
Abstract
Background
Explainability, the aspect of artificial intelligence-based decision support (ADS) systems that allows users to understand why predictions are made, offers many potential benefits. One common claim is that explainability increases user trust, yet this has not been established in healthcare contexts. For advanced algorithms such as artificial neural networks, the generation of explanations is not trivial, but requires the use of a second algorithm. The assumption of improved user trust should therefore be investigated to determine if it justifies the additional complexity.
Methods
Biochemistry staff completed a wrong blood in tube (WBIT) error identification task with the help of an ADS system. One-half of the volunteers were provided with both ADS predictions and explanations for those predictions, while the other half received predictions alone. The two groups were compared in terms of their rate of agreement with ADS predictions, as an index of user trust, and WBIT error detection performance. Since the AI model used to generate predictions was known to out-perform laboratory staff, increased trust was expected to improve user performance.
Results
Volunteers reviewed 1590 sets of results. The volunteers provided with explanations demonstrated no difference in their rate of agreement with the ADS system compared to volunteers receiving predictions alone (83.3% versus 81.8%, p = 0.46). The two volunteer groups were also equivalent in accuracy, sensitivity and specificity for WBIT error identification (p-values >0.78).
Conclusions
For a WBIT error identification task, there was no evidence to justify the additional complexity of explainability on the grounds of increased user trust.
Keywords
Introduction
There is considerable interest in the use of artificial intelligence (AI) as a decision support tool in clinical laboratories. Evidence demonstrating the predictive accuracy of AI for laboratory applications is emerging. However, many of the best-performing AI algorithms, such as artificial neural networks (ANNs), are not intrinsically comprehensible by humans. Explainability is the term applied to the concept whereby a user is provided with sufficient information to be able to reconstruct why an AI-driven system made a prediction. 1
The property of explainability offers a range of potential benefits. Foremost among these is the notion that users have greater trust in AI-based decision support (ADS) systems if they are explainable.2,3 However, other stakeholders also potentially benefit from explainability.1,3 For instance, developers of ADS systems may use explanations to detect flaws in their models, design better evaluation studies and identify opportunities for model improvement. Those responsible for implementing ADS systems may benefit from explainability assisting with the design of system validation and audit procedures, demonstrating that the system complies with regulations and identifying social bias in systems. More generally, non-AI researchers with an interest in the task being performed may benefit from model explanations generating novel hypotheses and suggesting fresh avenues of investigation.
An algorithm capable of generating explanations for black-box AI model predictions was recently developed. The ‘local interpretable model-agnostic explanations’ (LIME) algorithm perturbs the inputs used by a model for each prediction and observes whether the prediction is altered. 4 In this manner, LIME is able to identify the inputs the model considers most important for each prediction. The routine use of LIME, or a similar algorithm, introduces significant additional complexity to an ADS system, however, and therefore it is important to establish the circumstances in which its use has benefits.
This study examined whether the provision of explanations improved trust among users of an ADS system for WBIT error identification. The ANN used in this system had previously been demonstrated to out-perform laboratory staff and therefore increased trust would be expected to translate into improved user WBIT error detection. 5
Methods
Volunteers were asked to identify WBIT errors, simulated at a rate of 50%, among a test dataset (n = 14,132) comprised of current and previous (within 7 days) patient electrolyte, urea and creatinine results, patient age and sex, and the time and date of each collection. A previously evaluated ANN 5 was used to produce ADS predictions and the percentage ‘confidence’ of the predictions (the probability assigned by the model to the prediction) and for each sample in the test dataset. The LIME algorithm generated explanations by identifying the three factors from each case that were most responsible for the ANN’s prediction. Detailed descriptions of the data and models used are available as Supplemental Material.
New South Wales Health Pathology staff routinely involved in validating biochemistry results were invited to anonymously access a purpose-written web application. Ten sets of samples were randomly selected from the test dataset for each volunteer to predict whether WBIT errors were present. All volunteers were provided with ADS predictions and percentage confidence. One-half of the volunteers were randomised to additionally receive the LIME explanations for all the samples they reviewed.
Volunteers also gave information regarding the grade at which they were employed, whether they were employed full-time or part-time, the number of years they have been validating biochemistry results and the approximate proportion of their workday typically spent validating results (‘almost none’, ‘less than half’, ‘about half’, ‘more than half’, ‘almost all’). Ethics approval was not required because the study met criteria of the National Health and Medical Research Council for a quality improvement activity. 6
Results
Performance characteristics of an artificial intelligence-based decision support system for the identification of wrong blood in tube (WBIT) errors. All users had access to predictions from the decision support system as to whether or not WBIT was present. One-half of the users additionally received explanations for the predictions. The performance of the artificial neural network operating without human interaction is also presented (‘autonomous ANN’). 95% confidence intervals are shown in parentheses.
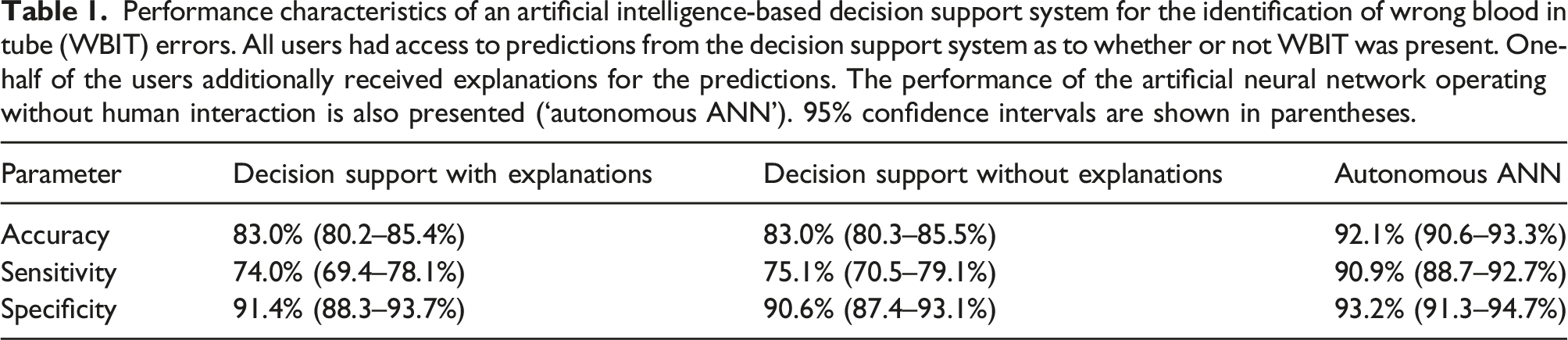
The volunteers who were provided with both ADS predictions and explanations (n = 79) agreed with the ADS system on 83.3% of occasions (95% CI 80.5–85.7%). This was not significantly different to volunteers provided with predictions alone (n = 80), who agreed with the ADS system on 81.8% of occasions (95% CI 78.9–84.3%; p = 0.46). Furthermore, there was no difference between the volunteer groups in terms of accuracy, sensitivity or specificity for WBIT error detection (p-values > 0.78; Table 1).
The performance of the ANN, if it had been permitted to classify results without human interaction, was equivalent to both volunteer groups in terms of specificity (p-values > 0.14), but superior in terms of accuracy and sensitivity (p-values <10-10).
Discussion
The provision of explanations is thought to increase trust among users of AI systems.2,3 For ADS systems based on advanced AI algorithms, however, generating explanations requires the use of a second algorithm. The current study found no evidence to justify the additional complexity of explainability on the basis of improved user trust.
This study only examined one purported benefit of explainability for a single stakeholder group. Regarding the specific issue of trust, it might be that explainability assists stakeholders other than end-users, for example, laboratory managers and independent auditors, trust in ADS systems. Explainability in this context might be highly relevant to the acceptance of laboratory-based ADS systems. Furthermore, end-users might benefit from explainability even if they do not experience a sense of increased trust. Explanations could, for instance, help them to better contextualise and integrate ADS predictions into their assessment of cases. These, and other, potential benefits of explainability were beyond the scope of the study and remain open for future investigation.
More generally, this study raises implicit questions about the nature of trust in technology. As discussed elsewhere, 7 trust is a complex, dynamic process, influenced by the characteristics of the user, the characteristics of the technology, institutional factors and the nature of the task being performed. Ideally, users would be able to appropriately calibrate their levels of trust, and scepticism, based on these factors. Explainability might serve an educational role in helping users determine suitable levels of trust.
ADS, it should also be acknowledged, may not be the optimal way to implement AI models for WBIT error detection. The best performance might be achieved by allowing models to function without human interaction. Since this lacks the ‘safety net’ provided by human review, considerable further investigation would be required to establish that AI systems are suitable to function autonomously.
The use of ADS tools for healthcare applications is a rapidly developing field. Consequently, many aspects of their use have not yet been investigated. Laboratorians should challenge assumptions that have entered the ADS literature and examine, in their own setting, the performance of systems considered for implementation. This approach will avoid unnecessary complexity and identify the best ADS system for local requirements.
Supplemental Material
Supplemental Material - Explainability does not improve biochemistry staff trust in artificial intelligence-based decision support
Supplemental Material for Explainability does not improve biochemistry staff trust in artificial intelligence-based decision support by Christopher-John Lancaster Farrell in Annals of Clinical Biochemistry
Footnotes
Acknowledgements
The author wishes to thank Dr Adam Polkinghorne, NSW Health Pathology, with assistance in preparing this manuscript and the volunteers who assisted with the study.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Ethical approval
Not applicable.
Guarantor
None.
Contributorship
CF conceived the study, developed the machine learning model and web application, analysed the data and wrote the original draft of the article.
Supplemental material
Supplemental Material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.