
Abstract
In most evaluation systems—such as those governing the allocation of prestigious awards—the evaluator’s primary task is to reward the highest quality candidates. However, these systems are imperfect; top performers may not be acknowledged and thus be underrecognized, and low performers may receive unwarranted recognition and thus be overrecognized. An important feature of many evaluation systems is that people alternate between being candidates and being evaluators. How does experiencing misrecognition as a candidate affect how people subsequently evaluate others? We develop novel theory that underrecognition and overrecognition lead people to reproduce those experiences when they are evaluators. Across three studies—a quasi-natural experiment and two preregistered, multistage experiments, we find that underrecognized evaluators are less likely to grant recognition to others—even to the highest-performing candidates. Conversely, overrecognized evaluators are more likely to grant rewards to others—even to the lowest-performing candidates. Whereas underrecognized evaluator behavior is driven by individuals’ perceptions that their experience was unfair, overrecognized evaluator behavior is driven by the informational cues people glean on how to evaluate others. Thus, in evaluation processes where people oscillate between being the evaluated and being the evaluator, we show how and why seemingly innocuous initial inefficiencies are reproduced in subsequent evaluations.
Evaluation processes are central to societal and organizational decisions governing the allocation of resources and rewards to individuals (Blau 1964; Homans 1951; Kim and DellaPosta 2022; Lamont 2012; Sharkey and Kovács 2017). This is particularly evident in professional contexts, where evaluations determine access to work opportunities (Mobasseri 2019; Weisshaar 2017) and who is recognized with prestigious awards (Bowers and Prato 2018; Jensen, Twardawski, and Younes 2021; Merton 1968). The goal of most evaluative processes, or at least their ideal, is to identify and recognize only the highest-quality candidates based on merit 1 —namely, a candidate’s performance and competencies (Alon and Tienda 2007; Castilla 2008; Castilla and Benard 2010; McNamee and Miller 2009; Mijs 2018; Scully 2000).
However, evaluative outcomes often deviate from this meritocratic ideal for a host of reasons, including that it is often difficult to objectively discern candidate performance (Correll, Benard, and Paik 2007; Lynn et al. 2009; Paik et al. 2023). Instead, factors unrelated to candidate quality, such as individuals’ status or demographic attributes, are factored into evaluations, unduly benefitting certain candidates in ostensibly merit-based evaluations (Bowers and Prato 2018; Castilla 2008; Dobbin, Schrage, and Kalev 2015). Additionally, the design and structure of evaluative processes—including the degree to which evaluative criteria are formalized—shape whether these processes can effectively identify and recognize top-performers (Botelho and Abraham 2017; Botelho et al. forthcoming; Correll et al. 2020; Lucas et al. 2021; Rivera and Tilcsik 2019).
There are clear consequences for individuals who experience unmeritocratic evaluative outcomes (i.e., those who do not receive the expected recognition or rewards). This phenomenon is commonly referred to as misrecognition, which encompasses both underrecognition and overrecognition (e.g., Kim and King 2014). In the case of underrecognition, high-quality individuals do not receive the recognition or rewards typical for their level of performance or quality, leading to subsequent disadvantages for that person. A classic example is Merton’s (1968) “41st chair,” which illustrates how scientists who just miss receiving a prestigious award, and thus were nearly identical in quality to the awardees, do not go on to enjoy the same future career benefits (see also Azoulay, Stuart, and Wang 2013). Conversely, overrecognition occurs when lower-quality candidates unexpectedly gain recognition and rewards, resulting in relative advantages over their comparable peers. A consequential and timely example of this phenomenon is college legacy admissions, where applicants benefit from preferential treatment due to familial connections to an institution, an advantage that is decoupled from academic merit (Espenshade and Radford 2009; Hurwitz 2011). Overrecognition similarly emerges in organizational contexts (Bond 2020). These instances of misrecognition highlight challenges inherent in evaluative processes that directly affect the resources a person later receives.
In this article, we shift from examining the implications of misrecognition for individuals experiencing these evaluative outcomes to focusing on the downstream implications of misrecognition for how these individuals subsequently evaluate others. Some evaluative processes involve a distinct set of evaluators, such as third-party evaluations by experts or ranking institutions (Bowers and Prato 2018; Campanario 1998; Ody-Brasier and Sharkey 2019; Sharkey and Kovács 2017; Siler, Lee, and Bero 2015), but people frequently oscillate between being evaluated and acting as the evaluator—across contexts and often even in the same evaluation system. This dynamic is observed, for example, in peer review systems prominent in science (Campanario 1998; Siler et al. 2015), performance evaluations in organizational contexts (Brett and Atwater 2001), and evaluations on digital platforms (Botelho 2024; Klapper, Piezunka, and Dahlander 2024). Identifying whether and how people’s prior experiences with misrecognition affect their subsequent evaluative behavior is crucial for understanding when and why these types of evaluation processes might fail in recognizing top performers.
Drawing on—and bridging—theories related to evaluations, fairness, equity, and role-fulfillment, we propose that misrecognition among evaluators directly affects how they later allocate recognition and rewards to others. Effectively fulfilling the expectations associated with being an evaluator necessitates that evaluators understand how to assess candidates. Generally, people strive to satisfy the expectations associated with their roles (Abelson 1981; Biddle 1986; Cialdini and Goldstein 2004; Goode 1960), and this motive tends to be even stronger for evaluators who serve as gatekeepers (Fini et al. 2022; Lamont 2012). Considering the widely-held belief in fair and merit-based outcomes (Lerner 1980; Mijs 2018), and the fact that most evaluation processes similarly espouse merit-based aims and criteria (Alon and Tienda 2007; Castilla 2008; McNamee and Miller 2009; Scully 2000), it seems plausible that evaluators would simply prioritize objective information about candidate quality in their assessments whenever possible. In other words, evaluators would generally recognize top performers—and not lower performers—irrespective of their own prior experiences having been evaluated.
However, we theorize that evaluators who have experienced misrecognition—or even simply believe they have been misrecognized—may be more apt to subsequently produce unmeritocratic evaluative outcomes. Specifically, experiences of misrecognition will lead evaluators to subsequently reproduce misrecognition in their evaluations of others—such that underrecognized evaluators are less apt to grant recognition and overrecognized evaluators are more apt to grant recognition to others than similarly performing but correctly recognized peers. Individuals who have experienced any type of misrecognition have encountered an evaluative outcome that starkly contradicts the belief that recognition is reserved for top performers, thus challenging the assumed meritocratic nature of evaluation processes. For instance, the experience of underrecognition—namely, strong performers who did not receive due recognition—works in direct opposition to the principle that the highest-quality candidates should be acknowledged. Evaluators who have experienced misrecognition may therefore be influenced by their own dissonant experience, such that they reproduce their experiences of misrecognition in their subsequent evaluations of others.
We further propose that two distinct mechanisms underly the reproduction of misrecognition: both stem from the notion that these experiences inherently violate the general principle of meritocracy. First, experiences of misrecognition are apt to be perceived as inequitable or unfair (Adams 1965; Cook and Hegtvedt 1983). This perception of unfairness should manifest even among overrecognized individuals, but it is apt to be particularly salient among those disadvantaged by the unfairness—namely the underrecognized evaluators. Thus, we propose that the perceived unfairness of misrecognition will be a primary driver of underrecognized evaluators’ subsequent behavior, leading them to underrecognize others.
Second, misrecognition provides distinct information about how evaluation processes work that may shape how individuals later evaluate others. In fact, people often rely not only on general information about how to behave or fulfill their role in a given context, but also on proximate environmental cues and personal experiences (Abelson 1981; Golden-Biddle and Rao 1997). Evaluators’ experience of misrecognition provides additional—likely salient—informational cues about the appropriate evaluative criteria, which may lead them to reproduce their own experiences in their later evaluations of others. While all experiences of misrecognition provide informational cues on how to evaluate others, we reason that these informational cues will be an especially potent driver of overrecognized evaluators’ subsequent behavior, leading them to overrecognize others.
To test our theoretical arguments, we pair a quasi-natural experiment in the field with two preregistered, multistage online survey experiments. In our field study (Study 1), we observe peer evaluations by investment professionals on a private online platform that brings these professionals together to exchange and evaluate investment opportunities. In this setting, the allocation of recognition can be considered as good as random, such that we observe top performing investment professionals who were correctly recognized with an award and equally deserving others who were not given the award (underrecognized). We examine how experiencing underrecognition affects professionals’ subsequent evaluative behavior by comparing the way these professionals evaluate peers on this platform before and then after not receiving the award.
In Studies 2 and 3, we aim to replicate our findings from Study 1 and extend these in two ways: by examining the effects of both underrecognition and overrecognition on how evaluators allocate recognition to others, and by exploring potential mechanisms underlying the effects of misrecognition. For these two latter studies, we recruited participants from an online sample and hired them to complete short jobs. They first completed an aptitude test that established whether they were a high or low performer. We then manipulated experiences of misrecognition by randomly assigning people to receive recognition (or not) and had them subsequently evaluate responses to a similar aptitude test from an ostensible peer.
Our field study provides initial evidence that professionals’ prior experience of underrecognition subsequently changes their behavior as an evaluator. Before the recognition event, investment professionals—both those who are later recognized (i.e., correctly recognized) and those who are not later recognized (i.e., underrecognized)—submitted similar ratings when evaluating peers’ recommendations. However, after the award, underrecognized professionals submitted lower ratings relative to those they had previously submitted and relative to those submitted by correctly recognized professionals. Study 2 replicates this effect of underrecognition, providing causal evidence that underrecognized evaluators were less likely to grant recognition to others—even those they indicated were the highest-performing candidates. Study 2 also extends our findings to causally identify the effect of overrecognition: we show that overrecognized evaluators were more than twice as likely as their correctly recognized counterparts to grant recognition to others—even to those they indicated as the poorest performers.
Studies 2 and 3 also test our theorized mechanisms. Consistent with our predictions, our results reveal two distinct mechanisms underlying the effects of misrecognition. For underrecognized evaluators, we find that perceptions they themselves were evaluated unfairly drive them to grant recognition to others at a lower rate. Although overrecognized evaluators perceived the way they were evaluated as similarly unfair, this is not a driver of their subsequent evaluative behavior. Rather, overrecognized evaluators’ subsequent behavior is driven by the informational cues they glean about how they ought to evaluate others from their own experiences having been evaluated. We do not find the same informational cues have a substantive influence on how underrecognized evaluators subsequently grant recognition to others.
This article thus advances our understanding of the effects of recognition and meritocracy in evaluation processes by bridging sociological and related research on evaluations and theories of equity, procedural fairness, and role fulfillment. Our results show how experiencing unmeritocratic outcomes (i.e., instances of misrecognition) are often reproduced in evaluation systems where people move between being candidates and being evaluators.
The Effects of Misrecognition on Subsequent Evaluations
Evaluators are at the heart of every evaluation process, serving as gatekeepers who control access to vital resources and opportunities (Bian et al. 2022; Fini et al. 2022; Lamont 2012; Rivera 2015; Smith 2005); therefore, the extent to which they adhere to meritocratic ideals dictates the efficacy of these processes. Indeed, decades of research confirms that people believe the allocation of resources and rewards is—and ought to be—fair and reflective of meritocratic processes (Jost and van der Toorn 2012; Lerner 1980), and these convictions have only strengthened over time (Mijs 2018). It is thus plausible that these beliefs dictate how evaluators engage in their assessments of others, such that they grant recognition only to those who are truly deserving based on their performance or merit. However, existing research documents notable variation in people’s adherence to these principles across professional contexts—even in cases where evaluators had concrete, unambiguous, and objective information about a candidate’s performance or quality on which to base their assessments (Botelho and Abraham 2017; Bowers and Prato 2018; Dobbin et al. 2015; Foschi 2000; Mobasseri 2019; Pedulla 2016).
Consistency in applying meritocratic principles across evaluators is requisite for any evaluative process to successfully identify—and reserve rewards for—top candidates. Understanding the factors that lead to variations in evaluative behavior is therefore critical, and existing research points to two distinct factors associated with such variation. The first factor is the design and structure of evaluation processes (Botelho 2024; Botelho and Abraham 2017; Botelho et al. forthcoming; Correll et al. 2020; Rivera and Tilcsik 2019). For example, evaluative behavior varies more significantly across evaluators, often leading to a higher propensity for unmeritocratic outcomes, when there are constraints on evaluators’ ability to focus on each candidate (e.g., time/cognitive constraints) (Botelho and Abraham 2017; Bowers and Prato 2018; Lynn et al. 2009; Simcoe and Waguespack 2010). Macro properties of evaluation processes may also have widespread effects on observed inequality, such as whether evaluative outcomes result in fine-grained distinctions between candidates (Accominotti, Lynn, and Sauder 2022). Similarly, less formalized processes, which offer greater discretion to evaluators, also promote inconsistencies in evaluative outcomes across evaluators (Anderson and Tomaskovic-Devey 1995; Dobbin 2009; Elvira and Graham 2002).
The second factor relates to characteristics of the evaluator. Research in this tradition has mostly focused on how certain demographic characteristics of evaluators (e.g., race or gender) are associated with variations in how they make merit-based resource allocation decisions. For example, members of marginalized groups, including women and racial minorities, often demonstrate a higher propensity to base evaluations on objective quality rather than on candidate characteristics unrelated to quality (e.g., gender, race) and thus tend to be more meritocratic (Abraham 2017; Cohen, Broschak, and Haveman 1998; Cohen and Huffman 2007; Yang and Aldrich 2014).
Because individuals frequently serve as both candidates and evaluators—across contexts but often even in the same evaluation system—we propose a third factor that is apt to drive variation in evaluative behavior: people’s prior experiences with having been evaluated. Recent sociological research generally supports this notion, indicating that prior positive (Botelho and Gertsberg 2021) and prior negative (Castilla and Ranganathan 2020) evaluations can lead individuals to adopt fairer and less biased approaches in their subsequent evaluations. Building on this foundation, we propose it is not simply the valence of how an evaluator was previously evaluated that shapes their subsequent evaluative behavior. Rather, experiences of misrecognition—whereby evaluators have previously received either less or more recognition than expected for their level of performance—will also significantly affect how people subsequently evaluate others. Instances of misrecognition directly contradict the central tenet of meritocratic norms that underlie most evaluative processes: that evaluation processes are centered on identifying and recognizing only top-performing candidates as determined by their accomplishments or contributions (Castilla 2008; Castilla and Benard 2010; McNamee and Miller 2009; Scully 2000). Therefore, misrecognized evaluators may be more inclined to deviate from meritocratic principles in their own evaluative roles, either consciously or subconsciously, such that they misrecognize others.
Importantly, how misrecognition affects subsequent evaluative behavior will depend on the specific type of misrecognition—namely, whether an evaluator has experienced under- or overrecognition. Unlike individuals who have received the recognition expected, we argue that evaluators who have experienced misrecognition—or even those who simply perceive they were misrecognized—will reproduce their experiences of misrecognition in how they subsequently grant recognition to others. Underrecognized evaluators are top performers who did not receive the recognition or rewards typical for their level of performance; thus, they will reproduce underrecognition by granting recognition to others at a lower rate. Overrecognized evaluators are lower performers who were nonetheless recognized and will thus grant recognition more freely, such that they overrecognize others.
Hypothesis 1a: Underrecognized evaluators will be less likely to grant recognition to others—even those they deem to be top performers—than will evaluators who performed similarly but were correctly recognized.
Hypothesis 2a: Overrecognized evaluators will be more likely to grant recognition to others—even those they deem to be poor performers—than will evaluators who performed similarly but were correctly recognized.
Drivers of the Reproduction of Misrecognition: (Un)Fairness and Informational Cues
We draw on broader theories related to equity, procedural fairness, and role-fulfillment to highlight the two main theoretical reasons why evaluators who have experienced misrecognition will reproduce such patterns in their subsequent assessments of others. Both reasons stem from the notion that each type of experience with misrecognition violates the general expectation that recognition is granted only to top performers: these experiences are apt to invoke perceptions of unfairness and provide distinct informational cues not available to those who have been correctly recognized. Misrecognition may thus affect how evaluators later grant recognition to others either because of the perceived (or inherent) unfairness they experienced, or by providing them with informational cues about how to evaluate others. In the following sections, we explore both underlying mechanisms to consider when each is most apt to drive the reproduction of misrecognition.
Perceptions of (Un)Fairness among Misrecognized Evaluators and Their Subsequent Evaluations of Others
Individuals who did not receive the recognition or reward consistent with their performance are apt to perceive these experiences as unfair, which may drive their subsequent assessments of others. Research in equity theory first brought attention to situations where rewards and contributions do not align (Adams 1965). Specifically, in cases where social comparison is possible (e.g., in workplaces), people tend to compare whether their outcomes (e.g., pay, promotion) are similar to those of co-workers who are analogous to them in terms of their contributions or merit (e.g., skills, performance) to determine whether these outcomes are equitable (Carrell and Dittrich 1978; Cook and Hegtvedt 1983). Moreover, detecting inequity can change how people engage at work. For example, underrecognized workers who did not receive a top performance rating are more likely to exit their firm than are similar peers who received a top rating (Bond 2024).
Experiences of misrecognition are likely to elicit perceptions of inequity, or unfairness, even in the absence of opportunities for direct social comparison. In fact, such violations of expectations are a key predictor of whether people interpret outcomes and processes as unjust (Cropanzano and Ambrose 2001), with people constantly making judgments about whether outcomes are fair or not (Lind 2001). For example, perceived unfairness is the most common cause of interpersonal sabotage and deviance in the workplace (Ambrose, Seabright, and Schminke 2002). Because experiences of misrecognition do not align with the meritocratic expectations that rewards ought to be granted only to the top-performing or best candidates, these situations are likely to be viewed as unfair. Specifically, misrecognized individuals are apt to perceive their outcome as procedurally unfair; that is, they are likely to see the decision-making process as unfair (Konovsky 2000; Lind and Tyler 1988).
A core focus of the current research is understanding how and under what conditions experiences of misrecognition—and by extension unfair outcomes—influence the way evaluators subsequently allocate recognition and rewards to others. Experiencing unfairness often shapes individuals’ behavior, typically eliciting negative (or undesirable) actions (Ambrose et al. 2002) aimed at rectifying their experiences of inequity (Adams 1965; Gaucher et al. 2010; Lerner 1980). For example, a large body of research has tested equity theory in the lab and the field, examining how job satisfaction and subsequent work behaviors are influenced by having respondents recall how their compensation compares to their peers (Sweeney 1990) or by experimentally manipulating inequity in resources (Carrell and Dittrich 1978; Shaw and Olson 2012). This research consistently reveals that people feel dissatisfaction or discomfort with inequity and try to reduce it by adjusting their contributions to align with the rewards and recognition they have received. In a study of professional baseball and basketball players, for instance, Harder (1992) found that underrecognized athletes (i.e., those who were under-rewarded for their performances) were less cooperative and more selfish. This point is supported by research that demonstrates how perceived unfairness triggers loss aversion concerns, such that people are intrinsically motivated to avoid such situations (Liberman, Idson, and Higgins 2005; Zhou and Wu 2011).
Although unfairness is often associated with experiences that are disadvantageous (i.e., instances of negative inequity such as underrecognition), advantageous outcomes where the reward exceeds what is warranted by merit (i.e., overrecognition) also constitute a form of unfairness, termed “positive inequity” (Adams 1965; Brockner 1985; Cook and Hegtvedt 1983; Rivera and Tedeschi 1976; Scheer, Kumar, and Steenkamp 2003). One key distinction is that people generally welcome favorable outcomes, irrespective of how they get them (van den Bos et al. 1998). Also, unlike negative inequity, positive inequity typically does not evoke distress or displeasure (Rivera and Tedeschi 1976; Weiss, Suckow, and Cropanzano 1999), nor does it lead to a sense of perceived loss (Kidd and Utne 1978; Walster and Piliavin 1972). In fact, many of the undesirable behaviors linked to unfairness are based on studies focused on instances of negative inequity (e.g., Cohen-Charash and Spector 2001; Gaucher et al. 2010; Harder 1992; Yang et al. 2014).
By contrast, positive inequity tends to elicit feelings of guilt (Baumeister, Stillwell, and Heatherton 1994). Consistent with this finding, and contrary to underpaid employees who tend to reduce their productivity, overpaid workers often increase their output, although the evidence for this positive effect is mixed (Adams and Rosenbaum 1962; Lawler 1968; for an example of a null effect, see Carrell and Dittrich 1978). In other words, positive inequity seems to lead to a greater investment in the inequality producing system, whereas negative inequity tends to have the opposite effect.
Evaluators who have experienced either under- or overrecognition are apt to perceive their experiences as less fair than those who have been correctly recognized, but the propensity for perceived unfairness to drive evaluators’ subsequent behavior is likely asymmetrical. Perceived unfairness is more likely to drive underrecognized evaluator behavior, because these individuals experienced an instance of negative inequity. Research consistently shows that the adverse effects of negative inequity are stronger than any positive effects of positive inequity (Austin and Walster 1974; Brockner et al. 1994). This research thus suggests that perceived unfairness will be an especially strong driver of evaluator behavior among people who have previously experienced underrecognition, but not for those who have been overrecognized.
Hypothesis 1b: The lower likelihood for underrecognized evaluators to grant recognition will be driven by perceptions of unfairness.
Informational Cues Available to Misrecognized Evaluators and Subsequent Evaluations
Perceived (un)fairness may not directly drive overrecognized evaluator behavior, but the positive inequity associated with overrecognition is apt to make these evaluators especially attentive to the prevailing evaluative criteria. Evaluators are responsible for making judgments about candidates to determine who ought to be selected and rewarded (Rivera 2015; Smith 2005). Understanding how to evaluate candidates—most importantly, the criteria defining what is valued—is thus requisite for effectively fulfilling one’s role as an evaluator. More generally, people tend to be motivated to fulfill the responsibilities and expectations associated with the roles and positions they occupy (Abelson 1981; Biddle 1986; Goode 1960), and this is especially true for evaluators who tend to value the importance of their gatekeeper position (Bourdieu 1993; Lamont 2012). Given that positive inequity leads people to make even greater investments in the systems that have advantaged them, it stands to reason that overrecognized evaluators will be particularly focused on available cues about the appropriate way to evaluate others.
Evaluators may draw inferences about how to assess candidates from multiple sources. The first of these is rooted in overarching meritocratic beliefs suggesting that evaluations are intended to identify and reward only the best performers. Although offering a reasonable and general guidepost, knowledge of meritocratic norms alone does not typically provide sufficient insight for how an evaluator should assess candidates (Alon and Tienda 2007). For instance, an evaluator needs to know what constitutes a candidate being the “best” or a “top performer” in a particular context. A more relevant and precise source of information thus comes from the criteria defined by the specific evaluation process. In more structured or formalized processes, these criteria are clearly defined and offer unambiguous rules and procedures governing how evaluators are expected to judge candidates (Elvira and Graham 2002; Reskin 2000; Sutton et al. 1994).
In many cases, however, these criteria include ambiguous elements, or they give evaluators latitude in determining how to assess others (Lamont 2012; Rahman 2021; Veen, Barratt, and Goods 2020). Moreover, evaluative criteria are sometimes intentionally designed to be ambiguous. In many professional contexts, for example, less formalized criteria afford managers greater discretion when doling out benefits (Gallus and Frey 2016). Evaluators are thus often left to determine on their own how to effectively fulfill their role. Hence, when criteria are left ambiguous or less formalized, there is greater variance in how evaluators assess candidates (Castilla 2008; Uhlmann and Cohen 2005).
Prior experiences being evaluated can serve as an additional guide for evaluators to determine how to effectively judge candidates. People often rely on their own relevant experiences to understand how they should behave in a given context (Biddle 1986; Golden-Biddle and Rao 1997). This implies that evaluators may rely on both the overarching evaluative criteria—which typically aligns with meritocratic principles that the highest-quality candidates should be recognized—and their prior experiences of being evaluated to inform how to effectively evaluate others. For example, recent qualitative research on how managers understand and define merit suggests people draw on their prior experiences having been evaluated throughout their careers and across organizations in order to determine how to effectively evaluate their current employees (Castilla and Ranganathan 2020). The most significant insights are likely drawn from experiences within the same system, given that the specific context and norms of this environment are most informative. Consistent with this line of reasoning, the way managers and executives enact their roles is heavily influenced by their experiences and observations within the specific organizational setting (Golden-Biddle and Rao 1997).
Evaluators’ prior experiences with being evaluated not only offer them information in cases where evaluation criteria are ambiguous, but they also provide misrecognized evaluators novel insights about how to judge candidates even when criteria are clear. Experiences of misrecognition are apt to violate the stated, merit-based evaluative criteria. When a person’s prior evaluative outcomes were correct, such that they received the warranted recognition given their performance, their experience reaffirms the expectation that recognition should be awarded only to the strongest performers. When top performers are duly recognized, for instance, it validates their a priori meritocratic assumptions. Conversely, experiences of misrecognition directly violate expectations that merit governs evaluative outcomes. In the case of underrecognition, a strong performer who does not receive recognition may question the validity of their prior assumptions about who ought to be recognized. Similarly, individuals who are overrecognized, who receive recognition despite their lower performance, might also develop a skewed perception of the appropriate way to assess others.
All misrecognized evaluators gain access to distinct informational cues stemming from their experience having been evaluated, but we reason that overrecognized evaluators will be especially attentive and reactive to these cues. As poorer performers who were still recognized, overrecognized evaluators are apt to infer that recognition is not exclusively reserved for top performers. More generally, they may infer that other factors are at play in determining who receives recognition. Because overrecognized evaluators have themselves been advantaged, they may be especially inclined to seek additional information to guide how they should recognize others. This point is consistent with classic research in equity theory that shows a person will increase their inputs (e.g., attention, effort) to account for their overrecognition (Adams and Rosenbaum 1962). Thus, attending to these informational cues on how to evaluate others would lead overrecognized evaluators to subsequently grant recognition to others more freely. Conversely, providing overrecognized evaluators with informational cues in the form of formalized criteria should curb their likelihood to overrecognize others.
Hypothesis 2b: The higher likelihood for overrecognized evaluators to grant recognition will be driven by the informational cues available.
Empirical Approach
Despite the prevalence of experiences of misrecognition, collecting appropriate observational data to test our theory about the downstream effects of misrecognition on subsequent evaluative behavior is challenging. Data on whether evaluators have previously experienced misrecognition and their subsequent evaluations of other candidates are not readily available. Furthermore, causally isolating the average effect of an evaluator’s experience of misrecognition on their subsequent assessments of others requires that evaluator misrecognition occurs in a random fashion and that subsequent and standardized evaluations of similar candidates are captured. To address these challenges and maintain high levels of external and internal validity, we leverage data from three studies: a quasi-natural experiment of investment professionals in the field and two comprehensive, preregistered multistage survey experiments. 2
Study 1
For an initial test of our theory, we used field data from the Real Investors Club (RIC, a pseudonym), a private digital platform for investment professionals to share investment recommendations with each other (see Botelho and Abraham 2017; for more detail on the setting, see Botelho 2024). To gain access to RIC, one must show proof of current employment as an investment professional at a buy-side investment management firm (e.g., hedge fund, mutual fund). Buy-side investment professionals are responsible for researching market opportunities (e.g., stocks) with the aim of investing significant amounts of capital on behalf of their employers and clients. Professionals on RIC submit investment recommendations to buy or short sell stocks and provide a detailed justification to support their recommendation. These justifications are comprehensive and resemble the analyses these professionals typically conduct within their firms when making investment decisions.
Once a recommendation is submitted, it is accessible to current and future members of the platform and can be viewed and evaluated by other platform members. Professionals initially view a summary of the recommendations submitted by peers—stock name, recommended position (i.e., buy or sell), performance to date, as well as recommender’s name and employment affiliation. Once a professional clicks on a recommendation, they gain access to the details supporting that recommendation; they can then evaluate the quality of these recommendations using a five-star (integer) rating. Each professional can thus move between being the candidate (i.e., having their own recommendations evaluated) and being the evaluator (i.e., rating the quality of recommendations submitted by others).
Quasi-Natural Experiment and Sample
Data for this study are from 2013 when a quasi-natural experiment related to misrecognition occurred on IC, allowing us to examine the relationship between underrecognition and subsequent evaluator behavior in a field setting. That year, the platform introduced a form of recognition via weekly emails to all users highlighting the professional and the recommendation that received the highest quality rating from other professionals in the prior week. Because this recognition was granted solely based on peer ratings of quality, the process for allocating recognition in this context was meritocratic, and instances of misrecognition were known to those who were underrecognized. Additionally, this recognition serves as a performance-based status designation common in professional contexts (Bowers and Prato 2018; Merton 1968). These professionals valued the platform as an opportunity to elicit acknowledgment from their peers. Our analytic sample includes 952 ratings submitted by 54 unique evaluators within a 180-day window before and after the recognition event (i.e., award email).
We observed 27 instances in which two recommendations had a perfect five-star rating and were thus equally deserving of the award. In these cases, the platform employee leading the award campaign simply chose which of the two recommendations—and thus which of the two professionals—would be recognized that week. This choice was “as good as random” because the employee did not have any explicit criteria for selecting between the two equally eligible professionals. Thus, this quasi-natural experiment provides an opportunity to test an essential element of our theory: the effect of a person experiencing an instance of underrecognition on their subsequent evaluations of others. 3
We first provide evidence in support of our assumption that misrecognition occurred in a good as random way by comparing whether professionals who were correctly recognized were similar to professionals who were underrecognized. Using five observable characteristics (see Table A1 in the online supplement), we find no statistical differences. However, given the small sample size, it is also important to consider substantive differences. We see no substantive difference between correctly recognized and underrecognized professionals in any measure besides elite education. We find that correctly recognized professionals are substantively more likely to have attended a highly ranked school (undergraduate or graduate) (0.59) relative to underrecognized professionals (0.44). Overall, this comparison supports the notion that professionals who received recognition were similar to those who did not.
Underrecognized professionals—as well as their counterparts who received recognition (i.e., were correctly recognized)—could provide ratings of recommendations submitted by others both before and after the award was allocated. To provide an initial test of our theory related to the effect of underrecognition, we examine whether underrecognized evaluators change their rating behavior following their experience of misrecognition. Specifically, we compare the average ratings provided before the award event (i.e., in the period before misrecognition occurred) to the average ratings after the award event (i.e., in the period after misrecognition occurred). By examining whether changes in rating behavior across these two periods differed for underrecognized versus correctly recognized professionals, we can establish whether underrecognition distinctly affects evaluative behavior.
Measures
The main outcome of interest is rating, which takes an integer value between 1 and 5, reflecting the rating a professional gave to recommendations submitted by others. Our main independent variable of interest captures whether the focal individual experienced misrecognition. Professionals are classified as either correctly recognized, if they were chosen to receive recognition, or underrecognized, if they were not chosen to receive recognition in a given week where there were two top-performing professionals (i.e., a tie).
Results
Professionals submitted a total of 351 ratings in the 180 days before the focal recognition (email) event and 601 ratings in the 180 days after the recognition event, representing a 70 percent increase in rating activity in the weeks following recognition events. This increase is consistent with recent research on how status affects an individual’s subsequent productivity. For example, Bol, de Vaan, and van de Rijt (2018) found that individuals who won early career grants were more likely to win midcareer grants and to secure more research funding across their careers. Importantly, this effect was driven by the fact that winners often participated more than non-winners. Given this work, we examined pre- and post-recognition rating behavior among individuals who were later correctly recognized (i.e., winners) and underrecognized (i.e., non-winners). In the pre-recognition period, we found no difference in rating behavior: correctly recognized professionals submitted 172 (49 percent) and underrecognized professionals submitted 179 (51 percent) of the 351 ratings. Consistent with this prior research, however, the observed increase in rating behavior in the post-recognition period was driven by correctly recognized professionals who submitted 380 of the 601 ratings (63 percent).
Next, we tested our main theoretical argument and Hypothesis 1a—that underrecognized evaluators will be less likely to recognize others. Specifically, we examined whether professionals who narrowly missed out on being recognized went on to give lower ratings to others by comparing the mean rating submitted by these evaluators before and after the recognition events (Figure 1, Panel A). Indeed, we see a substantial difference in the ratings submitted by underrecognized professionals across the pre- and post-recognition periods. In the pre-period, when these professionals had not yet been underrecognized, they rated others’ recommendations as 2.88 stars, on average. Importantly, the ratings provided in the pre-period did not significantly differ between individuals later underrecognized and those later correctly recognized: 2.88 versus 3.05 stars, respectively—a difference of 5.6 percent (p = 0.255). As evidence of the effect of misrecognition, underrecognized professionals significantly decreased their ratings in the post-recognition period, giving ratings 17.4 percent lower than they did in the pre-recognition period (2.38 versus 2.88; p < 0.001).
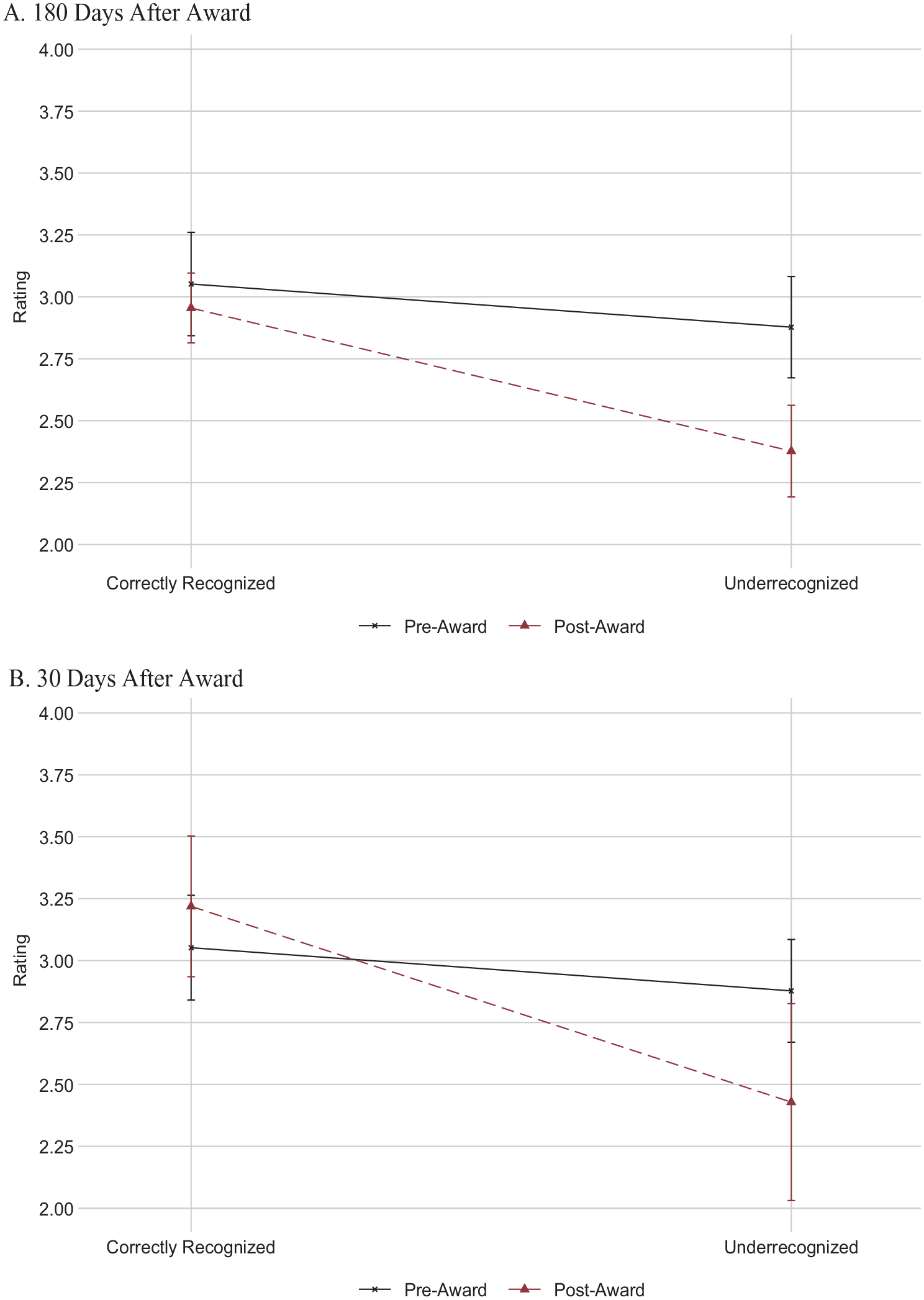
Comparing Average Rating between Correctly Recognized and Underrecognized (Study 1)
By contrast, correctly recognized professionals submitted similar ratings before and after being recognized. The average rating submitted by these professionals was 3.05 stars in the pre-recognition period and 2.96 stars in the post-recognition period, a difference of only 2.95 percent (p = 0.439). Ratings from underrecognized professionals represent the lowest ratings observed in this sample: nearly 20 percent lower than those from correctly recognized professionals in the post-recognition period (2.38 versus 2.96; p < 0.001). These findings are consistent when we restrict the post-recognition period to ratings submitted within 30 days following award events (Figure 1, Panel B).
This quasi-natural experiment provides field-based support for Hypothesis 1a: underrecognition affects how professionals subsequently dole out recognition to peers, such that they provide significantly lower ratings of quality. These data, however, do not allow us to directly examine the effect of overrecognition and offer only limited insight into potential mechanisms; we thus turn to our online survey experiments.
Study 2
Given the constraints on identification and sample in our field data, our goal was to maximize the internal validity of our empirical approach through controlled experimental protocols and clear, effective manipulations to examine our hypotheses more fully (Campbell and Stanley 1963; Kenny 2019; Thye 2000). As such, Study 2 uses a comprehensive, preregistered two-stage survey experiment on an online platform to replicate the effect of underrecognition found in the field (Study 1, Hypothesis 1a), extend these findings to include cases of overrecognition (Hypothesis 2a), and more directly examine the mechanism underlying the observed effect of underrecognition (Hypothesis 1b).
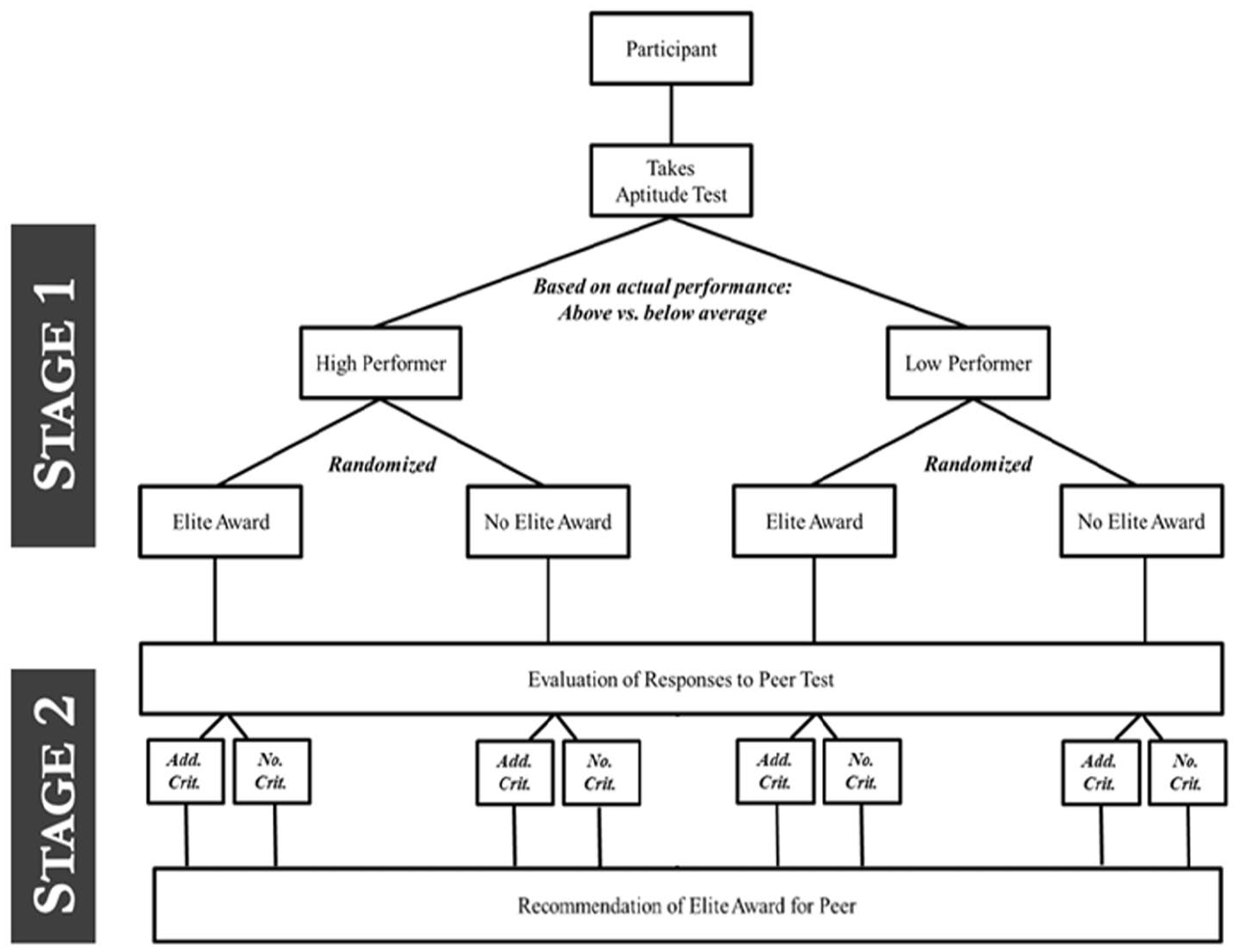
Materials
Our experimental design involved two sequential stages (Figure 2). In the first stage, participants completed an aptitude test for which they were evaluated and then were told whether they received our “Elite Award,” which we describe in detail below. In the second stage, participants shifted to being evaluators of another person’s responses to a similar aptitude test. Our goal was to compile a set of 10 questions for the aptitude tests that were likely to convince participants their responses provide a proxy for their general ability. Consistent with prior research that uses composite cognitive-assessment measures (Chapman et al. 2018; Dworak et al. 2021), we constructed both instruments using questions drawn from standardized aptitude-testing sources like the International Cognitive Ability Resource (ICAR-16) and MENSA IQ challenge (Vining 1984).
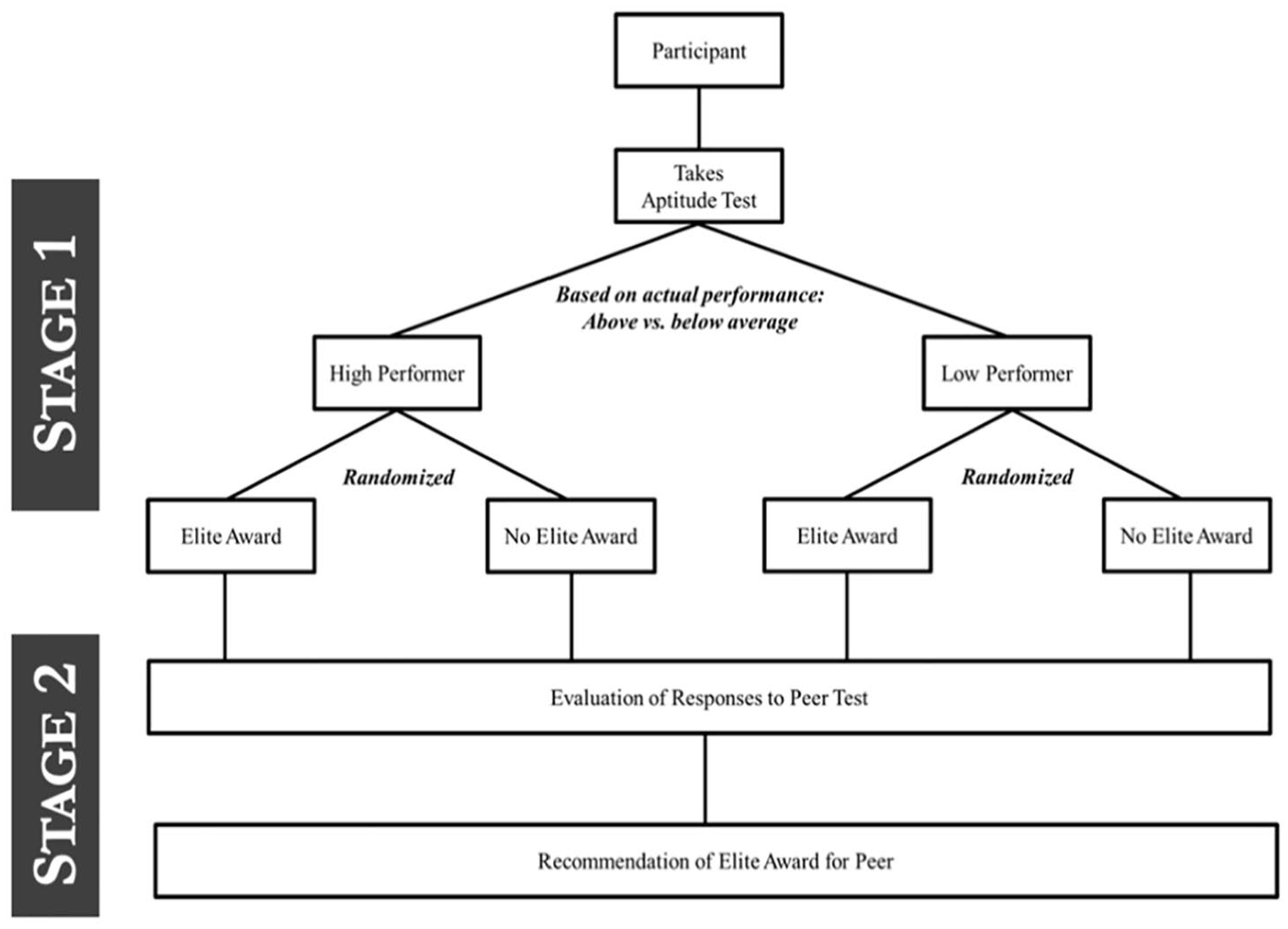
Experimental Design (Study 2)
We constructed two comparable versions of the aptitude test—one to be completed by participants and another to serve as peer responses for them to evaluate—by pretesting items for difficulty within question type and then matching them across the two versions. We grouped our initial sample of 39 questions into four types: “simple,” “challenge,” “logic,” and “pattern.” To find pairs of questions of comparable difficulty for the participant test and the peer test, we recruited 200 participants from Amazon’s Mechanical Turk (MTurk), randomly presented them 10 of the 39 questions in our set, and asked them to rate the difficulty of each question on a scale of 1 to 10. We then used the average perceived difficulty of each question to identify matches within each question type, which produced a total of 10 pairs of equally difficult questions to be split between the two tests. For more detail on the process of constructing the aptitude tests, examples of each type of question, and results of this pretest, see Part B of the online supplement.
Participants
We conducted our online survey experiment using CloudResearch (Litman, Robinson, and Abberbock 2017). CloudResearch is an online labor-market platform where gig workers (MTurkers) can complete tasks and jobs, known as Human Intelligence Tasks (HITs), posted by individuals and organizations. Our research team, serving as the employer, recruited workers to perform our task (i.e., to complete an aptitude test and evaluate a peer’s responses to a comparable test) and described this task as helping the research team develop an aptitude test. MTurk has been widely used in academic research, including by sociologists (Hahl, Kim, and Zuckerman Sivan 2018; Kuwabara 2015; Leung and Koppman 2018; Miles, Charron-Chénier, and Schleifer 2019; Paxton, Velasco, and Ressler 2020; Tilcsik 2021), because it provides access to participants who exhibit the classic heuristics and biases we tend to study and who are at least as attentive to directions as participants from other samples. Using MTurk is also an economical way of running large, complex experiments (Paolacci, Chandler, and Ipeirotis 2010).
Per our preregistration and a priori power analysis, we recruited 1,446 U.S.-based adult participants. We received full data (i.e., all measures of interest) from 1,560 participants due to CloudResearch’s tendency to oversample and high bounce rate (Litman et al. 2017). Completion of the task was estimated to take 15 minutes; participants were paid $2.00, with a guaranteed $0.50 bonus, which works out to an estimated hourly wage of $10 per hour. We embedded two attention checks in the experiment (see Figure C2 in the online supplement), one related to our explanation of the Elite Award and the other asked whether the participant had received the Elite Award. Per our preregistration, participants who answered either question incorrectly—312 participants (20 percent) in the first case and 45 (3 percent) in the second—were dropped from our analyses. Our final analytic sample contained data from 1,202 participants.
Procedures
Figure 2 provides an overview of the two-stage experimental design. The first stage called for participants to complete a 10-question aptitude test, and the second stage asked them to evaluate a peer’s responses to a different aptitude test with 10 similar questions.
Participants were then informed that their responses to the questions on the first-stage aptitude test would be evaluated by the study team. They were also told they would be considered for the Elite Award, our high-status distinction. Our goals in describing the Elite Award were twofold: (1) to make the award desirable, so as to increase the value participants would attribute to it (Besley and Ghatak 2005), and (2) to reveal that the award—like any prestigious distinction or valued recognition, including the recognition observed in Study 1—was in “limited supply” and intended to reward only “high performers” (Podolny 1993). We designed the award to create a clear status distinction between those who were given the award and those who were not, following recent research showing that the clarity of status hierarchies can influence material outcomes (Accominotti et al. 2022). To increase the desirability of the award, participants were told that those given the award would receive an Elite Award Certificate and early access to additional work (i.e., a future HIT; see Figure C1 in the online supplement). It is important to note that participants only learned information about the award and its subsequent benefits after agreeing to participate. After completing their test, participants were informed that their performance was either below or above the average of others and were told whether they had received the Elite Award. See Table C1 in the online supplement for details on the experimental language used across conditions. 4
To increase the ecological validity of the study and to provide misrecognized participants a realistic experience, participants were given accurate information about their performance on their aptitude test—the first stage of the experiment. We assumed participants would have a sense of how they performed, and thus we wanted them to receive an accurate measure of their relative performance. To achieve this, we automatically scored each participant’s responses and designated those who answered seven or more questions correctly to be high performers; all others were designated low performers. This categorization cutoff was based on average participant performance during pilot testing and then an examination of the first set of responses in the experiment (in the online supplement, see Table B2, Panel A, for the average percentage of correct responses by question, and Panel B for the distribution of the total number of questions answered correctly). Participants were simply told whether they had answered more (high performer) or fewer (low performer) questions correctly than average.
Once a participant’s test was scored, we randomly assigned participants to either receive or not receive the Elite Award. Participants were assigned to one of four conditions: (1) high performers who received the Elite Award (correctly recognized high performer), (2) high performers who did not receive the Elite Award (underrecognized), (3) low performers who did not receive the Elite Award (correctly recognized low performer), and (4) low performers who received the Elite Award (overrecognized).
During the second stage of the task, participants were told they would evaluate a peer test submitted by someone else; these responses were devised by the researchers and held constant across conditions. All participants were presented with an identical peer test where five questions were answered correctly and five were answered incorrectly. Participants were then tasked with evaluating whether each of the 10 responses was correct (for a sample of the peer responses presented to participants, see Figure B5 in the online supplement). Our focus is on comparing the propensity for evaluators to grant the Elite Award based on their perception of how the peer performed. Participants were neither aware of how many responses were correct or incorrect nor informed about the number of correct responses necessary to be deemed a high performer. After evaluating each of the peer’s responses, participants were asked about their overall perception of the peer’s performance and whether they recommended the peer be recognized with the Elite Award.
Measures of Interest
To capture evaluators’ overall perception of how their peer performed, we asked: “Overall, how well do you think this participant performed relative to others who have taken this test?” Perceived peer performance is based on responses on a 1 to 7 scale from (1) very poorly to (7) exceptional, with a midpoint of (4) good. Thus, higher values on the scale correspond to an evaluator perceiving their peer to be a stronger performer. We then asked evaluators whether they recommended the peer be recognized with the Elite Award. Recommend Elite Award, which serves as our main dependent variable, takes the value of 1 if the participant answered “yes” and 0 if “no.”
We also conducted analyses with control variables. These include self-reported measures and data collected through the experiment. Participants self-reported their age (age), education (college educated), familiarity with cognitive assessments (experience cognitive assessments), gender (female), political orientation (Democrat and Republican), race (White), and work status (full-time employee). We also collected two sets of measures capturing participants’ behavior throughout the experiment. The first set pertained to the aptitude test completed by the participant in the first stage of the experiment: participant test time spent is the number of seconds a participant spent completing the aptitude test, and participant test number correct is the number of questions the participant answered correctly. The second set pertained to the participant’s evaluation of the peer test: time spent on peer test measures the amount of time the participant spent evaluating the peer’s responses, number marked correct on peer test is the number of the peer’s responses to questions the participant marked as correct, and accuracy on peer test is the accuracy of the participant’s evaluation of the peer’s responses. Accuracy was calculated as the percentage of the peer’s responses participants accurately marked as correct or incorrect.
As is typical in experimental research, we sought to ensure we effectively simulated an experience of misrecognition among participants randomly assigned to our under- and overrecognition conditions (i.e., manipulation check). Specifically, we asked participants the extent to which they considered their Elite Award outcomes correct: “[Not] Being recognized with the Elite Award for my performance on the test felt correct,” measured on a 1 to 7 scale. As expected, correctly recognized participants were more apt to agree their recognition was correct (5.0 for high performers and 4.7 for low performers; average 4.8) than those who were not correctly recognized (3.2 for underrecognized and 3.3 for overrecognized; average 3.2) with this difference between correctly recognized and misrecognized participants being statistically significant (p < 0.001).
Results
Descriptive statistics. Table 1 provides descriptive statistics and Table C2 in the online supplement provides a correlation matrix for our main variables. On their own aptitude tests, participants answered an average of 6.7 of the 10 questions correctly. In their role as evaluators, participants reported their peer had answered 4.8 questions correctly, on average, which is in line with the actual number of correct responses on the peer test (5). On average, participants accurately identified peer responses as correct or incorrect 76 percent of the time. Evaluators perceived the peer’s overall performance as 3.9 (good) out of 7.0, on average, and recommended the peer receive the Elite Award 38 percent of the time.
Descriptive Statistics (Study 2)
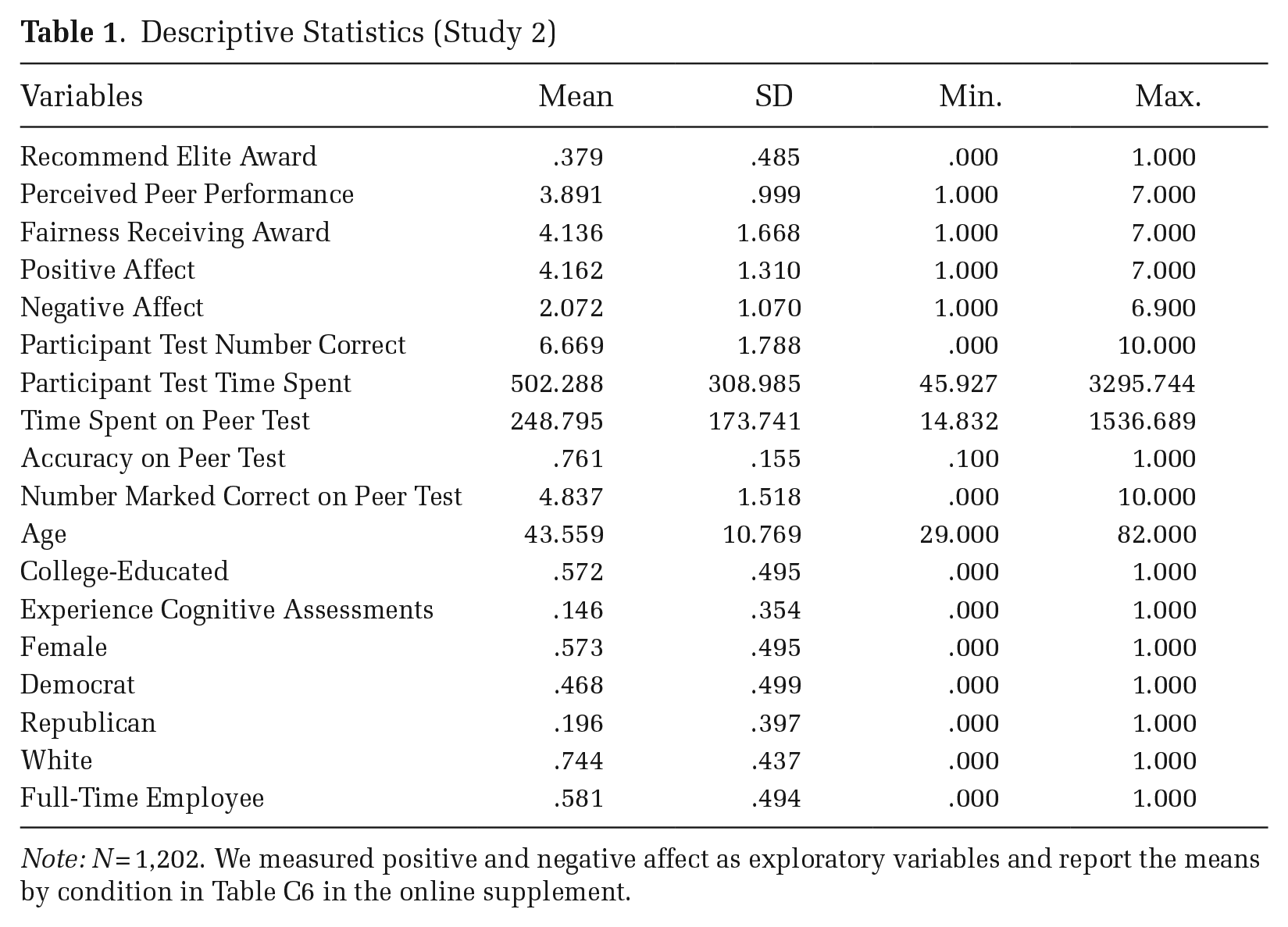
Note: N = 1,202. We measured positive and negative affect as exploratory variables and report the means by condition in Table C6 in the online supplement.
Demographically, participants were, on average, 44 years old with 57 percent self-reporting as female, 74 percent as White, 57 percent as college-educated, 47 percent as Democrats, 20 percent as Republicans, and 58 percent as full-time employees. Table C3 in the online supplement provides a randomization table for all variables.
Effect of recognition on evaluator’s propensity to recommend Elite Award to others. To test our first hypotheses—that underrecognized (overrecognized) evaluators will be less (more) likely to grant recognition to others—we turn to whether an evaluator’s propensity to grant the Elite Award varies across conditions. Table 2 (Model 1) shows the effect of our main conditions with controls, and Figure 3 provides the marginal effects from this regression. Our focal comparison is whether the propensity to grant recognition (i.e., recommend the Elite Award) varies for misrecognized participants relative to correctly recognized counterparts who performed similarly.
OLS Regressions of Recommend Elite Award by Evaluators’ Recognition and Fairness (Study 2)

Note: Unit of analysis is the participant’s evaluation of peer test. Recommend Elite Award takes the value 1 if the participant recommended the peer receive the Elite Award and 0 if they did not recommend it. Underrecognized takes the value 1 if the participant performed above average on their aptitude test and was not randomly assigned the Elite Award and 0 otherwise. Correctly recognized low performer takes the value 1 if the participant performed below average on their aptitude test and was not randomly assigned the Elite Award and 0 otherwise. Overrecognized takes the value 1 if the participant performed below average on their aptitude test and was randomly assigned the Elite Award and 0 otherwise. The reference category is correctly recognized high performer, which takes the value 1 if the participant performed above average on their aptitude test and was randomly assigned the Elite Award and 0 otherwise. Model 2 introduces unfair, which takes the value 1 if the participant reported three or less when asked about the fairness of Elite Award allocation. Model 2 does not include controls because the level of fairness felt by a participant is likely related to these control variables. Robust standard errors are in parentheses.
p < 0.05; **p < 0.01; ***p < 0.001 (two-tailed tests).
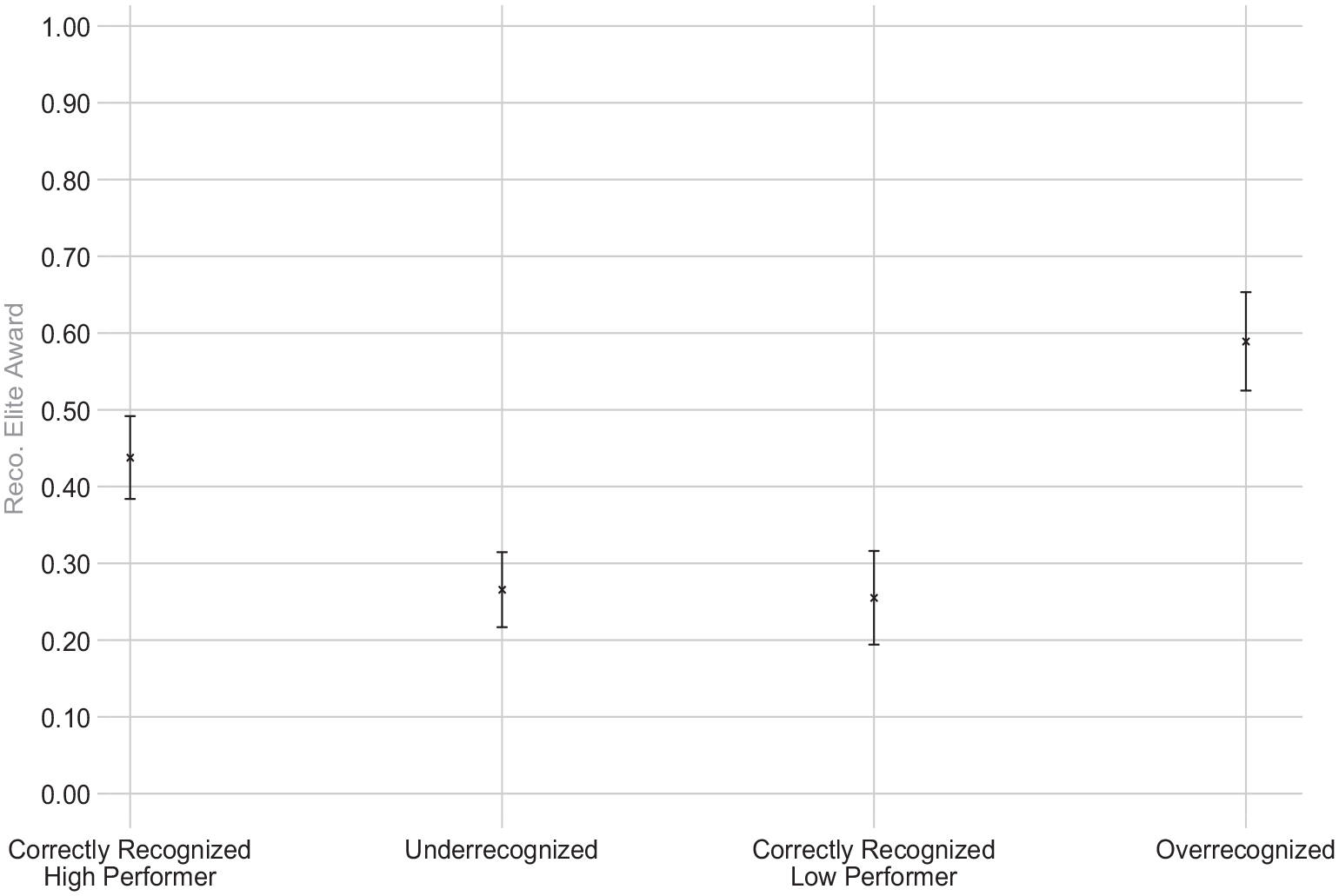
Participants’ Propensity to Recommend the Elite Award, by Condition, with Controls (Study 2)
These results provide causal evidence that misrecognition is reproduced. Among high performers, correctly recognized evaluators (i.e., those who received the Elite Award) granted the Elite Award to a peer 44 percent of the time; underrecognized evaluators (i.e., those who did not receive the Elite Award) granted the award only 27 percent of the time, or about 39 percent less often (p < 0.001). Thus, consistent with Study 1 and in support of Hypothesis 1a, we find that underrecognition decreases the likelihood that evaluators grant recognition to others.
Among low performers, correctly recognized evaluators—those who did not receive the Elite Award—granted recognition 26 percent of the time. In sharp contrast, overrecognized evaluators—low performers who received the Elite Award—granted recognition to a peer 59 percent of the time, more than twice as often as their correctly recognized counterparts (127 percent more often; p < 0.001). Thus, in support of Hypothesis 2a, we find that overrecognition significantly increases evaluators’ likelihood of granting recognition to others.
Overall, these results provide causal evidence that experiencing misrecognition alters evaluators’ likelihood of subsequently granting recognition to others. Consistent with Study 1, underrecognized evaluators were significantly less likely to grant recognition to others than were similar high-performing evaluators who (correctly) received the award themselves. Expanding on our results from Study 1, Study 2 provides insight into the causal effect of overrecognition (Hypothesis 2a): lower-performing evaluators who were granted the Elite Award were more than twice as likely to grant recognition to others than were similar-performing evaluators who (correctly) did not receive the status award. Importantly, our design ensured that all participants across recognition conditions evaluated an identical quality peer. As such, these differences can be fully attributed to misrecognition. Furthermore, these results are robust even when including respondents who failed attention checks (see the online supplement, Table C4, Model 1, and Figure C3). Together, these results support Hypotheses 1a and 2a.
Because we provided accurate information to participants regarding their relative performance on the aptitude test, we can further scrutinize the generalizability of our results by examining whether the effect of misrecognition is localized among participants who had the most pronounced misrecognition experience: that is, whether our effects are driven by respondents who were among the very top (or very bottom) performers and did not receive (or did receive) the Elite Award, and thus may have had the most pronounced misrecognition experience. Figure 4 plots the relationship between our four recognition conditions and the propensity to grant the Elite Award by the number of questions the participant answered correctly. These results reveal the robustness of our findings as the effects of under- and overrecognition emerge at all performance levels. Regardless of the number of questions participants answered correctly, underrecognized evaluators were—relative to correctly recognized evaluators—significantly less likely to recommend the award, and overrecognized evaluators were significantly more likely to do so.

Participants’ Propensity to Recommend the Elite Award, by Number of Questions They Answered Correctly (Study 2)
We now turn to evaluators at the cutoff of being labeled either a low or high performer (i.e., participants who answered six versus seven questions correctly); these analyses mirror Merton’s (1968) example of the 41st chair. This subset of similar participants demonstrated nearly identical ability, but a one question difference in the number answered correctly dictated whether they were classified as low or high performers. Evaluators’ propensity to grant recognition among this subset replicates our main results, providing the clearest evidence of the causal effect of being misrecognized on a person’s subsequent evaluations of others.
Is misrecognition being reproduced? The fact that underrecognized participants grant recognition at a lower rate—and overrecognized participants at a higher rate—is consistent with our theoretical argument that evaluators who experience misrecognition are more apt to subsequently produce unmeritocratic evaluative outcomes. To more directly examine the extent to which such reproduction emerges, it is useful to consider whether underrecognized evaluators are less likely to recognize even those they perceive to be top performers. Similarly, overrecognized evaluators granting recognition at a higher rate even to those they perceive to be poor performers would provide clear evidence of the reproduction of overrecognition.
To make this comparison, we used our preregistered measure of an evaluator’s overall opinion of their peer’s performance (perceived peer performance). Given the evaluative criteria we outlined stated the Elite Award be granted to high-performing candidates, those perceived as stronger performers should be the ones recognized with the award. Therefore, we focus on comparing the likelihood for evaluators to grant recognition across conditions at different levels of perceived peer performance. Figure 5 plots the marginal effects of a regression predicting recommend Elite Award by each condition interacted with the evaluator’s perceived peer performance (see Table C5 in the online supplement). Given the rarity of perceived peer performance scores at the lowest and highest levels, and to facilitate interpretation of our effects, we grouped the scores into three buckets: perception the peer was a weak performer (1 to 3), a neutral performer (4), or a strong performer (5 to 7). Consistent with the general notion that recognition—in this case the Elite Award—is reserved for high performers, perceived peer performance had a positive average effect on an evaluator’s likelihood of recommending an Elite Award for a peer (Table 2, Model 1). However, the relationship between perceived performance and recommending the Elite Award varied across conditions in meaningful ways.
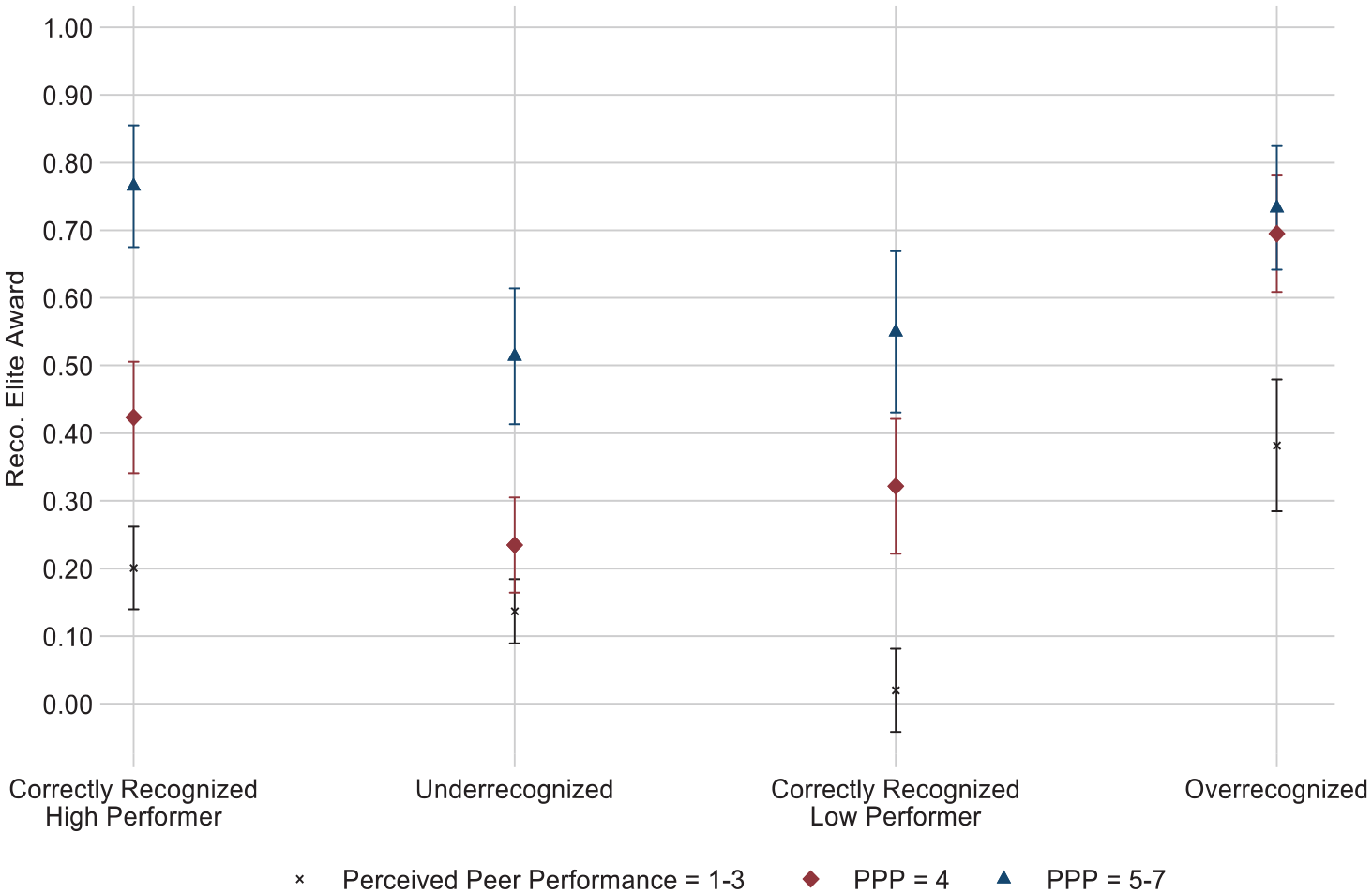
Participants’ Perception of Perceived Peer Performance and Recommending the Elite Award (Study 2)
First, these results provide evidence that the lower likelihood for underrecognized evaluators to grant recognition to others reflects a tendency for these evaluators to reproduce underrecognition in their subsequent evaluations. Among high performers, when perceived peer performance was highest (5 to 7), correctly recognized evaluators granted the award 77 percent of the time, whereas underrecognized evaluators granted it 51 percent of the time (p < 0.001). The fact that underrecognized evaluators were 34 percent less likely to recognize those whom they assessed to be the highest performers provides clear evidence that underrecognized evaluators reproduce their experience of misrecognition: they grant recognition far less than their correctly recognized counterparts even to those they deem high performers.
When perceived peer performance was lowest (1 to 3), correctly recognized low-performing evaluators granted recognition only 2 percent of the time, whereas overrecognized evaluators granted recognition 38 percent of the time (p < 0.001). The fact that overrecognized evaluators were 19 times more likely than correctly recognized low performers to recognize those whom they assessed to be low performers provides further evidence that overrecognized evaluators also reproduce their experience of misrecognition. Together, these analyses provide consistent support for Hypotheses 1a and 2a, showing that experiences of misrecognition lead evaluators to misrecognize subsequent others.
Examining fairness as a driver of underrecognized evaluator behavior. We theorized that misrecognized evaluators are apt to see the process for allocating recognition as fundamentally unfair, or at least as less equitable, than do their correctly recognized counterparts. In addition to violating our specification that the allocation of the award was reserved for top performances on the aptitude test, this experience also contradicts general meritocratic beliefs that rewards ought to be granted only to the best candidates (and not to weaker performers). Thus, high performers who are denied recognition and low performers who are nonetheless recognized are likely to perceive the evaluation process as relatively less fair.
We built on theories of positive and negative inequity to hypothesize that these perceptions of unfairness would drive the subsequent evaluative behavior of underrecognized but not overrecognized evaluators (Hypothesis 1b). We test this hypothesis using our preregistered measure of fairness receiving award. After participants evaluated their peer, we asked them to score on a 1 to 7 scale the extent to which they agreed with the statement: “The process for determining whether participants are recognized with the Elite Award felt fair.” Higher values indicate the participant saw the process as fairer; lower values represent perceptions the process was less fair. Consistent with our argument, misrecognized evaluators viewed the process of allocating the Elite Award as less fair than did correctly recognized evaluators (average of 3.51 versus 4.75; p < 0.001).
We dichotomized our fairness receiving award variable: unfairness takes a value of 1 for respondents indicating the process was relatively less fair (responses from 1 to 3) and 0 for those who said the process was neutral to fairer (responses from 4 to 7). Examining the effect of unfairness across conditions allows us to determine whether perceptions of (un)fairness uniquely drive underrecognized evaluators’ subsequent recognition behavior, as we predicted.
As we hypothesized, perceptions of unfairness only drive the propensity to recommend the Elite Award for underrecognized evaluators. Specifically, underrecognized evaluators grant recognition approximately 15 percent of the time when they see the process as unfair; when they perceive it to be fair, they are 73 percent more likely to grant recognition to others (26 percent of the time; p = 0.008). The likelihood of giving the award as a function of unfairness did not differ in any of the other three conditions (see Figure 6 for marginal plots). 5 These results are substantively unchanged when we include participants who failed either attention check (see the online supplement, Table C4, Model 2, and Figure C4). These findings support our theory and Hypothesis 1b, that perceived (un)fairness is a key driver of underrecognized—but not overrecognized—evaluators’ subsequent behaviors because experiences of negative inequity loom larger than experiences of positive inequity. Thus, perceptions of unfairness among underrecognized (but not overrecognized) evaluators meaningfully influence their likelihood to give the award to others.
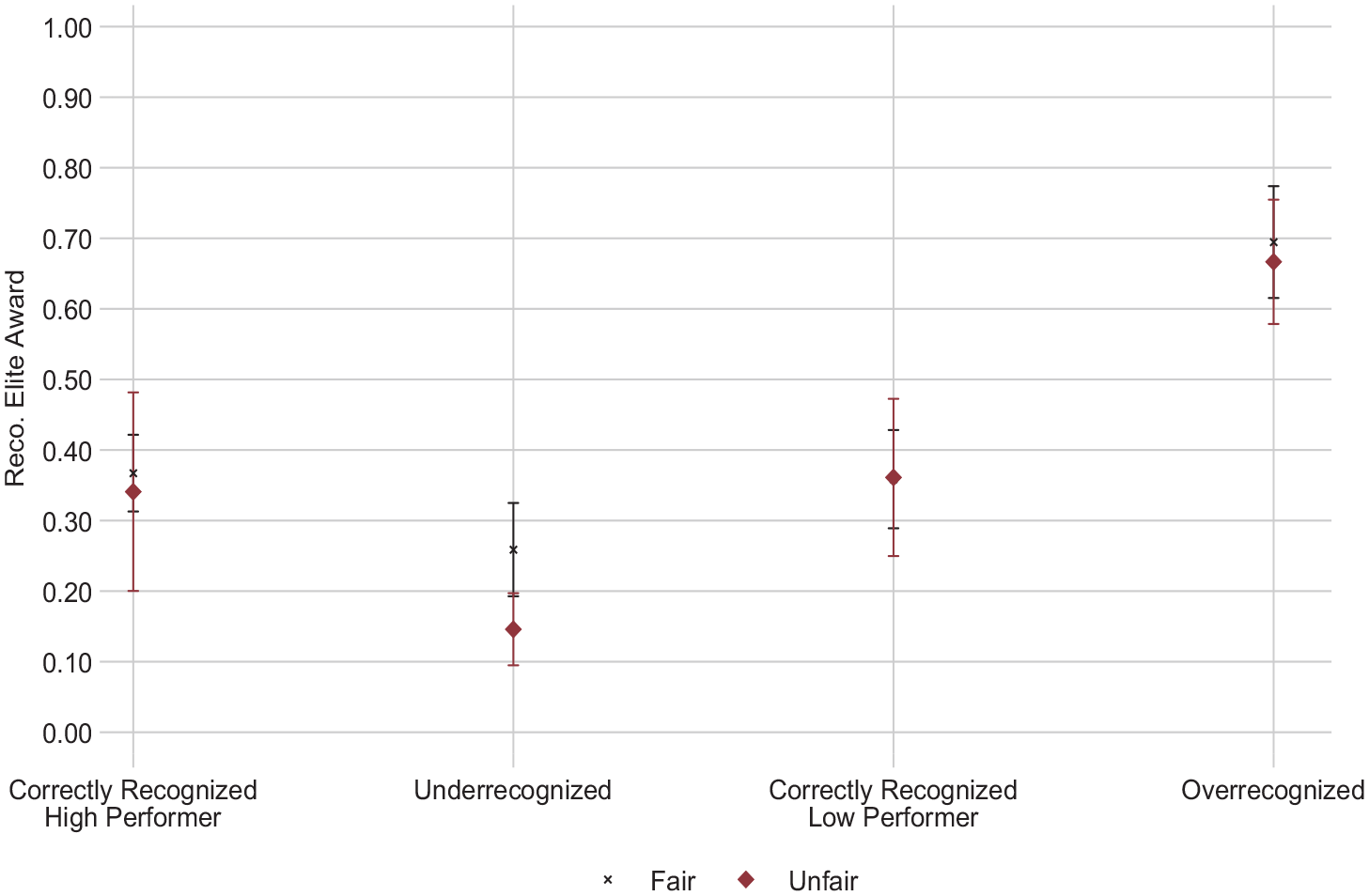
Participants’ Perception of Fairness and Recommending the Elite Award (Study 2)
Study 3
Studies 1 and 2 provide convergent and convincing evidence of our theory and support for Hypotheses 1a, 1b, and 2a. Thus, Study 3 focuses on testing Hypothesis 2b by examining whether informational cues drive our observed pattern of results for overrecognized evaluators.
Study 3 uses the same survey design as Study 2, but some participants were randomly assigned to receive an evaluative criteria manipulation before they assessed whether the peer should receive the award (see Figure 7). Participants assigned to receive this additional criteria manipulation were reminded that the award should go only to top performers and were given additional information about the performance threshold necessary for granting the award. To the extent that informational cues are driving overrecognized evaluators to overrecognize others, adding this detailed information about how one ought to grant recognition should attenuate this effect, effectually reducing overrecognized evaluators’ elevated propensity to grant recognition. Specifically, if overrecognized evaluators are making inferences about how to evaluate others from their experience having been overrecognized, as we hypothesize (Hypothesis 2b), they ought to grant recognition more similarly to their correctly recognized counterparts when they are given explicit information on how to evaluate (i.e., information that is more relevant than the cues available through their experience of overrecognition).
Experimental Design for Study 3
Participants and Procedures
Per our preregistration and a priori power analysis, we recruited 2,140 U.S.-based adult participants for our 2 (high performance, low performance) x 2 (Elite Award, no Elite Award) x 2 (additional criteria, no additional criteria) between-subjects design (see Figure 7). We received full data from 2,320 participants due to CloudResearch’s tendency to oversample. Completion of the task was estimated to take 15 to 20 minutes; participants were paid $3 for an estimated hourly wage of about $10 per hour. See the online supplement, Table D1 for full descriptives, Table D2 for randomization tables, and Table D3 for a correlation matrix of all variables. We used the same attention checks as in Study 2, but we added a check following the additional criteria intervention to ensure people were attentive to this treatment about the criteria for granting the award. Consistent with our preregistration, we dropped from our analyses participants who answered any of the three attention checks incorrectly—the benefits of the Elite Award (489 participants; 21 percent), whether they received the Elite Award (60 participants; 3 percent), or who should receive the award (31 participants; 1 percent). Our final analytic sample consisted of data from 1,740 participants.
During the study, participants were asked whether they would recommend the Elite Award. Participants in the additional criteria condition were told: “Next you will be making a recommendation about whether this person should get the Elite Award. As a reminder, this award should be given to the high-performing participants. Typically, participants who get at least 7 correct get the award. Would you recommend this participant be recognized with the Elite Award?” Respondents in the no additional criteria conditions were simply asked, “Would you recommend this participant be recognized with the Elite Award?” (the same as Study 2).
Our goal with adding the additional explicit criteria was to examine whether overrecognized evaluators were using procedural informational cues from their experience of misrecognition as guideposts on how to recognize others. That is, to what extent were these evaluators inferring how to allocate recognition from their prior experience having been evaluated? The additional criteria reduce ambiguity about how an evaluator ought to evaluate others, so we would expect overrecognized participants in the additional criteria condition to grant recognition at a lower rate than those in the no additional criteria condition. Thus, receiving the additional criteria ought to lead overrecognized evaluators to grant recognition more similarly to their correctly recognized counterparts. Conversely—although we do not theorize this will occur—if informational cues also underlie the effect of underrecognition, we might expect underrecognized evaluators in our additional criteria condition would grant recognition at a higher rate than those in the no additional criteria condition. In other words, to the extent that informational cues drive misrecognized evaluators’ behaviors, our additional evaluative criteria manipulation should attenuate the reproduction of misrecognition, such that misrecognized evaluators grant recognition more similarly to their correctly recognized counterparts.
Results
Informational cues as a driver of overrecognized evaluator behavior. We first replicated our main results from Study 2 (Figure 3) for participants who did not receive additional criteria; these results are presented in Table D4, Model 1, in the online supplement. Among high performers, underrecognized evaluators were approximately 21 percent less likely to grant recognition to others than were correctly recognized evaluators (p = 0.045). Also consistent with Study 2, among low performers, overrecognized evaluators were 124 percent more likely to recognize others than were correctly recognized evaluators (p < 0.001). The results are robust to the inclusion of respondents who failed any of the three attention checks (see Figure D2 and Table D4, Model 2, in the online supplement).
We next turn to the unique intervention in Study 3 aimed at assessing whether overrecognized evaluators’ behaviors were driven by informational cues, as we hypothesized. Specifically, we examined whether providing additional information about the appropriate criteria shaped overrecognized evaluator recognition behavior. We thus examined variation in the likelihood to grant the Elite Award based on whether or not the evaluator received the additional criteria, where our comparisons focused on recognition condition (e.g., whether the additional criteria changed evaluative behavior among overrecognized participants; see Figure 8, Panel A and Table 3).
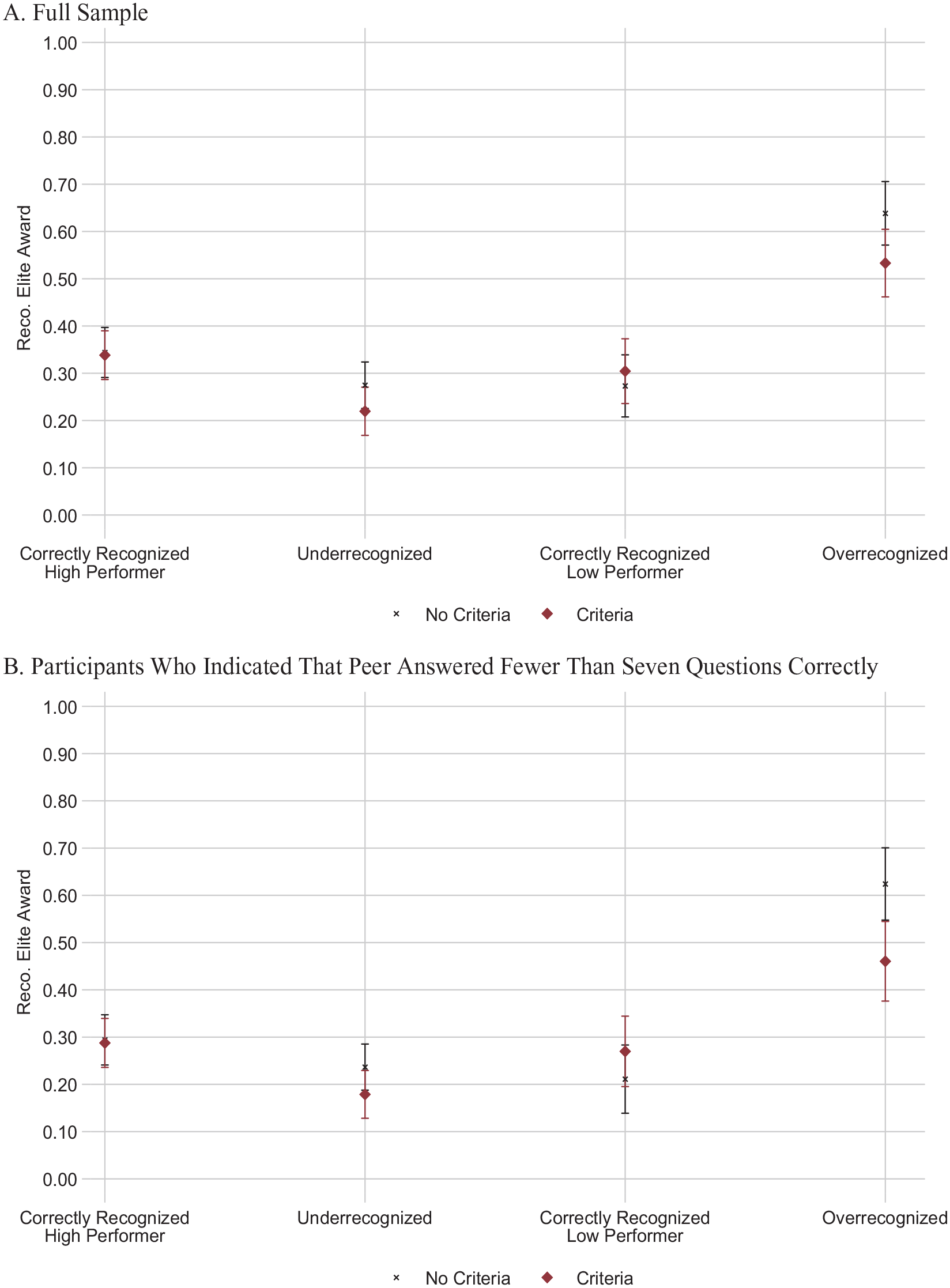
Participants’ Propensity to Recommend the Elite Award by Condition and Criteria, with Controls (Study 3)
OLS Regressions of Recommend Elite Award by Evaluators’ Recognition and Criteria (Study 3)
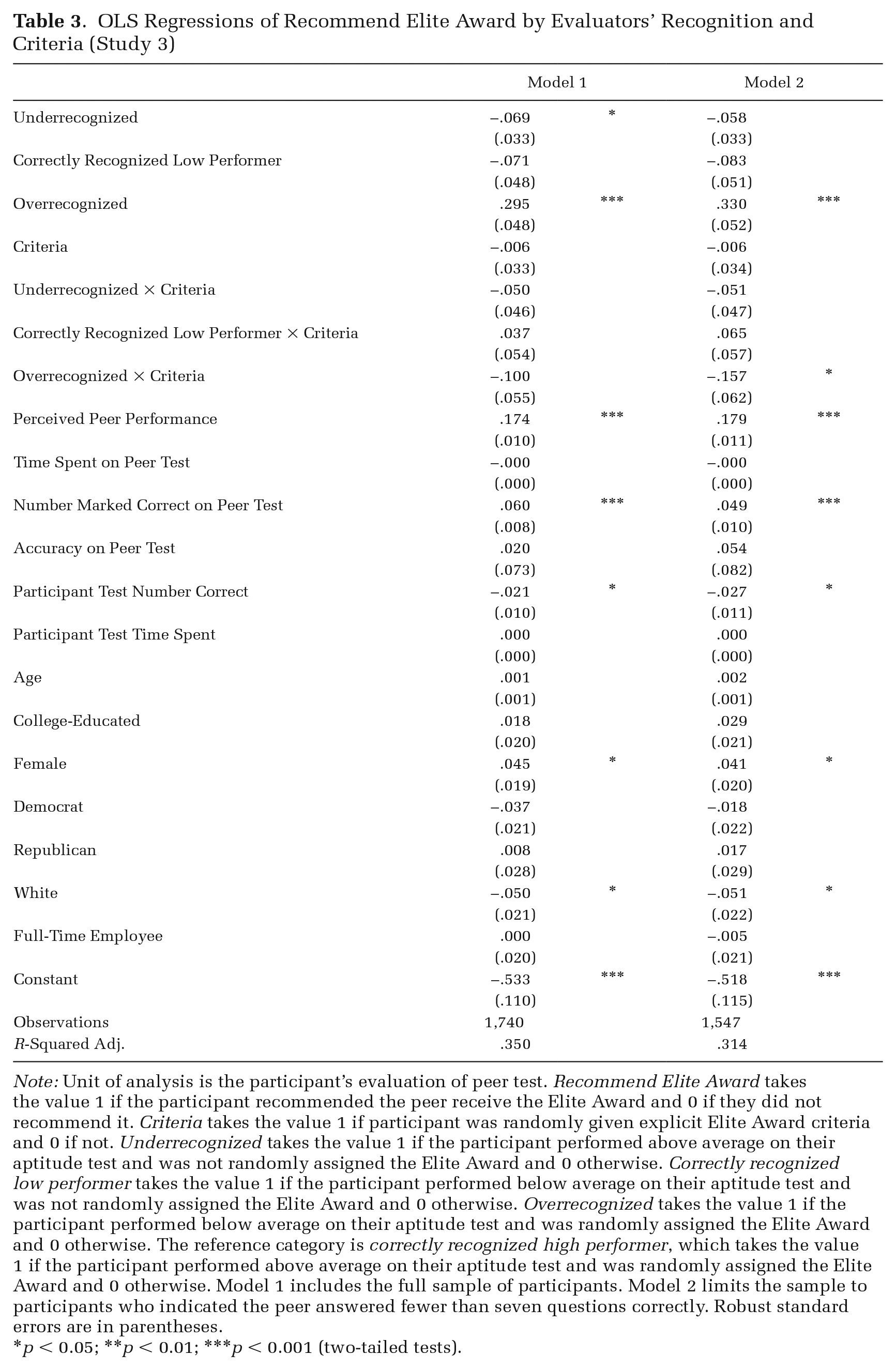
Note: Unit of analysis is the participant’s evaluation of peer test. Recommend Elite Award takes the value 1 if the participant recommended the peer receive the Elite Award and 0 if they did not recommend it. Criteria takes the value 1 if participant was randomly given explicit Elite Award criteria and 0 if not. Underrecognized takes the value 1 if the participant performed above average on their aptitude test and was not randomly assigned the Elite Award and 0 otherwise. Correctly recognized low performer takes the value 1 if the participant performed below average on their aptitude test and was not randomly assigned the Elite Award and 0 otherwise. Overrecognized takes the value 1 if the participant performed below average on their aptitude test and was randomly assigned the Elite Award and 0 otherwise. The reference category is correctly recognized high performer, which takes the value 1 if the participant performed above average on their aptitude test and was randomly assigned the Elite Award and 0 otherwise. Model 1 includes the full sample of participants. Model 2 limits the sample to participants who indicated the peer answered fewer than seven questions correctly. Robust standard errors are in parentheses.
p < 0.05; **p < 0.01; ***p < 0.001 (two-tailed tests).
In support of Hypothesis 2b, we find evidence that informational cues underlie the effect of overrecognition. For correctly recognized low performers, the additional evaluative criteria had no effect on their recognition behavior: those who did not receive the additional criteria language gave the award at similar rates to those who did receive the criteria language (27 versus 30 percent, p = 0.463). Among overrecognized evaluators, however, the additional criteria language significantly reduced their propensity to grant recognition to others. Respondents who did not receive the additional criteria manipulation gave the award about 64 percent of the time, whereas those who received the criteria gave the award about 53 percent of the time (a 17 percent difference; p = 0.017).
Moreover, and consistent with our theorizing, we do not find evidence that informational cues strongly underlie underrecognized evaluators’ behaviors. Among high performers who received the award (i.e., correctly recognized high performers), providing them with the additional criteria had no effect on their likelihood of subsequently granting recognition to others (34 versus 34 percent, p = 0.865). Similarly, this additional criteria had only a marginally significant effect on underrecognized evaluators’ likelihood of granting recognition (27 versus 22 percent, p = 0.088). Thus, informational cues meaningfully drive the evaluative behavior of overrecognized evaluators: telling them how they should evaluate reduces their propensity to overrecognize others.
As further evidence that informational cues uniquely drive evaluative behavior for overrecognized evaluators, we find the additional criteria has the strongest effect when we limit our analyses to participants who marked fewer than seven questions correct on the peer test—a performance level that is below that stated as requisite for granting the award in the additional criteria manipulation (Figure 8, Panel B). Specifically, among overrecognized evaluators who indicated the peer answered six or fewer correct (below this stated cutoff), the additional criteria significantly reduced the reproduction of overrecognition: whereas overrecognized evaluators who did not receive the additional criteria granted recognition 62 percent of the time, those who received the additional criteria granted recognition in 46 percent of these cases (a 16 percent decrease; p = 0.001).
This study thus provides causal evidence that our proposed informational cues mechanism underlies overrecognized evaluator behavior. In other words, overrecognized evaluators reproduce overrecognition because they rely on insights from their own experience in determining how to evaluate others. Reminding overrecognized evaluators of the award criteria—and, by extension, how to effectively grant recognition to others—materially attenuates the tendency for overrecognition to be reproduced. Importantly, and critical to our theorizing, our intervention does not meaningfully shift evaluative behavior for individuals who have been underrecognized or correctly recognized.
Further Exploring Generalizability: Two Additional Studies
We observed a robust effect of misrecognition on the subsequent allocation of recognition both in the field and across our two experiments, but we wanted to further examine the generalizability of our theory and results. 6 Across our studies, experiences of misrecognition were relatively easy to discern because individuals had some information about their performance and clarity on the criteria for granting recognition. However, this is not always the case, as there is variation in the degree of clarity people have about their own performance and the prevailing criteria for granting recognition across evaluative contexts. Therefore, we conducted two additional preregistered experiments aimed at establishing generalizability in contexts where there was less clarity on each of these dimensions.
Additional Study A: Clarity about Performance
In each of our prior studies, participants had a relatively clear sense of how well they performed. This was especially true in Study 1, but even in our survey experiments, participants were informed whether they performed above or below average. By providing participants with some concrete information about their performance, instances of misrecognition were relatively detectable: by knowing their performance, people can more easily detect instances where their own outcome did not align with their performance. In some cases, however, performance information is not explicitly available, leaving individuals to infer how they performed from their own self-assessment or vague performance feedback. Thus, the goal of this study was to test whether our main effect—that misrecognition influences subsequent recognition behavior—generalizes to cases where individuals do not receive concrete performance information and are instead left to make inferences.
We recruited 1,446 U.S.-based adult participants from MTurk. We received full data from 1,463 participants. This study followed the same experimental design as Study 2 with one important omission: participants did not receive information about their performance relative to others. Instead, after completing their aptitude test, they were simply notified whether or not they received the Elite Award. Thus, we still maintain our four conditions and used the same attention checks as in Study 2. In keeping with the terms of preregistration, we dropped participants who answered either question incorrectly—328 participants (22 percent) in the first case, 27 participants (2 percent) in the second case. Our final analytic sample contained data from 1,108 participants.
Given that in this study we withheld performance information, we wanted to ensure participants still detected whether they were correctly recognized or not, as in the other studies. Our results revealed that participants in the under- and overrecognized conditions did indeed feel a sense of misrecognition; specifically, respondents who were correctly recognized believed their evaluative outcome was correct more often than those who were not correctly recognized (4.79 versus 4.19, p < 0.001). In a way, this result reaffirms the prevalence of feeling under- and overrecognized—people are apt to sense when they are misrecognized even if their exact performance result is not communicated.
We find that among high performers, correctly recognized evaluators recommended a peer be recognized with the award 45 percent of the time, whereas underrecognized evaluators recommended it only 29 percent of the time (p < 0.001). Underrecognized evaluators were approximately 60 percent less likely to grant recognition to others, replicating our main effects and consistent with Hypothesis 1a.
Among low performers, overrecognized evaluators were 113 percent more likely to recognize others in their subsequent evaluations than were correctly recognized evaluators (p < 0.001). Specifically, whereas correctly recognized low performers recognized others about 23 percent of the time, overrecognized evaluators did so about 49 percent of the time. Again, these results replicate the main results from the previous studies and are consistent with Hypothesis 2a. Thus, we find that even when evaluators do not have direct information about how they performed, misrecognition still influences their propensity to grant recognition to others. This finding thus provides further ecological validity of our theory and experimental approach.
Additional Study B: Clarity of Evaluative Criteria
In Studies 2 and 3 we told participants that the award should be given to the “high” or “best” performers. Given that such clarity about evaluative criteria are not available to evaluators in all evaluative processes, we intentionally made the evaluative criteria vague in this additional study. Leveraging a similar experimental design as Study 2, participants were told the Elite Award would be given to individuals we believed would “add the most value” instead of those who were “high performers.” This modification naturally introduces a greater level of ambiguity about how recognition is granted and thus should make it more difficult for participants to discern that they have experienced misrecognition. As such, finding that misrecognition is still reproduced would strengthen the generalizability of our theory and findings.
We recruited 2,480 U.S.-based adult participants from MTurk, 2,472 of whom finished the entire task. This study followed the same experimental design as prior studies with the slight change mentioned above: participants were told the award would be given to those who “add the most value,” without explicating more precise criteria or what constitutes adding value. Using the same two attention checks as Study 2 and Additional Study A, we dropped all participants who answered either question incorrectly—474 participants (19 percent) in the first case and 32 (1 percent) in the second. Our final analytic sample contained data from 1,966 participants.
The results from Study 2 are replicated even when the evaluative criteria are less clear, such that misrecognition is reproduced. Among high performers, correctly recognized evaluators (i.e., received the Elite Award) granted recognition to others 39 percent of the time; underrecognized evaluators (i.e., did not receive the Elite Award) granted recognition only 13 percent of the time, or about 66 percent less often (p < 0.001). Among low performers, correctly recognized evaluators (i.e., did not receive the Elite Award) granted recognition about 33 percent of the time; overrecognized evaluators (i.e., received the Elite Award) granted recognition about 75 percent of the time, or over twice as often (p < 0.001). Thus, even in cases where evaluative criteria are vague, people still experience instances of misrecognition and reproduce those experiences in their subsequent assessments of others.
Conclusions and Discussion
Misrecognition is common even in evaluation processes that strive to identify and recognize only the best candidates (Botelho and Abraham 2017; Bowers and Prato 2018; Castilla 2008; Dencker 2009; Lynn et al. 2009; Paik et al. 2023). Implications for individuals experiencing such unmeritocratic evaluative outcomes are well established, yet existing research has not examined whether there are broader downstream effects of misrecognition on subsequent evaluations. Quite often, individuals move back and forth from being evaluated to serving as evaluators (e.g., in peer evaluation systems, see Brett and Atwater 2001; Siler et al. 2015). In this article, we thus shift the focus to identifying the downstream effects of misrecognition for how people later evaluate others within the same evaluation system. Specifically, we examine whether misrecognition is reproduced in subsequent evaluations.
We theorized that previously misrecognized evaluators would be more apt to deviate from meritocratic ideals prescribing that recognition only go to top performers, even in systems explicitly aimed at fulfilling this objective. Across a quasi-natural experiment in the field and two online survey experiments, we test our theory and show that misrecognized evaluators—those who do not receive the recognition or rewards expected for their level of performance—differ in how they subsequently evaluate their peers compared to those who performed similarly (whether high or low) and were correctly recognized. Whereas individuals who previously experienced underrecognition were less likely to grant recognition to others, those who experienced overrecognition were significantly more apt to subsequently allocate recognition. Importantly, our results also reveal that the underlying drivers leading to this reproduction of misrecognition are distinct and a function of the type of misrecognition experienced. Underrecognized evaluators are far less likely to grant recognition to others due to perceptions they had been evaluated unfairly. Overrecognized evaluators, in contrast, grant recognition to others more freely due to the informational cues they received in their experiences having been overrecognized.
First—and most centrally—these results contribute to sociological research on evaluations. Research on meritocracy is often situated within an evaluative context, but we directly bridge these areas of research to uncover the downstream effects of experiencing unmeritocratic evaluative outcomes for how people subsequently evaluate others. Scholars have recently begun to consider how an evaluator’s prior experiences being evaluated affect the way they later evaluate and allocate recognition to others. Specifically, this research has focused on the valence of one’s prior evaluations, suggesting that both positive and negative prior experiences can lead people to be more objective and meritocratic (e.g., Botelho and Gertsberg 2021; Castilla and Ranganathan 2020). One conclusion from this burgeoning research is that any prior experience being evaluated/recognized may strengthen evaluators’ subsequent adherence to norms of meritocracy.
We build on this line of inquiry by integrating broader sociological and psychological theories related to equity, procedural fairness, and role-fulfillment to uncover an important boundary condition: prior experiences of being misrecognized during an evaluation do not lead people to be more meritocratic in subsequent evaluator roles. Instead, under- and overrecognized evaluators may be most apt to deviate from meritocratic ideals of reserving recognition only for top-performing candidates. Importantly, this deviation manifests in divergent ways for the misrecognized, such that misrecognition tends to be reproduced in kind. By highlighting that evaluative outcomes are not simply positive or negative but vary in terms of whether they are—or at least, are perceived to be—meritocratic, we develop a more comprehensive understanding about the link between evaluators’ prior experiences and their subsequent evaluative behavior. Our results show that the degree to which recognition aligned with evaluators’ performance—and not just the valence of that prior experience—directly affects how they later evaluate others. Documenting how people’s prior experiences with misrecognition affect their evaluative behavior is crucial for understanding the conditions under which evaluation processes fail in accurately recognizing top performers.
Second, this research contributes to a growing body of sociological research on the implications of the design and structure of evaluative systems for producing objective and unbiased outcomes (Abraham, Botelho, and Lamont-Dobbin 2024; Botelho 2024; Botelho and Abraham 2017; Botelho et al. forthcoming; Correll et al. 2020; Rivera and Tilcsik 2019). A critical and related implication of these findings is that initial unmeritocratic outcomes become reproduced in evaluation systems when misrecognized candidates later serve as evaluators. In the case of evaluation systems aimed at allocating awards or recognition, the value of the recognition is often rooted in the assumption that a given accolade is strongly correlated with a candidate’s underlying quality. In other words, receiving recognition is a signal that one is a top performer (Lynn et al. 2009; Podolny 1993; Simcoe and Waguespack 2010).
By considering the downstream effects of initial failures in recognizing top candidates (i.e., instances of misrecognition), we suggest that evaluative systems risk increasing the likelihood of unmeritocratic outcomes when misrecognized evaluators move from being candidates to being evaluators. For instance, overrecognized evaluators grant recognition at a higher rate, even to those whom they see as the weakest performers. A strong interpretation of our results would suggest these initial instances of misrecognition will be consistently reproduced, leading to the breakdown of evaluative processes that rely on misrecognized evaluators. However, we caution against such an interpretation and highlight two important factors to consider. First, it is important to note that misrecognition is not the modal outcome—these systems generally identify candidates correctly. Second, and even more importantly, our results show that when misrecognition does happen, there is a higher likelihood it will be reproduced by misrecognized evaluators. That said, we do not find that misrecognized evaluators uniformly misrecognize others. Our research uncovers an additional pathway through which these systems can be imperfect: initial instances of misrecognition have the potential to meaningfully erode the link between candidate quality and the allocation of recognition in evaluative systems.
Third, our findings provide evidence about two distinct mechanisms behind the tendency of misrecognized evaluators to reproduce their prior experiences in subsequent evaluations of others. As we showed in Study 2, both under- and overrecognized evaluators accurately perceived their outcomes as unfair. However, this unfairness only motivated underrecognized evaluators to differentially recognize subsequent peers. Perceptions of unfairness did not play a substantive role in driving behavior for overrecognized evaluators. These unilateral effects of unfairness follow from our theoretical arguments that people tend to be most reactive to negative inequity (Austin and Walster 1974; Scheer et al. 2003), such as that experienced by underrecognized evaluators.
Given that our first two studies did not allow for a direct examination of informational cues—our proposed driver of overrecognized evaluators’ subsequent behavior—we designed Study 3 to achieve this aim. Indeed, we found that overrecognized evaluators’ propensity to grant recognition at a higher rate is largely driven by the inferences they draw from their experiences of misrecognition. One explanation for why overrecognized, but not underrecognized, evaluators take cues from their prior experiences relates to the notion that positive inequity leads people to experience tension (e.g., guilt, imposter syndrome) that they strive to redress (Adams 1965; Carrell and Dittrich 1978). One way they do so is by exerting more effort and improving performance (Greenberg 1988; Pritchard, Dunnette, and Gorgenson 1972). Therefore, unlike underrecognized evaluators, people who were previously overrecognized may be particularly attentive to available informational cues on how they are expected to evaluate others; in other words, they will be most focused on figuring out the appropriate way to evaluate others. It is important to note that although misrecognition may shape evaluator behavior consciously—such that under- and overrecognized evaluators intentionally misrecognize others—the effects of misrecognition may also be implicit. Future research might isolate the precise psychological motives driving misrecognized evaluators’ behaviors.
In this way, our work highlights two important levers for researchers and policymakers to keep in mind when considering how to potentially curb the problematic effects of misrecognition. First, we found it is possible to attenuate the reproduction of overrecognition by providing overrecognized evaluators with clarity on how to satisfy their role through clear information about the evaluation process. Importantly, this approach did not meaningfully remedy the reproduction of underrecognition. Our research thus suggests a structural solution for attenuating the reproduction of overrecognition in evaluation systems where individuals move between being candidates and evaluators. It seems imperative to implement formalized and explicit evaluative criteria to lower the likelihood that overrecognition is reproduced. These points are consistent with research on the advantages of formalized and structured evaluation processes for promoting consistency in how evaluators grant recognition (Castilla 2015; Castilla and Benard 2010). Second, our findings suggest that increasing perceptions of procedural fairness may mitigate the effects of underrecognition. Future research is needed to uncover how decisionmakers can effectively boost perceptions of fairness for people who feel they should have been recognized (e.g., communicating how it happens or what redress they can seek).
A key insight from our work is how readily prior experiences of misrecognition shape evaluator behavior. Across all three studies, our results show that singular experiences with misrecognition are enough to markedly shape subsequent evaluative behavior. In fact, most instances of misrecognition are similarly singular: a top-performing scientist who does not receive an expected award experiences an instance of underrecognition, and an employee who receives an unexpected promotion likely experiences an instance of overrecognition. Importantly, any individual experiencing an instance of misrecognition—in our studies and more generally—has inevitably had a range of other prior experiences that may or may not align with the focal misrecognition experience. Some people may have relatively consistent experiences with either over- or underrecognition, but it is more likely people experience a mix of each type of misrecognition and instances of correct recognition. Because the focal misrecognition (or correct recognition) experience occurred at random in our studies, our results reveal the average effect instances of misrecognition have on people’s subsequent evaluative behavior in the same evaluation system. In other words, we show that misrecognition is reproduced across individuals with a range of past experiences. This is consistent with research on the rapid emergence of status beliefs (Ridgeway and Correll 2006): on average, a single experience of misrecognition powerfully shapes an evaluator’s cognition and becomes more relevant than foundational norms of meritocracy or the evaluation system’s underlying goal to recognize only top performers.
Directly exploring such variation is out of scope for the current research, but it is plausible that the nature of evaluators’ prior experiences with misrecognition meaningfully alters the extent to which they reproduce misrecognition. On the one hand, experiences of misrecognition may be additive, such that people who have had more consistent prior experiences with misrecognition would be most apt to reproduce misrecognition in their evaluations of others. In fact, having repeat experiences of misrecognition would arguably intensify the salience of both the available information on how to grant recognition and that person’s perceptions of unfairness. However, we caution against drawing this conclusion and expect the relationship to be more complex. For instance, when we consider systemic inequalities and biases, historically marginalized groups (e.g., racial minorities, women, those with lower socioeconomic status) are more likely to have had repeat experiences of underrecognition. Yet, existing research suggests members of marginalized groups tend to advocate for equity on behalf of individuals who are commonly disadvantaged (Cohen and Huffman 2007; Greenberg and Mollick 2017; Saguy et al. 2020). Therefore, to advance this line of inquiry, future research should carefully consider how repeat and consistent experiences of misrecognition shape subsequent evaluative behavior in distinct ways.
Relatedly, we are limited in what we can say about the persistence of the effects of misrecognition over time, where people likely have additional experiences being evaluated. Our field study suggests the effects do persist; examining the 180-day period after the initial misrecognition in Study 1—when underrecognized evaluators have inevitably been evaluated again and thus potentially experienced different outcomes (i.e., over/under/correct recognition)—indicates the effect of underrecognition lasts beyond an immediate period. In our online survey experiments, however, the misrecognized evaluators were tasked with assessing a candidate soon after experiencing misrecognition. Given more time, individuals might rationalize their misrecognition as warranted or become more convinced it was not, leading to weakening or strengthening of our key findings. Future research could advance this line of work by examining whether the effects of misrecognition persist over time.
Finally, we deliberately chose a common-knowledge task for evaluation in our survey experiments because it aligned with our participants’ likely knowledge and experience, thus best mimicking a field experimental design. Although our field study among investment professionals certainly strengthens generalizability related to evaluator expertise and types of evaluation, future research can further expand on this work by studying misrecognition in different contexts.
In terms of the broader generalizability and scope conditions of our theory, it is important to note three conditions that may affect the magnitude of our observed effects: clarity of performance information, specificity of evaluative criteria, and visibility of evaluative outcomes (for the self and others). Each of these conditions affect a person’s awareness that they have been misrecognized. For instance, the more concretely a person knows they were a top performer, that recognition ought to go to top performers, and that similarly performing others were recognized, the more likely this person will experience underrecognition. Similarly, if a person who suspects they have been overrecognized observes that a stronger performer was not recognized, they may be particularly aware of their overrecognition. Therefore, when these conditions are present—particularly when multiple of these hold—we would expect it to be especially likely that misrecognized evaluators subsequently misrecognize others.
It is worth noting that these conditions operate on a continuum—they are not simply “present or not present” but often present at varying degrees. Thus, while these conditions are sufficient, we argue they are not necessary for misrecognition to be reproduced in evaluations. For instance, individuals do not simply know or not know how they performed; rather, the degree of clarity about how one performs varies across contexts and evaluative processes. Evaluators across all three of our studies had a reasonable sense of whether they were misrecognized. This was especially true in Study 1, given that participants in Studies 2 and 3 were simply told whether they performed above or below average but not provided details on the requisite performance level for receiving the award. Additional Study A was designed to make participants’ performance even more ambiguous, and Additional Study B made the evaluative criteria more ambiguous. Results from these additional studies are consistent with our main results, and thus support the conjecture that misrecognized evaluators are apt to misrecognize others even in the absence of these conditions. Future research might more deeply consider how these (and other related) conditions that commonly vary across evaluative contexts distinctly shape the reproduction of misrecognition.
Future research could also consider whether the effects of misrecognition carry across evaluation systems. We focused on peer evaluation systems because, in such processes, individuals who are evaluated typically also serve as evaluators. Furthermore, these types of evaluations are highly consequential and common in organizations, in science, and in society. Former candidates also often transition to evaluator positions in different systems, such as a manager being hired into a new organization (Castilla and Ranganathan 2020). Given that we find under- and overrecognition to have clear and substantively large causal effects on how people evaluate others within the same system, it is plausible that the effects of misrecognition in one system can shape evaluative behavior in another system. Future research should examine the conditions under which misrecognition can spill over from one evaluative system (or context) to another and ascertain whether distinct mechanisms emerge in these cases. More generally, our findings caution against making strong claims that an evaluative process is meritocratic in cases where there is a reasonable risk of misrecognition. Such claims are apt to heighten expectations that outcomes will be meritocratic and make instances of misrecognition more salient.
In summary, this article draws attention to how structural failures in evaluative processes can become reinforced as evaluators reproduce their experiences when evaluating others. Because evaluators rely on their prior experiences of having been evaluated, inefficiencies in evaluative systems tend to be reproduced over time. The stakes of these misrecognitions are thus significant for organizations and our society at large. As we have documented, the differences in how misrecognized evaluators recognize peers occur in two critical ways: misrecognized evaluators dole out recognition at different rates and deviate from the general norm of recognizing only the strongest performers. And because under- and overrecognized evaluators are sensitive to different mechanisms, it is imperative that in the design of evaluative systems, we better identify where breakdowns in meritocracy arise, how these breakdowns manifest differently for misrecognized individuals, and what the best solutions are to amend them.
Supplemental Material
sj-pdf-1-asr-10.1177_00031224251318051 – Supplemental material for (Not) Getting What You Deserve: How Misrecognized Evaluators Reproduce Misrecognition in Peer Evaluations
Supplemental material, sj-pdf-1-asr-10.1177_00031224251318051 for (Not) Getting What You Deserve: How Misrecognized Evaluators Reproduce Misrecognition in Peer Evaluations by Mabel Abraham, Tristan L. Botelho and James T. Carter in American Sociological Review
Footnotes
Acknowledgements
We gratefully acknowledge Joel Brockner, Vanessa Burbano, Emilio Castilla, Jen Dannals, Stephan Meier, Ray Reagans, Amanda Sharkey, Mario Small, and Ezra Zuckerman for helpful comments and conversations. We also thank participants at the Boston University Management and Organizations seminar, Columbia Business School Management Division seminar, Northeastern University Management & Organizational Development Seminar, and Yale University Sociology seminar.
Authors’ Note
Authors are listed in alphabetical order and contributed equally.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.