
Abstract
Applied researchers often encounter situations where certain item response categories receive very few endorsements, resulting in sparse data. Collapsing categories may mitigate sparsity by increasing cell counts, yet the methodological consequences of this practice remain insufficiently explored. The current study examined the effects of response collapsing in Likert-type scale data through a simulation study under the confirmatory factor analysis model. Sparse response categories were collapsed to determine the impact on fit indices (i.e., chi-square, comparative fit index [CFI], Tucker–Lewis index [TLI], root mean square error of approximation [RMSEA], and standardized root mean square residual [SRMR]). Findings indicate that category collapsing has a significant impact when sparsity is severe, leading to reduced model rejections in both correctly specified and misspecified models. In addition, different fit indices exhibited varying sensitivities to data collapsing. Specifically, RMSEA was recommended for the correctly identified model, and TLI with a cut-off value of .95 was recommended for the misspecified models. The empirical analysis was aligned with the simulation results. These results provide valuable insights for researchers confronted with sparse data in applied measurement contexts.
Introduction
In survey research, the Likert-type scale is among the most commonly employed item formats for data collection (Eichhorn, 2022). A Likert-type scale “has multiple categories from which respondents choose to indicate their opinions, attitudes, or feelings about a particular issue” (Nemoto & Beglar, 2014). Compared to open-ended questions, researchers can easily generate numerical quantitative results with data from Likert-type scale questions (e.g., calculating mean and standard deviation) to efficiently facilitate data analysis. The standardized format of a Likert-type scale for all survey items improves the reliability and validity by reducing ambiguity in response interpretations (Joshi et al., 2015).
One key advantage of Likert-type scales is their flexibility in design, as researchers can determine the number of response options and the labels used to describe them depending on the research purpose. However, it is important to recognize that individual Likert-type scale items yield ordinal data, where response options follow a ranked order but do not necessarily maintain equal intervals between categories (Sullivan & Artino, 2013). Research on various design elements of Likert-type scales—including scale length, response labels, and the number of response categories—has been extensively studied (e.g., Aybek & Toraman, 2022; Horan et al., 2003; Kankaraš & Capecchi, 2024; Lee & Paek, 2014). Among these factors, the number of response categories has received particular attention due to its substantial impact on measurement reliability and validity (Lozano et al., 2008).
Optimal Number of Response Categories
The optimal number of response categories for achieving high measurement quality remains a topic of debate in prior literature. In general, researchers argue that increasing the number of response options enhances psychometric properties up to a certain point. For example, Preston and Colman (2000) found that scales with five or more response options yield higher internal consistency and test–retest reliability compared to scales with fewer alternatives. Similarly, Lozano et al. (2008) demonstrated that while reliability and validity estimates improve with additional response options, these improvements tend to plateau at around seven categories based on existing simulation studies. This pattern is consistent with Matell and Jacoby (1971), who showed that reliability and validity increased sharply as the number of categories rose from two to about seven. Likewise, Oaster (1989) reported that increasing the number of response options from three to seven improved the stability of the results. On the contrary, other studies concluded that five categories are preferable to seven or eleven categories based on multitrait-multimethod analyses (e.g., Revilla et al., 2014).
While prior studies focused on basic psychometric analysis, recent studies have extended the investigation of the number of response categories into the confirmatory factor analysis (CFA) framework. CFA is a multivariate statistical method that tests whether data fits a pre-specified measurement model linking observed variables to their underlying latent constructs, offering advantages over traditional psychometric analyses by rigorously assessing model fit and complex inter-item relationships (Brown, 2015). Within this framework, Li (2016) reported that increasing the number of categories from four to ten can enhance the accuracy of factor loadings and inter-factor correlation estimates. In line with these findings, Maydeu-Olivares and colleagues (2017) recommended including at least five response alternatives in measurement instruments, highlighting concerns regarding model fit and the precision of parameter estimates. DiStefano and colleagues (2018) identified that the model fit indices of five response categories are better compared to two response categories while other parameters are consistent.
Model Estimation and Item Distribution
Despite inconsistent findings in previous studies, choosing the appropriate number of response options remains a significant decision in scale design and/or psychometric analysis, as it directly impacts the selection of the appropriate model estimation method in CFA (DiStefano & Morgan, 2014). Although Likert-type scale item responses represent ordered categories without equal interval spacing, researchers often treat them as approximately continuous by applying maximum likelihood (ML) estimation (Rhemtulla et al., 2012). This practice is problematic because the assumption of multivariate normality is frequently violated (Finney & DiStefano, 2013), particularly when fewer than five response categories are used (Rhemtulla et al., 2012). Although alternative ML-based estimators, such as Maximum Likelihood with Mean and Variance adjustment (MLMV), can help mitigate non-normality, they do not fully account for the ordinal nature of Likert-type scale data, as these methods treat responses as continuous and assume underlying interval-level measurement (Finney & DiStefano, 2013).
Employing estimation methods unsuitable for the data type can lead to biased parameter estimates and incorrect inferences (Rhemtulla et al., 2012) on CFA. To address this issue, alternative robust estimation methods, such as Unweighted Least Squares Mean and Variance Adjusted (ULSMV) and Weighted Least Squares Mean and Variance Adjusted (WLSMV), have been recommended (Finney & DiStefano, 2006) to appropriately account for the ordinal nature using polychoric correlations instead of Pearson correlations (Li, 2016).
Handling Sparse Data
One contributing factor to non-normality in Likert-type scale responses is sparse data, where certain response categories attract very few endorsements (DiStefano et al., 2021). Sparse data can result in excessively skewed distributions and increased kurtosis, further complicating model estimation processes. Sparse data are frequently observed in practice. For instance, social desirability may lead respondents to select extreme endpoints of an item (Liu et al., 2017), thereby reducing the frequency of intermediate responses. Such patterns have been observed in scales measuring academic dishonesty and alcohol consumption (e.g., Davis et al., 2010; Winrow et al., 2015), as well as in clinical and screening instruments assessing behavioral or psychiatric symptoms, where certain severity categories are rarely endorsed (e.g., Bowden et al., 2007; Wang et al., 2021). Overall, it is essential to select appropriate estimation methods that can properly account for sparse data, given its impact on model fit and parameter estimation (Li, 2016; Liang & Yang, 2014).
Sparseness levels can range from zero (Savalei, 2011) to low frequencies in certain categories (DiStefano et al., 2021; Rhemtulla et al., 2012). For low frequencies, the definition of “sparseness” in categorical data varies across researchers. For instance, Rutkowski et al. (2019) recommended collapsing categories when a cell contained fewer than 10 responses, whereas DiStefano et al. (2021) identified sparsity based on low percentages, typically 2% or 4% of the total response. Various methods have been proposed to address sparse data. Researchers could manually add a threshold to the category (categories) without any response (Savalei, 2011; Yang & Weng, 2024). However, this strategy is generally recommended for binary data rather than for items with more than two response categories. Another common approach is to collapse certain subcategories for all items to form a new category with greater frequencies (e.g., Zhao et al., 2023).
Researchers have explored the effect of collapsing responses, an alternative perspective examining the number of response categories. In a study of the Rosenberg Self-Esteem scale, Colvin and Gorgun (2020) found that models based on collapsed responses demonstrated better model fit indices than those using the original data. They suggested that while the scale should be administered in its original format, collapsing responses prior to data analysis may be beneficial. An earlier simulation study also confirmed the advantages of collapsing categories in CFA (Grimbeek et al., 2005). The results showed that collapsing responses from five categories to two categories illustrated a better fit (e.g., root mean square error of approximation [RMSEA], standardized root mean square residual [SRMR], chi-square tests).
Most prior studies collapsed all responses to reduce the number of categories. However, in practice, items within a scale often exhibit varying response distributions, and only a subset of items may exhibit sparse response patterns. Collapsing all items can lead to the loss of meaningful information, particularly for non-sparse items, and may introduce overgeneralization. An alternative approach is to collapse response categories only for items with sparse responses while preserving the original structure for non-sparse items (i.e., infrequent collapsing).
A recent study using measurement invariance testing, a follow-up test based on CFA result, suggested a meaningful impact on the model fit by employing infrequent collapsing, where only sparse categories of corresponding items are collapsed (Rutkowski et al., 2019). This study introduced new possibilities for applying collapsing strategies in CFA. In addition, infrequent collapsing allows for a more nuanced approach that retains the variability and interpretability of non-sparse items. DiStefano and colleagues (2021) examined infrequent collapsing in the framework of CFA and found that collapsing categories only for items with sparse responses was advantageous compared to analyzing the original data. When sparse categories were collapsed, results showed higher model convergence rates, more accurate parameter estimates, smaller standard errors, and chi-square testing rejection rates close to .05 under manipulated conditions (e.g., sample size, number of items with sparse data).
However, the authors did not include certain modeling conditions that warrant additional investigation. For instance, only correctly specified models were considered to study Type I error rates; however, model misspecification is a common practical condition in CFA models (Chen et al., 2008; DiStefano et al., 2018; Shi et al., 2019). Furthermore, more practical modeling conditions (e.g., different response categories & high or low factor loadings) remain underexplored. Finally, the performance of additional fit indices on top of the chi-square results has not been examined.
The Present Study
Therefore, the current study was conducted to fill the above research gaps. The following model fit indices were considered the main output in the current study. The chi-square fit index is an exact fit test, measuring the discrepancy between the observed data and the model-implied covariance matrix. Conceptually, observed covariances represent the actual relationships between items in the sample data, while predicted covariances are the expected relationships estimated by the model. Chi-square tests are sensitive to sample size. In large samples, even minor discrepancies between the observed and predicted covariances can lead to a significant chi-square result, which may incorrectly indicate model misfit (DiStefano, 2016). On the contrary, it is not realistic to expect an exact fit in practice due to the concern of measurement error and model complexity (Goretzko et al., 2024). Therefore, alternative fit indices were evaluated.
RMSEA is an absolute fit index that measures the misfit level of the hypothesized model by considering sample size and model complexity. As a “badness-of-fit” index, RMSEA reflects the degree of model misfit, with higher values indicating poorer fit (Kline, 2011; MacCallum et al., 1996). SRMR is another absolute fit index measuring the average standardized residuals between observed and predicted correlation matrices (Kline, 2011). It is also considered a badness-of-fit index, ranging from 0 to 1, with lower values indicating better fit. The comparative fit index (CFI) and Tucker–Lewis index (TLI) are incremental fit indices that measure the relative improvement in the fit of a hypothesized model compared to a baseline model, which assumes no relationships among the observed variables (Xia & Yang, 2019). CFI and TLI typically range from 0 to 1, with higher values indicating better model fit.
This study aims to provide a comprehensive understanding of various fit indices in the context of sparse data and infrequent collapsing. Specifically, this study investigates how correctly specified and misspecified models perform across different model fit indices while considering other modeling factors (e.g., degree of factor loadings, degree of item sparse levels, and sample size). Specifically, the study examines the model rejection rates and the stability of chi-square, CFI, TLI, RMSEA, and SRMR across correctly specified and misspecified models. This study seeks to provide practical guidance for researchers in selecting and interpreting fit indices more effectively when sparse data and model misspecification are present.
Methods
A Monte Carlo simulation study was conducted to examine the effect of collapsing item responses with sparse data. While many studies advocated for five or more response categories to enhance psychometric properties, the selection of a four-category scale was intentional. This choice aligns with findings that scales with four to seven response categories offer an optimal balance between psychometric properties and respondent burden (Lozano et al., 2008). As five response categories were generally recommended as the minimum for treating data as continuous (Rhemtulla et al., 2012), we selected four categories to ensure the use of a robust estimation method appropriate for ordinal data. Consequently, we employed the WLSMV estimator, which is specifically designed for ordinal data and does not assume normality. Data were generated in Mplus 8.11 (Muthén & Muthén, 2017). A three-factor CFA population model was specified: each factor was measured by five items, yielding 15 items in total. The factor correlations were fixed at .40.
Model Specification
Model specifications were established to assess the adequacy of model identification, wherein a correctly specified model should be retained, and a misspecified model should be rejected, based on statistical fit criteria (Goretzko et al., 2024; Shi & Maydeu-Olivares, 2020). Three conditions were estimated: (a) a correctly specified model with all items loading on the factors matching the population model, (b) Misspecification 1 with one item loading on a different factor (i.e., mild misspecification), and (c) misspecification with two factors collapsed (i.e., severe misspecification). These conditions are displayed in Figure 1.
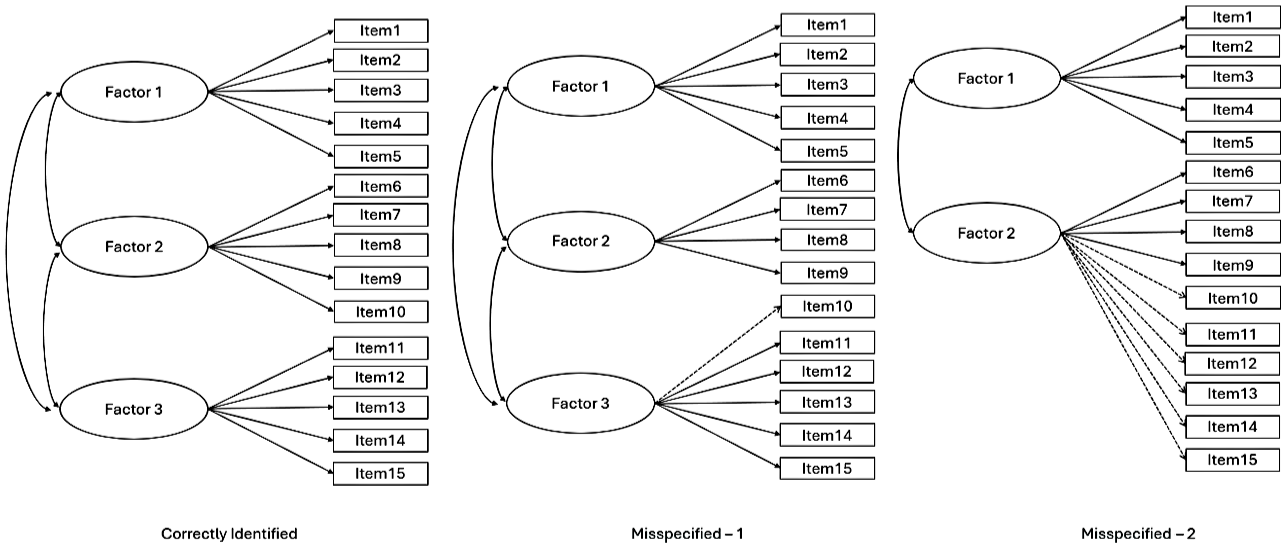
Model Specification.
Factor Loadings
Factor loadings influence the performance of model fit, with higher factor loadings generally leading to better model fit. All factor loadings set at .80 represented a high loading condition, and factor loadings set at .50 represented a moderate loading condition (DiStefano et al., 2018).
Sample Size
Sample size is a common factor to vary in simulation studies of CFA (Wolf et al., 2013). Two sample sizes were considered: N = 250 and N = 500, corresponding to sample size to number of items ratios of 17:1 and 33:1.
Sparse Data
The term “sparse” is somewhat subjective, as its definition can vary across studies. In this study, both the number of items and the degree of sparsity within each item were manipulated to represent different levels of sparsity, following the guidelines of prior research (DiStefano et al., 2021). Per factor, we considered the following three conditions: one item with sparse data, two items with sparse data, and four items with sparse data. Among these items with sparse data, we set up percentages of responses per category using different thresholds. Different distributions were considered, indicating the degree of sparse responses of each item. In one category with sparse responses, the initial percentages of 30%, 40%, 28%, and 2% were consolidated into 30%, 40%, and 30%. For two categories exhibiting sparse responses, the original distribution of 46%, 50%, 2%, and 2% was merged into 46% and 54% to eliminate sparseness. When three categories had sparse responses, the initial percentages of 94%, 2%, 2%, and 2% were combined into 94% and 6%. After sparse data were generated, sparse responses were recoded to generate collapsed data.
In sum, the simulation design included the following manipulated conditions: model specification (three levels), factor loadings (two levels), sample size (two levels), number of items with sparse responses (three levels), item response distributions (three levels), and data collapsing strategies (two levels), resulting in a total of 216 unique conditions. For each condition, 1,000 replications were conducted.
Data Analysis
First, model convergence rates were computed to show the percentages of completed replications for each simulation condition; percentages above .90 are generally considered acceptable (Gagné & Hancock, 2006; Moshagen & Musch, 2014). We then used multiple model fit indices to evaluate the performance of CFA models across simulation conditions: chi-square, RMSEA, CFI, TLI and SRMR. For chi-square statistics, when the model is correctly specified, researchers intend to control the Type I error rate (i.e., inappropriate rejection) at the nominal alpha level (i.e., .05). Conversely, when the model is misspecified, researchers expect it to be correctly rejected, reflecting statistical power. Statistical power is conventionally expected to reach the established threshold of .80 (Cohen, 1988).
For other fit indices, we referred to the following criteria: CFI ≥ .90, TLI ≥ .90, SRMR ≤ .10, and RMSEA ≤ .08 were considered to indicate adequate model fit; CFI ≥ .95, TLI ≥ .95, SRMR ≤ .08, and RMSEA ≤ .05 were considered to indicate good model fit (Hu & Bentler, 1999). In each replication of one condition, a model could be rejected or retained based on the comparison between the estimate and the cut-off value. Accumulating the model fit results across 1000 repetitions, model rejection rates were calculated based on the defined cut-off value for each condition. It was expected to retain the model when the model is misspecified at the level of .05, while we expect to reject the model when the model is correctly identified (80% or higher) in the long term. In each replication, model fit values were saved and then summarized across replications to indicate the fit stability using the mean and standard deviation.
Empirical Illustration
Scale
The revised version of the Ethics Position Questionnaire (EPQ-5; O’Boyle & Forsyth, 2021) is a shortened 10-item form of Forsyth’s (1980) original 20-item EPQ. Respondents rated their agreement with each statement on a five-point Likert-type scale: strongly agree, somewhat agree, neutral, somewhat disagree, and strongly disagree (5 to 1). The EPQ-5 consists of two subscales—Idealism (Items 1–5) and Relativism (Items 6–10; Table 1). Idealism measures concern for minimizing harm and maximizing benefits, while Relativism represents a focus on ethical flexibility and rejection of absolute moral principles. Higher Idealism scores indicate stricter ethical judgments, and higher Relativism scores indicate less adherence to universal moral rules. O’Boyle and Forsyth (2021) confirmed the two-factor structure, established measurement invariance across gender groups, and showed evidence of predictive and convergent validity through associations with related constructs.
Frequency Table of the Ethics Position Scale Items.
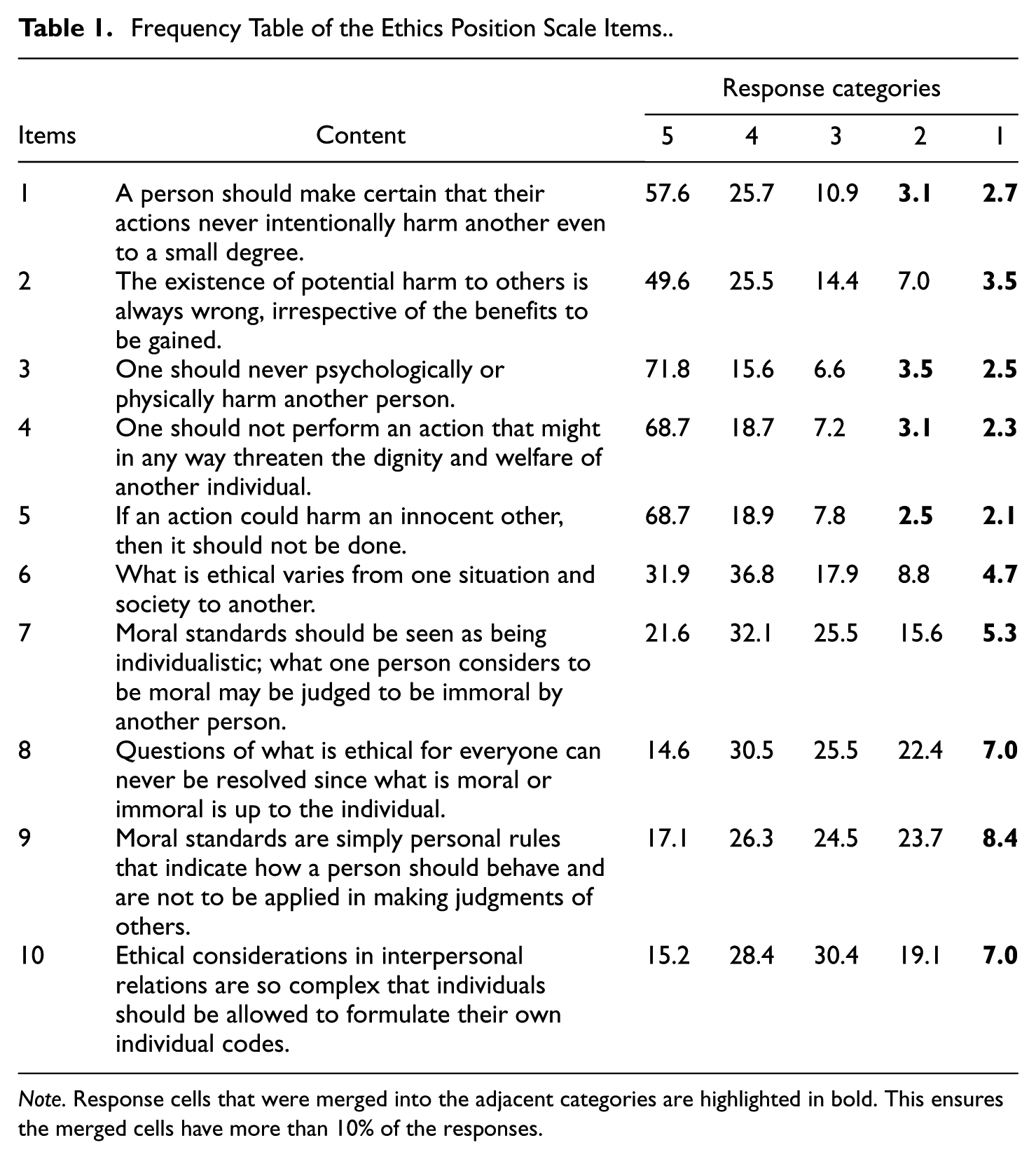
Note. Response cells that were merged into the adjacent categories are highlighted in bold. This ensures the merged cells have more than 10% of the responses.
Data Collection/Sample
Participants included students from diverse program areas and grade levels at an R1 university. Recruitment occurred through instructors of selected courses and via school email invitations or QR codes in the academic year of 2023 to 2024. The EPQ-5 was included as part of a larger survey study. A total of 514 students completed the survey, with 77.4% (n = 398) being undergraduates and 22.6% (n = 116) graduate students. Most participants were aged 18–24 (n = 431, 83.9%). The sample comprised 310 females (60.3%), 194 males (37.7%), and 10 respondents identifying as another gender (1.9%). In terms of race/ethnicity, 358 participants (69.6%) identified as White (non-Hispanic), 54 as African American (10.5%), 42 as Asian (8.2%), 32 as Hispanic (6.2%), and 28 as other races (5.4%).
Data manipulation
There was no missing data. Most sparse cells (<10%) occurred in Response Options 1 and 2, indicating the small chance of selecting disagree-related categories. We merged these cells with the next adjacent category/categories to mitigate sparse levels. The goal was to obtain a collapsed data file with all cells that were higher than 10%. For instance, Categories 1 and 2 were merged into Category 3 in Item 1. Consequently, two data sets were included—one before and one after collapsing—for comparative analysis following the same evaluation criteria described in the simulation phase. Finally, given that the theoretical framework of the scale was well-established in prior literature (O’Boyle & Forsyth, 2021), the two-factor model was treated as the correctly specified model. A minor misspecification was also introduced by loading Item 6 from Relativism to Idealism.
Results
Convergence Rates
Overall, convergence rates were high across the set of cells in the study design; low convergence rates were observed under certain conditions (e.g., sample size of 250, low loadings, and four items with sparse responses in three categories), indicating that results in these scenarios should be interpreted cautiously (Table 2). Notably, sparsity persisted even after collapsing when four items contained sparse responses. Collapsing sparse ordinal data significantly improved convergence rates in these conditions. For example, when the sample size was 250, factor loadings were moderate, and three response categories contained sparse data across four items, the convergence rate increased from .308 to .992 when the data were collapsed. Collapsing sparse data also increased convergence rates when the models were misspecified. In other words, collapsing sparse data may raise the likelihood of identifying an incorrect model.
Convergence Rates.
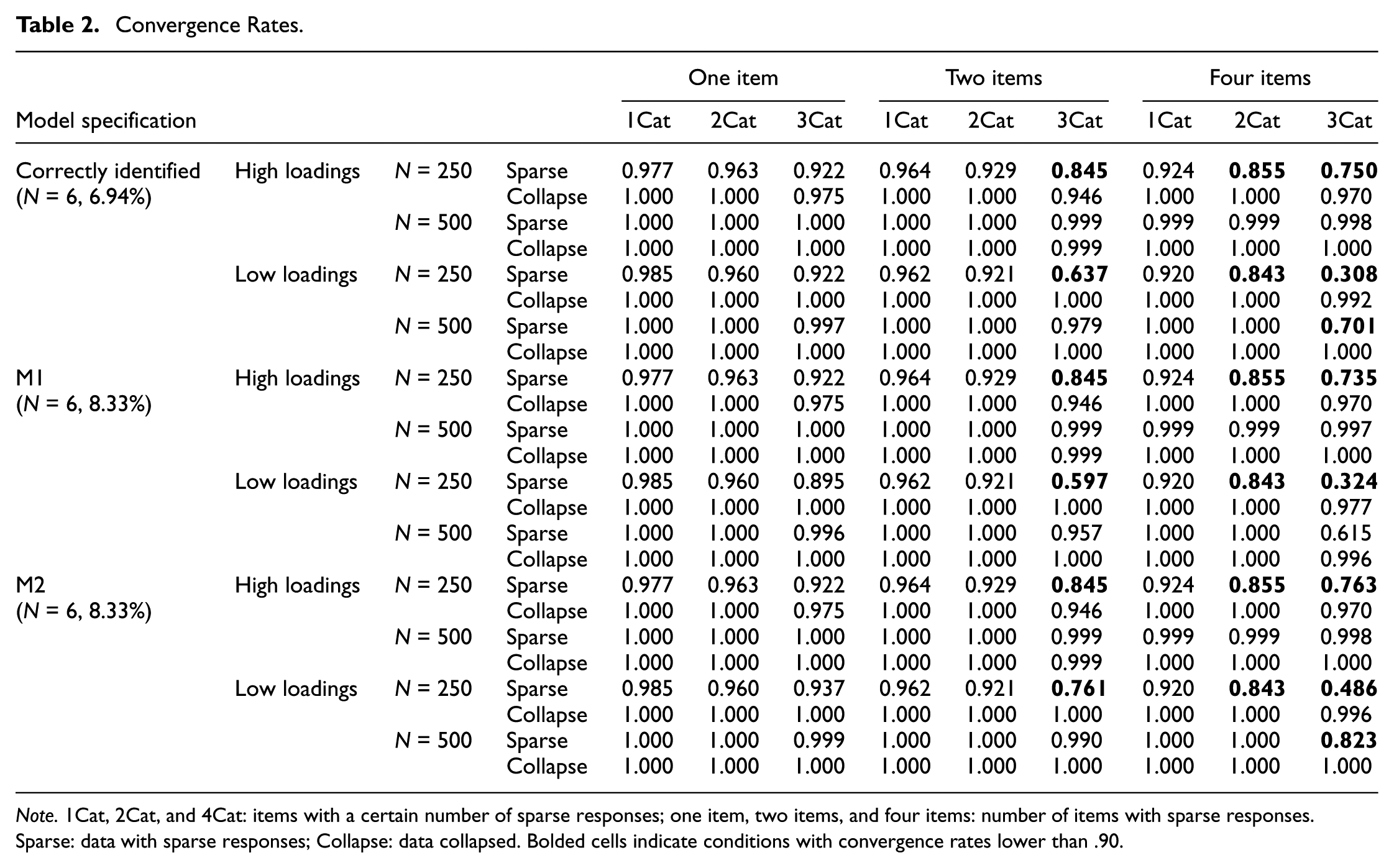
Note. 1Cat, 2Cat, and 4Cat: items with a certain number of sparse responses; one item, two items, and four items: number of items with sparse responses. Sparse: data with sparse responses; Collapse: data collapsed. Bolded cells indicate conditions with convergence rates lower than .90.
Model Rejection Rates
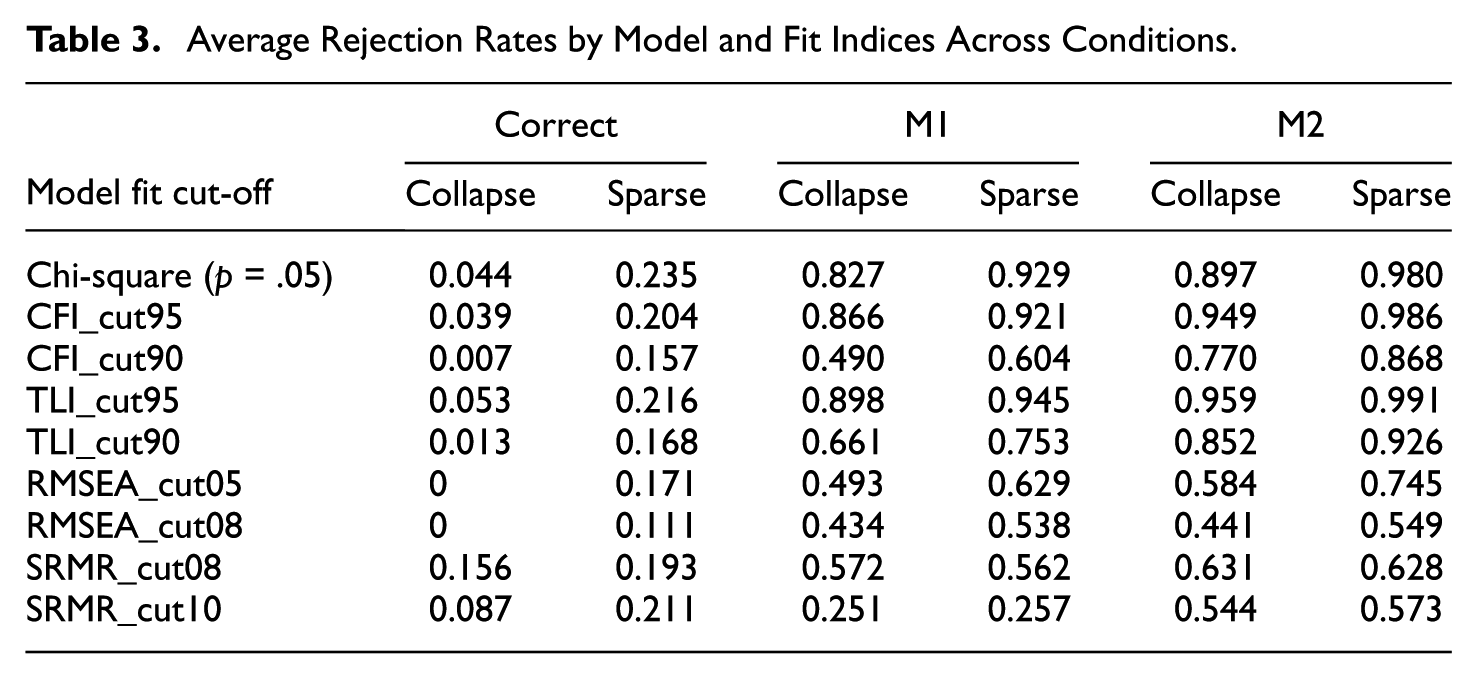
In the following sections, we summarized results for the fit indices of interest. To describe the patterns, we calculated the average model rejection rates by fit indices for each model (Table 3). Overall, average rejection rates were below .05 under the correctly specified model for collapsed responses, indicating that Type I error was generally controlled after collapsing. As expected, average rejection rates increased sharply under M1 (mild misspecification) and M2 (severe misspecification), with the highest rates observed for M2, especially with sparse responses. Sparse responses consistently yielded higher rejection rates than collapsed responses. Among the indices, CFI (.95), TLI (.95), and chi-square showed the strong ability to detect misspecification, while RMSEA (.05/.08) and SRMR (.08/.10) were more conservative, with lower rejection rates.
Average Rejection Rates by Model and Fit Indices Across Conditions.
Then, we presented line graphs of model rejection rates under simulation conditions. We organized the results by the model specification type (Figures 2–4). In each figure, 72 model rejection rates were plotted (factor loadings * 2, sample size * 2, number of items with sparse responses * 3, item response distributions * 3, and data collapsing strategies * 2). The number of inflated model rejection rates was reported under each subfigure. Finally, the stability of fit indices was estimated using the boxplots. Full results across conditions and fit distribution are available in the Supplemental Materials.
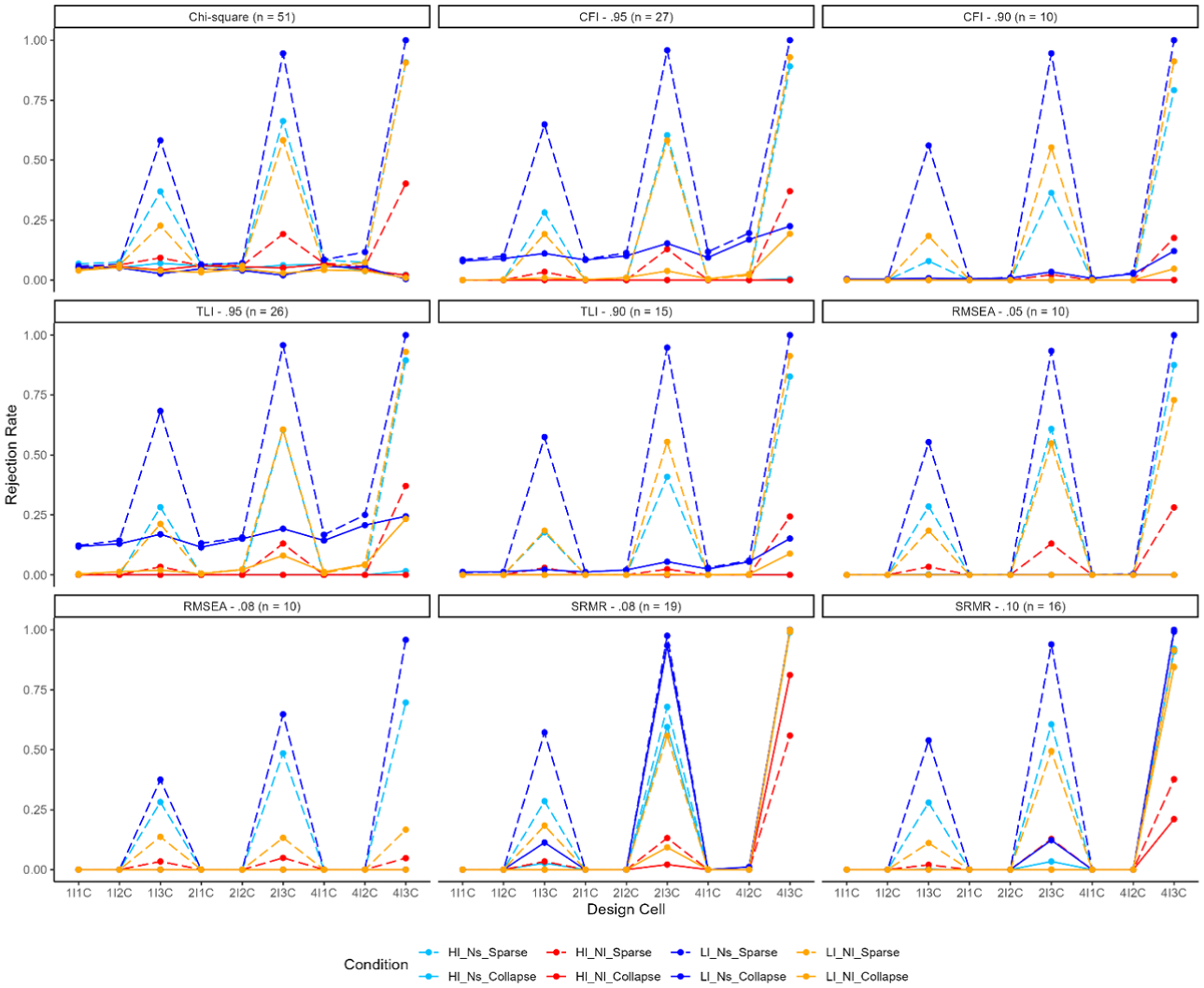
Model Rejection Rates Under Correctly Identified Models.
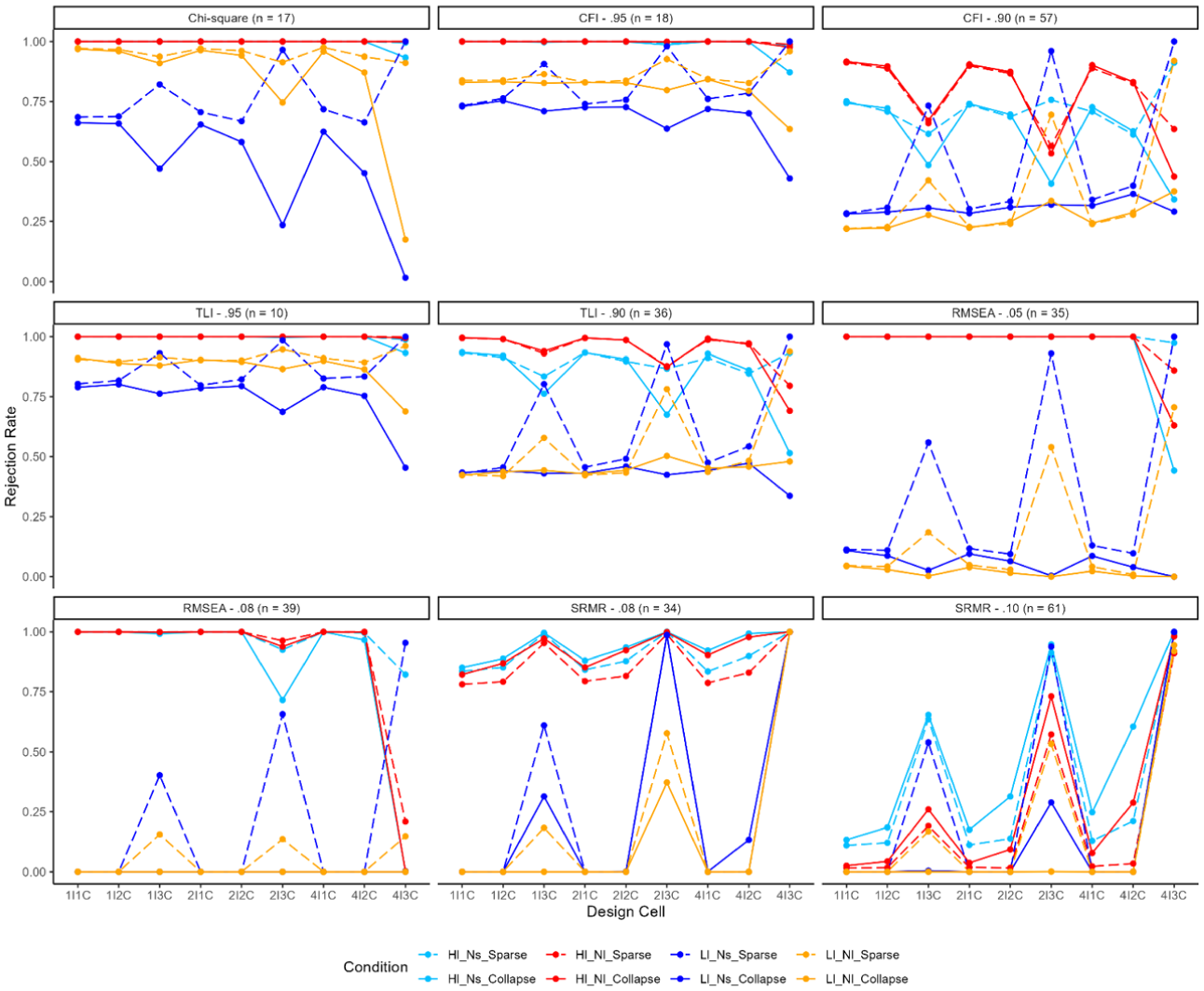
Model Rejection Rates Under Misspecified Model 1.
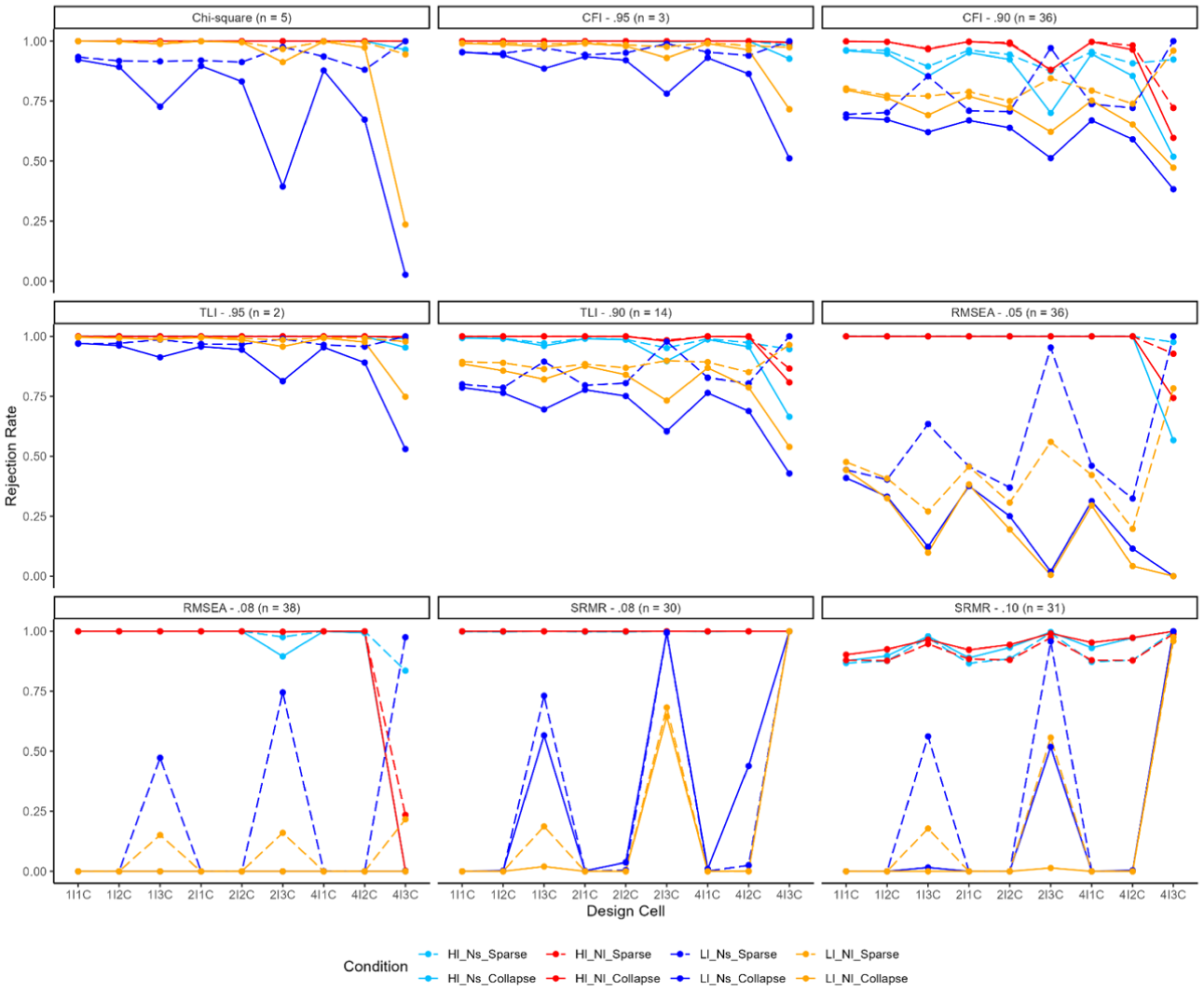
Model Rejection Rates Under Misspecified Model 2.
Model Rejection Under the Correctly Specified Model
Model rejections were examined for the correctly specified model (Figure 2). Collapsing data (solid lines) generally reduced model rejection rates while holding other conditions constant. Due to the varying patterns observed across different fit indices, the results were discussed separately. Inflated model rejection rates above .05 were commonly observed in conditions with sparse responses for chi-square statistics (51 out of 72 conditions). The number of response categories with sparse responses had a greater impact on model rejection rates than the number of items with sparse data. Low factor loadings and small sample sizes were linked with inflated model rejection rates. Collapsing responses effectively controlled model rejection rates (i.e., Type I error) under these conditions (average rejection rates from .235 to .044).
For CFI, the inflated model rejection rates were observed in 10 cells when the cut-off value was .90 and 27 cells when the cut-off value was .95 under all 72 conditions. Similar patterns were observed for TLI. When using a cut-off value of .95, 26 out of 72 cells demonstrated inflated model rejection rates, particularly in cases with low-factor loadings and a sample size of 250. In addition, 15 out of 72 cells exhibited model rejection rates exceeding .05, mainly under conditions with three sparse categories for a cut-off value of .90. Collapsing responses resulted in model rejection rates below .05 in most conditions when using the two cut-off values for both TLI and CFI, except for conditions with a small sample size of 250, low factor loadings of .5, and a cut-off value of .95. This aligned the average model rejection rates for both indices.
Finally, inflated model rejection rates existed in conditions with three sparse categories, and patterns were similar between the two cut-off values for RMSEA (10 out of 72 cells). Collapsing responses effectively controlled the model rejection rates to 0, and varying the cut-off values did not significantly impact the model rejection rates. Similarly, for SRMR, inflated model rejection rates occurred when there were three response categories with sparse responses under both cut-off values (N = 19 or 16). However, when combined with four items exhibiting sparse responses, SRMR displayed extremely high model rejection rates, and collapsing responses failed to mitigate the issue (Figure 2). Across all fit indices, conditions with high-factor loadings and small sample sizes yielded the highest model rejection rates at all levels of sparsity.
Model Rejection Under the Mild Misspecified Model (M1)
When models are misspecified, higher model rejection rates are desirable, as it reflects the fit indices’ effectiveness in identifying and rejecting poorly fitting models. Model rejection rates under the mild misspecified model (i.e., one item misloading on a different factor) were plotted in Figure 3, and the number of low model rejections below .80 was noted above each subfigure. First, low model rejection rates (<.80) were observed in approximately 10 to 20 out of 72 conditions (e.g., sample size of 250, low-factor loadings) for chi-square statistics, CFI (.95), and TLI (.95). When the cut-off value was .90, similar variations were observed for CFI and TLI. Low model rejection rates were more prevalent with a lower cut-off value. For instance, model rejection rates of CFI were low in most conditions (57 out of 72) with low loadings and/or low sample size (i.e., 250).
RMSEA and SRMR exhibited unique patterns compared to other fit indices. For RMSEA, low loadings had a major influence on model rejection rates across all conditions, and approximately half of the conditions displayed low model rejection rates under both cut-off values (35 or 39 out of 72 cells). SRMR was good at rejecting the model when the sparse levels were extremely high (i.e., four items and three responses) before and after collapsing, while SRMR cannot appropriately reject the model (i.e., low model rejection rates) in most other conditions, especially with a cut-off value of .10 (61 out of 72 cells).
Unfortunately, collapsing responses further lowered model rejection rates under certain conditions (Figure 3). For example, the rejection rate for RMSEA (cut-off = .05) decreased from .859 to .630 when the sample size was 500, factor loadings were .80, and four items with three sparse categories per factor were present. Similar patterns were observed for other fit indices. These results suggest that collapsing responses were not recommended, and that TLI was the most optimal index for maintaining acceptable model rejection rates (Figure 3).
Model Rejection Under the Severe Misspecified Model (M2)
Two factors were collapsed into one factor (Figure 1) in the severely specified model. Model rejection rates are presented in Figure 4, with the number of low model rejection rates (less than 0.80) noted below each subfigure. Collapsing responses reduced model rejection rates under these conditions. Model rejection was with minimal concern for chi-square statistics, CFI (.95), and TLI (.95) with frequencies ranging from 2 to 5. These fit indices can correctly reject the inappropriate model as long as no collapsing occurred. When the cut-off value was reduced to .90 for CFI, model rejection rates were significantly impacted by low factor loadings. In contrast, TLI performed better, maintaining model rejections within a reasonable range as long as responses were not collapsed. The results were aligned with the average model rejection rates (Table 3).
For RMSEA, low factor loadings had a substantial impact on model rejection across all conditions, with approximately half of the conditions showing low model rejection rates under both cut-off values (36 or 38 out of 72 cells). Similar patterns were observed for SRMR, except in conditions with severe sparse responses, where SRMR demonstrated high model rejection rates. While collapsing responses tended to reduce model rejection rates, the overall conclusion regarding high or low model rejection rates based on the cut-off value remained the same in most conditions.
Overall, collapsing responses reduced model rejection rates consistently, suggesting that it may lead to a higher likelihood of model acceptance under severely sparse conditions. The difference before and after collapsing was large in a few conditions with three categories of sparse responses (e.g., mild misspecified model, CFI: 90, sample size: 250, high loadings: .8, four items with sparse responses in three categories).
Stability of Fit Indices
The supplemental materials display the boxplots of CFI, TLI, RMSEA, and SRMR across all conditions. Overall, the estimates were stable, except for the conditions involving three categories with sparse responses. Collapsing responses led to an increase in RMSEA and SRMR and a decrease in CFI and TLI, increasing the stability of all four fit indices in such conditions. In addition, the correctly specified model produced more stable estimates compared to the misspecified models. Low factor loadings also contributed to decreased stability in TLI and CFI estimates.
Empirical Findings
Consistent with the simulation findings, when sparse responses were limited to a large number of items and a small number of categories (e.g., four items with one sparse response category), model decision (i.e., to retain or reject) was largely unaffected by data collapsing with minor variations (Table 4). However, model fit indices tended to improve under both correctly specified and misspecified models, aligning with the simulation results. In other words, data collapsing made it somewhat more likely for a model to be retained. For example, the CFI increased from .860 to .899, suggesting improved model fit following category collapsing. Finally, SRMR under the correctly specified model did not follow the same pattern as other fit indices, although the discrepancy was small (< .05).
Model Fit Indices of the Empirical Example.
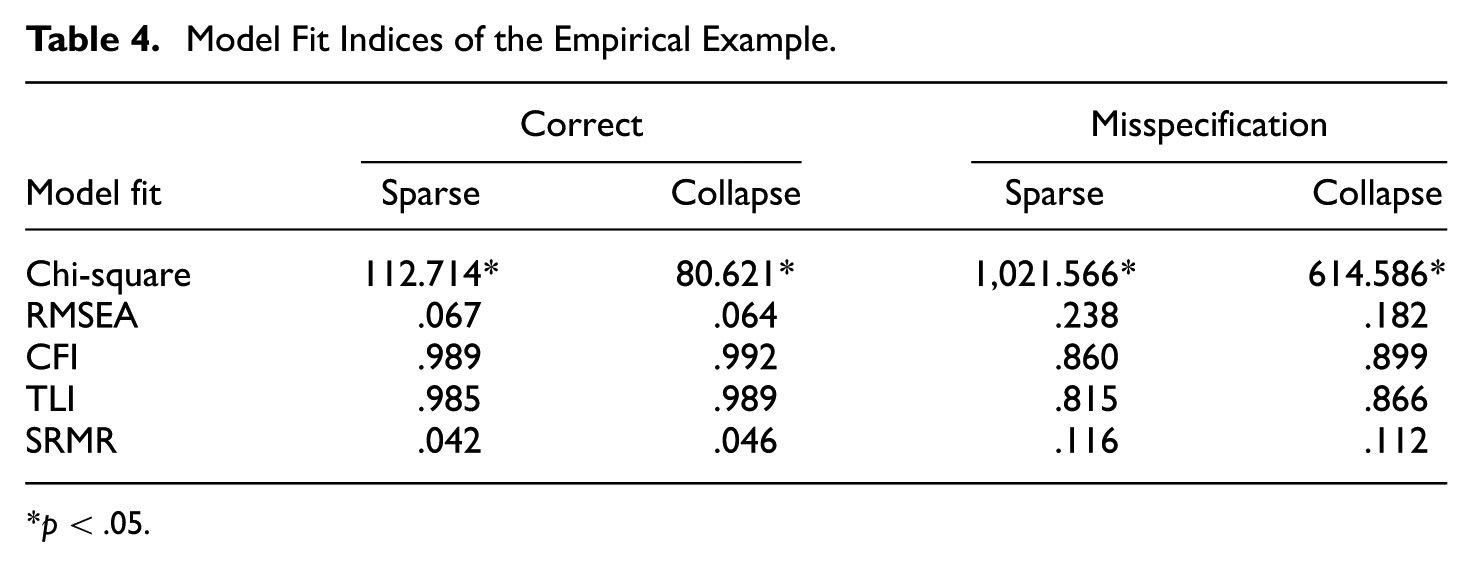
p < .05.
Discussion
The current study investigated the impact of infrequent collapsing to sparse ordinal data in CFA. Few prior studies have explored this issue, particularly under conditions involving model misspecification and its effect on rejection rates across various model fit indices. Data were simulated to vary sample size, factor loadings, sparseness levels, and model specification. In general, collapsing responses reduced the stability of fit estimates and model rejection rates when the variation was obvious in severely sparse conditions. Therefore, applied researchers must carefully weigh the benefits and risks of collapsing in practice.
First, the number of items exhibiting sparseness and item distribution of sparse items matter when considering collapsing responses for a scale (DiStefano et al., 2021). When there were one or two items with sparse responses on a factor and one or two sparse categories on these items, CFA models yielded relatively high convergence rates, decent model rejection rates, and stable fit indices. Importantly, the number of sparse categories had a greater influence on the model performance than the number of items exhibiting sparsity. One explanation is that sparseness was not fully recovered even after collapsing when there were sparse responses in three categories (from 94%, 2%, 2%, and 2% to 94% and 6%). In these conditions, item skewness (i.e., non-normality) causes inflated Type I error rates and low statistical power. In the current study, such problems were more pronounced when the sample size was small (i.e., 250) and factor loadings were low (i.e., .50). In those conditions, collapsing responses had obvious effects on various model fit indices.
In general, collapsing responses highlighted the improvement in convergence rates and Type I error rates under the correctly specified model (DiStefano et al., 2021), thereby mitigating issues caused by sparse data. Chi-square statistics were sensitive to sample sizes, with inflated model rejection rates (i.e., Type I error rates) above .05 in many cells (N = 51 out of 72). This sensitivity means that, particularly in large samples, even minor discrepancies between the observed data and the model can result in significant chi-square values, causing researchers to inappropriately reject correctly specified models (Alavi et al., 2020; Li, 2016). Consequently, applied researchers often encounter significant chi-square results and may choose to focus on alternative fit indices when selecting the optimal model.
RMSEA demonstrated the best performance in controlling model rejections for the correctly identified model, and collapsing responses completely resolved the concern of inflated model rejection rates. While CFI and TLI exhibited inflated model rejection rates in certain conditions, the conditions were mostly relieved by collapsing responses. However, with a stringent cut-off value of .95, low factor loadings, and a sample size of 250, all relevant conditions had inflated model rejection rates even after collapsing. Finally, model rejection rates of SRMR were out of control when the sparse levels were high, aligning with the conclusion that the accuracy of SRMR in controlling model rejection rates can be compromised in the presence of non-normal data (Pavlov et al., 2021). While collapsing responses reduced model rejection rates, conditions with four sparse items in three response categories had extremely high model rejection rates indicating that researchers are likely to reject the correctly identified model for SRMR.
Meanwhile, the simulation findings also highlighted the trade-off of increased risk in investigating misspecified models. Collapsing response uniformly reduced model rejections. Comparing two model misspecifications, the fit indices demonstrated lower model rejection rates overall when the model was mildly misspecified with one item misloaded on a different factor. This aligns with prior studies concluding different abilities to identify different levels of misspecification in CFA (e.g., DiStefano et al., 2018). In other words, it was relatively difficult to reject inappropriate models when they were a minor misspecification (McIntosh, 2012). Overall, chi-square, CFI, and TLI were superior to addressing model rejections under misspecified models than RMSEA and SRMR; a cut-off value of .95 was recommended for CFI and TLI as the threshold to filter out most under-factored models (Clark & Bowles, 2018) without collapsing responses.
RMSEA showed low model rejection rates with about half of the conditions due to low factor loadings. This is consistent with findings that the recovery of low factor loadings is poor in misspecified models (Ximénez, 2006) and that RMSEA is less sensitive to different types of model misspecification (Savalei, 2012). In contrast to its poor performance in controlling model rejection rates in the correctly identified model, SRMR effectively rejected incorrect models in severely sparse conditions. However, SRMR is not recommended for use in other conditions. For instance, under mildly misspecified models, SRMR exhibited low model rejection rates in 61 out of 72 cells. Moreover, based on the cut-off value of .8, the model rejection decision did not vary significantly before and after collapsing for both RMSEA and SRMR indicating the low sensitivity in data collapsing.
Examining the two sets of cut-off values results revealed that CFI and TLI were sensitive to the chosen cut-off values in response to data collapsing. A stringent cut-off of .95 led to elevated model rejection rates, which suggests that one fixed cut-off value may not be enough in practice (Groskurth et al., 2024). In contrast, RMSEA was not influenced by the cut-off values, yielding consistent conclusions regardless of the threshold. SRMR showed only a mild sensitivity to cut-off values under the mildly misspecified model, where a stringent cut-off of .08 was associated with increased model rejection rates.
Recommendations for Researchers
In the scale design phase, researchers should anticipate potential sparse response patterns and consider the need for collapsing responses. A preliminary step is to compute frequencies of each item on a scale to investigate potential sparse responses in pilot studies. While there are no definitive guidelines for applied researchers to select the best model fit, collapsing sparse responses offers potential benefits but involves trade-offs that must be carefully evaluated. While it is well-known that researchers should be cautious about rejecting a correctly specified model based on chi-square statistics (Alavi et al., 2020) in larger samples, chi-square statistics remain valuable for model selection, particularly in rejecting severely misspecified models under most conditions.
Recent studies have emphasized the importance of reporting chi-square statistics alongside other fit indices to provide a comprehensive assessment of model performance (Zheng & Bentler, 2024). However, it is common to have disagreement among fit indices due to their variations in theories (Lai & Green, 2016); thus, it is necessary to refer to different indices for different occasions. Based on our study findings, we recommend the use of RMSEA to address model rejections under the correctly identified model, while TLI with a cut-off value of .95 is suggested to address model rejections under the misspecified models. When high levels of sparsity exist, with many items having sparse responses across most categories, SRMR can be a useful indicator for identifying inappropriate models.
The empirical results were aligned with the simulation results in the current study and prior literature (DiStefano et al., 2021). In general, if the number of sparse response categories is low, maintaining the original categorical structure may be preferable, since model conclusions are unlikely to change due to collapsing. In addition to model fit differences before and after collapsing, such changes can alter the underlying meaning of response options. Such modifications to the scale format may affect how scores are interpreted, making results from different versions of the scale not directly comparable (Cabooter et al., 2016). Researchers applying category collapsing during data cleaning should avoid comparison of different versions of the same scale with different response structures unless measurement invariance has been established.
Limitations and Future Research Directions
First, the simulation conditions tested in the current study were predetermined based on researchers’ judgments, and we recognized that the findings were not generalizable to other conditions that were not tested here. Future studies could expand upon this work by incorporating additional simulation conditions to examine whether similar conclusions are reached. For instance, the current study employed four response categories; however, prior research has shown that the RMSEA is sensitive to the number of response categories (Monroe & Cai, 2015), suggesting that this factor could be varied in future studies. The current study focuses on two types of misspecified models, leaving other conditions, such as over-factored models (Clark & Bowles, 2018), to be explored. In addition, the current study only investigated a limited approach to item-level sparseness. Future research should consider more comprehensive frameworks for defining sparseness, including the location of sparseness within the scale and the distributional characteristics across items (Rutkowski et al., 2019; Tsai et al., 2024).
Model estimation methods could impact the performance of model fit (DiStefano et al., 2021; Shi et al., 2019). Modeling with different estimation methods can provide complementary information for researchers. Thus, this can be addressed in future studies. The popularity of treating Likert-type scale data as continuous variables is common in practice. Future research should consider incorporating ML-based methods. Our study did not explore the usage of more advanced estimation methods, such as Bayesian estimation, which have been shown to perform well under conditions of sparse categorical data structures (e.g., Bainter, 2017; Liang & Yang, 2014). The techniques employed in this study were intentionally selected with applied researchers in mind, recognizing that practitioners may face challenges in navigating the complexities of advanced methods, such as determining appropriate prior probabilities for Bayesian analyses (DiStefano et al., 2021). Future simulation studies could benefit from incorporating such methods.
In addition, while this study focused on a typical factor model, other CFA models, such as higher-order factor models and bifactor models, are also widely used in applied research (Morgan et al., 2015). Their performance under data conditions remains unclear. Future research should investigate the performance related to data sparsity to extend the findings in the current study.
Traditional cut-off scores were utilized to evaluate model rejection rates across simulation conditions. While this is a well-accepted practice, we admitted the limitations of overgeneralizing cut-off scores, especially for ordinal data (Monroe & Cai, 2015). Future research could integrate the Direct Discrepancy Dynamic (DDD) Fit Index framework (McNeish & Wolf, 2024) to complement traditional fixed cut-offs when evaluating model performance under sparse data conditions. In short, the DDD approach generates fit thresholds empirically for each model and dataset, which could provide more accurate evaluations of model rejection.
Finally, missing data is a common issue in research (Mirzaei et al., 2022) and often complicates scale analysis. When combined with sparse data, these challenges can become even more difficult to manage. While the current study solely focused on sparse data, future research could address both issues simultaneously to better understand their combined impact on model performance, which will provide practical guidance for researchers handling complex data situations (Jeong & Lee, 2016).
In summary, this study underscores the impact of collapsing sparse response categories in Likert-type scale data on the model fit of CFA. The findings highlight that such data collapsing can reduce model rejections in both correctly specified and misspecified models, with varying responses observed across different fit indices. These insights provide valuable guidance for researchers navigating issues relevant to sparse data.
Supplemental Material
sj-docx-1-epm-10.1177_00131644251401097 – Supplemental material for Collapsing Sparse Responses in Likert-Type Scale Data: Advantages and Disadvantages for Model Fit in CFA
Supplemental material, sj-docx-1-epm-10.1177_00131644251401097 for Collapsing Sparse Responses in Likert-Type Scale Data: Advantages and Disadvantages for Model Fit in CFA by Jin Liu, Yu Bao, Christine DiStefano and Wei Jiang in Educational and Psychological Measurement
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.