
Abstract
Background
ChatGPT has substantial potential to revolutionize medical education. We aim to assess how medical students and laypeople evaluate information produced by ChatGPT compared to an evidence-based resource on the diagnosis and management of 5 common surgical conditions.
Methods
A 60-question anonymous online survey was distributed to third- and fourth-year U.S. medical students and laypeople to evaluate articles produced by ChatGPT and an evidence-based source on clarity, relevance, reliability, validity, organization, and comprehensiveness. Participants received 2 blinded articles, 1 from each source, for each surgical condition. Paired-sample t-tests were used to compare ratings between the 2 sources.
Results
Of 56 survey participants, 50.9% (n = 28) were U.S. medical students and 49.1% (n = 27) were from the general population. Medical students reported that ChatGPT articles displayed significantly more clarity (appendicitis: 4.39 vs 3.89, P = .020; diverticulitis: 4.54 vs 3.68, P < .001; SBO 4.43 vs 3.79, P = .003; GI bleed: 4.36 vs 3.93, P = .020) and better organization (diverticulitis: 4.36 vs 3.68, P = .021; SBO: 4.39 vs 3.82, P = .033) than the evidence-based source. However, for all 5 conditions, medical students found evidence-based passages to be more comprehensive than ChatGPT articles (cholecystitis: 4.04 vs 3.36, P = .009; appendicitis: 4.07 vs 3.36, P = .015; diverticulitis: 4.07 vs 3.36, P = .015; small bowel obstruction: 4.11 vs 3.54, P = .030; upper GI bleed: 4.11 vs 3.29, P = .003).
Conclusion
Medical students perceived ChatGPT articles to be clearer and better organized than evidence-based sources on the pathogenesis, diagnosis, and management of 5 common surgical pathologies. However, evidence-based articles were rated as significantly more comprehensive.
Background
The practice of medicine is rapidly changing with advancements in machine learning that allow for new technology, such as artificial intelligence (AI), to improve diagnosis and treatment across medical specialties. 1 Included in this landscape of technologies is ChatGPT, an AI chatbot released by OpenAI in November 2022 that has performed complex tasks such as writing computer programs, summarizing information from multiple sources, and passing the United States Medical Licensing Examination (USMLE) Step 1 exam. 2 Despite being a new technology, it has gained over 100 million users only 2 months after its launch. 3
For the general population, ChatGPT’s ability to understand natural language and generate human-like responses makes it a useful tool for delivering personalized health information. 4 Already, studies have shown that ChatGPT may be useful in providing personalized medical information on mental health and general wellness.4,5 In the medical sector, research on ChatGPT’s potential contributions has been ongoing since its inception, with current literature exploring applications to education, ethics, research, and diagnostics. 6 As for medical education, current studies have found ChatGPT to be useful in enhancing students’ history-taking skills, pharmacotherapy revision, and creating standardized patient simulations.7,8 Furthermore, studies have shown that ChatGPT can be useful in tailoring a customized preclinical curriculum based on a student’s strengths and weaknesses. 9 A recent study also found that nursing students have benefitted from ChatGPT by receiving quick feedback and corrections and simplified explanations, something that medical schools may be able to implement in the future. 10
With the medical profession demanding rigorous cognitive skills, it is crucial for educational tools like ChatGPT to provide reliable and effective support. The literature on the effectiveness of ChatGPT in supporting medical education has significant gaps that require attention. The scarcity of training data available from publicly accessible sources for medical education limits the reliability and efficiency of educational tools like ChatGPT. 6 Therefore, before ChatGPT can be considered a trustworthy tool for medical education, more thorough evaluations of its performance are necessary. With this study, we aim to evaluate literature produced by ChatGPT compared to an evidence-based resource on the diagnosis and management of common surgical pathologies amongst U.S. medical students as well as laypeople to provide more context to the ongoing discussion about the use of AI in medical education as well as to provide evidence-based recommendations for future research and use.
Methods
Study Design
This is a cross-sectional survey composed of 60 evidence-based multiple-choice questions distributed to third- and fourth-year medical school students as well as laypeople to evaluate ChatGPT’s content production and reliability. 11 To do this, respondents were asked to evaluate articles on 5 surgical topics that were either produced by ChatGPT or taken from an evidence-based surgical textbook. The survey was distributed from March through April 2023. To guarantee the confidentiality of participants’ responses, a survey platform with robust data security measures was chosen. Participants were explicitly assured that their responses would be completely anonymous, with no identifying information collected, and all data collected were de-identified to minimize privacy breaches. All participants received a concise explanation of the data security measures in place.
Target Population
The target population included 2 groups: 1 with medical students from U.S.-accredited allopathic and osteopathic medicine programs, and 1 with laypeople with varying backgrounds of medical knowledge. Medical students were required to be in their third- or fourth-year clerkships and have completed at least 1 general surgery rotation to be included in the study. Laypeople were anonymously recruited via electronic email communication.
Survey Composition
The survey consisted of 8 sections, including the acknowledgment and consent, demographics, study description, and instructions, and 1 section for each of the 5 surgical conditions, including acute cholecystitis, appendicitis, diverticulitis, small bowel obstruction, and upper GI hemorrhage. The 5 diagnoses were selected as the most common ICD-10-CM Emergency General Surgery Diagnoses identified in a study conducted by Ingraham et al including 94 903 patients over 2 years. 12 For each condition, participants received 2 blinded articles: 1 from an evidence-based surgical textbook and 1 produced by ChatGPT, each consisting of a 1-page summary covering pathogenesis, clinical features, evaluation, and treatment of the respective diseases (Supplemental File 1). Summaries from ChatGPT were standardized to resemble the Current Diagnosis and Treatment Surgery 14th Edition textbook for content and organization consistency, using a specific input request: “Write an original article about [selected diagnosis], including sections: Pathogenesis, Symptoms and Signs, Laboratory Findings and Imaging, and Treatment and Management.” 13 Respondents were asked to rate each article in regard to its clarity, relevance, reliability, validity, organization, and comprehensiveness on a 5-point Likert scale ranging from “strongly disagree” to “strongly agree.” The selected outcomes were selected based on a study by Liu et al, which evaluated the effectiveness of ChatGPT in a clinical context. 11 These outcomes served as a basis for comparing the quality and reliability of the information provided by each article. A full list of survey questions can be found in eTable 1.
Statistical Analysis
Descriptive statistics, including mean, standard deviation, and frequencies, were reported for the sample. Data was stratified into 2 groups, one including the general population and the other including medical students. Each data set underwent paired-sample t-tests to evaluate differences within the groups, comparing the ChatGPT article data vs evidence-based resources for each survey group using SPSS V29 (Armonk, NY) for analysis. Statistical significance was defined as P < .05. This study was conducted in compliance with ethical standards and was reviewed by our Institutional Review Board and deemed exempt.
Results
Demographics and Population Characteristics
Of the 56 survey respondents, 50.9% (n = 28) were currently enrolled in a U.S. medical school, and 49.1% (n = 27) were members of the general population who were not involved in the health care field (eTable 2). One respondent was not included in the analysis for failure to complete the entire survey. Of all survey respondents, 58.2% (n = 32) reported having some experience or previous background knowledge relating to artificial intelligence systems. Additionally, when asked about the use of peer-reviewed text, 20% (n = 11) reported using peer-reviewed text for educational gain very often, 27.3% (n = 15) reported utilizing it often, 43.6% (n = 24) reported using it sometimes, and only 9.1% (n = 5) reported never using it for educational gain.
Medical Students
Common Surgical Conditions
Cholecystitis
For acute cholecystitis, medical students responded that the evidence-based source was significantly more comprehensive compared to the article written by ChatGPT (4.04 (±1.138) vs 3.36 (±1.254), P = .009) (eTable 3). When evaluating comprehensiveness, only 46.4% of medical students agreed (n = 13) and 14.3% strongly agreed (n = 4) that the ChatGPT article was comprehensive, compared to 35.7% who agreed (n = 10) and 42.9% who strongly agreed (n = 12) that the evidence-based source was comprehensive (eTable 4, Figures 1(A) and 1(B)). There were no significant differences found between the 2 sources on measures of clarity, relevance, reliability, validity, or organization. (A) Significant findings from medical student ratings in response to articles produced by ChatGPT. (B) Significant findings from medical student ratings in response to articles from an evidence-based source.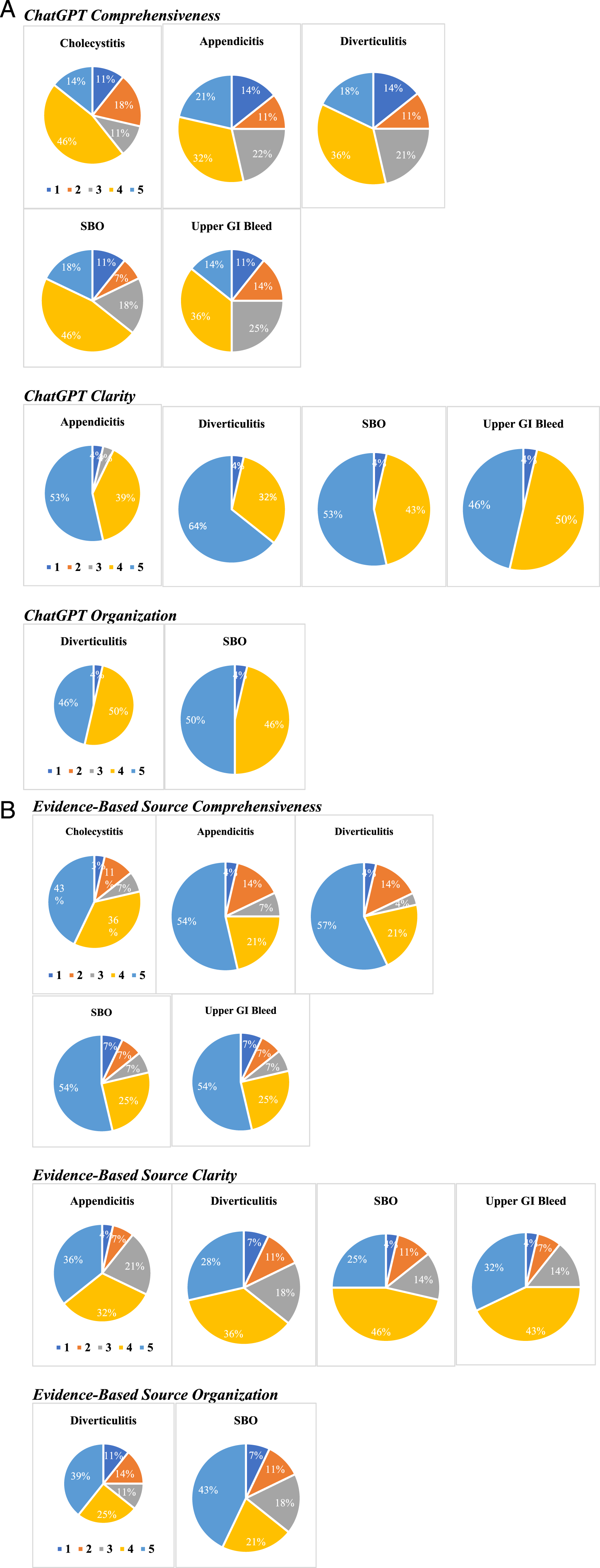
Appendicitis
For acute appendicitis, the medical students indicated that the evidence-based article was significantly more comprehensive in comparison with the article written by ChatGPT (4.07 (±1.245) vs 3.36 (±1.339), P = .015). Only 32.1% of medical students agreed (n = 19) and 21.4% strongly agreed (n = 6) that the ChatGPT article was comprehensive, compared to 21.4% who agreed (n = 6) and 53.6% who strongly agreed (n = 15) that the evidence-based source was comprehensive (eTable 4, Figures 1(A) and 1(B)). However, they indicated that the article written by ChatGPT had more clarity than the evidence-based article (4.39 (±.875) vs 3.89 (±1.100), P = .020) (eTable 3), with 39.3% agreeing (n = 11) and 53.6% strongly agreeing (n = 15) that the ChatGPT had clarity, while only 32.1% agreed (n = 9) and 35.7% strongly agreed (n = 11) about the clarity of the evidence-based source (eTable 4, Figures 1(A) and 1(B)). When evaluating article relevance, reliability, validity, and organization, there were no significant differences between sources.
Diverticulitis
For diverticulitis, medical students responded that the evidence-based article was significantly more comprehensive than the article by ChatGPT (4.14 (±1.239) vs 3.32 (±1.307), P = .004) (eTable 3), with 35.7% of medical students agreeing (n = 10) and 17.9% strongly agreeing (n = 5) that the ChatGPT article was comprehensive, compared to 21.4% who agreed (n = 6) and 57.1% who strongly agreed (n = 16) that the evidence-based source was comprehensive (eTable 4, Figures 1(A) and 1(B)). In contrast however, they found that the article by ChatGPT had significantly more clarity (4.54 (±.838) vs 3.68 (±1.219), P < .001) and organization (4.36 (±.826) vs 3.68 (±1.416), P = .021) than the evidence-based article (eTable 3). For clarity, 32.1% of medical students agreed (n = 9) and 64.3% strongly agreed (n = 18) that the ChatGPT article had clarity, compared to only 35.7% who agreed (n = 10) and 28.6% who strongly agreed (n = 8) that the evidence-based source had clarity (eTable 4, Figures 1(A) and 1(B)). Similarly, 50.0% of medical students agreed (n = 14) and 46.4% strongly agreed (n = 13) that the ChatGPT article was organized, compared to only 25.0% who agreed (n = 7) and 39.3% who strongly agreed (n = 11) that the evidence-based source was organized (eTable 4, Figures 1(A) and 1(B)). There were no significant differences in the assessment of relevance, reliability, and validity when comparing the 2 sources (eTable 3).
Small Bowel Obstruction
For small bowel obstruction, medical students responded that the evidence-based article was significantly more comprehensive than the article by ChatGPT (4.11 (±1.257) vs 3.54 (±1.201), P = .030) (eTable 3), with 25% of medical students agreeing (n = 7) and 53.6% of medical students strongly agreeing (n = 15) that the evidence-based article displayed comprehensiveness (eTable 4, Figures 1(A) and 1(B)). However, they also found that the article by ChatGPT had significantly more clarity (4.43 (±.836)) vs 3.79 (±1.067), P = .003) and organization (4.39 (±.832) vs 3.82 (±1.307), P = .033) than the evidence-based article (eTable 3). For clarity, 42.9% of medical students agreed (n = 12) and 53.6% of medical students strongly agreed (n = 15) that the ChatGPT article displayed clarity (eTable 4, Figures 1(A) and 1(B)). Similarly, 46.4% of medical students agreed (n = 13) and 50% of students strongly agreed (n = 14) that the ChatGPT article was organized (eTable 4, Figures 1(A) and 1(B)). Additionally, there were no significant differences in the assessment of relevance, reliability, and validity when comparing the 2 sources.
Upper Gastrointestinal Hemorrhage
For GI hemorrhage, medical students indicated that the evidence-based article was significantly more comprehensive in comparison with the article written by ChatGPT (4.11 (±1.257) vs 3.29 (±1.213), P = .003) (eTable 3), with 25% of medical students agreeing (n = 7) and 53.6% of student strongly agreeing (n = 15) that the evidence-based article was comprehensive (eTable 4, Figures 1(A) and 1(B)). However, they indicated that the article written by ChatGPT had more clarity than the evidence-based article (4.36 (±.826) vs 3.93 (±1.052), P = .020) (eTable 3), with 50% of medical students agreeing (n = 14) and 46.4% of students strongly agreeing (n = 13) that the ChatGPT article displayed clarity (eTable 4, Figures 1(A) and 1(B)). However, there were no significant differences found between the 2 sources on measures of relevance, reliability, validity, or organization.
General Population
Common Surgical Conditions
Appendicitis
For acute appendicitis, laypeople indicated that the ChatGPT article had significantly more clarity compared to the evidence-based source (4.48 (±.580) vs 3.85 (±.989), P = .007) (eTable 5), with 44.4% agreeing (n = 12) and 51.9% strongly agreeing (n = 14) that the ChatGPT had clarity, while only 37% agreed (n = 10) and 29.6% strongly agreed (n = 8) about the clarity of the evidence-based source (eTable 6). However, there were no significant differences found when comparing the articles on measures of relevance, reliability, validity, organization, or comprehensiveness.
Diverticulitis
For diverticulitis, laypeople indicated that the ChatGPT article had significantly better organization compared to the evidence-based source (4.26 (±.984) vs 3.37 (±1.391), P = .016) (eTable 5), with 29.6% agreeing and 51.9% strongly agreeing that the ChatGPT was organized, whereas only 29.6% agreed and 25.9% strongly agreed about the organization of the evidence-based source (eTable 6). In contrast, there were no significant differences found when comparing the articles on measures of clarity, relevance, reliability, validity, or comprehensiveness.
Other Surgical Pathologies
Amongst acute cholecystitis, small bowel obstruction, and upper GI hemorrhage, there were no significant differences found when comparing the articles on the 5 studied attributes (eTable 5).
Discussion
When comparing articles written by ChatGPT to those from an evidence-based source, at least 92.6% of medical students agreed or strongly agreed that articles written by ChatGPT displayed significantly more clarity across 4 of the studied surgical pathologies. Additionally, 96.4% of medical students agreed or strongly agreed on 2 topics that articles written by ChatGPT displayed significantly more organization than the evidence-based source. However, at least 75% of medical students indicated that passages from the evidence-based source were significantly more comprehensive than the articles produced by ChatGPT amongst all 5 studied pathologies. Amongst laypeople, respondents only indicated that the appendicitis article by ChatGPT had significantly more clarity than the evidence-based source and that the ChatGPT article on diverticulitis had better organization.
Literature on the clarity of AI-generated text vs evidence-based sources is limited. Though ChatGPT has been widely criticized for its inability to think critically and apply clinical reasoning, it has been praised for its ability to produce responses that are clear and easy to understand, with some sources suggesting it may help researchers with language barriers or limited writing skills to communicate their findings effectively. 14 Arif et al noted the potential of ChatGPT to revolutionize scientific writing by serving as an add-on tool for researchers to write constructively, review information, and rephrase sentences. 15 The outcomes of our study suggest that ChatGPT may provide material to medical students in a manner that is clearer on medical conditions than traditional evidence-based text. As such, ChatGPT may be useful when used in conjunction with current technologies and education strategies to help improve clarity for both producing writing and for simplifying materials.
As for organization of ChatGPT responses, other studies have identified that ChatGPT can be a useful tool in helping researchers and writers to organize their material into a structured response. 16 Current evidence suggests that the responses given by ChatGPT are largely based on the clarity of the prompt given. 17 A recent study by the American University of the Middle East assessed the composition of various texts created by ChatGPT and concluded that it was not competent at writing well-structured essays, supporting the idea that the program must be prompted with a highly organized outline in order to produce an organized response. 18 In another study, Kung et al pointed out that the accuracy of the reasoning of ChatGPT will continue to improve through the maturing of language learning models and the fine-tuning of the prompts. 19 Our study provided a prompt to ChatGPT based on the existing organizational structure of a medical textbook, allowing for organized responses, which likely contributed to the high ranking of organization for the ChatGPT. These results suggest that if ChatGPT were to be used, special attention must be placed on providing it with a prompt that gives detailed instructions for response organization.
With regard to the comprehensiveness of ChatGPT, Yeo et al identified that ChatGPT had extensive knowledge of cirrhosis (79.1% correct questionnaire answers) and hepatocellular carcinoma (HCC) (74.0% correct) in a study evaluating the accuracy and reproducibility of ChatGPT regarding knowledge, management, and emotional support for liver cirrhosis and HCC. 20 However, they also identified that only a small proportion of the information provided by ChatGPT on these topics was considered to be comprehensive (47.3% in cirrhosis, 41.1% in HCC). 20 Despite the lack of general knowledge of regional guideline variations, diagnostic power, and disease prevention found in ChatGPT responses, they found that the more succinct information it gave was better in terms of basic knowledge, lifestyle, and treatment. Thus, ChatGPT may have the capacity to serve as an adjunct information tool for patients and physicians in the future. 20 With regard to medical education, a lack of comprehensiveness may be a concern, as it is important for training physicians to acquire a thorough knowledge base of disease diagnosis and management in order to excel on exams and in clinical practice.
ChatGPT has been widely criticized in medical education over concerns that it will be used by students as a shortcut to replace writing.21,22 In a recent study by Gao et al, ChatGPT was used to generate new abstracts based on high-impact journal abstract samples. The artificial abstracts scored high on AI output detector programs, but low on plagiarism detectors. 23 Blinded human reviewers correctly identified 68% of the fabricated abstracts, but incorrectly flagged 14% of real abstracts as fabricated. 23 This suggests that while peer reviewers can identify some fabricated abstracts, better-written articles that undergo subsequent polishing may fool initial screening and inexperienced peer reviewers. Together, these findings support that while ChatGPT may be an important adjunct informational tool for patients and clinicians, more regulation and oversight are needed to ensure that its ethical use for improvement rather than a replacement for writing.
The results of this survey and the use of ChatGPT may have far-reaching implications for the future of medical education. ChatGPT may be a valuable organizational tool in helping students create study plans that efficiently balance their progress and performance throughout clerkship and standardized exams. It also may be a very valuable resource for training students to write scientific literature for publication that is organized and structured. Despite the aforementioned potential uses, concerns about the use of ChatGPT as a replacement for writing are warranted, as students may be able to use it to directly produce material for use instead. Additionally, though some software such as Turnitin are beginning to implement AI checkers to evaluate for plagiarism from an AI chatbot like ChatGPT, these programs may be expensive and not up to date, keeping plagiarism an important and ongoing concern in medical education. 24
There are several limitations to the study’s design. First, response bias may have occurred, with respondents potentially rating clarity or comprehensiveness based solely on the article’s length. Second, the assessment of reliability and validity is constrained because survey respondents were not given a comparison source to accurately evaluate the provided articles’ reliability and validity, instead asking them to rate it based on their own existing knowledge. Moreover, the general population’s limited understanding and background knowledge about the common surgical pathologies used might have impeded their ability to answer survey questions appropriately. Furthermore, students with experience in multiple surgical clerkships or other additional surgical backgrounds may have provided different responses compared to those who completed a single surgical rotation. With regard to response rate, the limited number of responses may impact the reliability and generalizability of these results.
Despite these limitations, this study provides preliminary insights into the performance of ChatGPT in providing educational medical information. As the technology continues to advance, its application in medicine will require further research to ensure its compatibility with scientific literature and effectiveness in producing competent medical professionals. Future research could expand on these findings by examining the ability of ChatGPT to provide information on a broader range of medical conditions and in different formats, such as audio or visual. Additionally, a larger and more diverse sample could be used to assess the generalizability of the current study’s findings to other areas of medicine, such as patient communication, documentation, or management and treatment of disease. Future studies may assess the generalizability of our results by exploring the use of ChatGPT in other professional health care fields. Finally, future research could also improve upon these results by administering a follow-up survey at 6 and 12 months out to evaluate the reliability and consistency of responses from medical students as they advance through their clerkship rotations and curriculum.
Conclusion
Amongst third- and fourth-year U.S. medical students, ChatGPT was perceived to have significantly more clarity and better organization than evidence-based sources regarding the pathogenesis, diagnosis, and management of 5 common surgical pathologies. However, medical students also found information from evidence-based sources to be significantly more comprehensive than that produced by ChatGPT. These results highlight that ChatGPT should be considered as an adjunct tool in medical education. Future research is needed to evaluate the accuracy and comprehensiveness of information it provides, as well as how to incorporate ChatGPT into curricula in a manner that preserves academic integrity.
Supplemental Material
Supplemental Material - The Utilization of ChatGPT in Reshaping Future Medical Education & Learning Perspectives: A Curse or a Blessing?
Supplemental Material for The Utilization of ChatGPT in Reshaping Future Medical Education & Learning Perspectives: A Curse or a Blessing? by Tessa Breeding, Brian Martinez, Heli Patel, Hazem Nasef, Hasan Arif, Don Nakayama, and Adel Elkbuli in The American Surgeon™.
Footnotes
Authors’ Note
All authors read and approved the final manuscript.
Author Contributions
Study design and conception: AE and DN; survey generation and review, data collection, analysis, and interpretations: TB, BM, HP, DN, and AE; manuscript preparation and drafting: TB, BM, HP, HN, HA, and AE; critical revisions of the manuscript: TB, BM, HP, HN, HA, DN, and AE.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.