
Abstract
Confirmatory factor analyses (CFA) are often used in psychological research when developing measurement models for psychological constructs. Evaluating CFA model fit can be quite challenging, as tests for exact model fit may focus on negligible deviances, while fit indices cannot be interpreted absolutely without specifying thresholds or cutoffs. In this study, we review how model fit in CFA is evaluated in psychological research using fit indices and compare the reported values with established cutoff rules. For this, we collected data on all CFA models in Psychological Assessment from the years 2015 to 2020
Introduction
Developing measurement models for psychological constructs is always challenging. For questionnaire development and test construction, researchers conduct several factor analyses to carve out the latent variables representing a psychological concept (e.g., Fabrigar et al., 1999). Usually, exploratory factor analysis (EFA) is used to explore an item set associated with a construct (or specifically designed to measure a certain psychological variable) and subsequently refine it. After several rounds of EFAs applied to different item sets and samples, researchers come up with a hypothesized factor model that describes how the latent variables are measured by the manifest indicators. These hypothesized factor models that are usually built around an assumption of independent clusters (i.e., that each indicator only measures one latent factor and has no substantial cross-loading on a second factor) can be tested in a confirmatory setting with a confirmatory factor analysis (CFA). CFA evaluates whether an assumed relationship among manifest indicators and latent factors is in line with the empirical data by testing whether the model-implied covariance structure reproduces the empirical covariance matrix (or resembles it very strongly). When conducting a CFA, the researcher specifies the number of latent factors, which manifest indicators are allowed to load on which latent factor (i.e., which loadings are freely estimated and which are constrained to be zero), whether between-factor correlations are allowed and whether there are any correlations among the residuals of the indicators. These specifications are based on empirical findings in previous studies (often based on EFA) as well as theoretical considerations (for a thorough introduction to CFA, see, for example, Brown, 2015). Since previous findings might support different models or contradict theoretical implications, different candidate models have to be compared. Hence, CFA users need to know which models fit their data and which model is the most plausible given their data. While there is a global model
In this study, we review the use of CFA in psychological research with a focus on model selection and the assessment of model fit (particularly the use of model fit indices). In doing so, we also reevaluate the model fit of published studies (where possible) using the Dynamic Fit Index Cutoffs approach by McNeish and Wolf (2021) as well as the ezCutoffs approach (Schmalbach et al., 2019). Based on our findings, we discuss the need for methodological rigor in the model evaluation as well as caveats that hinder the development of measurement models that better fit empirical data.
Fit Indices
A large set of fit indices have been developed to quantify the goodness of fit or the deviance from the perfect model fit. The latter are error-focused measures that quantify the difference between an empirical covariance matrix
The RMSEA (Steiger, 1998) quantifies the error of the approximate fit, that is, it replaces the “exact fit”-null-hypothesis of the global
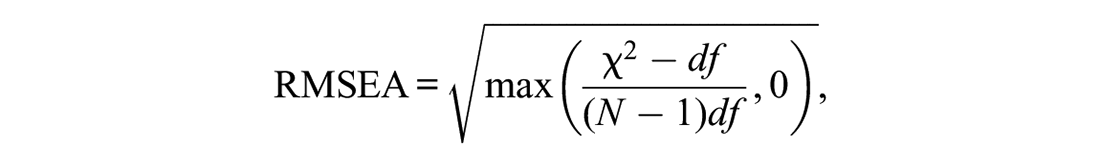
with
The SRMR is also a “badness of fit” measure as it quantifies the averaged squared differences between each bivariate empirical correlation and the respective model-implied counterpart (Hu & Bentler, 1998). Hence, the best possible value is zero indicating a perfect reproduction of the empirical correlation matrix, while higher SRMR values reflect a poorer model fit. By standardizing the residuals using the standard deviations of the respective manifest items the SRMR is scaled (compared with the Root Mean Square Residual [RMSR] index by Jöreskog & Sörbom, 1996) and its maximum possible value is one.
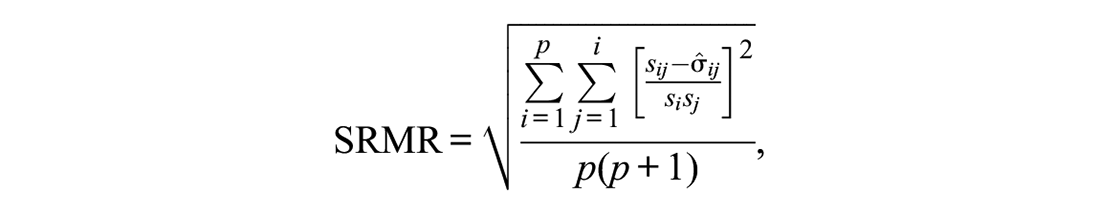
with
Besides these measures of model misfit, goodness-of-fit measures such as the Goodness-of-Fit Index (GFI; Jöreskog & Sörbom, 1984, as cited in Mulaik et al., 1989), the Normed Fit Index (NFI; Bentler & Bonett, 1980), the non-NFI that is also known as the Tucker–Lewis Index (TLI; Tucker & Lewis, 1973), or the Comparitive Fit Index (CFI; Bentler, 1990) exist. For these indices, a model comparison between the proposed model and a baseline model is conducted. The GFI quantifies how much better the proposed model fits the data compared to a null model as a baseline model (i.e., a model that can be described as a “no-factor null model”—it can also be interpreted similar to a coefficient of determination as the proportion of the variance/covariance that can be explained by the model, for more information on this and different versions of the GFI, see Mulaik et al., 1989). A value of one indicates that the proposed model provides the biggest improvement possible over the baseline model and is able to fit the data perfectly, while a value of zero means that the proposed model has no explanatory value.
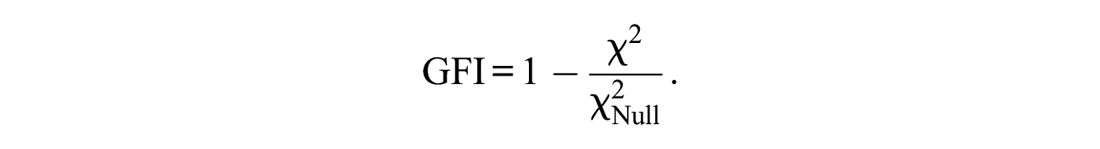
The NFI follows the same idea. Contrary to the GFI, the baseline model used to calculate the NFI is the so-called independence model which assumes the error variance to be zero and no existing associations among the observed variables (i.e., only the variances of the observed variables are estimated, so the independence model is basically a diagonal matrix with all off-diagonal elements—the covariances—being zero). Accordingly, the NFI can be written as
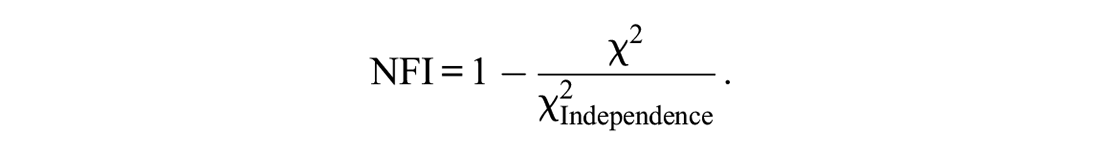
The TLI compares the proposed model to the independence model as well.

Its values normally range from zero to one, but as it is not normed, values outside this range that are less intuitive might occur. A TLI greater than one is possible (i.e., a value of one does not mean a perfect fit, contrary the other goodness of fit measures) and can be interpreted as indicative of a very good model fit.
The CFI also relies on the independence model for comparison. Contrary to the NFI or GFI and comparable to the TLI, the degrees of freedom (i.e., the expected value if the model is correctly specified) are taken into account.
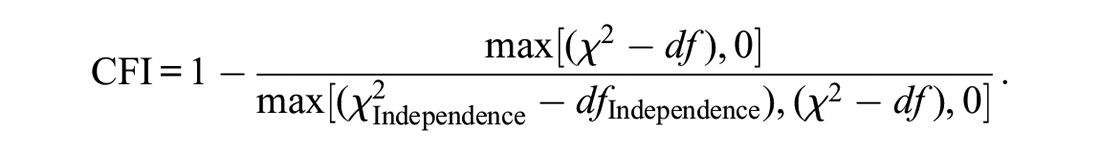
The CFI, just like both GFI and NFI, 2 becomes one if the proposed model fits the data perfectly and zero in a worst-case scenario where it is not superior to the baseline model.
While these and other fit indices are frequently applied to assess the model fit in structural equation modeling (SEM) in general, and in CFA in particular, several studies found them to be dependent on nuisance parameters and the underlying data conditions. Hence, their ability to detect model misspecifications does not only depend on the type of misspecification (e.g., Hu & Bentler, 1998) but also on the sample size (e.g., Ainur et al., 2017; Fan & Wang, 1998), the size of the loading parameters (e.g., Heene et al., 2011), the number of indicators per factor (e.g., Shi et al., 2019) or the overall model complexity (e.g., Marsh et al., 1996), the amount of missing data (e.g., Fitzgerald et al., 2021), and the estimation method (e.g., Fan et al., 1999; Xia & Yang, 2019). Crucially, poorly measured indicators (Heene et al., 2011; McNeish et al., 2018) as well as untreated missing data (Fitzgerald et al., 2021) may disguise model misfit and substantial misspecifications as fit indices show fallaciously good values indicating acceptable model fit.
Another problem that arises with the usage of fit indices is the challenge to determine which values are indicative of an “acceptable,” a “good” or an “excellent” model fit. When comparing candidate models and selecting a final model, relying on different fit indices is less problematic. However, when the absolute fit of a specific candidate model is evaluated, researchers usually look for cutoff values that categorize the goodness of fit. Often simple cutoff rules that are based on simulation studies with very narrow data conditions (e.g., Hu & Bentler, 1999) are used beyond the scope of the study they are derived from. Marsh et al. (2004) describe the dangers of overgeneralizing the results of these simulation studies and call for a more thoughtful handling of suggested cutoffs.
Tailored Cutoffs for Model Evaluation
To both accommodate the desire for categorical decisions, for example, labeling a model’s fit as “good/appropriate” or “bad,” and overcome the limitations of narrow data conditions and model specifications that were considered when developing fixed cutoffs for different fit indices, simulation-based methods were proposed to generate individual cutoffs for specific models and data in real-life applications (Millsap, 2007, 2012; Pornprasertmanit et al., 2013). One implementation of this idea was suggested by McNeish and Wolf (2021). The so-called Dynamic Fit Index Cutoff aims to generalize the methods applied by Hu and Bentler (1999). Their basic algorithm, also implemented in a Shiny web-application, first needs the user to specify the hypothesized CFA model with standardized factor loadings as well as the sample size. This information is then used to create an alternative model by adding an extra path with a non-zero coefficient. This perturbed model is then used as a population model in the data generating process to simulate
A similar approach called ezCutoffs (Schmalbach et al., 2019) was developed to derive tailored cutoff values for fit indices following the procedure of Hu and Bentler (1999). Contrary to the Dynamic Fit Index Cutoffs of McNeish and Wolf (2021), data are simulated for a specified model which is subsequently fitted to this data. Accordingly, ezCutoffs focuses on the distribution of the fit indices of correctly specified models and derives the cutoff values from a specific quantile of this distribution. This approach can be compared with null hypothesis significance testing where the test decision is solely based on the distribution of the test statistic under the null hypothesis. Thus, no area of ambiguity where both misspecified and correctly specified models are deemed appropriate exists for this approach. However, the ezCutoffs approach does not allow researchers to control the type-II error (as the Dynamic Fit Index Cutoffs approach does).
Groskurth et al. (2022) developed a different method to derive individual cutoffs tailored to the application context and empirical data at hand. Other than the two purely simulation-based approaches described earlier, Groskurth et al. (2022), in a first step, repeatedly simulate data using a population model that either correspond to the actual model that should be tested (i.e., treating the hypothesized model as a correctly specified model) or to a slightly altered model that serves as a misspecified analysis model.
4
In a second step, the receiver–operating characteristic (ROC) curves for a set of fit indices are estimated and well-performing fit indices (i.e., indices that reach a certain performance, e.g., an area under the curve
Method
For our review, we scanned the full texts of each publication in Psychological Assessment (PA) from 2015 to 2020 for the term “CFA OR confirmatory factor analysis” via PsycArticles. It was decided for PA due to its special focus on assessment- and scale validation as well as its broad range of studies using CFAs. Our strategy resulted in 456 initial studies, of which
To gain quantitative insight into how psychologists conduct CFA, we extracted and calculated information on model-characteristics, estimation results and compatibility with recommendations for fit evaluation (e.g., Hu & Bentler, 1999). The specific variables collected were: the number of manifest and latent variables, the number of variables per factor, whether correlations between latent variables and/or correlations among residuals were allowed, whether cross-loadings were specified or an independent clusters model was assumed, the median of primary factor loadings, if the same sample was used for preceding exploratory analyses, the sample size, the estimation algorithm, four common fit measures (CFI, RMSEA, SRMR, and TLI), the p value of
We used R (Version 4.2.2; R Core Team, 2021) and the R-packages apaTables (Version 2.0.8; Stanley, 2021), dplyr (Version 1.0.10; Wickham et al., 2021), ggplot2 (Version 3.4.0; Wickham, 2016), papaja (Version 0.1.1; Aust & Barth, 2020), shiny (Chang et al., 2021), and tinylabels (Version 0.2.3; Barth, 2022) for all our analyses and to write the article.
Results
First, we looked at the frequencies of sample size, number of variables per factor, and most common fit indices (i.e., RMSEA, SRMR, CFI, GFI, and TLI) by range for every single model (
Frequencies of Sample Size Ranges for All Models and for the Best Models Per Paper.
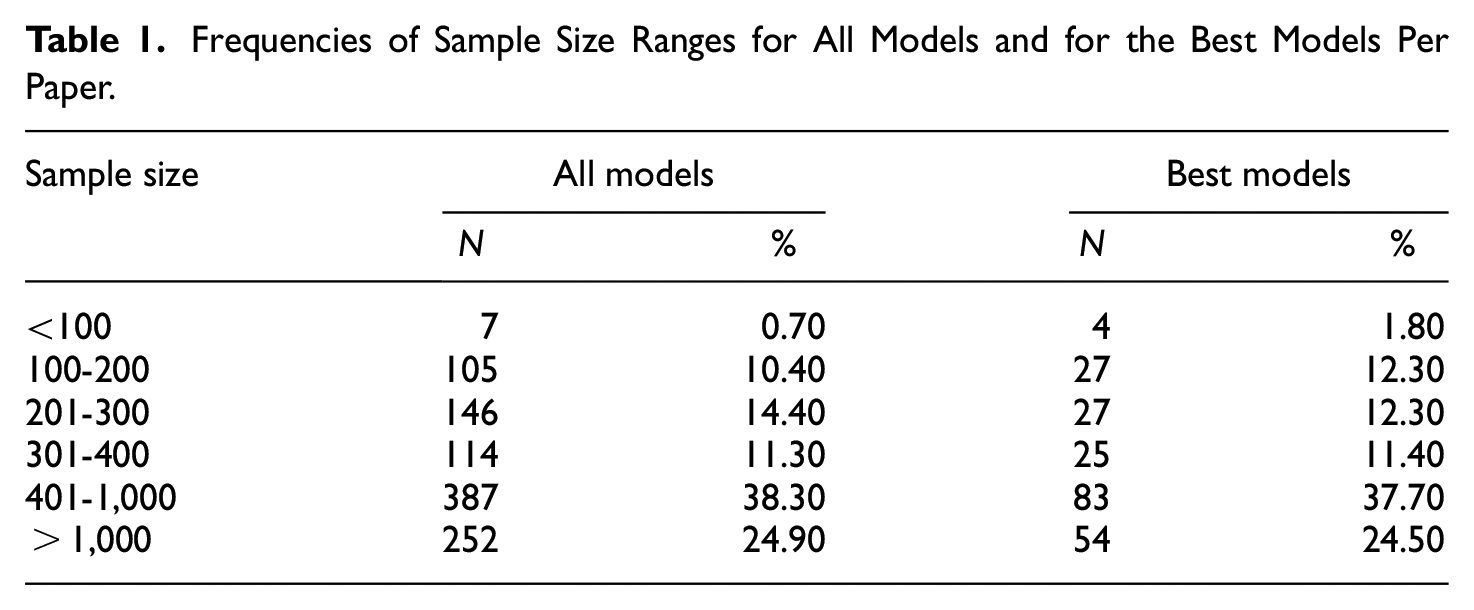
Frequencies of Item to Factor Ratios for All Models and for the Best Models Per Paper.
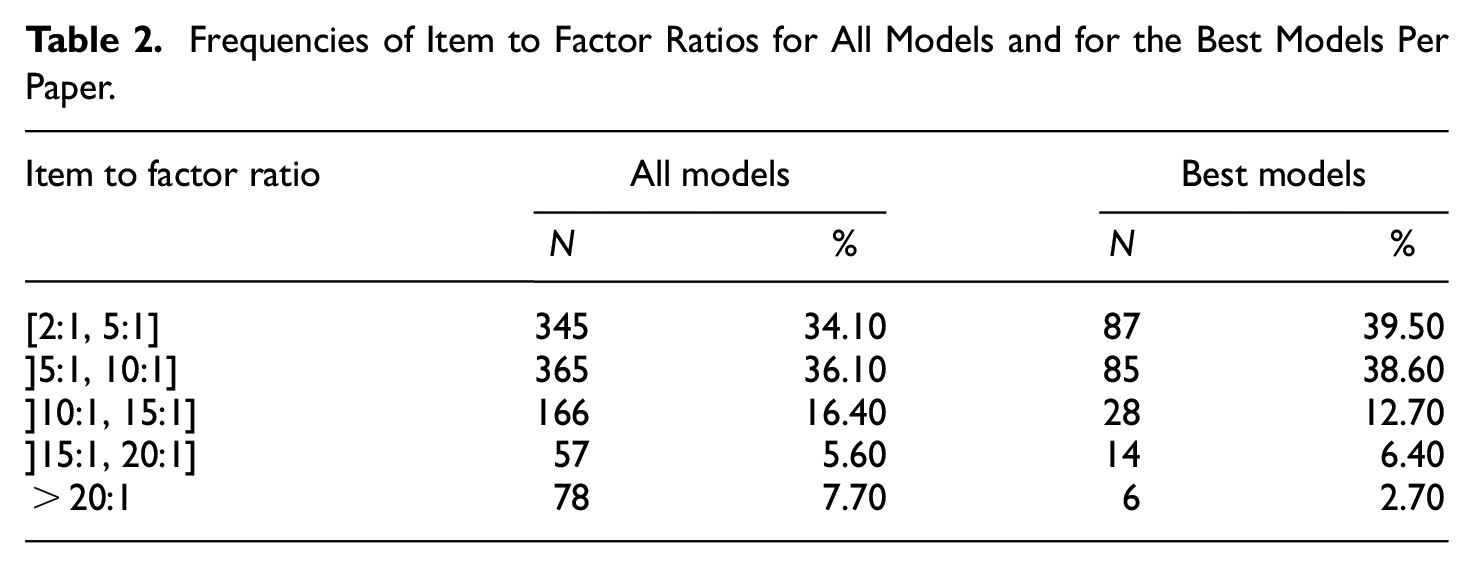
Frequencies of RMSEA Ranges for All Models and for the Best Models Per Paper.
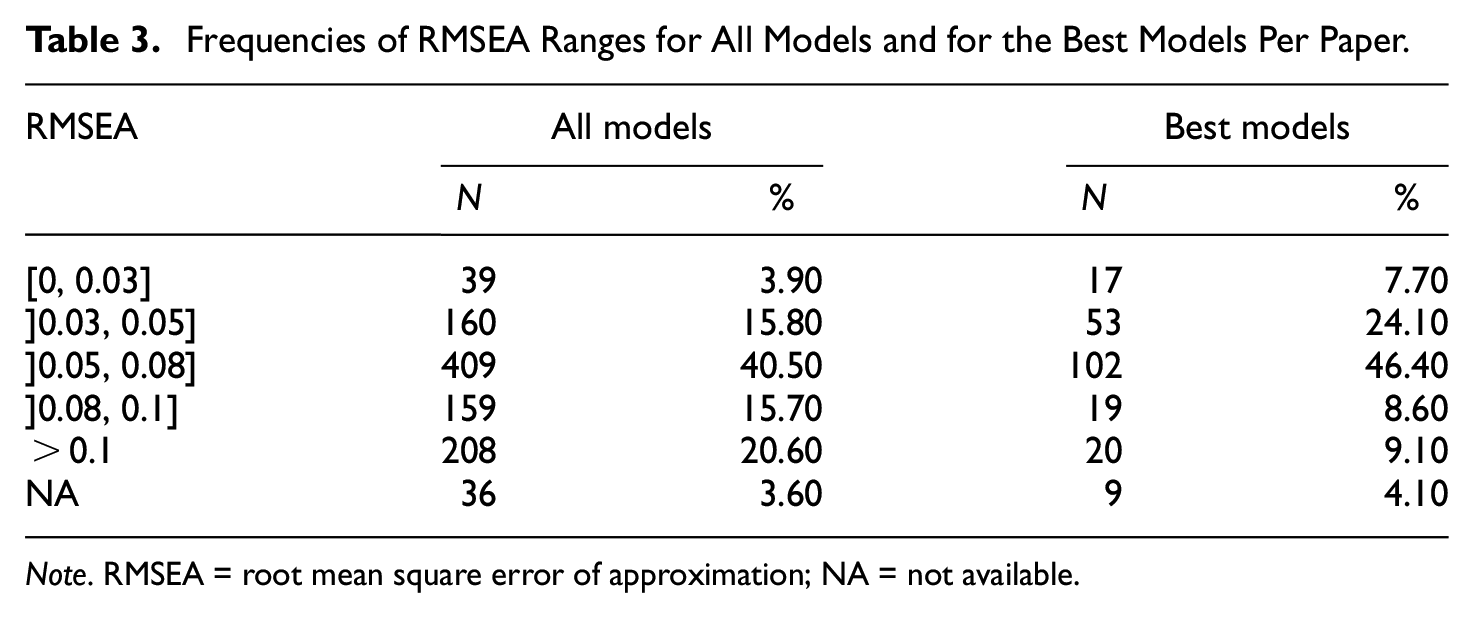
Note. RMSEA = root mean square error of approximation; NA = not available.
Frequencies of SRMR Ranges for All Models and for the Best Models Per Paper.
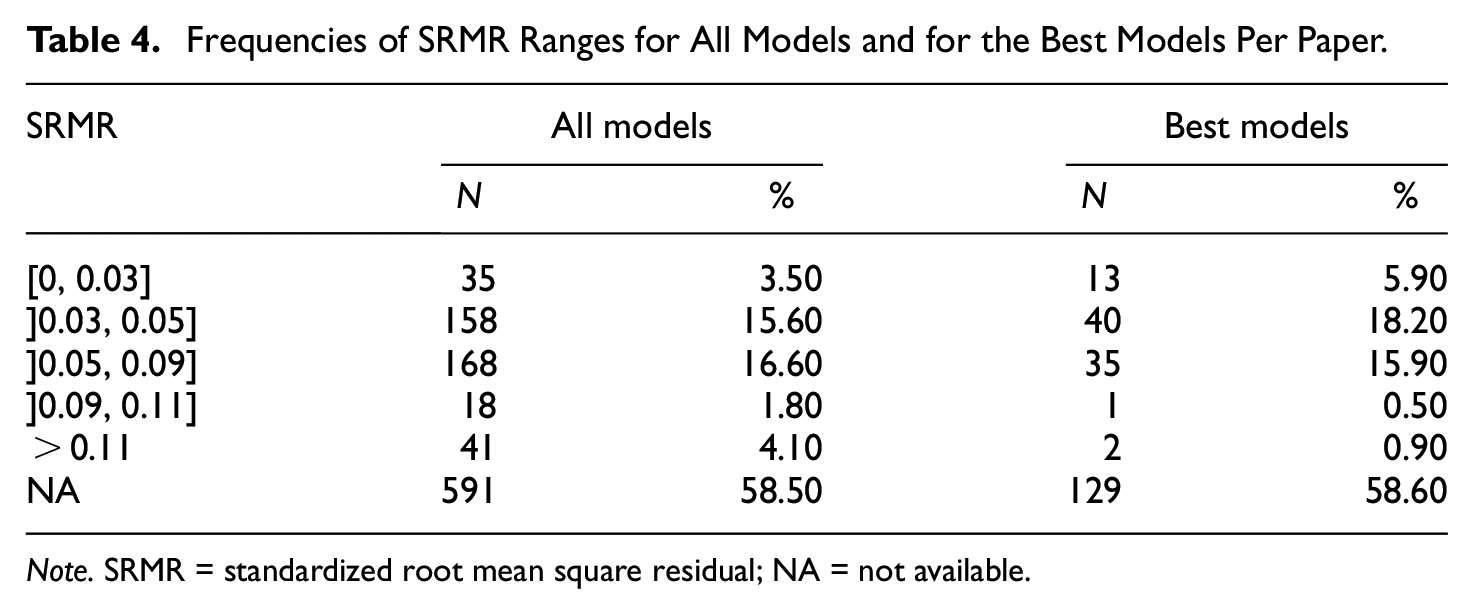
Note. SRMR = standardized root mean square residual; NA = not available.
Frequencies of CFI Ranges for All Models and for the Best Models Per Paper.
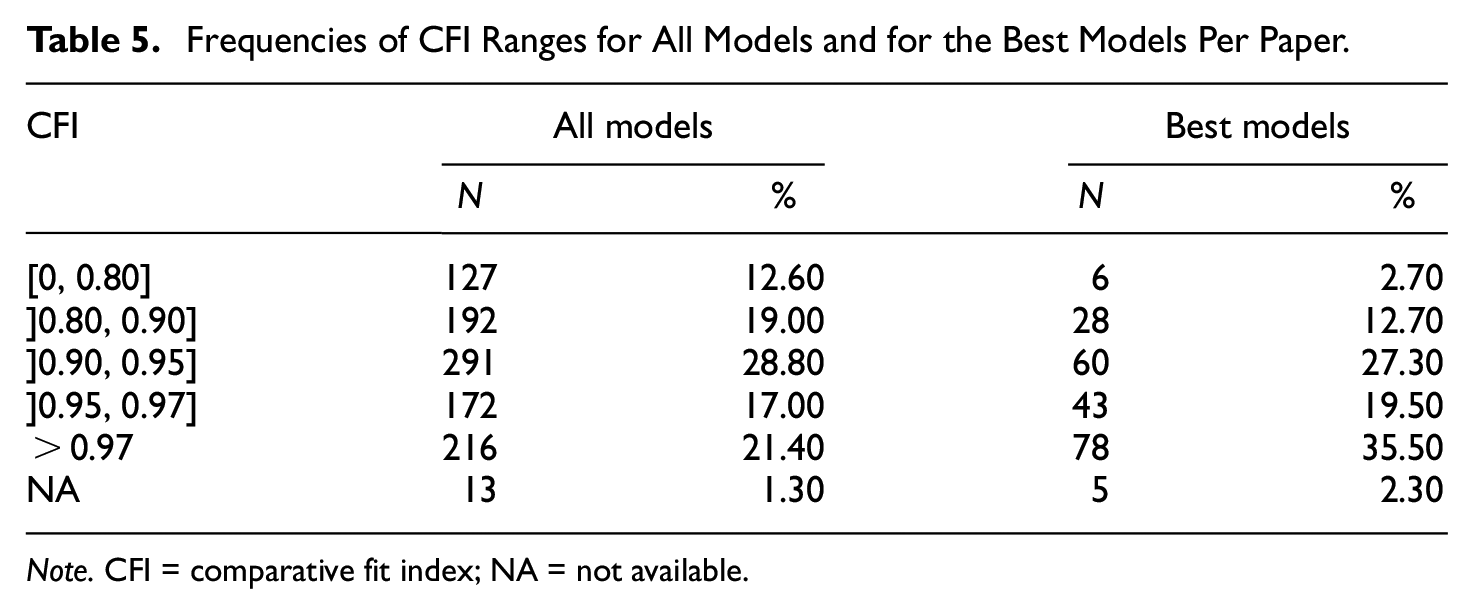
Note. CFI = comparative fit index; NA = not available.
Frequencies of TLI Ranges for All Models and for the Best Models Per Paper.
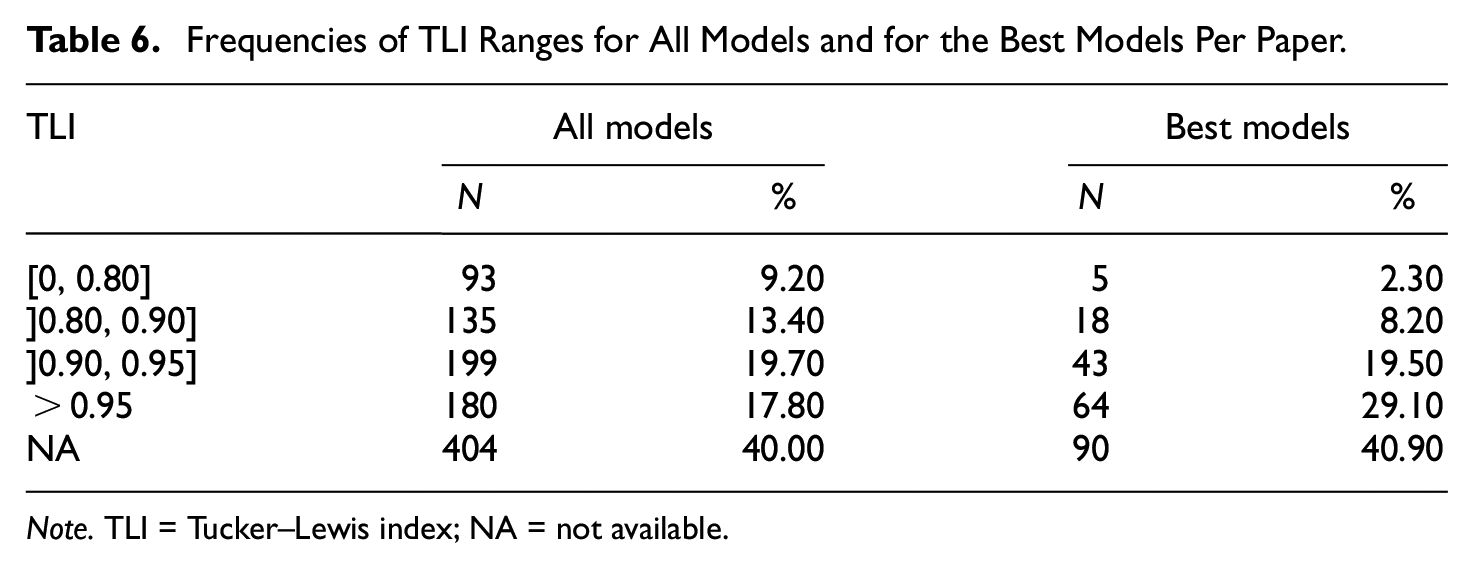
Note. TLI = Tucker–Lewis index; NA = not available.
Frequencies of Assumed Structures for All Models and for the Best Models Per Paper.
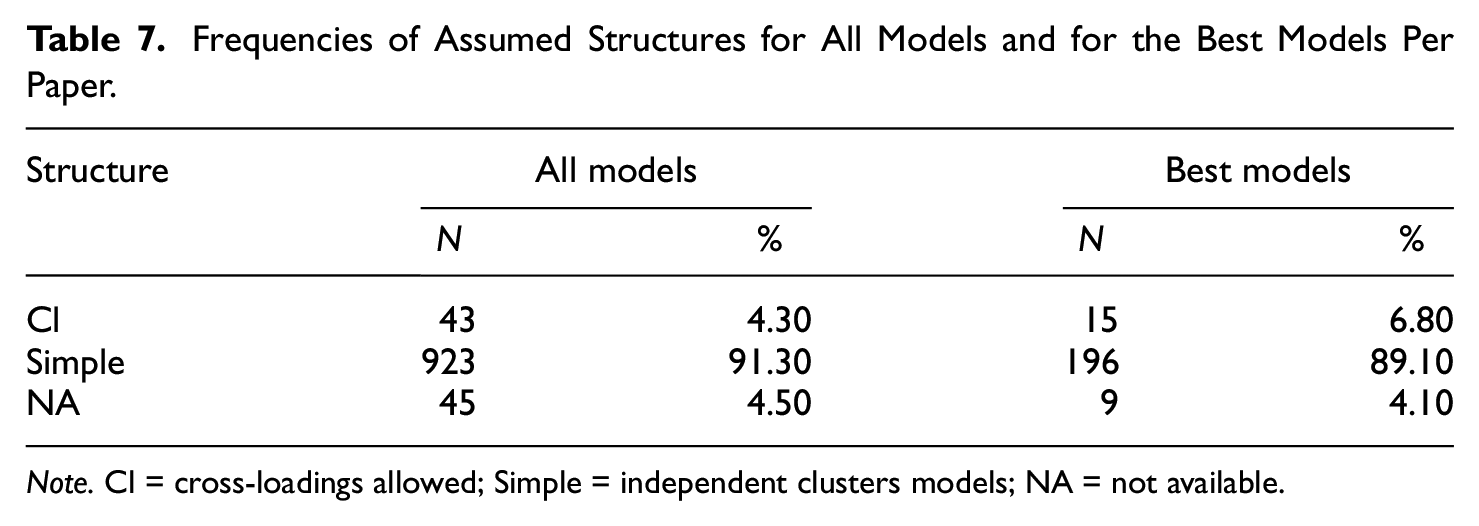
Note. Cl = cross-loadings allowed; Simple = independent clusters models; NA = not available.
Frequencies of Sample Strategies for All Models and for the Best Models Per Paper.
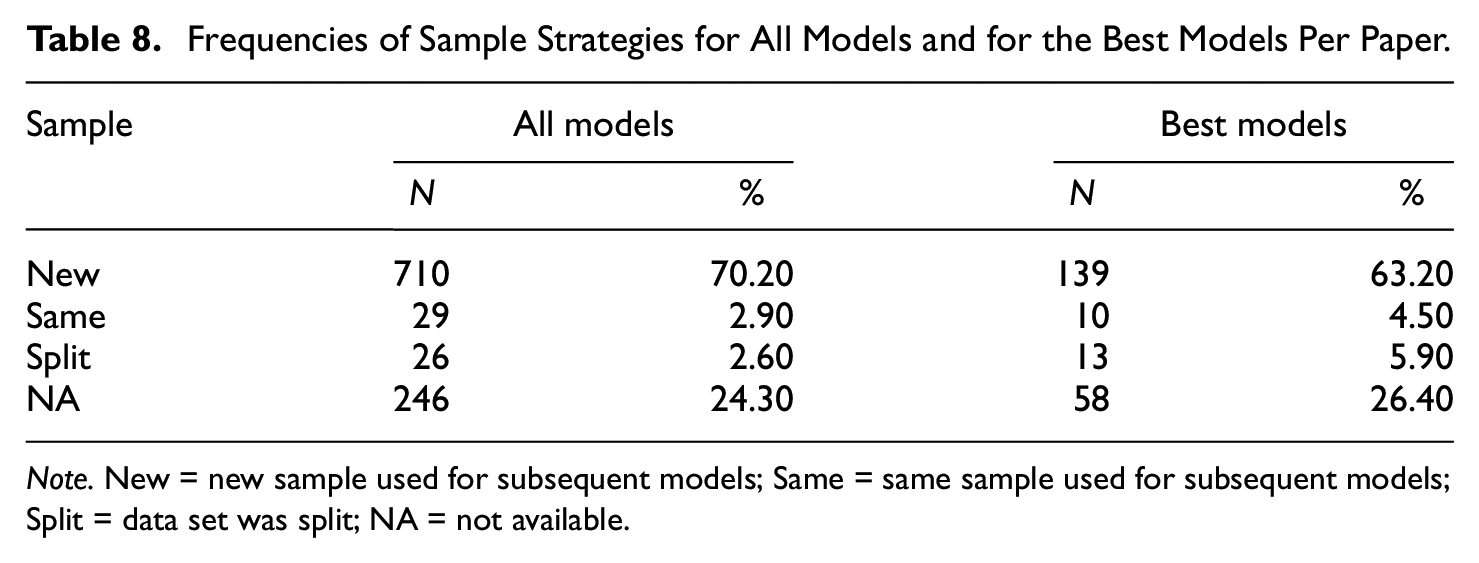
Note. New = new sample used for subsequent models; Same = same sample used for subsequent models; Split = data set was split; NA = not available.
Frequencies of Estimation Methods for All Models and for the Best Models Per Paper.
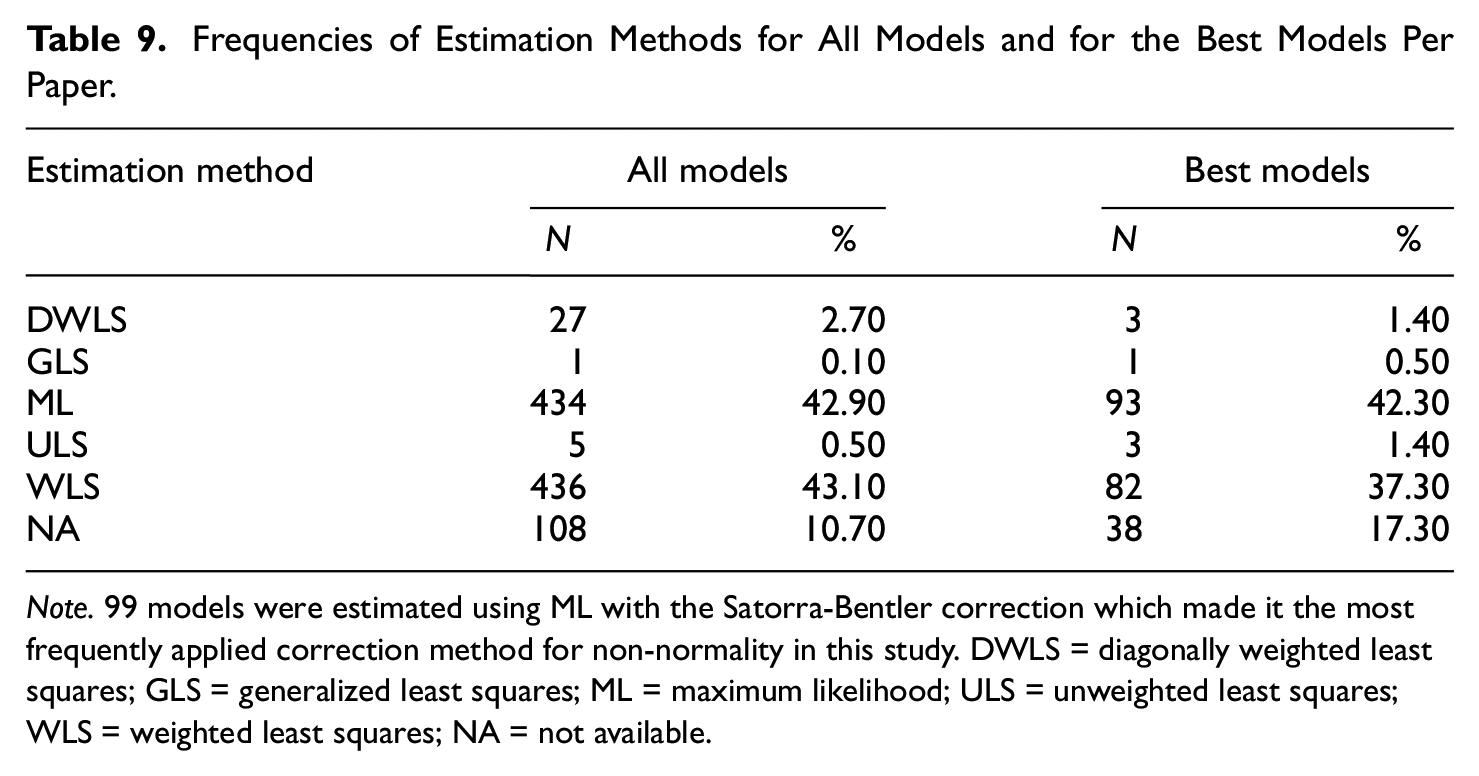
Note. 99 models were estimated using ML with the Satorra-Bentler correction which made it the most frequently applied correction method for non-normality in this study. DWLS = diagonally weighted least squares; GLS = generalized least squares; ML = maximum likelihood; ULS = unweighted least squares; WLS = weighted least squares; NA = not available.
Frequencies of Fit Evaluation Methods for All Models and for the Best Models Per Paper.
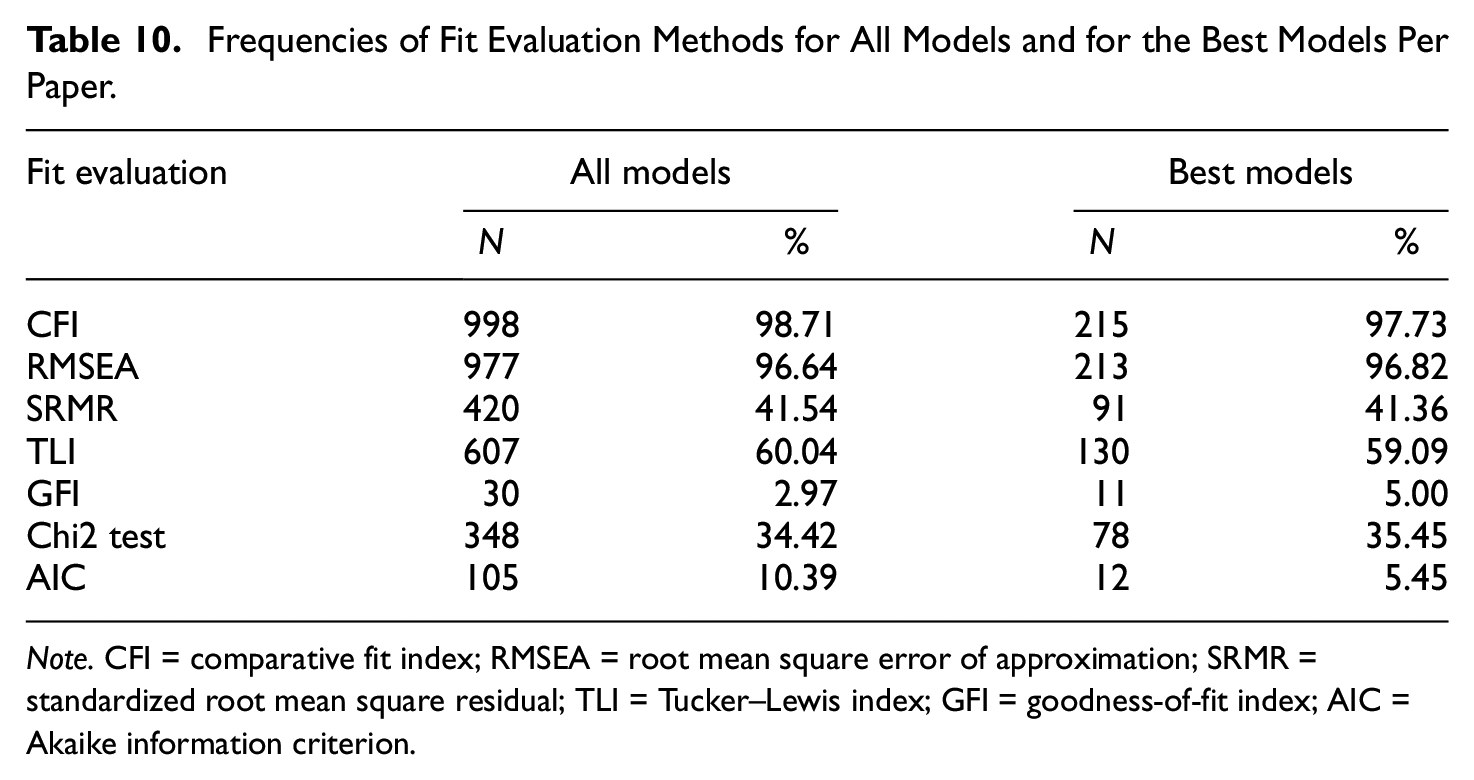
Note. CFI = comparative fit index; RMSEA = root mean square error of approximation; SRMR = standardized root mean square residual; TLI = Tucker–Lewis index; GFI = goodness-of-fit index; AIC = Akaike information criterion.
In a second step, we extracted the “best fitting” model per paper based on CFI and calculated the same frequencies as above for the resulting
Rules of Thumb
Applying common combinatory rules of thumb for fixed fit index cutoffs, a majority of models shows quite poor model fit. Using a “best model” per study (
Tailored Cutoffs for Fit Indices
Calculating the tailored cutoffs for the 34 selected models for which enough information was presented, the ezCutoffs approach yielded cutoffs of
Discussion
One reason for researchers to use fit indices instead of the exact model test to evaluate the model fit is the fact that the
As individual cutoffs also depend on the sample size and seem to perform reasonably well only with moderate sample sizes (i.e.,
An alternative to the close-fit approach of Moshagen and Erdfelder (2016) and the simulation-based methods by McNeish and Wolf (2021) or Groskurth et al. (2022) is equivalence testing as proposed by Yuan et al. (2016). The basic idea is to determine a so-called T-size which describes the minimum tolerable amount of model misspecification for a specific context (e.g., an empirical study). This T-size can be related to every common fit index that a researcher usually uses to quantify model (mis-)fit (Yuan et al., 2016). Accordingly, instead of testing the rather unrealistic null hypothesis that the proposed model exactly represents the population model (i.e., the
When relying on individual cutoffs, it becomes apparent that often CFI and SRMR show acceptable model fit while the RMSEA is higher than the tailored cutoff indicating poor model fit. Hu and Bentler (1999) showed that the different fit indices are sensitive to different types of misspecifications or model misfit. The SRMR signals misfit regarding the between-factor correlations, whereas the RMSEA focuses more strongly on misspecified loading patterns. Given the high percentage of articles that focus on models with a strict form of simple structure assumption (i.e., independent cluster models), it does not come as a surprise that it is often the RMSEA that questions the model fit for most of the evaluated models in our study. The common assumption that each indicator can be assigned one latent factor and substantial cross-loadings do not exist is quite appealing to researchers as it facilitates the interpretability of the factor model. However, this focus on overly simplified models is typically one reason why measurement models that were developed using exploratory factor analysis cannot be successfully replicated in subsequent CFAs (e.g., Hopwood & Donnellan, 2010; Sellbom & Tellegen, 2019). Hence, researchers should probably consider “imperfect” measurement models with substantial cross-loadings, this might hamper the interpretability of their models because a model with poor fit to the data potentially yields severe misinterpretations.
In this study, we can observe a tendency of models with higher overdetermination (i.e., more indicators per latent factor) to fit the data worse compared to models with a smaller item-to-factor ratio. This pattern of fit indices indicating worse fit for larger and more complex models was also found in simulation studies (e.g., Shi et al., 2019) and can be seen as a weak point of the discussed fit measures. The worse fit in this study could be caused by actual misfit, though, as it appears quite obvious that oftentimes high overdetermination may come at a price of some less suitable indicators. However, this should not be seen as a call for using less indicators per factor to reduce model complexity and artificially increase model fit. Higher overdetermination is in fact associated with higher estimation stability and fewer convergence problems (e.g., Gagne & Hancock, 2006) and usually with higher reliability estimates (e.g., Fabrigar et al., 1999). Besides psychometric considerations regarding the model fit, researchers have to ensure content validity and should therefore be very careful when reducing the number of indicators per factor (e.g., Goretzko et al., 2021).
When focusing on the best-fitting model of each article and comparing the reported fit indices to common cutoff recommendations (Browne & Cudeck, 1992; Hu & Bentler, 1999; Schermelleh-Engel et al., 2003), it has to be stated that several measurement models cannot be considered suitable for the empirical data. Given the usually more strict tailored cutoffs (e.g., the Dynamic Model Fit cutoffs) that should be preferred over fixed cutoffs, the comparable poor model fit of some measurement models has to be critically analyzed. As discussed earlier and debated by several authors (e.g., Hopwood & Donnellan, 2010; Marsh et al., 2009), interpretable, yet overly simplistic independent clusters models (i.e., models with an item complexity of one which means that each indicator is only allowed to load on a single factor) are probably responsible for the largest part of the model misfit. Another problem with how researchers usually develop measurement models may be found in earlier stages of the construction process. Goretzko et al. (2021) report that a majority of EFAs still rely on outdated factor retention criteria such as the infamously subjective Scree test or the eigenvalue-greater-one-rule to determine the number of latent factors, even though simulation studies have repeatedly shown that these methods do not provide accurate estimates for the dimensionality of a latent concept (e.g., Auerswald & Moshagen, 2019; Goretzko & Bühner, 2020, 2022; Zwick & Velicer, 1986). If the dimensionality assessment in a preceding EFA has been flawed, it is no surprise that a confirmatory model building on the respective EFA results does not fit empirical data well (e.g., Fabrigar et al., 1999). In combination with traditionally low item reliabilites and high measurement errors in psychological questionnaire data (Gnambs, 2015) and questionable measurement practices (Flake & Fried, 2020), poorly fitting measurement models may severely distort empirical findings and hamper the progress of certain research areas. As the vast majority of models were fitted to categorical data (usually Likert-type items of questionnaires), the actual model fit might be even worse than indicated by common fit indices (Savalei, 2021). In addition, researchers should also keep in mind that cutoffs stemming from simulation studies such as the ones proposed by Hu and Bentler (1999) or tailored cutoffs that are created by the approach of McNeish and Wolf (2021) usually only consider normally distributed data and ML estimation. Hence, the actual model misfit could be even higher for many of the models in our study.
To improve the measurement models that lack model fit, more researchers might consider using modification indices (MI, Saris et al., 1987) to revise their models (as authors indicated to use MI only in 19.1% of the studies in our review). Whittaker (2012) thoroughly describes how MI and related measures such as the expected parameter change (Saris et al., 1987) can be used iteratively to revise the model specification and improve model fit. This so-called specification search can be quite tedious so automated approaches using optimization algorithms have been discussed (G. A. Marcoulides & Drezner, 2003; G. A. Marcoulides et al., 1998). More recently, an automated specification search based on a combination of Tabu search (see also G. A. Marcoulides et al., 1998) and ant-colony optimization (see G. A. Marcoulides & Drezner, 2003) was developed (Jing et al., 2022). When engaging in specification search (especially when automating the procedure), and therefore shifting from confirmatory to exploratory analyses, researchers have to be aware of the risk of over fitting their models to the data (MacCallum et al., 1992). Accordingly, models that were derived from specification search procedures should always be validated on new data to ensure robustness of the measurement model.
While we want to urge psychologist to take the model evaluation of CFA models seriously by using tailored cutoffs instead of fixed cutoffs that do not reflect the respective data conditions and to revise poorly fitting measurement models by getting rid of independent clusters models or at least by reducing the focus on independent clusters factor patterns, we also want to emphasize that model misfit is normal to some degree and that we will not be able to develop perfectly fitting models. Depending on the application context of a scale or questionnaire, exact model fit might be less important and researchers can choose a rather moderate criterion for close model fit (Moshagen & Erdfelder, 2016). Especially in cases where the accuracy of an individual measurement is of little interest, for example, when group means are compared or predictions of an outside criterion at group-level are evaluated, a slightly misspecified model (that only closely fits the data according to an adjusted cutoff for evaluation) can still be useful to gain some insights. In assessment settings, however, where individuals are diagnosed and categorized based on a psychological measure, higher standards have to be in place. Either way, when encountering model misfit, researchers should always investigate the reasons for discrepancies between model predictions and observed data (Hayduk, 2014).
All in all, this study shows that many articles do not report all the necessary results to conduct a “re-analysis” of the model fit with one of the individual cutoff approaches. Especially the rather small number of studies reporting the full loading matrices has to be criticized. Without detailed information on the loading matrices, the respective measurement models can hardly be interpreted by readers or reanalyzed as in our case. Hence, we want to advocate for more thorough and detailed reporting standards for CFA. A transparent depiction of all model parameters (i.e., factor loadings, between-factor correlations, residual variances, correlations among residuals) as well as a comprehensive model evaluation should always be part of a paper that reports a CFA or an SEM in general. The Journal of the Society for Social Work and Research, for example, has developed rather strict rules how EFA and CFA results have to be presented (Cabrera-Nguyen, 2010).
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by a Grant from the German Research Foundation to David Goretzko (DFG GO 3499/1-1).