
Abstract
The prescribed performance control of a morphing aircraft with variable sweep wings is investigated based on switched nonlinear systems and reinforcement learning. Switched nonlinear systems in lower triangular form are first adopted to describe the longitudinal altitude motion, and an error transformation is applied to handle the prescribed performance bound. Then, the designed controller is divided into the basic part and supplementary part. For the basic part, the backstepping method with involvement of the modified dynamic surface control technique is utilized to avoid the “explosion of complexity” problem. Improved disturbance observers inspired from the idea of extended state observer are then designed to estimate the disturbances and combined with radial basis function neural networks to develop the common virtual control laws. Moreover, by using the error variables defined in the backstepping design, the reinforcement learning–based supplementary part controller is devised with the critic-action neural network structure, which can adjust its parameters online and further decrease the altitude tracking error. It is proved that all signals of the closed-loop system are uniformly ultimately bounded, and the prescribed performance bound for convergence of the altitude tracking error can be satisfied. Finally, comparative simulations demonstrate the effectiveness of the proposed control approach.
Keywords
Introduction
The morphing aircraft can alter its aerodynamic configuration to expand mission capabilities and obtain optimal flight performance.1–3 The change in aircraft geometrical shape resolves performance conflicts between high-speed and low-speed regimes. However, the large variations in mass distribution and applied aerodynamic forces during the morphing process may cause unstability of the aircraft, together with internal uncertainties and external disturbances. Hence, compared with traditional flight vehicles, the control of morphing aircraft is more challenging and has been explored by the worldwide researchers in recent years.4,5
The extant research on the morphing aircraft control mainly focuses on the longitudinal dynamics, where several representative control methods have been investigated based on linear parameter varying (LPV) model or general nonlinear systems. An inner loop linear quadratic controller is combined with outer loop gain-scheduled controller in Yue et al. 6 to guarantee stability. The linear matrix inequalities and sliding mode–based approaches are investigated in He et al. 7 and Wen et al. 8 for the LPV model, respectively. A high-order chained differentiator is combined with neural networks (NNs) to determine the control input in Wu et al., 9 where a coordinate transformation is adopted to obtain normal form of the aircraft motion model. The adaptive dynamic surface control is proposed in Wu et al. 10 to deal with input–output constraints via a barrier Lyapunov function, where system uncertainties are approximated by NNs. The constraints on active region of the NNs are further relaxed in Wu et al. 11 by a smooth switching between the neural controller and robust controller. He et al. 12 adopt NNs to deal with the model uncertainties and design a disturbance observer to attenuate the effects of the disturbances of a flapping wing micro aerial vehicle.
It is noted that the aforementioned LPV model–based approaches may degrade the control performance when the nonlinearities are severe. Meanwhile, the approximation of the variations in mass distribution and aerodynamic forces is difficult by a single NN in Wu et al.9–11 due to the time-varying characteristics. In contrast, switched systems provide a powerful tool for modeling of morphing aircraft dynamics, where the switching law describes the morphing process, and the subsystems correspond to the specific configurations along the transition trajectory. The longitudinal dynamics of a morphing aircraft with variable sweepback wings is approximated by uncertain switched linear systems in Wang et al.,
13
where a robust state feedback controller is designed to guarantee finite-time boundedness of the closed-loop system. Switched LPV models in the continuous domain are established in Jiang et al.,
14
and the smooth switching control problem is investigated via overlapped scheduled parameter subsets. The non-fragile
Considerable progress has been made in stability analysis and controller design for switched nonlinear systems during the past decade,17–21 where the studied control schemes mainly deal with stability of the closed-loop system and do not address the performance of tracking errors. Recently, the prescribed performance control proposed in Bechlioulis and Rovithakis22–24 and developed for various classes of nonlinear systems in previous studies25–27 has been extended to switched nonlinear systems. The main idea of prescribed performance control is coordinate transformation, and the convergence of tracking error can then be guaranteed with prescribed decay rate, maximum overshoot and steady value. The prescribed performance control of switched nonlinear systems in non-strict-feedback form is investigated in Li et al., 28 where semi-globally uniform ultimate boundedness is achieved. A prescribed performance adaptive controller is developed in Li and Xiang 29 to deal with the input saturation and unmodelled dynamics of a class of switched nonlinear systems. Mode-dependent adaptive laws are devised in Zhai et al. 30 to reflect the switchings between subsystems, which is less conservative compared with the common adaptive laws. However, to our best knowledge, the related research on control of morphing aircraft via switched nonlinear systems has not been fully investigated yet. Besides, the extended state observer (ESO)-based control approach provides a universal way of dealing with disturbances,31,32 where the disturbances are regarded as an extended state estimated by the ESO and compensated for by the controller. It is noteworthy that the research on ESO for switched nonlinear systems is also rare.
However, reinforcement learning has been studied to find optimal control solutions for various classes of systems over the last few decades.33–35 The critic-action structure is commonly utilized in the reinforcement learning, where two agents called critic agent and action agent are adopted to estimate performance index and revise the control policy, respectively. The reinforcement learning control problems of nonlinear systems including partially and fully unknown dynamics are addressed in literature,36–38 where NNs are adopted to implement the algorithm. The reinforcement learning control has also been applied to robot manipulators, 39 hypersonic vehicles, 40 autonomous underwater vehicles 41 and so on. In particular, it is worth pointing out that Mu et al. 40 combine sliding mode control and reinforcement learning to solve the tracking problem of hypersonic vehicles, where a supplementary strategy is generated by the reinforcement learning approach to further reduce tracking errors and improve control performance. In view of the online learning and adaption merit, it is desirable to integrate the reinforcement learning into morphing aircraft controller design.
Motivated by the above considerations, this paper investigates prescribed performance control of morphing aircraft based on switched nonlinear systems and reinforcement learning, where the prescribed performance bound is handled by error transformation. The main contributions of our work are summarized as follows:
The longitudinal altitude motion of morphing aircraft is modeled as switched nonlinear systems in lower triangular form, and it provides an efficient way to cope with the variations in mass distribution and applied aerodynamic forces.
The designed controller is split into two parts: the basic part and supplementary part. For the basic part, the backstepping approach with integration of the dynamic surface control technique is exploited to eliminate the “explosion of complexity” problem. The disturbance observers inspired from the idea of ESO are designed and combined with the radial basis function (RBF) NNs to generate the common virtual control laws.
The critic-action NN structure of the reinforcement learning scheme is adopted to devise the supplementary part on the basis of tracking errors defined in the backstepping design. The weight updating algorithm of the established critic-action NN structure and related convergence analysis are provided. The improved control performance via generating a supplementary strategy is validated by comparative simulation studies.
The remaining part of this study is organized as follows. Section “Model description” states the modeling of morphing aircraft by switched nonlinear systems. Section “Controller design” presents the basic part of the controller based on the switched nonlinear systems and the supplementary part of the controller based on reinforcement learning. Comparative simulation studies are addressed in section “Numerical simulation,” and final conclusion is drawn in section “Conclusion.”
Notations
The notations in this paper are standard.
Model description
The morphing aircraft with variable sweep wings considered in this study is similar with the research in Wu et al.9–11 and the longitudinal motion model is formulated as 10
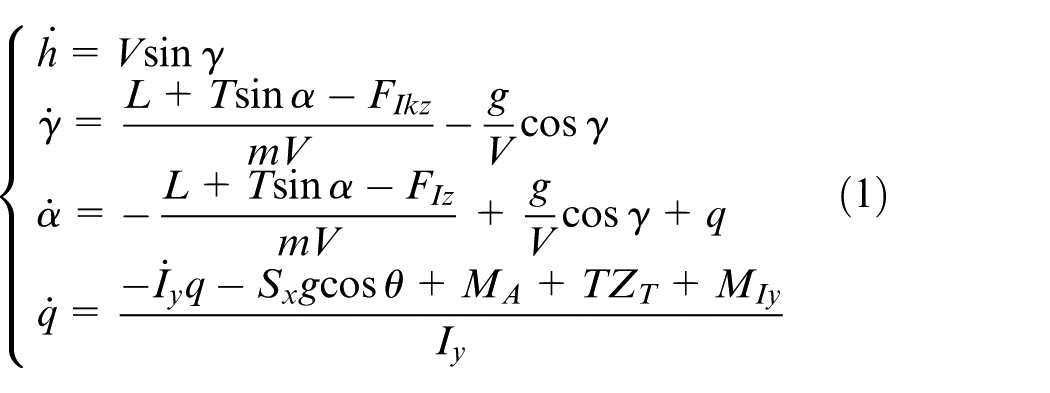
where
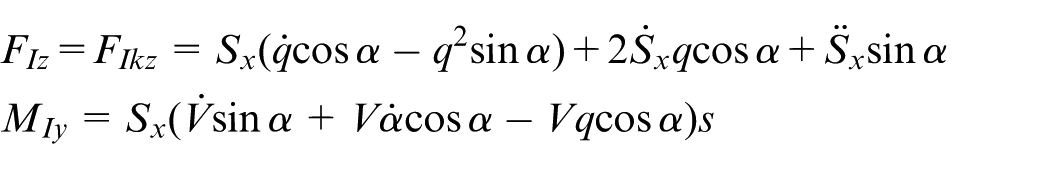
where
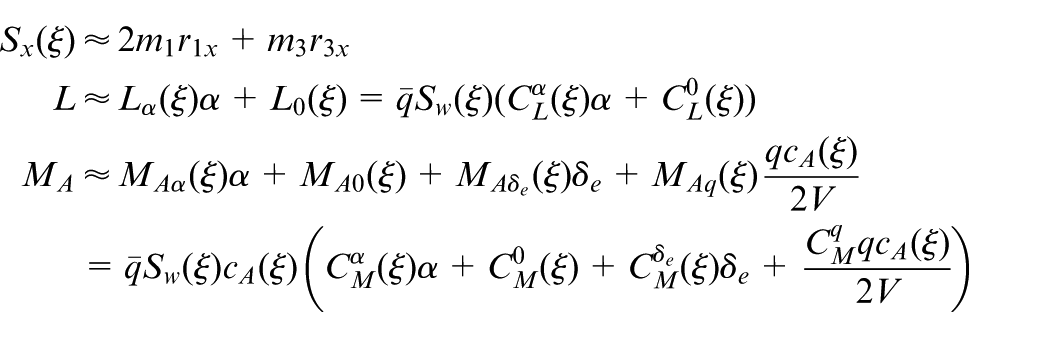
where
Assumption 1
The flight path angle
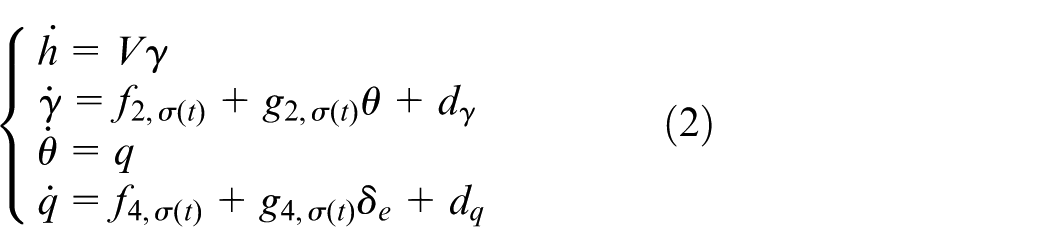
where
In this paper, the RBF NNs are applied to Equation (2) for obtaining common virtual control laws in the backstepping design procedure. For any continuous function
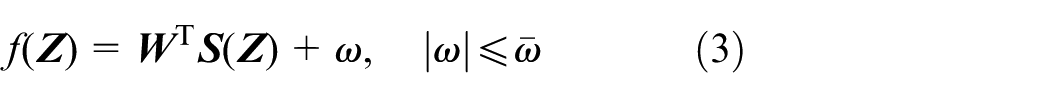
where
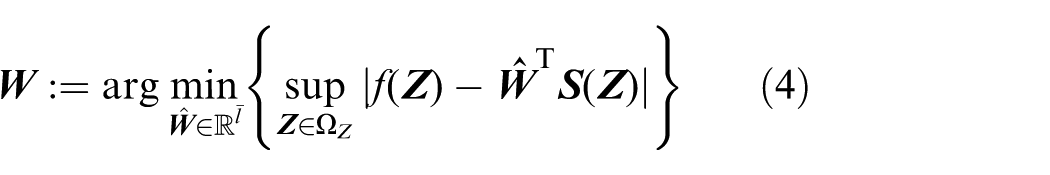
where
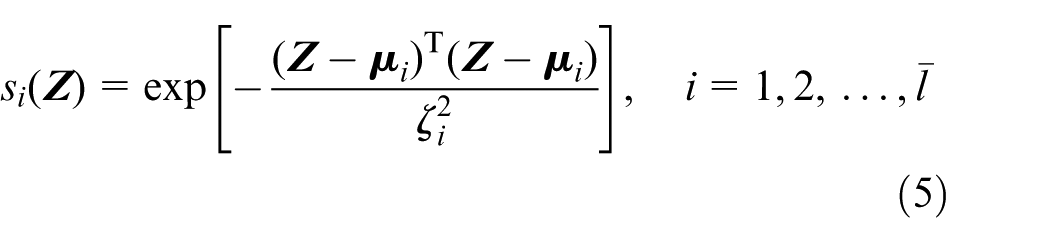
with
Lemma 1
The following inequality is satisfied for any
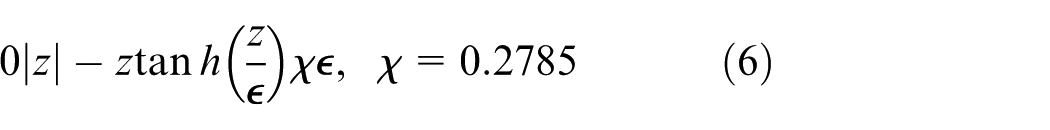
Controller design
The designed controller of this paper comprised two parts, that is,
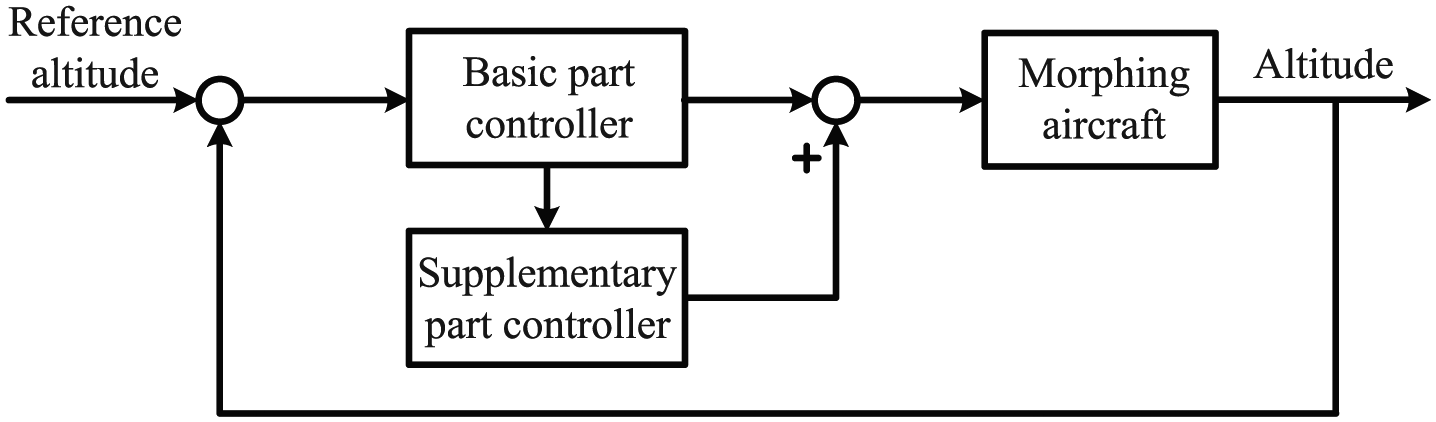
Structure diagram of the proposed controller.
Basic part design
The following assumptions are made for the switched nonlinear systems (2).
Assumption 2
The reference altitude
Assumption 3
The velocity
Assumption 4
The time derivatives of disturbances
Assumption 5
For any
Remark 1
Assumption 2 is rather general in the literature on aircraft longitudinal motion control.43,44 Assumption 3 is reasonable since the thrust force, drag force, and inertial force caused by morphing are indeed continuous and bounded. Assumption 4 is commonly adopted in extant references on disturbance observer design31,32,45 and facilitates the convergence analysis of the disturbance observer. Assumption 5 guarantees that the designed control laws are nonsingular 21 and can be satisfied by the model used in the numerical simulation.
The basic part of the controller is designed by the backstepping technique, which is described as follows.
Step 1. Define
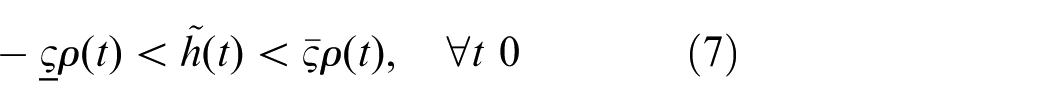
where

where
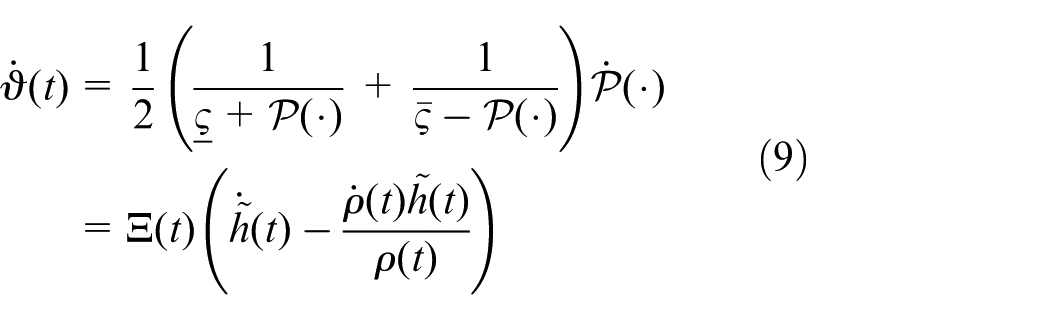
with
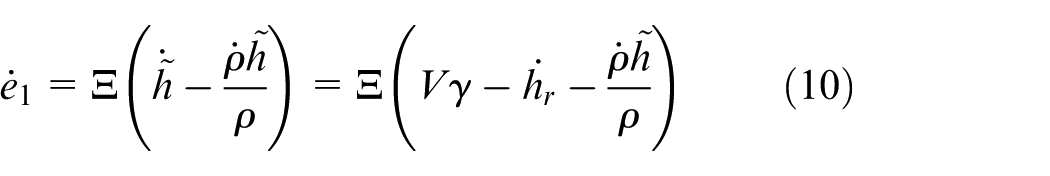
It is shown in Bechlioulis and Rovithakis
24
that the prescribed performance of altitude tracking error
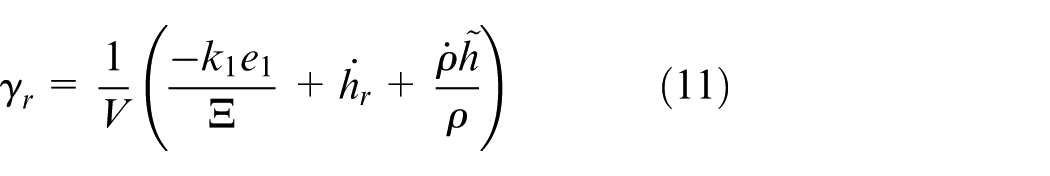
where

Define
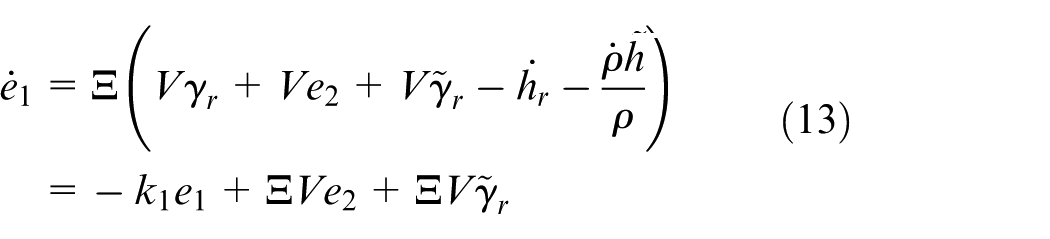
Choosing the following Lyapunov function candidate
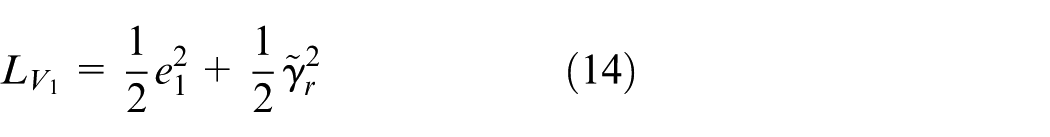
The time derivative of
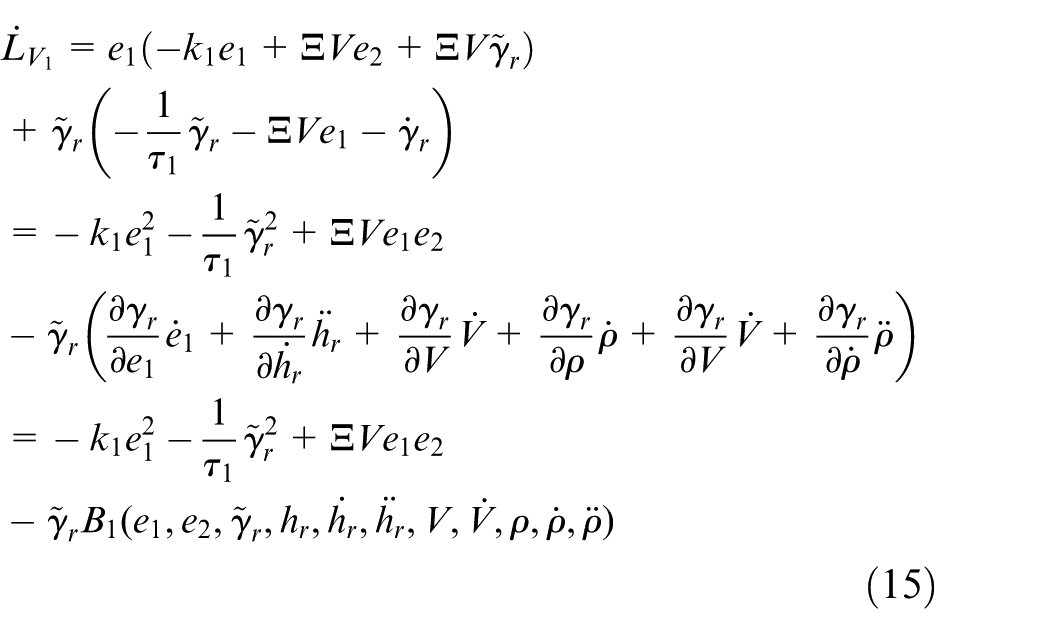
with
Step 2. Taking the time derivative of
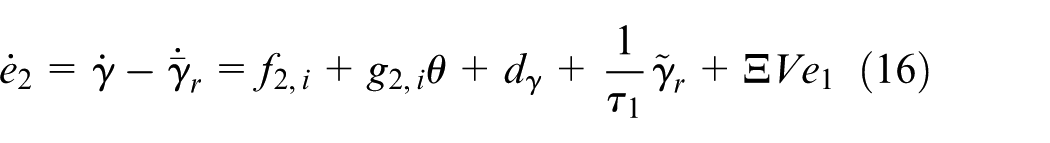
where
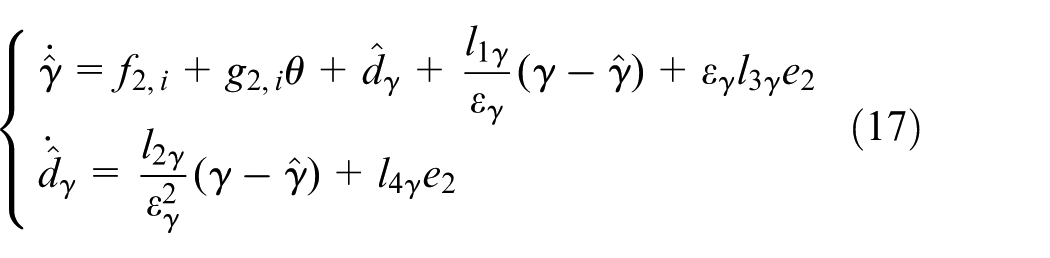
where
With the disturbance estimation
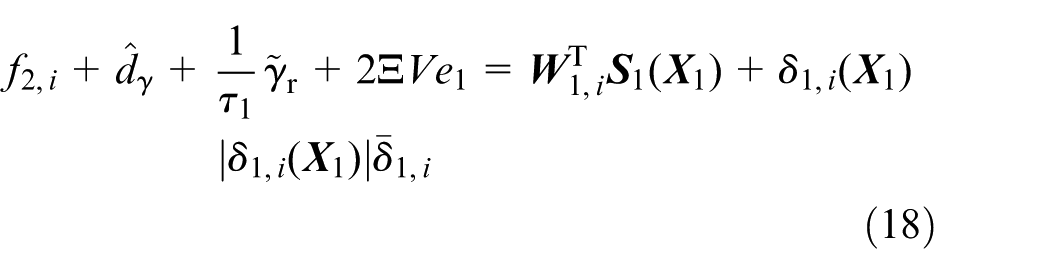
where
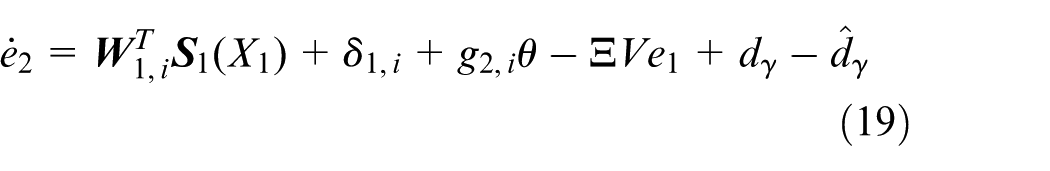
By Equation (19), it can be verified that
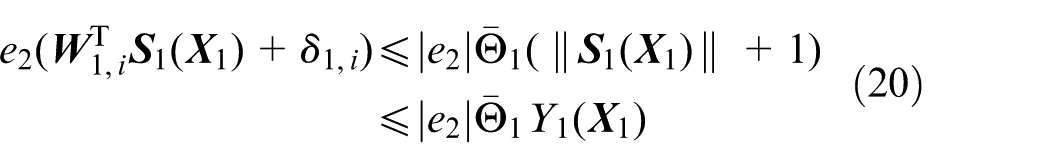
with
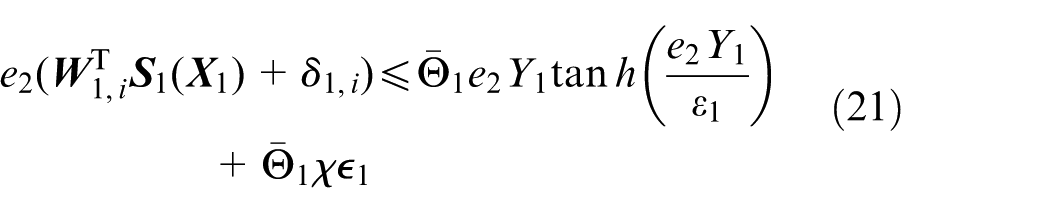
where

Define
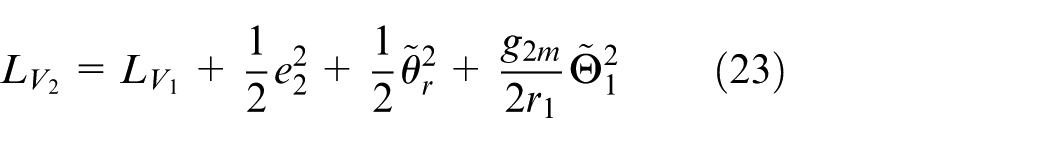
where
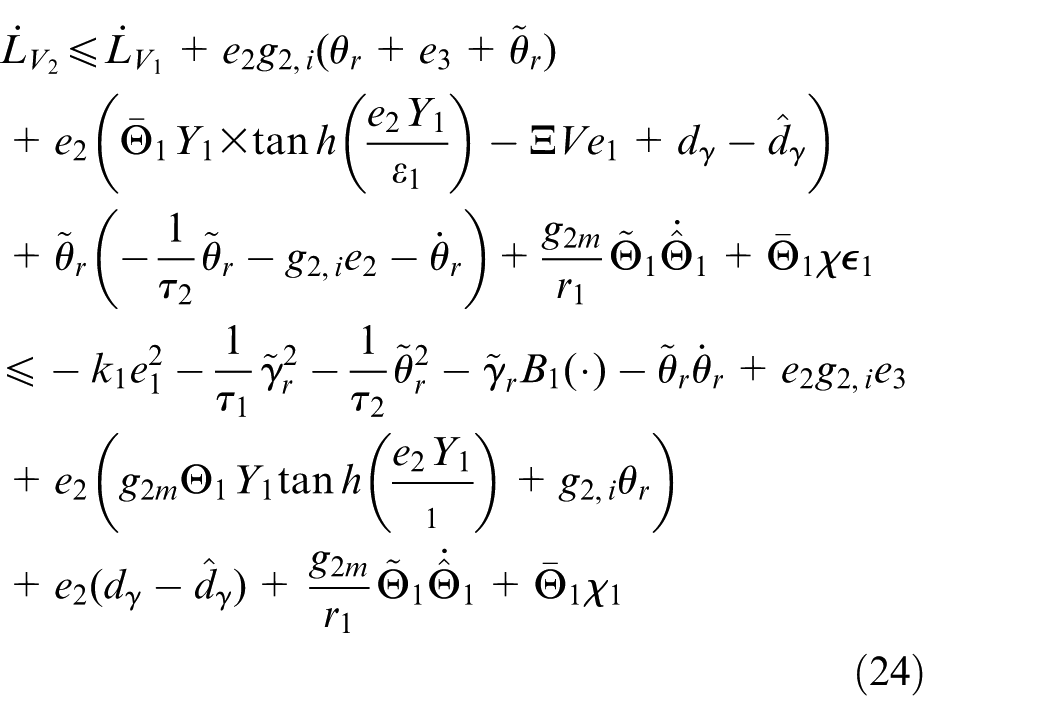
From Equation (24), the virtual control law
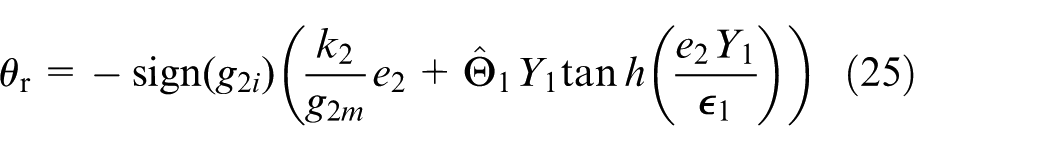
where
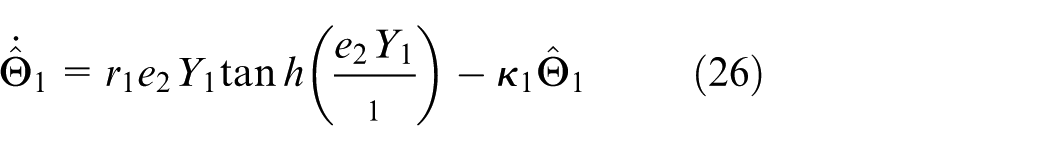
with
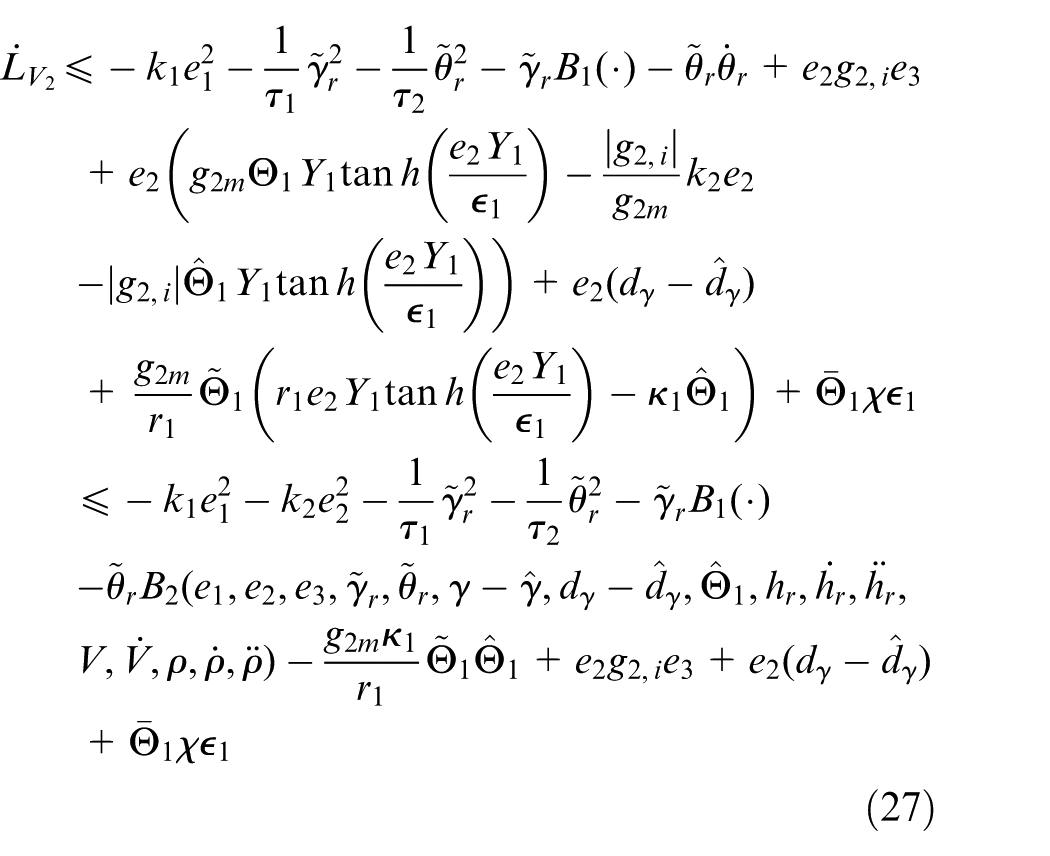
where
Step 3. Differentiating
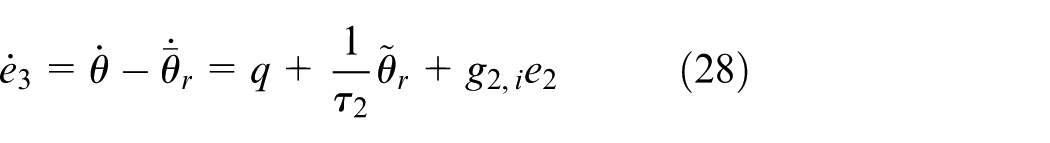
Let

Defining
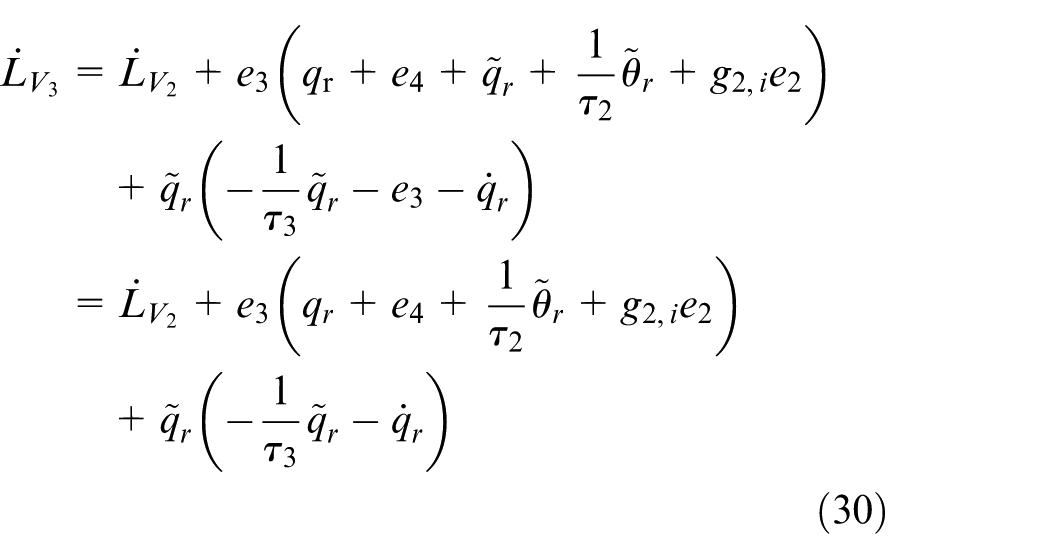
Taking
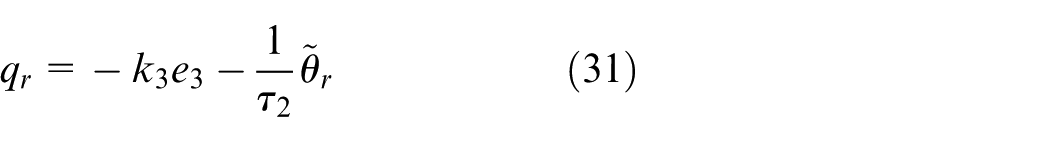
delivers
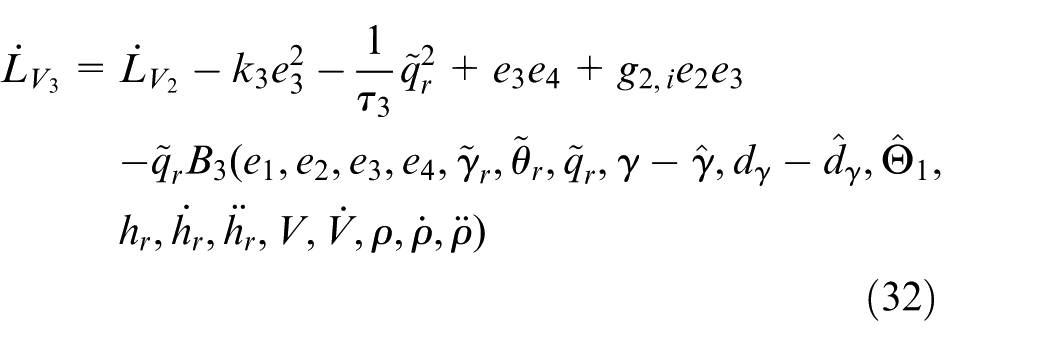
with
Step 4. The time derivative of
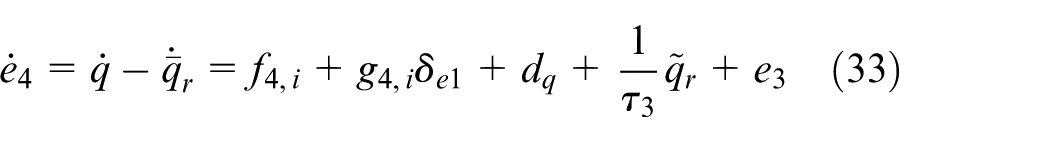
The improved disturbance observer for the
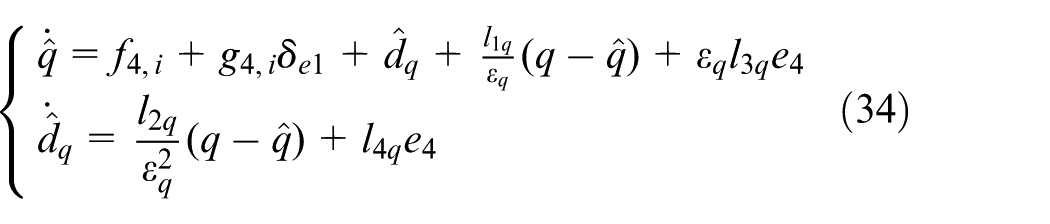
where
With the estimated value
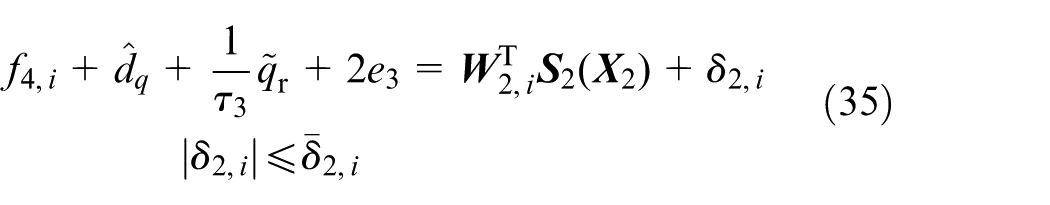
for any given constant
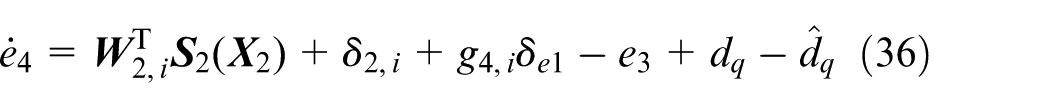
Since
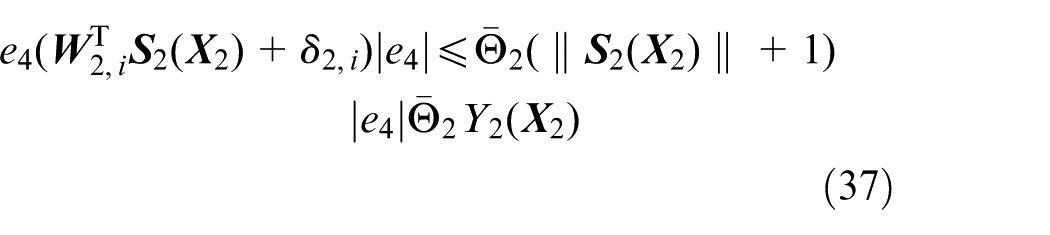
where
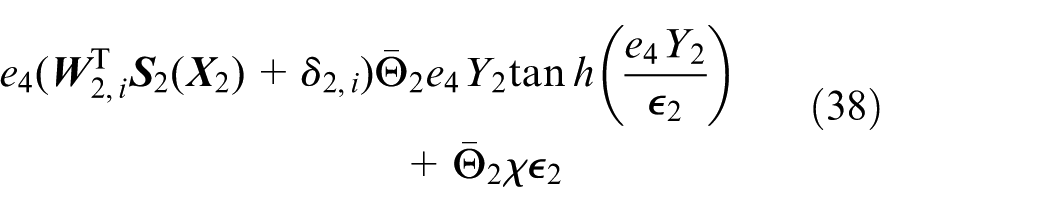
where
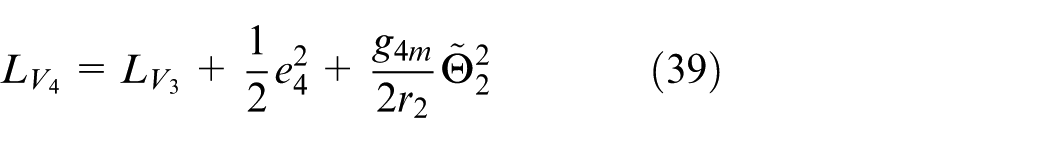
where
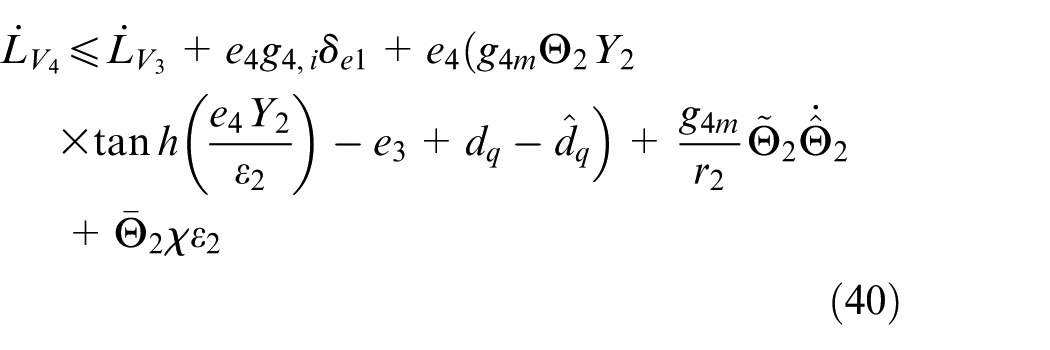
Consequently, the final basic control input
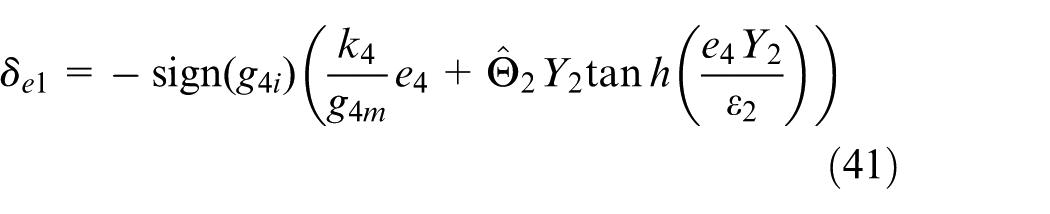
with
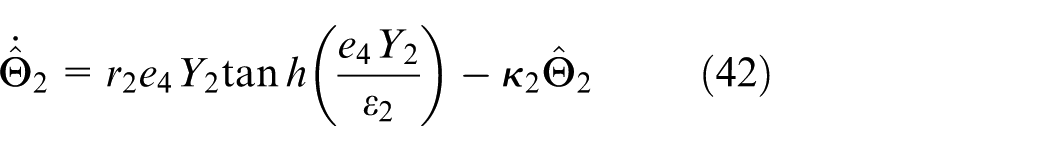
where
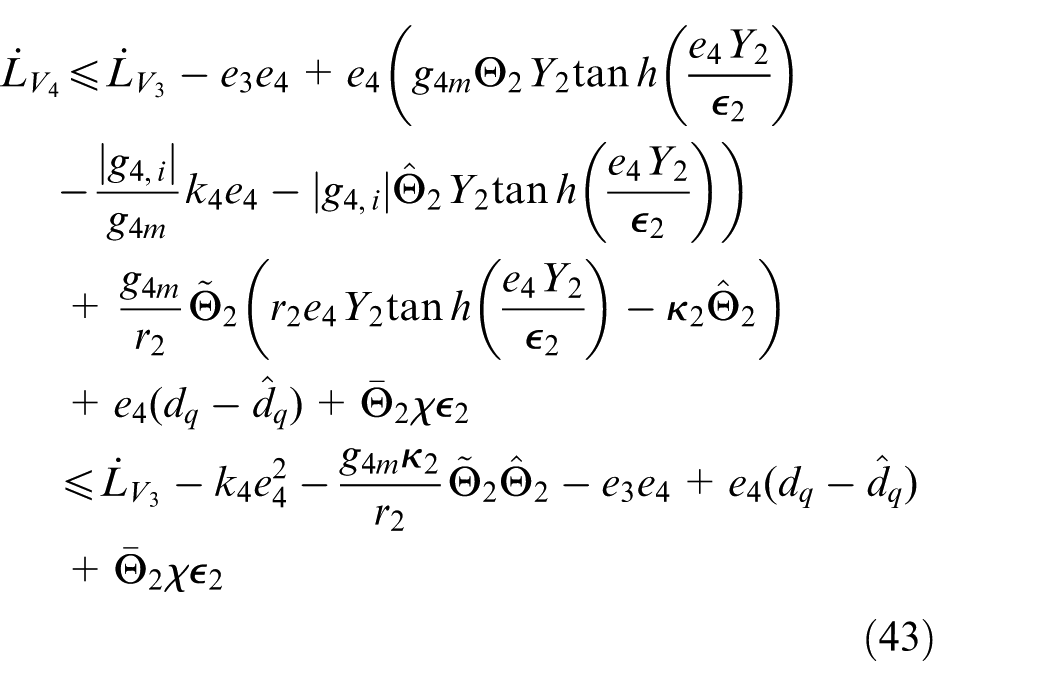
Remark 2
It should be pointed out that the nonlinearities including the disturbances of the systems cannot be canceled out directly when designing the common virtual control laws since the systems are of switched type. By the adoption of NNs, the focus becomes that the upper bound of related weight vector which is estimated and adopted to generate the common virtual control laws. Specifically, the updating law of the estimation of the upper bound is to ensure the stability of closed-loop system via the property of inequalities. Such technique is generally adopted for the research on backstepping control of switched nonlinear systems. 21
Remark 3
We note that there are also several excellent studies on neural learning design. For instance, tracking control of a flexible hypersonic vehicle via a combination of neural approximation and disturbance estimation is addressed in Xu et al., 43 where both the tracking error and prediction error are exploited to generate the weight updating law of NNs. The robust design is integrated into the updating laws for both the weight vector and approximation error of the adopted NNs in Xu 46 to develop a direct neural controller. The research in Xu et al.43,46 mainly adopts the general nonlinear systems in lower triangular form and there exists no system switching. As a result, the nonlinearity of the system can be canceled out directly via the employment of NNs as well as disturbance observers. However, the dynamics of morphing aircraft is described by switched nonlinear systems where the nonlinearities cannot be eliminated directly since these nonlinearities switch as the sweep angle of the morphing aircraft varies, which makes our work different from the research in Xu et al.43,46
For the basic part controller, we have the following theorem:
Theorem 1
Consider the closed-loop switched nonlinear systems formed of the plant (2); the improved disturbance observers (17) and (34); the modified dynamic surfaces (12), (22), and (29); the parameter update laws (26) and (42); and the basic control law (41). Suppose that
Proof
Define scaled estimation errors of the designed disturbance observers (17) and (34) as follows
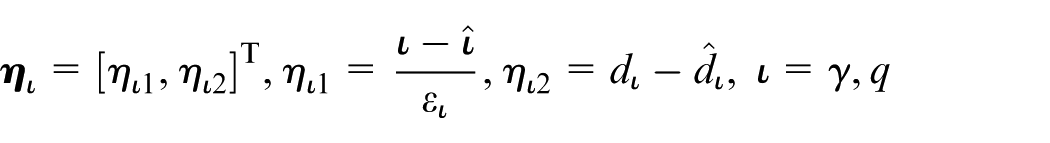
and the dynamics of the scaled estimation errors
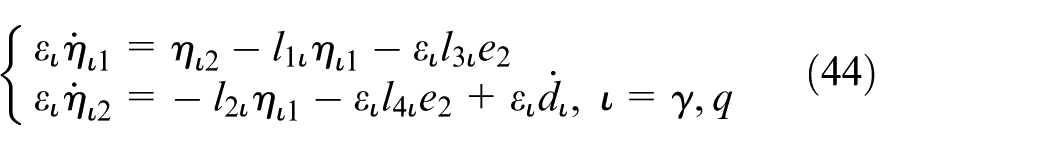
Let
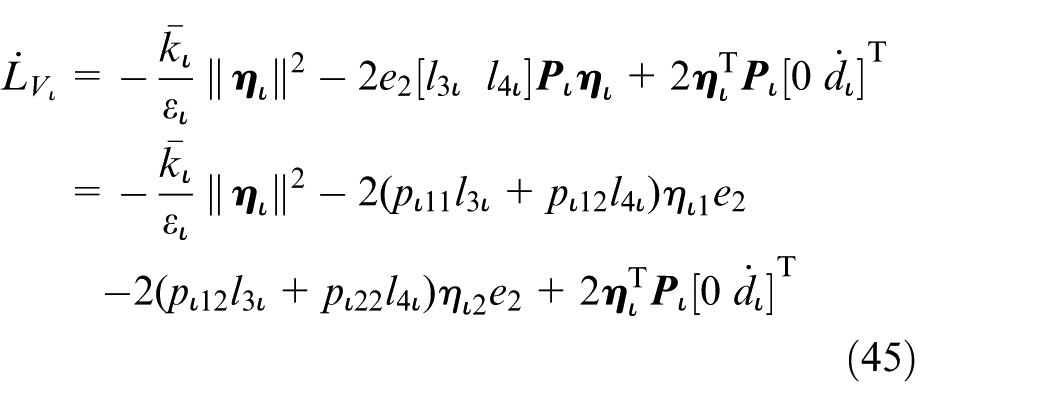
with
The constants
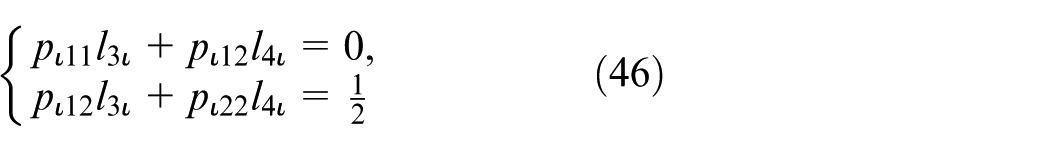
then the derivative of
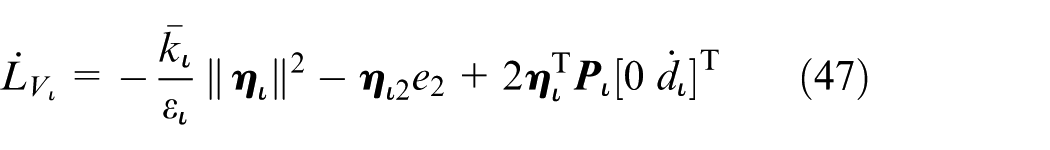
For the closed-loop system, consider now the Lyapunov function candidate

Invoking Equations (27), (32), and (43), it can be shown that
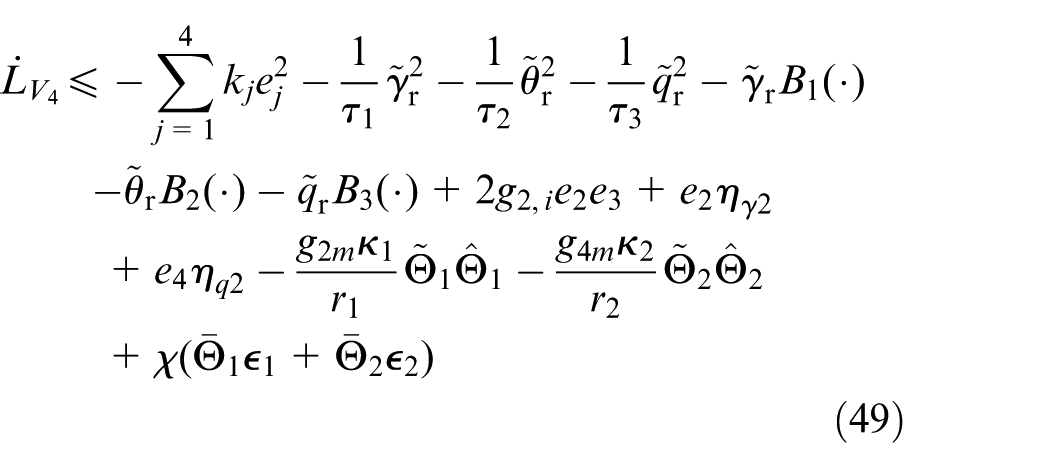
By Young’s inequality, 47 one gets

Moreover, with the definition of
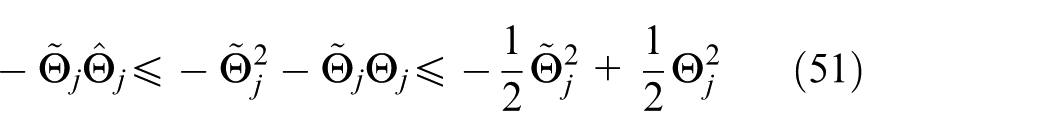
Substituting Equations (50) and (51) into Equation (49) yields
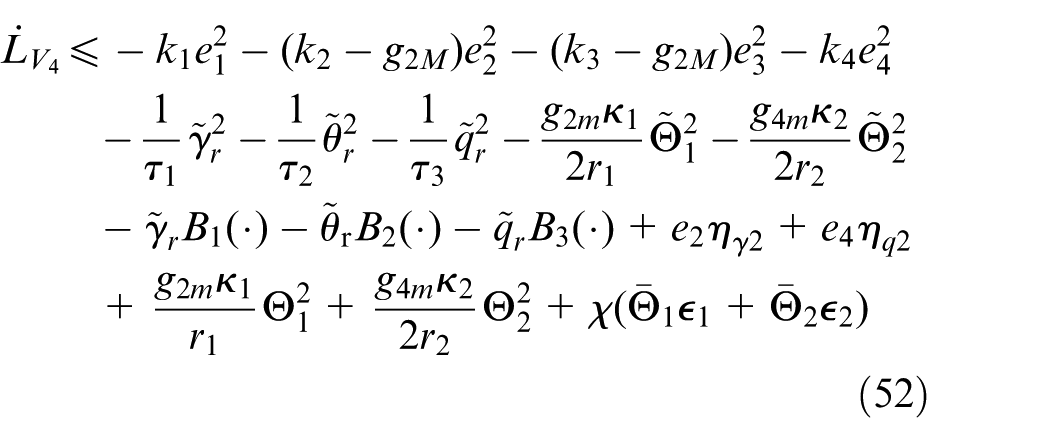
By Assumptions 2 and 3, for given positive constants
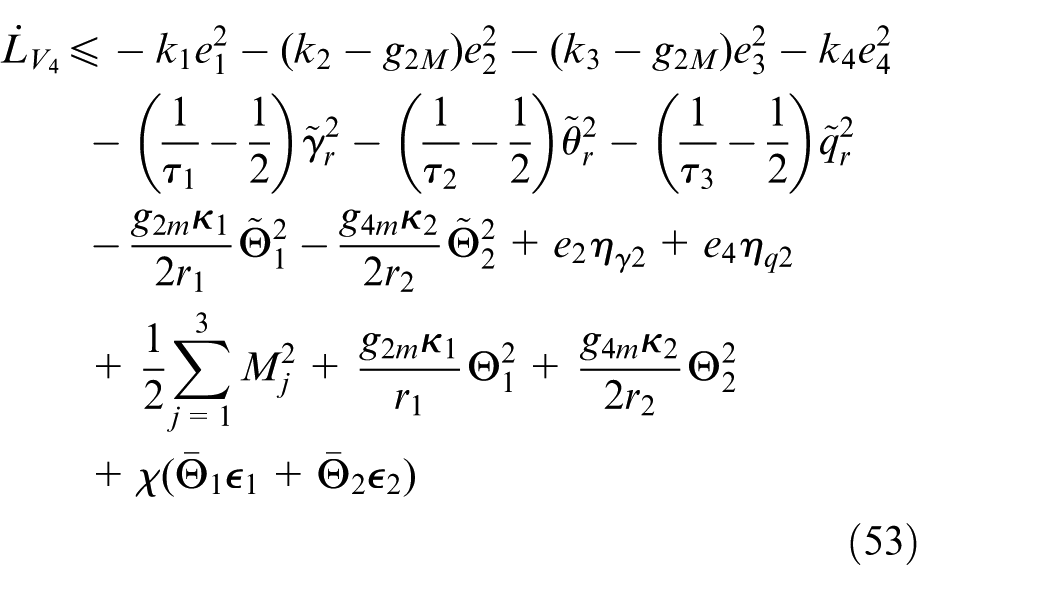
Note that with
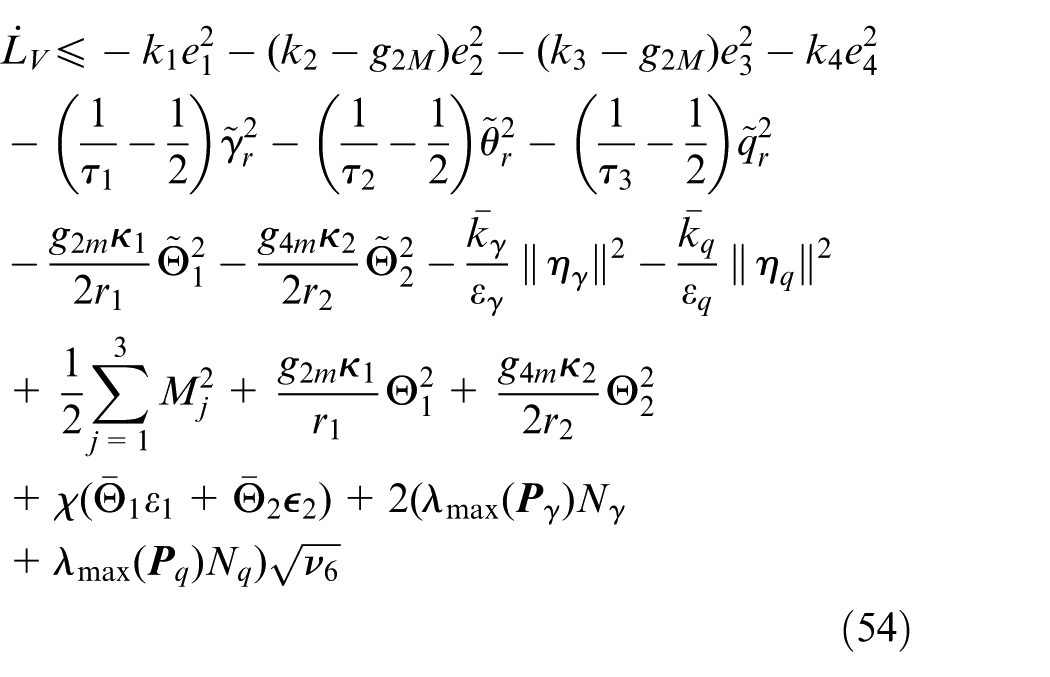
Setting the parameters to satisfy
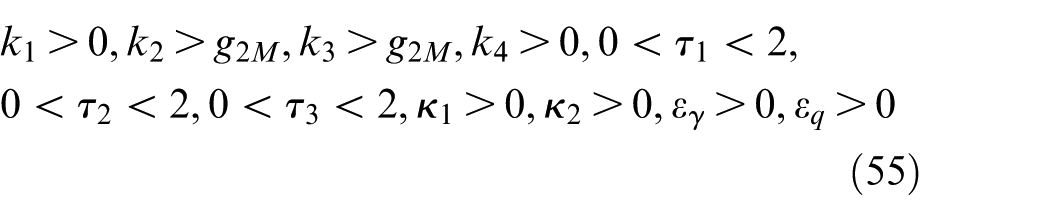
Then

where
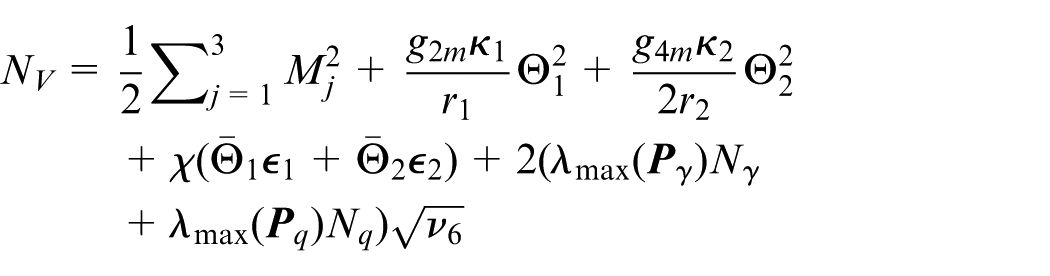
Using the comparison principle in Equation (55), we have
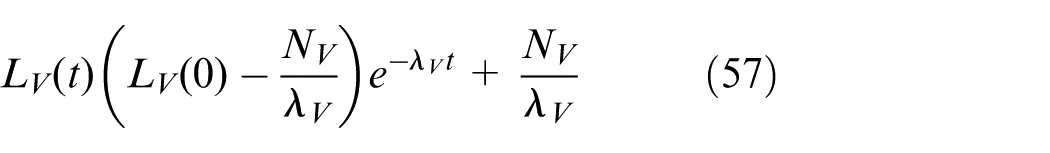
It is straightforward to see that all the signals in the closed-loop system are bounded, and the transformed error
Remark 4
It is noteworthy that the improved disturbance observers (17) and (34) and the modified dynamic surfaces (12), (22), and (29) contain the coupling terms related to
Supplementary part design
To expedite the control performance, the reinforcement learning approach is further applied to design the supplementary part controller, where both critic network and action network utilized are RBF NNs. The critic network is mainly for obtaining the estimation of a user-defined cost function, while the action network is mainly for generating the related control strategy which minimizes the estimated value of the cost function. The structure of the reinforcement learning scheme is shown in Figure 2. It is noted that the related error variables defined in the backstepping design are regarded as inputs of both the critic network and action network, and a supplementary control input is generated correspondingly.
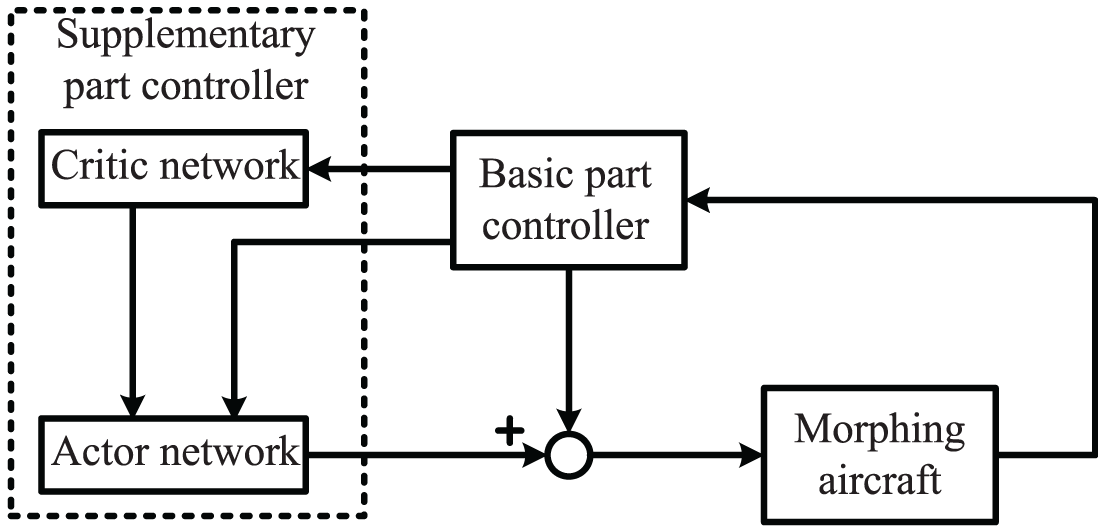
Structure diagram of the reinforcement learning scheme.
The input of the critic network is denoted by
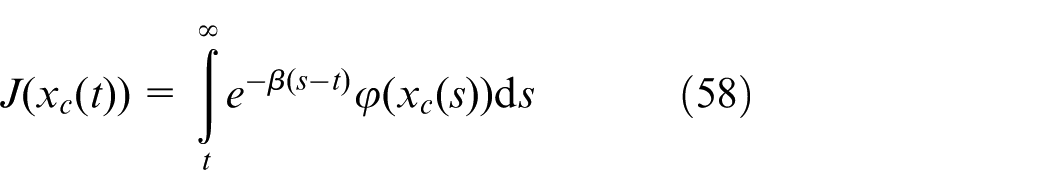
where
The error function for training the critic network is then constructed as
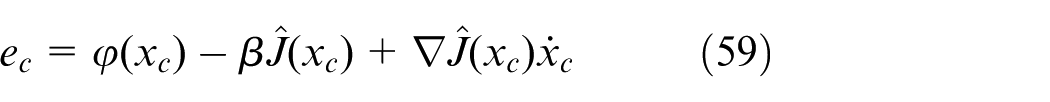
where

The weight updating of the critic network is to minimize
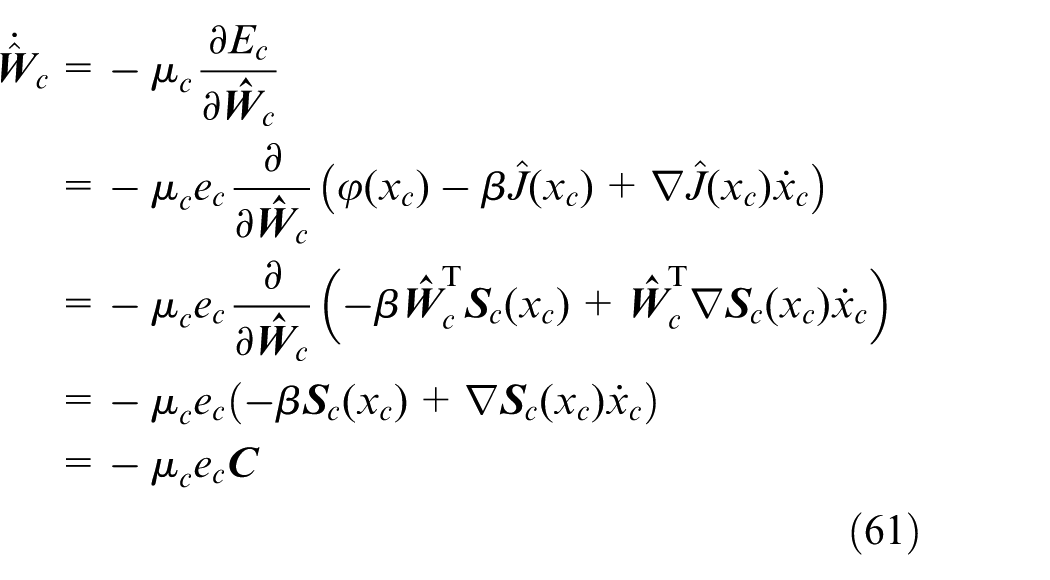
where
The action network takes
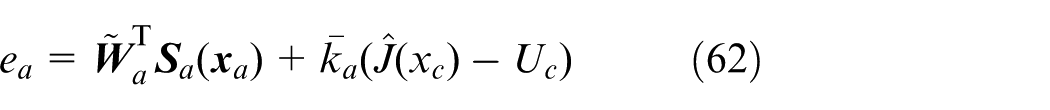
where
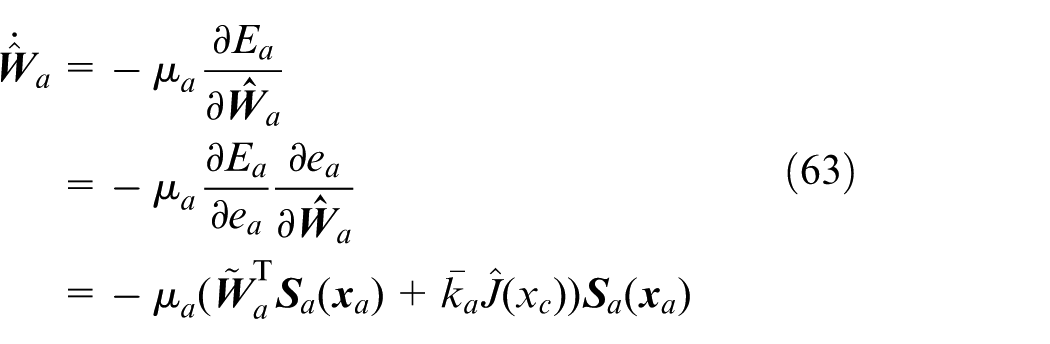
where
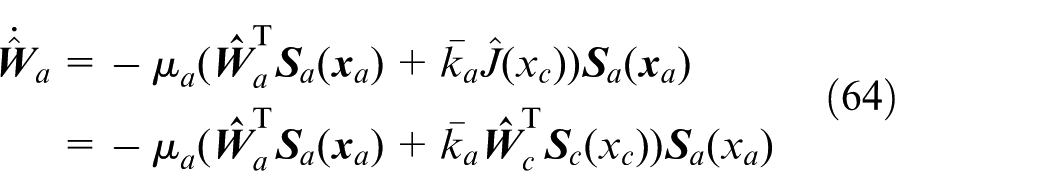
Remark 5
The reinforcement learning method adapts to the uncertain environment without model. Specifically, the reinforcement learning method is a data-driven framework for solving optimal control problems and the requirement of a model of the system dynamics or even the formulation of the reward function can be avoided. However, as stated in Buoniu et al., 34 the model-free property of the reinforcement learning method does not mean that the knowledge on the system dynamics cannot be employed when the model is in fact available, no matter partially or fully. The model of the system dynamics can be exploited to develop reinforcement learning algorithms depending upon the specific conditions, and many related reinforcement learning approaches have been proposed for computing optimal control input of general affine nonlinear systems in theory.35–37 To summarize, the reinforcement learning method is not restricted to the system model information, and the model can be appropriately adopted once available. In this paper, the reinforcement learning method without model information is devised to further decrease the altitude tracking error since the system model in the presence of the basic part controller is too complex and hence regarded as unknown.
Remark 6
For the supplement part, the RBF NNs are exploited to constitute the critic–action structure of the reinforcement learning algorithm. Both the critic network and action network can be of any appropriate type, such as the multi-layer perceptron structure with one hidden layer, 40 and the adoption of RBF NNs is mainly for the convenience of weight updating and convergence analysis. The weight updating for the critic network and action network is mainly along the line of reinforcement learning approach in a gradient-descent way. It is noted that the specific choice and structure of the critic network and action network is not the focus of our work. We aim to show that the integration of reinforcement learning technique can further improve the control performance, which is demonstrated in the numerical simulation part.
For the supplementary part controller, we have the following theorem:
Theorem 2
Consider the critic–action NN structure established as Equations (61) and (64). Let
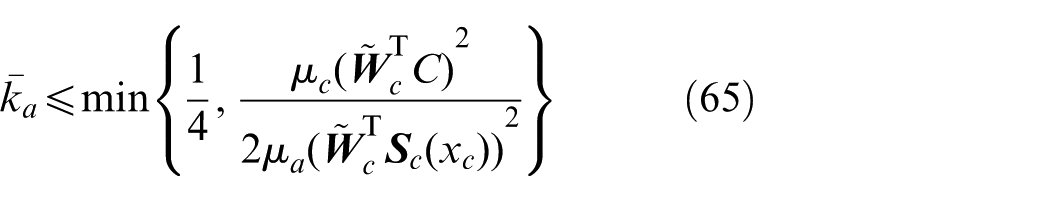
Proof
By Equation (61), the dynamics of
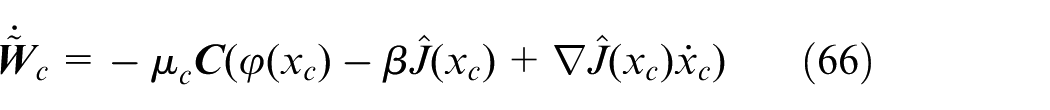
Notice that
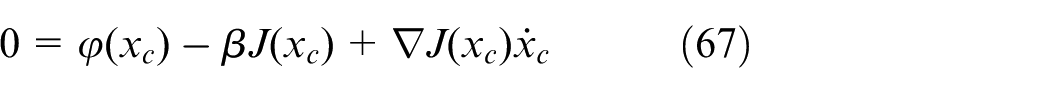
Using
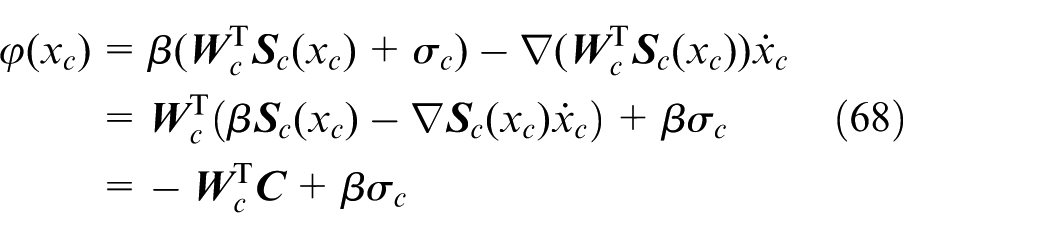
Substituting Equation (68) into Equation (66) delivers
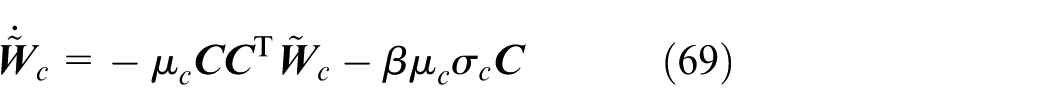
Moreover, the dynamics of
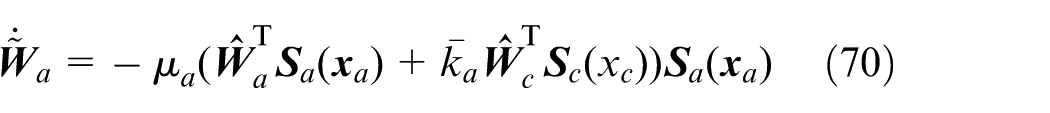
Choosing the Lyapunov function candidate as
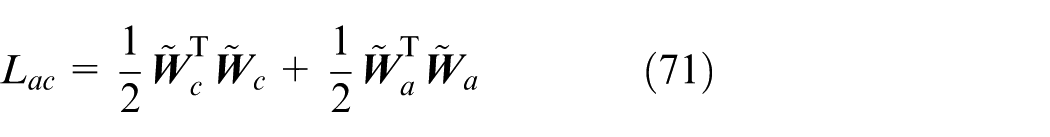
the derivative of
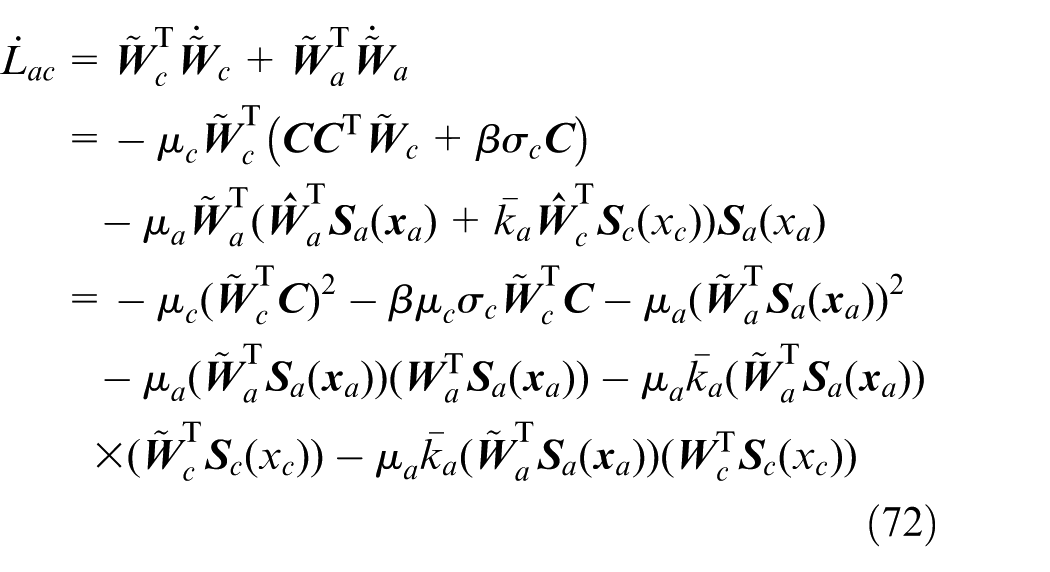
By Young’s inequality, 47 it follows that
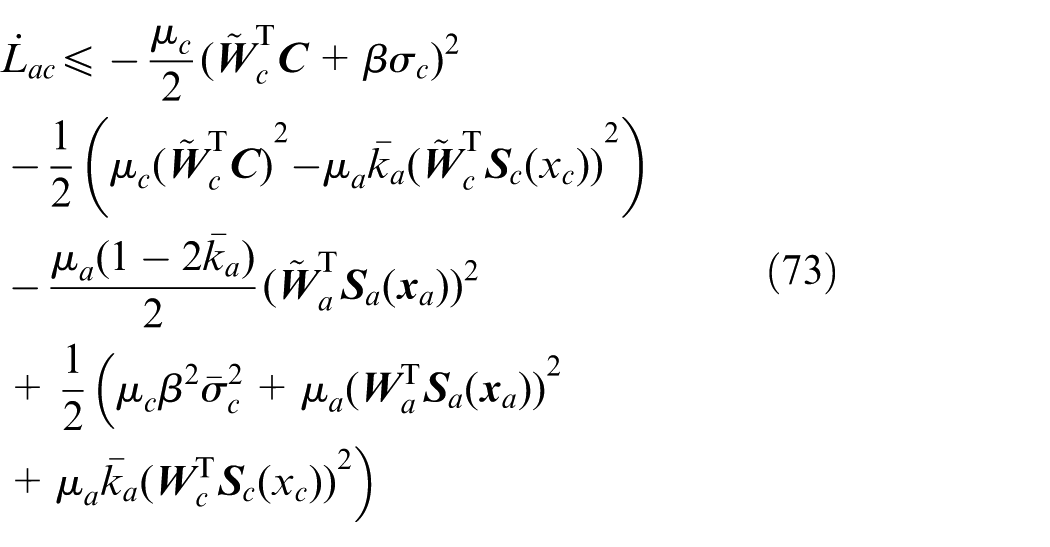
where
Case 1.
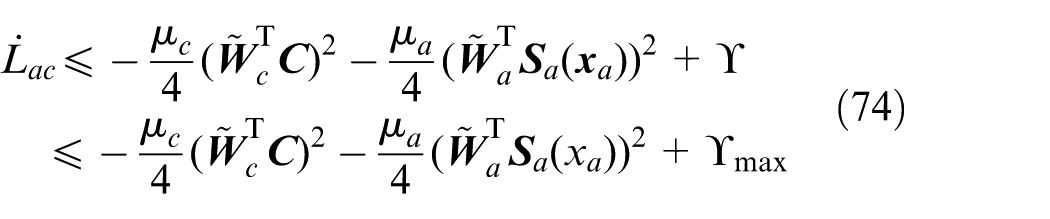
where
Case 2.
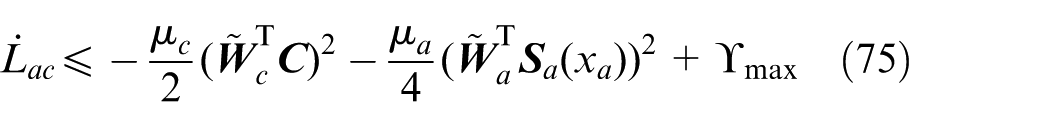
Summarizing the two cases, it can be verified that
Remark 7
The optimal cost function satisfies the Bellman equation according to optimal control theory, which has been addressed for general nonlinear systems in Buoniu et al. 34 and the references therein. Since the exact solution of the Bellman equation is difficult to obtain, the NNs are generally adopted in the reinforcement learning technique to generate the approximate solution. It is noteworthy that the recursive relationship of the Bellman equation is critical for constructing the weight updating laws of the NNs, as can be seen from Equations (58) and (66).
Remark 8
We note that the stability analysis in the proof of Theorem 2 is mainly on the boundedness of weight estimation errors
Remark 9
We note that the prescribed performance technique adopted in this paper follows from Bechlioulis and Rovithakis, 24 and many researchers have addressed prescribed performance control in recent years.49–51 We do not deliberately emphasize on the specific type of prescribed performance control method. The focus of our work is a union of the prescribed performance control and the reinforcement learning approach, which is achieved by the basic part and supplementary part controllers, respectively. Nevertheless, we approve that the specific design of the prescribed performance control method is important to the final control performance, which will be the topic of our further research.
Numerical simulation
The effectiveness of the proposed control scheme is illustrated by a comparative simulation study with the method in Wu et al.,
10
where the morphing aircraft model parameters are mainly taken from Wu et al.
9
and 20% uncertainties of aerodynamic coefficients are considered. Besides, we set
For the reinforcement learning–based supplementary part, the critic network has 30 nodes with the centers evenly spaced on
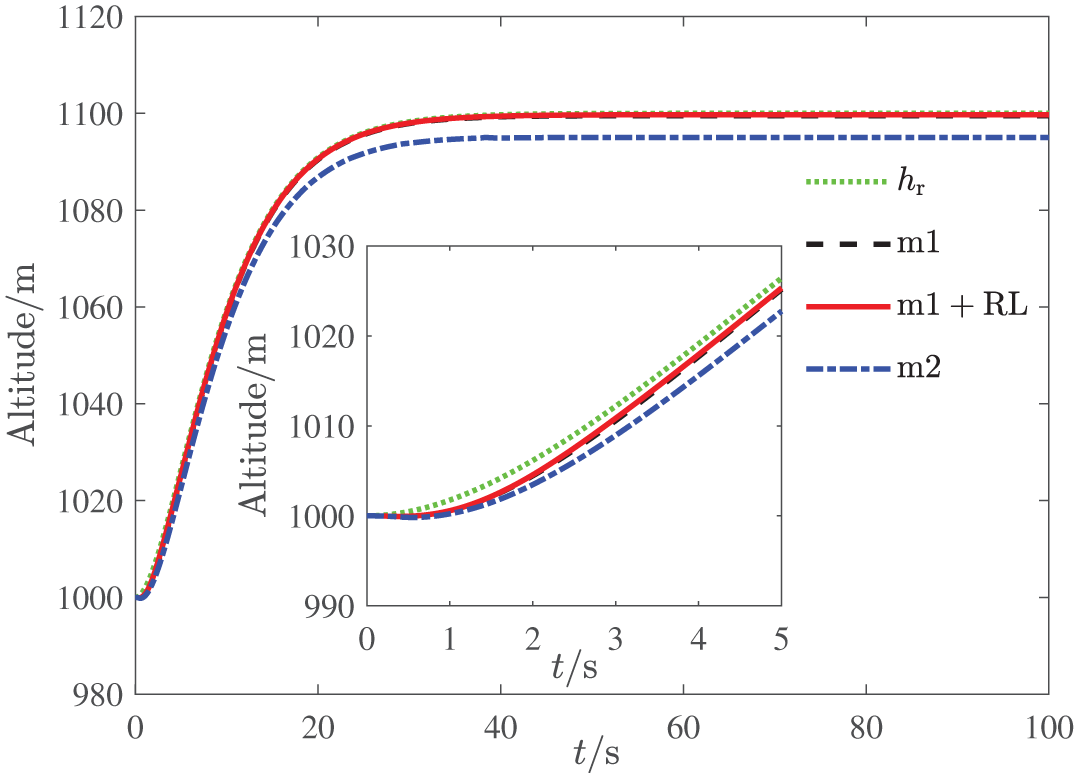
Altitude tracking.
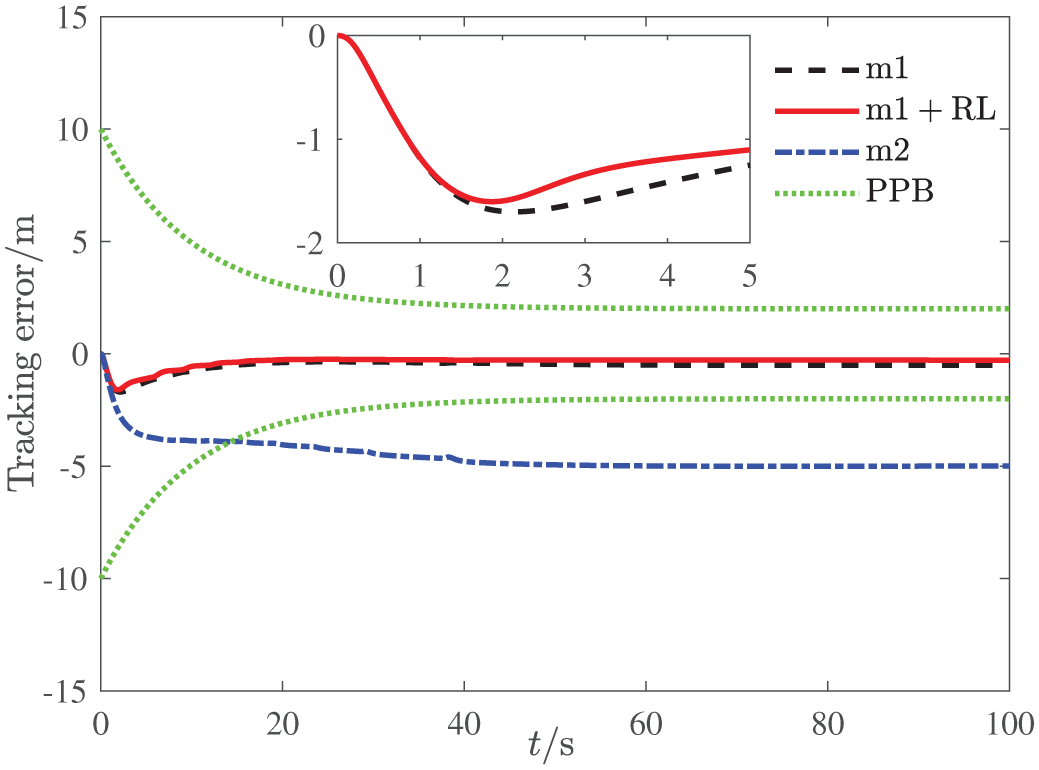
Altitude tracking error.
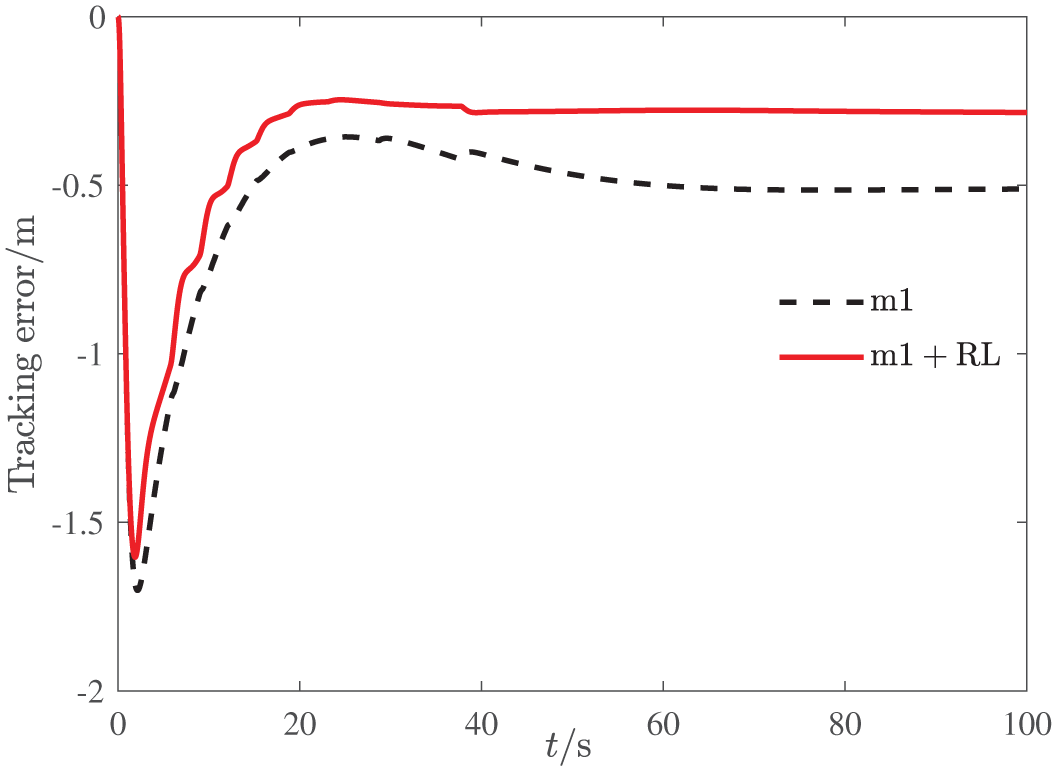
Altitude tracking error (m1 and m1 + RL).
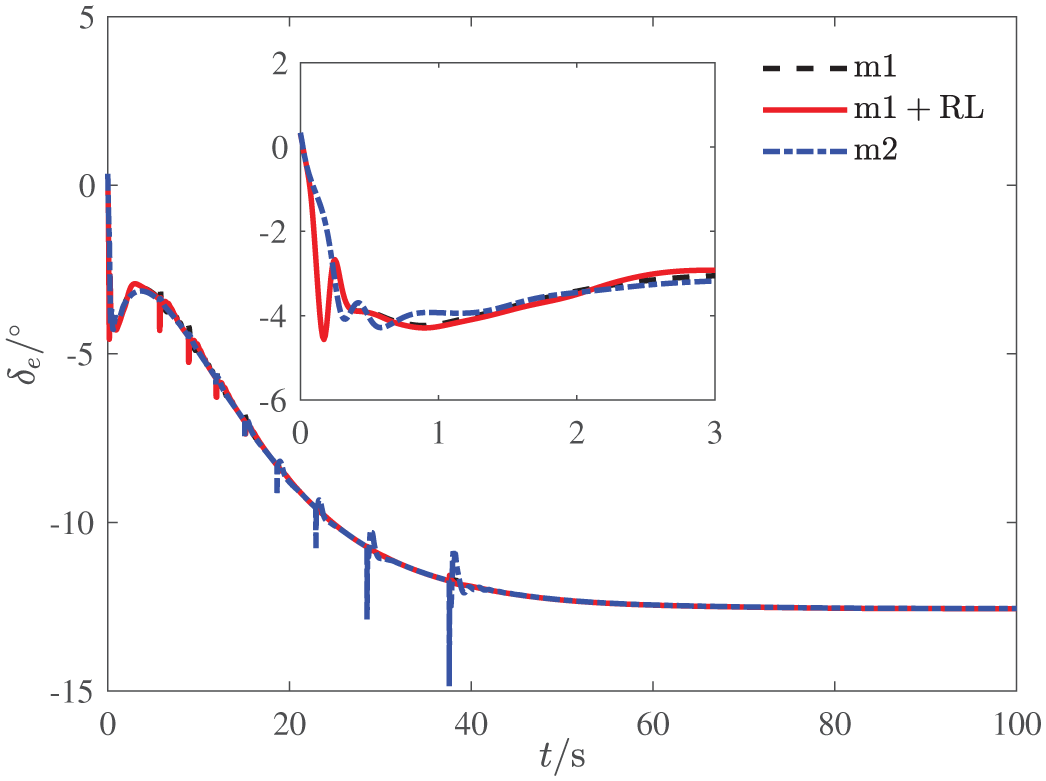
The control input
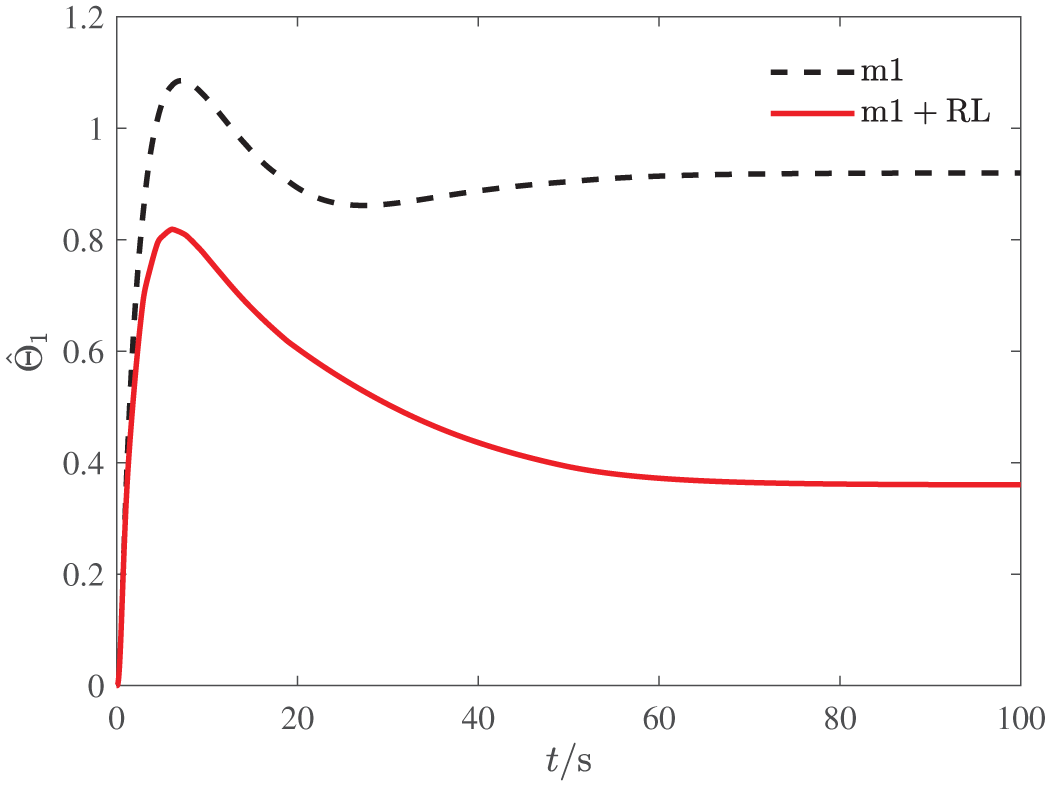
The response of
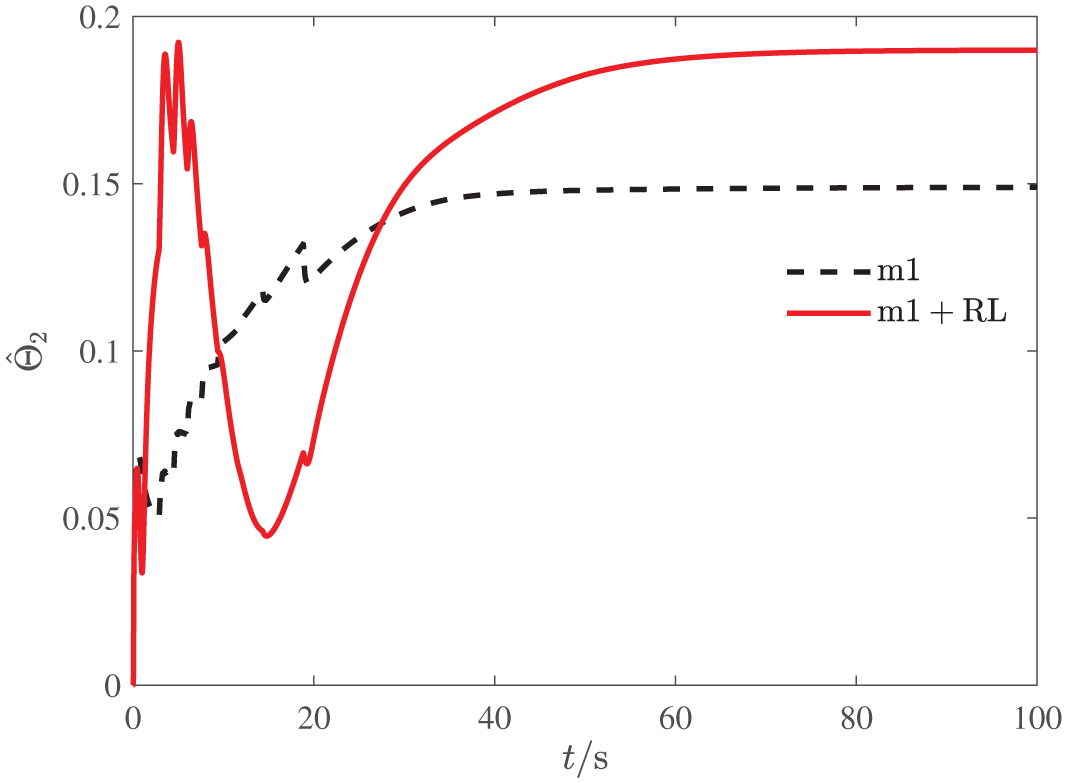
The response of
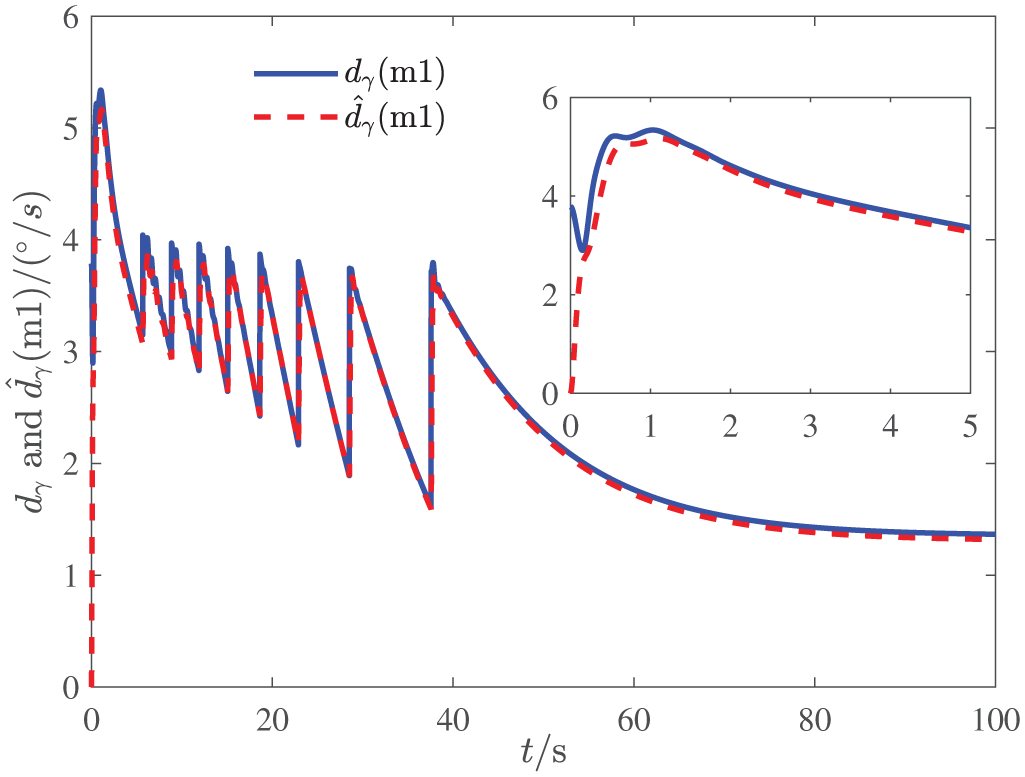
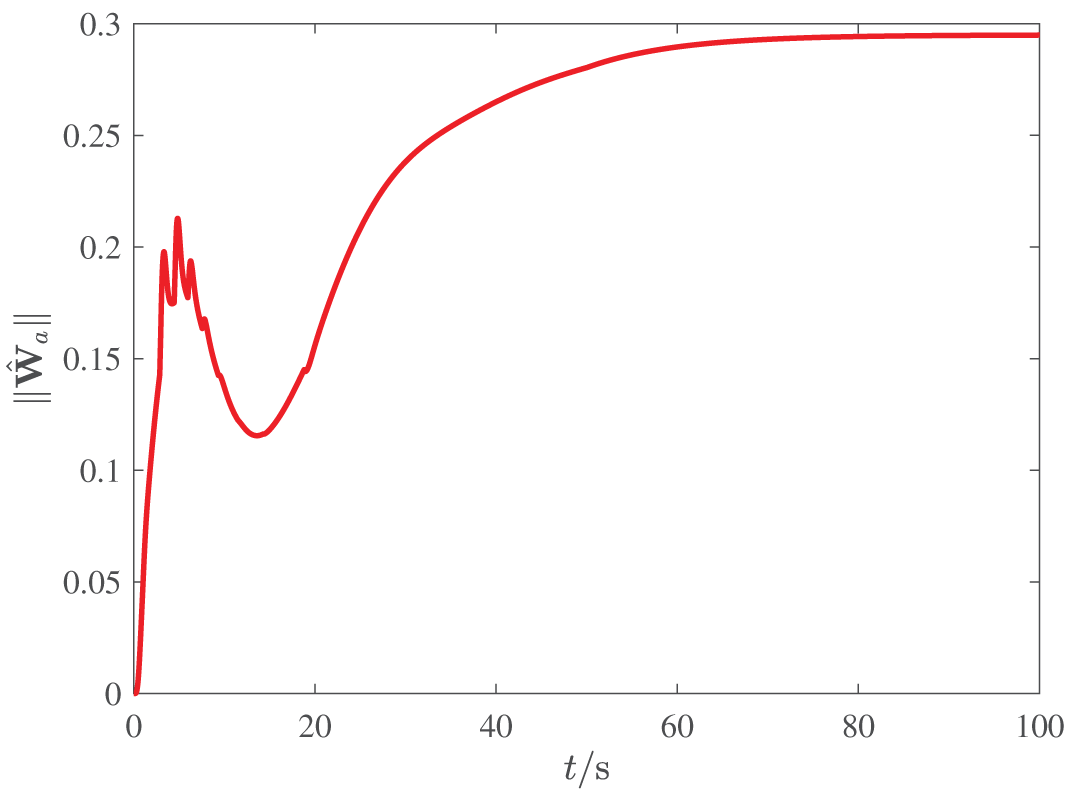
The responses of
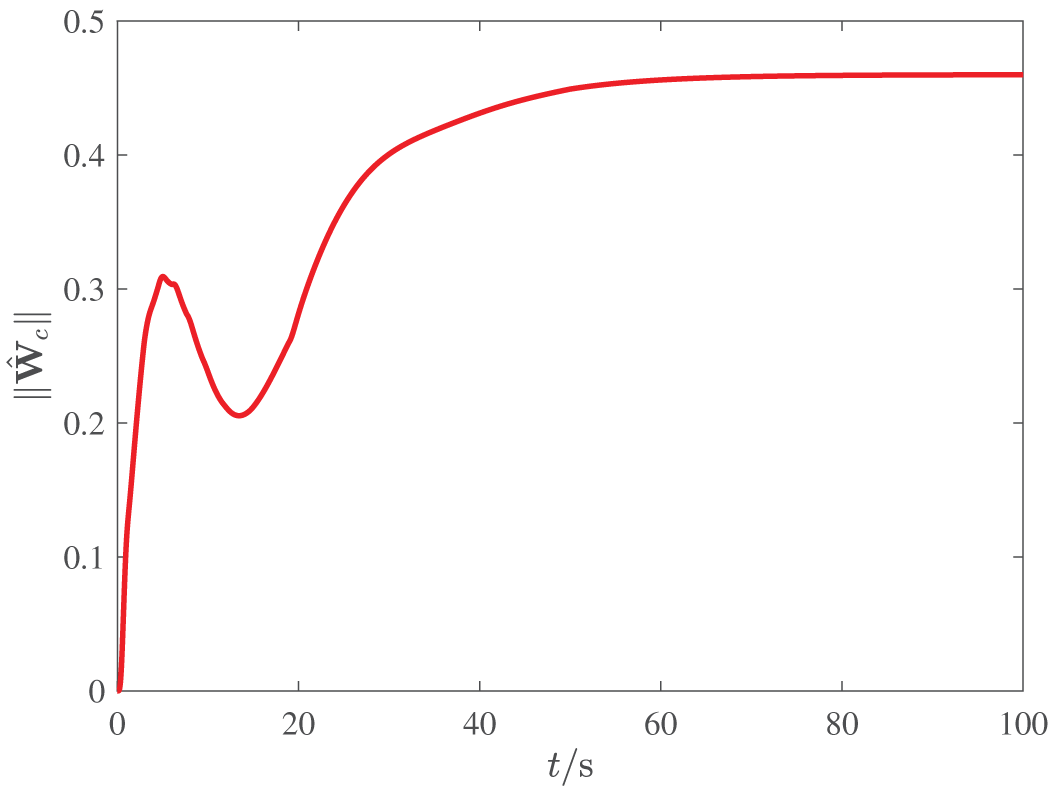
The response of
The altitude tracking responses of all three methods are depicted in Figures 3–5, and the boundedness of altitude tracking error can be guaranteed. However, the m2 method cannot ensure the prescribed performance bound, while the m1 and m1 + RL method can achieve the control goal. Besides, it is easy to see from Figure 5 that compared with the m1 method, the m1 + RL method has better transient performance and smaller steady error, which illustrates the effectiveness of the reinforcement learning.
The related control inputs are given in Figure 6, which are all less than
The response of
Remark 10
We have shown the advances of the work on reinforcement learning by comparative simulation studies. It is shown by the simulation results that the m1 method outperforms the m2 method in terms of prescribed performance of the altitude tracking, which indicates the advantage of the backstepping design via improved disturbance observer and dynamics surface technique. Furthermore, both the m1 method and m1 + RL method can ensure the prescribed performance bound, while the m1 + RL method has smaller tracking error when compared with the m1 method. Hence, the integration of reinforcement learning into the controller design can further improve control performance. It is noteworthy that the design philosophy of artificial intelligence community differs from that of control community although both of them contribute to the development of reinforcement learning greatly. 34 The former cares about the convergence of the learning algorithm to the optimal solution, while the stability during the learning process is neglected. The latter focuses on the closed-loop stability, and the convergence to the optimal solution is not a priority. As a result, most of the extant reinforcement learning methods cannot be applied to systems with disturbances directly. For our work, it can be considered that the basic part controller is designed to provide a stable environment for the reinforcement learning scheme.
Conclusion
This paper addresses the prescribed performance control of the longitudinal altitude of a morphing aircraft based on switched nonlinear systems and reinforcement learning. Switched nonlinear systems in lower triangular form are first derived to describe the morphing aircraft dynamics, and the prescribed performance bound of the altitude tracking is considered by error transformation. Then, the controller is designed with integration of two parts: the basic part and supplementary part. The backstepping scheme is adopted to devise the basic part, and the modified dynamic surface control technique is involved to avoid the “explosion of complexity” problem. The common control laws are obtained by uniting improved disturbance observers and RBF NNs with consideration of the disturbances of the systems. Besides, a critic–action NN structure of the reinforcement learning is applied to develop the supplementary part controller via the error variables defined in the backstepping design. Comparative simulations clearly show that the altitude tracking error satisfies the prescribed performance bound by the proposed control method. In particular, the integration of reinforcement learning into the controller design can further improve control performance when compared with the controller which contains the basic part only.
Footnotes
Acknowledgements
The authors would like to thank the anonymous reviewers for their constructive comments on improving this paper.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This study was supported by the National Natural Science Foundation of China (Grant Nos 61873295 and 61833016), the Aeronautical Science Foundation of China (Grant No. 2016ZA51011), and the Shanghai Aerospace Science and Technology Innovation Foundation (Grant No. SAST2017-096).