
Abstract
Large-scale assessments still focus on those aspects of students’ competence that can be evaluated using paper-and-pencil tests (or computer-administered versions thereof). Performance tests are considered costly due to administration and scoring, and, more importantly, they are limited in reliability and validity. In this article, we demonstrate how a sociocognitive perspective provides an understanding of these issues and how, based on this understanding, an argument-based approach to assessment design, interpretation, and use can help to develop comprehensive, yet reliable and valid, performance-based assessments of student competence. More specifically, we describe the development of a computer-administered, simulation-based assessment that can reliably and validly assess students’ competence to plan, perform, and analyze physics experiments at a large scale. Data from multiple validation studies support the potential of adopting a sociocognitive perspective and assessments based on an argument-based approach to design, interpretation, and use. We conclude by discussing the potential of simulations and automated scoring methods for reliable and valid performance-based assessments of student competence.
The increasing need for citizens sufficiently literate in science has led to a growing call for educational reform around the world (e.g., Bybee and Fuchs 2006). For too long, science education has focused on teaching students knowledge, skills, and abilities in isolation from each other (Schmidt, McKnight, and Raizen 1997). To adequately prepare students for a life in a world shaped by scientific and technological advancements, students must develop the competence to engage in the practices of science and engineering (e.g., National Research Council [NRC] 2012; for an overview, see Waddington, Nentwig, and Schanze 2007). These practices include identifying questions about phenomena, conducting investigations to examine phenomena, and constructing models to explain phenomena, as well as arguing over concurring explanations of the same phenomenon. One key method of investigation is experimentation (Emden and Sumfleth 2016, 29). Therefore, supporting students in developing competence in experimentation, that is, to plan and perform experiments as well as to analyze and interpret the data collected through these experiments, addresses the major aim of science education—to ensure a scientifically literate citizenship (NRC 2012).
To help implement educational reform that can support students in developing competence in experimentation, assessments are needed that can provide information on student learning—for purposes of classroom learning (i.e., to help teachers plan instruction) but also for accountability purposes (e.g., to evaluate curricula or educational programs; NRC 2014). However, whereas classroom assessments cover the full range of students’ competence in planning, performing, and analyzing experiments (e.g., Nawrath, Maiseyenka, and Schecker 2011), assessments for accountability or monitoring purposes (e.g., the National Assessment of Educational Progress) have mostly focused on the planning of experiments or the analysis of the collected data, if competence in experimentation is assessed at all (e.g., Grigg, Lauko, and Brockway 2006; see also Quellmalz et al. 2007). This is because assessing the performance of experiments comes with a range of difficulties when implemented at a large scale (e.g., Baxter et al. 1992). Paper-and-pencil tests, favored for use in large-scale studies for their efficiency with respect to administration and scoring (Clarke-Midura and Dede 2010), have been found to underrepresent competence in performing experiments (e.g., Shavelson, Ruiz-Primo, and Wiley 1999; Stecher et al. 2000). Performance tests, on the other hand, are costlier to develop and score (Stecher and Klein 1997); and, more importantly, student scores have been found to depend on multiple factors, including the specific selection of tasks (e.g., Shavelson, Baxter, and Gao 1993), the time the tasks are administered (e.g., Shavelson, Ruiz-Primo, and Wiley 1999), and content knowledge required to address the tasks (e.g., Gut-Glanzmann 2012). As a result, there is a paucity of assessments that can provide reliable and valid information on students’ competence in experimentation.
In this article, we describe our efforts to develop a performance assessment that can reliably and validly assess students’ competence in planning, performing, and analyzing physics experiments for use on a large scale. We begin with analyzing previous efforts from a sociocognitive perspective to obtain insights into the problems underlying these efforts. Based on this analysis we identify implications for developing the needed assessments. We then detail the steps we have taken to ensure that the assessment we constructed will provide reliable and valid information and draw on evidence from multiple validation studies undertaken throughout this process to create an argument for how the assessment we developed yields information about students’ competence in experimentation. We conclude by discussing the implications for the assessment of other aspects of student competence in science that have also been neglected because performance assessments have been deemed too ineffective for use on a large scale. In doing so, we briefly address the future of assessment and assessment development, highlighting the role of psychometric and technological developments for performance assessments.
A Sociocognitive Perspective on Assessing Experimentation Competence
Competence in the practices of science and engineering, although based on a profound knowledge of science, also requires a range of skills and abilities. Competence in any domain is in fact characterized by the capacity to integrate different knowledge, skills, and abilities (KSAs) required to identify and solve problems typical for the domain across a wide(r) range of contexts (Weinert 2001). Accordingly, the competence to plan, perform, and analyze experiments in physics requires a wide range of different KSAs; among them is disciplinary knowledge of physics concepts and principles (e.g., knowledge about the factors that may influence measurement of the current through a resistor as a function of the voltage applied to it), the skills to manipulate experimentation devices (e.g., the skill to adjust the voltage or use an amperemeter to measure the current), and the ability to represent the data obtained graphically (e.g., the ability to create a diagram showing voltage applied over current measured for the resistor). Taken together, these KSAs or more generally the competence to plan and perform experiments and to analyze and interpret the obtained data are termed “experimental (or experimentation) competence” (Gut-Glanzmann 2012).
Most efforts to model experimentation competence are based on Klahr and Dunbar’s (1988) scientific discovery as dual search (SDDS) model. This model describes experimentation in two spaces: the hypothesis space and the experiment space. The hypothesis space includes potential hypotheses in all variations, valid or not. The experiment space consists of the experiments suitable for testing the hypotheses. The actual process of scientific investigation through experimentation then involves (multiple iterations of) three consecutive steps: (1) the search for a potentially applicable hypothesis in the hypothesis space; (2) the testing of the identified hypothesis through the selection and implementation of an experiment from the experiment space; and (3) the analysis of the evidence obtained from the experiment in light of the hypothesis and the decision whether the hypothesis can be or needs to be rejected, that is, essentially, the planning, performance, and analysis of experiments (Emden and Sumfleth 2016). More differentiated models identify more steps. Nawrath, Maiseyenka, and Schecker (2011) propose one of the most differentiated models with seven steps: (1) developing a guiding question, (2) formulating a hypothesis, (3) planning the experiment, (4) setting up the (functioning) experiment, (5) observing and measuring, (6) analyzing data, and (7) drawing conclusions. All these models describe students’ experimentation competence in terms of steps in the experimentation process that need to be accomplished to successfully plan, perform, and analyze the experiment—assuming that each step requires different KSAs (for an overview across models, see Emden 2011). None of the models, however, identifies specific knowledge, abilities, or skills, although these are considered to be relevant in the experimentation process (Härtig, Erb, and Neumann 2017). This may be understood from a sociocognitive perspective (for details see Mislevy, this volume).
From a sociocognitive perspective, successful interaction with the world of experimentation requires specific patterns of behavior—so called linguistic, cultural, and substantive (LCS) patterns. These patterns reflect demonstrations of specific disciplinary KSAs required to successfully perform the steps of the experimentation process. Each step in the experimentation process requires the demonstration of different KSAs. Successful planning of an experiment to investigate the relationship between voltage over a resistor and the current through the resistor, for example, requires blending knowledge about how to correctly measure voltage and current, the ability to control potentially influencing variables (e.g., temperature; Schwichow et al. 2016), and the skills to plan the measurements. Underlying the demonstration of the different KSAs (and hence LCS patterns) are within student resources (Mislevy 2016)—in the simplest case, respective KSAs actually held by the individual student. In some cases, however, different resources (i.e., KSAs) may lead to the same demonstrations (i.e., LCS patterns). A student may, for example, combine the knowledge that temperature affects the resistance of a resistor and thus the current through the resistor under a given voltage with the skill to apply control of the variable strategy. Or the student may simply know that temperature needs to be controlled, maybe because it was explicitly covered during physics instruction. Understanding student experimentation competence as a capacity to demonstrate LCS patterns (varying across different steps of the experimentation process) as a product of cognitive resources (varying across students) may explain some of the limitations observed in the reliability and validity of assessing students’ experimentation competence on a large scale (i.e., across a wide range of tasks and students).
Assessments of experimentation competence have mostly deployed either paper-and-pencil tests or performance tests using real experiments. Paper-and-pencil tests have been criticized for a lack of validity, as they typically neglect the performance of experiments (e.g., Ruiz-Primo and Shavelson 1996). Instead, paper-and-pencil-based assessments focus on the formulation of hypotheses, the planning of experiments to test these hypotheses (often with a specific focus on the control of variables; e.g., Schwichow et al. 2016), the analysis of a given dataset (i.e., observations), or the drawing of conclusions from the given data (e.g., Lawson 1978). Lawson’s (1978) classroom test of formal reasoning (CTFR) may have served as a prototype for paper-and-pencil tests designed to assess experimentation competence. The test includes questions asking students to make predictions and justify them, designing experiments and applying the control of variables strategy, and drawing conclusions based on data. However, the assessment of student experimentation competence through paper-and-pencil tests has been criticized as meaningless and potentially dangerous as it fails to capture the complexity of the enterprise that is scientific investigation through experimentation (Hodson 1992), a critique that is supported by a wealth of research findings that students’ performance on real experiments and on paper-and-pencil tests are only weakly correlated, independent of whether the tests focus on the experimentation process as a whole or individual steps (Baxter et al. 1992; Ben-Zvi et al. 1977; Stecher et al. 2000).
Performance assessments based on real experiments are assumed to allow for more valid assessment of experimentation competence (Ayala et al. 2002; Baxter et al. 1992; Stecher et al. 2000). Such performance assessments typically provide students with a choice of experimental materials and a problem or task that needs to be solved using the experimental material. The “mystery box” assessment, for example, provides students with a set of (fully opaque) mystery boxes that may contain a combination of nothing, wiring, light bulb(s), or batteries. Students are additionally provided with the same choice of materials in a “naked” condition. Their task is then to find out what is in each of the boxes (Baxter, Elder, and Glaser 1996).
Two principal scoring procedures can be identified with respect to performance-based assessments: the product- (e.g., Baxter, Elder, and Glaser 1996) and the process-based procedure (e.g. Baxter et al. 1992). In the product-based procedure the product of students’ performance on the tasks (i.e., students’ written answer) is scored. The product-based procedure is more efficient and therefore more often utilized in large-scale assessments than in the process-based one (e.g., Garden 1999; Stebler, Reusser, and Ramseier 1997). However, a product-based procedure appears to limit the psychometric quality of the results, in particular the validity (e.g. Ruiz-Primo, Baxter, and Shavelson 1993; Shavelson, Baxter, and Gao 1993; Shavelson, Ruiz-Primo, and Wiley1999). The process-based procedure focuses on students’ proceedings while working on the tasks (i.e., how students obtain the answer; Baxter et al. 1992). As a result, the process-based procedure is considered to provide a more valid assessment of students’ experimental abilities and skills than the product-based one (e.g., Baxter et al. 1992). However, the process-based approach to analyzing performance-based assessments appears to be subject to issues of internal consistency (i.e., low intercorrelations among tasks; e.g., Koretz et al. 1994; see also Ruiz-Primo and Shavelson 1996). Close examination of these issues using generalizability theory indicates that a substantial amount of variability in student scores was explained by the person × task and person × task × occasion interactions. The former suggests that a students’ performance depends on the selection of tasks presented to the student, while the latter suggests that even if students receive the same tasks twice, on different occasions, their performance may vary substantially.
These findings have puzzled researchers and have raised questions of construct validity (i.e., performance on the tasks involves a substantial amount of construct-irrelevant variance) that become particularly apparent due to the small number of tasks each student can reasonably be expected to work through in a performance assessment (Baxter et al. 1992). Since increasing the number of performance tasks is typically not an option in a large-scale assessment setting, reducing construct-irrelevant variance would seem to be a priority. However, this is not easy to accomplish, since in this particular context (i.e., performance-based assessments of experimentation competence), what is commonly considered “construct-irrelevant variance” is not a problem but, rather, an important feature of the construct itself. This becomes understandable if we look at the problem situation from a sociocognitive perspective.
From a sociocognitive perspective, each step in the experimentation process requires different LCS patterns, which in turn can be produced by different within student resources. An electric circuit to measure the current through a resistor as a function of the voltage applied, for example, may be set up in different (equally good) ways, and there are different but equally good strategies to set up an electric circuit. In addition, experimentation is not a linear process. Sometimes students realize that they are going a wrong way while setting up the experiment (i.e., they have drawn on the wrong resources). In this case, they may abandon the process and start over (i.e., trying a new set of resources). Last, there are different meta-strategies in experimentation from trial-and-error through hill-climbing to planning ahead (Klahr et al. 2000). That is, students may not only have different resources for individual steps but also for how they approach the experiment altogether. Depending on the task and occasion students may simply activate different resources (i.e. KSAs), leading to different performances (i.e., LCS patterns) and eventually to the observed lack of internal consistency in performance assessments of students’ experimentation competence.
A sociocognitive perspective on the assessment of student experimentation competence for deployment in a large-scale assessment program requires reconceptualizing performance assessments. Large-scale performance assessments must (1) provide students with situations in the experimentation process that require them to demonstrate a set of clearly defined LCS patterns, (2) allow for students to consistently demonstrate these LCS patterns across multiple (real-world) situations, and (3) identify LCS patterns across persons to make claims about populations of students.
Situations in the experimentation process are typically situations in which students will activate complex blends of different resources (e.g., to analyze acquired data using a linear regression, students need to integrate knowledge about the underlying relationship between variables with the ability to perform a linear regression and the skills to represent their results graphically). However, different students might activate different resources or blend those resources in different ways. One blend of resources may also help in one situation but not in another (Mislevy 2016, 4). To reduce the realm of possible blends of resources (i.e., approaches to solving a particular task) to those we are specifically interested in it is important to define the LCS patterns students are expected to demonstrate as clearly as possible. The resources underlying LCS patterns are developed in and thus are closely bound to the situation of learning (Mislevy, this volume). That is, instruction in which students rarely have the chance to plan their own experiments will have only a very limited set of respective resources. Confronted with situations that require students to demonstrate a wide range of different LCS patterns, these students may succeed in one situation, but are likely to fail in another. Situations used in assessment need to resemble the situation of learning as closely as possible. This is not to say the situations need to be identical, but the situations need to be sufficiently similar in that the situation used for assessment provides sufficient cues to activate the resources acquired in the learning situation. This is despite the goal for assessing students’ ability to transfer, which has proven difficult (e.g., Bransford and Schwartz 1999; Pellegrino and Hilton 2012).
To validly assess student competence in experimentation, assessments must provide students with realistic application situations. For realistic application situations, the LCS patterns should not just be required to be demonstrated in the context of the situation but through dynamic interaction with the situation (Mislevy, this volume). This dynamic interaction calls for interactive assessments in which students are presented with a range of different situations resembling the realistic situations in which students would be likely expected to demonstrate the respective LCS patterns (Mislevy 2016). However, to be able to not only identify broader, more general patterns across students, but also fine-grained individual patterns, the tasks that students need to perform need to be sufficiently constrained and similar across different situations.
Last, scoring rubrics that allow for scoring performances reflecting LCS patterns at the same (level of) competence are needed, as are measurement models that allow students to be assigned a level of competence (with respect to each step in the experimentation process as well as with respect to students’ experimentation competence as a whole). This is particularly difficult since experimentation involves many different LCS patterns at many different levels of competence. Linking LCS patterns to more general levels of competence provides useful feedback to shape learning and instruction or, in the case of assessments for accountability purposes, curriculum and educational programs (see also Mislevy, this volume).
Developing a Reliable and Valid Large-Scale Assessment of Experimentation Competence
Assessments (large scale) need to present students with application situations that call upon LCS patterns developed through prior instruction and related learning experiences. These situations need to allow for students to interact with them much like in a real-world situation and demonstrate performance according to their resources. The performances must be scored, and the scores must be analyzed such that the large-scale assessments can provide information on, for example, how the sample of students is spread across different levels of competence with respect to specific areas of competence (see Ufer and Neumann [2018] for details). These steps form the basis for creating a purposive argument to show that the assessment can indeed provide reliable and valid information on student experimentation competence (for a detailed discussion of an argument-based approach to assessment, see Mislevy, this volume). Here, we detail our efforts to develop an assessment of student experimentation competence that aligns with these steps. More specifically, we show how we addressed the challenges identified by Mislevy (2016) that occur in the design and use of assessments, how to ground inferences and guide validation activities through specification of the assessment arguments, and how to embody the arguments in the objects and processes of operational assessments.
Step 1: Modeling and unpacking the construct
The first two challenges identified by Mislevy (2016) are to determine (1) the construct to be assessed and (2) the performances that need to be observed and the situations in which the performances need to be observed. The former step involves formulating a model of the construct, the latter unpacking the aspects of the construct as described by the model (see Neumann et al. 2016; NRC 2014). Formulating a model of experimentation competence relates to specifying typical LCS patterns needed to plan, perform, and carry out experiments and how to use them in the real world. In our work, in terms of a model of student experimentation competence, we build on Nawrath, Maiseyenka, and Schecker’s (2011) work. Based on the literature, we expected that each of the seven steps identified by Nawrath, Maiseyenka, and Schecker requires different LCS patterns. In contrast to previous large-scale assessments, we aimed to represent the experimentation process, including the steps of setting up an experiment and collecting data (i.e., observing and measuring), for a comprehensive assessment of student experimentation competence. In school physics, German students are provided plenty of opportunities to plan, perform, and analyze experiments and thus experience different (LCS) patterns related to experimentation. To limit the scope of LCS patterns reflected in our assessments, we focused on students at the end of middle school (i.e., ninth-grade, 15-year-old students). Understanding the performance expected as a result of a certain competence in a domain (or the situations in which such competence is expected to be developed) can help to further define performances that we expect to observe and in what kind of situations (Mislevy 2016, 6). To unpack the LCS patterns that students may have experienced, we performed an analysis of the curriculum, the results of which we had confirmed through a survey of middle school teachers.
In the curriculum analysis, we examined middle school physics curricula and textbooks. We analyzed the physics curricula for middle school gymnasium of all sixteen German states, as well as five major corresponding textbooks. Since textbooks are largely the same across states, we focused on the textbook editions for the largest-populated state, North-Rhine Westphalia. To account for potential differences, however, we also included the editions from four more states that showed the largest deviations from the North-Rhine Westphalian edition.
The analysis comprised two phases. In the first phase, we identified search terms in an inductive procedure. Due to differences across state curricula and textbook editions, we combined search terms into search term classes comprising sets of individual terms. The class “electric resistor,” for example, included terms “specific resistance,” “voltage-current-graphs,” or “conductivity.” Interrater reliability for this procedure ranged between κ = .78 and κ = .95 for the four main physics topics: mechanics, optics, electricity, and thermodynamics. In the second phase, we performed a systematic, criteria-based analysis in which we examined (1) whether the respective term class was found in the curriculum or textbook and (2) whether and how it was used in the context of the planning, performance, or analysis of an experiment. The data were processed into frequency tables from which we identified twenty-two experimental assignments most likely to be encountered by students throughout middle school (up to grade nine). However, the intended curriculum may not actually be matched by the implemented curriculum (i.e., instruction).
To confirm the extent to which the twenty-two experimental assignments align with classroom practices, we carried out an online expert survey with a total of fifty-three teachers. In this survey, we asked teachers how likely it was that students would have had appropriate learning opportunities, enabling them to complete the assignment. We also asked the teachers how likely students would be to be able to plan, perform, or analyze this or a very similar experiment by the end of middle school. We identified ten experimental assignments from three topics (three from mechanics and optics each, four from electricity) that met our main criterion (M ≥ 3.0 on a scale from 1: strong disagreement to 4: strong agreement). To further increase the range of assessment situations, we identified one more assignment for each of these topics that students had likely experienced based on teachers’ feedback. Thus, we had four assignments for each topic for assessment purposes and one additional training assignment from electricity to familiarize students with the assessment format (for more details, see Dickmann 2016).
In summary, we delineated the construct to be assessed—experimentation competence—into a model identifying seven steps in the experimentation process and described LCS patterns expected and situations in which they are expected to be demonstrated in terms of twelve typical experimental assignments that students are likely to have encountered during middle school physics instruction. These experimental assignments served as the basis for developing assessment tasks and items.
Step 2: Designing and authoring tasks assessing the construct
How we think about the construct is not only relevant for obtaining a precise description but has immediate implications for the design and authoring of the actual tasks used in assessing the construct. Delineating how we think about the construct helps in determining the features of the tasks that should be the same and features that can vary across tasks. This delineation is, thus, another important step in building an assessment argument (see Harris et al. 2016). From a sociocognitive perspective, assessment is about identifying similarities across an individual’s unique constellation of resources for LCS patterns (Mislevy 2016, 10). Such similarities can exist at different grain sizes given the LCS pattern(s) in question. Determining the relationship between the voltage over and the current through a resistor involves considerably more resources than representing the same relationship graphically from existing data. The fact that similarities across persons exist at different grain sizes may be another reason for the observed issues with performance tests, because (1) the more complex the resources (i.e., the more knowledge, skills, and abilities) involved, the more difficult it is to create a situation in which (only) one LCS pattern is required; and (2) the more (complex the) LCS pattern(s) required, the higher the chance that students fail because they are lacking a resource needed. Students may, for example, fail to investigate the relationship mentioned above because they are missing the skill to correctly set up an electric circuit. Still, they might have been able to ask the right question, plan the experiment, and collect and analyze the data. That is, similarities in resources for LCS patterns may be because of similarities in student experiences but also depend on the LCS pattern required by the situations presented to them (Mislevy, this volume).
To enhance the similarities of resources for LCS patterns activated in different situations, we decided to delineate the experimental assignments into tasks and items such that each experimental assignment would be represented by one task, which in turn would consist of several items, each one representing a different step in the experimentation process (Figure 1). Since the experimental assignments already determined question and hypotheses, we split the planning of the experiment step in Nawrath, Maiseyenka, and Schecker’s (2011) model into three steps: outlining a principle idea, detailing an experimental procedure, and preparing the measurement (protocol). We also differentiated the step of analyzing the data obtained into the development of an analysis strategy and the performance of the data analysis, resulting in a total of eight different steps in the experimentation process. For each experimental assignment we developed one task, consisting of six items covering six of the eight steps in the experimentation process as identified by our item development framework (Figure 1).
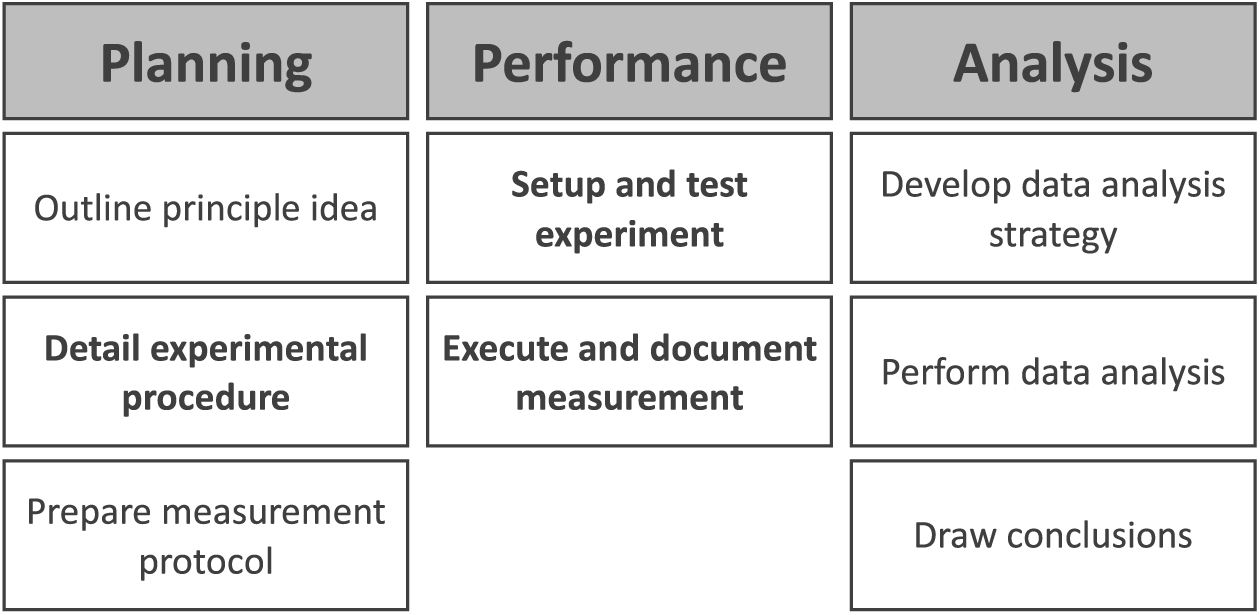
Item Development Framework
To retain the interactive nature in assessing experimentation and still limit the time needed to administer such a test, we addressed the second major challenge (i.e., how to assess higher-order constructs such as experimentation competence) by settling on a computer- administered, simulation-based format. That is, each task required students to plan, perform, and analyze a specific scientific experiment in a simulation presented to them through the computer. Each task started with a description of the experimental task in terms of the research question and hypothesis, which were presented as a question and hypothesis developed by Alina and Bodo, two fictional students (see Figure 2). We used Alina and Bodo to guide students through the task, since previous research has shown that students had stopped responding to tasks that required them to plan, perform, and analyze an experiment without further guidance (Schreiber 2012). After completion of each item, students were presented the solutions that Bodo and Alina had developed, so that they could continue working through the tasks (i.e., attempt to solve the next item), even though they might not have successfully solved an item in the process. This also allowed us to better isolate specific constellations of student resources (or assess LCS patterns, respectively).
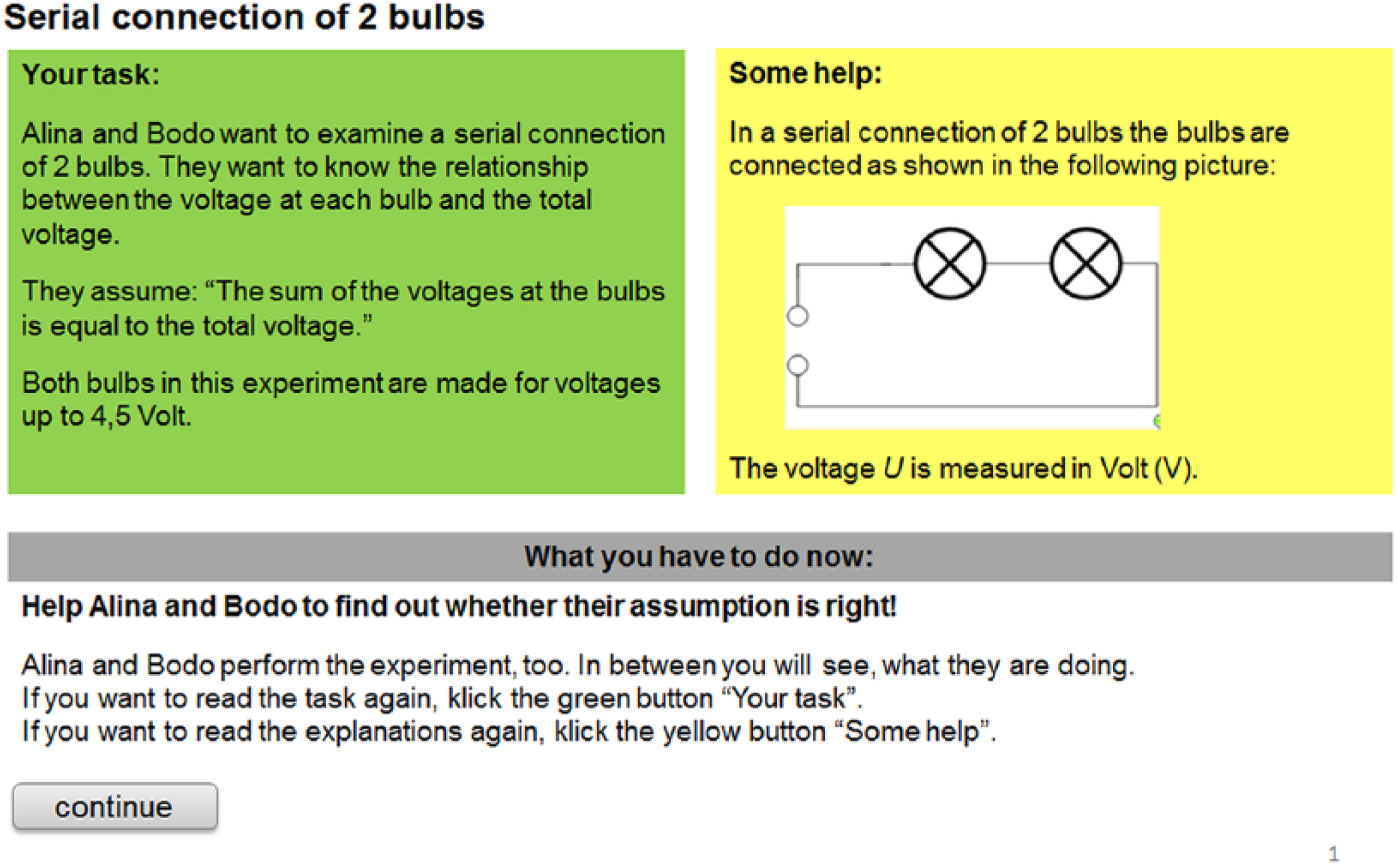
Sample Task with Research Question and Hypothesis, Developed by Fictional Students
As students’ performance in tests using interactive simulations has repeatedly been found to be closely correlated with students’ performance in hands-on experiments (e.g., Rosenquist, Shavelson, and Ruiz-Primo 2000; Shavelson, Ruiz-Primo, and Wiley 1999), we utilized simulations to assess LCS patterns related to performing experiments. A sample item assessing the execution and documentation of a measurement is shown in Figure 3. Altogether, we developed twelve experimental tasks consisting of a total of seventy-two items designed to assess students’ experimentation competence in three different content areas of middle school physics: mechanics, optics, and electricity. Each of the tasks represents a set of streamlined facsimiles of real-world situations in which students likely experienced the LCS patterns they are now expected to demonstrate.
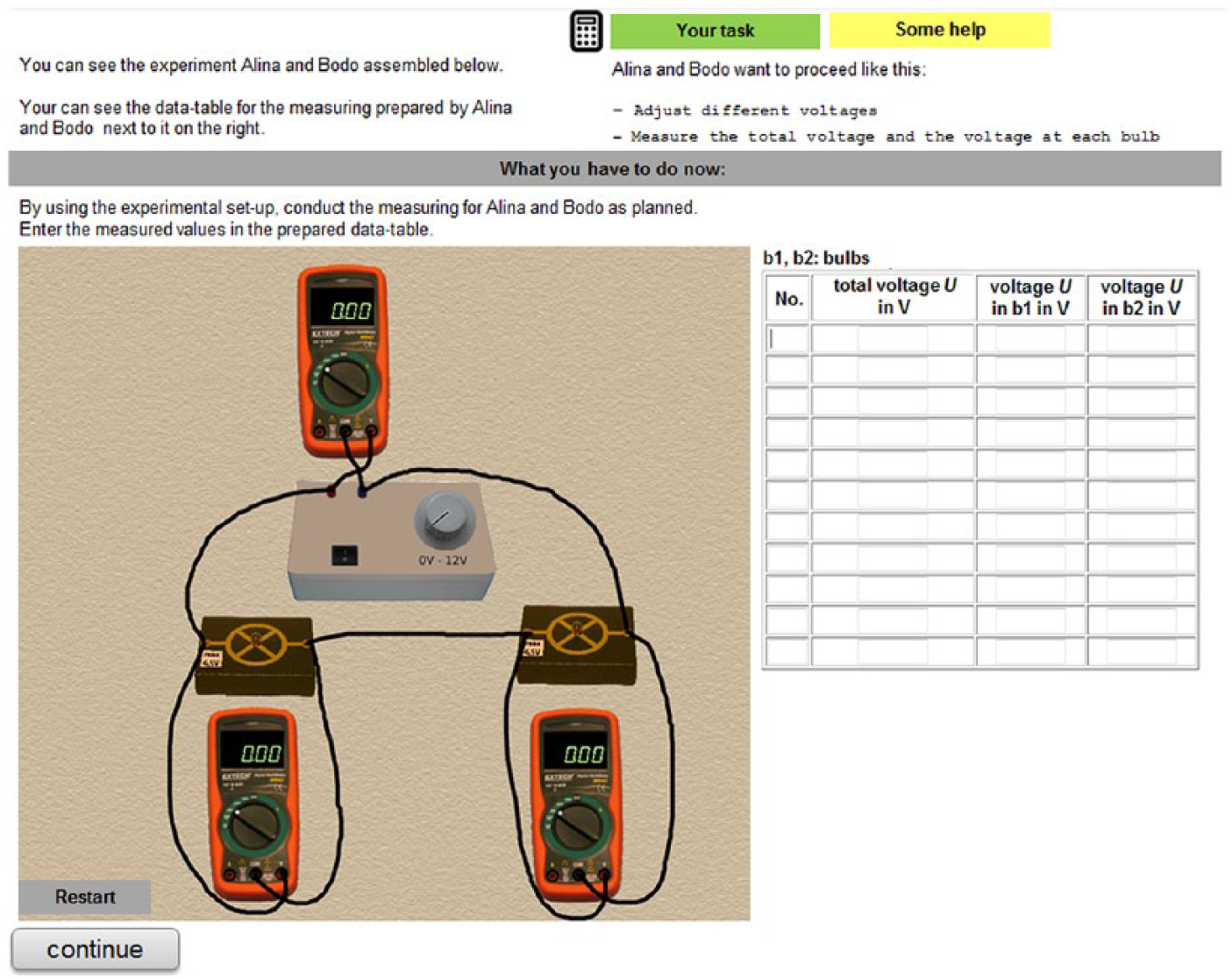
Sample Item Assessing the Execution and Documentation of a Measurement
To examine the extent to which these sets of facsimiles adequately (i.e., validly) represent actual real-world situations, we performed a think-aloud study that examined students’ thinking in both the computer-administered, simulation-based tasks and the actual real-world experimental tasks. In the study, a task was presented to students in the simulation-based version (nsim = forty students) and in a version based on hands-on experiments (nreal = twenty-five students). Students were asked to verbalize their thoughts when working through the task, and they were videotaped. Students’ verbalizations were coded on an interval-basis (10s) into one of five categories: (1) experiment-related (i.e., reflections on suitable experimental steps or the physics background of the experiment), (2) reproductive (i.e., related to reading out the task or describing one’s own actions), (3) technical (i.e., related to handling the apparatus or the software technically), (4) other, and (5) no verbalization. Interrater reliability was sufficient (.64 < κ < .90). Results suggested that experimental considerations dominated students’ solution strategies in both formats across all items (43–78 percent). Technical considerations were negligible (0– 20 percent). An analysis of variance (ANOVA) with test-format (i.e., simulation vs. hands-on) and item type (i.e., set up and test experiment; see Figure 1) as independent variables reveals that the percentage of experimental considerations varies significantly across items, F(3, 225) = 55.22, p < .001, ƞ2 = .424; but not across the test formats, F(1, 225) = 2.58, p =.110, ƞ2 = .011. No interaction between item and test format was observed, F(3, 225) = 1.87, p = .135, ƞ2 = .024 (Dickmann 2016, 121–24).
Step 3: Scoring and analyzing student performance
A third set of challenges relates to scoring and analyzing students’ performances, in particular, how to score (complex) performances on a large scale. Since performance-based assessments generally allow for different solutions (i.e., different constellations of resources), students’ performances were scored on a scale from not suitable to suitable. For items with higher interactivity (i.e., detail experimental procedure, set up and test experiment, and execute and document measurement) student performances were scored polytomously as not suitable (0), partially suitable (1), and suitable (2). Performances on the other items were scored dichotomously as not suitable (0) and suitable (1). Scoring guides provided specific indicators for each item, representing different levels of integration of the resources underlying the expected LCS patterns, where suitable solutions usually represented full integration (see also Neumann et al. 2016). For items assessing LCS patterns related to setting up and testing an experiment, the difference between partially suitable and suitable solutions is generally characterized by partially suitable setups, both being suitable to produce the phenomenon of investigation (e.g., electric current through a resistor), but not allowing for a meaningful measurement—for example, because multimeters were integrated in the circuit incorrectly. The developed scoring guides were used to score data from a field test. In the field test, the twelve experimental tasks were grouped into twelve test booklets with four experimental tasks each. Since each task took about 25 minutes to complete, the total test time was 100 minutes per booklet. The test was then administered to 1,262 students, with each student completing one booklet. Interrater agreement was determined to be very good on average (.63 < κ < 1, mean κ = .84; Theyßen et al. 2016). The time for scoring students’ responses for a full experimental task (i.e., six items) was roughly three minutes for trained coders.
A second challenge relates to how to analyze the scored data to obtain information about students’ experimentation competence. To obtain information about students’ experimentation competence as a whole, we chose a one-dimensional partial credit Rasch model. The results indicated a very good fit of the data to the Rasch model. Applying the usual cut off criterion for mean square (MNSQ) fit statistics (0.80 < weighted MNSQ < 1.20) seventy out of seventy-two items exhibited sufficient model fit (Theyßen et al. 2016). The difference between average item difficulty and person ability of –.10 logits suggested an adequate overall difficulty of the test. Analysis of the distribution of item difficulties in comparison to the distribution of person abilities yielded adequate coverage of the trait. We found a sufficient number of items at both ends of the spectrum of person abilities to differentiate between low and high achieving students (αWLE = .84). This indicates a remarkably good reliability given that there were twenty-four items administered per person. Next, we examined the extent to which the assessment would provide us with reliable information about students’ experimentation competence at a finer grain, that is, in terms of planning, performing, and analyzing experiments. For this purpose, we used a three-dimensional partial credit Rasch model. Students’ competence in each of the three areas was found to be measured with satisfactory reliability (planning: αEAP = .77, performance: αEAP = .75, analysis: αEAP = .73), suggesting that our instrument cannot only provide reliable information about experimentation competence as a whole but also about students’ competence to perform individual steps of the experimentation process (i.e., demonstrate the LCS patterns required by each step in the experimentation process).
Summary and Conclusion
Specific aspects of students’ science competence have traditionally been neglected in large-scale assessment programs (i.e., the actual performance of experiments as the central part of students’ experimentation competence). One reason is that there have been persistent issues with reliability and validity of performance assessments that researchers have not been able to satisfactorily resolve for decades.
Taking a sociocognitive perspective on assessments, we employed an argument-based approach to developing a performance assessment that can reliably and validly assess students’ experimentation competence. Our approach to assessment design, interpretation, and use involves multiple steps: (1) modeling the construct and unpacking it in terms of LCS patterns using insights from a curriculum analysis, confirmed through an expert survey; (2) carefully designing and authoring tasks using a framework for the development of computer-administered items and using simulations to assess students planning, performance, and analysis of experiments validly; and (3) analyzing students experimentation competence reliably at different grain sizes. With each step, we addressed a different set of challenges to reliability and validity that arise in the process of assessment development (Mislevy 2016). We used the empirical insights gathered in each step to construct an argument that our instrument assesses students’ experimentation competence in physics reliably and validly.
There are, however, two challenges that remain mostly unaddressed in our efforts: how we assess interactional skills and how we take advantage of complex performance tasks. Practical constraints often limit complexity and interactivity of tasks (Mislevy 2016). In our assessment, we aimed to find the right complexity and interactivity of tasks to allow for students to find their own approach to solving the experimental problem but, at the same time, limit the LCS patterns to a reasonably scorable number. However, in our approach we are taking a product-based scoring approach, not taking advantage of the data available from the simulations (i.e., how students interact with the experiment). The fact that our assessment is computer-administered and simulation-based, however, offers potential for examining students’ interaction with the simulation or the administration environment more closely using data science methods. One approach could, for example, be to use knowledge discovery procedures to identify patterns in students’ interactions with the simulation (based on log file data) and try to align these patterns with different experimentation strategies (for an example for the use of knowledge discovery procedures in e-learning environments, see Lara et al. 2014). Such an approach to analyzing students’ interactions with the simulations may help us to understand what resources more competent students hold over less competent students instead of simply being able to describe what more competent students can do better than less competent students, as current approaches to describing levels of proficiency do (Schecker et al. 2016).
Footnotes
Note:
This work has been supported by a grant of the German Federal Ministry of Education and Research (FKZ 01LSA005).
Knut Neumann is a professor of physics education at the IPN Kiel. His research focuses on the assessment of student competence in science.
Horst Schecker is a professor of physics education at the University of Bremen. His research focuses on modeling and improving students’ competencies in physics.
Heike Theyßen is a professor of physics education at the University Duisburg-Essen. Her research focuses on experimental skills and knowledge development in physics.