
Abstract
Objective
We developed a taxonomy for human–agent teams (HATs) and conducted a literature review of existing HAT testbeds using our proposed taxonomy.
Background
With the increasing interest in HATs, numerous research studies in this field have utilized different testbeds. Despite this, there is a lack of comprehensive understanding regarding the capabilities and limitations of the existing testbeds.
Method
We first developed a taxonomy for HATs by modifying the existing framework for classifying human teams. Our proposed taxonomy comprises ten attributes. Subsequently, using the taxonomy, we analyzed 103 testbeds identified from 235 empirical research studies. After coding each testbed, we conducted frequency analyses on each attribute to determine the distribution of the testbeds.
Results
Regarding team composition, the majority of testbeds afford single human participants paired with few agents, typically in subordinate roles. Also, in most testbeds, the leadership structure is designated, with humans assuming leadership roles, or none. The communication dynamics present an area for further exploration, especially with larger team sizes. Additionally, nearly all reviewed testbeds focus on long-term teams, overlooking dynamics in ad hoc teams, which are common in real-world settings.
Conclusion
Our findings underscore the importance of further research into diverse team attributes, such as team composition, leadership structure, communication structure, direction, and medium. It would facilitate a deeper understanding of complex team dynamics in HATs and lead to designing effective teams.
Application
The current study would be valuable for discussing future research directions when developing new testbeds or designing novel experiments leveraging existing ones.
Keywords
Introduction
With the growing adoption of autonomous technologies across various domains, human–agent team (HAT) has become a key area of research across multiple disciplines such as human factors, robotics, and computer science. Most studies on HATs have utilized proprietary testbeds developed by the respective research teams. Consequently, each testbed possesses distinct characteristics. For instance, the Mixed Initiative Experimental Testbed (MIX) (Barber et al., 2008) involves a RoboLeader capable of gathering information from subordinate robots with limited autonomy, making tactical decisions, and coordinating the robots. In this testbed, one human is tasked with target detection utilizing the multiple subordinate robots and route replanning with assistance from the RoboLeader. Another frequently utilized testbed, Blocks World for Teams (BW4T) (Johnson et al., 2009) features a multi-human multi-agent team in which all members cooperate to search through rooms and deliver blocks in a specific order (Chung & Yang, 2025a, 2025c). Another multi-agent testbed developed recently utilizes the “team of teams” (McChrystal et al., 2015) idea and allows the teams to reconfigure as problem contexts evolve (Guo et al., 2023a, 2024). These and other testbeds differ in their team designs, task domains, objectives, and team compositions.
Using various testbeds, research studies have explored the effects of a multitude of factors, including human-related factors such as culture, past experience, and spatial ability (Bhat et al., 2022; Chen et al., 2008; Hafızoğlu & Sen, 2018); agent-related factors such as reliability, autonomy level, reputation, and value alignment (Bhat et al., 2024b; Hafizoglu & Sen, 2018; Hillesheim & Rusnock, 2016; Hoffman & Breazeal, 2007; Mercado et al., 2016); task-related factors including task difficulty and design (Chen et al., 2011a, 2013; Cohen & Imada, 2005); and team-related factors such as team composition, communication type, and communication medium (Chen, Barnes, Qu, & Snyder, 2010; Walliser et al., 2019). Recent reviews on HATs by O’Neill et al. (2022), Lyons et al. (2021), and Chen and Barnes (2014) provide excellent overviews of this literature, with a focus on the dependent and independent variables examined in prior studies.
Despite these contributions, a comprehensive overview of HAT testbeds themselves remains lacking (Chung et al., 2024), and this absence raises several important concerns: First, oftentimes testbed design constrains which constructs can be manipulated or measured; for example, examining the “team of teams” (Guo et al., 2023a; McChrystal et al., 2015) concept can only be evaluated on platforms where team composition can dynamically change. Second, the field has increasingly called for studies involving larger, more heterogeneous teams that reflect real-world teaming scenarios (Karwowski et al., 2025; Lyons et al., 2021; Nguyen et al., 2022; O’Neill et al., 2022). However, without a structured overview of testbed capabilities, researchers cannot easily identify which platforms support the next generation of research questions. Last but not least, in the absence of a review, laboratories frequently “re-invent the wheel” and develop environments that duplicate existing functionality, wasting valuable resources from theory-driven experimentation to infrastructure building.
To address this need, we conducted a literature review of HAT testbeds featured in prior research to better understand the current landscape of existing HAT testbeds. Our scope is limited to virtual agents without physical embodiment. Testbeds implemented through software programming offer significant flexibility in simulating a wide range of teaming scenarios (e.g., emergency response to fires or crimes), some of which are extremely challenging to create with embodied agents. This review aims to answer the following research questions: What kinds of HAT testbeds exist, and how are they designed? What types of team characteristics do they support? For each key team attribute, how are existing testbeds distributed, and are there any prevalent or underrepresented attributes that need further attention?
We identified a total of 103 testbeds used in 235 studies and analyzed them using a taxonomy developed to categorize HATs. Our taxonomy is based on the widely accepted classification scheme for human–human teams from Wildman et al. (2012), which originally comprises six team-level attributes: task interdependence, role structure, leadership structure, communication structure, physical distribution, and team life span. We iteratively modified the scheme to suit the context of HATs. Notably, we introduced four new attributes relevant to HATs: team composition, leadership role assignment, communication direction, and communication medium.
The current study has made several significant contributions: (1) We developed a novel taxonomy specifically tailored for HATs by adapting a widely recognized framework for classifying human–human teams. This taxonomy includes ten attributes: team composition, task interdependence, role structure, leadership structure, leadership role assignment, communication structure, communication direction, communication medium, physical distribution, and team life span. (2) Utilizing this taxonomy, we performed a comprehensive review of 103 testbeds used in 235 studies. This analysis offers detailed insights into the structures and characteristics of these testbeds, highlighting their unique functionalities and configurations. (3) We identified significant gaps in the current design of testbeds and studies of HATs. Our findings reveal that the majority of testbeds were designed to examine dyadic HATs with fixed role and leadership structures, relying on primitive communication channels. We highlight the need for more flexible, customizable testbeds that allow researchers to manipulate various team attributes, paving the way for richer investigations into how team attributes influence HAT performance.
Method
Development of Taxonomy for Human–Agent Teams (HATs)
To develop a comprehensive HAT taxonomy for analyzing and defining team characteristics in existing HAT testbeds, we referred to previous literature on human team classification. We first referred to frameworks and taxonomies for classifying human–automation interaction (Endsley & Kaber, 1999; Hancock et al., 2011; Parasuraman et al., 2000). Yet, their focus is primarily on defining levels of automation and outlining the factors that shape human–automation interaction. Their perspective is not necessarily centered on analyzing how humans and agents, as a “team,” work together to achieve a common goal, which is the focus of the current review.
A work team and teaming are defined as the adaptive, interdependent, and dynamic interaction of two or more individuals working toward a common and valued goal (Salas et al., 1992). This definition remains applicable regardless of whether the team members are human or computer-programmed intelligent agents. Consequently, we decided to adopt a well-defined framework from traditional human team research that outlines a holistic set of team-level attributes, and adapted it to the HAT context.
Several taxonomies or systematic frameworks of key team dimensions have been proposed in the human team literature. For example, Hollenbeck et al. (2012) defined three major axes that characterize various types of teams: skill differentiation, which concerns the role assignments of team members; authority differentiation, which defines leadership and hierarchical structures; and temporal stability, which describes whether structural linkages among team members are short-term or long-lasting. While insightful, this framework lacks an explicit emphasis on interaction and communication processes. Tiferes and Bisantz (2018) proposed a broader set of eleven team dimensions; however, many of these focus more on task demands or individual characteristics (e.g., task load, time pressure, and prior experience) than on the structural attributes of the team itself. Other influential frameworks, such as those from Salas et al. (2005) and Klein et al. (2010), emphasize behavioral markers of effective teamwork, including mutual performance monitoring, backup behavior, and sensemaking. While these are valuable for evaluating team functioning, they are less suited for classifying HATs with a special focus on testbed design.
Taxonomy for Human–Agent Teams (HATs).
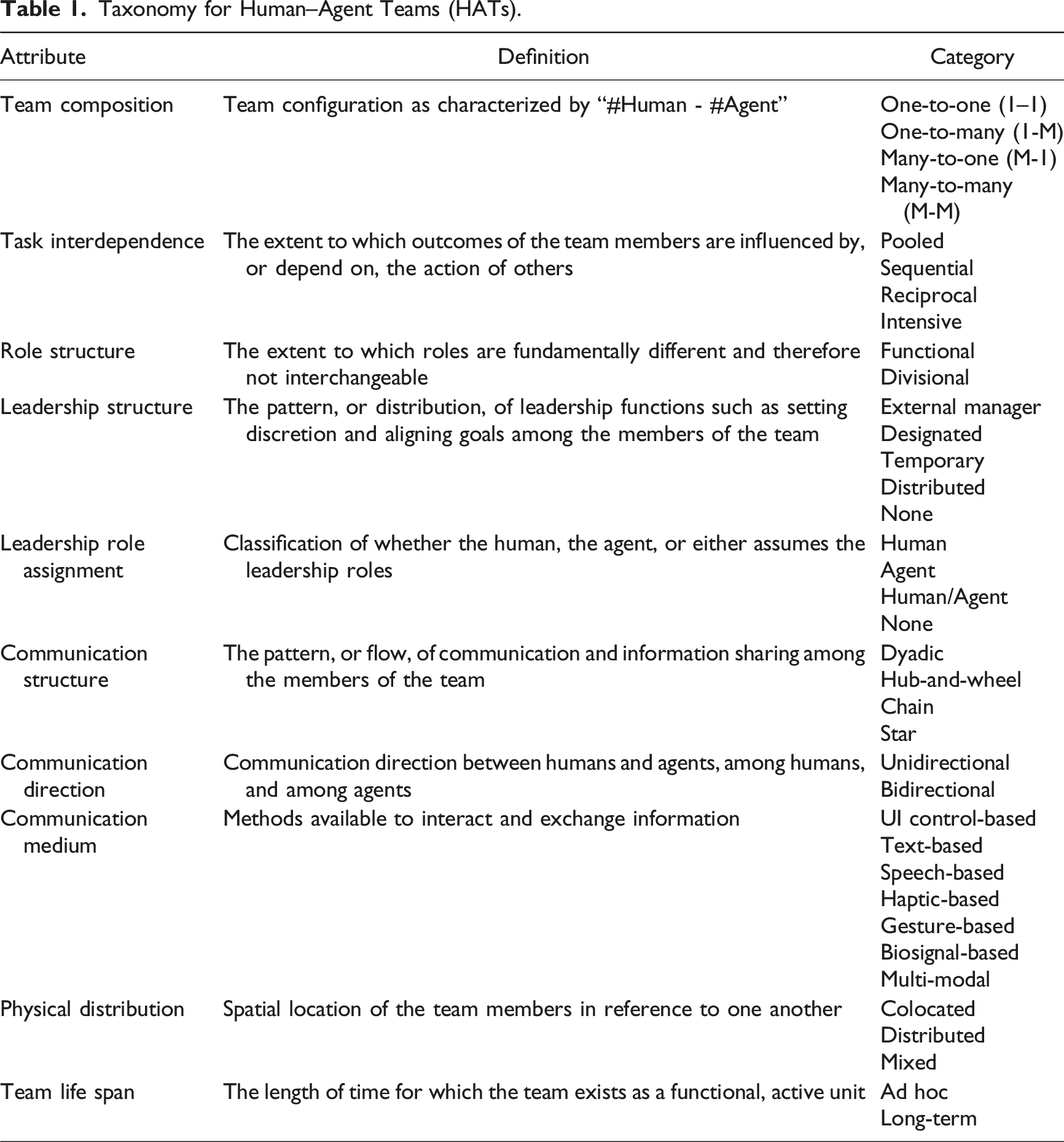
While the original taxonomy emphasizes mutually exclusive categories, our adapted HAT taxonomy can be applied more flexibly based on experimental configurations. This approach allows for double-coding when a single testbed supports multiple configurations.
Team composition refers to the mix of humans and artificial agents that make up the team to achieve a common goal. In the context of HATs, it is essential to consider the composition of the team, as it not only influences the behaviors of each individual within a team but also the collective behaviors of the team. A large portion of early studies in HATs focuses on the classical dyadic interaction between one human and one agent. However, there is growing attention to non-dyadic teams (Schneiders et al., 2022; Guo et al., 2023a, 2023b; O’Neill et al., 2022). There are four discrete classes for this attribute: one-to-one (1–1), one-to-many (1-M), many-to-one (M-1), and many-to-many (M-M). One-to-one (1–1) refers to one human interacting with one artificial agent. This is the classical dyadic interaction. In the one-to-many (1-M) category, one human interacts with at least two artificial agents. Studies on human-swarm interaction (Nagi et al., 2014) often fall into this category. In the many-to-one (M-1) category, at least two humans interact with one artificial agent. Examples include a robotic tour guide in museums, wherein many visitors interact with one artificial agent (Faber et al., 2009). The last category, many-to-many (M-M), refers to a team where at least two humans interact with at least two artificial agents. One example of this category is the study of Guo et al. (2023b) wherein two humans and two artificial agents perform a search detection task.
Task interdependence attribute refers to how team members’ actions influence their outcomes (Saavedra et al., 1993). This attribute can be categorized into four distinct levels. In the pooled level, each team member, either a human or an agent, independently contributes to the outcome without requiring interaction with others. In sequential, one team member’s actions must precede another team member’s actions, resembling an assembly line setup. Reciprocal type involves team members interacting with each other in a back-and-forth manner on a one-to-one basis, but not simultaneously with multiple members. Lastly, intensive task interdependence represents the highest degree of interaction. At this level, the entire team collaborates and works together as a cohesive unit to achieve their shared objective.
Role structure describes the extent to which team roles are specialized or interchangeable (Thylefors et al., 2005). Work can be divided in a functional or divisional manner (Harris & Raviv, 2002; Wildman et al., 2012). If team members perform different roles that are not interchangeable, this is considered a functional role structure. Examples include the cross-functional design team comprising people from marketing, engineering design, user experience, and manufacturing (Yang et al., 2012). On the contrary, if every team member can perform the same function and can replace one another, this is considered a divisional role structure.
Leadership structure refers to how leadership functions are distributed within a team (Wildman et al., 2012). Wildman et al. (2012) identified four configurations of leadership structure by incorporating relevant leadership literature: external manager, designated, temporary, and distributed. In the external manager structure, the leadership role is performed by someone outside the team. The designated structure involves assigning one team member as the leader. In the temporary structure, leadership rotates among team members across different tasks and timeframes, with different members acting as the leader as needed. In the distributed structure, leadership functions are divided among various team members. Additionally, a none type is introduced into our taxonomy for the leadership structure attribute. This type is relevant in the context of HATs since there are instances where neither a human nor an agent team member is responsible for the leadership role during the experiment (Frieder et al., 2021; Hoffman & Breazeal, 2007).
Leadership role assignment refers to who has the decision-making responsibility and assumes the leadership roles (Hollenbeck et al., 2012). In our taxonomy, this attribute specifically identifies who (human or agent) holds the authority to make final decisions, which is closely associated with the autonomy level of an agent. For instance, among the 10 autonomy levels proposed by Sheridan & Verplank (1978), in lower levels (1–6), humans retain the responsibility for making final decisions, even though automation may provide recommendations or suggestions. On the other hand, in higher levels (7–10), automation is granted the authority to determine actions without requiring explicit human approval or intervention.
Communication structure refers to the specific patterns of communication that exist within a team (Dyer, 1984). There are three primary communication patterns: hub-and-wheel, star, and chain. In the hub-and-wheel communication structure, communication flows through a central control team member, often the team leader, known as the “hub.” This central figure then disseminates information to all other team members, creating a hub-and-spoke-like network of communication. Chain structure applies when communication follows a hierarchical path “up and down the line.” Information is passed from one team member to the next in a linear sequence, based on the established hierarchy within the team. In star structure, information is shared freely among all team members without any central point of contact or hierarchical structure. This type of communication allows for open and direct communication between team members, promoting a free-flowing exchange of ideas and information. This category also applies when all team members freely exchange information via shared displays. In addition, a dyadic type is added to the communication structure attribute. This is relevant in HAT literature, where many scenarios involve a team comprising one human and one artificial agent (e.g., Hanna et al., 2015; Harriott et al., 2012). In these scenarios, communication is limited to a dyadic interaction between the human and the agent, as the team consists of only two members.
Communication direction defines how information is exchanged between human members and artificial agents, among humans, and among agents. Two primary modes of communication direction can be applied across all three types of pairings: unidirectional and bidirectional. In the unidirectional communication mode, information flows in one direction only. In the case of human–agent communication, the direction can be either from humans to agents or from agents to humans. For instance, a human might give a command to a robotic arm in a manufacturing setting, and the robot acts upon the command without providing any feedback to the human (Tian et al., 2023). In contrast, bidirectional communication involves information flowing back and forth between the two parties, allowing both sides to give and receive information (Chiou & Lee, 2016). This type of communication fosters a two-way exchange of information and feedback between the team members.
Communication medium refers to the methods available for interaction and information exchange (Tiferes & Bisantz, 2018). There are UI control-based, text-based, speech-based, haptic-based, gesture-based, biosignal-based, and multi-modal. UI control-based medium includes buttons, menus, sliders, or other user interface elements that a person can manipulate to interact with an artificial agent. For instance, controlling an AI-powered drone using a software interface would correspond to UI control-based. Text-based medium involves the exchange of written information. For example, a user might type queries for a text-based AI chatbot. The speech-based medium involves verbal communication. An example would be a voice-controlled AI assistant like Siri or Alexa, which can receive spoken commands and provide audio responses. Haptic-based medium involves the sense of touch, where force, vibration, or motion is used to communicate with an AI system, such as in certain virtual reality (VR) or augmented reality (AR) environments. Gesture-based medium involves communicating through physical gestures. For example, an AI-powered robot might interpret hand signals from a human team member. Biosignal-based medium involves the use of biosignals such as electroencephalogram (EEG), functional near-infrared spectroscopy (fNIRS), and eye gaze data. For example, a brain–computer interface (BCI) enables the translation of brain signals into system inputs for communication. Finally, multi-modal medium uses a combination of the above mediums.
Physical distribution refers to the classification of how spatially proximal team members are (Wildman et al., 2012). Teams can be fully colocated, meaning all members are close enough in physical location to collaborate directly on shared tasks. For example, a team assembling furniture together in a room would be considered colocated. Alternatively, teams can be fully distributed, where members are physically separated. In an urban search and rescue task, for instance, team members may be assigned to search different rooms independently while using a messaging tool to communicate the locations of identified victims. Teams can also exhibit a mixed physical distribution, in which a subset of the team is colocated while others are distributed. For example, two pilots sharing the same cockpit to control multiple autonomous UAVs which are operating in different locations, represent a mixed team: the pilots are colocated, while the UAVs are distributed across various areas. In the context of virtual HATs, the physical distribution attribute can be applied by considering the characteristics of the task. The classification depends on whether the task assumes physically colocated cooperation (e.g., assembly), distributed cooperation (e.g., independent reconnaissance over distant locations), or a mixed form involving both.
Lastly, team life span refers to the length of time for which the team exists (Devine, 2002). Teams can be classified as either ad hoc or long-term. An ad hoc team is formed to accomplish a specific, temporary task and dissolves upon its completion, while a long-term team exists for the duration of its defined purpose. It is very important to note that the classification of a team as ad hoc or long-term is relative to how its purpose and duration are defined. For example, a cross-functional team assembled to develop a new software product might include a software engineer, UX designer, product manager, and marketing strategist, each contributing distinct expertise toward a common goal (Yang et al., 2012). From the broader organizational perspective, such a team is considered ad hoc because it exists only temporarily in support of a larger, ongoing mission. However, if the team’s defined purpose is bounded specifically to the software development project, and the team composition remains stable throughout that period, it should be considered long-term within the defined purpose. In traditional human teams and organizational settings, the classification of team life span typically reflects the team’s functional role within a larger organizational structure (Wildman et al., 2012). Adapting this concept to the context of HATs, where the full organizational context is often not reflected in experimental settings, we define team life span as the bounded duration from the start to the end of a team task. If, during the task, team members are instructed or allowed to freely form and dissolve teams based on a series of temporary subtasks, the team is classified as ad hoc. In contrast, if the team configuration remains fixed throughout the task as determined by the experimenter, the team is considered long-term.
Human–Agent Teaming Testbed Analysis
Based on the proposed HAT taxonomy (Table 1), a total of 103 testbeds used in 235 empirical research studies were analyzed. The objective of the analysis was to investigate how the existing HATs are designed and what kind of team characteristics they have.
Testbed Search
Building on the recent review by O’Neill et al. (2022), our search strategy applied an expanded set of criteria to capture a more comprehensive set of studies, with particular attention to testbed design. Six inclusion criteria were used to select eligible studies: The study must: (a) be empirical, (b) include a detailed description of the autonomous agent, (c) involve at least one autonomous agent and one human, (d) involve these entities working interdependently on a task toward a shared goal, (e) feature only virtual agents implemented as software programs, excluding physically embodied agents such as industrial robots or cobots that perform actions in the physical world, and (f) provide sufficient descriptions of how human(s) and autonomous agent(s) interact with each other. Note that the first five criteria were adapted from O’Neill et al. (2022). The last criterion was added because our focus is on discovering and analyzing team characteristics featured in testbeds.
Following the PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) guidelines (Moher et al., 2009), we conducted a systematic database search across six electronic databases using a predefined keyword search strategy. The databases included: Web of Science, Scopus, Science Direct, ACM Digital Library, IEEE Xplore Digital Library, and Sage Journals. The search included all records published until December 2024 (inclusive).
To develop our search string, we built on the approach by O’Neill et al. (2022) and expanded their keyword set. Specifically, we broadened the term “teaming” to “team*” to capture records containing “team,” “teams,” and “teaming,” and added key terms of “human-machine interaction” and “human-machine systems.” The full search query was as follows:
In addition to records retrieved through the database search, we included all records identified in O’Neill et al. (2022), along with five additional records recommended by anonymous reviewers.
The database search resulted in a total of 3660 records. After screening abstracts and methodologies, we excluded 2948 records that were duplicates, nonempirical studies (e.g., reviews and workshops), involved physically embodied agents, or were out of scope. We then assessed 712 full-text articles for eligibility, carefully applying the six inclusion criteria. Additionally, to ensure the relevance, reliability, validity, and applicability of each paper, we assessed each study using the following questions: (1) Was the testbed used in a controlled human-subjects experiment? (2) Does the paper include a clear description of the agent’s capabilities, the design of human–agent interaction, and the team configurations? (3) Does the testbed meaningfully simulate a HAT scenario involving shared goals and interdependence? This process resulted in the inclusion of 235 full-text articles.
Finally, we compiled all included full-text articles (n = 235) and identified testbeds described in the literature, yielding a total of 103 testbeds. Figure 1 illustrates the overall flow of the literature search. The final list of testbeds included in this paper can be found in Table 2. PRISMA flow diagram for literature search. List of Testbeds.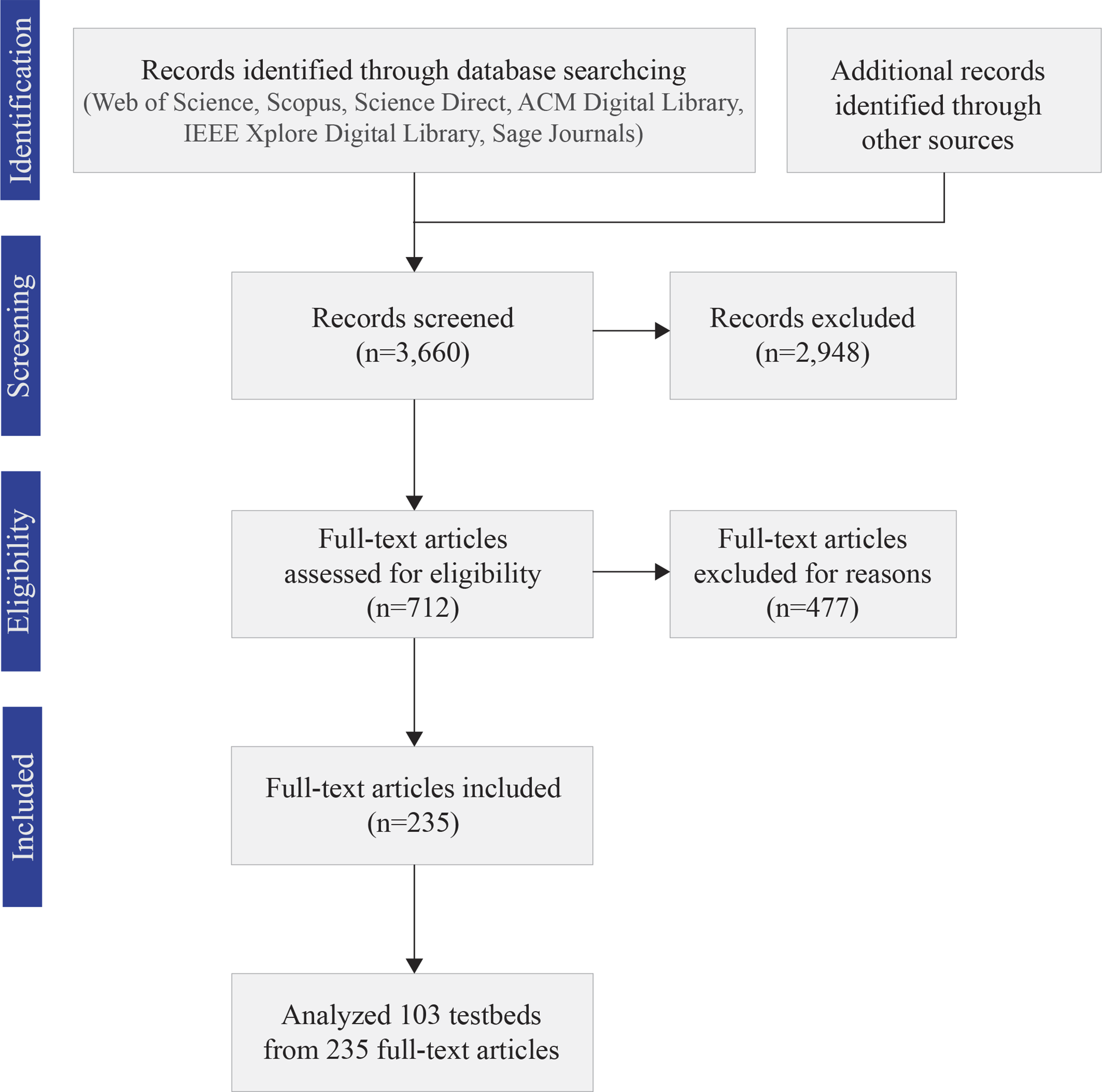
Testbed Coding Based on Team Classification Taxonomy
Using our taxonomy (Table 1), we reviewed and coded all 103 testbeds used in 235 empirical studies. As our focus in this paper is on analyzing and classifying the testbed, we thoroughly recorded and scrutinized the information related to the testbeds.
Furthermore, to enhance our understanding of how the testbeds have been implemented and utilized, we recorded additional information about each testbed beyond the ten team classification attributes: the domain to which the testbed belongs and its main task goal, the accessibility of the testbed, whether the Wizard of Oz (WoZ) technique (Dahlbäck et al., 1993) was employed to implement agent roles, and the types of metrics recorded to analyze team outcomes.
In terms of the testbed accessibility, several testbeds explicitly referred to publicly available applications (e.g., Overcooked game), or publicly shared their testbeds on a developer platform such as GitHub. Since this information provides useful insight into how the testbeds were developed and how future studies might build on them, we recorded the testbed accessibility details as reported in each paper.
The information on WoZ relates to how agent intelligence was implemented. The use of the WoZ technique implies that a human experimenter operated in place of the agent while deceiving participants into believing they were interacting with autonomous virtual teammates. If any empirical study using a given testbed specified the use of WoZ, we noted this in our records for that testbed.
Finally, the data recorded and generated by each testbed serve as key evaluation metrics for assessing HATs. Accordingly, we documented the types of dependent variables related to team outcomes, such as performance, behavior, and communication, based on the results reported in the original papers.
During the coding process, the researchers carefully examined the explicit explanations and illustrations provided in the papers. We tried to avoid any inference about the capabilities and underlying algorithms of computer-programmed agents. Instead, we focused on documenting the specific tasks assigned to human participants and agents, as well as their actions during the experiments. In cases when the team composition attribute was used as an independent variable (i.e., comparing the team performance of all-human teams to teams with artificial agents, Fan et al., 2005), we only considered and recorded conditions where at least one agent was present. Also, it should be noted that the coding was conducted at the experimental session level, based on the specific team configuration used in each session. In other words, when a single testbed was used across multiple categories within an attribute across different experimental sessions (e.g., in one experimental session, there were one human and one agent, while in another session using the same testbed, there were one human and two agents), we double-coded the testbed into all applicable categories (in this example, both 1-1 and 1-M).
Two researchers, HC and TH, first carefully reviewed n = 8 randomly selected research records and independently coded m = 4 testbeds used in the eight studies. After that, all authors held sessions to discuss and calibrate the coding logic. Any confusion in the coding scheme was resolved. After that, HC and TH continued to code another 21 testbeds. Inter-rater reliability for the first 25 testbeds reached 91%. In cases where discrepancies arose, all authors convened to share their perspectives and reach a consensus. Subsequently, HC independently coded the remaining testbeds. Finally, descriptive analyses were conducted to examine the coding results for each attribute in the team classification taxonomy.
Results
We identified a total of 103 different testbeds from the 235 empirical research studies analyzed (see Table 2). It is worth noting that some testbeds were utilized in multiple research studies, with CERTT (testbed #2) (n = 33) and MIX (testbed #1) (n = 15) being the two most frequently employed. Most of the other testbeds appeared in only one or two research studies. The frequency analysis of the testbeds is visualized in Figure 2. Overall testbed frequency (only testbeds with frequency ≥2 are presented (n = 47)).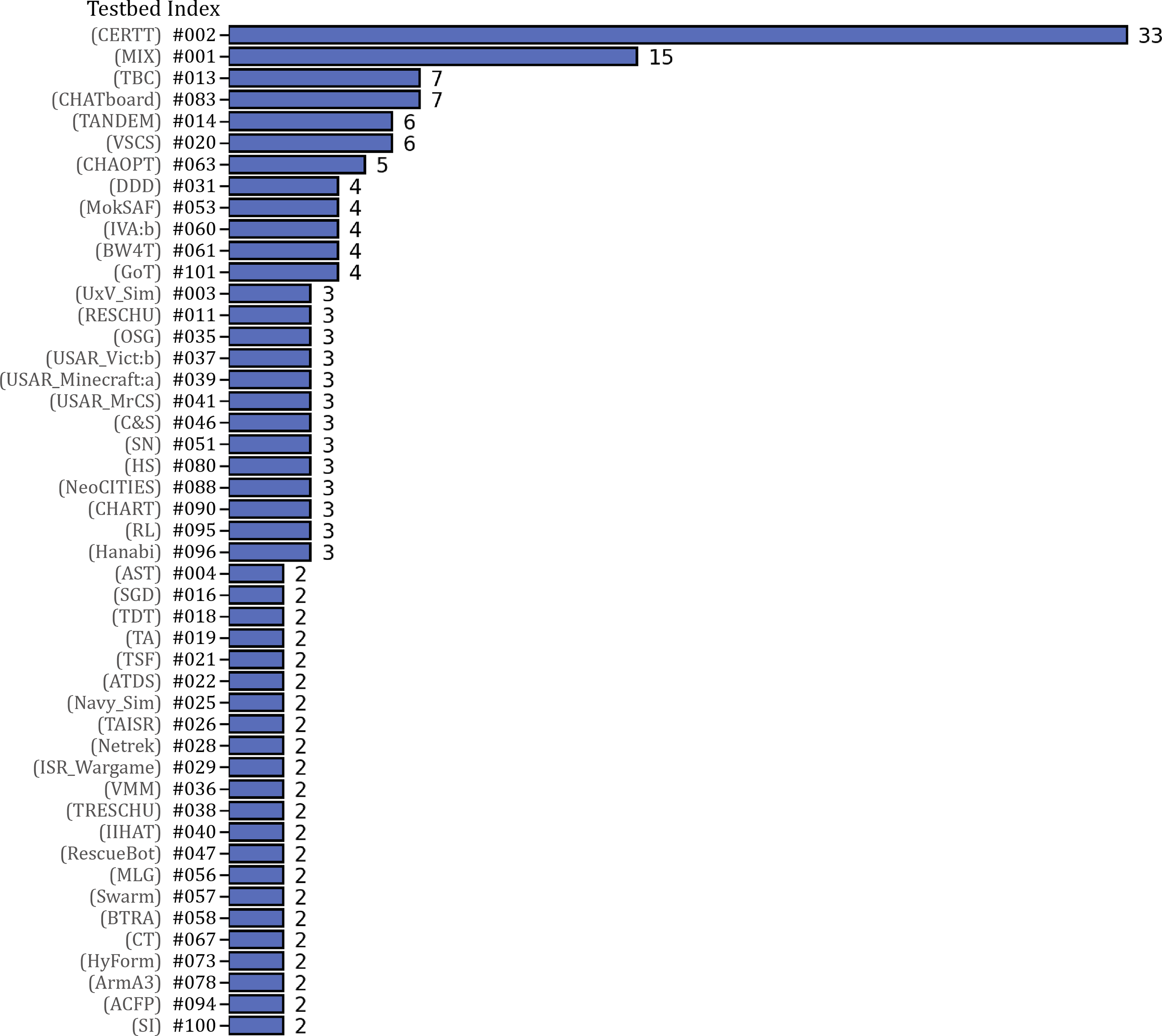
For each testbed, we recorded its task goal and overall interaction scenario, which provides insights into the specific focus of the testbeds (see Appendix A). Notably, a significant proportion of the testbeds are situated within military-related fields. Consequently, many of the testbeds’ task goals are associated with target search and elimination, navigation, and route planning. For instance, in the MIX (testbed #1), human participants are tasked with identifying targets by monitoring and supervising subordinate unmanned vehicles. In another testbed, TANDEM (testbed #14), the goal of the team is to closely communicate with each other to gather information about targets and make proper decisions on whether to engage or clear each target.
Another significant portion of the testbeds focuses on search and rescue tasks. For example, USAR_Vict:a (testbed #34) and USAR_Vict:b (testbed #37) both feature a human–agent dyad rescue team collaborating to perform urban search and rescue tasks. The first testbed’s shared task involves reporting the number of casualties in as many rooms as possible, while the latter focuses on exploring buildings damaged by an earthquake and extracting victims from the disaster area as quickly as possible.
There are also some testbeds that offer relatively unique tasks. For instance, in the BW4T (testbed #61), human participants are required to deliver a sequence of blocks in a specific order by cooperating with agent teammates. CHAOPT (testbed #63) simulates a kitchen environment where a human and an agent collaborate to prepare dishes. CHATboard (testbed #83) focuses on task allocation dynamics. In this testbed, a human participant selects from a list of four subtasks (identifying language, identifying a landmark, solving a word grid, and identifying an event) and continues making selections throughout the interaction, indicating which tasks they want their agent teammate to perform on their behalf. The selection happens within the context that the task set must be effectively completed by both team members. In addition, the GoT (testbed #101) involves two players collectively completing a team task of audio transcription.
Team Composition
Regarding the team composition attribute, the analysis reveals that among the 103 testbeds, 56.3% (n = 58) of them are designed as environments where a participant interacts with one agent, referred to as one-to-one (1–1) configuration. The second most prevalent type is one-to-many (1-M), where a single human participant works on a task with multiple agents. For example, in the UxV_Sim (testbed #3), a human operator is responsible for identifying and attacking targets using unmanned vehicles, with the assistance of an autonomous planner that provides scheduling recommendations to the human.
There are also cases where multiple human operators are involved, leading to configurations such as many-to-one (M-1) and many-to-many (M-M). For example, in many studies utilizing the CERTT (testbed #2), two human participants serve as a navigator and a photographer, respectively, collaborating closely with an agent functioning as a pilot. The team comprises three members, exhibiting a many-to-one (M-1) team composition, and they collaborate to take photographs of ground targets.
Team Composition.
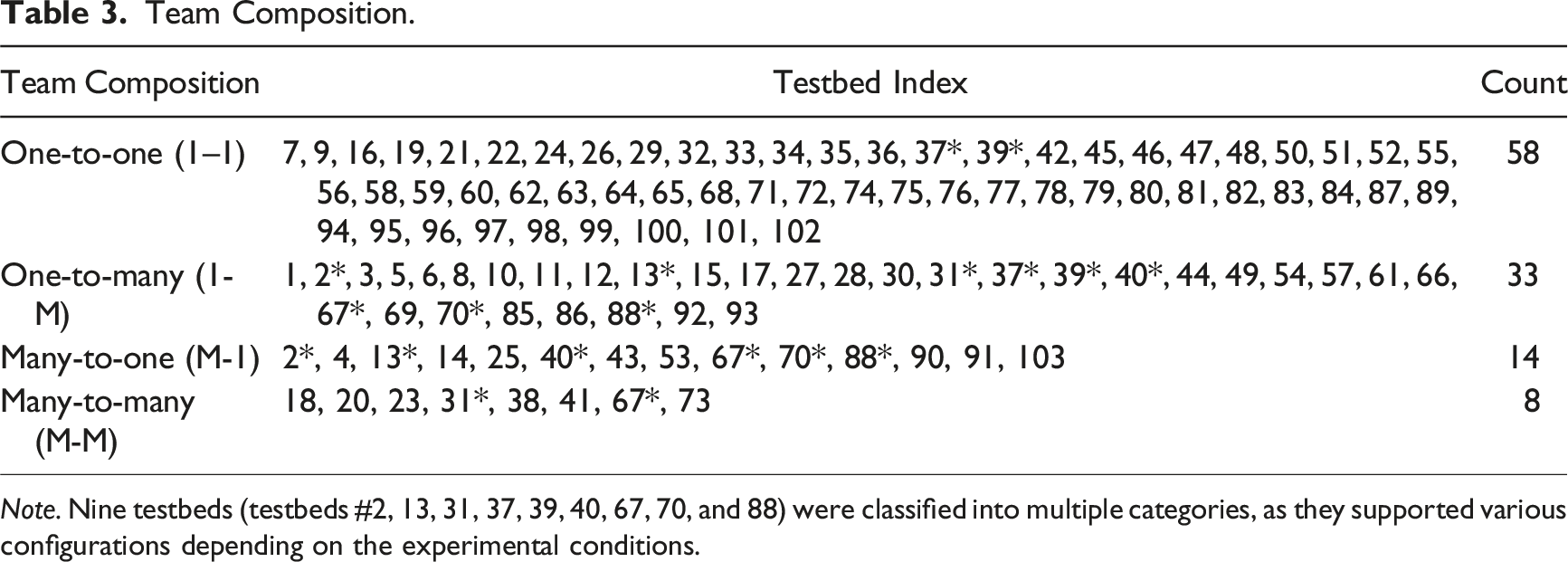
Note. Nine testbeds (testbeds #2, 13, 31, 37, 39, 40, 67, 70, and 88) were classified into multiple categories, as they supported various configurations depending on the experimental conditions.
Task Interdependence
In terms of task interdependence, approximately 41% of the testbeds (n = 42) are classified as intensive. This indicates a high level of interdependence among team members, where their actions and performance significantly rely on each other. The second most common type is reciprocal, which closely corresponds to the one-to-one (1–1) team composition. In this type, a high level of interdependence exists; however, since there are only two members, the interaction between team members occurs exclusively on an individual-to-individual basis, rather than involving multiple members simultaneously.
Twenty testbeds are classified as sequential, where team members act in a sequential manner, with one team member’s action depending on the completion of a previous team member’s action. One example testbed is the Fcty_Sim (testbed #62), where a human and an agent collaborate to assemble carts. In this testbed, the human’s role is to carry the necessary parts for assembly and position them on the workbench. The agent, in turn, fetches the correct tool and applies it to the configuration in a sequential manner.
Task Interdependence.
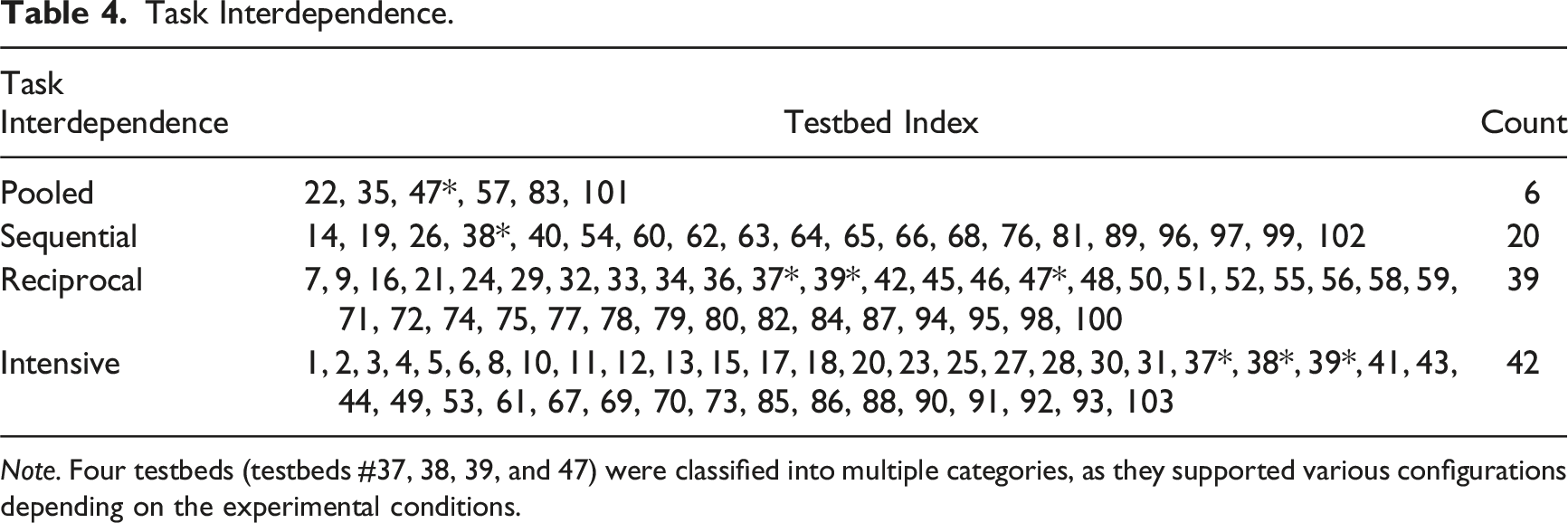
Note. Four testbeds (testbeds #37, 38, 39, and 47) were classified into multiple categories, as they supported various configurations depending on the experimental conditions.
Role Structure
Role Structure.

Note. Two testbeds (testbeds #38 and 47) were classified into multiple categories, as they supported various configurations depending on the experimental conditions.
Leadership Structure and Leadership Role Assignment
Regarding leadership structure and leadership role assignment, we coded based on the following definition of a leader: a team member who is authorized to lead the team and make final decisions in a situation of disagreement. It is worth noting that in 30 out of the 103 testbeds, there are no explicit leaders in a team (i.e., none). Among the other 73 testbeds, 61 are classified as designated. In the majority of these testbeds (n = 59), humans assume the leader role (leadership role assignment: human). Only two testbeds were used to include a condition where the agent could also serve as a leader, depending on the experimental setup (leadership role assignment: human/agent). For instance, in the TBC (testbed #13), which involves three members each assigned to the “intelligent,” “operations,” and “logistics” cell roles, the individual responsible for the intelligent cell role could be considered the leader. This role has the authority to determine whether the approaching object is a neutral force or an enemy unit. Depending on the experimental condition, either a human participant or the R-CAST (agent) could perform the intelligent cell role.
Notably, one testbed, CT (testbed #67), was identified as exhibiting a temporary leadership structure, and the leadership role assignment could be either a human or an agent (human/agent). In this testbed, six participants were grouped together to complete multiple rounds of delivering packages, with some members’ identities openly shared as humans while others were presented as agents. Participants freely formed groups of two or three by negotiating. Any team member could voluntarily initiate group formation and propose specific others to collaborate with for each round. As a result, leadership rotated among team members during the task.
Leadership Structure & Leadership Role Assignment.

Note. One testbed (testbeds #31) was classified into multiple categories, as it supported various configurations depending on the experimental conditions.
Communication Structure, Direction, and Medium
In terms of communication structure, the most common type is the dyadic structure, as all 58 testbeds with the team composition configuration of 1–1 inherently represent dyadic communication between the two members. Of these 58 testbeds, the majority (n = 45) feature bidirectional communication between the human and the agent. In contrast, fourteen testbeds featured unidirectional communication between them. For example, in SN (testbed #51), the agent provides task assistance to the human by generating trajectories, while the human does not provide any feedback to the agent.
Twenty-two testbeds are coded as having a hub-and-wheel communication structure. Within this category, both unidirectional and bidirectional communication between humans and agents were observed. For example, in MITPAS (testbed #12) and Combat_Sim (testbed #23), the human provides unidirectional commands to the agents, which they follow without offering any feedback. In contrast, several other testbeds (e.g., testbeds #1, 3, 11, 15, 54, 85, and 86) involve multiple subordinate agents and one primary decision aid/task assistance agent. The primary agent assists the human, while all other subordinates receive and follow commands from the human, representing a bidirectional exchange of information between the human and the agents. One testbed, WS (testbed #66), demonstrates relatively unique communication dynamics within the hub-and-wheel structure, also featuring bidirectional communication. In this testbed, a human acts as the hub and supports two agents, each requesting help to search for and collect specific items from a virtual supermarket.
Communication Structure and Communication Direction (H-A).
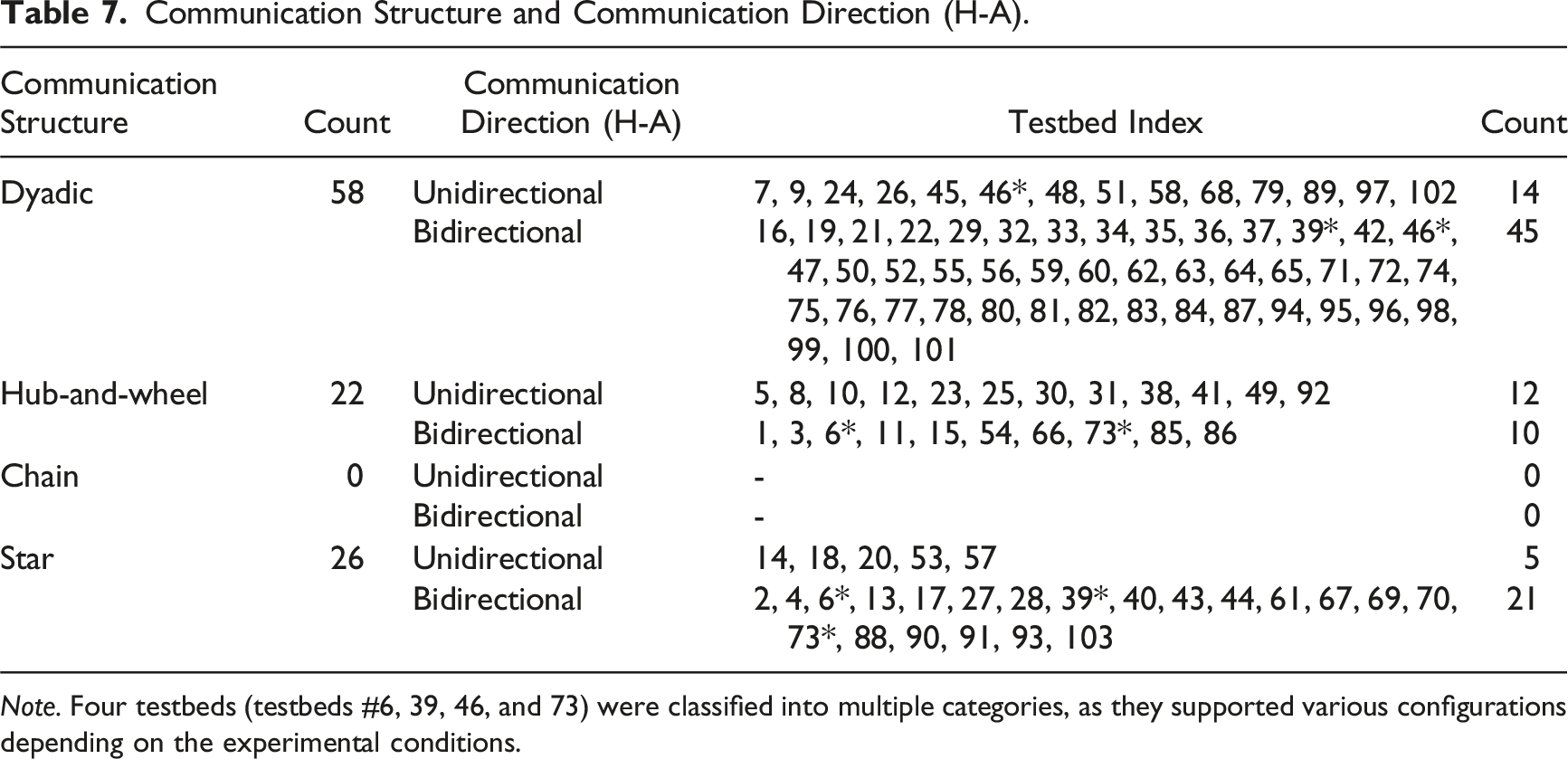
Note. Four testbeds (testbeds #6, 39, 46, and 73) were classified into multiple categories, as they supported various configurations depending on the experimental conditions.
In Table 7, we present the classification of communication direction between humans and agents, as this applies to all testbeds, given that every HAT includes communication between the two. For communication direction between humans and between agents, we examined only the testbeds that are not one-to-one (1–1) configurations, as only those are applicable for such classifications.
For the communication direction between humans, we found that all applicable testbeds involved bidirectional communication among human members.
For communication direction among agents in testbeds with multiple agents, the classification is closely tied to the overall communication structure. In a hub-and-wheel configuration, where humans commonly serve as the communication hub and agents typically take subordinate roles, there is no explicit communication between agents. In contrast, in a star configuration, which allows free-flowing communication among all members, agents in most testbeds exhibit bidirectional communication and collaborative teaming relationships (e.g., BW4T, testbed #61).
Communication Medium.
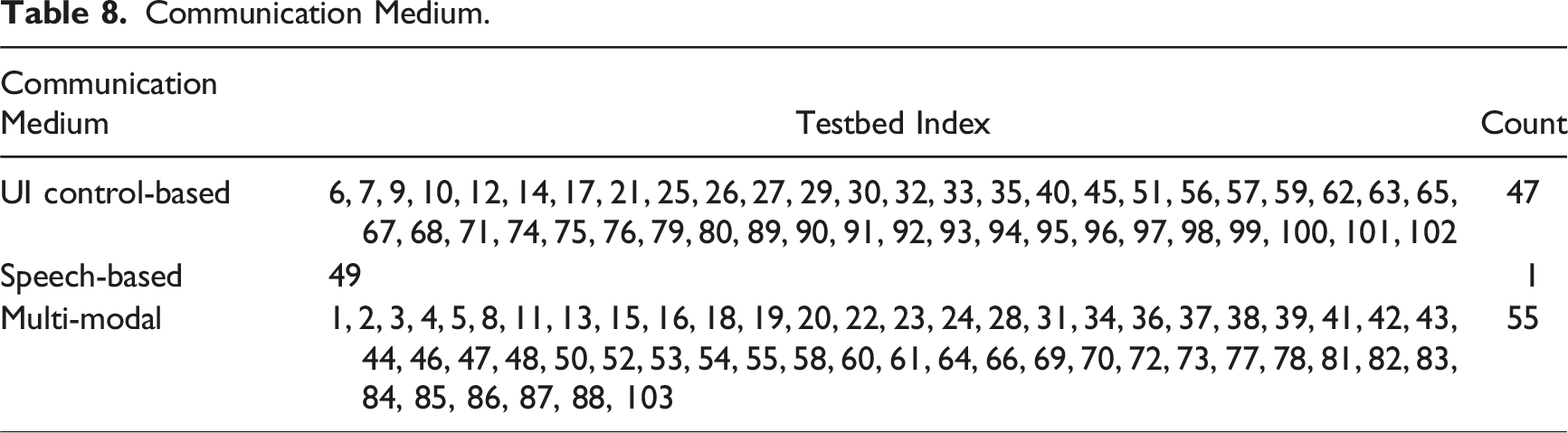
Physical Distribution
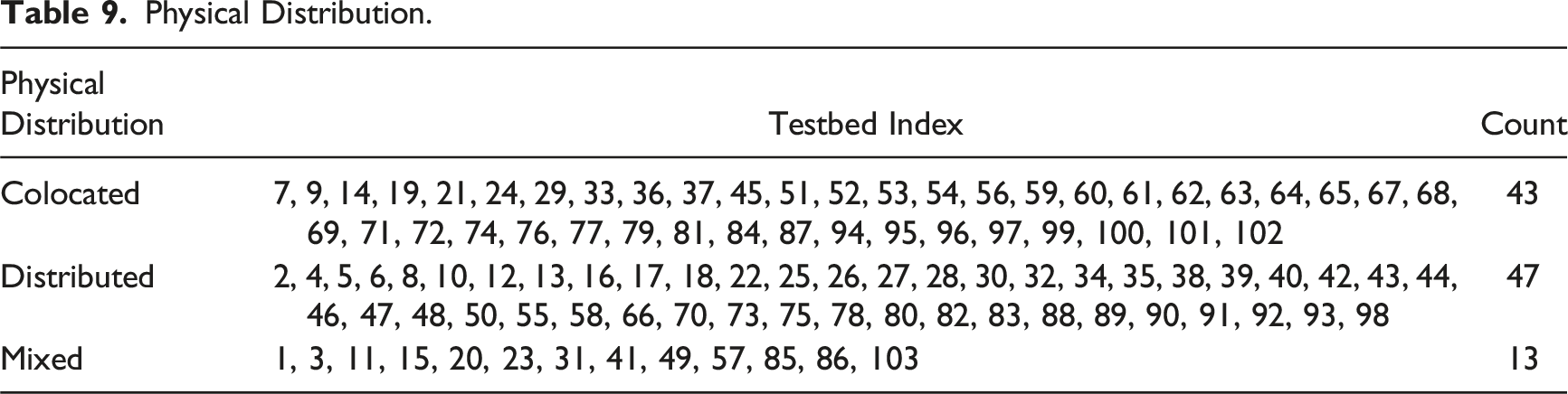
For the physical distribution attribute, nearly equal numbers of testbeds were classified as colocated (n = 43) or distributed (n = 47). The colocated tasks include relatively simple threat assessment and identification tasks (e.g., TA, testbed #19) or route planning tasks (e.g., SN, testbed #51) supported by a locally available decision aid, assembly (e.g., Fcty_Sim, testbed #62), food cooking (e.g., Overcooked, testbed #64), co-delivery of objects (e.g., MB, testbed #71), scheduling and planning (e.g., ETP, testbed #84), and playing card or puzzle games (e.g., Chess, testbed #97).
On the other hand, distributed testbeds centered around teleoperating and controlling UAVs (e.g., AST, testbed #4), collaborating to identify targets by dividing roles such as reconnaissance and standby (e.g., TAISR, testbed #26), urban search and rescue tasks with teammates responsible for different locations (e.g., IIHAT, testbed #40), and emergency response (e.g., NeoCITIES, testbed #88).
Physical Distribution.
Team Life Span
Concerning the team life span attribute, nearly all of the testbeds are classified as long-term. This means that, in most testbeds, team characteristics remain consistent throughout the entire duration of the experimental session.
Notably, three testbeds featured ad hoc teams. In TSF (testbed #21), a human and an agent were randomly assigned to one of two roles: either bait (responsible for attracting the fortress’s attention) or shooter (responsible for attacking and destroying the fortress). The two members underwent dynamic role changes. In CT (testbed #67), participants were allowed to freely form groups of two or three to deliver packages based on their evaluations of teammates. After completing the delivery of a single package, the team was disbanded, and participants selected new teammates or decided to be on their own for the next delivery. Lastly, in CHATboard (testbed #83), task allocation was also temporary and dynamic. After each round, the human participant decided which and how many tasks the agent should perform, based on their cumulative evaluations and perceptions of the agent’s performance.
Testbed Accessibility, Wizard-of-Oz (WoZ), and Agent Implementation
Among the 103 testbeds analyzed in this study, seventeen were made publicly accessible through open links (testbeds #1, 17, 29, 44, 45, 53, 56, 61, 63, 64, 66, 67, 72, 76, 95, 96, 103). These accessible testbeds and their corresponding links are listed in Appendix A.
Regarding the agent implementation, nineteen testbeds were identified in which at least one associated paper explicitly mentioned that the experiment employed the Wizard of Oz technique to implement agent roles (testbeds #2, 16, 28, 36, 37, 39, 40, 55, 58, 63, 64, 67, 70, 72, 78, 84, 86, 88, 98). In these cases, a deception study was used to ensure that participants believed they were interacting with a virtual agent, although the interaction was actually mediated by a human operator.
Additionally, all the identified testbeds have been actively used to analyze team outcomes. While the names of the measures are often highly task-specific (e.g., “proportion of correctly identified victims” and “path trajectory similarity”), they can be broadly categorized into performance-, human/agent behavior-, and communication-related metrics.
For performance, common measures included task completion time, accuracy, scores, and error rates. For behavior, human-related measures focused on reliance on and compliance with agents, as well as task delegation strategies. Agent-related measures typically included actual task performance and reliability. Regarding communication, many testbeds measured total communication frequency. Some studies further analyzed time spent communicating with team members, the differentiated amounts of information pulled versus pushed, and the length of communication messages. In many cases involving text-based communication, raw communication logs were saved to support both quantitative and qualitative analyses.
However, it should be noted that the measures reported in the papers may not fully reflect all metrics available from the testbeds, as the dependent variables reported are often closely tied to the specific research questions of each study.
Discussion
Studies on HATs have utilized a variety of testbeds, each uniquely developed and employed by different research teams and featuring distinctive characteristics. We review testbeds used in prior research and identify significant gaps in the current design. It is important to note that while our analysis is testbed-oriented, the design of testbeds and the goals of HAT studies are closely coupled. Therefore, our analysis will also inform future research directions.
Existing Testbeds and Research, and Future Directions
In terms of team composition, most testbeds involve only one human participant, with the majority of them having one agent (1–1, Table 3). Among the testbeds featuring multiple agents (1-M or M-M), many of the agents function as subordinate autonomous vehicles with minimal engagement, performing assigned tasks without actively interacting with humans (e.g., Chien et al., 2016; Mercado et al., 2016). Therefore, future research could focus on developing and exploring more diverse types of agents. Additionally, the existing testbeds lack configuration of multiple humans and multiple agents working together (M-M), there are only eight (testbeds #18, 20, 23, 31, 38, 41, 67, 73). Still, in these testbeds, the multiple agents are mostly limited to being decision-support displays (testbed #18) and subordinate vehicles (testbeds #20, 23, 31, 38).
Although implementing multiple agents and enabling real-time, seamless connectivity between multiple humans and agents present significant challenges, future research should aim to develop M-M testbeds and examine complex teaming scenarios involving multiple agents with advanced capabilities and functionalities (Karwowski et al., 2025; Wildman et al., 2024). This direction offers two clear benefits: (1) it allows HAT research to more accurately reflect real-world systems without oversimplification, thereby enhancing applicability and (2) it addresses critical research questions that inherently require such configurations. For instance, it enables the examination of inter-team collaboration within organizations. As demonstrated by HyForm (testbed #73), an M-M configuration supports experimentation of the adoption of autonomous technologies across various sectors within a company. Additionally, this setup can help us understand how multiple humans collectively develop strategies for effectively utilizing multiple autonomous agents. USAR_MrCS (testbed #41), which allowed two participants to work with multiple search and rescue robots operating based on an autonomous path planner, serves as a good example.
Regarding task interdependence, the majority of testbeds exhibit intensive type when the team size is three or greater, and reciprocal type when the team size is two (Table 4). Around 19% of the testbeds were classified as sequential, primarily due to the turn-taking nature of the tasks, such as in assembly line settings. Another contributing factor was the limited autonomy of the agents, which often acted as decision aids that provided recommendations either before or in response to human decision making, resulting in a clear sequential order in the interactions. Still, the predominance of intensive and reciprocal configurations suggests that the overall HAT research landscape is oriented toward and interested in exploring higher degrees of interdependence in human–agent interactions.
Concerning role structure, functional type is more common than divisional (Table 5), which implies that team members are assigned different tasks that are not interchangeable. This aligns with the earlier observation that agents in some of the testbeds possess lower levels of autonomy. As a result of these limitations, humans assume a more pivotal role, while the agents take on subordinate roles, executing commands issued by the humans.
For leadership structure and leadership role assignment, designated or none leadership structures are most prevalent, with a human participant typically assuming the leader role within teams (Table 6). Once again, the predominance of human leadership role assignments reflects the limited autonomy of agents in many testbeds.
Despite the real-world advancements in highly autonomous technologies, including generative AI, many agents in current testbeds remain limited to roles that involve receiving commands from humans and operating in a highly structured and rule-based manner. To enable agents to assume a leadership role, they must demonstrate significantly higher levels of intelligence, capable of independently planning, issuing appropriate commands to humans, and interpreting human intentions to provide contextually relevant guidance that enhances task efficiency.
With the implementation of such advanced intelligent agents, we envision that a broader range of leadership structures could be explored to study team dynamics and performance. Investigating how team dynamics and outcomes are influenced when an agent assumes the leader role, or when humans and agents collaborate as co-leaders, could yield valuable insights. Furthermore, introducing novel leadership structures into larger teams would facilitate complex team dynamics, enabling a deeper exploration of complex hierarchies and power dynamics among members.
The analysis of communication structures reveals that dyadic, hub-and-wheel, and star configurations are commonly observed in the testbeds, while the chain structure is absent (Table 7). The prevalence of the hub-and-wheel structure closely reflects the abundance of military-domain tasks, where a human, serving as the “hub,” performs target identification/reconnaissance/surveillance tasks by controlling multiple autonomous agents. The star structure represents cases where multiple teammates collaborate on assembly/transportation/manufacturing-related or search and rescue tasks, which necessitate free-flowing communication between all pairs of teammates.
The absence of the chain structure can be attributed to the relative lack of testbeds simulating large-scale HATs or even organizations, for instance, human–agent teaming in a multi-echelon network. Multi-echelon networks are commonly found in large-scale organizations, where nodes (human or agent) are hierarchically or sequentially arranged across layers (echelons), and direct interactions typically occur only between adjacent layers. A representative example is an emergency response system: first aid team members interact with unmanned aerial or ground vehicles for search and rescue operations, report to their team leader, who in turn reports to the incident commander. In nearly all reviewed testbeds, group size was limited to a maximum of six members. With such a small-scale setting, unrestricted communication among all members is feasible and perhaps more effective. However, as the size of the team or organization increases, more complex organizational forms, such as multi-echelon networks, are likely to emerge, in which the chain structure becomes more relevant and applicable.
Considering the results in conjunction with team composition, there is potential for further exploration of communication dynamics, particularly as the team size increases. As various communication strategies can emerge within larger teams (Butchibabu et al., 2016), the M-M configuration could enable a discovery of new forms of communication dynamics in HATs.
For example, the hub-and-wheel type can be further explored with more complex team configurations. Currently, in all testbeds that are classified as hub-and-wheel, the majority of agents are subordinate autonomous vehicles that simply follow a human’s commands and controls. A new type of hub-and-wheel structure can be evaluated, such as a team consisting of multiple humans and agents (M-M), where one human serves as the hub connecting with multiple human and agent teammates at the same hierarchical level. This setup would allow researchers to investigate how the human hub interacts with other humans and agents. One testbed (Combat_Sim, testbed #23) characterizes a similar type of team, consisting of one human commander and six human crew members. However, the two agents in this setup are robotic combat vehicles controlled by the human crews. Accordingly, the setup does not allow for the exploration of how the human commander differentially interacts with and assigns tasks to human and agent team members.
Exploring the chain structure by exploring inter-team communication is also a promising avenue. For instance, by employing a setup similar to the HyForm (testbed #73), an organization may be structured across three levels, such as supply ordering and supply chain management, the production line, and sales and business operations. While free-flow communication across all sectors offers certain advantages, it can also result in inefficiencies and delays, particularly when decisions require consensus among all parties. In such cases, a chain communication structure may be more effective. The success of this structure often hinges on who occupies the central position in the communication chain and how effectively they manage the flow of information. Investigating this dynamic in teams that include agent teammates presents a novel direction.
Regarding communication direction among humans and among agents, relatively straightforward patterns were observed. Communication between human pairs was bidirectional, whereas communication between agent pairs was either bidirectional or not explicitly defined. However, it is important to note that these classifications may become significantly more complex with larger team sizes. As team size increases, the communication patterns among each possible human/agent pair can be highly variant.
In terms of communication medium, most testbeds employed relatively traditional forms, such as text or voice message exchange (Table 8). A wider range of channels and methods could be developed and explored. For example, incorporating haptic interfaces or image processing technologies would allow humans to convey information through facial expressions or gestures. Such advancements would enhance the richness and versatility of communication within HATs.
For physical distribution, the relatively small proportion of mixed configuration compared to colocated once again reflects the relatively small team sizes featured in the testbeds (Table 9). As team sizes increase, it becomes infeasible for all members to remain colocated. In either distributed or mixed configurations, research on effective communication strategies that facilitate teamwork and coordination will become increasingly important.
Concerning team life span, most current studies focus on evaluating performance and coordination within a single, fixed team configuration; all but three testbeds in this review are classified as long-term. This points to a critical gap in understanding how HATs operate in more dynamic contexts, where both human and agent teammates may be reassigned or self-select into new ad hoc teams. Emerging work has begun to draw on organizational models such as the “team of teams” framework (McChrystal et al., 2015), which emphasizes fluid HAT composition and the continual reconfiguration of members as problem contexts evolve (Guo et al., 2023a, 2024). To advance this line of research, it would be valuable to examine why and how HATs evolve over time, particularly as a function of task demands, individual preferences, or other contextual factors. Longitudinal studies that extend beyond a single session would provide the temporal resolution necessary to investigate such dynamics.
In summary, our study highlights the need for further exploration of team attributes across all dimensions addressed in this research. The classification results presented in this paper can serve as a valuable reference for HAT researchers in identifying the appropriate types of team characteristics to incorporate into their testbeds. Testbeds that implemented relatively complex and advanced agent functionalities or enabled less common configurations such as M-M setups can serve as strong benchmarks for future work. Additionally, as an alternative to developing multiple high-autonomy agents, the use of the WoZ technique can help address specific research objectives and facilitate early-stage investigations (Dahlbäck et al., 1993).
Designing Future Testbeds
The previous section presents the need to develop new testbeds to enable the examination of more sophisticated teaming scenarios. Even though identifying characteristics of an “ideal” next-generation HAT testbed is out of the scope of this literature review, we do note some important characteristics: flexibility, open-source accessibility, and modularity.
Advocating for Flexible Testbeds
In our classification, we double-coded testbeds into all applicable categories and noted those assigned to multiple classifications in Tables 3–9. These testbeds can be considered flexible testbeds, offering researchers the freedom to design and explore different types of team configurations. Such flexibility enables the use of adaptable features as key independent variables to examine their effects on team performance, teammate satisfaction, and other outcomes.
However, there are relatively few double-coded examples. This aligns with the observation that much of the existing HAT literature has focused on comparing the performance of all-human teams to that of HATs (e.g., Fan et al., 2005; Harriott et al., 2012), with limited attention given to examining how specific team characteristics influence team outcomes.
To address this gap, we advocate for the design of testbeds that allow for flexible manipulation of team characteristics. Alternatively, existing testbeds could be extended to support such variability. Both approaches would open up valuable research opportunities to systematically investigate team dynamics across a wide range of configurations within a consistent experimental framework.
Testbeds that were double-coded in Tables 3–9 can serve as good examples. For instance, TRESCHU (testbed #38) offered flexibility in both task interdependence and role structure. In one configuration, all autonomous vehicles of a given type were assigned to a single human operator, who then became fully responsible for tasks requiring that vehicle type. This created a sequential task dependency, where team members had to wait for the operator’s completion, and established a functional role structure. In an alternative configuration, each operator was assigned one vehicle of each type, enabling any operator to complete any task as needed. This arrangement resulted in intensive task interdependence between all humans and autonomous agents and a divisional role structure. Likewise, testbeds can be developed to allow experimenters to freely manipulate specific roles, access permissions to team resources, and other attributes for each team member during the configuration setup phase.
Advocating for Designing Open-Source Testbeds
In the field of HATs, it is common for research teams to develop their own testbeds tailored to the specific needs of their studies. Unfortunately, many testbeds remain closed or are shared with only a limited group of researchers. This lack of accessibility restricts the broader research community’s ability to replicate findings, build on prior work, and accelerate innovation. It also creates inefficiencies, as other researchers may need to reinvent the wheel.
A great open-source example, although not considered as an HAT testbed, is the Multi-Attribute Task Battery (MATB) (Comstock & Arnegard, 1992). MATB is a widely used tool for assessing human multi-tasking performance. Originally developed by NASA, the MATB has been continuously improved over the years and remains easily accessible to researchers. Notably, the open-source version, OpenMATB (Cegarra et al., 2020), became available recently, allowing researchers to customize and utilize the testbed freely.
Another great example is the BW4T testbed (Johnson et al., 2009), developed at the Delft University of Technology (TU Delft) as an open-source testbed from the beginning. The testbed has been used by many researchers to study team coordination among human–human, agent–agent, and human–agent teams (e.g., Harbers, Bradshaw, Johnson, Feltovich, van den Bosch, & Meyer, 2011, Harbers, Bradshaw, Johnson, Feltovich, Van Den Bosch, & Meyer, 2011; Butchibabu et al., 2016).
A major hurdle of using open-source testbeds is that they may not possess enough flexibility or customization options, and therefore, cannot be modified to suit the needs of specific research. For example, an open-source testbed may have predefined tasks, environments, or agent behaviors that cannot be easily modified to suit a particular study’s needs. To address this challenge, one potential solution is to use modular design (Schilling, 2000). Modular design is a design theory that subdivides a system into smaller elements (i.e., modules), which can be independently created, modified, replaced, or exchanged between different systems. A testbed can be structured into different modules, for example, a task module that defines the task scenarios or activities, an agent module that defines agent behaviors including underlining algorithms, a graphic interface module that manages the interface between human and autonomous agents, a communication module that manages communication channels and medium, and a performance measure module that tracks various dependent variables of interest.
In addition, we acknowledge that making a testbed publicly available is not always feasible, especially when its development is closely tied to specific hardware, proprietary datasets, or confidential project agreements. In such cases, it remains essential for researchers to provide clear and transparent descriptions of the teaming scenarios involved. It would facilitate meaningful comparisons with other studies employing similar team configurations, even when different testbeds are used. The taxonomy proposed in this work can serve as a useful reference for researchers when outlining the team characteristics of their testbeds.
Practical Applications of the HAT Taxonomy
Beyond organizing the existing literature, the proposed taxonomy can serve as a practical framework for guiding future research in HATs. Researchers and designers can use the taxonomy in multiple ways. First, for testbed development, the taxonomy can help identify which attributes to incorporate or modify when designing new testbeds or refining existing ones. Second, in experimental design, the taxonomy can support the ideation of new HAT research questions by highlighting which team characteristics are worth comparing, helping researchers formulate hypotheses and design their studies accordingly. Third, the taxonomy can be used as a standardized reporting guideline when describing testbeds in future publications, allowing researchers to clearly position their work within the broader landscape. This reduces ambiguity about key team attributes and ensures that other researchers can easily interpret the scope and capabilities of a given testbed. Lastly, the taxonomy can serve as a foundation for meta-analyses, enabling researchers to systematically examine how specific sets of team attributes relate to HAT outcomes. Overall, the taxonomy not only supports the synthesis of past work but also serves as a practical tool throughout the entire HAT research process, from testbed development and study design to positioning the study within the broader literature.
Limitations and Future Research
The study should be viewed in light of the following limitations. First, our work focused exclusively on virtual agents, excluding physically embodied agents. A key advantage of software-based testbeds is their greater flexibility in modeling diverse interaction and collaboration scenarios without hardware or deployment constraints. Additional reviews could be conducted to incorporate embodied agents.
Second, the proposed team classification taxonomy and the team attributes analyzed in this review are primarily centered on the characteristics of the team task itself. While this study adapts the well-established human team taxonomy by Wildman et al. (2024), we make no claim that our taxonomy is exhaustive. Future work could incorporate additional dimensions to capture other critical aspects of HAT. For instance, dynamic team processes, which reflect how team coordination and structure evolve over time, could be an important dimension, especially as the nature of HATs becomes more advanced and supports prolonged, complex cooperation. Additionally, although the review briefly discusses team evaluation metrics as reported in prior HAT research, a more in-depth synthesis and analysis of HAT measurement approaches would be a valuable direction for future review work.
Third, the scope of the review was to examine the distribution of existing testbeds in terms of team characteristics, rather than to conduct a meta-analysis of the results to address questions such as which team compositions lead to optimal performance, higher trust, or greater satisfaction. By leveraging the findings from this review, future research can refine research questions, identify specific team attributes of interest, and focus on synthesizing relevant results from existing studies. This approach would facilitate a comparative evaluation of different categories within each attribute, helping to identify trends in the findings.
Fourth, the field of HAT research is rapidly evolving. With advances in human-level (i.e., the ability to learn from experience, adapt to new situations, handle abstract concepts, and apply knowledge effectively) (Sternberg, 1982) or even superhuman-level (i.e., surpassing the cognitive performance of humans in virtually all domains of interest) (Bostrom, 1998) artificial intelligence, future HATs may take forms that are unprecedented in either human–human teams or existing HAT configurations. As these new forms emerge, additional dimensions may need to be incorporated into the taxonomy to adequately capture their characteristics. In this sense, our review is not intended as a final synthesis, but rather as a starting point that future reviews can build upon as the field progresses.
Finally, extending the fourth point, new testbeds are continuously being developed and studied. This review should be viewed as an archival snapshot based on research records that meet the inclusion criteria and were published up to 2024. Given the growing interest and rapid development in this field, the review needs to be updated in the future to reflect more recent studies. For instance, additional testbeds have been featured in recent work, such as the Scout Exploration Game (Xu et al., 2025) and Mass Evacuation Testbed (Chung et al., 2025; Chung & Yang, 2025b, 2025d).
Conclusion
With advances in machine learning, artificial intelligence, and robotics, agents with human-level intelligence or even superintelligence are no longer just a concept but a real possibility. As the agents are becoming more capable, integrating them effectively with human teams presents not only opportunities but also profound challenges. Consequently, HAT has emerged as a topic of significant research interest. Compared to existing literature review papers, we took a different approach by focusing on the testbeds themselves.
This study conducted a literature review on HAT literature to provide a comprehensive understanding of the available testbeds in this field. Initially, we developed a team classification taxonomy to analyze HATs, adapting an existing scheme used for human-human teams. This scheme was then applied to analyze 103 testbeds utilized in 235 empirical studies. Our study not only identified the distribution of existing HAT testbeds but also highlighted areas that require further investigation. For instance, we found that a significant portion of the literature on HATs focuses on teams consisting of one human and one agent, with humans typically assuming leadership roles. Moreover, the dynamics within these teams tended to remain static over time. Our findings underscore the importance of further research into diverse team attributes, such as team composition, leadership structure, and communication structure, direction, and medium. Such efforts would facilitate a deeper understanding of more complex team dynamics in HATs, potentially leading to more effective collaborations.
Key Points
• We developed a taxonomy for classifying human–agent teams (HATs) by modifying the existing framework for human teams. • Using the taxonomy, we analyzed 103 HAT testbeds identified from 235 empirical research studies. • The frequency analysis indicates that existing research studies are centered on certain team types, emphasizing the importance of exploring new forms of HATs. • Testbeds that allow flexibility in manipulating various team characteristics-related features would greatly enrich research in HATs. • The proposed taxonomy can serve as a practical framework to guide testbed development, experimental design, and standardized reporting in HAT research.
Supplemental Material
Supplemental Material - A Systematic Review and Taxonomy of Human-Agent Teaming Testbeds
Supplemental Material for A Systematic Review and Taxonomy of Human–Agent Teaming Testbeds by Hyesun Chung, Timothy Holder, Julie A. Shah and X. Jessie Yang in Human Factors.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Science Foundation under Grant No. 2045009 and the Air Force Office of Scientific Research under grant number FA9550-23-1-0044.
Supplemental Material
Supplemental material for this article is available online.
Author Biographies
Hyesun Chung is a PhD candidate in the Department of Industrial and Operations Engineering at the University of Michigan, Ann Arbor. She received her BS degree in industrial engineering, BFA in design, and BBA in 2020, and MS in industrial engineering in 2022, all from Seoul National University.
Timothy Holder is a postdoctoral fellow in the Department of Aeronautics and Astronautics at the Massachusetts Institute of Technology. He obtained his PhD in biomedical engineering from North Carolina State University and the University of North Carolina at Chapel Hill in 2022.
Julie A. Shah is the H.N. Slater Professor in the Department of Aeronautics and Astronautics at the Massachusetts Institute of Technology. She obtained her PhD in aeronautics and astronautics engineering from MIT in 2011.
X. Jessie Yang is an associate professor in the Department of Industrial and Operations Engineering at the University of Michigan, Ann Arbor. She obtained a PhD in mechanical and aerospace engineering (human factors) from Nanyang Technological University Singapore in 2014.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.