
Abstract
With the advent of the Internet of Things (IoT), it has become increasingly challenging for users to assess the privacy risks associated with consumer products and the continuous stream of user data needed to operate them. In this study, we propose and test three mechanisms with the potential to help users make more accurate assessments of privacy risks. We refer to these mechanisms as framing (i.e., presenting information on the collection and use of user data with or without direct reference to privacy risks), comparing (i.e., presenting a product and the associated information on data collection and use with or without reference to an alternative product), and educating (i.e., augmenting users’ general privacy literacy). To assess these mechanisms in different IoT contexts, we conducted two scenario-based online experiments with reference to a telematics device (n = 317) and a fitness tracker (n = 356). In both studies, we find that actual privacy risks as manipulated in the experiment are only moderately related to the privacy risks perceived by users. However, comparing and educating each helped users make more accurate privacy risk assessments. In Study 2, framing and comparing jointly enabled especially users with low privacy literacy to assess privacy risks more accurately. These findings have meaningful implications for key actors in the IoT ecosystem and those regulating it.
With the rise of the Internet of Things (IoT), smart products such as fitness trackers, smart speakers, and connected cars have become digital companions in all spheres of life (Porter & Heppelmann, 2015). Smart products promise more customized and convenient user experiences (Raff et al., 2020). Yet, smart products also bring unprecedented risks for users’ data privacy given the continuous stream of user data typically needed to operate them. Privacy risks occur when users lose their ability to exercise control over their personal information (Moon, 2000; Westin, 1967). In the IoT context, privacy risks arise from smart products collecting, processing, and storing user data (Lowry et al., 2017). For IoT users, privacy risks can materialize in different ways, including psychological costs (e.g., feeling of surveillance), social costs (e.g., stigmatization as poor user), or monetary costs (e.g., decline of warranty claims; Koester et al., 2022). If users are to make informed product adoption and data sharing decisions, they need to be able to accurately assess both the benefits and costs of data sharing (Acquisti et al., 2015; Bélanger & Crossler, 2011).
However, IoT devices and smart products make it increasingly challenging for users to assess the associated privacy risks (Cichy et al., 2021). In contrast to conventional products, IoT devices tend to be always collecting an uninterrupted stream of data on the device itself, its interaction with the user, and the environment. As a case in point, the former CEO of Volkswagen, Martin Winterkorn, expressed concern about the potential for cars to become the next “data monsters” already during a CeBIT keynote in 2014. Today, a modern connected car is equipped with more than 100 sensors collecting between 1 and 20 terabytes of raw data per hour of driving related to vehicle’s health as well as driving behavior. This trend is expected to continue growing, for example, with the installation of onboard cameras and motion sensors not least to monitor drivers’ attention during automated driving modes (Consumer Reports, 2022). Moreover, digital players such as Apple with CarPlay and Google with Android Auto are increasingly integrated into the connected car ecosystem, and eager to establish data-driven business models like those seen in the mobile context with their third-party app platforms. It is projected that by 2023 worldwide sales of connected vehicles will surpass 76 million units (70% globally, 90% in the United States; Forbes, 2022), which will open up large potential for new forms of user data exploitation. While some welcome the innovative services that this might trigger (e.g., pay-how-you-drive insurance schemes), around half of car owners in the European Union report to be seriously concerned about the collection and usage of their car data (Otonomo, 2020). Significant privacy concerns can also be found in regard to other smart products like fitness trackers and smartwatches, which have the capability to capture sensitive data about an individual’s location, fitness activities, and vital signs. As unrestricted data are essential for IoT devices to function optimally, users typically have minimal or no authority over controlling the flow of data from their devices, which invade not only users’ informational but also their physical space.
While prior research has shown that users are often unaware of privacy risks and struggle to detect such risks unless made explicit (Balebako et al., 2013; Brakemeier et al., 2017; Norberg et al., 2007; Tsai et al., 2011), with a few notable exceptions (Adjerid et al., 2019), little is still known about how users can be enabled to assess privacy risks more accurately even in highly complex settings such as smart products. It is against this backdrop that our study not only measures the extent to which users can accurately assess the actual privacy risks of smart products but also—and more importantly—identifies and tests three mechanisms with the potential of enhancing the accuracy of users’ privacy risk assessments.
For this purpose, we draw on insights from behavioral economics that show how elements of the choice architecture and individual capabilities influence decision outcomes (Kahneman, 2003). We investigate two critical elements of the choice architecture understood as the design in which decision options are presented: framing, that is the way in which information on the collection and use of user data are communicated (with or without direct reference to privacy risks), and comparing, that is the way in which a product and the associated information on data collection and use are presented (with or without reference to an alternative product). As for users’ individual capabilities, we focus on educating, that is, that way in which users’ general privacy literacy, understood as users’ ability to manage their data privacy, can be augmented (LaRose & Rifon, 2007).
As privacy research has long acknowledged the importance of context as reflected in the idiosyncrasies and usage context of the information systems artifact as a precondition for deriving meaningful implications for research, practice, and policy (Hong et al., 2014; Orlikowski & Iacono, 2001), we adopt a context-sensitive research design and examine two smart products, a telematics device and a fitness tracker, that differ in conceptually important ways (Malhotra et al., 2004). Telematics devices can be plugged into the OBD-II port of any modern car and fall into the broader category of connected car technologies, while fitness trackers are part of the broader category of wearable technologies. Telematics devices collect a continuous stream of car and driving data (including vehicle conditions, routes traveled, driving style), while fitness trackers collect users’ physical activity and health data (including vital signs, routes traveled, and training intensity and success). For each of these smart products, we conducted an independent online experiment with a 2 × 2 × 2 factorial design (Study 1 with telematics device: n = 317; Study 2 with fitness tracker: n = 356). In our experiments, we manipulated the actual privacy risks associated with each of two smart products by creating a low-risk and high-risk version of each and measured users’ perceived privacy risks.
In both studies, we find that actual privacy risks are only moderately related to the privacy risks perceived by users. However, comparing and educating each helped users significantly increase the accuracy of their privacy risk assessments. In Study 2, framing and comparing jointly enabled especially users with low privacy literacy to assess privacy risks more accurately. These findings support prior research (Balebako et al., 2013; Brakemeier et al., 2017; Norberg et al., 2007; Tsai et al., 2011) by documenting users’ difficulty to accurately assess privacy risks also in the IoT in an experimental setting where actual risk is carefully controlled. Our findings also extend prior research by identifying and demonstrating the effectiveness of three mechanisms available to device manufacturers (framing), device distributors (comparing), and device users (educating) that enable users to make more accurate privacy risk assessments.
Next, we present the state-of-the-art of privacy research in general and users’ privacy risk assessments in particular followed by our hypotheses and methods.
Theoretical Background
Smart Products and Data Privacy
The exponential growth in computing power and data is accelerating technological development (Tegmark, 2018). At the same time, the costs of technology are dropping drastically, which allows equipping products with sophisticated sensors, processors, and actuators at a low cost and, hence, further accelerate the diffusion of smart products (Raff et al., 2020).
Once integrated into everyday life, smart products collect a broad array of user data. As a case in point, Amazon’s smart speaker, Alexa, answers questions and controls lights in response to voice commands. To enable its services, Alexa sends voice commands to Amazon’s servers, where data are analyzed (Chung et al., 2017). A data breach, where requested voice recordings were sent to the wrong user, puts Amazon’s data practices in the spotlight. Contrary to what users expect and legal text suggests (e.g., GDPR, 2016, Art. 5-11), voice recordings are not deleted after the analysis, and Alexa seems to record conversations apart from voice commands (Bleich, 2018). Sent to the wrong user or accessed by third parties, such personal information threatens users’ privacy. Similarly, in the realm of connected cars, Tesla employees were recently found to access and share internally user data from car cameras, exposing users in their cars and their homes (Reuters, 2023).
While smart products provide convenient services, they expose users to new and arguably more far-reaching risks to their data privacy. The definition of privacy has shifted from privacy as an absolute right toward an interpretation of privacy as a tradeable commodity (Smith et al., 2011), which is subject to the economic principles of cost-benefit analysis (Davies, 1997). Today, data privacy is defined as individuals’ ability to control the terms under which information about them is collected, by whom it is accessed, and what it is used for (Stone et al., 1983). By this definition, smart products that gather, store, and process user data can be considered as being privacy invasive. Using smart products puts users’ privacy at risk because the collection and storage of personal data are typically associated with a loss of control over such data (Malhotra et al., 2004). Once data are shared, users need to trust smart product providers to treat their data responsibly and in accordance with the law. The examples of Amazon and Tesla show that users might experience unexpected threats to their privacy.
Users’ Privacy Risk Assessment
A rich body of privacy literature exists and is dedicated to explaining how individuals manage their privacy in various situations, that is, how they decide whether they want to share personal data with other actors/organizations or not. Studies on individuals’ privacy behavior traditionally rely on the notion of privacy calculus as an analytical framework (Smith et al., 2011; Yun et al., 2019). The privacy calculus model postulates that individuals weigh positive against negative consequences of an information disclosure and act in a way that will result in the most favorable net outcome (Stone et al., 1983). Positive consequences of data sharing come in different forms, including personalized services or financial rewards (Hui et al., 2007; Xu et al., 2009). Negative consequences of data disclosure manifest in privacy risks (Chellappa & Sin, 2005), that is, adverse consequences that mainly stem from other parties—authorized or unauthorized—behaving opportunistically once they gain access to an individual’s personal information (Dinev & Hart, 2006; van Slyke et al., 2006). The specific consequences individuals anticipate in their disclosure decision-making vary by context (Karwatzki et al., 2022), but can be generally assigned to one of seven different categories. These are physical, social, resource-related, psychological, prosecution-related, career-related, and freedom-related consequences (Karwatzki et al., 2017). In the context of connected cars, for example, Koester and colleagues (2022) found that drivers associate granting other parties access to their car data with stressful feelings of surveillance (i.e., psychological consequences), a potential manipulation of vehicle functions through hackers (i.e., physical consequences) and automatized prosecution of their traffic offenses (i.e., prosecution-related consequences).
Various contextual factors have been found to affect an individual’s perception of privacy risks in a given situation. Phelps and colleagues (2000), for example, argue that a greater amount and variety of data collected is associated with higher privacy risks. This is because linking and combining different data can reveal information beyond what is encoded in isolated data: The whole picture can be more than just the sum of its parts (Chen et al., 2012). Furthermore, increased sensitivity of information is associated with a higher perception of privacy risks (Mothersbaugh et al., 2012). For example, health, financial, and location data are considered highly sensitive and thus carry higher risks (Anderson & Agarwal, 2011; Phelps et al., 2000). Privacy risks arise not only from the specific data that are collected but also where and how it is stored. Storing data, for example, on the service provider’s server leaves it at risk of being used for other purposes or being illegally accessed by hackers (Culnan & Williams, 2009).
In light of the significance and prevalence of privacy risks in our increasingly digitized society, it is concerning that initial evidence suggests that consumers seem to struggle in accurately assessing privacy risks. In consequence, their privacy calculus—that is, the careful evaluation of costs and benefits of a data disclosure—would be severely ill-informed and lead them to expose themselves to risks they have not anticipated properly. For example, Norberg and colleagues (2007) found that the amount of information study participants disclosed was the same in a low-risk and a high-risk scenario, indicating that higher risks went unnoticed. A similar finding emerged in an experiment by Brakemeier et al. (2017), where manipulating the privacy risks of a smartphone application did not always affect the perceptions of privacy risks reported by study participants. Tsai and colleagues (2011) found that privacy risks only affected data disclosure decisions when the risks were explicitly indicated. Balebako and colleagues (2013) found users of smartphone apps to be generally unaware of data collection practices and surprised at how frequently the apps access their personal information. These challenges are likely to be particularly salient in the case of smart products given the volume, variety, and continuity of user data collected as essential preconditions for the functioning of the device and the provision of value-added services. See Appendix B for an overview on extant studies on privacy risk (perceptions) in the context of individuals’ disclosure decision-making.
Despite the mounting body of evidence on the challenges users face when assessing privacy risks, there is little research on the specific mechanisms—and their effectiveness—to help users make more accurate privacy risks assessments in complex contexts such as smart products. However, insights from behavioral economics serve as a useful point of departure for theory building. According to this perspective, individuals search for risk-related information as part of their privacy risk assessment (Bettman et al., 1998), thereby relying on external and internal information (Conchar et al., 2004). In this regard, the choice architecture, that is, the context within which decision options are presented, provides external information and includes the number of choices available (Agarwal & Teas, 2001), privacy policies (Gerlach et al., 2015), and privacy seals (Hui et al., 2007). A user’s prior experiences and privacy knowledge constitute individual capabilities (internal information; Bansal et al., 2016).
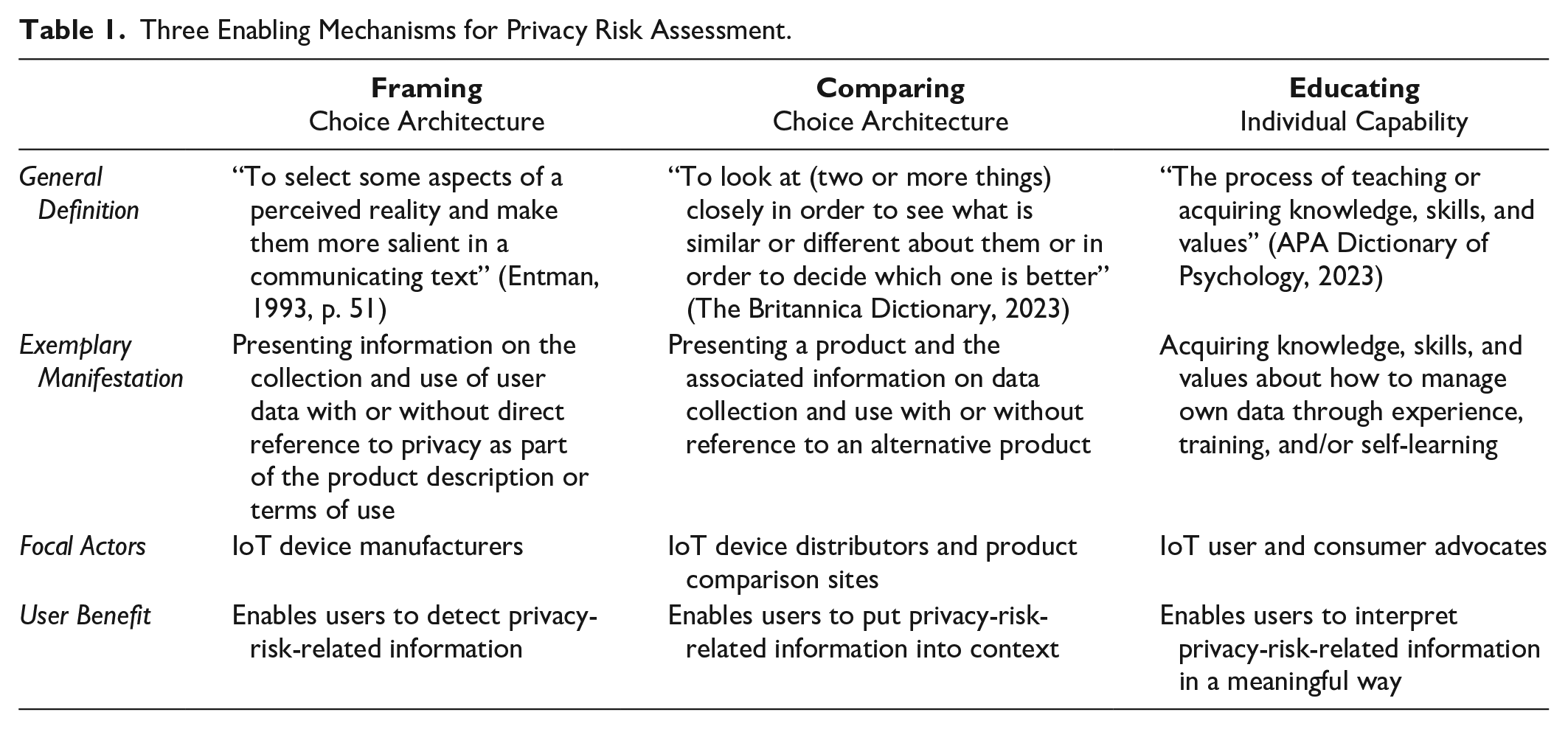
Building on these insights on the role of choice architecture and individual capabilities for decision outcomes (Kahneman, 2003), we examine three mechanisms with the potential to enable users to assess privacy risks more accurately. We refer to the two mechanisms related to the choice architecture as framing and comparing and the one mechanism related to individual capabilities as educating. These factors build on each other, such that (a) framing—the way a choice is presented—enables users to detect privacy-risk-related information (Adjerid et al., 2019), while (b) comparing enables users to put that information into context (Brakemeier et al., 2017), and (c) educating enables users to interpret the risk information (Pötzsch, 2008). Table 1 summarizes key attributes of the three mechanisms.
Three Enabling Mechanisms for Privacy Risk Assessment.
Hypotheses
The Interplay Between Perceived and Actual Privacy Risks in Shaping Intentions to Use
Smart products that gather, store, and process data are considered privacy-invasive (Bier & Krempel, 2012) and expose their users to a potential loss of control over personal data (Chellappa & Sin, 2005). When assessing privacy risks, individuals need to consider multiple factors, including the amount and sensitivity of data collected and the data storage location. Following the logic of the privacy calculus, privacy risks are widely assumed to be negatively related to individuals’ data sharing and usage intentions. Indeed, numerous studies demonstrate a negative effect of privacy risks as perceived by users on the intention to use and thus disclose personal data (Featherman et al., 2010). We hence formulate the following baseline hypothesis:
Perceived privacy risks have moved to the foreground as they function as a proxy of actual privacy risks, are measurable using established scales, and typically exhibit substantial variance across users (Malhotra et al., 2004). Individuals confronted with data disclosure decisions can only consider those privacy risks that they are aware of. Objective risks (actual privacy risks) will hence affect individual data sharing and usage decisions primarily via subjectively assessed privacy risks (perceived privacy risks; Calo, 2011).
However, the link between actual and perceived privacy risks is unlikely to be perfect. Although the privacy calculus and prevalent theories of decision-making such as utility maximization theory (Marshall, 1961) and expectancy-value theory (Neumann & Morgenstern, 1947) it builds on, assume that decision-makers make informed data disclosure decisions, individual risk assessment will often be compromised. First, privacy risks are becoming increasingly multifaceted and complex (Acquisti et al., 2015). Second, the potential negative consequences arising from privacy risks might occur far in the future and hence seem disconnected from individuals’ original data disclosure decisions. Individuals may underestimate the future consequences of losing control over personal data (Acquisti, 2004).
For these reasons, the degree to which people can accurately assess privacy risks might be limited (Brakemeier et al., 2017). Thus, we expect perceived privacy risks to serve as mediator of the relationship between actual privacy risks and intentions to use:
The Effect of Framing on the Accuracy of Users’ Privacy Risk Assessments
For privacy risks to be accurately assessed, information on such risks first needs to attract users’ attention (Sheng et al., 2020). Once detected, individuals have to estimate the severity and likelihood of the negative consequences (Dowling & Staelin, 1994), taking key risk factors such as the amount of data, sensitivity of data, and data storage location. Clearly introduced privacy risks make it easier for individuals to detect that information. Decision framing refers to the presentation of decisions (Kühberger et al., 1999). Changes in the presentation of decision options can cause differences in decision outcomes. These changes in decision outcomes are called framing effects and have been widely documented in the psychological literature (Tversky & Kahneman, 1981).
There is evidence that framing effects materialize in privacy decisions. Adjerid and colleagues (2019) found that altering the decision frame of identical choices can have a strong effect on data disclosure decisions. Labeling privacy-related choices as “Survey Settings” instead of “Privacy Settings” resulted in participants being 56% less likely to choose a privacy-protective option and hence share more data (Adjerid et al., 2019). Following these empirical findings, we propose that a privacy-related framing, unlike a neutral framing, directs individuals’ attention to privacy risks. Recognizing the information available on privacy risks is a necessary first step to accurately assess them. Therefore, we expect the effect of actual privacy risks on perceived privacy risks to be stronger if a privacy-related instead of a neutral framing is used for describing the way in which a smart product collects, stores, and uses personal data:
The Effect of Comparing on the Accuracy of Users’ Privacy Risk Assessments
Evaluability theory suggests that the availability of reference information can affect the decision outcome, as it influences individuals’ ability to assess product attributes, among which privacy risks. Evaluability is defined as “the extent to which a person has relevant reference information to gauge the desirability of target values and map them onto evaluation” (Hsee & Zhang, 2010, p. 345). The evaluability hypothesis suggests that individuals might be insensitive to differences of difficult-to-assess product attributes (Hsee, 1996). Providing reference information in decision situations increases evaluability and, thus, users’ sensitivity to differences in the investigated attributes (Hsee & Zhang, 2010). This enables users to assess product attributes more accurately.
Ratings provide reference information on product attributes. For instance, traffic light systems are widely used to rate products such as food and beverages (Thorndike et al., 2014) by using interpretive color codes such as green, yellow, and red for low, medium, and high levels of undesirable nutrients (Roberto et al., 2012). Seals that certify products to fulfill certain standards are another way to provide reference information (e.g., The Trusted Shops seal).
Both ratings and seals assess and classify products according to certain attributes. A subtler way that leaves the assessment to the user is to provide a reference product that is similar but differs in the attributes of interest. We refer to this approach as comparing. The presence of a reference product allows individuals to put the information into context and assess critical product attributes more accurately than when no reference product is present. Product websites often use this approach to facilitate customers’ choice by listing the specifications of two or more similar products. Providing a reference product to increase individuals’ ability to assess product attributes is also a widely used approach in empirical studies (González-Vallejo & Moran, 2001).
Privacy risks are difficult-to-evaluate product attributes (Acquisti, 2004). An individual might find it highly challenging to assess the privacy risks of a smart product only by reading the descriptions of data collection (Englehardt & Narayanan, 2016). However, provided with information on data handling for another product, the same individual can compare the privacy risks and put that information into context: one product is riskier than the other (Phelps et al., 2000). Based on the evaluability theory, we expect that comparing products that differ in their privacy risks will increase users’ ability to accurately assess those:
The Effect of Comparing on the Accuracy of Users’ Privacy Risk Assessments
Privacy literacy is the quality that gives users the ability to manage their privacy (Rifon et al., 2005) and to make informed privacy decisions (Pötzsch, 2008). It has been described as a “principle to support, encourage and empower users to undertake informed control of their digital identities” (Park, 2013, p. 217). In the context of smart products, people need to understand how their data are collected, processed, and stored to assess privacy risks (Lowry et al., 2017). The more users know about data flows, the better equipped they will be to take control of their privacy by making informed decisions (Turow, 2003). Individuals with high privacy literacy are found to incorporate privacy risks into their data disclosure decision. In contrast, individuals with low privacy literacy seem to focus only on the benefits of data disclosure (Wagner & Mesbah, 2019).
Taking informed control of personal data does not imply revealing more or less information. It allows individuals to behave in accordance with their privacy preferences (Taylor, 2004). Educating individuals about data flows and privacy risks increases their privacy literacy and empowers them to make informed decisions (Acquisti et al., 2017).
A person’s privacy literacy, as an internal source of information, influences individual privacy risk assessment. We thus expect the effect of actual privacy risks on perceived privacy risks to be stronger for users with high privacy literacy than for those with a low privacy literacy:
Figure 1 summarizes our hypotheses and displays the conceptual model developed above.
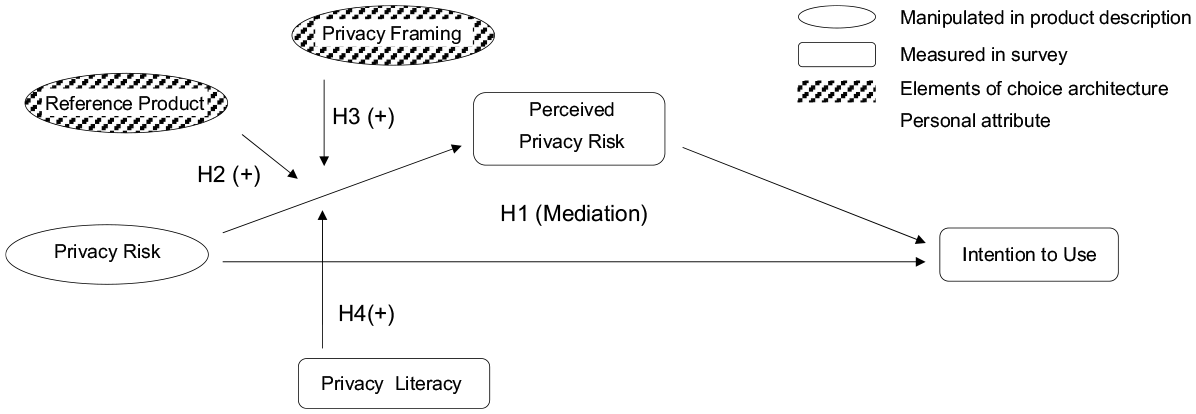
Conceptual Model.
Experimental Study 1—Telematics Device
Research Method and Experimental Design
In our first experiment, we relied on a plug-in telematics device as a stimulus. Such a device is used with a car’s on-board diagnostics port, the OBD-II port, and transmits various types of car data to a corresponding smartphone application. These data include time and distance traveled, speed, acceleration, braking, and cornering, as well as technical data such as engine temperature and battery condition. The smartphone application aggregates and displays the data and rates the driving behavior of each trip based on acceleration, braking, cornering, and idling.
We recruited study participants using email invitations in February 2018. The participants were registered at a laboratory for economic research at a leading German university. As an incentive, we offered a ticket to a raffle of gift cards from an online retailer. The experiment was conducted online and in German language. In the experiment, we first presented participants with a description of a telematics device consisting of three core elements: (a) benefits—functions and services of the product, (b) privacy risks—data collection and storage, and (c) framing of the risks—a heading separating the risks from the benefits.
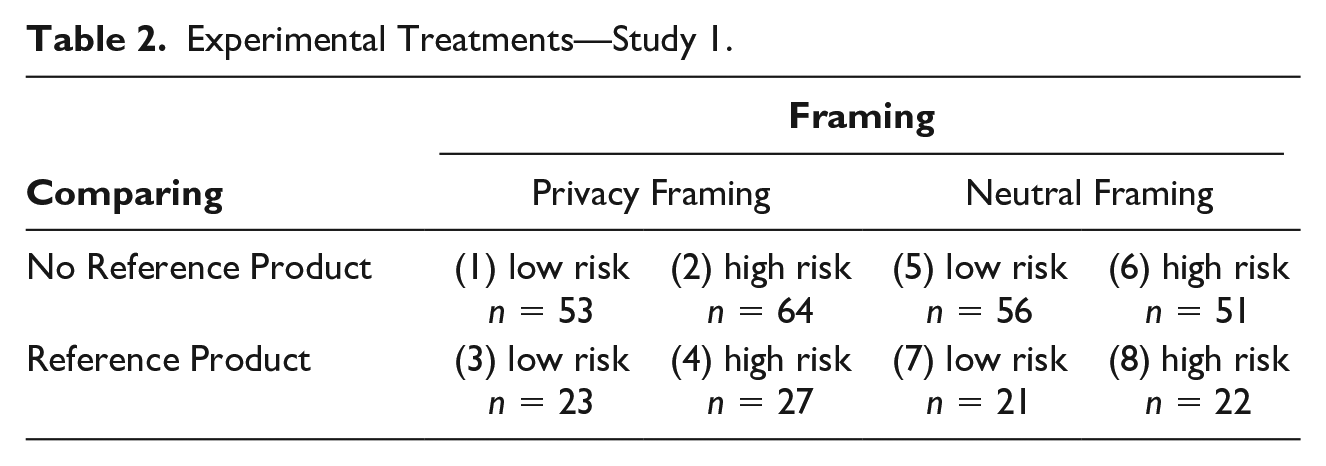
Holding the benefits of the device constant, we manipulated three aspects: (a) the level of privacy risks, (b) their framing, and (c) the presence of a reference product for purposes of comparing. This resulted in a 2 × 2 × 2 factorial design with eight treatment groups (Table 2; Cochran & Cox, 1950). Participants were randomly assigned to one of the eight treatments.
Experimental Treatments—Study 1.
To design the treatments, we developed four product descriptions of a telematics device. The actual privacy risk of the product was either low or high and framed as either a Notice on Data Privacy (privacy framing) or a Notice on Technical Functions (neutral framing). Participants were either presented with one of the four product descriptions—the low-risk or the high-risk product—or with two product descriptions side by side—the low-risk and the high-risk product. Participants presented with two products answered all items for both products in a randomly assigned order. Figure 2 shows an example of the product descriptions used.

Product Description Telematics Device. Treatment: Comparing (Reference Product Present) and Privacy Framing (Notice on Data Privacy)—Study 1.
Actual Privacy Risk
Drawing on insights from previous studies on the perceived sensitivity of different types of car data (Cichy et al., 2021), we developed a low-risk and a high-risk scenario to vary the actual privacy risks associated with the device. In the low-risk treatment, the telematics device would collect only the following data: (a) rating scores of each trip based on acceleration, braking, cornering, and idling data; (b) distance traveled; and (c) time traveled. In the high-risk treatment, we added the following data to the list: (d) location data; (e) minimum and maximum speed, including location-based speed; and (f) information on accidents. Location data are considered highly sensitive (Cichy et al., 2014). In the high-risk treatment, not only is more data collected, but the additional data are also more sensitive, which further increases the risk associated with this treatment. Furthermore, in the low-risk treatment, we claim that data are stored locally on the user’s smartphone, while in the high-risk treatment, the data are stored on the telematics provider’s server, which is associated with a higher potential loss of control over the data. In summary, we varied three aspects of the risks to create a low-risk and a high-risk scenario: amount of data, sensitivity of data, and data storage location.
Framing
Besides the privacy risk itself, we also manipulated how the risk was presented. Following Adjerid and colleagues (2019), we modified the heading introducing the privacy risks. In the data privacy–related treatment, the heading stated, “Notice on Data Privacy,” indicating that information on users’ data privacy will follow. To frame the risks more neutrally so that participants did not necessarily relate the data collected with a threat to their data privacy, we used the heading “Notice on Technical Functions.”
Comparing
To investigate how comparing, as part of the choice architecture, influences privacy risk assessment, we varied the presence of a reference product. In the no reference product treatment, participants were presented with only one product, either the low-risk or the high-risk product. In the reference product treatment, in contrast, participants were presented with both products side by side. Following empirical studies building on general evaluability theory, we used the presence of a reference product to create a scenario enhancing individuals’ ability to compare privacy risks and put this information into context. In contrast, the absence of a reference product is considered to create situations where individuals struggle to assess difficult-to-evaluate product attributes (Hsee, 1996).
Measures
Intention to Use
After reading the allocated product description, participants were asked to state their intention to use the telematics device. The intention to use was measured by a single item, as described by Fishbein and Ajzen (1975). Participants answered the question, “What is your intention to use the presented telematics device?” on a 7-point semantic differential with the anchors low and high.
Perceived Privacy Risk
To measure the perceived privacy risk associated with using the telematics device, we used a scale developed by Malhotra and colleagues (2004) and adjusted it to our case (Appendix A). The scale consists of five items (α = .88) that are rated on a 7-point Likert-type scale with the anchors strongly disagree and strongly agree. A sample item is, “There would be a high potential for loss associated with the collection and analysis of personal driving data by the telematics device.”
Privacy Literacy
To measure participant’s privacy literacy as a proxy for prior educating, we asked participants to indicate the extent to which they understand the functioning of smart products and the implications that these have for their data privacy (Appendix A). The items used were developed by the authors, by referring to the dimensions of the online privacy literacy scale developed by (Park, 2013). Park’s scale includes three dimensions: (a) technical familiarity, (b) institutional practices, and (c) privacy policy. The scale does not suit our purpose as it captures general online privacy literacy, which includes familiarity with HTML and website tracking.
The development of the items included a multistage process. First, literacy items were collected from the literature (Lobschat et al., 2021). Second, the collected items were adapted to the context of smart, connected products. Then, the items were assigned to the dimensions above by each author. If there were discrepancies, the fit to the dimension was discussed and adjusted. Then, the authors summarized similar items into a single item. Again, an iterative approach of individual assessment and collective discussion was applied. In a final step, each author rated the relevance of the item (7-point Likert-type scale ranging from irrelevant to relevant). Items with low relevance values were dropped. The process resulted in five items, including “I have a good technical understanding of smart products and digital services” and “I know the implications of smart products and digital services for my privacy.” The items were answered on a 7-point Likert-type scale ranging from strongly disagree to strongly agree (α = .83).
Control Variables
Although we assigned participants randomly to the eight treatment groups, we also controlled for several potentially confounding factors. First, we accounted for differences in the demographics (age, gender, and education). Second, we controlled for experience with smart products, such as smartphones, and digital services, such as online social networks, online banking, and fitness apps, by assessing the usage intensity. The intensity of the usage of each product and service was measured using a 4-point scale: (1) never, (2) occasionally, (3) frequently, and (4) always. Third, we captured whether participants owned a car with a simple yes/no question (yes = 1; no = 0). The lack of car ownership might introduce a downward bias into participants’ assessment of both the perceived privacy risk and their intention to use the device, given the arguably lower personal relevance of the scenario. Finally, we included a measurement of personal innovativeness using a three-item combined with a 7-point Likert-type scale (α = 72) anchored by strongly disagree and strongly agree as used by Ailawadi and colleagues (2001). As the telematics device is a relatively new product, the behavioral intentions of those with a high score of innovativeness might be guided by curiosity rather than by the benefits and privacy risks presented.
Data Analysis
To test our hypotheses, we conducted an additive multiple moderation analysis using ordinary least squares analysis (Hayes, 2018). We investigated whether the effect of actual privacy risk on the intention to use the telematics device is mediated by perceived privacy risk to test Hypothesis 1. We then added framing, comparing, and privacy literacy to investigate their effects on the accuracy of privacy risk assessments as stipulated in Hypotheses 2, 3, and 4.
Results
Descriptive Statistics
Our study was completed by 317 participants, with a balanced share of males and females (48% female). The mean age is 25. About 42% of the participants finished high school, and another 48% hold an academic degree. About 60% own a car. Performing mean difference tests using a t test, we did not find significant differences in our control variables across the experimental groups. Descriptive statistics, bivariate correlations, and Cronbach’s alphas for all study variables are presented in Table 3.
Descriptive Statistics, Bivariate Correlations, and Cronbach’s Alphas—Study 1.
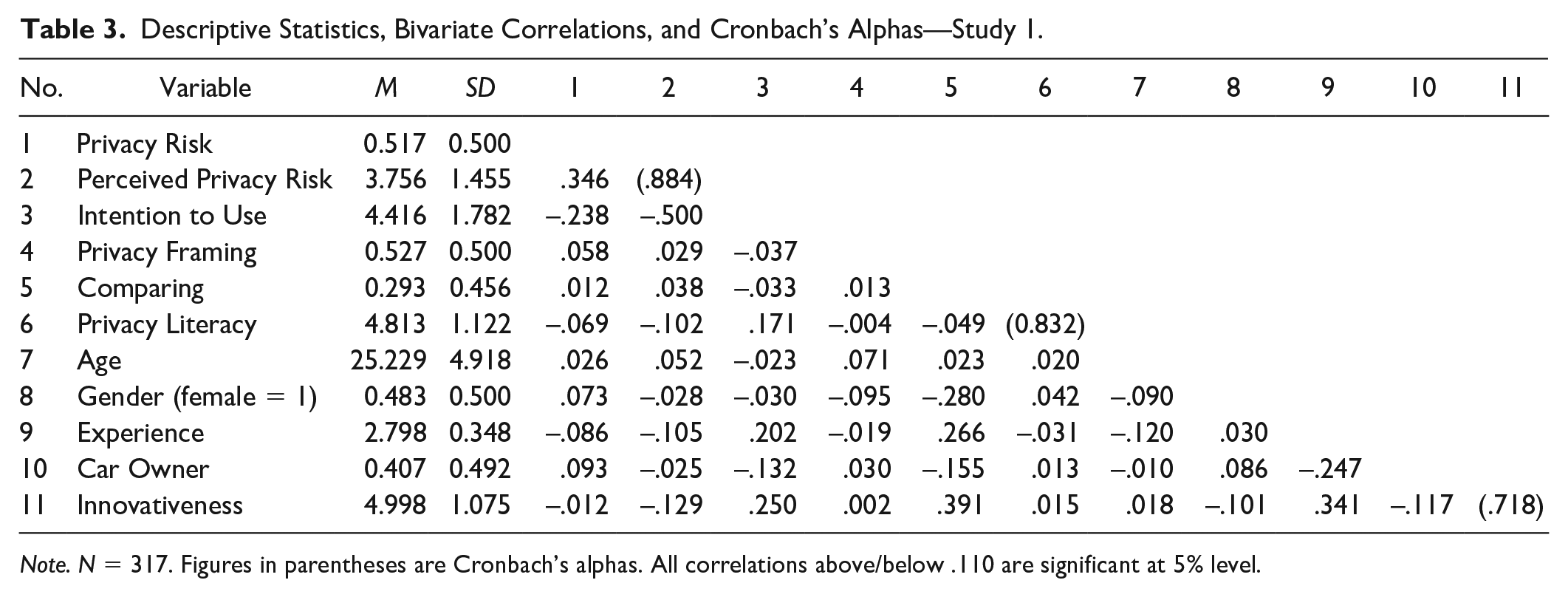
Note. N = 317. Figures in parentheses are Cronbach’s alphas. All correlations above/below .110 are significant at 5% level.
We find perceived privacy risk in the low-risk treatment (n = 152; M = 3.21, SD = 1.28) to be lower than in the high-risk treatment (n = 163; M = 4.26, SD = 1.40). A correlation analysis shows a significant, but moderate positive correlation (r = .35, p < .01) between actual privacy risk and perceived privacy risk (M = 3.76, SD = 1.44). The results indicate that our manipulation, introducing a low-risk and a high-risk product, was successful.
Hypothesis Testing
Table 4 presents our regression analyses. Model 1 shows the relation between the independent variable and the mediator, Model 2 is the regression on our dependent variable, and Model 3 introduces all moderators. We find that actual privacy risk affects perceived privacy risk positively (B = .686, p < .001), while perceived privacy risk (α = .93) affects intention to use negatively (B = −.459, p < .001). We did not find a significant direct effect of actual privacy risk on the intention to use (B = −.123, ns). To formally test our mediation, we performed a bootstrap test for the indirect effect (Preacher & Hayes, 2004). Consistent with our main analyses, a bootstrap analysis with 5,000 replicates shows a significant indirect effect of actual privacy risk on intention to use (B = −.22, 95% bias-corrected and accelerated confidence interval [Bca CI] = [−.38, −.08]). Taken together, the effect of actual privacy risk on intention to use is found to be fully mediated by perceived privacy risk. Hypothesis 1 is, thus, supported. When actual privacy risk changes from low (coded = 0) to high (coded = 1), then perceived privacy risk increases by .686 points on the 7-point scale.
Regression Analysis—Study 1.
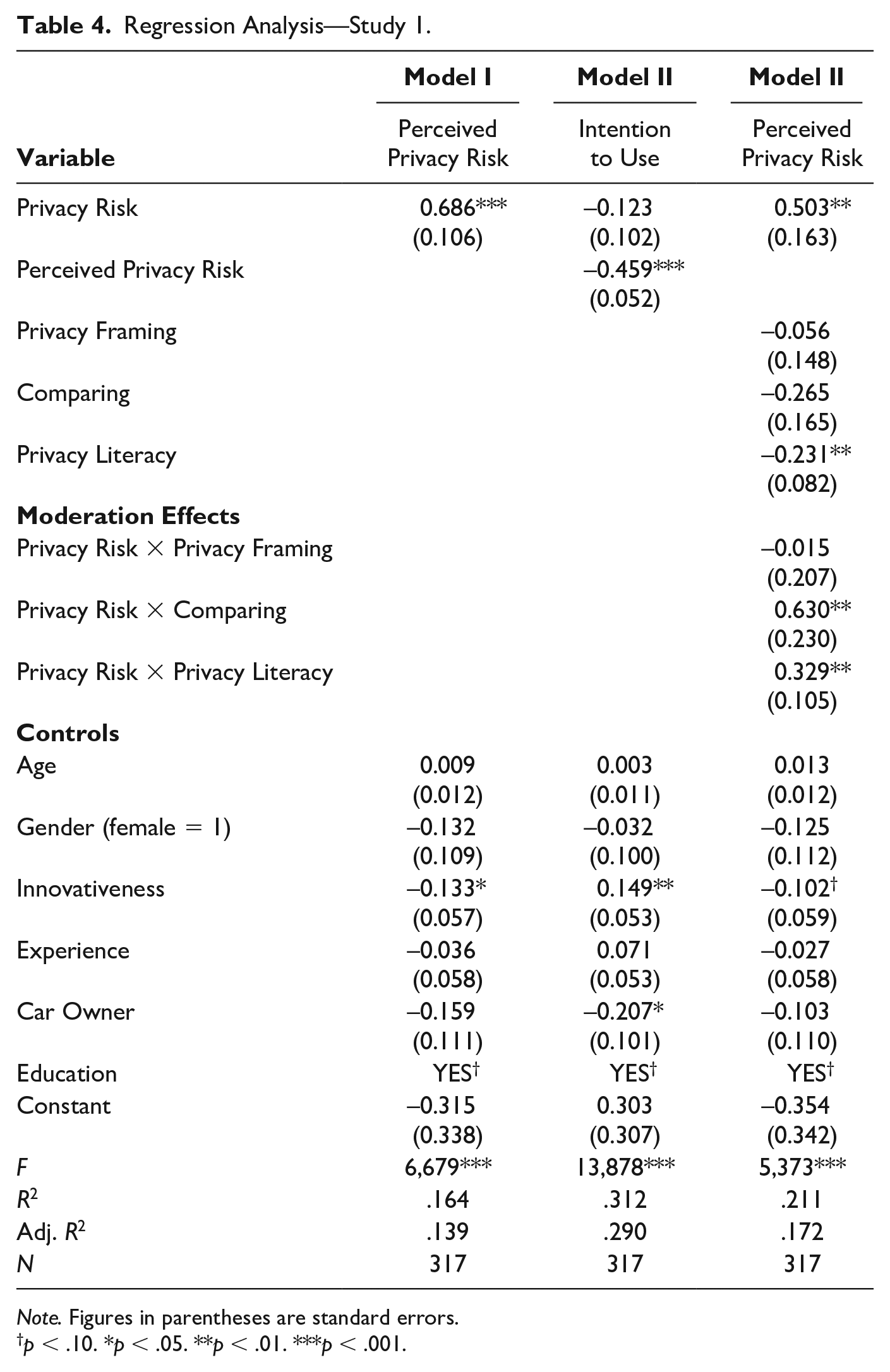
Note. Figures in parentheses are standard errors.
p < .10. *p < .05. **p < .01. ***p < .001.
Regarding our proposed moderators capturing critical dimensions of the manipulated choice architecture and individuals’ capabilities, our results provide mixed support. Contrary to our theoretical expectations, we did not find a significant moderating effect of framing (B = −.02, ns). Our results, hence, do not support Hypothesis 2. Comparing two products that differ in privacy risks seems to enhance individuals’ privacy risk assessment. Our results point to a significant positive moderating effect of comparing on the relationship between actual privacy risk and perceived privacy risk (B = .63, p < .01). Hypothesis 3 is thus supported. Privacy literacy (α = .84) is found to have a significant positive moderating effect on privacy risk assessment (B = .33, p < .01), meaning that we can expect perceived privacy risk to be tied more strongly to actual privacy risk the higher the level of individual privacy literacy. This result supports Hypothesis 4. The results are summarized in Table 4 and illustrated in Figure 3.
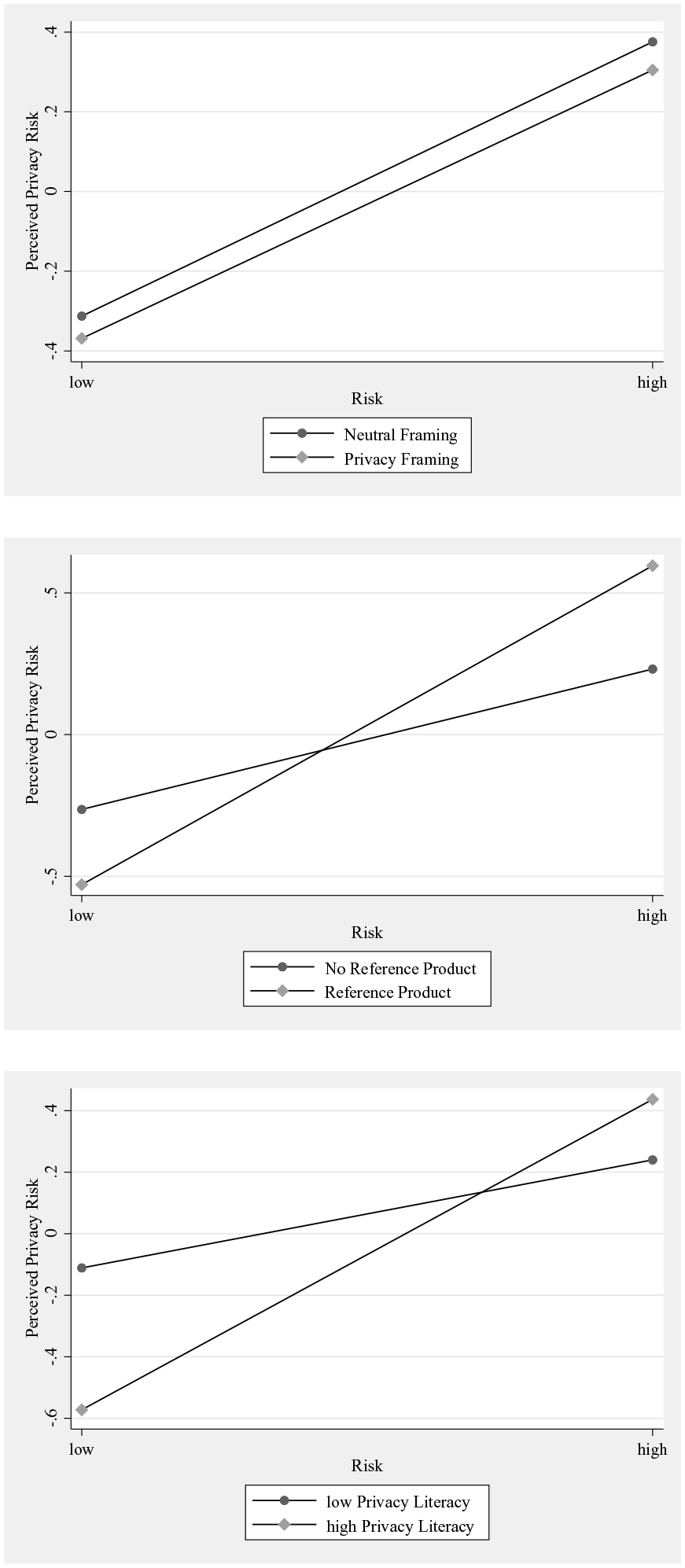
Moderation Effects—Study 1.
Conditional Effects
To better understand the effects of framing, comparing, and educating (i.e., privacy literacy) on the accuracy of individuals’ risk assessments, we performed conditional regression analyses using OLS. Here, we focused on the effect of actual privacy risk on perceived privacy risk at different levels of framing (privacy framing, neutral framing), comparing (reference product, no reference product), and educating (1 SD above the sample mean of privacy literacy, 1 SD below the mean).
We find the effect of actual privacy risk on perceived privacy risk to be significant for individuals with high privacy literacy. The effect is significant, regardless of the level of framing and comparing. The results indicate that high privacy literacy individuals can accurately assess privacy risk regardless of the choice architecture, especially the availability of a reference product increases individuals’ ability to assess privacy risk.
The effect of actual privacy risk on perceived privacy risk is not significant for individuals with low privacy literacy unless the individuals are presented with a reference product. The nonsignificant conditional effects imply that in the absence of a reference product, these respondents are not able to accurately assess privacy risks, as their perceived privacy risk does not increase with an increase in actual privacy risk. Table 5 summarizes the conditional effects.
Conditional Linear Path Coefficients of Actual Risk on Perceived Risk—Study 1.
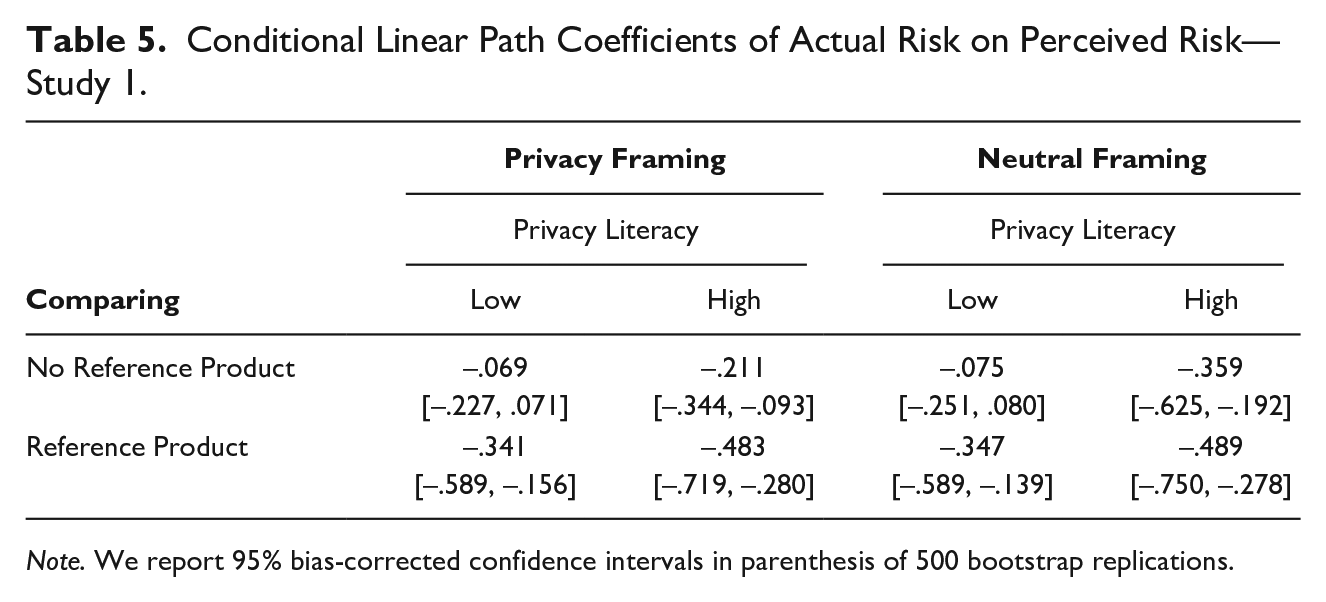
Note. We report 95% bias-corrected confidence intervals in parenthesis of 500 bootstrap replications.
Overall, the investigation of the conditional effects of actual privacy risk on perceived privacy risk unearthed important differences in individuals’ ability to assess privacy risks at different levels of framing, comparing, and educating (i.e., privacy literacy). We found that in cases where a respondent’s privacy literacy was low, and a reference product was available, there was a significant effect of actual privacy risk on perceived privacy risk.
Post Hoc
In an additional additive multiple moderation analysis, we performed OLS regressions investigating the conditional effects of perceived privacy risk on the intentions to use at different levels of framing, comparing, and privacy literacy following the logic above. Independent of the level of the investigated moderators, the effect was always significant.
Experimental Study 2—Fitness Tracker
Research Method and Experimental Design
In our second experimental study, we relied on a fitness tracker as a stimulus. Fitness trackers are rooted in the so-called “quantified self” movement, a loosely connected group of people believing in getting to know themselves better through numbers. As widely used wearable technology, fitness trackers fulfill users’ needs to quantify their physical activities (Swan, 2013). Equipped with gyro and heart rate sensors, fitness trackers collect and analyze activity data. Such data include steps taken, distance walked, floors climbed, calories burnt, and heart rate.
The procedure of Study 2 is the same, mutatis mutandis, as that of Study 1. Participants were recruited via email invitations in October 2018, the same laboratory for economic research was contacted, 1 and the same incentives were provided. Again, participants were presented with a product description. Only this time, a fitness tracking device was presented. The structure of the product description was identical to Study 1, consisting of the same three core elements: (a) benefits, (b) privacy risks, and (c) framing of the privacy risks. As in Study 1, we manipulated three aspects: (a) privacy risks, (b) framing, and (c) the presence of a reference product for the purposes of comparing. This resulted in a 2 × 2 × 2 factorial design (Table 6).
Experimental Treatments—Study 2.
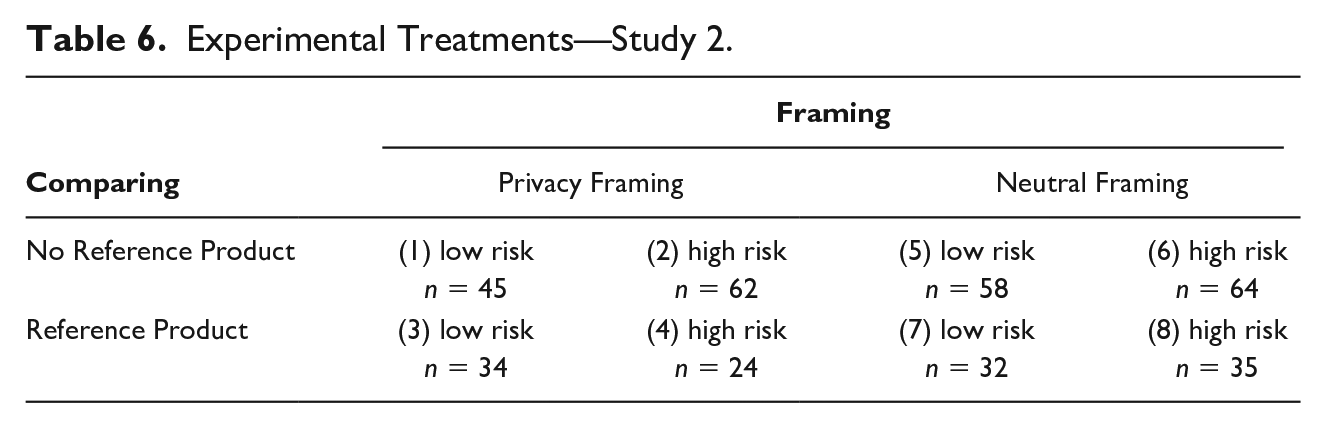
To design the treatments, we developed four product descriptions of a fitness tracker. As in Study 1, the actual privacy risk of the product was set as either low or high and was presented following either a privacy framing or a neutral framing. Participants were either presented with one product description—the low-risk or the high-risk product—or with two product descriptions side-by-side—the low-risk and the high-risk product.
Actual Privacy Risk
Following the same approach as in Study 1, we created a low-risk and high-risk scenario by varying the amount of data, the sensitivity of data, and data storage location. In the low-risk treatment, we said the fitness tracker would collect only the following data: (a) steps taken and distance walked, (b) calories burnt, (c) heart rate, and (d) hours slept. In the high-risk treatment, we said the fitness tracker would also collect the following additional data: (e) sleep phases and sleep quality, (f) location data including real-time location and running speed, (g) stress level, and (h) alcohol consumption. As in Study 1, in the low-risk treatment, we said that the data would be stored locally on the user’s smartphone, while in the high-risk treatment, we said it would be stored on the provider’s server.
Measures
We used the same measures as in Study 1 to capture individuals’ intention to use, perceived privacy risk, and privacy literacy. We adjusted each item to the specific context. We controlled for the same confounding factors as in Study 1: age, gender, education, experience, innovativeness, and fitness tracker ownership.
Data Analysis
As in Study 1, we conducted a mediation analysis and an additive multiple moderation analysis to test our hypotheses (Hayes, 2018). To test Hypothesis 1, we investigated whether the effect of actual privacy risk on the intention to use the fitness tracker is mediated by perceived privacy risk. As for Hypotheses 2, 3, and 4, we analyzed the moderating effect of framing, comparing, and educating on the effect between actual privacy risk on perceived privacy risk.
Results
Descriptive Statistics
The experiment was completed by 356 participants. Fifty-nine percent were female. The mean age was 30. About 30% of the participants had finished high school, and another 61% had a university degree. About 32% owned a fitness tracker or a smartwatch. Using t tests, we found no significant differences in means in our control variables across treatments. Descriptive statistics, bivariate correlations, and Cronbach’s alphas are shown in Table 7.
Descriptive Statistics, Bivariate Correlations, and Cronbach’s Alphas—Study 2.
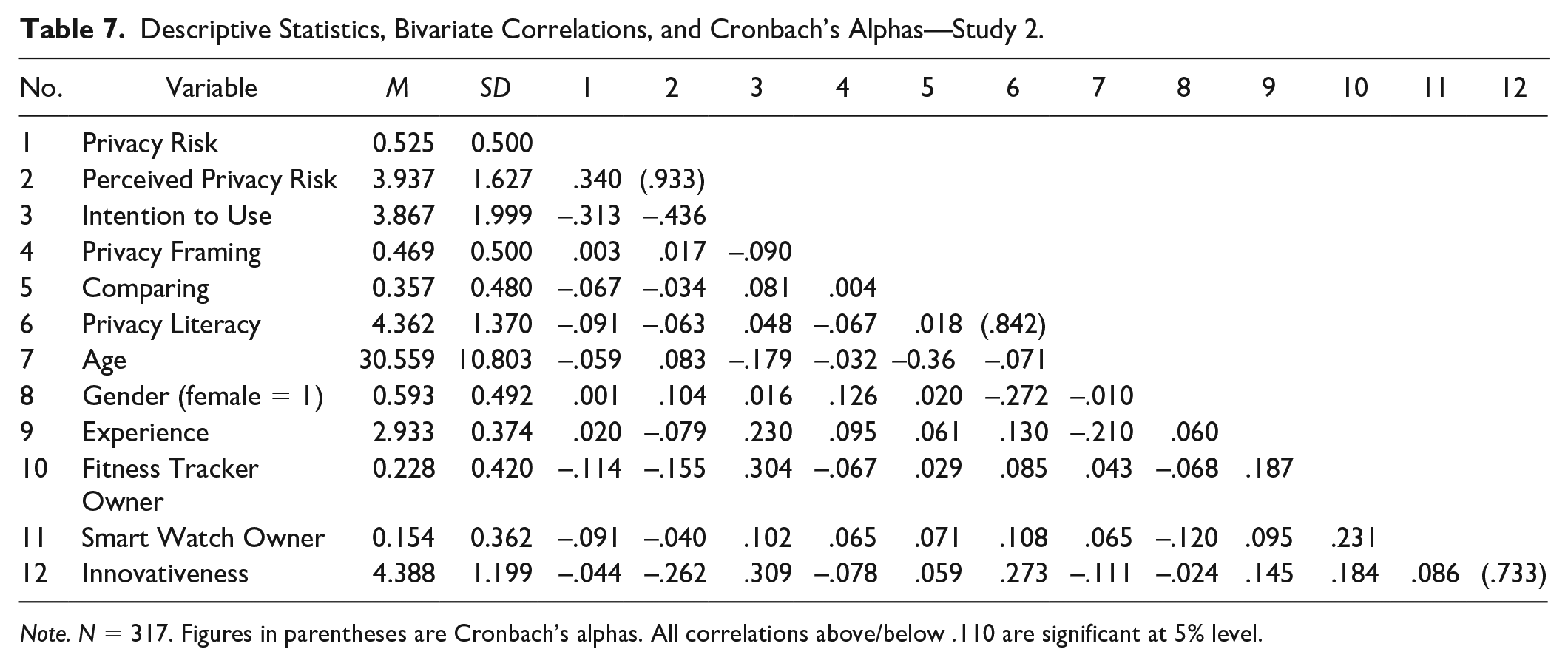
Note. N = 317. Figures in parentheses are Cronbach’s alphas. All correlations above/below .110 are significant at 5% level.
We find perceived privacy risk in the low-risk treatment (n = 169; M = 3.36, SD = 1.52) to be lower than in the high-risk treatment (n = 187; M = 4.46, SD = 1.54). Correlation analysis shows a significant positive, but again moderately strong correlation (r = .34, p < .01) between actual privacy risk and perceived privacy risk (M = 3.95, SD = 1.62). The results indicate that, on average, individuals perceived the privacy risk of the high-risk fitness tracker as being higher than the privacy risk of the low-risk fitness tracker.
Hypothesis Testing
Overall, the results of our study on fitness trackers are similar to those of our study on telematics devices. We find that actual privacy risk affects perceived privacy risk positively (B = .67, p < .001), while perceived privacy risk affects intention to use negatively (B = −.28, p < .001). In contrast to our findings from Study 1, we did find a significant direct effect of actual privacy risk on intention to use (B = −.42, p < .001). A bootstrap analysis with 5,000 replicates shows a significant indirect effect of actual privacy risk on intention to use (B = −.12, 95% Bca CI = [−.23, −.05]). Taken together, the effect of actual privacy risk on intention to use is partially mediated by perceived privacy risk. Hence, Study 2 supports Hypothesis 1 (Table 8). If the actual privacy risk changes from low (coded = 0) to high (coded = 1), the perceived privacy risk increases by .67 points on the 7-point scale.
Regression Analysis—Study 2.
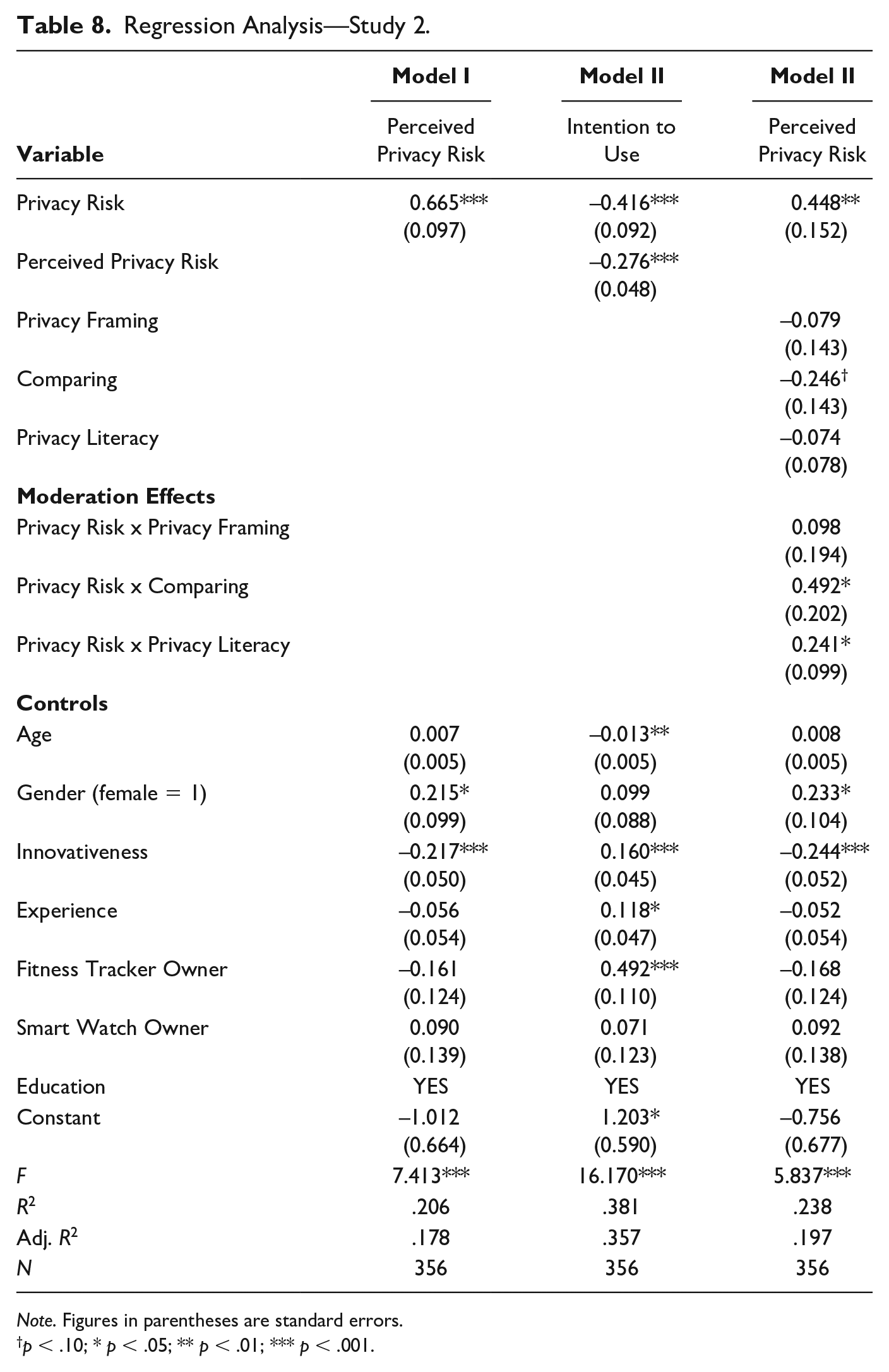
Note. Figures in parentheses are standard errors.
p < .10; * p < .05; ** p < .01; *** p < .001.
The proposed moderators—framing, comparing, and educating—show effects that are similar to those from Study 1 (Table 8). A change in how privacy risk is framed (privacy framing vs. neutral framing) does not affect the effect of actual privacy risk on perceived privacy risk. Hence, as in Study 1, we did not find a significant moderating effect of framing (B = .10, ns). The results of this study, hence, do not support Hypothesis 2. Providing individuals with a reference product while assessing privacy risks increases the effect of actual privacy risk on perceived privacy risk. Our results show a significant positive moderating effect of comparing (B = .49, p < .05) and, hence, provide evidence supporting Hypothesis 3. As in Study 1, privacy literacy as a proxy for prior educating is found to have a significant positive moderating effect (B = .24, p < .05). Educating is linked to stronger effects of actual privacy risk on perceived privacy risk. Hypothesis 4 is, hence, supported. The moderating effects are illustrated in Figure 4.
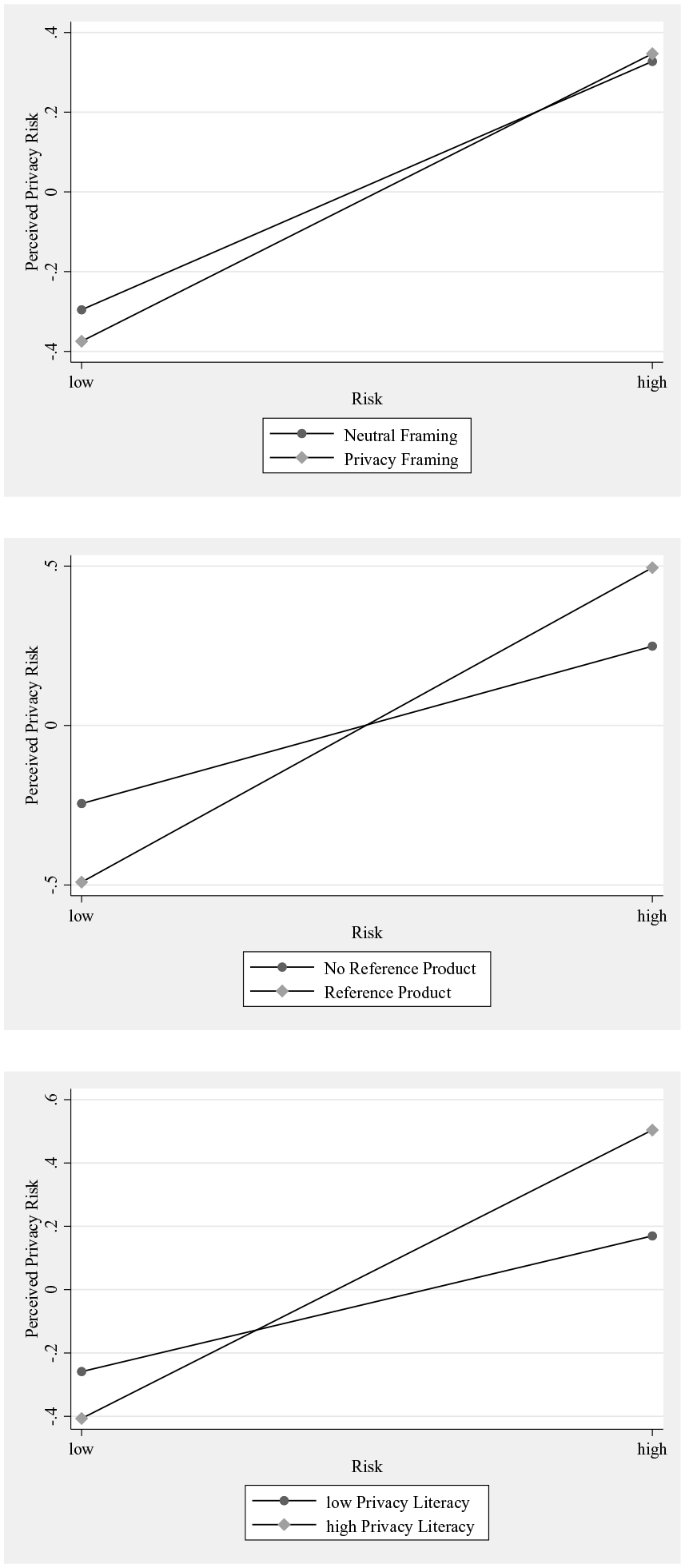
Moderation Effects—Study 2.
Conditional Effects
To understand the effects of the moderators more deeply, we performed conditional regression analyses. As in Study 1, we calculated the effect of actual privacy risk on perceived privacy risk at different levels of framing (privacy framing, neutral framing), comparing (reference product, no reference product), and educating (1 SD above the sample mean of privacy literacy, 1 SD below mean). The conditional effects are presented in Table 8. We find the effect of actual privacy risk on perceived privacy risk to be significant for individuals with high privacy literacy. Among individuals with high privacy literacy, the effect is larger when a reference product is present than if no reference product is present. For individuals with high privacy literacy, the effect is strongest when presented with a reference product and when risks are framed transparently as “Notice on Data Privacy” (B = −.279, 95% Bca CI = [−.45, −.16]). Our results show that even individuals with high privacy literacy benefit from clearly stated privacy risks and the presence of a reference product, as reflected in more accurate privacy risks assessments. Table 9 summerizes the conditional effects.
Conditional Linear Path Coefficients of Actual Risk on Perceived Risk—Study 2.
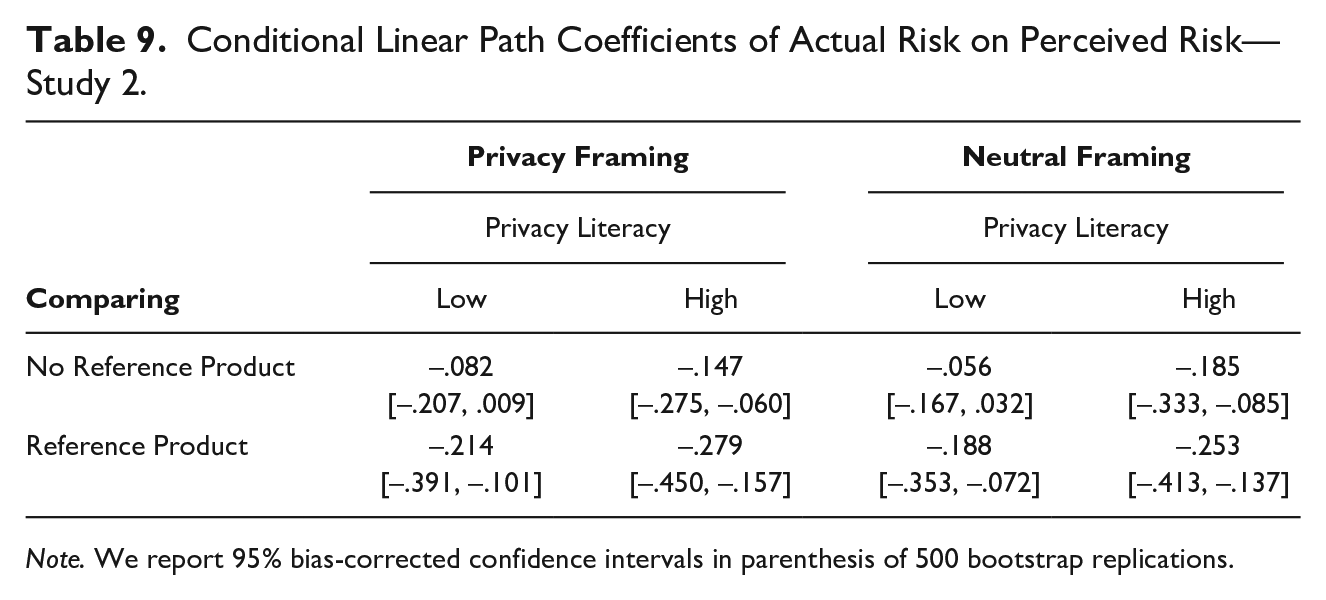
Note. We report 95% bias-corrected confidence intervals in parenthesis of 500 bootstrap replications.
Looking at individuals with low privacy literacy, we found that the effect of actual privacy risk on perceived privacy risk is not significant. The effect turns significant, however, when individuals with low privacy literacy are presented with a reference product and is strongest when both a reference product and a transparent framing of privacy risks are present (B = −.214, 95% Bca CI = [−.39, −.10]).
Overall, Study 2 confirms that individuals in general, but especially those with low privacy literacy, have difficulties accurately assessing privacy risks. The results also support the contention that privacy framing and the presence of a reference product (comparing) enables especially individuals with low privacy literacy to more accurately assess privacy risks.
Post Hoc
As in Study 1, we performed OLS regressions to investigate the conditional effects of perceived privacy risk on the intentions to use at different levels of framing, comparing, and educating. The effect was found to be significant at all levels of the moderators.
Discussion
Our findings help to paint a nuanced picture of users’ ability to assess privacy risks associated with smart products and arguably beyond. At their core, our analyses showed that comparing and educating (i.e., higher privacy literacy) can each empower individuals to make more accurate privacy risk assessments. Jointly, framing and comparing can enable even individuals with low privacy literacy to assess privacy risks. Although our studies were embedded in two different contexts, they generated a remarkably consistent pattern of results, with effects being replicable across both contexts. One difference pertained to the role of perceived privacy risks, which fully mediated the link between actual privacy risk and intention to use in the context of connected cars and only partially did so in the context of fitness trackers. One reason for this finding might be that participants in our experiments were more familiar with fitness trackers than with telematics devices, which are more widespread in professional contexts (e.g., fleet management; Aries, 2019). Perceived privacy risks might, therefore, lose in relative importance as mechanisms through which actual privacy risks affect participants’ intentions to use. Our findings hold meaningful implications for research and for practice and policy.
Implications for Research
At a broad level, our study contributes to a better understanding of both individuals’ ability to assess privacy risks and effective empowering tools—namely, framing, comparing, and educating—for providers of smart products to facilitate accurate privacy risk assessment. In both studies, an increase in actual privacy risks induced by our experimental manipulation was associated with a notably weaker increase in the privacy risks perceived by participants. Participants—especially those with lower privacy literacy—struggled to detect the privacy risks inherent in smart products. This is understandable in that the potential negative consequences of information disclosure will not occur immediately, but with an unknown probability at some unknown point in the future (Acquisti, 2004). Given the rapid progress in both machine learning algorithms and companies’ own analytical capabilities, user data are likely to be exploited in ways that are today unforeseeable not only to the average user but also to the providers of smart products themselves. This has at least two important implications for research.
First, researchers need to appreciate that the privacy risks users perceive will often be disconnected from the actual privacy risks they are exposed to. Critically, we found that individuals systematically underestimate the actual privacy risk associated with high-risk products when a reference product and clear privacy framing are absent. Individuals tend to overestimate the actual privacy risk of low-risk products under the same circumstances. As such, our study adds to the growing body of evidence (Balebako et al., 2013; Brakemeier et al., 2017; Norberg et al., 2007; Tsai et al., 2011) that challenges the common assumption that perceived privacy risk mirrors actual privacy risk. While perceived privacy risks remain an important predictor for user behavior (Dinev et al., 2006; Xu et al., 2009), researchers interested in privacy risks as such are well-advised to shift their attention from privacy risk perceptions to actual privacy risks.
Second, more research effort is needed to better understand the mechanisms at the level of individual ability and the choice architecture that can be employed to support individuals with different abilities in their privacy risk assessments. While educating (i.e., building privacy literacy) empowers individuals to make more accurate privacy risk assessments, there are even more short-term and less resource-intensive, yet effective, tools pertaining to the choice architecture. As both our experiments demonstrated, especially comparing (i.e., the presence of a reference product) is a highly effective, yet inexpensive, means to help users assess privacy risks. This finding is consistent with initial evidence on users’ privacy risk assessments in the presence and absence of external reference information in the context of smartphone applications (Brakemeier et al., 2017). Similarly, a transparent framing of privacy risks has been established as effective in the context of privacy settings in online social networks (Adjerid et al., 2019). While framing effects tended to be less pronounced in our experiments, a transparent privacy framing coupled with the presence of a reference product notably increased privacy risk detection among individuals with low privacy literacy. This finding also demonstrates that the three mechanisms—educating, framing, and comparing—act as complements rather than as substitutes. Indeed, users’ risk assessment will be most accurate when users exhibit high privacy literacy, see privacy information clearly framed as such, and can compare alternative products with different privacy risks.
At a more fundamental level, our research presents a strong case for integrating behavioral economics into privacy research (Goes, 2014). This is particularly fruitful for the domain of privacy, which is known to contain paradoxical behaviors that are not easily explained by established conceptual models as the privacy calculus (Acquisti, 2004; Dinev et al., 2015). By integrating behavioral economics into privacy research, apparently paradoxical user behaviors can be better understood and investigated.
Implications for Practice and Policy
Our experimental studies provide empirical evidence that individuals are often unable to accurately assess privacy risks. This makes them vulnerable to uninformed data disclosure decisions that might contradict their privacy preferences (Taylor, 2004). A close alignment between actual and perceived privacy risks is desirable but cannot be ensured by regulatory measures alone. This puts various other actors (companies, consumer advocate organizations, educational institutions, etc.) and the society as a whole into the responsibility to empower consumers so that they are able to make informed data disclosure decisions. The three mechanisms that our research indicates to be effective in such an empowerment—framing, comparing, and educating—are promising starting points in this regard.
The first suggestion is that distributors/retailers as well as manufacturers of smart products use a framing that clearly indicates the privacy risk of the respective product. This enhances the transparency of the relevant privacy information and makes it easier for individuals to recognize the actual risk that is associated with the use of a specific smart product. In practice, we frequently find inconsistent and misleading terms framing the information on privacy risk. Besides the common term “Privacy Policies,” information on data privacy is found under “Location Information” and “Settings” (Adjerid et al., 2019). Hence, there is substantial room for improvement and a need to enforce an explicit and clearly visible framing of privacy-risk-related information.
We also recommend integrating comparing into the choice architecture as an effective tool to improve individuals’ privacy risk assessments. Providing a reference product allows individuals to put the information on privacy risk into context by comparing it with the privacy risk of other products. Comparing, hence, increases individuals’ ability to assess privacy risk through increased evaluability (Hsee & Zhang, 2010). Another means to integrate comparing is through labels indicating the level of privacy risk (Kelley et al., 2009). Short privacy statements make it easier to compare privacy risks across products (Milne & Culnan, 2004). Our findings encourage distributors, product comparison websites, and product testers to opt for comparative product presentations and include information on privacy risks in their comparisons.
Our results also show that privacy literacy improves individuals’ effectiveness in assessing privacy risks. Educating individuals about data collection, storage, and analysis practices increases their privacy literacy and serves as an additional tool to empower individuals to make informed data disclosure decisions. A standardized process and language informing individuals about privacy risks allows them to learn to assess privacy risk (Kelley et al., 2009). Likewise, consumer advocate groups and educational institutions from school to university have an important role to play in helping users increase their ability to manage their personal data. A summary of our recommendations is depicted in Figure 5.
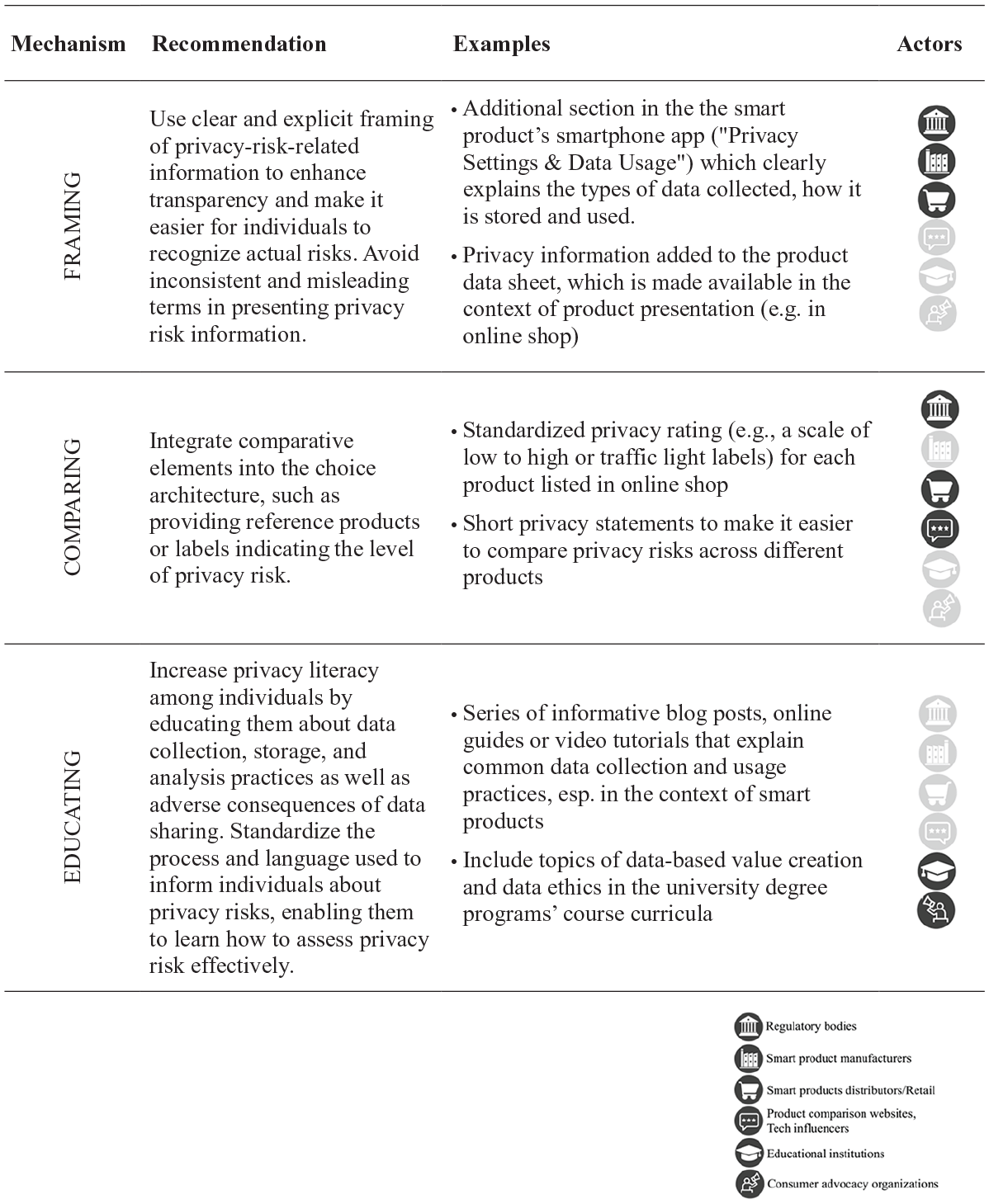
Overview of Practical Recommendations.
The three empowering tools can benefit users of smart products by supporting more accurate risk assessments and informed data disclosure decisions. Responsibly employing framing, comparing, and educating can also serve the interests of manufacturers, distributors, and product comparison sites. Building choice architectures that support individuals in making informed decisions is an ethically favorable practice of the type that makes strict government regulations unnecessary. Self-regulation is beneficial for organizations, making them more flexible and able to react to changes more quickly (Sarathy & Robertson, 2003). Flexibility is a crucial success factor in a fast-changing environment, as the environment of smart products is, and thus appears desirable from an organizational perspective. Organizations that actively help to align actual privacy risks and users’ perceived privacy risks by empowering users to accurately assess privacy risk send strong signals of corporate digital responsibility and will likely be rewarded by more trust and stronger customer relationships, both of which can be vital sources of competitive advantage in an increasingly global and maturing market (Kang & Hustvedt, 2014; Tsai et al., 2011). Visible misalignment, in contrast, can trigger negative attitudes toward the organization (Wright & Xie, 2019) as manifested, for instance, in a loss of trust (Martin, 2020) or user boycotts that can hurt even quasi-monopolists such as Amazon.
Limitations and Future Research
Despite the two independent experimental studies it is built on, this research has limitations that offer opportunities for future research. First, our samples were not representative of the broader population. With a mean age of 25 (Study 1) and 30 (Study 2) years, participants were notably younger than the German average of 44.5 years. However, smart products are extensively used by younger individuals, who possess, on average, more technology-related knowledge (Margaryan et al., 2011). Therefore, they might be even better positioned to assess privacy risks than the average user. Similarly, the average education level in our sample is above the population mean. Individuals with a higher education level are expected to assess privacy risks more readily (Phelps et al., 2000; Turow, 2003). Given the composition of our sample, our estimates might well be rather conservative. We hold that replication studies with older and less tech-savvy participants could find even stronger effects with regard to our hypotheses. A second limitation might arise from the fact that our experiments were conducted prior to the global Covid pandemic, which has arguably increased user engagement with smart products of all types. A third limitation concerns the operationalization of framing, comparing, and educating. As for framing, we chose to contrast a more explicit framing of privacy information (i.e., Notice on Data Privacy) with a neutral framing (i.e., Notice on Technical Functions). Although both framings reflect current practice, they clearly do not exhaust the full set of framing options. Alternatives include contrasting gain and loss, positive and negative, as well as promotion and prevention-focused framings. As for comparing, we chose to include a reference product, which differed in the privacy risks. Our results on comparing are, therefore, limited to reference products. Future research could focus on different types of reference information, such as privacy seals or a traffic light principle indicating low and high privacy risks. As for educating, we chose to focus on users’ privacy literacy as an individual capability of the user. Similarly, we could imagine that smart product manufacturers, distributors, or comparison websites provide privacy awareness trainings, opening up opportunities for alternative operationalizations in future studies.
Conclusion
Our research provides valuable insights into individual privacy risk assessment as a necessary precondition for informed data disclosure decisions associated with the use of smart products. Our two studies provide new evidence on the remarkable disconnect between individuals’ privacy risk perceptions and the actual privacy risks they are exposed to. Our studies also demonstrate the effectiveness of three empowering tools—framing, comparing, and educating—that help individuals assess privacy risks more accurately. In particular, both comparing and educating (i.e., higher privacy literacy) independently have a beneficial effect on the accuracy of individuals’ privacy risk assessment. Moreover, framing and comparing can jointly enable especially individuals with low privacy literacy to assess privacy risks. These findings highlight the value of a behavioral perspective on data privacy and contribute to more evidence-based data privacy practices as an increasingly important field of action in corporate digital responsibility.
Footnotes
Appendix A
Appendix B
Literature Review on Privacy Risk (Perceptions) in Data Disclosure Decision-Making.
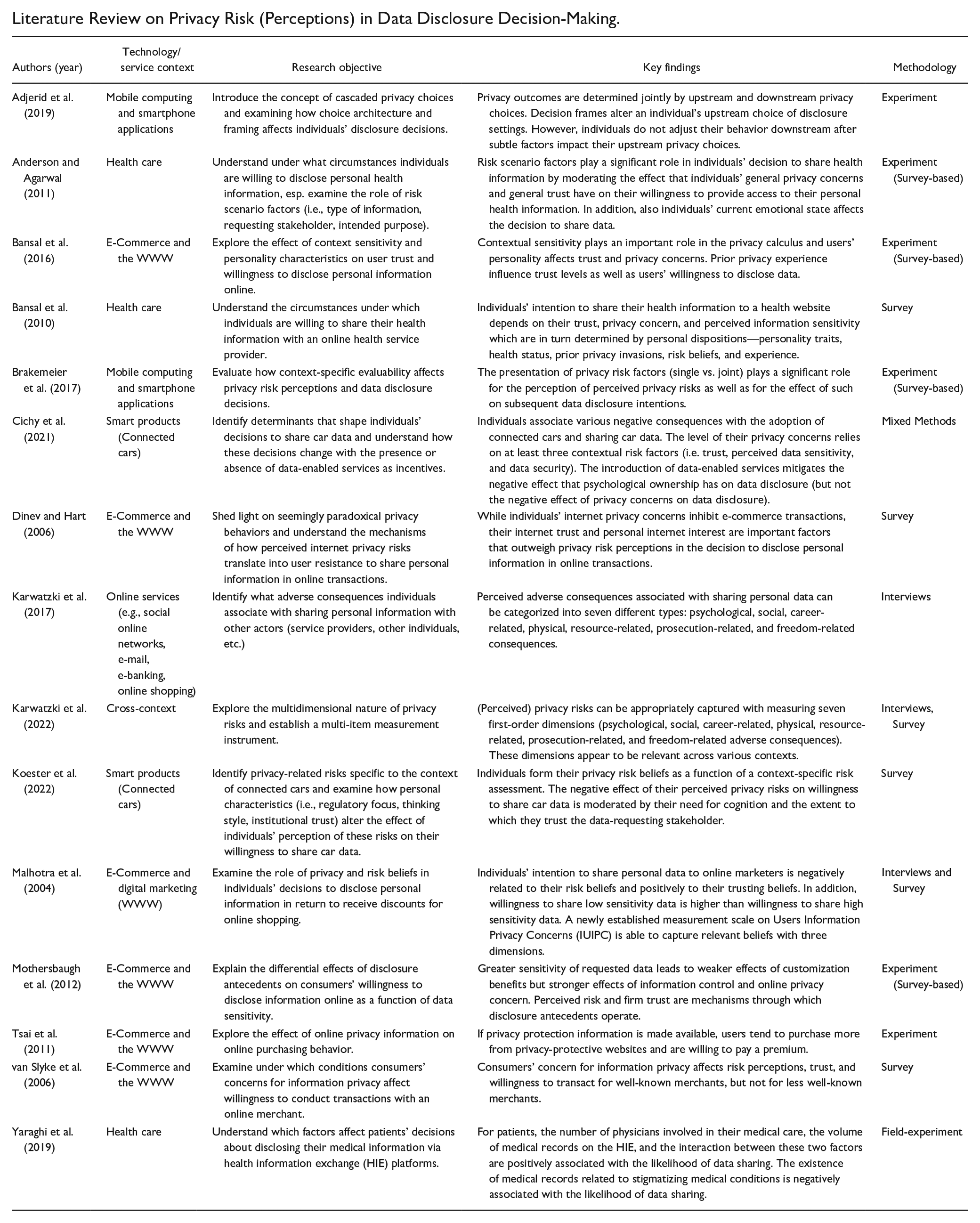
| Authors (year) | Technology/service context | Research objective | Key findings | Methodology |
|---|---|---|---|---|
| Adjerid et al. (2019) | Mobile computing and smartphone applications | Introduce the concept of cascaded privacy choices and examining how choice architecture and framing affects individuals’ disclosure decisions. | Privacy outcomes are determined jointly by upstream and downstream privacy choices. Decision frames alter an individual’s upstream choice of disclosure settings. However, individuals do not adjust their behavior downstream after subtle factors impact their upstream privacy choices. | Experiment |
| Anderson and Agarwal (2011) | Health care | Understand under what circumstances individuals are willing to disclose personal health information, esp. examine the role of risk scenario factors (i.e., type of information, requesting stakeholder, intended purpose). | Risk scenario factors play a significant role in individuals’ decision to share health information by moderating the effect that individuals’ general privacy concerns and general trust have on their willingness to provide access to their personal health information. In addition, also individuals’ current emotional state affects the decision to share data. | Experiment (Survey-based) |
| Bansal et al. (2016) | E-Commerce and the WWW | Explore the effect of context sensitivity and personality characteristics on user trust and willingness to disclose personal information online. | Contextual sensitivity plays an important role in the privacy calculus and users’ personality affects trust and privacy concerns. Prior privacy experience influence trust levels as well as users’ willingness to disclose data. | Experiment (Survey-based) |
| Bansal et al. (2010) | Health care | Understand the circumstances under which individuals are willing to share their health information with an online health service provider. | Individuals’ intention to share their health information to a health website depends on their trust, privacy concern, and perceived information sensitivity which are in turn determined by personal dispositions—personality traits, health status, prior privacy invasions, risk beliefs, and experience. | Survey |
| Brakemeier et al. (2017) | Mobile computing and smartphone applications | Evaluate how context-specific evaluability affects privacy risk perceptions and data disclosure decisions. | The presentation of privacy risk factors (single vs. joint) plays a significant role for the perception of perceived privacy risks as well as for the effect of such on subsequent data disclosure intentions. | Experiment (Survey-based) |
| Cichy et al. (2021) | Smart products (Connected cars) | Identify determinants that shape individuals’ decisions to share car data and understand how these decisions change with the presence or absence of data-enabled services as incentives. | Individuals associate various negative consequences with the adoption of connected cars and sharing car data. The level of their privacy concerns relies on at least three contextual risk factors (i.e. trust, perceived data sensitivity, and data security). The introduction of data-enabled services mitigates the negative effect that psychological ownership has on data disclosure (but not the negative effect of privacy concerns on data disclosure). | Mixed Methods |
| Dinev and Hart (2006) | E-Commerce and the WWW | Shed light on seemingly paradoxical privacy behaviors and understand the mechanisms of how perceived internet privacy risks translate into user resistance to share personal information in online transactions. | While individuals’ internet privacy concerns inhibit e-commerce transactions, their internet trust and personal internet interest are important factors that outweigh privacy risk perceptions in the decision to disclose personal information in online transactions. | Survey |
| Karwatzki et al. (2017) | Online services (e.g., social online networks, e-mail, e-banking, online shopping) | Identify what adverse consequences individuals associate with sharing personal information with other actors (service providers, other individuals, etc.) | Perceived adverse consequences associated with sharing personal data can be categorized into seven different types: psychological, social, career-related, physical, resource-related, prosecution-related, and freedom-related consequences. | Interviews |
| Karwatzki et al. (2022) | Cross-context | Explore the multidimensional nature of privacy risks and establish a multi-item measurement instrument. | (Perceived) privacy risks can be appropriately captured with measuring seven first-order dimensions (psychological, social, career-related, physical, resource-related, prosecution-related, and freedom-related adverse consequences). These dimensions appear to be relevant across various contexts. | Interviews, Survey |
| Koester et al. (2022) | Smart products (Connected cars) | Identify privacy-related risks specific to the context of connected cars and examine how personal characteristics (i.e., regulatory focus, thinking style, institutional trust) alter the effect of individuals’ perception of these risks on their willingness to share car data. | Individuals form their privacy risk beliefs as a function of a context-specific risk assessment. The negative effect of their perceived privacy risks on willingness to share car data is moderated by their need for cognition and the extent to which they trust the data-requesting stakeholder. | Survey |
| Malhotra et al. (2004) | E-Commerce and digital marketing (WWW) | Examine the role of privacy and risk beliefs in individuals’ decisions to disclose personal information in return to receive discounts for online shopping. | Individuals’ intention to share personal data to online marketers is negatively related to their risk beliefs and positively to their trusting beliefs. In addition, willingness to share low sensitivity data is higher than willingness to share high sensitivity data. A newly established measurement scale on Users Information Privacy Concerns (IUIPC) is able to capture relevant beliefs with three dimensions. | Interviews and Survey |
| Mothersbaugh et al. (2012) | E-Commerce and the WWW | Explain the differential effects of disclosure antecedents on consumers’ willingness to disclose information online as a function of data sensitivity. | Greater sensitivity of requested data leads to weaker effects of customization benefits but stronger effects of information control and online privacy concern. Perceived risk and firm trust are mechanisms through which disclosure antecedents operate. | Experiment (Survey-based) |
| Tsai et al. (2011) | E-Commerce and the WWW | Explore the effect of online privacy information on online purchasing behavior. | If privacy protection information is made available, users tend to purchase more from privacy-protective websites and are willing to pay a premium. | Experiment |
| van Slyke et al. (2006) | E-Commerce and the WWW | Examine under which conditions consumers’ concerns for information privacy affect willingness to conduct transactions with an online merchant. | Consumers’ concern for information privacy affects risk perceptions, trust, and willingness to transact for well-known merchants, but not for less well-known merchants. | Survey |
| Yaraghi et al. (2019) | Health care | Understand which factors affect patients’ decisions about disclosing their medical information via health information exchange (HIE) platforms. | For patients, the number of physicians involved in their medical care, the volume of medical records on the HIE, and the interaction between these two factors are positively associated with the likelihood of data sharing. The existence of medical records related to stigmatizing medical conditions is negatively associated with the likelihood of data sharing. | Field-experiment |
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was funded by the German Federal Ministry of Justice with the Grant No. 28V21002. The German Federal Ministry of Justice has not approved or influenced the results of this study.