
Abstract
In today's competitive market environment, it is vital for companies to gain insight about competitors' new product launches. Past studies have demonstrated the predictive value of prerelease online search traffic (PROST) for new product forecasting. Relying on these findings and the public availability of PROST, we investigate its usefulness for estimating sales of competing products. We propose a model for predicting the success of competitors' product launches, based on own past product sales data and competitor's prerelease Google Trends. We find that PROST increases predictive accuracy by more than 18% compared to models that only use internally available sales data and product characteristics of video game sales. We conclude that this inexpensive source of competitive intelligence can be helpful when managing the marketing mix and planning new product releases.
INTRODUCTION
In today's competitive market environment, predicting competitors' actions is a key priority for senior management (Crayon SCIP, 2022). At the same time, decision makers often choose to not react to competitor activities (Steenkamp et al., 2005), partially because of the high cost of obtaining predictive competitive intelligence (CI) and the uncertainty around such information (Montgomery et al., 2005). While the Internet and Big Data have facilitated data collection and observation of competitors' actions (Calof & Wright, 2008; Feng & Shanthikumar, 2018; Fleisher, 2008; Teo & Choo, 2001) from sources like user‐generated content, this research is predominantly descriptive (e.g., Gutt et al., 2019; Netzer et al., 2012; Xu et al., 2011) or the models lack decision metrics, such as sales (Silva et al., 2019). Moreover, the literature on leading indicators either focuses on user‐generated content (e.g., Boone et al., 2018; Cui et al., 2018; Lau et al., 2018), clickstream traffic (e.g., Huang et al., 2014), or incorporates sources such as weather information (Steinker et al., 2017) and economic indicators (Sagaert et al., 2018) to predict demand.
One of the main drivers of disruption is new product introductions (Palacios Fenech & Tellis, 2016; Peres et al., 2010) and insights on potential success are crucial to determine market share and defensive strategies (e.g., Kumar et al., 2020; Roberts et al., 2005). Predicting the success of new products prior to launch is a challenging task (Goodwin et al., 2013; Trusov et al., 2013), but recent studies suggest that prerelease buzz (PRB) information can substantially improve new product forecasting (e.g., Kim et al., 2015; Schaer et al., 2019b; Xiong & Bharadwaj, 2014). PRB represents the aggregated anticipated interest of consumers toward a new product (Houston et al., 2018) and has been collected, for example, in the forms of online search traffic information (e.g., Schaer et al., 2019b; Tian et al., 2014), blogs (e.g., Dhar & Chang, 2009; Kim et al., 2015), or microblogs (e.g., Asur & Huberman, 2010; Gelper et al., 2015). It differs from postrelease signals where both pre‐ and postconsumption behavior occurs (Houston et al., 2018). Nonetheless, there are several examples that show it is more difficult to extract a clear leading signal from postrelease information (for an overview, see Schaer et al., 2019a).
Companies can easily obtain PRB information for competitor products. This is, in particular, true for pre‐release online search traffic (PROST) that is available through Google Trends or Baidu. Not only is this information freely accessible but the platforms also report historic data that simplify the data collection process and is a frequently used data source in the literature (for an overview, see Schaer et al., 2019b). This makes it attractive to apply PROST information into new product forecasting for CI, so as to infer the success of competitors' products. Predicting competitors' success can provide vital insights to help allocate resources (Kumar et al., 2020) and time new product releases (Schoenherr & Swink, 2015; Sun & Kumar, 2020).
Studies that include PRB information have focused on own product sales only (Schaer et al., 2019b) or they have estimated and predicted new product sales from a data set that includes products from multiple brands (e.g., Divakaran et al., 2017; Onishi & Manchanda, 2012). While the latter typically provides better estimates, it does not reflect a real‐world environment in which sales information is only available for own brands. This questions the realism and feasibility of the reported value of these estimates. In the analysis that follows, we use the word “brand” as a synonym for companies, publishers, or producers. We distinguish between internal and competitor information; brands typically have unconstrained access to their own sales history and marketing activities, but external competitor insights are constrained to only what is publicly available. Assuming some degree of homogeneity among competing products, that is, similar product characteristics, a key question is whether competitor PROST can be used together with internal sales data to infer competitor success.
To understand the potential of PROST, in this study, we focus on video games that have a short life cycle and exhibit intense competition. We find that competitor PROST information improves predictions of competitors' new video games market potential by more than 18% compared to models without PROST information. Furthermore, splitting the data by brands is as effective as data‐driven clustering, which supports our homogeneity assumption for the video games market.
Ranjan and Foropon (2021) find that organizations are rarely tapping into Big Data for CI. Market analysts often track competitors' activities in a nonsystematic fashion, based on informal processes relying on unstructured judgment. Feedback that the authors received from the data science team at 2K Games, a video game publisher with more than $3bn revenue, confirms this. The team indicated the need to better understand the competitive market dynamics to support managers' decisions on own product launches and to counteract by adjusting marketing parameters like price and ad spend. Moreover, the improved predictive capabilities could help acquire and retain players and achieve key company goals, like determining return on investment (ROI). Our proposed approach supports this by directly linking PROST with sales. Furthermore, contrary to models without PROST, the predicted values may be incorporated into marketing‐mix models (Luan & Sudhir, 2010).
In this paper, we first review and examine how the literature on new product forecasting with PRB information has addressed competition. Next, in Section 3, we describe our approach for forecasting the market potential of competitors' products using own sales and competitors' PROST. Section 4 evaluates the predictive performance for video game sales using PROST from Google Trends. Finally, Section 5 discusses the findings and practical managerial implications, with conclusions following in Section 6. Our primary contribution is to demonstrate the value of PROST in fulfilling companies' key needs. When companies use appropriate methods, like PROST, they can more accurately understand the competition and predict sales, giving them a competitive edge.
PREDICTING NEW PRODUCTS WITH PRB AND COMPETITOR INFORMATION
The efficiency of predicting the success of a new product using PRB information has been well researched, as Table 1 illustrates. The majority of scholars focused on box office sales; others looked at the sales of music albums (Dhar & Chang, 2009; Hann et al., 2011), alpine skis (Mülbacher et al., 2011), and video games (Schaer et al., 2019b; Xiong & Bharadwaj, 2014). In their studies, they used a variety of PRB sources including forums (e.g., Craig et al., 2015; Liu, 2006), blogs (e.g., Divakaran et al., 2017; Onishi & Manchanda, 2012), Twitter (e.g., Asur & Huberman, 2010; Gelper et al., 2015), and Facebook (Ding et al., 2017; Kim et al., 2017). Another major PRB source is online search traffic available through Google Trends (e.g., Kim, 2021; Kim & Hanssens, 2017; Kulkarni et al., 2012) or Baidu (Tian et al., 2014). Studies that forecast with online information, including PRB, stem from a broad range of disciplines and therefore many lack adherence to well‐established forecasting principles, as highlighted by Schaer et al. (2019a). Most notably they lack hold‐out‐sample validation (column 3, Table 1). Moreover, researchers routinely benchmark their PRB models against same‐model families but omit testing with a naïve model, making it difficult to compare across studies. Nevertheless, we conclude that PRB substantially improves prerelease estimation when including PRB as volume or valance.
Summary of literature on forecasting with prerelease buzz (PRB)
Abbreviations: BAU, Baidu; BLG, Blog; FBK, Facebook; FOM, Forum; GTD, Google Trends; P2P, Peer‐to‐Peer Network; SNS, Social Network Services; TWR, Twitter; VSX, Virtual Stock Exchange; x, cross‐brands; i, intrabrand; c, competitor; ‐, no hold‐out evaluation; b, brand variable; m, market variables; ALFC, analogy life cycle curves; BC, Bass curve; FR, functional regression; LogR, logistic regression; LR, linear regression; ML, machine learning; SEM, structural equation model; Vol., volume‐based PRB measure; Val., valence‐based PRB measure; d, daily; w, weekly; m, monthly; PLC, product life cycle.
In Table 1 the column estimation/hold‐out shows that most studies estimate and evaluate their models across multiple brands. While such a cross‐brand approach has the advantage of evaluating the effects of PRB on a richer data set, it is somewhat impractical in terms of operational decision support, as it does not reflect what might be seen in practice, where companies typically only have access to sales data of their own products. Any additional competitor information would need to be sourced, typically via market research agencies that may come at a hefty price. Alternatively, PRB is available at a relatively low cost and has been shown to provide significant accuracy improvements, even with a smaller intrabrand sample (Schaer et al., 2019b). However, its potential remains unexplored for competitor products. Furthermore, other brand‐related variables are not straightforward to use for intrabrand‐based estimation (Dhar & Chang, 2009; Foutz & Jank, 2010; Onishi & Manchanda, 2012) and their predictive information has been questioned (Foutz & Jank, 2010). This possibly explains why only limited studies have included marktet information, as the column company control depicts.
The general scholarly view is that, in addition to own brand strength, the success of a company's entertainment product largely depends on its competition (see Hennig‐Thurau & Houston, 2019). However, there are mixed findings regarding the relevance of this variable. For example, studies that measured competition by the number of competitors' products released during the same period found an insignificant competition effect on sales (Divakaran et al., 2017; Kulkarni et al., 2012; Liu, 2006; Xiong & Bharadwaj, 2014). Contrary to this finding, Kim et al. (2017) reported substantial gains in forecast accuracy when including a broader set of competition variables, such as the number of seats and screens for top movies. However, none of these studies used any competitor PRB information.
Research suggests that PRB is impacted by advertising expenditure, genre (Xiong & Bharadwaj, 2014), and whether it refers to a sequential or nonsequential product (Craig et al., 2015; Kim, 2021). For movies, Divakaran et al. (2017) reported significant effects from the cast's star power. Xiong and Bharadwaj noted that for video games there is a brand effect, but it is only significant in the early prerelease phase, it vanishes closer to the release as more details about the video game emerge. This illustrates that PRB is a wide measure that carries various informative dimensions, which are difficult to measure directly for competitors.
Another stream of CI literature investigated how mining user‐generated content can identify competitors (Abrahams et al., 2013; Li & Netessine, 2012) or compared customer reviews (Xu et al., 2011), interactions (Chau & Xu, 2012; Netzer et al., 2012), product ratings (Gutt et al., 2019), prices (Carta et al., 2019), and brand reputations (Rust et al., 2021; Silva et al., 2019). Other studies, such as He et al. (2013, 2015), developed benchmarks to assess own and competitors' social media performance. However, we are unaware of specific research for the prerelease phase. Gopinath et al. (2013) analyzed blog market coverage of movie studios, but not in a predictive context.
This motivated our investigation into the extent to which PRB contains predictive value for competitor's products, with the objective of further enhancing CI insights. For this study, we focus on PROST information, as it is one of the most frequently used data sources. Nonetheless, it is easy to apply the same methodology to other PRB sources.
Scenario (i) in Figure 1 illustrates the standard approach used in most studies that investigate new product forecasting with PRB: All brands and their corresponding products are represented randomly in the training and test sample. This is ineffective for our research since we are interested in forecasting competitor sales from only own brand information (intrabrand), which is more realistic than this approach. We propose to split the data set according to scenario (ii), and formulate our first research question: Does PROST improve the predictions of a competitor's new product sales, compared to non‐PROST models?
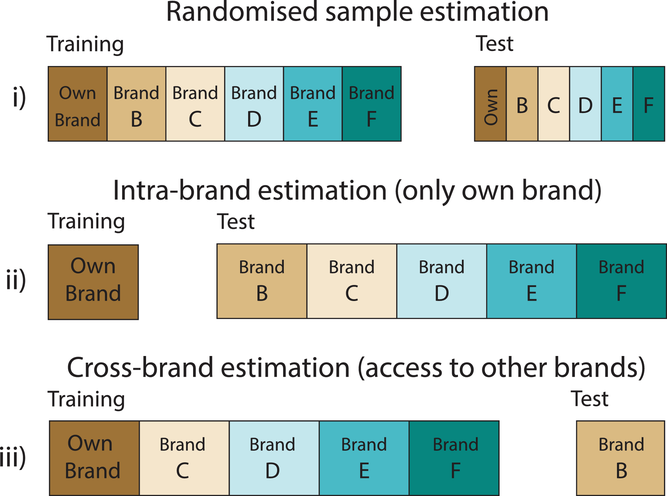
Different ways to split a data set
While this will allow us to investigate the impact of PROST, it does not demonstrate its efficiency compared to cross‐brand estimation. Therefore, we propose a second research question that investigates the information loss when restricting the training to intrabrand data: Do PROST models with cross‐brand information outperform intrabrand PROST competitor models?
To answer this question, we alter the sampling methodology to the case shown in scenario (iii) in Figure 1, where public sales from multiple brands are available to assess predictions for a single competitor brand, increasing the training sample over the previous case. As we noted, in many cases, this may be infeasible in practice.
Strictly speaking, restricting the data set from the cross‐brand data to just intrabrand data is a crude form of clustering, that is, on a priori segmentation (see Morwitz & Schmittlein, 1992, for a discussion on forecasting with segmentation). This only works when the different brand products are homogeneous enough so that the internal products act as analogies for the competition. Using analogies is a common forecasting approach (e.g., Hu et al., 2019; Martínez‐de Albéniz et al., 2020). Research from the retail industry suggests there is often little brand segmentation (Hammon et al., 1996). If the products are indeed homogeneous, then splitting by brands should make little difference on forecasting performance, other than limiting the sample size, as indicated in Research Question 2. However, if the products differ, an alternative approach is to use data‐driven clustering and to split the data set into more homogeneous subsamples, or product segments, instead of brands, using the same training set as scenario (iii). Our third research question investigates the value of using product segments instead of brands. Are predictions by brands superior to using product segments?
In summary, our first research question investigates the efficacy of PROST in inferring competitors' sales, while the other research questions explore the efficiency and conditions of good performance of the proposed model, while also taking into account the limited data availability in practice. Moreover, as suggested by Schaer et al. (2019a), we provide comparisons with findings from previous literature and other benchmarks.
PREDICTING THE MARKET POTENTIAL OF COMPETITORS' NEW PRODUCTS
To answer the outlined research questions, we use functional data analysis (FDA), a common way to predict new product sales (e.g., Foutz & Jank, 2010; Hann et al., 2011; Xiong & Bharadwaj, 2014). In contrast to classical regression, FDA does not regress the raw inputs directly on the target variable, but instead, for each observation, compresses vectors of values (curves) into scalars (Ramsay & Silverman, 2005). An advantage of this representation is that it allows us to mix variables of different lengths, that is, time series–based PROST information and product characteristics. This is achieved by reducing the vectors across time into scalars that summarize their characteristics. This is detailed in the next subsection. Additionally, by using FDA, we eliminate the time dimension, which supports our aim to facilitate estimation using small sample sizes, as is often the case for new products. We introduce the two models outlined in Figure 2 to forecast sales. The first is a regression‐based model that can be applied to both intrabrand and cross‐brand data, abbreviated with iRg and xRg, respectively. The second is a two‐staged model, based on segmentation, using clustering and classification. Although, in principle, we can cluster intrabrand data, the available sample size of own products might limit its applicability in practice. Therefore, we consider the segmentation model only for the cross‐brand data, which we use as a benchmark, labelled as xCl.
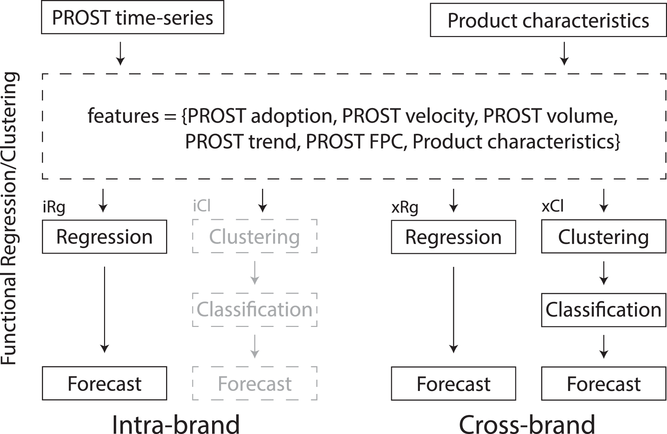
Different approaches to obtain competitor forecasts from common PROST features and product characteristics. The clustering for intrabrand data is subject to a sufficient sample
Functional regression
To derive a feature‐based time‐series representation, we consider a variety of parametric and nonparametric methods (for a general overview on time‐series dimensionality reduction methods, see Fulcher, 2018). Specifically, instead of considering all past PROST up to period t as a vector of length t, we use a single value, total PROST volume. In the context of functional regression, we regress this on the cumulative sales 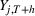
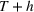
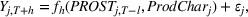
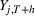
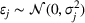
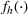
The most common ways researchers reduce the PRB time dimension are summing its volume over a certain period (e.g., Gelper et al., 2015; Tian et al., 2014; Wang et al., 2010) or capturing its adoption dynamics with diffusion model parameters (Kulkarni et al., 2012) and functional principal components (FPCs; Foutz & Jank, 2010; Hann et al., 2011; Xiong & Bharadwaj, 2014). Although Xiong and Bharadwaj (2014) and Foutz and Jank (2010) directly compared FPC against volume‐based PRB models, they did not include PRB valence; valence and volume are complementary, as they summarize PRB information in different ways. Since our goal is to maximize predictive power, we use all information types and let the model determine the influential ones. In addition to these measures, we also quantify the velocity and trend, which are defined below.
PROSTvolume
We define the per‐period PROST as 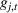
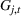
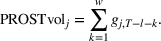
Characterizing PROST by its volume has the disadvantage that any dynamics are lost. The same volume may follow very different trajectories, which can affect product adoption (see Xiong & Bharadwaj, 2014). The subsequent variables capture these dynamics in different ways.
PROSTtrend
One way to assess the dynamics of PROST is to fit a linear trend through to the observed PROST up to the point 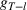
PROSTvelocity
A simple way to measure the adoption speed is to measure the number of periods it takes to reach a certain percentage of the PROST adoption over 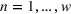
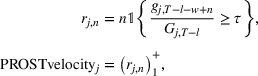

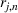
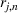
PROSTadoption
We parameterize the increasing buzz through diffusion curves (e.g., Hann et al., 2011; Kulkarni et al., 2012). The best‐known diffusion curve is Bass (1969), which describes the word‐of‐mouth process through innovators and imitators, captured by coefficients p and q, respectively. First, we fit a Bass curve to each product 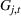
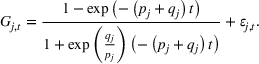
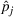
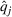
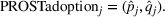
PROST FPCs
FPC analysis has gained popularity for predicting new product adoption (e.g., Fan‐Osuala et al., 2018; Sood et al., 2009). Studies that use FPC for forecasting with PRB report better predictive performance against diffusion curves (Hann et al., 2011) and volume‐based models (Foutz & Jank, 2010; Xiong & Bharadwaj, 2014). The idea is to characterize and identify unique shapes of all PROST adoption curves through a principal components analysis. It is recommended to first reduce the noise by smoothing the raw shape by using smoothing splines (Ramsay & Silverman, 2005).
We decompose the smoothed curves into principal components and use the resulting values as our PROSTfpc measure, that is, include for each product a vector of individual principal component scores. FPC requires that all PROST curves are of the same length and may therefore trim some data, however, the FPC will still take dynamics, such as slow adoption, into account.
Product characteristics
In addition to PROST information, we consider product characteristics related to competitors' products that are available before release. Since we aim to evaluate our research questions using video game sales data, we consider information that is typically available for entertainment products. These include information such as the Genre (PCTGenre; Kim & Hanssens, 2017; Xiong & Bharadwaj, 2014), the Sequel number (PCTsequel; Craig et al., 2015; Foutz & Jank, 2010; Hann et al., 2011; Liu, 2006; Xiong & Bharadwaj, 2014), and information about the Release time (PCTrelease; Kim & Hanssens, 2017; Xiong & Bharadwaj, 2014). In this research, we focus on freely available sources, and therefore, although extant studies have included marketing information such as ad spend (e.g., Kim & Hanssens, 2017; Xiong & Bharadwaj, 2014) or competition (e.g., Gopinath et al., 2013; Kim et al., 2017), we exclude these variables because only companies with marketing intelligence databases may access this information. These variables are also at an aggregation level that limits usefulness for predicting individual product launches.
The full model in Equation (1) can be written as:
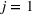
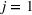
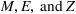
Functional clustering
For our second forecasting approach, we use product segmentation to obtain and use homogeneous subgroups. We construct segments using clustering, which is a common approach to predict new product sales (recent examples include Baardman et al., 2017; Basallo‐Triana et al., 2017; Hu et al., 2019), though we are not aware of applications to PRB data. We use functional clustering where functions are used to reduce the time dimensionality, similarly to FDA (see Goia et al., 2010; Sood et al., 2009, for applications to short time series). We obtain k‐clusters and then train a multiclass classification algorithm to predict the corresponding cluster of a new product. The products in this cluster are then used to forecast sales.
By including additional postrelease information, we create richer classifier inputs, leading to better performance. For this study, we include product reviews (labelled as PCTreview; see Chintagunta & Lee, 2012; Dellarocas et al., 2007; Zhu & Zhang, 2010) and dynamics of sales to enrich our data set. Additionally, we include sales volume (SLSsales), the time it takes until a certain percentage of total sales is reached (SLSvelocity), and the Bass adoption curve parameters (SLSadoption), as introduced in Section 3.1. These additional inputs are only used for clustering. The classification algorithm only uses data that are available prelaunch, as in Equation (6).
PREDICTING THE SUCCESS OF NEW VIDEO GAMES RELEASES
We empirically investigate the value of PROST (Research Question 1), comparing cross‐brand and intrabrand models (Research Question 2), and the value of predicting by brands (Research Question 3) in the video game industry, a highly competitive multibillion dollar market (Tripp et al., 2020). It is common for consumers to actively discuss prerelease games on online platforms, such as blogs or social media websites. This is further fueled by advertising activities (Marchand & Hennig‐Thurau, 2013). Furthermore, the relative homogeneity of products and short life cycles is helpful for our research. Although the literature on PROST predominately focuses on forecasting opening sales, Schaer et al. (2019b) showed that Google Trends contains valuable information to predict complete life cycle sales. Because one goal of CI is to meet a long‐term strategic focus, we evaluate both horizons, opening and total sales achieved by end‐of‐life (EoL).
Data
Our data set consists of weekly physical video games sales data from VGChartz (
In some instances, the sales history of a game spans several years, with its tail only capturing a few sales. In these cases, we truncate the sales time series when the growth rate of the cumulative sales becomes less than 0.05% per week. With this treatment, the average EoL is typically reached 40 weeks after launch. This is considered our total sales target.
To represent PROST, we collect information from Google Trends for each video game in our sample. Figure 3 illustrates the available signal before release and the subsequent adoption of sales. For each game, we download its topic popularity, using the Google Knowledge Graph entity. This method combines linguistic and semantic–related keywords into one search query, which leads to a more robust search traffic coverage (see discussion by Schaer et al., 2019a; Siliverstovs & Wochner, 2018). If there is no Google Knowledge Graph entity, then we use the video game title as the keyword.
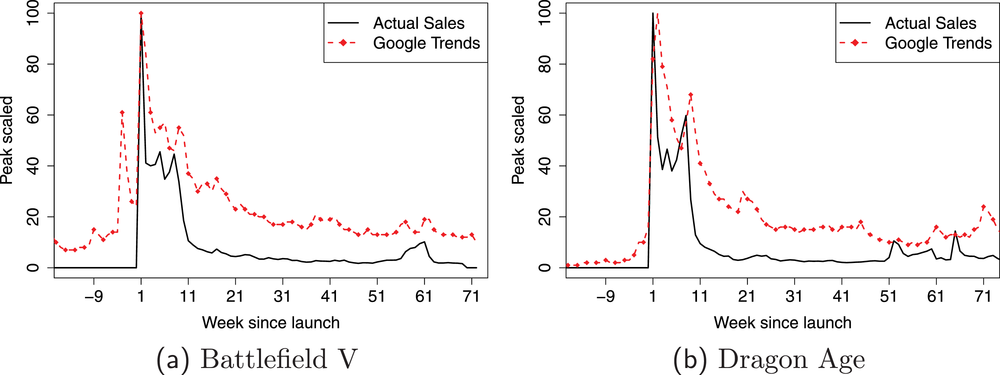
Typical video game sales pattern and the prerelease buzz of search traffic
Since Google Trends is peak scaled (values between 0 and 100), it makes individual data queries noncomparable. Although Google allows retrieving search popularity for up to five keywords per request, downloading multiple keywords becomes complicated, as new keywords might have a higher volume, which requires rescaling. To overcome this, we use the same scaling procedure as proposed by Schaer et al. (2019b). They use the neutral scaling keyword “marker” to scale each video game's popularity accordingly.
Feature estimation
PROST data
Several scholars have showed the predictive power of buzz increases toward release (e.g., Kim & Hanssens, 2017; Xiong & Bharadwaj, 2014). Therefore, the decision lead time becomes a trade‐off between maximizing forecast performance and the management's operational requirements. For this experiment, we investigate lead times l of 1, 4, and 8 weeks. For a further discussion about the lead time properties of PROST, and its application on video games, we refer the reader to Schaer et al. (2019b) and Xiong and Bharadwaj (2014).
For PROSTfpc we set the window length w to 26 weeks (182 days) similar to Xiong and Bharadwaj (2014). For all other measures, we use a flexible window length w for each product, dependent on when search traffic becomes available. To avoid any spurious start of PROST, we limit the maximum window length to 40 weeks and require two consecutive observations. The week when PROST becomes available marks our 0% entry for PROSTvelocity, with further inputs measured at 25%, 50%, and 75% of the observed PROST adoption.
All analysis and model estimation is carried out in the statistical programming language R (R Core Team, 2019). We estimate the PROSTtrend coefficient with ordinary least squares. The PROSTadoption coefficients for the Bass curve are estimated using nonlinear least squares on the per‐period adoption with Hooke–Jeeves optimization algorithm, as implemented in the diffusion package for R (Schaer & Kourentzes, 2021). All PROST curves are smoothed with b‐splines, using Akaike information criterion to determine the smoothing parameter λ, that is available in the cobs package for R (Ng & Maechler, 2020). For PROSTfpc we include the first 4 PC, as this provided the best predictive performance (similar methodology to Hann et al., 2011; Xiong & Bharadwaj, 2014). For Equation (6), 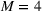
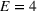
Product characteristics data
We encode the video games for genre (PCTgenre; Equation (6) 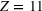
Sales data
Similarly to the PROSTvelocity defined in Equation (3), we measure the SLSvelocity of sales as the number of weeks it takes to reach 25%, 50%, 75%, and 95% of the overall adoption. We use the diffusion package (Schaer & Kourentzes, 2021) in R to estimate the parameters of the Bass curve for the inputs of SLSadoption. The last two inputs included in the model are the opening week and total sales (SLSsales).
Predictive algorithm
Functional regression
To estimate the market potential of competitors' new products with PROST information, compressed into scalars, we use Random Forest (RF) (Breiman, 2001). This machine learning method is an ensemble technique that uses bootstrapping to build a large number of decision trees and then selects the most voted one. We opt for RF instead of linear regression, as the former can capture flexible variable inputs beyond simple linear ones. An additional motivation to use RF is that it is performing well in both regression and classification, simplifying modeling. The RF algorithm is available in the caret package for R (Kuhn et al., 2021).
We train a PROST model for both the intrabrand and cross‐brand scenarios, labelled hereafter as iRgPROST and xRgPROST, respectively. In the cross‐brand case, we use a 10‐fold cross‐validation approach and tune the number of variables sampled at each split via a grid search tracking the root mean squared error (RMSE). The restrictive intrabrand sample size requires the use of leave‐one‐out cross‐validation. We considered alternative algorithms, such as gradient boosting in the form of XGBoost (Chen & Guestrin, 2016), and sparse regression in the form of Ridge and LASSO (Hastie et al., 2015). However, the RF results consistently performed best. We note that Ridge and LASSO are strictly linear models, while XGBoost is more sensitive to hyperparameter tuning than RF. The detailed results are available in the Supporting Information.
Segmentation
Since our data set contains both continuous and categorical data, we use the Gower similarity coefficient to create the distance matrix (Gower, 1971). We avoid transforming categories into binary variables as this leads to information loss (Xu & Wunsch, 2009). For the clustering, we use the Partitioning Around Medoids algorithm, as suggested by Kaufman and Rousseeuw (2005) and implemented in the cluster package for R (Maechler et al., 2018). In contrast to k‐means, k‐medoids is not dependent on having squared Euclidean distances and is suitable to use with the Gower distance (Hastie et al., 2008). Note that the segmentation uses the same data for training and prediction as xRgPROST. As mentioned in Section 3.2, the postrelease information for the distance matrix creation is only based on the training sample.
Once the clusters are determined, the second step is to train a classifier that can allocate new prelaunch information of a new product to a cluster. The restricted sample size within clusters makes it challenging to run the proposed regression on clusters. Instead, we directly predict total sales 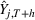
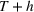
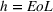
There are a variety of measures that help in selecting the optimal number of clusters, such as the Gap statistics (Tibshirani et al., 2001) or the Jump method (Sugar & James, 2003). While these measures rely solely on cluster characteristics, our two‐stage process of clustering and forecasting has the advantage that it allows measuring the clustering quality directly on the target variable. More specifically, we select the cluster with the smallest mean squared error (MSE) on sales using 10‐fold cross‐validation, considering up to 30 clusters. We refer to this model as xClPROST.
Benchmark models
To assess the predictive value of PROST, we introduce two types of benchmarks that use both intra‐ and cross‐brand data. The first is based on regression that uses no PROST information and draws upon observed sales and product characteristics (iRgPCT & xRgPCT). The iRgPCT model reflects how companies base their competitors' forecast without PROST information available. The second is a naïve model where we calculate the median of the entire training sample (xMdSLS & iMdSLS). Despite being trivial to implement, such parsimonious benchmarks are good forecasting practices and often hard to beat (Ord et al., 2017). For convenience, we summarize all included features of the different forecasting models in Table 2. The first two columns list and describe the input features. The other columns indicate their inclusion into the different forecasting models.
Overview of features included for different prediction models
Performance evaluation
Our research design is based on scenarios (ii) and (iii) with intra‐ and cross‐brand estimation, as illustrated in Figure 1. More specifically, we generate individual product forecasts 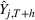
Brand represented within the training and test sample
We have a total of 2186 out‐of‐sample predictions for each horizon, from different training samples for each of the previously outlined models. Note that we retrain the models for every forecast horizon. We measure the forecast accuracy using the geometric mean relative absolute error (GMRAE) (Armstrong & Collopy, 1992):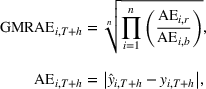
Results
Table 4 presents the predictive performance of the different forecasting models against the benchmark iRgPCT for the opening week (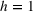
GMRAE performance of models against iRgPCT (product characteristics only)
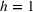
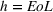
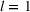
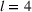
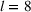
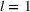
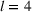
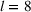
Note: Column s describes the data sample being intra‐ (i) or cross‐brand (x) based. Column e indicates the estimation method: regression (Rg), segmentation (Cl), and medians (Md). Column v notes the inputs of the model using PROST or only product characteristics (PCT) and sales (SLS). Column h indicates the forecast horizon and l the lead time.
Within the intrabrand model category, iRgPROST outperforms iRgPCT on average by nearly 20% for 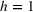
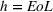
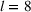
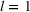
Nemenyi test results at 5% significance level for
Compared to cross‐brand data, iRgPROST provides better forecast accuracy than xRgPCT and xMdSLS, even though the improvements are less impressive compared to the intrabrand benchmarks, with gains of at least 6% and 1.7% for the opening and EoL horizon. In the latter case, differences are also no longer significantly different. If we compare the RgPROST‐based models, we see that the cross‐brand model significantly outperforms its intrabrand counterpart by more than 19%. It appears that the richer cross‐brand training can generate substantially more accurate predictions than just intrabrand PROST, which confirms Research Question 2. However, this does not hold for the clustering approach, which falls significantly short against both regression PROST models. This again supports our Research Question 3. We attribute this to the relative homogeneity of the video games sector.
In addition to the relative error performance, the first two columns in Table 5 show the percentage a model performs best and in the last two columns the percentage each model outperforms the iRgPCT benchmark. Within the intrabrand category, iRgPROST is most often the best choice over any of its category benchmarks. If compared to cross‐brand candidates, iRgPROST still remains the model that achieves most often the second best forecast accuracy. The drop between 1‐ and 8‐week lead time is only 1% for iRgPROST. Last but not least, the times iRgPROST outperforms iRgPCT is higher within the category and is similar to cross‐brand models.
Percentage best overall (per group) and percentage better than iRgPCT at 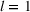
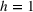
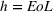
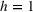
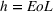
Note: Column s describes the data sample being intra‐ (i) or cross‐brand (x) based. Column e indicates the estimation method: regression (Rg), segmentation (Cl), and medians (Md). Column v notes the inputs of the model using prerelease online search traffic (PROST) or only product characteristics (PCT) and sales (SLS).
We include multiple inputs into the regression model and let it flexibly identify the most influential ones. We tested more restricted models, with prefiltering variables based on their PROST feature category, for example, only using inputs from PROSTvelocity, PROSTfpc. We find that all of them provide predictive value, and, in some cases, they can provide slightly better performance. However, the approach that includes all variables has the overall most stable performance and greatly simplifies the modeling process. More details are available in the Supporting Information. The results are also consistent for MAPE and MAE but offer little interpretability on cumulative data.
DISCUSSION
In this study, we set out two research questions to test the suitability of PROST for predicting the success of competitors' new products. We propose a model that is able to generate sales forecasts and empirically test its performance using global video games sales. We find support for Research Question 1; PROST significantly improves competitors' new product predictions over models that use only internal sales and product characteristics. The literature review highlighted that very little research is concerned with using competitor user‐generated content, like PROST, in a predictive context. Our findings suggest that companies may find great value in linking their internal sales data with competitor‐related online content.
Beyond the proposed competitor PROST model, in our third question, we look at an alternative that can consider potential heterogeneity in a market using segmentation. Our findings indicate that the video games market is fairly homogeneous, and although this model can outperform benchmarks, it is inferior to the regression‐based model. This supports Research Question 3: Separating by brands is better than product segmentation in the case of video games sales. Nevertheless, this insight may not hold in other markets, and further research could reinforce this work with additional empirical evidence. Researchers may pay particular attention to brands that observe a distinctive reputation in terms of product quality or associated lifestyle. For example, Apple products might be perceived differently in terms of PRB and actual product adoption compared to less dominant tech brands.
Arguably, our benchmark model iRgPCT is limited by not considering all possible product categories. We argue that any cross‐brand data set is based on information that is not readily available to all organizations. With that in mind, the performance against xRgPCT is useful to assess whether PROST can overcome those restrictions, but is otherwise not practical. We find that using PROST outperforms opening sales and matches the performance on total sales, demonstrating the efficacy of the proposed model. All models, however, fall short against the xRgPROST model. This is expected, as it can draw from a much richer data set than the intrabrand models and confirms Research Question 2. Nonetheless, the practical usefulness of xRgPROST is questionable, but exemplifies the gap between research and practice.
One interesting aspect to investigate further is the performance at the brand level. Table 6 reports the GMRAE of iRgPROST model against individual benchmark models. The results show that iRgPROST outperforms iRgPCT, except in the case of Nintendo for 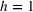
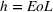
GMRAE performance of iRgPROST against various benchmarks at the brand level
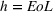
Note: Cases where iRgPROST outperforms the benchmarks are highlighted in bold.
It is worth noting that the forecasting performance of iRgPROST is similar for the two different forecast horizons. Similar observations have been reported, where PROST not only provides value for predictions close to release, but also contains predictive information for long‐term forecasts (Schaer et al., 2019b). We also find that PROST is relatively consistent for the tested lead times, confirming findings by Schaer et al. (2019b) and Xiong and Bharadwaj (2014).
Managerial implications
Our study shows that it is not only possible to gain valuable insights from PROST for own sales product launches, but can also provide valuable insights for competitor launches. The lead time provided by PROST enables firms to counteract or support their own sales, for example, with marketing activities. As such, it can also provide insights when planning a product release, by monitoring competing products that might impact the release success. Moreover, the predicted market potential offers ways to be incorporated into market share models (e.g Chen & Steckel, 2012; Du et al., 2007; Kumar et al., 2020; Luan & Sudhir, 2010; Zheng et al., 2012). Linking PROST to first week and life cycle sales provides a simple‐to‐interpret measure that allows contextualizing competitive pressures. Crayon SCIP (2022) indicates that competitors' revenue and sales are some of the most important key performance indicators for managers.
As Figure 3 illustrates, most video game sales are accrued in the first few weeks after launch. Therefore, having an accurate understanding of competitors' launch sales, either at the entry weeks or as cumulative to the EoL, is valuable information to manage competitive forces. A publisher can use these forecasts to inform their own launch decisions in order to either maximize sales, or use a game launch to increase competitive pressure. Similarly, this information can be paired with associated marketing instruments, such as pricing, advertising, or promotions, for both new and existing products. However, due to their short life cycles, the competition is often not on price but on quality and matching emerging consumer tastes. Therefore, research suggests that managing the release timing is more important (Calantone et al., 2010; Engelstätter & Ward, 2018). Another way to retain an active player base is to provide feature updates (Hyeong et al., 2020) and engage with the gaming community. Knowing the likely market success of competing products in advance allows for better deploying those countermeasures, depending on the publisher's objective, and avoids wasteful activities. The director of data science and Analytics at 2K Games indicated the importance of a systematic model‐based approach to support such decisions, something that, across the industry, is currently done ad hoc and primarily using human judgment. He highlighted the team at 2K Games indicated interest in ideas discussed here, and saw potential expansions, for example, including Twitch or Reddit. We draw parallels on these from other sectors in Section 5.2.
PROST is freely available and can readily be implemented into predictive frameworks, as outlined in this research. Preannouncing new products, igniting the PROST signal, is common practice, especially in competitive markets (e.g., for software, see Bayus et al., 2001), where the benefit of being able to choose the desired launch date upfront and attract customer attention outweighs the risk of direct imitators (Bhaskaran & Ramachandran, 2011; Su & Rao, 2010). In the video game industry, as our analysis shows, such a PROST signal usually becomes available well in advance, and the forecasting model can be updated once new information arrives. This is relevant to practitioners as consumer preference often changes during the prerelease phase (Meeran et al., 2017), and getting timely CI information is one of the biggest struggles brands face (Crayon SCIP, 2022). One of the main benefits of PROST is that it adds value even when the own product sample size is relatively small. This is a particularly effective strategy for minor publishers and independent developers, who lack the resources and historical data of established major publishers. Although this process can be fully automated, we would expect it to be operationalized in a supervised setting and used to supplement analysts' judgment‐based forecasts.
Moreover, PROST includes information for the near‐term open sales but also provides insights on the strategic horizon by explaining some of the overall market potential. This also creates the opportunity for new research avenues with direct impact on practice as the gaming sector evolves. 2K Games indicated that, for instance, now it is common practice to foster a community around games on online platforms, such as Discord or Reddit, with exclusive prerelease availability of titles to associated or independent streamers on platforms such as YouTube and Twitch. This not only provides the potential for richer PRB information, but also for managing it (Dost et al., 2019). Finally, our communication with the publisher makes it apparent that the proposed model enables further research into how to best translate new competition insights into optimal marketing and launch strategy responses.
Model extensions
In this study, we focus on measuring the future market potential of competitors' products and provide initial insights on the suitability of PROST. A natural next step is to formulate a framework that also measures the competitive impact on own products. Recent research suggests that incorporating CI improves not only short‐term forecast accuracy (Huang et al., 2014; Li et al., 2019), but also helps identifying analogies for new product forecasting (Baardman et al., 2017). In these cases, PROST can be a more cost‐effective alternative to external market research services.
Search traffic information has, for example, been incorporated into a market response model that measures impact on sales (e.g., Du & Kamakura, 2012; Du et al., 2015) or advertising (e.g., Hu et al., 2014). An extension, into this area of new products would have two potential implications (for a prerelease application with survey data, see Roberts et al., 2005): first, to improve the marketing mix (for an application without PROST, see Luan & Sudhir, 2010), and second, to better manage product release timing. For example, postponing a release is common practice in the movie industry (Einav, 2010). There is limited work to help identify when the loss in revenue due to competitors' launches outweighs the cost of postponement that can impact stock value (Einav & Ravid, 2009) and brand trust (Herm, 2013). An alternative is to look directly into the impact on sales and associated decisions, such as to improve inventory management and dynamic pricing (e.g., Huang et al., 2014; Martínez‐de Albéniz et al., 2020). However, we would expect this to be of more importance for the postrelease phase. All of those directions would generally profit from a deeper focus on the assessment of confidence and risk that is involved when forecasting with user‐generated content.
While our research suggests PROST models are useful over naïve ones, it remains an open question how PRB compares to commercially available market data. As Kumar et al. (2020) argue, such data sources quickly become costly, especially if tracked over time. Therefore, many companies heavily rely on human judgment for their models, remaining relatively immature in their competitor analysis (see Crayon SCIP, 2022; Ranjan & Foropon, 2021). This is further amplified by the judgmental processes used for new products (Kahn & Chase, 2018). We see an interesting avenue of future research in how this new kind of marketing intelligence can integrate into decision‐making processes, hopefully mitigating biases involved with new products (Belvedere & Goodwin, 2017; Markovitch et al., 2014).
Our modeling approach is based on a set of well‐established methods to reduce the dimensionality of PROST. While our results are in favor of a data‐driven variable selection, there is room to experiment further with different time‐series characterizations (e.g., Lubba et al., 2019). It is also possible to expand our framework to a more granular level, for example, using regional PROST for better planning of the distribution. However, depending on the product, search traffic information might be limited (Schaer et al., 2019a). A way forward for future researchers might be to use a top‐down approach and split global search interest to regional sales observation. Moreover, researchers may include other types of PRB sources, in particular those involving unstructured data, from platforms such as Reddit and video content (see Balducci & Marinova, 2018). Although video games are a specific type of entertainment product, we anticipate our findings to hold for other products such as electronics and outdoor gear, as long they observe a similarly active online community.
We show that FW and EoL sales have similar performance. Although our research is at the product level and tracks consumer interest, research focused on stock returns indicates that investors change their beliefs during the prerelease phase, based on the expectation that any preannouncements can affect in the long term (Sorescu et al., 2007). Similarly, we conjecture that depending on the prerelease strategy, the adoption dynamic might be different, and, in turn, may affect the market potential. There is a lack of research that investigates PRB adoption dynamics and its link to sales. This might also partially explain why we found little value in clustering video games sales.
Clustering might prove valuable on different data sets that observe greater heterogeneity. Our cluster sizes were very small, and therefore we could not use RFs. A data set with a large number of products might profit from experimenting with the combination of more advanced algorithms that also utilize within‐cluster information. This would not only permit researchers to combine the clustering with the regression modeling, but also to explore the intrabrand segmentation. That said, there is room for researchers to explore more advanced clustering methods for prerelease forecasting, such as those presented by Hu et al. (2019) and Baardman et al. (2017).
Finally, our work has focused on the development of the methods that use PROST to enhance CI. We discuss some of the decision‐making advantages this can provide, yet this research is limited in that it does not present observations from a company case investigation. Targeted future research would not only enable identifying direct benefits, for instance, revenue impact based on better CI, but also track potential changes in the decision‐making process.
CONCLUSIONS
Although research on CI is well established and frequently draws from user‐generated content, there is limited focus on its predictive value for new products. Moreover, it can miss the connection to decision variables, such as sales. Our study contributes to the growing literature on using Big Data for CI (e.g., Choi et al., 2018, for an overview in applications in operations management) by providing insights into the predictive value of publicly available PROST information of competitor products, linking it directly to sales. While most of the literature evaluates the proposed approaches on randomized cross‐brand data sets, we limit the training of our forecasting model to internal‐brand information and competitor PROST. This is both more difficult and realistic. Our results suggest PROST provides valuable insights for companies to better understand their competitive standing.
Shorter life cycles have led to increased competition on product launches, making it important to have insights on future market developments (Calantone et al., 2010). As such, companies have increased their CI efforts, yet they struggle to acquire data in a timely fashion (Crayon SCIP, 2022). In comparison to other market intelligence, PROST is an inexpensive source of information that reflects consumer interest (Houston et al., 2018). Moreover, it has the advantage that is available over time, which allows capturing its dynamics and change in consumer preference. We show that in a relatively homogeneous market setting, only a few internal sales observations are required to produce valuable insights into the competitors' market potential. This information can be taken into consideration when managing the marketing mix and can support new product release planning.
Footnotes
ACKNOWLEDGMENTS
We would like to thank the editor and three anonymous reviewers for their comments. We are thankful for having received valuable feedback from Florian Dost, Nigel Meade, Catherine Owsik, and Doug Thomas, as well as for the operational insights by the 2K Games data science team.