
Abstract
One of the major challenges for humanitarian organizations in response planning is dealing with the inherent ambiguity and uncertainty in disaster situations. The available information that comes from different sources in postdisaster settings may involve missing elements and inconsistencies, which can hamper effective humanitarian decision‐making. In this paper, we propose a new methodological framework based on graph clustering and stochastic optimization to support humanitarian decision‐makers in analyzing the implications of divergent estimates from multiple data sources on final decisions and efficiently integrating these estimates into decision‐making. To the best of our knowledge, the integration of ambiguous information into decision‐making by combining a cluster machine learning method with stochastic optimization has not been done before. We illustrate the proposed approach on a realistic case study that focuses on locating shelters to serve internally displaced people (IDP) in a conflict setting, specifically, the Syrian civil war. We use the needs assessment data from two different reliable sources to estimate the shelter needs in Idleb, a district of Syria. The analysis of data provided by two assessment sources has indicated a high degree of ambiguity due to inconsistent estimates. We apply the proposed methodology to integrate divergent estimates in making shelter location decisions. The results highlight that our methodology leads to higher satisfaction of demand for shelters than other approaches such as a classical stochastic programming model. Moreover, we show that our solution integrates information coming from both sources more efficiently thereby hedging against the ambiguity more effectively. With the newly proposed methodology, the decision‐maker is able to analyze the degree of ambiguity in the data and the degree of consensus between different data sources to ultimately make better decisions for delivering humanitarian aid.
INTRODUCTION
While the availability of high‐quality information is crucial to make effective decisions for all organizations, it can be difficult to access complete and accurate information in some settings. In particular, the nature of the information flow in complex humanitarian environments (such as after a natural disaster or during a conflict) can significantly impede effective decision‐making processes of humanitarian agencies, which aim to provide timely and sufficient aid (Altay & Labonte, 2014; Day et al., 2012). Specifically, humanitarian agencies have to make decisions under significant uncertainty due to lack of sufficient information on various parameters (e.g., needs, infrastructure conditions) that are critical for disaster response. Moreover, to estimate these parameters, agencies often need to make sense of a large amount of information with missing and inconsistent elements, which can create high degrees of ambiguity in decision‐making. Specifically, ambiguity is defined as “uncertainty about probability, created by missing information that is relevant and could be known” (Snow, 2010). While eliminating ambiguity in postdisaster environments may not be possible, we propose a methodological framework that enhances agencies' capabilities to deal with ambiguity in decision‐making.
In postdisaster environments, available information may involve inconsistencies since data can come from a variety of sources (Altay & Labonte, 2014; Day et al., 2012). For instance, postdisaster needs may be estimated by using predisaster information (e.g., governmental statistics) and postdisaster information obtained through various technologies (e.g., aerial images from satellites and drones), and media reports and interviews made by local key informants (such as community leaders). In addition to the large number and diversity of information sources, different methods and assumptions can be used in data processing, which can lead to different estimates on critical parameters used for planning response activities. While considering all available information may be attractive in making plans, it is challenging for humanitarian organizations to systematically integrate different estimates into decision‐making in an environment where the pressure and stakes for acting quickly are high. There is an overarching need for approaches that support humanitarian decision‐makers to integrate information processing and decision‐making in postdisaster settings effectively (Comes et al., 2020; O'Brien, 2017; Raymond & Al Achkar, 2016). In this study, we aim to address this important research gap.
Given multiple estimates on a parameter (e.g., the proportion of people with shelter or food needs), a humanitarian decision‐maker can combine different values into a single value by applying simple aggregation techniques such as taking the highest data value to “play it safe” (Day et al., 2012) or computing the average (Benini et al., 2017). Defining a triangular distribution based on the best, minimum, and maximum estimates is also possible (Benini et al., 2017). In the humanitarian logistics literature, it is common to define probability distributions to represent the uncertainties brought by different estimates and then to use stochastic optimization to support postdisaster decisions such as last‐mile relief distribution and shelter location (Dönmez et al., 2021; Liberatore et al., 2013). However, such mathematical aggregation of data without examining its consequences on decision‐making can mask the effects and contributions of individual data sources in final decisions (Benini et al., 2017). When the data from different sources are aggregated into a single value or a probability distribution, it is not possible to observe whether the final solution would correspond to a consensus decision if the individual assessments were considered. Thus, one cannot identify which decisions are supported by different estimates, and which ones are significantly affected by the differences among assessments. Decision‐makers may also not know which data aggregation techniques to use (computing simple averages or using more sophisticated techniques), and, most importantly, the effects of the chosen aggregation techniques on the final decisions. Therefore, additional information that would reduce such a high level of ambiguity in decision‐making would be valuable (Snow, 2010).
Rather than merging data coming from different sources by aggregating before solving a decision‐making problem, we develop a method that can effectively integrate the data aggregation and decision‐making processes. Specifically, given different estimates provided by multiple data sources on critical parameters for postdisaster decision‐making, we present an approach based on stochastic optimization and unsupervised machine learning, specifically graph clustering, which aims to identify groups of scenarios whose associated solutions are similar. The resulting clusters provide the information that directly reduces the level of ambiguity faced by the decision‐maker. More specifically, the proposed methodological framework aims to deal with ambiguity in humanitarian decision‐making by (i) analyzing solutions systematically to identify whether there exists a high degree of consensus among different estimates in terms of their implications on decisions and observe how different estimates influence the decisions, and (ii) integrating the data from different sources into decision‐making in a meaningful way by adjusting the weights to different solutions to obtain the most “agreed” solution.
While our methodology is general and can be applied to different decision‐making environments where quantitative estimates are available from multiple sources, we illustrate the implementation of the proposed approach in a case study focusing on the integration of needs assessment data with shelter location decisions during the Syrian conflict. Since the beginning of the conflict, sector‐specific (e.g., shelter, nutrition) needs across the country have been systematically assessed by different humanitarian initiatives. However, discrepancies may occur between different assessments since different initiatives may follow different methodologies to conduct surveys with different key informants, as well as they may use different assumptions and techniques while cleaning and aggregating the collected information. For instance, as reported by Benini et al. (2017), the estimated proportion of internally displaced people (IDP) in a single subdistrict of Syria varies between 15% and 74% across different data sources. We apply the proposed methodology to the needs assessment data provided by two reliable assessment initiatives, which were collected in July/August 2018 from the Idleb subdistrict of Syria. We integrate the needs assessment data related to the shelter needs of the affected population into decision‐making for designing a shelter network and show the benefits of the proposed approach in dealing with information ambiguity compared to traditional approaches.
To summarize, the contributions of this paper are as follows: We design a novel and computationally efficient two‐phase methodological framework to support the humanitarian decision‐making process in a postdisaster setting that includes a descriptive phase that directly analyzes the levels of information ambiguity stemming from the obtained parameter assessments from the different data sources; a prescriptive phase that defines a stochastic optimization model by adjusting the relative weights given to each scenario generated in such a way as to reduce the level of ambiguity in the informational context. We demonstrate how the scenario clustering method developed in Hewitt et al. (2022), which relies on the use of a decision‐based opportunity loss dissimilarity function to identify patterns in a scenario set, can be generalized and extended to directly analyze the levels of ambiguity that humanitarian decision‐makers face when planning operations following a disaster. Specifically, we show that the defined dissimilarity function provides the key to search for clusters of scenarios that exhibit a higher level of decision consensus across multiple data sources. Such clusters then directly reduce the levels of ambiguity in the informational context involved in the planning, which, in turn, provide value to the humanitarian decision‐makers. The development of a clustering method in combination with stochastic programming to reduce ambiguity has not yet been done. We illustrate the usefulness and efficiency of our proposed methodological framework using real‐world data. Specifically, our case study addresses the integration of needs assessment data with the decisions of locating shelters during the Syrian conflict. We evaluate the quality of our solutions with respect to a naïve approach and a common stochastic optimization model. We also derive insights on the benefits of our proposed approach for the humanitarian decision‐makers.
To the best of our knowledge, this is the first study to address the problem of ambiguity and divergence of estimates in humanitarian decision‐making processes.
The rest of this paper is organized as follows. In Section 2, we review the relevant literature. In Section 3, we define our problem and in Section 4, we describe our methodological framework. We present a numerical analysis to illustrate the implementation and advantages of the proposed methodology in Section 5. Finally, we conclude and discuss future research in Section 6.
LITERATURE REVIEW
In this section, we review the relevant literature on decision‐making and information management in humanitarian operations (Section 2.1), machine learning and ambiguity (Section 2.2), and shelter location problems (Section 2.3).
Humanitarian decision‐making and information management
This study is motivated by the need for systematical approaches to facilitate linking information management and decision‐making processes, which is a primary challenge in humanitarian environments. There exists a rich literature that present analytical models to address a variety of humanitarian decision‐making problems arising in different settings, including transportation planning and fleet management (e.g., Gralla et al., 2016; McCoy & Lee, 2014), inventory and distribution planning (e.g., Azizi et al., 2021; Gallien et al., 2021), prepositioning and network design (e.g., Balcik et al., 2019; Dufour et al., 2018), and postdisaster debris operations (e.g., Lorca et al., 2017). As described by Gralla et al. (2016), humanitarian logisticians must make decisions quickly in emergency situations by using incomplete and large amount of information coming from different sources. Because of the urgency involved, information must be gathered quickly and disseminated to the relevant stakeholders. Several studies highlight the important role of accurate information for humanitarian decision‐making and the challenges of information management in disaster contexts (e.g., Altay & Labonte, 2014; Comes et al., 2020; Day et al., 2012; Ergun et al., 2014; Gupta et al., 2016, 2019; P. Shi et al., 2023; Van de Walle & Comes, 2015).
While humanitarian organizations have traditionally suffered from lack of consistent data and information (Starr & Van Wassenhove, 2014), recent advances in technology present major opportunities for leveraging data and information to improve humanitarian operations (Swaminathan, 2018). Humanitarian organizations are increasingly interested in utilizing the benefits of technological innovations in dealing with the complex and dynamic operational environment (Besiou & Van Wassenhove, 2020; Marić et al., 2022; Yoo et al., 2020). However, given that disaster managers are faced with large amounts of information, integration of multiple sources to achieve accurate information for effective decision‐making has become an important concern (Gupta et al., 2019). Moreover, no single actor can be the source of all required data in humanitarian environments (Balcik et al., 2010), and different agencies may have different estimates about needs (Ruesch et al., 2022).
Furthermore, in the case of violent conflict situations, it may not be even safe for aid workers to collect data on the ground. Indeed, humanitarian organizations often use external data as it is not feasible for them to collect their own data relevant to plan their response. Therefore, different initiatives (e.g., Humanitarian Data Exchange platform, which is managed by United Nations Office for the Coordination of Humanitarian Affairs (OCHA's) Centre for Humanitarian Data) have been launched to ensure access to quality‐assured or accurate data and support evidence‐based decision‐making. How to facilitate such open data by humanitarian agencies operating in the field is also discussed in the literature (e.g., Abuoda et al., 2021; Paulus et al., 2018; Swamy et al., 2019).
Large amounts of information from heterogeneous sources can bring significant challenges for humanitarian organizations that have limited time to make decisions (e.g., Hosseinnezhad & Saidi‐mehrabad, 2018). Swaminathan (2018) stresses the need for methods that can effectively synthesize different data streams. Taylor et al. (2021) discuss that ambiguity and uncertainty are the main reasons for the difference between postdisaster policy formulation and its actual implementation and emphasize the need for new approaches integrating ambiguity, vagueness, and inconsistency. Zagorecki et al. (2013) highlight the importance of applying advanced analysis techniques that creates new knowledge from available data, rather than processing the data in a prescribed manner. We aim to address the need for innovative methods to better link information management and decision‐making in humanitarian supply chains, which is increasingly stressed as an important research gap (e.g., Comes et al., 2020; Van Wassenhove & Besiou, 2013). While the existing humanitarian decision‐making studies may consider the effects of uncertainties due to data unavailability by using various stochastic and robust optimization approaches, to the best of our knowledge, our study is the first to explicitly analyze the information from different viable sources and integrate them into decision‐making.
In this study, we link data processing and decision‐making by proposing a methodology based on unsupervised machine learning. The increasing use of technology in disaster settings enables the accessibility to ever greater amounts and types of data, making machine learning techniques increasingly popular in disaster management (e.g., Ofli et al., 2016; Sokat et al., 2016). Machine learning algorithms have a wide range of applications in disaster management such as identifying damaged buildings, detecting victim locations, predicting the behavior of crowds, assessing risks, and making predictions about disaster occurrences such as floods or fires (e.g., see reviews by Chamola et al., 2020; Linardos et al., 2022; Sun et al., 2020; Zagorecki et al., 2013). The existing techniques mostly focus on developing methodologies to utilize various sources of data to make predictions for informed decision‐making in disaster management. However, to the best of our knowledge, there exists no study that utilizes machine learning techniques to integrate estimates from different data sources into decision‐making by analyzing and reducing ambiguity, which we address in this study by presenting a novel method.
Machine learning and ambiguity
There is a vast literature on combining machine learning and optimization in general: for example, Bengio et al. (2021) and Vesselinova et al. (2020) for supervised approaches and Mazyavkina et al. (2021) for reinforcement learning applied to optimization. Applications of machine learning also appear with increasing frequency in humanitarian logistics, for example, Chamola et al. (2020). In the machine learning literature, the term “ambiguity” appears sometimes (e.g., Ghysels et al., 2021), but it has a different meaning in that context. There, ambiguity is defined in terms of inaccuracy in the data. This presupposes the existence of a ground truth from which the dataset diverges, which does not correspond to our meaning of the term: we do not assume that the ground truth is knowable. To the best of our knowledge, our specific contribution of reducing ambiguity through unsupervised machine learning has not previously been tackled.
Several review papers (e.g., Grass & Fischer, 2016; Gutjahr & Nolz, 2016) show that discrete scenarios are most often used to capture the uncertainties in disaster contexts. There are two general ways of generating scenarios in a humanitarian setting, either by deriving them from past data on disasters or by interviewing experts (Yáñez‐Sandivari et al., 2020). For instance, Andres et al. (2020) propose a scenario‐based artificial intelligence approach where scenarios are based on empirical data to forecast the number of forcibly displaced people.
In this study, we propose a scenario clustering approach to specifically analyze the levels of ambiguity regarding the source‐specific scenarios. Scenario clustering techniques have been primarily used to search for patterns in, or associated with, scenarios or to reduce the number of scenarios. (See Appendix A for an overview on scenario clustering approaches in the Supporting Information.) The generally large size of the scenario set (Birge & Louveaux, 2011) can lead to formulations that are intractable to solve directly (e.g., Dyer & Stougie, 2006). Our approach uses and extends the methodology of Hewitt et al. (2022) by analyzing the level of decision agreement among scenarios and integrating these scenarios through optimization to reach a consensus decision. Note that the approach of Hewitt et al. (2022) alone is not set up to analyze ambiguity.
Shelter location problems
In this study, we propose an integrated data aggregation and decision‐making methodology, which is illustrated in a postdisaster setting that focuses on linking the needs assessment data and shelter location decisions during a complex emergency. Both postdisaster needs assessment planning and shelter location problems are widely studied in different humanitarian contexts (e.g., see the reviews by Farahani et al., 2020; Galindo & Batta, 2013). While the assessment information may highly affect the design and management of relief operations, existing studies usually consider data analysis and decision‐making in an integrated way; rather, available assessment data is processed first to estimate the values of uncertain critical parameters (i.e., demand), which are then used as deterministic or stochastic inputs to solve an optimization problem for making disaster response decisions (e.g., Lorca et al., 2017; Stauffer et al., 2016). In contrast to the traditional sequential approach, we present a new method that integrates the available needs assessment data into decision‐making for disaster response, which can provide more intuition to decision‐makers in understanding the effects of data aggregation and making sense of different solutions generated by data from different assessment sources.
Locating shelters such as town halls, gyms, or tents, to serve the affected people after a disaster is an active research field (Kılcı et al., 2015; Kınay et al., 2018; Ni et al., 2018). Given that location decisions are extremely impeded by the high degree of uncertainty inherent in disaster and crisis situations, stochastic optimization techniques are widely utilized (Dönmez et al., 2021). Specifically, two‐stage stochastic models have been often used to model uncertainty, which consists of decisions made before (i.e., first stage) and after (i.e., second stage) the realization of uncertainty represented by scenarios. Two‐stage stochastic programming is well suited in the chaotic aftermath of a disaster where there exists a high level of uncertainty regarding needs in the affected region. We consider a two‐stage stochastic model to locate shelters with limited capacities by exploring how ambiguous needs assessment information can be integrated into the decision‐making. Note that robust optimization, particularly distributionally robust optimization, is an approach that can be applied to solve problems that involve ambiguity and to find solutions that hedge against the risks associated with this ambiguity. This is done by considering the worst case across the ambiguity, see, for example, the review by Rahimian and Mehrotra (2019). However, our objective here is to allow the decision‐maker to analyze and link the decisions to be made with the information provided by the different data sources, which cannot be achieved by applying robust optimization.
As discussed in Dönmez et al. (2021), shelter location decisions, which are widely addressed in the literature, are made under significant demand uncertainty (e.g., Kınay et al., 2018; Ozbay et al., 2019). The demand scenarios in the existing papers are often generated based on available data sources (i.e., historical data) by using various methods that rely on different assumptions. That is, there exist no standard datasets and methods followed to generate scenarios based on data. In this paper, we address an important concern that has been raised by practitioners (e.g., Benini et al., 2017), but not been addressed by the studies that use scenario‐based approaches in shelter location problems or other humanitarian logistics problems, which is dealing with the ambiguity that may be caused by multiple reliable data sources related to uncertain parameters for disaster response. We illustrate the benefits of the proposed approach by a case study developed with real data from the Syrian conflict.
In summary, this study contributes to the literature by developing a new methodology that links information processing with decision‐making in a postdisaster environment that involves uncertainty and ambiguity and presenting the benefits of the proposed approach in a complex emergency setting with real data. The proposed methodology can support humanitarian decision‐makers to eliminate the excessive effort and energy spent to deal with information ambiguity without connecting it to decisions and hence shifting the focus from aggregation of data to aggregation of data with respect to conclusions to be drawn. Although the proposed approach is illustrated with a shelter location problem formulated as a two‐stage stochastic model, it is general and would apply to any kind of optimization model involving scenarios.
PROBLEM DEFINITION
In this section, we first define the problem in general terms (Section 3.1) and then introduce a shelter location problem in a humanitarian setting (Section 3.2).
General problem statement
Consider a decision‐maker who faces a given problem involving uncertainty, such as the allocation of relief resources under demand or supply uncertainty. Specifically, the decision‐maker must make a series of decisions, which we represent as the variable vector x, while the informational context in which the problem appears contains uncertain parameters, which we represent as the parameter vector ξ. We further assume that
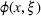
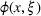
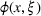
In the context of our shelter location problem (Section 3.2), x is the choice of shelter locations to serve the affected population that need shelter, whereas ξ represents a number of uncertain parameters that affect the outcome of the allocation of aid, such as the number of people in need of shelter. The function
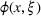
The probability measure
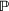
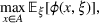
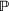
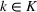
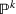
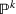

Stochastic optimization enables problems to be solved by formulating the uncertain parameters using a probability measure that is explicitly defined (see Birge and Louveaux, 2011). Although this approach does not directly tackle ambiguity, it allows a problem to be solved using different probability measures. When the approach is applied to the present problem, given any
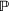
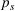

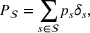
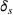
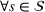
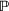
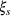
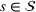
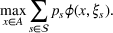
Assuming that problem (3) is solved using a given set
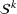
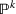
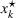
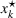
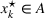
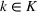
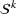
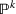
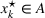

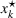
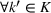
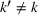
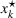
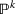
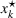

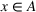
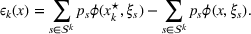
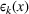
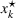
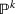
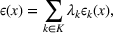
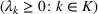
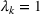
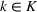
To deal with the ambiguity encoded in the probability measure, we then propose to search for a solution
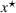
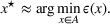
In the present paper, we will show that, by using a novel clustering methodology to perform a systematic analysis of the scenarios included in
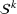

Shelter location problem and model
As stated in the introduction, when considering the type of problems that are faced by humanitarian organizations (such as the deployment of aid in postdisaster environments) another important imperative for decision‐makers is the need to analyze how the various data sources
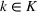
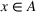
In this subsection, we consider a problem of accommodating people or families affected by a disaster, for example, a civil war as in our case, where it is difficult to obtain accurate information. For our case study in Section 5.2, we use two data sources, that is,
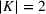
METHODOLOGICAL FRAMEWORK
We now detail the proposed methodological framework, which enables a large amount of information contained in the assessments emanating from the set of data sources
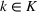
As discussed in the previous section, since the different data sources
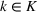
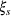
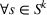

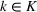

General methodological process.
In the first phase (descriptive phase), a descriptive analysis is performed on the source‐specific probability measures obtained from the set of data sources. The general objective of this phase is not only to specify the information provided by the data sources but also to assess the impacts that this information has on the considered planning problem. Upon completion, knowledge is obtained on the unknown contextual information of the problem and on the level of overall decision agreement between the models generated from the data sources.
The second phase of our framework is dedicated to the use of this knowledge to prescribe an appropriate solution to the problem (prescriptive phase). Through the use of novel decision analysis techniques and mathematical programming methods, the information extracted from the data sources is efficiently interpreted and aggregated to provide decision support. Specifically, we will show how an alternative approximation model of type (3) can be defined to obtain a consensus solution
In the rest of the section, we describe the two phases included in the framework, which involve five steps. The descriptive phase is explained in Section 4.1, while the prescriptive phase is presented in Section 4.2. Step I generates sets of scenarios that represent the assessments provided by each data source, following the general stochastic programming approach. Step II calculates the opportunity cost between scenarios in order to quantify the error of predicting the wrong one. Step III identifies groups of scenarios that are close to each other with respect to the opportunity cost defined in Step II. Steps II and III apply a version of the clustering methodology of Hewitt et al. (2022) adapted to our setting. Finally, Steps IV (ambiguity analysis) and V (integration through optimization) are new and make up the key methodological innovations of this paper. Overall, these last two steps lead to defining an optimization model which, once solved, provides us with the consensus solution.
Descriptive phase
Following Figure 1, the descriptive phase consists of performing the following four steps: scenario generation, opportunity cost distance computation, cluster generation, and ambiguity analysis.
Step I: Scenario generation
Obtaining information from each data source is subject to two types of error (Hoffman & Hammonds, 1994). On the one hand, there is the uncertainty encoded in the data source which we call intrinsic uncertainty. It is this type of uncertainty that motivates giving a range, rather than a point estimate. On the other hand, there is uncertainty not encoded in the data source, or extrinsic uncertainty. For example, any data source expressed through an expert assessment is likely subject to overestimation of the precision regarding the expert's predictions (Hammitt & Shlyakhter, 2006). Also, unlikely outcomes may not have occurred (or be explicitly considered) in the dataset, which leads to their probability being underestimated (Abdellaoui et al., 2011). In the extreme case, the range of values for an uncertain parameter obtained from different data sources may not even overlap: all values in the possible range extracted from one data source may be considered impossible by the other.
In order to hedge the risk posed by this extrinsic uncertainty, we formulate a larger prediction uncertainty than that given by any individual data source (see Section 5.1.1 and Appendix E for more details in the Supporting Information). Let us recall that we denote by
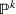
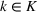
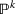
From these probability distributions, we then sample discrete values for the uncertain parameters and include them into scenarios: each scenario being associated with one set of values that the uncertain parameter vector takes. (See King and Wallace, 2012, for more details on sampling methods that can be applied in this context.) In the following, we will denote the discretization of the probability measure
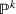
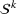
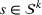
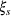
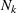
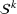
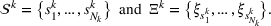
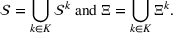
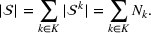
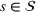
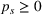
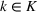
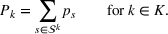
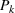
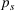
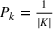
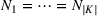
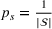
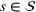
Step II: Opportunity cost distance
The second step of the descriptive phase defines the basis over which the scenarios included in the sets
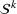

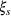
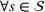
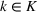
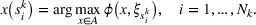
These solutions can be understood as follows: if one were somehow certain that scenario
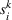
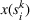
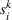
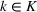
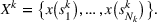
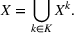
We now apply a notion of distance between scenarios, called opportunity cost distance that was first introduced in Hewitt et al. (2022). For any pair of scenarios
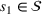
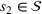
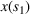
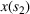
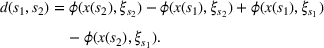
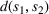
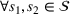
Step III: Cluster generation
Equipped with the opportunity cost distance function, and having computed the associated distance matrix, we now look for groups of scenarios that are very close to each other, but relatively far away from the other groups. This step reduces to solving a clustering problem over the scenario set
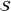
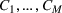
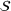
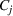
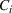
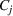
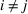
We will choose M so as to maximize a particular notion of clustering quality called the Silhouette score, which measures how close each scenario is to other members of its own cluster, compared to its distance to other clusters (Rousseeuw, 1987). In the literature, the elbow method (Bishop & Nasrabadi, 2006) is sometimes used. In this work, we prefer the Silhouette score because it takes into account both intercluster and intracluster distances. Moreover, the elbow method requires a subjective choice made by the modeler and is therefore less reproducible (Ketchen & Shook, 1996).
Step IV: Ambiguity analysis
This step is dedicated to analyzing the obtained clusters with a focus on diagnosing the level of decision agreement among the scenarios and data sources. We begin by identifying the level of agreement between data sources in terms of the decisions to be made, by analyzing the clusters generated above. For any subset
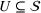
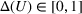
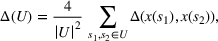
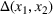
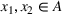
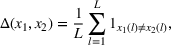
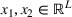
In this way, we can calculate the decision level of agreement within the clusters, that is,
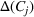
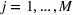
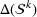
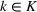
Another important dimension to consider in this analysis is the distribution of scenarios' origin within a cluster. We will be interested in distinguishing between clusters where all scenarios were generated by a single data source and clusters with a mix of scenarios from different data sources. In other words, we analyze the distribution of data sources in a cluster. By explicitly considering this information, the decision‐maker is able to directly analyze the levels of ambiguity related to the overall assessments provided by the different data sources (i.e., the context information contained in Ξ). Therefore, the more data sources are present in a given cluster, the less ambiguity is involved between them regarding the scenarios contained within the cluster. That is, even though the scenarios may originate from different data sources and may specify different values for the uncertain parameters, they all lead to make decisions (find solutions to the problem) that are similar (solutions that are good surrogates for one another). This analysis thus provides value for an ambiguity‐averse decision‐maker. Next, we show how a measure can be defined to quantify such observations. More precisely, for a cluster
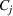
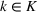
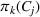
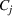
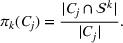
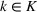
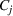
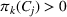
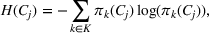
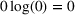
The value of
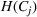
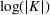
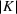
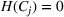
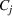
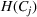
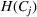
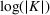
Prescriptive phase
As indicated in Figure 1, the prescriptive phase consists of performing the integration through optimization to achieve a consensus decision.
Step V: Integration through optimization
In order to integrate the different estimates coming from various sources, we introduce two choices, namely a subset
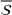
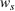
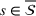
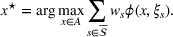
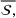
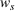
Regarding the choice of
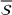
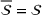
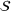
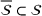
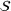
We define the weight
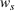
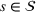
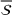
In the first part, we place more weights on scenarios in clusters that contain more data sources. This is done as a means to prioritize the context information emanating from a cluster where there is less ambiguity related to the data sources that are present within it. When the data sources provide a differing view on the underlying uncertainty, this can lead to a skewed representation of the information sources in clusters. Recall that in our setting we cannot judge the reliability of each source, and each source is assigned the same level of confidence. Thus, a source whose information leads to a higher level of uncertainty in our model will be represented in a larger number of different clusters. In turn, this knowledge allows us to better hedge against the risks of inaccurate predictions. This motivates the second part, where we place more weight on scenarios generated by data sources that appear in more clusters.
Diversity weight
The first weight
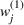
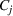
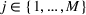
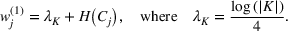
Stochasticity weight
As explained above, we also place more weight on scenarios generated from data sources that appear in more clusters. The second weight is the same for each scenario that was generated from the same source. We, therefore, denote the second weight by
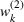
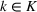
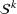
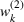
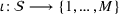
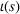
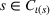
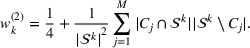
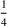
Defining the overall weight
Having defined the two weights
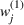
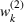
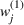
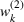
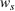
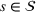
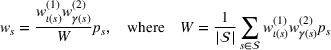
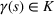
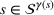
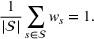
NUMERICAL STUDIES
In this section, we present numerical studies developed based on data from the Syrian conflict to illustrate the implementation of the proposed methodology and assess its value for decision‐makers. We focus on the integration of the needs assessment data with decision‐making for locating shelters to serve IDPs in Idleb. We generate synthetic assessment data and analyze our approach in Section 5.1. In Section 5.2, we focus on real assessments provided by two humanitarian initiatives active on the ground.
Synthetic tests
Syria has been at civil war since 2011, which has led to millions of casualties and displaced people (UN Refugee Agency, 2021). For the studies, we focus on the assessments of Idleb district, which is located in the northwestern part of the country bordering Turkey. Idleb is one of the most tormented parts of Syria due to frequent skirmishes between the Syrian government and the opposition forces. Due to the recurring bombardment and air strikes, about 1.7 million people have fled the area seeking security in neighboring countries like Turkey. Those who stay require essential supplies like water, food, and medical care. To illustrate our approach, we focus on people in need of shelter in Idleb and use the shelter location model given in Appendix B in the Supporting Information. In our synthetic tests, we suppose that there are five fictitious data sources, denoted by #1 to #5, from which we randomly generate shelter needs assessments. We further distinguish between the “close,” “medium,” and “wide” cases and simulate from each. The “close” case means that the shelter demand estimations provided by the five sources are rather similar, while in the “wide” case they are far apart. All remaining parameters are presented in Section 5.2.1.
Implementation of the methodology
In this section, we explain each step of our methodology.
Step I: Scenario generation
We randomly generate 1000 scenarios, that is, 200 from each fictitious source. Each scenario s can occur with the same probability, that is,
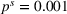
Step II: Opportunity cost distance
In the second step of our methodological process, the opportunity cost distances
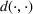
Step III: Cluster generation
Using the opportunity cost distance
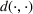
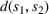
Step IV: Ambiguity analysis
In the last step of the descriptive phase, we analyze the consensus level between sources by determining the decisional level of agreement (11) and the diversity of sources in a cluster (13) based on the previously generated clusters.
Step V: Integration through optimization (prescriptive phase)
The integration step involves identifying the consensus decisions, which are obtained through optimization (14). The determination of the corresponding weights
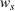
Let us define
Expected value approach: The expectation is applied over the information based on both sources as the means to integrate. When applied in our case problem, this entails that we define the expected scenario
Stochastic optimization: This is the traditional stochastic programming approach, which approximates the stochastic phenomena that is present in the considered problem by generating a set of representative scenarios. In this case, we thus define
Scenario clustering: The clusters generated in Step III of our methodology are used to perform the ambiguity analysis to assess the level of consistency between the sources regarding the information they are providing. In the present case, we set
Source‐specific integration: This approach relies solely on the information provided by the five sources. Therefore, we define
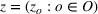
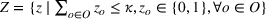
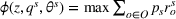
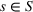
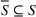
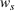
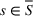
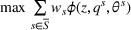
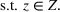
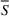
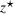
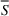
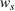
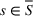
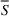
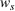
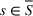
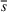
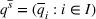

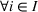
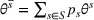
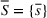
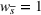

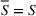
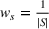
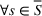
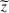
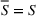
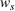
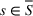

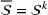
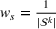
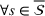
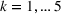
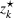
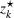
As we have no information about the relative reliability of the five sources, we weight them equally. This corresponds to choosing
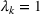
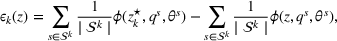
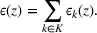
Results and analysis
In this section, we apply the steps of our methodology and present results for our cases that focus on making shelter location decisions based on multiple needs assessments. Based on the scenarios generated in Step I and shelter solutions
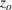
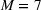
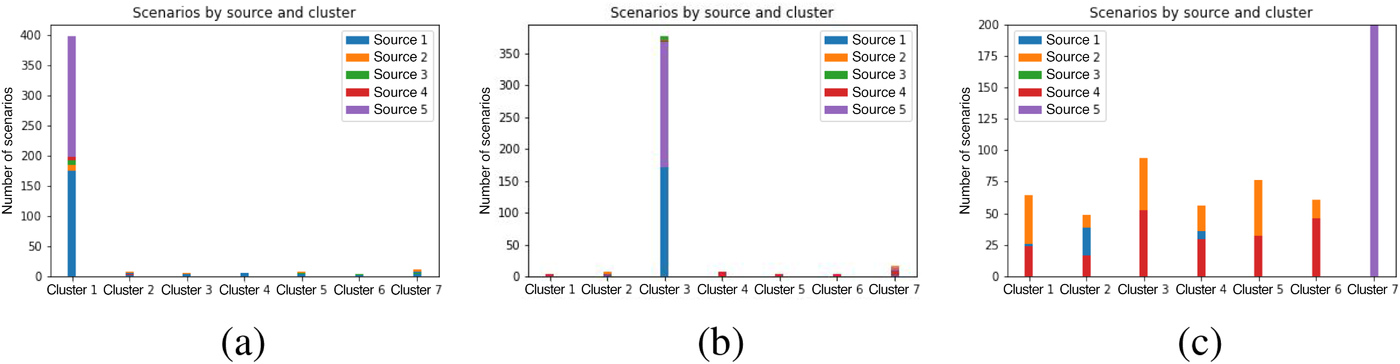
Distribution of scenarios across the clusters for case (a) “close,” (b) “medium,” and (c) “wide.”
We now implement Step V of our methodology by identifying consensus decisions
Comparison of gaps between the expected value and the new clustering approach for the “close,” “medium,” and “wide” cases.
These results confirm our intuition that our newly proposed methodological framework is particularly beneficial when there is a wider range of source estimates, less consensus on the solutions, and less diversity of sources within the clusters. Given that humanitarian environments highly exhibit these characteristics due to the large number and diversity of primary and secondary data sources, as highlighted by the literature, the proposed methodology can be highly useful for bridging humanitarian information management and decision‐making.
Idleb case study
We give background information on the needs assessment data provided by two different sources (Section 5.2.1) and conclude with the corresponding results (Sections 5.2.2 and 5.2.3).
Case dataset
In the light of the hazardous circumstances in Syria, gathering accurate information on the humanitarian situation is extremely challenging. Various humanitarian initiatives conduct needs assessments in the affected regions to gather information on the community necessities. The collected information is processed (cleaned, combined, cross‐checked with secondary sources) and the sector‐specific needs (shelter, nutrition, etc.) in each district are published publicly.
We focus on two major assessment datasets, which are made publicly available by two humanitarian initiatives, the Humanitarian Needs Overview (HNO) and REACH. There are other initiatives and organizations in Syria that focus on collecting and disseminating assessment data at different capacities (e.g., The International Organization for Migration, United Nations High Commissioner for Refugees). Because HNO and REACH data are available for the same period of time for shelter needs in the our focus district Idleb, we consider two sources.
HNO, a joint effort by the United Nations (UN) and its partners to assess the humanitarian situation in Syria, provides a consolidated and comprehensive dataset including estimates on the number of people in need for different types of relief in each district of Syria. We consider the nationwide needs assessment of HNO conducted for 6322 communities in Syria between July and August 2018. Specifically, 95,000 surveys at the household level were carried out. REACH (2018) also conducts need assessments in Syria on a regular basis since 2012. The assessments are based on community‐level interviews by key informants, which are selected based on their knowledge of resident populations and IDPs in the community and sector‐specific expertise. Specifically, three to seven key informants at each location are interviewed.
REACH, a nonprofit organization that aims to support humanitarian response through better information management, provides needs assessment data for the estimated total number of people residing in a district and the percentage of people requiring different types of supplies, for example, water, food. and shelters. We consider the assessment dataset of REACH based on the interviews conducted between 12 and 20 August 2018. In the following, we refer to HNO as source #1 and REACH as source #2 which provides estimates on the humanitarian needs.
While source #1 provides the estimated number of people requiring shelter in detail, source #2 provides an aggregate estimate according to which about 56% of local people are in need of shelter (REACH, 2018). We, therefore, multiplied the reported total population by 0.56 to obtain an estimation for shelter needs. We obtain two assessment values for shelter needs in each subdistrict, which can be used to represent demand for shelter at each subdistrict of Idleb.
As mentioned in Section 4, triangular probability distributions, consisting of a minimum value 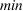
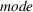
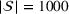
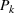
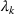
Idleb consists of 26 subdistricts, and we assume that a shelter can be opened at every of these subdistricts. Google Maps was used to obtain distances between the centers of the subdistricts. Since 2016, the OCHA organization has provided monthly information on the locations of shelters in Idleb and Aleppo, the types of shelters, and the number of IDPs accommodated. According to OCHA (2018), shelters were opened in 10 subdistricts of Idleb in August 2018, accommodating an average of 80,000 IPDs. Based on this information, we set that no more than 10 shelters can be opened, each with an average capacity of 80,000 people; hence, the maximum available shelter capacity is 800,000. As indicated by the Syria Needs Analysis Report (ACAPS, 2014), most IDPs have fled to their neighboring districts. Therefore, the maximum coverage distance is set to 35 km, which is the average distance between two neighboring districts.
Results and analysis
In the following, we again follow the steps presented in Section 5.1.1. Given the scenarios generated in Step I of our methodology, Step II consists in solving model (22)–(31) (Appendix B in the Supporting Information) for each scenario 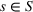
Location decisions to open shelters.
The reason for the “controversial” cases can be found in the distribution of overall demand according to the two sources. In some cases, these predictions are quite far apart. Consider, for example, the distribution of the overall demand prediction for Abul Thohur, illustrated in Figure 3a. Here, the ranges of estimated values based on the two sources barely overlap. In other words, there is high ambiguity between the two data sources with respect to the prediction of shelter demand, as the sources do not even agree on the range of feasible values.
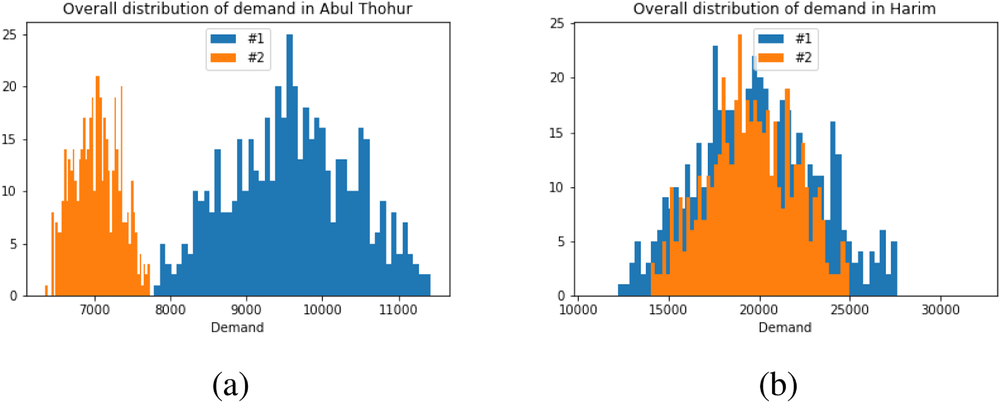
Overall demand prediction for Abul Thohur (a) and Harim (b), according to sources #1 and #2.
At the other extreme, there are districts where there is very low ambiguity since the predictions of the two sources almost completely coincide. Consider for example Figure 3b, where the overall demand prediction for Harim is shown. The question arises as to where shelter locations should be opened when demand assessments differ greatly in some cases, for example, as in Abul Thohur, and most shelter locations are “controversial” (Table 2). To answer this question, the ambiguity of both data sources has to be analyzed and integrated in the decision‐making process.
By implementing Step III of the proposed methodology and based on the Silhouette score, the optimal number of clusters is 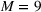
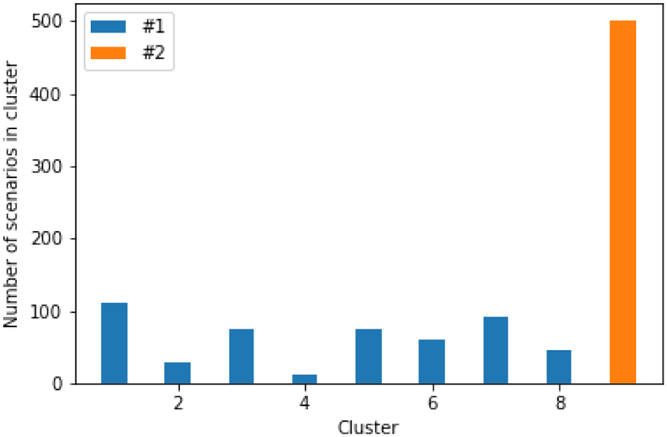
Distribution of scenarios across the clusters.
Within each of the nine generated clusters, the decision level of agreement (11) is shown in Table 3. A graphical representation of the distribution of opened shelters across the clusters is also given in Figure 7 in Appendix F in the Supporting Information. According to the results, in clusters consisting of scenarios from source #1, that is, C 1–C 8, there is relatively less consensus regarding shelter locations than in those from source #2, that is, C 9, resulting in a higher credibility of source #2. Such analyses allow the decision‐maker to understand the level of ambiguity in the information coming from different sources and its impact on shelter locations. Such insights cannot be gained when traditional stochastic optimization approaches are utilized.
Decision level of agreement by cluster 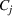
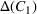
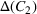
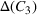
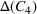
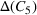
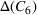
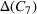
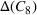
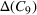
The shelter solutions for the different approaches described in Step V in Section 5.1.1 are shown in Table 4. Column “Actual” indicates where shelters were actually opened in August 2018 in Idleb (OCHA, 2018). As sources #1 and #2 estimate shelter needs for some districts differently, for example, as in the case of Abul Thohur, shelter solutions 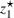
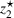
Shelter locations for different approaches.
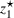
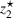

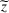

Notably, shelter locations chosen by the expected value and the stochastic approach have more overlaps with sources #1 and #2 than our clustering approach. To account for the underlying ambiguity, the shelter solution for the clustering approach has been computed with weights 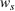
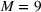
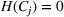
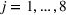
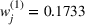
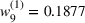
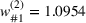
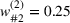
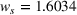
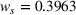

Out‐of‐sample tests
Now, we evaluate the objective value obtained by the proposed clustering method compared with respect to the expected value and stochastic approaches. For this purpose, out‐of‐samples tests were carried out, where 5000 scenarios were generated for source #1 and #2 each, based on the same principles as before and shelter locations from Table 4 were used as an input.
Table 5 shows the gaps (20) and (21) between the objective values of the out‐of‐sample tests for the different approaches. For instance, solution of the expected value accommodates 22,789 fewer people than the solution based on source #2. Though the shelter solution of the expected value approach has many overlaps with both data sources, it performs worst in terms of the objective value. The number of overlaps alone is no guarantee for a good objective value.
Gaps of objective values for different approaches.
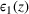
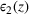
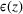
According to Table 5, the stochastic approach results in a smaller gap for source #2: 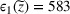
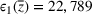
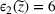
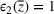

Recall that these numerical experiments only involve the Idleb region and the specific planning of the aid that is provided to service the needs for shelter for the IDPs. The proposed clustering method could bring more benefits if applied to multiple affected districts in Syria by considering a broader set of needs for the IDP such as different relief items (e.g., food, hygiene sets, etc.). In this case, it can be expected that further gains will be obtained for both the overall efficiency of the aid that is provided and the hedge that is obtained against the risks stemming from both the ambiguity and the uncertainty in the planning setting.
The out‐of‐sample tests highlight the overall value of the clustering approach: the shelter needs assessments provided by sources #1 and #2 disagree strongly for some locations. One cannot agree with both sources at the same time, but we do not know which of the predictions is closer to the true values. Our clustering approach obtains the smallest gaps while at the same time integrating the ambiguous information. That is, the characteristics of our solution are closer to the solutions provided by each source. In this way, a higher level of efficiency is achieved terms of the gaps obtained and the solutions. We have provided a more effective approach that can deal with the ambiguity and the uncertainty that is faced by humanitarian decision‐makers.
CONCLUSION
The inherent uncertainty in disaster situations complicates the humanitarian decision‐making process. Critical disaster response decisions must be made under significant uncertainty. Furthermore, the complexity of information flow in disaster situations brings significant challenges in making effective decisions. Specifically, different information sources might deliver high‐volume data, varying in type and nature, that humanitarian organizations have to gather, analyze, and aggregate to estimate the values of important parameters for response such as the needs of the affected people. The available information and estimates from different sources might involve inconsistent elements, which create high levels of ambiguity in decision‐making. We present the first methodological framework that can support humanitarian decision‐making to analyze the information provided by multiple viable data sources in a systematic and transparent way so that ambiguous information can be transformed into actionable insights and solutions.
We illustrate the proposed approach by focusing on a conflict setting where significant uncertainty may exist in important parameters for making response decisions (such as needs). Specifically, we analyze the estimates of shelter needs in the Syrian civil war derived from two reliable data sources. Our analyses have revealed a high degree of ambiguity and disagreement between both data sources, as there is a large number of “controversial” shelter locations and a lack of diversity of data sources within the resulting clusters. Our numerical results show that the proposed methodology better integrates such ambiguous information compared to other common approaches such as the expected value method and stochastic optimization. Specifically, the solutions produced by the new approach are closer to both data sources while achieving greater demand satisfaction, as evidenced by the smaller gaps. This is also confirmed by additional synthetic tests for different levels of estimation ranges, ambiguity, and consensus, where the clustering method outperforms the naïve approach in every single case. These tests have revealed that our clustering method is particularly advantageous when there is a wider range of source estimates, less consensus on the solutions, and less diversity of sources within the clusters. Overall, our results suggest that our clustering approach is likely to be particularly valuable in cases with a high degree of ambiguity and can therefore offer humanitarian decision‐makers an effective and efficient way to hedge against both ambiguity and uncertainty.
Our work suggests several future research directions. Our optimization model focuses on a simplified shelter location problem for illustration. The impact of using the proposed methodology in terms of gaps is likely to increase further when more complex models are used. It would be interesting to evaluate this improvement when addressing more complex planning problems (e.g., multiple items and periods). In this paper, we have focused solely on a classical stochastic optimization approach, minimizing expected cost. The methodology of this paper can also be translated to variants of stochastic programming with alternative objective functions and also robust optimization framework (e.g., using our analytical method to reduce the size of the ambiguity sets in distributionally robust models), which can be addressed by future studies.
Footnotes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.