
Abstract
In this paper, we studied the cooperative control problem for a class of high-order nonlinear multi-agent systems (MASs) with external disturbance and system uncertainty. A neuro-adaptive robust controller with sliding mode variable structure method, with an online-learning RBF-like neural network was proposed to approximate the nonlinear terms. Further, sliding mode variable structure method was used to eliminate the influence of external disturbance and system uncertainty. Lyapunov stability theorem verified the capability of system consensus, and the sufficient conditions for cooperatively uniformly ultimately bounded (CUUB) are also given. At last, two numerical simulations on both homogeneous and heterogeneous MASs demonstrated the effectiveness of our proposed method.
Introduction
Leader-following cooperative control of multi-agent systems (MASs) has been an attractive research topic due to its distributed control feature, which can strengthen the group communication, robustness, flexibility, and deipersion.1–4
Bechlioulis and Rovithakis, 5 Yang and Li 6 designed a robust control based on observer for a class of high-order nonlinear multi-agent systems that satisfies the Lipschitz condition to solve the problem of state enclosing control of multi-agent systems. Aryankia and Selmic 7 proposed an adaptive neural network-based backstepping controller that uses rigid graph theory to address the distance-based formation control problem and target tracking for nonlinear multi-agent systems with bounded time-delay and disturbance. Radial basis function (RBF) neural network is used to overcome and compensate for the unknown nonlinearity and disturbance in the system dynamics. Ni et al. 8 designed a type of sliding mode observer under the condition of input delay, which can send leader information to followers within a limited time. Meng et al. 9 proposed an adaptive neural distributed synchronization scheme with guaranteed performance, which is used to deals with the synchronization control problem in the leader-follower format of a class of high-order nonaffine nonlinear multiagent systems under a directed communication protocol. In order to handle the unknown nonlinear problem, the adaptive fuzzy control problem for a class of high-order stochastic nonlinear systems is also designed, and the control performance is guaranteed in a prescribed bound. 10
For linear systems, Ma and Miao 11 proposed a solution that the leader follows the heterogeneous multi-agent system in the network to achieve consistent output. When the state information is not easy to directly measure, a solution based on the dynamic regulator of the state observer is used to reconstruct the state. For the second-order nonlinear system, Liu and Jia 12 aims at the second-order nonlinear system, uses the universal approximation function of neural network to estimate and approximate unknown functions online, and obtains an adaptive protocol based on neural network.
However, most of existing works only focus on first- or second-order dynamic systems,13–20 while many practical engineering systems are high-order dynamics based, such as single-link flexible-joint manipulators,21,22 robot formation cooperation,23,24 and synchronous generator coordination.25–27 On the other hand, due to the model uncertainty, nonlinear dynamics, as well as the system noise, makes it difficult even impossible to obtain the accurate control model in mathematical. The existence of the nonlinear dynamics may transform the system from homogeneous to heterogeneous, which brings difficulties to the cooperative control of nonlinear systems. 28
Consider the above mentioned problems, this paper focuses on the Brunovsky-type high-order nonlinear cooperative control tasks of leader-following MASs. Each follower couples the unknown nonlinearity with external disturbance through a high-order integrator, while the dynamics of them may be completely different. 29 Further, the leader agent is also a high-order nonlinear but non-autonomous system, and its dynamics is also unknown to all the followers.
In this paper, we propose a neuro-adaptive cooperative control method for a class of high-order nonlinear MASs with uncertainty. During the controller design, sliding mode variable structure control approach is used to fasten the systems response speed. Further, an online-learning RBF-like neural network is proposed to deal with the system nonlinearity. Theoretical analysis is given to prove the system stability under our proposed controller, and numerical simulations are also constructed to verified the correctness and effectiveness.
The main contribution can be concluded as:
We consider the cooperative problem for a class of high-order nonlinear MASs, which contains external disturbance or system uncertainty. This dynamical models are more suitable for practical engineering.
We propose a distributed neuro-adaptive cooperative controller with online-learning RBF-like neural network, where the neural network can update its own weights according to the network output and agent state. For both homogeneous and heterogeneous MASs, the proposed online-learning neural network can always approximate to the target signal with a tiny fitting error.
The rest of paper is organized as follows: Section “Preliminaries and problem statement” introduces some preliminaries about graph theory and problem formulation. Section “Proposed neuro-adaptive controller” gives the proposed neuro-adaptive control method. In Section “Main results,” we proves the stability of our controller by using Lyapunov analysis theorem. In Section “Numeric simulation,” two kinds of MAS simulations are conducted to demonstrate the effectiveness of our method. At last, Section “Conclusion” summaries the paper as an end.
Preliminaries and problem statement
Graph theory and notation
According to graph theory, a directed graph
In this paper, the following notations are used:

and the Frobenius norm is defined as the sum of the squares of the absolute values of the elements of a matrix, that is,
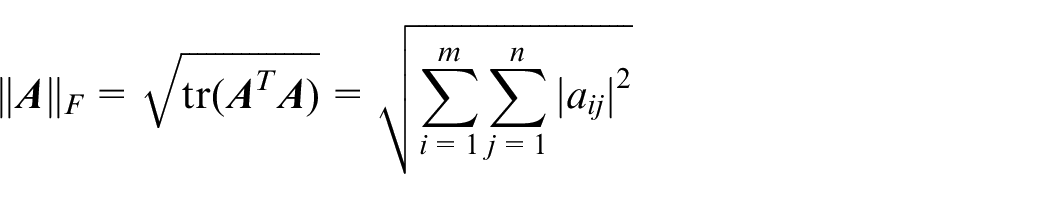
Problem statement
Given a MAS system consisted of a leader agent and
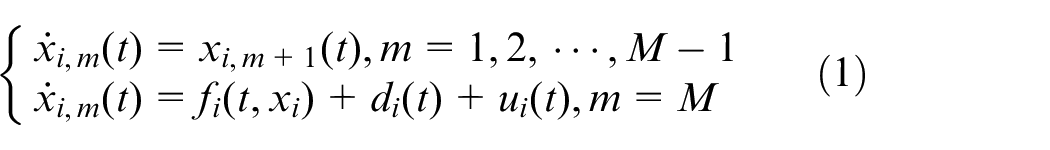
where
The dynamics of leader agent (labeled by 0) is described by
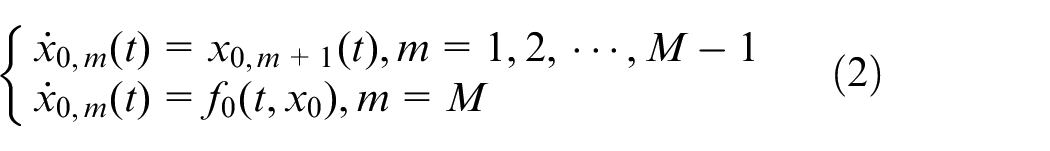
where
The
There exists an upper bound
For agent
The local neighborhood error of the agent
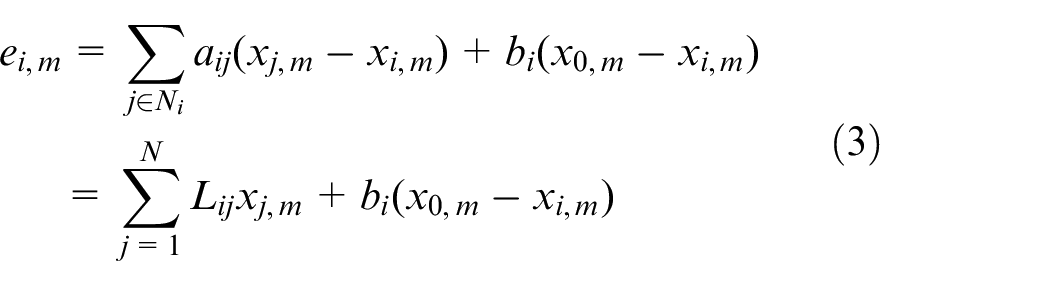
where
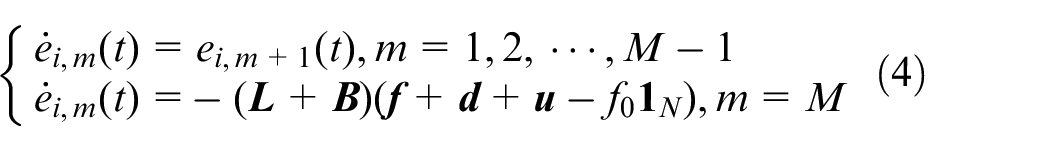
Define the extended directed network graph composed of the leader and the follower agents as
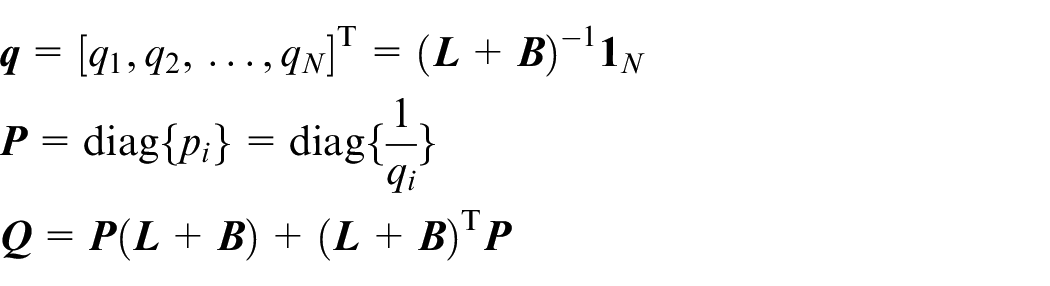
thus we have both
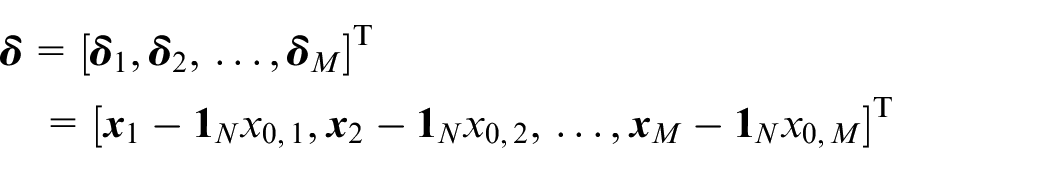
where
Then, the global error vector of graph
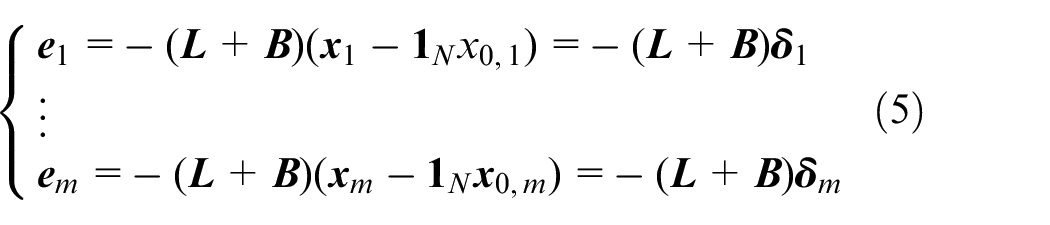
According to Assumption 1, the matrix

Thus,
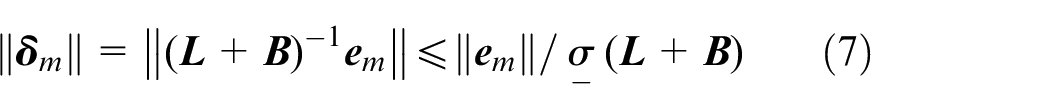
Proposed neuro-adaptive controller
For MASs with unknown disturbance or unmodeled dynamics, we designed a distributed adaptive controller by using siding mode variable structure control method and online-learning RBF neural network, where the sliding mode variable structure control can rapidly response while ensuring the system stability, and neural network can adaptively fine-tune the weights in real-time.
Sliding mode surface function design
The sliding mode surface function of agent
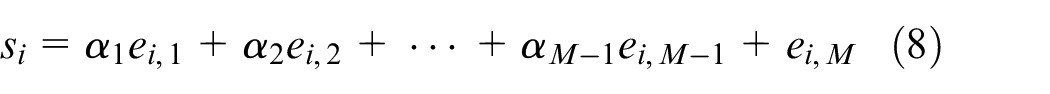
where the
Thus, the global error vector of sliding mode surface function can be formulated as
Define
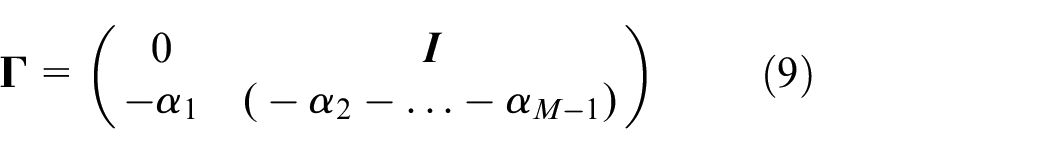
Thus we have
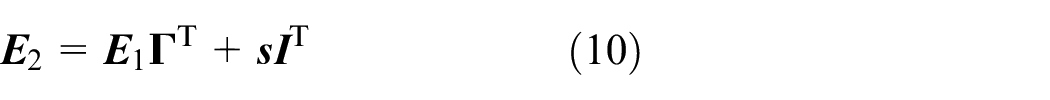
Since

The derivative of the dynamic sliding mode error
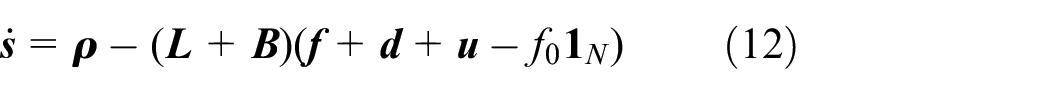
where
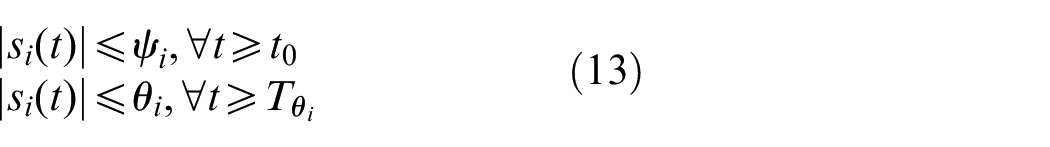
where time
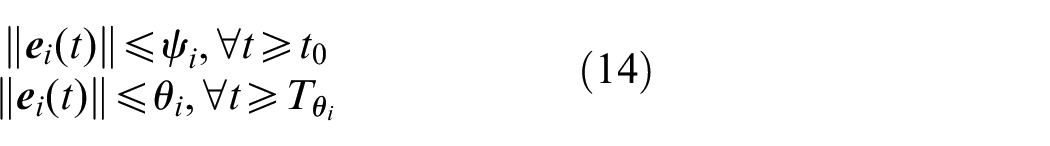
Proof: Let
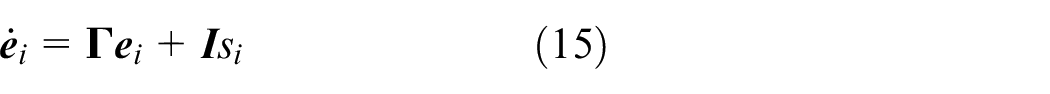
By (15),
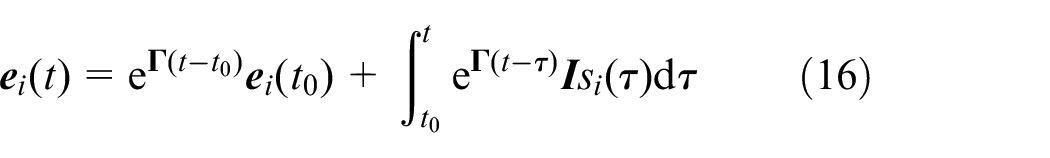
Considering

So we have the inequality of (16),
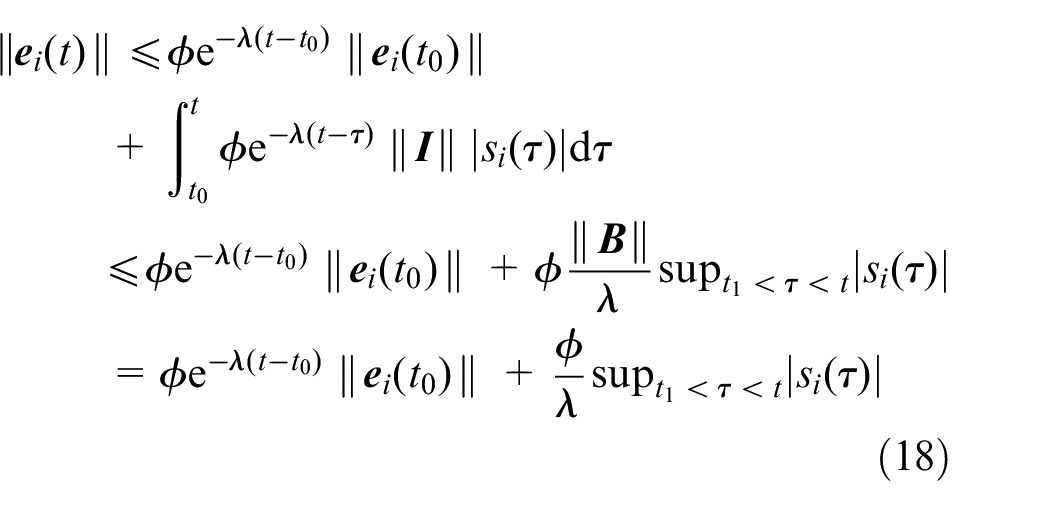
It can be seen from (18) that if
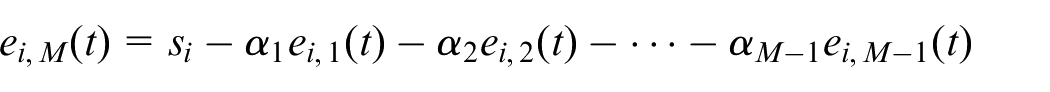
is also bounded. Therefore,
Then it is proved that if
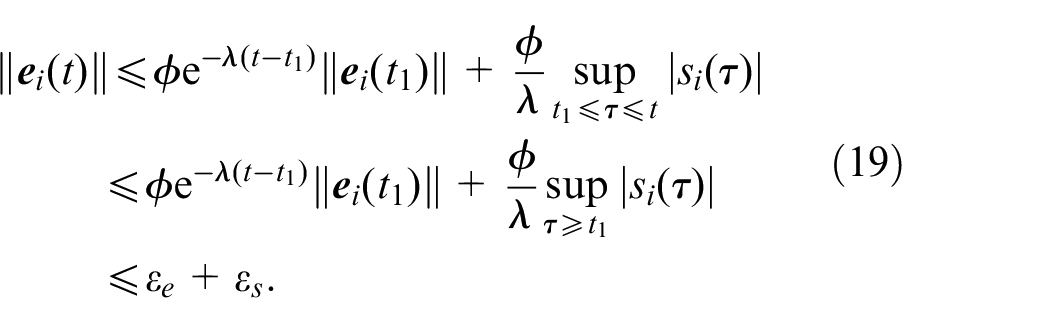
According to the arbitrariness of
Distributed control protocol design
Before designing the neuro-adaptive control protocol for each follower agent, the following assumptions should be made.
By Assumption 3, there exists an upper limit
The kernel function of our proposed online-adaptive RBF-like neural network is Gaussian function,
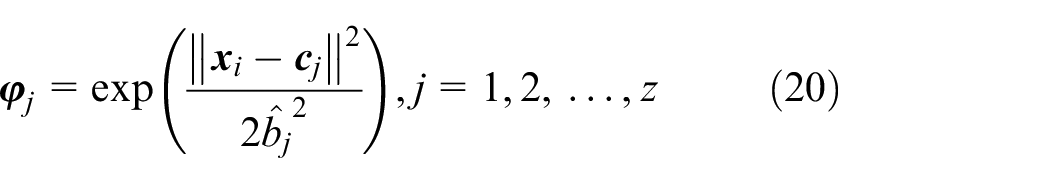
where
The network output is calculated by

where the output weights

According to the Stone-Weierstrass theorem,
33
given a compact set
The system state

where
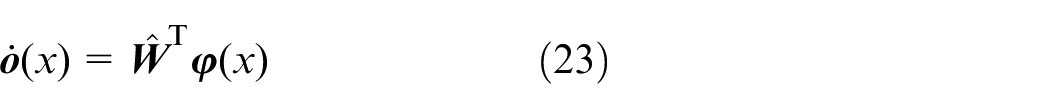
where the approximation error
Design the weight adaptive update method for proposed online-learning neural network as
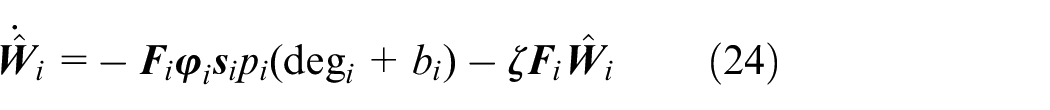
Thus the vector form of all the network weights is

where
Further, we define the maximal value of Gaussian function output, ideal weights to be
We propose the neuro-adaptive control protocol for each agent
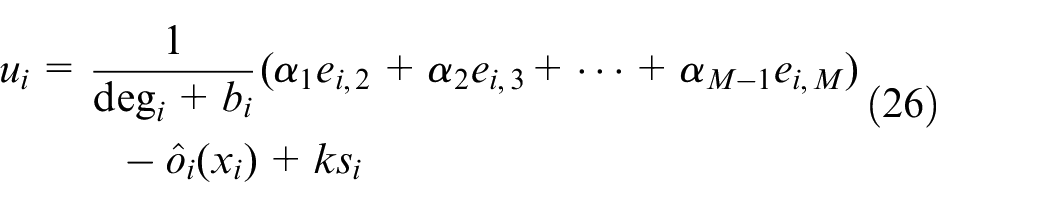
Thus, the vector form for all follower agents can be written as
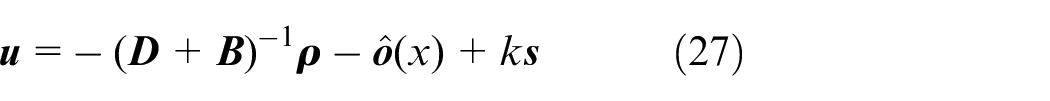
where the control gain satisfies
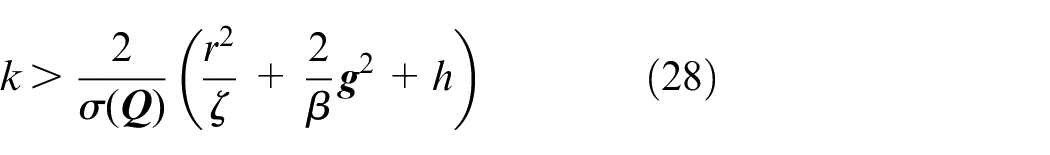
where
Main Results
Let
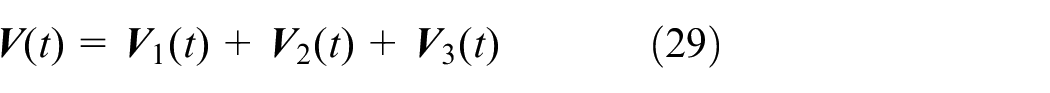
where
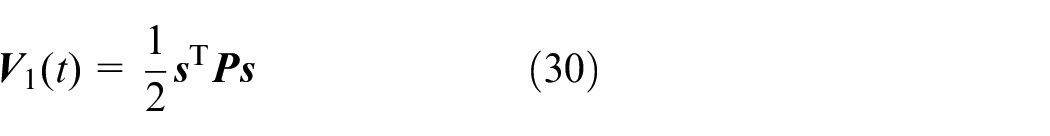


The derivative of
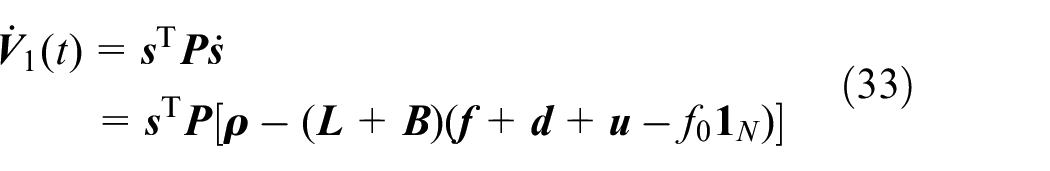
Considering
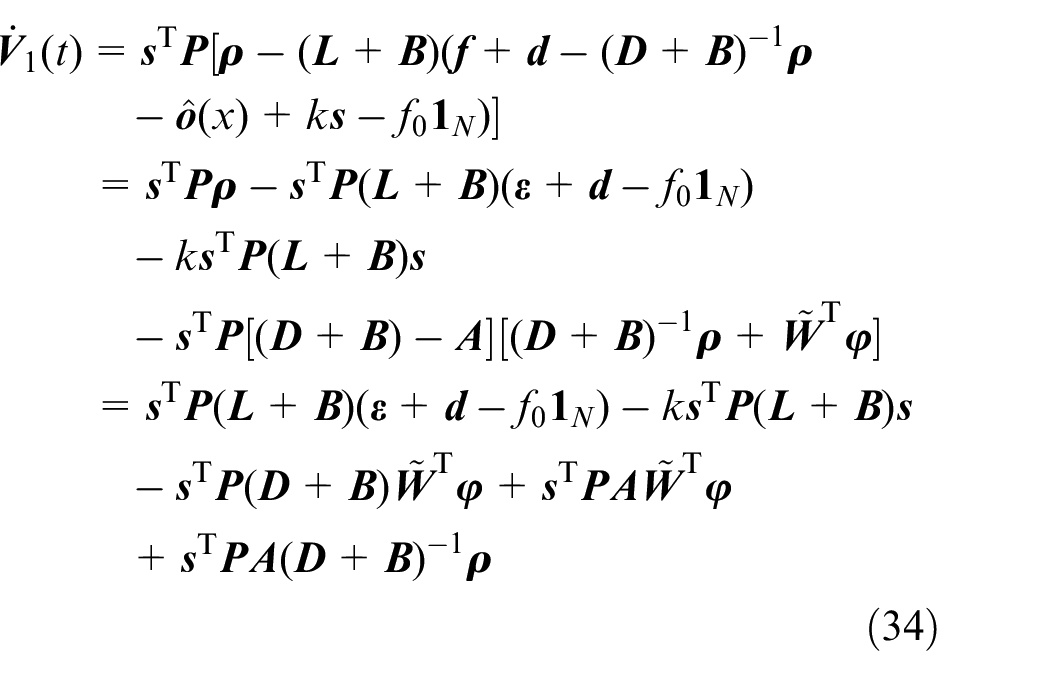
According to Lemma 1 and
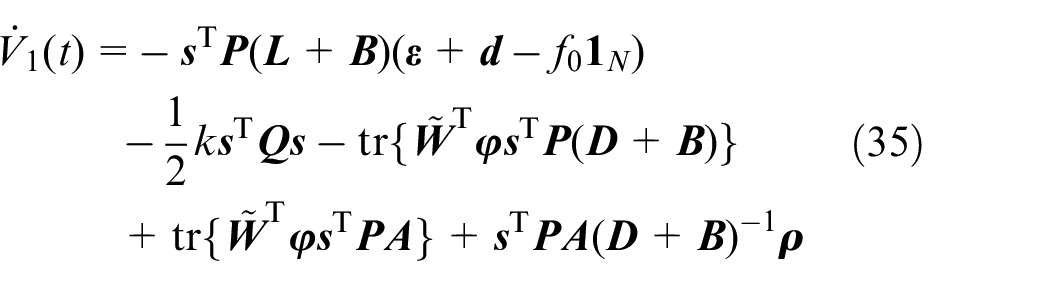
Because
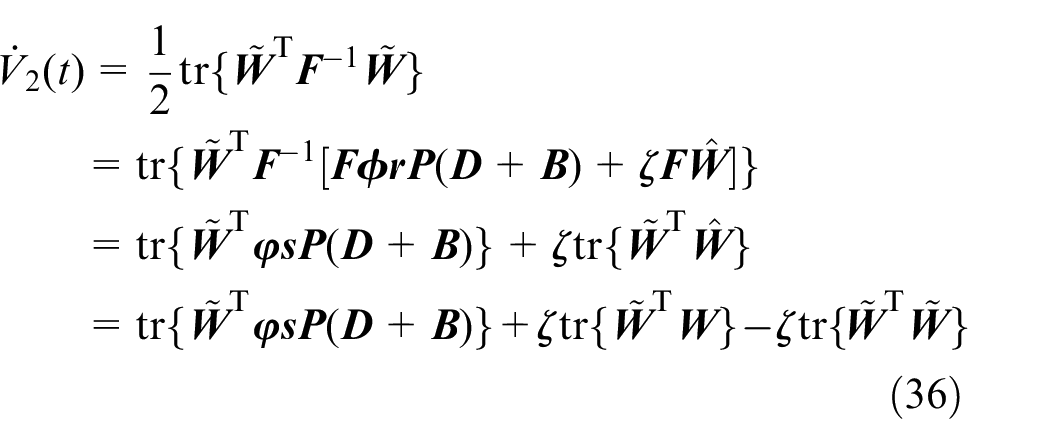
Solving the derivative of

Substituting (10) to (37), and considering (11),
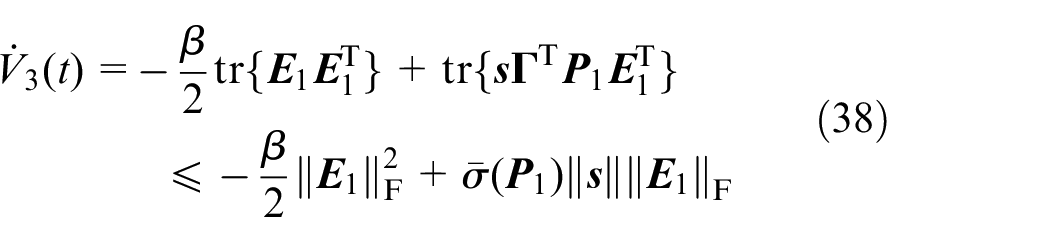
Thus, the overall derivative of Lyapunov function
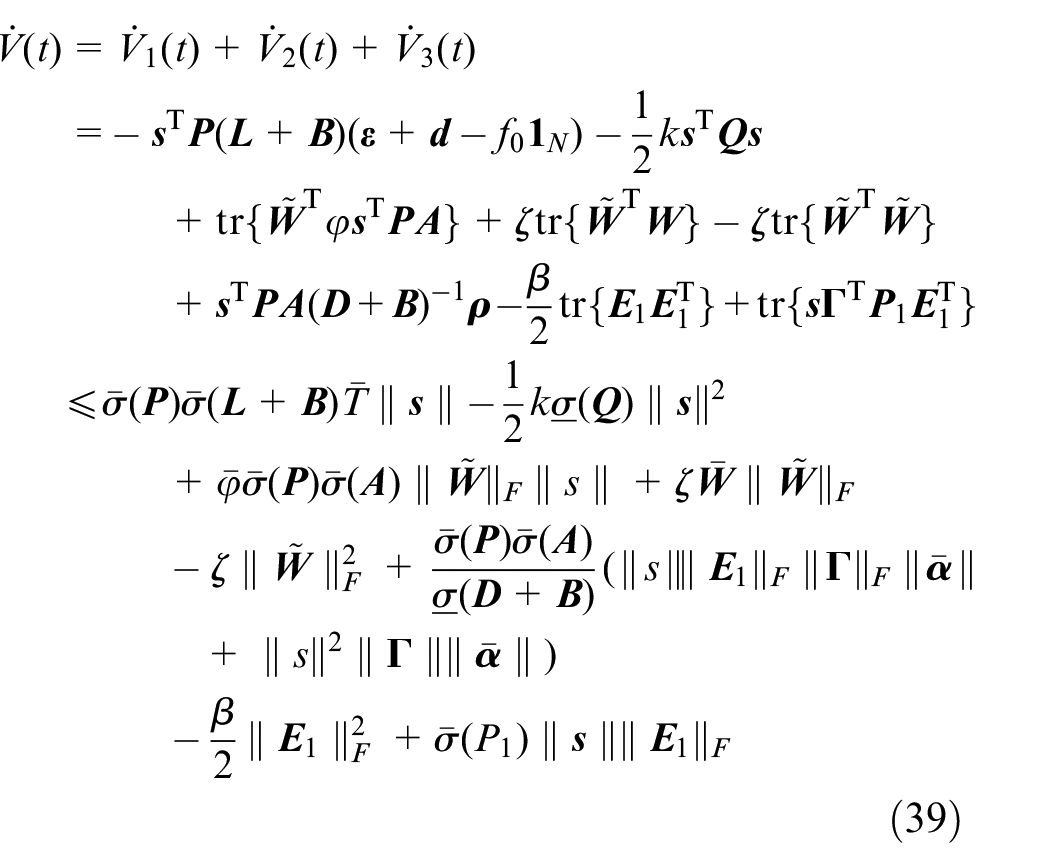
where
Note the definition of

Let
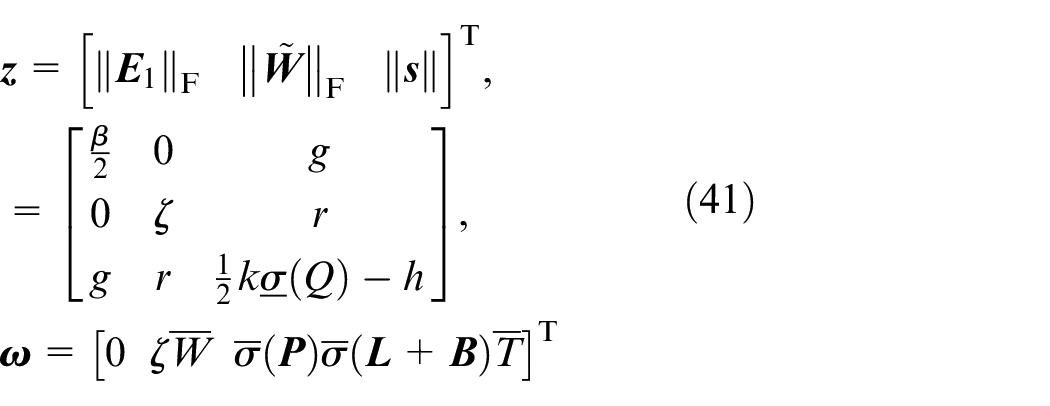
Therefore, we have
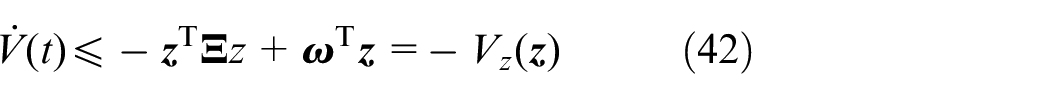
Achieving asymptotic stability of the above mentioned MAS requires
The matrix
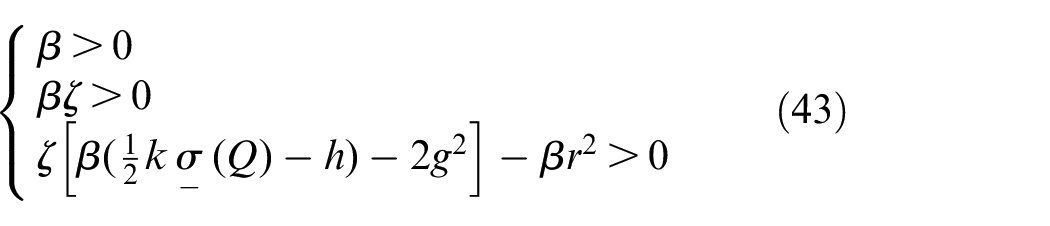
It is easy to know that
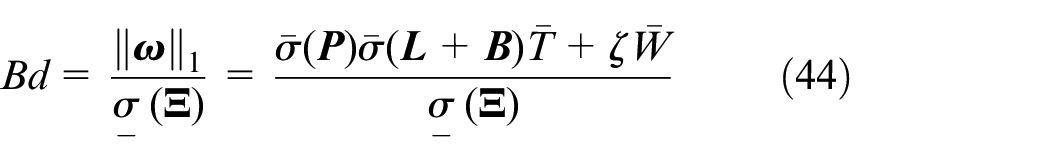
Therefore, both conditions 1 and 2 are met, so we have

and
Numeric simulation
In this section, numeric results on both homogeneous and heterogeneous multi-agent systems are provided to verify the effectiveness of our proposed control method. Homogeneous system means that the mathematical models of each agent dynamics are the same, while the heterogeneous means that the models are different with each other. Figure 1 shows the directed communication topology of the agents for the two numeric experiments, it includes one leader and six follower agents. All the communication weights among agents are assumed to be 1.
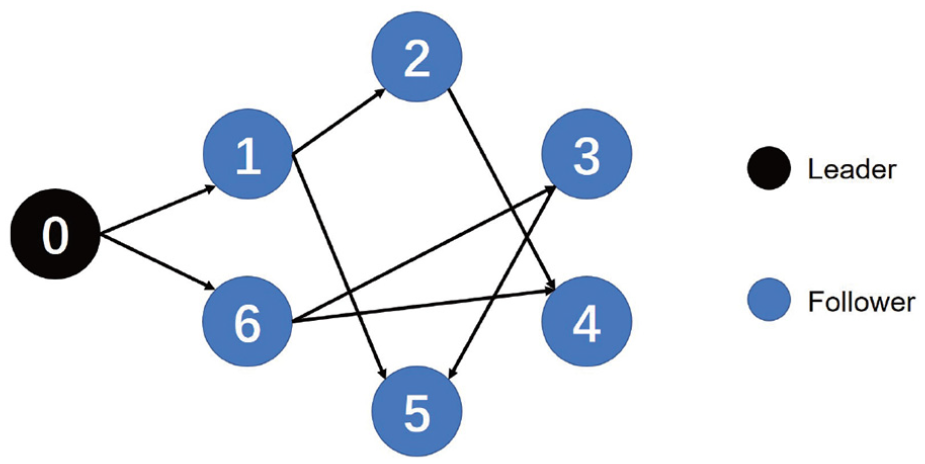
Directed communication topology with six followers and one leader.
The mathematical models of the dynamics for all the six followers are assumed to be third-order nonlinear systems with uncertainty:
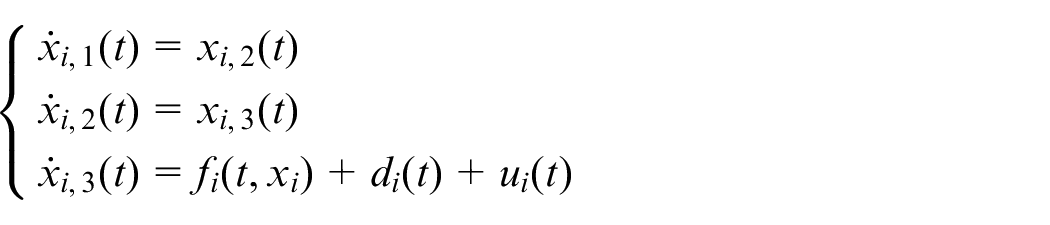
The parameters, including number of hidden nodes and connection weights of the proposed online-learning neural network are randomly initialized in advance.
Consensus of homogeneous MASs
Let the nonlinear function
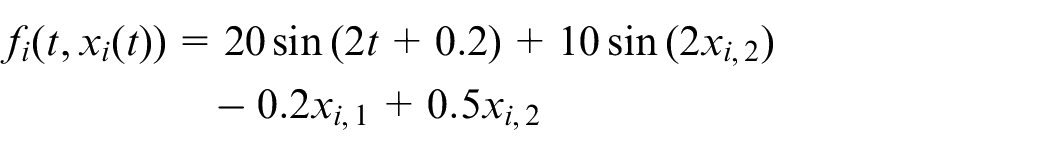
where
We initialize the state of the leader and follower agents as
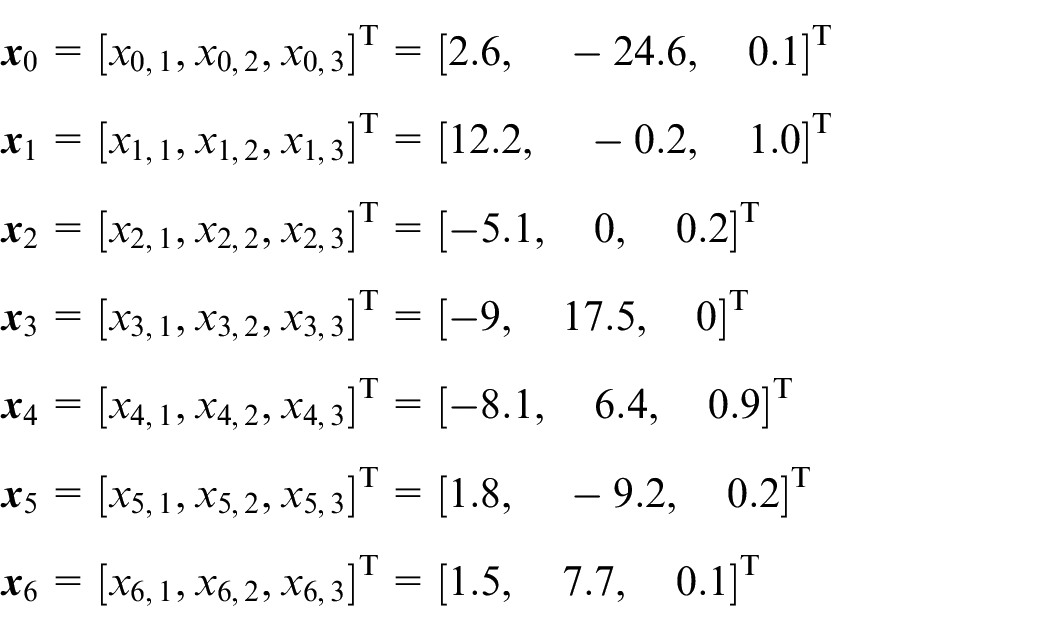
For the
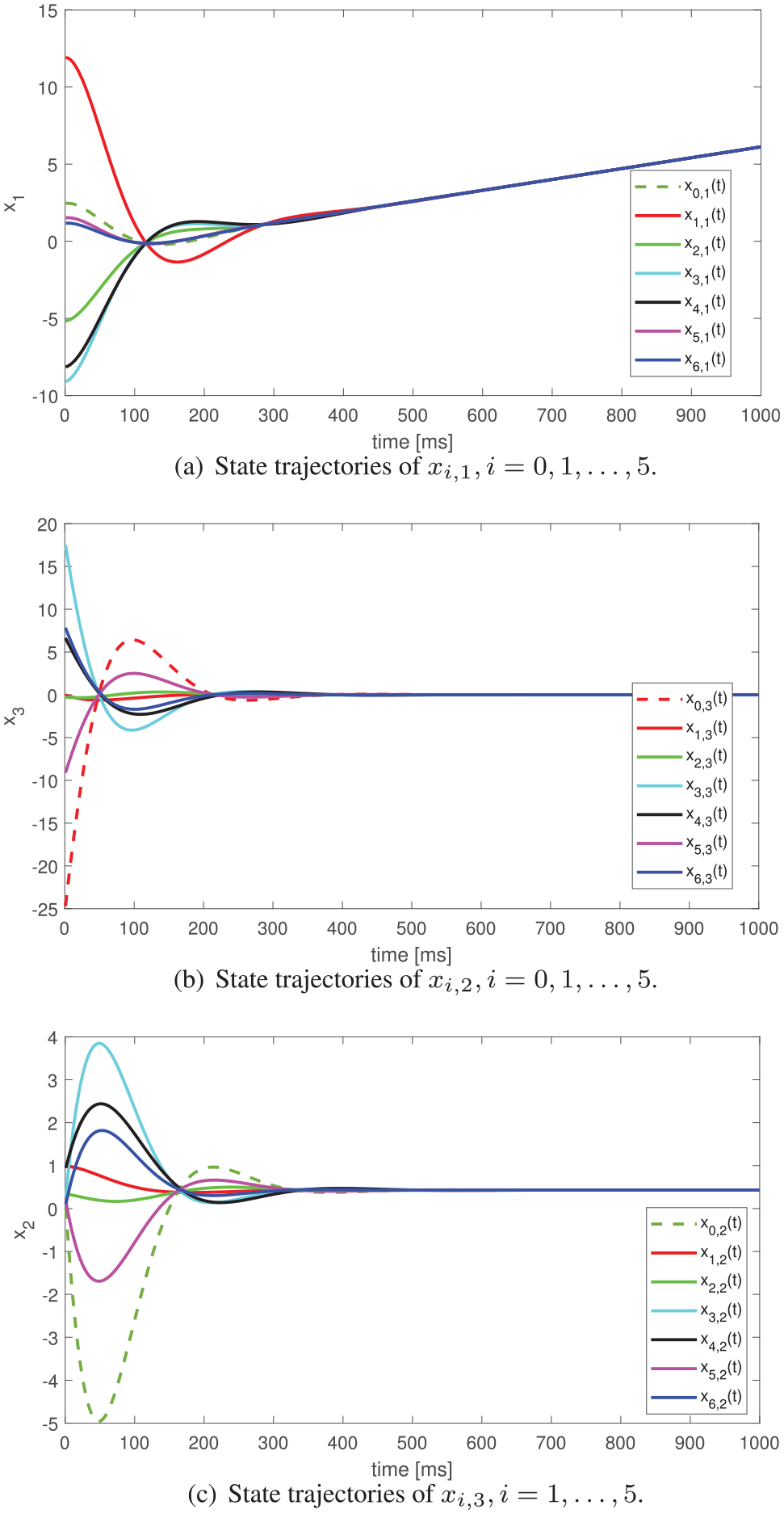
Homogeneous systems state trajectories: (a) state trajectories of
Consensus of heterogeneous MASs
For the heterogeneous MAS, reconsider the third-order system of with six followers, where the nonlinear function
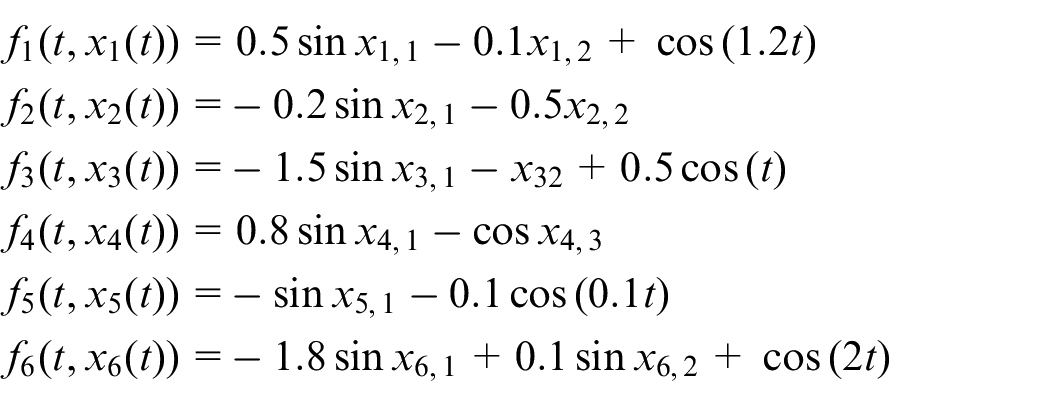
We initialize the state of the leader and follower agents as
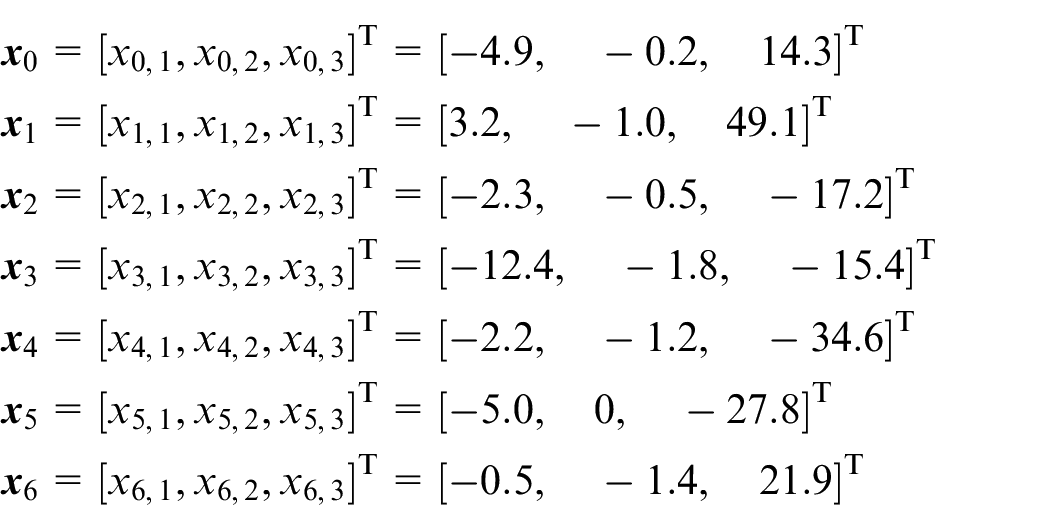
The controller and the parameters of neural network, network topology, the uncertain term
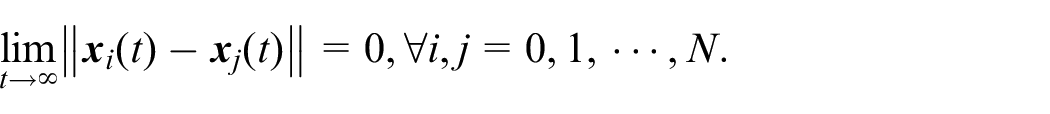
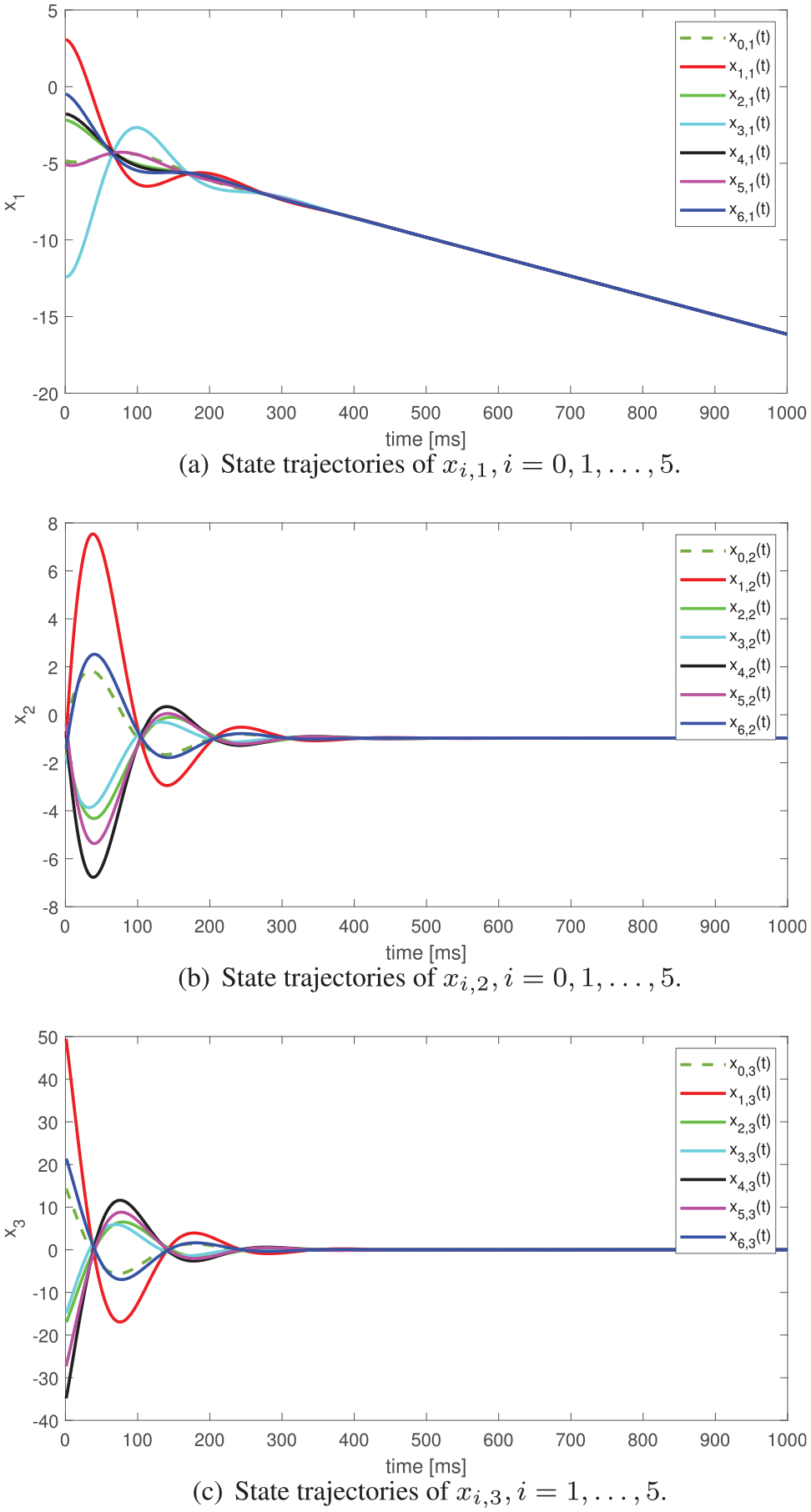
Heterogeneous systems state trajectories: (a) state trajectories of
Through the numeric simulations, it is verified that the proposed adaptive consensus control protocol is not only applicable to homogeneous multi-agent systems, but also to heterogeneous multi-agent systems.
It should be noted in view of the problems of external disturbances and uncertain items in the system, currently there are mainly robust control methods and state observer methods. Robust control has a certain inhibitory effect on external disturbances, but it cannot effectively eliminate the influence of external disturbances on consistency. At present, the more commonly used method is to use a state observer to estimate the uncertain items of the multi-agent system to compensate for the unknown items, to achieve the consistency of the multi-agent, and the design is for the linear systems. In this paper, researches on high-order nonlinear uncertain multi-agent systems are carried out. The nonlinear term of the system is approximated by RBF neural network. A sliding mode controller is designed to compensate for external disturbances, so that the multi-agent can be stabilized, thereby realizing the leader-follower consistency problem.
Conclusion
In this paper, we proposed a neuro-adaptive cooperative controller for high-order nonlinear leader-following MASs with uncertainty, where sliding mode variable structure control is used. The highlights are the method does not need to precisely know the upper bounds of both nonlinear terms and uncertain terms. Further, the proposed online-learning neural network can approximate the unknown nonlinearity of dynamical system and disturbance adaptively. Theoretical analysis based on Lyapunov stability theory shows the CUUB of consensus error. The simulation results verified the performance on both homogeneous and heterogeneous MASs, the proposed controller can not only effectively deal with unknown nonlinear dynamics, but also has good anti-interference ability to ensure the convergence of tracking consensus.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.