
Abstract
Data linkage is a powerful tool for understanding the multifaceted needs and priorities of mental health care from the perspective of users and providers. Its potential remains underutilised in Australian settings – the Productivity Commission Inquiry into Mental Health in 2020 highlighted a significant gap: routinely collected administrative data are seldom leveraged in mental health research and service evaluation. In this manuscript, we provide insights into how data linkage has been used in mental health research, the type of questions that can be addressed, the steps involved in conducting data linkage research and the benefits and limitations of the use of this methodology. We propose crucial recommendations for advancing this field including: enhancing education for stakeholders (including the public, data custodians, ethics committees and policy makers); fostering stronger collaborative relationships with individuals with lived experiences throughout the research journey; improving infrastructure and resources for data linkage activities and linking data across sectors to address complex meaningful research questions. Data linkage is not just a method but a critical strategy to transform mental health research and service evaluation, ensuring more informed, effective and holistic mental health care.
Keywords
Introduction
Data linkage involves the merging of two or more discrete data records pertaining to an individual and/or family (Andrew et al., 2016). In Australia, data linkage has a long history, dating back to 1995 with the establishment of the first data linkage unit (DLU) in Western Australia (Boyle and Emery, 2017; see Supplementary Material for a more detailed history). Data linkage has been used for a range activities including follow-up of cohorts or registry studies (e.g. Iorfino et al., 2023; Iveson et al., 2024), epidemiological and disease surveillance research (e.g. Fahridin et al., 2024; Papalia et al., 2024), health services research (e.g. Bradley et al., 2010; Fahridin et al., 2024; Young et al., 2020), economic analysis (Fahridin et al., 2024) and clinical trials (Fahridin et al., 2024). Such research can inform clinical and policy changes. For example, in Australia, world leading data linkage research identified the association between folate deficiency and neural tube defects (Bower and Stanley, 1989) and later demonstrated that folate supplementation in pregnant mothers could mitigate these defects (Bower et al., 2002).
The uptake of data linkage in mental health has been much slower than other disciplines. According to the Productivity Commission, administrative databases are rarely scrutinised for service evaluation and mental health research despite substantial data collection;
Exemplars in mental health
The Australian and New Zealand Journal of Psychiatry has published a range of data linkage studies; these demonstrate the breadth of research questions that can be addressed. Table 1 provides exemplars of such research, covering diverse areas of interest including health and mental health service use patterns (Borschmann et al., 2017; Cvejic et al., 2022; Ducat et al., 2013; Meurk et al., 2022; Young et al., 2024, self-harm and suicidal behaviours (Borschmann et al., 2017), psychotropic medication prescription (Young et al., 2024) and mortality (Borschmann et al., 2017; Meurk et al., 2022). Examined populations have included those with severe mental illness (Cvejic et al., 2022) or history of self-harm (Meurk et al., 2022), forensic populations (Borschmann et al., 2017; Ducat et al., 2013), general community (Hafekost et al., 2016) and Indigenous youth (Young et al., 2024).
Examples of Australian data linkage studies focusing on mental health published in the Australian and New Zealand Journal of Psychiatry.
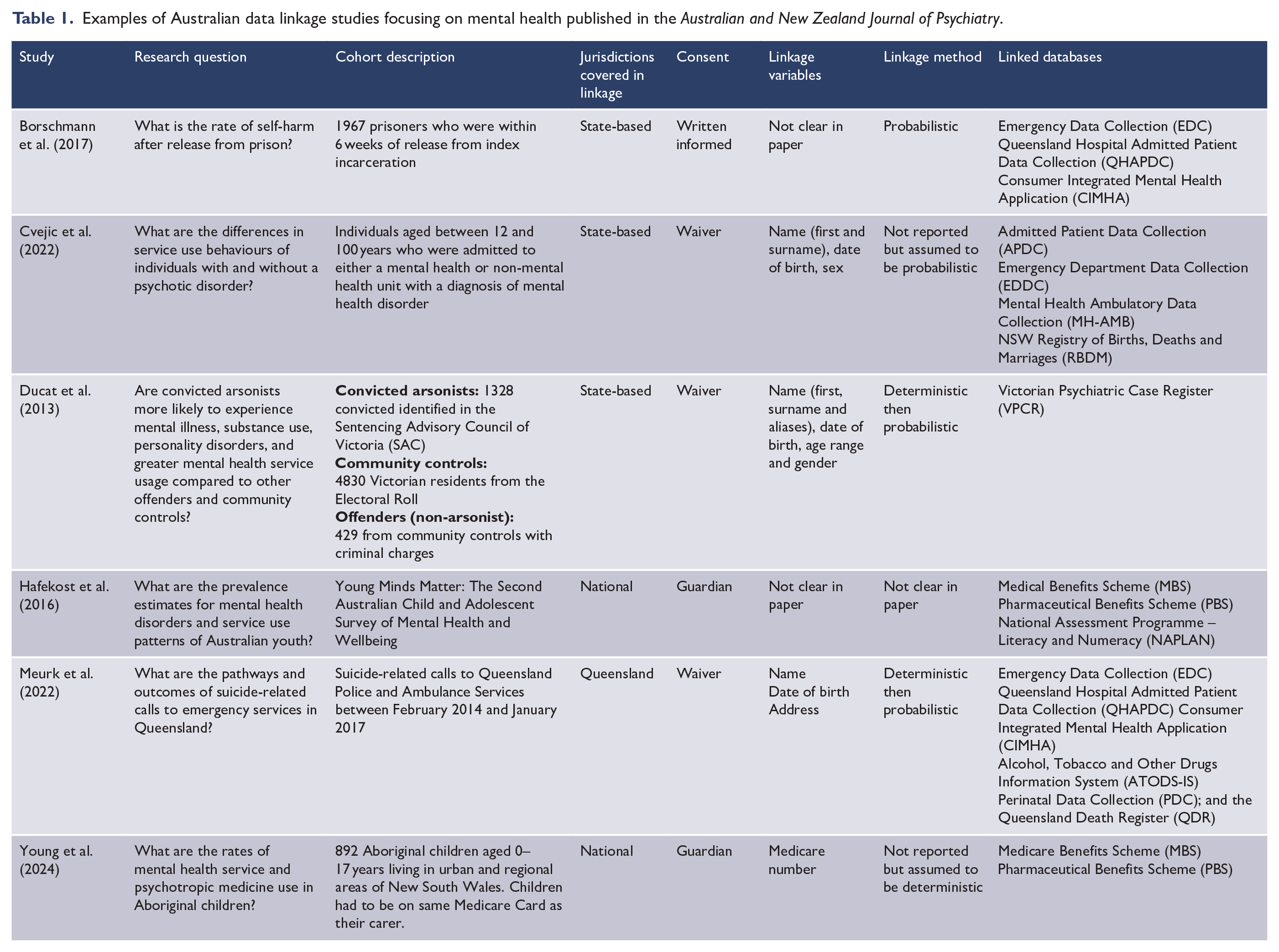
Such studies can have impact and reach. For example, Ducat et al. (2013) examined Victorian public mental health service usage of the entire Victorian population of convicted arsonists (n = 1328, between 2000 and 2009) and was able to generate two controls groups: 1328 matched community controls (based on electoral roll) and 421 non-firesetting offenders. Contacts with mental health services and rates of psychiatric disorders (viz., substance use, mood and personality disorders) were much higher in the firesetters (37%) compared to the two other control groups (other offenders 29.3%, community 8.7%). The need for early detection and intervention for individuals who experience psychiatric disorders and who are at risk of firesetting behaviours was highlighted as of great public benefit. The researchers also stressed that not all firesetters had contact with psychiatric services and/or had a diagnosis, and more research was needed to characterise firesetters. Even though this paper is over 10 years old, in 2024, it was cited across 55 news outlets regarding the rates of deliberately set bushfires within Australia (Altmetrics, database for tracking online attention for a study). Altmetrics has highlighted that is the ninth highest scoring paper in terms of receiving online attention of 2654 papers published in the Australian and New Zealand Journal of Psychiatry.
In other journals, a range of Australian data linkage studies have been recently published including studies examining the relationship between maternal mental health and adverse birth outcomes in the Northern Territory (Dadi et al., 2024), suicide and mortality in Culturally and Linguistic Communities in Victoria (Pham et al., 2024), prediction of psychiatric hospitalisations in young people discharged from New South Wales criminal justice services (Akpanekpo et al., 2024) and follow-up of children and adolescents with a history of suicide-related contact with police or ambulance services in Queensland (Wittenhagen et al., 2024).
There are international studies that demonstrate how data linkage can address pertinent societal issues. The impacts of COVID-19 on mental health, health and mortality outcomes is one example (e.g. Yu et al., 2023a; Yu et al., 2023b). Another recent example is research examining the possible association between social media and poor mental health outcomes, particularly for young people (e.g. Bye et al., 2023; Bye et al., 2024). Such research has the potential to lead to changes in service delivery, resource allocation and policy.
Thus, using data linkage, a broad range of questions can be asked for either specific groups or the general population for a wide variety of outcomes (e.g. pathways through care, service use, medication use, self-harm and mortality).
Data linkage methods
Our research team is currently undertaking a range of data linkage studies in the youth mental health space. This includes focusing on population-level patterns of health and human service utilisation in youth people with mental health problems (NHMRC Partnership Grant GNT#1198696), follow-up of specific clinical cohorts (Cotton et al., 2022) and evaluations of specific care models (e.g. youth-specific Hospital-in-the-Home model, HCF Health and Melbourne Health). In undertaking these activities, we have operationalised the steps involved in planning a data linkage project. The steps for setting up a data linkage project include (1) study planning; (2) institutional ethics, governance and data custodian approvals; (3) linking and data preparation; (4) data cleaning and analysis and (5) reporting of findings (see Figure 1).
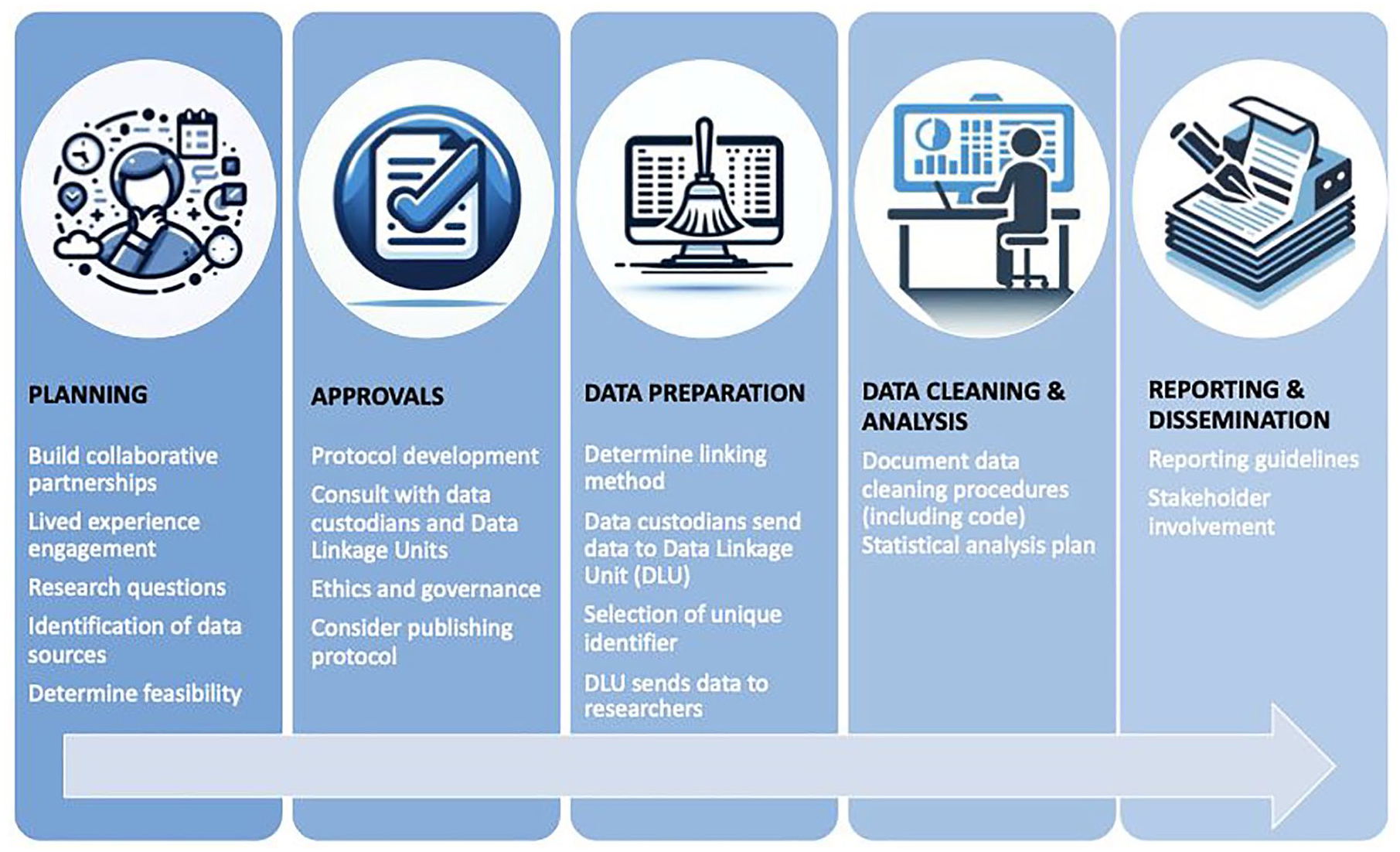
Activities and processes involved in data linkage.
Planning
Clear aims and research questions should be identified and assessed for feasibility given constraints of data (e.g. missingness). Developing relationships with key stakeholders is critical for these activities (Bradley et al., 2010; Downs et al., 2019). DLUs can guide researchers in identifying strengths and limitations of data sets, assessing technical feasibility of the linkage, navigating approvals and statutory requirements and informing protocol content for ethics submissions. Engagement with consumers, clinicians, advocacy groups, health service planners and commissioners, as well as other government bodies is strongly recommended (Downs et al., 2019). Lived experience and consumer involvement is commonly overlooked but can improve the relevance of work and aid protocol development and selection of outcomes (Jewell et al., 2019). Meaningful and authentic engagement with consumers is becoming increasingly recognised by both researchers and Australian grant funding bodies as critical component to advancing medical research (National Health and Medical Research Council and Consumers Health Forum of Australia, 2016). In the early stages of our research, we have consulted with young people with mental health problems to ensure that our research questions are meaningful to them, to gauge their understanding of data linkage and the ethical use of personal, sensitive and health data.
Institutional ethics and governance
Data linkage research requires ethics approval from a local Human Research and Ethics Committee (HREC) as well as approvals from DLUs and each data custodian (often coordinated by the DLU). Some Commonwealth linkage authorities (e.g. Australian Institute of Health and Welfare, AIHW) require a separate, second ethical approval from their own in-house HREC. It is imperative that researchers do their groundwork early and engage with appropriate stakeholders to inform ethics and governance applications. Consideration of principles of research merit and integrity, justice, beneficence and respect is essential (National Health and Medical Research Council et al., 2023). There are also specific principles and legislative requirements for data linkage that are covered in the Principles for Accessing and Using Publicly Funded Data for Health Research (National Health and Medical Research Council, 2015; see Table 2). If a data linkage study involves Indigenous peoples and communities, it must be Indigenous-led or conducted in directed collaboration with Indigenous researchers. The following material should be reviewed: the Ethical Conduct in Research with Aboriginal and Torres Strait Islander Peoples and Communities (National Health and Medical Research Council, 2018) and the Australian Institute of Aboriginal and Torres Strait Islander Studies (Australian Institute of Aboriginal and Torres Strait Islander Studies (AIATSIS), 2020). More recently there has been a discussion paper focusing on Indigenous data governance and sovereignty (Lowitja Institute, 2024). This discussion paper highlights the rights of Indigenous peoples to control the way that their data are collected, accessed and used to ensure that their priorities, values, cultures, views and diversity are embraced. We recommend that researchers consult the relevant groups such as the Lowitja Institute, if their work involves Indigenous peoples and communities.
The three principles for data linkage research as outlined in the National Health and Medical Research Council’s publication on principles for accessing and using publicly funded data for health research.

Consent-related issues are a specific concern for data linkage research. Addressing these issues requires clear policies, robust privacy protection protocols, transparent communication and opportunities for individuals to exercise control over their data (da Silva Marinho et al., 2012). Data linkage involves access to personal identifiers, such as name, date of birth (DOB) and address. Accordingly, this has sparked debate regarding the need for formal prospective consent processes (Bradfield, 2022; da Silva Marinho et al., 2012; Palamuthusingam et al., 2019). When individuals present to health and human services, large amounts of routine and personal data are typically generated, collected and compiled into datasets. Often information about data use is mentioned in fine print, so even though individuals technically consent to their data being used, consent is not necessarily informed (Boyle and Emery, 2017; Bradfield, 2022). Often, the primary purpose of this data collection is for service monitoring, improvement and/or quality assurance. Data linkage, however, involves secondary data use beyond the original reason for collection, raising concerns of contextual integrity (how privacy is maintained when information flows consistently with social context’s norms and expectations) (Nissenbaum, 2009). There are various approaches for how to address the issue of informed consent. Two methods of informed consent include opt-in and opt-out methods, with the opt-in method being more frequently used (de Man et al., 2023). For data linkage involving registries, prospective informed consent is usually required. Opt-out informed consent can be used where individuals are included in the dataset unless they express their desire not to participate ((Andrew et al., 2016; Australian Commission on Safety and Quality in Health Care, 2008). However, this option is complicated in that some ethics bodies may require opt-in consent for registry data linkage (Andrew et al., 2016).
Obtaining informed consent for the data use and linkage can be impractical, labour-intensive and costly (Bradfield, 2022; Palamuthusingam et al., 2019). For de-identified data, it would be difficult to justify re-identifying individuals to seek consent (Bradfield, 2022). Seeking consent is not possible for those who are deceased, or in situations where services do not have individuals’ most recent contact information. Obtaining informed consent, especially through opt-in methods, can also introduce response biases due to inherent differences between those who do and do not consent, which ultimately impacts the external validity of the research (Bohensky et al., 2011; Bradfield, 2022; de Man et al., 2023).
As an alternative to informed consent, a waiver of consent approach has been suggested (Bradfield, 2022; Downs et al., 2019). A HREC must approve a waiver of consent. In Section 2.3 of the National Statement of Ethical Conduct in Human Research (National Health and Medical Research Council et al., 2023), the guidelines for a waiver of consent are provided. For a waiver of consent to be granted, researchers must justify that the linkage study is of low risk (e.g. use of de-identified data), there are minimal harms associated with not seeking consent, that obtaining informed consent is impracticable and that it is not unreasonable to expect that individuals would have provided consent. There must also be no jurisdiction laws prohibiting a waiver and researchers need to demonstrate that there are effective processes in place for protecting individuals’ privacy and confidentiality (e.g. data de-identification, use of secure storage servers) (Bradfield, 2022; National Health and Medical Research Council et al., 2023; da Silva Marinho et al., 2012; Palamuthusingam et al., 2019). We highly recommend that researchers explicitly address each of these points in applying for a waiver of consent.
Linking and data preparation
The procedures and pipelines of data linkage research vary according to the project’s design and requirements (see Figure 2). The ‘separation’ principle and Privacy-Preserving Record Linkage (PPRL) are used to protect privacy by separating roles of DLUs, data custodians and researchers (Vatsalan et al., 2017). The Australian Bureau of Statistics (ABS) and the AIHW now adhere to the ‘Fife Safes’ framework which involves a multidimensional approach to balancing the interface between disclosure risk and the utility of data (https://www.abs.gov.au/about/data-services/data-confidentiality-guide/five-safes-framework). Safety and risk are evaluated in terms of people involved, project purpose and details, the access environment, data protection and outputs.
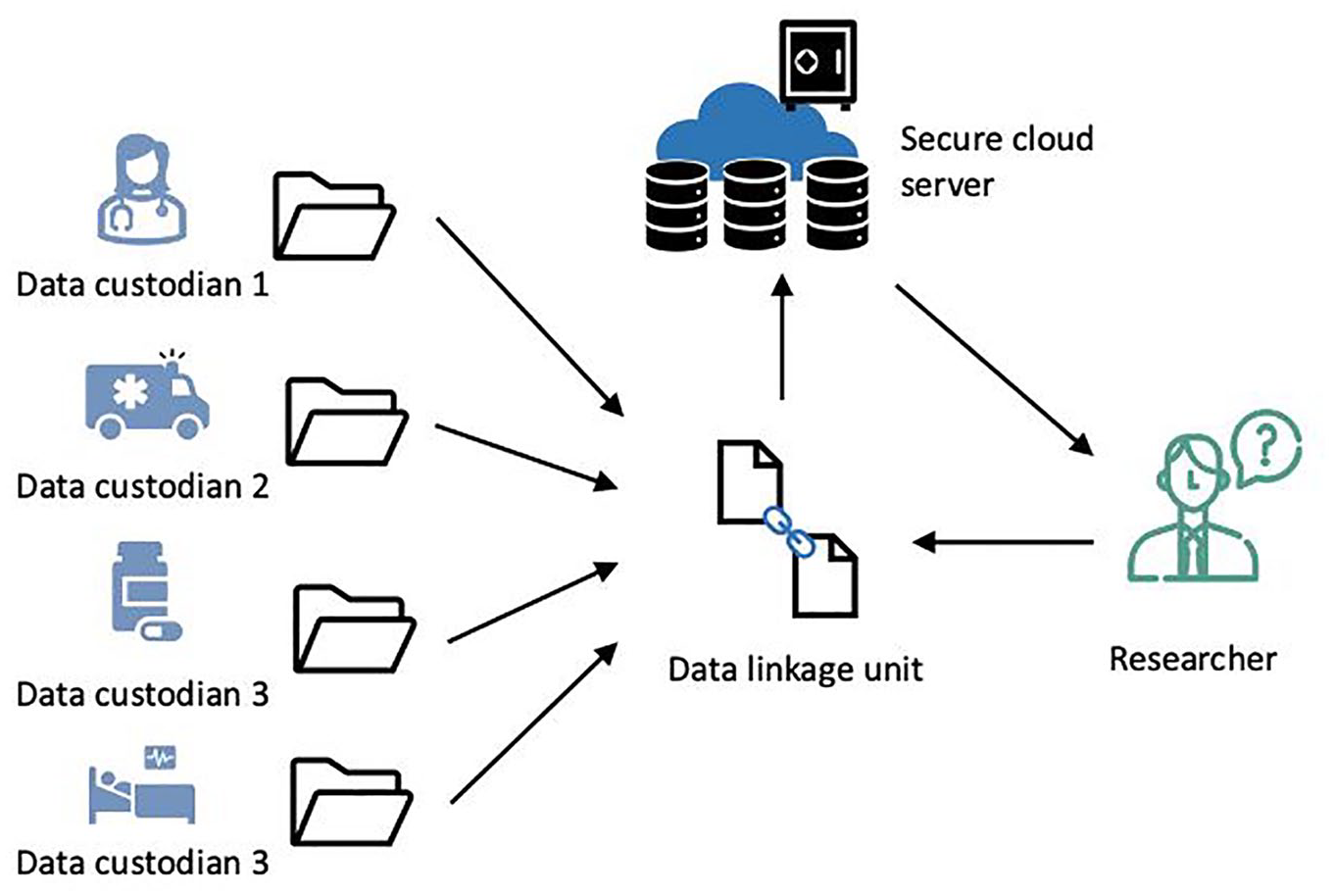
Data linkage pipelines.
Researchers provide identifiable information (e.g. names, DOB, sex), but not content or clinical data, to data custodians or DLUs. In Australia, a unique identifier across datasets (e.g. Medicare number) would facilitate easier and accurate linkage; however, no such option is available across health and human services. As a result, DLUs must develop statistical linkage keys (SLKs) based on personal identifiers (e.g. letters of surname and given name, DOB and sex) (Andrew et al., 2016; Boyle and Emery, 2017; Harron et al., 2016). DLUs use the SLK to identify individuals across databases.
The goal of linkage is to achieve a
DLUs have a high degree of responsibility for protection, storage and use of data (Bradley et al., 2010). Datasets are stored on secure cloud-based servers to reduce data privacy and safety risks and enable regulatory control about data access (e.g. AIHW uses Secure Unified Research Environment [SURE]). Researchers complete all statistical analyses on these servers. Any outputs that are taken off the server are checked to ensure compliance with confidentiality and privacy requirements.
Data cleaning and analysis
Administrative datasets have been criticised for inconsistency in structure, format and content (Harron et al., 2017a; Harron et al., 2016). A systematic approach to preparing and cleaning the data is required to improve quality (Guo and Chen, 2023; Randall et al., 2013; Tran et al., 2017). This involves adjusting, eliminating or modifying data fields (Randall et al., 2013). Appropriate documentation and transparency in the adopted approaches are recommended (Gilbert et al., 2018; Tran et al., 2017). Data custodians, clinical experts and other individuals involved in data entry should be consulted to improve the robustness of data cleaning. Tran et al. (2017) provided a data cleaning and management protocol for cross-jurisdictional linkage of perinatal records from two states in Australia, linking other state-based data and national pharmaceutical dispensing data. They proposed 22 steps to examine uniqueness of records, consistency of reporting variables within and across datasets and identify cross-jurisdictional movement. Such procedures are important for identifying duplicates, mismatches, missing and inconsistent data. While data cleaning is time-consuming – estimated to take up to 70% of analysis time in a data linkage study (Christen and Goiser, 2007) – systematic approaches are essential to ensure statistical analyses and research findings are robust and generalisable.
Statistical analysis plans should be developed a priori, with appropriate documentation and record-keeping for replication. Code and algorithms should be openly available for how the target population was delineated, data files linked, whether a blocking step was used in matching (comparisons applied to records grouped together on blocking variables, increasing manageability of data and reducing number of comparisons), how the success of the data linkage was assessed (including rates of linkage biases), data cleaning, methods of analysis and any sensitivity analyses (i.e. impact of missing data, representativeness of the population, testing for choice of threshold or matching rules, controlling for linkage error) that have been conducted (Benchimol et al., 2015; Boyd et al., 2015; Gilbert et al., 2018; Harron, 2022; Harron et al., 2017a).
Research questions drive statistical technique choice. A range of frequentist statistics can be used such as simple descriptive analysis, regression models (e.g. linear, logistic, Poisson, LASSO regression models), survival models (e.g. Cox survival model and recurrent event survival model), longitudinal models (e.g. linear mixed effects model, Generalised Estimating Equation [GEE]) and Markov modelling (Haneef et al., 2022). However, given the size and breadth of linked data, advanced machine learning techniques including prediction models, clustering techniques, pattern mining and other advanced models such as large language models (LLM), deep learning and artificial intelligence algorithms can be exploited (Guo and Chen, 2023; Haneef et al., 2022). There has also been work related to statistical methods for causal inference with observational data, such as those applied to emulated trial designs (viz., mimics an randomised controlled trial [RCT] design but uses observational data to contrive groups) (Hernán et al., 2022; Szmulewicz, 2024).
Due to data sensitivity, both data cleaning and statistical analyses must be conducted within the secure server environments of DLUs, often associated with significant costs. At the time of writing, fees for one year’s worth of access to the AIHW’s SURE database for a small-to-medium sized project (approximately 10GB in size) for one researcher is $2674 AUD per annum. One proposed solution is to construct a dataset based on a synthetic population (Nicolaie et al., 2023). A synthetic population has all the characteristics of the available population data, but does not comprise data on real persons (Nicolaie et al., 2023). Data analysts can develop code and algorithms on the synthetic data and apply them to real data on secure servers, maintaining privacy, reducing the need to access real data and therefore minimising costs (Nicolaie et al., 2023).
Reporting and dissemination of findings
Various guidelines have been developed for reporting of research findings for specific research designs and to improve the quality, completeness and rigour of research (Simera, 2014). The
Advantages and disadvantages of data linkage
Data linkage is a rapidly growing field; with this growth there is better understanding of the advantages and disadvantages associated with this methodology. It is important to consider these factors in planning a data linkage study (see Figure 3 for a summary of these advantages and disadvantages).
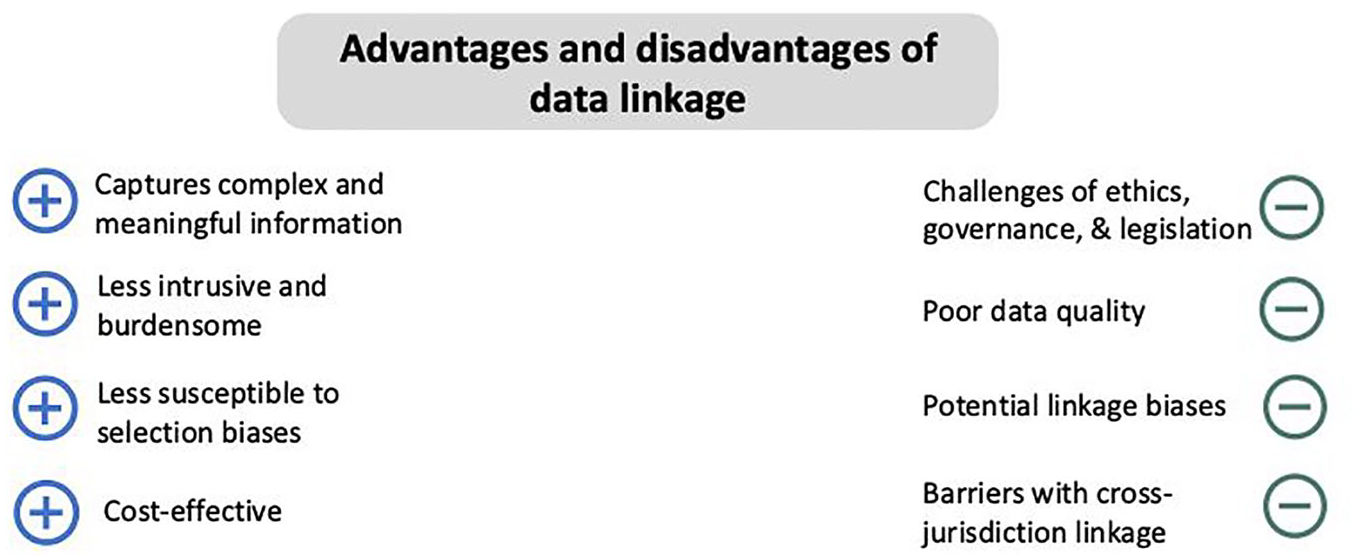
Advantages and disadvantages associated with data linkage.
Advantages
Complex and meaningful information
Based on the richness of data collected through data linkage, especially across multiple datasets, more complex, holistic and meaningful questions can be addressed than can be achieved using single-source data (Andrew et al., 2016; Bradfield, 2022; Bradley et al., 2010; Fahridin et al., 2024; Harron, 2022). Linking health-related data with sociodemographic data provides insights into social determinants of health and mental health (e.g. (Cybulski et al., 2024; Marino et al., 2022). Retrospective historical data can allow for evaluating long-term trends in service use and outcomes (Dibben et al., 2016). Control groups or counterfactuals can be determined post hoc (Dibben et al., 2016), and linked data can be more extensive than that available through prospective cohort studies (Andrew et al., 2016; Brownell and Jutte, 2013). Data linkage can also be used as an alternative to a RCT. For example, we are using an emulated trial design to examine the effectiveness of a hospital-in-home as an alternative care model to inpatient care for young people with acute mental illness (HCF Research Foundation, Melbourne Health). Because of logistic and safety issues a RCT would not be appropriate for addressing whether the two care models differ.
Reduced burden and intrusion
Linkage of routinely collected data and/or follow-up of cohorts can be burdensome and intrusive to the individual participant (Boyd et al., 2015; Bradley et al., 2010; Harron, 2022). A key benefit is that it avoids duplication of effort and has minimal impact on individuals (Andrew et al., 2016; Boyd et al., 2015; Bradley et al., 2010; Dibben et al., 2016).
Minimisation of certain biases
Longitudinal studies involving follow-up of participants, can lead to biases in the data and participant-related biases in those consenting and those retained at follow-up (Downs et al., 2019). If the research involves sensitive topics (e.g. child maltreatment, suicide), then there are risks of social desirability and recall biases due to stigma (Brownell and Jutte, 2013) ultimately threatening the validity of research findings (Brownell and Jutte, 2013; Downs et al., 2019). Data linkage studies reduce and minimises these biases as routine data collection ensures that most individuals within a service are followed up (Brownell and Jutte, 2013; Downs et al., 2019; Fahridin et al., 2024), thereby enhancing the generalisability of the research undertaken in this field. It is also worth acknowledging that data linkage does not reduce all biases as individuals can be lost to follow-up or missing for other reasons (e.g. moving states, death, not being in contact with services); some of these issues are described under Disadvantages.
Cost-effectiveness
Data linkage is a cost-effective alternative to prospective studies and large-scale surveys, as it does not necessitate the resources, labour and time required to recruit participants to research (Andrew et al., 2016; Boyd et al., 2012; Bradley et al., 2010; Brownell and Jutte, 2013; da Silva Marinho et al., 2012; Dibben et al., 2016; Downs et al., 2019). The time taken could be shorter than a 5 year trial and could improve time to knowledge translation. Costs are mainly associated with protocol development for ethics and governance applications, data matching and extraction, computation, data storage, access to secure environments, cleaning, data analysis and importantly, stakeholder engagement.
Disadvantages
Challenges of ethics, governance and legislation
Data linkage involves navigating complex legal and ethical frameworks, including consent requirements, data ownership rights and regulatory compliance (Andrew et al., 2016). These matters can be further complication by any research involving vulnerable populations (e.g. individuals with mental disorders) and when there is use of very sensitive data (e.g. sexual or child abuse, criminal activities). There is ambiguity in interpreting legislations, fragmented policies around data use and often outdated and cumbersome legal requirements (Andrew et al., 2016; Brownell and Jutte, 2013; Carson et al., 2020; Olver, 2014; Palamuthusingam et al., 2019).
Within the Australian context, datasets can be based in different jurisdictions (e.g. State vs Commonwealth), which means that there are varied mechanisms for seeking approvals, and distinct legislative and governance requirements (Andrew et al., 2016; Olver, 2014). Cross-jurisdiction data linkage adds ethical issues relating to privacy and confidentiality, including sharing information with third parties such as sharing identifiers and data between State and Commonwealth departments (Andrew et al., 2016). Resolving such issues, while adhering to ethical standards, can be time-consuming and resource-intensive. There is often duplication of effort and significant delays between obtaining approvals from data custodians and ethical bodies to eventually receiving the data for analysis (Andrew et al., 2016; Boyd et al., 2012; Fahridin et al., 2024; Ritchie et al., 2015). It has been suggested that ethics approval processes should fall in line with changes that have occurred with multisite clinical trials; there is one ethics committee providing oversight and the addition of sites is through amendments rather than new applications (Carson et al., 2020).
Use of secondary data and data quality
Data linkage involves the secondary use of administrative data and consequently, there are concerns about data quality (Boyle and Emery, 2017; Harron et al., 2017b; Harron et al., 2016; Palamuthusingam et al., 2019). First, administrative data are often referred to as
Second, there are often
Third, there can be
Fourth, there can be
DLUs are driving ongoing work to improve the quality of data collected and to minimise the impact of these issues (Harron et al., 2016). Researchers need to carefully plan their approaches to these issues, conduct data cleaning and standardisation and provide appropriate documentation of their approaches (Tran et al., 2017).
Biases in matching
Related to data quality are potential biases in matching processes. Matching biases, even when minimal, can reduce confidence in the accuracy of data and generalisability of research findings (Bohensky et al., 2011; Downs et al., 2019; Harron, 2022). Errors in matching can result from discrepancies in how identifiers are recorded or due to missing data (Bohensky, 2015; Boyd et al., 2012; Gilbert et al., 2018; Harron, 2022). Variations in names (e.g. typographic errors, cultural and tribal names, maiden vs married surnames) can increase the risk of linkage errors (Tahamont et al., 2021; Tibble et al., 2018). The mismatching of ethnic minorities and Indigenous people is more likely to occur because of misspelling of names, inaccurately recorded birth dates, residential instability and geographic mobility (Downs et al., 2019; Gilbert et al., 2018; Thompson et al., 2012).
Biases in data matching can also be due to the choice of matching method (Bohensky, 2015). Because of the inflexibility of deterministic matching methods, there is a greater likelihood of mismatching and false negatives (Downs et al., 2019; Haneef et al., 2022; Lariscy, 2011). Probabilistic linkage techniques are more robust against errors and more adaptable when there are larger datasets (Randall et al., 2013).
The application of the ‘separation principle’ can also increase the likelihood of linkage biases (Gilbert et al., 2018). Because of the distinction between the roles of linkers and analysts and what information is available to them, it may be unclear as to whether specific groups are at greater risk of linkage error (Gilbert et al., 2018). DLUs should work on providing researchers with a detailed report on data linkage error so researchers can develop strategies to deal with them in the analyses. Assessing the potential for data linkage errors should occur during data cleaning.
Barriers with cross-jurisdiction linkage
Cross-jurisdiction linkage is crucial for understanding national health outcomes and reducing biases due to the increasing mobility of the Australian population, but limited infrastructure and legal/regulatory challenges hinder its use (Andrew et al., 2016; Boyd et al., 2012; Boyd et al., 2015; Fahridin et al., 2024). Currently, the environment and infrastructure to support cross-jurisdiction linkage is limited, and researchers face several challenges (Lloyd et al., 2024; Palamuthusingam et al., 2019).
These challenges first include variability in legal and regulatory compliances and in jurisdictions’ interpretation of laws; difficult issues to navigate can delay approvals for years (Andrew et al., 2016; Lloyd et al., 2024; Palamuthusingam et al., 2019). Second, duplication of effort is a problem, with different applications and procedures required in each jurisdiction (Andrew et al., 2016). Third, there are differences in data quality and lack of data standardisation (Olver, 2014). Fourth, technical and infrastructure issues may arise due to different software and platforms used across jurisdictions, requiring significant technical expertise and resources. Fifth, there may be privacy issues with release of data with identifiable information across jurisdictions (third-party) for linkage (Andrew et al., 2016; Boyd et al., 2015). Finally, data governance and ownership issues require careful consideration including clear governance frameworks and agreements to facilitate data access.
Despite these challenges, there are successful examples of cross-jurisdiction linkage such as Boyd et al. (2015) who linked over 44 million records from state-based hospital admission data across four Australian states to examine national mortality records. The accuracy of data linkage was determined to be high (Boyd et al., 2015). Andrew et al. (2016) have also shown how registry data (Australian Stroke Clinical Registry, AuSCR) could be linked across jurisdictions to hospital and mortality datasets.
Government agencies are also in the process of developing large data assets integrating data from across sectors and jurisdictions. Individuals are encouraged to monitor and check what mental health–related data are contained in these assets. The Person Level Integrated Data Asset (PLIDA) comprises health, education, government payments, income, employment and Census data as well as including survey responses to the 2022 National Health Study of Mental Health and Wellbeing. Another asset is the National Health Data Hub (NHDH) which is a national health data linkage system comprising data from states and territory as well as the Commonwealth. There are plans to further add other mental health datasets to NHDH including the National Community Mental Health Care Database and National Residential Mental Health Care Database.
Moving forward
Data linkage research is both necessary and for the public good (Bradley et al., 2010). Holman et al. (2008) predicted that ‘health data linkage systems may become normal infrastructure for health services research in nations like Australia within the next decade’ (p. 767); however, the rate of uptake has been slower, particularly in mental health (Productivity Commission, 2020). This is at the opportunity cost for Australian mental health research. The Productivity Commission (2020) suggested the imperative for existing data to be used, rather than extending resources to collect new, but similar data, which may be more likely to be incomplete and at greater burden to individuals. We also advocate that using data linkage allows for a broad range of research questions to be addressed that would otherwise remain unanswered. In advancing the adoption of data linkage in research activities, several approaches are needed.
Greater awareness and education across stakeholder groups regarding data linkage and its benefits is required. The development of a social licence for data linkage has been suggested and involves (1) ensuring there are shared values of the importance of such work across stakeholder groups; (2) empowering individuals with control over their own data and how it is utilised; (3) building public trust that safeguards are in place to ensure that data is well-protected and (4) making sure that there is genuine transparency and accountability of the processes involved in data linkage (Muller et al., 2021; Productivity Commission, 2020). Without a social licence for data linkage, there may well be enduring challenges and contestation from the public (Carter et al., 2015). However, there are no guidelines to support how a social licence would be developed and implemented.
While raising public awareness is crucial, the education of ethics committees and policy makers is equally important (Bradfield, 2022; Brownell and Jutte, 2013; Tan et al., 2015). Training programmes have been established and successfully implemented to build confidence among ethics committee members in their ability to review data linkage applications (Tan et al., 2015). Researchers are encouraged to share their knowledge and experiences in the literature, focusing on topics such as risk management (Ritchie et al., 2015). In addition, educational toolkits can be developed and used for advocacy and policy discussions (Ritchie et al., 2015).
Building strong relationships between stakeholder groups is crucial for successful data linkage research (Bradley et al., 2010; Ritchie et al., 2015). A multidisciplinary team including clinical researchers, data custodians, DLUs, epidemiologists, statisticians and data scientists is required. Consumer involvement in data linkage research is generally overlooked but essential for ensuring meaningful outcomes (Jewell et al., 2019).
More infrastructure and resources to support data linkage research are needed. This includes more funding for DLUs to bolster their capacity to meet growing demands (Andrew et al., 2016), as well as greater investment from funding bodies for data linkage research (Andrew et al., 2016; Bradley et al., 2010; Downs et al., 2019). Data linkage expenses are increasing including DLUs expenses (linkage and storage of data), costs for analysts and stakeholder engagement. Researchers, health policy makers and data custodians need to remove barriers to accessing linked health datasets (Olver, 2014) and promote cross-jurisdiction research ((Boyd et al., 2015; Lloyd et al., 2024). Streamlining and harmonising approaches and processes for ethics and governance also needs to be addressed (Andrew et al., 2016; Carson et al., 2020; Lloyd et al., 2024). Such work is necessary to mitigate lengthy delays and resource duplication in research activities.
Researchers should adhere to various reporting guidelines specific to data linkage. Many of the guidelines have been published in recent years and have not been used or referenced in studies. However, such guidelines are designed to improve research quality, transparency and replicability.
Researchers should consider the full breadth of administrative data collected across sectors and explore how cross-sectoral data linkage can address complex and meaningful questions. Examining sensitive and difficult-to-investigate research topics using data linkage, including homelessness, family violence, self-harm, suicidality, mortality and health service utilisation, has clear benefits (Borschmann et al., 2017; Cvejic et al., 2022; Ducat et al., 2013; Meurk et al., 2022; Young et al., 2024. However, the impacts of mental illness are far broader. Consideration of other sectors such as education, disability, family, child protection, homelessness and housing support, substance use and forensic services will provide insights into gaps between sectors, improve estimation of service use and health outcomes, identify those individuals who are socially excluded from health services and allow the examination of social determinants of mental illness (Pearce et al., 2023).
There is also the need to look at how and what mental health-related data are collected across databases, sectors and jurisdictions. Can consensus be obtained regarding core routine outcome measures for mental health? Are these measures meaningful to key stakeholders such as those with a lived experience, their caregivers, clinicians, service providers and policy makers? Do they have appropriate psychometric properties? Can primary health and mental health care data be integrated to national data assets such as PLIDA?
Finally, a community of practice for data linkage research in mental health in Australia is needed. Efforts should focus on capacity-building via sharing and publishing experiences, methodologies and approaches (e.g. development of more sophisticated models such as foundation models, LLMs) and research translation for policy and practice.
Conclusion
In this manuscript, we have provided a comprehensive and up-to-date overview of data linkage methodologies, from the planning stages of research to reporting of research findings. We have also highlighted diverse research questions that have been addressed using data linkage in mental health research in Australia. To advance the field of data linkage research in mental health, there needs to be greater education across stakeholder groups, better engagement with lived experience, improved infrastructure and funding and further exploration of benefits and utility of cross-jurisdictional and cross-sectoral linkage. Such work will enable us to address complex and meaningful questions regarding mental health that other research designs cannot adequately address.
Supplemental Material
sj-docx-1-anp-10.1177_00048674251333574 – Supplemental material for Using data linkage for mental health research in Australia
Supplemental material, sj-docx-1-anp-10.1177_00048674251333574 for Using data linkage for mental health research in Australia by Sue M Cotton, Jana M Menssink, Matthew Hamilton, Kate M Filia, Shu Mei Teo, Mengmeng Wang, Dan ZQ Gan, Wenhua Yu, Amity Watson, Katrina Witt, Melissa Hasty, Carl Moller, Alison Yung and Caroline X Gao in Australian & New Zealand Journal of Psychiatry
Footnotes
Declaration of Conflicting Interests
The author (s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author (s) received no financial support for the research, authorship, and/or publication of this article.
ORCID iDs
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.