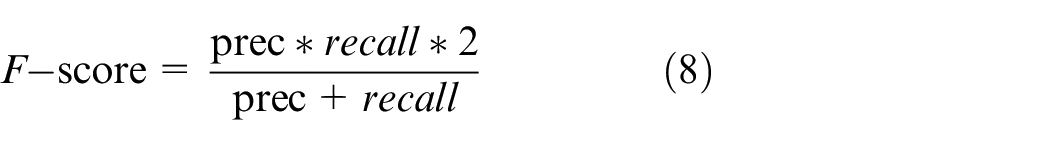
Besides, considering performance evaluation of the model proposed in recognition task (Figure 7), another three metrics are given, namely dialing RR, meter RR, and mean absolute error, with detailed description as follows.
Since baseline model has the primary task of properly identifying meter readings, namely series numbers, the meter RR is applied in evaluating the model recognition capability. The meter RR includes both projected sequence (predm) and ground truth sequence (gtm). Equation (9) is adopted for the meter RR for each N meter:
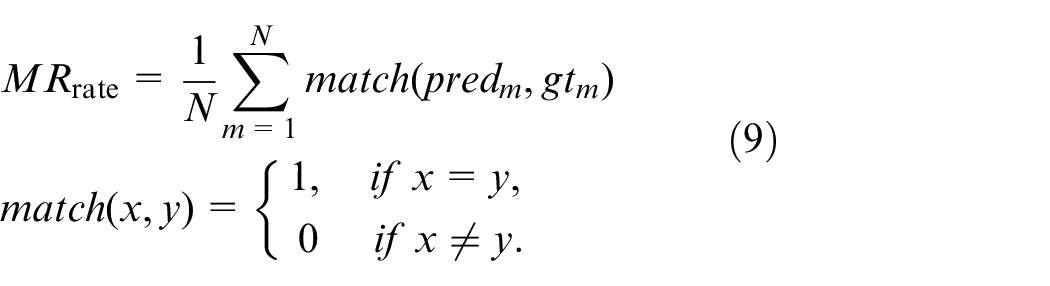
Regarding dialing RR, Levenstein distance (also called edit distance) is adopted, and it is a common measure applied in calculating the distance of two character sequences. Levenstein distance can measure the minimal edits (adding, deleting, or replacing characters) needed to convert one sequence to another within a sequence. Levenstein distance is suited to our evaluation. By adopting this distance, the small sequence mistaken as large errors when adopting other metrics can be disposed. For example, when having ground truth sequence, and assuming one = “1234” and projected sequence b = “234”, the error of 4 shall be considered by evaluation metric for each character, while the Levenstein distance shall be 1 due to single-digit projection of the difference between them. The calculation of Levenstein distance of sequences a and b adopts equation (10).
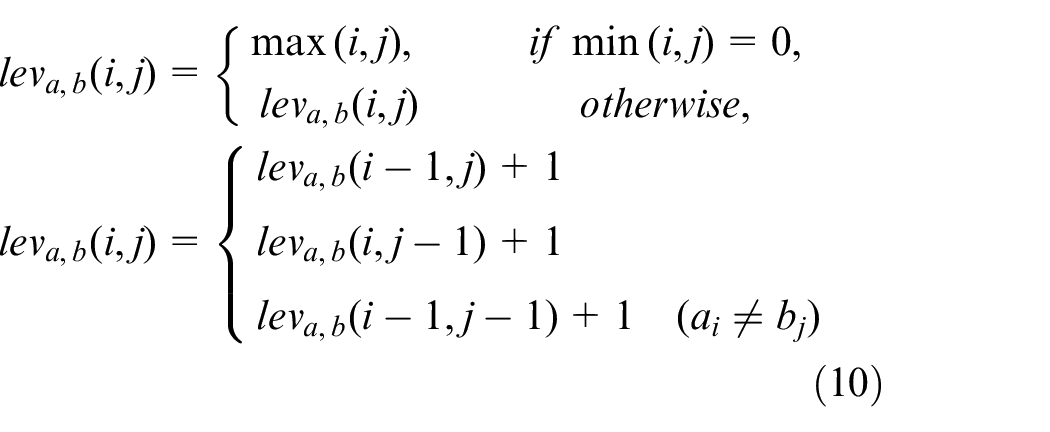
As the digits composing meter reading is actually a number (integer), it is not very important to correctly predict the last digit in the sequence by comparing to the accurate projection of the first one (namely the most important digit). When differentiating and penalizing errors of the most important digits, it is simple but effective to adopt mean absolute error. By converting digits to integers (converting predm and gtm to integers pm and gm, respectively), equation below is applied to obtain the mean absolute error.
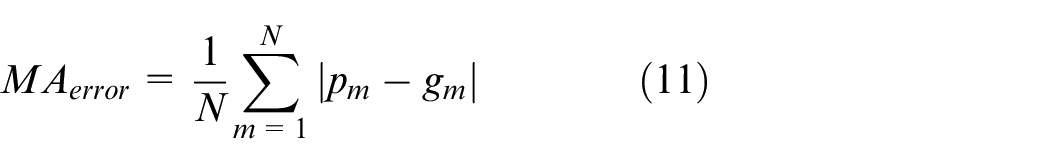
Loss calculation, also called sum square error, is adopted in the overall process of object detection algorithm YOLO. 33 In the YOLO end to end network, there are simple differences of addition, including errors of classification, coordinate, and IOU. Equation (12) can be applied in calculating the loss function, as well as. 34 CNN is used in medical science, thereby detecting the polyp in colonoscopy images, and further improving it for model accuracy promotion.
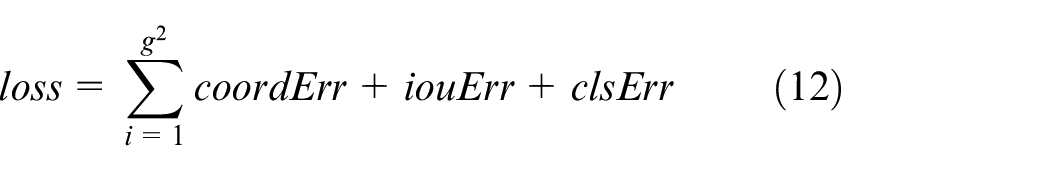
Results and training
Experiment is conducted on the NVIDIA Jetson AGX Xavier, a modular AI supercomputer with a dedicated NVIDIA Volta and 512 CUDA-core GPU. In the training stage of Improved YOLOv7 model, weights are generated after every 10,000 iterations (with a total of 100,000 iterations), thereby obtaining a model with better stability and smaller loss value. The weights with the highest mean accuracy (mAP) are selected for model test. After completing model training, mAP reaches the highest level of 90.91%. With the increase of iterations, the loss value also decreases gradually. After 100,000th iteration, the loss value decreases to 0.5 (Figure 19), achieving a good fitting effect. As observed, the improved YOLOv7 model obtained by training has good projection effect and small loss value.
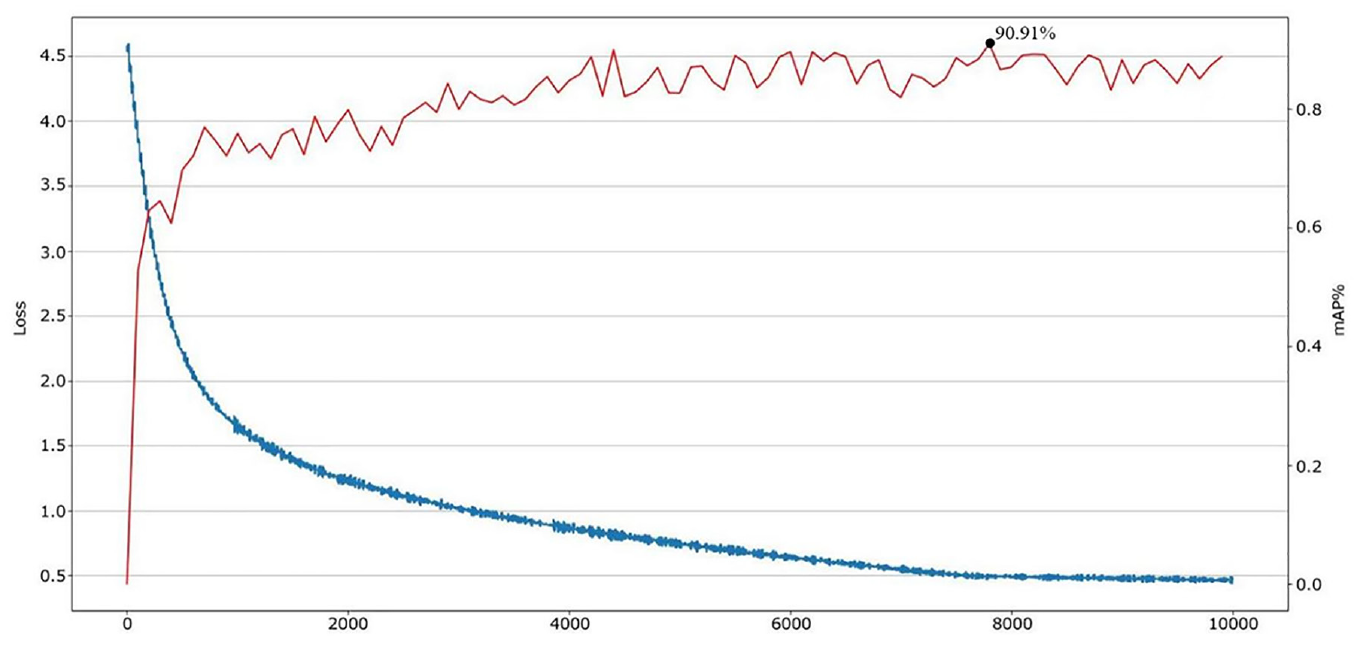
Improve YOLOv7 model loss function and mAP results.
Faster R-CNN model training is conducted to compare the results. In training stage of Faster R-CNN model, weights are generated every 10,000 iterations, with total 100,000 iterations. The weights with mAP are selected to test the model. After model training, mAP reaches the highest level of 85.46%. With the increase of iterations, the loss value also declines progressively. After 100,000 iterations, the loss value declines to 0.6 (Figure 20).
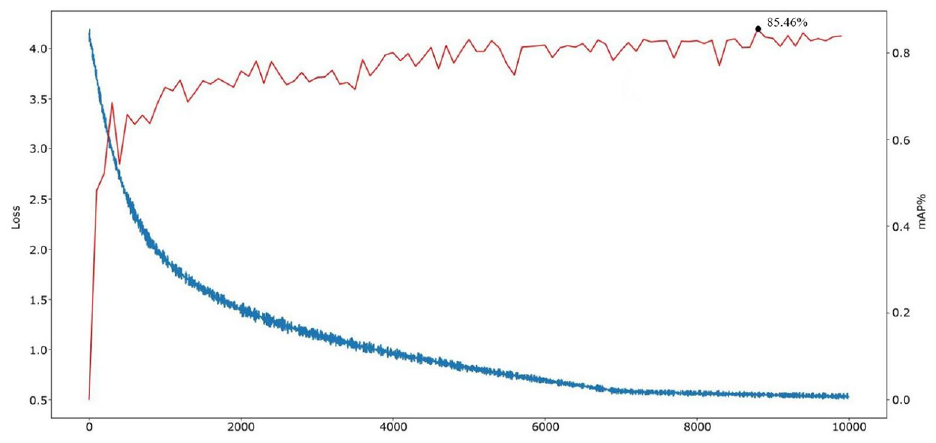
Loss function of Faster R-CNN model and Results of mAP.
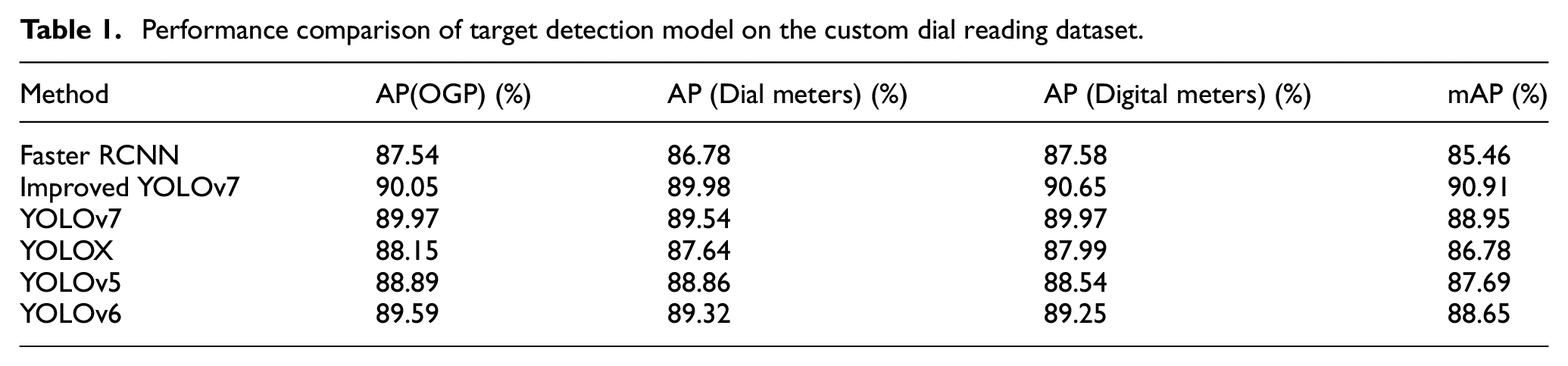
To further demonstrate the superiority of the proposed improved YOLOv7 model, we conducted training and testing on the Custom Dial Reading datasets, and compared its evaluation indexes (such as average accuracy (mAP) of all categories and average accuracy AP of each category). It is compared with advanced target detection models (including YOLOv7, 13 YOLOv6, 14 YOLOv5, 15 YOLOX, 17 and Faster-RCNN 16 models), and the results are shown in Table 1. From the table, it can be seen that the improved YOLOv7 model outperforms the other detection algorithms, with mAP 1.96% higher than YOLOv7, and 2.26%, 3.22% and 4.13% higher than YOLOv6, YOLOv5, YOLOX and Faster-RCNN, respectively; the AP of OGP is higher than that of YOLOv7, YOLOv6 and YOLOv5, YOLOX and Faster-RCNN models, up to 90.05%, and the AP of Dial meters and Digital meters are also the highest, up to 89.98% and 90.65%. These experimental results demonstrate the practical advantages of the proposed method in OGD target recognition.
Performance comparison of target detection model on the custom dial reading dataset.
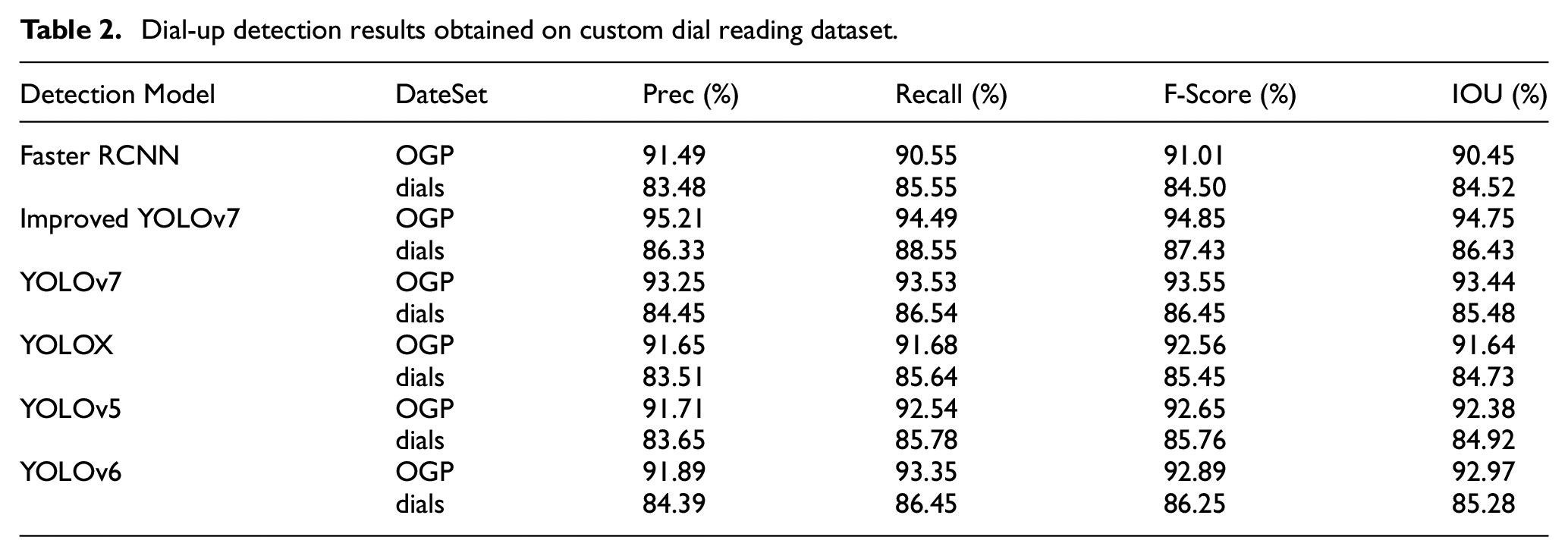
YOLO(YOLOv5, 15 YOLOX, 17 YOLOv6, 14 and YOLOv7 13 ) and Faster R-CNN 16 models are used in detecting the data image of pipeline and dial, with experimental results exhibited in Table 2.
Dial-up detection results obtained on custom dial reading dataset.
Simultaneously, identification (reading) is performed by bonding identified numbers (from the far left to the far right). The three indexes described in the previous section are adopted to identify and compare with the pointed values, with models of YOLO and Faster R-CNN employed. Identification results and FPS rate obtained are as described in Table 3.
Recognition results obtained with network model.
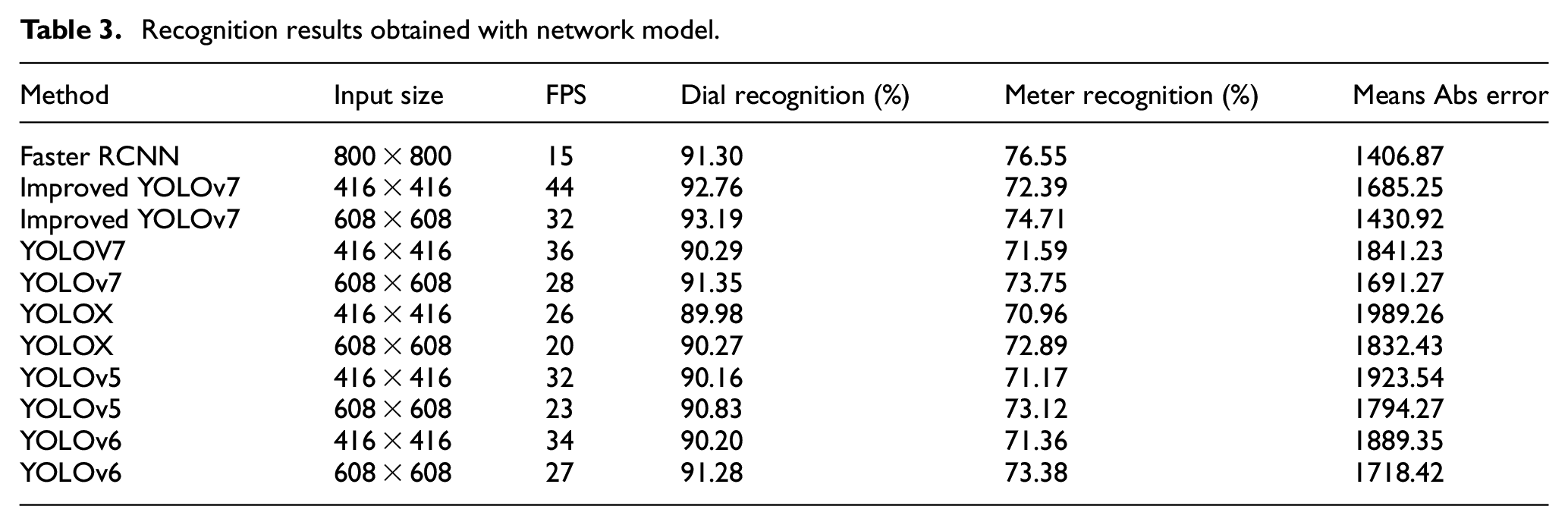
Table 4 mainly applies YOLO and Faster R-CNN models in predicting the number 1–5 in the instrument, and in forecasting the error frequency.
Error distribution by dial location.
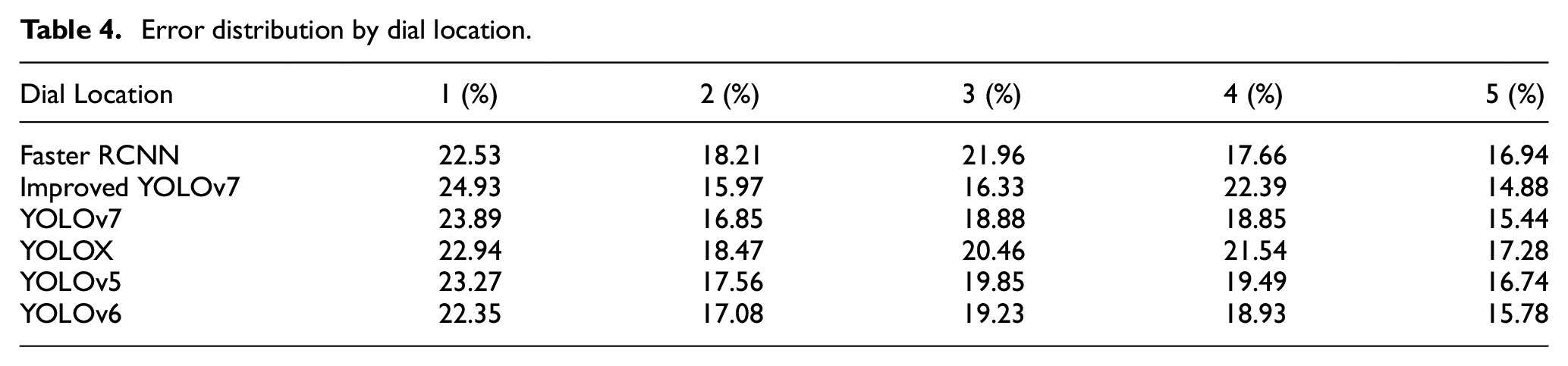
Figure 21 exhibits several accurate projection results. Noteworthy, Levenshtein distance between each right projection and own ground-truth annotation is usually equal to 0.

Accurate identification of meter ground truth, projection examples, and Levenshtein distance (Noteworthy, Levenshtein distance is 0; (a) neighboring values; (b) harsh lighting conditions; (c) rotation; (d) neighboring values and symmetries).
Figure 22 shows some of the wrong projection results. Most of the errors are caused by the neighboring value issues. If the pointer is before the mark, it shall be difficult to confirm whether pointed value should be the one after or before mark. Other reasons need to be explored in detail in the next section.
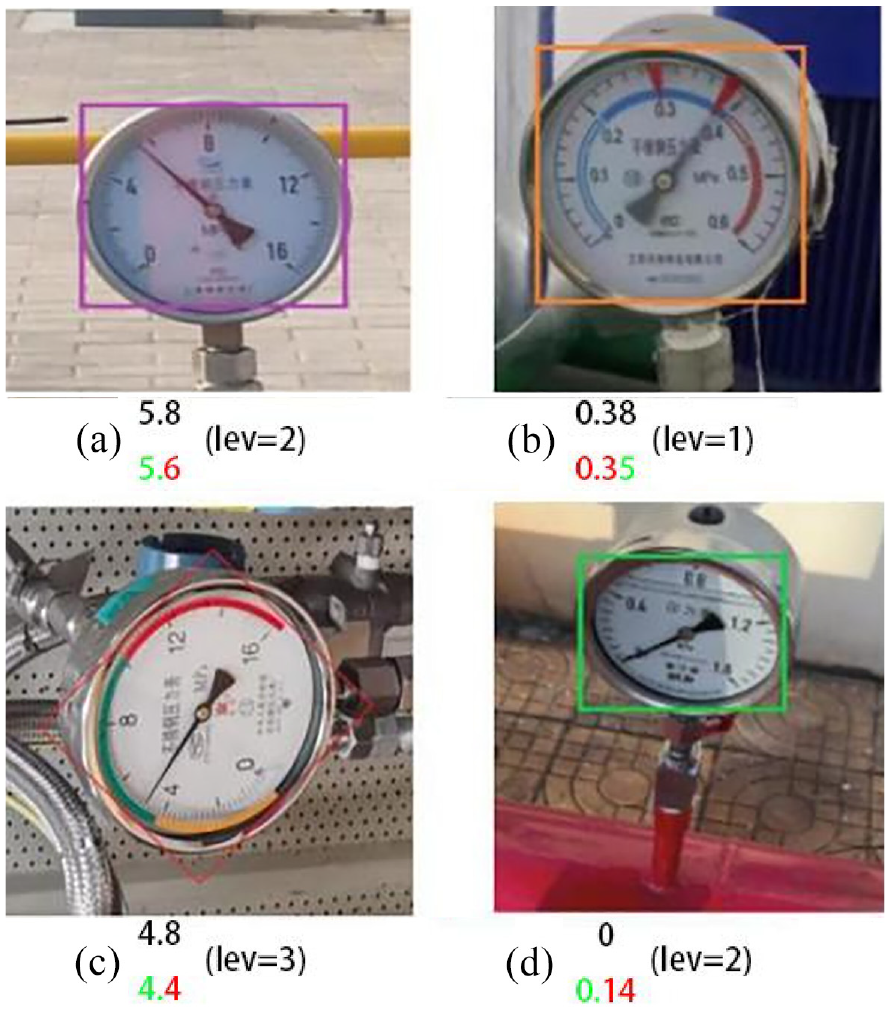
Projected results and errors in the Levinshtein distance marked in red ((a) neighboring values; (b) harsh lighting conditions; (c) rotation; (d) neighboring values and symmetries).
Ablation experiments of the custom dial reading datasets
We conducted ablation experiments on the improved YOLOv7 model to evaluate the impact of different improvements on the model performance. Firstly, in this paper, the designed ResNet-ACmix and improved E-ELAN models are used to extract the target features, and then GAM is introduced to enhance the ability of the network to extract deep and important features efficiently, and finally it is used for the detection and recognition of OGDs. The experimental results are shown in Table 5.
Ablation comparison of model performance improvement on the Custom Dial Reading datasets.

From Table 5, it can be seen that the use of the improved ResNet-ACmix module increases the mAP value by 1.38%, and the improved E-ELAN module as the backbone network of the model to obtain more useful features is the most crucial improvement, which improves the mAP of the model by another 1.34% on top of the introduction of ResNet-ACmix. Finally, by adding GAM, more target feature information is acquired and the mAP is also improved by 0.68% based on the previous experiments respectively.
Discussion
The challenges of detecting and identifying targets (pipelines and OGD) in harsh OGP scenes are attributable to color distortion, low visibility, and blur owing to medium scattering and absorption in optical images in low light, bright light, and shadowed environments. To overcome these challenges, an innovative use of the ACmix module is proposed based on the original YOLOv7 network, and the ACmix-based ResNet-ACmix module and Improved E-ELAN module are designed with the introduction of GAM, thereby enhancing the extraction of information features. The experimental results show (see Tables 2 and 3) that the improved YOLOv7 model is effective, feasible and robust in harsh OGP scenarios. Compared with YOLO (YOLOv5,
15
YOLOX,
17
YOLOv6,
14
and YOLOv7
13
) and Faster R-CNN
16
models, the improved YOLOv7 not only accurately detects OGPs and OGDs but also has a fast detection rate, which provides good performance. However, despite the improved performance of the improved YOLOv
When adopting YOLOX, 17 YOLOv5, 15 YOLOv6, 14 YOLOv7, 13 improved YOLOv7, and Faster R-CNN 16 models to identify readings from OGP dials, the accuracy, network convergence rate, and projection error frequency of the improved YOLOv7 model are mainly as follows. The first is the accuracy rate. The accuracy of the improved YOLOv7 model is 95.21% for OGP and 86.33% for dial reading data. The accuracy of the Faster R-CNN model is 91.49% for OGP and 83.48% for dial reading data. YOLOX model is 91.65% accurate for OGP and 83.51% accurate for dial reading data. YOLOv5 model is 91.71% accurate for OGP and 83.65% accurate for dial reading data. YOLOv6 model is 91.89% accurate for OGP and 84.39% accurate for dial reading data. The accuracy of the YOLOv7 model is 93.25% for OGP and 84.25% for dial reading data with an accuracy of 84.45%. When applying an 800 × 800 pixel image, Faster R-CNN has the smallest accuracy of 76.55% for meter recognition and 91.30% for dial reading data with an average absolute error of 1406.87. The second is the FPS rate. The FPS rate of the improved YOLOv7 model is 44, which is the highest in the table, indicating that the improved YOLOv7 network has a faster convergence rate. The third is the IOU. The IOU of Faster R-CNN is 90.45% for OGP and 84.52% for dial readout data. The improved YOLOv7 model has 94.75% IOU for OGP and 86.43% IOU for dial readout data. The YOLOv7 model has 93.44% IOU for OGP and 85.48% IOU for dial readout data. The YOLOX model has an IOU of 91.64% for OGP and 84.73% for dial readout data. The YOLOv5 model has an IOU of 92.38% for OGP and 84.92% for dial readout data. The YOLOv6 model has an IOU of 92.97% for OGP and 85.28% for dial readout data. The fourth is the error rate. The error rates of the improved YOLOv7 model are 24.96%, 15.97%, 16.33%, 22.39%, and 14.88%, while the error rates of the Faster R-CNN model are 22.53%, 18.21%, 21.96%, 17.66%, and 16.94% for the recognition of data 1–5, and the error rates of the YOLOv7 recognition are 23.89%, 16.85%, 18.88%, 18.85%, and 15.44%, and the error rates of the YOLOX recognition are 22.94%, 18.47%, 20.46%, 21.54% and 17.28%, and the error rates of the YOLOv5 recognition are 23.27%, 17.56%, 19.85%, 19.49% and 16.74%, and the error rates of the YOLOv6 recognition are 22.35%, 17.08%, 19.23%, 18.93% and 15.78%. That is, the improved YOLOv7 model predicts fewer errors on the most important numbers. Table 3 confirms this statement, because YOLOX has fewer errors on the most prominent dial (far left). In conclusion, compared with other YOLO and Faster-RCNN models, the improved YOLOv7 model performs well in terms of accuracy and network convergence in identifying dial reading data for OGP.
When identifying dials of OGP with Improved YOLOv7, YOLOX, YOLOv5, YOLOv6, and YOLOv7 models, the most common errors are caused by the following factors. The first is symmetry. Considering clockwise and counterclockwise dials, this method cannot differentiate the direction when the digits are blurred, thus outputting mirrored value of real projection. The second is neighboring value, which is the most common error. The variables such as lighting, shadows, and occlusion (if the pointer is before dial scale mark), may impede dial reading. Different authors have different opinions on accurate pointed value in such conditions. The third is harsh lighting conditions/dirt. That is, the shadows, glares, reflections, and dirt can cause network confusion, especially for low-contrast images with artifacts emerged exceeding the pointer, thus making network deeming it as a pointer border by mistake, and further leading to incorrect projection. The fourth is rotation. It is harder to project the rotated images, due to inexistence of the pointed value in the regular location. The projections can be allocated to the adjacent digits in present angle of pointer when image remains no rotation.
Conclusions
This study presents a technology for autonomous detection of OGP by UAVs, combining an improved YOLOv7 model and Canny edge detection algorithm, aiming at achieving autonomous navigation and automatic OGD reading based on pipeline routes. In the autonomous navigation process, a tolerance selection method is developed for angular displacement and angle correction, thereby reducing angular errors and further obtaining the optimal pipeline route. After some initial buffering and a few seconds of oscillation, the angular error again stabilizes within the angular error tolerance by employing our proposed method, with good results achieved.
Six model algorithms (Faster R-CNN, 16 YOLOX, 17 YOLOv5, 15 YOLOv6, 14 YOLOv7, 13 and improved YOLOv7.) have been employed for the recognition of OGP and OGD. The UAV applies the improved YOLOv7 model algorithm in detecting and identifying dial data on pipelines along the pipeline route. As indicated by the experimental results, the improved YOLOv7 model has an accuracy of 95.21% for OGP, 94.85% for F-Score, 94.75% for IOU, and 86.33%, 87.43%, and 86.43% for dial data detection, with the maximum mAP of 90.91%. In terms of the dial read data, the faster R-CNN model has an accuracy of 91.49%, F-Score of 91.01%, IOU of 90.45%, and 83.48%, F-Score of 84.50%, and IOU of 84.52%, with the maximum mAP of 85.46%. Furthermore, the YOLOv7 model has accuracy of 93.25%, F-Score of 93.55%, and IOU of 93.44% for OGP, as well as accuracy of 84.45%, F-Score of 86.45%, and IOU of 85.48% for dial reading data, and the YOLOX model has accuracy of 91.65%, F-Score of 92.56%, and IOU of 91.64% for OGP, as well as accuracy of 83.51%, F-Score of 85.45%, and IOU of 84.73% for dial reading data, and the YOLOv5 model has accuracy of 91.71%, F-Score of 92.65%, and IOU of 92.38% for OGP, as well as accuracy of 83.65%, F-Score of 85.76%, and IOU of 84.92% for dial reading data, and the YOLOv6 model has accuracy of 91.89%, F-Score of 92.89%, and IOU of 92.97% for OGP, as well as accuracy of 84.39%, F-Score of 86.25%, and IOU of 85.28% for dial reading data. In summary, compared with other YOLO and Faster-RCNN models, the improved YOLOv7 model has higher F-Score, faster RR, quicker network convergence, greater IOU and more stable network structure, which also verifies its robustness, validity, and reliability.
This study still can be further improved, including a new method for solving the boundary problem between markers, as well as most errors. Besides, multiple training of the new loss function for the error on the leftmost dial may contribute to the reduction of absolute error.
Footnotes
Acknowledgements
This study was accomplished under the auspices of Chengdu Bobei Technology Co., Ltd. Chengdu, China.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was funded by Basic Research Program of China (grant number 2019YFE0126600), Fund project of central government guided local science and technology development (no. 226Z0302G), Innovation Fund of Production, Study and Research in Chinese Universities (2021ZYA08001), and National and Doctoral Research Startup Fund Project (BKY-2021-32).