
Abstract
Background
ML predictive models have shown their capability to improve risk prediction and assist medical decision‐making, nevertheless, there is a lack of accuracy systems to early identify future rapid CKD progressors in Colombia and even in South America.
Objective
The purpose of this study was to develop a series of interpretable machine learning models that predict GFR at 6-months, 9-months, and 12-months.
Study Design and Setting
Over 29,000 CKD patients stage 1 to 3b (estimated GFR, <60 mL/min/1.73 m2) with an average of 3-year follow-up data were included. We used the machine learning extreme gradient boosting (XGBoost) to build three models to predict the next eGFR. Models were internally and externally validated. In addition, we included SHapley Additive exPlanation (SHAP) values to offer interpretable global and local prediction models.
Results
All models showed a good performance in development and external validation. However, the 6-months XGBoost prediction model showed the best performance in internal (MAE average = 6.07; RSME = 78.87), and in external validation (MAE average = 6.45, RSME = 18.94). The top 3 most influential features that pushed the predicted eGFR value to lower values were the interpolated values for eGFR and creatinine, and eGFR at baseline.
Conclusion
In the current study we have developed and validated machine learning models to predict the next eGFR value at different intervals. Furthermore, we attempted to approach the need for prediction explanation by offering transparent predictions.
Introduction
Chronic kidney disease (CKD) is considered a global public health problem, being one of the main contributing diseases to the global burden of non-communicable diseases. 1 It is associated with important serious outcomes including increased risk of mortality, accelerated cardiovascular disease, adverse metabolic and nutritional consequences, reduced cognitive function, and increased risk of acute kidney injury. 2
CKD is a significant and gradual problem in low- and middle-income countries (LMICs) due to the increasing number of people with type 2 diabetes, hypertension, obesity, and vascular diseases. 3 Besides, 63% percent of the global burden of CKD occurs in LMICs. 4
In developing countries high mortality rates due to poor access to renal replacement therapy, as well as increased incidence of CKD, are expected to result in a substantial financial burden on health systems. 5 In this regard, systematic approaches to detecting and monitoring CKD can substantially mitigate cardiovascular complications and delay the progression of end-stage renal disease. 3
It is well known that inexpensive interventions can slow the rate of kidney function loss, consequently, there is some enthusiasm for population-based screening to allow early intervention in both low-income and high-income countries. 6 Despite the growing burden of CKD in LMICs, few population-based screening models have been implemented at the national or local clinical level to specifically prevent or manage complications related to CKD. 3
An approach that has been shown promising results, is risk stratification using machine learning (ML) techniques. 7 Several studies have reported that machine learning outperforms conventional statistical methods due to its ability to better identify variables relevant to clinical outcomes and its better modeling of complex relationships. 8 Furthermore, in healthcare is still a challenge to deal with the vast amount of data from different types of structures, a problem that machine learning techniques have proven to overcome because of its robustness to data noise and its ability to learn from multiple data sets. 9
Considering that CKD is one of the highest costly diseases in Colombia and in Latin America, risk stratification models with few but sufficient predictors are highly desirable.10,11 Further, a predictive model to estimate the next eGFR, using very few predictors, could be highly useful due to its ease of use in clinical practice, a greater possibility of reproducibility in other clinical contexts, and for the potential application of prediction in the design of targeted interventions.
In the present study, we developed interpretable prediction models for the next eGFR estimation. Using ML techniques incorporating a few clinical parameters, we developed and internally and externally validated ML models to predict the 6-months, 9-months, and 12-months eGFR value using data from a large cohort of Colombian CKD patients from the Caribbean region. This risk stratification system is designed to assist case managers and physicians in predicting CKD prognosis quickly and accurately.
Methods
Population - study cohorts
The retrospective cohort study was performed including a large CKD Colombian Caribbean Cohort coming from primary and secondary ambulatory care.
We used one observational study cohort derived from primary care records of a Colombian health service provider specialized in the treatment of chronic diseases. The cohort was composed of follow-up data from 29,447 patients with a diagnosis of CKD stages 1 to 3b (estimated GFR, <60 mL/min/1.73 m2) collected after 2017 (Mean of follow-up = 3 years). Records were extracted from the laboratory information system and electronic health records.
Records on the cohort were screened based on eGFR and were included after checking according to the eligibility and exclusion criteria. The key eligibility criteria were Colombian, 18–90 years, eGFR: >30 mL/min/1.73 m2, and no initiation of renal replacement therapy (RRT). The key exclusion criteria were follow-up time <12 months, less than three outcome and predictor measurements during follow-up, diagnostic of Polycystic kidney disease (PKD), HIV, cancer treatment in the past 2 years, and renal transplantation, according to medical records.
The exclusion criteria were implemented to address specific limitations in the data provided by the healthcare provider for this study. In Colombia, healthcare providers often specialize in managing particular diagnoses or groups of related conditions. The provider that supplied our study database focuses on chronic diseases, including hypertension, diabetes, and chronic kidney disease (prior to renal replacement therapy). Patients with additional conditions such as HIV, cancer, or those undergoing renal replacement therapy are managed by other specialized providers. Consequently, follow-up data for these conditions are not included in the database provided. By excluding these cases, we aimed to reduce potential bias due to the unavailability of relevant data.
Outcome
The outcome variable was eGFR estimation at 6, 9, and 12 months, as a key clinical indicator of CKD progression. GFR was estimated using the Cockcroft‐Gault equation. 12 Therefore, the medical tasks that the model is intended to support are diagnostic staging and prognosis.
Candidate predictors
Candidate predictors were pre-identified from a literature review, and their face validity according to clinical expertise. Demographic variables such as age and sex were included as well as routine clinical variables such as body mass index (BMI), systolic blood pressure (SBP), diastolic blood pressure (SBP), type 2 diabetes, hypertension; and routine clinical laboratory variables (creatinine) and GFRe at different intervals.
Estimating values for prediction intervals
To estimate the value of each continuous variable at the end of the prediction period, we used linear interpolation based on the two closest available measurements. This method applied to serum creatinine, blood pressure (both systolic and diastolic), BMI, and GFR to model how these variables change over time.
We began by taking a measurement from the start of the observation period (baseline) and another from the end of this period (beginning of the prediction period). The observation period is the time before the prediction period when data was collected to forecast the next GFR.
The linear interpolation was performed using the formula:
For example, to estimate the serum creatinine value at the start of the prediction period: • y1 is the serum creatinine value closest to the start of the prediction period (0.80 mg/dL). • y2 is the serum creatinine value closest but later than y1 (0.70 mg/dL). • x is the start of the prediction period (March 2, 2022). • x1 is the most recent date before the prediction period (February 22, 2022). • x2 is the first date after the prediction period (March 18, 2022).
Then,
The interpolation method using only two values was chosen considering the data availability scenario in a low- and middle-income country (LMIC) like Colombia. In clinical settings, the availability and frequency of measurements can vary significantly. Therefore, a method that is broadly applicable, even in scenarios with minimal data points, is more suitable. By relying on two points, this method can be applied consistently across different patient records, including those with sparse data.
Internal and external validation samples
The development cohort was composed of follow-up data from 11,730 CKD patients for the 6-month prediction model (mean age: 66.18; 68.52% women), 9,974 patients for the 9-month prediction model (mean age: 66.43; 68.28% women), and 8,191 patients for the 12-month prediction model (mean age: 66.57; 68.25% women).
The external validation cohort for the 6-month prediction model included 2,933 CKD patients (mean age: 66.69; 68.80% women), 2,494 patients for the 9-month prediction model (mean age: 65.99; 70.44% women), and 2,048 patients for the 12-month prediction model (mean age: 66.54; 69.67% women).
The external validation cohort consisted of a sub-sample of the Caribbean region cohort, which was not used during model training. Although this cohort is derived from the same overall population, it includes data from different healthcare centers located in various cities across the Caribbean region of Colombia, introducing variability in clinical practices and patient demographics. This diversity allows the external validation cohort to function effectively as an independent dataset, assessing the model’s generalizability in a slightly different context.
All patients were from 8 healthcare centers focused on primary and secondary care, located in different cities across the Caribbean region of Colombia. Figure 1 shows the workflow process of patient inclusion and exclusion. Work-flow process of inclusion-exclusion of patients in both cohorts.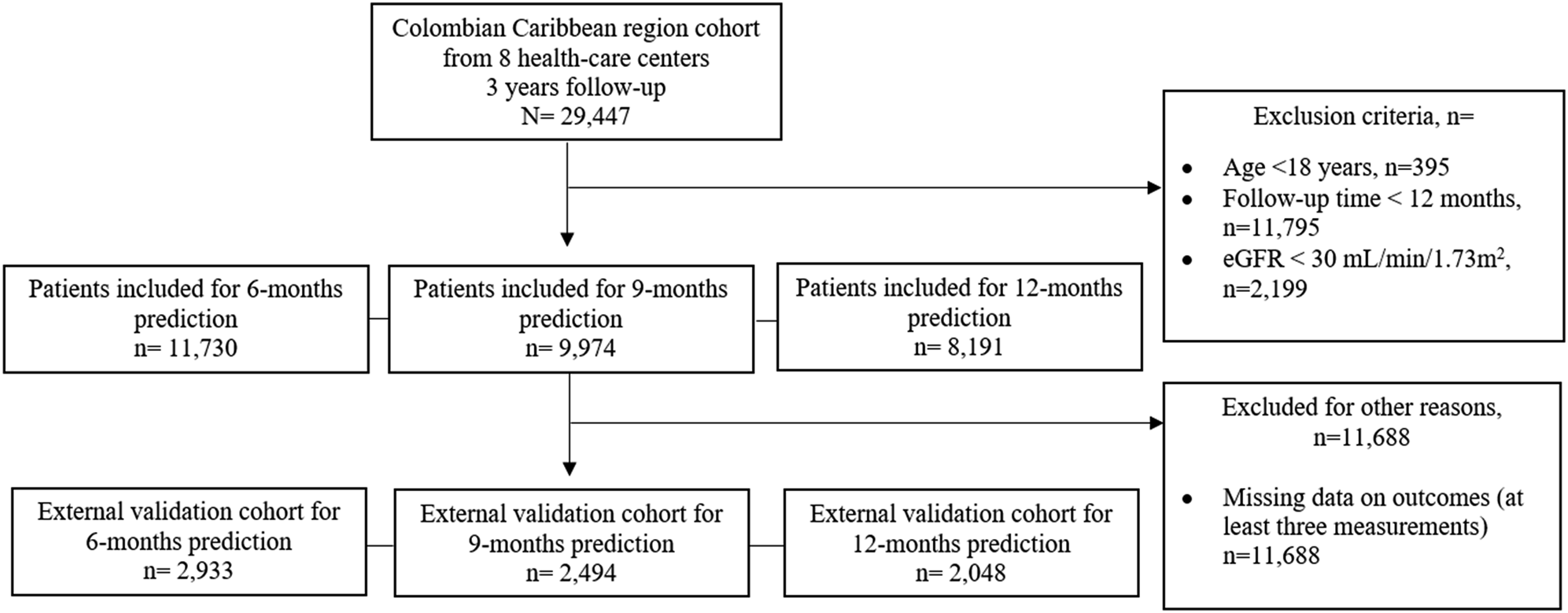
Models developing
Variables with more than 30% missing values were excluded from the analysis. Bivariate analyses were conducted using Student’s t-test and the χ2 test to assess differences across cohorts, with a significance level of 0.05. These statistical analyses were conducted in Python.
We trained a series of linear regression models using eXtreme Gradient Boosting (XGBoost) to predict the next eGFR value. XGBoost is a machine learning technique that constructs an ensemble of decision trees to build a predictive model. During training, it iteratively generates new decision trees to correct errors from the current model, improving the prediction of the outcome variable. The final output is the cumulative score of all decision trees, representing the predicted outcome likelihood.
XGBoost offers a significant advantage over other machine learning techniques due to its scalability. It can run more than ten times faster than existing popular solutions on a single machine and scales effectively to billions of examples in distributed or memory-limited settings. 13
Model performance was evaluated using three metrics: • Mean Absolute Error (MAE): Measures the average absolute difference between predicted and observed values, reflecting the average prediction error. • Root Mean Squared Error (RMSE): Assesses the square root of the average squared differences between predicted and actual values, emphasizing larger errors. • R-squared (R2): Indicates the proportion of variance in the outcome variable explained by the model.
These metrics were used to assess the accuracy and robustness of the XGBoost models trained to predict eGFR. For external validation, the Relative RMSE (RMSE/SD) was also reported to normalize the RMSE relative to the variability in the data.
Parameters for the XGBoost algorithm were optimized using a grid search over 3,456 models with 3-fold cross-validation. The grid search included the following parameter ranges: the learning rate was set from 0.0001 to 0.1, the number of boosted trees (n_estimators) ranged from 50 to 500, the subsample parameter (to add randomness and robustness to noise) ranged from 0.6 to 1.0, and the maximum depth of a tree (to reduce model complexity) was set to either 3 or 4. The specific parameter grid is shown below: grid_param = { “min_child_weight”: [1, 5, 10], “gamma”: [0.5, 1, 1.5, 2], “subsample”: [0.6, 0.8, 1.0], “colsample_bytree”: [0.6, 1.0], “max_depth”: [3, 4], “n_estimators”: [50, 100, 200, 300, 400, 500], “learning_rate”: [0.0001, 0.001, 0.01, 0.1]}
A total of 3,456 combinations (3 × 4 × 3 × 2 × 2 × 6 × 4) were tested.
To address class imbalance during model training, we analyzed class distributions and used XGBoost’s inherent class weighting capabilities to adjust the impact of imbalanced classes. The scale_pos_weight parameter was configured to account for class imbalance. Additionally, we monitored model performance metrics, including MAE, RMSE, and R-squared, to ensure effective model fitting and assess the influence of any class imbalances.
All analyses were conducted in Python using xgboost v. 1.5.2, shap v. 0.40.0, and scikit-learn v. 1.0.1 packages.
Internal and external validation
For internal validation, datasets were randomly split into training and testing datasets for each interval: 6 months (training n = 11,730, testing n = 2,933), 9 months (training n = 9,974, testing n = 2,494), and 12 months (training n = 8,191, testing n = 2,048). Additionally, the best-performing prediction models in the internal validation dataset were evaluated in external datasets.
Interpretability of models
Since the target users of the described models are clinicians and hospital management teams, we made efforts to include a way of visualizing the model results. To enhance the interpretation of the models, mitigate the black-box issue associated with ML techniques, and improve clinical usability, we employed the Shapley Additive exPlanations (SHAP) method. 14
SHAP is a Python framework designed for explaining the output of any machine learning model using classical Shapley values from game theory. It leverages a combination of feature contributions and Shapley values to generate SHAP values, quantifying the contribution of each feature to the prediction. Additionally, SHAP calculates global feature importance by averaging the magnitudes of the SHAP values across the dataset. 15
The SHAP approach provides both global and local interpretability of each model. It highlights the importance of each predictor feature globally and indicates the importance relative to a specific individual locally. SHAP explains the model’s outcome as the sum of each contributing variable. A value greater than zero signifies that the variable increases the predicted outcome for the individual, while a value less than zero indicates the opposite. 16
This study adhered to the principles outlined in the Declaration of Helsinki. Written informed consent was not necessary since the data were extracted from medical history records, and the analysis did not include identifiable information (Health Insurance Portability and Accountability Act Privacy Rule). 17 Therefore, approval from the institutional review board was not required for this study.
Furthermore, this report follows the comprehensive checklist for the (self)-assessment of medical AI studies. 18
Results
Baseline characteristics of development and external validation cohorts.
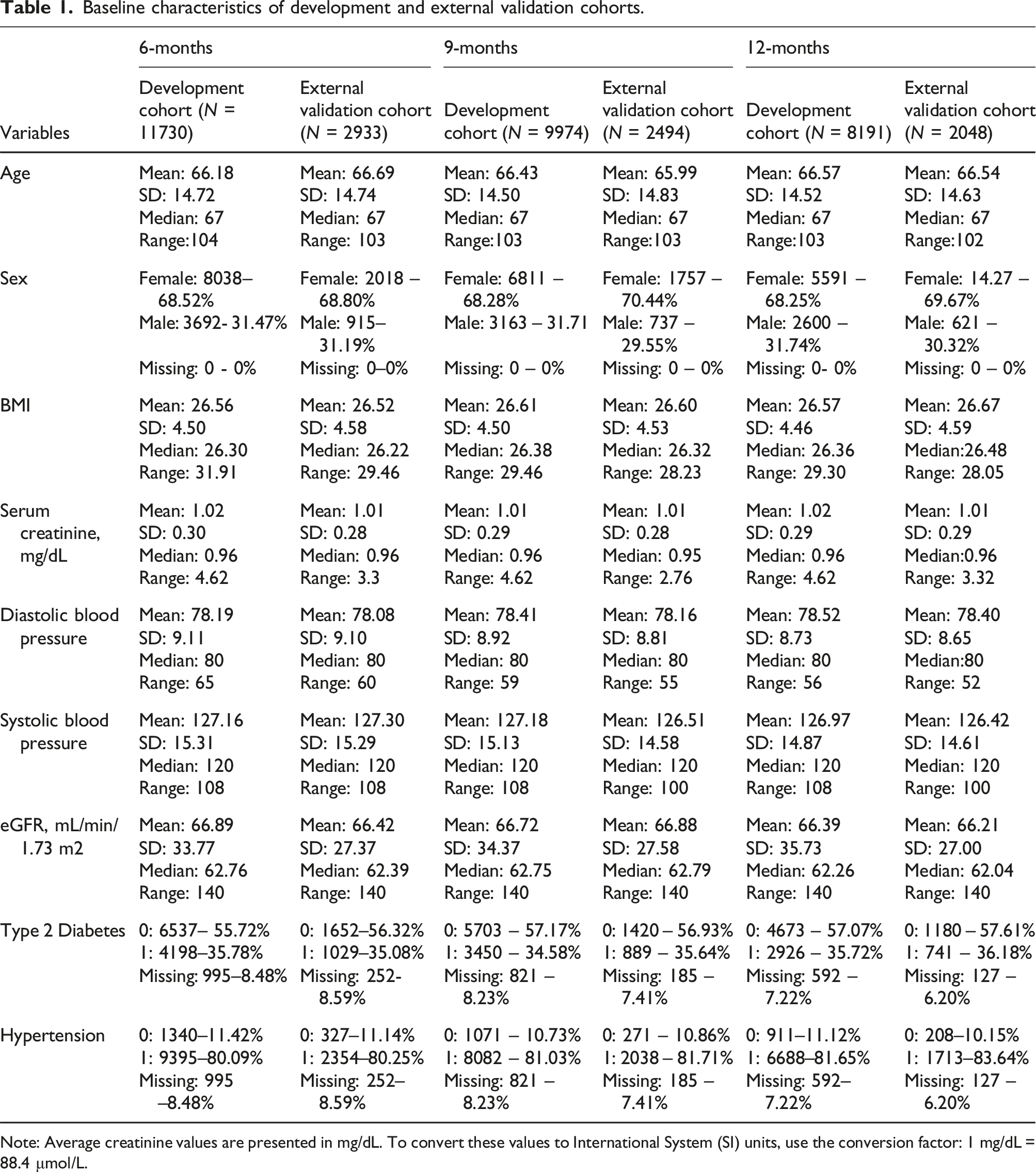
Note: Average creatinine values are presented in mg/dL. To convert these values to International System (SI) units, use the conversion factor: 1 mg/dL = 88.4 μmol/L.
The XGBoost model for prediction at 6-months had the best performance in training dataset (MAE average = 6.07; RSME = 78.87), and in testing dataset (MAE average = 6.73; RSME = 799.47) compared with model at 9-months (MAE average training dataset = 7.84, RSME = 125.57; MAE average testing dataset = 6.73, RMSE = 799.47) and with model at 12-months (MAE average training dataset = 7.80, RSME = 190.4; MAE average testing dataset = 8.14, RMSE = 128.73).
In external validation datasets the performance was quite similar for the model at 6-months prediction (MAE average = 6.45, RSME = 18.94, RMSE/SD = 0.722, R2 = 0.47), at 9-months prediction (MAE average = 6.45, RSME = 361.89, RMSE/SD = 0.398, R2 = 0.84), and at 12-months prediction (MAE average = 8.33, RSME = 378.23, RMSE/SD = 0.408; R2 = 0.83).
Predictors selected using XGboost and their importance score for eGFR estimation models.
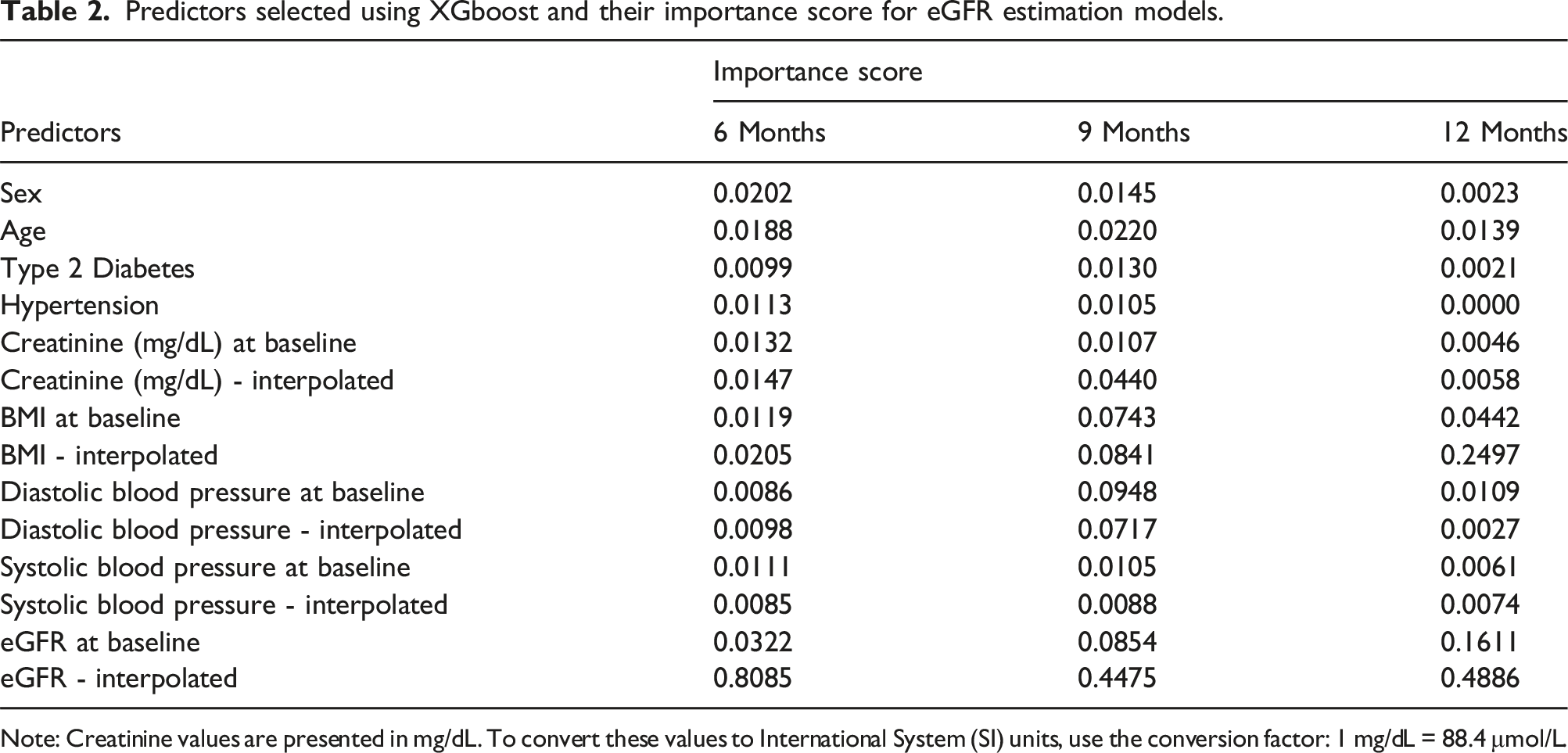
Note: Creatinine values are presented in mg/dL. To convert these values to International System (SI) units, use the conversion factor: 1 mg/dL = 88.4 μmol/L.
As regards global interpretability, SHAP explains the outcome of a model as the sum of each contributing variable. For our models, greater than zero means that the variable in the present value increases the predicted eGFR, while less than zero indicates the opposite. Figure 2 shows the global feature contribution for each model. In that figure, are shown the features that help drive the model output from the base value (the average model output over the training data set) to the model output. Features that push the highest prediction are shown in red, those that push the lowest prediction are in blue. Beeswarm plot where each point corresponds to an individual patient in the study. Dot position on the x-axis shows the impact that characteristic has on the model’s prediction for that patient. When several dots fall on the same x-position, they accumulate to show the density. (a) 6-months prediction model; (b) 9-months prediction model, (c) 12-months prediction model.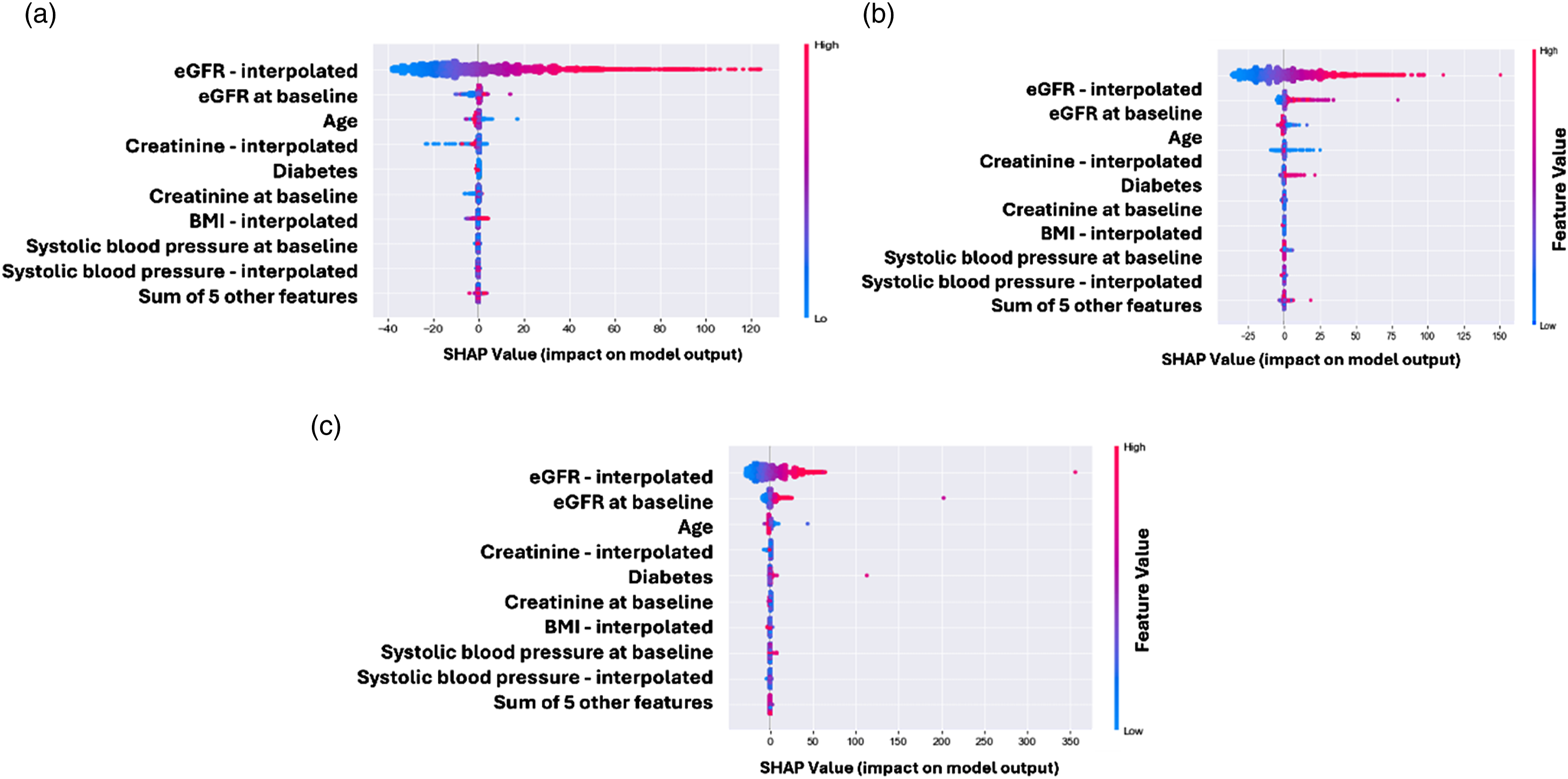
For all prediction models, the most contributing variables were eGFR– interpolated, eGFR at baseline, age, and creatinine– interpolated with lower values (below zero) indicating lower predicted eGFR values. Furthermore, only for the 6-month prediction model, type 2 diabetes was in the top 5 of the predictors with the highest contributions.
It is interesting to note that interpolated variables were the most important features, pointing out the relevance of the longitudinal treatment of the variables in ML models.
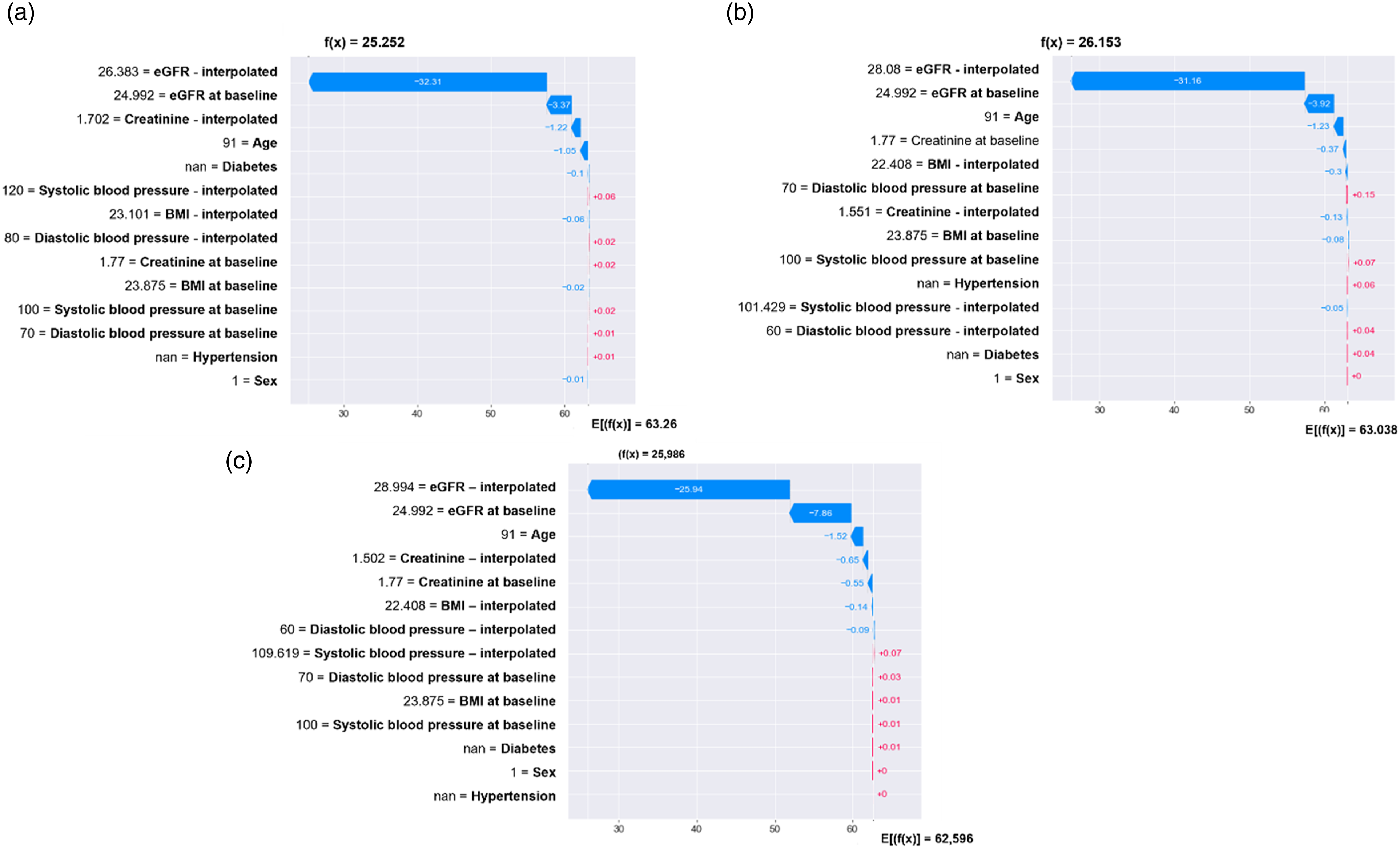
Figures 3 and 4 show the use of SHAP for local interpretability aimed to know the attribution of each variable in terms of its weight indicated as the length of the bar and direction force towards the outcome score (positive or negative). Besides, f(x) indicates the predicted eGFR value for that individual patient, while E[f(X)] indicates the average predicted eGFR for the entire cohort. Waterfall plot for a single patient. The contributing variables are arranged in the x-position, sorted by the absolute value of their impact. Variables in the red arrow mean the impact values are positive while blue means negative. (a) The predicted eGFR value at 6-months is 62.88. eGFR – interpolated 65.59, creatinine (mg/dL) – interpolated 1.23, and SBP at baseline 150 were the main factors that pushed the predicted eGFR value to lower values. eGFR at baseline 70.63, age 51, not having diabetes diagnosis, and creatinine at baseline 1.05 were the main factors that pushed the predicted eGFR value to higher values. (b) The predicted eGFR value at 9-months. (c) The predicted eGFR value at 12-months. Waterfall plot for a single patient. (a) The predicted eGFR value at 6 months is 25.25. eGFR – interpolated 26.38, eGFR at baseline 24.99, creatinine (mg/dL) interpolated 1.70, and age 91 were the main factors that pushed the predicted eGFR value to lower values. Almost no other variable pushed the predicted eGFR value to higher values. (b) The predicted eGFR value at 9-months. (c) The predicted eGFR value at 12-months.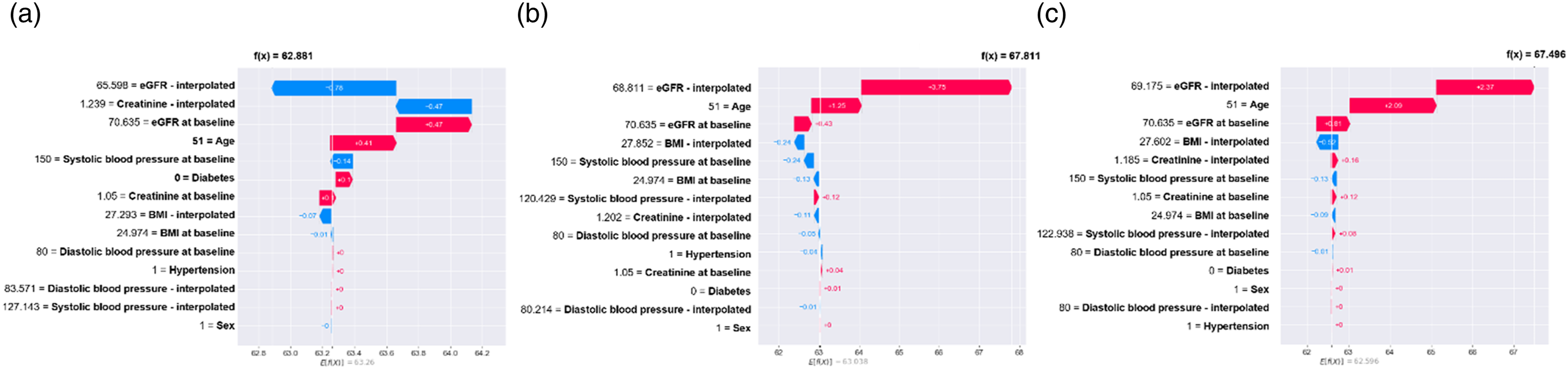
Discussion
In this study, we developed three machine learning models to predict the next eGFR at different intervals. We used few and commonly captured variables, even for resource-constraint environments. MAE values showed that all predictive models had a good performance, and they can be implemented as a useful early warning system for screening and identification of patients at high risk of CKD progression.
Our models have an additional advantage over most other predictive models for CKD, they are not black-boxes, and their interpretation is available for clinicians. The aforementioned is a highly relevant factor since healthcare professionals need interpretable and transparent information to support the intervention they will perform according to the risk level identified in the patient.19,20
Decision-makers in healthcare have pointed out the interpretability of model predictions as a priority for implementation and utilization. 21 Hence, in the current study we considered two aspects: (1) ML models described in this study are designed to assist healthcare professionals across clinical care and costs domains; (2) decisions based on predictions will inform clinical care pathways, patient risk stratification, and possibly many others.
To the best of our knowledge, there are few published reports about predictive models that have attempted to predict the next eGFR. Besides, none have captured clinical and laboratory variables commonly collected in care models for chronically ill patients in low- and middle-income countries. For instance, although with excellent performance some of them have included laboratory variables such as serum calcium, bicarbonate, and phosphorous which are not collected for the entire at-risk CKD population in Colombia. 22
On the other hand, we implemented a method to handle and take advantage of longitudinal data. Recently, a group of evidence has emphasized the need to overcome using cross-sectional data for predictive models as an essential forward-step for public health.23,24 Studies using large population samples with data extracted from electronic health records showed that models developed with transformed longitudinal data outperformed the traditional predictive models used clinically.25–27
Likewise, our study is the first one that attempted to predict eGFR using transformed clinical longitudinal data into interpretable ML models. Besides, to our knowledge, this is the first study that includes such a large South American sample of CKD patients to develop predictive models. The models’ performance was good in external validation cohorts and with similar performance to previously developed predictive models. 28
In this study, we selected the XGBoost (Extreme Gradient Boosting) algorithm for predicting the next eGFR due to its superior performance in handling complex datasets and its effectiveness in capturing non-linear relationships. XGBoost is a gradient boosting framework that is renowned for its efficiency, scalability, and accuracy in predictive modeling. 29 It combines several boosting techniques to create a powerful model that can handle large datasets with high dimensionality, making it particularly suitable for our prediction tasks.
XGBoost has been widely recognized in the literature for its high accuracy and performance across various machine learning challenges, including regression tasks similar to our study. 30 Its ability to improve model performance through boosting and regularization techniques ensures accurate predictions. Furthermore, the algorithm’s capacity to model complex, non-linear interactions between features allows it to effectively capture intricate patterns in the data, which is crucial for predicting eGFR with a high degree of precision. Lastly, XGBoost provides insights into feature importance, which helps in understanding the contribution of different variables to the prediction outcome. 31 This interpretability is valuable for clinical applications where understanding the impact of various factors on eGFR is essential.
The findings of the present study support the use of ML models to identify CKD patients at higher risk for accelerated CKD progression who may benefit from effective preventive strategies. Furthermore, our predictive models have been recently implemented on a care model for chronically ill Colombian patients through an application programming interface. The next step will be to evaluate the cost-effectiveness and clinical utility of these models in real-world practice.
Our study has some limitations. First, the impossibility to include a geographically different population from that of the Colombian Caribbean region to assess models’ external validity. In addition, laboratory variables such as albuminuria, glycosylated hemoglobin, total cholesterol, and high-density lipoprotein cholesterol were not included due to a large amount of missing data. As well as relevant sociodemographic variables such as household monthly income and education level were also not included.
The above is pertinent since those variables could be relevant predictors for CKD progression in our population.32,33 Nevertheless, through the use in real-world practice, ML models can be continuously updated as these data become available in additional cohorts.
Lastly, an additional significant limitation was the absence of medication data within the dataset. Medications can profoundly affect kidney function and progression, and their exclusion from our analysis means we could not account for these potential influences on GFR predictions. Future research should aim to include detailed medication information to better assess its effects on GFR and improve predictive accuracy.34,35
Conclusions
Our study developed and validated machine learning models to predict eGFR at 6, 9, and 12-month intervals, demonstrating good performance across both internal and external validation cohorts. The 6-month prediction model showed the best overall performance. Key predictors included interpolated eGFR values and baseline measurements, which proved crucial for accurate forecasts. The models’ interpretability, enabled by SHAP values, enhances their clinical relevance by offering insights into how individual variables influence eGFR predictions. Despite some limitations, such as missing data on certain laboratory variables and medication information, our models provide a valuable tool for early risk identification and intervention in CKD management. The interpretability of the prediction results can offer deeper insight into the changes in eGFR induced by specific variables, hence could support the decision-makers in healthcare and clinicians for early intervention of the modifiable factors.
Future studies should incorporate additional data to further refine these predictions and assess their real-world utility and cost-effectiveness.
Footnotes
Acknowledgements
The authors would like to thank Asociación Colombiana de Nefrología e Hipertensión Arterial for their discussions.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Science for Life (S4L).
Ethical approval
This study adhered to the principles outlined in the Declaration of Helsinki. Written informed consent was not necessary since the data were extracted from medical history records, and the analysis did not include identifiable information (Health Insurance Portability and Accountability Act Privacy Rule). 17 Therefore, approval from the institutional review board was not required for this study.
Guarantor
LHR.
Contributorship
LHR, AM, and AJPM conceived the study. LHR, WA and AM were involved in protocol development and data analysis. WA was involved in database management and data analysis. VD and WV were involved in databases building and reviewing results. AJPM wrote the first draft of the manuscript. All authors reviewed and edited the manuscript and approved the final version.
Data availability statement
The authors reserve data and code availability due to the existence of a confidentiality agreement with the health care provider who shared their data for the study. Furthermore, the models described, and data sets included are currently part of an ongoing research project to implement a risk stratification system in clinical practice.