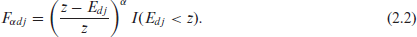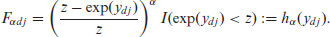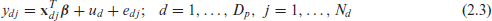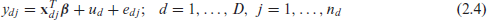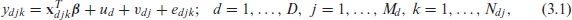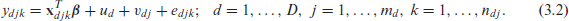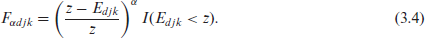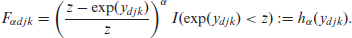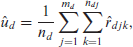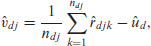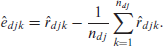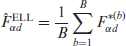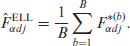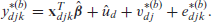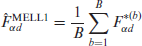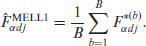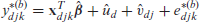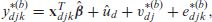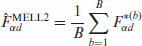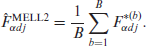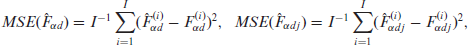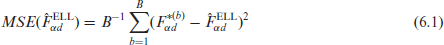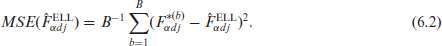Demand for reliable statistics at a local area (small area) level has greatly increased in recent years. Traditional area-specific estimators based on probability samples are not adequate because of small sample size or even zero sample size in a local area. As a result, methods based on models linking the areas are widely used. World Bank focused on estimating poverty measures, in particular poverty incidence and poverty gap called FGT measures, using a simulated census method, called ELL, based on a one-fold nested error model for a suitable transformation of the welfare variable. Modified ELL methods leading to significant gain in efficiency over ELL also have been proposed under the one-fold model. An advantage of ELL and modified ELL methods is that distributional assumptions on the random effects in the model are not needed. In this article, we extend ELL and modified ELL to two-fold nested error models to estimate poverty indicators for areas (say a state) and subareas (say counties within a state). Our simulation results indicate that the modified ELL estimators lead to large efficiency gains over ELL at the area level and subarea level. Further, modified ELL method retaining both area and subarea estimated effects in the model (called MELL2) performs significantly better in terms of mean squared error (MSE) for sampled subareas than the modified ELL retaining only estimated area effect in the model (called MELLI).
Data collected from probability samples can provide reliable estimates of parameters of interest for domains (subpopulations) with large enough sample sizes to permit direct, domain-specific estimators of desired precision. We call such domains as large areas. On the other hand, sample sizes can be very small or even zero for local areas (called small areas) and direct estimators are not adequate or feasible. Demand for reliable statistics at the level of small areas has increased greatly and it is necessary to use model-based methods that can yield reliable estimates for small areas by integrating information across areas through linking models. Rao and Molina[13] provide a comprehensive account of model-based small area estimation of means, totals, and more complex parameters like poverty measures.
In this article, we focus on the estimation of FGT poverty measures, proposed by Foster et al.[6] Poverty incidence, gap and severity belong to the family of FGT measures. World Bank widely used a method proposed by Elbers et al.[5], called the ELL method, to provide FGT poverty measures for specified local areas in many developing countries. The ELL method involves the following steps: (a) Simulate multiple censuses of the welfare variable of interest based on an assumed model relating the welfare variable to auxiliary variables obtained from a recent census; (b) Calculate the FGT measure for specified local areas from each simulated census and then take the average over the censuses as the ELL estimator; (c) Variance of the simulated census estimators is taken as the estimator of mean squared error (MSE) of the ELL estimator. An advantage of the ELL method is that it is free of parametric distributional assumptions and computationally simple. However, Molina and RaO[11] showed that the ELL method can lead to large MSE compared to an optimal method, called the Empirical Best (EB) method, assuming a one-fold nested error linear regression model with normally distributed random effects. Diallo and Rao[4] developed a modification to ELL method that leads to substantial reduction in MSE and compares favorably to the normality-based EB method. As in the ELL method, the modified ELL method is free of parametric distributional assumptions. The proposed ELL, modified ELL and EB methods are based on a one-fold nested error linear regression model relating a suitable function of the welfare variable to the census variables and a random area effect. Sample survey data observing the welfare variable and the census variables, based on two-stage cluster sampling, are used to fit the one-fold model. In the traditional ELL method, random cluster effects are included in the model and simulated censuses are generated. From a simulated census, a desired poverty measure is calculated for any desired small area. Note that it is not necessary to specify the areas in advance because area effects are not included in the ELL one-fold model. Hossain et al.[9] used a two-stage sample of districts and household within districts to estimate a food insecurity measure at the district level in Bangladesh. In this case, clusters are areas. In this article, we focus on two-fold random effect models involving area and subarea random effects. For example, an area could refer to a state and a subarea to a county within a state. Marhuenda et al.[10] studied EB estimation of FGT poverty measures under the two-fold model, assuming that the random effects in the model are normally distributed, as in the case of the onefold model studied by Molina and Rao[13]. In their application to Spanish survey data, areas are provinces and subareas are comarcas, and it is of interest to obtain estimates of poverty measures at the domain as well as subdomain level.
Section 2 sets the stage by briefly describing the ELL, modified ELL and EB methods for estimating poverty indicators for areas under a one-fold nested error regression model. Section 3 introduces the two-fold model and the associated FGT poverty measures for domains and subdomains. Section 4 extends the ELL and modified ELL methods to two-fold models with no distributional
assumptions on the random effects in the model, as in the case of the one-fold model. Section 5 presents some results of a simulation study on the performance of ELL and modified ELL estimators. Finally, some remarks on the estimation of MSE of the estimators are given in Section 6.
One-fold Nested Error Model
In this section, we introduce the ELL method and its modification (MELL), based on a one-fold nested error linear regression model relating a log transformation of a welfare variable of interest to known census variables for the finite population of interest. In the ELL method, a twostage cluster sample is used in conjunction with known population records/census variables , where denote the number of clusters in the population and the sample, and denote the number of population units and sample units in cluster . An intercept term is included in the covariate vector . To reduce skewness in the welfare variable, a suitable transformation is used, where . is one-to-one. In the ELL method, is used. Typically, clusters are nested in the areas of interest. For simplicity, we assume here that clusters are the same as the areas.
The FGT poverty indicator for area is given by
where
In (2.2), is the known poverty line and is the indicator variable taking the value 1 when is smaller than and 0 otherwise. Poverty incidence, poverty gap and poverty severity correspond to , and , respectively. We use a one-to-one transformation of the welfare variable . Often, a positive constant is added to to ensure . Here we assume for all the population units. We can express in terms of the transformed variable as
We focus here on the additive FGT poverty measures, , but the ELL method and its modifications are applicable to general measures of the form .
ELL Method
We assume a one-fold nested error linear regression model relating to :
where and denote random area effect and residual error and independently distributed with means zero and variances and respectively. Parametric distributions on the two random effects are not assumed. Sampling is assumed to be non-informative in the sense that the population model holds for the sample data:
where we denote the first units as the sample in area , without loss of generality. The following steps are used in the ELL method: (a) Calculate the sample residuals , where is the ordinary least square (OLS) estimator of the regression coefficient in the sample model (2.4) with estimated covariance matrix ; (b) The random area effect is estimated as ; (c) Unit level residual is estimated as . Two referees noted that the above estimators are equivalent to estimators obtained from an analysis of covariance model treating as fixed effect and imposing the condition ; (d) Draw sets of bootstrap values from , the empirical distribution of , and the empirical distribution of , respectively; (e) Construct sets of simulated census values as follows: , using the census values of the covariates ; (f) Calculate simulated population FGT measures , where ; (g) Calculate the ELL estimator of by taking average of over :
The ELL method is also applicable to non-sampled areas following steps 4-7 above.
Modified ELL Method
The modified ELL method, proposed by Diallo and Rao,[4] retains the estimated area effects for sampled area , unlike using as in the ELL method. The simulated values are generated from and steps (f) and (g) above are implemented using the simulated values to calculate the modified ELL (MELL) estimator of , denoted as . For non-sampled areas we use the ELL method by generating the simulated values from .
A simulation study with skew normal error showed large gain in efficiency for MELL estimator over ELL estimator for sampled areas . For non-sampled areas , ELL and MELL are the same. Diallo[3] studied the performance of MELL when the ELL estimator is replaced by the EBLUP estimator of , using moment estimators of the variance components in the nested error model (2.4) which are distribution-free. The resulting MELL estimators of the FGT measures were not significantly more efficient than the MELL estimators based on the ELL estimators . A plausible reason for this lack of improved efficiency is due to the fact that the EBLUP estimators of the are designed for optimal estimation of the area means of the transformed variables and not for estimating FGT measures for the areas.
In the special case of area mean , its ELL estimator is approximately equal to the synthetic estimator for all areas, as noted in Molina and Rao[13]. On the other hand, MELL estimator of for a sampled area is approximately equal to the sample regression estimator , where and are the sample means for area . For a non-sampled area, MELL estimator of reduces to the synthetic estimator.
Both ELL and MELL are applicable to more complex measures, such as the Gini coefficient and the Fuzzy Monetary Index (Neri et al.[12]). Those measures are not additive non-linear functions of the welfare variable , unlike the FGT measure. An advantage of those complex measures over the FGT measure is that the knowledge of the poverty line is not required. Further, note that both ELL and MELL do not require linking the sample file to the population register from where the auxiliary variables are obtained.
EB Method
Molina and Rao[13] studied empirical best (EB) estimation of FGT poverty measures, assuming normality of the area effects and the unit errors . The best estimator of for a non-sampled unit in area is obtained as the expectation with respect to the conditional distribution of given the vector of sampled values in area . A closed form expression for the best estimator does not exist in general, but it can be approximated by simulating from the conditional distribution. Molina and Rao[13] showed that can be generated from a univariate normal distribution. EB estimator is obtained by replacing the model parameters in the best estimator by suitable estimators.
A limitation of EB estimation is that it requires linking the sample to the population for identifying the non-sampled units in each area, unlike ELL estimation. If linking is not feasible, then we can obtain EB estimator of for all the population units in area , leading to Census EB estimator (Guadarrama et al.[8]). The Census EB estimator is less efficient than the EB estimator when linking is feasible, but the loss in efficiency is small when the area sampling fraction is small. Corral-Rodas et al.[2] provide refinements and extensions to the EB method of Molina and Rao (MR). A referee noted that the poverty maps produced by the World Bank recently were based on the EB method rather than the ELL method.
Diallo and Rao[4] studied EB estimation under the one-fold model (2.4) with skew normal (SN) errors and normal area effects . Their simulation results showed that the normality-based EB of Molina and Rao[11] can be inefficient due to inflation of MSE caused by substantial bias in the estimator. However, the EB estimator of Diallo and Rao[4] is very complex, and they proposed a simplified EB method which performed quite well compared to the EB method under SN errors. The modified ELL method is less efficient than the tailor-made EB methods of Diallo and Rao[4] under the model with SN errors. Note that distributional assumptions on and are not needed for the ELL and modified ELL methods. Graf et al.[7] developed EB estimators by modelling the welfare variable directly using a Generalized Beta distribution of the Second Kind.
Two-fold Nested Error Model
As in Marhuenda et al.[10], the finite population of interest consists of areas (domains) , and area is divided into subareas (subdomains) . The subdomain within the domain contains elements . The population data is denoted as , where is the welfare variable of interest and is a -vector of known census variables. If an intercept term is needed, then we set for all the population units. To reduce skewness in the welfare variable, a suitable transformation is used. For the FGT poverty measures, we make a transformation , assuming for all the population units, as in Section 2.
A two-fold nested error population model relating the transformed variable to the census variables is given by
where is a vector of unknown regression parameters, are the area effects, are the cluster effects, and are the residual errors. The three random errors , and are independent with . Parametric distributions on the two random effects and the unit errors are not assumed.
We assume two-stage sampling in each area: a sample, , of subareas is selected from area and if subarea is sampled then a subsample, of elements is selected from subarea . We further assume that the population model (3.1) also holds for the sample data . Therefore, the model for the sample data is given by
The FGT population measure for area is given by
where and
In (3.4), is the known poverty line and is the indicator variable taking the value 1 when is smaller than and 0 otherwise. Also, the FGT measure for subarea within area is given by
Estimators of FGT Poverty Measures
In this section, we describe how to estimate FGT poverty measures (3.3) and (3.5) for areas and subareas, respectively. Suppose that there is a one-to-one transformation of the welfare variables, assuming for all the population units. Then we can express given by (3.4) in terms of :
ELL Method
In this section, we extend the ELL method under the one-fold nested error model to the two-fold nested error model (3.1) when the model has area level random effect term, unit level random effect term, and unit level error term. The proposed extension of the ELL method to two-fold models consists of drawing from the estimated area, subarea and unit level residuals to create a simulated census. The steps of the ELL method can be summarized as follows:
Estimate from the nested error model given by (3.2) and obtain unit level residuals where denotes the OLS estimator of .
The area effect , the subarea effect , and the unit level errors are estimated as
and
Draw , and from , the empirical distribution of , the empirical distribution of , and the empirical distribution of , respectively. Also, denotes the estimated covariance of .
Construct simulated census values as follows: , using the census values of the covariates.
Population measures and are calculated from each simulated census , where .
The ELL estimators of and are calculated by averaging over the simulated measures as follows:
and
The estimators and are similar to those obtained under an analysis of covariance model treating and as fixed and imposing side conditions on and to ensure estimability, as done in the case of the one-fold model studied in section 2.1.
Modified ELL Methods
Method 1. This modification retains in constructing the predictors , unlike the use of in the ELL method. We have the following modified ELL method:
From the nested error model given by (3.2), estimate the fixed effects using OLS.
Estimate , and as in the traditional ELL method.
Draw and from the empirical distributions of and , respectively.
Construct simulated census values as follows:
Then, the simulated population measures and are calculated as in the traditional ELL method from each simulated census . The modified ELL estimators of and , denoted by and , respectively, are as follows:
and
Method 2. This modification retains and , for , and uses for subarea not sampled from area in constructing the predictors . Then, the modification is as follows:
From the nested error model given by (3.2), estimate the fixed effects using OLS.
Estimate , and as in the traditional ELL method.
Draw from the empirical distribution of .
Construct simulated census values for the units in the sampled subareas as
and for subareas that are not sampled are generated from
where , are drawn from the empirical distribution .
Then, the simulated population measures and are calculated as in the traditional ELL method from each simulated census , and the second modified ELL estimators of and , denoted by and , respectively, are as follows:
and
In the special case of area mean , its ELL estimator is approximately equal to the synthetic estimator , as noted in Marhuenda et al.[10] On the other hand, both MELL1 and MELL2 estimators for a sampled area are approximately equal to the sample regression estimator . For a non-sampled area, both reduce to the synthetic estimator.
Turning to a subarea mean , MELL1 is approximately equal to for all subareas within a sampled area. On the other hand, MELL2 is approximately equal to the subarea level sample regression estimator for a sampled subarea. For a non-sampled subarea within a sampled area, MELL2 is equal to MELL1. For subareas within a non-sampled area, both MELL1 and MELL2 estimators are approximately equal to the synthetic estimator . On the other hand, ELL estimator for all subareas is approximately equal to the synthetic estimator .
EB Method
Marhuenda et al.[10] studied EB estimation of FGT poverty measures for area and subareas under the two-fold nested error model (3.1), assuming the population model holds for the sample. This leads to the sample model (3.2). Unlike the ELL method, they assume normality of the area effects , subarea effects and unit errors . The model on the unit error permits unequal variance with known heteroscedasticity weight . Under the above set-up, they extended the EB method of Molina and Rao[11] to derive EB estimators of FGT measures for areas and both sampled and non-sampled subareas within an area. This EB method is applicable only to additive measures like the FGT measure. They also conducted an extensive simulation study and compared the EB estimators for subareas under the two-fold model with those obtained under models with only subarea effects, when all subareas are sampled or not sampled. Here we consider the special case of and denote the EB estimator of Marhuenda et al.[10] as EB2.
Simulation Study
We conduced a simulation study to examine the performance of the two modified ELL methods under the two-fold nested error linear regression model (3.1). Marhuenda et al.[10] conducted a simulation study on the performance of EB estimators of FGT measures for areas and subareas under a two-fold nested error model assuming and are normally distributed. We follow their simulation set-up but also considered a skew normal scenario with normal (N) and skew normal (SN). Marhuenda et al.[10] made an extensive study for the two-fold model in the normal case, by fixing and considering two marginal scenarios for : (a) fixed and varied; (b) fixed and varied. The range of values considered included corresponding to a model with subarea effects only, and corresponding to a model with area effects only. Their results suggested that assuming the two-fold model when the correct model involves only area random effect or subarea random effect may not lead to significant loss in efficiency. We also included the case of normal (N) studied by Marhuenda et al.[10]
We set as in Marhuenda et al.[10], and consider two scenarios for setting the values of and : (a) Between area variation is larger than the between subarea variation ; (b) is smaller than . We also considered the case of smaller and to reflect more accurate covariates in the model: (c) and .
We generated populations each of size composed of areas each containing subareas each containing units. As in Marhuenda et al.[10], all the areas are sampled. We first generated the covariate vector for each population unit, based on and with probabilities and . The generated population covariate values are held fixed and used to generate the dependent variable from the two-fold model using and specified distributions for , and with mean zero and standard deviations and , respectively. For the case, we took and with and chosen to make the mean and standard deviation of equal to zero and , and which leads to moderate skewness. As in Marhuenda et al.[10], we set . The above process was repeated to generate population values .
We calculated the FGT measures for each area and for each subarea from each of the simulated populations . We focus on poverty incidence and poverty gap . Following Marhuenda et al.[10], we took the poverty line as for a population generated as above.
We considered two cases for generating a sample of units. In case 1, all subareas are sampled by selecting units from each subarea by simple random sampling. In case 2, a simple random sample of subareas is selected from each area and then a simple random sample of units is drawn from each sampled subarea. In both cases, the over all sample size within each area is equal to 100 and the number of bootstrap simulated censuses, , is taken as .
As in Marhuenda et al.[10], we used a model-based set up by conditioning on the selected sample of units and extracting the corresponding sample data from each simulated population . Using the sample data, we then obtained the desired estimates for areas and subareas from the assumed two-fold model. Denoting the estimators for areas and subareas for any given method by and respectively, we computed empirical MSEs of the estimators for areas and subareas as
where and denote the estimators for the simulated population .
Skew Normal
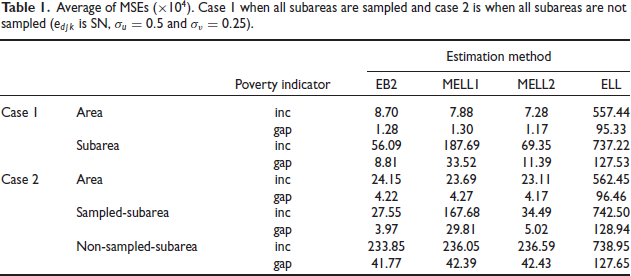
Table 1 reports results on average MSE for the areas, sampled subareas and non-sampled subareas for scenario 1: and . Table 1 shows that ELL leads to very large average MSE in all cases compared to the other methods. For areas, MELL2 and MELL1 are comparable and slightly better than EB2 in terms of average MSE. For subareas when all subareas are sampled (case 1), MELL2 leads to large reduction in average MSE over MELL1. This is to be expected because MELL1 does not use subarea specific method unlike MELL2. Also, EB2 seems to be somewhat better than MELL2 in terms of average MSE: 8.81 for EB2 vs. 11.39 for MELL2 in the case of poverty gap.
Average of MSEs . Case I when all subareas are sampled and case 2 is when all subareas are not sampled ( is and .
Estimation method
Poverty indicator
EB2
MELLI
MELL2
ELL
Case I
Area
inc
8.70
7.88
7.28
557.44
gap
1.28
1.30
1.17
95.33
Subarea
inc
56.09
187.69
69.35
737.22
gap
8.81
33.52
11.39
127.53
Case 2
Area
inc
24.15
23.69
23.11
562.45
gap
4.22
4.27
4.17
96.46
Sampled-subarea
inc
27.55
167.68
34.49
742.50
gap
3.97
29.81
5.02
128.94
Non-sampled-subarea
inc
233.85
236.05
236.59
738.95
gap
41.77
42.39
42.43
127.65
Turning to case 2 where not all subareas are sampled, results for sampled subareas are similar those for case 1 where all subareas are sampled. Note that the average MSE is significantly decreased for sampled subareas because the sample size in those subareas is doubled relative to case 1. On the other hand, for areas the average MSE is significantly increased in case 2 compared to case 1 because the number of sampled subareas is reduced by half compared to case 1.
For nonsampled subareas (case 2), MELL1, MELL2 and EB2 are comparable in terms of average MSE. This is to be expected because for non-sampled subareas MELL1 and MELL2 are similar. Note that the average MSE is significantly increased for nonsampled subareas compared to corresponding values for sampled subareas. Box plots (not presented here) lead to conclusions like those arrived from the values of average MSE.
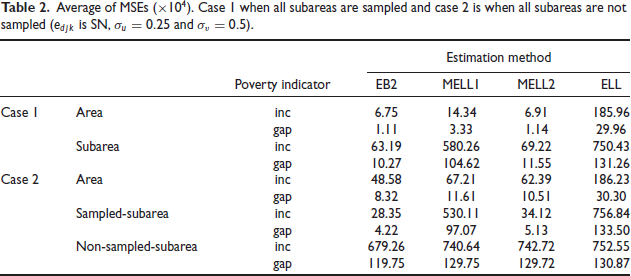
Average of MSEs . Case I when all subareas are sampled and case 2 is when all subareas are not sampled ( is and .
Estimation method
Poverty indicator
EB2
MELLI
MELL2
ELL
Case I
Area
inc
6.75
14.34
6.91
185.96
gap
1.11
3.33
1.14
29.96
Subarea
inc
63.19
580.26
69.22
750.43
gap
10.27
104.62
11.55
131.26
Case 2
Area
inc
48.58
67.21
62.39
186.23
gap
8.32
11.61
10.51
30.30
Sampled-subarea
inc
28.35
530.11
34.12
756.84
gap
4.22
97.07
5.13
133.50
Non-sampled-subarea
inc
679.26
740.64
742.72
752.55
gap
119.75
129.75
129.72
130.87
Table 2 reports results on average MSE for scenario 2: and , corresponding to those in Table 1 for scenario 1. Comparing the two tables, conclusions for the case all subareas are sampled are similar for EB2 and MELL2, but average MSE for MELL1 has significantly increased. For the case not all subareas are sampled, average MSE values for EB2, MELL1 and MELL2 are substantially increased for areas, although conclusions are similar. For sampled subareas, EB2 and MELL2 gave similar average MSE values. For nonsampled subareas in case 2, MELL1, MELL2 and ELL are comparable in terms of average MSE while EB2 exhibits slightly smaller average MSE.
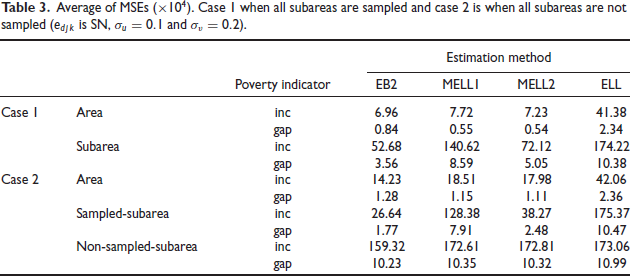
Results on average MSE for scenario 3 with and are reported in Table 3. For the case 1 with all subareas sampled, MELL1 and MELL2 are similar for areas in terms of average MSE, and slightly larger than the average MSE for EB2. ELL leads to a much larger average MSE for areas in both cases 1 and 2. Turning to subareas, MELL2 leads to large reduction in MSE relative to MELL1 and ELL, and slightly larger average MSE relative to EB2 in both cases 1 and 2. For the nonsampled subareas in case 2, average MSE is comparable across EB2, MELL1, MELL2 and ELL. Note that scenario 3 is favorable to ELL because the area and subarea effects are small.
Average of MSEs . Case I when all subareas are sampled and case 2 is when all subareas are not sampled ( is and ).
Estimation method
Poverty indicator
EB2
MELLI
MELL2
ELL
Case I
Area
inc
6.96
7.72
7.23
41.38
gap
0.84
0.55
0.54
2.34
Subarea
inc
52.68
140.62
72.12
174.22
gap
3.56
8.59
5.05
10.38
Case 2
Area
inc
14.23
18.51
17.98
42.06
gap
1.28
1.15
1.11
2.36
Sampled-subarea
inc
26.64
128.38
38.27
175.37
gap
1.77
7.91
2.48
10.47
Non-sampled-subarea
inc
159.32
172.61
172.81
173.06
gap
10.23
10.35
10.32
10.99
Normal
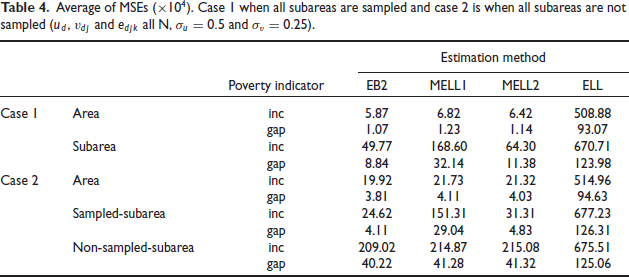
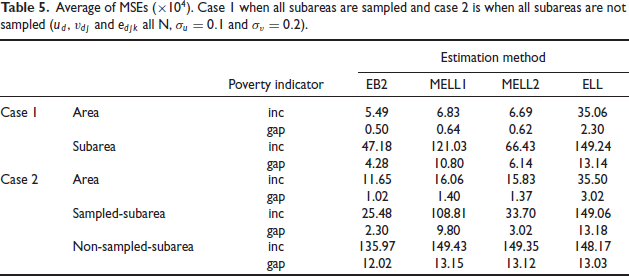
We also considered the case where and are normally distributed. Marhuenda et al.[10] studied this case in the context of EB2. Table 4 gives the average MSE under scenario 1. Table 4 indicates that the results on MSE for areas, sampled subareas and non-sampled subareas are similar with the results in section 5.1 corresponding to skew normal. We also note that EB2 leads to substantial reduction in average MSE over MELL2 for subareas in case 1 where all subareas are sampled: 49.77 vs. 64.30 for incidence and 8.84 vs. 11.38 for gap. This is to be expected because EB2 is optimal under normality. Table 5 reports average MSE for the normal case under scenario 3. Results are similar to those in Table 4.
Average of MSEs . Case I when all subareas are sampled and case 2 is when all subareas are not sampled and all and .
Poverty indicator
Estimation method
EB2
MELLI
MELL2
ELL
Case I
Area
inc
5.87
6.82
6.42
508.88
gap
1.07
1.23
1.14
93.07
Subarea
inc
49.77
168.60
64.30
670.71
gap
8.84
32.14
11.38
123.98
Case 2
Area
inc
19.92
21.73
21.32
514.96
gap
3.81
4.11
4.03
94.63
Sampled-subarea
inc
24.62
151.31
31.31
677.23
gap
4.11
29.04
4.83
126.31
Non-sampled-subarea
inc
209.02
214.87
215.08
675.51
gap
40.22
41.28
41.32
125.06
Average of MSEs . Case I when all subareas are sampled and case 2 is when all subareas are not sampled and all and .
Estimation method
Poverty indicator
EB2
MELLI
MELL2
ELL
Case 1
Area
inc
5.49
6.83
6.69
35.06
gap
0.50
0.64
0.62
2.30
Subarea
inc
47.18
121.03
66.43
149.24
gap
4.28
10.80
6.14
13.14
Case 2
Area
inc
11.65
16.06
15.83
35.50
gap
1.02
1.40
1.37
3.02
Sampled-subarea
inc
25.48
108.81
33.70
149.06
gap
2.30
9.80
3.02
13.18
Non-sampled-subarea
inc
135.97
149.43
149.35
148.17
gap
12.02
13.15
13.12
13.03
MSE Estimation
In the ELL method for the one-fold model, the variability of the simulated census measures is taken as the estimator of MSE of the ELL estimator. Similarly, under the two-fold model the corresponding MSE estimators of ELL for areas and subareas are given by
and
MSE estimators similar to (6.1) and (6.2) are applicable to MELL1 and MELL2, using simulated census measures. The proposed MSE estimators are simple, but they can lead to significant underestimation of the true MSE because the model parameters and the random effects in the model are not re-estimated in each replicate from the replicated sample data .
Marhuenda et al.[10] proposed a proper parametric bootstrap MSE estimator for EB2 estimators, based on re-estimating model parameters and random effects in the two-fold model under normality. A similar procedure may be developed for ELL and MELL using a distribution free bootstrap, like the ELL method.
Concluding Remarks
We considered the estimation of FGT poverty measures under a two-fold nested error model. We developed extensions of the ELL method and the modified ELL method of Diallo and Rao[4] to twofold models. The methods are free of parametric distributional assumptions on the random effects in the two-fold model. Our simulation results indicate that the proposed modified ELL methods lead to large efficiency gains over the ELL for both areas and subareas. Further, MELL2 leads to significant reduction in MSE over MELL1 for sampled subareas, and it is comparable to the EB2 method of Marhuenda et al.[10] under normality assumption. Our simulation study is somewhat limited. It would be desirable to conduct a more extensive simulation study with different parameter combinations, as well as design-based simulations, as in Marhuenda et al.[10] Bootstrap MSE estimation for MELL methods, along the lines of Marhuenda et al.[10] but without normality assumption, needs a detailed investigation.
The EB2 method of Marhuenda et al.[10] is applicable to additive functions like the FGT measures, and its extensions to more complex parameters remain to be investigated. On the other hand, as noted earlier, MELL2 is readily applicable to general parameters, not necessarily additive in the individual values like the FGT measures.
Footnotes
Acknowledgements
We thank two referees for several constructive comments and suggestions.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: We would like to express our sincere gratitude to Statistics Canada and the Natural Sciences and Engineering Research Council of Canada (NSERC) for their valuable support in funding our research.
References
1.
BatteseGE, HarterRM, FullerWA.An error-components model for prediction of county crop areas using survey and satellite data. J Amer Stat Assoc1988; 83: 28–36.
2.
Corral-RodasP, MolinaI, NguyenM.Pull your small area estimates up by the bootstraps. J Stat Comput Simul2021; 91: 3304–3357.
3.
DialloMS.Small area estimation under Skew-Normal nested error model. PhD Thesis, Carleton University, Ottawa, Canada, 2014.
4.
DialloMS, RaoJNK.Small area estimation of complex parameters under unit-level models with skewnormal errors. Scandinavian J Stat2018; 45: 1092–1116.
5.
ElbersC, LanjouwJO, LanjouwP.Welfare in villages and towns: micro-level estimation of poverty and inequality. Unpublished manuscript, The World Bank, 2001.
6.
FosterJ, GreerJ, ThorbeckeE.A class of decomposable poverty measures. Econometrica1984; 52: 761766.
7.
GrafM, MartinJM, MolinaI.A generalized mixed model for skewed distributions applied to small area estimation. Test2019; 28: 565–597.
8.
GuadarramaM, MolinaI, RaoJNK.A comparison of small area estimation methods for poverty mapping. Stat Transit New Ser Surv Meth Joint Issue2014; 17: 41–66.
9.
HossainJ, DasS, ChandraH, IslamMA.Disaggregate level estimates and spatial mapping of food insecurity in Bangladesh by linking survey and census data. Plos One2020; 15: 1–16.
10.
MarhuendaY, MolinaI, MoralesD, RaoJNK.Poverty mapping in small areas under a twofold nested error regression model. J Royal Stat Soc: Series A2017; 180: 1111–1136.
11.
MolinaI, RaoJNK.Small area estimation of poverty indicators. Cananadian J Stat2010; 38: 369–385.
12.
NeriL, BalliniF, BettiG.Poverty and inequality mapping in transition countries. Stat in Transit2005; 7: 135–157.
13.
RaoJNK, MolinaI.Small area estimation (2nd ed.). Hoboken, NJ: Wiley2015.