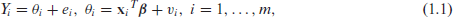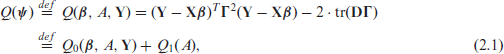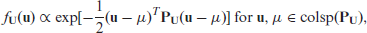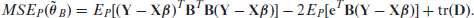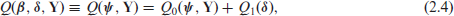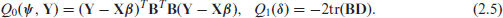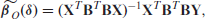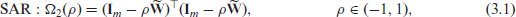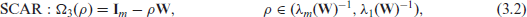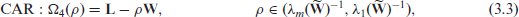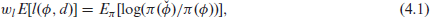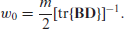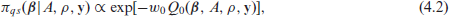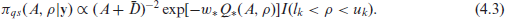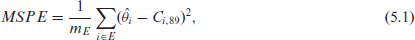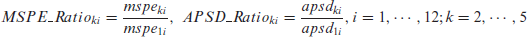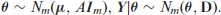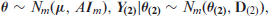The empirical best linear unbiased prediction (EBLUP) method has been the dominant model-based approach in small area estimation. As an alternative to this frequentist method, the observed best prediction (OBP) method, also frequentist, was proposed by Jiang et al.[11] where the parameters of the model are estimated by minimizing an objective function which is implied by the total mean squared prediction error. In a recent article, Datta et al.[6] followed a general Bayesian approach, proposed recently by Bissiri et al.[2], to develop a quasi-Bayesian method by appropriately calibrating the objective function for the OBP method for the Fay-Herriot model. In a different article, Chung and Datta[4] demonstrated that in the absence of covariates with good predictive power the small area estimates from the standard Fay-Herriot model can be improved by using spatially dependent random effects. In this article, we develop a quasi-Bayesian small area estimation method using several spatial alternatives to the independent Fay-Herriot random effects model. Evaluation of the proposed method based on an application to estimation of four-person family median incomes for the U.S. states shows its usefulness. Limited but related simulation studies for the median incomes application reinforce our conclusion.
Shrinkage estimation of the mean vector of a multivariate normal distribution is a pioneering breakthrough in statistics by Stein[21]. He showed that the vector of shrinkage estimators of the individual means has lower frequentist risk under a sum of squared error loss than that of the uniformly minimum variance unbiased estimator vector. Shrinkage estimation makes sense when the components of the mean vector have similar interpretation such as means of a characteristic for many similar subpopulations. Concurrent estimation of subpopulation means is of fundamental importance in small area estimation. Small areas in survey sampling are subpopulations, defined by demographic and/or geographic partitioning of a suitable population. Small areas are actually subpopulations or subdomains of some target population which do not get enough allocations of samples to estimate their means with adequate accuracy.
In a pioneering paper, Efron and Morris[8] showed Stein’s estimators can be interpreted as empirical Bayes (EB) estimators of the means if one assumes some appropriate models for the mean vector. This EB representation presents a heuristic justification for the above-mentioned risk domination that shrinkage estimators enjoy.
Reliable estimates of subpopulation characteristics are urgently needed by many national statistical offices to help government administrators implement various social and fiscal policies of their governments. However, a traditional estimate , also called a direct estimate, of based only on the sample from that subpopulation may have unacceptable level of estimation error if the corresponding sample size is small. To improve low accuracy of direct estimates of small area means, researchers recommended combining information from the other subpopulations, possibly similar, through model-based estimation of small area means by using suitable models for the s based on appropriate covariates, if available.
In a large-scale pioneering application of model based small area estimation of average incomes of many small localities in US, Fay and Herriot[9] proposed a model which is now extensively used in small area estimation. Their model, which is known as the Fay-Herriot model in small area estimation literature, implicitly connects direct estimator of with related covariates .
Fay and Herriot[9] proposed a mixed effects model given by
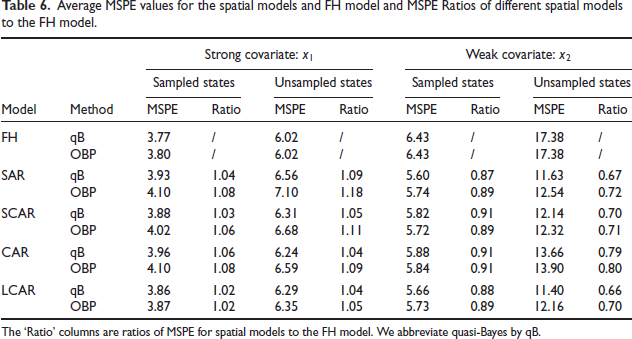
where is related to via the sampling model, and is related to the covariates via the linking model. It assumes that the sampling error satisfies and , where the subscript refers to the sampling design. Sampling errors are assumed to be independent and normally distributed, and are independent of linking errors, , the area-specific random effects, which are assumed to be independent and normally distributed with zero mean and a common variance . The sampling variances, ’s, which are usually estimated, are treated as known. We denote model parameters by , where is a vector of unknown regression coefficients. In the FayHerriot model, for a vector of known covariates , estimation of small area means becomes prediction of the mixed effects .
While Fay and Herriot[9] used the EB approach to estimate based on the model given by equation (1.1), Prasad and RaO[15], Lahiri and RaO[12], Datta and Lahiri[5] and Datta et al.[7] used the empirical best linear unbiased predictor (EBLUP) method, a frequentist approach, and they derived the second-order approximate mean squared error (MSE) of the EBLUPs of , and second-order approximate unbiased estimators of the MSE’s for various estimators of the variance parameter (see Datta and Lahiri[5]). However, Ghosh[10] developed hierarchical Bayes (HB) estimation of by augmenting the model in equation (1.1) by an improper uniform prior for and . Later on, Datta et al.[7] also considered the HB prediction of ’s for the Fay-Herriot model.
The model in equation (1.1) assumes independence of the random effects terms ’s across small areas. For subsequent reference we will call this model as the independent Fay-Herriot model. Small area means of geographic areas often display a strong spatial dependence among themselves. In the absence of effective covariates, there maybe a systematic model misspecification by the independent FH model for the means due to spatial correlation among random effects. In such applications, it is recommended to use suitable spatial models for the random effects. In a recent article, Chung and Datta[4] developed comprehensive estimation of ’s under many popular spatial models based on certain noninformative priors on the model parameters. We briefly describe these spatial models in the next section.
The EBLUP approach played a major role in small area estimation (cf. Battese et al.[1]; Prasad and RaO[15]). While the independent model has been a very popular model for creating the EBLUPs of small area means, many authors in the last twenty years alternatively used spatial random effects models. See, for example, Saei and Chambers[19], Singh et al.[20], Petrucci and Salvati[14], Pratesi and Salvati[17] and Pratesi et al.[16].
The EBLUP or the EB predictions of small area means are carried out in two steps, and these predictors are derived under the popular sum of squared error loss function. For simplicity, we present the main ideas below for the independent FH model. First, for known model parameters , the best predictor (BP) of , given by
is derived, where . However, since is unknown, the predictor cannot be used. Estimators of and the regression coefficient are typically obtained by iterative computation based on the marginal distribution of the data.
In a pioneering paper, Jiang et al.[11] argued that the second step in developing the EBLUPs is not suitable for prediction of since areas with less accurate ’s have less influence in determining the model parameters. The maximum likelihood or weighted least squares estimator of assigns relatively lower weights to direct estimators with larger sampling error variances ’s. Since prediction of ’s is the main interest, they argued for a purely predictive procedure where both the predictor of and the estimators of model parameters are derived by minimization of a total predictive mean squared error. We review their method in the next section. These authors also argued that their proposal, which they called observed best prediction (OBP), an alternative to the EBLUP, is less sensitive to misspecification of the mean function. Since both the spatial random effects model and the OBP method are effective tools to address misspecification of the mean function of ’s, in this article we develop a method by combining these two ideas. To address this objective we will extend a quasi-Bayesian method recently developed by Datta et al.[6]. This method allows us to compute meaningful measure of uncertainty for the Bayesian analogs of OBP estimates for the spatial models. Asymptotically justified estimator of mean squared error of OBP predictor has been derived by Liu et al.[13] for the independent Fay-Herriot model. This derivation is non-trivial, and no such results exist nor can be easily derived for the spatial Fay-Herriot models. Moreover, such estimator may not always be positive. Our proposed measure of uncertainty, quasi-Bayesian posterior variance, is computational and nonnegative. We showed in Datta et al.[6] that the quasi-Bayesian method for the independent Fay-Herriot setup is a competitive alternative to the OBP method.
A Brief Review of the OBP Method
We use the notation to denote the mean vector and to denote the vector of direct estimates. We first review the objective function crucial to the OBP method of Jiang et al.[11] for the independent Fay-Herriot model. Under the sum of squared error loss function to estimate by an estimator , (Rao and Molina[18], p. 166) presented an alternative and transparent derivation of the objective function obtained by Jiang et al.[11] to estimate the model parameters . (Rao and Molina[18], p. 166) computed the total sampling MSE of . Using equation (6.4.52) in their book, they obtained . They dropped the last term, , which is known, to obtain the objective function of Jiang et al.[11]. This function is given by
where , and is the shrinkage matrix shrinking to the regression function. The resulting estimator , obtained by minimizing , is referred to as the best predictive estimator (BPE) of .
The objective function in (2.1), which is valid for the independent Fay-Herriot model, has been generalized by Jiang et al.[11] even for dependent random effects model. To allow a greater generality for random effects distribution we use the precision matrix to denote a multivariate normal pdf for random effects so that even a singular pdf can be considered. If this matrix is positive definite, it is equivalent to the inverse of the variance-covariance matrix of the random effects. We present the pdf of random effects under various spatial models considered in the next section by using the precision matrix. While the precision matrices for most spatial models are p.d., it is not so for the intrinsic autoregression (IAR) model (discussed later). If a random vector has the pdf given by
we use the notation . Here, the symmetric matrix is n.n.d. and is the column space of the matrix . If is singular, then the distribution of is singular. Following equation (27) of Jiang et al.[11] we consider the following mixed effects model
where and are independently distributed with and . Here, we assume that is known, and depends on a parameter vector . We also assume that is p.d., which is identical to , where is the sampling variance-covariance matrix. Let the mixed effects that we need to predict be denoted by . If the precision matrix is singular, then the distribution of will be singular, and in that case, we also need that . Consequently, if , then rank of the matrix is at least . We redefine the model parameter vector by .
Considering known, the best predictor (BP) of , denoted by , can be obtained from the distribution of and . The is given by
where . The associated measure of uncertainty, , is given by . Following the argument of Rao and Molina[18] presented above, we will derive below the equivalent expression of the objective function in (2.1) for the model given by equation (2.2). Noting that , it can be shown that
Using , and dropping the term , and the operator from the first term we get from the previous display the following objective function
where and are given by
We will simplify this general expression of the objective function for various spatial models that we introduce in the next section.
If is known, the BPE of can be obtained by minimizing , the first term on the right-hand side of (2.4). This yields a closed-form solution
where the rank of the matrix is , which follows from the assumption that the rank of the matrix is and .
Now, , the BPE of , is obtained by minimizing with respect to . Then , the BPE of when is unknown is . We denote the BPE of by . Finally, following Jiang et al.[11], the observed best predictor (OBP) of the mixed effects will be obtained by replacing in the BP (2.3) with its BPE .
Fay-Herriot Model for Spatially Dependent Random Effects
To highlight importance of spatial models in SAE Chung and Datta[4] commented that in many problems the area characteristic of interest is closely related to various factors such as population size, ethnicity, age-group and education level which usually change geographically. Many economic and health characteristics display certain spatial patterns. When available covariates do not fully explain such spatial association, the independence and equal variance assumptions of random effects for the model in (1.1) fail, and this simple model may generate unreliable estimates. As an example, they noted that the spatial correlation, measured by Moran’s , for the 1989 four-person family median incomes based on the 1990 Census of the forty-nine contiguous states (including Washington, D.C.) of the U.S. is 0.44, which indicates a strong spatial dependence. For this example, which we consider later in Section 5, Chung and Datta[4] showed that if the independent Fay-Herriot model does not employ an effective covariate with strong correlation with the SAE characteristic (the 1989 median income), both the accuracy (in terms of bias) and the precision (in terms of variance) of the resulting estimates drop. In terms of these measures, the paper by Chung and Datta[4] showed that in the absence of covariates with good predictive power, various spatial random effects models provide better predictions than the independent Fay-Herriot model (see the right half of Table 1 of this article).
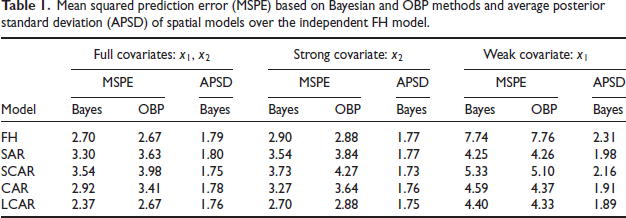
Mean squared prediction error (MSPE) based on Bayesian and OBP methods and average posterior standard deviation (APSD) of spatial models over the independent FH model.
Model
Full covariates:
Strong covariate:
Weak covariate:
MSPE
APSD
MSPE
APSD
MSPE
APSD
Bayes
OBP
Bayes
Bayes
OBP
Bayes
Bayes
OBP
Bayes
FH
2.70
2.67
1.79
2.90
2.88
1.77
7.74
7.76
2.31
SAR
3.30
3.63
1.80
3.54
3.84
I. 77
4.25
4.26
1.98
SCAR
3.54
3.98
1.75
3.73
4.27
1.73
5.33
5.10
2.16
CAR
2.92
3.41
1.78
3.27
3.64
1.76
4.59
4.37
1.91
LCAR
2.37
2.67
1.76
2.70
2.88
1.75
4.40
4.33
1.89
All the spatial models we consider here are described through the adjacency matrix of small areas , which plays an important role in capturing spatial association. Here, if the th and th small areas are neighbors, and , otherwise. Also, for . Let be the sum of the th row of and . Assume that all small areas have at least 1 neighboring area. This implies that is p.d. We define . We present a few key facts about the eigenvalues of and . First, is a symmetric matrix, all its eigenvalues are real. We denote the th largest eigenvalue of by . Since is non-null and , it follows that . Since is a row stochastic matrix, all of its eigenvalues are bounded above by 1, and at least one of them is 1, that is, . Since and have the same eigenvalues, and the second matrix is symmetric, the eigenvalues of are real. Finally, implies must be negative.
We will use to denote the matrix . Four important spatially dependent random effects models are represented by the following positive definite matrices:
where is the spatial parameter that controls the strength of spatial dependence. Even though we are using the same notation in all four models, meaning of this parameter changes from one model to another. For the th model, varies between and ; these bounds are given above by (3.1)-(3.4). Chung and Datta[4] argued that all the precision matrices above are positive definite. Note that , and the matrix is the precision matrix of the intrinsic autoregressive (IAR) model, another popular spatial model. This matrix is singular since is a singular matrix .
The model (3.2) is a simple version of conditional autoregressive model (Rao and Molina[18], Ch. 9.6.2) where diagonal entries of the precision matrix are all equal to one. This model is known as the simple conditional autoregressive (SCAR) model. The model (3.3) is the widely used conditional autoregressive (CAR) model. Diagonal entries of the precision matrix are for the CAR model, and these entries are between 1 and for the LCAR model. The conditional autoregressive models, SCAR, CAR, and LCAR, assume that depends only on neighboring small area means. In other words, is correlated with ’s, , only for the surrounding areas. On the contrary, the simultaneous autoregressive (SAR) model assumes that is dependent on all other concurrently, , but has stronger (weaker) correlations for neighboring (remote) areas. The independent model can be viewed as a special case of the SAR, SCAR, or LCAR model with . In an analogy to the spatial models, the precision matrix of the independent FH model is . For convenience of notation, although this precision matrix is free from , we denote it by . We note that for various models we considered here the matrices correspond to the precision matrix in the model (2.2).
A full Bayesian analysis for the spatial models above based on a class of improper priors for and was pursued by Chung and Datta[4]. For the CAR model with with , the intrinsic CAR model (which we refer to here also as the IAR model), a fully Bayesian analysis based on a proper inverse gamma prior for has been considered by Vogt[22] and Vogt et al.[23]. Even though the IAR model is a limiting case of the model with , Chung and Datta[4] did not pursue the IAR model, and the proof of the propriety of the posterior for the CAR model will not automatically extend to the ICAR (or IAR) model without appropriate modification.
The EBLUP approach to small area estimation for some spatial models has been considered by several authors. Singh et al.[20] made a pioneering effort for the SAR model. Following the approach of Datta and Lahiri[5], Singh et al.[20] derived a second-order approximation to the MSE of the EBLUP and a second-order unbiased estimator the MSE. Petrucci and Salvati[14], Pratesi and Salvati[17] and Pratesi et al.[16] used Singh et al.[20] results to several useful applications.
A Quasi-Bayesian Alternative to the OBP
For the independent Fay-Herriot model Datta et al.[6] developed an alternative Bayesian version of the OBP method of Jiang et al.[11]. While they referred to this method as pseudo-Bayes, the term pseudo’ seems to have a pejorative meaning. Consequently, in this article we will replace pseudo’ by quasi’.
In a recent article Liu et al.[13] obtained a suitably justified estimator of the MSE of the OBP predictors of small area means for the independent Fay-Herriot model. However, derivation of the estimator is challenging and the estimator is occasionally negative. Quasi-Bayesian method of Datta et al.[6] not only produces point estimates comparable with the OBPs, the associated posterior variances, naturally positive, are comparable with MSE estimates. Additionally, the quasiBayesian method provides useful credible intervals for the small area means in a straightforward manner. Even though the frequentist OBP point predictors for the spatial models can be calculated, no valid estimators of their MSEs are available yet. Any reasonable extension of the tedious calculations for the estimators of MSE, presented in Liu et al.[13] only for the independent model, will be far more challenging for the spatial models. Moreover, these estimators may be negative. Due to much usefulness of both the spatial models and the OBP method, a quasi-Bayesian extension of Datta et al.[6] solution for the independent Fay-Herriot model to a spatial dependent setup can serve as a way to provide reasonable credible intervals as well as uncertainty estimates of the estimators for small area means.
The standard Bayesian method updates a prior distribution of the parameters in a model by their likelihood. In a recent article, Bissiri et al.[2] presented a general method to update a prior distribution for parameters to a posterior distribution when the parameters are connected to observations through a loss function rather than the traditional likelihood. Since the OBP procedure uses only a loss function and not the likelihood for the model parameters to estimate them, in our Bayesian analog to the OBP solution we use the OBP loss function and an algorithm from Bissiri et al.[2] to create a quasi-likelihood function. Indeed, Datta et al.[6] followed this algorithm to construct a quasi-likelihood from the OBP loss function under the independent Fay-Herriot model and a quasi-Bayesian solution from this likelihood.
Update of a Prior by a Loss Function: a Quasi-posterior
The discussion in this subsection is based on modification of Section 2.1 of Datta et al.[6]. To derive a quasi-posterior pdf for , we adopt the framework for general Bayesian inference put forward by Bissiri et al.[2]. According to these authors, the information’ about the parameter in the loss function should be appropriately calibrated to update the prior distribution for . We update the uniform prior on by creating an ad hoc likelihood’ for from this loss function. Since the loss function depends on the scale of the data , the ad hoc likelihood needs to be calibrated so that both the ad hoc likelihood and the prior pdf of become scale-free’.
In general, for some data with the density and prior for the parameter , the usual Bayes' rule updates the prior to the posterior pdf determined by normalization of the kernel of . This kernel is proportional to , where and is a suitably chosen value of . Bissiri et al.[2] and Bissiri and Walker[3] developed a general Bayesian method which generalizes the usual Bayes' rule to facilitate updating a prior pdf by loss information on the parameter . A brief review of their solution is below.
If a nonnegative function is the loss information on based on data , Bissiri et al.[2] suggests a general Bayes’ method to update a prior pdf by the normalized version of the kernel , where is an appropriate constant to calibrate the loss information so that the components and are on a comparable scale. When is , the self-information loss, is the natural choice to combine the data loss with the prior to update the prior distribution. In our application, the loss function for is not a self-information loss. Bissiri et al.[2] (cf. Section 3) argues that when different types of loss functions are combined, their calibration is crucial. In particular, the loss function should be commensurate to the prior distribution.
One way to combine two losses and is based on a prior evaluation of the expected value of to determine for the calibration (Bissiri et al.[2], Section 3.2). To pick , solve
where the left hand expectation is with respect to a joint distribution for and , say , and the resulting marginal for is . Here, is taken as the maximizer of . Specifically, if given has mean and variance and , respectively, and if is normal with mean and variance , then for squared error , the scale is . This calibration relates the loss to the self-information loss for normally distributed data. The scaling constant is independent of both and . Hence, by taking a very large , one can approach a uniform prior for and calibrate the squared error loss function relative to this approximate prior.
Calibration for : Quasi-posterior of Given
We calibrate , the first component of our loss function. For given , following an argument similar to the one from Section 2.2 of Datta et al.[6], we find that for a multivariate normal
prior for an appropriate scaling factor, , is given by
The matrix has been defined following equation (2.3). This scalar is free from the parameters of the multivariate normal prior. By taking the variance of this prior very large’, we can use the traditional uniform prior for . Thus the posterior for is
see (Bissiri et al.[2]). The above posterior distribution, conditional on , is multivariate normal with mean vector and variance-covariance matrix .
Approximate Calibration of Loss Function for and
The two-step minimization of the loss function to estimate the model parameters gives the loss function for and . For a prior on and , we need to calibrate the loss function by suitable weight to create a quasi-likelihood for and .
Let . We use a uniform prior for over its allowable range , and an independent prior . It can be shown that . We remark that this value is specific to the prior . For another proper prior , we need to recompute the corresponding value, which we may do by the Monte Carlo method. We also need to compute , where the expectation is with respect to the joint distribution of and the model parameters. We can simplify this via iterative expectation by using the first two moments of (given ). The result depends on , but not on , and we find the Monte Carlo expectation of this function with respect to the prior for and by drawing 10000 values for the pair from their joint prior distribution. Using this value, we get the calibration coefficient using appropriate modification of the equation (4.1).
Using the above calibration weight, for the loss function , an update of the prior is given by the quasi-posterior
To make quasi-Bayesian inference on , first generate generate and from the quasi-posterior in (4.3), then use the generated and to get from its conditional quasi-posterior in (4.2). Finally, use the generated values of to draw from an MVN distribution with mean in (2.3) and variance-covariance matrix .
For a suitably large , we generate , following the method outlined above. Based on these generated values of , we can create various summaries of the posterior distribution including the posterior mean, variance and posterior quantiles of to find their point estimates and credible intervals.
Finally, for the IAR model we have no spatial correlation parameter and the precision matrix of is given by . Using this precision matrix we can easily obtain and , which will provide the quasi-posterior distributions of and .
Application to the Current Population Survey Data
We apply our quasi-Bayesian method for the spatial models to estimate the four-person family median incomes for forty-eight states of the continental US and the District of Columbia for the income year 1989. We exclude Alaska and Hawaii from this application because they are geographically isolated from the continental US. The US Department of Health and Human Services (HHS) needs accurate state-level median income estimates to implement an energy assistance program for low-income families. The yearly household income data is collected from the Annual Demographic Supplement to the monthly Current Population Survey (CPS). The state-level estimates for most states from the CPS sample, unfortunately, are not adequately accurate. Using the CPS estimates as direct estimates, and relevant administrative data and past census data as covariates, the US Census Bureau developed model based estimates of the median incomes by using the regular Fay-Herriot model with independent random effects. In this application, we develop alternative small area estimates of median incomes based on the spatial models and compare their performances with the estimates from the traditional Fay-Herriot model. We consider estimation of incomes for the year 1989 since more accurate estimates of the 1989 unknown incomes are available from the 1990 decennial census. Since census values are accurate, we treat these estimates as true values’ and compare our various predictions against these values.
We denote the true 1989 four-person family median income for th state by , and the direct estimate of from the 1990 CPS by . Two available covariates for this problem are
: 1979 four-person family median income of the ith state from the 1980 census,
: adjusted 1979 census four-person family median income of the ith state,
where PCI is state level per capita income from the U.S. Bureau of Economic Analysis. From our present and previous analyses (cf. Chung and Datta[4] and Datta et al.[6]) we found that the covariate is more effective in accounting the variability of the median income in small areas. When we look at the spatial dependence within each covariate, we find that the Moran’s I measuring the spatial dependence for the 1989 census state median incomes is 0.50. The corresponding value for is 0.43. The Moran’s I for the direct estimates from the 1989 CPS is 0.31. But the same for is 0.22. While the CPS estimates track closely in terms of Moran’s I of the true’ values, the 1989 census values, they have high variances. Based on Moran’s I, borrowing information from may be more effective than using to track spatial patterns of ’s. We use mean squared prediction error (MSPE) from the truth’ , which are unknown. In their place, we use the median income values we obtained from the 1990 census. We denote these values by . We also compute average of posterior standard deviations (APSD) to evaluate the accuracy of predictions. We define these criteria by
where is the estimated value from each model and is the true median income value. Here is a suitable subset of , which is determined by indices only of the sampled or non-sampled small areas, and is the number of elements in . Finally, is the posterior standard deviation of based on the model under consideration.
Median Incomes of 4-person Families by State
We fit four spatial models defined by (3.1) to (3.4) and the FH model with three subsets of covariates, given by the design matrix , or , or . The first setting is the most efficient one and the last setting is the least efficient. We calculate the MSPEs and APSDs over 49 areas from respective ’s and results are summarized in Table 1. Results reported for Bayes are based on the quasi-Bayes predictors we develop here.
Table 1 above shows that for the most efficient set of covariates (full covariates) the LCAR model has about 12 per cent smaller MSPE and 2 per cent smaller APSD than those of the independent FH model for quasi-Bayes. Since displays a good spatial pattern, it can explain most of the variability of . As a result, it is not surprising that in terms of MSPE, except the LCAR model, the independent FH model is at least as good as the spatial models. In terms of the APSD values, all five models are comparable. Moreover, in terms of MSPE, quasi-Bayes outperforms OBP method for all four spatial models. The quasi-Bayes method has about 14 per cent smaller MSPE than those of the OBP method of CAR model.
On the other extreme, when only the weaker variable is included in the regression model, it is no surprise that the MSPE and the APSD for all five models are higher in comparison with the other two combinations of covariates for both quasi-Bayes and OBP. In this case, under quasi-Bayes method, however, the MSPE and the APSD of the SAR are approximately 45 per cent and 14 per cent, respectively, less than those of the independent FH model. The LCAR is the second-best model in terms of MSPE, with an MSPE that is 43 per cent smaller, and in terms of the APSD the LCAR is the best for which the APSD is 18 per cent smaller than that for the independent FH model. By removing the strong covariate from the full model, the MSPE of the SAR and LCAR models increase by about 29 per cent and 86 per cent, respectively, while the MSPE of the independent FH model increases by roughly 187 per cent. These results show that when covariates are less than effective in explaining existing spatial variation, spatial models that account for such variation can generate much more accurate predictions than the independent FH model.
Table 1 provides MSPE values for the OBP method. In terms of the MSPE, only when the weak covariate is used in the regression function, the OBP only marginally performs better than the quasiBayes predictors for the SCAR and CAR models. However, the OBP has no estimated root mean squared error of prediction for spatial models.
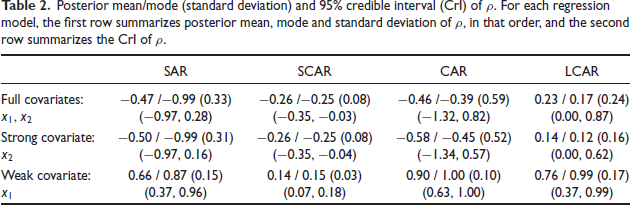
In Table 2 we provide point estimates and credible intervals of the spatial parameter for various models. Among the three sets of regression models we considered, only for the case of , credible intervals of the spatial parameter for all four models do not include 0, the null value; these intervals quite strongly indicate the presence of a significantly nonzero spatial pattern.
Posterior mean/mode (standard deviation) and 95% credible interval (Crl) of . For each regression model, the first row summarizes posterior mean, mode and standard deviation of , in that order, and the second row summarizes the Crl of .
SAR
SCAR
CAR
LCAR
Full covariates:
Strong covariate:
Weak covariate:
Estimation of Some Non-sampled State Means
We evaluate the spatial models in terms of the accuracy of their predictions for non-sampled small areas. In this study we have evaluated both the approaches, quasi-Bayesian and OBP. Again, our two covariate settings are and . To check the quality of prediction for non-sampled areas with no direct estimates, we follow an idea of Chung and Datta[4]. Suppose there are nonsampled areas and sampled areas. We constructed 12 data sets in an arbitrary manner, eleven of which lack four direct estimates and one lacks five direct estimates. We do not use CPS estimates (direct estimates) of the states omitted at each example and predict the ’s of the omitted states. Suppose is the subvector of corresponding to the non-sampled areas, and is the subvector of corresponding to the sampled areas. Let denote the vector of direct estimates for the sampled areas. We arrange the elements of and define an indicator matrix so that . The matrix is with its last columns form an identity matrix, and the first columns are null vectors. We then define .
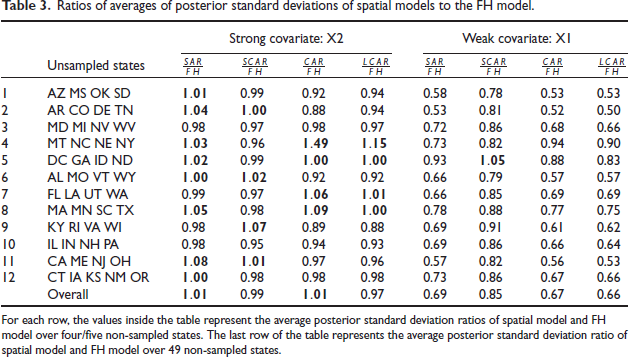
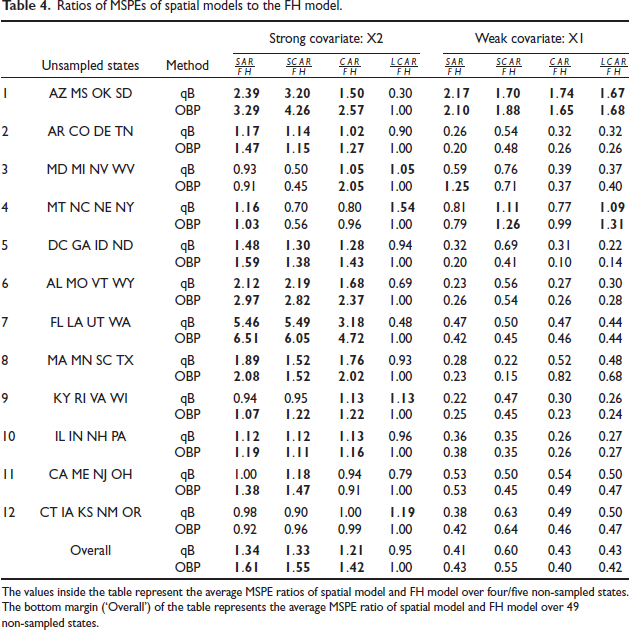
We obtain OBP and quasi-Bayes predictions of based on for all five models. Using these predictions, we compute, for each non-sampled area under the FH model and spatial models for each data set, the squared prediction error for both the quasi-Bayes and OBP point predictors. Obviously, we get the posterior standard deviations only for the quasi-Bayes method. We summarize the mean squared prediction error (MSPE) over non-sampled areas for each data set in Table 4 and average posterior standard deviation (APSD) in Table 3. Evaluation of prediction performance is based on the following ratios:
Ratios of averages of posterior standard deviations of spatial models to the model.
Unsampled states
Strong covariate: X2
Weak covariate: XI
I
AZ MS OK SD
1.01
0.99
0.92
0.94
0.58
0.78
0.53
0.53
2
AR CO DE TN
1.04
1.00
0.88
0.94
0.53
0.81
0.52
0.50
3
MD MI NV WV
0.98
0.97
0.98
0.97
0.72
0.86
0.68
0.66
4
MT NC NE NY
1.03
0.96
1.49
1.15
0.73
0.82
0.94
0.90
5
DC GA ID ND
1.02
0.99
1.00
1.00
0.93
1.05
0.88
0.83
6
AL MO VT WY
1.00
1.02
0.92
0.92
0.66
0.79
0.57
0.57
7
FL LA UT WA
0.99
0.97
1.06
1.01
0.66
0.85
0.69
0.69
8
MA MN SC TX
1.05
0.98
1.09
1.00
0.78
0.88
0.77
0.75
9
KY RI VA WI
0.98
1.07
0.89
0.88
0.69
0.91
0.61
0.62
10
IL IN NH PA
0.98
0.95
0.94
0.93
0.69
0.86
0.66
0.64
II
CA ME NJ OH
1.08
1.01
0.97
0.96
0.57
0.82
0.56
0.53
12
CT IA KS NM OR
1.00
0.98
0.98
0.98
0.73
0.86
0.67
0.66
Overall
1.01
0.99
1.01
0.97
0.69
0.85
0.67
0.66
For each row, the values inside the table represent the average posterior standard deviation ratios of spatial model and model over four/five non-sampled states. The last row of the table represents the average posterior standard deviation ratio of spatial model and FH model over 49 non-sampled states.
where is the average posterior standard deviations of all omitted ’s (four or five) under the th model for the th data set. A similar meaning is for . The value of MSPE_Ratio or APSD_Ratio k less than one means that the kth spatial model using ith data set has a smaller mean squared prediction error or average posterior standard deviation than the FH model. Ratios higher than one are highlighted in bold in Table 3 and Table 4.
Ratios of MSPEs of spatial models to the FH model.
Unsampled states
Method
Strong covariate:
Weak covariate:
1
AZ MS OK SD
qB
2.39
3.20
1.50
0.30
2.17
1.70
1.74
1.67
OBP
3.29
4.26
2.57
1.00
2.10
1.88
1.65
1.68
2
AR CO DE TN
qB
1.17
1.14
1.02
0.90
0.26
0.54
0.32
0.32
OBP
1.47
1.15
1.27
1.00
0.20
0.48
0.26
0.26
3
MD MI NV WV
qB
0.93
0.50
1.05
1.05
0.59
0.76
0.39
0.37
OBP
0.91
0.45
2.05
1.00
1.25
0.71
0.37
0.40
4
MT NC NE NY
qB
1.16
0.70
0.80
1.54
0.81
1.11
0.77
1.09
OBP
1.03
0.56
0.96
1.00
0.79
1.26
0.99
1.31
5
DC GA ID ND
qB
1.48
1.30
1.28
0.94
0.32
0.69
0.31
0.22
OBP
1.59
1.38
1.43
1.00
0.20
0.41
0.10
0.14
6
AL MO VT WY
qB
2.12
2.19
1.68
0.69
0.23
0.56
0.27
0.30
OBP
2.97
2.82
2.37
1.00
0.26
0.54
0.26
0.28
7
FL LA UT WA
qB
5.46
5.49
3.18
0.48
0.47
0.50
0.47
0.44
OBP
6.51
6.05
4.72
1.00
0.42
0.45
0.46
0.44
8
MA MN SC TX
qB
1.89
1.52
1.76
0.93
0.28
0.22
0.52
0.48
OBP
2.08
1.52
2.02
1.00
0.23
0.15
0.82
0.68
9
KY RI VA WI
qB
0.94
0.95
1.13
1.13
0.22
0.47
0.30
0.26
OBP
1.07
1.22
1.22
1.00
0.25
0.45
0.23
0.24
10
IL IN NH PA
qB
1.12
1.12
1.13
0.96
0.36
0.35
0.26
0.27
OBP
1.19
1.11
1.16
1.00
0.38
0.35
0.26
0.27
11
CA ME NJ OH
qB
1.00
1.18
0.94
0.79
0.53
0.50
0.54
0.50
OBP
1.38
1.47
0.91
1.00
0.53
0.45
0.49
0.47
12
CT IA KS NM OR
qB
0.98
0.90
1.00
1.19
0.38
0.63
0.49
0.50
OBP
0.92
0.96
0.99
1.00
0.42
0.64
0.46
0.47
Overall
qB
1.34
1.33
1.21
0.95
0.41
0.60
0.43
0.43
OBP
1.61
1.55
1.42
1.00
0.43
0.55
0.40
0.42
The values inside the table represent the average MSPE ratios of spatial model and FH model over four/five non-sampled states. The bottom margin ('Overall') of the table represents the average MSPE ratio of spatial model and FH model over 49 non-sampled states.
When using a weak covariate, the MSPEs and APSDs of SAR, SCAR, CAR, and LCAR models for the non-sampled states are usually smaller than those based on the independent FH model. Their Overall’ MSPE ratios (to the FH independent model) are and 0.43, respectively. The Overall’ APSD ratios are and 0.66, respectively. Both SAR and CAR models produce an MSPE ratio greater than 1 for one data set, whereas SCAR and LCAR models produce MSPE ratios greater than 1 for two data sets. Even after substantial exploratory analysis we have been unable to hit on a possible explanation for this anomaly.
For the more effective covariate setting, in terms of both MSPE and APSD ratios, except the LCAR model all other spatial models fare worse than the independent FH model. In this case, the LCAR model has the smallest MSPE ratio of 0.95 and the APSD ratio of 0.97.
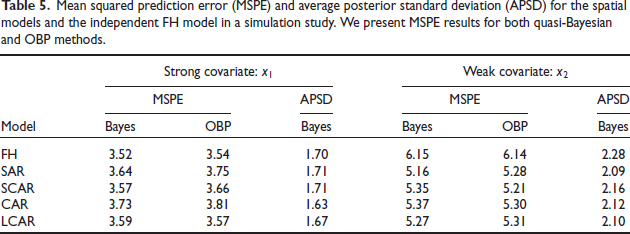
Mean squared prediction error (MSPE) and average posterior standard deviation (APSD) for the spatial models and the independent FH model in a simulation study. We present MSPE results for both quasi-Bayesian and OBP methods.
Model
Strong covariate:
Weak covariate:
MSPE
APSD
MSPE
APSD
Bayes
OBP
Bayes
Bayes
OBP
Bayes
3.52
3.54
1.70
6.15
6.14
2.28
SAR
3.64
3.75
I.7I
5.16
5.28
2.09
SCAR
3.57
3.66
I.7I
5.35
5.21
2.16
CAR
3.73
3.81
1.63
5.37
5.30
2.12
LCAR
3.59
3.57
I. 67
5.27
5.31
2.10
Finally, from the right half of Table 4 we see that for the weak covariate case, the average MSPEs for the OBP predictors are lower under the spatial models than under the independent FH model. Also, the same part of this table shows that improvements in these MSPE ratios are slightly better for the OBP method than for the quasi-Bayesian method. However, for the SAR model, the Bayesian method is at least as good as the OBP method. We reiterate that while the Bayesian method provides a measure of uncertainty of the point estimates, the OBP method has no such measure available.
Simulation Studies
In this section, we present two simulation studies to examine our proposed quasi-Bayes approach to spatial models under two scenarios. To make the simulation setting realistic, we mimic the 1989 4 -person family median income data described in Section 5. The first scenario evaluates the quality of prediction under two different informative covariate settings with all contiguous areas (48 states and Washington, D.C.) of U.S. and the second scenario evaluates the quality of prediction in the absence of direct estimates, details are shown in Subsections 6.1 and 6.2, respectively.
A Simulation Study Without Non-sampled Areas
In the first simulation, we mainly evaluate the quality of prediction under different covariate settings, strong and weak covariates. There are no non-sampled areas. For each setting, we consider S replicated data sets.
Data generation: We use the values from the application as the ’s in the simulations. Let . We set so that the Morans I values of 100 replicated small area means range from 0.32 to 0.66 with mean 0.50 (which is consisitent with Moran’s I value for the 1989 census state median incomes in Section 5) and and consider two independent covariates and with SAR spatial dependence, that is, . Then, letting and , we generate small area means and direct estimates from the following independent FH model:
The covariate introduces stronger (weaker) spatial pattern to the ’s, and we refer as the strong (weak) covariate.
The simulation outcomes presented in Table 5 align with the real data analysis outcomes presented in Table 1. At the strong covariate setting, the independent model is a very competitive model for both quasi-Bayes and OBP methods. At the weak covariate setting, the LCAR model has roughly 14 per cent smaller MSPE (quasi-Bayes method) and 8 per cent lower APSD than the FH model. In contrast, with the strong covariate setting, the MSPE and APSD values for the LCAR and FH models are comparable since can explain the majority of variability of ’s. Moreover, when only the weaker variable is included in the regression model, the MSPE and APSD for all five models are greater than their counterparts when only the stronger covariate is included. Across these covaiate settings, the MSPEs of the SAR, SCAR, CAR and LCAR models increase by approximately 42 per cent, 50 per cent, 44 per cent and 47 per cent, respectively, for the quasi-Bayes method, and 41 per cent, 42 per cent, 39 per cent and 49 per cent, respectively, for the OBP method. While the MSPE of the independent FH model increases by 75 per cent and 73 per cent, respectively for the quasi-Bayes and OBP methods. These results again validate usefulness of spatial models when available covariates are not much effective in explaining existing spatial variation.
A Simulation Study with Non-sampled Areas
In the second simulation study, we compare prediction performances of the model and the four spatial models in the absence of informative covariates with several non-sampled areas. Following the setup in Chung and Datta[4], we also do not simulate direct estimates for the following states: Delaware, Massachusetts, Michigan, Nebraska, Rhode Island, South Dakota, and Texas. For the remaining areas we have direct estimates.
Data generation: Similar to the first simulation, the only difference is we do not simulate direct estimates of states. We denote and . We set and and consider two independent covariates and with SAR spatial dependence, that is, . Then, letting and . However, we generate small area means and direct estimates from the following independent FH model:
where the components of and correspond to the sampled small areas.
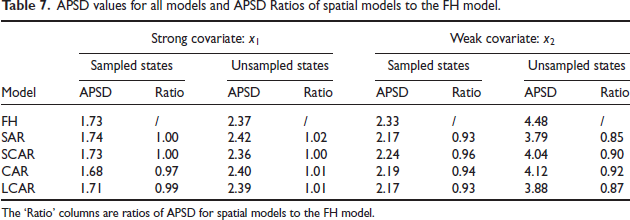
Table 6 presents the average MSPE and MSPE ratios across four spatial models and the FH model if only the strong or weak covariate or is included. When only a strong covariate is given, the independent model is a very competitive model for both quasi-Bayes and OBP methods for both sample states and non-sampled states. Improvements are greater when only a weak covariate is added compared to when only a strong covariate is included. For the quasi-Bayes method under weak covariate setting, LCAR and SAR models have roughly 12 per cent and 13 per cent lower MSPEs than the FH model for sampled states, respectively. For un-sampled states, both LCAR and SAR models have about 33 per cent lower MSPEs than the FH model. We reach a similar conclusion about the spatial models when we compare them in terms of APSD presented in Table 7. Overall, among the four spatial models, LCAR is the most competitive, considering the data were generated using the SAR model. In terms of MSPEs our quasi-Bayes predictors generally outperform the OBP predictors for all spatial models.
Average MSPE values for the spatial models and FH model and MSPE Ratios of different spatial models to the model.
Model
Method
Strong covariate:
Weak covariate:
Sampled states
Unsampled states
Sampled states
Unsampled states
MSPE
Ratio
MSPE
Ratio
MSPE
Ratio
MSPE
Ratio
3.77
I
6.02
I
6.43
I
17.38
I
OBP
3.80
I
6.02
I
6.43
I
17.38
I
SAR
3.93
1.04
6.56
1.09
5.60
0.87
11.63
0.67
OBP
4.10
1.08
7.10
1.18
5.74
0.89
12.54
0.72
SCAR
3.88
1.03
6.31
1.05
5.82
0.91
12.14
0.70
OBP
4.02
1.06
6.68
I.II
5.72
0.89
12.32
CAR
3.96
1.06
6.24
1.04
5.88
0.91
13.66
0.79
OBP
4.10
1.08
6.59
1.09
5.84
0.91
13.90
0.80
LCAR
3.86
1.02
6.29
1.04
5.66
0.88
11.40
0.66
OBP
3.87
1.02
6.35
1.05
5.73
0.89
12.16
0.70
The Ratio’ columns are ratios of MSPE for spatial models to the FH model. We abbreviate quasi-Bayes by qB.
APSD values for all models and APSD Ratios of spatial models to the FH model.
Model
Strong covariate:
Weak covariate:
Sampled states
Unsampled states
Sampled states
Unsampled states
APSD
Ratio
APSD
Ratio
APSD
Ratio
APSD
Ratio
1.73
I
2.37
I
2.33
I
4.48
I
SAR
I. 74
1.00
2.42
1.02
2.17
0.93
3.79
0.85
SCAR
1.73
1.00
2.36
1.00
2.24
0.96
4.04
0.90
CAR
1.68
0.97
2.40
1.01
2.19
0.94
4.12
0.92
LCAR
I.71
0.99
2.39
1.01
2.17
0.93
3.88
0.87
The Ratio’ columns are ratios of APSD for spatial models to the FH model.
Conclusions
Jiang et al.[11] suggested the OBP method as an alternative to the EBLUP method to predict small area means. Although these authors suggested the OBP approach for a general mixed effects model, accurate estimation of the mean squared error of the OBP predictors of small area means are available only for the independent Fay-Herriot model (cf. Liu et al.[13]). Derivation of the MSE estimator by Liu et al.[13] is tedious and the estimator is not guaranteed to be positive. No such results are available for spatial random effects models. Spatial random effects models provide useful prediction of small area means in the absence of good covariates to explain the spatial variation of the small area means (cf. Chung and Datta[4]). In this work, we have developed a quasi-Bayesian version of the OBP method for prediction of small area means based on various spatial random effects model. This work is a generalization for spatial models of the quasi-Bayesian method by Datta et al.[6]. It also generalizes the regular Bayesian spatial method of Chung and Datta[4] for the OBP method based on a quasi-Bayesian argument. Evaluation of the proposed quasi-Bayes spatial predictions based on available Census data and realistic simulations show the usefulness of quasi-Bayesian spatial predictors of small area means. These methods are straightforward to implement to create reliable measures of uncertainty and credible intervals for the small area means.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.
ORCID iD
Gauri S. Datta
References
1.
BatteseGE, HarterRM, FullerWA.An error-components model for prediction of county crop areas using survey and satellite data. J Amer Stat Assoc1988; 83: 28–36.
2.
BissiriPG, HolmesCC, WalkerSG.A general framework for updating belief distributions. J Royal Stat Soc: Series B (Stat Meth)2016; 78: 1103–1130.
3.
BissiriPG, WalkerSG.On general Bayesian inference using loss functions. Stat Prob Lett2019; 152: 89–91.
4.
ChungHC, DattaGS.Bayesian spatial models for estimating means of sampled and non-sampled small areas. Surv Meth2022; 48.2: 463–489.
5.
DattaGS, LahiriP.A unified measure of uncertainty of estimated best linear unbiased predictors in small area estimation problems. Stat Sinica2000; 10: 613–627.
6.
DattaGS, LeeJ, LiJ.Pseudo-Bayesian small area estimation. J Surv Stat Meth2023.
7.
DattaGS, RaoJNK, SmithDD.On measuring the variability of small area estimators under a basic area level model. Biometrika2005; 92: 183–196.
8.
EfronB, MorrisC.Empirical Bayes on vector observations: An extension of Stein’s method. Biometrika1972; 59: 335–347.
9.
FayRE, HerriotRA.Estimates of income for small places: an application of James-Stein procedures to census data. J Amer Stat Assoc1979; 74: 269–277.
10.
GhoshM.Hierarchical and empirical Bayes multivariate estimation, In: Current issues in statistical inference: Essays in honor of D. Basu, IMS Lecture Notes - Monograph Series, Volume 17, GhoshM and PathakPK, Editors. Beachwood, OH: Institute of Mathematical Statistics1992.
11.
JiangJ, NguyenT, RaoJS.Best predictive small area estimation. J Amer Stat Assoc2011; 106: 732–745.
12.
LahiriP, RaoJ.Robust estimation of mean squared error of small area estimators. J Amer Stat Assoc1995; 90: 758–766.
13.
LiuY, LiuX, PanY, JiangJ, XiaoP.An empirical comparison of various MSPE estimators and associated prediction intervals for small area means. J Stat Comput Simulat2022; 93: 1–27.
14.
PetrucciA, SalvatiN.Small area estimation for spatial correlation in watershed erosion assessment. J Agri Bio Env Stat2006; 11: 169–182.
15.
PrasadNGN, RaoJNK.The estimation of the mean squared error of small-area estimators. J Amer Stat Assoc1990; 85: 163–171.
16.
PratesiM, PetrucciA, SalvatiN.Spatial disaggregation and small-area estimation methods for agricultural surveys: solutions and perspectives. 2015: 1–160.
17.
PratesiM, SalvatiN.Small area estimation: the EBLUP estimator based on spatially correlated random area effects. Stat Meth App2008; 17: 113–141.
18.
RaoJNK, MolinaI.Small area estimation. Hoboken, NJ: John Wiley & Sons, Inc2015.
19.
SaeiA, ChambersR.Out of sample estimation for small areas using area level data. 2005. Url: https://eprints.soton.ac.uk/14327/1/14327-01.pdf.
20.
SinghBB, ShuklaGK, KunduD.Spatio-temporal models in small area estimation. Surv Meth2005; 31: 183.
21.
SteinC.Inadmissibility of the usual estimator for the mean of a multivariate normal distribution. Biometrika1956; 1: 197–206.
22.
VogtM.Bayesian spatial modeling: propriety and applications to small area estimation with focus on the German census 2011. PhD thesis, Dissertation, Trier, Universität Trier, 2010.
23.
VogtM, LahiriP, MunnichR.Spatial prediction in small area estimation. Stat Trans New Series2023; 24.