
Abstract
Research on integrated process planning and scheduling (IPPS) is of great significance to the improvement of the overall quality of machinery manufacturing system. In the actual manufacturing process, the manufacturing system is often accompanied by some unpredictable uncertain disturbance factors, for instance uncertain processing time of jobs and changes of due date, etc. These uncertain disturbance events will ultimately affect production efficiency and customer satisfaction. Consequently, this paper considers the multi-objective IPPS problem with uncertain processing time and uncertain due date. A multi-layer collaborative optimization (MLCO) method is designed for the fuzzy multi-objective IPPS (FMOIPPS) problem, including three layers. For the process planning layer, the basic genetic algorithm is used to provide various near optimal process plans for the process selection system. For the process selection layer, a multi-objective genetic algorithm (MOGA) is designed to optimize the process selection population. A sharing function method is introduced to maintain population diversity. An individual comprehensive evaluation method is introduced to evaluate non-dominated solutions. The crowded distance, fast non-dominated sorting and elite strategy based on NSGAII is adopted in the proposed MOGA. The external archive method is employed to preserve the non-dominated solutions generated during population evolution. For the scheduling layer, a MOGA with a boundary search strategy is proposed. The boundary search strategy is designed to improve the search ability of boundary solutions. Three optimization objectives are minimizing the spread of fuzzy makespan, minimizing fuzzy makespan and maximizing average customer satisfaction simultaneously. The target of scheduling layer is to make scheduling arrangements for the process information obtained by process selection layer. Through mutual cooperation among each layer, guide the overall optimization process, and finally get satisfactory solutions. Different problem examples of various scales are employed to verify feasibility and effectiveness of the MLCO method. The experimental results indicate that the MLCO method can effectively address FMOIPPS problem.
Keywords
Introduction
Process planning and scheduling are important links in manufacturing system which are inseparable for the development of advanced manufacturing industry.1,2 With the development of computer technology, process planning and scheduling began to develop from artificial experience to precise planning and scientific decision-making of computer-aided. In the actual production, process planning and scheduling are closely linked. But, in traditional production, process planning and scheduling are often carried out separately, resulting in mutual constraints. The main performance is that process planning often causes conflicts and unreasonable allocation of production resources. Therefore, it is difficult to reach the best scheduling plan. Meanwhile, due to the influence of many uncertain factors in the scheduling process, the process plans often needs to be modified.3,4 In the 1980s, some scholars proposed the integrated process planning and scheduling (IPPS) problem. 5 After decades of development, solving IPPS has accumulated abundant theoretical and practical achievements. 6
Many results of researches show that IPPS is of great significance to resolution resource conflicts, improvement of equipment utilization ratio and production efficiency.7,8 The research of IPPS has become an effective way to solve the problems of workshop production management. IPPS is an expansion of shop scheduling problem, so the problem solution space is larger and more complicated. Process plan flexibilities, machine flexibilities, different jobs, different operations, and various resources and operations’ constraints should be considered simultaneously for solving IPPS problems.9,10 The IPPS problem is non-deterministic polynomial (NP)-complete problem.11,12 With the development of new information technology, many intelligent optimization algorithms are widely used in intelligent manufacturing,13,14 a large number of swarm intelligent algorithms are utilized in IPPS, which provide a theoretical guidance for the realization of intelligent manufacturing.
With the in-depth study of related IPPS, new problems are constantly being discovered. Workshop production is a complex process, so solving IPPS problem can not only meet a single objective, but need to consider multiple objectives. Generally, it is necessary to consider production efficiency, due date and other objectives. In the production process of the workshop, tool loading and unloading, the proficiency of personnel in the workshop, the operating status of the equipment, the transmission status of the jobs are usually uncertain conditions.15–17 Therefore, considering the uncertain factors in the IPPS problems is more in line with the actual production status. Especially, with the requirements of on-time and the development of intelligent manufacturing technology, it is vital to fully estimate the system uncertainty. Considering multi-objective and uncertain factors is helpful to make the research closer to the actual production situation.18,19 But it also makes the IPPS problem more complicated. Therefore, it is a significant work to design an appropriate model and an effective solution method.
At present, there are many studies on multi-objective IPPS and uncertain IPPS. The weighted method and Pareto method are adopted to solve the multi-objective problem in the existing research. The uncertainty of the system is mainly expressed by fuzzy numbers, interval numbers, and random numbers, such as fuzzy due date, fuzzy processing time, etc. 20 It noticed that there are few researches IPPS considering uncertainty and multi-objectives at the same time. Therefore, in this paper, an effective layered algorithm is designed for the fuzzy multi-objective IPPS (FMOIPPS) problem. Process planning and workshop scheduling are both very complex problems. The IPPS problem is extended on the basis of process planning and scheduling, which makes the problem solving more complex. The FMOIPPS problem considers the uncertain factors and multi-objective of the production process on the basis of the IPPS problem, making the solution of the problem more difficult. Therefore, a multi-objective collaborative optimization (MLCO) method is designed to solve the problem in three steps, and a better solution is finally obtained through three levels of cooperation. The MLCO method including three layers of process planning layers, process selection layers and scheduling layers is designed. The basic genetic algorithm is utilized in the process planning layer to produce the process plans for jobs. In the process selection layer, considering the processing information of all jobs, a multi-objective genetic algorithm (MOGA) is designed to select the process plan for each job. In the scheduling layer, a MOGA with a boundary search strategy is proposed to assign process information for all jobs. For the multi-objective problem, the Pareto-based method is used, and the final result is a Pareto solution set. Finally, 32 sets problem examples of different scales are employed to test feasibility and effectiveness of the MLCO method.
The remainder of this paper is organized as follows: “Literature Review” section introduce the development of the IPPS problem. “Problem description” section elaborates the FMOIPPS problem settled in this paper. “The proposed MLCO method” section presents proposed MLCO method for fuzzy multi-objective IPPS. “Experiments and discussions” section, the experiments design and result analyses are given. The conclusions and future works are reported in last section.
Literature review
IPPS was first proposed by Chryssolouris et al. 5 After decades of development, IPPS has accumulated vast theoretical and practical values. Li et al.4,6 summarized the research results of IPPS problem and proposed the future development direction. At present, the research on IPPS mainly focuses on model establishment and solution method.
There are three types of IPPS problem modeling, non-linear process planning, closed loop process planning, distributed process planning.6,8 Many models for IPPS problems have been established, Jain et al. 21 adopted a two-module integration method to select the process plan through process planning and scheduling. Li et al. 22 designed an agent-based IPPS integration method, which process planning and scheduling are executed simultaneously and use optimized agents based on evolutionary algorithms to manage the interaction and communication between agents. Phanden et al. 3 proposed the integration of four modules: process plan selection module, scheduling module, schedule analysis module, and plan modification module. Chu et al. 23 proposed an integrated model of uncertain bi-level programming. The upper layer solves planning problem and the lower layer solves scheduling problems.
Over the years, the algorithm for solving IPPS problem has developed rapidly. For single-objective optimization, Seker et al. 24 designed a hybrid algorithm by combining GA and fuzzy neural network for the IPPS problem with makespan as the optimization objective. Li et al. 25 proposed an active learning genetic algorithm with makepan as the objective to solve the IPPS problem. Leung et al. 26 used makepan as the optimization objective, and proposed an ant colony optimization algorithm based on agent system to solve the IPPS problem. Zhang et al. 27 designed an objective-coding genetic algorithm solution with makepan as the optimization objective and achieved well results. Sobeyko et al. 28 adopted a heuristic algorithm based on variable neighborhood search with the goal of total weighted tardiness. The single-objective optimization algorithm has abundant accumulation, and the algorithm mainly used makespan as the optimization objective. Recently, the use of multi-objective algorithm to solve IPPS is increasing. Shokouhi et al. 29 constructed a mathematical model considering multiple factors to solve the complexity of IPPS and proposed a multi-objective genetic algorithm with three objective weights, makespan, critical machine workload and machines total workload. Li et al. 30 designed a novel hybrid algorithm for the multi-objective IPPS problem based on Nash equilibrium in game theory. Luo et al. 31 proposed a multi-objective genetic algorithm based on the principle of immunity and external archive for the MOIPPS problem.
Due to the consideration of multi-objective to meet the actual production needs of the workshop, multi-objective algorithm has been widely used in solving the workshop scheduling problem. Li et al. 32 studied the process and scheduling problems of welding workshop. Aiming at the WSSP problem in real life, a multi-objective mathematical model considering both energy efficient and production efficiency is proposed, and an effective multi-objective artificial bee colony algorithm is designed to solve the problem. Yin et al. 33 established a low-carbon scheduling model for flexible job shop scheduling problem, considering the three objectives of productivity, energy efficiency and noise reduction, and proposed a multi-objective genetic algorithm. Lu et al. 34 proposed a model of multi-objective dynamic welding scheduling problem and designed a multi-objective gray wolf optimization algorithm to solve the problem. Lu et al. 35 designed a multi-objective mathematical model considering both the maximum makespan and energy consumption for the flow shop scheduling problem, and adopted a hybrid multi-objective backtracking search algorithm. Consider multi-objective to make the production plan more in line with the requirements. So, the design of multi-objective algorithm is of great significance for the solution of practical problems.
Recently, uncertain factors have been extensive considered in various scheduling problems. Gao et al. 36 studied the scheduling problem of flexible workshops, established an FJSP model with uncertain processing time, the uncertainty of processing time is represented by triangular fuzzy number. Jamrus et al. 37 considering the uncertainty of process and equipment control process, fuzzy number is adopted to express the uncertainty of processing time, used a hybrid algorithm combining particle swarm optimization and genetic operators for flexible job shop scheduling problems. Lei 38 applied interval number theory to scheduling, established the scheduling model of interval number processing time, and it is proved by examples that the real makespan of each scheme is within the makespan interval indicated by the interval number. Lei 39 established the mathematical model of FJSP problem with fuzzy processing time, and aiming at the complexity of FJSP problem, an effective co-evolution algorithm is proposed. Hu et al. 40 proposed an uncertain job shop scheduling problem with fuzzy numbers, which represents the processing time and due date, and established a corresponding objective function to ensure that the optimal scheduling plan is obtained. According to the uncertain characteristics of the processing time in the remanufacturing workshop, Gao et al. 41 use the fuzzy number to express the processing time and an effective discrete harmony search algorithm is designed to solve it. Gao et al. 42 took the fuzzy processing time into consideration in flexible job shop scheduling, use the maximum fuzzy makespan as the objective, and an improved two-stage artificial bee colony algorithm is designed for FJSP with fuzzy processing time. Lu et al. 43 considering the uncertainty of processing parameters, studied the multi-objective FJSP with CPT problem and established the corresponding mathematical model. Finally, a new multi-objective discrete virus optimization algorithm is designed to solve this problem.
Gradually, uncertain factors have also been taken into account in the IPPS problem by some scholars. Zhang et al. 15 adopted triangular fuzzy numbers to r express the processing time and transportation time of the machine, and solved distributed integration of fuzzy process planning and scheduling. Li et al. 16 used interval numbers to represent the processing time, proposed an uncertain IPPS model, and designed a corresponding hybrid algorithm combining genetic algorithm and particle swarm algorithm. Wen et al. 17 designed a multi-objective IPPS mathematical model with uncertain processing time and fuzzy due date, and designed an improved bee colony algorithm for the problem. Haddadzade et al. 2 used random numbers to represent the processing time, and designed a hybrid algorithm combining simulated annealing and tabu search. The research results show that taking multi-objective and uncertainty factors into account in the IPPS problem increases the difficulty of solving, but makes the problem closer to the actual situation, which is conducive to improving the quality of the scheme. It is very complicated for solving IPPS problems considering both uncertainty and multi-objectives, therefore, this paper design an effective method to solve FMOIPPS problems.
Problem description
The research of fuzzy set theory to deal with uncertain parameters of scheduling has gained wide attention in the field of scheduling. Trapezoidal fuzzy number and triangular fuzzy number are used to express the uncertainty of due date and processing time, respectively. The IPPS problem belongs to the field of shop scheduling problems, so this paper also applies fuzzy set theory to solve the FMOIPPS problem. In mathematical model, triangular fuzzy number and trapezoidal fuzzy number are used to represent fuzzy processing time and fuzzy due date respectively, and the fuzzy numbers operations are presented from Wen et al. 17
The FMOIPPS problem studied in this paper can be described as follows: There is a set of jobs
The mathematical model of FMOIPPS and the fuzzy numbers operations can be found in Wen et al. 17 In order to better describe the mathematical model, first define the following symbols.
n : the number of all jobs
Ji : the set of jobs.
MS : fuzzy the spread of fuzzy makespan
C1 : the best completion time of job
C3 : the worst completion time of job
Fuzzy maximum makespan, fuzzy average customer satisfaction and the spread of fuzzy makespan are used as the optimization objectives for solving the FMOIPPS in this paper, the objective functions are given as follows:
f 1: Minimizing fuzzy makespan

f 2: Minimizing average customer satisfaction
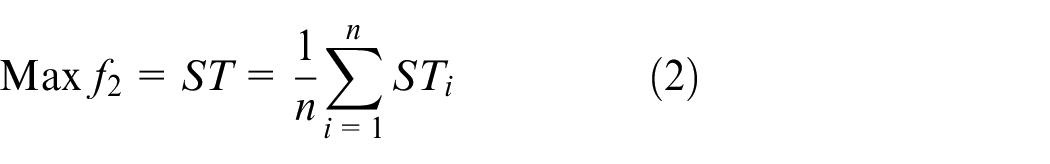
f 3: Minimizing the spread of fuzzy makespan

In the above FMOIPPS problem model, the smaller the fuzzy makespan, the smaller costs and energy. The greater the average customer satisfaction, the greater the probability that jobs of on-time delivery. The evaluation method of customer satisfaction and the calculation method of average customer satisfaction were proposed by Wen et al. 17 The shorter the span of the fuzzy makespan, the smaller the uncertainty of the fuzzy makespan, which is conducive to cost savings, reduced energy consumption, and improved on-time of completion time of jobs.
The following constraints also need to be taken into account.
Only one operation for each job must be processed simultaneously.
Only one operation can only be processed on each machine at a time.
Each job can only choose one process plan at a time.
Only one optional processing machine for each operation can be chosen.
The processing process is not limited by the buffer.
A simple example is given to better clarify the FMOIPPS problem in Table 1. Each job has different features with precedence constraints, some features have multiple operations companying operations sequences, each operation can be machined various machines with different fuzzy processing time, each job has different fuzzy due date. In Table 1, Job 1 includes 6 features, and the first feature F1 must be machined before all features. The first and second features of job 1 have 2 alternative operations. The operations sequence of first candidate operations for the first feature F1 have two operations O1-O2, however, the operations sequence of second candidate operations of F1 contains only one operation O3. There are various machines to process some operations. O1 can be processed on two machines, which are M1 and M2. Moreover, different processing machines have different fuzzy processing times, and different processed jobs contain different fuzzy due date.
The processing information of 3 jobs processed in 10 machines.
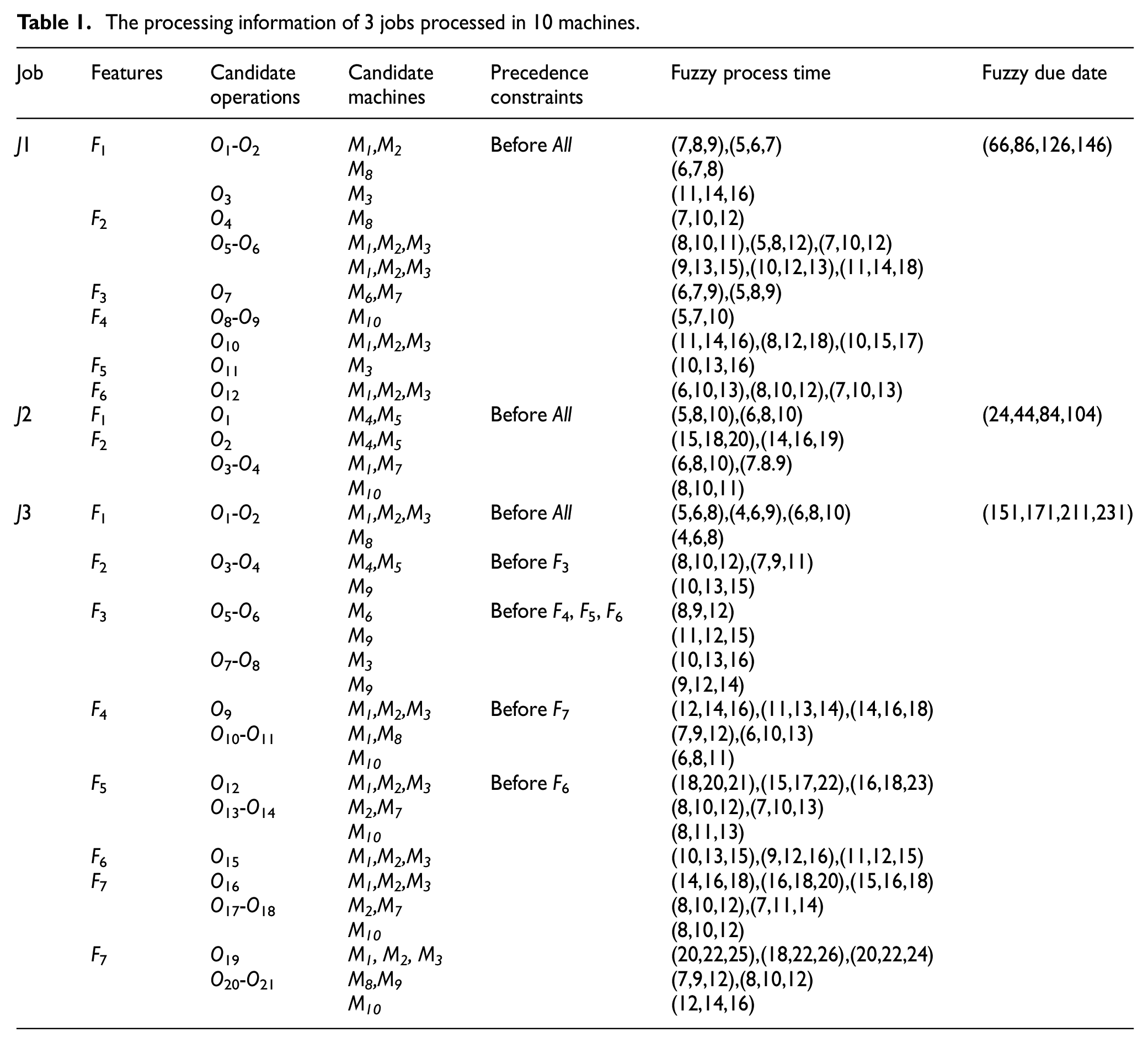
According to the processing information in Table 1, the processing time of the first process O1 of the J1 on the machine M1 is (7, 8, 9), which means that the shortest processing time of O1 is 7, the longest processing time is 9, and the processing time with the greatest possibility is 8. The due time of J1 is (66, 86, 126, 146), which means that the earliest due time of the job is 66, the latest due time is 146, and the best due time is 86 to 126. When a scheduling plan is determined, the processing technology, process sequence and processing machine of each process will be determined. Through the fuzzy number summing operation, the fuzzy makespan of each job can be obtained by the operation of fuzzy number summation, and then calculate the value of the three objective functions. Get the final solution through comparison.
Proposed multi-layer collaborative optimization method for fuzzymulti-objective IPPS
Flowchart of MLCO
MLCO method is designed to address the FMOIPPS problem, including three layers. For the process planning layer, the basic genetic algorithm (GA) is applied to provide various near optimal process plans for the process selection system. For the process selection layer, a multi-objective genetic algorithm (MOGA) is designed to optimize the process selection population and select a process plan for each job, considering the overall machining process of all jobs. An individual comprehensive evaluation method is introduced to evaluate non-dominated solutions. A sharing function method is introduced to maintain population diversity. Based on the NSGAII algorithm, the basic elements of fast non-dominated sorting, elite strategy, crowed distance, and tournament selection is used in the optimization method. The external archive method is adopted to preserve the non-dominated solutions generated during population evolution. Minimizing processing time of all jobs and processing time with the maximum processing machine are selected as the optimization objectives. The goal of process selection layer is to combine optimization of the process plans of all jobs. For the scheduling layer, a MOGA with a boundary search strategy is adopted. The boundary search strategy is designed to improve the search ability of boundary solutions. Three optimization objectives are minimizing fuzzy makespan, maximizing average customer satisfaction and minimizing the spread of fuzzy makespan simultaneously. The target of scheduling layer is to make scheduling arrangements for the process information obtained by process selection layer. Through mutual cooperation among each layer, guide the overall optimization process, and finally get satisfactory solutions. The workflow of proposed MLCO method for FMOIPPS is shown in Figure 1.
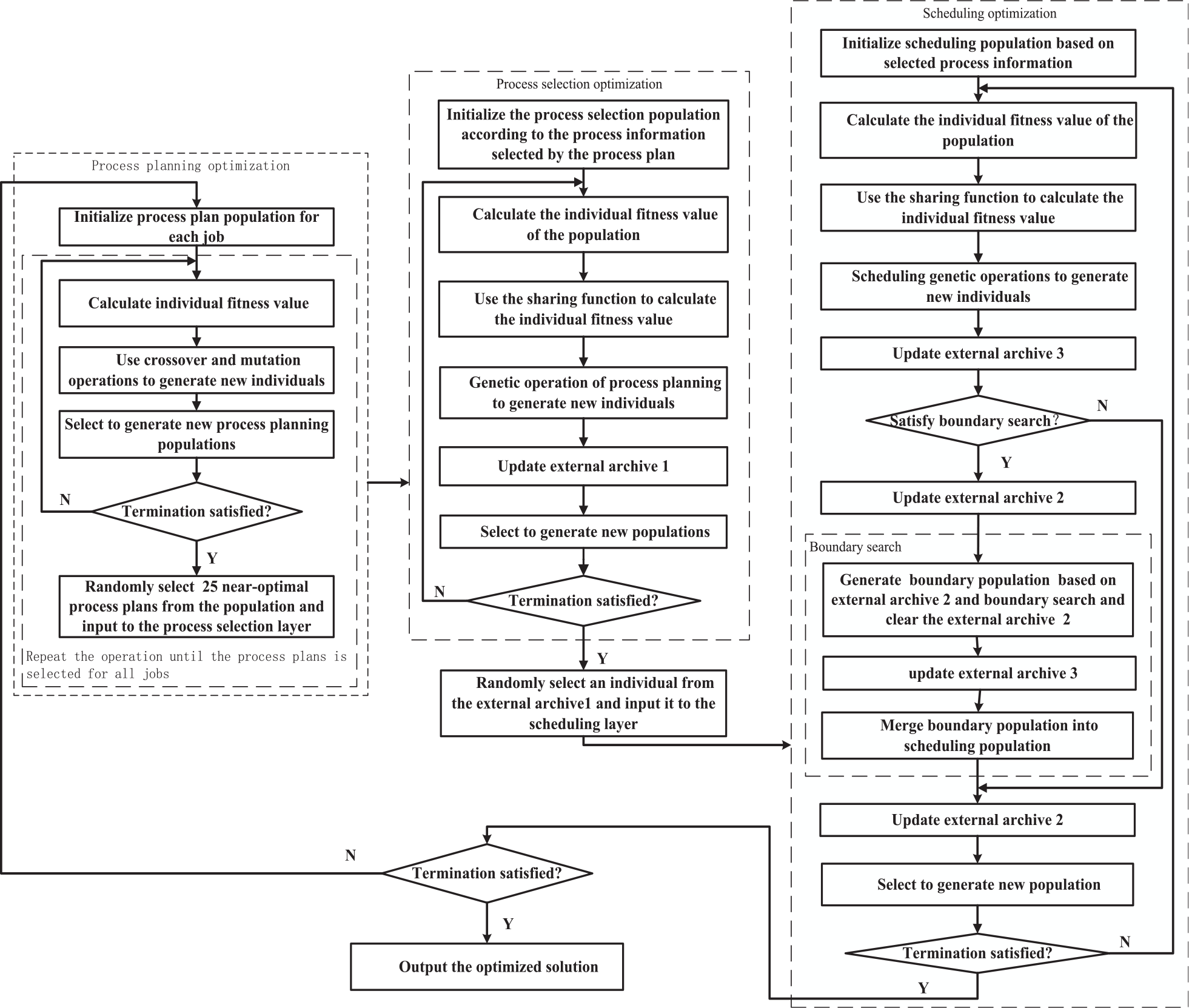
The workflow of MLCO method for FMOIPPS.
The main steps of MLCO method are as follows:
Step 1: Initialize process planning population.
Step 2: The optimized process plans is provided for each job through GA.
Step 3: Generate process selection population based on process plans’ information of jobs.
Step 4: Use MOGA to optimize the process selection population and select a process plan for each job, considering the overall machining process of all jobs.
Step 5: Initialize the scheduling population based on the processing information of jobs.
Step 6: Use a MOGA with a boundary search strategy to optimize scheduling population and generate the scheduling scheme.
Step 7: If the number of current generation reached, output the optimized solution. Otherwise, get on first step.
Methods for process planning layer
For the process planning layer, the basic GA is adopted to optimize the completion of each job. The process planning layer mainly provides the near optimal process plans for the process selection layer. Minimizing fuzzy processing time is selected as the optimization objectives. The workflow of GA for process planning layer is shown in Figure 2.
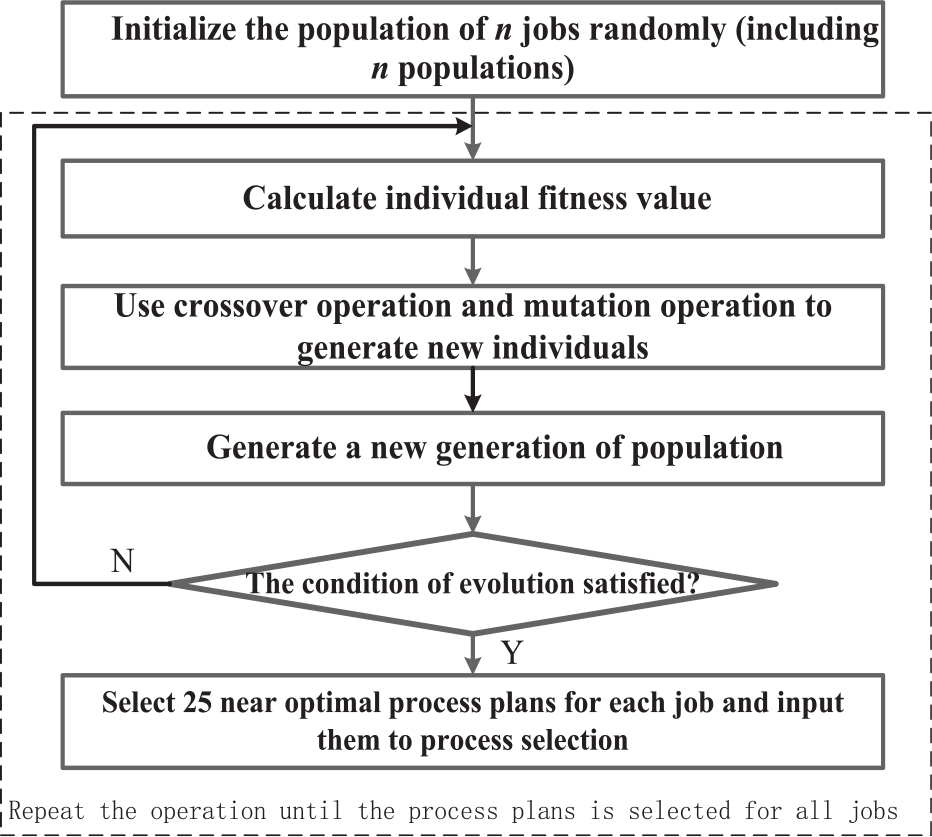
The workflow of GA for process planning layer.
The detailed steps of population optimization in process planning layer as follows:
Step 1: Randomly initialize population for each job.
Step 2: Calculate the fitness value of each individual. Take the fuzzy processing time of job as individual fitness value.
Step 3: According to the fitness value, tournament selection is adopted to select parent individuals. The crossover operators and mutation operators proposed by Li et al. 8 and were adopt to generate new population.
Step 4: Offspring selection: According to the comparison criteria of triangular fuzzy numbers,
17
selecting individuals with small fuzzy processing time to generate new population
Step 5: When evolutionary algebra is satisfied, go to Step 6. Otherwise, go to Step 2.
Step 6: Select near optimal process plans and input them to process selection layer.
Step 7: From Step 2 to Step 6 is repeat to complete the optimization of all jobs populations.
Encoding and decoding: The multi-dimensional encoding method and decoding method from Li et al.
44
is adopted for process planning populations. An individual consists of three chromosomes, there is a feasible encoding scheme is constructed in Figure 3. There are 3 chromosomes in total, the length of the features string in chromosome 1 and the alternative operations string in chromosome 2 is the number of the features. For the features string, the features string contains 4 features, the features sequence of first part in chromosome 1 is
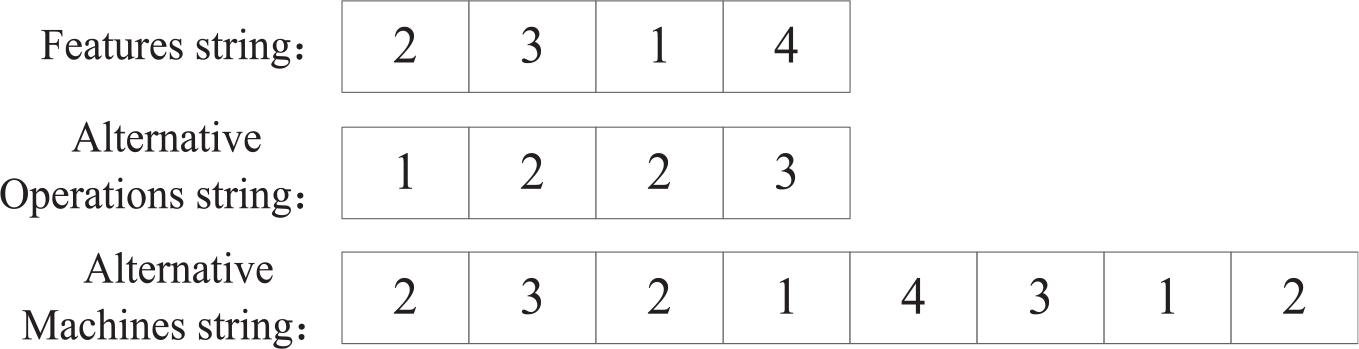
Encoding of process planning layer.
Methods for process selection layer
The process selection is mainly responsible for providing process information for the scheduling system. The process planning population only generates process plan of a single job, but the scheduling is for all jobs. Therefore, it is important to consider the processing plan of each job base on processing information of all the jobs. The main purpose of this layer is to determine the processing information of all jobs. MOGA is designed to optimize the process selection population and select a process plan of each job based on the two indexes of the minimizing processing time of all jobs and processing time with the maximum processing machine. The MOGA algorithm adopts fast non-dominated sorting based on NSGAII, individual crowding strategy and elite retention strategy. The Pareto-based method is used to deal with multi-objective problems. Introduce the non-dominated solution obtained from the optimization process of external archive. In addition, the method of sharing function is used to reduce the individual fitness value in the solution dense area, reduce the possibility of producing offspring, and maintain the diversity of the population. A method of individual comprehensive evaluation is designed to select the branch solution to the external archive or to the new generation population. The workflow of MOGA for process selection layer is shown in Figure 4.
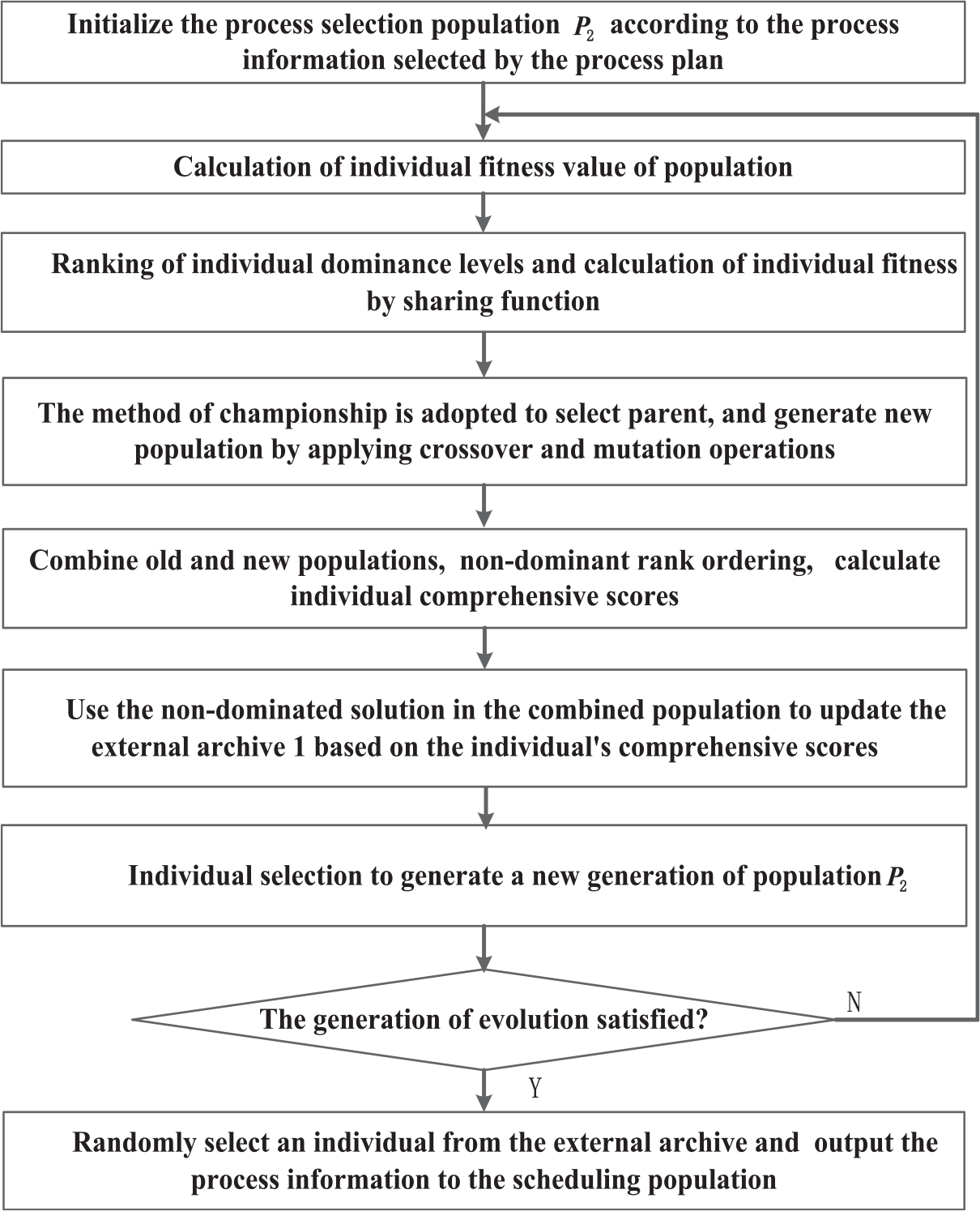
The workflow of MOGA for process selection layer.
The detailed steps of population optimization in process selection population optimization layer are presented as follows:
Step 1: According to the information provided by process planning, initialize population
Step 2: Calculate the fitness value of individuals of P2 population.
Step 3: Processing time of all jobs and the processing time with the maximum processing machine as evaluation indicators. The Pareto method and the triangular fuzzy number comparison method,
17
non-dominated rank sorting is used to allocate dominant ranks to individuals in the population
Step 4: According to the two indexes of dominance level and population fitness value, the individual is selected as the parent from the population by using tournament selection, and the crossover and mutation operators designed by the alternative operation string are used to generate new populations. 44
Step 5: Process selection population
Step 6: The external archive 1 is updated with the non-dominated solution of the population
Step 7: Generate a new generation of population, Firstly, the non-dominated solution is liberated into a new population, and then the new population is filled according to individual crowding degree. If the number of non-dominated solutions is greater than the population
Step 8: If the evolutionary generation is satisfied, go to Step 9. Otherwise go to Step 2.
Step 9: Randomly select an individual from the non-dominated solution of the archive 1, input the revised process plan into the scheduling system.
Encoding and decoding scheme
The encoding scheme is shown in the Figure 5. Each individual contains a chromosome. The length of the chromosome is the number of all jobs. The element 3 in the first position indicates that the job 1 selects the process plan P3. From the process selection string, the process plans selected for the 4 jobs can be decoded as P3→P2→P5→P4. The process information is provided by the process planning layer, the processing method and processing machine of each job can be obtained. Finally, the processing time of each job can be obtained.

Encoding of process selection layer.
Fitness evaluation
Considering the processing time of all jobs and processing time with the maximum processing machine, the individual fitness value is calculated as follows:
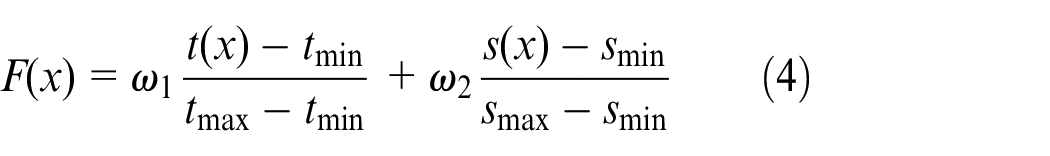
In the formula (4), t(x) is the processing time of all jobs, and s(x) is the processing time with the maximum processing machine, tmax and smax represent the maximum value found, tmin and smin represent the minimum value found, the average value of fuzzy number is used.
Sharing function
The sharing function is a method to determine the decline in the fitness value of an individual according to how close the individual is to other individuals within a certain distance. As the fitness value decreases, individuals in densely populated areas are less likely to generate offspring. The detailed steps of the sharing function are described as follows:
Step 1: Select individual i in the population and calculate the regional range
Step 2: Calculate the difference
Step 3: Compare the regional range
Step 4: Update the fitness value
Step 5: Repeat Step 2 and Step 4, and complete the comparison between individual i and all individuals in the population.
Step 6: Repeat the above steps to update the fitness value of all individuals in the population.
Individual comprehensive evaluation
Multi-objective optimization is usually to obtain a solution with better overall performance. In the population, individuals with better overall performance usually carry more valuable information. A comprehensive performance evaluation method based on ranking individuals is designed in this paper. According to the ranking of individuals, the problem of dimensional non-uniformity between the objective values can be ignored, and the impact of each objective on the individual performance can be considered. At the same time, the value of a single objective excellent individual is considered, and the weight of the first ranked individual need to be increased.
Suppose a population size n is 5, and the number m of optimization objective is 3. The individual populations are represented by vectors
The ranking of individual individuals under different objectives.
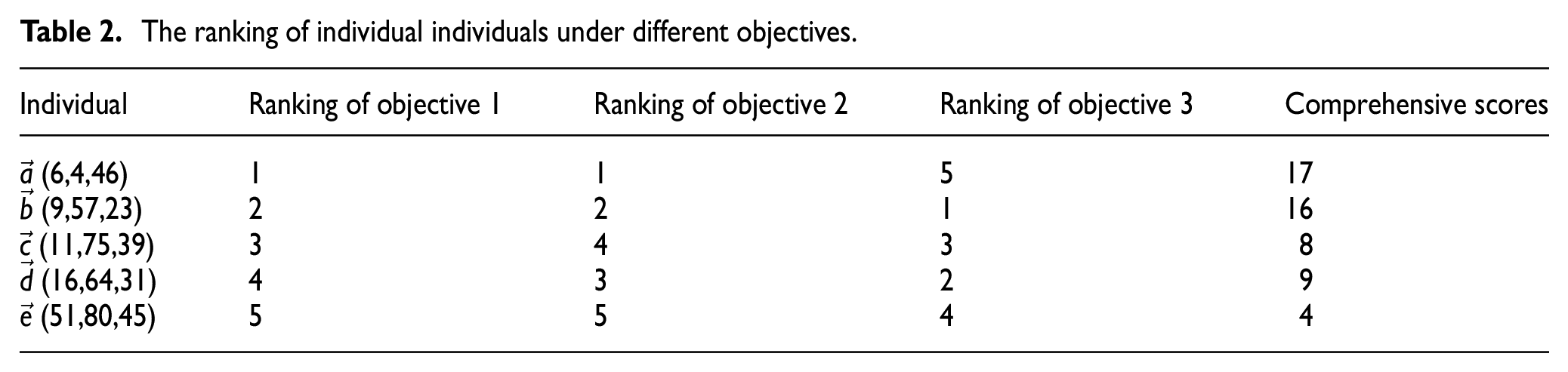
Comprehensive performance is used to evaluate an individual’s overall performance. A higher score indicates that the individual’s overall performance is better. Conversely, if the score is lower, the individual’s overall performance is worse.
Update external archive
In this paper, the external archive method is adopted to preserve the non-dominated solutions generated during population evolution. The solution to update the external archive can be a non-dominated population solution or other archive solutions. The external archive is updated as follows:
Step 1: Combine the non-dominated solution of the population, or the solution of other archive with the solution of the current archive to be combined into a combined solution set S.
Step 2: According to the function value of the optimization objective for the population, according to Pareto definition and comparison method of triangular fuzzy number, 17 fast non-dominated sorting is used to find the non-dominated solutions in the merged solution set S.
Step 3: Empty the current archive, liberate the non-dominated in the merged solution set S into the current archive.
Methods for job shop scheduling layer
The optimization of scheduling population is the most important part of the overall optimization process. It mainly completes the arrangement of processing sequence and processing time of jobs. A MOGA with a boundary search strategy is adopted. The objectives of scheduling optimization for FMOIPPS are minimizing fuzzy makespan, shorting spread of fuzzy makespan and maximizing customer satisfaction simultaneously. The algorithm used in the scheduling layer is based on the MOGA algorithm with a boundary search strategy. Boundary search is to perform genetic operations on non-dominated solutions generated in the optimization process to enhance the search capabilities of boundary solutions. The workflow of MOGA with a boundary search strategy for scheduling layer is shown in Figure 6.
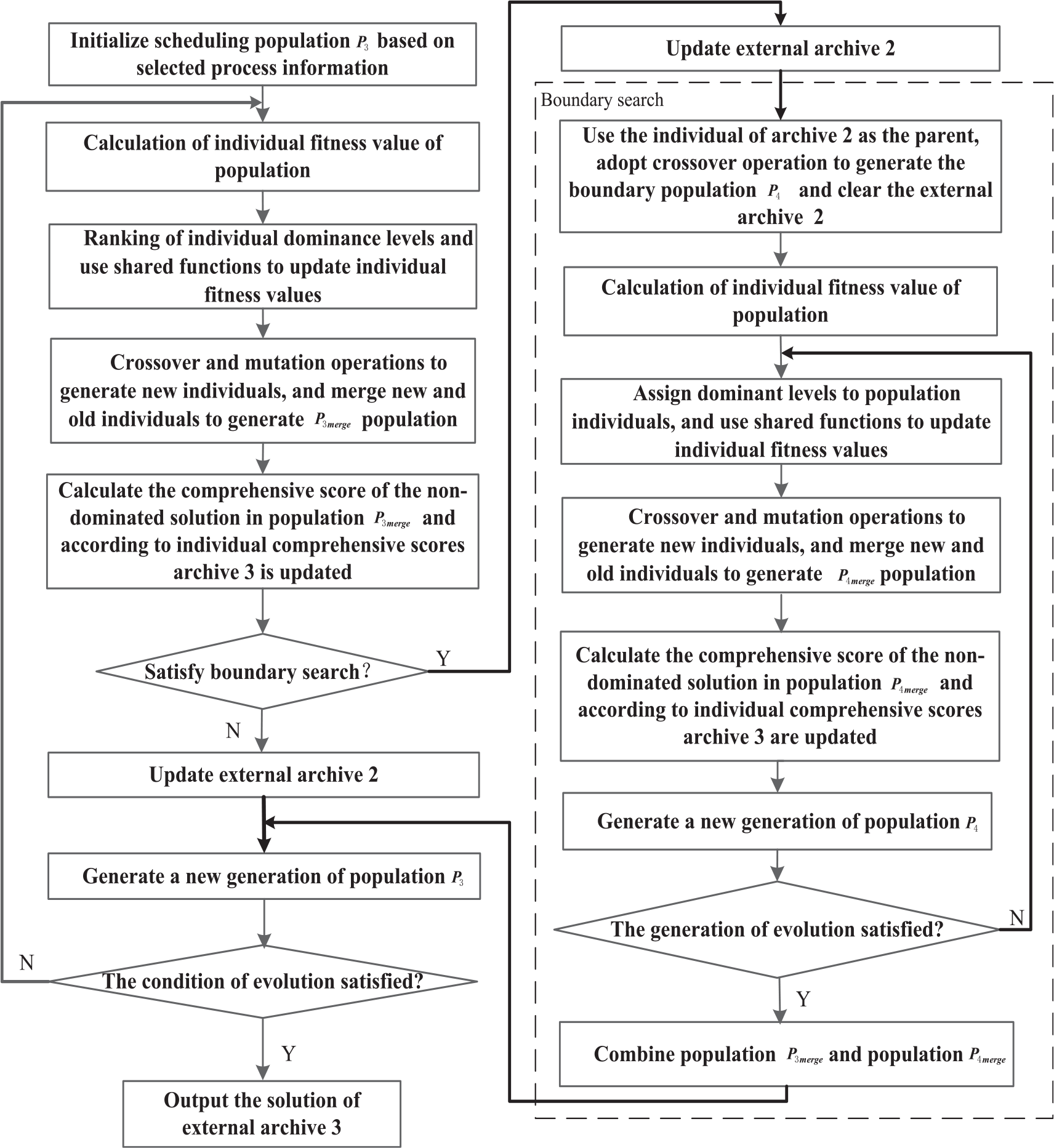
The workflow of MOGA with a boundary search strategy for scheduling layer.
The detailed steps of population optimization in scheduling layer are presented as follows:
Step 1: Initialize the scheduling population
Step 2: Calculate the fitness value of population
Step 3: Fuzzy makespan, spread of fuzzy makespan and average customer satisfaction are optimization indicators. Decode processing information of each individual, and solve the three objective values of the individual. According to the Pareto method and the triangular fuzzy number comparison method,
17
non-dominated rank sorting is used to allocate dominant ranks to individuals in the population
Step 4: According to the two indexes of dominance rank and population fitness value, the individual is selected as the parent from the population by using the tournament method. A new population is generated by adopt crossover operation and mutation operation proposed by Li et al. 8
Step 5: Individual selection: merge population
Step 6: If there is a solution in population
Step 7: Perform the boundary search.
Step 7.1: Each non-dominated solution from the archive 2 is randomly crossed with other non-dominated solutions according to POX operator or a crossover operator based on job to generate offspring, and these individuals and individuals in the external archive 2 are formed into boundary population
Step 7.2: Calculate the fitness value of population
Step 7.3: According to the method of scheduling optimization in Step 3, calculate the dominance level and update he fitness value of the population
Step 7.4: According to the method of scheduling optimization in Step 4, generate population
Step 7.5: Assign dominant ranks for population
Step 7.6: If the evolution times are satisfied, then go to Step 7.8. Otherwise, carry on next step.
Step 7.7: According to the method of scheduling optimization in Step 8, generate a new generation of population
Step 7.8: Combine the population
Step 8: update the external archive 2 with the non-dominated solution in the population
Step 9: Liberate the non-dominated population from the population
Step 10: If the evolution times are satisfied, go to last step. Otherwise, go to Step 3.
Step 11: Output the solution of external archive 3.
Encoding and decoding scheme
Operation-based encoding method 8 is used in this paper. As seen in Figure 7, the length of the scheduling string is the number of all the operations for jobs. The element in the scheduling string represents the jobs’ serial number. The element 2 in the first position indicates the first operation of job 2 and the number 2 in the 3rd position denotes the second operation of job 2. The greedy decoding method is adopted to decode the coding scheme into active scheduling, 8 which can get the start time, end time of each job.

Encoding of scheduling optimization layer.
Fitness evaluation
Three objective functions of minimizing fuzzy makespan f1, maximizing average customer satisfaction f2, and minimizing the spread of fuzzy makespan f3 are selected for scheduling layer. Considering the conflict between objectives, the individual fitness value is replaced by the individual comprehensive evaluation score.
Boundary search
The global optimal solution of many optimization problems usually exists on the boundary of the feasible region, 45 especially the non-dominated solution generated by the evolution of the population, which often carries the information closest to the optimal solution in the current population. It is very necessary to mine the information of these solutions comprehensively. So the non-dominated solutions generated during the evolution of the scheduling population are randomly combined to generate the boundary search population and perform the genetic search in this paper. The operation flow of boundary search is as follows:
Step 1: The obtained non-dominated solutions are sequentially cross-operated to generate the initial boundary population.
Step 2: Calculate individual fitness value.
Step 3: Genetic operation to generate new individuals.
Step 4: Select individuals to form a new generation of population.
Step 5: If the evolutionary algebra is satisfied, go to step 6, otherwise return to step 2.
Step 6: Merging boundary populations and scheduling populations.
Experiments and discussions
Experiments
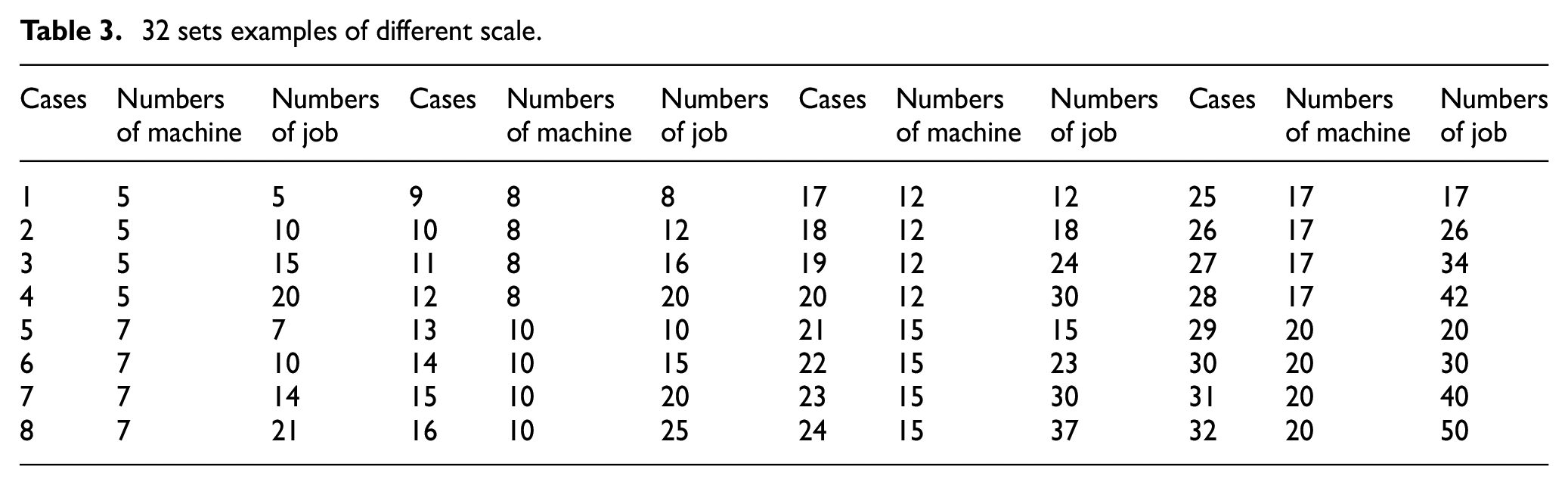
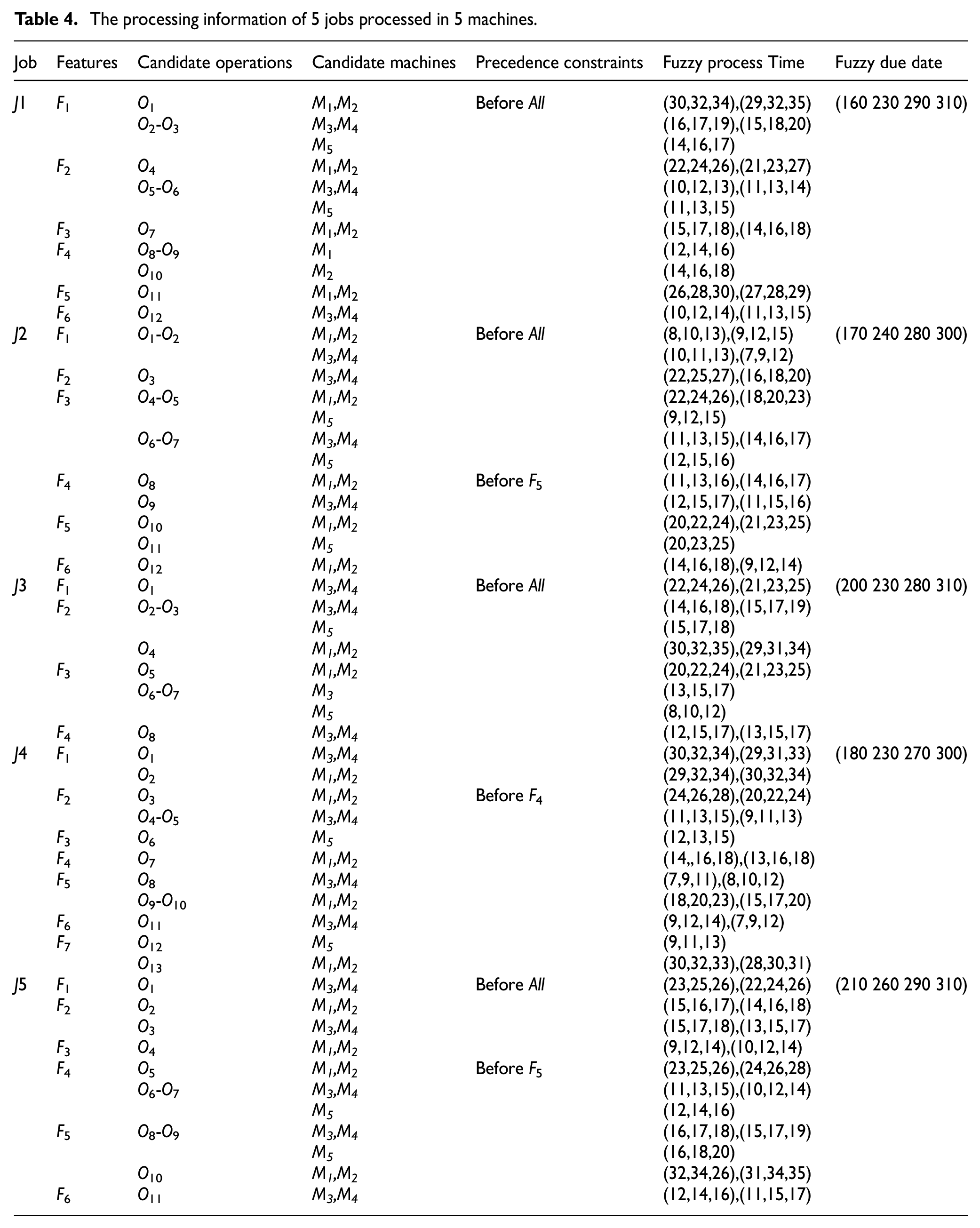
Due to lack of FMOIPPS benchmarks, 32 sets of examples with different sizes are designed to verify the proposed MLCO method for solving the FMOIPPS problems in Table 3. The processing information of an instance with 5 jobs processed in 5 machines is shown in Table 4.
32 sets examples of different scale.
The processing information of 5 jobs processed in 5 machines.
MLCO, NSGAII and NSGAII+N5 three methods are used to solve 32 sets of cases with various scales. NSGAII and NSGAII+N5 as two control groups, adopting two-stage optimization methods, namely the process planning stage and the scheduling stage. The process planning stage provides near-optimal process plans for each job, and the scheduling stage arranges the processing sequence and processing time of the jobs. GA is used in the process planning stage, and the NSGAII algorithm, NSGAII algorithm with N5 neighborhood search algorithm are employed in the scheduling stage. The performance of the algorithms is evaluated from the convergence and divergence of the algorithm and the ability to find solutions.
The operating environment is as follows: the three algorithms is programmed by Visual C++, The computer performance is intel (R)Core(TM)i5-5000 CPU@2.00GHz. The parameters in the proposed algorithm are selected after a lot of trials. The selected parameters are listed in Table 5.
The parameters in the proposed algorithm.

Evaluation indicators of algorithm performance
Generation distance
Generation distance (GD) is used to express the convergence of the obtained solution set. The smaller the GD value, the closer the solution set obtained by the algorithm to the real Pareto optimal solution set. The GD indicator represents the distance between the known Pareto front end (

In the formula (5), n is the number of solutions in
Inverse generation distance
Inverse generation distance (IGD) is used to simultaneously evaluate the convergence and diversity of the solution set. The smaller the IGD value, the better the algorithm performance. IGD is distance
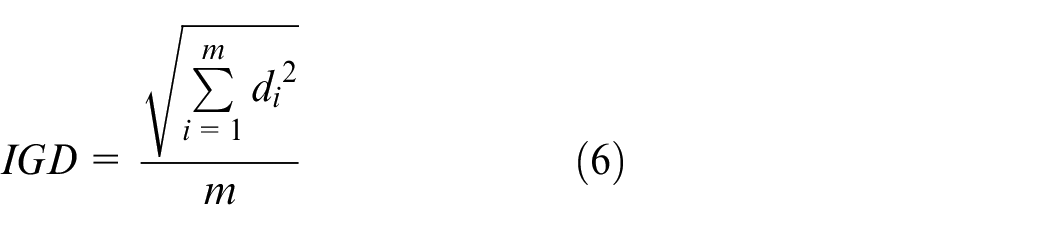
In the formula (6), n is the number of solutions in
For each group of cases, three algorithms are used to run independently 20 times. The solutions obtained by each algorithm constitute their own
Reference point for experiment 1.
GD and IGD indicators’ average values of three algorithms.
The bold-faced values indicate that the values obtained by MLCO are better than the values obtained by NSGA-II and NSGA-II+N5.
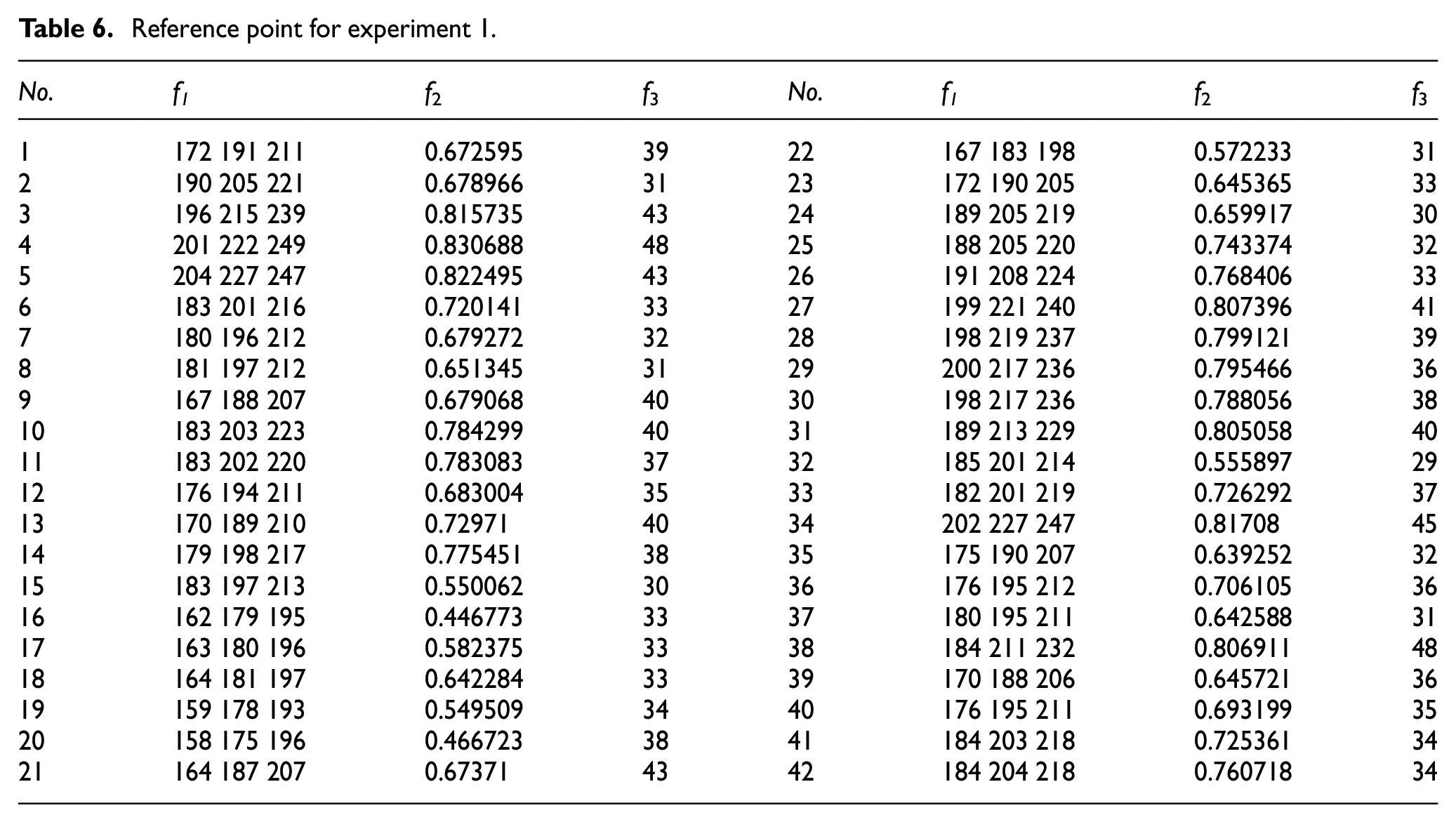
According to the result in Table 7, the GD values obtained using the MLCO method are all less than the GD values obtained by NSGAII, NSGAII+N5, except for the 31 sets of experiments, the GD of other groups are less than 1 and mostly maintained at below 0.5, it shows that the solution set obtained by the MLCO method is closer to the real Pareto front end. Comparing the IGD values, in the 32 groups of experiments, when using the MLCO method, the IGD values of 31 groups of experiments were all less than the obtained IGD values by NSGAII, NSGAII+N5, and the IGD value of 19 groups of experiments were 0. The experimental results indicated that the MLCO method can effectively solve FMOIPPS problems and demonstrate the better performance than NSGAII and NSGAII+N5.
Calculation results and discussion
1. The number and proportion of Pareto solutions.
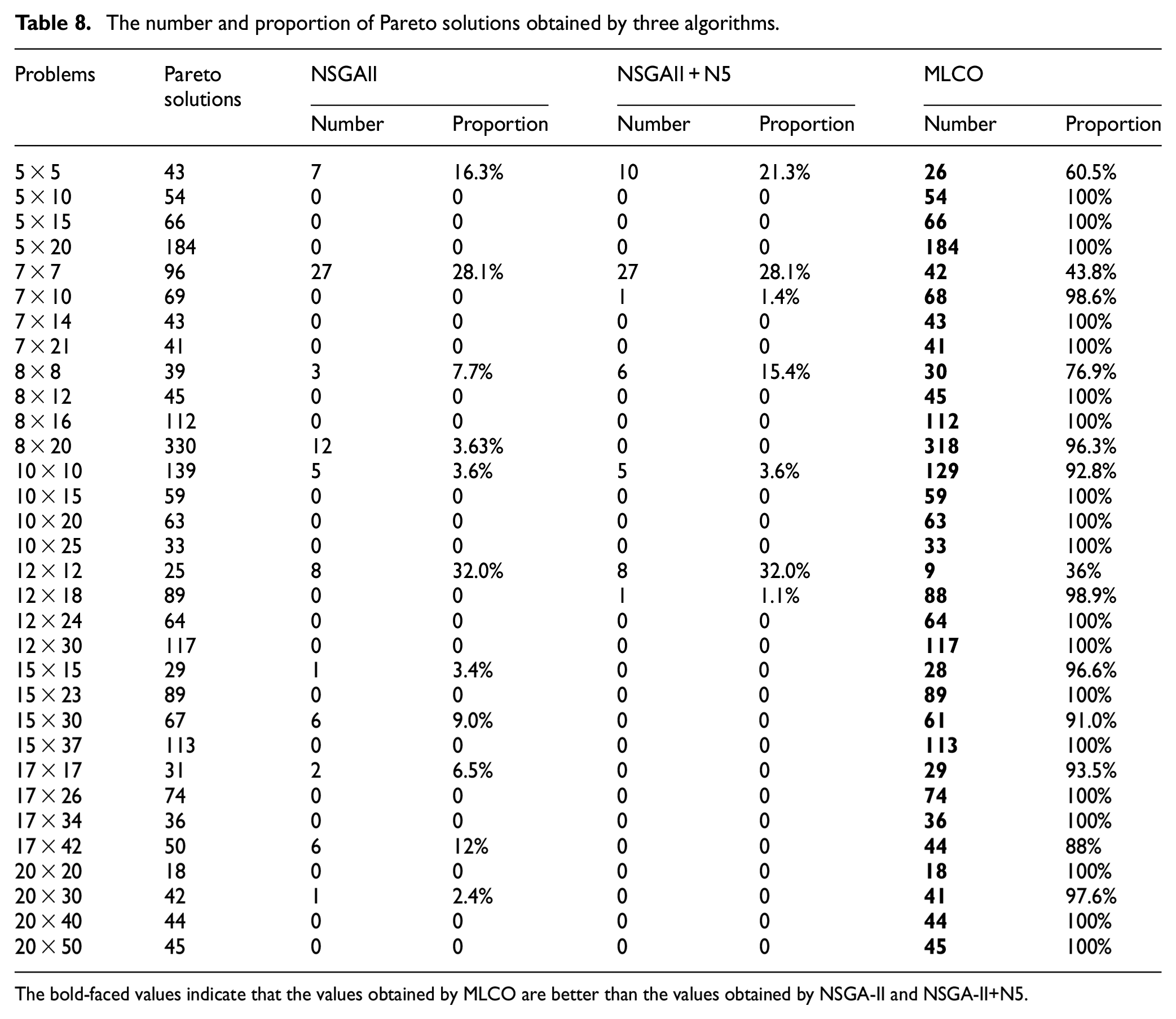
The solution sets optimized by the three algorithms are combined, and the global non-dominated solution set is obtained according to the dominant relationship. Calculate the number and percentage of global non-dominated solutions for each algorithm. The results of Pareto solutions obtained by three algorithms are shown in Table 8.
The number and proportion of Pareto solutions obtained by three algorithms.
The bold-faced values indicate that the values obtained by MLCO are better than the values obtained by NSGA-II and NSGA-II+N5.
According to the results in Table 8, the number of non-dominated solutions obtained by the MLCO method is more than the number of non-dominated solutions obtained by NSGAII and NSGAII+N5. In addition, as the scale of the problem increases, the number of non-dominated solutions obtained by the MLCO method becomes more and more. In the case of the same number of machines, with the increase of the number of jobs, the proportion of non-dominated solutions obtained by the MLCO method is also increasing.
2. Performance indicator of evaluating optimization results
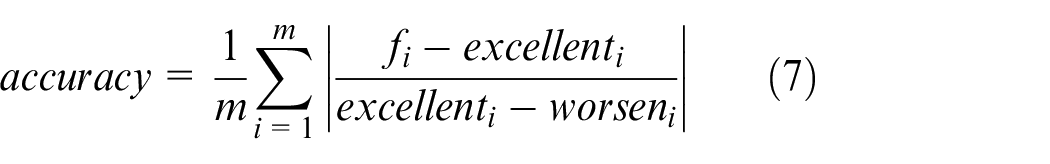
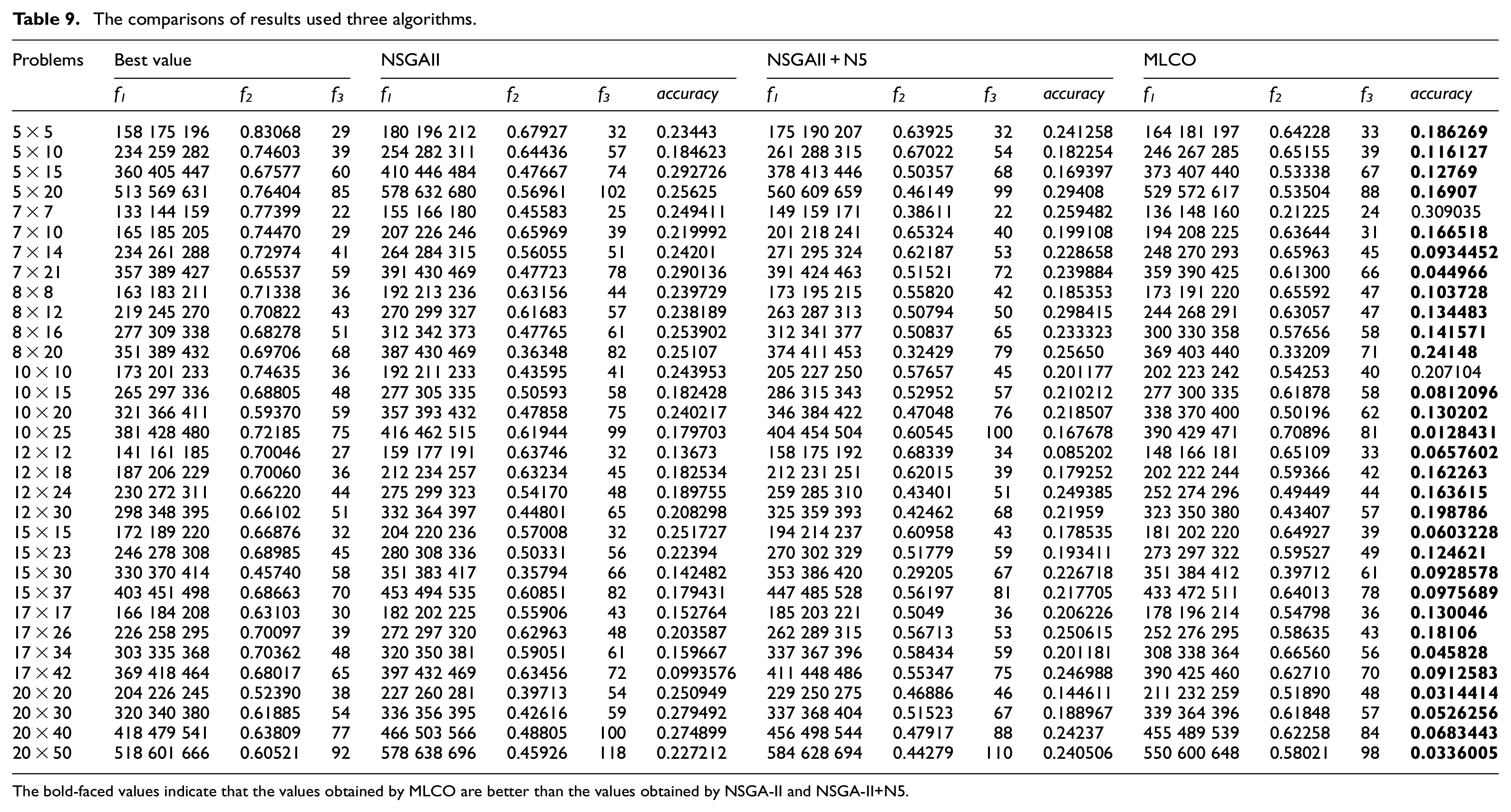
In the formula (7), accuracy represents the optimization performance of optimization algorithm, m is the number of optimization objectives, fi represents the number of the objectives. excellenti and worseni are the best values and worst value respectively. The smaller the value of accuracy, the better the optimization result. The solution sets obtained by the three algorithms are combined, and the optimal value of each optimization objective is found from the combined solution set. The solution set is obtained from each algorithm, and the solution with the best comprehensive performance is selected as the optimal solution of the algorithm. The results are obtained according to the calculation formula of accuracy, as shown in Table 9.
The comparisons of results used three algorithms.
The bold-faced values indicate that the values obtained by MLCO are better than the values obtained by NSGA-II and NSGA-II+N5.
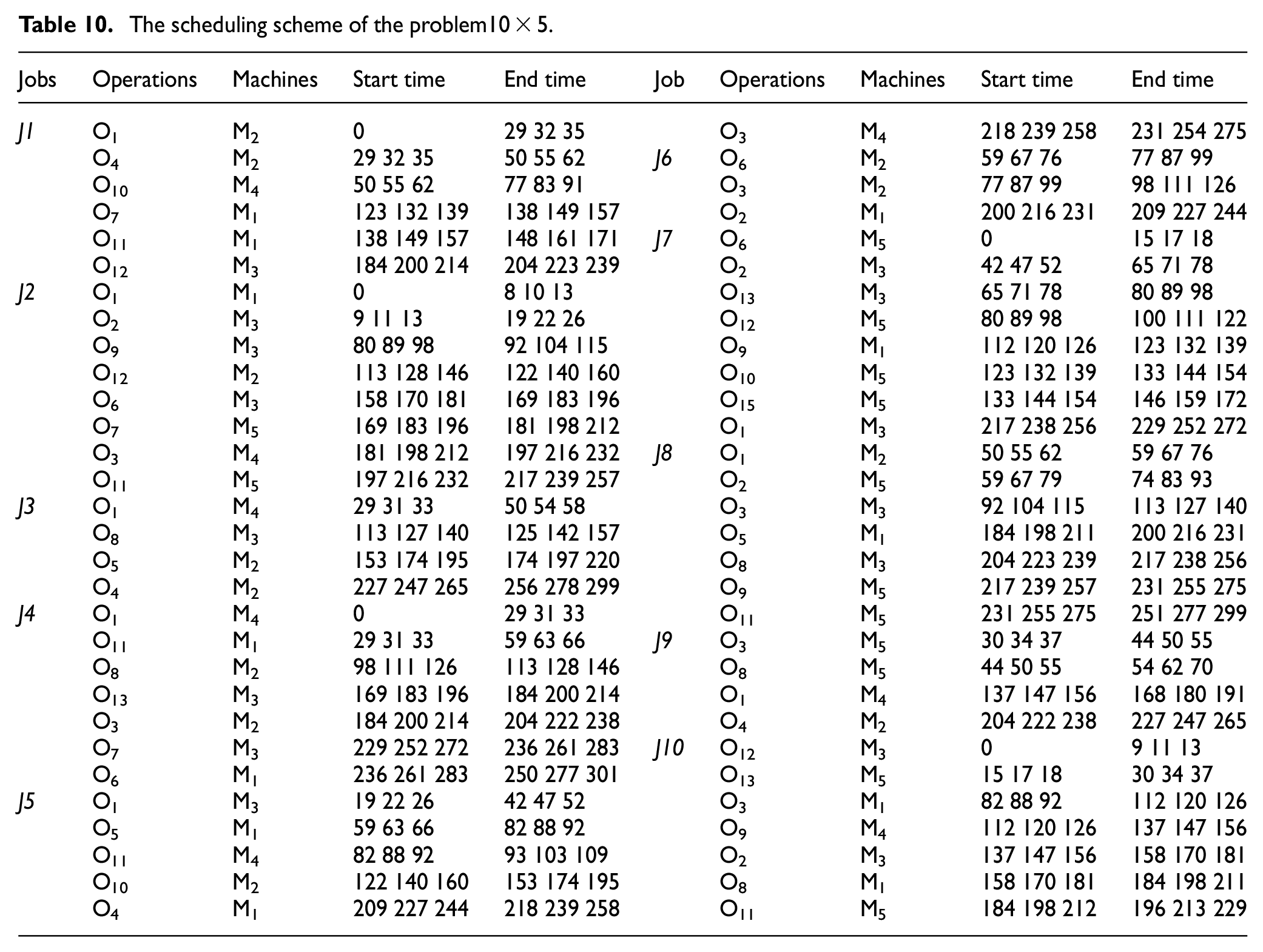
As shown in the results of Table 9, the accuracy values of 32 sets problem examples are obtained by using the MLCO. It found that the accuracy values of 30 experiments were less than the accuracy values obtained by NSGAII and NSGAII+N5, and the accuracy values of 14 experiments were less than 0.1. It showed that the algorithm has a high performance of optimization. Table 10 is scheduling scheme for the problem 10 × 5.
The scheduling scheme of the problem10 × 5.
The results of 32 sets of experiments show that the ability of the MLCO method to find the optimal solution is better than the other two methods. According to the data in Tables 7 and 8, it can be seen that the MLCO method has better optimization ability. The MLCO method is divided into three layers to solve the problem step by step. The process planning layer formulates near-optimal process plans for each job. The second layer considers all the processing tasks, selects the process plan for each job, and the third layer arranges processing time for all jobs. Compared with NSGAII and NSGAII+N5, MLCO method can make full use of the data information and processing information of the optimization process, and it also reduces the randomness of the optimization process. Especially with the expansion of the problem scale, reducing the randomness of the optimization is helpful to improve the ability to find the optimal solution. In addition, the MLCO method adopts a boundary search strategy in the third layer to enhance the search ability of boundary solutions. The results in Table 9 show that the accuracy value of the MLCO method is smaller, indicating that the quality of the non-dominated solutions obtained by the MLCO method is better. The individual comprehensive evaluation strategy is adopted in MLCO method to select the non-dominated solutions and improve the quality of non-dominated solutions. The experimental results show that the MLCO method proposed in this paper is effective for solving the FMOIPPS problem.
Conclusion and future works
In view of the complexity of actual production companying many uncertain factors, the diversity of demands and uncertain factors are comprehensively considered in this paper. For the multi-objective IPPS problem under uncertain conditions, the triangular fuzzy number is used to describe the uncertain processing time, and the trapezoid fuzzy number is adopted to indicate the uncertain due date. Minimize fuzzy makespan, maximize average customer satisfaction and minimize the spread of fuzzy makespan are planned as optimization objective. MLCO method is proposed to solve the FMOIPPS problem. The algorithm uses three layers of optimization methods including process planning layer, process selection layer, and scheduling layer. A sharing function strategy was adopted to maintain the population. A boundary search strategy is proposed to improve the search ability of the algorithm. An individual comprehensive evaluation strategy is proposed to selecting non-dominated solutions. The feasibility and effectiveness of the MLCO method are proved by 32 sets of examples with different scales. The results of the examples show that the algorithm has good practicability in solving uncertain multi-objective IPPS problems.
However, the actual workshop production process is often accompanied by many uncertainties, and more uncertainties should be considered in the IPPS problem. To solve the more complex and uncertain multi-objective IPPS problem and how to study the dynamic IPPS problem become the direction of further research in this paper.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research work is supported by the National Natural Science Foundation of China (grand no. 51905494 and 51775517), MOE (Ministry of Education in China) Project of Humanities and Social Sciences (grand no. 19YJCZH185), Key Scientific and Technological Research Project in Henan Province (grand no. 202102210088).