
Abstract
Defect detection plays a crucial role in the manufacturing industry, ensuring the quality of industrial products. Despite advancements in this field, current defect detection methods face two primary challenges: (1) extracting visually similar features from the background poses difficult and (2) these methods struggle to identify tiny defects in the target objects. We present a feature enhancement module called the SE-CAR, which aims to handle the identified problems effectively. This module is designed to efficiently capture tiny defects in images, prioritize defect information features, and ultimately enhance the model’s predictive performance and accuracy in defect recognition tasks. In addition, Distance-IoU Non-Maximum Suppression is employed as a substitution for the original Non-Maximum Suppression. This enhances the recognition accuracy of bounding boxes, ensuring that the model maintains high detection accuracy even after complex scenarios. Moreover, the proposed methodology exhibits broad applicability across a wide spectrum of prevalent defect detection paradigms. In empirical experiments, we employ the YOLOv7 architecture as the foundation framework, integrating the proposed methodologies for the purpose of detecting defects in the membrane. The empirical evidence demonstrates a notable improvement in the performance of detecting defects in membrane products using the SE-CAR feature enhancement module and Distance-IoU Non-Maximum Suppression algorithm. In comparison to baseline networks, an increase in mAp by 6.29%, precision by 1.63%, and recall by 8.76%.
Keywords
Introduction
The identification of surface defects in industrial products has been a long-standing challenge in industrial production. 1 Several objective factors, such as machine failures, material inhomogeneity, and environmental disturbances during production, frequently give rise to surface defects in products, resulting in significant economic losses for enterprises. 2 Automatic defect detection is indispensable in effectively controlling product quality. Traditionally, surface defect inspection has relied on manual visual inspection. Nevertheless, even the most proficient workers are capable of identifying only 70% of defects during the production process, and prolonged engagement in this labor-intensive task can deteriorate visual accuracy.3,4 Therefore, it becomes imperative to propose an automatic defect detection method specifically for this purpose.
Within the contemporary domain of defect detection, target recognition strategies can be predominantly categorized into two primary methodologies: traditional approaches and deep learning-based methodologies. Traditional object detection methods primarily rely on feature extraction and machine learning approaches within computer vision. These methods typically employ manually designed features. Machine learning algorithms are subsequently employed for the purpose of classification. The primary advantages of traditional methods lie in their simplicity, speed, and suitability for real-time applications. Over time, deep learning-based object detection methodologies have emerged, facilitated by the advancements in deep neural network. These methods comprehensively learn object representations and classifiers directly from raw images through an end-to-end approach. Currently, there are two main kinds of deep learning-based object identification methodologies: one-stage and two-stage methods. One-stage methods, unify object detection and classification tasks within a single network.5,6 Conversely, two-stage methods, initially employ a Region Proposal Network (RPN) to locate possible object areas first, and then categorize and localize them.7,8 The primary advantages of deep learning methods lie in their automatic feature learning capabilities and robust expression, well-suited for addressing complex scenarios and various object classes.
Convolutional Neural Networks (CNNs) have emerged as the most critical and foundational deep learning methodology. CNNs have demonstrated unparalleled performance in feature extraction and spatial analysis, making them an indispensable tool for computer vision tasks. Despite the remarkable performance of the CNNs in object detection, the model faces shortcomings, including diminished accuracy and suboptimal detection of tiny objects in specific scenarios. To address these challenges, extensive efforts have been dedicated to enhancing and optimizing the CNNs model. An array of innovative approaches has been introduced, encompassing advancements in network architectures, data augmentation techniques, and refinements to loss functions. These strategies are all aimed at improving the model’s performance. As a result, the discipline of defect detection has seen notable advancements in terms of accuracy and resilience. 9 Among these methods, Faster Region-based Convolutional Neural Network (Faster R-CNN) stands out as a swift algorithm for object detection, which harnesses the capabilities of region-based convolutional neural networks. 10 Numerous researchers have conducted enhancements to Faster RCNN, with the aim of improving various aspects, such as detection accuracy and speed.11–13 On the other hand, single shot multibox detector (SSD), which is based on convolutional neural networks, has become a well-known object detection technology. 14 Numerous studies, research have made improvements to SSD in order to enhance its detection accuracy and speed.15–17 Researchers have made significant progress in improving the original YOLO algorithm’s performance. Notable versions, such as YOLOv518,19 and YOLOv7,20,21 have been developed to enhance both detection accuracy and speed. This work aims to enhance object detection algorithms’ efficiency and performance so they can be more accurate and versatile in a range of application scenarios. 6 Nevertheless, there remain several challenges that necessitate further investigation within this domain. Firstly, the extraction of visually similar features from the background poses difficulty. 22 Secondly, the existing methods tend to struggle in accurately identifying tiny defects in the target object. 23 This paper presents a detection framework with two parts to address these issues: the feature enhancement module and the Distance-IoU Non-Maximum Suppression (DIoU-NMS) technique. 24 The feature enhancement module integrates the Squeeze-and-Excitation (SE) attention module 25 and the Content-Aware ReAssembly of FEatures (CARAFE) up-sampling module 26 to effectively preserve detailed information, enhance feature representation, and improve overall performance by dynamically adjusting the importance of each channel. For the sake of brevity, the feature enhancement module is referred to as SE-CAR later. Additionally, in order to tackle the issue of overlapping bounding boxes in object recognition, DIoU-NMS is utilized. This method efficiently removes excessively overlapping bounding boxes and improves the precision and stability of object detection outcomes. To confirm that the suggested approach is effective, a specific dataset focused on membrane product defects was constructed, and the proposed framework was applied to YOLOv7 27 for experimentation. The empirical experiments conducted demonstrate substantial improvements in the proposed framework’s ability to detect membrane product defects. Impressively, the average precision (mAP) achieved an outstanding value of 97.87%, while precision and recall reached 99.5% and 97.12%, respectively. Compared to the baseline networks, our approach resulted in significant improvements, increasing the mAP, precision, and recall by 6.29%, 1.63%, and 8.76%, respectively. These experimental findings conclusively affirm the outstanding performance and applicability of the proposed framework. The following are this paper’s main contributions:
(1) We propose a feature enhancement module named SE-CAR, by integrating CARAFE into the SE attention mechanism. The SE-CAR model has the capability to enhance image features, thereby improving the overall performance of visual tasks.
(2) We introduce DIoU-NMS into the framework, which can be more effective in addressing challenges presented by overlapping or densely packed target boxes.
(3) We carried out comparative studies on the job of membrane product defect identification after integrating the suggested framework into YOLOv7. Comparing our experimental findings to the benchmark, we find substantial improvements of 6.29% in mAP, 1.63% in accuracy, and 8.76% in recall. The suggested technique achieves intelligent recognition when it is used in the industrial membrane product manufacturing line.
The rest of this paper is organized as follows: Section “Related work” reviews related work on traditional and deep learning-based defect detection methods. Section “Methodology” presents the proposed methodology, detailing the SE-CAR feature enhancement module, the DIoU-NMS algorithm and object detection techniques. Section “Empirical experiments” describes the empirical experiments, including data collection and preprocessing, evaluation metrics, and experimental results and analysis. Finally, Section “Conclusion and future work” concludes the paper and outlines future research directions.
Related work
Traditional detection methods
Traditional automated defect detection methods primarily focus on identifying and assessing defects or faults that could potentially impact the quality and performance of materials. These methods commonly involve a combination of manual visual inspection and machine vision techniques.28,29 For instance, widely utilized approaches such as edge detection and threshold processing are employed to detect defect regions. 30 Several different methodologies have been suggested in prior scholarly works for identifying and categorizing defects. Ren et al. 31 presented a novel method that makes use of color histograms to assess how comparable Electrical Resistance Tomography pictures are to one another. Lambert and Bock 32 employed a multi-scale wavelet-based approach to detect texture defects, which not only allows for precise defect localization but also enables defect classification. Ma et al. 33 addressed the limitations of manually setting parameters and poor adaptability of the traditional Canny operator by proposing an adaptive Canny operator-based algorithm. Vladimir et al. 34 presented a digital image processing-based approach that achieves higher speed and accuracy. Ngan et al. 35 developed a direct threshold technique predicated on detailed sub-images of WT, which can effectively segment defect areas on patterned fabrics. Dou et al. 36 proposed a novel algorithm, named the Fast Railway Bolt Detection Algorithm, which overcomes the time-consuming task of manually collecting and training the training dataset, by utilizing rapid template matching techniques. These methods often rely on extensive manual feature extraction, making them time-consuming and constrained by resource limitations for manual inspection.
Deep-learning-based segmentation methods
The ascent of deep learning, notably through the utilization of CNNs, has heralded remarkable advancements in computer vision. CNNs serve as potent tools for feature learning, allowing the automatic acquisition of feature representations from unprocessed data, eliminating the requirement for manual design. The integration of this technology has empowered computer vision systems to gain a more profound comprehension of various image defects, thus bolstering the precision and resilience of defect detection. Numerous scholars have put forth diverse algorithms for detecting defects. For instance, Balzategui et al. 37 employed a fully convolutional network to accurately identify and localize defects in polycrystalline solar cells. Gao et al. 38 introduced a deep learning FCN-RCNN model to precisely and rapidly identify multiple tunnel defects, considering the intricate tunnel environments. Xia et al. 39 developed a algorithm that integrates the structural similarity index (SSIM) and MobileNet for accurate and efficient detection of surface defects in printed circuit boards. Their approach demonstrates a significant improvement in computational efficiency, achieving at least a 12-fold increase in speed compared to the Faster RCNN method while maintaining a high level of accuracy. Lei and Sui 40 presented a deep CNN adapted from the Faster R-CNN framework for intelligent fault detection in high-voltage power lines, specifically targeting the identification of damaged insulators and the presence of bird nests. Yu et al. 41 addressed several critical challenges in the realm of X-ray flaw identification in castings, including the subtle differences between defect classes, the significant variations in defect sizes, and the inherent uncertainties in annotation. To effectively tackle these challenges, the authors proposed an innovative adaptive network that dynamically selects optimal deep and receptive fields for the semantic segmentation of defects. Using Generative Adversarial Networks (GANs) as the foundation, Liu et al. 42 presented a framework for fabric fault detection. This framework addresses challenges associated with the intricate diversity of fabric textures and defects. Cui et al. 43 presented a swift and precise network for detecting surface defects, denoted as SDDNet. Their approach is particularly effective in handling issues like significant variations in texture and the detection of small-sized defects. Su and Yan 44 addressed various challenges in gear end face defect detection, including small defects, complex tooth surfaces, intricate processing environments, and the requirement for real-time detection. They proposed a method based on an improved YOLOv3 model. Li et al. 45 has proposed a lightweight and enhanced algorithm, leveraging YOLOv5, to tackle the challenges of low efficiency in detecting flat jujubes in the field, as well as the complexity of deploying target detection algorithms on low-cost devices.
Currently, small object detection, with a focus on identifying incredibly small objects within images, has recently emerged as a prominent research area. Due to the inherent characteristics of tiny objects, such as a reduced number of pixels and less pronounced object information, conventional object detection algorithms often grapple with the accurate detection and localization of such objects. To address this challenge, researchers have proposed a range of specialized detection algorithms specifically tailored for tiny objects. These methods leverage multi-scale feature fusion and attention mechanisms, yielding substantial enhancements in the detection performance of diminutive objects at the expense of increased computational requirements. Tiny object detection has emerged as highly active research topics within the field of object detection. Scholars consistently develop novel strategies to address these issues and improve object detection algorithms’ performance in progressively more challenging situations. To address the challenge of detecting tiny defects with complex multi-scale characteristics amidst intricate background interference prevalent in industrial environments, Zhang et al. 46 introduced a novel anchor-free network, DsPAN, intended for tiny object detection. In order to explicitly address the difficulties involved with recognizing microscopic objects, Deng et al. 47 presented an inventive Extended Feature Pyramid Network (EFPN) that smoothly incorporates pyramid levels with ultra-high resolutions. To improve the precision of identifying small objects, Lim et al. 48 presented a context-based object identification technique, which addresses the difficulty presented by poor resolution and sparse information related to these targets.
Methodology
Feature enhancement module
One of the most important tools used to improve the quality and recognition of features in picture data is the feature enhancement module. Its goal is to augment the valuable information present in the data, thus assisting algorithms or systems in processing the data more effectively.
We present a feature enhancement module called SE-CAR in this paper, which seamlessly integrates the CARAFE into the SE attention mechanism. The SE attention mechanism serves as a key component of the SE-CAR module, dynamically recalibrating the feature map weights to enhance representational power. This method begins by applying global average pooling to the feature maps, compressing the spatial information of each channel into a scalar, thereby creating a channel descriptor vector. Then, this vector is input into a small network composed of two fully connected layers, adaptively learning the importance weights for each channel. Finally, the learned weights are applied to the corresponding channels of the original feature maps, highlighting important features and suppressing less important ones.
Another significant component of the SE-CAR module is the CARAFE module, which leverages a learning-based approach to improve upsampling results through specific sampling and reconstruction processes. In the subsequent sections, we present a comprehensive explanation of the CARAFE module and the SE attention mechanism.
The SE attention module is a potent and flexible technique intended to improve deep neural network performance and representational capacity. Its purpose is to dynamically learn and adaptively recalibrate the importance weights of features across different channels. In convolutional neural networks, different channels have varying importance in representing distinct features. By incorporating the SE attention mechanism allows for the adjustment of channel weights to enhance the capture of crucial information. Figure 1 the architectural design and key components of the SE attention module. The SE attention module is composed of several key components, which include:
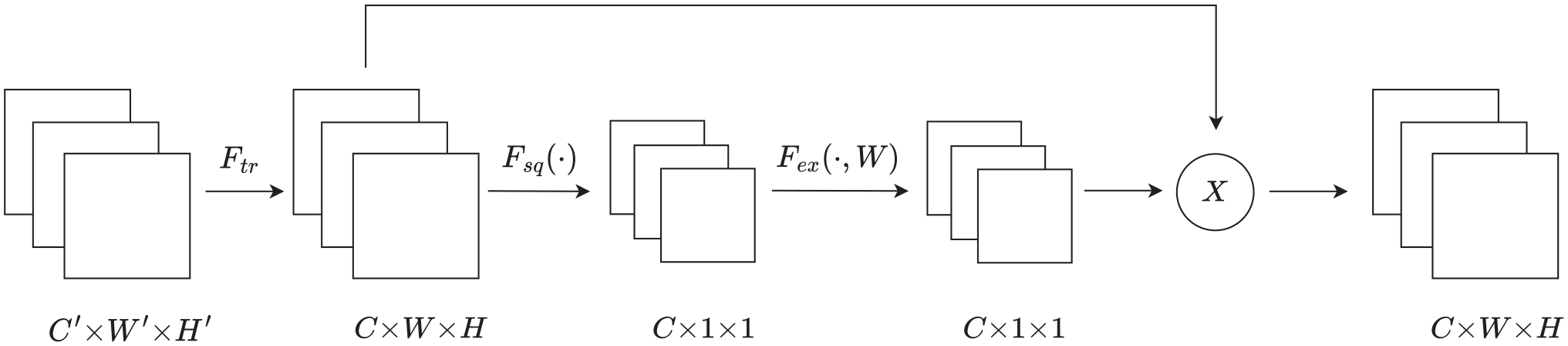
The structure of SE attention module.
Squeeze
To get the global average value for each channel, the input defect feature map was first globally pooled in the spatial dimension. This provides, a scalar value that represents the global importance of each channel’s features. In Figure 1, the operation of squeeze is denoted by using
Excitation
Subsequently, a small multilayer perceptron is employed to learn the global average values, resulting in the acquisition of a new set of weights that represent the relative importance of each channel. In Figure 1, the operation of excitation is denoted by using
Scale
Finally, an element-wise multiplicative operation is used to modify the initial input feature map using the channel-wise significance weights that have been adaptively learnt via the attention process. The action of scale in Figure 1 is shown by
In Figure 1
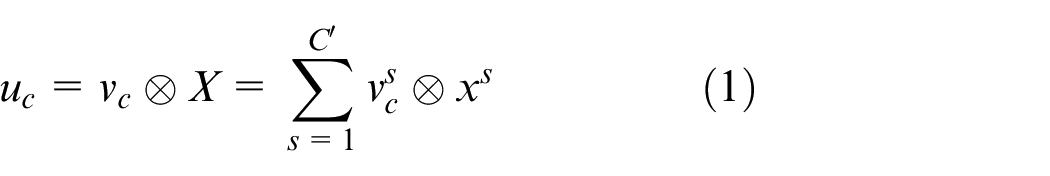
where ⊗ represents the convolution operation,
The module CARAFE is designed for upsampling, as seen in Figure 2. To gradually raise the low-resolution feature map’s spatial resolution is the main goal of the upsampling process, ultimately aligning its dimensions with those of the original input image, thereby enabling pixel-wise correspondence and facilitating subsequent high-resolution spatial reasoning tasks. The CARAFE module is built upon the fundamental concept of leveraging both local pixel information and surrounding contextual information during the upsampling process. It extracts the context information from the feature map through reversible operations and combining it with the outcomes of conventional up-sampling. As a result, CARAFE enables more precise upsampling results and improved restoration of details from the original image.
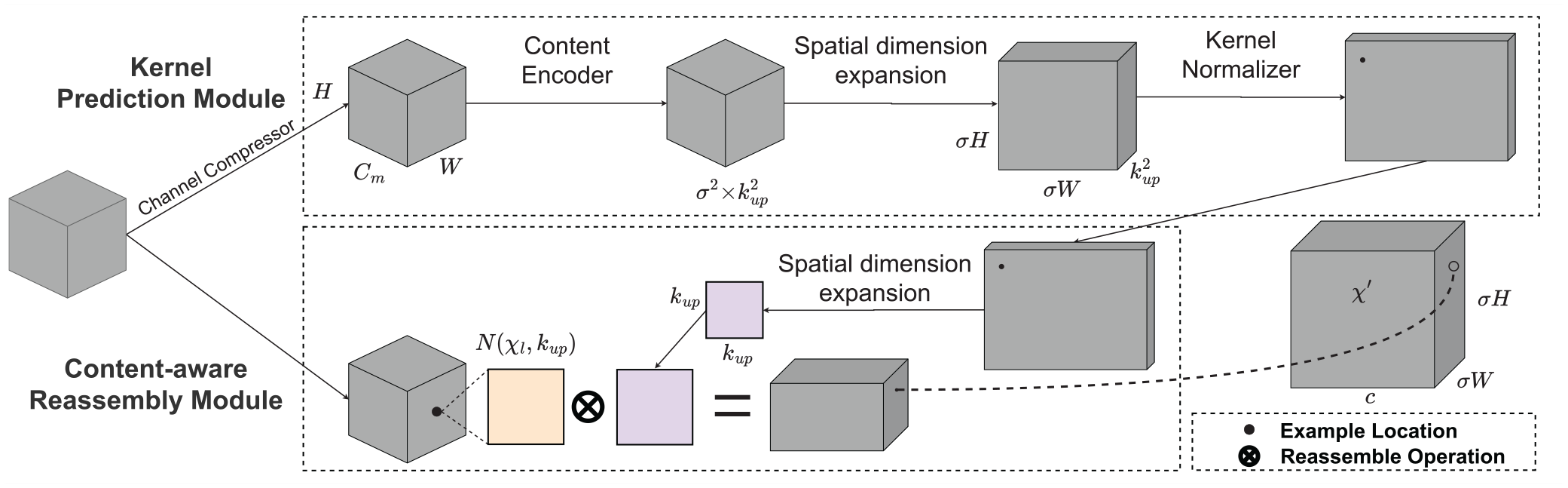
The structure of CARAFE up-sampling.
CARAFE network architecture comprises two modules: the Kernel Prediction Module and the Content-aware Reassembly Module. Within the Kernel Prediction Module,
In the Content-aware Reassembly Module, the feature map patches extracted from the original high-resolution input undergo element-wise multiplication with their spatially corresponding adaptive kernels generated by the Kernel Prediction Module, yielding the final output.
To acquire defect feature maps of superior quality, the CARAFE upsampling method is employed. First, a convolutional layer is used to generate a reassembly kernel, which is responsible for capturing local contextual information. Then, the input feature maps are preliminarily upsampled, typically using the nearest neighbor interpolation method, to match the target output size. Next, the upsampled feature maps are weightedly reassembled using the generated reassembly kernel, a process that actually redistributes features while considering local context. Finally, the CARAFE module outputs the reassembled feature maps, which retain the information of the original features and integrate contextual information, thus obtaining a higher quality defect feature representation. This optimized feature map is then passed to subsequent layers of the network for further processing.
DIoU-NMS
The Intersection over Union (IoU) metric is used by NMS approaches to measure the extent of overlap between several detection bounding boxes. Based on a predefined threshold, this metric is used to determine whether to retain a specific detection box. Equation (2) illustrates the formula for calculating IoU. 49

Traditional NMS methods have primarily relied on a single IoU metric. However, practical applications necessitate the consideration of various influential factors. It is important to take into account not just the common area between the grounded frame and the forecast frame, but also the aspect ratio and the separation from each centroid point. In cases where two targets are in close proximity and exhibit a substantial IoU value, traditional NMS may mistakenly identify them as a single object, which could result in unintended exclusion. On the other hand, DIoU-NMS offers advantages by not eliminating the other frame in instances where the centroids of the two frames are considerably distant, even when the IoU value is high. Consequently, the implementation of DIoU-NMS serves to diminish the incidence of false deletions. DIoU-NMS is better than NMS because it becomes possible to more effectively address challenges presented by overlapping or densely packed target boxes. This not only leads to better suppression of redundant detection results but also enhances the accuracy and stability of target detection. The formula for calculating DIoU 50 is demonstrated in equation (3). Figure 3 illustrates the concept. The anticipated box is represented by the black box, while the actual box is represented by the green box.
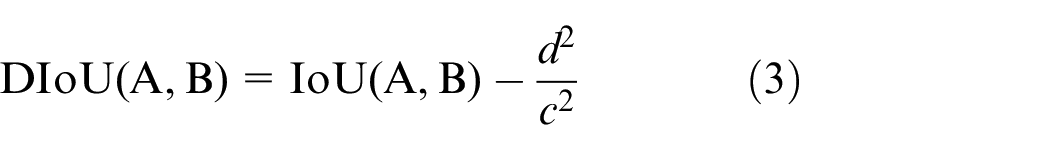
where
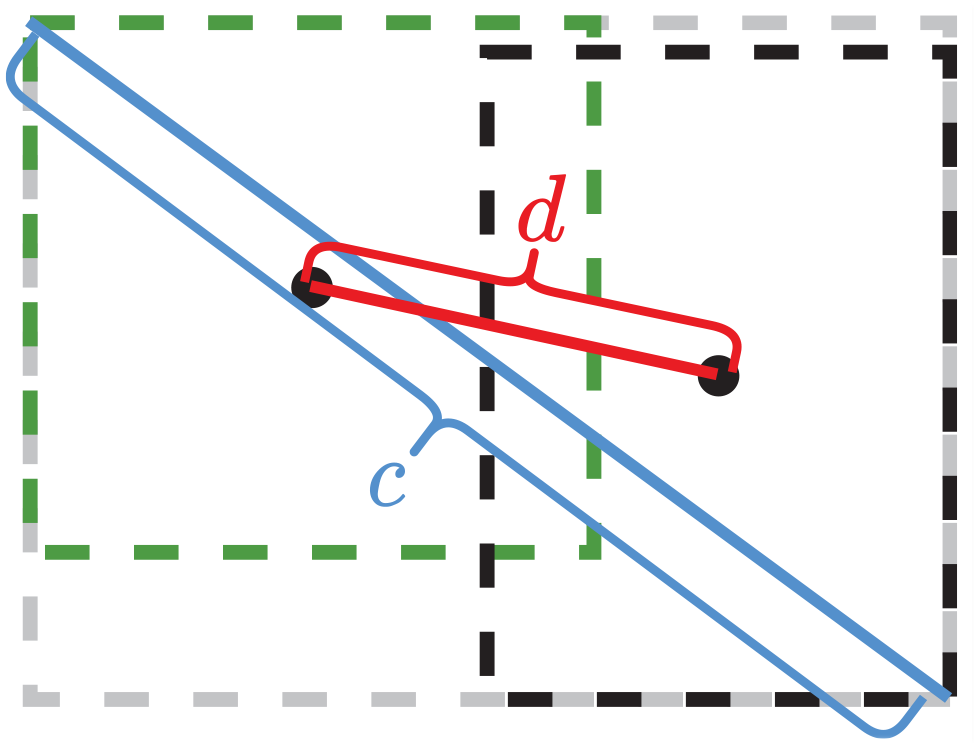
The schematic diagram of DIoU calculation.
In summary, Algorithm 1 illustrates the computational procedure of the SE-CAR and DIoU-NMS methods. The algorithm takes as input a feature vector

Object detection techniques
Currently, there are several commonly used target detection algorithms in computer vision, namely SSD, Faster RCNN, and the YOLO series. The algorithms in question are engineered to ascertain and accurately demarcate objects spanning diverse classifications within both still imagery and video content. SSD, an anchor-based object detector, is capable of simultaneous prediction of multiple bounding boxes and corresponding classes within an image, enabling real-time detection. It accomplishes this by utilizing predetermined anchor boxes of various scales on the feature maps, enabling the detection of objects across a wide range of sizes. SSD, an anchor-based object detector, is capable of simultaneous prediction of multiple bounding boxes and corresponding classes within an image, enabling real-time detection. In contrast, Faster RCNN is a two-stage object detection algorithm that employs a RPN to generate initial candidate bounding boxes, which are then refined and classified. Although Faster RCNN achieves higher detection accuracy compared to SSD, it comes at the cost of slower processing speed. The complexity of the computation involved in the generation of candidate bounding boxes leads to an overall decrease in speed. On the other hand, YOLOv7 is among the most sophisticated single-level object detection systems out there. With YOLOv7, inference is remarkably rapid yet detection accuracy is still high. This is achieved via convolutional neural network prediction of both the bounding box and its associated class probabilities simultaneously. Due to its superior speed, YOLOv7 is highly suitable for real-time object detection applications, offering a notable advantage.
YOLOv7 model
YOLOv7 is an evolution of the YOLO series and is known for its high accuracy and real-time performance. The model consists of three main components: an input preprocessor, a backbone network, and a detection head.
The YOLOv7 1 model consists of three main components: an input terminal, a backbone network, and a detection head. Initially, the faulty image is first uniformly resized by the input component to a typical 640 × .640 three-channel RGB training image. Efficient Layer Aggregation Networks (ELAN) and Max-Pooling (MP) modules make up the Backbone module. The input feature layer’s dimensions are maintained by the stacked convolution blocks that make up the ELAN module. It enhances interaction between different feature layers by expanding, randomly combining, and concatenating them, thereby improving the model’s learning capability. The MP module ensures consistency in channel numbers between the input and output. The head structure comprises a Spatial Pyramid Pooling with Cross Stage Partial Convolution (SPPCSPC) layer, followed by a sequence of CBS layers, MPConv layers, CatConv layers, and Residual Pose Representation (RepConv) layers, which serve as the output layers of the network. Each layer is obtained by several distinct convolution layers performing various operations. The network performs feature extraction by iteratively fusing high-level and low-level feature maps, then uses these refined features to generate and output the final predictions.
Empirical experiments
The empirical trials that were conducted to confirm the suggested method’s effectiveness are described in this section. Every experiment was run on a GPU server with 64 GB of RAM. The server was equipped with an Intel® Xeon® Gold 5218 CPU operating at 2.30 GHz and an NVIDIA GeForce RTX 3090 GPU. The experimental code was implemented using Python 3.9. The process of software development can be divided into the following steps:
(1) Data acquisition: Acquire images using an industrial camera and preprocess the gathered data.
(2) Data preparation: Divide data into training, validation, and testing sets, and annotate the data.
(3) Model selection: Choose YOLOv7 as the fundamental model for training.
(4) Model improvement: Utilize an improved version of YOLOv7 to train the model for increased fault detection accuracy.
(5) Defect detection: Deploy the trained model to identify and precisely locate defects.
A visual representation of the software workflow can be observed in Figure 4.

Software flowchart of membrane product detection algorithm.
Data collection and preprocess
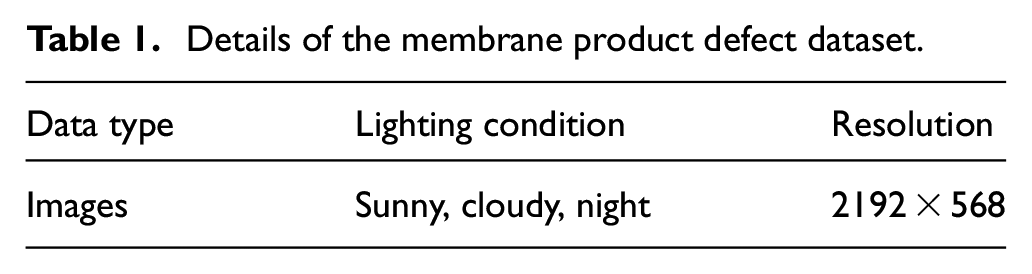
The data for experiments was obtained from an operating membrane product factory located in Zhejiang Province. The dataset contains images of membrane products captured under various lighting conditions and manufacturing environments. Table 1 summarizes the various types of data collected and the environmental conditions under which the data was acquired.
Details of the membrane product defect dataset.
A high-resolution industrial camera mounted on the production line was used to capture real-time images, which were then transmitted to a GPU server for further processing. The process of data collection is depicted in Figure 5.
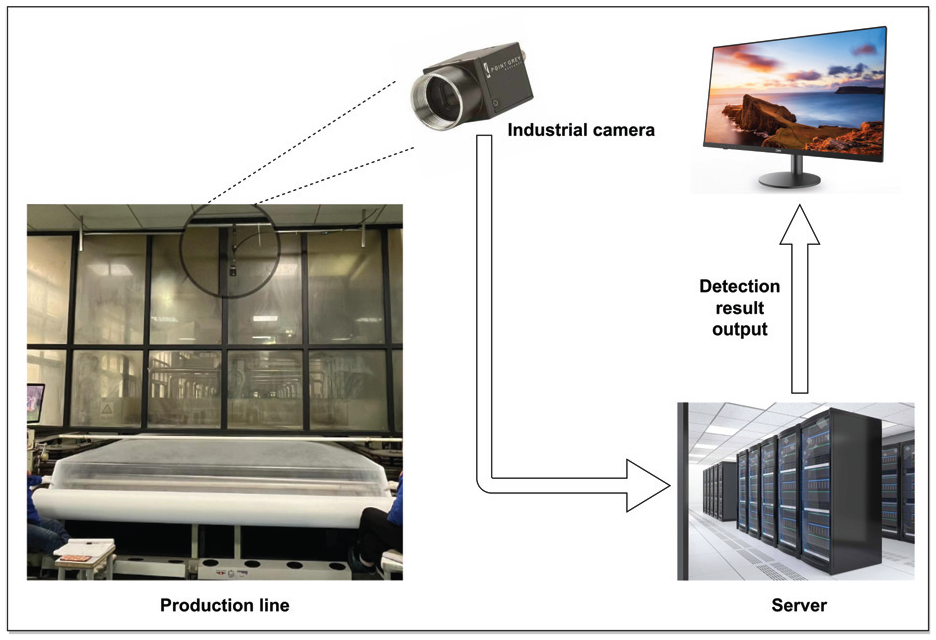
Diagram illustrating data collection for membrane products.
The inspection process faces a significant challenge when dealing with membrane products, as their thin nature is a result of specific craftsmanship techniques. In order to address this challenge, we conducted multiple experiments and implemented several modifications to the existing production line. Ultimately, we decided to use a deep blue color with low saturation as the background. This choice aimed to reduce potential interference caused by complex backgrounds and improve the accuracy of defect detection. Figure 6 depicts a schematic diagram illustrating the process of data collection for membrane products under various conditions. The defect dataset in this paper focuses on a particular type of defect labeled as “hole”, which manifests as circular holes. To account for the influence of different environmental factors, images of the membrane products were uniformly collected under different light conditions, including sunny, cloudy, and nighttime scenarios, as depicted in Figure 7.

(a) The original production environment, (b) the original data collection, (c) the production environment with added bottom plate, and (d) the data collection with added bottom plate.

Schematic diagram of the data sets collected under different light environments.
To improve the quality and diversity of the dataset, several data preprocessing and augmentation techniques were applied:
(1) Normalization: The pixel values of each image were normalized to a range of 0 to 1.
(2) Resizing: Every image was resized to 568 × 568 pixels.
(3) Image augmentation: Conventional image augmentation techniques such as translation, rotation, flipping, and mirroring were applied during the training phase.
The initial dataset of 586 images was expanded to 2630 images after preprocessing and augmentation. The augmented dataset was then split into training (1841 images), validation (526 images), and test (263 images) sets with a 7:2:1 ratio. Figure 8 illustrates the schematic diagram of the image preprocessing procedure.
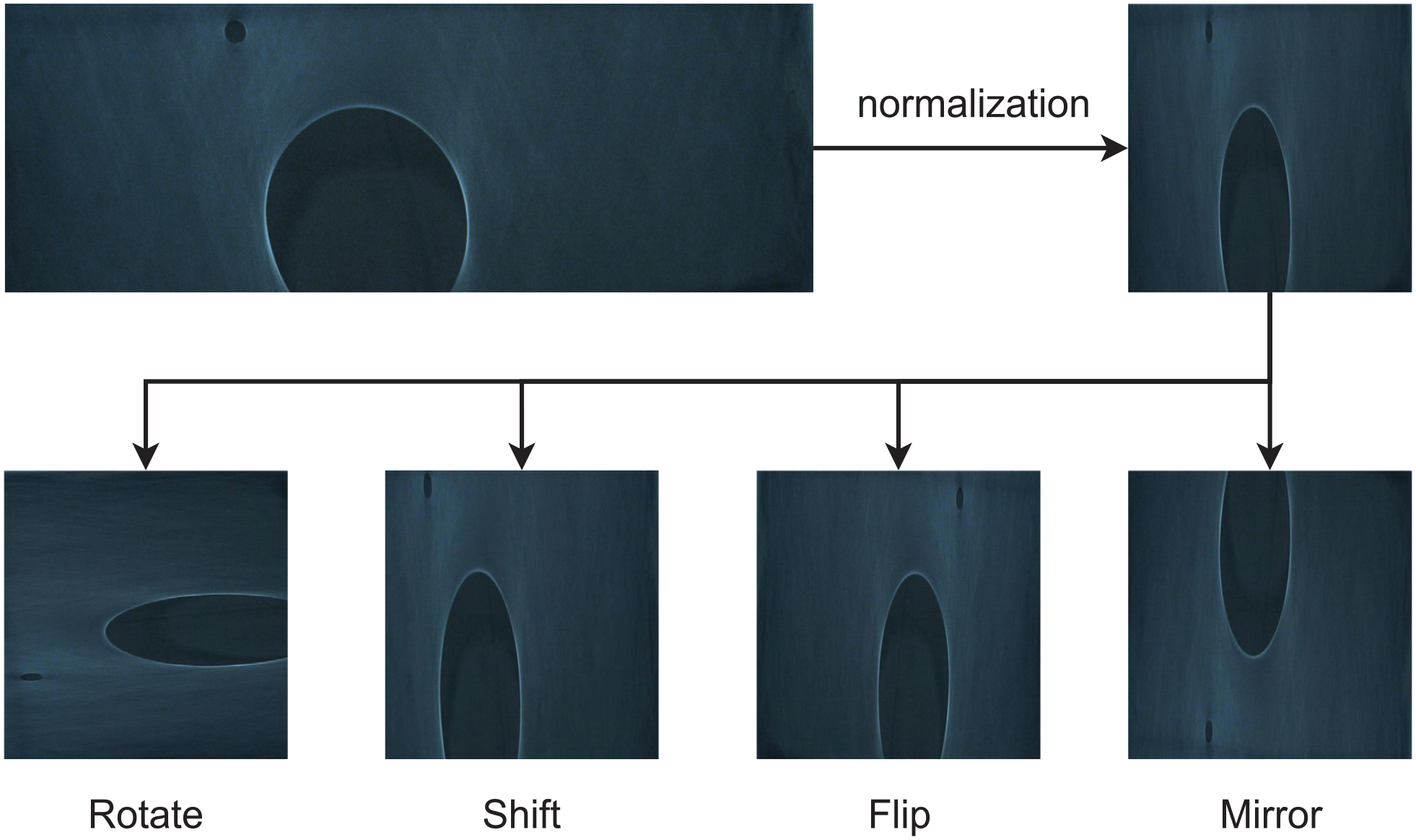
Preprocessing and augmentation effects of membrane product images.
Determination of judgment index
In our experiment, the primary assessment statistic we employ to gauge the model’s effectiveness is the mAP. The mAP stands for the arithmetic mean of the Average Precision (AP) ratings for each class in the dataset, which offers a thorough assessment of the model’s overall accuracy. The steps involved in calculating mAP, recall, and accuracy are outlined below.
Precision
Out of all the samples that were expected to be positive, precision is the percentage of samples that the model properly identifies as positive. According to equation (4), precision can be computed mathematically by dividing the number of true positive samples (positive samples that were correctly predicted) by the total number of false positives (positive samples that were forecasted incorrectly).

where True Positives (TP) are the samples the model correctly classified as positive, False Negatives (FN) are the samples the model incorrectly classified as negative, and False Positives (FP) are the number of negative samples the model mistakenly predicted to be positive.
Recall
Recall evaluates how well a model detects positive samples. It is also known as true positive rate or sensitivity at times. As shown in equation (5), it is computed by dividing the total number of TP by the sum of FN and TP.

mAP
By calculating the arithmetic mean of the AP scores for each object category, mAP is a comprehensive performance statistic that provides an overview of an object detection system’s overall accuracy. The system’s comprehensive assessment of object detection and classification accuracy, as stated in equation (6), is provided.

where
Higher precision and recall values generally result in an increase in the model’s accuracy and recall rate when it comes to target detection. Similarly, a higher mAP signifies improved detection performance in the model. This suggests that the model can detect targets more precisely and reduce the likelihood that they would be missed.
Experimental results and analysis
Comparison experiment
In order to determine the baseline network that can meet the industrial inspection needs, we employed the membrane defect dataset to train and evaluate several object detection models, including SSD, Faster RCNN, and various algorithms from the YOLO series (YOLOv5, YOLOv7, YOLOv8, YOLOv9). The detection results in terms of mAP are presented in Table 2. The mAP was employed as the primary metric to evaluate the models’ robustness and detection accuracy for identifying flaws in membrane products. The results indicate that YOLOv7 achieved the highest mAP of 91.58% among the compared models, outperforming SSD (86.53%), Faster RCNN (87.21%), YOLOv5 (88.98%), YOLOv8 (89.38%), and YOLOv9 (88.21%). The comparison reveals that the YOLOv7 algorithm significantly outperforms the other evaluated models in terms of mAP for the membrane defect detection task. Consequently, the YOLOv7 algorithm demonstrated superior performance in detecting defects on membrane products, rendering it the most suitable choice for practical production processes. Therefore, we selected YOLOv7 as the baseline architecture for further improvements and experiments.
Performance comparison of SSD, faster RCNN, and YOLOv7 with algorithm.

Enhanced module ablation experiment
We employed YOLOv7 as the base network with the same configuration to validate the experimental findings. In an extensive series of ablation trials, we evaluated the effect of adding the SE-CAR module on detection accuracy. Table 3 presents the detection outcomes that were obtained as a result. Figure 9 shows the performance comparison of the models.
The results of ablation experimental results.
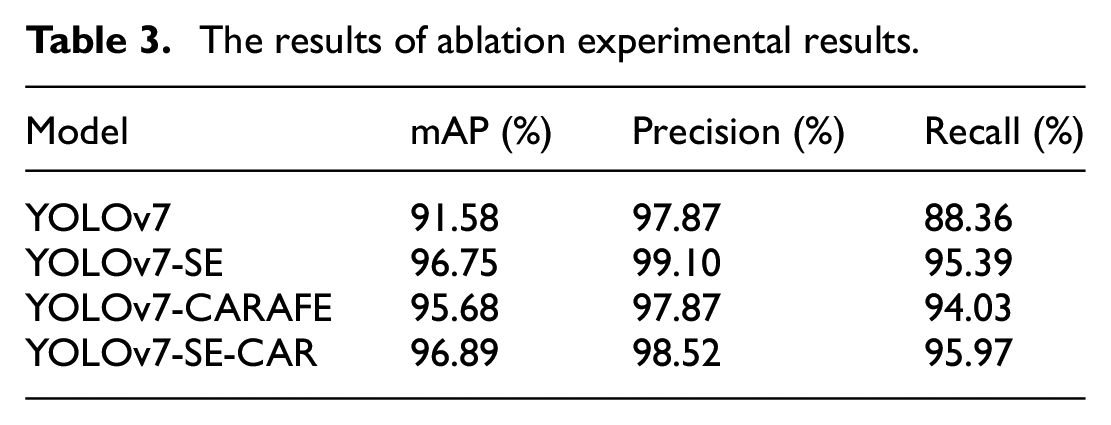
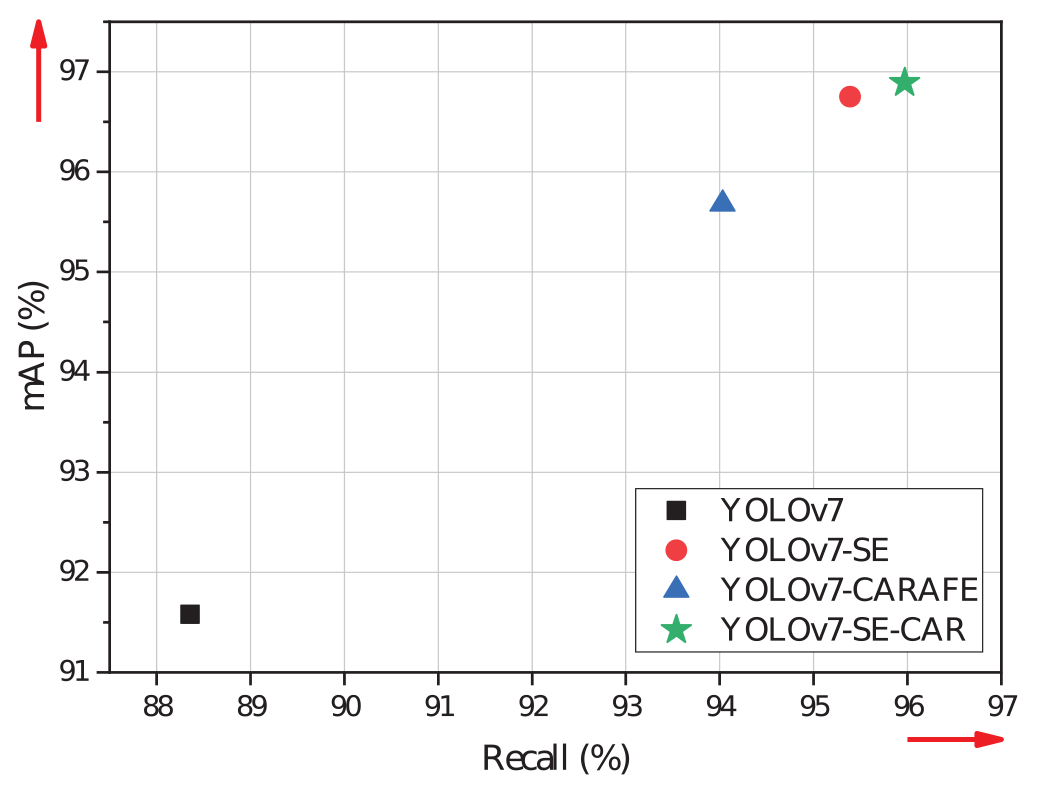
Model performance comparison, YOLOv7-SE-CAR model has high performance in membrane product tiny defect detection tasks.
The analysis of the ablation study data reveals that the enhanced YOLOv7 architecture significantly outperforms the original YOLOv7 architecture in terms of defect detection performance for membrane products. The original YOLOv7 architecture achieved a mAP of 91.58%, a precision of 97.87%, and a recall of 88.36%, which served as the baseline performance for subsequent modifications. By introducing the selective attention mechanism, the mAP increased to 96.75%, the precision rose to 99.10%, and the recall improved to 95.39%. These findings imply that the model is better able to concentrate on important characteristics for detection tasks as a result of the SE attention mechanism’s integration, which raises detection accuracy and recall. Moreover, the incorporation of the CAFARE upsampling module further enhanced the model’s performance, with the mAP reaching 95.68%, the precision remaining at 97.87%, and the recall increasing to 94.03%. This indicates that the CAFARE upsampling module helps the model capture more detailed and edge information, resulting in improved detection accuracy. Furthermore, the SE-CAR feature enhancement module, which combines both the SE attention mechanism and the CAFARE upsampling module, achieved the highest performance, with a mAP of 96.89%, a precision of 98.52%, and a recall of 95.97%. This synergistic integration of the SE attention mechanism and CAFARE upsampling module further optimizes the model’s ability to adapt to task requirements and attain superior mAP and precision metrics for membrane product defect detection.
The experiment shows that using the SE-CAR feature improvement module can help identify defects in membrane products, compared to the original YOLOv7, mAP, precision, and recall increased by 5.31%, 0.65%, and 7.61% respectively. We believe that the SE-CAR module allows the model to concentrate on essential features, extract more sophisticated feature information, and enhance detection performance through the integration of the advantages of the SE attention mechanism and the CAFARE upsampling module.
Figure 10 illustrates the network structure proposed for improved the YOLOv7 model. Our aim is to establish an intelligent defect recognition model tailored specifically for membrane products. Initially, the SE-CAR feature enhancement module is incorporated to enhance the overall accuracy of recognition. The central portion depicts the overall architecture of the network, while the sections with a gray background represent the sub-modules within the architecture. The figure includes a highlighted dashed box, which represents our proposed SE-CAR feature enhancement module.
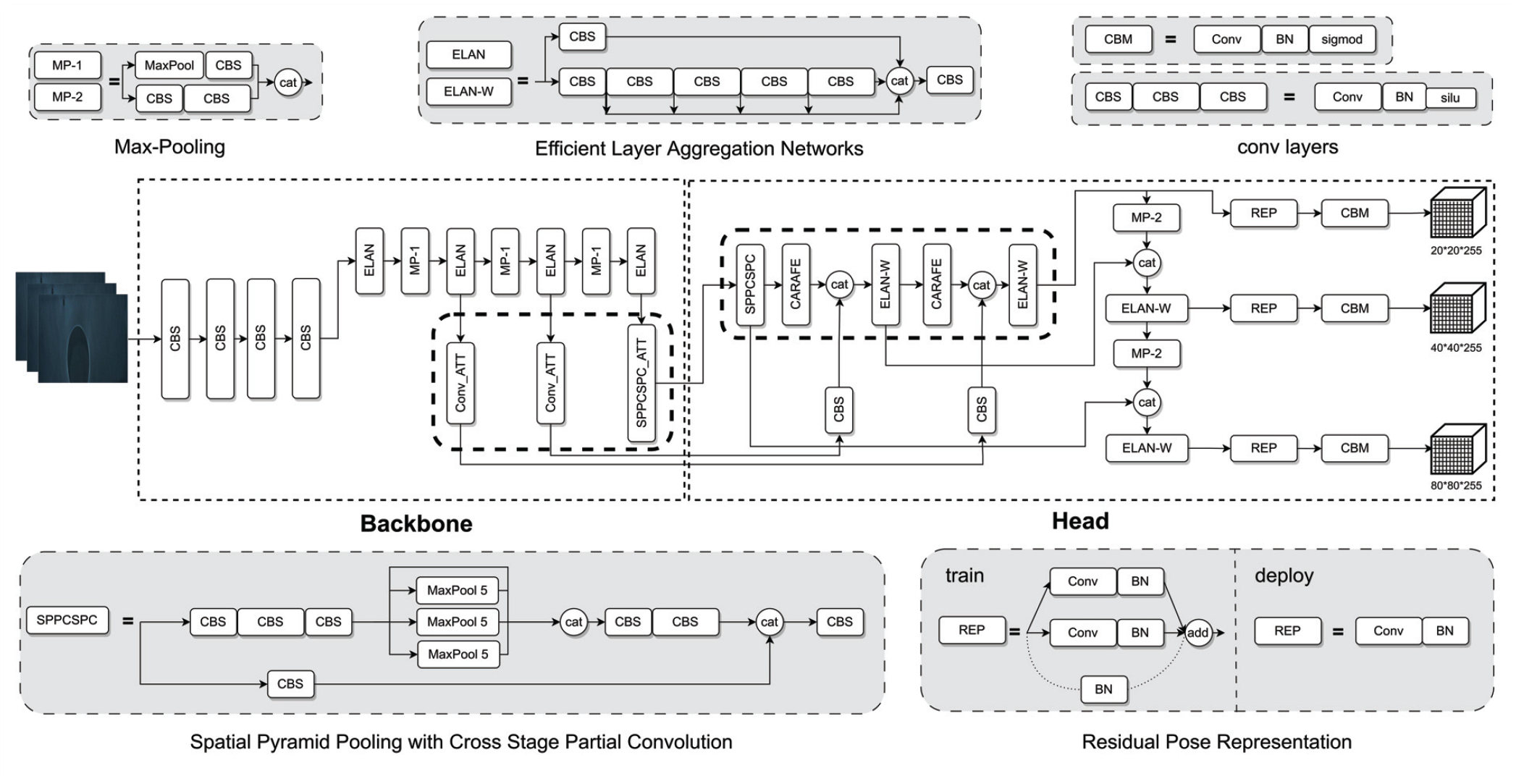
The structure of the improved network architecture of YOLOv7.
DIoU-NMS ablation experiment
In the same experimental setting, the performance of DIoU-NMS was compared and evaluated under various conditions. The results are presented in Table 4. The initial YOLOv7 implementation employed the conventional NMS algorithm, which employs a threshold to determine whether to retain overlapping bounding boxes. A low threshold could lead to more duplicated bounding boxes, whereas a high threshold might miss detections. Moreover, the size of the boxes was not taken into account, potentially leading to the neglect or redundant detection of tiny objects. Consequently, the mAP achieved was 91.58%, with precision at 97.87% and recall at 88.36%. Figure 11 shows the performance comparison of the models.
The results of ablation experimental results.
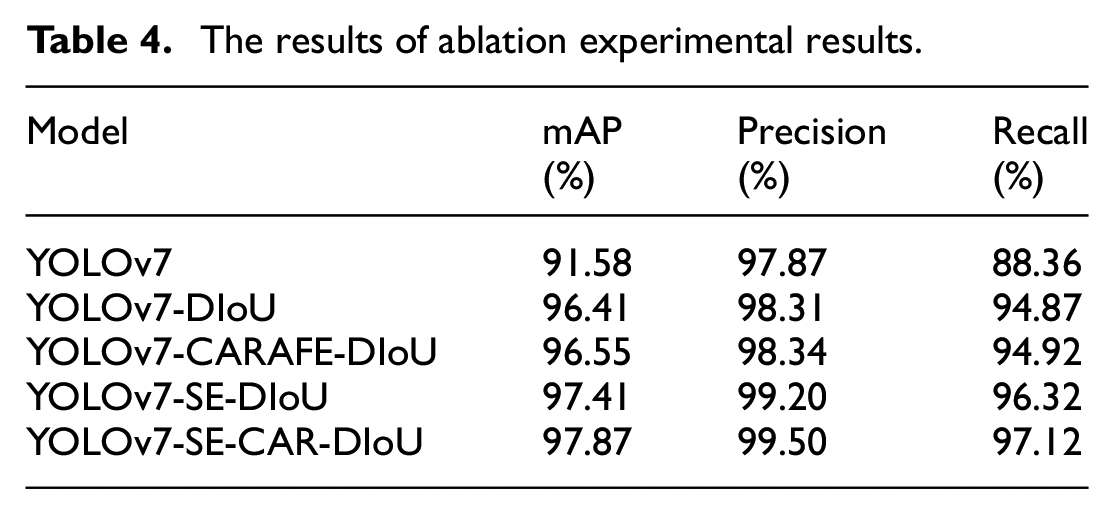
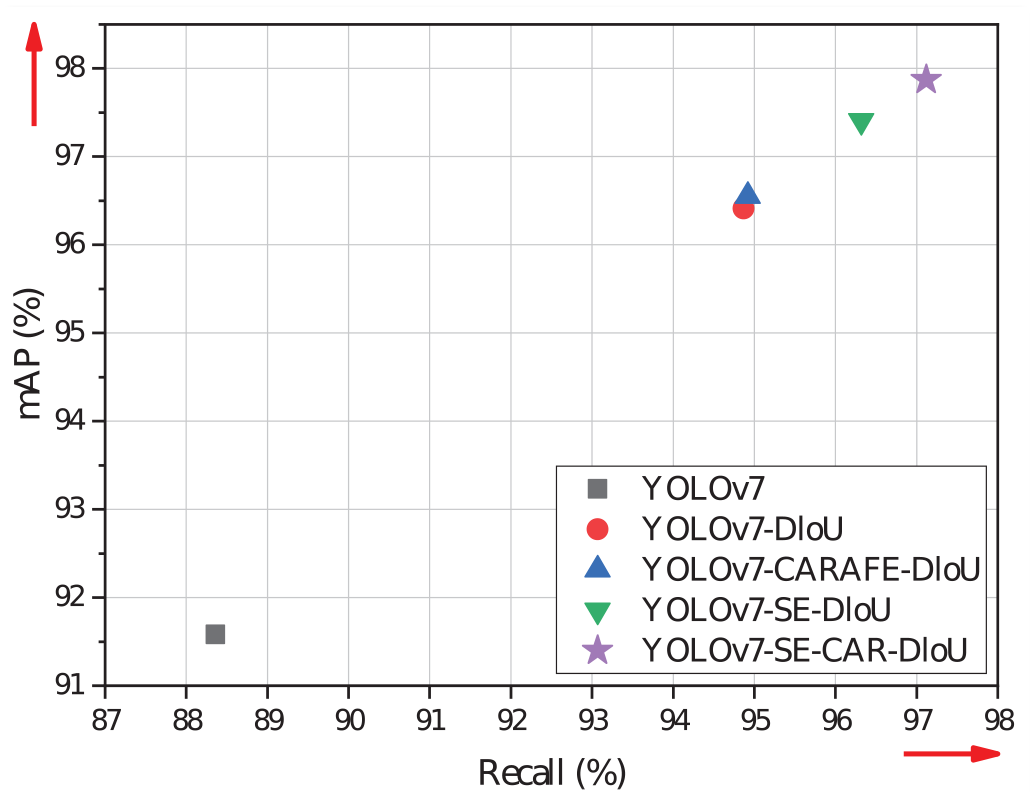
Model performance comparison, YOLOv7-SE-CAR-DIOU model has high performance in membrane product defect detection tasks.
To assess the effectiveness of DIoU-NMS, experiments were conducted on various YOLOv7 models, including the original version, one incorporating CAFARE undersampling, another with an added SE attention mechanism, and a model featuring the SE-CAR feature enhancement module. Notably, replacing the traditional NMS with DIoU-NMS yielded a substantial improvement in mAP, precision, and recall. The most notable enhancement was observed in the YOLOv7 model with the SE-CAR feature enhancement module, yielding respective values of 97.81%, 99.50%, and 97.12% for mAP, precision, and recall. These metrics registered improvements of 6.29%, 1.63%, and 8.76%, respectively, compared to the original YOLOV7 model. The experimental results offered compelling evidence regarding the influence of the DIoU-NMS algorithm on the performance of object detection tasks. By incorporating a distance measurement factor, the DIoU-NMS algorithm effectively evaluates the overlap between bounding boxes utilizing distance information. This capability enables DIoU-NMS to deliver more accurate outcomes, particularly in scenarios with high levels of overlapping bounding boxes.
These findings confirm that our suggested model has a major influence on the identification of surface flaws in membrane products. As seen in Figure 12, we compare the detection results of our enhanced YOLOv7 model with those of the original YOLOv7 model. The comparison between the two images above is evident. When two defects are in close proximity, the original NMS algorithm of YOLOv7 disregards the detection boxes of smaller defects, consequently leading to missed detections. However, the subsequent pair of images demonstrates the successful detection of extremely tiny defects by our algorithm, effectively compensating for the deficiencies of YOLOv7. Furthermore, a clear observation from the images is that our algorithm has substantially enhanced the confidence level in detecting these defects.

Comparison of test results under different models.
To evaluate the suggested algorithm’s performance in real-world industrial settings, we implemented this method in a membrane product factory production line. We deployed the improved YOLOv7 method in the actual environment for testing, enabling real-time intelligent defect detection. The results of these tests are illustrated in Figure 13.

Defect detection results of membrane products.
Conclusion and future work
Identifying surface flaws in industrial items is one of the most crucial tasks in the production process. However, this particular area is replete with a myriad of challenges that necessitate further investigation and resolution. Firstly, the extraction of visually similar features from the background poses a difficulty, and secondly, the existing methods tend to struggle in accurately identifying tiny defects in the target object. This research proposes a comprehensive detection framework that encompasses two essential components: the SE-CAR feature enhancement module and the DIoU-NMS. The SE-CAR module is aimed at effectively preserving detailed information, enhancing feature representation, and improving overall performance by dynamically adjusting the importance of each channel. Moreover, the DIoU-NMS algorithm is employed to tackle the issue of overlapping bounding boxes in object detection tasks. This approach improves the object detection results in terms of accuracy and stability by eliminating bounding boxes that overlap excessively. An exclusive dataset designed specifically for membrane product defects is selected to confirm the effectiveness of the proposed method. The suggested framework is used to explore with YOLOv7. The effectiveness of these optimization techniques has been effectively shown by the experimental results. With a mAP of 97.87%, the enhanced method outperformed the original algorithm by a noteworthy 6.29%. The research findings clearly show how well the suggested method performs in identifying membrane faults, increasing its efficacy and broad application in actual production settings.
In future research, our objective is to precisely detect areas of defects and comprehensively classify these flaws utilizing the Rapid method proposed by Wang et al. 51 Additionally, we aspire for our proposed method can be applied to other models such as the SSD, the Faster R-CNN, and the YOLO series for use in other target detection research areas.
Supplemental Material
sj-zip-1-mac-10.1177_00202940241268952 – Supplemental material for Defect intelligent recognition of membrane product based on deep learning
Supplemental material, sj-zip-1-mac-10.1177_00202940241268952 for Defect intelligent recognition of membrane product based on deep learning by Maonian Wu, Ling Li, Wei Peng, Tao Wu, Jinwei Yu, Bo Zheng and Shaojun Zhu in Measurement and Control
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: National Natural Science Foundation of China (61906066); 2024 Zhejiang University Students’ Science and Technology Innovation Activity Program (New Seedling Talent Program) Project (2024R430C028); A Project Supported by Scientific Research Fund of Zhejiang Provincial Education Department (Y202351126); Postgraduate Research and Innovation Project of Huzhou University (2023KYCX36); 2022 Huzhou Science and Technology Plan Project (2022GZ04).
Data availability statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
Notes
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.