
Abstract
Based on normal vector and particle swarm optimization (NVP), a point cloud registration algorithm is proposed by searching the corresponding points. It provides a new method for point cloud registration using feature point registration. First, in order to find the nearest eight neighbor nodes, the k-d tree is employed to build the relationship between points. Then, the normal vector and the distance between the point and the center gravity of eight neighbor points can be calculated. Second, the particle swarm optimization is used to search the corresponding points. There are two conditions to terminate the search in particle swarm optimization: one is that the normal vector of node in the original point cloud is the most similar to that in the target point cloud, and the other is that the distance between the point and the center gravity of eight neighbor points of node is the most similar to that in the target point cloud. Third, after obtaining the corresponding points, they are tested by random sample consensus in order to obtain the right corresponding points. Fourth, the right corresponding points are registered by the quaternion method. The experiments demonstrate that this algorithm is effective. Even in the case of point cloud data lost, it also has high registration accuracy.
Keywords
Introduction
In recent years, signal analysis and image processing have been booming. In particular, laser scanning technology has made great progress in obtaining three-dimensional (3D) point cloud model of physical objects and made point cloud become the mainstream data in 3D processing. High-precision scanning equipment can effectively obtain the detailed data of the physical objects. Due to the limitations of measuring instruments and environment, the data cannot be completed in one laser scan. Point cloud data should be obtained by scanning separately from different perspectives, and then point cloud data from multiple perspectives should be registered to obtain a complete point cloud model of physical objects. Therefore, point cloud registration is widely used in 3D reconstruction, reverse engineering, target recognition and other fields, and it is an important part in point cloud data processing. The accuracy of point cloud registration directly affects the quality of subsequent processing technology. 1
The existing point cloud registration methods can be divided into two types: one is the accurate positioning of the navigation system in the scanning process and the other is the accurate alignment of point clouds from different perspectives. The algorithm in this paper belongs to the second type.
The most classical algorithms in the automatic registration of point cloud model are iterative closest point (ICP) and its improved algorithms. They are methods based on point-to-point or point-to-surface search technology, and point cloud registration is completed by minimizing the distance between point clouds. ICP is easy to implement, but it requires that there is a constraint between two point clouds, and the positions of the two point clouds are relatively close. The algorithm results depend on the initial position of the point cloud, which is easy to cause the problem of rapid convergence to local optimal. Therefore, there are a lot of works to do to improve the ICP algorithm.2–4
Non-feature registration
One of the improvements in the ICP algorithm is non-feature registration. The non-feature registration does not need to extract the feature data. It aims at improving registration efficiency. Many scholars have proposed non-feature registration algorithm. Some have studied the key points or key areas how to detect to reduce the mismatch points,5–7 some have studied the corresponding points how to search and some speed up the operation of ICP. 8
Feature registration
The other improvement in the ICP algorithm is to feature registration. They usually study the rough registration first and then study the non-rough registration. Rough registration is a registration method without any initial position information at all. The main purpose of this method is to quickly estimate a general point cloud registration matrix with unknown initial conditions. The whole calculation process requires a high calculation speed, and the accuracy of the registration is not too high, such as the method based on local feature description, based on global search strategy, through statistical probability and so on.
The method based on local feature description is to extract the neighborhood geometric features of source and target point clouds. The corresponding points between them can be quickly determined by geometric features to achieve registration.
The representative algorithm based on global search strategy is sampling consistency algorithm. The algorithm randomly selects corresponding points with the same geometric features between source and target point clouds and obtains the optimal solution by calculating the transformation relationship of corresponding points.
Statistical probability method based on normal distribution is that according to the normal distribution of point cloud, the corresponding points are determined so as to calculate the transformation relationship between target and source point clouds.
In above strategy, the method based on feature point matching is popular. There are a lot of research achievements in feature registration.9,10 The method which was proposed by Kase et al. 11 is to extract effective feature correspondence points, determine the initial position of two point clouds and then use ICP algorithm to non-rough registration. However, feature points are often defined as points with large-scale surface gradient. A single feature point often has similar geometric features, so using a single feature point to rough registration ignores the local structural information of feature points, which is prone to mismatching and affects the precision of non-rough registration.
In order to solve the problem of the single feature point, a point cloud registration algorithm based on normal vector and particle swarm optimization (NVP) is proposed. This method is the continuation of the previous article. 12 The previous article mainly focused on the noise of input point cloud and the accuracy of registration. The particle swarm optimization (PSO) in the previous article was used to search the rotation matrix. It was with randomness. In order to solve the randomness, the method of finding the corresponding points is proposed in this paper and then the registration is achieved by quaternion method. The main contributions are shown as shown follows:
In order to extract multiple feature data, the k-d tree is employed to find the nearest eight neighbor nodes. Then, the normal vector of the node and the distance between the point and the center gravity of the eight neighbor nodes are defined. The feature data will not change by the geometric transformation; they are regarded as the feature data of the node.
In order to search the corresponding points with the same feature data between the two point clouds, PSO is used. The fitness function is that the normal vector of the node in the original point cloud is the most similar to that in the target point cloud and the distance between the point and the center gravity of eight points of the node is the most similar to that in the target point cloud.
After obtaining the corresponding points, they are tested by random sample consensus (RANSAC) and then the registration is employed by quaternion method.
The experiments demonstrate that this algorithm is effective. Even in the case of point cloud data lost, it also has high registration accuracy.
Related work and results
Definition of NVP
We propose NVP to find the corresponding points to achieve registration. The main process is demonstrated in Figure 1. First, it builds k-d tree in the point cloud to search the nearest eight neighbor nodes and uses the neighbor nodes to calculate the normal vector of the point node and the distance between the point and the center gravity of the eight neighbor nodes, which are as two feature data of each node. Second, PSO is used to search the corresponding points. The fitness function is that the normal vector of the node in the original point cloud is the most similar to that in the target and the distance between the point and the center gravity of eight points of the node is the most similar to that in the target point cloud. After obtaining the corresponding points, they are tested by RANSAC in order to obtain the right corresponding points. Finally, point cloud registration is realized by quaternion method.
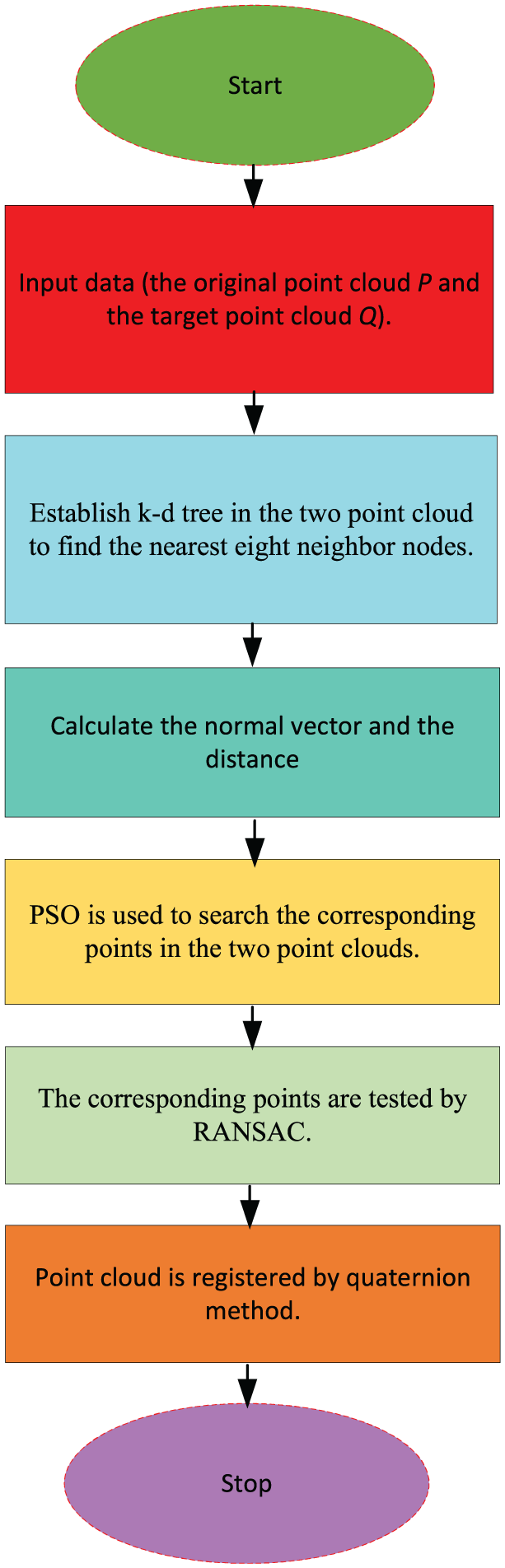
The process of NVP.
K-d tree
K-d tree is short for k-dimensional tree. It is a kind of data structure that divides k-dimensional data. It is mainly used in the key data search of multidimensional space, such as range search and nearest neighbor search.13,14K-d tree is used by scale-invariant feature transform (SIFT) when matching feature points. Feature point matching is actually a problem of similarity retrieval between high-dimensional vectors by distance function. How to find the nearest neighbor of the query point quickly and accurately is a hot issue. Many scholars have proposed their algorithms. K-d tree is one of the algorithms which is applied widely. There are two ways to search the similarity in an index structure: one is the range search and the other is the nearest neighbor search. The range search is finding all the data in the data set whose distance from the query point is less than the threshold value. The nearest neighbor search is finding k data from the data set closest to the query point. If k is set to 1, it is the nearest neighbor search.
There are two types of feature matching algorithms. One is the linear scanning method. The points in the data set are compared with the query points one by one. It does not establish any data structures and the search efficiency is very low. The other is to establish data index and then to do the feature match quickly. Because the actual data generally present a cluster-like clustering form, the retrieval speed can be greatly accelerated by the effective index structure. K-d tree belongs to the second type. The main idea is to divide the search space into different levels.
The search space is to find the nodes in axis-aligned rectangle by performing the following three steps: the first step is to check whether point in node lies in given rectangle, the second is to recursively search left/bottom (if any could fall in rectangle) and the third is to recursively search right/top (if any could fall in rectangle).
K-d tree is used in this paper to establish the data structure in point cloud to search the nearest eight neighbor nodes. After finding the nearest eight neighbor nodes, the normal vector of the point node, the distance between the point and the center gravity of the eight neighbor nodes can be calculated.
The normal vector
One of the essential features of the node in point cloud is the normal vector. The accurate and high-quality point-based drawing methods not only depend on the normal vectors, but the precise reconstruction results also need the precise normal vectors. The reconstruction algorithm especially needs normal vector aggregation, such as multi-level partition of unity (MPU), implicit surface reconstruction algorithm and detection and recovery of sharp features.
The point cloud normal vector calculation methods can be divided into three types. They are methods based on local surface fitting, Delaunay or Voronoi and robust statistics. The point curvature calculation in this paper belongs to the first type. The method was first proposed by Hoppe 15 when he studied the surface reconstruction algorithm based on signed distance function. Assume that the plane of the point cloud is smooth everywhere. The steps of calculating curvature are shown as follows.
Suppose
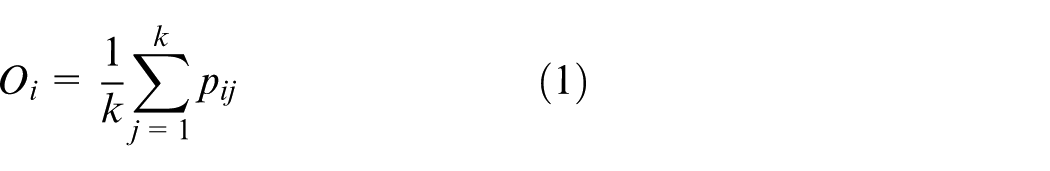
The covariance matrix of
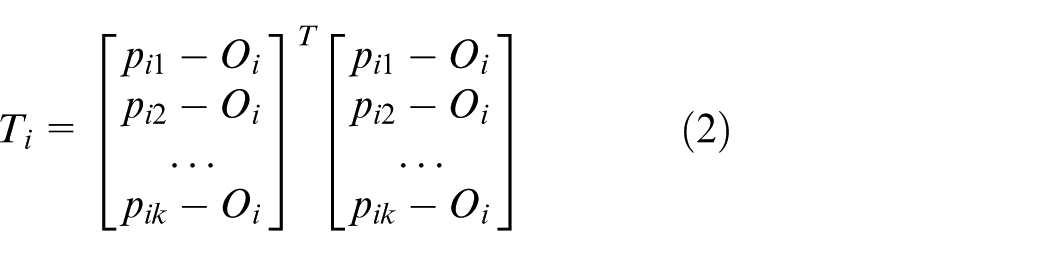
where
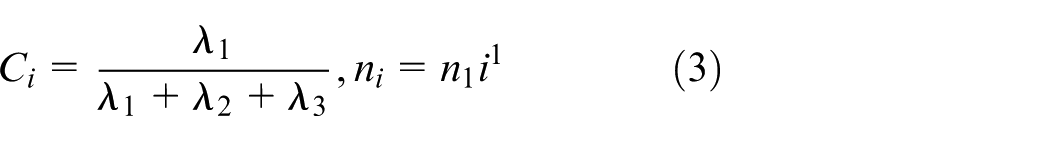
By definition, it is shown that greater the change of surface is, the larger the point curvature is (see Figure 2).
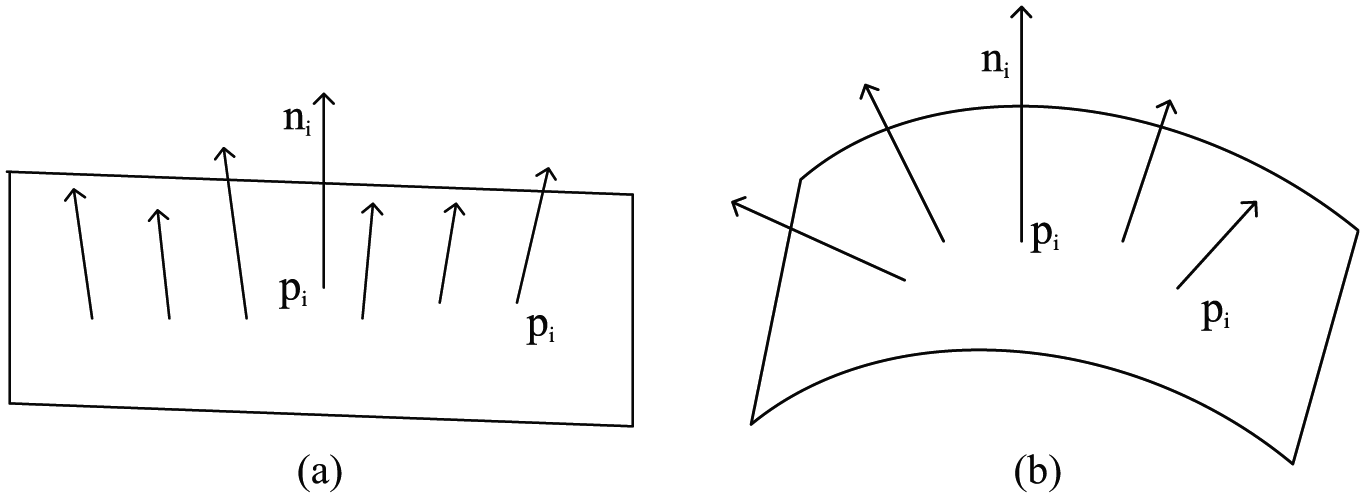
Normal vectors from different surfaces: (a) the flat surface and (b) the non-flat surface.
Distance between the point and its neighbor center of gravity
Another feature of the node in point cloud is the distance between the point and its neighbor center of gravity. It is defined as follows (see Figure 3)
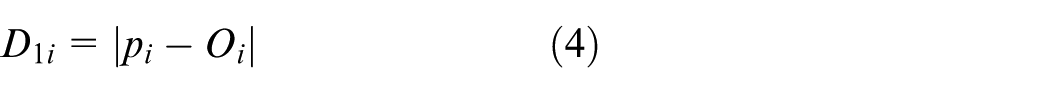
Different distances from the point to its neighbor center of gravity: (a) boundary point and its neighbor gravity center and (b) interior point and its neighbor gravity center.
PSO
After obtaining the two feature data of the node, we need to find corresponding points with the same feature data between the two point clouds. Therefore, we resort to PSO. 16 PSO and genetic algorithm (GA) are widely used in many fields.17–19 PSO is a kind of evolutionary algorithm and is similar to the simulated annealing algorithm. It starts from the random solution and seeks the optimal solution through iteration. It evaluates the quality of the solution through fitness and is simpler than GA. Crossover and mutation operation are not needed in PSO. This algorithm has attracted academic attention because of its advantages such as easy implementation, high accuracy and fast convergence. The formula of PSO is as follows
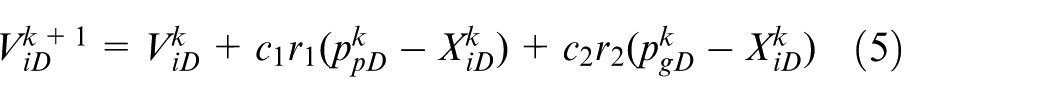

where
The particle of PSO in this paper starts by calculating the two feature data (the point curvature, the distance from the point to its neighbor center of gravity). The particle from the target point cloud moves in the search space by setting to zero or to small random values. If the search criterion meets, the particles’ velocities are no more updated. The search criterion is that the normal vector of the node in the original point cloud is the most similar to that in the target point cloud, and the distance between the point and the center gravity of eight neighbor points of the node is the most similar to that in the target point cloud. The main flow is shown in Figure 4.
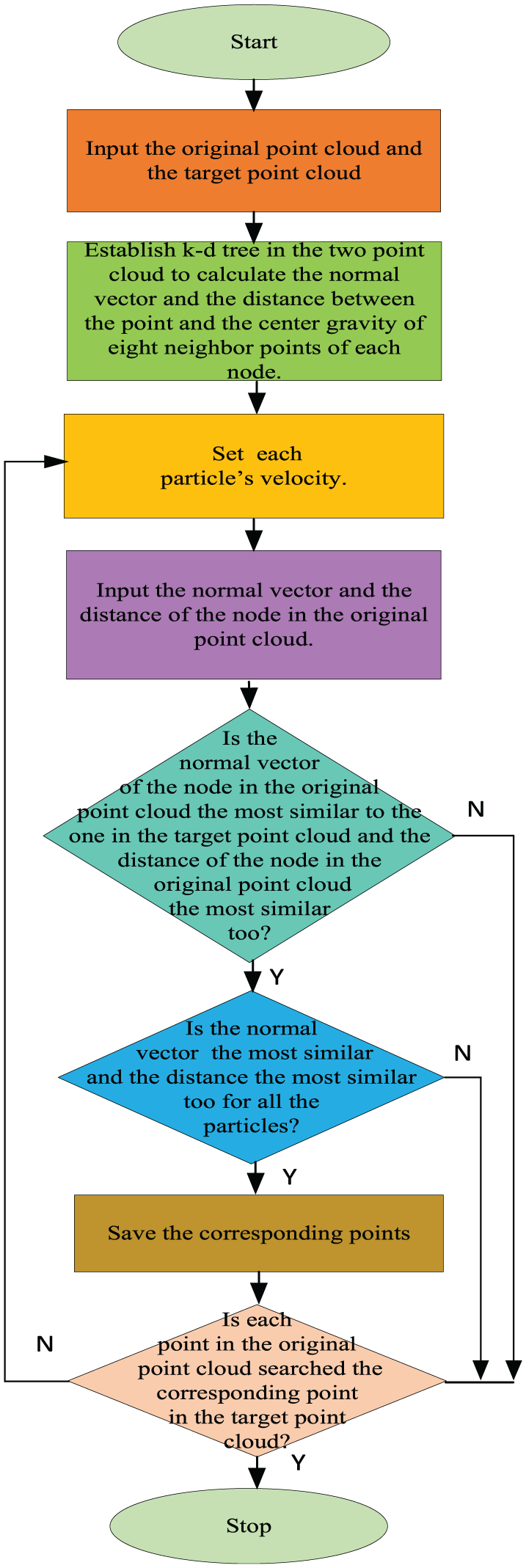
The PSO flow diagram.
RANSAC
There are, usually, outlier data among the corresponding points. Therefore, the RANSAC is employed in searching the right corresponding points. The algorithm was first proposed by Fischler and Bolles 20 in 1981. RANSAC is based on the following assumptions:
Data are composed of reasonable points, for example, the distribution of data can be explained by some model parameters.
Outlier data do not fit the model.
Other data are noise.
There are several reasons to generate the outlier data, such as the extreme value of noise, wrong measurement method and incorrect assumptions about data. RANSAC is used in searching the right corresponding points in this paper; the main steps are shown in Algorithm 1.

Quaternion method
After obtaining the right corresponding points, point cloud registration is realized by quaternion method. It was proposed by Horn 21 in 1987. He used a quaternion-based least square method to solve the motion parameters between adjacent point clouds. ICP, which is the most widely used in point cloud registration, adopts this method too. The algorithm flow is as follows.
Suppose
The center gravity of the two point clouds is defined as follows

Gravity-centralize the two point clouds.
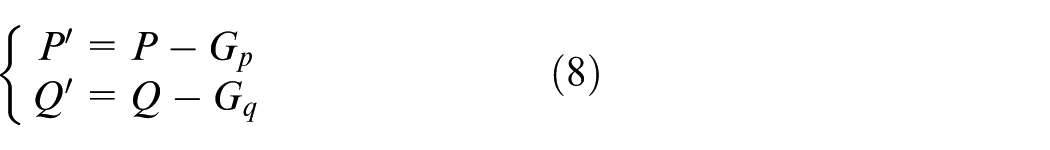
Construct the covariance matrix.
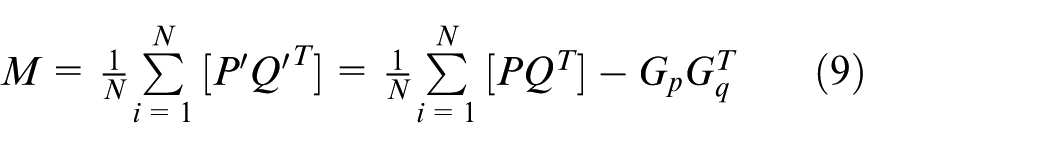
Construct the symmetric matrix by the covariance matrix
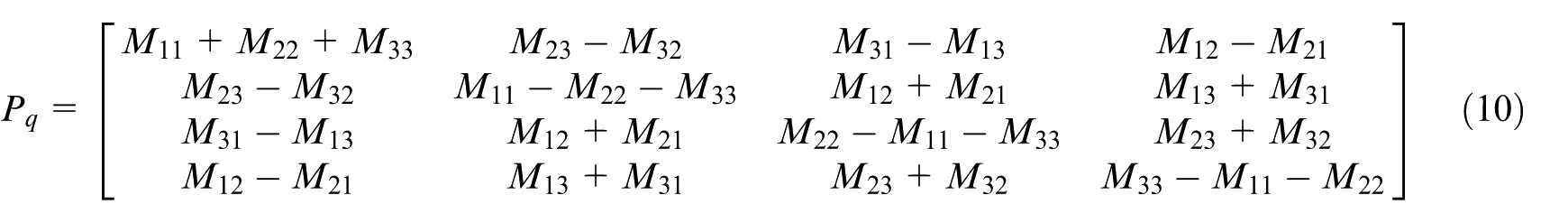
Find and calculate the maximum eigenvalue of

where
Construct the rotation matrix
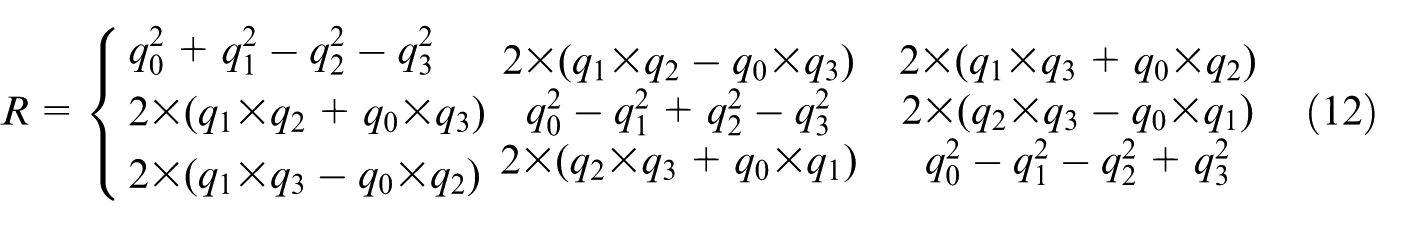
Calculate the translation matrix
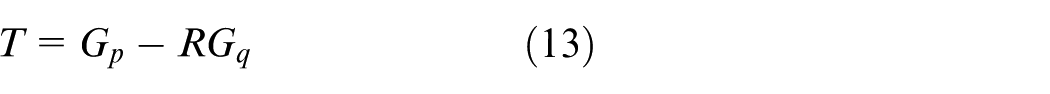
The experimental simulation
The performance of this algorithm is made in MATLAB and the data sets are used from Stanford’s experimental database http://graphics.stanford.edu/data/3Dscanrep/.
The registration accuracy test
Two models (“cow,”“feet” of “man”) are adopted in this experiment (see Figure 5): the red one is the original point cloud and the blue one is the target point cloud.
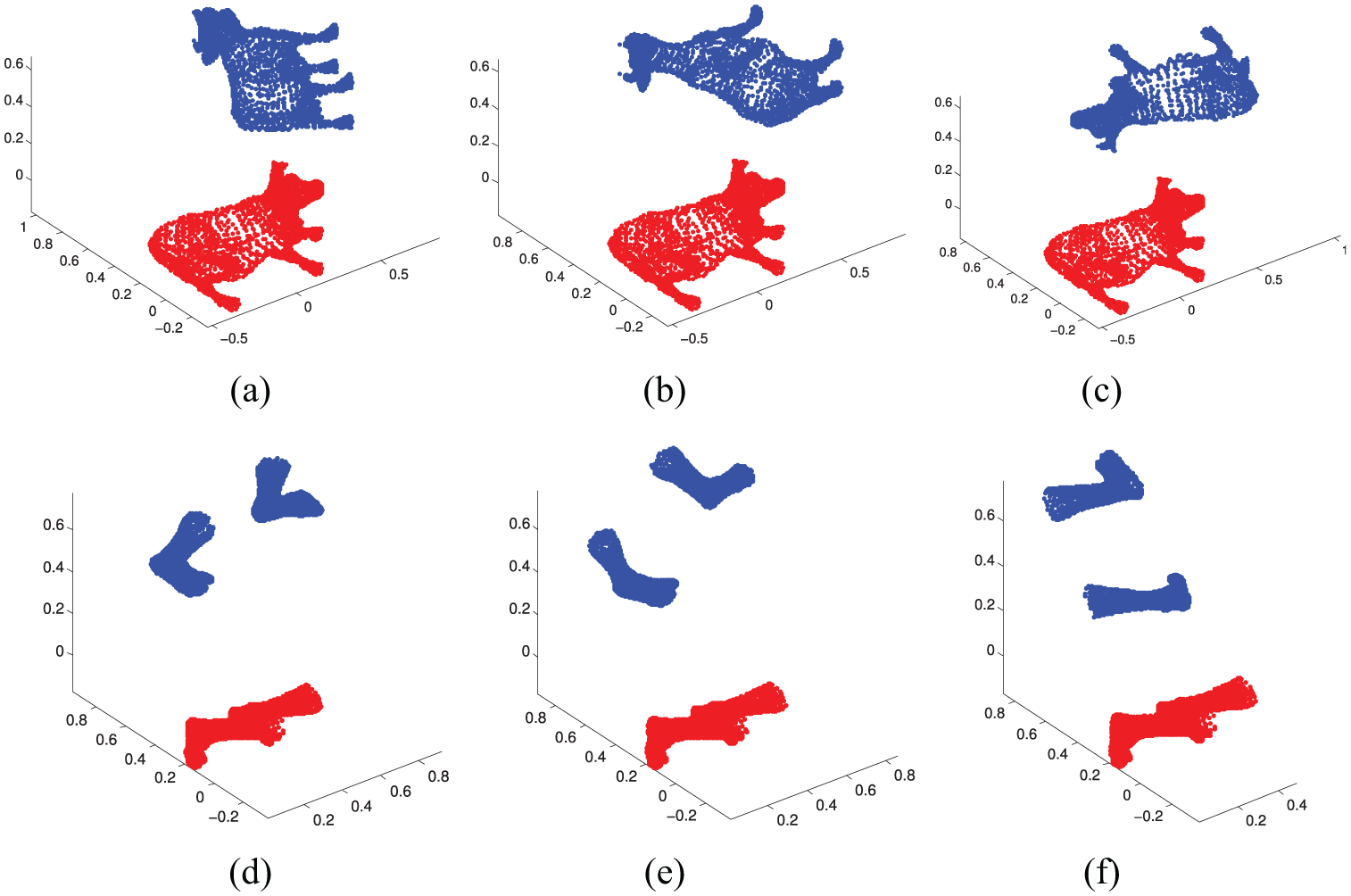
Data sets: (a) Cowview1, (b) Cowview2, (c) Cowview3, (d) Feetview1, (e) Feetview2 and (f) Feetview3.
In order to further test the performance of NVP, the mean square error (MSE) is used in the experiment. The formula is as follows
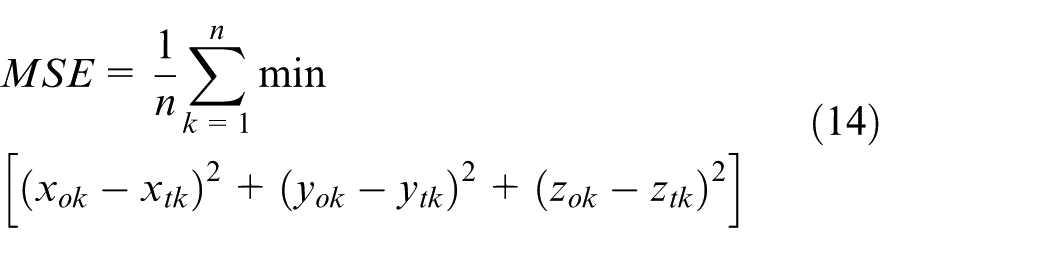
where

After obtaining the corresponding points, they are tested by RANSAC (see section “RANSAC”) and then point cloud is registered by quaternion method (see section “Quaternion method”).
Point cloud registration without data lost
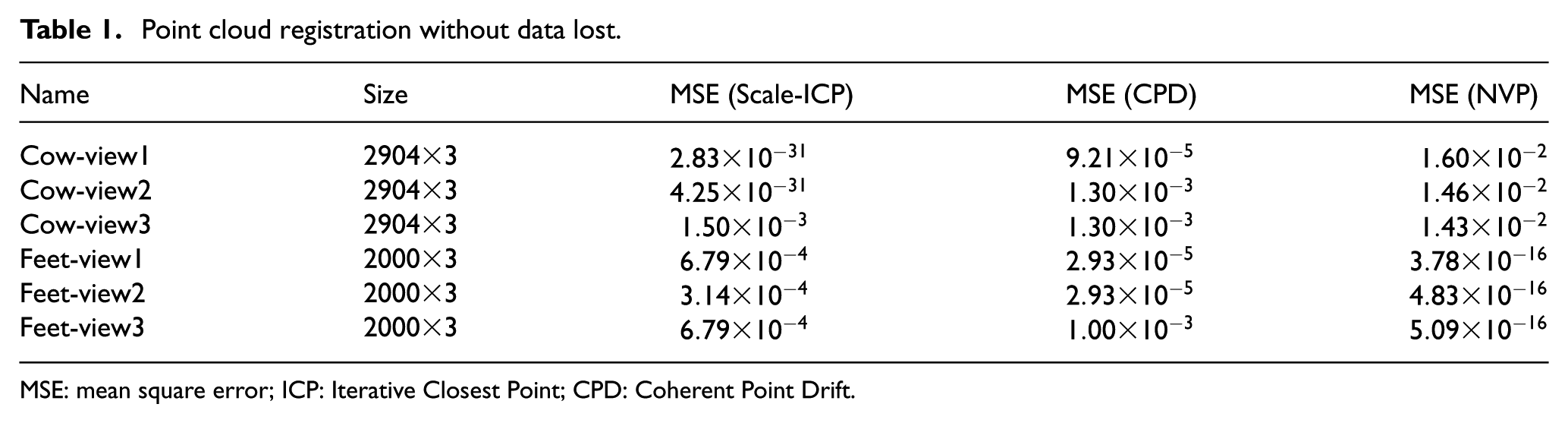
The point cloud registration without data lost is that the size of original point cloud is the same as the target. The experiment is made by comparing NVP with the descriptor Scale-ICP 22 and CPD (Coherent Point Drift). 23
The results of the experimental data set are shown in Figures 6 and 7, and the size of the experimental data sets and the MSE are shown in Table 1. It can be seen from the results that the Scale-ICP registration accuracy depends on the initial position, but the accuracy is very high if the good initial position is provided. The CPD does not depend on the initial position, but it is sometimes not workable. The description which we proposed can work well and sometimes show high registration accuracy.
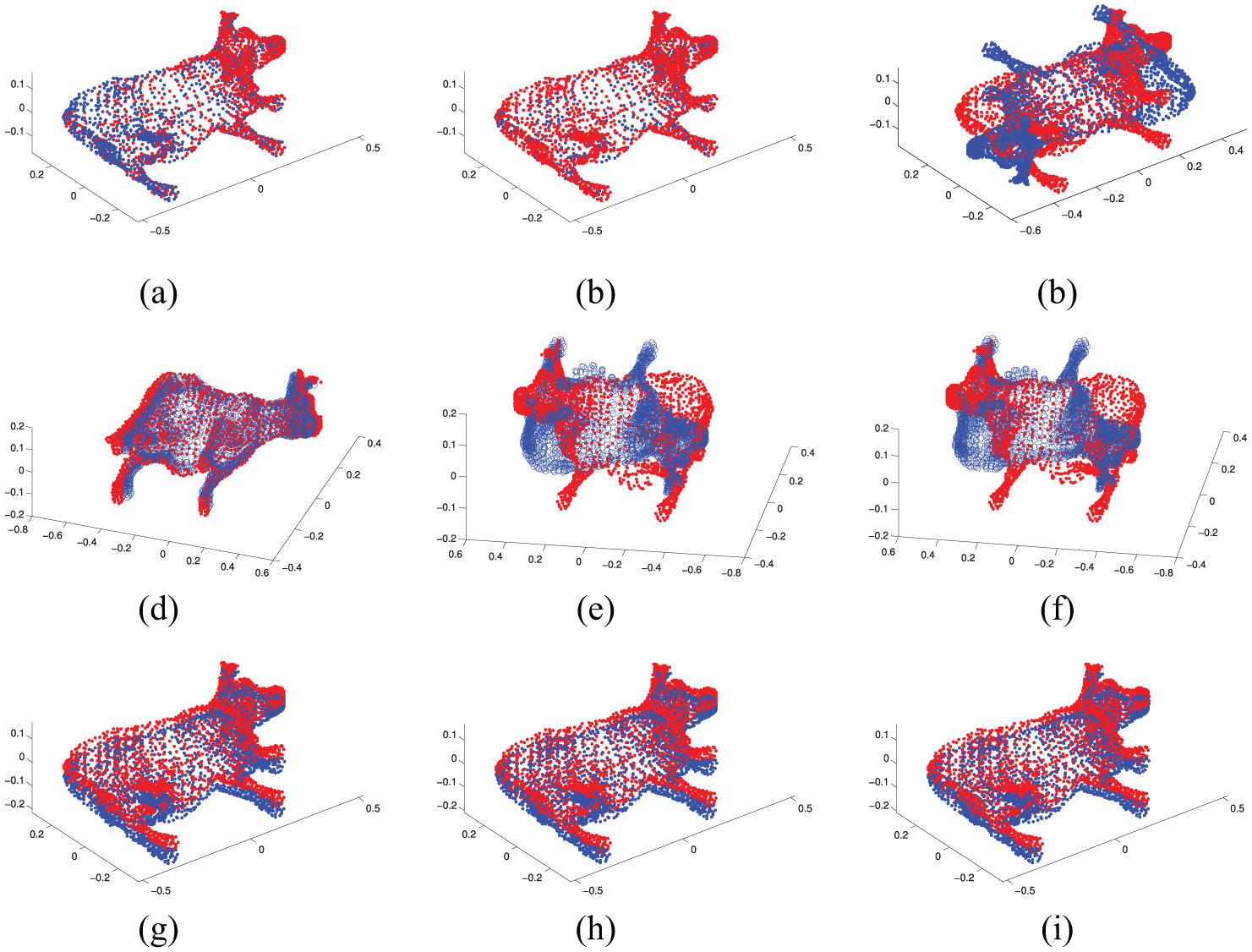
Point cloud registration without data lost: (a) Cow1 (Scale-ICP), (b) Cow2 (Scale-ICP), (c) Cow3 (Scale-ICP), (d) Cowview1 (CPD), (e) Cowview2, (f) Cowview3 (CPD), (g) Cowview1 (NVP), (h) Cowview2 (NVP) and (i) Cowview3 (NVP).
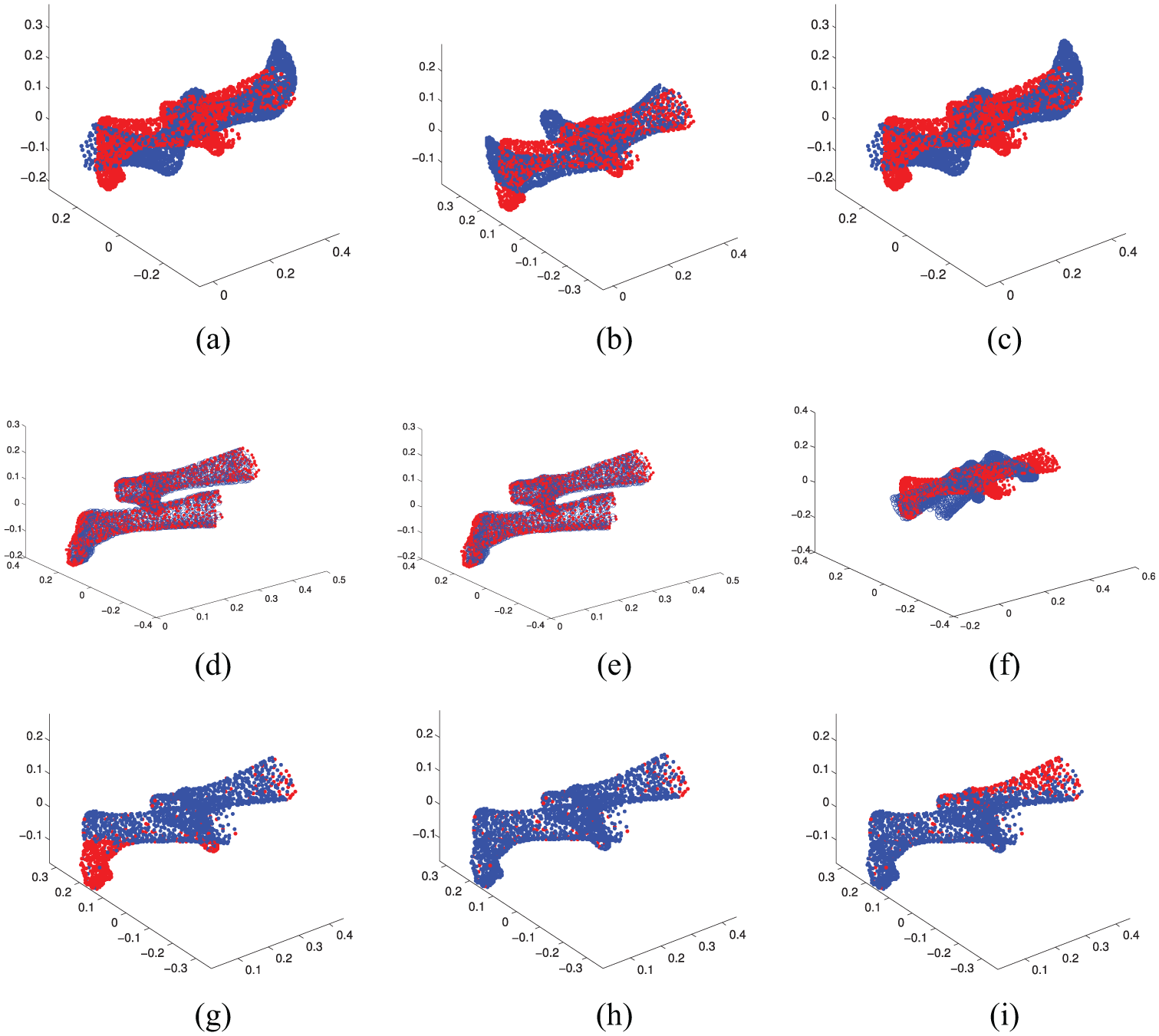
Point cloud registration without data lost: (a) Feet1 (Scale-ICP), (b) Feet2 (Scale-ICP), (c) Feet3 (Scale-ICP), (d) Feetview1 (CPD), (e) Feetview2 (CPD), (f) Feetview3 (CPD), (g) Feetview1 (NVP), (h) Feetview2 (NVP) and (i) Feetview3 (NVP).
Point cloud registration without data lost.
MSE: mean square error; ICP: Iterative Closest Point; CPD: Coherent Point Drift.
Point cloud registration with data lost
The point cloud registration with data lost is that the size of original point cloud is not same as the target. A random data loss experiment is tested by comparing NVP with the descriptor Scale-ICP 22 and CPD. 23 The results of the experimental data set are shown in Figures 8 and 9 and Table 2. It can be seen from the results that the Scale-ICP registration and CPD are not workable, but the NVP still works well when facing such challenging case.
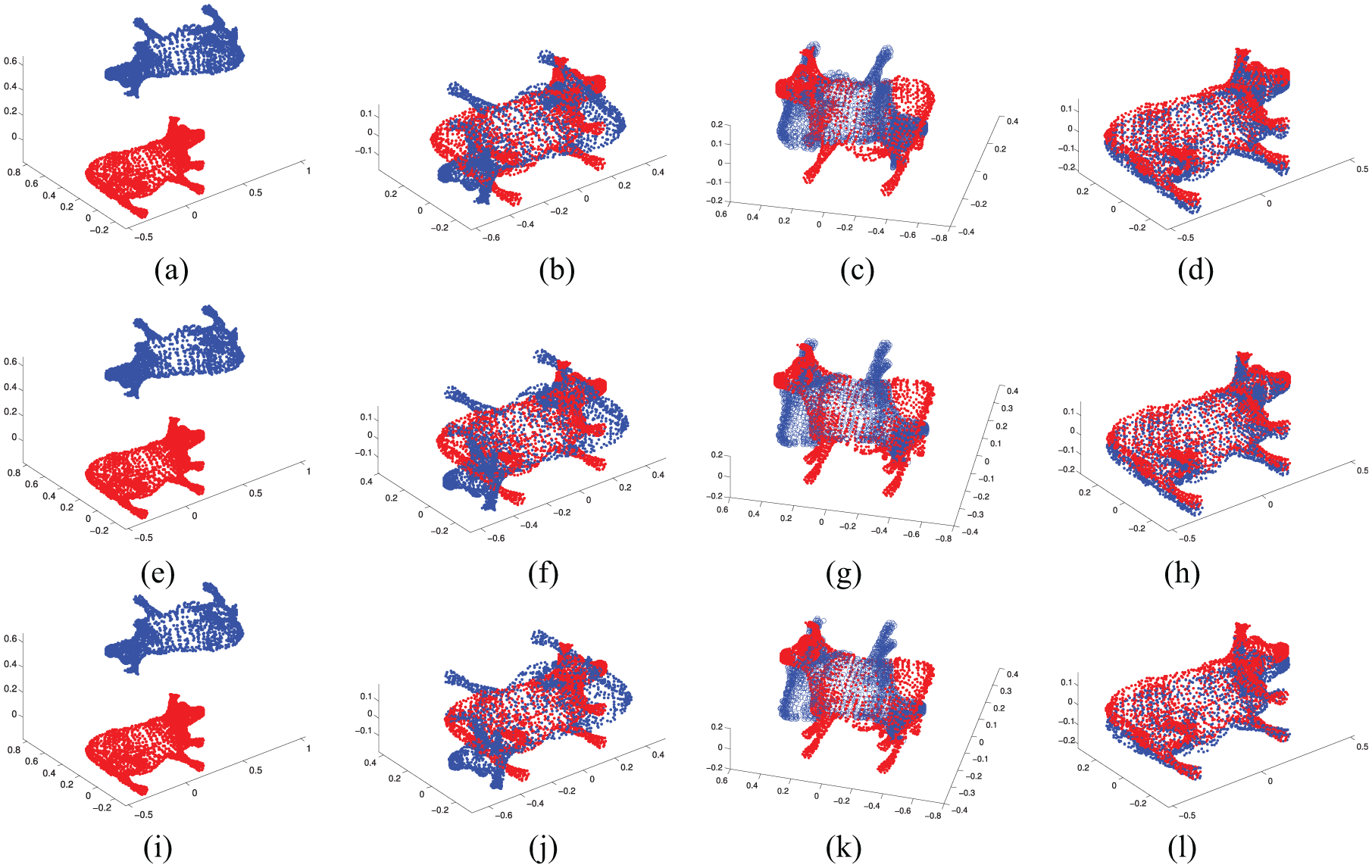
Point cloud registration with data lost: (a) Cow (data lost 5%), (b) Result (Scale-ICP), (c) Result (CPD), (d) Result (NVP), (e) Cow (data lost 15%), (f) Result (Scale-ICP), (g) Result (CPD), (h) Result (NVP), (i) Cow (data lost 25%), (j) Result (Scale-ICP), (k) Result (CPD) and (l) Result (NVP).
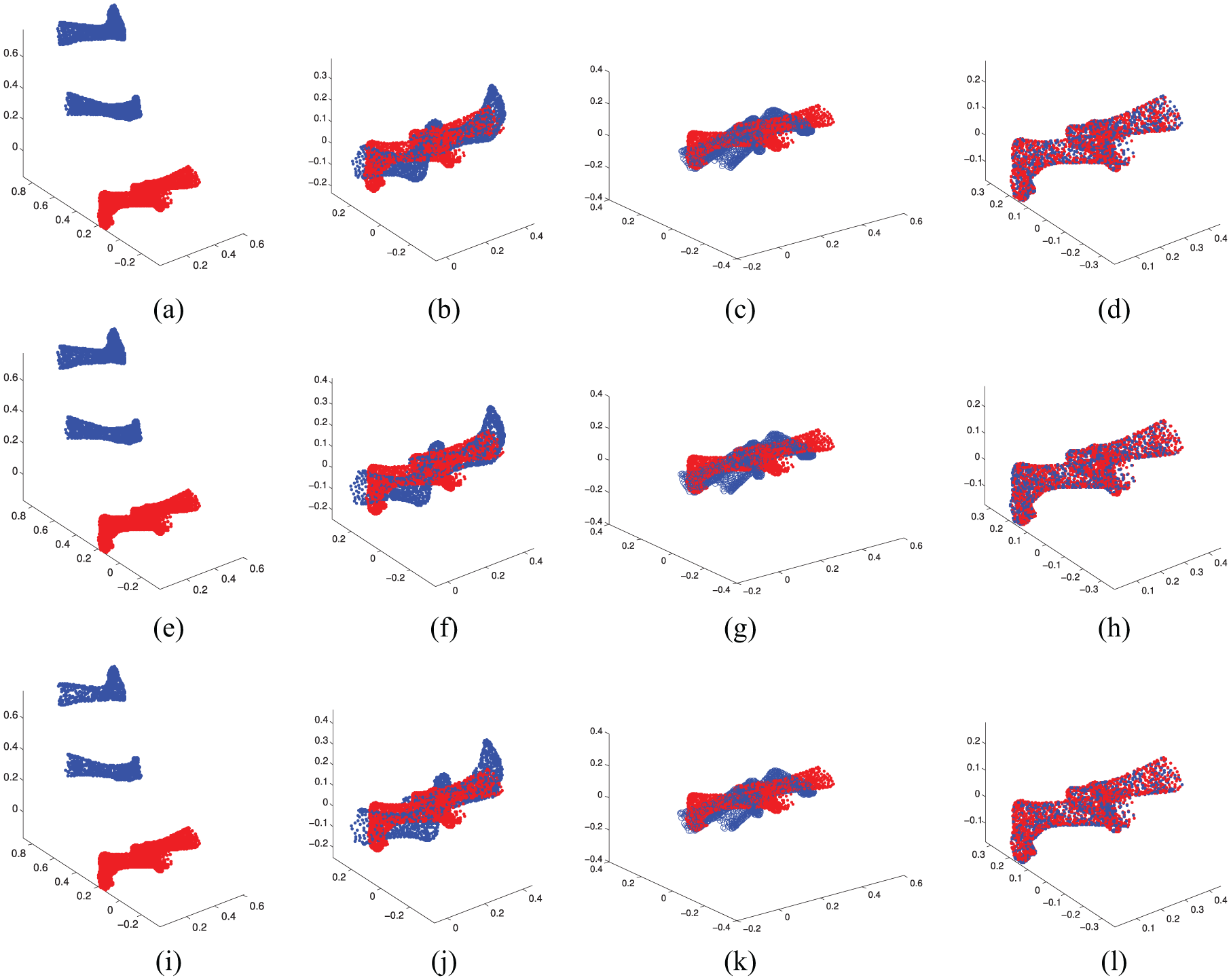
Point cloud registration with data lost: (a) Feet (data lost 5%), (b) Result (Scale-ICP), (c) Result (CPD), (d) Result (NVP), (e) Feet (data lost 15%), (f) Result (Scale-ICP), (g) Result (CPD), (h) Result (NVP), (i) Feet (data lost 25%), (j) Result (Scale-ICP), (k) Result (CPD) and (l) Result (NVP).
Point cloud registration with data lost.
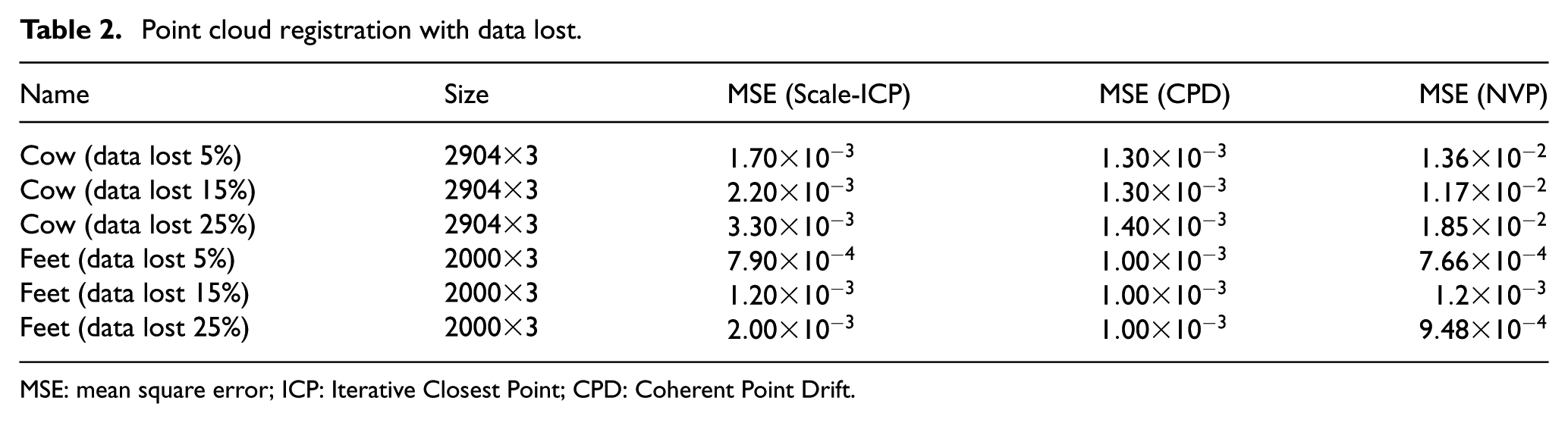
MSE: mean square error; ICP: Iterative Closest Point; CPD: Coherent Point Drift.
Conclusion
Point cloud registration algorithm based on normal vector and particle swarm optimization is proposed in this paper. It provides a new method for point cloud registration using feature point registration. First, it is given a method on how to extract the feature data of each point in the point cloud, and the feature data are used to search the corresponding points in two point clouds in PSO. Second, the corresponding points are tested by RANSAC to obtain right corresponding points. After receiving the right corresponding points, the original point cloud is transformed to the target by the quaternion method. The experiments demonstrate that this algorithm is effective. Even if the data are lost, it still works well.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This work was jointly supported by National Natural Science Foundation of China (grant no. 11705122), Department of Building and Real Estate of The Hong Kong Polytechnic University, the General Research Fund (grant no. BRE/PolyU 152099/18E) entitled “Proactive Monitoring of Work-Related MSD Risk Factors and Fall Risks of Construction Workers Using Wearable Insoles” and Natural Science Foundation of The Hong Kong Polytechnic University (grant no. G-YW3X).