
Abstract
We present a new semiparametric extension of the Fay-Herriot model, termed the agnostic Fay-Herriot model (AGFH), in which the sampling-level model is expressed in terms of an unknown general function
Introduction
In area-level small area studies, the Fay-Herriot model Fay III and Herriot [9] is a commonly used framework and is given by the following two-layered structure:
In the above models and throughout this article, all vectors are column vectors, and the notation
Discussions, including theoretical as well a variety of applications of the above framework may be found in the book Rao and Molina [22] and in the papers Jiang et al. [12]; Das et al. [5]; Pfeffermann and Glickman [18]; Datta et al. [8]; Rao [20]; Jiang and Lahiri [11]; Chatterjee et al. [3]; Li andLahiri [15]; Salvati et al. [24]; Datta et al. [6]; Pfeffermann [17]; Yoshimori and Lahiri [30, 31]; Molina et al. [16]; Sugasawa and Kubokawa [25], Rao [21].
Notationally, the Fay-Herriot model may be written as
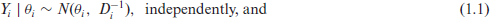
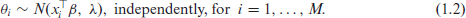
Thus, we have the marginal distribution specification
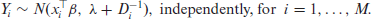
Some routine frequentist computations can be readily performed on this model, and we can first obtain an ordinary least squares (OLS) estimator of
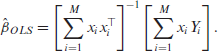
Using this, we may obtain the moment-based estimator of
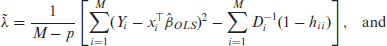
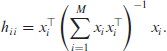
Works on profile and residual likelihoods, and adjustments thereof, have made improvements in estimating
The central problem in small area statistics is to predict the
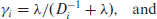
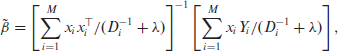
and their empirical versions, with estimates
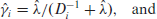
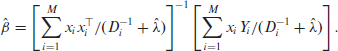
Based on these, we follow Rao and Molina [22] and define the BLUP and its empirical version EBLUP as follows:
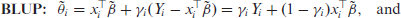
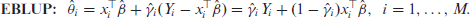
The above frequentist predictors are straightforward and widely used but seem to depend critically on the parametric assumptions given in (1.1) being correct. However in real applications, the Fay-Herriot and other area or unit level small area models are used on observed data that may be bounded in nature or strictly positive. Examples of such cases are proportions and variables like income or lifespan. While (1.1) is often justifiable when large samples are available, this may not always be the case in small area contexts. At the very least, the robustness of the EBLUP-based prediction technique against distributional misspecifications needs to be studied.
In this article, we present a semiparametric extension to the sampling distribution component of the Fay-Herriot model. The semiparametric extension is designed to encapsulate any distributional choice, consequently, we call this extended model the agnostic Fay-Herriot model (AGFH often hereafter). We present a Bayesian modelling technique using a Gaussian Process prior for the unknown functional component of the AGFH model and some theoretical properties of the proposed model. Additionally, we detail a Bayesian computational approach to estimating the AGFH model, which involves a Metropolis within Gibbs Markov Chain Monte Carlo procedure.
We compare the performance of the AGFH model with that of three other techniques in a variety of numeric experiments. We study four different choices of sampling distributions, including the traditional Fay-Herriot framework and cases where the observations are non-negative or bounded. The nature of the sampling distribution is the signal the AGFH learns amidst the noise of the linking model’s variability, and multiple signal-to-noise ratio conditions are studied. The rival techniques we consider include the EBLUP-based approach outlined above, and a hierarchical Bayesian (HB) technique based on the traditional Fay-Herriot model (1.1)(1.2). In addition, we also study the performance of a regression-based predictor that ignores the multi-level dependency present in small area models but is straightforward to implement. In many of the cases we consider, especially where the sampling distribution is bounded or where the sampling variance is high, the AGFH registers a lower Mean Squared Prediction Error (MSPE) value compared to other techniques. However, there are interesting and subtle details about the robustness aspect of the EBLUP-based prediction or hierarchical Bayesian prediction, which we discuss later in the article.
To ensure fair comparison, we always restrict the first two moments of the observable data


Thus, based on the first two moments, the traditional frequentist approach outlined above remains a reasonable and valid technique to use. Using the moment conditions (1.3) and (1.4) is important to ensure a level playing field for the traditional EBLUP-based approach; the HB approach and the semi-parametric modelling approach easily adapts to alternate sets of conditions.
In this article, we report results only for the case where the sampling distribution is potentially misspecified. If instead only the linking model were misspecified, then the analysis and results are similar to the ones reported here, and we do not include them to reduce redundancy. When both the sampling and the linking models are misspecified, we need considerably more technical assumptions and mathematical details to ensure identifiability and address theoretical and algorithmic challenges; these will be presented in a future article. Note that for the hierarchical Bayesian study, we are interested in misspecification in the Fay-Herriot model itself, thus we do not address Bayesian robustness questions where robustness with respect to prior specifications is studied. Our preliminary studies on Bayesian robustness, for reasonable choices of priors, do not produce predictions that are fundamentally dissimilar to the results reported here. We will also address Bayesian robustness issues in a future publication.
Robustness in small area problems has been studied from several other perspectives earlier, but to the best of our knowledge not from the distributional misspecification and Bayesian computational viewpoint that we present in this article. A comprehensive recent review of existing perspectives is available in Jiang and Rao [13]. A major initial work in small area robustness studies is Lahiri and Rao [14], where it was shown that for the problem of estimating the Mean Squared Prediction Error (MSPE), the normality-based Prasad-Rao MSPE estimator remains second-order unbiased under non-normality of the latent linking model when a simple method-of-moments estimator (e.g., Rao and Molina [22] Section 6.1.2) is used for the variance component and the sampling error distribution is normal. However, in Chen et al. [4], it was established that the normality-based MSPE estimator is no longer second-order unbiased when the sampling error distribution is non-normal or when the Fay-Herriot moment method is used to estimate the variance component, even when the sampling error distribution is normal. The robust estimation perspective of MSPE is presented in Wu and Jiang [29]. Robustness with respect to data issues is studied in Chatterjee [2]. Robustness in small area models have also been explored from the perspective of having more broad modelling assumptions in place of (1.1). In Datta and Mandal [7], a general model with uncertain linking model was considered. More recently, Chakraborty et al. [1] proposed an extension of the traditional Fay-Herriot model where the linking model is given by a mixture of two Normal distributions. In Ghosh et al. [10], Student’s t-distribution and a hierarchical Bayesian modelling was used in studying robustness.
We discuss the hierarchical Bayesian analysis of the traditional Fay-Herriot model in Section 2. Following this, we present the semiparmetric extension of the Fay-Herriot model, the AGFH, in Section 3. In Section 3 we discuss some theoretical properties of this model as well. Following this, in Section 4 we present the methodological details of the Bayesian analysis in the AGFH model. In Section 5, we report result from numerical simulation experiments, and compare performances of different small area predictors under two different scenarios. Our concluding remarks are collected in Section 6.
For a hierarchical Bayesian study, we augment (1.1) and (1.2) with priors on the parameters
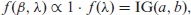
where the notation
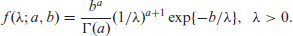
Let us use the notation
We set up a Gibbs sampling scheme for the Markov Chain Monte Carlo procedure to approximate the posterior distribution of these parameters. Note that conditional on
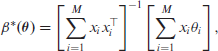
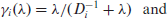
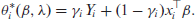
Then the conditional distributions for the Gibbs sampling algorithm are
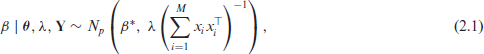
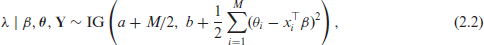
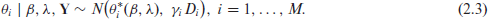
In this section, we propose an extension of the Fay-Herriot model (1.1)–(1.2) using a semiparametric framework. We use the term agnostic Fay-Herriot model (AGFH in short often hereafter) to denote this model as it relaxes the distributional assumptions on the sampling level in the traditional Fay-Herriot model.
Suppose we have an unknown function
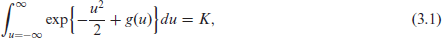
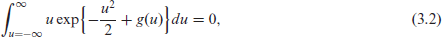
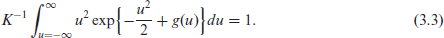
Without loss of generality, we may assume that
Condition (3.1) ensures that
Let
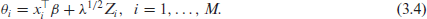
Conditional on
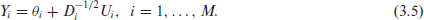
Notice that (3.4) presents a generalization of the linking model (1.2). If
We present below some probabilistic and theoretical properties related to the AGFH model which will be useful for methodological steps outlined later in this article. For notational simplicity, in several of the algebraic steps below we will drop the subscript i when there is no source of confusion.
For any
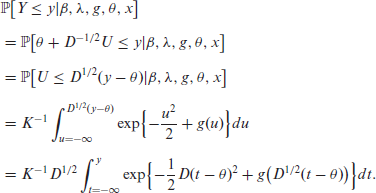
using
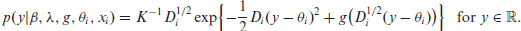
Thus, the AGFH model can be expressed more compactly using the following conditions:
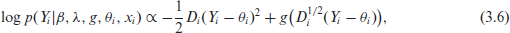

Note that in principle, the AGFH model can express many distributions in the sampling model, since the choice of
Let us now compute the first two moments of
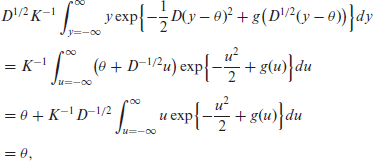
using (3.2). For the second non-central moment we have
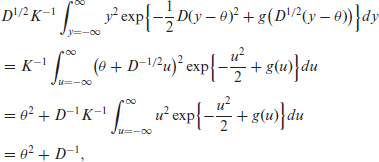
using (3.1), (3.2), and (3.3). So, the conditional variance of
The marginal mean and variance of
First,

Similiarly
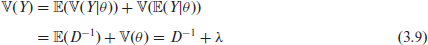
Thus, the AGFH also matches the FH in terms of the marginal mean and variance expressions (1.3)(1.4) for the observed data.
Next, define
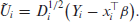
Rearranging (3.5) yields
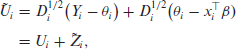
where
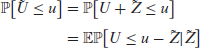
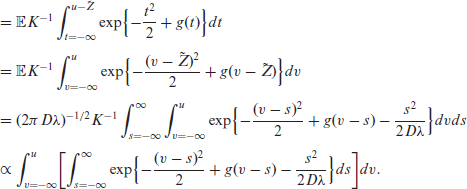
Thus, the density of
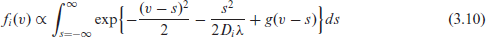
Note that the finite dimensional parameters
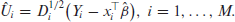
These in turn, can be used (3.10) to estimate
Bayesian Approach for Analysing the AGFH Model
The AGFH model lends itself readily to Bayesian analysis, which we study below. On the finite dimensional parameters
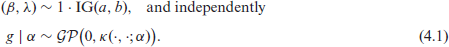
Here,
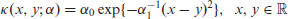
and we fix the hyperparameter
The unknown quantities in the AGFH framework are
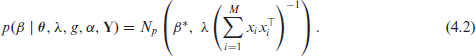
Similarly,
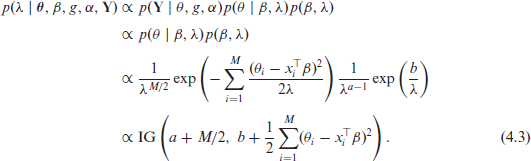
Thus, conditional on
We individually sample the
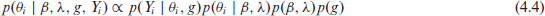
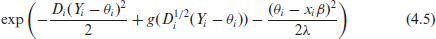
Note that at this point
Finally,
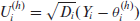
approximate draws from (3.1). At each sampling iteration, let

Then, treat

The potential advantage of the agnostic Fay-Herriot model is its ability to accommodate non-Normal error structures in the Fay-Herriot sampling model. Doing so may improve the sampling and estimation of the small area means
We explore that here in the presence of Gamma, symmetric Beta, and asymmetric Beta errors. Doing so also provides an opportunity to investigate the robustness extant estimation methods exhibit in the presence of these errors. In all cases, sampling errors are transformed to satisfy the moment conditions (1.3) and (1.4).
Three estimation methods are explored in addition to the AGFH model. First, the the standard hierarchical Bayes (HB) Gibbs sampler from Section 2 provides a Bayesian baseline to the AGFH. Both the HB and AGFH samplers use the prior
The following two examples highlight the impact the relative size each source of variability—sampling variability through
High Sampling Variability
We first consider the case where the sampling variability
Empirical Sampling Error Distributions and their Estimates by AGFH. Here,
,
,
, and
. From Top Left: Normal Errors, Gamma Errors, Symmetric Beta Errors, Asymmetric Beta Errors.
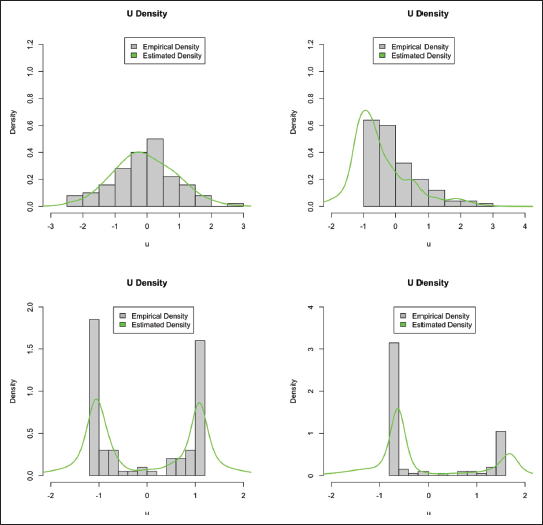
Empirical Sampling Error Distributions and their Estimates by AGFH. Here,
,
,
, and
. From Top Left: Normal Errors, Gamma Errors, Symmetric Beta Errors, Asymmetric Beta Errors.
An accurate representation of the sampling errors by the AGFH model appears to engender more accurate estimation of
For the most extreme departure from normality (the two bimodal Beta scenarios, which still respect the moment conditions), AGFH is the most competitive method. Otherwise, extant methods are more performant, most notably the HB approach. A more detailed representation of the relationship among MSPEs is shown in Figure 2 for the
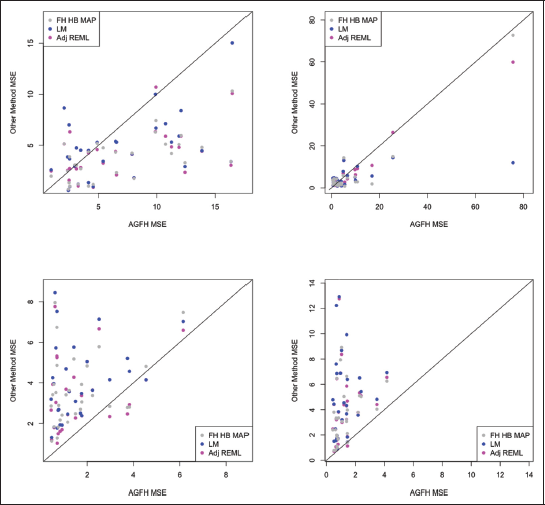
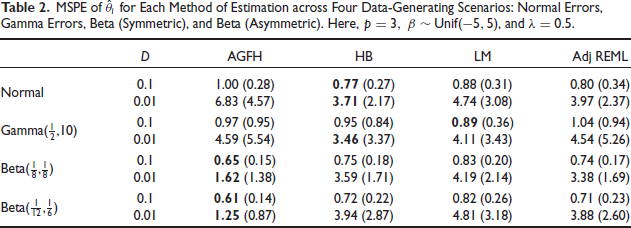
It is clear from Figure 1 that the AGFH model can accurately capture the shape of the sampling distribution. This is also reflected in its generally superior or competitive performance in terms of the MSPE, as noted in Tables 1 and 2. Under the Normality assumption (traditional Fay-Herriot model) in Table 1, the AGFH model’s performance is almost identical to that of the traditional EBLUP-based approach, while the hierarchical Bayesian approach performs marginally better. When the sampling distribution is highly non-Normal, as in the case of the Beta-distribution based cases under study, the AGFH clearly dominates. In general, using ordinary linear regression does not result in good prediction in small area models as demonstrated by the third column in Tables 1 and 2. However, when the linking model’s mean (
MSPE of
for Each Method of Estimation across Four Data-generating Scenarios: Normal Errors, Gamma Errors, Beta (symmetric), and Beta (Asymmetric). Here,
, and
.
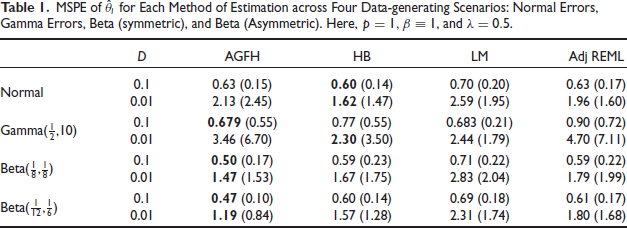
Comparison Between AGFH MSPEs and those of the Other Estimating Values, with a Diagonal Line Drawn along Parity. Points Lying above the Line Indicate AGFH is Favorable; Points Below Parity Favor Other Methods. Here,
,
,
, and
. From Top Left: Normal Errors, Gamma Errors, Symmetric Beta Errors, Asymmetric Beta Errors.
MSPE of
for Each Method of Estimation across Four Data-Generating Scenarios: Normal Errors, Gamma Errors, Beta (Symmetric), and Beta (Asymmetric). Here,
, and
.
MSPE of
for Each Method of Estimation across Four Data-Generating Scenarios: Normal Errors, Gamma Errors, Beta (Symmetric), and Beta (Asymmetric). Here,
, and
.
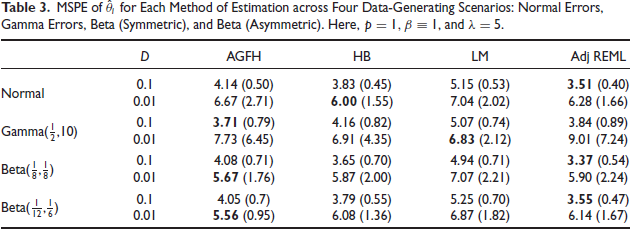
Here, we consider the case where
MSPE of
for Each Method of Estimation across Four Data-Generating Scenarios: Normal Errors, Gamma Errors, Beta (Symmetric), and Beta (Asymmetric). Here,
,
, and
.
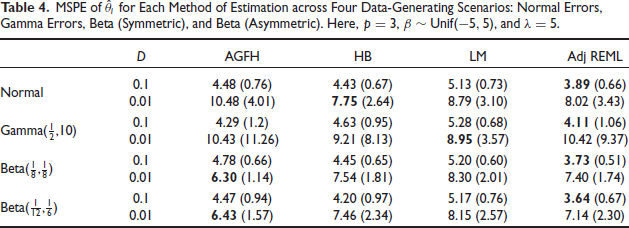
MSPE of
for Each Method of Estimation across Four Data-Generating Scenarios: Normal Errors, Gamma Errors, Beta (Symmetric), and Beta (Asymmetric). Here,
,
, and
.
In this article, we present a new semiparametric extension of the Fay-Herriot model, termed the agnostic Fay-Herriot model (AGFH). Here, the sampling-level model is expressed in terms of an unknown general function
It can be seen that in general the AGFH method performs very well. It clearly outperforms rival techniques when the sampling-level precision is small (i.e., variance is high) and when the sampling distribution is bounded. The hierarchical Bayesian method also generally performs well. When the signal-to-noise ratio is weaker, the EBLUP-based method is often very competitive. The linear regression-based method is generally not very competitive unless the mean of the linking model,
Overall, our simulation results show that when the moment conditions (1.3) and (1.4) are imposed, the hierarchical Bayesian technique and even the empirical Bayesian technique can yield very reasonable predictions even from misspecified models. This suggests strong robustness properties of these techniques. While the AGFH framework often produces better numeric results, it also requires considerable additional computations. Our additional simulations studies suggest that as sample size
Instead of generalizing the sampling model, we could have taken that as some known parametric distribution and considered the linking model to be completely unknown and modeled that using the AGFH. The modelling strategy for this case is similar to the one presented above, involving a Gaussian Process prior and Bayesian techniques. We will report results for this case in a future article. However, the case where both the sampling distribution and the linking distribution are unknown is more complicated. There, identifiability conditions and other technical restrictions need to be imposed. In general, the Bayesian framework we use with the AGFH model can handle known constraints on the sampling and linking models, and can be extremely flexible owing to the versatility of Gaussian Processes in approximating broad class of unknown functions. However, modelling flexibility should be balanced with computational requirements and data size availability.
In the simulation results presented above, we could have considerably improved the performance of the AGFH model by assuming certain properties of the sampling distribution. For example, when the distribution is Gamma, the performance of the AGFH model can be improved by assuming the knowledge that the sampling errors are bounded below. In order to use such knowledge for the hierarchical Bayesian or empirical Bayesian model, we would need the precise knowledge about the sampling distribution.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is partially supported by the US National Science Foundation (NSF) under grants 1939916, 1939956.