
Abstract
When personality assessments are employed in high-stakes contexts, there is the risk that test-takers provide overly positive descriptions of themselves. This response bias is known as faking and has often been addressed in latent variable models through an additional dimension capturing each test-taker’s faking degree. Such models typically assume a homogeneous response strategy for all test-takers, with substantive traits and faking jointly influencing responses to all items. In this article, we present a latent response mixture item response theory (IRT) model of faking that accounts for changes in test-takers’ response strategies over the course of the assessment. The model translates theoretical considerations about test-taker behavior into different model components for item responses and corresponding item-level response times (RT), thereby allowing to account for, identify, and investigate different faking-related response strategies on the person-by-item level. In a parameter recovery study, we found that the model parameters can be estimated well under realistic conditions. Also, we applied the model to an empirical dataset (N = 1,824) from a job application context, showcasing its utility in real high-stakes assessment data. We conclude the article by discussing the role of the model for psychological measurement as well as substantive research.
Introduction
Personality questionnaires based on self-report are commonly used in high-stakes contexts like personnel selection or college admission, as personality traits have repeatedly been shown to predict relevant outcomes such as job performance or academic success (e.g., Poropat, 2009; Sackett & Walmsley, 2014). Nevertheless, employing self-report personality tests in contexts where the assessment results have important consequences for test-takers holds the risk that test-takers portray themselves in an overly positive light. This behavior is commonly referred to as faking, and its effects on the psychometric properties of a test are well documented (Ziegler et al., 2011). For instance, faking leads to negatively (positively) skewed distributions of items and scales measuring desirable (undesirable) attributes (e.g., Hu & Connelly, 2021). Also, it alters rank orders of test-takers (e.g., Mueller-Hanson et al., 2003), which impacts decisions where test-takers are selected based on their test scores. Most importantly, however, faking distorts construct validity of personality measures as it introduces an additional source of systematic variance. This leads to inflated inter-item and inter-scale correlations, diminishing the test’s factor structure (e.g., Schmit & Ryan, 1993) and rendering the obtained scores inappropriate for their intended purpose of usage (Messick, 1989). Hence, it is vital to have psychometric tools that effectively account for faking, especially in the context of high-stakes assessments. Such methods can be used to detect and statistically control for faking, but also to study the associated response process. Whereas the former can pay dividends when data have already been collected, the latter is important for advancing the theoretical understanding of faking, which can in turn be used to develop assessment tools that are less susceptible to faking.
Faking is especially problematic because of its heterogeneity. This is evidenced by studies investigating the prevalence of faking in job applications. Griffith and Converse (2011) reviewed the literature on this topic and concluded that roughly 30% (±10%) of applicants engage in faking behavior. That is, some test-takers indeed respond in a way that facilitates their appearance, whereas others do not. This is supported by Robie et al. (2007), who conducted a think-aloud study of test-takers responding to a personality test in a high-stakes condition. Using a verbal protocol analysis, they found one group of test-takers being fully honest in their responses, one group considering both their actual personality and the criteria of an “ideal” applicant, as well as one group exclusively responding based on “ideal” applicant considerations. In a related study, Röhner et al. (2025) identified as many as 35 different behaviors constituting distinct faking strategies.
To account for heterogeneity in faking, several model-based approaches have been proposed. Most of them either quantify the degree of faking on a latent continuum (e.g., Hendy et al., 2021; Klehe et al., 2012; Seitz et al., 2024; Seitz, Spengler, & Meiser, 2025) or assign test-takers to latent classes that represent qualitatively different response behaviors related to faking (e.g., Zickar et al., 2004). Other models combine quantitative and qualitative conceptualizations of faking to better describe the nature of the construct (Seitz, Alagöz, & Meiser, 2025; Ziegler et al., 2015). What most models have in common, however, is that they treat faking as a person variable that is constant across test items (see Böckenholt, 2014; Brown & Böckenholt, 2022; for exceptions). Yet, one can for multiple reasons question whether it is appropriate to conceptualize faking as constant throughout the entire test: First, faking is a complex interaction of person and situation characteristics, such as ability, opportunity, and motivation to fake (Tett & Simonet, 2011). Motivation to fake in personnel selection, for instance, may vary between items when some items are perceived as more instrumental than others to elevate the chance of being hired in a given job context (e.g., Ellingson & McFarland, 2011). Second, lying research has shown that people tend to behave dishonestly to the extent that they profit, but not to the extent that they damage their self-concept of being an honorable person (Mazar et al., 2008). If one has nothing to conceal at a particular item such that misreporting would not pay off, it can hence be expected that people will not engage in faking (Tourangeau & Yan, 2007). Third, test-takers have conflicting goals in high-stakes assessments. On the one hand, they want to impress a prospective employer. On the other hand, conveying a credible impression and staying true to oneself have also been identified as important motives of test-taking behavior (Kuncel et al., 2011). All these arguments suggest it is more plausible to assume that faking also varies between items than to treat it as a constant person variable.
In this work, we present a mixture item response theory (IRT) model that allows to account for, identify, and investigate different faking-related response strategies on the person-by-item level. The model we propose translates theoretical considerations about test-taker behavior into different model components (i.e., latent classes) for item responses and corresponding item-level response times (RT). Modeling RTs serves two purposes: First, from a statistical perspective, incorporating additional behavioral data into the model facilitates class separation. Second, from a substantive perspective, doing so allows investigating the response process behind faking in a sophisticated manner. It, for instance, allows examining the question of whether faking actually increases or decreases RTs. Also, the model as a whole can be used to identify what items are especially susceptible to faking, or to study relationships of substantive person characteristics with different faking tendencies. The inclusion of RTs thus constitutes an important extension over existing models allowing for varying faking behavior across items. Furthermore, our proposed model has the advantage of being able to account for nonmonotonic faking effects (see Figure 2) as well as including an additional faking class (a more detailed description of differences to related models can be found below).
Proposed Model
The model we present builds on work by Seitz, Alagöz, and Meiser (2025), who modeled faking using three latent classes related to distinct response strategies test-takers can employ in high-stakes assessments. We extend their model by adding an item-wise mixture component and combine it with approaches that make use of RT data to account for disengaged and careless responding in the context of cognitive and non-cognitive assessments (e.g., Ulitzsch et al., 2020; Ulitzsch, Pohl, et al., 2022). The full model is displayed in Figure 1.
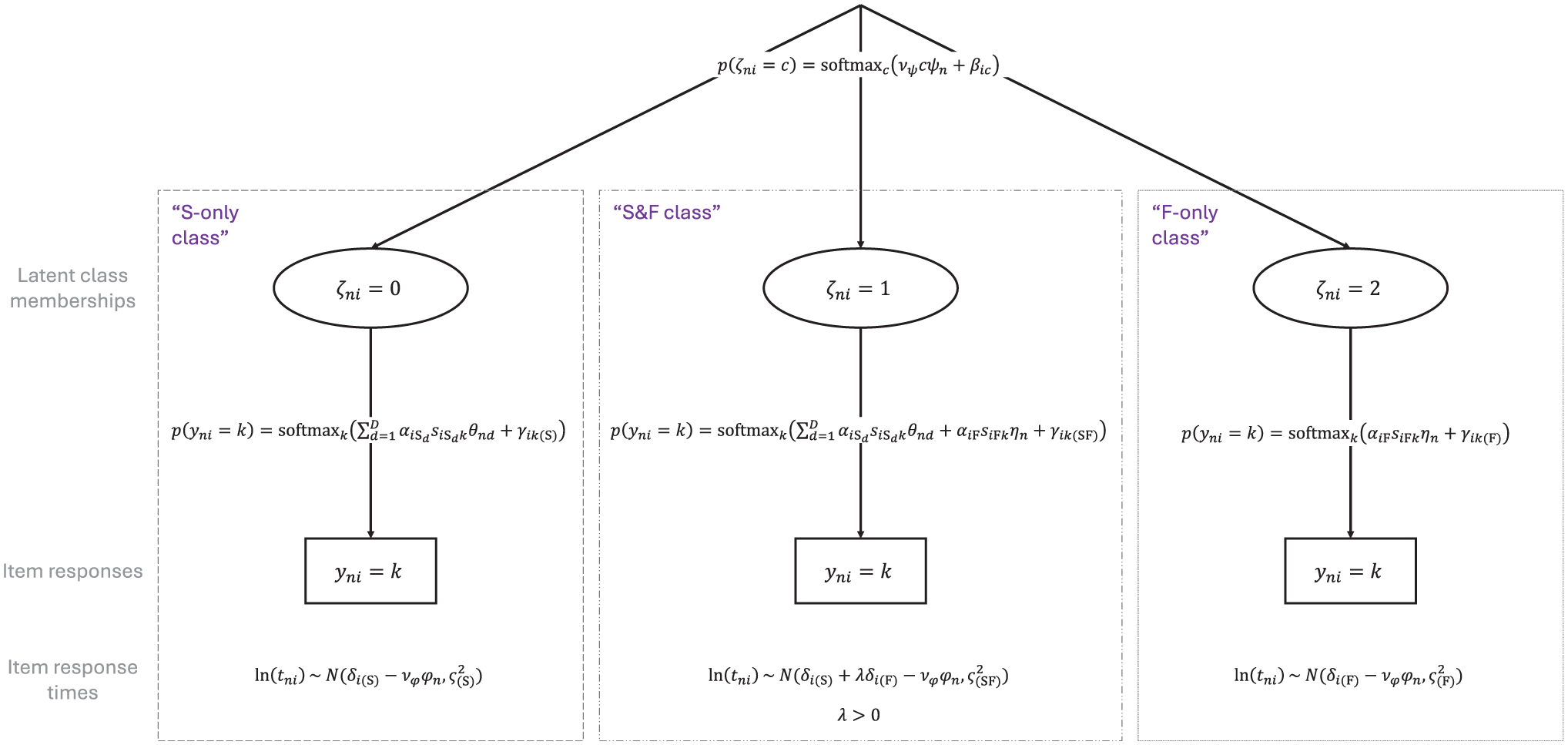
The Proposed Response-Time-Based Latent Response Mixture Model of Faking.
Model Components
Item Response Models
Similar to Seitz, Alagöz, and Meiser (2025), we assume that item responses are mixtures of three response strategies (see also the study by Robie et al., 2007, described above). The first response strategy (“S-only class”) is a strategy where test-takers respond according to their substantive traits, that is, respond honestly and do not align responses with social desirability. The second response strategy (“S&F class”) is a strategy where item responses are a function of test-takers’ substantive traits as well as a faking dimension. Responses thus represent edited versions of honest responses depending on the faking degree of a test-taker. The third response strategy (“F-only class”) is a strategy where item responses are independent of test-takers’ substantive traits. Instead, responses are solely influenced by the faking dimension.
Item responses
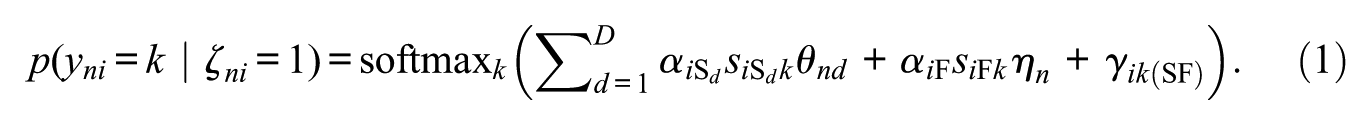
This softmax function (aka multinomial logistic function) converts a vector of
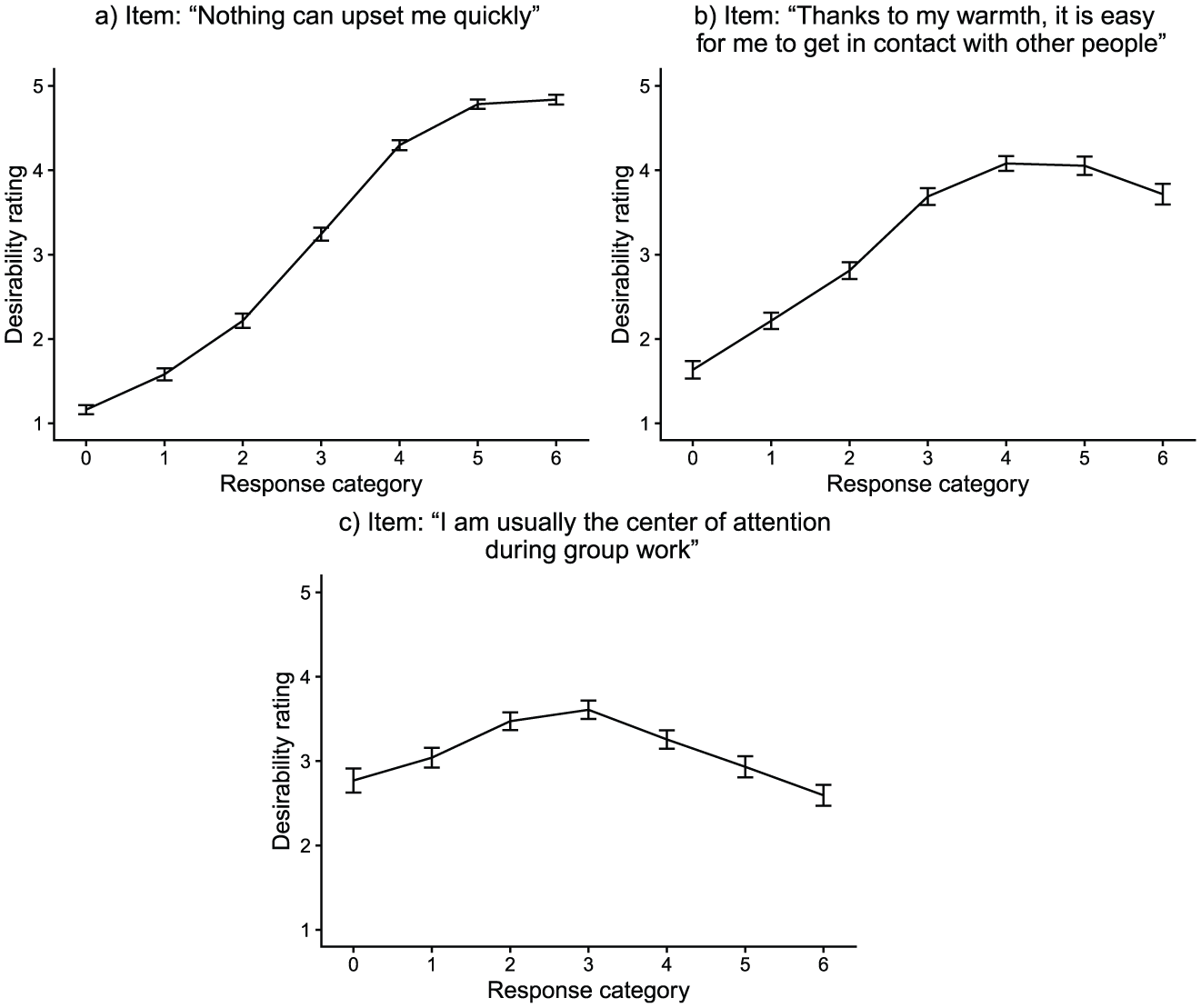
Desirability Trajectories of Three Exemplary Items From the Empirical Demonstration.
In both the “S-only class” and “F-only class,” theory-motivated constraints are imposed on item slope parameters (Alagöz & Meiser, 2024; Seitz, Alagöz, & Meiser, 2025). Because responses are not influenced by faking in the “S-only class” (
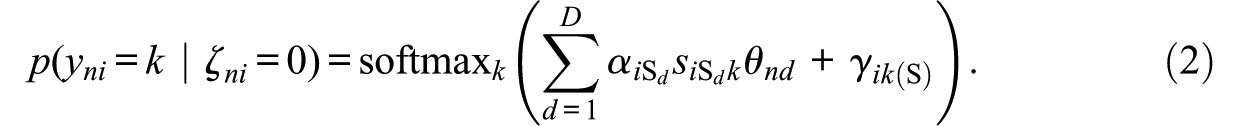
This model is equivalent to a multidimensional generalized partial credit model (MGPCM; Muraki, 1992). By contrast, in the “F-only class” (
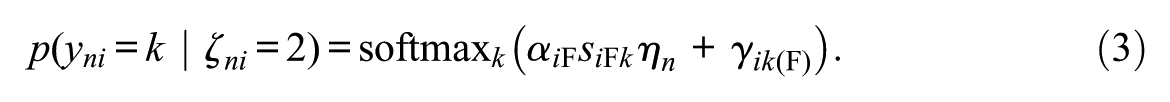
Note that non-fixed slopes in this model are class-invariant, whereas item-category intercepts are class-specific. This has the purpose of measuring the same latent variables across classes, while at the same time being able to capture different item response distributions in the three classes. For model identification, the intercept of the first category is fixed to 0 for all items in all classes.
Item Response Time Models
Research has repeatedly demonstrated RT differences associated with response sets like honest responding, responding under conditions of heightened desirability concerns, or instructed faking (e.g., Holden et al., 1992; Holtgraves, 2004). To utilize this information in our mixture modeling approach, we specify different RT models associated with the different response strategies (see Ulitzsch et al., 2020; Ulitzsch, Pohl, et al., 2022, for similar approaches). Specifically, RTs
To capture mean differences in RTs between classes, item time intensities are class-specific. Regarding the question of whether honest responding or faking takes longer, the literature is inconsistent. Some studies found faking to be associated with reduced RTs (e.g., Holden, 1995; Holden et al., 1992; Hsu et al., 1989), while other studies found faking to increase RTs (e.g., Fine & Pirak, 2016; Holtgraves, 2004; Walczyk et al., 2003). Hence, no constraints are put on time intensities in the “S-only class” (
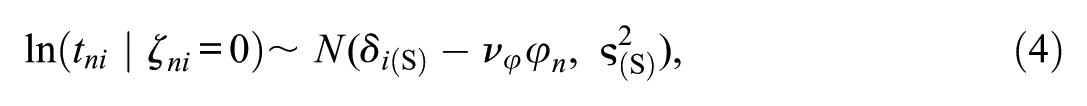
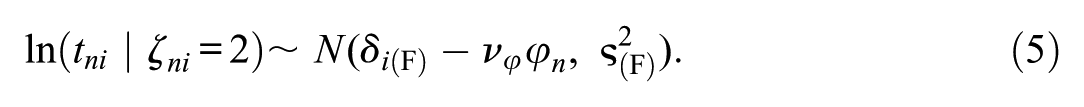
The parameter
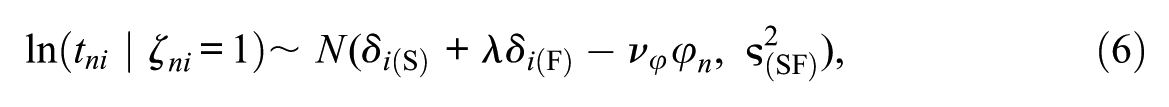
with
Note that, in the proposed model, RTs are modeled as indicators of class membership as opposed to predictors of class membership (see Nagy & Ulitzsch, 2022; cf. Ulitzsch et al., 2020; Ulitzsch, Pohl, et al., 2022). That is, RTs are reflections of strategy use and contribute to the classification of responses by their relative typicality for the respective class. Since RT distributions are allowed to overlap, classification is not based on fixed RT cutoffs. While “S&F class” responses are assumed to take on average longer than their single-process counterparts, the overlap of RT distributions allows also short responses to be classified as “S&F class” responses, as well as also long responses to be classified as “S-only class” or “F-only class” responses.
Latent Response Model
Test-takers’ latent class memberships
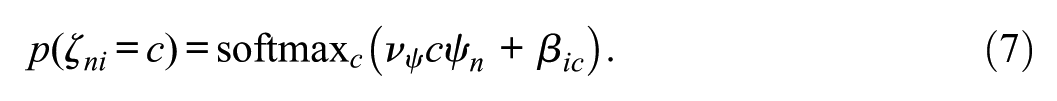
This model represents a partial credit model (PCM; Masters, 1982) with an item-invariant strategy inclination slope
The

To identify the scale of latent variables, latent means are set to 0 and latent variances to 1, such that latent covariances represent latent correlations. Assuming conditional independence of item responses and RTs, the model’s joint likelihood of the data, marginalized over the three latent classes, can be denoted as
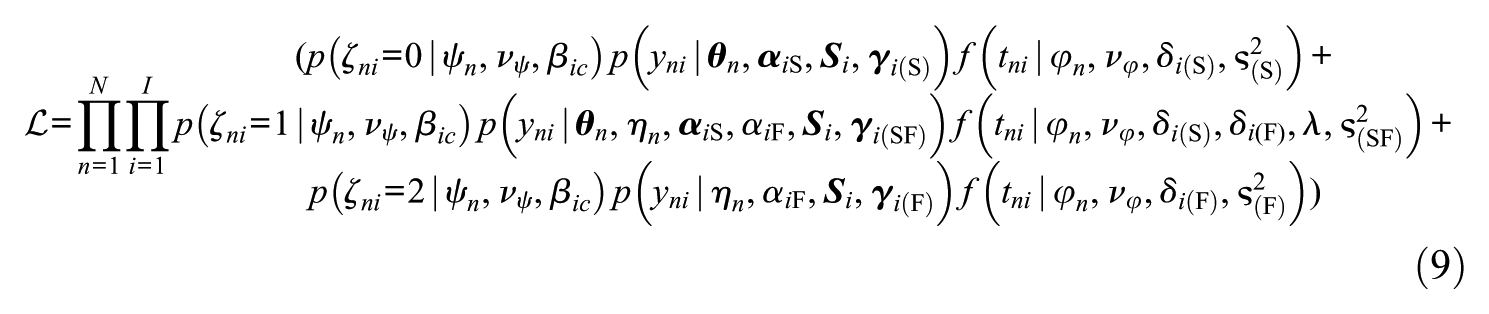
where
Model Estimation
The proposed person-by-item mixture model can be estimated with a Bayesian Markov chain Monte Carlo (MCMC) procedure. We used the software JAGS (version 4.3.2; Plummer, 2017) for model estimation, accessed through the R environment (version 4.4.3) using the package runjags (Denwood, 2016). To process MCMC outputs, we employed the packages coda (Plummer et al., 2006) and MCMCvis (Youngflesh, 2018). The JAGS syntax as well as R code for estimating the model can be found at https://osf.io/crmv4/.
We used the following prior distributions for the different model parameters: Slope parameters were drawn from positively truncated normal priors (
We considered means of posterior distributions as point estimates of model parameters. In addition, we derived posterior class probabilities and class proportions estimates. Since class probabilities are a direct function of the parameters from the latent response model, posterior class probabilities can be computed by plugging the samples of the latent response model parameters into Equation 7 for each non-discarded MCMC iteration before aggregating across iterations. To get class proportion estimates, mean class probabilities across persons and iterations can be calculated, either per item or aggregated across items. It is worth noting that class labels in the proposed model are not arbitrary since the measurement models of the three classes are explicitly specified. This confirmatory specification of latent classes avoids the issue of label switching, which is often encountered when estimating mixture models in a Bayesian framework (Jasra et al., 2005).
Differences to Related Faking Mixture Models
As elaborated above, most faking models do not account for a faking process that varies between items. However, there are some models that do allow for inter-item variation in how item responses are (not) affected by substantive traits and faking. Böckenholt (2014), for instance, presented a model of motivated misreports that is characterized by possible response editing before providing answers to sensitive survey questions (see also Leng et al., 2020). This model includes for every item a dichotomous latent class variable indicating if a test-taker edits his or her retrieved response. In the case of editing, a transition function models the selection of response categories that are more desirable than the category that would have been chosen without editing. Though theoretically appealing, the model is limited to only one substantive trait dimension. Also, response editing is restricted to go in the direction of high (low) categories if the measured substantive trait is generally desirable (undesirable).
Another model allowing for switches between response strategies over the course of the test is Brown and Böckenholt’s (2022) model of intermittent faking. This model assumes that item responses are mixtures of honest and faked responses, with honest (“real”) responses influenced by substantive traits and faked (“ideal”) responses influenced by a faking factor. Whether responses are honest or faked is modeled through an editing factor and item characteristics. This model is not limited to a single substantive trait; however, its frequentist estimation curbs the number of dimensions that can practically be modeled. Also, the model adopts a structural equation modeling (SEM) approach, which was empirically demonstrated using total scale scores as indicator variables and not individual items. In addition, the possibility of nonlinear and nonmonotonic item desirability trajectories (Kuncel & Tellegen, 2009; Seitz et al., 2024; see Figure 2) is not directly taken into account. Furthermore, the model does not include a class where substantive traits and faking influence item responses. However, such a class is conceivable because studies have found faking to operate at the editing stage of item responding and not at the retrieval stage (Holtgraves, 2004; Sudman et al., 1996; Walczyk et al., 2003). Robie et al. (2007) also showed that a considerable share of test-takers in high-stakes assessments refer to both their true personality and the ideal applicant when giving item responses.
Along with addressing several limitations of related mixture models of faking (modeling multiple substantive traits, nonmonotonic faking effects, and an “S&F class”), the proposed model also incorporates item-level RTs. As elaborated above, this can provide valuable insights into the cognitive processes associated with faking. The use of collateral data can also be expected to facilitate the estimation of such a person-by-item mixture model, where the information for class assignment is very sparse compared to a mixture model with constant class membership per person.
Parameter Recovery Study
To evaluate the proposed model under realistic conditions, we conducted a parameter recovery study. The purpose of this study was twofold: a) to examine the model’s ability to accurately recover parameters and b) to compare it to the performance of less complex models.
Data Generation and Fitted Models
For emulating realistic conditions, data-generating values for item responses and item RTs were in line with parameter estimates from the empirical demonstration below. Resembling our empirical dataset, data from a test measuring 3 substantive traits with 10 items each on a 7-point Likert scale were simulated using the R packages MASS (Venables & Ripley, 2002) and extraDistr (Wolodzko, 2023). For the parameter recovery study, a sample size of N = 500 was considered. 50 independent replications were performed. Further details on the data generation procedure can be found in the Online Supplement.
Each simulated dataset was analyzed using the proposed person-by-item mixture model including RTs. In addition, four less complex models were fitted to every dataset: a person-by-item mixture model not accounting for RTs, a person mixture model accounting for RTs, a person mixture model not accounting for RTs, as well as a non-mixture model. Comparing models with and without RTs allowed investigating how the inclusion of RTs improves model estimation in terms of parameter recovery and class separation. Comparing person-by-item and person mixture models allowed investigating the consequences of disregarding varying strategy use across items. Comparing mixture and non-mixture models allowed examining the effect of assuming a single response strategy across persons and items.
The non-mixture model was an MNRM accounting for substantive traits and faking with specified scoring weights (see Equation 1). All mixture models included the three described latent classes; however, the two person mixture models did not have the latent response model component. Instead, latent class membership in the person mixture models was only a person variable sampled from a categorical distribution
Results of the Parameter Recovery Study
The person-by-item mixture model with RTs converged in 49 out of 50 replications (98%). The person-by-item mixture model without RTs, however, only converged in 37 replications (74%). With regard to the two person mixture models, the model with RTs converged in 39 replications (78%) and the model without RTs in 48 replications (96%). The non-mixture model converged in all 50 replications (100%).
We analyzed parameter recovery based on converged models. In particular, we looked at bias to examine systematic over- or underestimation of parameters as well as at root mean square error (RMSE) to investigate estimation accuracy. For the recovery of person parameters, we considered the correlation between estimated and true parameters. Results are displayed in Figures 3–8. Overall, the data-generating person-by-item mixture model with RTs estimated parameters with negligible bias. Only for item-category intercepts, the model yielded slightly negatively biased estimates (corresponding to an average underestimation of 5-10% compared to the data-generating values). In contrast, all of the other models produced biased estimates for most of the model parameters. Regarding RMSE, too, the less complex models yielded for all parameters worse results than the person-by-item mixture model with RTs. Even though such a result pattern can in principle be expected since the data were generated based on a person-by-item mixture population, the results do indicate that conclusions drawn from models that do not capture the full data-generating process are indeed considerably less accurate. For instance, RMSE for RT model parameters (Figure 4b) and latent response model parameters (Figure 5b) was much larger in the corresponding person mixture model and person-by-item mixture model without RTs than in the full model. In addition, whereas both person-by-item mixture models yielded unbiased and fairly accurate estimates of class proportions, both person mixture models severely overestimated the overall proportion of the “S&F class” and underestimated the “F-only class” proportion (Figure 6). The person mixture model without RTs additionally overestimated the proportion of the “S-only class.” Regarding person parameters, the less complex models also yielded poorer estimates than the data-generating person-by-item mixture model with RTs (Figure 8). Effects were most pronounced for faking scores, where correlations between estimated and true person parameters differed considerably between models. For substantive trait, speed, and strategy inclination scores, the person-by-item mixture model with RTs yielded the highest correlations as well, but the less complex models did not perform much worse.
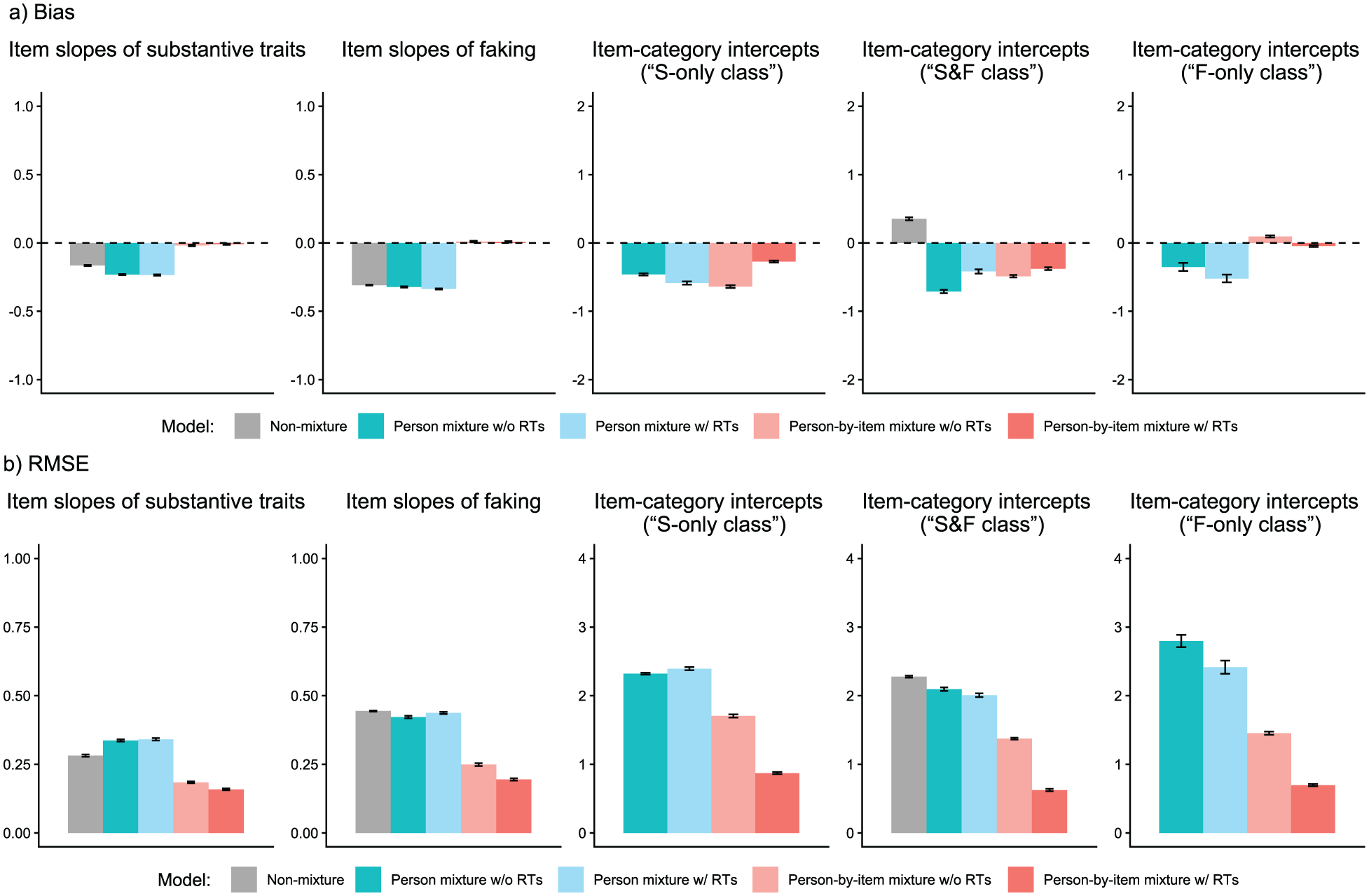
Parameter Recovery Study: Recovery of Item Response Model Parameters.
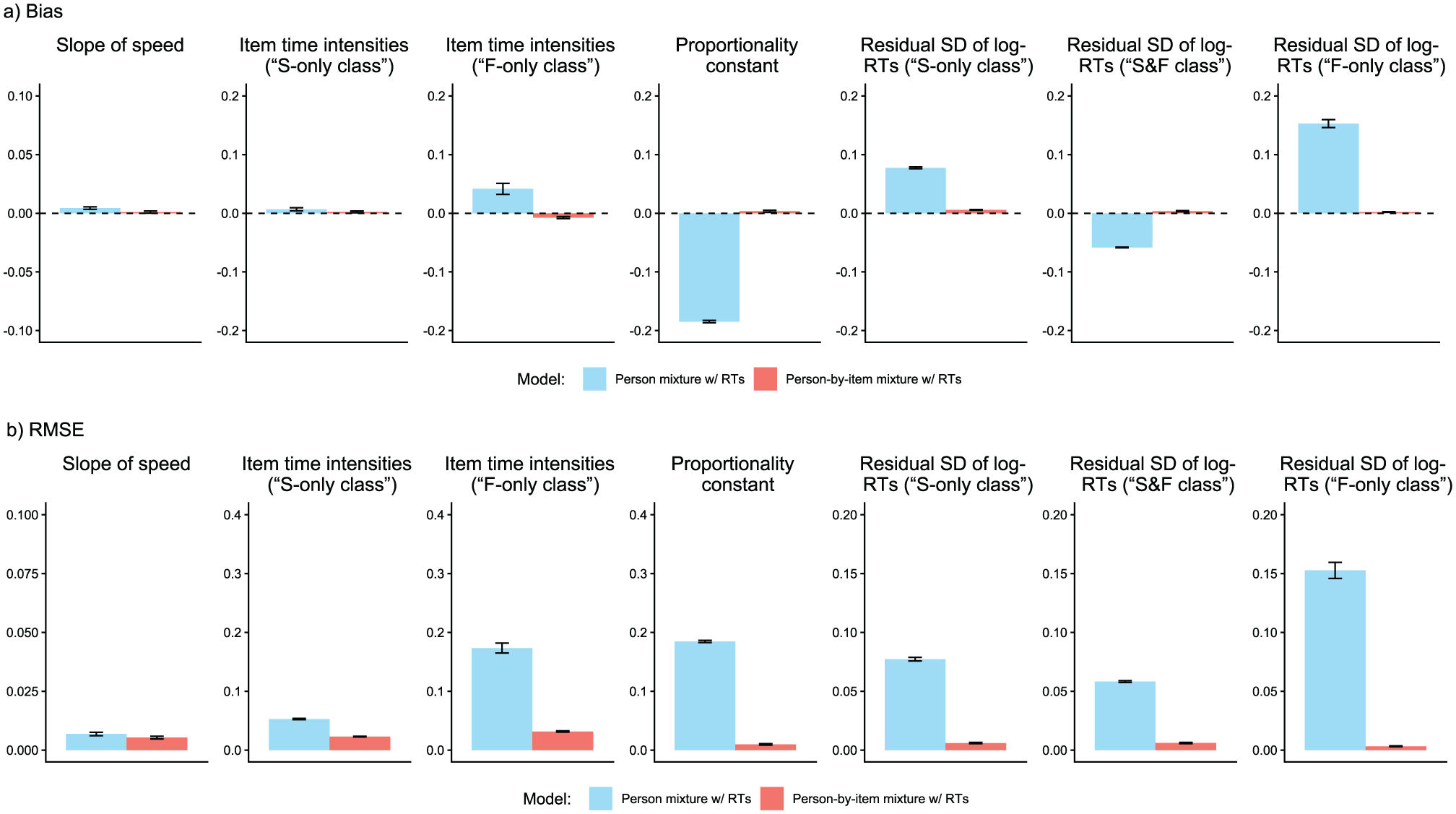
Parameter Recovery Study: Recovery of Item Response Time Model Parameters.
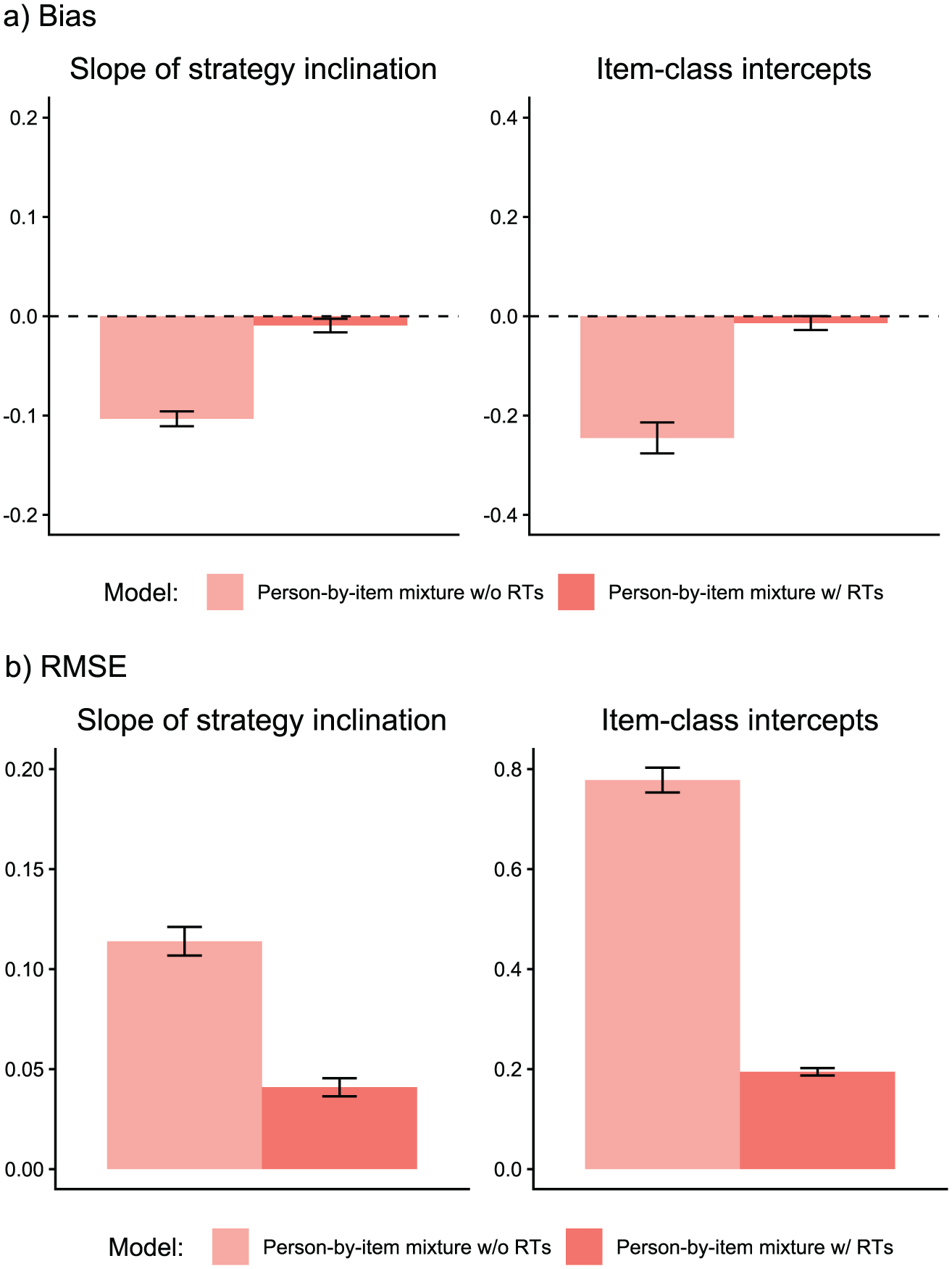
Parameter Recovery Study: Recovery of Latent Response Model Parameters.
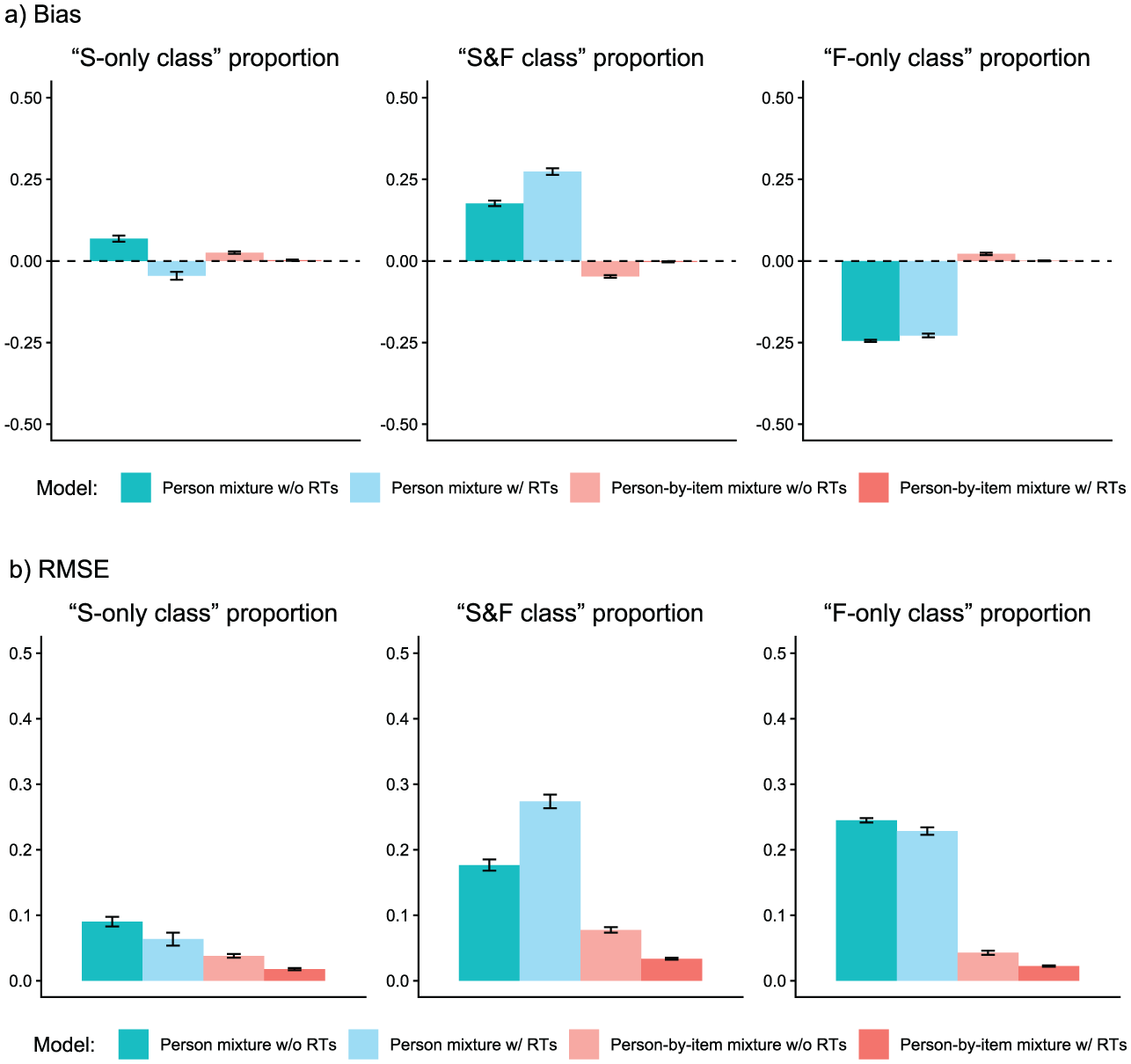
Parameter Recovery Study: Recovery of Class Proportions.
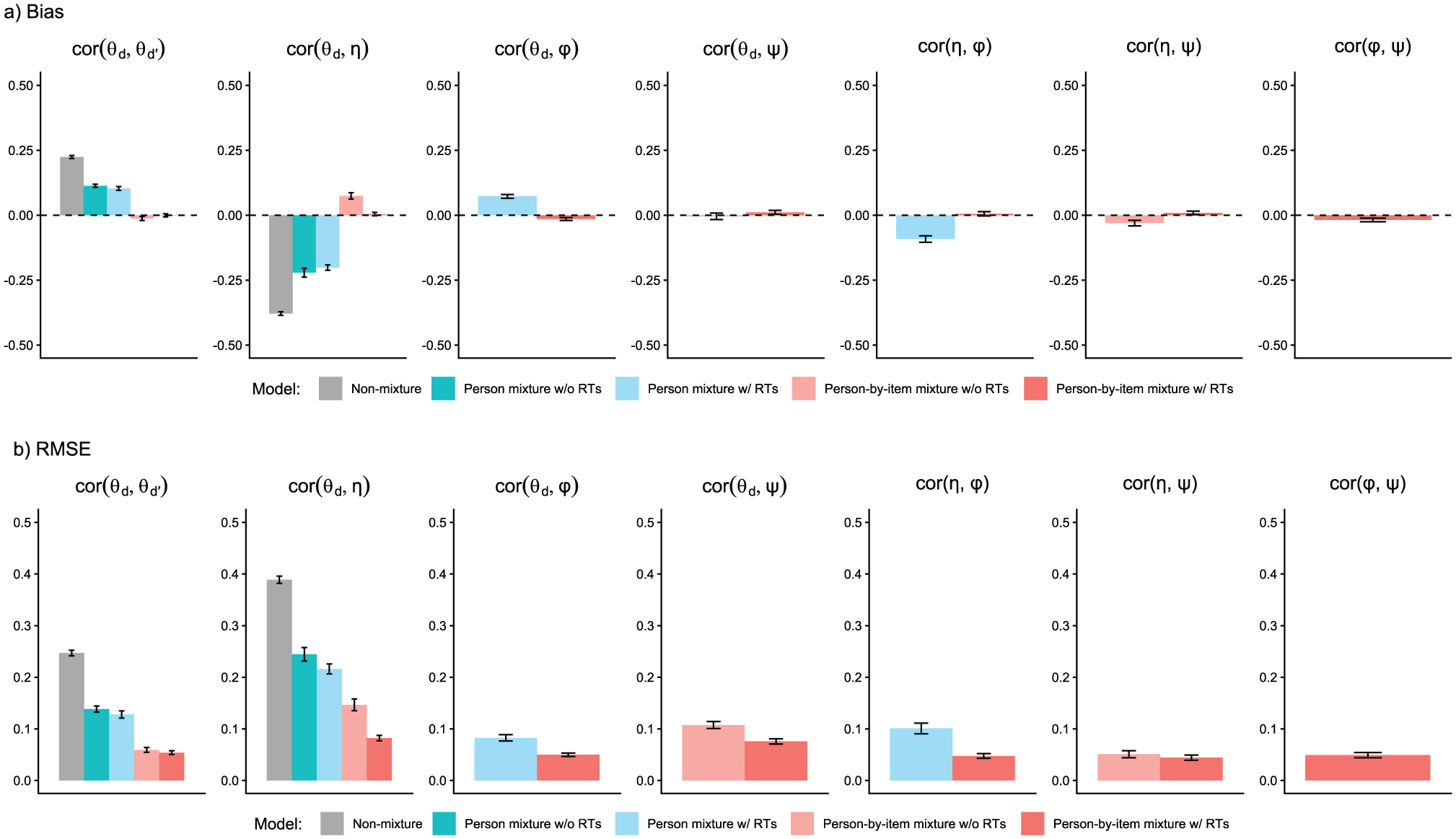
Parameter Recovery Study: Recovery of Latent Correlations.
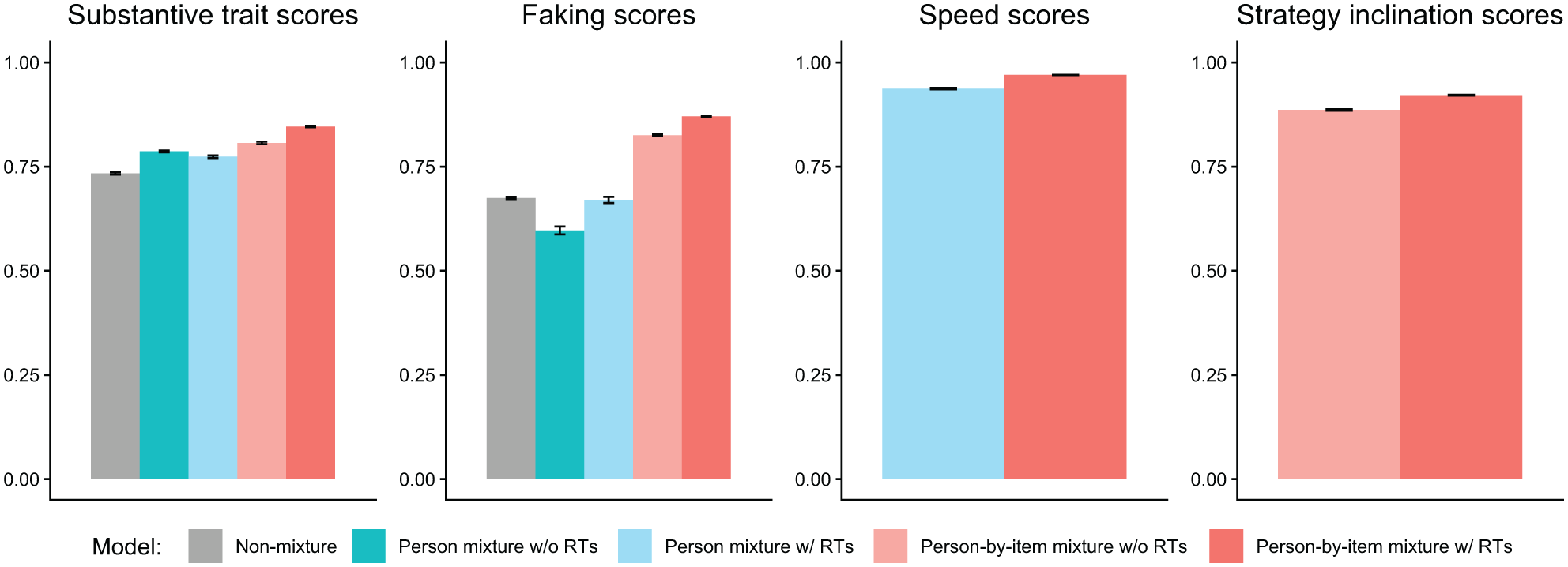
Parameter Recovery Study: Recovery of Person Parameters.
Furthermore, we examined the mixture models’ classification accuracy based on a modal class assignment rule (i.e., assignment to the class with the highest posterior class probability; Dias & Vermunt, 2008). We hereby looked at item-level hit rates, which indicate percentages of correct class assignments of individual item responses. The person-by-item mixture model with RTs yielded a mean hit rate of 63.3%, whereas the person-by-item mixture model without RTs only afforded a mean hit rate of 58.5%. Classification accuracy in the person mixture model with RTs (hit rate: 51.0%) and without RTs (hit rate: 51.7%) was even lower, which is conceivable given that a person’s class membership was not constant in the data generation. The size of the observed hit rates will be put into context in the Discussion section.
Empirical Demonstration
To empirically demonstrate the proposed model, we analyzed data from an actual high-stakes job application context. Along with technical aspects like convergence and model fit in empirical settings, the empirical demonstration allowed investigating the consistency of test-takers’ response strategy use across items, class proportions on the level of items and the entire test, as well as RT differences associated with the three response strategies.
Dataset
The data for the empirical demonstration were made available by a Germany-based testing company that develops psychological measurement tools for personnel selection. The dataset included N = 1,824 test-takers who had taken a personality test as part of their application for a police officer traineeship at a German police department between 2023 and 2024. 4 The sample comprised 70.0% male and 30.0% female test-takers with a mean age of M = 21.02 years (SD = 4.61, range = [15, 39]). Along with item responses, the dataset contained item-level RTs (measured down to milliseconds). Exact timing of item-level response latencies was possible because every item had been presented on a separate questionnaire page.
For our empirical demonstration, we modeled item responses and RTs from three substantive trait scales available in the dataset. These were a scale of Emotional Stability (measured with 12 items; Cronbach’s
Pilot Study to Assess Desirability Values
We set scoring weights of substantive trait dimensions to
Results of the Empirical Demonstration
Like in the parameter recovery study, we fitted the person-by-item mixture model both with and without RTs as well as the person mixture model with and without RTs. We also fitted the three non-mixture models representing the measurement models of three modeled response strategies (Equations 1 to 3), that is, an MNRM, an MGPCM, and a unidimensional NRM with specified scoring weights of faking. We again used JAGS via the R environment for model estimation. In the empirical analysis, we estimated each model by running 12 parallel MCMC chains with 15,000 iterations following a 5000-iteration burnin phase.
Model Convergence and Model Fit
We checked model convergence based on
Table 1 shows model fit indices. The person-by-item mixture model with RTs yielded by far the highest log-likelihood. 5 Crucially, this model was also selected by the widely applicable information criterion (WAIC; Watanabe, 2010) and the leave-one-out information criterion (LOOIC; Vehtari et al., 2017), indicating that the person-by-item mixture model with RTs yielded a better compromise between fit and parsimony than the other models. To quantify absolute fit, we applied posterior predictive model checking (PPMC; Sinharay et al., 2006), which is a technique that entails simulating data from the posterior distribution of model parameters and evaluating how the simulated data aligns with the observed data. Regarding item responses, we considered the standardized root mean square residual (SRMR), which indicates the misfit between model-implied and observed item intercorrelations. Compared to the other models, the SRMR of the person-by-item mixture model with RTs was smallest (.054), indicating that this model fit the item responses best. Regarding item RTs, we considered posterior predictive p-values (PPP) with respect to the discrepancy between model-implied and observed item means of log-RTs. Across items, PPPs ranged from .182 to .554 with a mean of .382, indicating that the RTs predicted by the model were not systematically higher or lower than the empirical RTs. 6
Empirical Demonstration: Model Fit Indices of Converged Models.
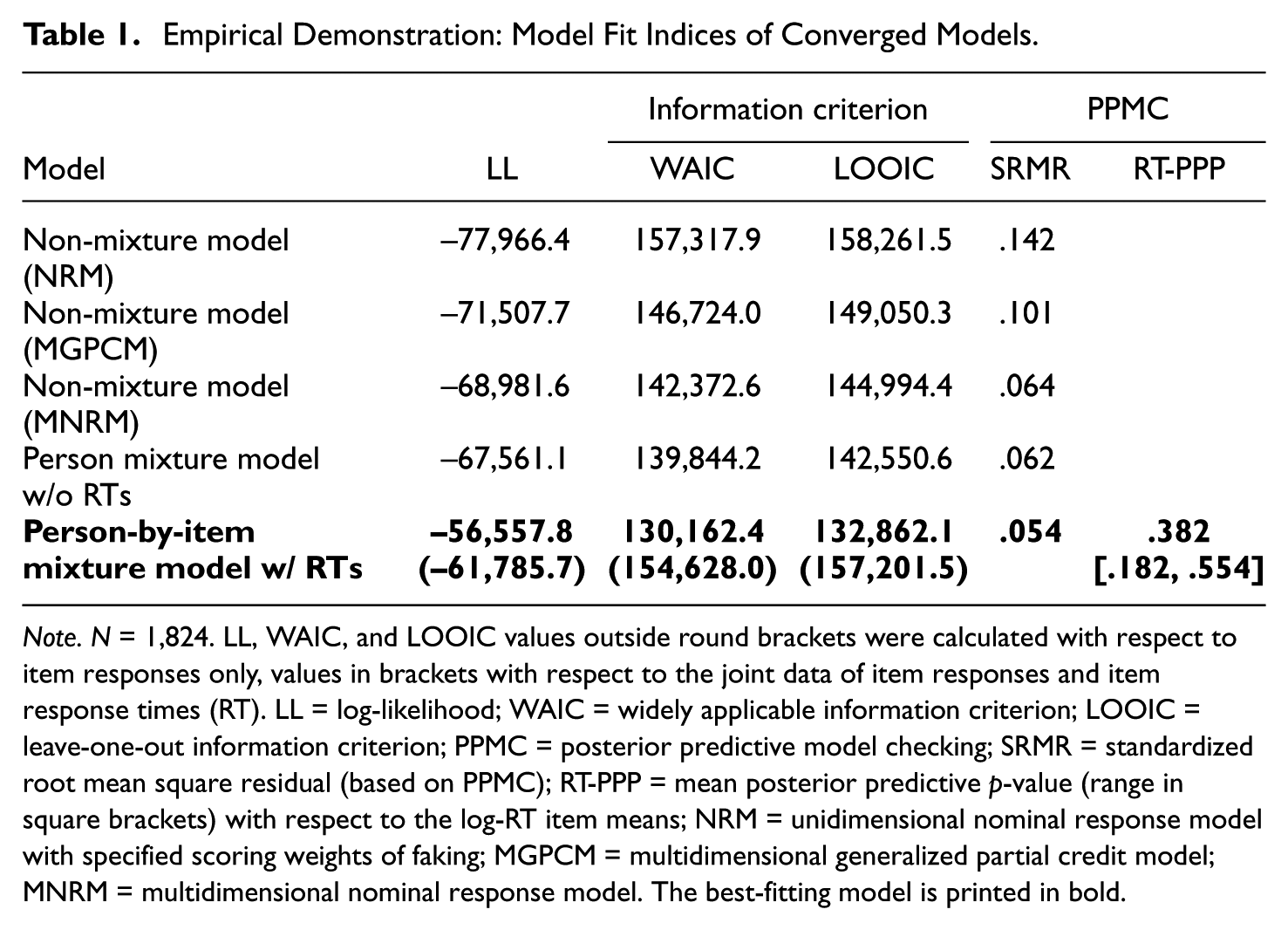
Note. N = 1,824. LL, WAIC, and LOOIC values outside round brackets were calculated with respect to item responses only, values in brackets with respect to the joint data of item responses and item response times (RT). LL = log-likelihood; WAIC = widely applicable information criterion; LOOIC = leave-one-out information criterion; PPMC = posterior predictive model checking; SRMR = standardized root mean square residual (based on PPMC); RT-PPP = mean posterior predictive p-value (range in square brackets) with respect to the log-RT item means; NRM = unidimensional nominal response model with specified scoring weights of faking; MGPCM = multidimensional generalized partial credit model; MNRM = multidimensional nominal response model. The best-fitting model is printed in bold.
Table 2 contains the latent correlations between dimensions estimated in the person-by-item mixture model with RTs. Most correlations were estimated not large in size, but different credibly from 0. An interpretation of the observed latent correlations is provided in the Discussion section.
Empirical Demonstration: Estimated Latent Correlations
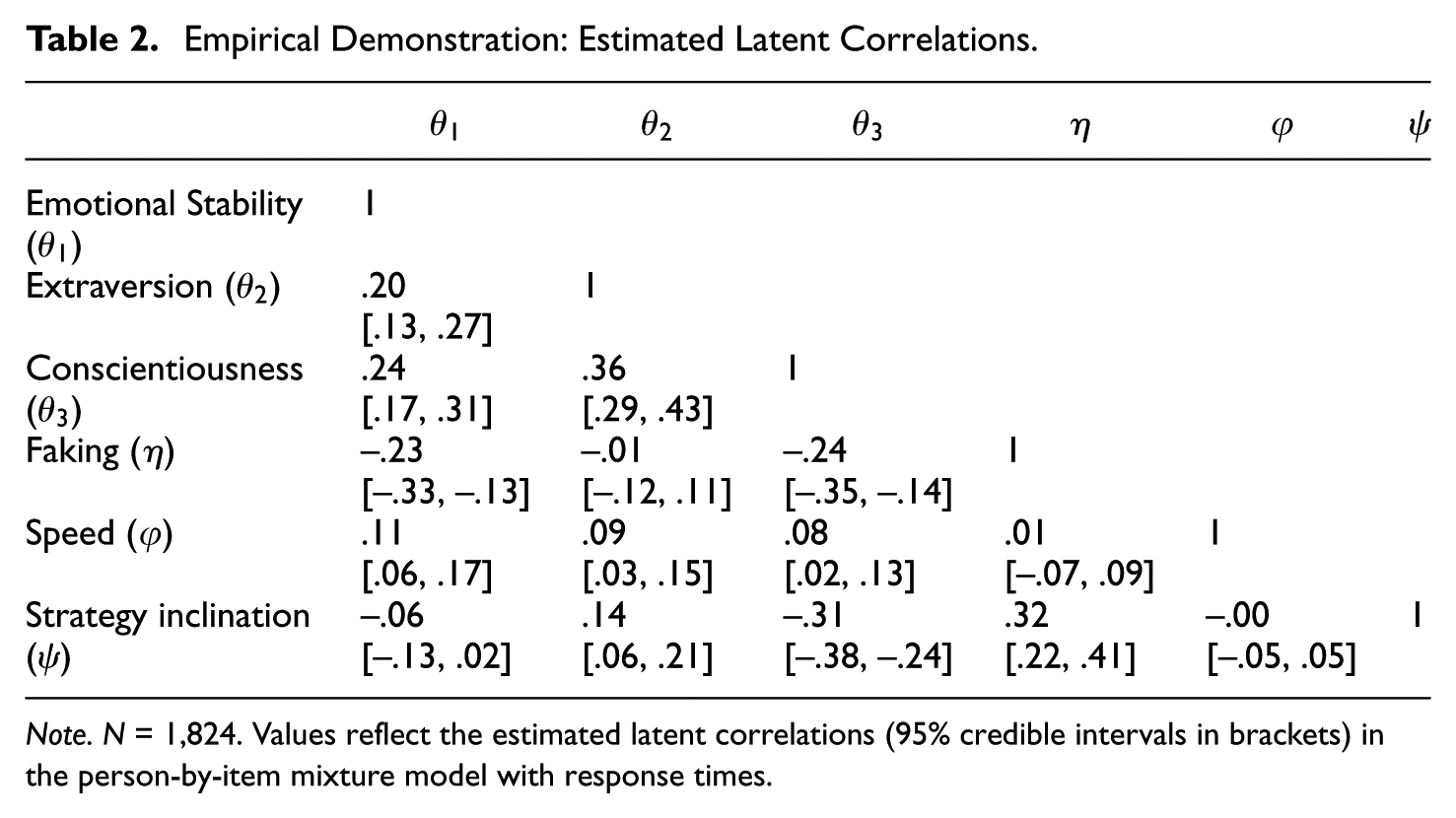
Note. N = 1,824. Values reflect the estimated latent correlations (95% credible intervals in brackets) in the person-by-item mixture model with response times.
Class Proportions and Class-Specific Item Response Distributions
With an estimated strategy inclination slope of
Across all items, the person-by-item mixture model with RTs estimated that 48.6% (95% CrI: [47.0%, 50.1%]) of individual item responses stemmed from the “S-only class,” whereas 25.9% (95% CrI: [24.5%, 27.4%]) stemmed from the “S&F class” and 25.5% (95% CrI: [24.7%, 26.2%]) stemmed from the “F-only class.” The person mixture model without RTs estimated a similar class proportion for the “S-only class” (48.7%, 95% CrI: [44.7%, 52.7%]), however, it yielded a considerably larger “S&F class” proportion (47.0%, 95% CrI: [43.2%, 51.0%]) and a considerably smaller “F-only class” proportion (4.2%, 95% CrI: [3.2%, 5.3%]). Note that this pattern is in line with the parameter recovery results above, where overall proportions of the “S&F class” and “F-only class” were strongly biased in person mixture models.
Class proportions in the proposed model could also be computed item-specifically. Results showed that class proportions varied substantially from item to item. “S-only class” proportions ranged from 28.9% to 65.6% across items, “S&F class” proportions ranged from 9.3% to 44.2%, and “F-only class” proportions ranged from 8.0% to 51.6%. These estimates indicate that some items were more prone than other items to the different response strategies. At the same time, however, there were no items where all responses were based on the same strategy for all test-takers. Figure 9 displays class probabilities as a function of strategy inclination scores for the three items of the test with the largest estimated proportion of the “S-only class,”“S&F class,” and “F-only class,” respectively.
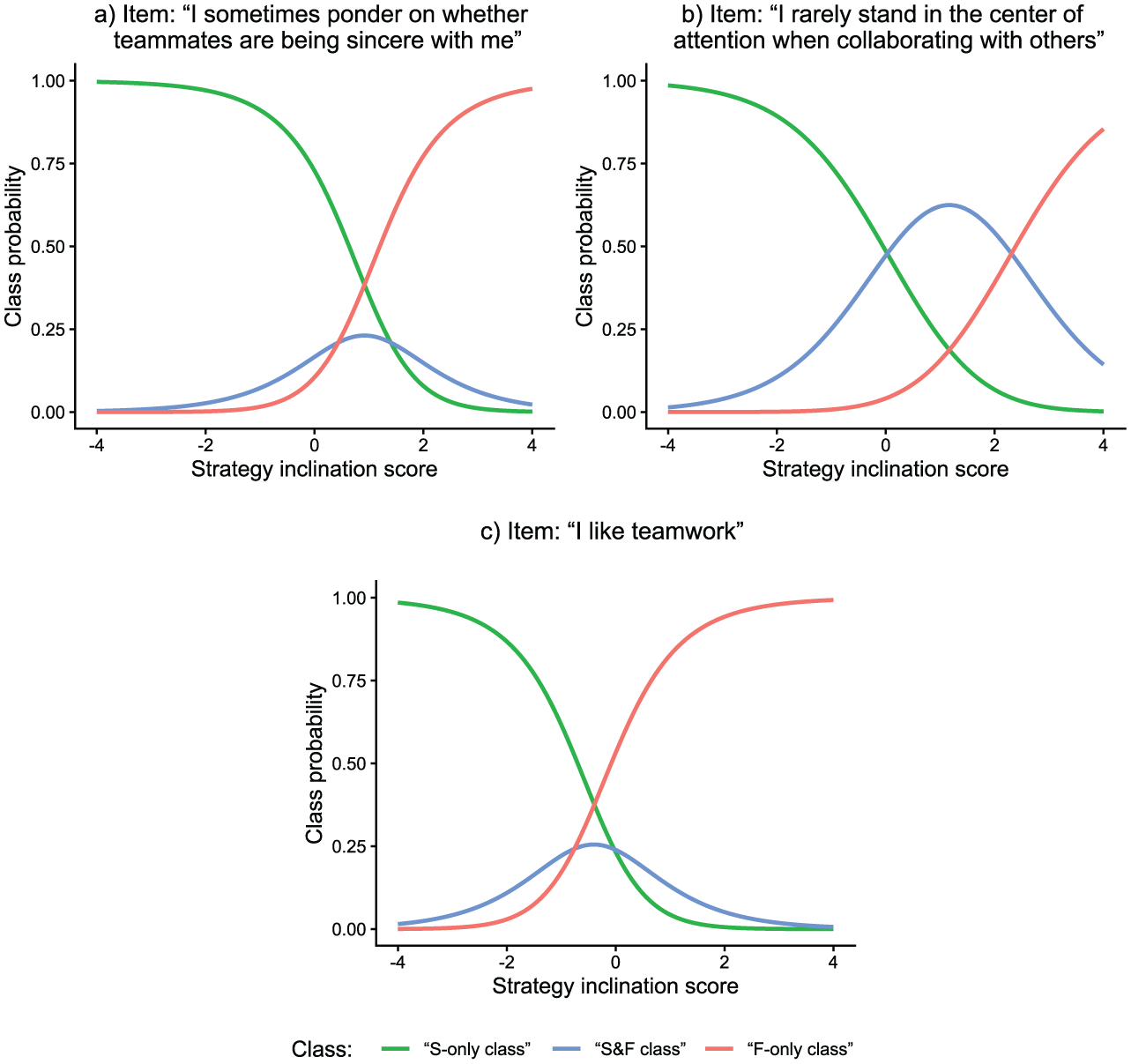
Empirical Demonstration: Latent Response Functions of Three Items.
Apart from different class sizes across items, the classes also differed in their response distributions depending on the items’ desirability characteristics (see Figure 10). For items at which the highest response category was most desirable (cf. Figure 2a), mean item responses were highest in the “F-only class” and lowest in the “S-only class.” This effect, though slightly less pronounced, also emerged for items having their category of highest desirability above the scale midpoint but not at the extreme (cf. Figure 2b). However, for items with a highest-desirability category at the scale midpoint (cf. Figure 2c), there were no considerable mean differences in item responses between classes.
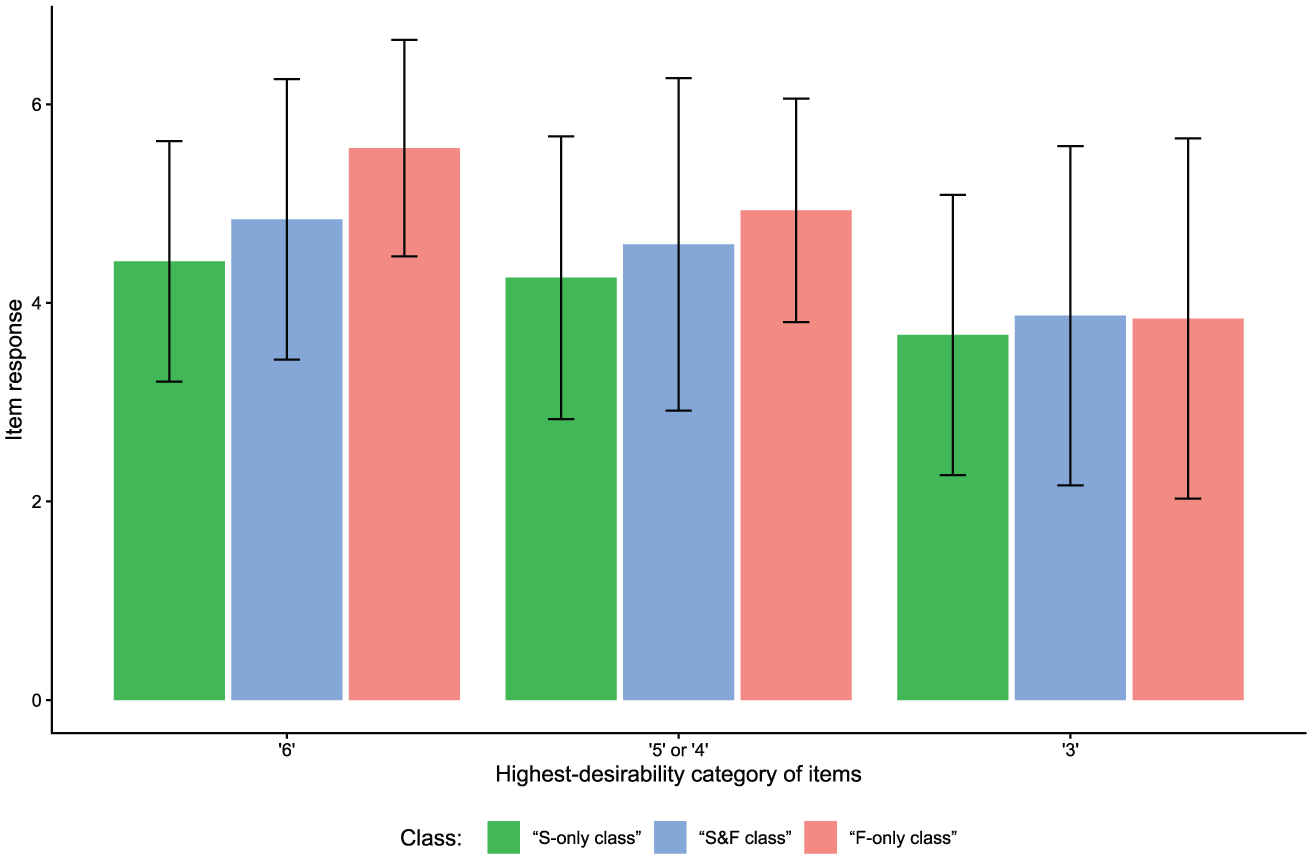
Empirical Demonstration: Class-Specific Mean Item Responses for Items With Different Desirability Characteristics.
Response Time Results
The person-by-item mixture model with RTs also yielded pronounced class differences concerning RTs. Across items, the mean “S-only class” time intensity was
General Discussion
In the current work, we presented a mixture IRT model that allows researchers and practitioners to account for, identify, and investigate different faking-related response strategies. The proposed model assumes that item responses of each test-taker are mixtures of three latent classes (pure substantive trait responding, response editing in the direction of desirability, and pure faking), and entails an RT-based latent response model that classifies item responses on the person-by-item level. RTs are modeled as indicators of class membership. That is, instead of being class membership predictors, RTs are reflections of strategy use and facilitate class separation by their relative typicality for the respective class. The model hence falls into the category of independent latent class IRT models (Nagy & Ulitzsch, 2022).
From a psychometric point of view, the presented person-by-item mixture modeling approach can flexibly account for heterogeneity in faking and thus constitutes an important extension over approaches assuming a constant faking strategy for each test-taker throughout the test or even a single measurement model for all test-takers. From a substantive research perspective, the proposed model can be used to study the response process behind faking in a sophisticated way. For example, differences in estimated item time intensity parameters reflect differences in RT distributions associated with the different response strategies, estimated item-class intercepts reveal which items are especially prone to a particular response strategy, and estimated latent correlations between substantive traits and faking and/or strategy inclination indicate how substantive person attributes are related to different faking tendencies. From an applied testing perspective, the model aids in ensuring the validity of inferences about test-takers, as substantive trait scores are estimated by accounting for potential switches between response strategies over the course of the assessment.
Summary and Discussion of Results
Parameter Recovery
We examined the proposed model in a parameter recovery study with datasets representative of high-stakes assessment data. Along with examining parameter recovery of the proposed model, this study also allowed investigating the consequences of not modeling RTs as well as of assuming a constant response strategy per person or across the entire sample. In general, the proposed person-by-time mixture model with RTs exhibited good parameter recovery in terms of negligible bias and decent accuracy considering the not too large sample size in our parameter recovery study. Also, it was found that models that lack components of the data-generating process, which was based on the results of the empirical demonstration, indeed produce systematically biased and much less accurate parameter estimates than the proposed model. Several other findings stand out and are worth discussing.
First, whereas the person-by-item mixture model with RTs converged in almost all replications (98%), the person-by-item mixture model without RTs converged in only 74% of the replications. Non-convergence of the person-by-item mixture model without RTs was mainly due to several item-class intercepts in the latent response model component failing to converge. This is evidence that RTs have a facilitating effect on the estimation of the presented person-by-item mixture model despite not being direct predictors of class membership (see Nagy & Ulitzsch, 2022). Along with improving convergence, the results also suggest that modeling RTs has a positive effect on the accuracy of parameter estimation. In our parameter recovery study, the size of the effect varied between the different model parameters but was most pronounced for the latent response model parameters.
Second, the recovery of most model parameters differed substantially between person-by-item and person mixture models, with person mixture models yielding biased and less accurate estimates. This is not too surprising considering class membership varied both between persons and items in the data generation. However, it is important to note that person mixture models indeed lead to biased conclusions in data situations in which test-takers employ different response strategies over the course of the test (as was the case in our empirical demonstration). Particularly, class proportions estimated in person mixture models seem to be strongly biased, with the proportion of the “S&F class” systematically overestimated and the proportion of the “F-only class” systematically underestimated. 7
Third, the parameter recovery study showed for the proposed model a rather low classification accuracy compared to other recent confirmatory mixture modeling approaches (e.g., Alagöz & Meiser, 2024; Seitz, Alagöz, & Meiser, 2025). Note, however, that the metric considered in the current article were hit rates on the item level (i.e., percentages of correct class assignments on the level of individual item responses), whereas articles studying classification accuracy of person mixture models considered hit rates on the level of test-takers. Taking into account that the information for assigning single item responses to latent classes is very sparse and naturally less reliable than the information for classifying whole response vectors, it is unsurprising that the obtained hit rates were not as high as the hit rates found in articles on person mixture models. Nevertheless, considering the size of the observed hit rates in the parameter recovery study, it is important to emphasize that response strategy classifications of individual item responses should be interpreted with caution. Because of the uncertainty associated with single classifications, it is arguably more advisable to look for general trends regarding the model-implied class memberships, be it for a particular test-taker or for a particular item.
Empirical Results
Seitz, Alagöz, and Meiser (2025) provided evidence for the prevalence of the three modeled response strategies on the person level. The empirical demonstration of the current article allowed investigating the consistency of response strategy use over the course of the assessment. As described above, the estimated parameters in the latent response model component implied class memberships that varied between persons and, crucially, within persons also between items. This empirically justifies the use of the more complex person-by-item mixture modeling approach, which is nevertheless flexible enough to yield a constant class membership for a person whose response pattern suggests that. This flexibility of the model indeed yielded an interesting classification pattern regarding how consistently test-takers used the three response strategies. Namely, if test-takers used an “S-only” strategy, they usually did so across all items, whereas test-takers engaging in faking mostly switched between an “S&F” and “F-only” strategy.
Regarding the overall class proportions, the model estimated that about one-half of individual item responses stemmed from the “S-only class,” whereas about one-quarter each stemmed from the “S&F class” and the “F-only class.” That is, according to the model, around half of the responses in total were honest in terms of being solely influenced by substantive traits, whereas the other half were at least partially influenced by faking. These proportions are well in line with the proportions Brown and Böckenholt (2022) found in their model including only two classes (49% honest vs. 51% faked). However, our results suggest that some responses influenced by faking can still contain information on substantive traits and hence do not need to be discarded for the estimation of substantive trait scores.
With respect to the latent correlations between dimensions, the model’s estimates were generally not large in size, but most were credibly different from 0. For instance, the substantive traits were estimated to be moderately positively correlated, which is in line with research on associations between the Big Five personality factors (e.g., van der Linden et al., 2010), but were not unreasonably inflated as is typically observed in high-stakes assessments when faking is not statistically accounted for (e.g., Schmit & Ryan, 1993; Seitz, Spengler, & Meiser, 2025). At the same time, there were non-negligible latent correlations of substantive traits with faking and strategy inclination. Conscientiousness, for instance, was estimated to be moderately negatively correlated with both faking (–.24) and strategy inclination (–.31). However, the latent correlations were not so high that one would have to assume that faking and strategy inclination absorb a disproportionately large amount of substantive personality variance. Furthermore, note the estimated latent correlation between faking and strategy inclination. This correlation of .32 indicates a positive association between aligning responses with desirability and using a pronounced self-presentation strategy; however, it also speaks against a full overlap of the two dimensions. Hence, to sum up, the model’s estimated latent correlations provide validity evidence regarding the meaning and non-redundancy of the modeled latent dimensions.
Another interesting empirical finding concerns the model’s RT results, indicating that pure faking is faster than pure substantive trait responding and that a combination of the two processes takes longest. These findings could reconcile some of the conflicting results in the literature regarding the effect of faking on RTs. In particular, our findings suggest that the question of whether faking increases or decreases RTs cannot be answered straightforwardly, but that it depends on the response process underlying a response that involves faking. If test-takers retrieve an honest response before they edit this response according to desirability (i.e., “S&F class”; cf. the theory by Walczyk et al., 2003), the results suggest that this goes along with increased RTs (Fine & Pirak, 2016; Holtgraves, 2004; Walczyk et al., 2003). Such a response set corresponds to the response set triggered by the experimental condition in the study by Holtgraves (2004), who induced faking along with honest responding through a subtle desirability manipulation. If, however, test-takers bypass the retrieval of an honest response and instead just provide a desirable answer (i.e., “F-only class”; cf. the theory by Holden, 1995), the results suggest that this reduces RTs. Such a response set is analogous to response sets induced through mere instructed-faking conditions, in which subjects are simply asked to fake without referring to their true personality (Holden, 1995; Holden et al., 1992; Hsu et al., 1989). Taking this into account, the model’s RT results imply a limited potential of simple (i.e., non-model-based) faking detection methods that perform faking classifications based on a single RT threshold (Fine & Pirak, 2016).
Limitations and Future Research Directions
Some limitations and directions for future research need to be mentioned. One aspect concerns the model’s assumptions, which need to be kept in mind when applying the model and interpreting its parameter estimates: First, as is also the case in non-mixture applications of the MNRM when modeling faking, the specification of scoring weights of faking is constant across persons. That is, it is implicitly assumed that test-takers do not differ systematically in the mere perception of social desirability. A simulation study on the non-mixture version of the model might have shown that the model is fairly robust when test-takers perceive desirability differently (Kleinbub & Seitz, 2025), but it remains to be investigated how this transfers to the model extension of the current article. Second, in order for RTs to have a facilitating effect on model estimation and class separation, there should be differences in RT distributions between classes. With RT distributions becoming less distinct, one can expect the facilitating effect of modeling RTs shown in the parameter recovery study to weaken and eventually disappear (Pokropek, 2016; Ulitzsch et al., 2024). Third, along with separable RT distributions, item response distributions should also exhibit good between-class separability. Future studies can explore which questionnaire characteristics are required to achieve this (cf. Uglanova et al., 2025). Fourth, completion speed is assumed to be constant across the test. This stationarity assumption (van der Linden, 2007), however, is likely to be violated when test-takers become exhausted at later parts of the assessment or become more acquainted with the questionnaire format.
Another aspect of limitations and future research directions concerns the current parameterizations of some of the model components. For instance, the latent response model has been parametrized as a PCM, which assumes the classes to be ordinal. For a more general formulation, the latent response model could in principle also be implemented as an NRM, which would relax the ordinality assumption. However, in initial simulation runs in the model development phase, we found this increased estimation complexity to pose a challenge to model convergence. Different parameter restrictions would probably be necessary in this case. Likewise, future studies could try to estimate time intensities of the “S&F class” in a less restrictive way. Based on theoretical considerations, we constrained “S&F class” time intensities to be a function of “S-only class” and “F-only class” time intensities and restricted the proportionality constant
A further alternative way of parameterizing the model would also be to implement item-level predictors of class membership and/or RTs. This could be achieved by restricting item-class intercepts and/or item time intensities through linear combinations of variables that describe the items, such as item keying, item length, item position, or item content features (see Ulitzsch, Yildirim-Erbasli, et al., 2022). Researchers could use such a parametrization to study item characteristics that make certain response strategies especially likely or have a systematic effect on response latencies. If, for instance, particular item characteristics were found to strongly predict “F-only class” membership, this would be a valuable piece of information for test construction, as it could help to develop instruments that are less susceptible to faking in the first place.
In addition, it would be important to conduct validation analyses in future studies. From the perspective of applied measurement, it would be particularly relevant to further investigate the validity of the model’s adjustments of substantive trait score estimates because substantive trait scores are the parameters of primary interest in contexts where test-takers are ranked and selected based on their test scores. In this regard, future research should study whether the adjustments of substantive trait score estimates increase correlations with faking-resistant measures of personality. Ultimately, it would also be interesting to see the effects of the adjustments on the prediction of job-relevant performance outcomes.
Finally, practical issues associated with the presented method of modeling faking are to be mentioned. In particular, the presented approach comes with the limitation of requiring a lot of resources in the form of computation power and time, as fitting the model can demand a substantial amount of working memory and take quite some time to achieve convergence. The actual estimation time will ultimately depend on sample size, test length, and the available computer. In the case of our parameter recovery study, a single estimation of the model took around twelve hours on a high-performance computer. This can be a major obstacle for applications of the model in practice. However, estimation time can be drastically reduced in an applied measurement context where only person parameters of new incoming test-takers need to be estimated. Here, one can estimate model parameters once in a sufficiently large calibration sample and then treat person-invariant parameters as fixed for the estimation of person parameters of additional test-takers. Computation time will in this case reduce to just a few seconds.
Conclusion
In conclusion, the presented RT-based person-by-item mixture model constitutes an appealing approach to modeling faking in high-stakes personality testings. As opposed to most other faking models, it accounts for switches between different faking-related response strategies over the course of the assessment. It thereby makes use of additional behavioral data by modeling strategy-specific RT distributions, thus allowing for a sophisticated investigation of the response process associated with faking. Future research can examine different parametrizations of the model and conduct validation analyses of particular model parameters.
Supplemental Material
sj-docx-1-epm-10.1177_00131644261422169 – Supplemental material for Faking in High-Stakes Personality Assessments: A Response-Time-Based Latent Response Mixture Modeling Approach
Supplemental material, sj-docx-1-epm-10.1177_00131644261422169 for Faking in High-Stakes Personality Assessments: A Response-Time-Based Latent Response Mixture Modeling Approach by Timo Seitz and Esther Ulitzsch in Educational and Psychological Measurement
Footnotes
Appendix
Acknowledgements
The authors cordially thank HR Diagnostics for providing the data for the empirical demonstration of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation)—GRK 2277—Projektnummer 310365261, and partially supported by the Research Council of Norway through its Centers of Excellence scheme, project number 33160.
Ethical Considerations
Not applicable because the study involves analyses of simulated datasets as well as a reanalysis of an existing empirical dataset.
Consent to Participate
Not applicable because the study involves analyses of simulated datasets as well as a reanalysis of an existing empirical dataset.
Consent for Publication
Not applicable because the study involves analyses of simulated datasets as well as a reanalysis of an existing empirical dataset.
Material and Data Availability
Supplemental Material
Supplemental material for this article is available online.