
Abstract
In industrial and medical laboratories, prior to initiating the daily test procedure, the accuracy of the system is observed by measuring the reference control values. Measurements and test results may be below or above the reference value. Hence, the control data is employed in order to ensure that the test scores lie in the targeted range values, and the results obtained from the control data are evaluated via computer-based analysis. The results of the analysis have significant importance for control and improvement of process. Furthermore, the data to be analyzed may be the test results of a product as well as the measurement outcomes obtained from a laboratory. In this study, an algorithm named as Adaptive Precision Point Algorithm is proposed to evaluate the control data and to increase the stability by reducing the loss. In this schema, the contribution to the reduction of the total systematic error was observed by calculating the target working point and the Adaptive Precision Point deviations. Measurement outputs, in other terms the data, are processed in Adaptive Precision Point Algorithm. The algorithm determines a new adaptive working point for the incoming data by doing the required computations for precision working point. Moreover, the deviation between adaptive working point and the specified working point, which is defined according to the standards and rules, is calculated. By this way, adaptive working point is being utilized throughout the reduction of systemic errors. According to the results of the research, Adaptive Precision Point Algorithm eliminates the systematic errors on a large scale. The suggested algorithm provides results within the accepted quality deviation limits so it does not form a negativity in the understanding of quality. It is also observed that the algorithm sets a positive correlation between the minimized test results and reduction of time and material usage. Furthermore, the research and the algorithm offer a cost-effective solution. Consequently, the contribution and significance of the proposed algorithm can be understood in a better way by considering that it does not only maintain the quality limits but it also minimizes the cost and time spent during the testing of thousands of laboratory samples.
Introduction
Studies in the field of informatics play an important role throughout the stages of producing, storing, and processing the data in industrial and medical laboratories. The data which are subjected to the results of measurement and test give an idea of the quality of the laboratory. As is known, in order to verify the tests, certified reference control materials are being employed.1,2 Furthermore, the control data are obtained by measuring these materials and the accuracy of the measurement is interpreted by comparing the control data with the reference values in the certificates. It is a well-known fact that the factors such as calibration, preventive maintenance, trainings, material–material qualities, and the environmental conditions that affect the control data result in errors. These faults which cause pecuniary and non-pecuniary losses affect the accuracy and quality of measurements. One of the primary aims and contributions of this study is to detect faulty control data that is out of limits on the results of measurement, on real time.3,4 Hence, determining the type and source of errors by analyzing them is one of the important problems to be solved.5–7 Meanwhile, the errors are addressed in two classes: (1) random and (2) systematic.8,9 Random errors affect the process output instantaneously while the systemic ones do it continuously.10,11 Another important useful outcome of our proposed model is that this work enables to conclude whether the faulty data is random or systematic by defining the type of errors detected.12,13 Mistakes sourced from incorrect sampling, lack of attention, and instantaneous voltage change are examples of random errors. On the other hand, errors such as incorrect calibration, incorrectly conditioned test environment (i.e. high or low ambient temperature, out of limit humidity, and light), and human factor can be counted as the examples of systematic errors. The detection and correction of the effects caused by errors on the measurement results is an open and vital research topic.14,15 In this study, by isolating the error types from the results, it is now possible for the working system to be able to control itself constantly and have a capability of self-correction. This is believed to be a significant contribution to the literature. This feature provides a cost-effective and efficient solution.
Figure 1 shows an example of systematic error. In Figure 1, the shift between the ideal operating point and the measured value is shown as Δwp (working point). The amount of shifting that occurs to the right or left of the ideal working point is shaped by the systematic error.
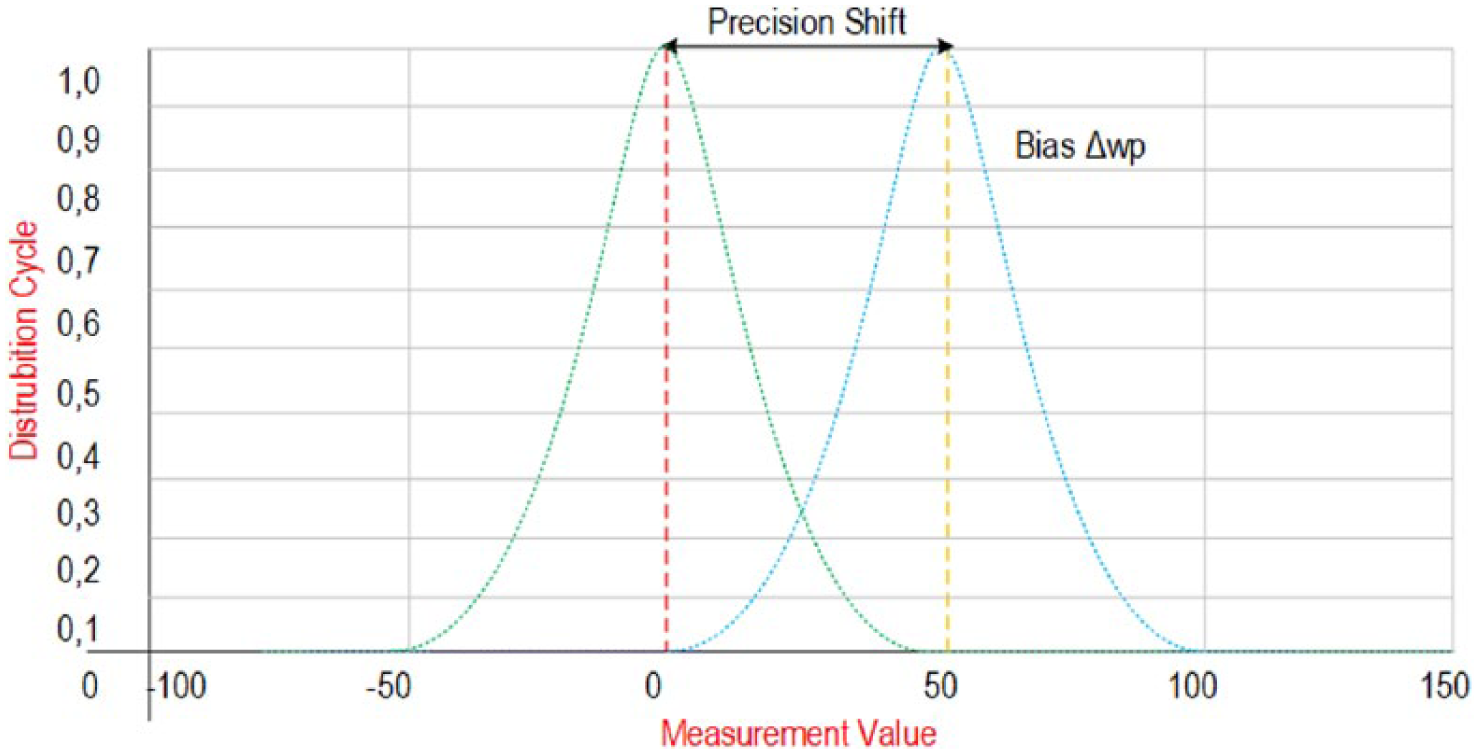
Systematic shift between the ideal working point and measured value—∆wp.
The concept of quality, which began to be used in Japan and America in 1950s, now has an indispensable importance in many sectors such as health, industry, service, and transportation. 7 The quality process is governed by the software, test, and measurement technologies which organize standard-compliant production, measurement, and operating conditions. The quality of the laboratory is measured with the help of these technologies.16,17 Furthermore, statistical quality control methods and standards are used in order to measure test quality in medical laboratories. 7 It should be noted that the Clinical Laboratory Improvement Amendments (CLIA 88), College of American Pathologists (CAP), the International Quality Assurance Services (UK), the International Quality Assurance Services (UK), INSTAND (Germany), EUCAST (European Committee on Antimicrobial Susceptibility Testing), and similar institutions take place throughout the establishment and supervision of these methods and standards. 18
Rule of quality control
The concept of quality control is an indication of the deviation of the measurement result from the expected values and errors that cause these deviations are evaluated by internal and external control mechanisms.5,16 Internal quality control is an internal assessment that is not internationally validated by the laboratory using reference control material. Therefore, external quality control must be carried out by the accredited organizations in order for the laboratory’s control results to be valid in international manner.
Parameters affecting control data
The leading factors affecting the control data used for quality control cover various metrics such as accuracy, trueness, precision, interference, limit of detection (LoD), limit of quantitation (LoQ), linearity, uncertainty, reproducibility, duration of measurement, and robustness.19,20 Moreover, the metrics of accuracy and precision have a critical importance in order to validate whether the results are in concordance with the expected reference values.
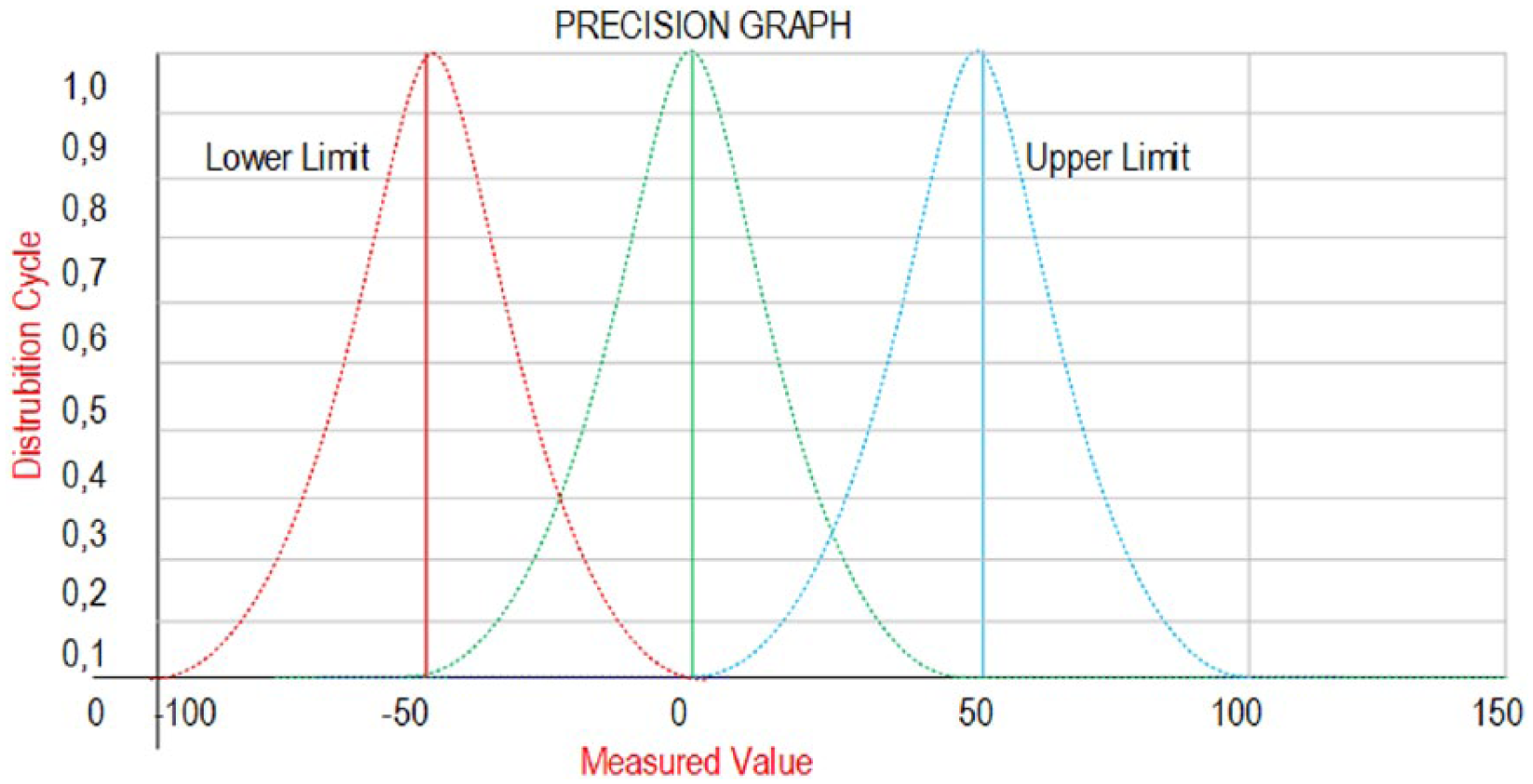
By definition, the accuracy is the measure of closeness between the reference value and the measured value, whereas the precision is defined as retrieving same results from repeated measurements. 21 Likewise, the Gaussian curve depicted in Figure 2 is used to represent accuracy and precision. Note that the results under this curve constitute the accuracy while the normal at the center of the curve represents the precision. 22 Besides, the methods such as OPSpec and Six Sigma are employed in order to measure the process performance of accuracy and precision analysis.10,20,23
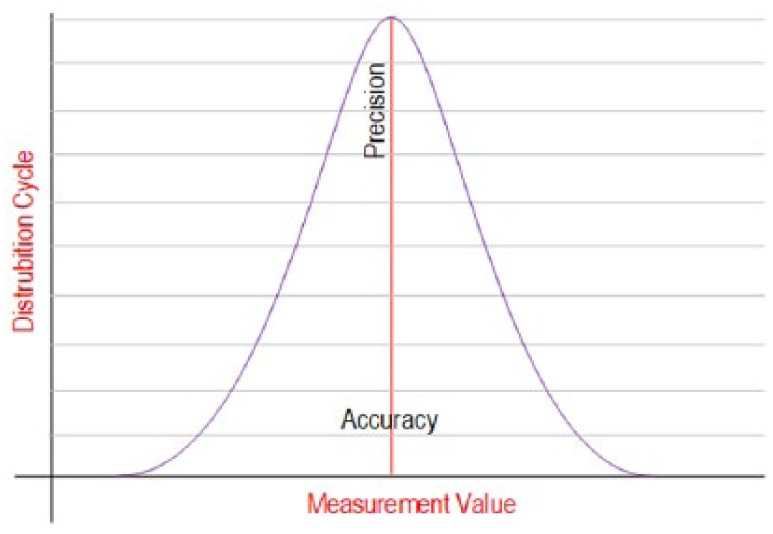
Accuracy and precision values in terms of measurement frequency and value.
Control chart and control limits
Visual control charts involving deviation values and upper and lower bounds are utilized for easy interpretation of the measurement data. Control charts are also widely used to determine the number of control data and control rules. The control data are evaluated according to time and working order by placing them on the chart and determining whether they are within the upper and lower limits.11,24 Having the control data appear within the specified ranges indicates the conformity while the opposite case shows non-conformance.
Measuring the quality of models
For the measurement of the quality models, the models of P-A-F (Prevention-Appraisal-Failure), Crosby, Opportunity Cost, Process Cost, and ABC (Activity-Based Costing) are commonly employed.21,23 Note that their efficiencies are measured by considering the parameters of prevention, appraisal, failure, and conformity. The above stated models and their efficiency classes are given in Table 1.
Models for quality data evaluation and their efficiency classes.
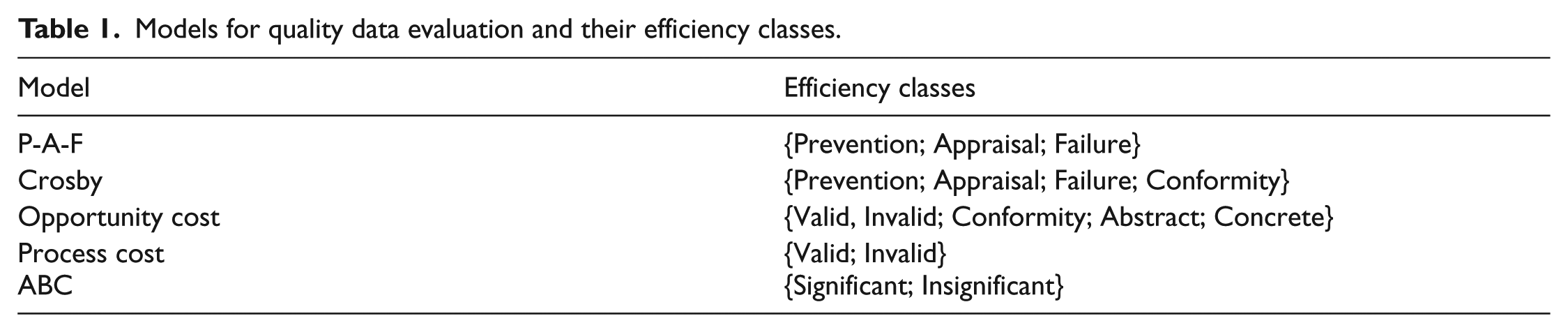
The P-A-F Model, accepted by the American Society for Quality Control and the British Standard Institute, is vulnerable to internal and external control failures and is partially inadequate in determining high costs, while reducing errors with prevention and appraisal processes.25,26 On the other hand, according to the Crosby model, there exist conformity and error costs toward achieving quality. While the cost of adaptation represents the costs incurred for the requirements of the qualification, the cost of error represents the costs incurred when the targeted outcome cannot be achieved. Besides, the Opportunity Cost Model attaches importance to the transformation of opportunities and expectations in total quality process. For instance, the morale of an employee, the loss of work power, and gaining or losing the trust of the customer can be expressed by this model. Apart from the other models, the Process Cost model focuses on the total quality of the whole process. Compared to P-A-F model, the correction steps in the process can be identified in an easier fashion while it takes more time to observe repeated results obtained by connected processes. With the establishment of ABC model, activity-based measurement approach has been developed in which the quality is measured in terms of accuracy and precision. 27
Test life cycle
The test life cycle (TLC), which starts with test preparation and ends up with the valuation of the results, is shown in Figure 3.
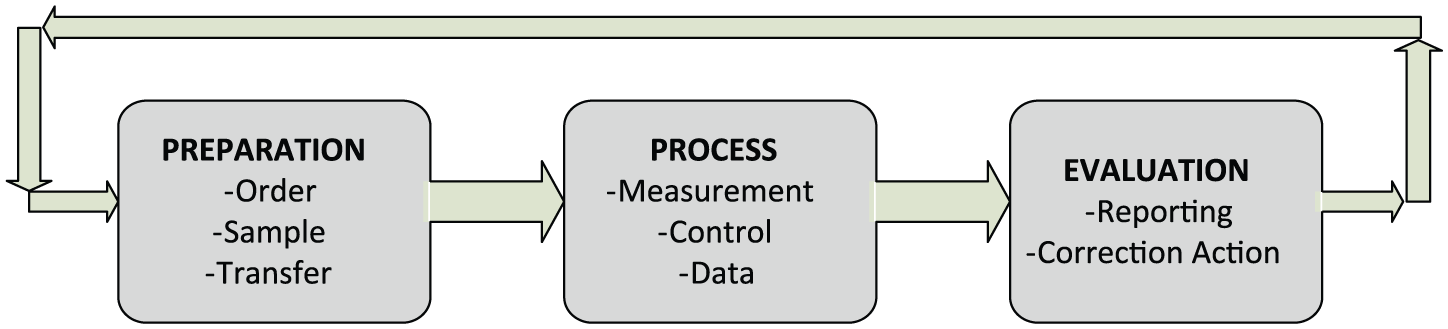
Test life cycle.
During the preliminary phase of TLC, preoperational preparations such as pre-measurement request and transfer are carried out and it is passed to process phase. Data for measurement, observation, and control are generated during the process phase in which digital data emerge. Nonetheless, achieving cost efficiency at this phase, which focuses on performance improvement, is a difficult problem. 28 For the performance centric purposes, analytical errors in the control data are analyzed. 29 The process is repeated until the errors are brought to a predetermined acceptable level and the estimated results are obtained in order to carry out the evaluation phase for the next stage. Next, the results obtained during the evaluation phase are reported and distributed.
In this study, a new approach which targets cost-effective improvement of the random and systematic errors that are dealt with in the TLC process phase is proposed. The proposed approach named as adaptive stable working point (ASWP) enables to use Westgard rules to identify the random errors in industry for the first time. With the proposed approach, moreover, it is aimed to create a cost-effective solution with a correct, effective, sustainable, and developable TLC.
Method
The proposed approach attempts to correct random and systematic error factors affecting the control data without deviating from the targeted quality values. In order to achieve this, datasets consisting of different numbers of control data have been employed. Application steps of the proposed model are given in Table 2.
Application phases of adaptive stable working point.
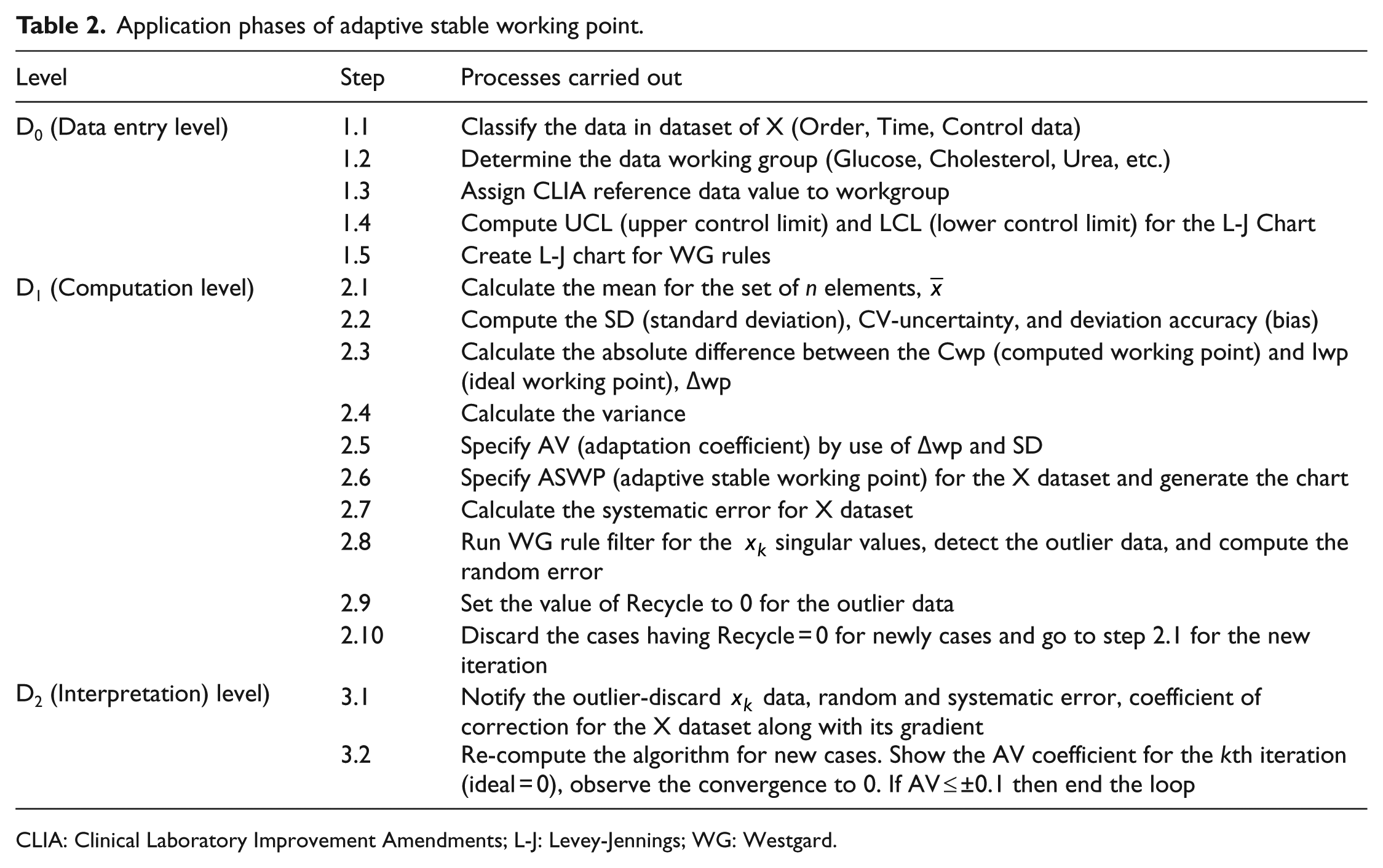
CLIA: Clinical Laboratory Improvement Amendments; L-J: Levey-Jennings; WG: Westgard.
Experimental studies
Implementation of the Westgard rules and generation of Levey-Jennings charts were achieved using a desktop computer with Intel Pentium dual core 2.6 GHz processor running Windows 10. Furthermore, the software MATLAB was employed to model and calculate the gain curves of the experimental data.
Levey-Jennings charts
Levey-Jennings, shortened as L-J, charts are generated for the dataset by considering all new
Implementation of Westgard rules
We utilized the rules which were suggested by JO Westgard
31
in order to evaluate the control results in statistical manner. Westgard rules were widely used in laboratory measurement and control systems to analyze the results (Figure 4).
31,32
First, we consider the error throughout the control process. As is known, OPSpecs chart, which is a method existing in the literature, constitutes a relation between the quality and accuracy of the conducted tests. Given the number of measurements, N, probability of error detection (Ped) and probability of false rejection (Pfr) are calculated.
33
Next, based on these calculations, we compute the SD, coefficient of variation (CV), and bias values.23,34 The main parameters in which we use Westgard rules are the precomputed parameters such as SD, CV, and control limits.
32
For the random error prediction, in particular, we have carried out our analysis via the rules proposed by Westgard and applied it into the dataset. Throughout the random error detection, if the singular data of
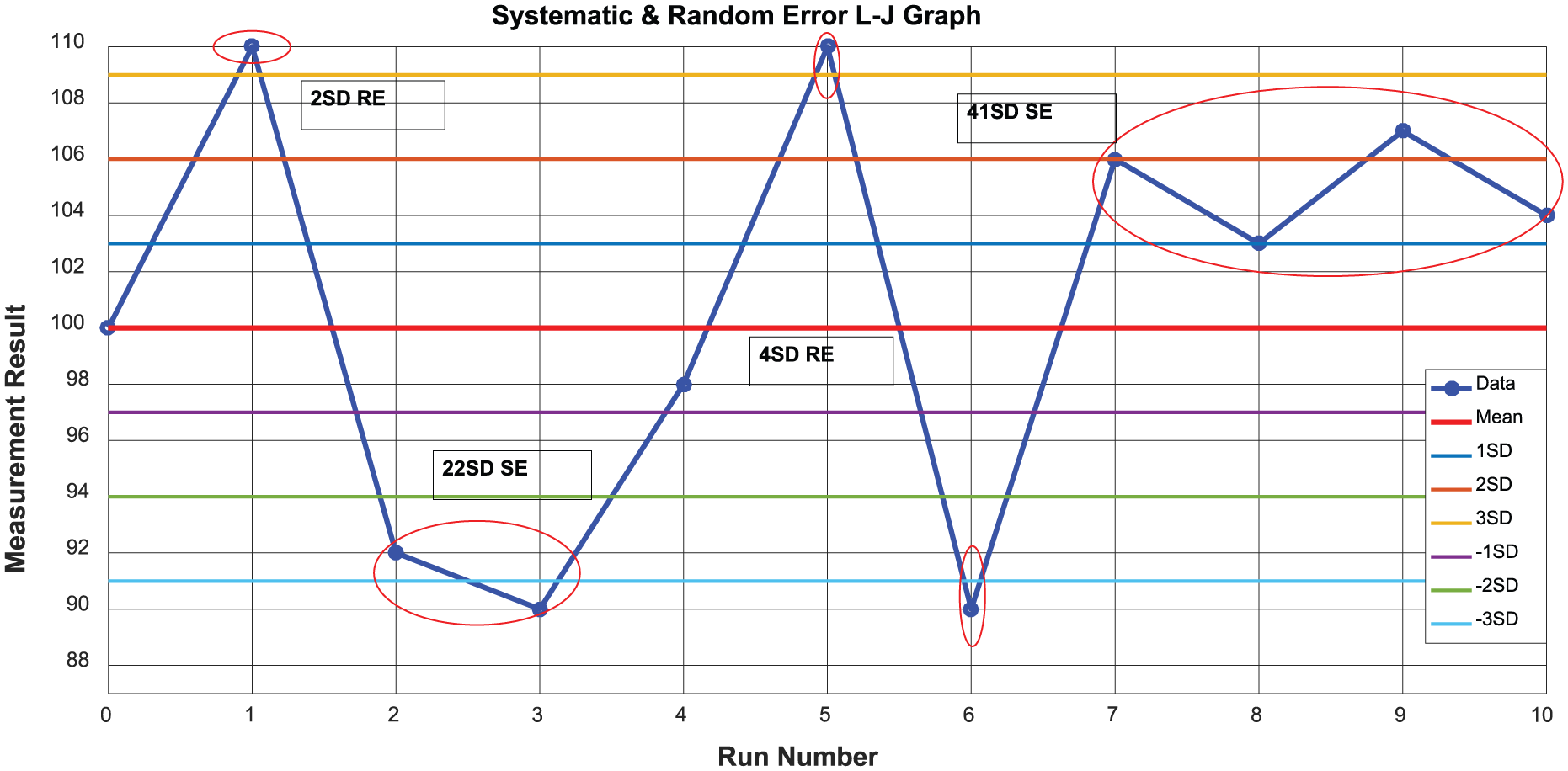
Application of the Westgard rules on the Levey-Jennings chart.
Generating the dataset
In this study, the actual laboratory control test results which have ethics committee approval were used as the base dataset. Besides, we have employed the standard reference values—which are used to verify the accuracy of the system prior to daily tests—as the control values. The control data is read from the device and recorded along with their timestamps. With this information, a table of control data for the laboratory and the test being studied is obtained. A sample dataset is presented in Table 3.
X Dataset example—actual test data.
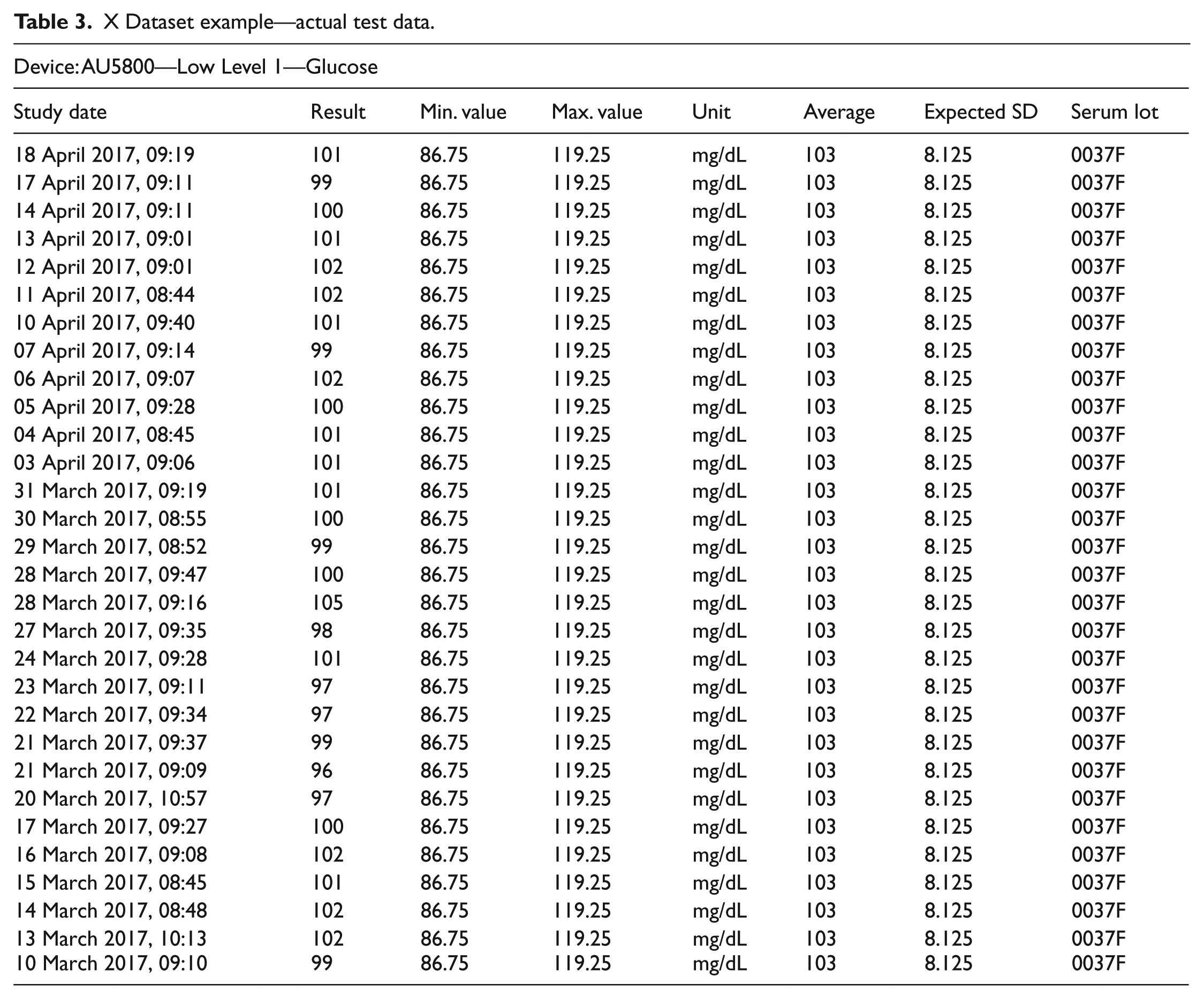
An excel chart was created for the glucose tests containing control data of 30 days obtained from the device. Moreover, the data from the table was used in the model flow process. As it can be seen from Table 3, minimum and maximum limit values refer to the lower and upper bounds of the standard control values. Thus, measurement results to be made in the system are expected to lie between these two limits. In this configuration, it should be noted that the average values constitute the control values themselves and there may be deviations from these values where the permitted SDs were indicated in Table 3. As presented in Table 3, the employed test device is AU5800 and it was used for low-level glucose test along with serum lot “0037F.”
Pre-analysis calculations
According to the range of distribution, variance-variability, SD, and CV are the required parameters to be computed prior to statistical interpretation and evaluation of the Gaussian curves drawn according to accuracy and precision values.32,34,35 The calculation of SD is given in formula (1) below
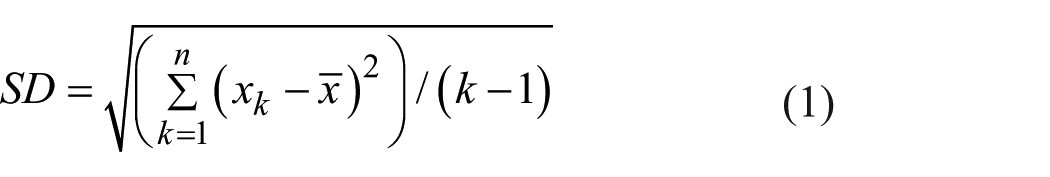
According to equation (1), n represents the total number of data in dataset, whereas

Moreover, the upper and lower control limits are calculated via formula (3) using the computed SD and mean values

The coefficient of m expresses the distribution of positive and negative sides of the SD and, in practice, it is often set to 1, 2, or 3.36,37 Meanwhile, Levey-Jennings tables are constructed with the calculated values and the whole scattering is observed by plotting the control data on the table.38,39 At this stage, we run the Westgard rules by taking into account the positioning of the data which are above and below the average values around the
Next, the value of ∆wp is computed by taking the difference of Cwp (calculated working point) and Iwp (ideal working point) using formula (4)

The direction of bias to the ideal, that is, bias direction, for the test results is determined according to whether Δwp is negative or positive. In this regard, if the result is positive, the working point shift takes place on the right side of the ideal, whereas it is on the left side for the opposite case. In Figure 5, right and left shifts are depicted on precision chart. This finding sheds light on the direction of the systematic error for the process using the equation below
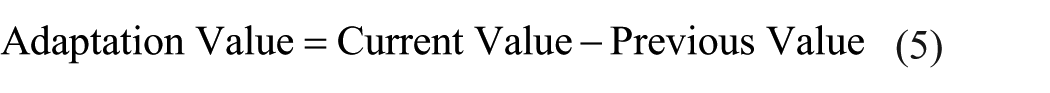
Shifting for the weighted averages of the calculated dataset according to the reference value.
As a result of applying the calculated adaptation value to the system, the correction for error reduction and the increase in the result accuracy are shown in the Accuracy–Error curve depicted in Figure 6. Thus, the measured error based on the initial control data obtained from the system and the resulting improvement by use of our model implementation are plotted as adaptation resultant error point. In Figure 6, the decrease in the error margin and the increase in accuracy are shown by applying the model. At this point, our expectation is generating the results using the control data closer to the point where the accuracy reaches to the value of 1. In contrast, it is also aimed that the results having too many errors should appear near to the point where the error reaches to the value of 1.
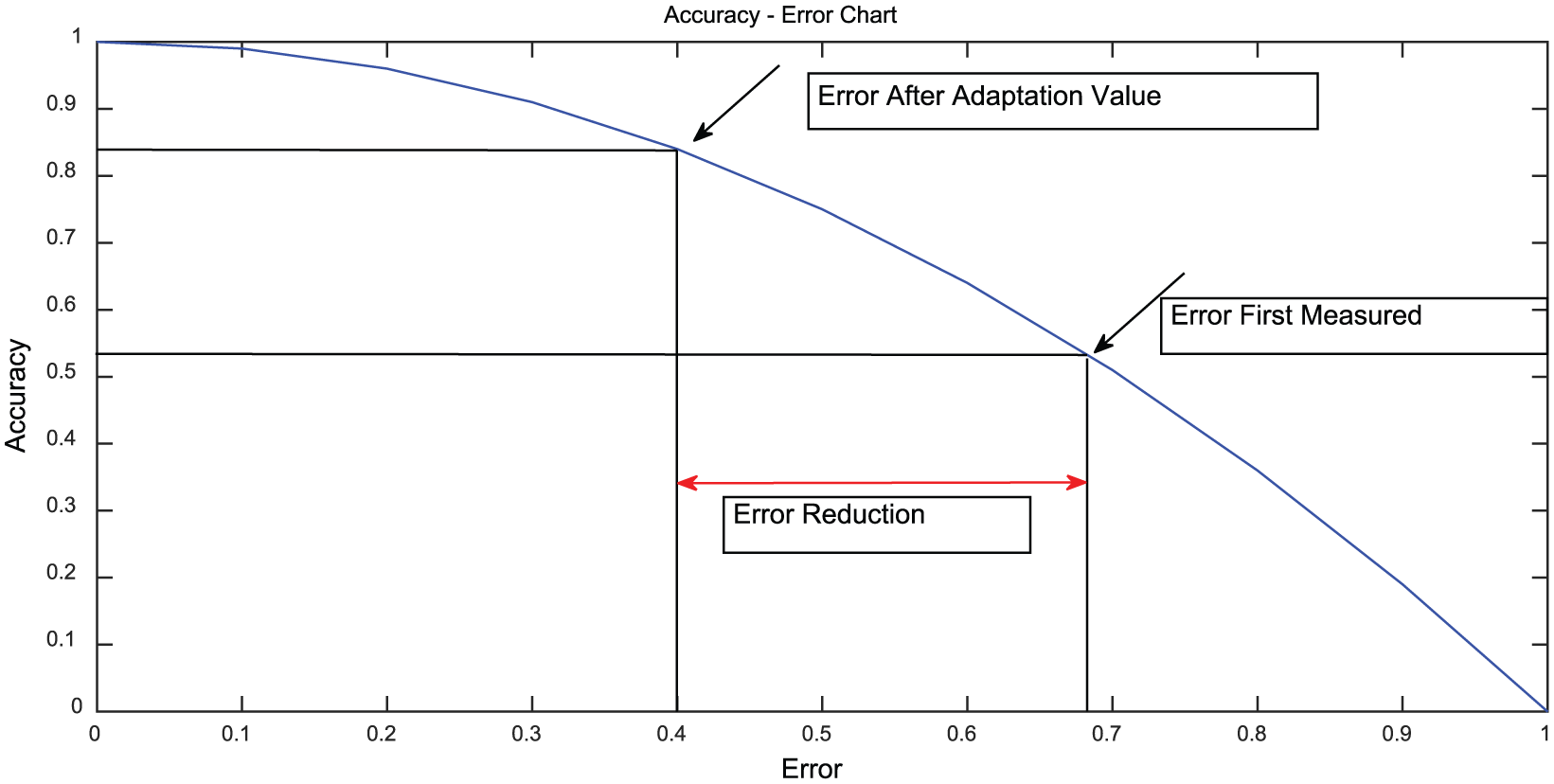
Error reduction effect of the proposed algorithm on accuracy-error chart.
Experimental works and results
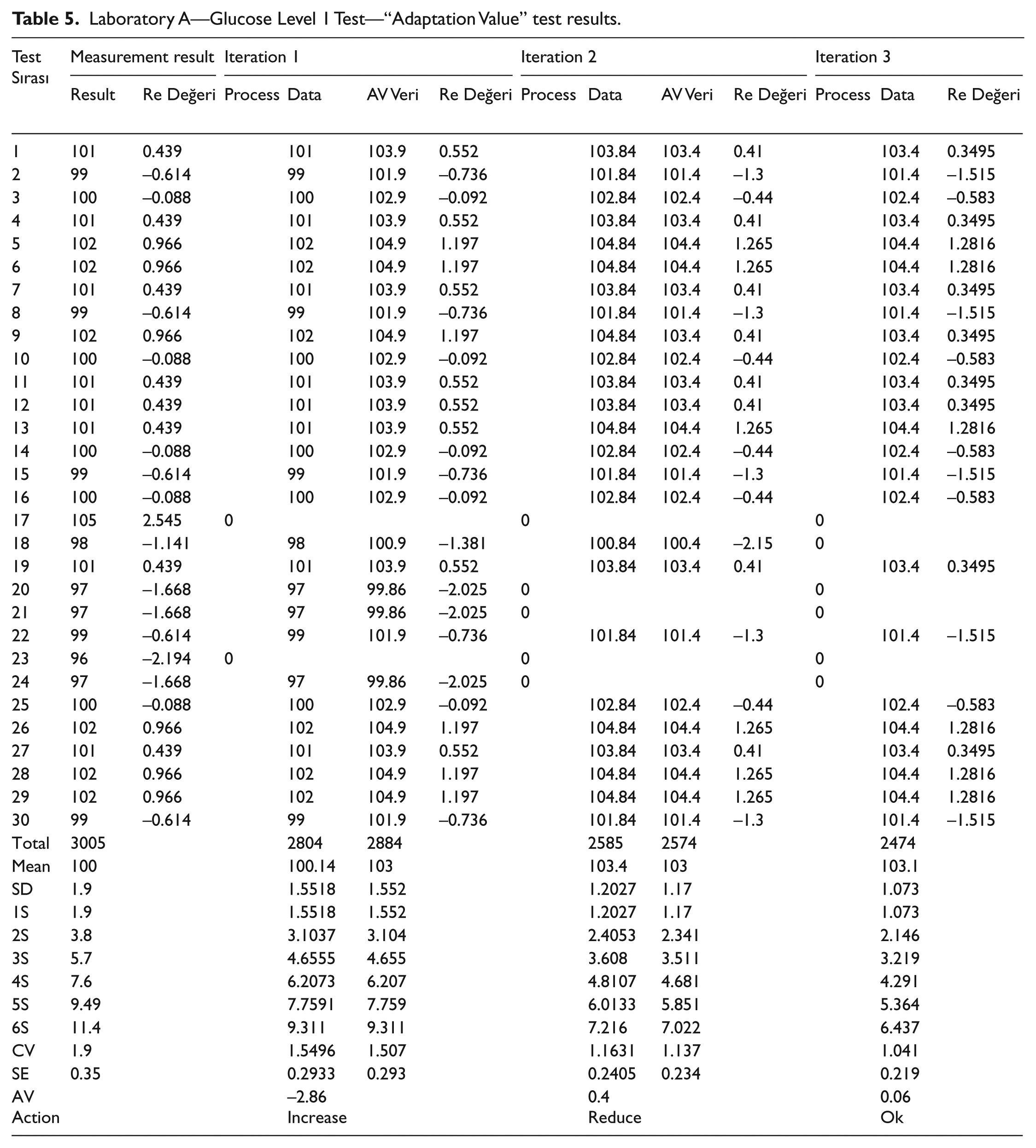
Throughout the experiments, control data from the laboratory were processed with the reference Glucose values according to CLIA 88. For the glucose test, we have used the control value of ±6 mg/dL or the mean value of ±10% that were specified by the standards. Measurements were made with two devices—called as Device A and B—using the dataset shown in Table 3. It should be noted that these devices are in the same condition. The standard test kit certificate values used in the laboratory are given in Table 4 for device A. The results obtained according to these values are shown in Table 5.
Standard (reference) test kit values for Device A Glucose Level 1 Test.

Laboratory A—Glucose Level 1 Test—“Adaptation Value” test results.
The standard values for the device B used for the measurement are given in Table 6, and the results obtained according to this are shown in Table 7.
Standard (reference) test kit values for Device B Glucose Level 1 Test.

Laboratory A Glucose Level 1 Test—“Adaptation Value” test results.
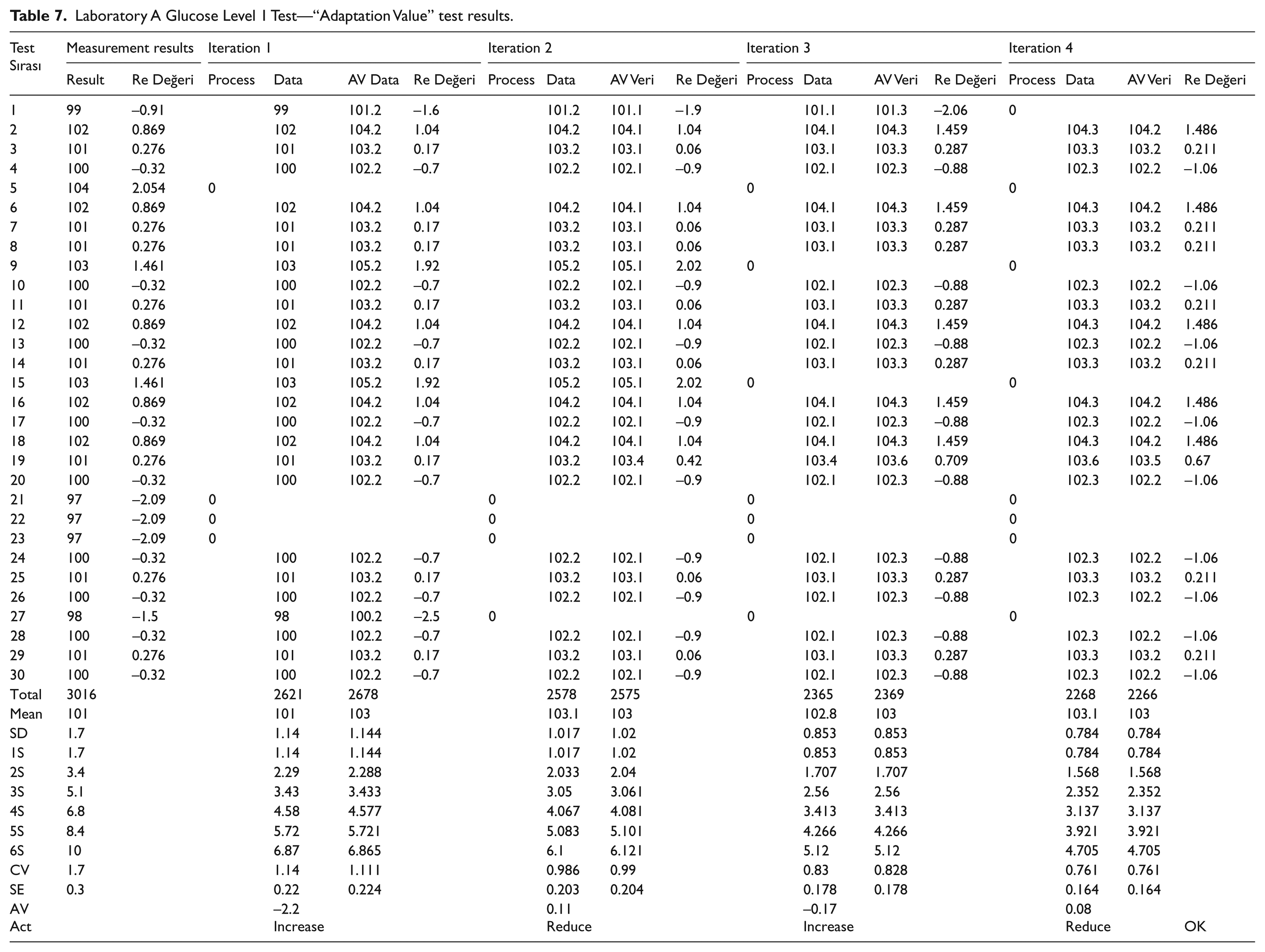
The model was applied to the data which have been collected in 30 days and it was listed in Table 7. For the first raw data, ±6 SD parameters are separately calculated to observe SD within SD, CV, standard error (SE), ±3 SD, and Six Sigma. For the first data, ±2 SD value (z-score) is calculated for each individual data. Note that, since the data above this value means a random error in the system, it has a destructive effect on the whole system. In the first step, random errors are detected and the systematic error contribution that the data group has in the next step is investigated. Next, the corresponding adaptation value (AV) is used to determine the magnitude and orientation of the adaptation quantity in order to reduce the systematic error. According to Table 7, having the negative sign of AV for the iteration result indicates that the dataset has shifted to the left from the ideal value, that is, the negative direction, and needs to shift to the right by the specified amount. On the other hand, the value of AV = +0.11 indicates that the dataset has shifted to the right-positive region with a systematic error and that this amount has to be shifted to the left.
For the experiment listed in Table 5, the results settled down to the ±2 SD band within three iterations. As a result, while 28 individual data were in ±1.9 SD distribution range at initial stage, it was found that 24 individual data were placed in the range of ±1.07 SD at the third iteration. Moreover, the initial CV value which was 1.9 reduced to 1.041 at the third iteration. We have also observed that the initial SE which was 0.35 has decreased to 0.22 at the end of the computation. Note that, for three iterations of this experiment, the adaptation values were suggested as 2.86 (increase), 0.4 (decrease), and 0.06 (decrease), respectively. In the last iteration, the process was terminated since the computed values fell within the expected deviation limits.
For the experiment listed in Table 7, the results settled down to the ±2 SD band within four iterations. While 26 individual data were in ±1.7 SD distribution range at initial stage, it was found that 22 individual data were placed in the range of ±0.78 SD at the fourth iteration. Besides, the initial CV value which was 1.7 reduced to 0.76 at the fourth iteration. Furthermore, initial SE which was 0.3 has decreased to 0.16 at the end of the process. For four iterations of this experiment, the adaptation values were determined as 2.2 (increase), 0.11 (decrease), 0.17 (increase), and 0.08 (decrease), respectively. Similar to the experiment given in the paragraph above, the process was terminated since the values in last iteration fell within the expected deviation limits.
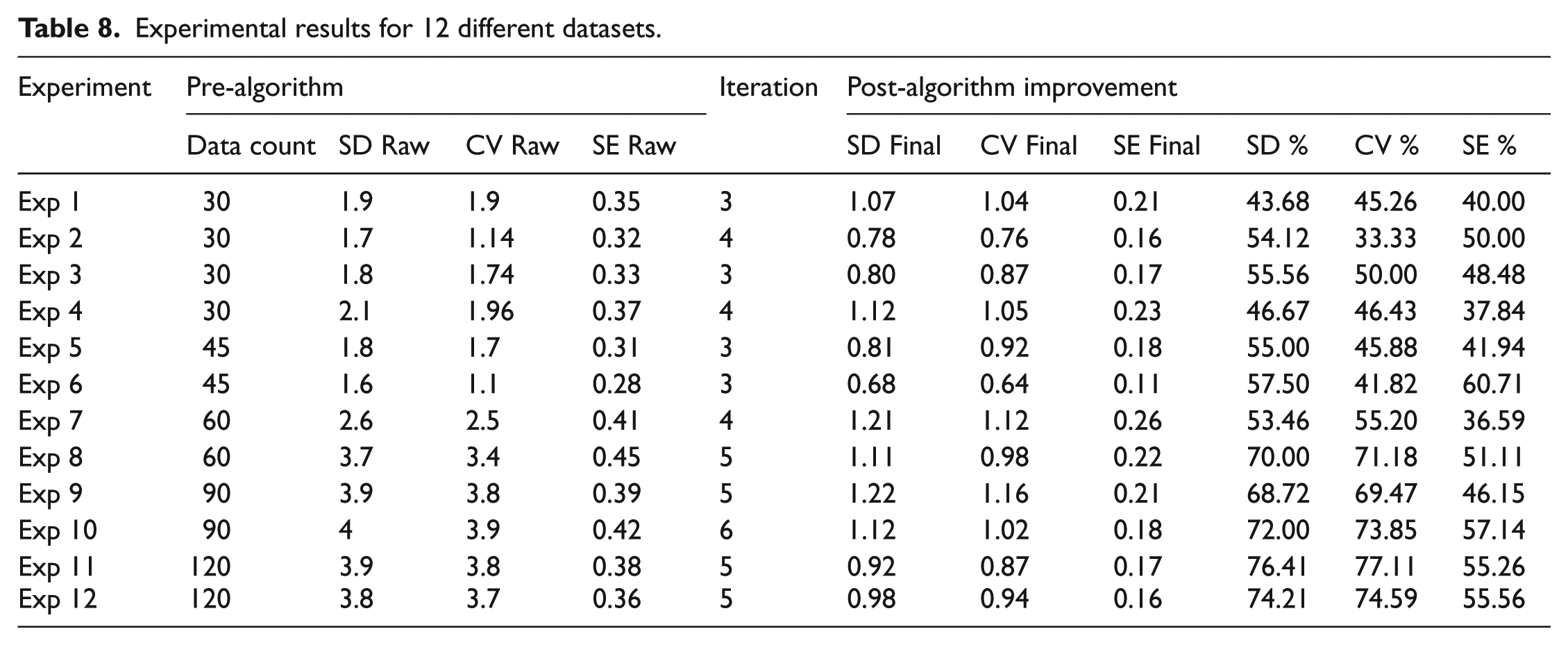
The results listed in Table 8 were obtained for a total of 12 different control data groups. For the control data of 12 different experiments, SD, CV, and SE values belonging to the raw data were calculated and listed. Moreover, random and systematic errors were detected. In each iteration, SD, CV, and SE values are recalculated and interpreted. Besides, iterations were terminated at the point where the adaptation value is 0.1 and below. At this step, the last SD, CV, and SE values obtained were listed. The error correction percentages obtained using Adaptive Precision Point Algorithm on initial data are given in the SE% column. For the group having 30 individual control data, correction ranging between 37.84% and 50.00% was obtained for the systematic error. Similarly, for the group having 45 individual control data, systematic error has been computed ranging from 41.94% to 60.71%, while it has been measured between 36.59% and 51.11% for the group having 60 data. These value ranges have been detected as 46.15% to 57.14% and 46.15% to 57.14% for the control datasets having 90 and 120 individual data, respectively.
Experimental results for 12 different datasets.
Conclusion
In this study, an algorithmic approach called “Adaptive Precision Point Algorithm” has been proposed. Furthermore, its effectiveness and utilization on reaching to the target measurement value for the out-of-assessment data have been investigated by detecting and correcting the random and systematic errors in control data. Besides, the developed algorithm was proposed to be used for industrial laboratories for the first time.
For the experiments, 12 control datasets each having different number of data were used. Test results present a correction of 37.84%–50.00% compared to the initial value of SE at the end of the third and fourth iterations compared to the raw data at the beginning.
Based on the experimental results, 16 individual data having random and systematic errors at the beginning were recovered as useful data using the proposed approach and 24 out of 30 individual data were used as useful.
Test results for the group involving 45 data have shown a correction of 41.94%–60.71% compared to the initial value of SE at the end of the third iteration compared to the raw data at the beginning. For this dataset, 27 individual data having random and systematic errors at the beginning were recovered as useful data, and 39 out of 45 were used as useful.
Test results for the group involving 60 data have shown a correction of 36.59%–51.11% compared to the initial value of SE at the end of the fourth and fifth iterations compared to the raw data at the beginning. For this dataset, 38 individual data having random and systematic errors at the beginning were recovered as useful data, and 52 out of 60 were used as useful.
Test results for the group involving 90 data have shown a correction of 46.15%–57.14% compared to the initial value of SE at the end of the fifth and sixth iterations compared to the raw data at the beginning. For this dataset, 58 individual data having random and systematic errors at the beginning were recovered as useful data, and 81 out of 90 were used as useful.
Test results for the group involving 120 data have shown a correction of 55.26%–55.56% compared to the initial value of SE at the end of the fifth iteration compared to the raw data at the beginning. For this dataset, 71 individual data having random and systematic errors at the beginning were recovered as useful data, and 107 out of 120 were used as useful.
As another goal of the study, the recovery of the data extracted from random and systematic errors and the total contribution to the result have been shown provided that they remain within the ±2 SD band that is used as the evaluation limit in the quality control data. Moreover, for the groups having control data ranging from 30 to 120, corrections between 36.59% and 60.71% were observed regarding the systematic error. Thus, increase in the stability and accuracy at the working point enables the control cost to be reduced along with increase in reliability.
Consequently, the proposed model is remarkable in terms of the amounts of savings to be gained from the perspective of a laboratory if thousands of tests that are made each year are considered. Thus, investigation of the applicability of the proposed approach to different types of control data is another issue that needs to be studied in the future.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.