
Abstract
When dealing with complex trajectories, and the interference by the unmanned aerial vehicle (UAV) itself or other flying objects, the traditional detecting methods based on YOLOv5 network mainly focus on one UAV and difficult to detect the multi-UAV effectively. In order to improve the detection method, a novel algorithm combined with swin transformer blocks and a fusion-concat method based on YOLOv5 network, so called SF-YOLOv5, is proposed. Furthermore, by using the distance intersection over union and non-maximum suppression (DIoU-NMS) as post-processing method, the proposed network can remove redundant detection boxes and improve the efficiency of the multi-UAV detection. Experimental results verify the feasibility and effectiveness of the proposed network, and show that the mAP trained on the two datasets used in experiments has been improved by 2.5 and 4.11% respectively. The proposed network can detect multi-UAV while ensuring accuracy and speed, and can be effectively used in the field of UAV monitoring or other types of multi-object detection applications.
Introduction
Due to small size, flexible movement and easy control, unmanned aerial vehicle (UAV) has been more and more widely used in civil, military, scientific research, and other fields, such as atmospheric environment detection, 1 rescue and disaster relief, 2 and collaborative positioning, 3 and so on. In order to achieve better control and avoid safety and illegal problems, a reliable and fast detection algorithm for multi-UAV is highly demanded in applications.
The tasks of UAV detection include classification and localization of the UAV from images or videos. A traditional algorithm for object detection, like the histogram of oriented gradients (HOG), 4 deformable parts model (DPM), 5 usually has the following steps: firstly, traverses the entire image or frame by a sliding window to generate candidate boxes. Secondly, extracts the object features inside the candidate boxes. Finally, determines the object by classifying those features. However, the limitation of traditional algorithm is to extract features manually, and affects the performance and accuracy of the algorithms. In order to overcome the limitation, object detection algorithms based on deep learning 6 are emerged, for example, the two-stage algorithm represented by Faster R-CNN, 7 and the one-stage algorithm represented by single shot multibox detector (SSD) 8 and you only look once (YOLO). 9 Since SSD and YOLO can directly generate the category probability and position coordinates of objects through the convolution neural network (CNN), the speed of the one-stage algorithm is faster than the two-stage algorithm.
Hence, many algorithms based on CNN are proposed for object detection. MS-Faster R-CNN uses a new novel multi-stream (MS) architecture as the backbone of the Faster-R-CNN and combines the pyramid method to achieve effective detection of UAVs at different flight heights. 10 FastUAV-NET extends the convolution layer depth of Darknet-19, the backbone network of YOLOv3-tiny, which can extract UAV features more accurately and improve detection accuracy without increasing additional computational costs. 11 SPB-YOLO designs a strip bottleneck (SPB) module to improve the detection accuracy of UAV targets of different scales by using the attention mechanism, and adds another one detection head compared to YOLOv5 to deal with the situation of dense targets. 12 TPH-YOLOv5 also uses four detection heads, which replaces the original prediction heads with transformer prediction heads (TPH), the convolutional block attention model (CBAM) 13 is used to find the attention area in the scene with dense objects. 14 In addition, some networks improve the accuracy of object detection by improving the method of loss function. 15
However, due to the characteristics of the multi-UAV and the scenes, such as the inconspicuous features among multiple UAVs, the interference of birds or flying objects, complex trajectories, various background environments and so on, the effective and reliable multi-UAV detection algorithm is demanded. By combining with swin transformer and fusion-concat method, SF-YOLOv5 detection algorithm based on YOLOv5 is proposed for the detection of multi-UAV.
Structure of YOLOv5
YOLOv5 is a single-stage algorithm that can guarantee the accuracy and speed of detection at the same time, and its architecture is shown in Figure 1.
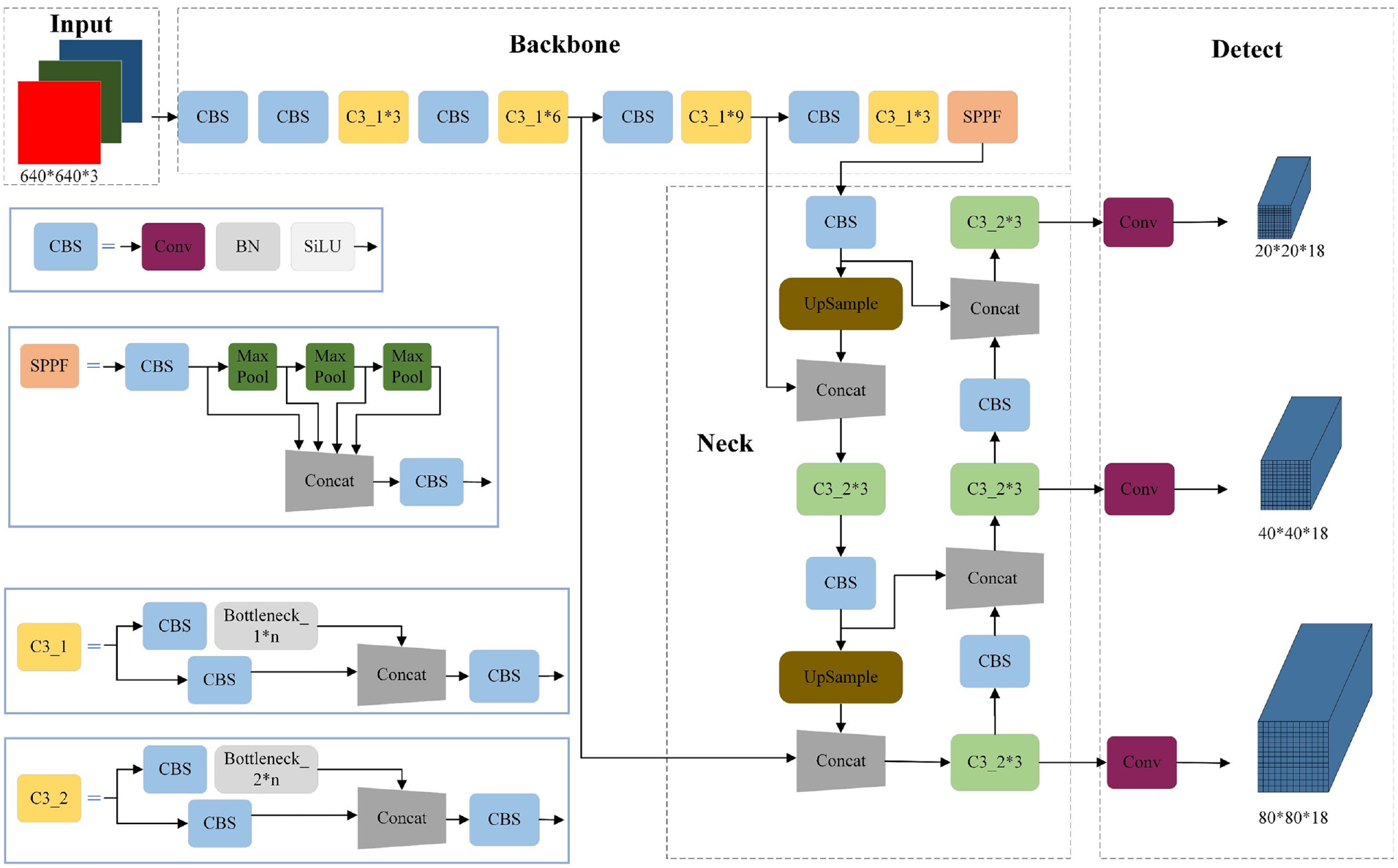
The architecture of YOLOv5.
The structure of YOLOv5 has four parts: input, backbone, neck and detect. The input part uses preprocessing methods to process the input images in order to enhance the robustness of the network and improve the detection accuracy. After preprocessing, the images are input into the backbone part, which extracts rich information features from them through three structures: CBS, C3 and SPPF. 16 CBS obtains the output by convolving, normalizing, and activating the input features, C3 is a simplified BottleneckCSP containing three CBS layers and multiple bottleneck modules, SPPF can realize the fusion of local features and global features. Then the neck part uses the PANet 17 structure to aggregate the parameters of different detection layers of the backbone part, the path from top to bottom transmits semantic features, while the path from bottom to top transmits positioning features. In the final, the detect part uses complete intersection over union (CIoU) as the loss function, which improves the speed and accuracy of prediction box regression, and uses non-maximum suppression (NMS) 18 to enhance the ability to recognize multiple objects and occluded objects.
Structure of SF-YOLOv5
To solve the problem that YOLOv5 is insensitive to multi-UAV, it is improved by adding swin transformer blocks in the backbone part for feature extraction, using fusion-concat method in the neck part for feature fusion, and using non-maximum suppression (DIoU-NMS) to delete redundant detection boxes. The proposed network SF-YOLOv5 is shown in Figure 2, where C3SwinTR blocks and fusion-concat blocks are improved structures.
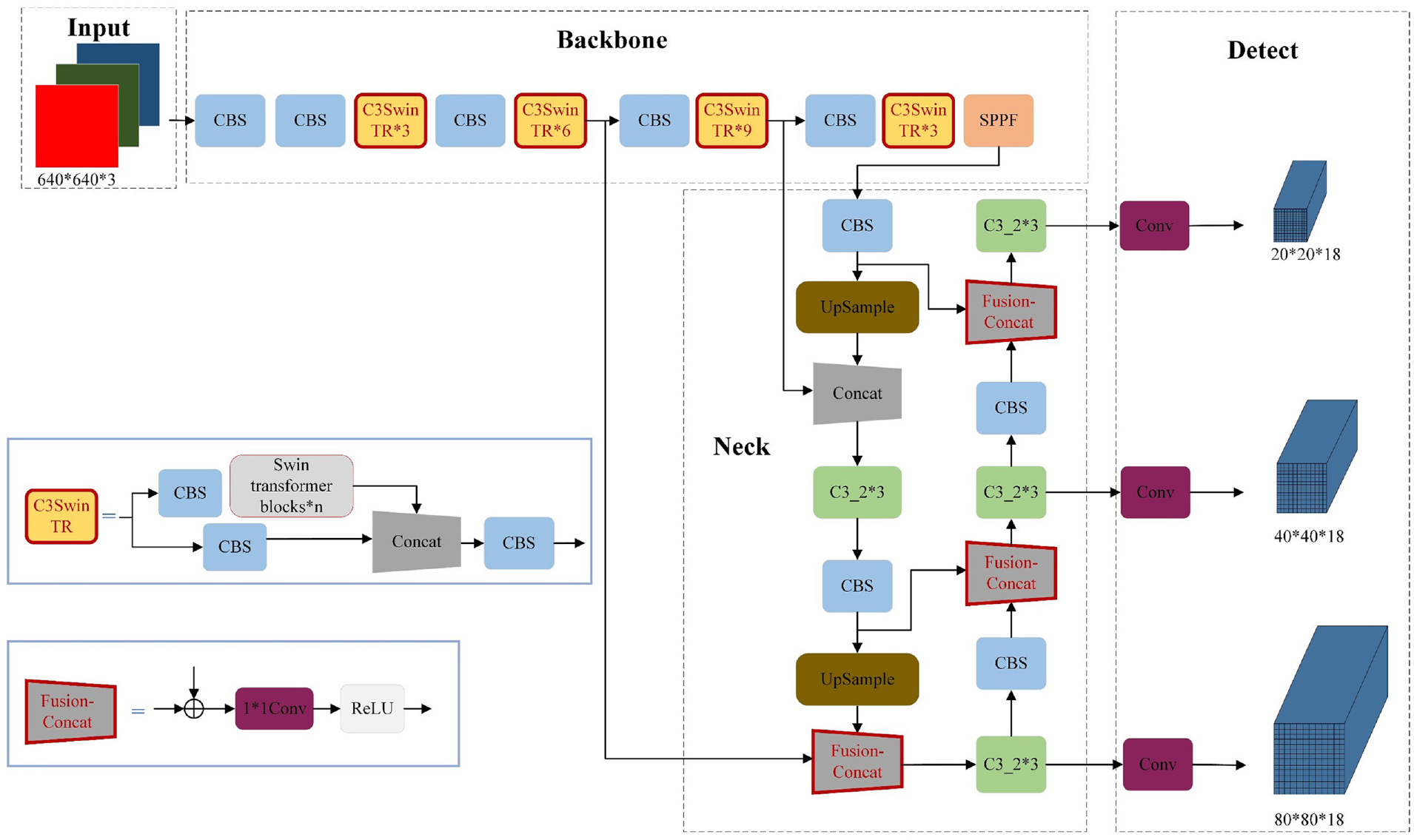
The architecture of SF-YOLOv5.
C3SwinTR
SF-YOLOv5 uses the swin transformer blocks to replace the bottlenecks in C3 block as C3SwinTR. C3 block completely relies on high-quality local convolution features to detect targets from the image, and only processes the image locally, while C3SwinTR block combines CNN with transformer blocks to captu4re global information of images. The structure of C3SwinTR is shown in Figure 3.
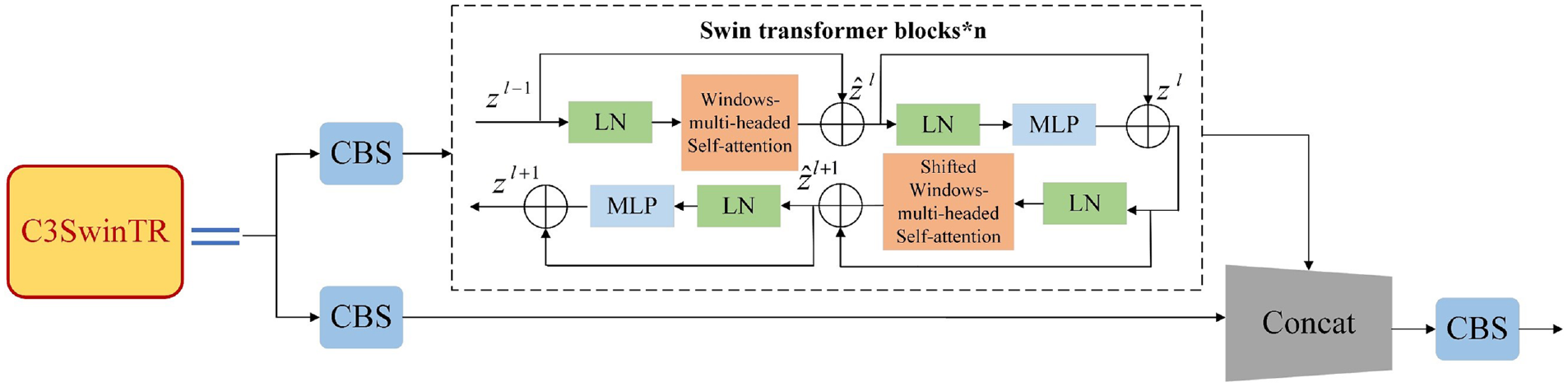
The architecture of C3SwinTR.
C3SwinTR structure separates the channel layer and convolutes only half of the features before concat block, which can ensure the accuracy. Swin transformer block is composed of Windows-multi-headed Self-attention (W-MSA), Shifted Windows-multi-headed Self-attention (SW-MSA), Multilayer Perceptron (MLP), and Layer Normalization (LN). W-MSA and SW-MSA both add window partition strategies to Multi-head Attention (MSA), the calculation of self-attention 19 is as follows:
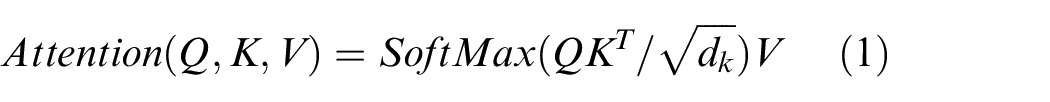
where,
As shown in Figure 4, suppose that each window contains M × M patches, the first module uses the regular window strategy to partition from the top-left pixel, and the 8 × 8 feature map is evenly partitioned into 2 × 2 windows of size 4 × 4. Then, the next module replaces the windows by 2 × 2 pixels from the regularly partitioned windows. The self-attention computation of new windows spans the boundaries of the previous windows with the regular window strategy and provides a connection between the windows.
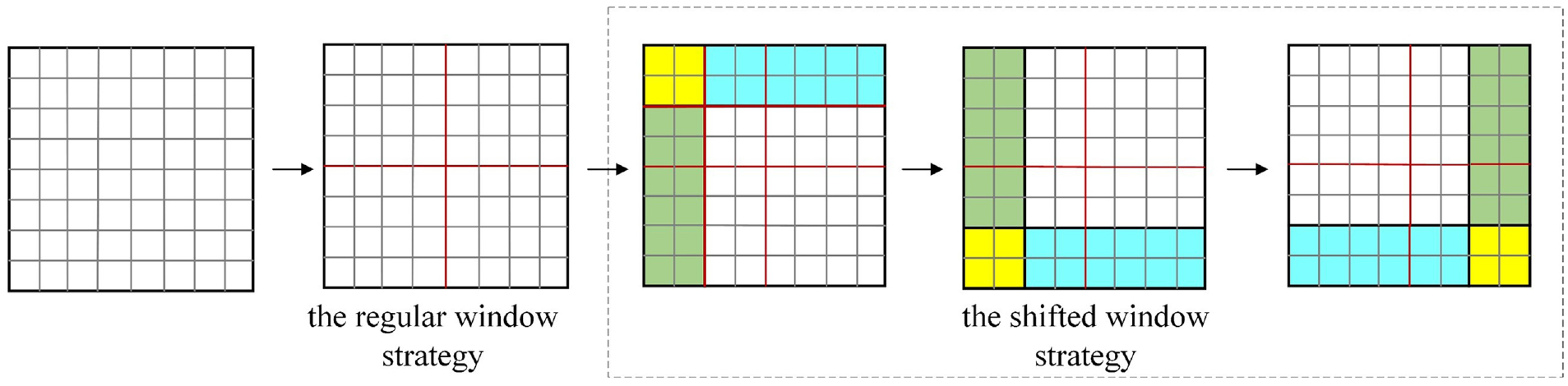
The window division diagrams of regular window strategy and shift window strategy.
The computational complexity increases linearly with the size of images rather than the square order because the self-attention is calculated within the window. At the same time, the shifted window strategy causes adjacent windows to interact with each other, thereby forming a cross-window connection between the upper and the lower layers. Hence, adding swing transformer blocks to the backbone can enable the network to better focus on global information and rich contextual information.
Fusion-concat method
In order to solve the problem of multi-scale in object detection, different structures are often used for feature fusion to improve the performance of small object detection. Figure 5 shows three common feature fusion structures: FPN, PAN, BiFPN. Multi-scale feature fusion aims to aggregate features at different resolutions, P1, P2 and P3 represent the features of three different resolutions, the blue lines represent upsampling, the red lines represent downsampling, and the red circles represent feature fusion operations.
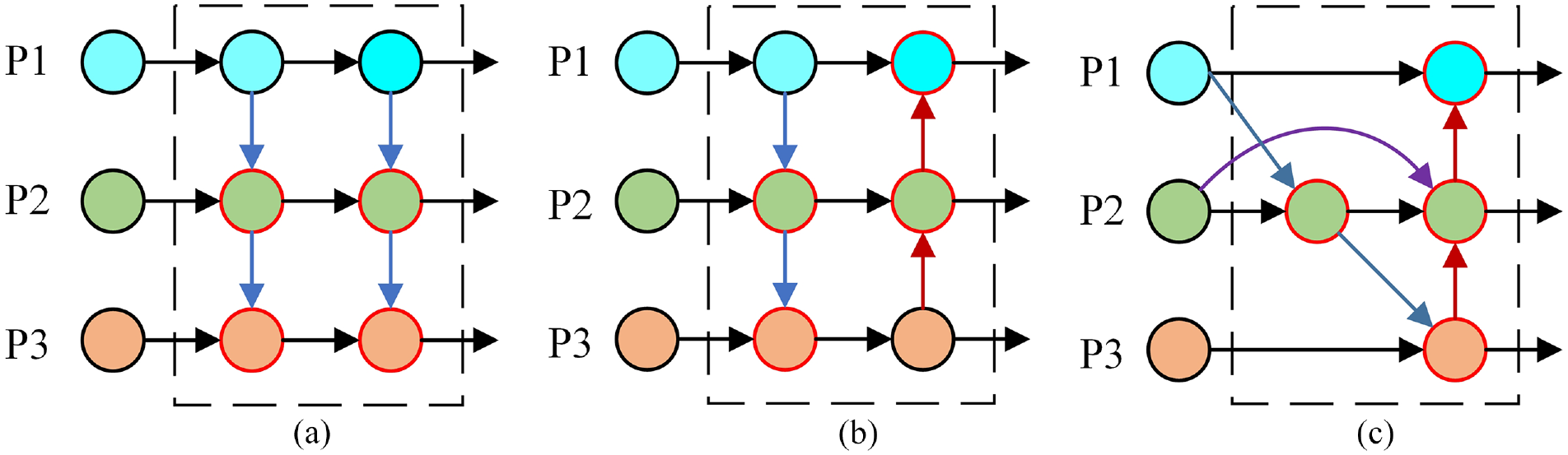
Different feature fusion structures: (a) FPN, (b) PAN, and (c) BiFPN.
As shown in Figure 5, FPN is only the path from top to bottom, passing information from high dimensions to low dimensions. On the basis of FPN, PAN adds the bottom-up path to transfer semantic information from low dimensions to high dimensions. BiFPN deletes the part without feature fusion, and adds a path from original input to output for features of the same resolutions. In addition, considering that different feature layers have different resolutions, the contribution to feature fusion is unequal. BiFPN adds an additional weight to each input during feature fusion, so that the network can learn the importance of each input feature, that is, the fast normalized fusion method. 21
YOLOv5 uses three different scale feature maps for prediction, the BiFPN structure has more operations to fuse three paths than the PAN structure, which increases the complexity of the network. Therefore, this paper retains the PAN structure, but adds the fast normalized fusion method, which allows the network to fuse more features without adding too much cost. Figure 6 shows the PANet structure using fusion-concat method.
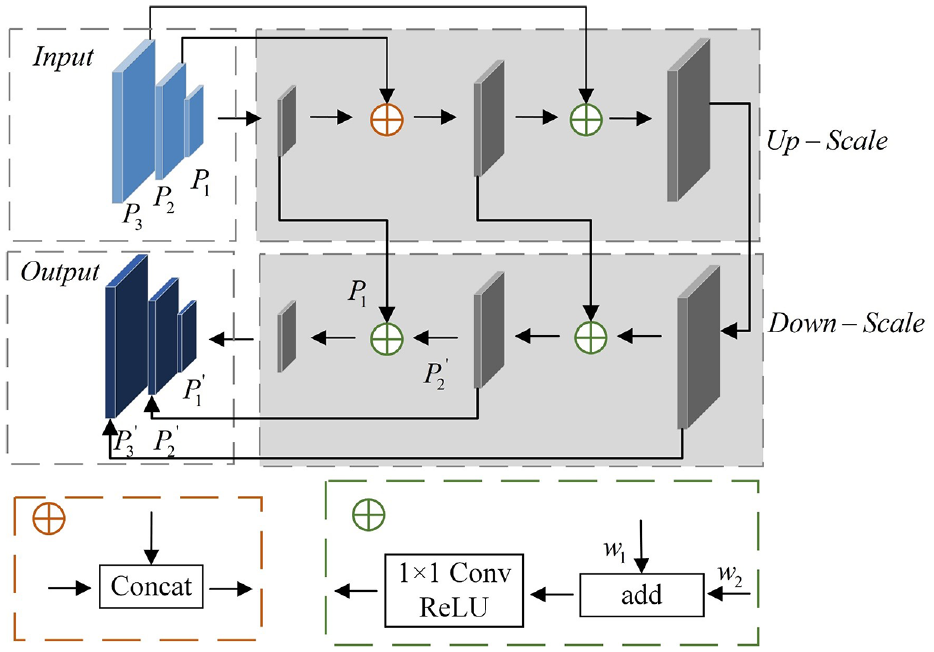
The structure of PANet using fusion-concat method.
In Figure 6, the bottom left is the concat block of PANet, and the bottom right is the proposed fusion-concat. Concat block is the splicing of feature maps, the dimension of the feature maps increases, but the amount of information remains unchanged. Add block is the addition of feature maps, the amount of information increases, but the dimensions of the image itself do not increase, which is obviously conducive to the final image classification. Taking P1 in Figure 6 as an example, the output after fusion-concat is:

where,
DIoU-NMS
NMS for post-processing in YOLOv5 has two disadvantages, one is that there will be missed detection when the targets are dense. The other is that high confidence boxes are directly judged as correct targets, but there is no direct correlation between classification and regression tasks. In contrast to NMS, DIoU-NMS considers not only the value of IoU but the distance between the center points of two boxes.
DIoU-NMS filters the prediction box based on the difference between IoU and DIoU. First, select

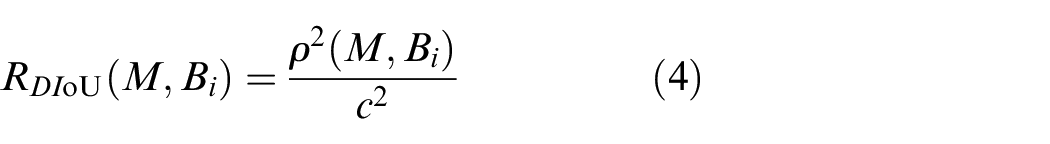
where,
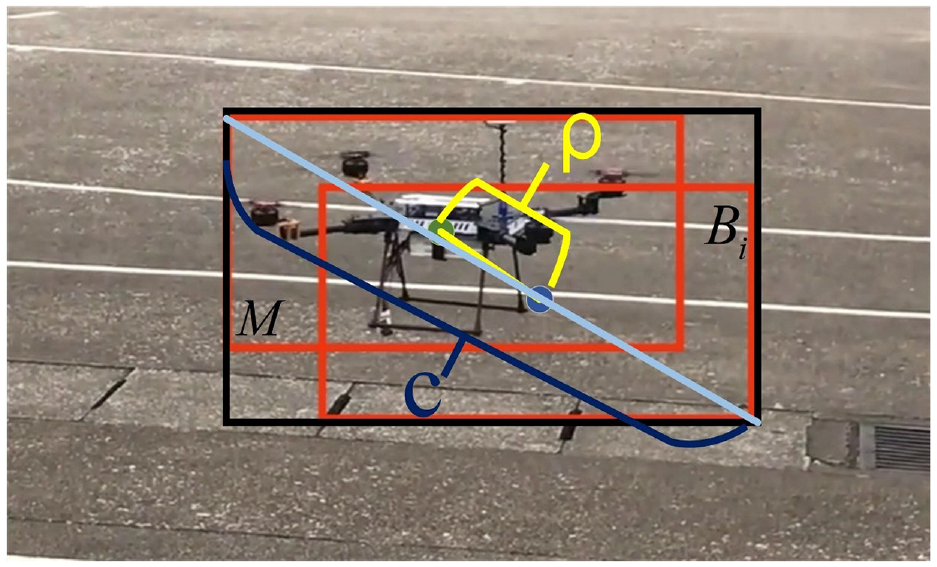
Illustration of the calculation of
DIoU-NMS can solve the two problems of NMS at the same time. SF-YOLOv5 uses DIoU-NMS instead of NMS, which can reduce missed detection in the case of dense targets, and the filtered results are more realistic.
Experiments
Setup and datasets
The experimental platform is running on Windows 10, with NVIDIA Quadro RTX 4000 GPU, Intel® CoreTM i7-9700 CPU @ 3.00GHz, memory 32G, and the PyTorch framework is used for training.
Since there are few open datasets for UAV detection and only one UAV exists in most of the datasets, we have made a dataset (GUET-UAV dataset) that includes not only one UAV, but also multi-UAV (at least two UAVs) for UAV detection. A total of 5174 UAV images are collected, and the image resolution is 1920 × 1280.
The datasets used in our experiments include the TIB-Net public dataset and the GUET-UAV dataset, and have 12,370 images in total, all images are labeled in the PASCAL VOC format. 80% of the datasets are used for training and 20% for testing (Figure 8).

Exhibition of GUET-UAV dataset with different number of UAVs: (a) single UAV, (b) two UAVs, (c) three UAVs, and (d) four UAVs.
Evaluation metrics
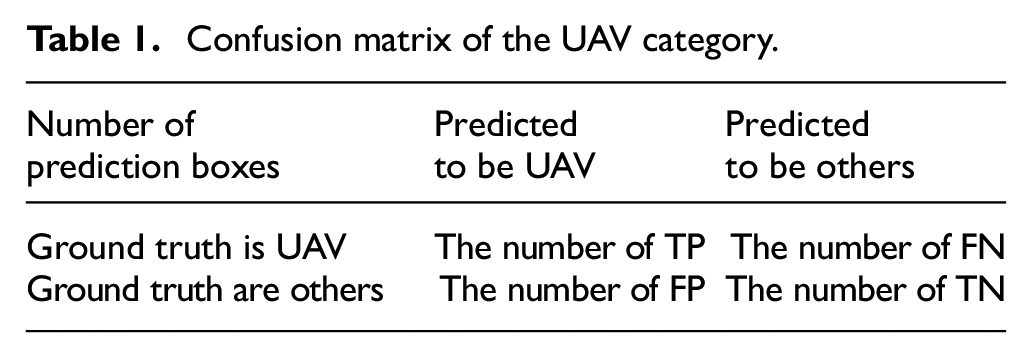
Evaluation metrics are needed to measure the generalizability ability of the model. For a specific category, the number of true positive (TP), false positive (FP), false negative (FN), and true negative (TN) prediction boxes constitute a confusion matrix. For example, the confusion matrix of UAV category is shown in Table 1.
Confusion matrix of the UAV category.
Precision refers to the proportion of correct predictions in all prediction boxes, and its formula is:

Recall refers to the proportion of all labeling boxes that are correctly predicted, and its formula is:
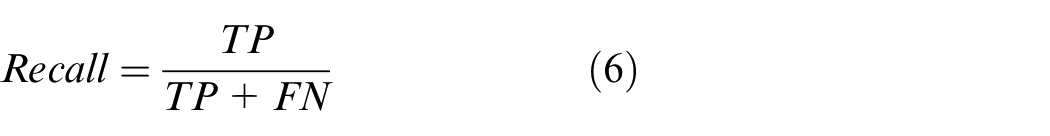
The corresponding precision and recall can be plotted as PR curve, the area enclosed by PR curve is average precision (AP) of the category. The mean average precision (mAP) is the average value of AP values of all categories, when IoUthresh is taken as 0.5, mAP represents

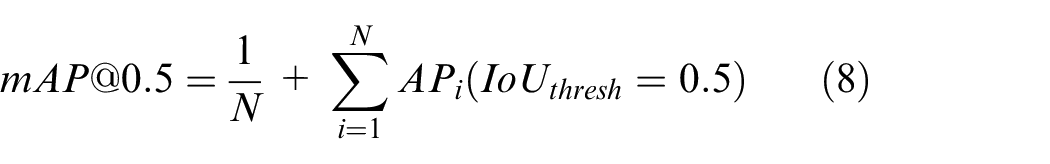
Ablation experiments
The GUET-UAV dataset is used for ablation experiments, the initial learning rate is 0.01, the momentum parameter is 0.937, the training epochs are 120, and the batch size is 10. Ablation experiments are designed to illustrate the impact of each component on detection accuracy.
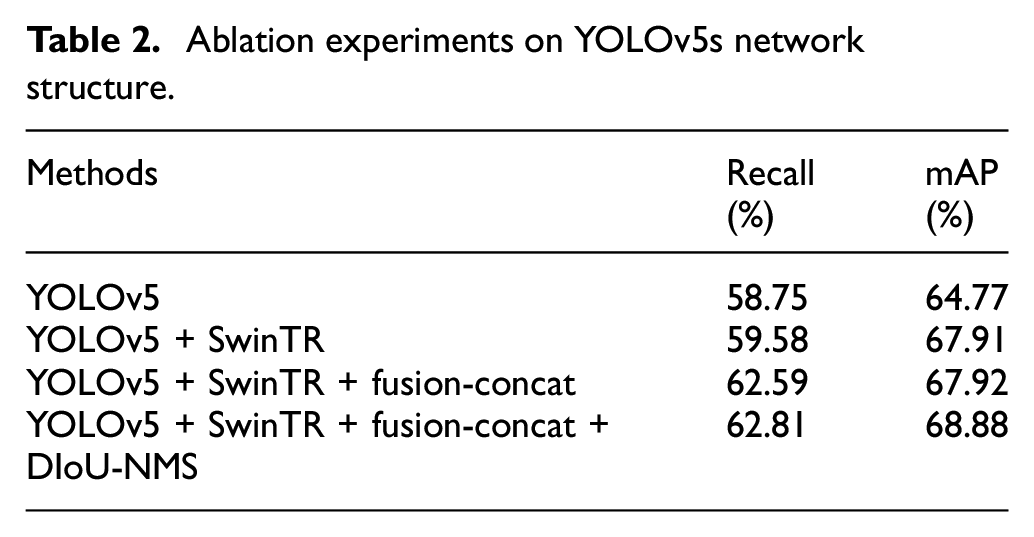
As shown in Table 2, recall shows an upward trend in the process of improving each structure of YOLOv5 network, and the mAP of the improved network structure increases by 4.11% compared with the original structure. Figure 9 shows the impact of adding each component on the network detection results, provides a more intuitive illustration of the improvement of detection effect.
Ablation experiments on YOLOv5s network structure.

Comparison of ablation experiments detection results: (a) YOLOv5, (b) YOLOv5 + SwinTR, (c) YOLOv5 + SwinTR + fusion-concat, and (d) YOLOv5 + SwinTR + fusion-concat + DIoU-NMS.
Figure 9(a) shows that none of the three UAVs were detected using the original YOLOv5 network. With the addition of SwinTR and fusion-concat, the network’s attention to UAV is increased and detectable, but missed due to intensive issues. After filtering with DIoU-NMS, three UAVs are successfully detected, as shown in Figure 9(d).
Figure 10 shows the comparison curves of mAP and loss obtained in the training process of YOLOv5 and SF-YOLOv5. MAP illustrates the detection accuracy, loss function estimates the inconsistency between the predicted value and the real value of the model. The smaller the loss function, the better the robustness of the model.
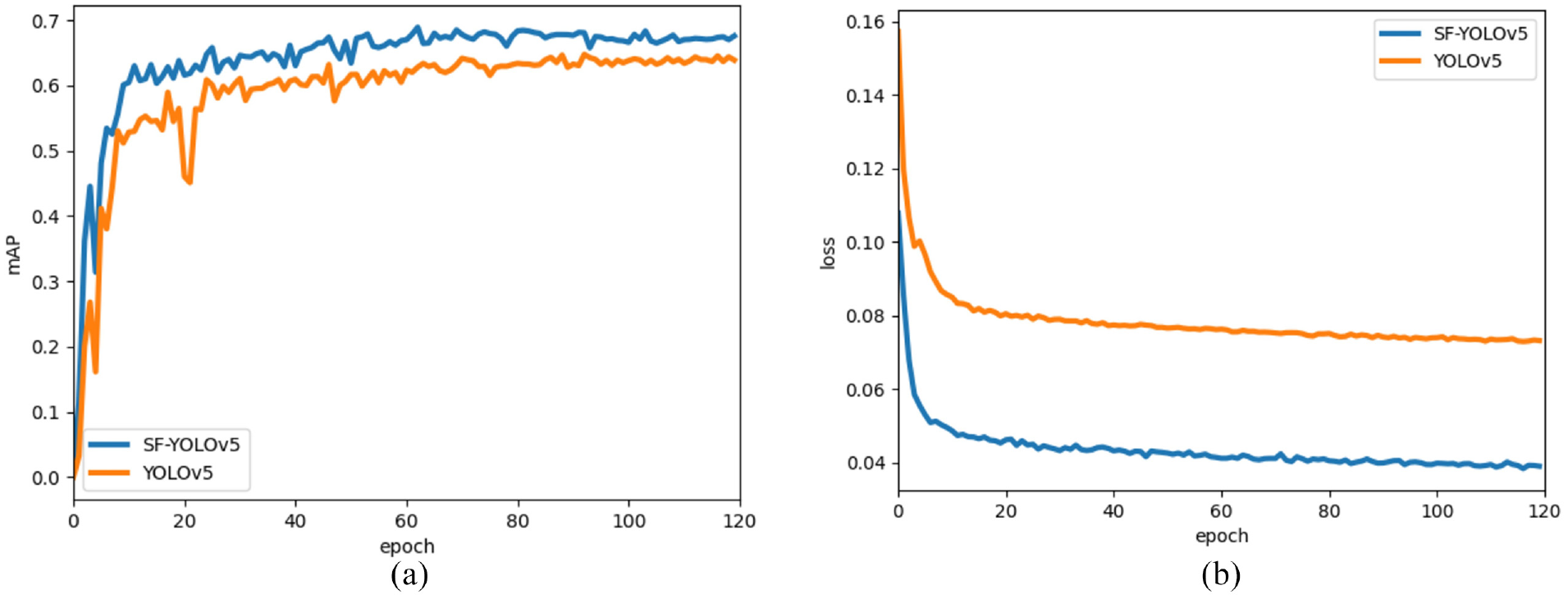
YOLOv5 and SF-YOLOv5 training process comparison curves: (a) mAP and (b) loss function.
It can be observed that the mAP of SF-YOLOv5 is higher and the loss is significantly reduced, indicating that the performance of the improved model has better detection performance.
Figure 11 is a comparison of detection results by selecting different numbers of UAV images in the GUET-UAV dataset. The comparison results show that SF-YOLOv5 improve the detection accuracy, reduce the misses and errors, and is applicable to various backgrounds, single or multi-UAV images.

Comparison of detection results: (a) one UAV in the figure is not detected by YOLOv5, (b) one UAV in the figure is detected by SF-YOLOv5, (c) only one of the two UAVs in the figure is detected by YOLOv5, (d) the two UAVs in the figure are detected by SF-YOLOv5, (e) only two of the three UAVs in the figure are detected by YOLOv5, and (f) the three UAVs in the figure are detected by SF-YOLOv5.
Effectiveness and feasibility of SF-YOLOv5
Table 3 shows the results of four different versions of YOLOv5 trained with GUET-UAV dataset, further illustrating the effectiveness of the improved method.
Performance comparison of four models before and after improvement.
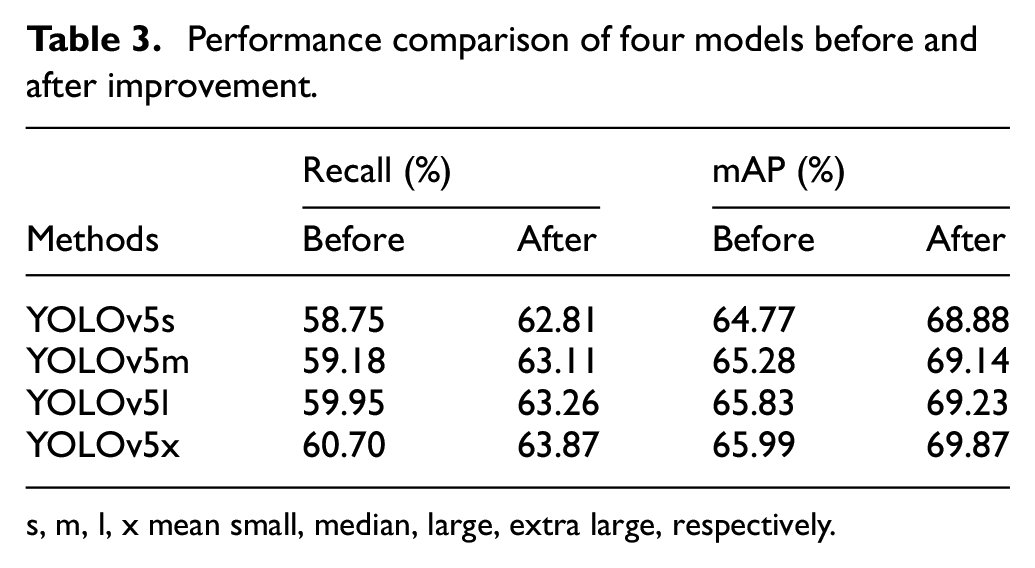
s, m, l, x mean small, median, large, extra large, respectively.
To evaluate the detection performance and illustrate the feasibility of the proposed model, we compared several representative methods: Faster-rcnn, SSD, YOLOv3, YOLOv4, and SF-YOLOv5. Table 4 summarizes the detection results in terms of the recall, mAP and frame per second (fps) using the TIB-NET and GUET-UAV dataset.
Comparison of different algorithms.
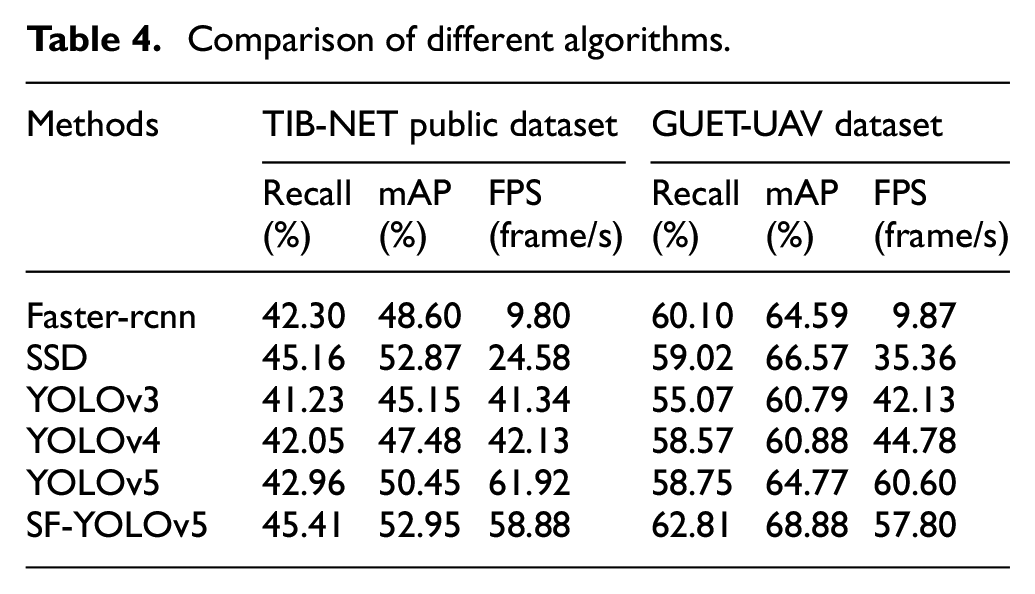
By comparing with other algorithms and on different datasets, it can be seen that SF-YOLOv5 guarantees fps while improving recall and mAP, which shows the effectiveness of the network.
Conclusion
Aiming at the limitations of existing UAV detection methods, SF-YOLOv5 network for multi-UAV is proposed. Based on the structure of YOLOv5 network, firstly, swin transformer blocks are used in the backbone to make the network better focus on global information and rich context information, and better realize the feature extraction and detection of UAVs. Secondly, the fusion-concat method is used for feature fusion, which improves the detection accuracy and reduces the computational load. Finally, DIoU-NMS is used to remove redundant detection boxes in order to prevent misses in dense UVA scenarios. The experimental results show that, compared with YOLOv5, the mAP of SF-YOLOv5 on the GUET-UAV dataset is improved by about 4%, and the number of misses and errors is reduced. The SF-YOLOv5 network proposed in this paper can achieve high-accuracy detection of multi-UAV in different scenarios, and solve the problem of detection failure caused by small size, complex background, and mutual occlusion of targets when using UAVs as objects. It can realize the supervision of UAVs and is conducive to the safe use of UAVs. In addition, it can be used for the detection of other objects or the recognition of specific objects in surveillance video scenes, which has practical application value.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was by the Innovation Project of GUET Graduate Education(2022YCXS154) and also partially supported by the National Natural Science Foundation of China (61671008).