
Abstract
Storage assets are critical for physical trading of commodities under volatile prices. State‐of‐the‐art methods for managing storage facilities such as the reoptimization heuristic (RH), which are part of commercial software, approximate a Markov Decision Process (MDP) assuming full information regarding the state and the stochastic commodity price process and hence suffer from informational inconsistencies with observed price data and structural inconsistencies with the true optimal policy, which are both components of generalization error. Focusing on spot trades, we find via an extensive backtest that this error can lead to significantly suboptimal RH policies. We develop a forward‐looking data‐driven approach (DDA) to learn policies and reduce generalization error. This approach extends standard (backward‐looking) DDA in two ways: (i) It represents historical and estimated future profits as functions of features in the training objective, which typically includes only past profits; and (ii) it enforces structural properties of the optimal policy. To elaborate, DDA trains parameters of bang‐bang and base‐stock policies, respectively, using linear‐ and mixed‐integer programs, thereby extending known DDAs that parameterize decisions as functions of features without policy structure. We backtest the performance of RH and DDA on six major commodities, employing feature selection across data from Reuters, Bloomberg, and other public data sets. DDA can improve RH on real data, with policy structure needed to realize this improvement. Our research advances the state‐of‐the‐art for storage operations and can be extended beyond spot trading to handle generalization error when also including forward trades.
Keywords
INTRODUCTION
Storage assets play a fundamental role in commodity markets. Examples include natural gas and oil storage caverns, grain silos, and metal warehouses. In 2017, more than 600 warehouses across 14 countries were approved by the London Metal Exchange (LME), with several million tonnes of metal delivered into and taken out of LME warehouses (LME, 2017). The Chicago Merchantile Exchange (CME), another major marketplace for physical metal trading, is also expanding its storage network. CME‐registered warehouses in Salt Lake City held 131,774 tonnes of copper in January 2018 (Reuters, 2018), which translated into 927 million USD of inventory.
Merchant trading companies use storage to benefit from positive commodity price differentials over time, that is, they buy low, store, and sell high at a later date (Williams & Wright, 1991, p. 24). These assets have finite space and constraints on the rates of injection and withdrawal. Maximizing the profit from operating storage requires adapting the timing of constrained injections and withdrawals to the movement of uncertain commodity spot prices. The related optimization of storage operations can be approached using a Markov decision process (MDP) that contains in its state the on‐hand inventory (i.e., endogenous state) and multiple factors (i.e., exogenous state) of a Markovian stochastic process describing the evolution of spot prices. The extant storage literature formulates this MDP assuming that the stochastic process is known. A common choice for the exogenous state is a vector of futures contract prices (Lai et al., 2010) since they are available for commodities with futures markets and expectations of the spot price equals futures prices under the risk‐neutral measure.
Storage MDPs with realistic price dynamics are high‐dimensional and thus intractable to solve directly. Least‐squares Monte Carlo (LSM) and reoptimization heuristics (RH) are state‐of‐the‐art approaches (Breslin et al., 2008; Breslin et al., 2009; Gray & Khandelwal, 2004a, 2004b) for approximating the aforementioned intractable MDP and are part of commercial storage management software (Energy Quants, 2018; Kyos, 2018; Lacima, 2018; MathWorks, 2018). LSM computes a parametric approximation of the MDP value function using backward induction and regression, which is then used to compute storage decisions (Nadarajah et al., 2015). RH obtains storage decisions at a given stage and state by solving a deterministic linear program, referred to as an intrinsic linear program (ILP), which is based on futures prices available at the current time. For RH, ILP is reoptimized at each stage after accounting for updated futures price information (Lai et al., 2010; Secomandi, 2015). An advantage of RH over LSM is that its inputs are agnostic to the assumed commodity price process in the MDP. Moreover, in the context of natural gas, RH storage policies have been shown to be near‐optimal in computational studies that assume
Focusing on spot trades, we perform an extensive backtest of the RH policy on price data across six commodities (i.e., copper, gold, crude oil, natural gas, corn, soybean) from Thomson Reuters over the period 2000–2017. The goal of this backtest is to understand the true performance of RH by applying its decisions on a historical sample path of prices and benchmarking the resulting profit against the value of an optimal perfect foresight solution on this price path, which is indeed optimistic but immune to assumptions implicit in the MDP. We observe that several insights regarding the performance of RH change fundamentally as explained next: RH yields smaller profits than ILP on A one‐period look‐ahead policy leads to higher profits than RH on several instances, that is, ignoring futures price information may be beneficial. This result differs from the literature on forecast horizons in the full‐information setting, which argues that far‐ahead futures price information does not affect optimal first‐stage decisions (Cruise et al., 2019). RH yields an average value of
We rationalize the aforementioned stark differences using the train‐test paradigm of machine learning (ML). Specifically, existing performance evaluations of RH (as well as other methods such as LSM) in the storage literature both compute policy parameters/decisions (i.e., train the policy) and test the performance of these decisions under the full‐information setting, which the actual data may not satisfy. Informally speaking, the performance difference in the training environment (i.e., full‐information setting) and the testing environment is referred to as generalization error. Our backtest suggests this error may be significant when employing the RH policy.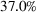
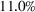
Motivated by the above observations, we take an ML approach to target the reduction of generalization error and learn storage policies. To this end, we relax the full‐information assumption and formulate a feature‐based storage stochastic dynamic program (F‐SDP) where the exogenous state is represented by a generic set of features that evolve according to an unknown stochastic process. We then develop a data‐driven approach (DDA) to tackle F‐SDP that extends existing approaches in two key ways. First, it is forward‐looking and uses financial‐market features (e.g., futures prices) to include future estimates of profit in the training objective, in addition to historical profits considered by standard DDAs (see, e.g., Bertsimas & Kallus, 2020). Second, it allows one to enforce structural properties of an optimal F‐SDP policy when computing data‐driven policies. Within this framework, we begin by considering standard linear decision rules (DDA‐LDRs) from the literature (see, e.g., Ban & Rudin, 2019) that specify decisions as a linear parameterization of random variables. The DDA‐LDR parameters are trained using the empirical risk minimization (ERM) framework (Friedman et al., 2001), which involves solving a regularized convex program. DDA‐LDRs do not encode any structure of the F‐SDP optimal policy and thus training them in our forward‐looking approach allows us to understand the value of such future information alone without considering the impact of policy structure. We subsequently propose structured data‐driven policies (DDA‐SPs) that encode bang‐bang and double base‐stock structures shared by the F‐SDP optimal policy for storage assets with different operating characteristics. In contrast to DDA‐LDRs, DDA‐SPs are parameterized by coefficients of price thresholds or base‐stock levels, which are trained using linear and mixed‐integer programming. We discuss how the regularized training procedure and the policy structure used when computing DDA‐SP make it robust to price uncertainty (i.e., it accounts for downside risk) and estimation error, respectively.
We perform a backtest of DDA approaches across the same six commodities used in our RH backtest. As candidate features, we consider spot and futures prices from Thomson Reuters, analyst forecasts of spot prices from Bloomberg, temperature, the S&P 500 index, and the Trade Weighted U.S. Dollar index. Feature selection reveals several practical insights. First, in the absence of futures prices and analyst forecasts as features, adding the S&P 500 and trade weighted U.S. dollar indices can improve profits compared to using only spot prices. This finding is relevant when futures markets or analyst forecasts are absent, which is the case for commodities such as asphalt and specific types of polyethylene. Second, while futures prices have large errors when treated as forecasts of spot prices, their inclusion on top of spot prices can improve storage profits. Third, embedding analyst forecasts further enhances storage profits by 7%, that is, spot and futures prices along with these forecasts lead to median profits that are undominated by other feature combinations, which is consistent with the hypothesis that futures prices and analyst forecasts account for factors that affect prices. We thus use this feature combination for our performance analysis.
The median profits of DDA‐LDR range between 2.1% and 2.4% (of the perfect foresight value) for different feature choices, while the RH median profit is 12%. That is, despite being a data‐driven policy, DDA‐LDR performs even worse than RH. In contrast, we observe that DDA‐SP generates median profits between 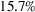
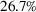
Our findings advance the state‐of‐the‐art for commodity storage operations. The extended DDA and structured policies highlight potential opportunities to enhance storage software by considering generalization error. In particular, although we apply our framework for spot trading, it can be extended to evaluate and handle generalization error when combined with forward trading.
Related work and novelty
Our models, methods, and findings extend the literature on commodity storage, data‐driven optimization, and commodity finance as discussed below.
The literature on commodity storage dates back to the warehouse management problem introduced by Cahn (1948) and further studied by Charnes and Cooper (1955), Bellman (1956), and Dreyfus (1957). The storage assets in these very early papers were managed under deterministic prices. Charnes et al. (1966) and Secomandi (2010) consider the stochastic version of the storage problem with and without rate constraints, respectively, and characterize the optimal policy. Significant recent effort has gone toward using approximate dynamic programming techniques to find near‐optimal policies to the intractable storage SDP in the full‐information setting (Cruise et al., 2019; Lai et al., 2010; Nadarajah et al., 2015; Nadarajah & Secomandi, 2018; Nascimento & Powell, 2008; Wu et al., 2012). Secomandi et al. (2015) consider the impact of choosing an incorrect number of factors in a prespecified price model on storage valuation and hedging. They term this price‐model error. Secomandi (2015) and Nadarajah and Secomandi (2018) argue in single and network storage settings, respectively, that the RH policy is price model error‐free as it uses only market futures prices as input. However, they do not analyze the impact of futures prices providing poor forecasts of the spot price as they work under the risk‐neutral measure where the expected spot price equals the futures price. In summary, the extant storage literature has not empirically studied the impact of generalization error on the storage operating policy or developed data‐driven operating policies that target this error. Our backtest of RH, development of DDA approaches that leverage known policy characterizations, and related empirical insights are novel to this literature. Moreover, our use of regularization and policy structure provides an ML and optimization‐inspired view of managing storage operations, which is relevant beyond this setting to other real options involving commodities such as soybean, corn, and palm (Boyabatlı et al., 2017; Devalkar et al., 2011, 2018; Goel & Tanrisever, 2017) and energy (Nadarajah & Secomandi, 2021).
Our work builds on methodological work from empirical optimization (Bartlett & Mendelson, 2006; Esfahani et al., 2018) and the emerging data‐driven optimization literature (see, e.g., Ban et al., 2018; Bertsimas & Kallus, 2020; Curtis & Scheinberg, 2017; Elmachtoub & Grigas, 2022), which addresses generalization error by explicitly focusing on out‐of‐sample performance. Strictly speaking, our paper belongs to the growing literature (e.g., Ban & Rudin, 2019; Chenreddy et al., 2019; Mandl & Minner, 2020) that empirically tests the value of data‐driven optimization in operations management problems. Data‐driven optimization has been applied to single‐period inventory control or newsvendor applications (Ban & Rudin, 2019) and in multiperiod settings using linear or piece‐wise linear decision rule approximations (Ben‐Tal et al., 2005; See & Sim, 2010), for instance, for financial contracting (Mandl & Minner, 2020). In a marketing setting, Chenreddy et al. (2019) combine ERM with polynomial approximations and inverse reinforcement learning. The forward‐looking DDA that we propose extends the backward‐looking DDAs in this literature. While linear decision rules are known, our assessment of their performance for commodity storage, especially when trained using estimates of future profits is new. Our structured data‐driven policy and the evaluation of the value of enforcing policy structure are both novel. In addition, the parameters of the structured policies that we train are thresholds, which are easily interpretable by managers. Our models for training these data‐driven policies add to the literature on interpretable ML, an area that has studied several applications ranging from classification to healthcare (see Lakkaraju & Rudin, 2017, and references therein) but none that share the structure of the commodity storage application. More broadly, our empirical finding that enforcing policy structure can improve out‐of‐sample performance of data‐driven policies is relevant for other operations management problems where characterizations of the optimal policy structure are known.
Finally, our results contribute to recent work in commodity finance that brings to light the value of features for price prediction (Alquist & Kilian, 2010; Cortazar et al., 2018; Heath, 2019). These papers emphasize the importance of the true distribution of spot prices (as opposed to risk‐neutral distributions), which is consistent with our focus. However, the aforementioned papers take a statistical view and do not focus on decision making, while we take an ML perspective and train operating policy parameters. Therefore, our comparison of DDA approaches and feature selection in the context of storage decisions add novel components to this literature. Our forward‐looking DDA shows how the presence of financial markets allows one to obtain future profit estimates that can be leveraged as part of the training objective. We also assess the values of futures prices and analyst forecasts of spot prices as features when training decision rules for storage to be significant. In particular, while futures prices may provide poor forecasts of spot prices, they nevertheless provide valuable information to train policies. This finding motivates further research on the differential impact of data on prediction versus decision making.
COMMODITY STORAGE OPERATIONS AND POLICY PERFORMANCE
In Section 2.1, we present a feature‐based extension of the well‐known storage SDP. In Section 2.2, we describe the statistical perspective used to evaluate storage policies in the literature and make a case for the value in using an ML perspective instead.
Feature‐based storage MDP
We extend the (stochastic) commodity storage problem formulated by Charnes et al. (1966), Secomandi (2010), and Lai et al. (2010). Consider a single‐item, multiperiod, discrete‐time, periodic‐review inventory replenishment problem at a single commodity storage asset (e.g., warehouse) with a finite planning horizon 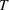
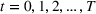
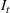

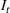
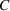
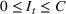
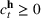
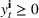

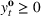
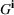
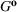
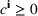
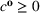
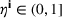
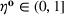

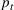
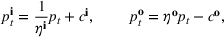
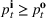
Injection and withdrawal decisions at each period are conditioned on the information available to the user (i.e., the MDP state). Let 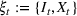
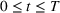
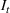
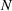
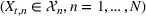

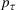
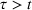
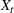
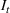

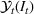
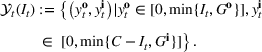
A storage operating policy 
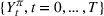
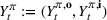
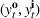
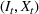


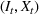

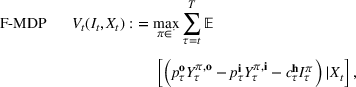
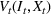

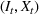
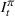

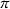
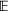
An optimal policy to the storage MDP can be sequentially computed using the following stochastic dynamic programming recursion: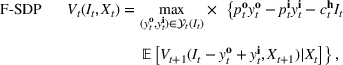
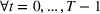
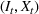
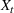
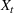
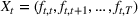
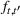
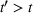

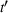
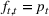
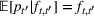
The structure of the optimal policy known in the commodity storage literature (see, e.g., Secomandi et al., 2015) extends to F‐SDP as stated in Proposition 1 under Assumption 1. Assume that for all stages 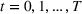
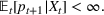
The following holds under Assumption 1: Suppose Suppose
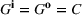
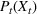

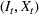
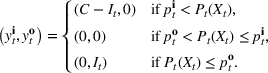
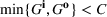
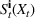
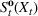
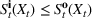

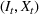
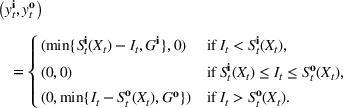
We omit the proof of Proposition 1 as it follows standard reasoning available in the literature. When Assumption 1 holds, the value function can be shown to be bounded following the arguments in Lemma B.1 of Nadarajah and Secomandi (2018). The remaining parts of the proof to establish policy structure mirror Lemma B.2 of Secomandi et al. (2015).
Proposition 1(a) summarizes the bang‐bang structure of the optimal policy when the storage asset is fast, that is, it has full operational flexibility (FF) and no rate constraints. In this case, the optimal policy is based on the value taken by a state‐dependent price threshold 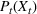
Policy performance evaluation
Solving F‐MDP directly is challenging since we do not have a feature representation 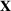
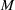
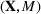
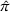
The literature on storage operations evaluates the performance of a heuristic policy 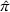
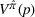
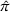
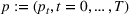
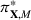
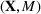
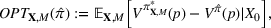
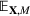
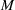
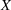
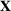
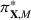
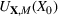
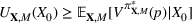
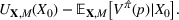
The evaluation of the optimality gap in the literature is tied to the feature representation and stochastic model assumptions. This estimate of policy performance can be misleading if the assumed pair 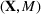
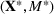
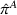
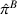
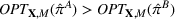
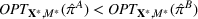
Motivated by the above observation, we consider evaluating the performance of policies in a data‐driven manner. Our starting point is the following definition of idealized generalization error used in reinforcement learning (see Murphy, 2005, section 4):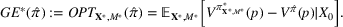
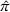
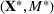
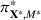
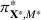
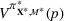
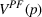
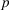
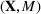
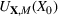
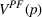
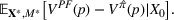
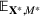
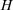
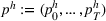
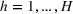
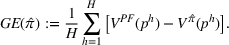
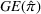
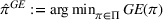
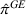
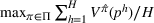
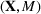
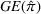
Minimizing 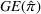
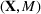
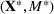
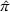
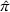
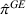
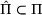
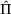
RH BACKTEST
In this section, we perform an extensive backtest to evaluate the performance of RH based on generalization error as defined in (12). We describe RH in Section 3.1. We overview the data set used for our backtest in Section 3.2 and present results in Section 3.3.
Algorithm
RH, which is sometimes referred to as forward dynamic optimization (Eydeland & Wolyniec, 2003, p. 355), is a sequential RH and a type of certainty‐equivalent control that determines injection and withdrawal decisions by solving an “intrinsic” linear program formulated using point estimates of future spot prices. It does not require any training, which makes its implementation easy. We denote the time 
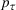
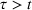
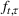
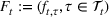
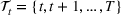
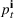
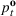
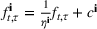
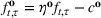
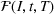
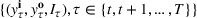
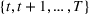
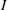





The ILP at period 
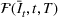
The RH policy is based on solving ILP (18)–(19) at each stage. To elaborate, ILP is solved in the current period 
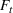
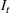
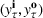
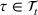

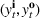
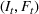
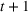
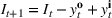
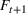
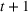
RH is popular for managing natural gas storage, where 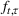


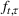
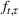
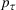
When F‐SDP is formulated for a commodity with a futures market (i.e., 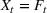
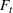
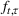
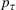
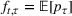
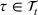
Data and instances
Our RH backtest is based on spot and futures price data between 2000 and 2017 for the following six commodities: copper, gold, crude oil, natural gas, corn, and soybean. Futures contracts for metals and energy are traded at the New York Mercantile Exchange (NYMEX) and for agricultural commodities at the Chicago Board of Trade (CBOT). We consider futures prices for the first 12 maturities, that is, 1‐ to 12‐months‐ahead contracts, and use monthly prices at the first trading day of the corresponding month. Even though contracts beyond 1 year are available for various commodities, these markets are typically highly illiquid with only very few contracts traded, which implies that the predictive content for future spot prices might be low (Alquist & Kilian, 2010). Furthermore, our perfect foresight analysis on the empirical data indicates that planning horizons that are significantly smaller than 12 months are sufficient for optimal first‐stage decisions (see Figure EC.1 of the Supporting Information).
Among the six commodities we consider, four of them have futures contracts with monthly maturities. The exceptions are CBOT corn and soybean futures. The former futures mature in March, May, July, September, and December while the latter futures mature in January, March, May, July, August, September, and November (
Commodity spot and futures price data from Thomson Reuters (2000–2017)
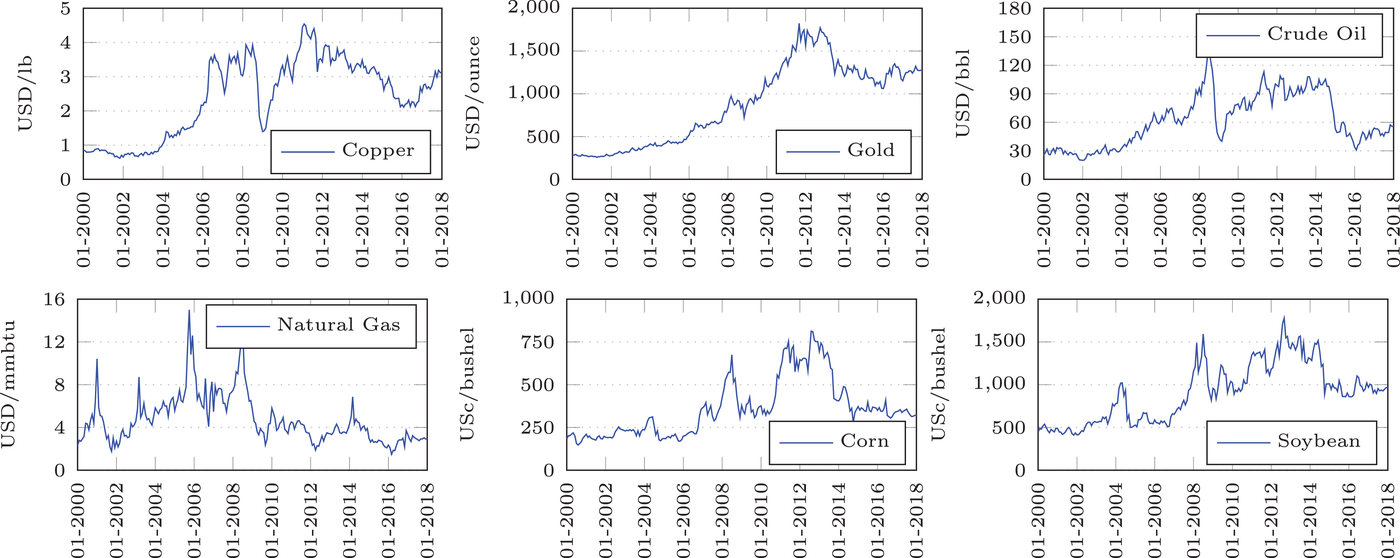
Spot prices for copper, gold, crude oil, natural gas, corn, and soybean from 2000 to 2017
For each commodity, we consider various operational settings for the storage asset in our backtest. Table 2 summarizes the parameters that we vary to obtain 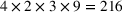
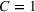
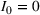
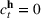
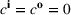
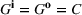
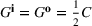
Summary of the numerical design
Results
Our implementation of RH assumes monthly inventory review periods so that each storage decision period coincides with a futures contract maturity. This assumption is consistent with past studies of RH (see, e.g., Lai et al., 2010; Secomandi, 2015). We also note that futures markets can be more liquid than spot markets, which are often thinly traded (Geman & Smith, 2013). We tested RH based on trading in the futures market with the closest expiry (the so‐called front‐month contract) as a proxy for the spot price. As the results were similar, we do not report them in the paper.
Empirical performance of RH
Table 3 reports statistics of the RH backtest across the 1296 instances summarized in Table 2. We obtain an assessment of the true generalization error by measuring 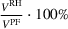
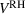
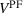
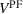
Performance of futures‐based RH in 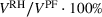
Mean w/o 2008–2009 (financial crisis).
Mean w/o 2014–2015 (oil price drop).
We find that RH achieves 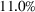
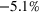
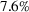
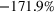
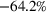
The performance of RH varies with the operational storage parameters 
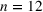
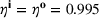
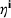
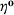
The small RH profit percentages relative to the perfect foresight solution are not themselves concerning because our benchmark is anticipative but it does raise the question of whether RH can be improved. Note that this question does not arise in the RH performance results reported for natural gas in the literature (see, e.g., Lai et al., 2010), which are performed under statistical model assumptions and show that RH is within a few percent of the optimal policy value. These differences in the assessment of RH suggest that information inconsistency may be at play here but confirming this suspicion requires comparing against a method that targets generalization error, which will be the focus of Sections 4 and 5.
Performance impact of the planning horizon
To understand if the performance of RH can be improved, we define variants of RH that solve an ILP at each stage formulated over a shorter horizon than 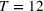
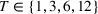
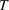
Figure 2 shows that the performance of RH is sensitive to the planning horizon 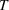
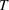




Average performance of RH
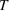
We investigate the results of Figure 2 further in the dominance matrix shown in Table 4. The one‐step look‐ahead policy based on RH
Dominance matrix of RHT for different planning horizons 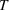
Specifically, RH1 strictly improves RH12 on 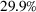
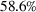
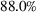

NYMEX futures curves (dashed) and realized spot prices (
Value of reoptimization
The preceding qualitative deviation from the literature also brings into question whether there is value in the reoptimization of ILP, which is needed to define the RH policy. Under the risk‐neutral measure and standard statistical model assumptions, reoptimization has been shown to add significant value over the intrinsic (static) policy based on the forward curve available at the initial stage (Lai et al., 2010; Secomandi, 2015). We assess if this remains the case in our backtest. We define the value of reoptimization as 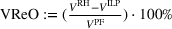
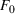

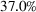
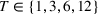
Value of reoptimization for
Value of perfect price information
In Section EC.2.3 of the Supporting Information, we investigate what information (albeit idealistic) could be provided to RH in lieu of futures prices to improve its performance. Our results show that one‐step‐ahead spot price information generates significant additional profits compared to standard RH with futures price information. The perfect foresight value for flexible storage assets can almost fully (on average 98.5%) be captured by correctly classifying the direction of one‐step‐ahead price movements. The improvement for limited flexibility is over 50%.
Therefore, we show that there is opportunity to improve on RH for spot trading. This observation motivates the development of DDAs for managing storage that targets generalization error.
DATA‐DRIVEN DECISION RULES
In this section, we focus on data‐driven decision rules for managing commodity storage. In Section 4.1, we present a forward‐looking DDA. We apply this approach using linear decision rules and structured policies in Section 4.2 and Section 4.3, respectively. Finally, we discuss robustness aspects of these policies in Section 4.4.
Forward‐looking policy training and evaluation framework
We consider the computation of data‐driven injection and withdrawal decision rules 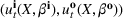
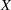
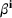
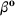
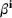
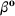
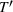
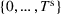
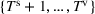
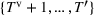
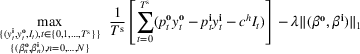
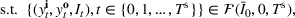
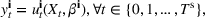
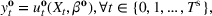
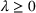
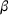
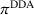
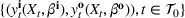
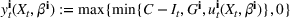
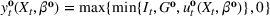
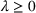
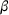
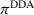
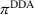
An important property of (20)–(23) is that all the data used in its definition are available at or before period 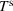
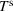
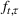
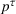
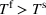

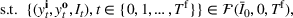
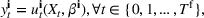
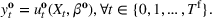
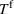
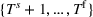
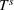
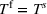
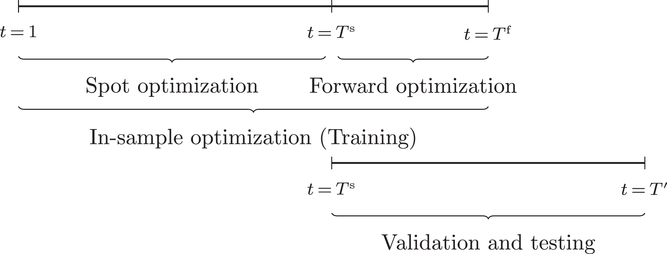
Optimization (training) and evaluation framework
The data‐driven framework described above can be used to target generalization error, which as discussed in Section 2.2 can be viewed as having components due to information inconsistency and structural inconsistency. The effect of the former inconsistency can be mitigated via feature selection in the context of the training, validation, and testing framework. The effect of latter inconsistency depends on the choice of 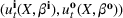
Linear decision rules (DDA‐LDR)
The common choice for decision rules is an affine mapping of features to decisions, referred to as linear decision rules (LDRs; see Ban & Rudin, 2019, for a newsvendor example and for additional references). Such a mapping for 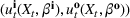

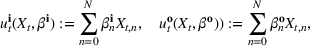
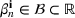
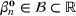
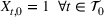
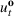
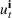
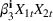
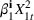
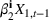
We refer to the policy obtained based on the choice (28) as DDA‐LDR. A computational advantage of DDA‐LDR is that (24)–(27) becomes a linear program that is efficient to solve. In terms of structural consistency, an LDR will in general not have the same structure as an optimal storage policy. Thus, it may suffer from generalization error because of this inconsistency, which motivates the structured decision rules considered next.
Structured decision rules (DDA‐SP)
We choose 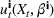
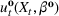
We begin by considering the optimal policy structure in the full flexibility case (i.e., Proposition 1(a)), which is based on a price threshold 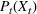
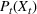
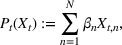
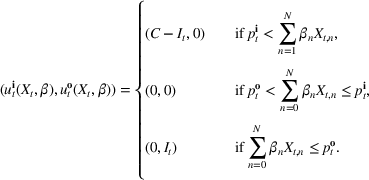
The choice for 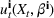
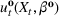
For a storage asset with limited flexibility, the estimation of a single price threshold is not sufficient because at the same market price 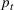
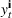
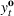
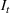
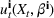
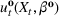
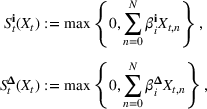
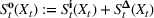
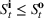
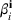
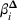
Robustness of DDA‐SP
Storage policies need to account for price and estimation risk. Price risk arises because commodity prices are uncertain, while estimation risk is a consequence of errors incurred when determining the parameters of a policy. DDA‐SP accounts for both these risks as discussed below.
Differences between in‐sample and out‐of‐sample profits of a storage policy can be attributed to the informational and structural components of generalization error (discussed in Section 2.2). The informational component arises due to commodity spot prices in the test set being uncertain and different from the training set (i.e., price risk). Regularization adds bias to the estimator to improve out‐of‐sample performance by avoiding overfitting (Mohri et al., 2012).
It can also be viewed as ensuring that the policy is trained using a robust objective in the forward‐looking math program (20)–(23). To understand this, note that setting 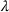
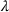
The structural component of generalization error, interestingly, has implications on both model complexity and the impact of estimation error. Consider DDA‐LDR, which is inconsistent with the optimal policy structure in general. The complexity of the class of policies represented by LDRs is a function of the richness of features. For instance, if features used in the definition (28) of LDR include the class of prespecified threshold and/or base‐stock policies, then the class of LDRs subsume the set of structured policies considered by DDA‐SP. In contrast, regardless of the richness of features, the class of policies that DDA‐SP considers is restricted to those satisfying optimal policy structure, thus potentially reducing model complexity relative to LDRs. Additionally, policy structure makes DDA‐SP robust to estimation error. To see this, consider DDA‐LDR again. Changes in feature values 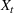
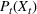
We numerically verify robustness of DDA‐SP compared to DDA‐LDR in Section 5.3.
PERFORMANCE EVALUATION OF DDA
In this section, we evaluate the performance of DDA‐LDR/SP compared to ILP and RH.
Setup
Table 5 summarizes the approaches we compare and the data that they exploit. In addition to the data considered in the RH backtest (Section 3.2), we also include analyst forecast data based on a feature selection study detailed in Section 5.4, which shows that spot prices, futures prices, and median analyst forecast constitute an undominated feature combination. We use 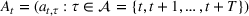
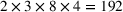
Benchmarks and feature data
Data availability allows analyst forecasts to be used from Jan 2008.
Backtesting setup
Referring to Table 6, we optimize based on a single sample path (e.g., 2000–2001) and evaluate on a test set (e.g., 2002–2003). We repeat this procedure for all test sets on a broad variation of operational storage parameters and then show the results as mean and quartile statistics across the 192 instances. The rationale behind this is that it represents the setting for decision making in practice: The storage manager trains the policy parameters on a training set (including validation on a validation set) and evaluates on a test set.
We tested sensitivity on training horizons by evaluating DDA‐SP for three different training set lengths, that is, 12 months, 24 months, and 36 months. A training length of 24 months resulted in the best performance on average. Using a shorter training cycle of 12 months or a longer training of 36 months can deteriorate the downside performance of data‐driven policies and foster downside outliers by not fully capturing the underlying price behavior (too short training sets) or by training on structural breaks (too long training sets). Apart from that, median performance when employing 12 and 24 months of training is similar. For more details, we refer to Section EC.7.1 of the Supporting Information. The following results are based on 24 months of training.
We further test DDA‐LDR and DDA‐SP with and without forward optimization. For the forward optimization, we use 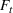
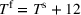
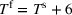
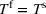
Performance evaluation
Figure 6 summarizes the performance results of the different storage policies. More detailed numbers are reported in the Supporting Information (TableEC. EC.4 and EC.6). Note that the mean performance in general increases by excluding subperiods 2008–2009 (financial crisis) and 2014–2015 (oil price drop), which is shown in Figure EC.5 of the Supporting Information.
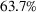
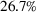
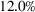
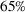
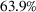
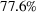
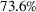
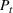
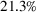
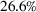
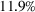
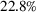
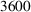
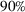
Out‐of‐sample performance of the different policies from 2002 until 2017 across all instances.
Performance of DDA‐SP in 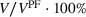
Improvement of downside risk
We investigate the performance of methods in terms of the 25%‐quartile of the profit distribution on each instance, which is representative of downside risk.
Figure 7 displays these results. Despite the DDA‐LDR policies being trained using regularization, their 25‐th percentile of profits are worse than RH on roughly 50% of the commodities and instances. In contrast, DDA‐SP policies improve on the downside risk of RH policies or are comparable for all commodities except natural gas. For natural gas, where RH was shown to be a strong competitor, the downside risk measured as the 25%‐quartile performance can be improved by monthly reoptimization of DDA‐SP, which increases the 25%‐quartile performance from −31.8% to −14.0% of the perfect foresight value. Thus, consistent with the discussion in Section 4.4, both regularization and policy structure in DDA‐SP are valuable to manage downside risk.
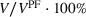
25%‐quartile of
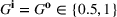
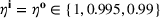
Feature selection
For effectively using DDA‐SP, and in particular reducing information inconsistency, selecting the right initial feature set is crucial. We consider the following candidate features: spot prices, futures prices, analyst forecasts, temperature, the S&P 500 index, and the Trade Weighted U.S. Dollar Index. We will employ as a reference the feature combination used to obtain the results in earlier sections, specifically spot prices, futures prices, and analyst forecasts. Our results show that all three feature categories were relevant for storage decisions. In addition to the feature type, the lag of features also matters (see Tables EC.16– EC.19 of the Supporting Information).
Our results reported in Supporting Information EC.7.5 show that ignoring futures and analyst forecast features from the reference feature combination and relying on a pure backward‐looking approach with spot price features only deteriorates performance.
However, there can be situations when liquid futures contracts or analyst forecasts are absent. In this case, it may be worth considering other features. Table EC.12 of the Supporting Information therefore compares the performance of DDA‐SP with spot price features only to DDA‐SP with spot price and macroeconomic features (i.e., the S&P 500 index and the Trade Weighted U.S. Dollar Index) that have been shown to drive commodity prices. The results show that in the absence of futures and analyst forecasts, adding macroeconomic features can help in particular with respect to downside risk. This is an important result with practical implications as there are commodities where futures and analyst forecasts are not available, for example, for commodities without liquid futures markets (e.g., asphalt or specific types of polyethylene such as HDPE, LDPE, and LLDPE).
Our additional results reported in Table EC.13 of the Supporting Information also show that whenever both futures and analyst forecasts are consistently available, additional macroeconomic features do not lead to a consistent performance improvement. One reason may be that macroeconomic information is already priced into futures and analyst forecast rates (Rational Expectation Hypothesis).
The absence of analyst forecasts however deteriorates storage performance (see Table EC.14 of the Supporting Information). This observation adds to the empirical findings from Cortazar et al. (2018) by showing that analyst forecasts also improve storage decisions. Cortazar et al. (2018) find similar support for price forecasting. Specifically, adding analyst forecasts as features on top of futures prices improves spot price forecast accuracy, arguing that this improvement is likely because futures‐based forecasts alone may not incorporate explicit information about the risk premium.
For natural gas where DDA performs comparatively poor in our experiments, we test the effect of the additional feature
Summary of insights
Our findings have implications on both storage practice and data‐driven optimization research.
The existing literature evaluates the performance of the RH policy relative to the optimal policy of a storage MDP with full‐information assumptions. In this setting, RH has been shown to yield near‐optimal profits. However, we show that this evaluation may be misleading if applied to operate storage on real data due to generalization error. We make four related observations from Section 3.2: (i) RH can yield unprofitable storage operations (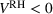
We show that there are two potential sources of generalization error: informational inconsistencies and structural inconsistencies. To mitigate the adverse effects of generalization error, we propose data‐driven and ML‐based policies that explore feature data (e.g., available analyst forecasts and futures prices or macroeconomic and weather features). We find that these policies can outperform RH without requiring the reoptimization of a linear program or tuning the planning horizon. Further, the linear decision rule approach from the data‐driven optimization literature is not effective in our setting. Structured policies that encode properties of an optimal policy are instead needed to improve on RH. Finally, extending the standard ERM approach to include forward‐looking information (if available, as is the case in commodity markets) can improve the performance of data‐driven policies.
CONCLUSIONS
We study the fundamental commodity storage problem. RHs are widely used in academia and practice to compute storage operating policies due to their computational attractiveness and known near‐optimality in simulation experiments based on specific model assumptions. We demonstrate on real data that the empirical performance of RH can be suboptimal due to generalization error and propose a forward‐looking ERM approach to compute linear decision rules and structured data‐driven policies, also highlighting how it addresses informational and structural inconsistencies. We find that data‐driven policies that encode an optimal policy structure exhibit robust performance across commodities and time periods in our data set, while linear decision rules perform worse than RH, despite being trained using data. In addition to uncovering the importance of policy structure in a data‐driven optimization setting, using forward‐looking futures price information in the training phase on top of historical spot prices can be crucial to improve out‐of‐sample performance. On the other hand, the additional value of learning from historical spot price data in our best data‐driven storage policy compared to using only futures prices for this purpose sheds light on its performance relative to RH, which uses futures price alone. For markets such as natural gas, which are highly efficient and exhibit high volatility, the value of learning from historical spot prices appears to be limited and both RH and our DDA show good performance. In contrast, this value is substantial in less efficient and/or less volatile commodity markets such as copper, gold, crude oil, corn, and soybean, where the DDA can outperform RH.
Our DDA and structured policies advance the state‐of‐the‐art for commodity storage. They suggest potential value in having existing software, which already incorporates backtesting capabilities, to also directly target generalization error when computing storage decisions. This research can be enhanced in several ways, of which we briefly state three. The first is to improve our backtest by allowing more granular intramonthly trading and leveraging data on trading volume to select only “liquid” futures contracts for use in RH and DDA. The second is to extend our backtest to understand the impact of generalization error and the performance of RH and DDA when forward trades are combined with spot trades. The third is to investigate DDAs that directly minimize downside risk when computing operating policies as opposed to relying on regularization for potential risk mitigation as we do in this paper.