
Abstract
Teachers use assessment to ascertain and enhance student learning, thus the importance of assessment literacy. One of the instruments that has been used to examine teachers’ assessment literacy is the Assessment Literacy Inventory developed by Mertler and Campbell. The Assessment Literacy Inventory has been validated using pre-service teachers and employing traditional statistical techniques. This study reports on the evaluation of the Assessment Literacy Inventory utility using 582 in-service teachers through employing the Rasch model and confirmatory factor analysis. The results indicate that the Assessment Literacy Inventory works well at the item level. However, the Assessment Literacy Inventory seven-factor structure, based on the Standards for Teacher Competence in Educational Assessment of Students, poses challenges against newer psychometric techniques. Hence, recommendations are presented. This article concludes with relevant implications for instrument development, educational assessment research, policy and practice, and teachers’ professional development.
Introduction
Teachers have the potential to influence student development in the classroom. As primary agents in the educational process, teachers make instruction and learning beneficial for students. However, their success in making the teaching-learning process effective depends on several factors, and includes the sound knowledge and application of educational concepts that involve assessment (Churchill, Ferguson, Godinho, Johnson, Keddie, Letts, Mackay, McGill, Moss, Nagel, Nicholson, & Vick, 2011). The assessment component of teacher professional standards such as the Australian Professional Standards for Teachers (Australian Institute for Teaching and School Leadership, 2013) and the Philippine National Competency-Based Teacher Standards (Philippine Department of Education, 2006) further highlight this requirement. Hence, assessment literacy is pertinent to teachers’ professional competence (Popham, 2009; Stiggins, 1991a). Assessment literacy is defined as teachers’ ‘knowledge of and abilities to apply assessment concepts and techniques to inform decision making and guide practice’ (Mertler & Campbell, 2005, p. 16).
The need for sound assessment literacy stems from the fact that assessment is an essential part of teachers’ professional responsibilities (Mertler, 2003, 2004). Teachers have the accountability to establish and improve student learning through assessment and it is incumbent upon them to use appropriate means and provide evidence of that learning (Phye, 1997). The utilisation of a variety of assessment methods and strategies in ascertaining student learning requires teachers’ knowledge and skills in employing assessment. Moreover, continuous and meaningful use of assessment requires teachers to possess assessment literacy. It has been estimated that about 30% to 50% of teachers’ instructional time is spent on assessment-related activities (Stiggins & Conklin, 1992), which include designing, developing, selecting, administering, scoring, recording, reporting, evaluating, and revising assessment methods (Stiggins, 1988). These assessment activities can be made more effective where teachers possess the relevant knowledge and skills of and for assessment (Popham, 2009, 2011; Stiggins, 1988, 1991a, 1991b; Stiggins, Arter, Chappuis & Chappuis, 2007; Stiggins & Conklin, 1992).
As well as recording what has been learnt, assessment is also meant to support and improve teaching and learning in the classroom (Boone, Staver & Yale, 2014a, 2014b; Brookhart, 1999; Pellegrino, Chudowsky, & Glaser, 2001; Popham, 2011; Stiggins, 1991b, 2010; Stiggins & Conklin, 1992). Here, assessment results guide teachers' decisions regarding a range of pedagogy elements, which include the:
Learning aims and objectives; Subject contents and activities that need to be given emphasis; Methods and strategies to deliver the targets and the contents effectively; ‘What’ and ‘how’ of assessing student learning; Judgement whether or not the learning aims have been achieved; and Identification of improvement needs (Black & Wiliam, 1998a, 1998b; Kellaghan & Greany, 2001; Popham, 2011; Stiggins, 2010; Stiggins & Conklin, 1992).
Subscribing to the view that sound teaching requires sound student assessment, and recognising the need for teachers to possess knowledge and skills in student assessment, the American Federation of Teachers (AFT), National Council on Measurement in Education (NCME), and National Education Association (NEA) (1990) developed the Standards for Teacher Competence in Educational Assessment of Students that cover seven broad areas. These include: (1) Choosing assessment methods appropriate for instructional decisions; (2) Developing assessment methods appropriate for instructional decisions; (3) Administering, scoring and interpreting the results of both externally-produced and teacher-produced assessment methods; (4) Using assessment results when making decisions about individual students, planning teaching, developing curriculum, and school improvement; (5) Developing valid pupil grading procedures which use pupil assessments; (6) Communicating assessment results to students, parents, other lay audiences, and other educators; and (7) Recognizing unethical, illegal, and otherwise inappropriate assessment methods and uses of assessment information (pp. 2–5).
Likewise, Berry and Adamson (2011) and Masters (2013) highlight the importance of assessment, its principles, and associated challenges. Internationally, the OECD (2013, p.17) acknowledges the ‘widespread recognition that evaluation and assessment arrangements are key to both improvement and accountability in school systems.’ This comprehensive review examines the various components of assessment and evaluation frameworks that countries use with the objective of improving student outcomes (OECD, 2013).
Consistent in all these reports and reviews on ‘assessment and evaluation’ is the centrality of teachers’ assessment literacy and its influence on student learning outcomes. Gardner, Harlen, Hayward, & Stobart, (2011, p.106) reiterate that teachers need to be empowered to undertake meaningful assessment. For example, Chick and Pierce (2008) and Pierce and Chick (2010) highlight that teachers have difficulty interpreting assessment results. Thus, assessment is a vital element of education, and an understanding of associated processes is fundamental to teacher professionalism (OECD, 2013; Santiago, Donaldson, Herman, & Shewbridge, 2011).
With the aim of examining whether or not teachers in the field have the required assessment literacy and to identify any areas on which teachers need further training, the aforementioned standards have become the basis of assessment literacy research. In turn, the need to examine teachers’ assessment literacy using these standards has necessitated the development of various scales and instruments. One of the instruments which has been proposed, is the Assessment Literacy Inventory (ALI) developed by Mertler and Campbell (2005). This article reports on the utility of the ALI using data from 582 in-service teachers who were selected from schools from the list provided by DepEd-Tawi-Tawi Division Office in Bongao, Tawi-Tawi, Philippines. This sample, which was different to that of Mertler and Campbell (2005), provided the opportunity to test the portability of the scale. The data are examined using the Rasch model (Rasch, 1960, 1966; Wright, 1988) and confirmatory factor analysis (CFA) to provide information regarding item/scale-fit, factor structure and structural invariance of the scale. This paper aims to:
Add to ALI’s previous validation findings which were based on samples from the United States (Mertler & Campbell, 2005); Ascertain its measurement properties and utility; and Importantly gauge its portability to other education systems such as the countries in the Asia Pacific region
The Assessment Literacy Inventory (ALI)
Mertler and Campbell (2005) developed the ALI to measure teachers’ assessment literacy as a result of the findings on the psychometric utility of their previous instruments. For instance, they reported that in 1991, the first scale called the ‘Teacher Assessment Literacy Questionnaire (TALQ)’, developed by Plake (1993, cited in Mertler & Campbell, 2005), was employed in a national survey both to establish its psychometric properties and to measure the teachers’ assessment literacy. Using a sample of 555 in-service teachers from across the US, the reliability for the whole test employing KR20 was 0.54 (Plake, Impara, & Fager, 1993). This was below the acceptable threshold of at least 0.65 (Chase, 1999, as cited in Mertler & Campbell, 2005). Campbell et al. (2002, cited in Mertler and Campbell, 2005) applied the identical scale called the ‘Assessment Literacy Inventory (ALI)’ to 220 students undertaking pre-service education program. This study yielded a reliability of 0.74 using the same statistical procedures.
Mertler (2003) compared the assessment literacy levels of both in-service and pre-service teachers. Like Campbell et al. (2002, as cited in Mertler & Campbell, 2005), Mertler (2003) used a slightly modified version of TALQ and called the instrument, the ‘Classroom Assessment Literacy Inventory (CALI)’. He noted that his study yielded similar results to those of Plake et al. (1993) and Campbell et al. (2002). Using KR20, Mertler (2003) obtained a reliability of 0.57 for the in-service teachers (Plake et al. study, KR20 = 0.54) and 0.74 for the pre-service teachers (Campbell et al. study, KR20 = 0.74). Mertler and Campbell (2005) emphasised that the assessment literacy scales used previously showed low reliability for in-service teachers but exhibited a much greater reliability for pre-service teachers.
Having employed instruments that were identical to TALQ and having obtained consistently low reliability results for in-service teachers, both Campbell et al. (2002) and Mertler (2003) concluded that the original instrument possessed poor psychometric qualities. The original scale was considered ‘difficult to read, extremely lengthy, and contained items that were presented in a decontextualized way’ (pp. 8–9) which led to a complete redevelopment of the assessment literacy scale. Hence, the new ALI, which differs in items and structure from the earlier instruments, was developed in 2003 (Mertler & Campbell, 2005).
The ALI consists of 35 multiple-choice items that are embedded in five classroom-based scenarios. Each scenario reflects a classroom situation that features a teacher undertaking assessment-related activities and making assessment-related decisions. The situation in each scenario is followed by seven items that are aligned to the seven Standards for Teacher Competence in the Educational Assessment of Students (STCEAS) (AFT, NCME, & NEA, 1990). Each ALI stem has four options, with one correct answer and three distractors (Mertler & Campbell, 2005).
Previous ALI Validation
After the development of the ALI, the authors reviewed the items to ensure alignment with the STCEAS and to check for item clarity, readability, and the accuracy of the correct answers. Problematic items were reviewed ‘until consensus was reached regarding the item appropriateness and quality’ (Mertler & Campbell, 2005, p. 10).
After this initial face validity check, the ALI was trialed twice to examine its psychometric properties. The ALI was first administered in 2003 to 152 undergraduate pre-service teaching students who took the introductory assessment courses that were aligned with the STCEAS. The ALI was analysed using the Test Analysis Program (TAP) of Brooks and Johanson (2003, cited in Mertler & Campbell, 2005) to conduct test-level analysis, item-level analysis, reliability analysis, and options/distracters analysis. Some items of the ALI scale were revised and four items were completely removed based on the results of these analyses. In its second trial in 2004, the revised ALI was administered to 250 undergraduate pre-service teaching students after completing a course in testing and measurement. Results of the analyses with an overall reliability (KR20) of 0.74, mean item difficulty of 0.68, and mean item discrimination of 0.31 showed ALI to have acceptable psychometric properties (Mertler & Campbell, 2005). The ALI developed in this way consisted of five scenarios with a total of 31 items. Each of the five scenarios consisted of seven questions. Mertler and Campbell (2005) describe the items as Related to the seven Standards for Teacher Competence in the Educational Assessment of Students (SSTCEAS). Some of the items are intended to measure general concepts related to testing and assessment, including the use of assessment activities for assigning student grades and communicating the results of assessments to students and parents; other items are related to knowledge of standardized testing, and the remaining items are related to classroom assessment (p. 26)
Validation techniques
The central validation technique that was used in the current validation of the ALI was the Rasch model developed by Georg Rasch (Rasch, 1960, 1966), a Danish mathematician, in the 1960s (Baker, 2001). It is a popular one-parameter item response model (Ben, Hailaya, & Alagumalai, 2012) that can be utilised to judge items at the pilot or validation stage (Wu & Adams, 2007) and to review the psychometric properties of the existing scale (Tennant & Conaghan, 2007). The Rasch model defines the probability of a specified response in relation to the test takers’ ability and the item difficulty. The probability of success in answering an item correctly is modelled as a logistic function of the difference between the person ability and the item difficulty (Van Alphen, Halfens, Hasman, & Imbos, 1994).
The model has the special properties of specific objectivity and unidimensionality. The property of specific objectivity emphasises that the estimation of item and person parameters are independent of each other (Bond & Fox, 2007; Ewing, Salzberger, & Sinkovics, 2005). The model positions person and item parameters on the same scale and both parameters are sample independent (Hambleton & Jones, 1993; Tinsley & Dawis, 1975; Van Alphen, Halfens, Hasman, & Imbos, 1994). Moreover, unidimensionality requires the measurement of one underlying or dominant factor, construct or attribute at a time (Bond & Fox, 2007). Thus, items that fit the Rasch model are expected to follow a structure that has a single or dominant dimension. It has been highlighted by Alagumalai and Curtis (2005, p. 2) that the Rasch model has a ‘unique property that embodies measurement.’ It provides a probabilistic insight into how the data operate within a unidimensional model, when understanding how a construct operates. The advantage of using Rasch model lies in its objectivity and fulfilment of measurement requirements, thus enhancing the measurement capacity of an instrument (Cavanagh & Romanoski, 2006). It offers a fresh perspective to overcoming challenges associated with traditional sample-dependent reliabilities and test statistics (Alagumalai & Curtis, 2005).
The Rasch model is employed to estimate measures of individuals and item characteristics on a particular scale. It determines whether the responses conform to the requirements of a measurement model. In judging the responses, fit indicators, which the model provides are used. Items that conform to the measurement requirements are retained while those that fail to satisfy the requirements are removed (Ben, Hailaya, & Alagumalai, 2012; Curtis & Boman, 2007).
As another validation technique, confirmatory factor analysis (CFA) was used to examine the factor structure of the ALI.
CFA is used to verify the factor structures of any scale (Schreiber, Nora, Stage, Barlow, & King, 2006). It is employed to provide evidence of construct validity (Probst, 2003). This statistical procedure can be considered as a ‘macro-level’ analytic practice as it examines whether or not a hypothesised relationship between the observed variables and their underlying latent constructs exists. CFA assumes that the researcher has some knowledge of the underlying factor structure of a set of measures (Byrne, 2001) and therefore it is used as ‘a test whether an a priori dimensional structure is consistent with the structure obtained in a particular set of measures’ (Stewart, 2001, p. 76). In other words, CFA is a theory-testing model in which a hypothesis is first put forward by the researcher before proceeding to analyse (Stapleton, 1997) – planning is driven by the theoretical relationships between the observed and latent variables (Schreiber et al., 2006). The theoretical relationships are empirically tested and confirmed by a set of data (Schreiber et al., 2006).
In the present study, the correlated seven-factor structure was examined based on the SSTCEAS upon which the ALI was developed. The seven factors including their corresponding items are as follows:
Choosing assessment methods appropriate for instructional decisions (items 1, 8, 15, 22 and 29); Developing assessment methods appropriate for instructional decisions (items 2, 9, 16, 23 and 30); Administering, scoring, and interpreting assessment results (items 3, 10, 17, 24 and 31); Using assessment results when making decisions about individual students, planning teaching, developing curriculum, and school improvement (items 4, 11, 18, 25 and 32); Developing valid grading procedures (items 5, 12, 19, 26 and 33); Communicating assessment results to students, parents, lay audiences, and other educators (items 6, 13, 20, 27 and 34); and Recognising unethical, illegal, and otherwise inappropriate use of assessment information (items 7, 14, 21, 28 and 35).
CFA was applied using structural equation modelling (SEM) (Schreiber et al., 2006).
Wright (1996) highlighted the use of the Rasch model and CFA as complementary techniques to identify model fit and confirm underlying factorial structures. In addition, Rasch and CFA are used to assess measurement invariance (Randall & Engelhard, 2010). Salzberger (2011, p.2) argued that, ‘it is pivotal to outline the requirements of measurement and to ensure that the Rasch philosophy and the theory of the construct guide the scale development and formation.’ Moreover, it is important to note Riemer and Kearns (2010, p.263) who highlighted ‘since confirmatory analysis can only demonstrate that the current model fits the current data reasonably well, but not whether it is the model that would best explain the variance-covariance structure in the data, additional tests like Rasch measurement’s dimensionality investigation to provide further evidence for the proposed factorial structure.’
Methods
Modification of the ALI
The ALI items were adapted to suit the Tawi-Tawi/Philippine context where the research was conducted. Adaptations were made mainly to teacher names and topics in the scenarios depicted. Still, while items were adapted the ALI’s original structure of the scenarios and items was preserved to maintain the integrity of the instrument. Face validation was undertaken by the authors of this article and by two university lecturers in the Philippines who were knowledgeable in the field (i.e. measurement, assessment and evaluation and teacher education) and familiar with the context. The modified ALI was pilot tested with 45 elementary and secondary school teachers of the Mindanao State University-Tawi-Tawi to check for its reliability. A Cronbach Alpha of 0.75 was obtained indicating acceptable reliability. The ALI was then administered to the intended respondents.
Administration of the ALI
Prior to data collection, ethics clearance for the study was sought from the University’s Human Research Ethics Committee. In addition, permission to administer the ALI was secured from the Philippine Department of Education (DepEd) at the national, regional, and local levels and from all other schools outside DepEd jurisdiction.
After approval was obtained, the ALI was administered to all Grade 6 (elementary level), Second Year and Fourth Year high school (Secondary level) teachers in the province of Tawi-Tawi, Philippines. The schools involved in the study were taken from the list provided by the DepEd’s Tawi-Tawi Division Office in Bongao, Tawi-Tawi, Philippines. All public and private elementary and secondary schools were initially identified. However, as the schools are located in the different islands all throughout the province, only those that could be reached and accessed, and that posed no hazard to the researcher were finally selected. A total of 128 schools (elementary: 91; secondary: 37) participated in the study. After selection of the schools, teachers and students were identified through the support of the DepEd-Tawi-Tawi Division; the DepEd’s engagement saw 100% of teachers identified responding to the ALI. A total of 582 teachers (321 elementary school teachers and 261 high school teachers) completed the instrument.
Validation analysis of the ALI
The ConQuest 2.0 (Wu, Adams, Wilson, & Haldane, 2007) software was used to undertake the Rasch analysis. To judge the acceptability of the items, the residual-based fit statistics were employed. The infit weighted mean square (IWMS) and the t-statistic (t) were used to examine whether or not items conformed to the Rasch model. Values for IWMS of 0.80 to 1.20 (Linacre, 2002), and −2 to +2 for t (Wu & Adams, 2007) were considered to indicate acceptable item fit. Items outside these ranges were removed from the analysis one at a time as they violated the measurement requirements.
As the ALI was developed based on STCEAS, the proposed seven-factor structure was re-tested for structural invariance. CFA was performed using LISREL version 8.80 (Jöreskog & Sörbom, 2006). How well the proposed seven-factor structure of the ALI fits the data was assessed using several fit indices. These indices include the chi-square (χ2) statistic, ratio of chi-square to the degrees of freedom, root mean square error of approximation (RMSEA), standardised root mean square residual (SRMR), goodness-of-fit index (GFI), adjusted goodness-of-fit index (AGFI), and comparative fit index (CFI).
The χ2 is described as an index of ‘exact fit’ as it evaluates the perfect fit of a model to empirical data (Matsunaga, 2010). However, although often used, it has been considered to be sensitive to sample size and is almost always indicative of bad model fit. Thus, there is a need to divide the χ2 by the number of degrees of freedom (df) to further assess the model (Probst, 2003). The RMSEA is an index of ‘approximate fit’ (Schermelleh-Engel, Moosbrugger, & Müller, 2003) and it determines how close the model fits to the data (Matsunaga, 2010). Considered as one the most informative fit indices and that represents error due to approximation (Diamantopoulos & Siguaw, 2000), it shows ‘how well would the model, with unknown but optimally chosen parameter values, fit the population covariance matrix if it were available?’ (Byrne, 2001, p. 82). The SRMR is a residual-based index that shows the average value of the standardised residuals between observed and predicted covariances (Matsunaga, 2010). It is a summary measure of standardised residuals (Diamantopoulos & Siguaw, 2000). The GFI and AGFI are absolute fit indices that estimate the extent to which the sample variances and covariances are reproduced by the hypothesised model (Bollen & Long, 1993). The AGFI’s defining characteristic that differs from GFI is that it adjusts for the number of degrees of freedom in the specified model. However, caution was taken with the use of these fit indices as they can be overly influenced by sample size (Fan, Thompson, & Wang, 1999, as cited in Byrne, 2001). The CFI is one of the major incremental fit indices that ‘measure the proportionate improvement in fit by comparing a target model with a more restricted, nested baseline model’ (Diamantopoulos & Siguaw, 2000, p. 87).
Summary of fit indices and their corresponding permissible values.
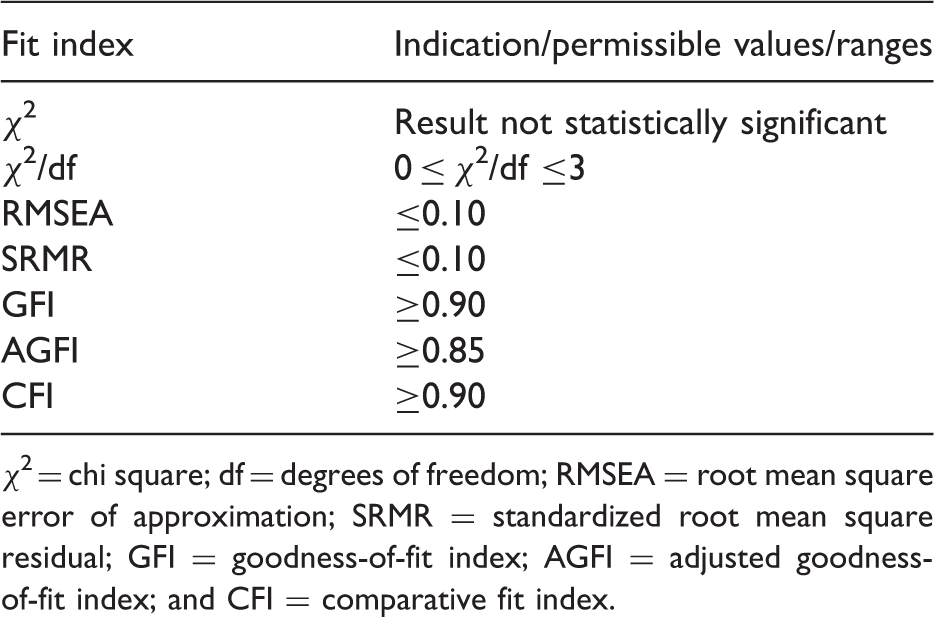
χ2 = chi square; df = degrees of freedom; RMSEA = root mean square error of approximation; SRMR = standardized root mean square residual; GFI = goodness-of-fit index; AGFI = adjusted goodness-of-fit index; and CFI = comparative fit index.
Results
Item analysis of the ALI using the Rasch model
Results of the initial analysis of ALI items.
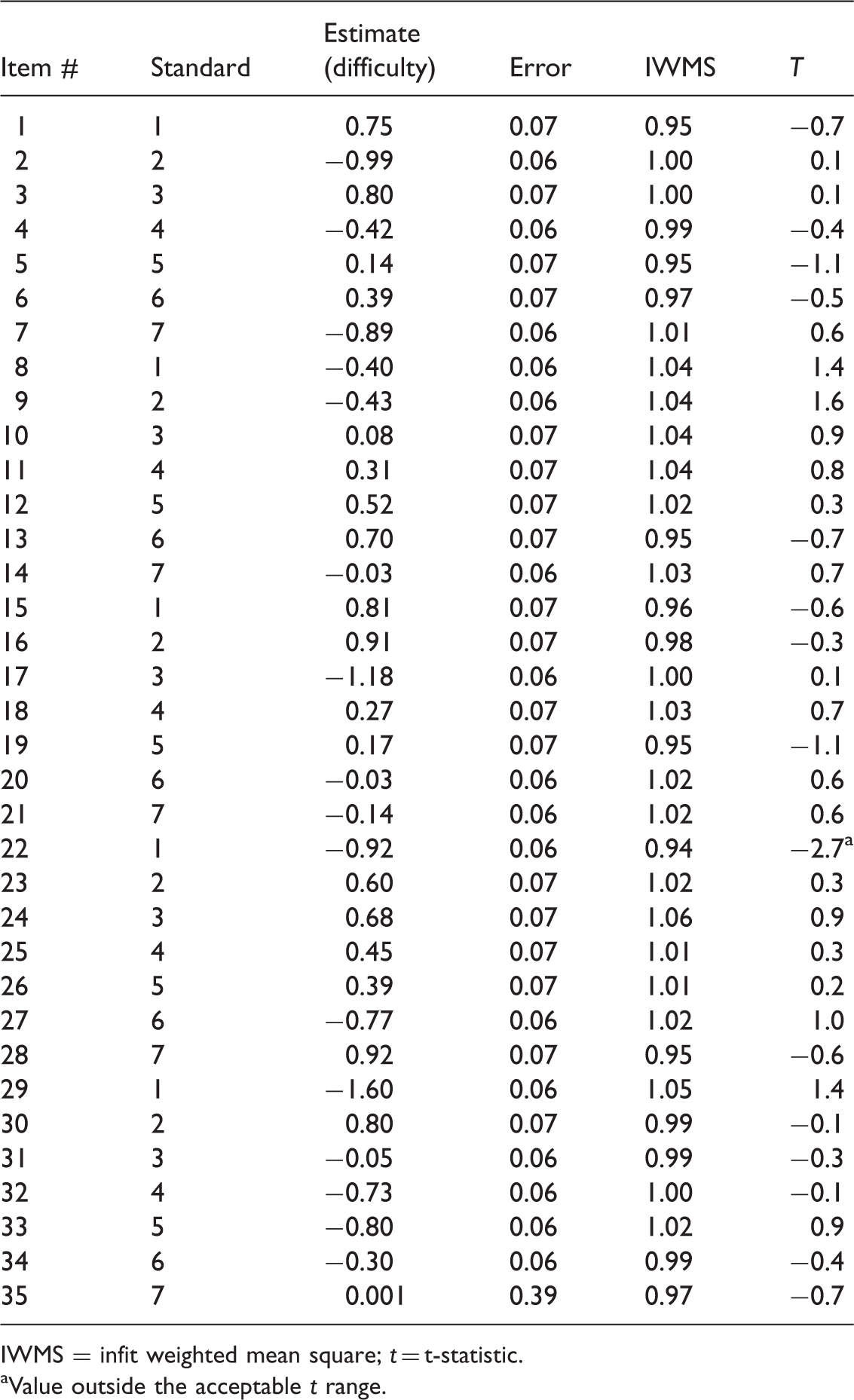
IWMS = infit weighted mean square; t = t-statistic.
aValue outside the acceptable t range.
Results of the final analysis of ALI items.
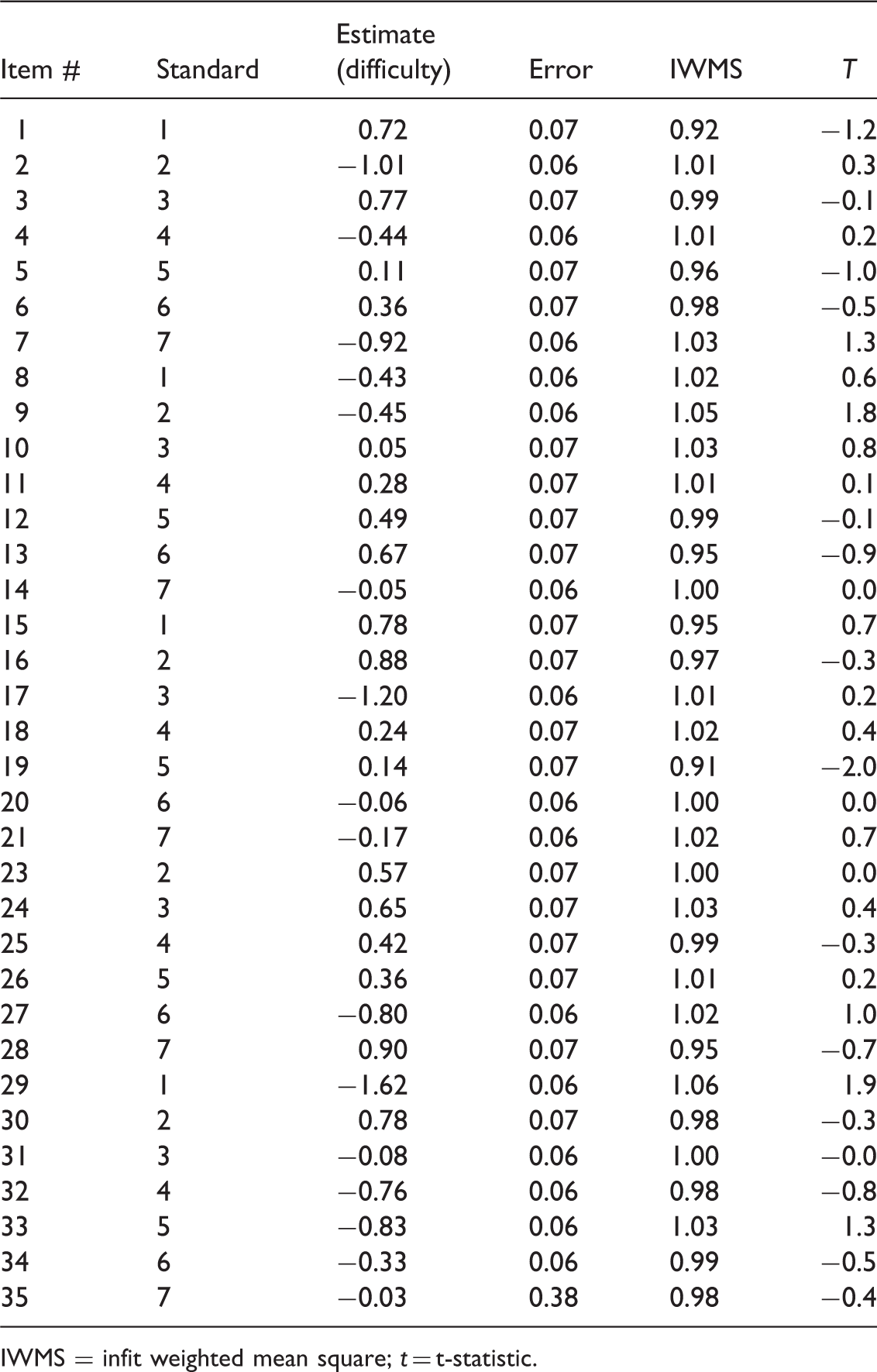
IWMS = infit weighted mean square; t = t-statistic.
Analysis of the ALI structure using CFA
The ALI items were tested in terms of the seven-factor structure based on the STCEAS (Standard 1 to Standard 7) (AFT, NCME, & NEA, 1990).
In this structure, four items (items 1, 8, 15, and 29) served as observed variables for the first latent factor (Standard 1). The rest of the latent factors (Standards) were each represented by five items as follows: items 2, 9, 16, 23, and 30 for the second latent factor (Standard 2); items 3, 10, 17, 24, and 31 for the third latent factor (Standard 3); items 4, 11, 18, 25, and 32 for the fourth latent factor (Standard 4); items 5, 12, 19, 26, and 33 for the fifth latent factor (Standard 5); items 6, 13, 20, 27, and 34 for the sixth latent factor (Standard 6); and items 7, 14, 21, 28, and 35 for the seventh latent factor (Standard 7). A conventional cut-off of 0.40 (Matsunaga, 2010) was used to evaluate the factorial coherence of ALI items. Items with a factor loading of at least 0.40 were to be retained while those with a factor loading of below 0.40 were to be discarded. The structure of the seven-factor model is presented in Figure 1.
Seven-factor structure of the ALI.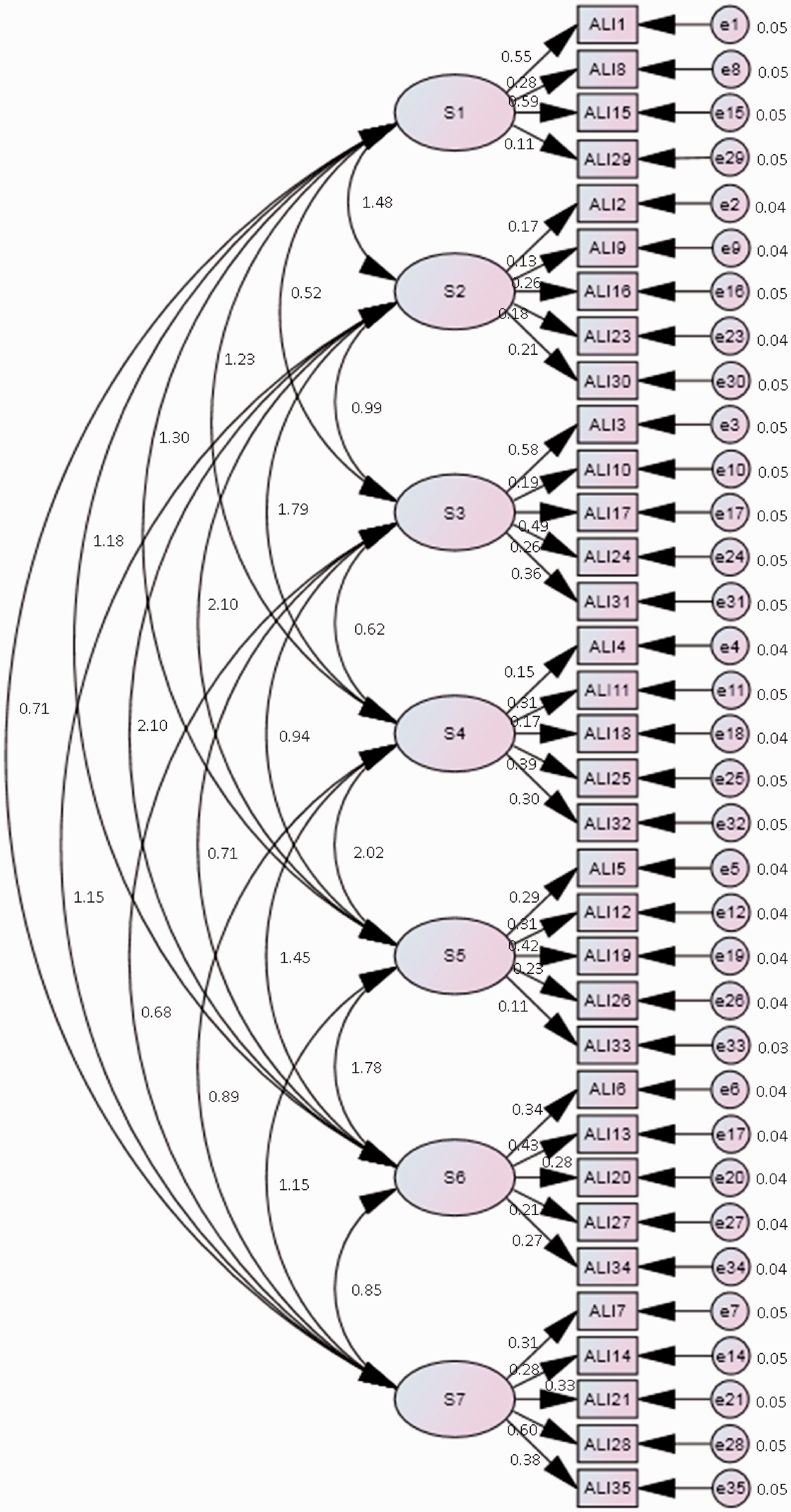
Model fit indices
Summary of fit indices for the 7-factor ALI structure.
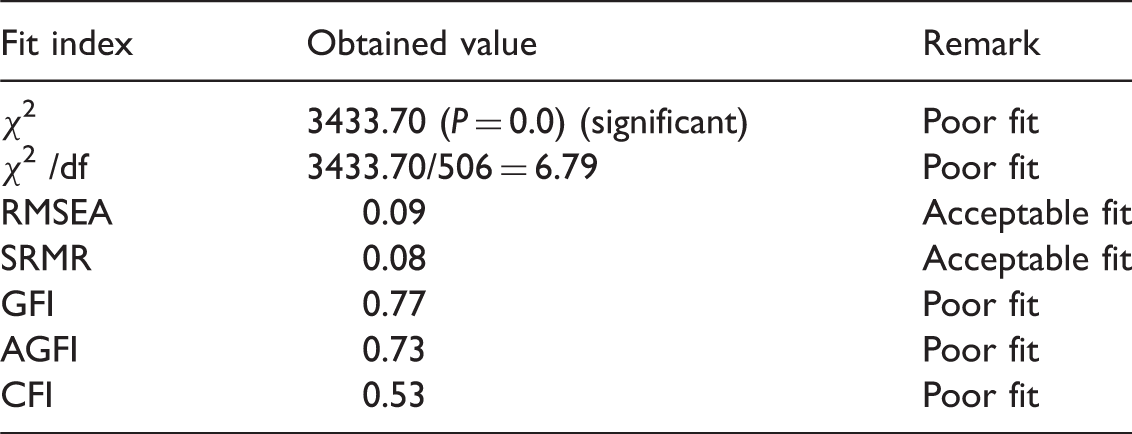
CFA of the ALI hypothesised measurement model
In addition to checking the overall model fit, factor loadings of the ALI items were examined to gauge whether or not the items reflected the factors as intended.
Factor loadings of ALI items under the seven-factor model.
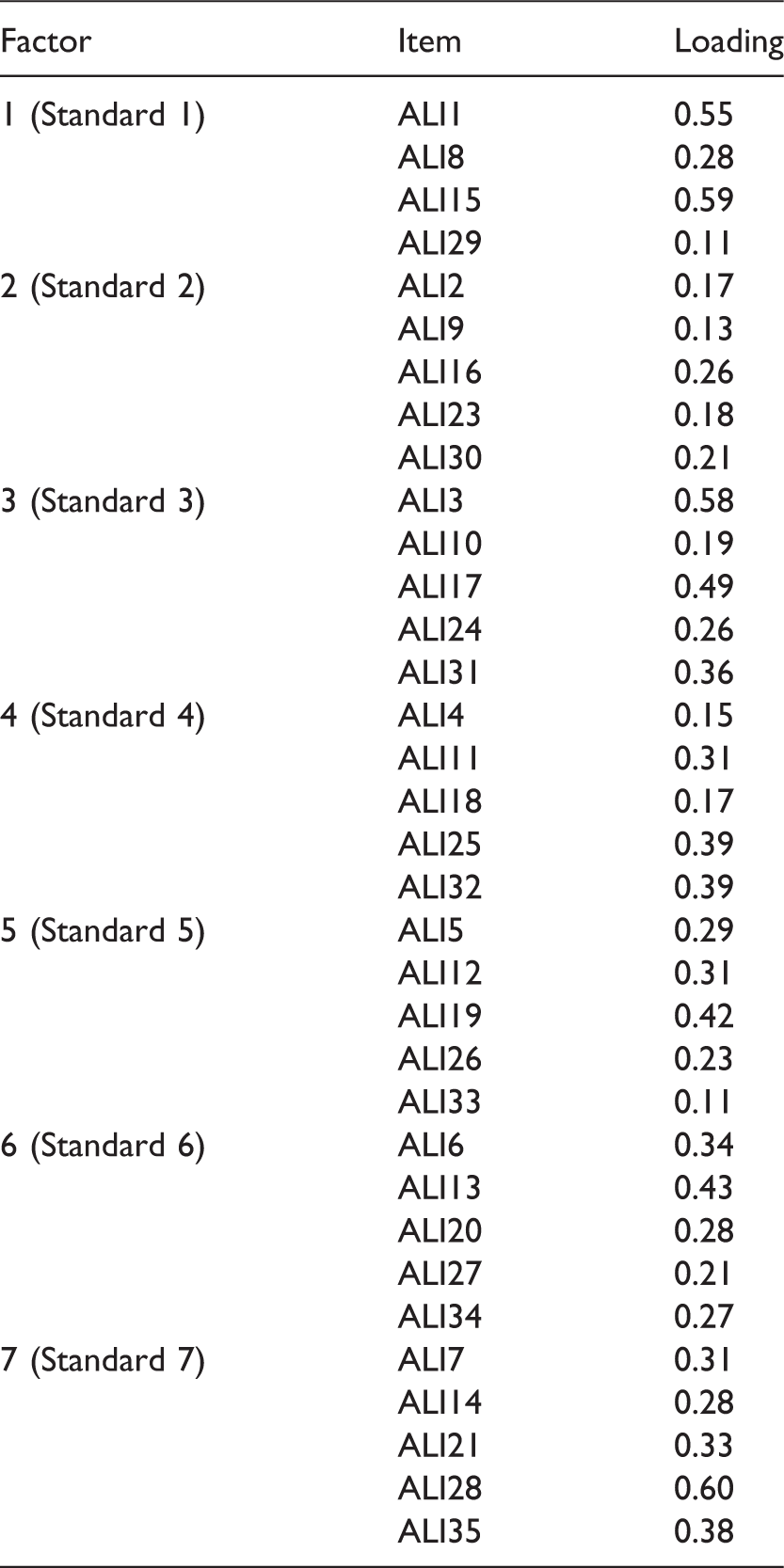
Rasch analyses plus CFA: Item-test fit and structural coherence
To understand better the links between item-test fits and the scale’s structural coherence, the Rasch Item Map of Latent Distribution and Response Model Parameter Estimates was positioned alongside the CFA of ALI (Figure 2).
Item-test fit and structural coherence of the ALI.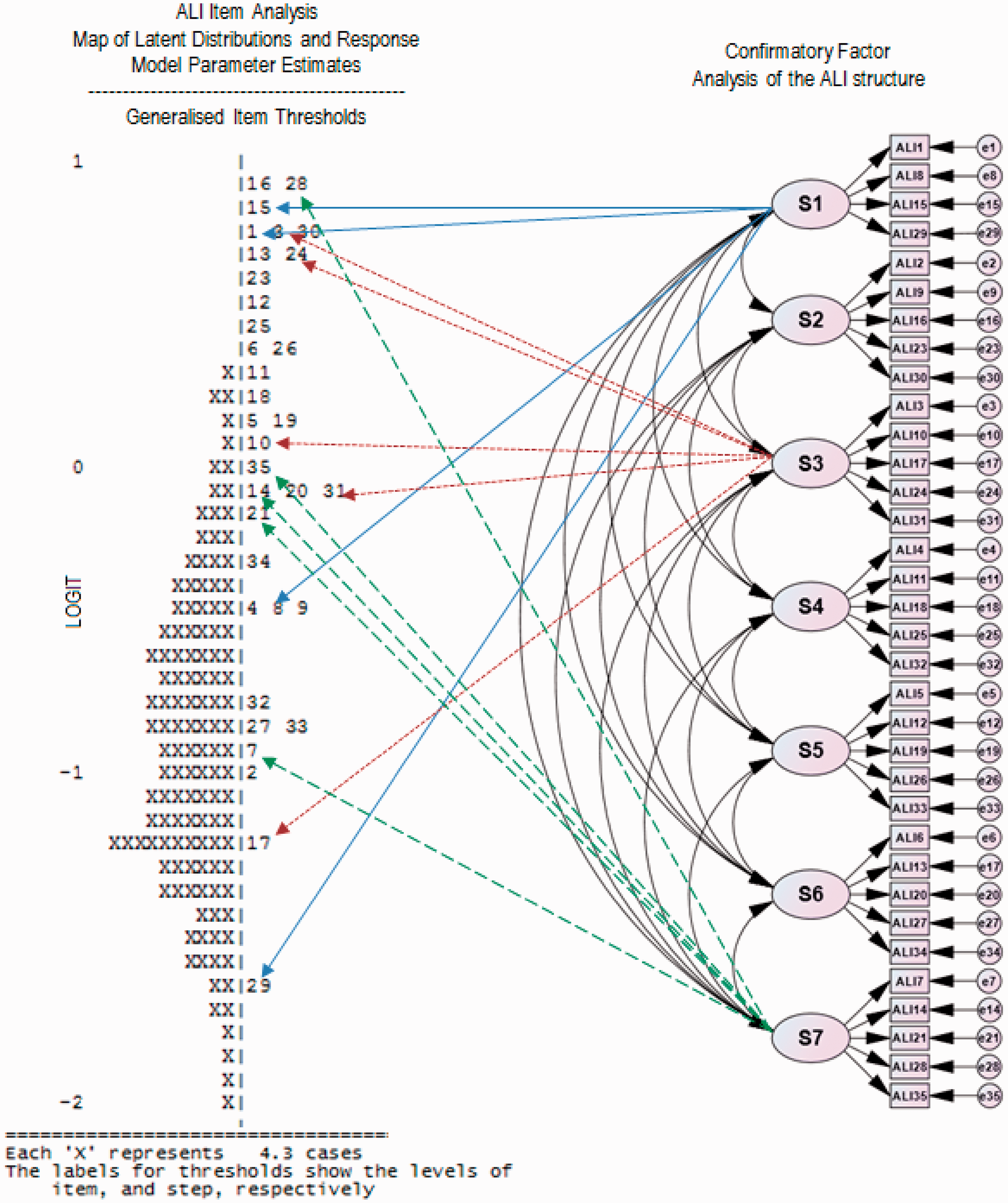
It is evident from the item-plots and ALI’s CFA structure in Figure 2 (see right part of the map on the left) that no clear hierarchy exists between the standards. Overlapping items between standards make it difficult to specify clearly the ‘steps’ between standards, and thus its articulation for the denoted competency.
In a comprehensive study, the Education Department of Western Australia (1994) reported information regarding the articulation of steps or stages in the Standards Framework (for example, in working scientifically) and the associated establishment of the levels of achievement or competencies. This supports the need for an axiomatic application of measurement, i.e., linking a conceptual or theoretical framework to how items in a scale or test are distributed. There are varying bandwidths for selected standards, and it may be necessary to adopt Ingvarson’s (2002, p. 8) Content – Evidential – Performance tripartite standards model to guide the development of educational aims and standards.
Discussion
Results of the Rasch analysis provide evidence of acceptable measurement properties of the ALI instrument. This means that ALI is a reliable scale that can be employed to measure the assessment literacy of in-service teachers. Hence, the ALI can be considered an appropriate tool to gauge teachers’ assessment literacy and their readiness in undertaking classroom assessments. It can likewise be employed to examine teachers’ weaknesses or misconceptions in assessment as suggested by the ALI authors and to devise relevant interventions in the form of professional development. However, while the results of the micro-level analysis of the ALI items are consistent with the previous ALI validation findings, results of the macro-level analysis provide findings that are not in agreement with the ALI’s development framework. Thus, there is a need to review or re-examine the seven-factor structure of the ALI.
The problematic results of the ALI’s seven-factor structure in terms of poor model fit and low factor loadings can possibly be explained by three reasons. The first reason appears to be the absence of hierarchy among the items and factors (standards) as indicated by the overlapping of the items across the factors (standards) as shown in Figure 2. The absence of hierarchy among the items and the standards can pose some problems. In any instrument that takes the form of a test, it is recommended that the items should be of an increasing difficulty (Brizuela & Montero-Rojas, 2013; Ludlow & Haley, 1995). This is to motivate and at the same time challenge the examinees as they progress through the test. Having ‘difficult’ or challenging items at the start of the test can adversely affect the examinees' interest and performance in the test. Hence, the model proposed by Mertler and Campbell (2005) can be challenged. It is useful to note Stiggins’ (1999, as cited in Mertler & Campbell, 2005, p. 6) assertion that STCEAS are not sufficiently comprehensive to prepare teachers for the realities of the classroom. It will be useful for practitioners and researchers if constructs, standards and competencies are clearly defined and not confounded by complex nesting and hierarchies. Thus, explicit structures will enable targeted professional learning towards areas of need. If constructs, standards and competencies are nested within each other in a complex manner, interpretation of the underlying dimensions will be difficult. This, in turn would make it even more challenging to target and direct professional learning towards areas of need.
In discussing standards for Australian teachers, and those engaged in preparing teachers and providing for professional development, Ingvarson (2002, p. 3) highlighted that: As measures, standards will not only describe what teachers need to know and be able to do to put these values into practice; they will describe how attainment of that knowledge will be assessed, and what counts as meeting the standard. A standard, in the latter sense, is the level of performance on the criterion being assessed that is considered satisfactory in terms of the purpose of the evaluation.
The second possible reason relates to the ambiguities and interpretation challenges associated with ALI. In order to obtain a more meaningful interpretation of the validation results, a common understanding of the key term used in the ALI instrument is essential. One might be tempted to consider the term ‘standard’ to be synonymous with the term ‘factor’ that is often used in scale validation. The ambiguity in the use of these important terms has to be clarified before proceeding to further analyses and drawing meaningful inferences.
As the ALI is essentially a test, the ‘standard’ as a ‘principle’ has been well defined by AFT, NCME, & NEA (1990) when developing the STCEAS. However, a ‘standard’ is not equivalent to a ‘factor’. A factor refers to an element, circumstance or influence, which contributes to producing a particular result or situation. In other words, a factor is anything that contributes to a result. According to Royce (1963, p. 522), factors are ‘dimensions, determinants, functional unities, parameters, and taxonomic categories.’ Furthermore, in the context of this paper, the term ‘standard’ means ‘standards for teacher competence in educational assessment of students’ (Brookhart, 2011, p. 4). However, if we adhere to this line of argument the standards (or at least the items in each standard) need to adhere to different levels of cognitive processing with increasing levels of difficulty (Brady & Kennedy, 2012), which can be examined using the Rasch Model. Hence, there is a need to clarify the terms factors and standards before appropriate structural analysis of the ALI can be undertaken.
Finally, the third possible reason could be related to ALI having a different structure than the Mertler and Campbell (2005) hypothesised seven-factor model. The poor model fit and the low factor loadings indicate that the ALI does not follow a seven-factor structure or there exists factorial or structural variance across countries and cultures. This further suggests that the ALI may have other underlying factorial structure than what has been currently hypothesised. One possible structure is a one-factor model as indicated by the results of Rasch analysis. As highlighted earlier, the Rasch model strictly adheres to the requirements of unidimensionality. As 34 of the 35 items fit the Rasch model, it could be concluded that the ALI has a one-factor structure pertaining to the assessment literacy. These items will contribute to the development of modules for professional learning programs for teachers.
Conclusion
In any educational context, teachers’ assessment literacy is of prime importance in order to ascertain learning. Results reported in this article have shown that the ALI has some psychometric qualities that make it useful for measuring teachers’ assessment literacy. At the item level, the ALI can be a potential instrument in examining teachers’ knowledge on classroom concepts and application, and can be used among in-service teachers.
However, further examination of the ALI using in-service teachers in other contexts (cultural context beyond the Mertler and Campbell (2005) study) and perhaps employing other validation procedures is warranted. Thus, ALI needs further review, validation and clarification to establish a meaningful structure of the instrument particularly with a view to the portability of the test across contexts.
Still, analyses reported in this article demonstrate how two psychometric techniques, namely Rasch analysis and confirmatory factor analyses can complement each other to examine the appropriateness of a scale in terms of its measurement properties and underlying theoretical foundations.
Footnotes
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Declaration of conflicting interests
None declared.
Acknowledgments
The first author wishes to thank Dr. Mertler and Dr. Campbell for the permission to use the ALI.