
Abstract
Traditional named entity recognition methods mainly explore the application of hand-crafted features. Currently, with the popularity of deep learning, neural networks have been introduced to capture deep features for named entity recognition. However, most existing methods only aim at modern corpus. Named entity recognition in ancient literature is challenging because names in it have evolved over time. In this paper, we attempt to recognise entities by exploring the characteristics of characters and strokes. The enhanced character embedding model, named ECEM, is proposed on the basis of bidirectional encoder representations from transformers and strokes. First, ECEM can generate the semantic vectors dynamically according to the context of the words. Second, the proposed algorithm introduces morphological-level information of Chinese words. Finally, the enhanced character embedding is fed into the bidirectional long short term memory-conditional random field model for training. To explore the effect of our proposed algorithm, experiments are carried out on both ancient literature and modern corpus. The results indicate that our algorithm is very effective and powerful, compared with traditional ones.
Keywords
Introduction
Because of the popularity of the web, a great many unstructured texts have emerged to represent web contents. These texts contain many named entities which include time, location and organisation, etc. Given a text, the results generated by the named entity recognition (NER) bring valuable information for several downstream natural language processing (NLP) task, such as relation extraction,1,2 event extraction 3 and question answering.4,5 During the past few years, traditional NER approaches are based on rules. For example, RENAR concerns some rules which are independent of any language, and obtains a precision of 83.15% on organisation, 87.7% on person, and 85.9% on location. 6 Singh et al. develops various rules to extract thirteen named entities. 7 Gazetteers are shown to be benefit to NER. 8 The rule-based methods usually rely on hand-designed features to build a special dictionary or some basic rules, according to the existing entities. Recently, numerous machine learning approaches have been carefully studied for NER task, including Conditional Random Fields (CRFs), Support Vector Machines (SVMs) and Hidden Markov Models (HMMs). 9 Meanwhile, with the popularity of artificial intelligence, neural networks have been applied in NER task.10,11 Word embedding is beneficial to NER. Word2vec, fastText and glove were used to train word embedding in the past. Recently, Language model pre-training has emerged, such as ELMo, 12 GPT 13 and Bidirectional Encoder Representations from Transformers (BERT), 14 which can effectively process the context to improve many natural language processing tasks.
Although the methods discussed above have achieved great improvements, some issues need to be addressed further. On the one hand, most recognition results are affected with word segmentation. English NER assumes that each word can be clearly separated by explicit word separators, such as blank space, to predict the tag of each word. Although word-based algorithms have achieved certain effect in Chinese NER,11,15 there are still many challenges. This is because the names of people, places and organisations are increasing without a uniform naming rule, and the ambiguity of Chinese language is inherent. Therefore, in most cases, the granularity of word segmentation is difficult to determine. Recently, some research results suggested that character-based algorithms outperformed word-based algorithms in NER task.16–19 For Chinese NER, existing character-based algorithms not only loss context information, but also cannot leverage morphological level information of Chinese characters. On the other, researchers mainly pay attention to modern corpus. However, there is few research on ancient literature named entity recognition. Xie et al. firstly attempted to recognise entities on Historical Records and obtained F1 score of 67.02%, 20 which relied on the result of new word detection. Therefore, the precision is high, but recall is low. In response to these challenges, an enhanced character embedding algorithm, named ECEM, is proposed, while BERT and strokes are integrated to learn the character representation and explore the performance in the Chinese NER domain. BERT is pre-trained on a large corpus to capture semantic features and abundant knowledge, which is of critical importance for the NER tasks. The strokes denote the basic structures of Chinese characters, which represent the semantic information hidden in morphology. Our main contributions are illustrated as follows.
BERT and strokes are integrated to learn the embeddings of Chinese characters. The new language representation is crucial for improving the learning of Chinese character embeddings.
ECEM is first used in ancient literature named entity recognition, which not only captures context information and abundant knowledge by fine-tuning BERT, but also flexibly acquires morphological information generated through strokes.
The annotated ancient poetry dataset is important for further research in ancient literature NER. ECEM helps to extract useful entity information, which is of great significance to understand ancient books and documents efficiently. The experimental results demonstrate that ECEM is superior to traditional methods, especially in the ancient corpus.
The structure of the rest of this paper is as follows. Section 2 is about the related work. The recognition algorithm is shown in Section 3, and the experimental results are described in Section 4. Section 5 concerns the conclusions and some suggestions for future work.
Related works
NER has been studied extensively for many years in big data processing. Early approaches relied on feature engineering. However, this kind of method depended heavily on domain-specific corpus and required a large number of experts in the field. For solving the above problems, some researchers try to introduce machine learning into NER. Lafferty used CRF to build probabilistic algorithms to segment and label sequence data. 9 Isozaki et al. gave better scores than conventional systems based on the SVM method. 21 Bikel et al. presented a statistical, learned approach to find names and other non-recursive entities in texts, using a variant of the standard hidden Markov algorithm. 22 Ratinov et al. gave some analysis of the design challenges to improve the efficiency and robustness of NER system. 23 Zhou et al. formulated Chinese NER as a joint identification and categorisation task. 24
Recently, neural network models play important roles in NER tasks. Hammerton tried to solve this problem based on a unidirectional LSTM, which was among the first neural models for NER. 25 A CNN-CRF model also produced the best results in all statistical models. 26 Character CNN was explored to enhance a CNN-CRF model. 27 LSTM-CRF architecture was leveraged in most recent work. Huang et al. attempted to use LSTM to obtain features and feed them into CRF decoder. 28 After that, many researchers have exploited LSTM-CRF model as the baseline.29,30 Lample et al. used a character LSTM to represent spelling characteristics. 10 Moreover, a gated convolutional neural network (GCNN) was presented by Wang et al. for Chinese NER. 31 Peng et al. jointly trained Chinese NER with the CWS task. However, the specific features brought by the CWS task can lower the performance of the Chinese NER task. 11 Cao et al. tried to use adversarial transfer learning framework to solve the problem mentioned above and gave a 58.70% F1 score on Weibo dataset. 32 Zhang et al. made use of a lattice-structured LSTM to choose the more useful characters and words for Chinese NER. 33 On Weibo dataset and Resume dataset, this method obtained F1 score of 58.79% and 94.46% respectively. Hang et al. 34 utilised relative positional encoding to capture character-level information. Meanwhile, some NER research focuses on neural representation learning. Cao et al. exploited stroke-level information to learn Chinese word embeddings and the experiment showed better word embeddings was effectiveness for NER tasks. 35 In addition, BERT obtained the semantic vectors dynamically according to the context of the words, which has achieved successful answering, 36 information retrieval,37,38 and the text classification. 39 Therefore, fine-tuning of the pre-trained BERT model on the basis of one additional output layer can produce some state-of-the-art models for various downstream tasks. Huang et al. proposed a multi-criteria method of CWS, who adopt BERT to introduce external knowledge. 40 The above methods mainly focus on the modern corpus and cannot obtain deep semantic information of characters from multiple levels. We are the first to explore the NER method in the Chinese ancient literature. Meanwhile, the smallest component of Chinese character is stroke, which represents the morphological level information. The combination of BERT and strokes will achieve better characters embedding for the Chinese NER, which contains rich syntactic and semantic information.
The proposed recognition algorithm
For Chinese, each character is semantically meaningful. Therefore, this recognition algorithm attempts to obtain better character embedding for Chinese NER. To achieve this, ECEM is proposed, which combines BERT with strokes. The character embedding can extract useful features and is fed into BiLSTM layer. As illustrated in Figure 1, the whole algorithm consists of four components. Data pre-processing is the first component. The purpose is to repartition the corpora, segment it based on character-level and use the BIO method for token relabelling. The enhanced character embedding layer is constructed to convert each character into context-level embeddings and stroke-level embeddings through BERT and CW2VEC respectively. The third component concatenates the deeper context information output by two BiLSTMs as the final representations of the characters. The fourth component adopts CRF to predict the sequence labels.
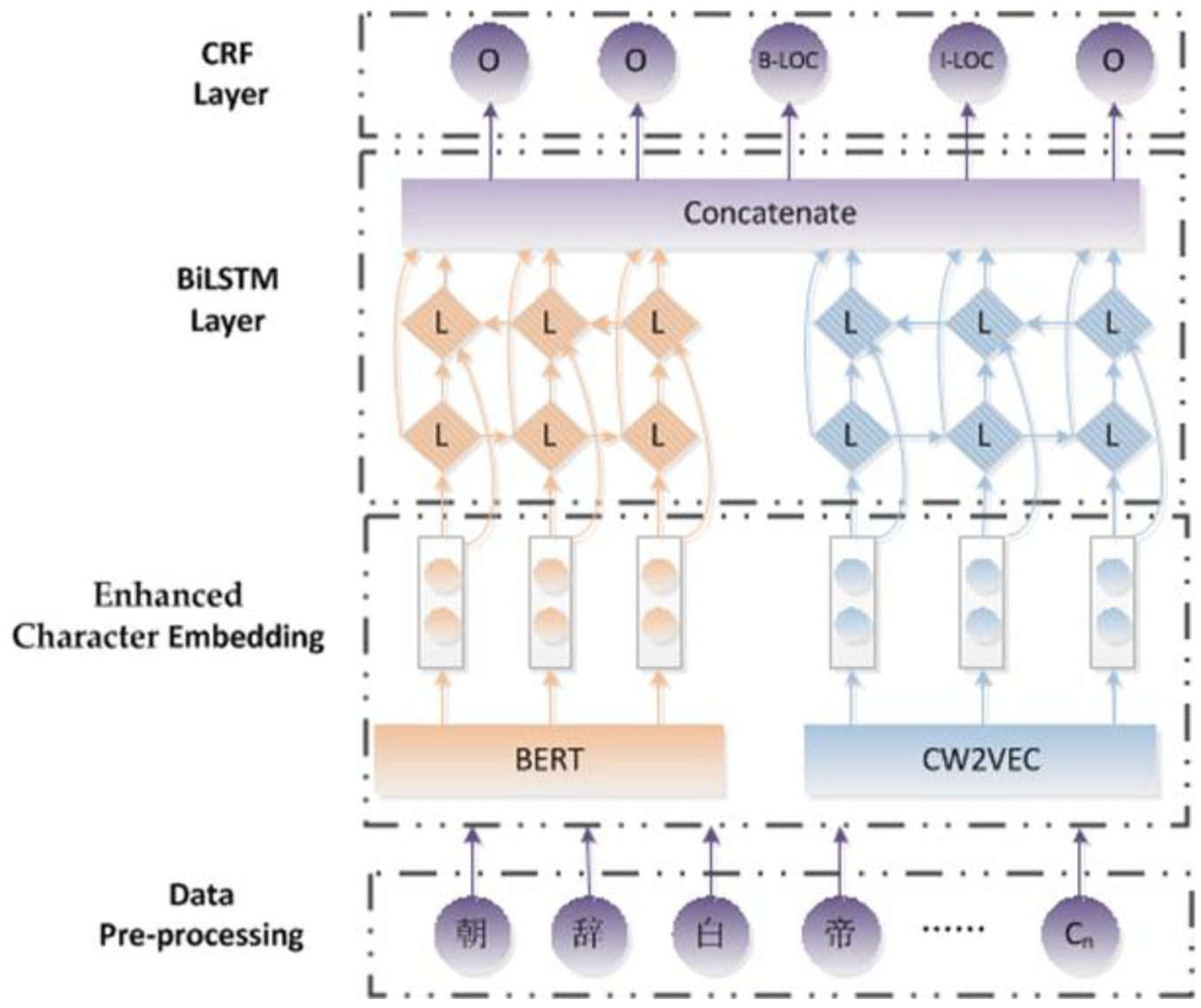
The whole algorithm framework based on enhanced character embedding.
Data pre-processing
This paper mainly explores the method of Chinese NER on ancient literature. The easiest way for dealing with NER problems is to transform them into sequence labelling problems. Each word needs to be assigned a named entity tag in an input sentence. There are two common tag schemes: BIO and BIOES. The tag B-X denotes the first word of a named entity of type X, that is, LOC(Location), PER(Person), ORG(Organisation), while E-X is used for the last word of a named entity. The tag I-X represents that a word is part of an entity but not the first word. The tag S-X indicates that a word is an entity. The tag O-X shows all non-entity words. 41 Table 1 gives the tag scheme comparison between them.
Tag scheme comparison.

In most cases, BIOES tags are better than BIO. However, ancient Chinese corpus contain more short syllables and monosyllables. The use of BIOES scheme may lead to fewer E-X labels and more unbalanced data, so that the final training model cannot make a good prediction of the end of the entity. Therefore, ECEM uses BIO scheme as the annotation scheme.
Enhanced character embedding
Chinese character-level embedding can avoid errors which are caused due to wrong segmentation and beingout-of-vocabulary. However, character embeddings may lose words and word sequence information. How to better explore implicit context features and integrate morphological features is the key to solve the aforementioned problem. Therefore, EMEC learns the character embedding from two levels. Strokes denote how the words and characters are constructed, and they provide morphological level information of Chinese characters. Meanwhile, BERT is pre-trained on a large corpus to capture semantic features and abundant knowledge, which is vital for obtaining context-level information. Therefore, this layer mainly contains two modules.
BERT
BERT facilitates pre-training deep bidirectional representations on unlabelled texts by fusing the right and the left context in all layers.
14
The corresponding segment, token, and position embeddings are concatenated as the input representation. A special classification embedding [CLS] is added as the first token of every sequence, and [SEP] is inserted as the final token. The symbol [CLS] is utilised for aggregating features. The core structure of BERT is illustrated in Figure 2. Trm is the abbreviation of transformer block. Given the input embedding
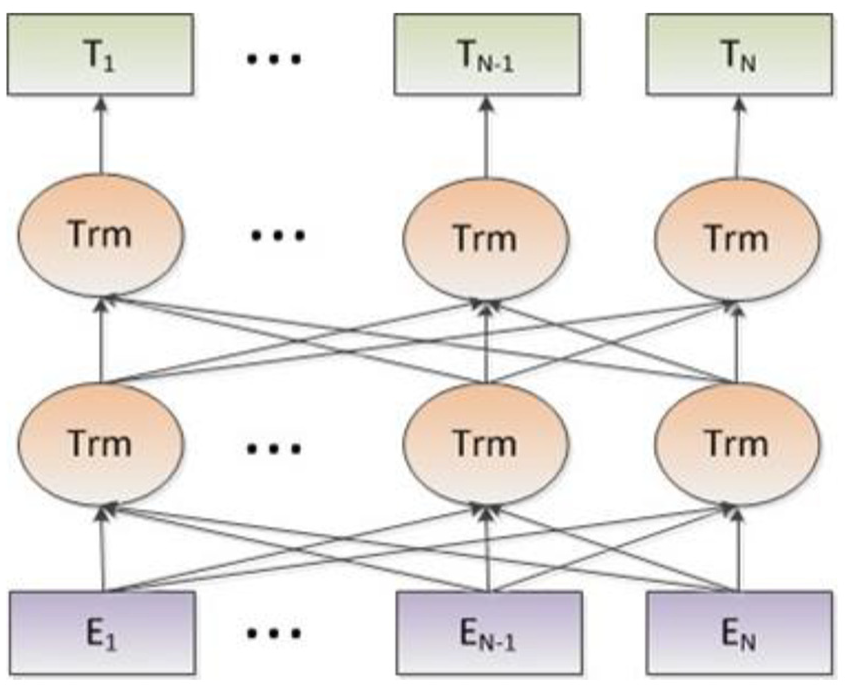
The structure of BERT.
Pre-training and fine-tuning are the two steps of BERT. During pre-training, the model is trained on large unlabelled texts using two strategies, for example, Masked Language Model (MLM) and Next Sentence Prediction (NSP). MLM trains a deep bidirectional representation by masking some percentage.
CW2VEC
Most character representation methods focus on English, which uses a completely different writing system from Chinese. Each Chinese character has fruitful semantic information in its structure. Strokes provide the most basic unit for building character meanings and give some guidelines in exploring semantic information hidden in the morphology. Therefore, cw2vec improves the learning of Chinese word embeddings based on stroke-level information. Equation (1) shows the objective function of this algorithm.
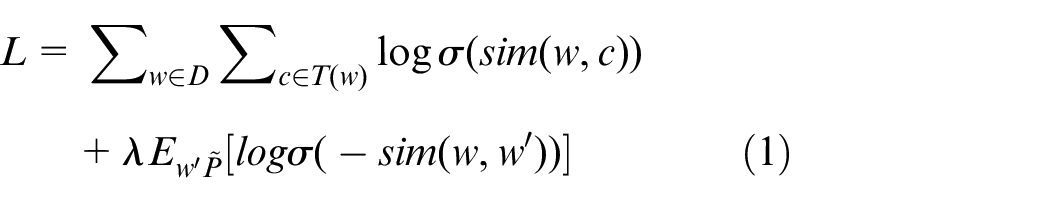
where w is the current word and c denotes one of its context words. T(w) denotes the set of contextual words given current word w within a window size. D is the set of all words within the training corpus. λ is the number of negative samples and
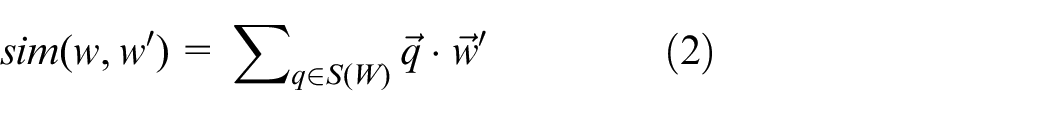
where S(w) denotes the set of stroke n-grams of the word w and
A Chinese word can be mapped into stroke n-grams according to the following four steps. (1) Word segmentation: dividing Chinese words into characters. (2) Strokes acquisition: retrieving the stroke sequence from each character and concatenating them together. (3) Representing stroke sequence by stroke ID: the strokes are classified into five types shown in Table 2, from 1 to 5 respectively. (4) Capturing stroke features: generating stroke n-grams within a slide window of size n.
The corresponding relation between strokes and number.

Take the verse 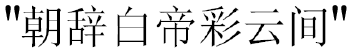 (leaving at dawn the White King crowned with rainbow cloud) for example. Figure 3 shows the overall architecture of cw2vec with this example. First, the current word
(leaving at dawn the White King crowned with rainbow cloud) for example. Figure 3 shows the overall architecture of cw2vec with this example. First, the current word  (White King) is reduced into stroke n-grams. Second, the similarity is computed between the current word and its context words
(White King) is reduced into stroke n-grams. Second, the similarity is computed between the current word and its context words  and
and  . Third, the above objective function is updated, and the context word embeddings are the final output word embeddings. In this paper, cw2vec is leveraged to generate character embeddings.
. Third, the above objective function is updated, and the context word embeddings are the final output word embeddings. In this paper, cw2vec is leveraged to generate character embeddings.
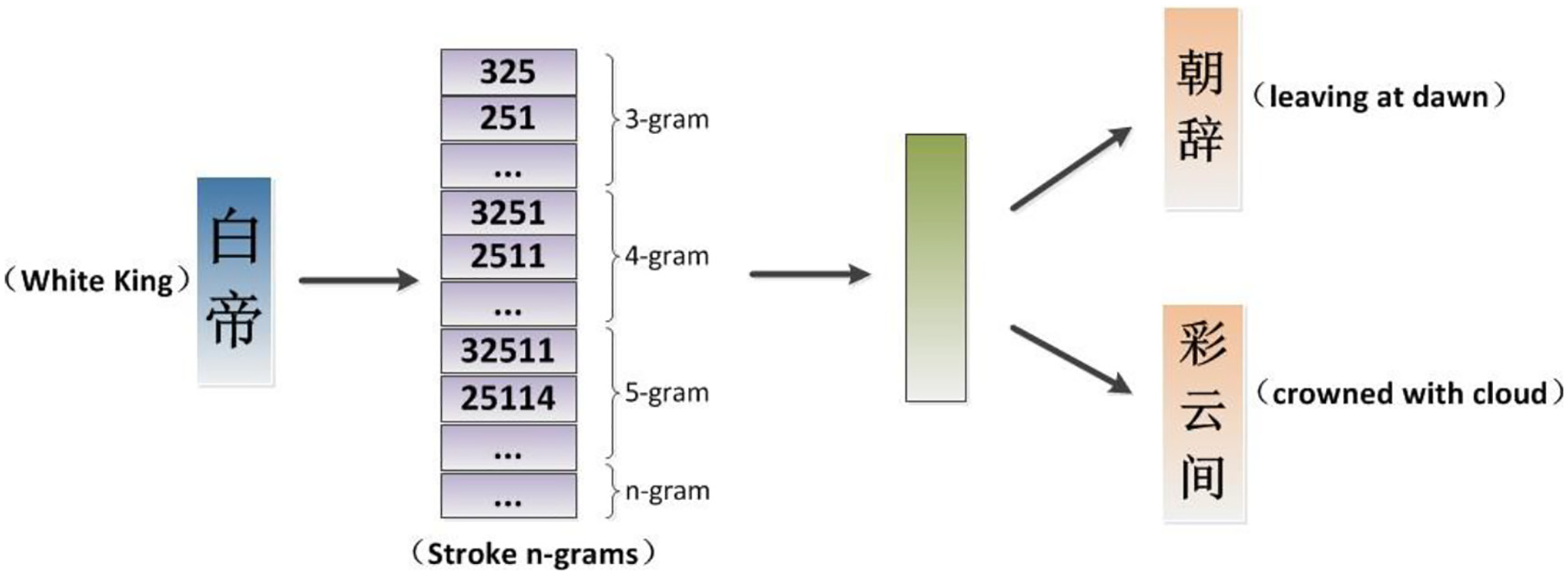
The example of “leaving at dawn the White King crowned with rainbow cloud.”
Each character is converted into a multi-dimensional vector through BERT and cw2vec respectively, and the vector dimensions are the same. They carry semantic information hidden in the morphology and the context, which is fed into BiLSTM layer respectively.
BiLSTM layer
LSTM is a member of the RNN family, which overcomes long-range dependencies problem by utilising memory cell and gate mechanism. The unidirectional LSTM Mainly depends on past information, ignoring future information. However, BiLSTM will run the inputs in two ways, one from past to future and one from future to past. Therefore, BiLSTM is adopted to capture features from both sides of sequence for better understanding context. Given a sequence vector, which is the output of BERT and an input of BiLSTM. The hidden state of BiLSTM could be calculated through the following equations at each time t.
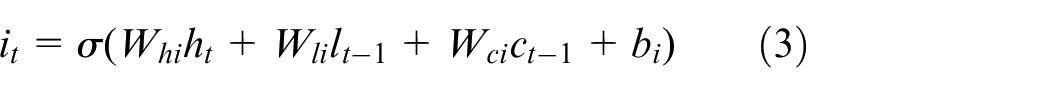
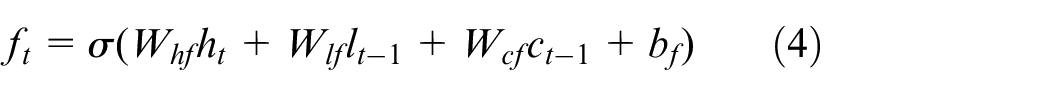
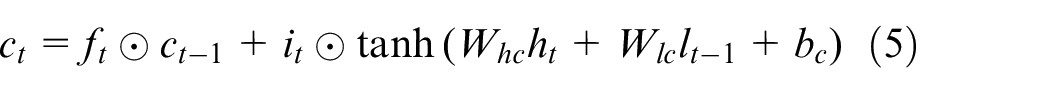
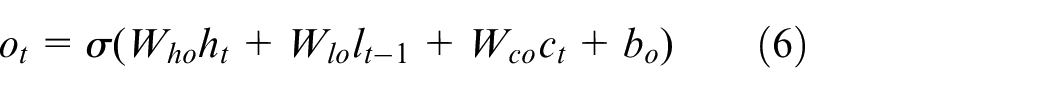

where σ denotes the element-wise sigmoid function. i, f, o and c represent input gate, forget gate, output gate and the current cell state, respectively.
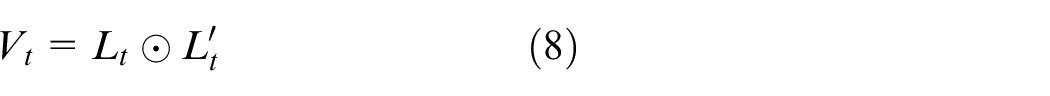
CRF layer
Although the hidden vector Vt can be regarded as the direct features when predicting independent tagging, the tags sequences are not independent. For example, an I-LOC cannot follow a B-PER tag. Therefore, the CRF layer is used to predict the optimal sequence of tags. Given an input sentence
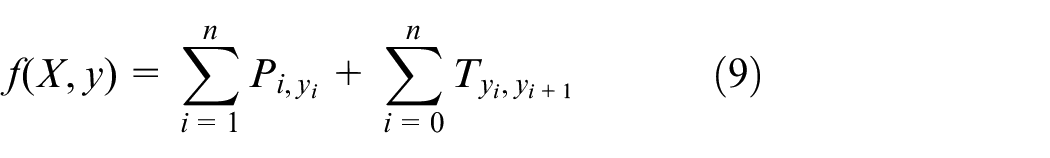
where the transition from tag i to tag j is modelled by the matrix of transition scores T. Then, the probability of the sequence y is calculated using a softmax on the basis of all possible tag sequences.

where
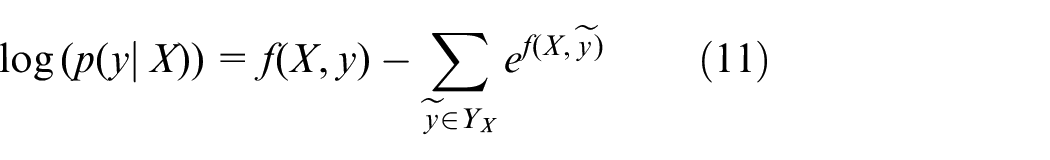
The purpose of our model is to produce efficient output sequence. Therefore, the output sequence y* will be find with the maximum score given by equation (12) compared with all the feasible outputs y.

Experimental results
In order to explore the effect of our proposed algorithm, an extensive set of experiments is carried out. This section details the datasets, parameter settings and results.
DataSet
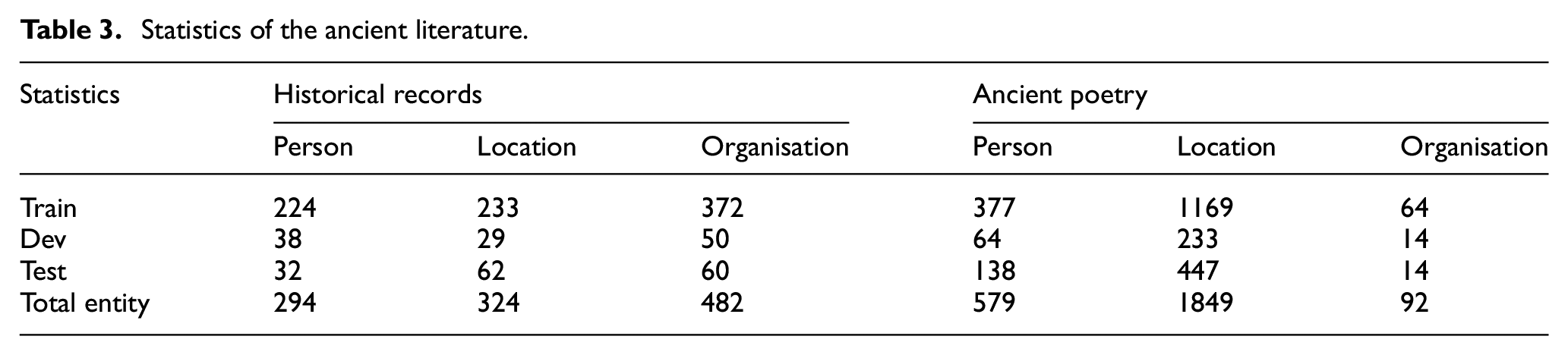
Most existing NER methods focus on the standard corpus provided by many public competitions. However, researchers pay little attention to the ancient literature named entity recognition. At present, there is no large-scale labelled ancient dataset. Therefore, this paper uses the Historical Records dataset labelled manually 20 and a Ancient Poetry dataset that we annotate. The Historical Records dataset contains 3200 short sentences randomly extracted from historical records, and has 1100 named entities. The entire dataset is partitioned into training set, development set and testing set according to the ratio of 8:1:1. Our Ancient Poetry dataset is from “A Dictionary of Chinese Poems on Scenic Spots and Historical Sites” and we use it to annotate 2520 named entities. The entire dataset is split in accordance with the ratio of 7:2:1. The statistics of ancient literature are detailed in Table 3.
Statistics of the ancient literature.
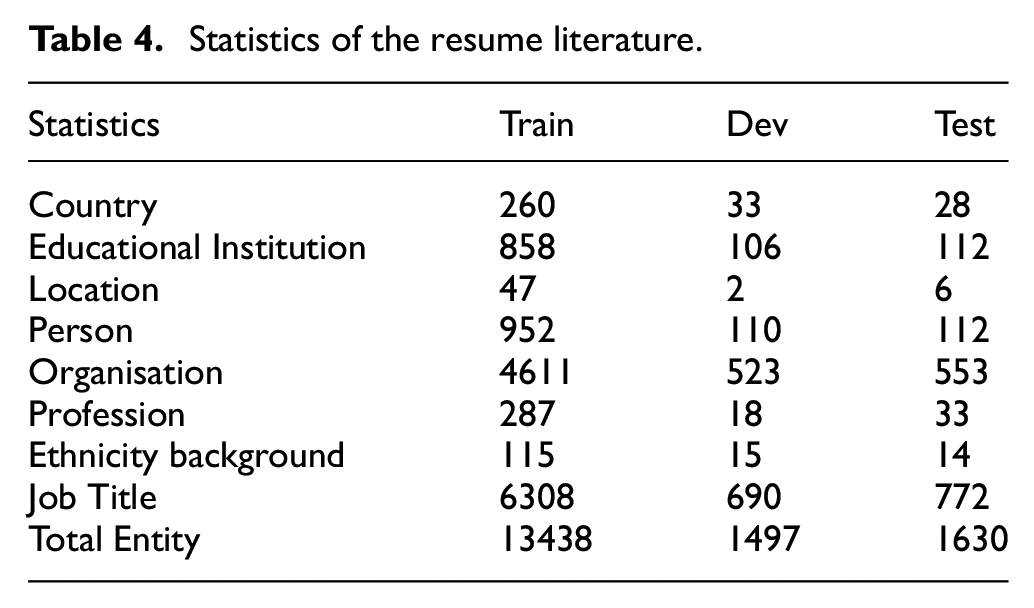
To further check the effect of our proposed algorithm in other domains, experiments are conducted on modern corpus, which includes Resume NER dataset. Chinese Resume dataset is a standard dataset, which is extracted from Sina Finance and has eight types of named entities. 33 The detailed statistic information of Resume NER dataset is illustrated in Table 4. For this dataset, official data split is used.
Statistics of the resume literature.
Baselines
The proposed ECEM method is compared with some variants of it. In order to be more convenient when referring to the models later, the models are briefly introduced as follows.
STROKE-BiLSTM-CRF. The character embeddings, which is the input of BiLSTM-CRF, is learned from the stroke-level information of Chinese words.
BERT-BiLSTM-CRF. This model first uses BERT to learn the character embedding. Then, a sequence of character vectors is fed into BiLSTM-CRF layer.
ECEM. It is the method proposed in this paper. ECEM can enhance character embeddings for ancient literature and modern corpus.
In order to illustrate the performance of BiLSTM, the BiLSTM layers in the above four models are replaced with LSTM layers. The new generated models are LSTM-CRF, STROKE-LSTM-CRF, BERT-LSTM-CRF and BERT-STROKE-LSTM-CRF.
Tag scheme and evaluation measure
The ancient text contains many short syllables and monosyllables. Consequently, for a fair comparison, all models except Lattice use BIO scheme as the annotation scheme of all datasets. The entity will be correctly predicted when the entity boundary and category labels are all correct.
There are different metrics in evaluating NER. This paper mainly employs Precision (P), Recall (R) and F1 score to assess recognition results. 21 More precisely, precision is the ratio of the number of correctly recognise entities to total recognised entities, recall is the number of correctly recognised entities divided by the number of real entities, and F1 score is the harmonic mean of precision and recall. Based on these descriptions, the details of precision, recall and F1 score are given in equations (13) to (15), respectively.

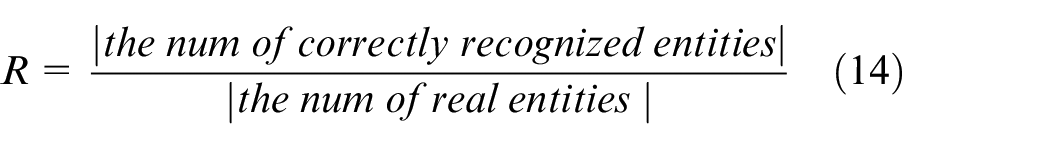
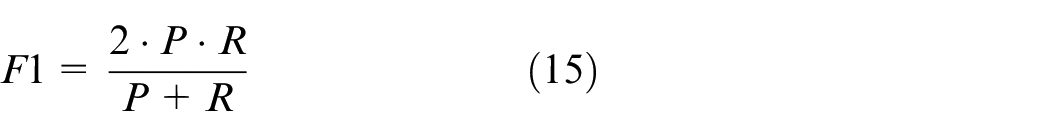
Parameter settings
The Chinese BERT-Base model is used, which has 12 layers, 12 heads and 768 hidden states. Therefore, the number of character embeddings output by cw2vec is also set as 768, and the max sequence length is set to 128. Characters with length less than 128, will be padded with all-zero vectors, and character sequences that exceed length 128 are ignored. During fine-tuning, parameters are adjusted according to the performance on the development set of Historical Records. The hidden-layer dimension of BiLSTM and LSTM is set as 150. Adam is used for optimisation, with a dropout of 0.5, a batch size of 16, and the learning rate of 1e-5. When learning word embeddings through cw2vec, the window size is set as 5 and the learning rate is 2.5e-3. During training, the parameters will be updated.
To fine-turn the epochs, some variants of ECEM are compared. Each model is trained with 20 epochs totally, and the version with the highest F1 score is selected. Tables 5, 6 and 7 illustrate the F1 score of LSTM-CRF, STROKE-LSTM-CRF, BERT-LSTM-CRF, BERT-STROKE-LSTM-CRF, BiLSTM-CRF, STROKE-BiLSTM-CRF, BERT-BiLSTM-CRF, and ECEM models against the number of epochs. In addition, Figure 4 shows the effect of each model intuitively. It can be seen from Figure 4 that BiLSTM improves the NER effect compared with LSTM on all datasets. In addition, both BERT and stroke can boost the performance. One reason is that the fine-tuning of BERT will learn sentence-level representation and word-level representation from longer sequences. On the other hand, stroke can provide the meaningful sub-word information, which is useful for character embeddings. Therefore, ECEM obtains a certain improvement compared with some variant of it. Concretely, in terms of History Records, LSTM-CRF, STROKE-LSTM-CRF, BERT-LSTM-CRF, BERT- STROKE -LSTM-CRF, BiLSTM-CRF, STROKE-BiLSTM-CRF, BERT-BiLSTM-CRF, and ECEM obtains a corresponding highest F1 score of 62.75%, 64.45%, 79.01%, 81.76%, 65.16%, 66.24%, 82.50% and 84.01% for 16, 18, 16, 20, 12, 20, 16, 10 epochs, with a corresponding highest F1 score of 55.11%, 57.70%, 73.92%, 74.59%, 58.94%, 59.58%, 75.03% and 75.34% for 11, 17, 20, 16, 17, 20, 18, 9 epochs on the Ancient Poetry, and a corresponding highest F1 score of 91.06%, 92.51%, 94.99%, 95.18%, 92.29%, 93.39%, 95.31% and 95.83% for 14, 16, 17, 20, 19, 17, 18, 14 epochs on Resume.
F1 of each epoch on Historical Records (%).
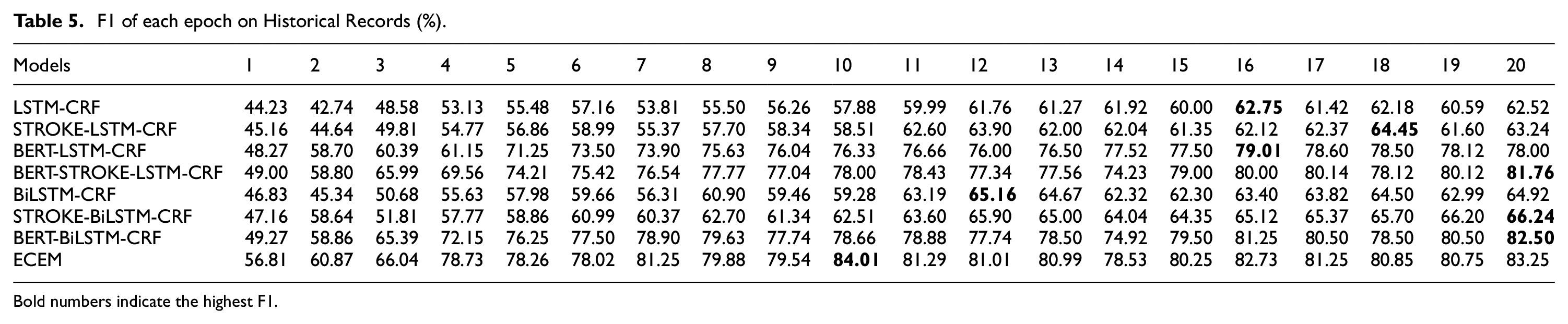
Bold numbers indicate the highest F1.
F1 of each epoch on Ancient Poetry (%).
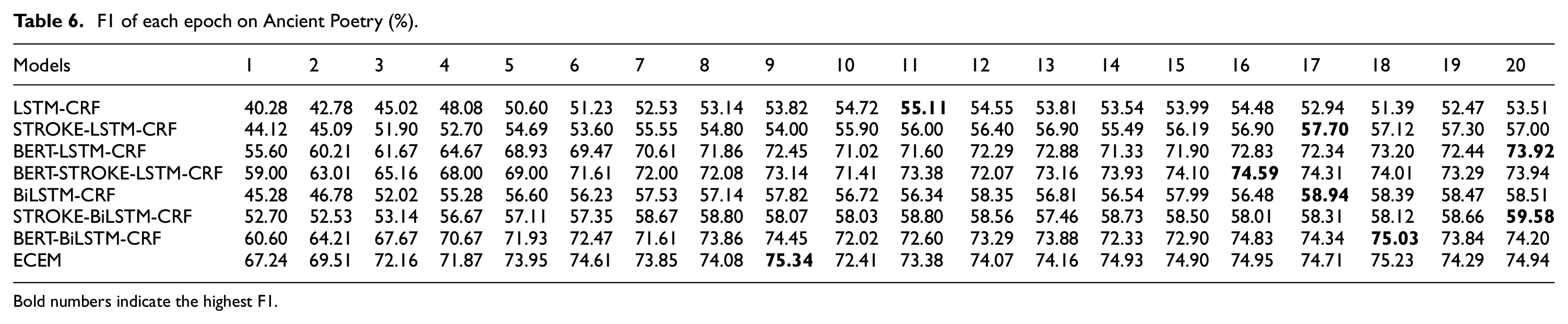
Bold numbers indicate the highest F1.
F1 of each epoch on Resume (%).
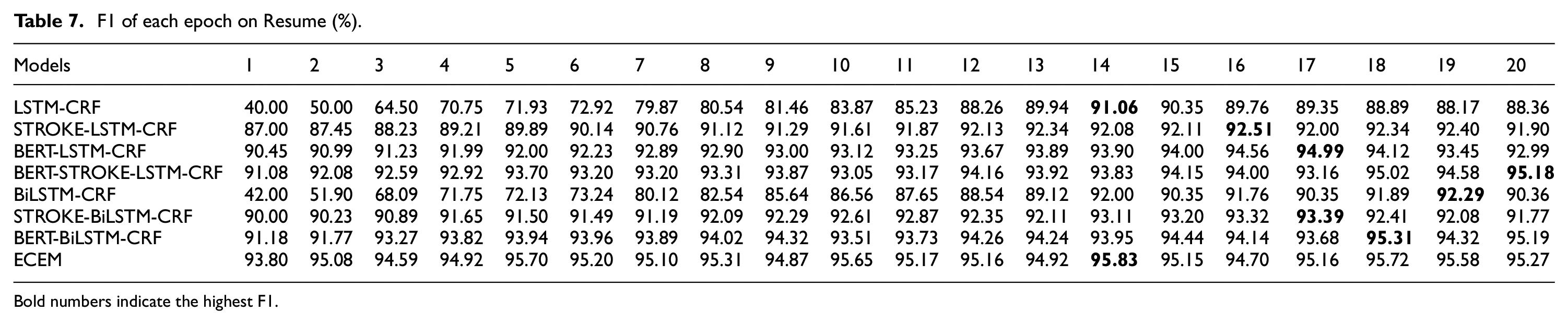
Bold numbers indicate the highest F1.
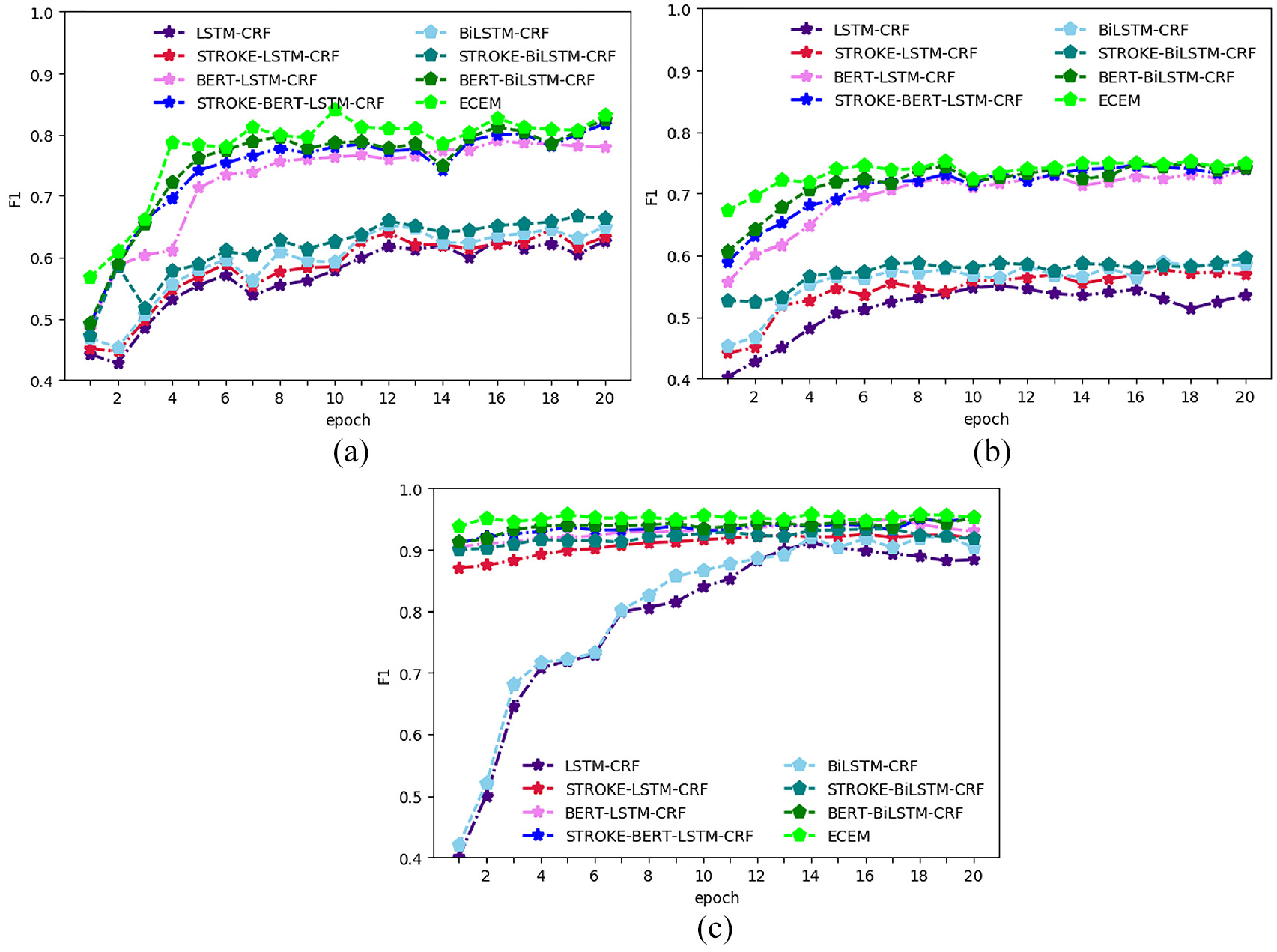
F1 against epoch number: (a) F1 against epoch number on History Records, (b) F1 against epoch number on Ancient Poetry, and (c) F1 against epoch number on Resume.
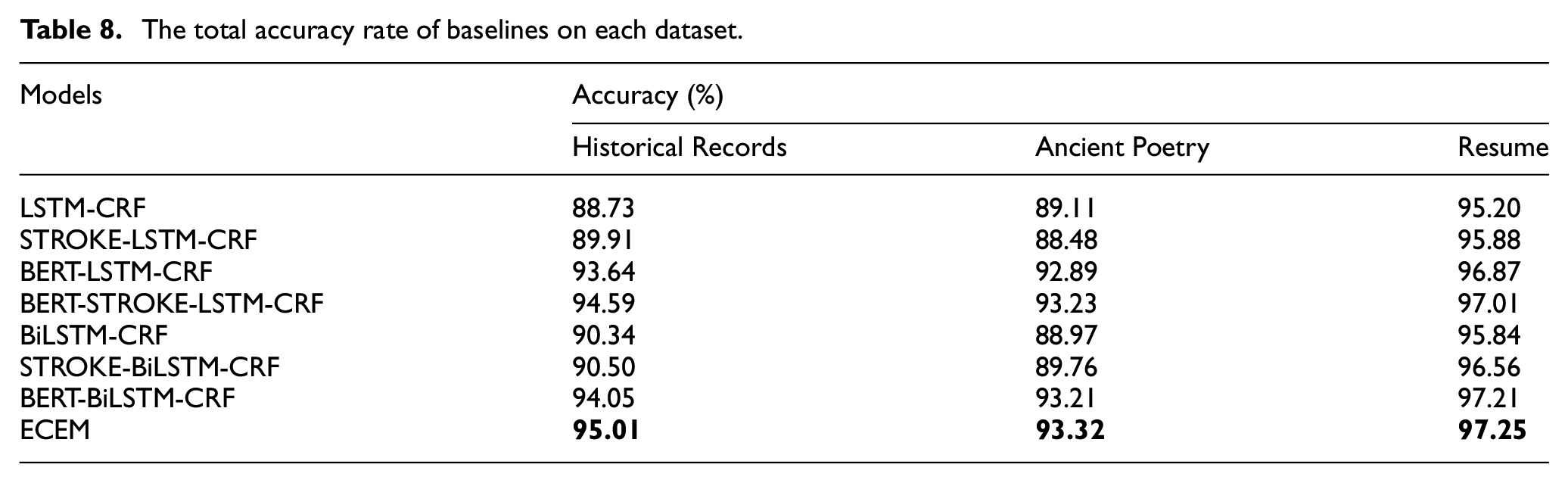
When F1 score is highest, Table 8 denotes the overall recognition accuracy of baselines on each dataset. As illustrated in the table, our proposed ECEM method acquires the highest accuracy (95.01%, 93.32% and 97.25%) on three datasets. It denotes that the enhanced character embedding can improve recognition result, which indeed helps to capture context and morphological information together.
The total accuracy rate of baselines on each dataset.
Time comparison
Runtime implies the complexity of the model. We conduct our experiments on a physical machine with Ubuntu 14.04, 2 Intel Xeon E5-2609 v4 CPUs, and 4 GTX 1080 GUPs. Each epoch will take out 10 minutes to train corpus using cw2vec. On this basis, we train some variants of ECEM with the above parameters for a total of 20 epochs. Therefore, we can obtain the average training time per epoch. As is illustrated in Figure 5, ECEM performs better with little loss in time on the all datasets.
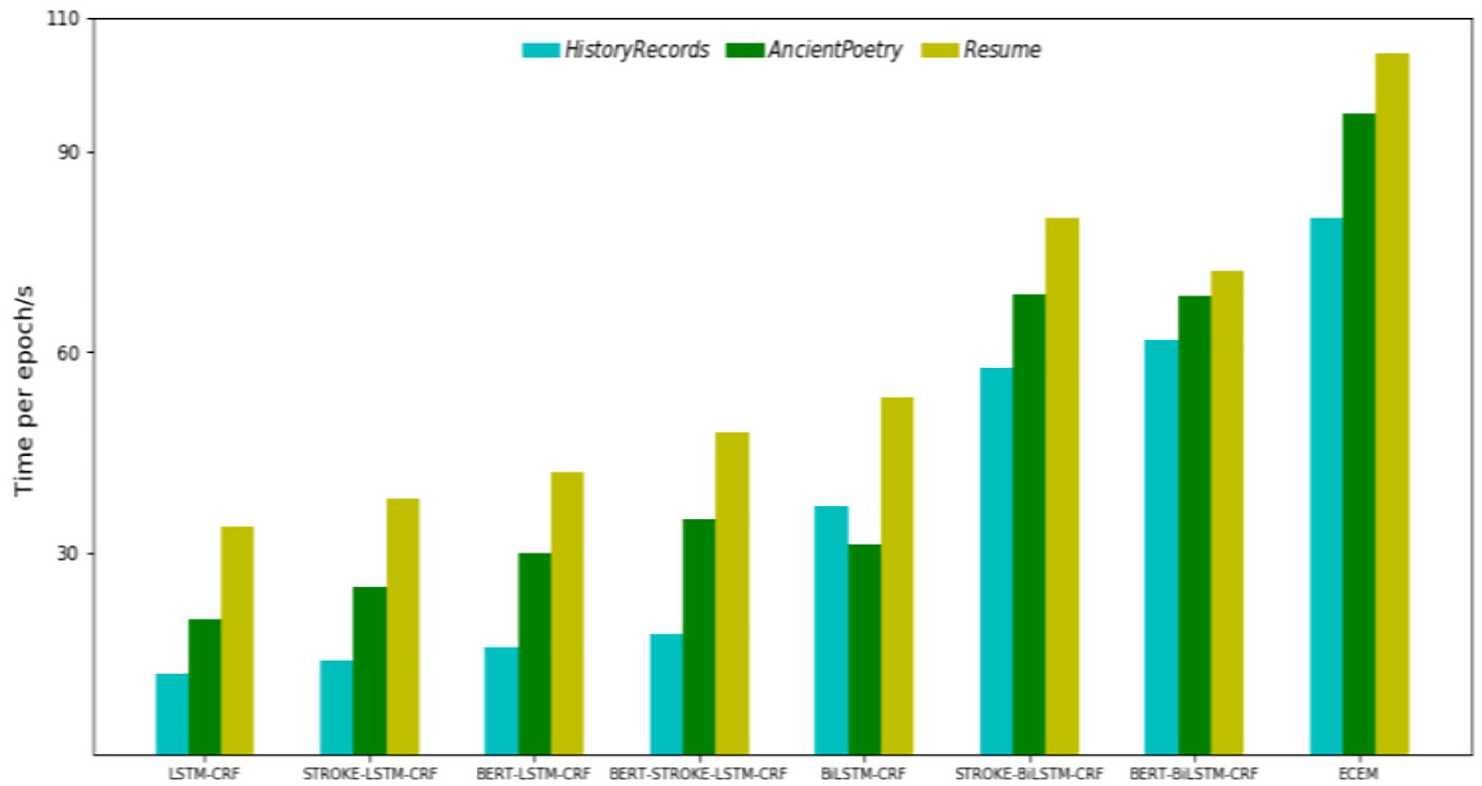
Running time of baselines.
Final results
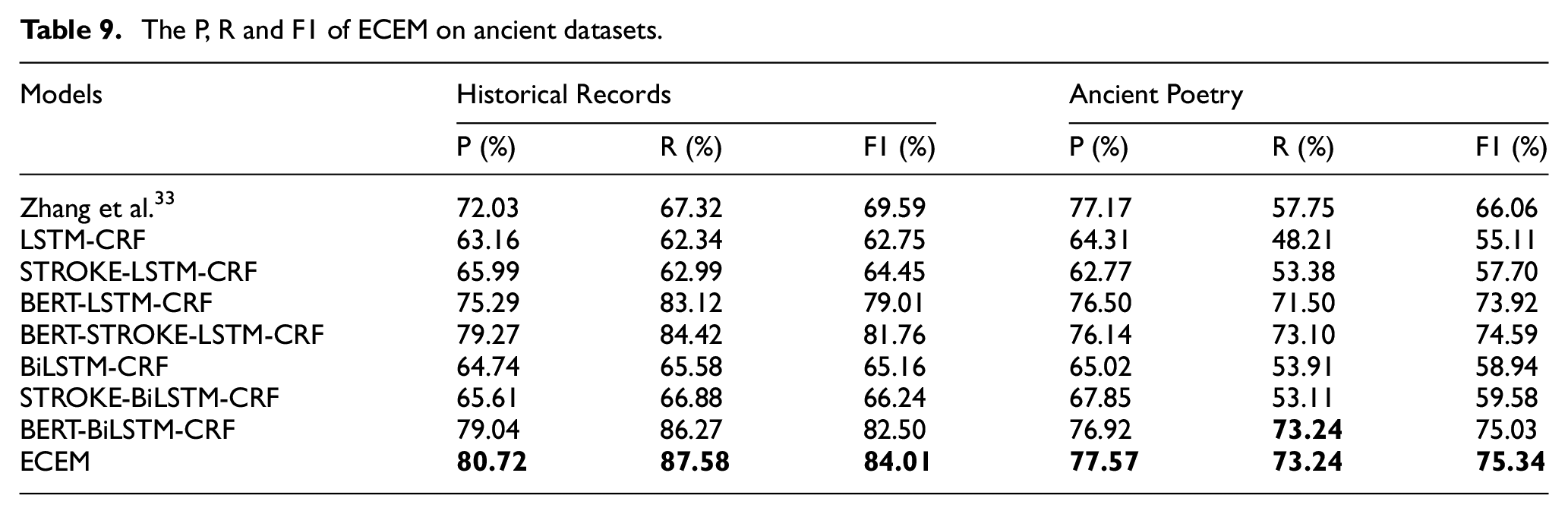
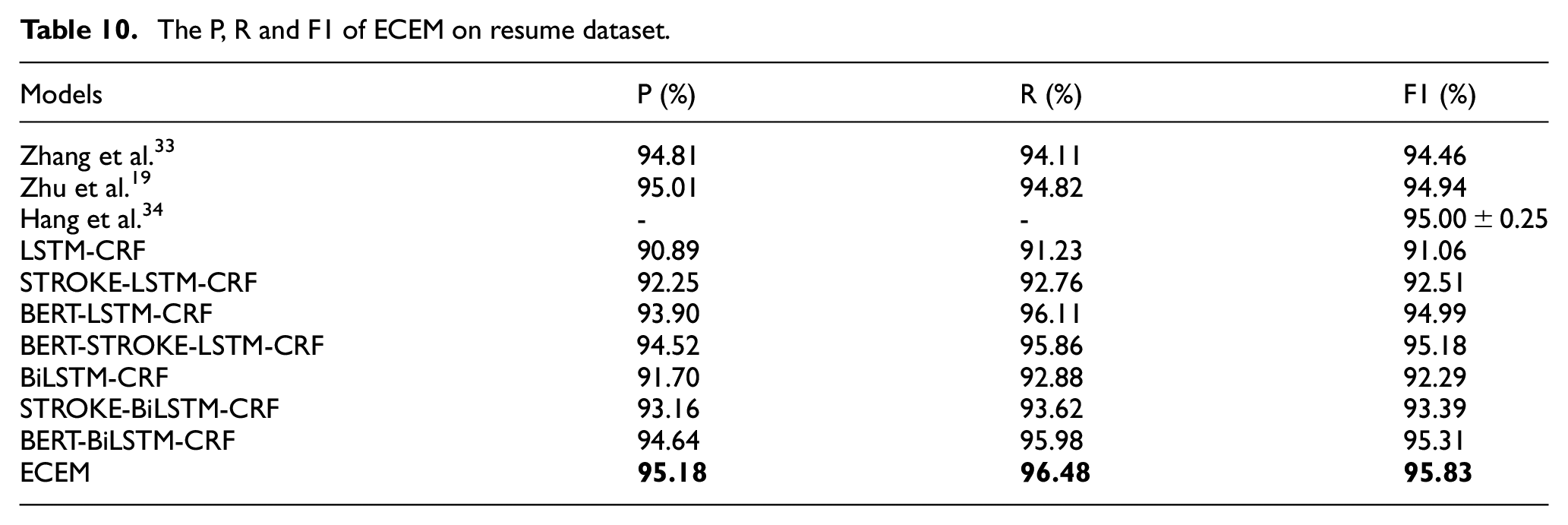
To further understand the results, Tables 9 and 10 introduce the precision, recall and F1 score on three datasets, which are from different domains. The top part shows the results compared with previous state-of-the-art models and the other parts demonstrates the results of the baselines we proposed above. Overall, ECEM has obtained the competitive improvements compared with other models.
The P, R and F1 of ECEM on ancient datasets.
The P, R and F1 of ECEM on resume dataset.
Ancient datasets
Zhang et al. 33 not only leverages character information, but also uses words and word sequence information without segmentation errors. However, the relationship between characters is not close in ancient datasets. Meanwhile, noise characters may affect the recognition results. Therefore, this model only achieves the F1 score of 69.59% and 66.06% on Historical Records and Ancient Poetry, respectively. In the second block of Table 9, LSTM-CRF acquires the relatively low performance on all the corpora, especially on the ancient poetry dataset. The results imply that LSTM-CRF cannot obtain deep semantic features from the sparse and unbalanced corpora. In addition, to check the role of various components, we also report the performance of STROKE-LSTM-CRF, BERT-LSTM-CRF and BERT-STROKE-LSTM-CRF. The last block of Table 9 presents the results of the models based on BiLSTM. BiLSTM-CRF outperforms LSTM-CRF. Compared with LSTM-CRF, BERT-LSTM-CRF improves the F1 score by 17.34% on the Historical Records dataset and 16.09% on the Ancient Poetry dataset. Correspondingly, the F1 score of STROKE-BiLSTM-CRF improves 1.08% on the Historical Records dataset and 0.64% on the Ancient Poetry dataset. It means that the semantic features and morphological information captured by BERT and STROKE can help the algorithm improve the recognition effect. For ancient datasets, BERT-BiLSTM-CRF gives a slightly higher F1 score compared to STROKE-BiLSTM-CRF. Eventually, ECEM achieves the best results on both datasets. The results reveal that the combination of BERT and strokes performs best.
Resume dataset
Experimental results for Resume dataset are given in Table 10. Zhu et al. 19 capture semantic knowledge from contexts and adjacent characters based on a character-based convolutional neural network and a gated recurrent unit. This method improves the F1 score from 94.46% to 94.94% compared with the model proposed by Zhang et al. 33 Hang et al. 34 proposed that transformer was incorporated with the distance-aware, direction-aware, and un-scaled attention. The model gave the F1 score of 95.00 ± 0.25%. BiLSTM-CRF achieves a F1 score of 92.29%. STROKE-BiLSTM-CRF improves the F1 score to 93.39%, and BERT-BiLSTM-CRF improves the F1 score to 95.31%. ECEM significantly improve the F1 score to 95.83% by using enhanced character embeddings, which is the highest result among existing models. Overall, ECEM is more suitable for ancient literature, and the effect of strokes on modern corpora is better. One reason is that the contents of the ancient texts are short, which leads to lack of context information. Another reason is that the ancient texts are more diverse in terms of expression, which increases the difficulty of feature extraction. Therefore, ancient literature relies heavily on enhanced character embedding. Surprisingly, ECEM also achieves the best results on modern corpora. The results demonstrate that our model is more efficient and robust than other models.
To visualise the effect of the proposed algorithm, the relative errors of F1 score is shown regarding each compared model in Figure 6. Each column is obtained by computing the difference of F1 score between the compared model and our ECEM. As can be seen from the figure, ECEM has significant superiority to most other models.
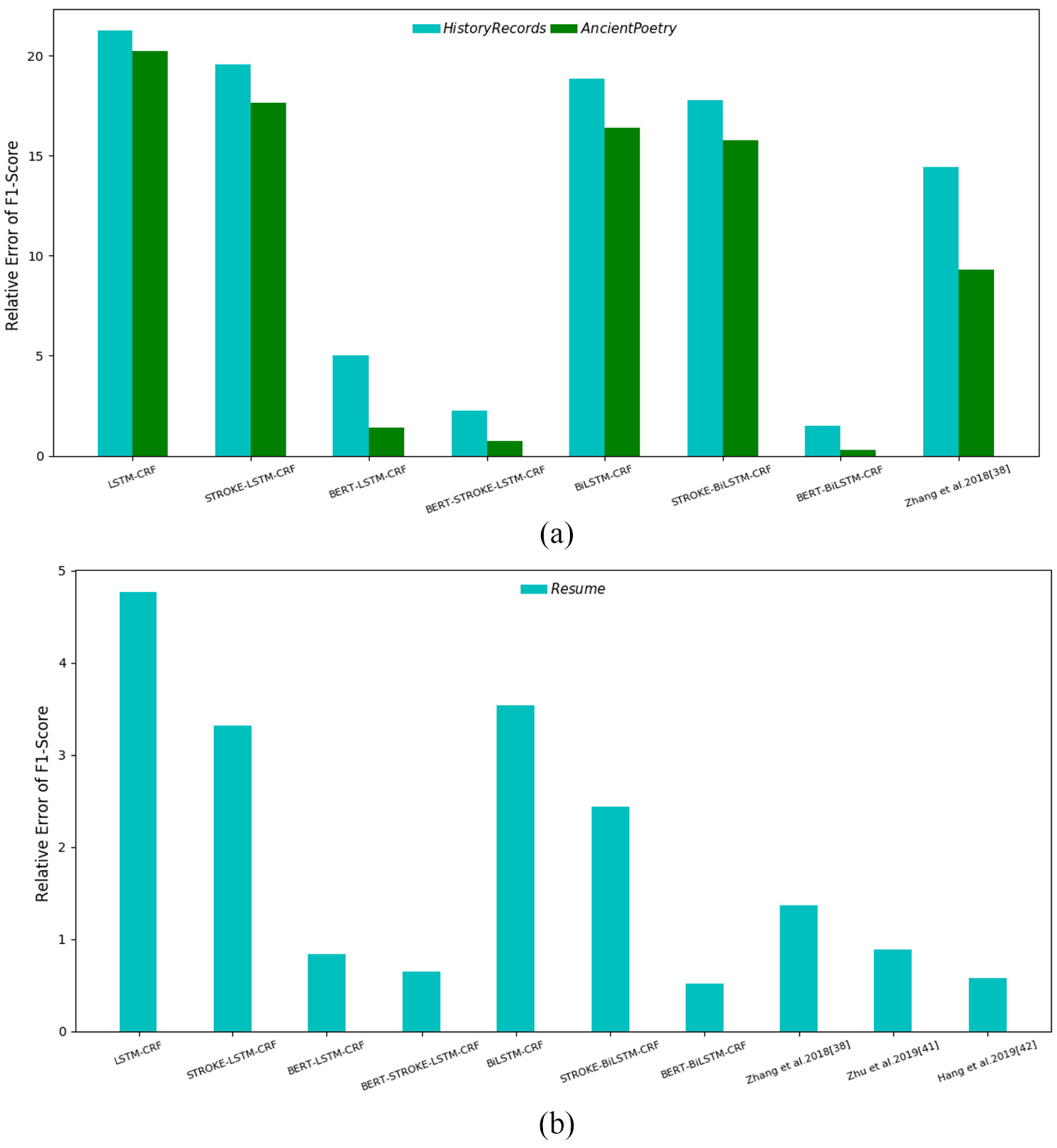
Relative error of F1 Score of each model compared with ECEM. (a) comparison results of ancient dataset and (b) comparison results of resume dataset.
Conclusion
The present NER methods mainly focus on modern corpus. Occasionally, researchers have made some attempts and explorations in domain-specific NER, such as microblog, biomedical corpus, telecommunications corpus and legal file corpus. However, little research pays attention to ancient literature named entity recognition. With the digitisation of a large number of ancient books and documents in the future, it will be of great significance if the NER technology can be used to help researchers extract useful entity information from the vast amount of ancient books and documents efficiently.
ECEM, which is based on enhanced character embedding, explores to recognise entities in ancient literature and modern corpus. This algorithm not only captures context information and abundant knowledge by fine-tuning BERT, but also flexibly acquires morphological information generated through strokes. Extensive experiments are conducted to explore the recognition effect of enhanced character embedding on three datasets by setting parameters. The results indicate that the ECEM algorithm has a substantial improvement compared with the traditional models. The proposed algorithm also gives guidelines for the future research in this domain.
Although this paper has addressed some problems, there is still something untouched in the model. The size of training set will lead to the out-of-vocabulary problem. For example, given a sentence “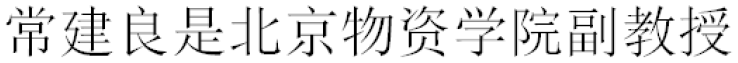 (Chang Jianliang is an associate professor of Beijing Wuzi University)”. If the organisation name “
(Chang Jianliang is an associate professor of Beijing Wuzi University)”. If the organisation name “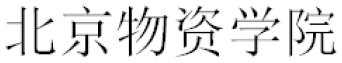 (Beijing Wuzi University)” is not in the training set, it would not be recognised by ECEM. When the training examples are less, it is difficult to capture sufficient morphological and contextual information. Therefore, ECME needs further improvement and exploration in the following research. We will plan to cut the training time without reducing accuracy, and the new neural network model will be utilised to solve Chinese NER problems.
(Beijing Wuzi University)” is not in the training set, it would not be recognised by ECEM. When the training examples are less, it is difficult to capture sufficient morphological and contextual information. Therefore, ECME needs further improvement and exploration in the following research. We will plan to cut the training time without reducing accuracy, and the new neural network model will be utilised to solve Chinese NER problems.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the National Key R&D Program of China (No.2018YFC0831500), the National Natural Science Foundation of China (No. 61972047), the Key Project of Natural Science Research of Universities in Anhui (No.KJ2020A0062), and the Key Project of University Outstanding Young Talents Project in Anhui (No.gxyqZD2018069). We are grateful to the anonymous reviewers for their careful reading.