
Abstract
The flexible job shop problem (FJSP), as one branch of the job shop scheduling, has been studied during recent years. However, several realistic constraints including the transportation time between machines and energy consumptions are generally ignored. To fill this gap, this study investigated a FJSP considering energy consumption and transportation time constraints. A sequence-based mixed integer linear programming (MILP) model based on the problem is established, and the weighted sum of maximum completion time and energy consumption is optimized. Then, we present a combinational meta-heuristic algorithm based on a simulated annealing (SA) algorithm and an artificial immune algorithm (AIA) for this problem. In the proposed algorithm, the AIA with an information entropy strategy is utilized for global optimization. In addition, the SA algorithm is embedded to enhance the local search abilities. Eventually, the Taguchi method is used to evaluate various parameters. Computational comparison with the other meta-heuristic algorithms shows that the improved artificial immune algorithm (IAIA) is more efficient for solving FJSP with different problem scales.
Keywords
Introduction
In recent years, increasing numbers of enterprises have been paying more attention to the problem of how to optimize the scheduling of workshop to maximize their efficiency. As a result, the job-shop problem (JSP) has become one of most popular research topics in the literature owing to its potential to dramatically decrease costs and increase throughput. This has created a need for research on the scheduling problem. Traditional JSP can be concluded as follows: there are a set of jobs to be carried out on a set of machines, where each job involves multiple operations and each operation can be carried out by only one machine. In addition, each machine can process only one job at a time. However, the canonical JSP is restricted by factors related to having a rigid model, while flexible job shop scheduling resembles actual job shop circumstances more accurately. 1 Compared to the traditional JSP, the flexible job shop problem (FJSP) is a practically useful extension of the JSP in which each operation should be assigned to a set of alternative machines, with the result that the FJSP is much more complicated than the traditional JSP. 2 Because the JSP is strongly NP-hard, the FJSP is strongly NP-hard as well. 3
In view of the fact that FJSP can effectively improve the production efficiency of the job shop and shorten the manufacturing time, multiple heuristic or meta-heuristic algorithms have been developed to optimize the problem. For example, Pezzella et al. 4 introduced a genetic algorithm (GA) framework integrating different strategies for developing efficient algorithms for the problem effectively. Girish and Jawahar 5 described a powerful particle swarm optimization (PSO)-based heuristic algorithm for FJSP to minimize the makespan. Li et al. 6 proposed a novel tabu search (TS) algorithm by combining an effective neighborhood structure and local search methods based on the critical block theory. Aiming for flexible job shop scheduling with the constraint of preventive maintenance activity, Gao et al. 7 presented a hybrid GA that integrated a local search to optimize the problem effectively. Wang et al. 8 proposed an artificial bee colony (ABC) algorithm, hybrid with a local search based on the critical path theory, effectively solved the FJSP. Li and Gao 9 developed a combinational GA and TS algorithm to achieve solution convergence effectively. At present, the literature regarding FJSP is most focused on single objectives. However, multiple objectives must be considered simultaneously, and these objectives usually conflict. For an enterprise, different departments have various expectations aimed at maximizing their own interests. Considering completion time and complex machine energy consumption, Liu et al. 10 developed a combinational algorithm based on glowworm swarm optimization (GSO) algorithm and GA, hybrid with a heuristic strategy of green transmission that effectively solves the FJSP with crane transportation. Piroozfard et al. 11 considered both the total late work criterion and the total emitted carbon footprint bi-objectives, proposed an improved multi-objective evolutionary algorithm (MOEA), and verified its efficiency in comparison with two other multi-objective algorithms. Li et al. 12 combined several heuristic strategies and a TS algorithm, constructed a discrete artificial bee colony (DABC) algorithm, and addressed a scheduling problem that simultaneously minimizes makespan, total work load, and maximal workload. Soto et al. 13 studied the multi-objective FJSP with the aim of minimizing the total workload, maximal workload and makespan, and proposed a parallel branch and bound algorithm (B&B). With the consideration of the deterioration effect and environmental pollution problem, Wu et al. 14 formulated a multi-objective optimization model based on the energy consumption and step-deterioration effect model. Then, a multi-objective hybrid pigeon-inspired optimization (PIO) and a SA algorithm are developed to solve this problem. Ebrahimi et al. 15 investigated an energy-aware model to minimize the energy consumption and tardiness penalty simultaneously in the FJSP with scheduling-layout problem, and four meta-heuristic algorithms are introduced in the study.
Literature review shows that several assumptions in canonical FJSP being considered are unreasonable, for example, each operation can be processed after it is finished on the previous machine. 16 Most researchers have omitted the intermediate process of transportation time between two machines while the transportation of jobs really requires the participation of cranes, automatic guided vehicles or other tools, which is an essential characteristic of actual industrial scheduling. Few studies have conducted such investigations. Yu et al. 17 presented an imperialist competition algorithm for FJSP in physical examination system. Rossi and Dini 18 applied an ant colony optimization (ACO) approach to solving flexible manufacturing systems with transportation times, setup times, and alternative machines. Karimi et al. 16 developed a novel imperialist competitive algorithm (ICA) that combines with a novel local search strategy inspired by simulated annealing (SA), finally achieved outstanding performance. Dai et al. 19 adopted an enhanced GA (EGA) based on a combination of GA, PSO, and SA, which solved the multi-objective FJSP efficiently. Nouri et al. 20 combined neighborhood-based GA with TS technique to optimize the FJSP with transportation time and robots. Lu et al. 21 considered multiple dynamic events in welding scheduling, including setup time, transportation time, etc. A hybrid multi-objective grey wolf optimizer is developed to optimize makespan, machine load and instability simultaneously. With the consideration of processing interval constraint and transportation time, Qin et al. 22 designed a hybrid meta-heuristic algorithm based on grey wolf optimization (GWO) algorithm and TS algorithm to tackle discrete combinatorial optimization. Li et al. 23 focused on the impact of transportation time and setup time on processing time, constructed a mathematical model with the aim of minimizing the makespan and total energy consumption, and proposed an improved Jaya algorithm. Zhou and Liao 24 proposed an efficient hybrid algorithm based on decomposed MOEA and PSO algorithm for flexible job shop green scheduling problem with crane transportation. Particle filter and Levy flights are fused into the algorithm to enhance the computational performance.
The artificial immune algorithm (AIA), inspired by biological immune system, was proposed as a new intelligent approach by Castro et al. 25 Compared with other heuristic algorithms, the AIA makes use of the advantages of generating diverse solutions to maintain diversity of the population and an immune memory mechanism, thereby overcoming the inevitable prematurity problem of other heuristic algorithms in the process of optimization in order to obtain the optimal solution. 26 The AIA has been widely used owing to its efficient global search capability, and many hybrid meta-heuristic algorithms have also appeared. Bagheri et al. 27 integrated several initial strategies and mutation operators of antibodies, successfully applying the AIA to solve the FJSP. Lin and Ying 28 introduced a hybrid algorithm of AIA and SA to effectively solve the blocking flow shop scheduling problem. Savsani et al. 29 presented four variants of hybrid metaheuristic optimization algorithms that combine the characteristics of biogeography-based optimization (BBO) with AIA and ACO, and verified their effectiveness on many benchmark problems. Zeng and Wang 30 embedded PSO and SA algorithm into the framework of AIA and proposed a hybrid meta-heuristic algorithm to solve the problem with multiple objectives. Roshanaei et al. 31 constructed two mathematical models including sequence-based and position-based, and proposed a hybrid meta-heuristic algorithm based on the of AIA and SA. With the consideration of fuzzy processing time of realistic system, Li et al. 23 proposed an improved version of AIA, designed four initialization heuristic algorithms, and embedded SA to enhance the exploitation ability.
At present, there are mainly three approaches to solve the multi-objective optimization problems. 32 Multi-objective evolutionary algorithms based on decomposition (MOEA/D),33,34 including the algorithms based on weight decomposition,6,35,36 Chebyshev approach, 24 etc. The non-pareto approach, in which different operators are used in a separated way. The Pareto approach, a method that is based on the pareto dominance relation, in which solutions converging to the Pareto front.37–39 In this study, an approach based on the weight decomposition is used to optimize this problem in order to transform the multi-objective problem into a single-objective problem and reduce the complexity of the algorithm.
Among the modern meta-heuristic algorithms, the AIA and SA algorithms have become an effective and efficient algorithm to solve combinational optimization problems. 28 In this study, a hybrid meta-heuristic algorithm is proposed to solve the current problem, using a combination of the AIA and a SA algorithm, taking the maximum completion time (makespan) and energy consumption as the objective function, and assigning different weight coefficients to the objectives. In the proposed combinational meta-heuristic algorithm, an information entropy theory is applied to obtain better antibodies and some potential high-quality antibodies are searched from the point of view of global search. At the same time, four kinds of mutation operators which based on machine selection and operation sequence parts are utilized to perform further local searches in the neighborhood structure, and the Taguchi method are used to calibrate parameters. 40 To testify the availability of the model, the proposed MILP model is constructed by CPLEX.
The outline of this paper is organized as follows. The FJSP considering transportation time and energy consumption and a sequence-based mixed integer linear model are introduced in section “Problem description and mathematical modeling.” In section “IAIA,” an improved artificial immune algorithm (IAIA) is proposed to solve this problem. The parameters and experimental results are shown in section “Experiment analyses.” The section “Conclusion and future research” draws conclusions and describes directions for future work.
Problem description and mathematical modeling
Problem description
The FJSP-T model is improved over the canonical FJSP, adding constraints of transportation time and total energy consumption generated during the scheduling process. Accordingly, two objectives are of concern: (1) minimize the makespan; and (2) minimize the energy consumption. The weighted sum of makespan and total energy consumption is used as the target of optimization. To take the transportation time of jobs from assembly line to processing machine into consideration, we assumed an additional virtual machine which called machine zero in place of the assembly line. The FJSP-T must satisfy the following assumptions:
Machines cannot process multiple jobs simultaneously.
All of the jobs are ready when the process is started.
When entire process begins, operations cannot be interrupted until it is completed.
Each operation of a job is handled by only one machine.
Sufficiently many cranes are available to transfer jobs from one machine to another machine.
Each machine has a sufficient buffer to store jobs.
The energy consumption of cranes is ignored.
Mathematical modeling
In this paper, we propose a mathematical model based on the FJSP with energy consumption and transportation time, which can be defined as follows. There is a set of jobs {I1, I2, …, In} to be executed on a set of machines {M1, M2, …, Mm} in which each job Ii consists of a sequence of opi operations and each operation Oi,j is applied to on one of a subset of eligible machines Mi,j⊆M. In terms of transportation time, every operation Oi,j of each job Ii has its own transportation time tti,k′,k of transferring from machine k′ to another machine k. In addition, the energy consumption generated when jobs are processed on machines is taken into account. When jobs are being processed on machines, they produce disparate energy consumption eci,j per unit time. It worth noting that all the machines are assumed to be the same, and variables given in the mathematical model, that is, processing time of each operation, transportation time and unit energy consumption, are fixed and not affected by the state of machines. The parameters defined in this model are showed as follows.
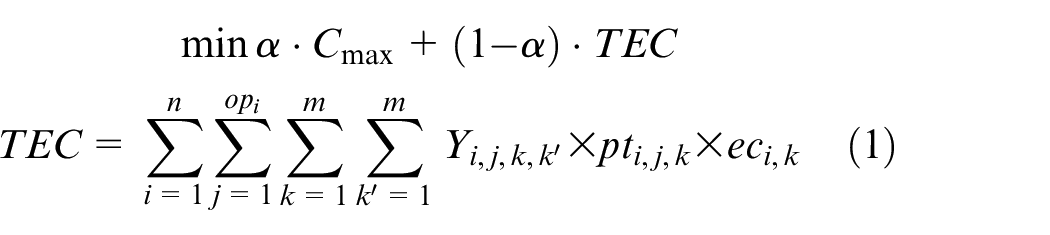
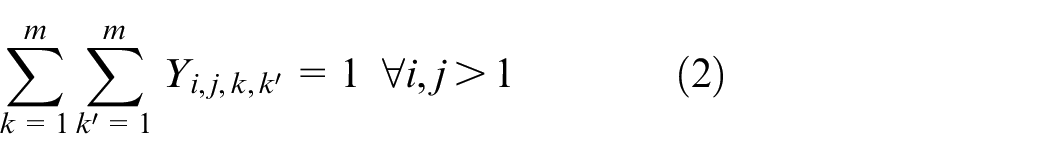
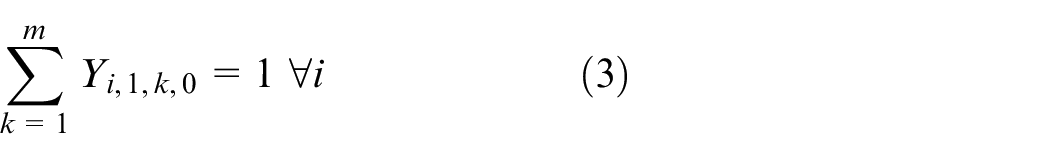
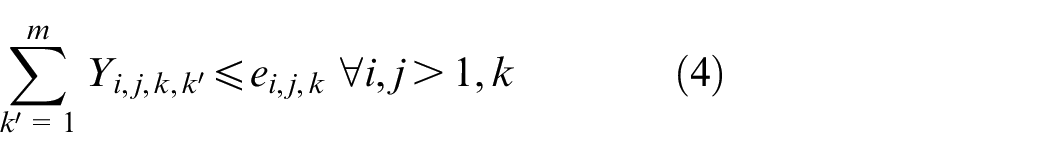

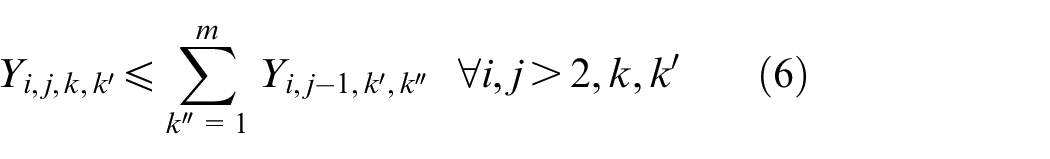

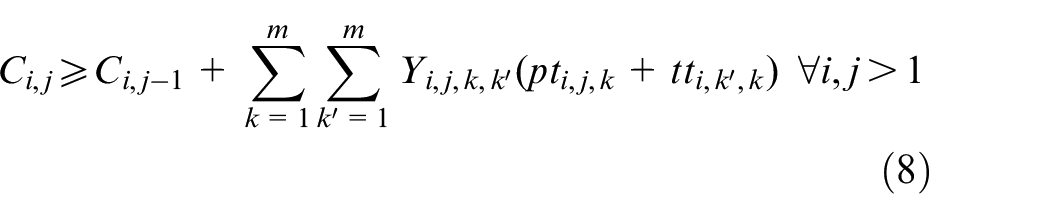
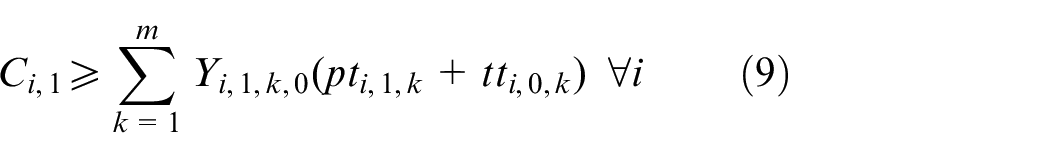
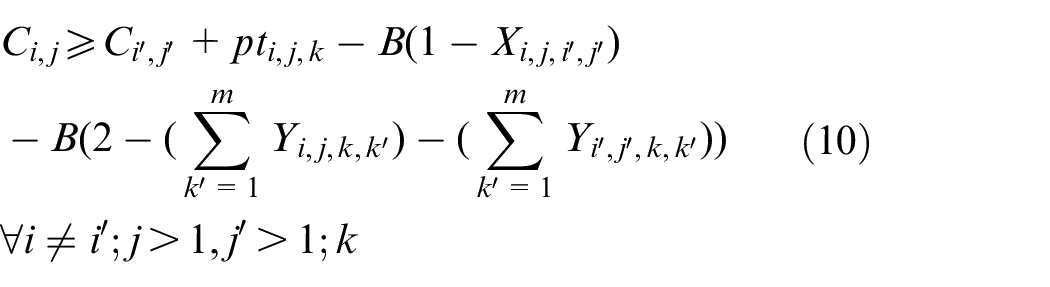
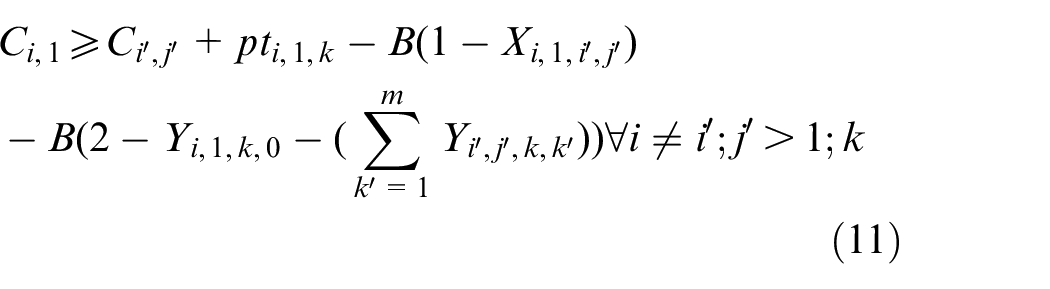
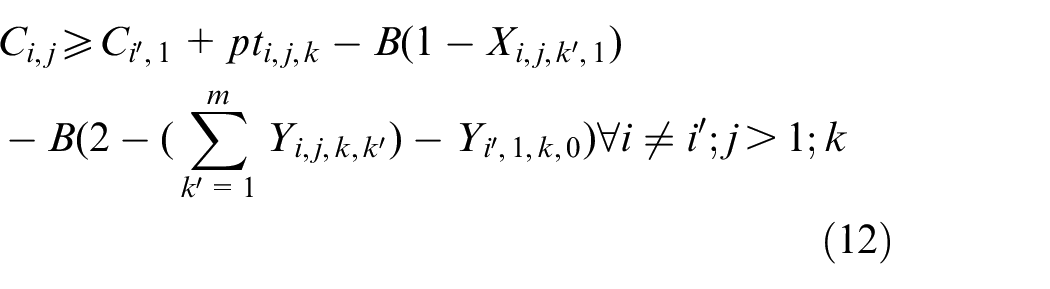
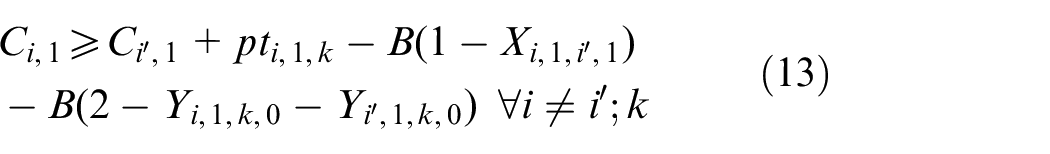
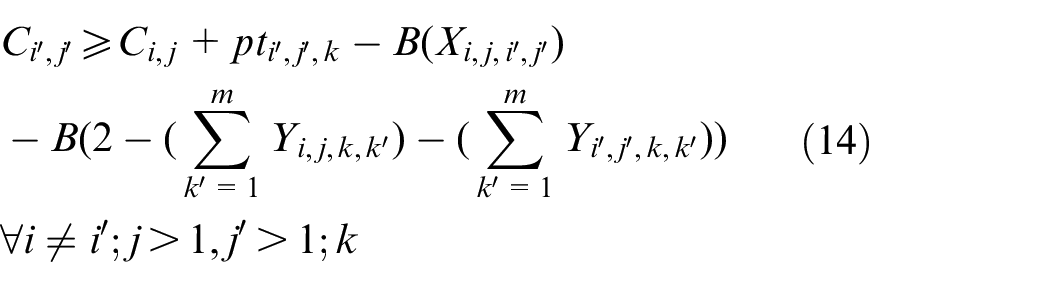
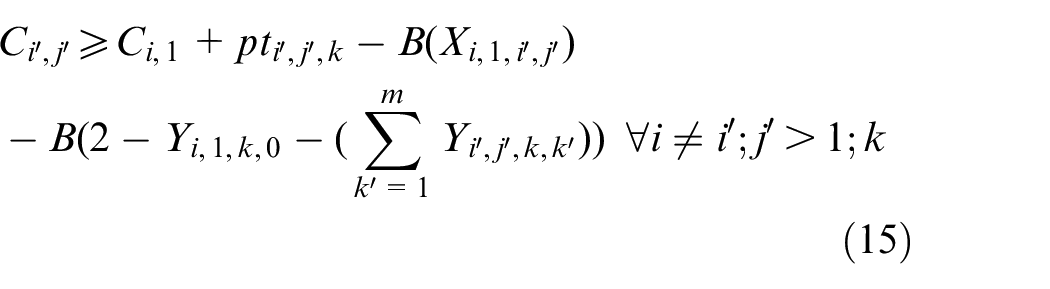
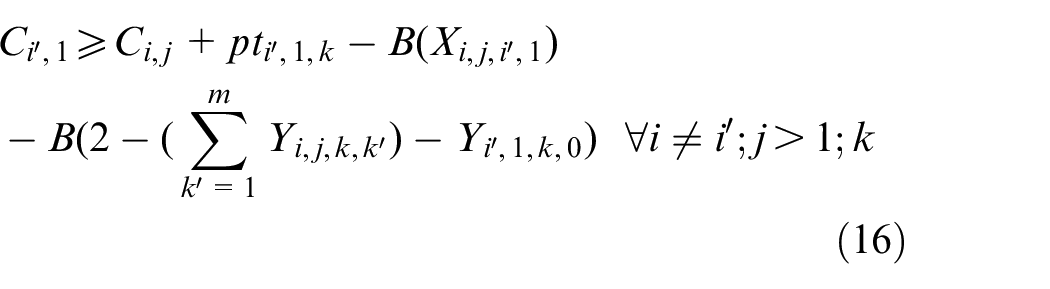
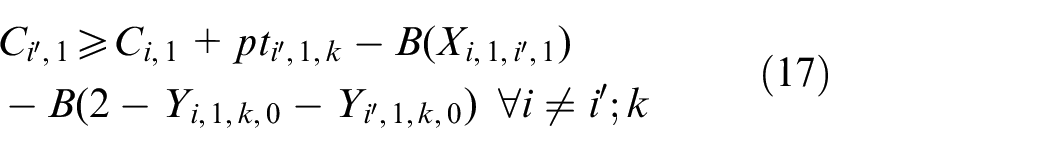
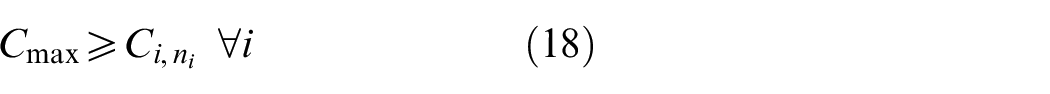
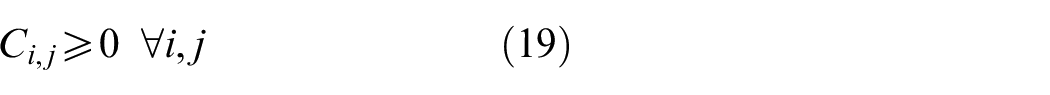

The objective aims to minimize the weighted value of makespan plus energy consumption. The constraint (1) is to calculate the total energy consumption of all operations when they are being processed on the machines. The constraints (2) and (3) ensure that each operation Oi,j is processed on only a specified machine. For any random operation selected from all of the operations, it is possible that not all of the machines have the ability to handle that operation, and there is a significant possibility that eligible machines comprise only a proper subset of all machines; hence, constraint (4) and (5) are included to make sure that each operation is to be allocated to a feasible machine. Constraints (6) and (7) limit the processing relation of the previous and next operations; if Oi,j is processed on the machine k, then Oi,j−1 must be processed on the machine k′. To calculate the completion time, we summarize the constraints (8) and (9) that each operation begins after the completion time and transportation time of the previous operation. Constraints (10)–(17) guarantee that every operation is to be processed on only one machine at a particular time. Constraint (18) ensures that the final result, the maximum completion time of the last operation, has been obtained. The range of values of three decision variables are defined by constraint (19) and constraint (20). The validity of this model has been verified by coding the problem formula in IBM ILOG CPLEX 12.7 and running various small instances, as discussed in section “Comparison with the exact solver CPLEX.”
Example of the FJSP-T model
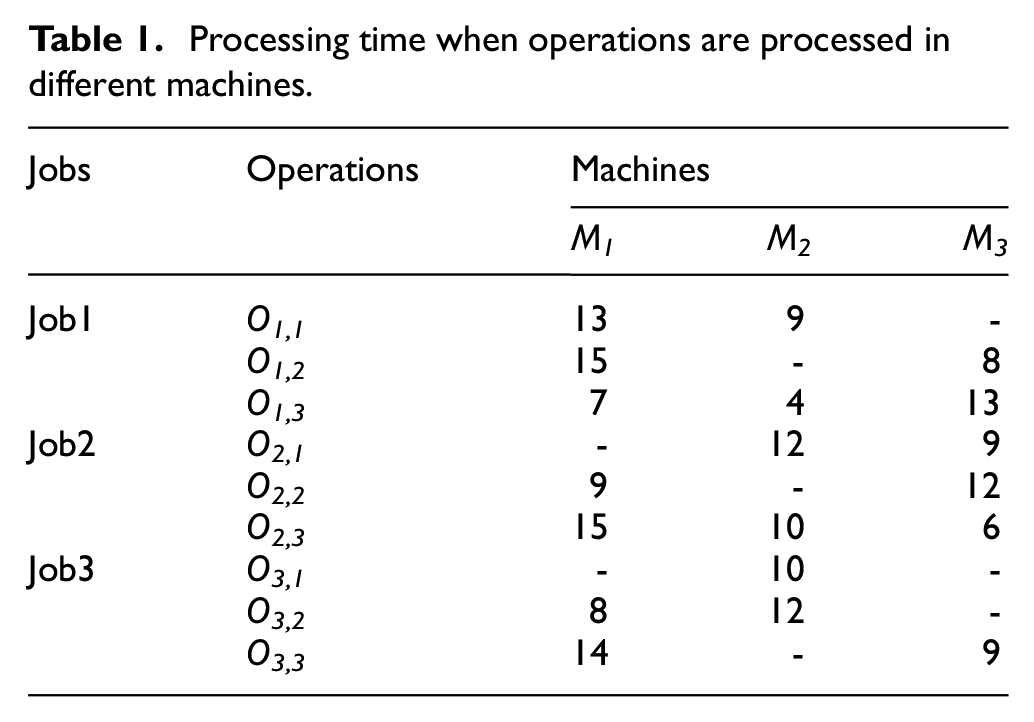
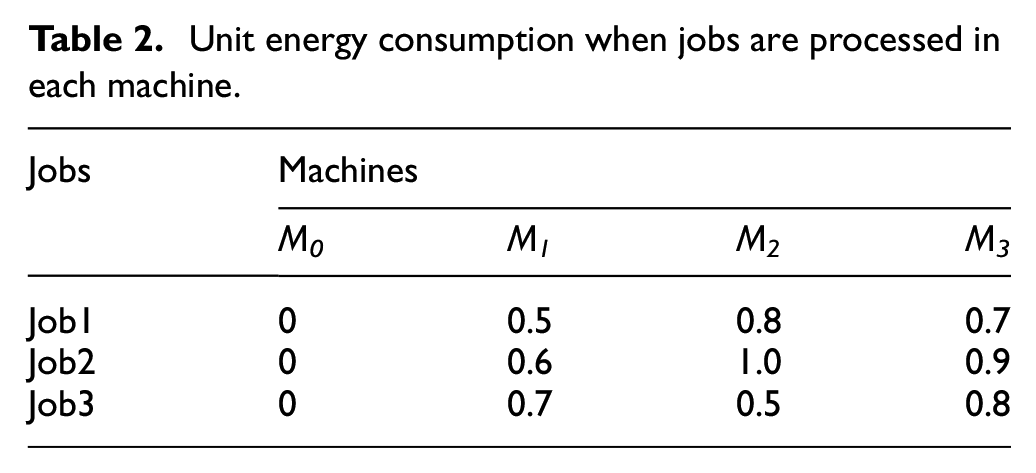
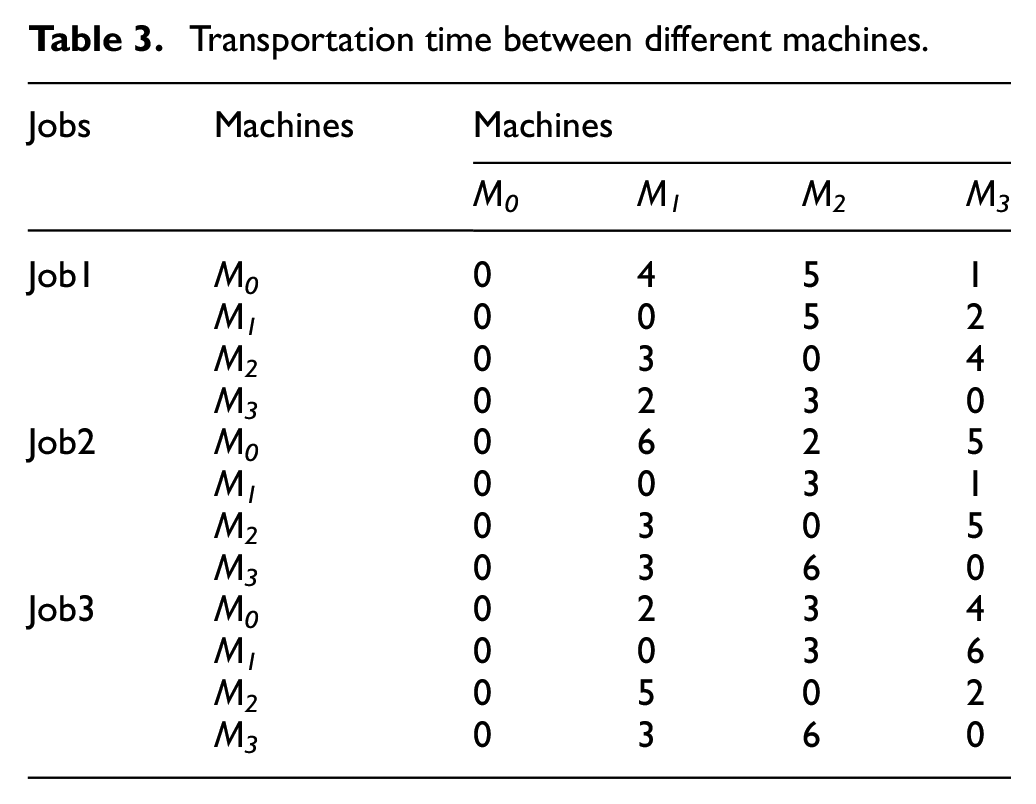
There gives a typical example to illustrate the FJSP with the constraint of transportation time, the processing time is shown in Table 1, in which the symbol “-” indicates that the machine does not have ability to process the job. The unit energy consumption generated by each job during the processing of each machine is listed in Table 2. Because the M0 machine is a virtual machine that represents the assembly line, the energy consumption generated by M0 is zero, as is the related transportation time. The transportation time required for each job to be moved from one machine to another is listed in Table 3, as shown in Figure 1, where O1,1 is the first operation of the first job. Once the process starts, O1,1 is first transferred to M1 and then transferred to M3 for further processing. Since O2,1 has finished processing at this time, some idle time appears. Other operations follow the identical process. The result is an optimal solution in which once an operation is completed, the job begins to be transported immediately to another machine in prepare for further processing, as illustrated in Figure 1.

Processing time when operations are processed in different machines.
Unit energy consumption when jobs are processed in each machine.
Transportation time between different machines.
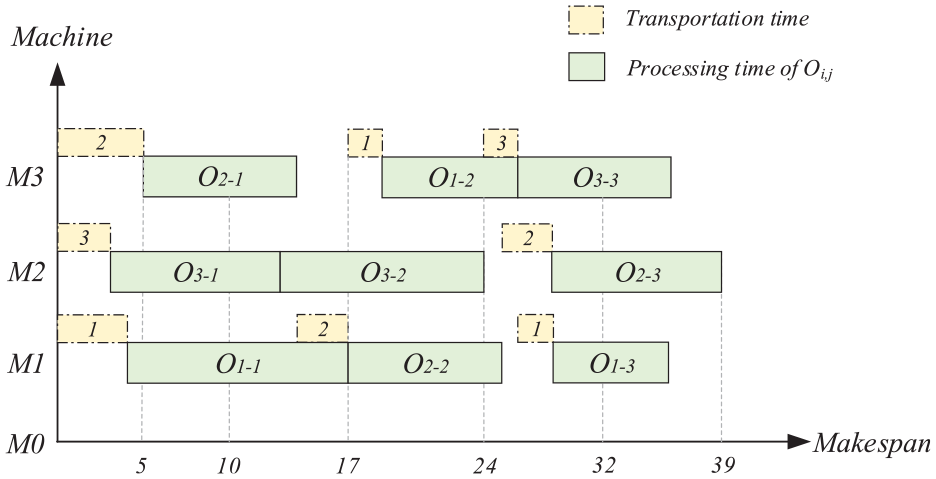
Gantt chart for the solution of the example.
IAIA
The immune algorithm (IA) was first introduced by Burnt (1958). The AIA is a novel intelligent optimization algorithm, inspired by the human immune mechanism. The artificial immune system is an adaptive system modeled after the mechanism of human self-protection, including mechanisms as antigen recognition, clone selection, clone inhibition, and immune memory function. 27 The resulting information processing mechanism based on the immune system is applied to the problem of scheduling.
In this study, the AIA, based on information entropy theory, is used to implement global search, taking the reciprocal of the makespan as the criterion of affinity evaluation. The similarity of the chromosomes is evaluated and the antibody concentration is determined on the basis. Then, the population is sorted according to two criteria, antigen affinity and antibody concentration, antibodies, with antibodies of quality then selected for further local search based on SA and an immune suppression operation.
Representation of antibodies and initialization of the population
In the population, a complete chromosome sequence is called an antibody (solution). An antibody is represented by a sequence of numbers which are composed of two parts, the machine-selection (MS) part and the operation-sequence (OS) part. As shown in Figure 2, in the MS part, the number of each gene represents the number of the corresponding processing machine. The first gene in the MS part is the first operation O2,1 of the job I2, and the number two on the gene position indicating that this operation is carried out by the second machine of a set of machines that are available for the O2,1. There are two available machines that can implement the operation O2,2 and the first machine is selected, resulting in the second gene position of the MS part to be one. Other numbers have the respective same meanings. In the OS part, each job Ii appears opi times, where opi indicates the number of operations of job Ii, and the order in which each job emerges determines the operation it is. The processing sequence illustrated in Figure 2 is O3,1– O1,1– O2,1– O3,2– O2,2– O2,3– O1,2– O1,3– O3,3. The total length of the chromosome is
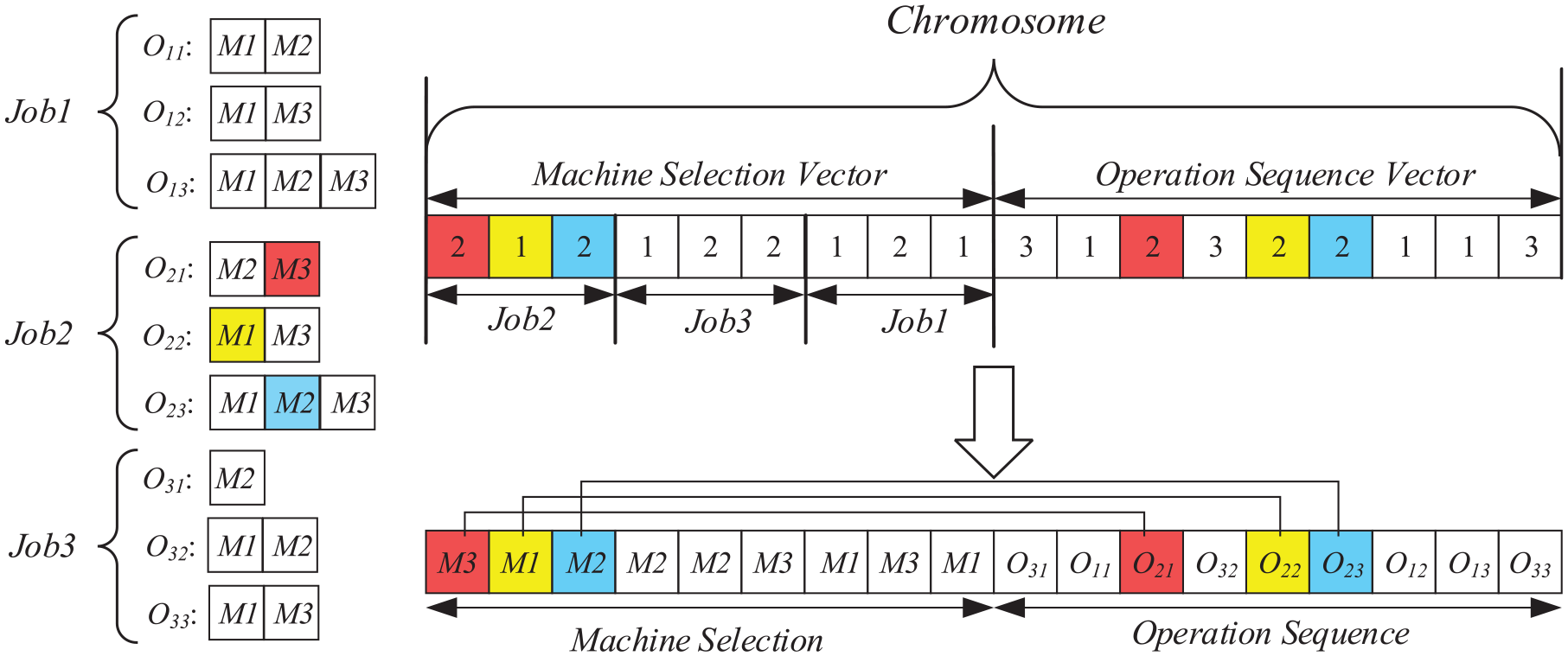
Representation of an antibody.
To maintain the diversity of the population and enable coding scheme to obtain the optimal solution quickly, global selection (GS), location selection (LS), and random selection (RS) are applied to the generated MS part. These three encoding schemes, all designed by Karimi et al., 16 require no repair mechanism thereby substantially reducing the time complexity. First, each job Ii is assigned a different integer in the interval [1,N] representing the priority of each job to be processed. Then, each operation is allocated to a feasible machine in turn. Meanwhile, the operation-selection part is initialized using RS. For the MS part, all of the jobs are assigned randomly, and each operation is arranged successively to a feasible machine respectively, with number k indicating that the kth available machine is assigned to corresponding operation. For the OS part, all of the operations are disorganized and inserted into the chromosome.
Affinity calculation
In this study, evaluation criteria of antibodies are determined by affinity between antibody and antigen (aff) and individual concentration (den). After evaluation, only antibodies with higher expected reproduction probability (ERP) will be subject to immune operation, where ERP is the probability that a selected antibody being selected. The formula for calculating the ERP is as follows:
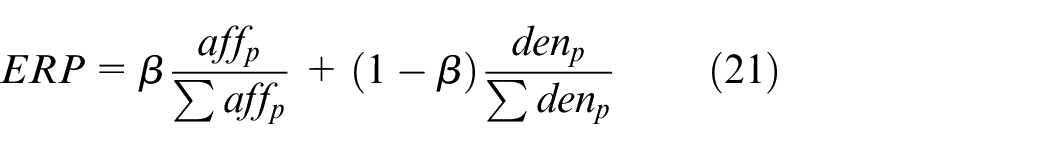
where affp is the affinity between antibody p and the antigen, denp is the individual concentration of the antibody p, and the variable β is used to determine their respective weights. After normalization, antibodies with higher affinity and lower concentration can obtain better values of ERP.
Affinity of antigen
Each antibody has its own affinity for the antigen, which is related to the maximum completion time (Cmax). To calculate the affinity between antibody and antigen, the following equation is used:
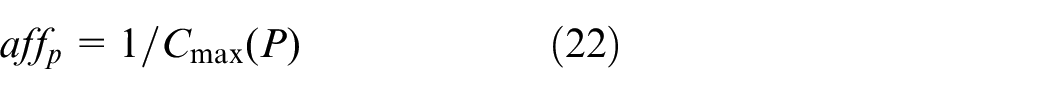
This equation, makes it clear that the affinity of each antibody is determined by the makespan and that a greater affinity of the antibody corresponds to a lower makespan.
Antibody concentration
To decrease the number of the same antibodies and increase the diversity of the population, the proposed algorithm introduces affinity between antibody and other antibodies in the population. We calculate the particular affinity based on the immunity and entropy theory presented by Cui et al. 41 For each antibody, the number of antibodies that resemble another antibody divided by the total number of antibodies is the concentration of an antibody. More similar antibodies in the population, results in a higher concentration of an antibody and the more expected reproduction probability of an antibody, resulting in a degrading of the ERP. 42 The calculation of antibody concentration is detailed as follows:
Step 1: Information entropy theory of antibodies
The evaluation of antibody concentration through information entropy is essentially to calculate the number of the same genes in the chromosome. The average entropy (H) is calculated using equation (23):
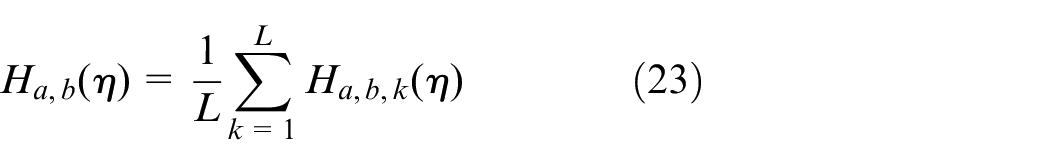
where η is the number of antibodies with its value being two in general, representing average information entropy of the two antibodies. Assuming that there are L genes in a chromosome, the information entropy of each gene is calculated using equation (24):
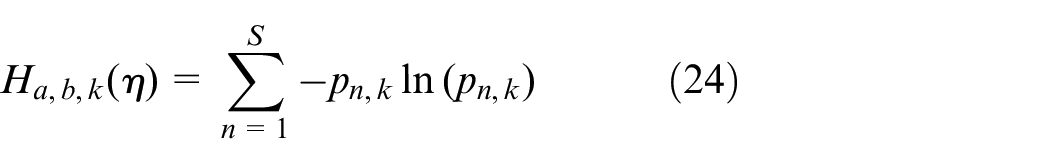
where pn,k is the ratio that the nth number emerges at the kth locus, with pn,k = (total number of occurrences of the nth number at the kth position among individuals)/η.
Step 2: Similar extent of antibodies
The Similar extent of each antibody (Πa,b) represents the similarity between individual a and b and it determined by the average information entropy between two antibodies. The similarity of an antibody is calculated as follows:
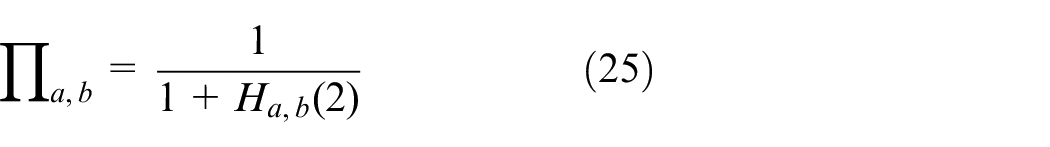
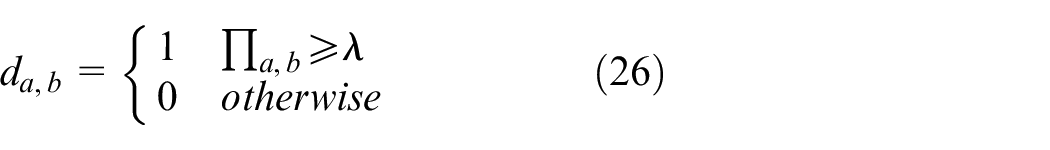
where Ha,b (2) is the common case in which η equals two, representing the average information entropy between individual a and individual b. To calculate the antibody similarity, an intermediate variable Πa,b and a binary variable da,b are introduced. A greater Ha,b (2) value between two antibodies, corresponds to a smaller Πa,b value between them. Πa,b ranges from zero to one, and da,b is equals to one if the Πa,b value exceeds the threshold λ; otherwise, it is zero.
Step 3: Density of antibody.
The density of an antibody, denoted by denp, is the rate of the number of antibodies that similar to antibody i in the population, which is defined as follows:
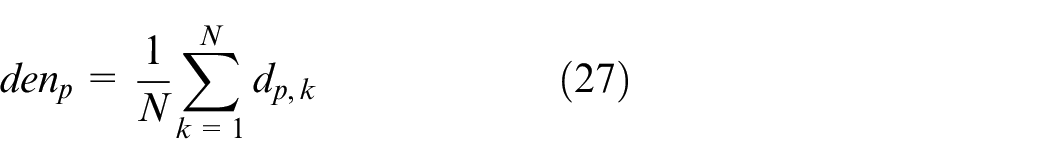
where dp,k denotes the summary between the antibody p and the other antibodies, and N denotes the size of population.
Selecting and cloning
To search better antibodies, Nc antibodies with the highest affinity are selected in the initial population to undergo the clone operation. The clone number of each selected antibody can be defined as: Nc− k +1, in which k indicates that this antibody is the kth antibody with the highest affinity. Accordingly, Nc (Nc+1) clones are generated in preparation for next step.
Mutation
Mutation aims to search its neighboring solution by altering one or more genes on the chromosome. The chromosome is composed of MS part and OS part. Thus, we apply different mutation operators in each part of each clone antibodies.
For the MS part, the random rule is used to change the sequence of the part. Two genes are randomly selected and replaced with other available machines. The new genes are also the serial numbers in the collection of available machines, rather than the number of the current machine. Considering the example in Figure 2, the MS mutation operator is shown in Figure 3(a), with the gene at the third position, as the third operation of J2, is replaced by three in the collection of available machines that can process O2,3.
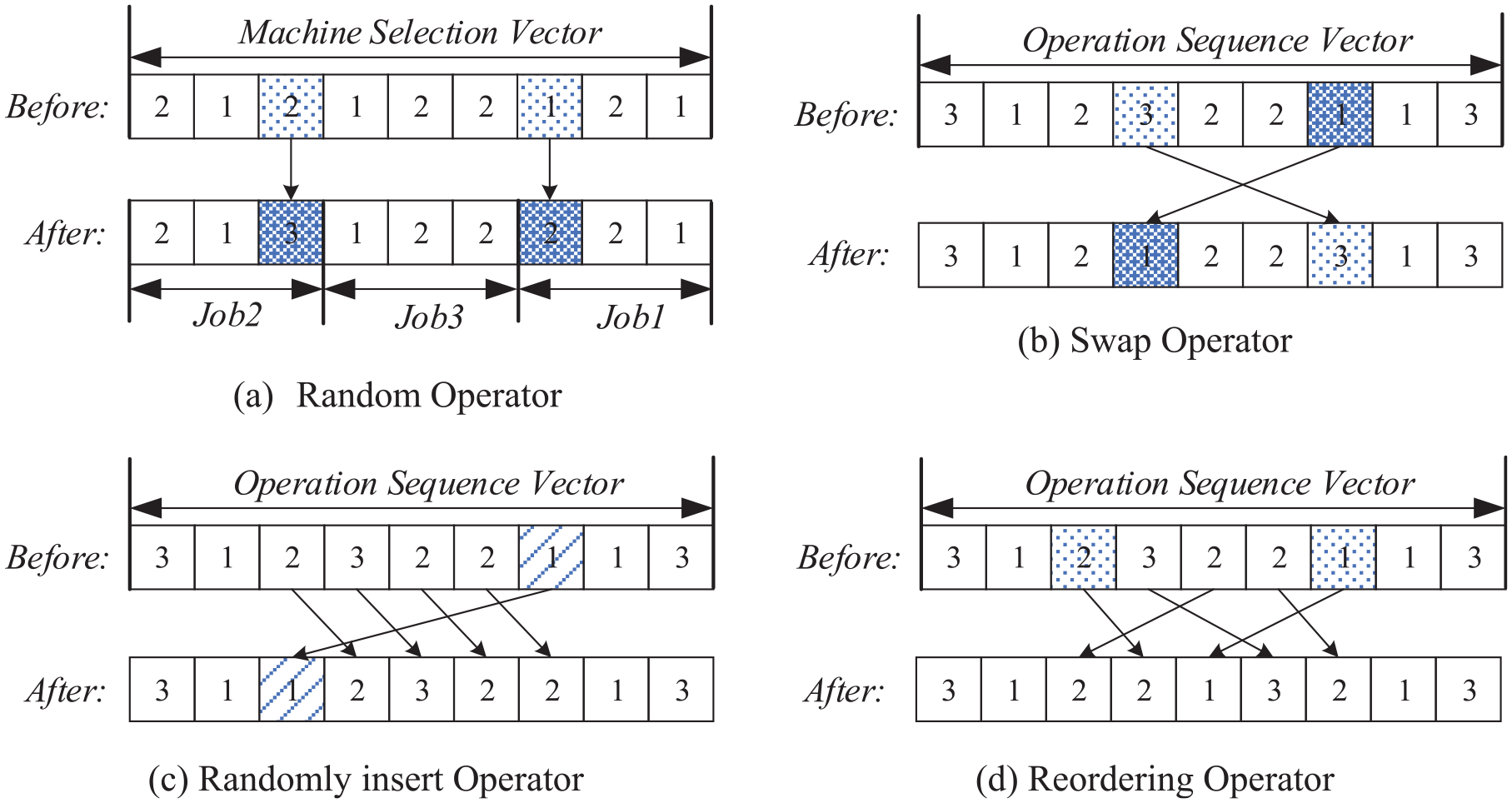
Illustration of the various mutation operators.
For another OS, three different canonical mutation operators are used to search other optimal solutions in the neighbor field.
(1) Swap operator: To form a new neighborhood solution, two different gene positions are selected randomly in the current solution to be exchanged at the selection positions. 6
(2) Randomly insert operator: A gene position is randomly selected and shifted it into a previous position. 43
(3) Reordering operator: We randomly select two different gene positions on the current chromosome and reorder the genes between the two selected positions.
To clarify the process, three OS mutation operators are shown in the Figure 3(b)−(d).
Update antibodies population
The clonal suppression operator selects the cloned and mutated antibodies, with lower-affinity antibodies are inhibited, leaving high affinity antibodies in a new antibody population. In this study, after the cloning and mutation processes, the selected high-quality antibodies are mixed with the cloned antibodies into a temporary antibody population. Then, the population is arranged in descending order according to the criterion of ERP, in which the Nc antibodies with the highest affinity is selected to replace the antibody with the lowest affinity in the initial population.
However, to avoid being trapped in local optimization, Nc antibodies with the highest affinity in the population are mutated through SA. The SA algorithm is an efficient heuristic algorithm. With its strong local search ability, it has been effectively applied to kinds of job shop scheduling problems combined with multiple optimization algorithms. In this study, on the basis of the original SA algorithm, a memory function is added to save the best solution obtained during search process and change the annealing rate. For each Nc antibody, a gene in the MS part is selected randomly selected and replaced with another available machine, and two genes randomly selected in the OS part are exchanged with each other. The mutated antibody replaces the previous one directly if the mutated antibody is better, and whether the best antibody needs to be updated is determined. Otherwise, the solution is accepted with a random probability, following the Metropolis criterion described in equation (28):
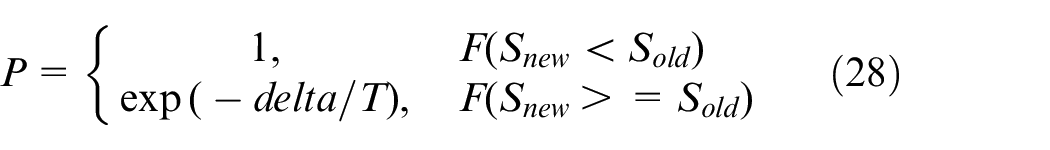
in which the probability of replacement is gradually reduced by temperature decline. When the system is at a higher temperature, the acceptance of the inferior solution is close to one, but the system no longer receives any inferior solutions when the temperature approaches T0.
Compared to the traditional SA algorithm, in which the annealing rate is typically a fixed constant ranging from 0.75 to 0.95, therefore, the search of the algorithm at low temperatures is very slow and insufficient. Dai et al. 44 improved the decline rate in accordance with the Hill function, after the completion of each isothermal search, the annealing using the following calculation criterion:
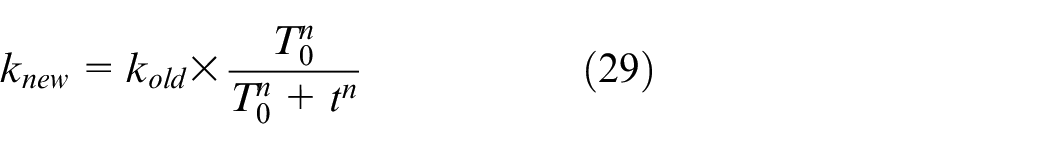
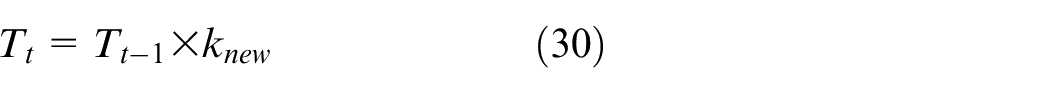
in which the t is the number of the annealing operation, and n represents is the Hill coefficient, whose value is typically greater than one. Consequently, the SA can be searched fully in the space of the solution to achieve the optimal effect.
Experiment analyses
In this chapter, the proposed IAIA is applied to solve the FJSP-T using C++. To testify the efficiency of the algorithm, the experimental tests are conducted on a PC with a 2.40-GHz Intel Core i7 CPU and 8 GB of RAM. Weight decomposition has been proved to be an effective way to optimize multi-objective problems. In this study, the proposed algorithm based on weight decomposition is used to optimize the FJSP-T model. In the part of proving the effectiveness of information entropy theory and SA algorithm, the coefficient of makespan α is set to 0.8, and the coefficient of total energy consumption is set to 0.2 because we prefer to take the completion time as the principal optimization objective. Then, in the section of multi-algorithm comparison, the performance of proposed algorithm is analyzed under three sets of weight coefficients, that is, 0.2, 0.5, and 0.8.
Instances
We randomly generated 30 instances based on the actual processing circumstances of a factory. The instances are divided into two parts, of which the first represents the job scale with values ranging from 10 to 100 and the number of jobs being n = {10,20, 30,50,100}, and the second represents the total number of machines, with the value m = {3,5,6,7,8,10}. In accordance with the characteristics of the FJSP, the number of operations contains a degree of randomness, with values randomly ranging from m/2 to m when the number of machines exceeds five. For example, the instance 10-5 involves 10 jobs processed on five machines, with the number of operations of jobs evenly valued within the interval [m/2, m]. In addition, the processing time of each operation is set to the interval [10,20], and the transportation time between two machines is set to [5,20], and the unit energy consumption when machines are processing is set to [0.5,1]. In actual production, for each operation, machines can be out of order or in preventive maintenance. Consequently, we randomly set up some machines with no processing capability with the value ranging from one to half number of the machines for each operation.
Parameter selection of the algorithm
Some key parameters in IAIA are evaluated because the final experimental effect will be affected by parameter selection, which involves some significant parameters. The selection of parameters determines the convergence speed and effect of the algorithm. Accordingly, four of the more critical parameters are selected to process the parameters adjustment experiment, with other parameters being selected from previous experience or other papers, as follows:
Population size Popsize = 100
Ratio of initial assignment with GS: 60%
Ratio of initial assignment with LS: 30%
Ratio of initial assignment with RS: 10%
Original temperature T0 = n × m
Final temperature Tf = 10
Iteration number of each temperature L = 100
Hill function t = 2
Selected probability of each operator Pm = 1/3
There are four significant parameters we considered in this study, that is, the number of selected antibodies with higher affinity (Nc), the weight of the objective (β), the concentration threshold (λ), and the annealing rate (K). The Taguchi method of Design of Experiment (DOE) was applied to verify the effect of these four parameters on the performance of the algorithm. For each parameter, we considered four levels, as shown in Table 4. A set of orthogonal arrays L16 (4 2 ) was constructed to combine the parameters, and for each combination, which runs 30 times independently, the average value obtained is taken as the response value (RV). Table 5 shows all of the combinations of the four parameters and their corresponding RV values.
Different values of each parameter.
Combination situations of the algorithm parameters.
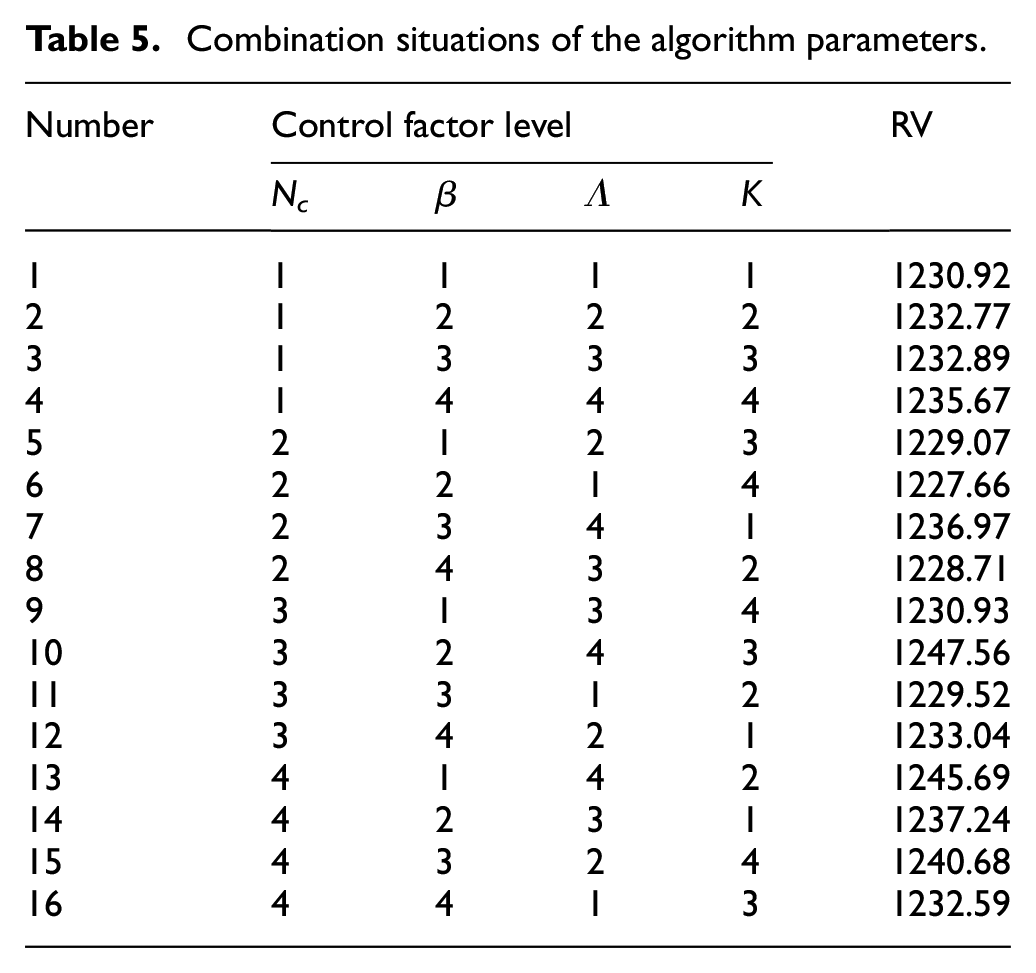


The instance 50-8 was used to evaluate each parameter of each combination. We show the factor level trend of each parameter in the Figure 4. According to this analysis, we can infer that Nc = 6, β = 0.8, λ = 0.90, K = 0.99 comprise the best set of parameters.
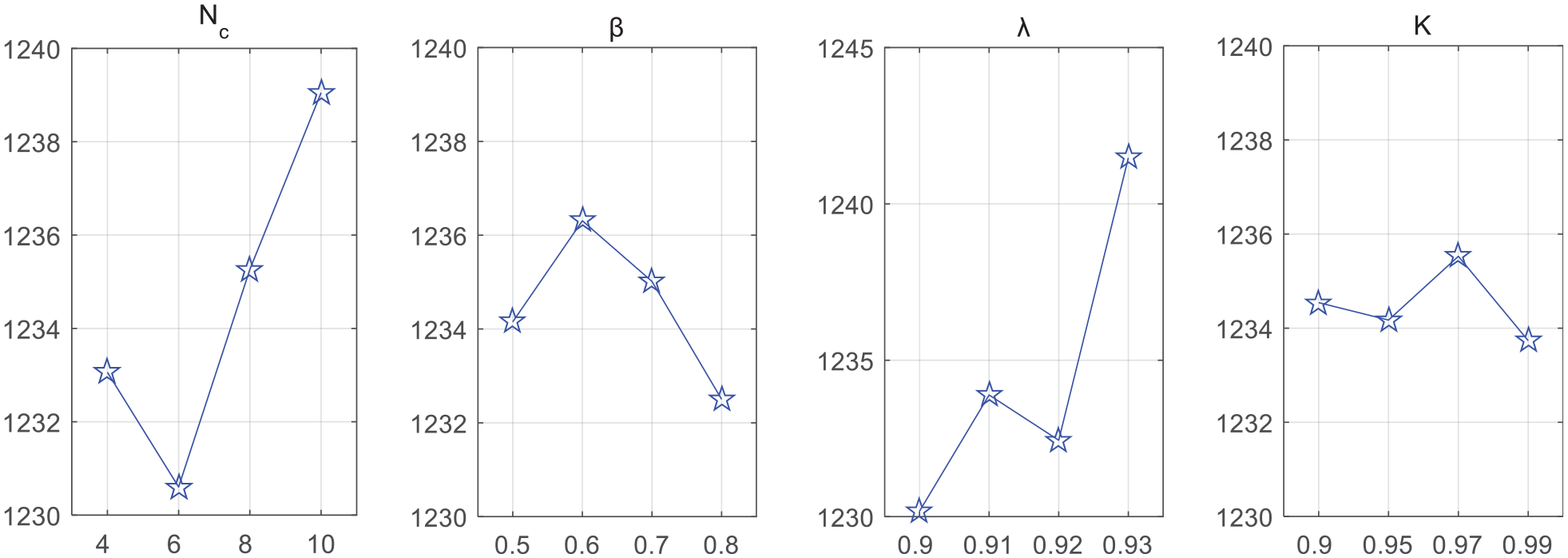
Factor level trend of parameters.
Comparison with the exact solver CPLEX
To certify the validity of the FJSP-T model, we coded the problem formula in IBM ILOG CPLEX 12.7 and ran various small-scale instances. Meanwhile, to verify the efficiency of the IAIA further, CPLEX was used as the benchmark for performing a comparison with the IAIA. Because CPLEX uses an exact algorithm based on branch and bound, calculating an accurate result requires substantial time. Consequently, the total computing time of CPLEX is limited to 1 h, and the number of threads is set to three. Each algorithm calculates the relative percentage increase (RPI) based on the best value, using the following equation:
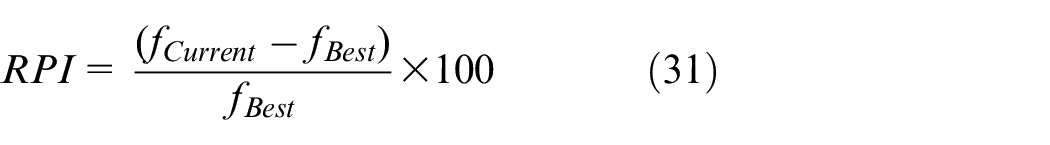
where fCurrent is the fitness value of the current algorithm that we compared to, and fBest is the best fitness value obtained from all of the given algorithms.
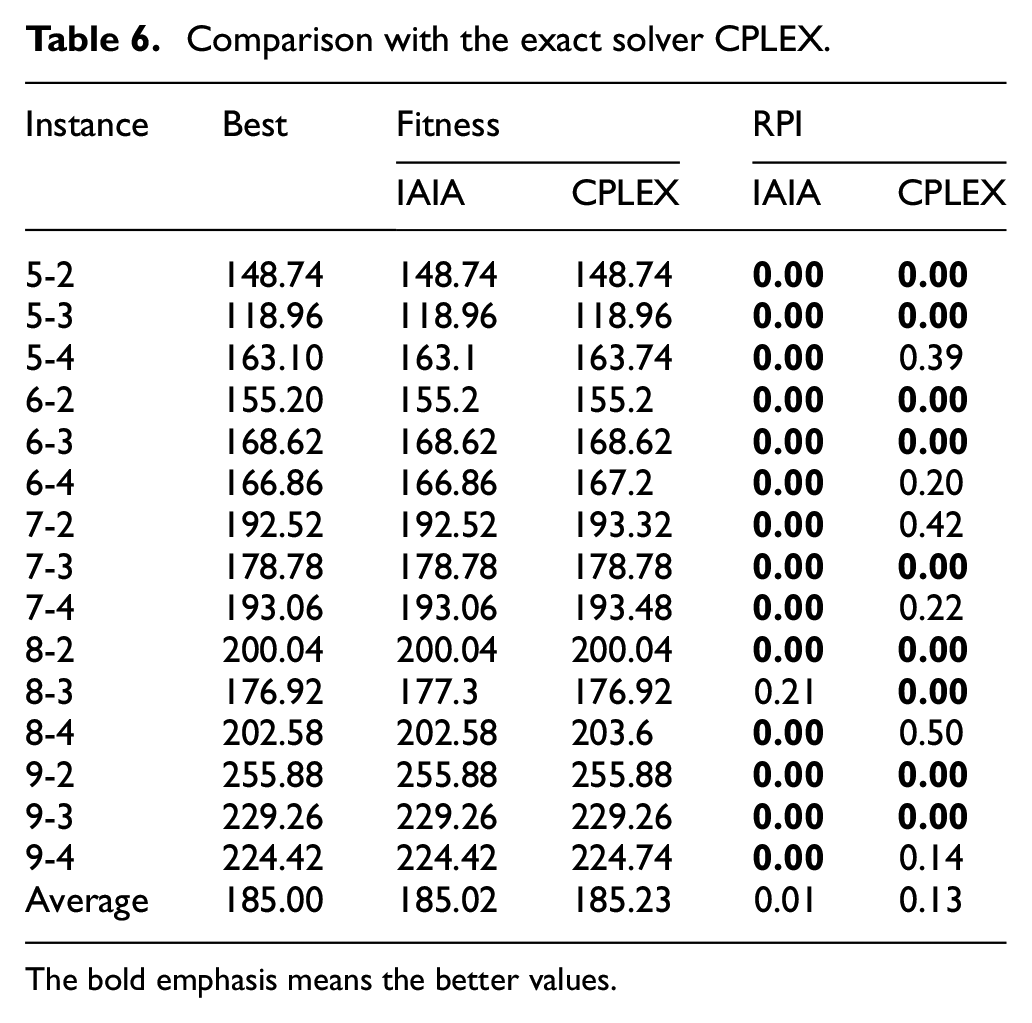
As shown in Table 6, the scale of each instance is listed in the first column, in which all the instances are generated randomly following the above generation rule. The best values selected from two algorithms are listed in the second column. The following two columns display the fitness values of two comparison algorithms, and the RPI values are displayed in the last two columns. In the illustrated 15 small instances, the proposed IAIA is able achieves better result as in most instances.
Comparison with the exact solver CPLEX.
The bold emphasis means the better values.
Efficiency of the local search
In this subsection, the SA algorithm is verified as to whether it can optimize the solution effectively. Then, the experiment is tested between the IAIA and the IAIA without the SA algorithm, denoted as IAIA-NSA.
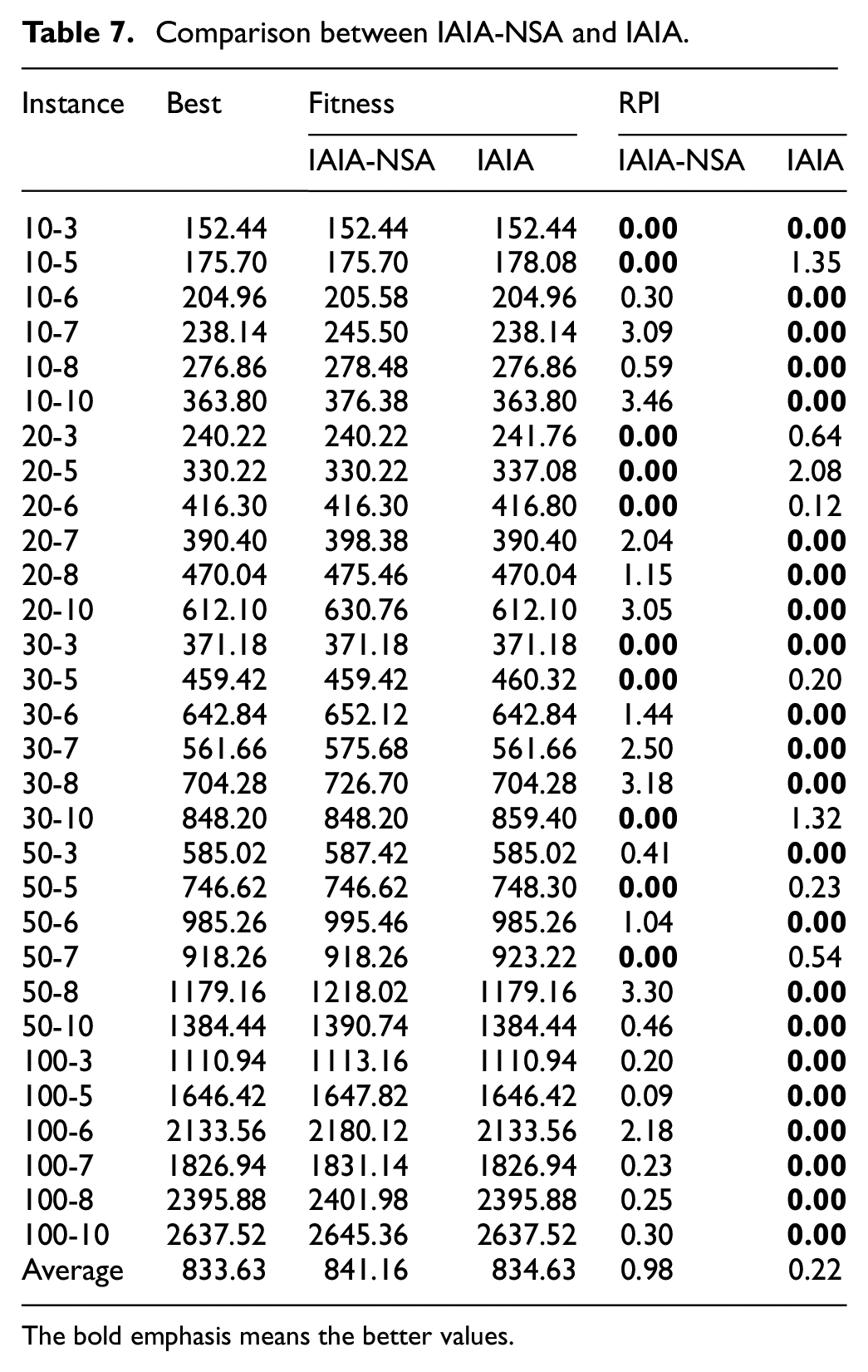
As shown in Table 7, the scale of instances is listed in the first column, with the best value obtained from the comparison between two algorithms are displayed in second column. The average fitness value after 30 independent runs and the RPI value obtained from two algorithms are displayed in other columns. It can be observed that: (1) in the illustrated 30 instances, the IAIA obtained 22 optimal values and performed better than the IAIA-NSA, and (2) from the last row, the average RPI value obtained by IAIA is less than that of IAIA without the SA algorithm, which proves the efficiency of this improvement.
Comparison between IAIA-NSA and IAIA.
The bold emphasis means the better values.
To testify the efficiency of the IAIA, a multifactor analysis of variance (ANOVA) is applied to describe the significant difference between two algorithms. The means and the 95% least-significant difference (LSD) interval are shown in Figure 5. The p-value, 1.1794e-07, is much less than 0.05, and that shows there are significant differences between two algorithms. Therefore, we can conclude that the proposed IAIA is significantly improved over the IAIA-NSA. The proposed algorithm has been greatly improved as a result of the utilization of the improved SA algorithm.
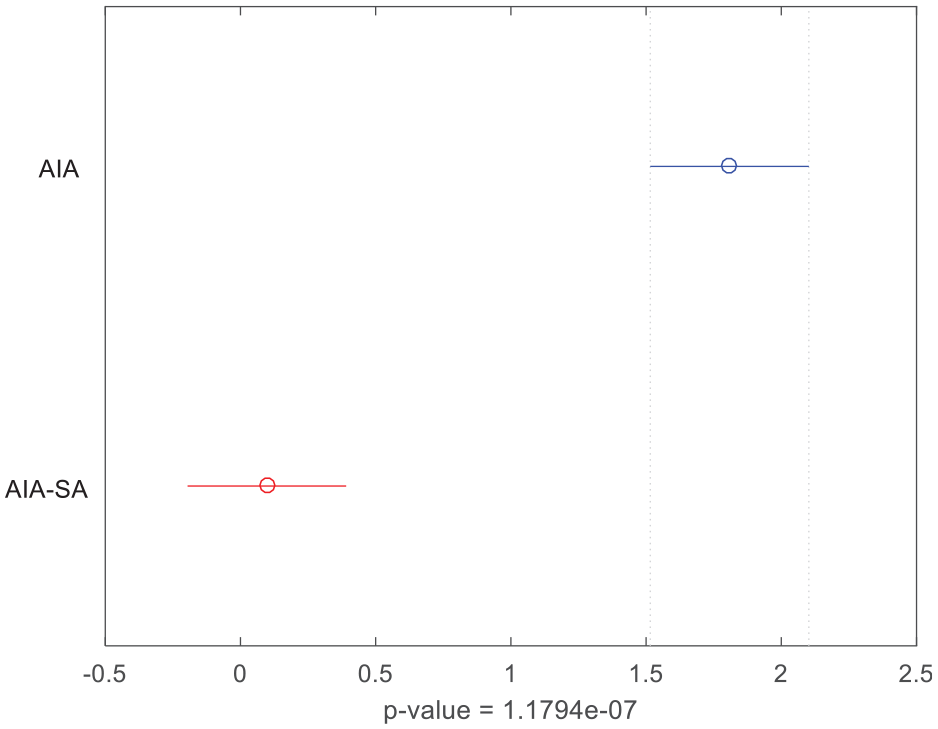
Means and 95% LSD interval for IAIA-NSA and IAIA.
Efficiency of the information entropy strategy
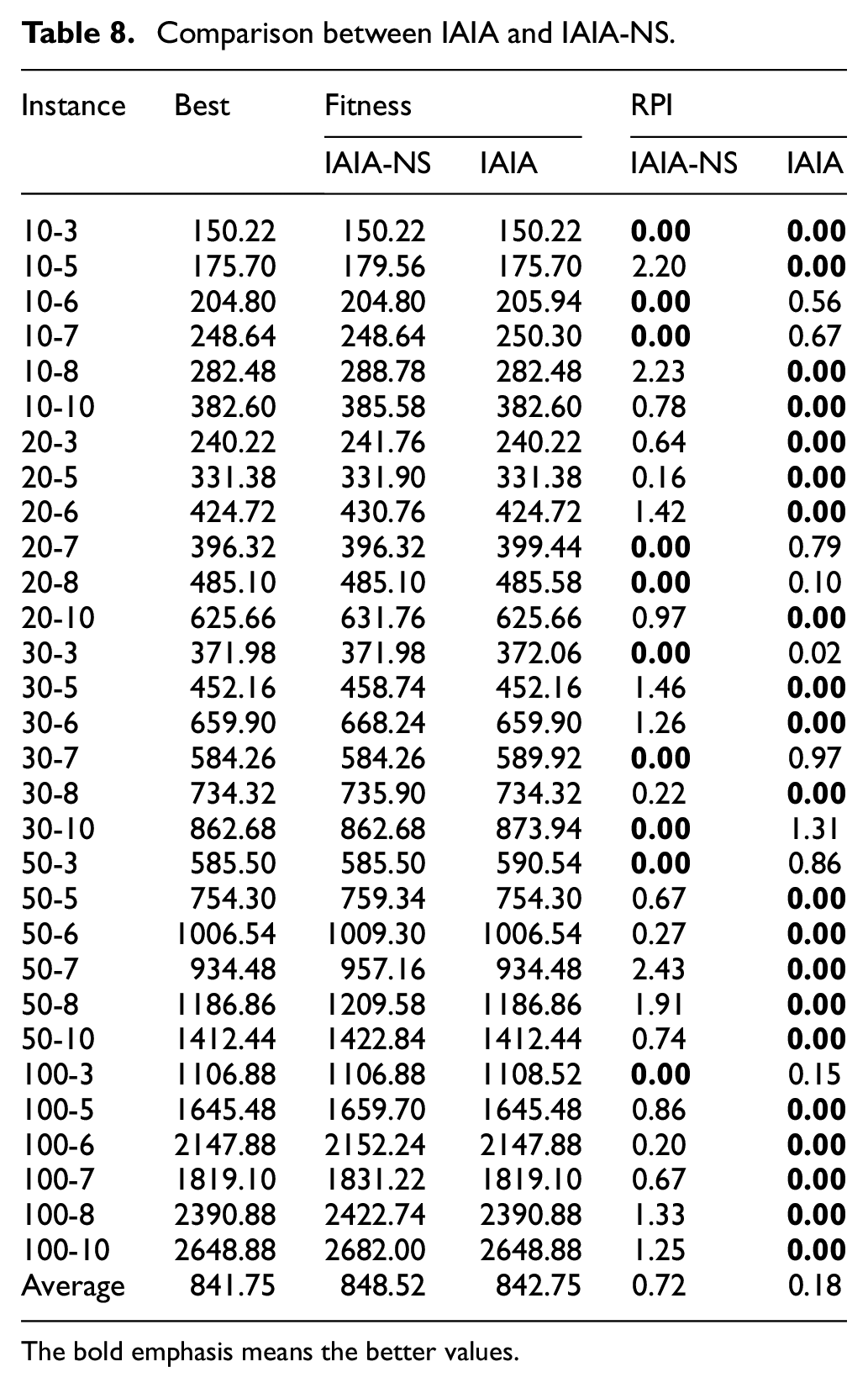
To testify the efficiency of the information entropy strategy, a method not using the information entropy strategy, which denoted as IAIA-NS, is described in this section. In this method, the antibody population of cloned antibodies and selected Nc antibodies is sorted according to affinity value between antibodies and antigens, rather than the ERP. Both the IAIA and IAIA-NS algorithms were implemented 30 times independently for 30 s each time. The minimum value obtained after 30 runs and the RPI values between the two algorithms are shown in the Table 8.
Comparison between IAIA and IAIA-NS.
The bold emphasis means the better values.
The illustrated 30 instances shown in Table 8 shows that (1) the IAIA obtained 21 better solutions while IAIA-NS obtained only nine better solutions out of the 30 given instances; and (2) the average RPI value obtained by IAIA is less than that of IAIA without the strategy of information entropy, which proves the efficiency of the strategy.
Meanwhile, ANOVA was conducted with the confidence interval shown in Figure 6, with the obtained p-value is 0.0009, which is far less than 0.05. In conclusion, the application of the information entropy strategy performs better in solving this problem.
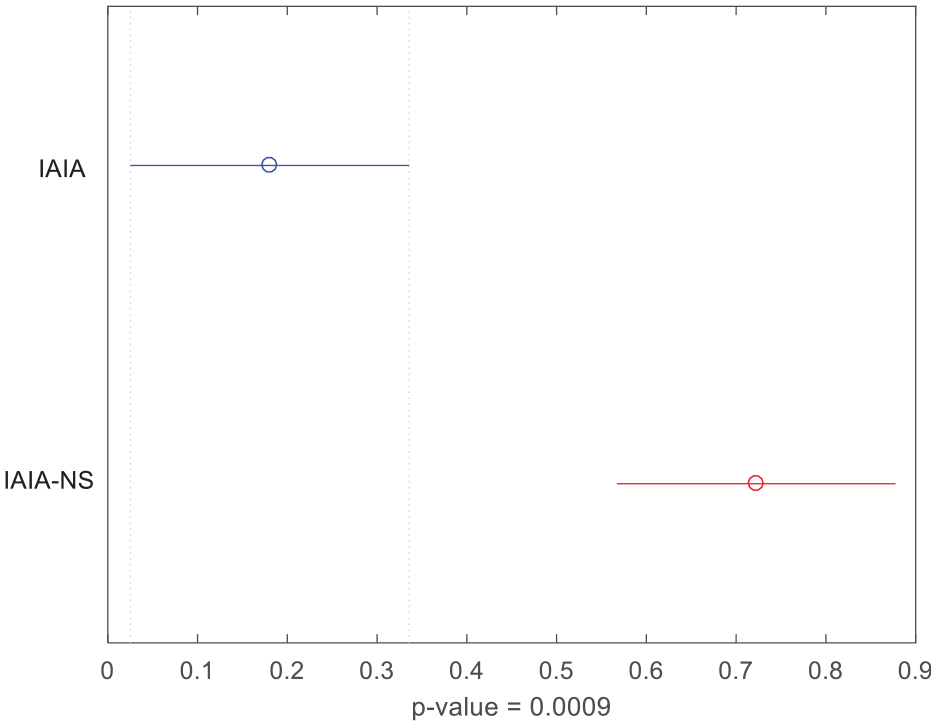
Means and 95% LSD interval for IAIA-NSA and IAIA.
Comparison with other efficient algorithms
To verify the proposed algorithm has a great improvement, three other algorithms were selected to compare with the IAIA (1) the imperialist competitive algorithm, 16 (2) the enhanced GA, 19 and (3) the variable neighborhood search algorithm. 45 The first and second comparison algorithms have been proved to have significant advantages in solving this problem, and the variable neighborhood search algorithm is also widely accepted because of its effective local search ability. Consequently, the advantages and competitive performance are better highlighted. Each algorithm runs 30 times independently and 30 s for each time, and the average value is used for comparison. In order to verify the performance of algorithms fairly, all the algorithms are implemented in accordance with the parameter, strategies and framework mentioned in the references, and the performance of each algorithm is compared under different weight coefficient. The experiment results are illustrated in the Tables 9 to 11, the average value for 30 runs for each instance of the four algorithms are displayed and the RPI values are obtained using the equation (31). As shown in Tables 9 to 11, we can observe that the proposed IAIA obtains the optimal values in most instances, obtaining RPI value equal to zero, with an absolutely advantage over the other algorithms. This shows the most effective performance in solving the FJSP-T model.
Comparison with other meta-heuristic algorithms under α = 0.8.
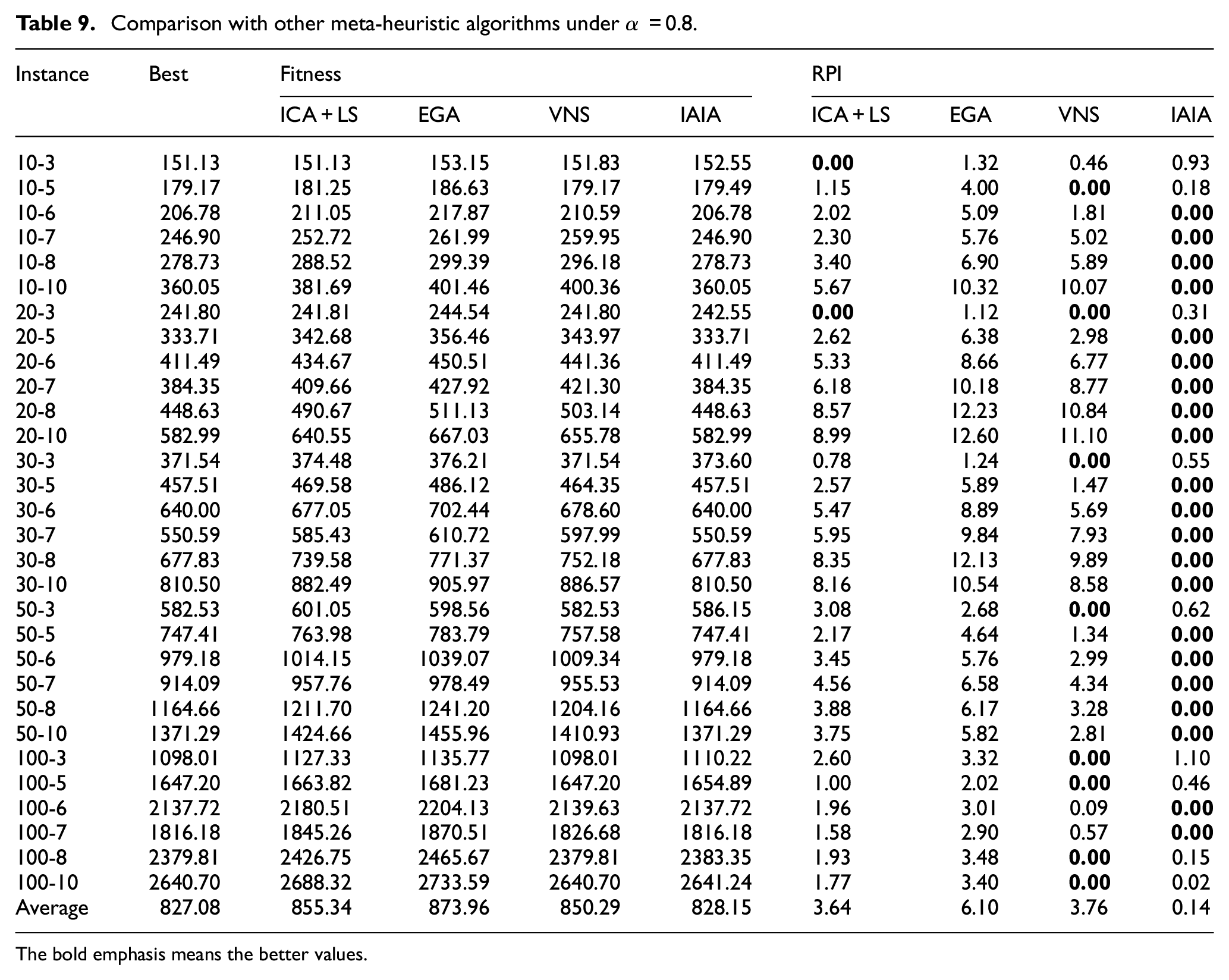
The bold emphasis means the better values.
Comparison with other meta-heuristic algorithms under α = 0.2.
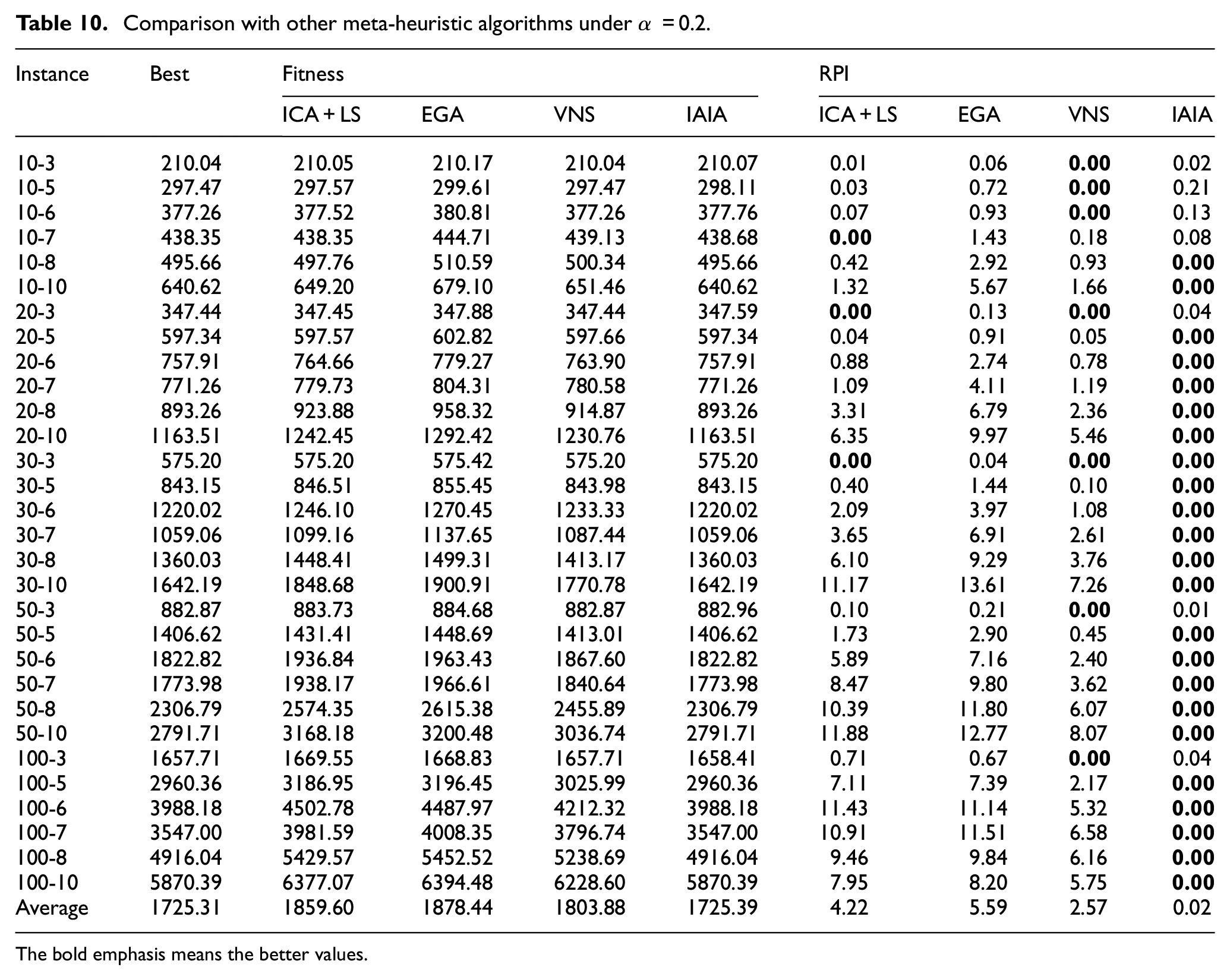
The bold emphasis means the better values.
Comparison with other meta-heuristic algorithms under α = 0.5.
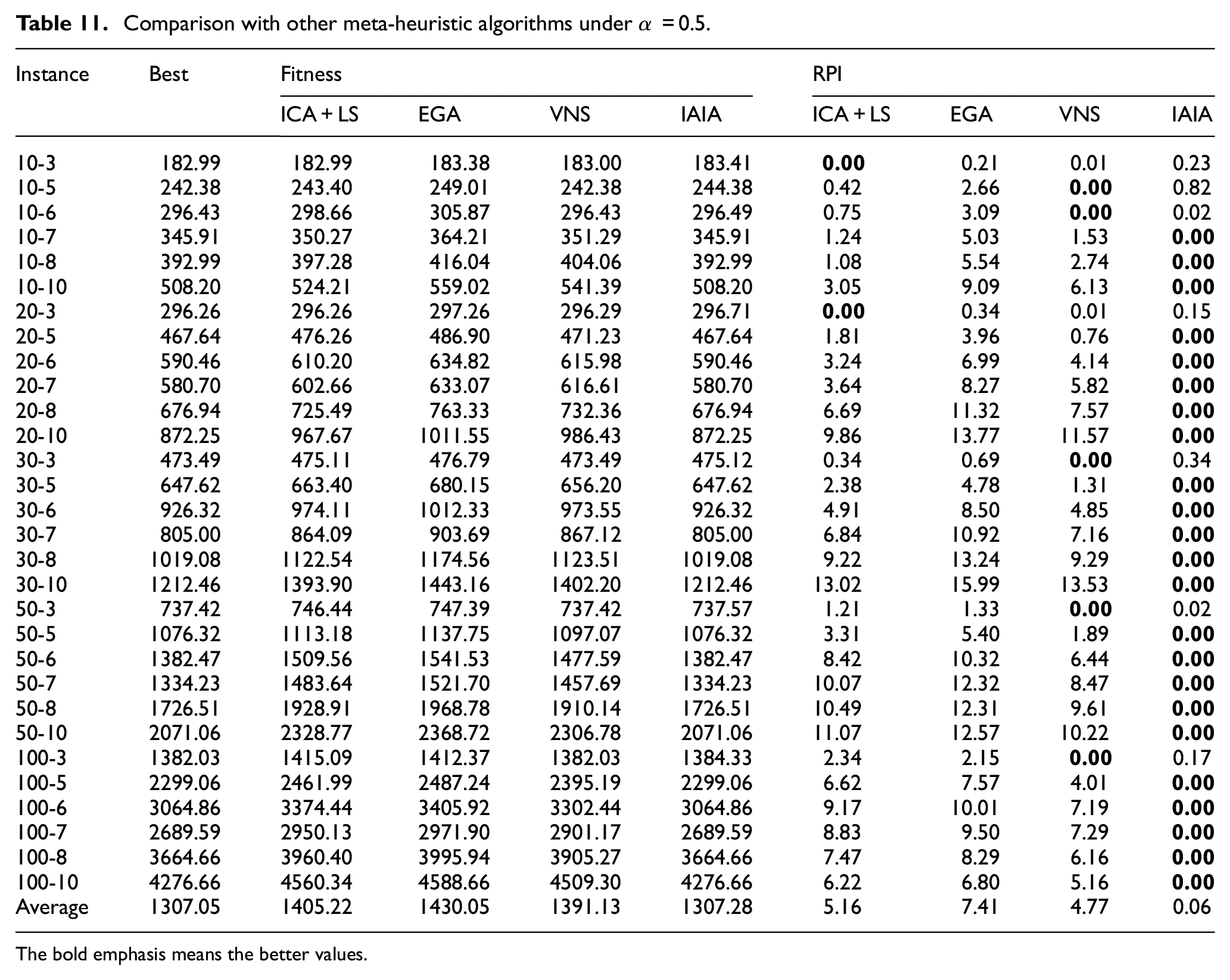
The bold emphasis means the better values.
In order to visualize the results of the comparison, ANOVA is applied to evaluate the performance of each algorithm. As shown in Figure 7(a)−(c), which represents different ANOVA diagram under three sets of weight coefficients, that is, 0.8, 0.2, and 0.5, and the p-value under three different sets of weight coefficients are all far less than 0.05, showing that the four compared algorithms have significant differences. Eight instances are selected randomly, and their corresponding convergence curves are showed in the Figure 8(a)−(h). In the illustrated convergence curves, the initial solution of IAIA is superior to the other three algorithms through the application of three initialization strategies. Meanwhile, the IAIA shows effective global search and local search abilities. Figure 9 illustrates a Gantt chart of an optimal solution of the instance 20-8, and this solution optimized by IAIA is feasible and efficient.
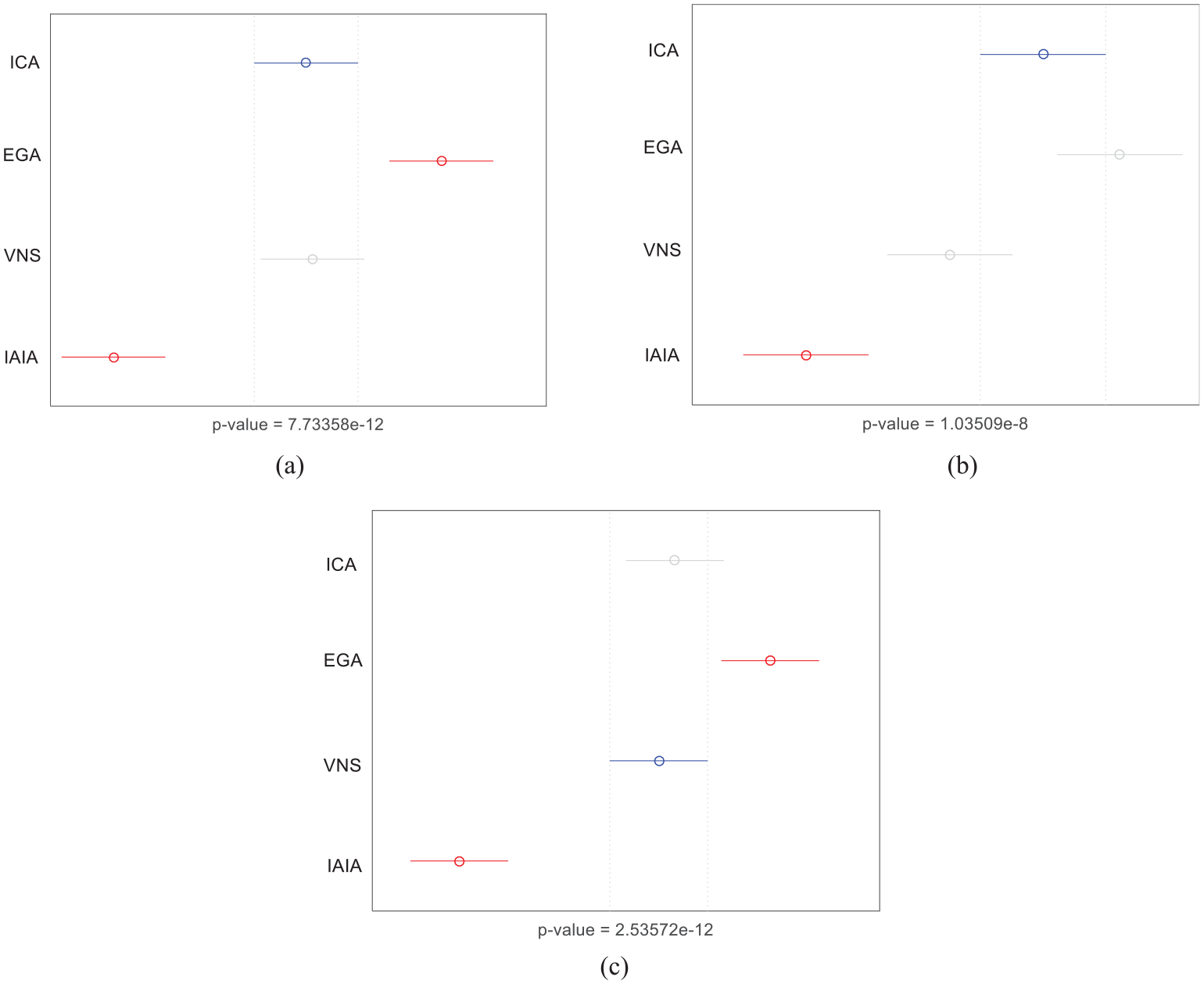
Means and 95% LSD interval for the compared algorithms under different coefficients.
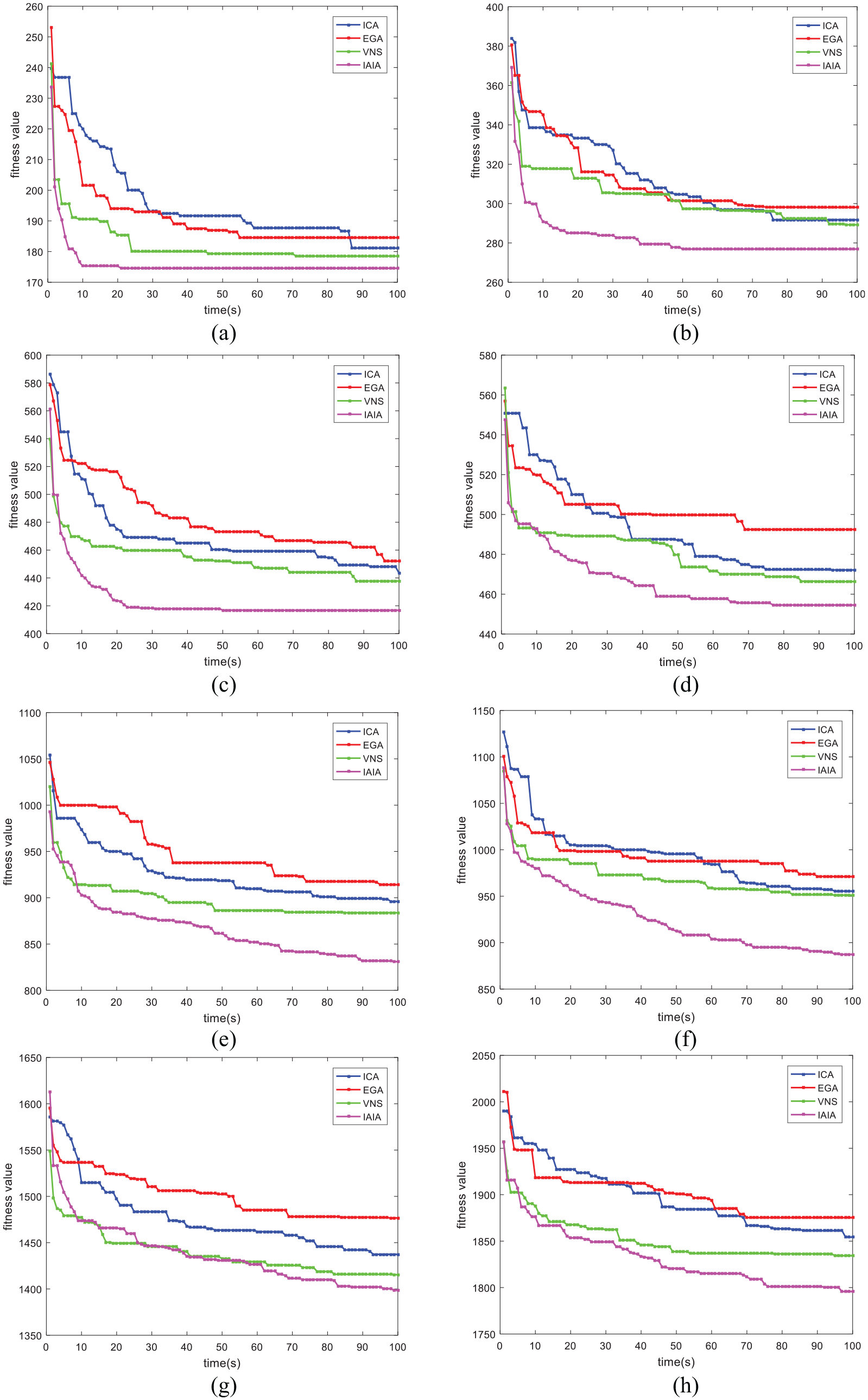
Convergence curve for instances under α = 0.8: (a) convergence curve for instance 10-5, (b) convergence curve for instance 10-8, (c) convergence curve for instance 20-6, (d) convergence curve for instance 30-5, (e) convergence curve for instance 30-10, (f) convergence curve for instance 50-7, (g) convergence curve for instance 50-10, and (h) convergence curve for instance 100-6.
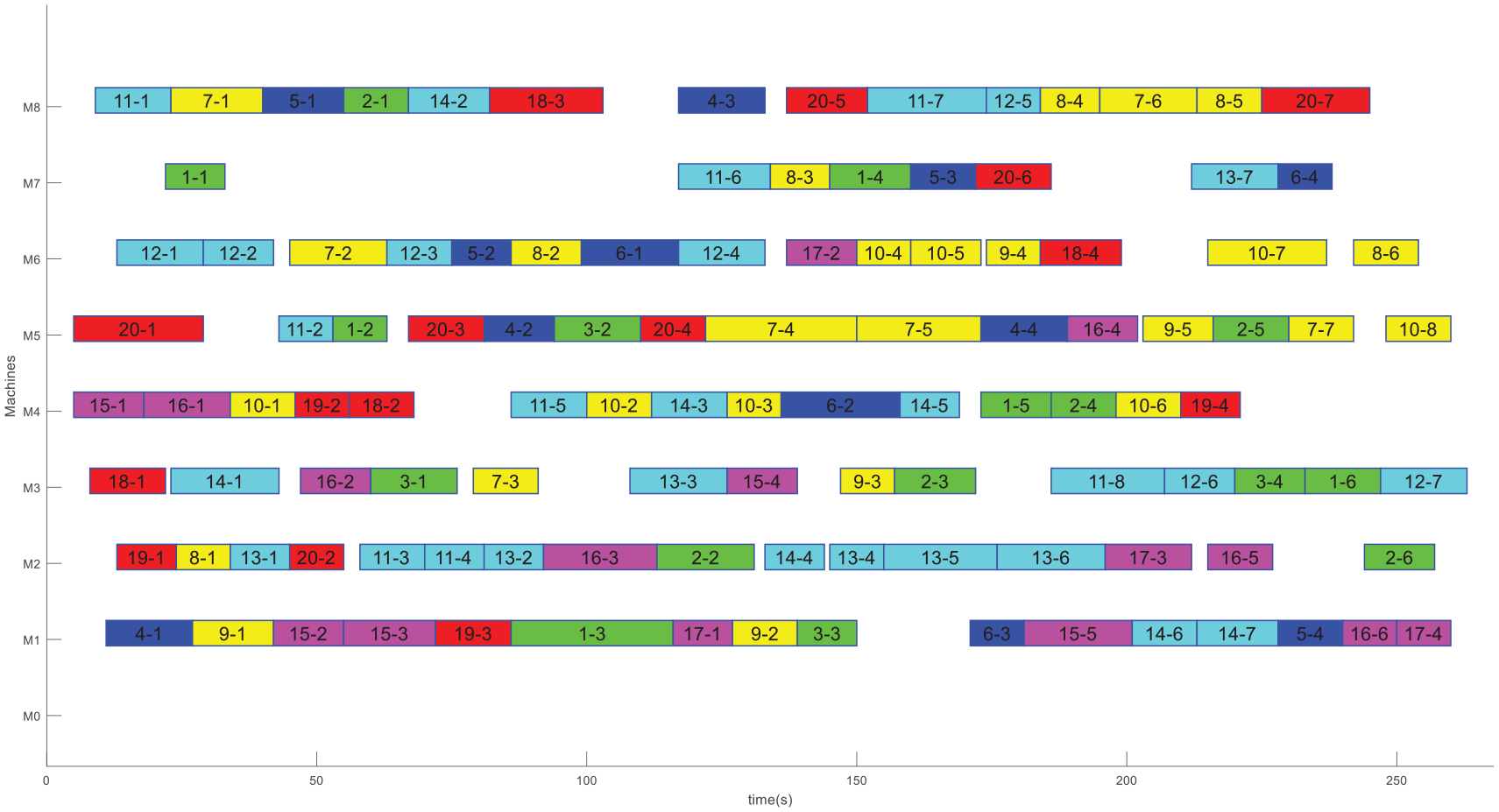
Gantt chart for instance 20-8 optimized using the IAIA.
We analyzed and summarized the reasons that the performance of the proposed algorithm is better than other three efficient algorithms as follows:
(1) we applied three initial strategies to ensure that we can obtain effective solution, and these initial strategies do not require the repair mechanism.
(2) the AIA is essentially an extension of the traditional GA and that not only has a powerful global search ability which but also improves the selection operator. To accelerate the convergence and avoid to fall in to local optimization, we introduced an operator of ERP that contains two parts, the calculation of fitness between antibodies and antigens, and the calculation of concentration between an antibody and other antibodies.
(3) to avoid to fall into the local optimization, the SA algorithm is applied to local search in each neighborhood space of solutions.
In conclusion, the proposed algorithm achieved great improvement for optimizing the FJSP regardless of the solution accuracy and the computational time.
Conclusion and future research
Scheduling has always been one of the hot topics in manufacturing and production fields, and FJSP, as an extension of JSP, has received widespread attention because of its flexibility and realistic. In this study, we considered transportation time between machines, which are typically ignored in most literatures. We first modeled the FJSP with the transportation time as an extension of the canonical FJSP, denoting it as FJSP-T. Two objectives were considered simultaneously in the mathematical model, that is, the maximal completion time and the total energy consumption, and the weight decomposition is used to optimized the objectives. To solve this problem, a hybrid meta-heuristic algorithm based on the AIA and SA algorithm are proposed. In this algorithm, each solution is represented by two components, that is machine selection vector and operation sequence vector. Then, three initial strategies are applied to initial populations. To maintain the diversity of the population during iterations, an information entropy theory is embedded into the AIA for better global optimization. Meanwhile, the SA algorithm is proposed for further local search. Finally, a set of optimal parameters is obtained by using Taguchi method. To verify the validity of the FJSP-T model, the FJSP-T model is constructed by CPLEX, it is verified that the results obtained by CPLEX are not as good as that of proposed algorithm. In addition, we also carried out weight experiments under different coefficients, and analyzed the effectiveness of the algorithm under different coefficients. The multifactor ANOVA results and convergence curve comparisons also verified the competitiveness of the proposed algorithm. According to comparison with other meta-heuristic algorithms, the efficiency of the proposed algorithm is further proved.
However, there is still work to be considered in the future, we could (1) consider combining the flexible job shop scheduling problem with other complicated constraints that are typically ignored in this field to deploy our research to actual production, for example, fuzzy processing time, 46 setup time, 47 and distributed multi-factories 36 ; (2) consider factors that we have not considered thoroughly enough, for example, the energy consumption generated by cranes in the process of handling and transferring, the energy consumption generated by machines in idle time 48 ; (3) consider the normalization of multiple objectives 49 ; (4) consider combining algorithms with neural model50,51; and (5) consider applying the proposed algorithms to other scheduling fields.52–54
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is partially supported by National Science Foundation of China under Grant 61773192, 61803192, 61773246, Shandong Province Higher Educational Science and Technology Program (J17KZ005).